


Important
🚨pgwatch2 is now in maintenance mode, accepting only bug fixes. Check out the WIP pgwatch3 repository for new features and enhancements!
Flexible self-contained PostgreSQL metrics monitoring/dashboarding solution. Supports monitoring PG versions 9.0 to 16 out of the box.
https://pgwatch2.readthedocs.io/en/latest/
For the fastest setup experience Docker images are provided via Docker Hub (for a Docker quickstart see here). For custom setups see the according chapter from documentation or turn to the "Releases" tab for pre-built DEB / RPM / Tar packages directly.
# fetch and run the latest Docker image, exposing Grafana on port 3000, the administrative web UI on port 8080
# and the internal configuration and metrics DB on localhost port 5432
docker run -d --restart=unless-stopped --name pw2 \
-p 3000:3000 -p 8080:8080 -p 127.0.0.1:5432:5432 \
-e PW2_TESTDB=true \
cybertec/pgwatch2-postgres:latest
After some minutes you could open the "db-overview" dashboard and start looking at metrics. For defining your own dashboards you need to log in as admin (admin/pgwatch2admin).
NB! If you don't want to add the "test" database (the pgwatch2 configuration db) for monitoring, remove the NOTESTDB=1 env parameter when launching the container.
The behaviour of the Docker images can be customized in many ways - for a complete list of all supported Docker environment variables see ENV_VARIABLES.md.
- Non-invasive setup, no extensions nor superuser rights required for the base functionality
- Intuitive metrics presentation using the Grafana dashboarding engine with optional Alerting
- Lots of pre-configured dashboards and metric configurations covering all Statistics Collector data
- Easy extensibility by defining metrics in pure SQL (thus they could also be from business domain)
- 4 supported data stores for metrics storage (PostgreSQL with or without TimescaleDB, InfluxDB, Graphite, Prometheus)
- Multiple configuration options (YAML, PostgreSQL, ENV) supporting both "push" and "pull" models
- Possible to monitoring all or a subset of DBs of a PostgreSQL cluster
- Global or DB level configuration of metrics/intervals
- Kubernetes/OpenShift ready with sample templates and a Helm chart
- PgBouncer, Pgpool-II, AWS RDS and Patroni support
- Internal health-check API to monitor metrics gathering status
- Security options like SSL / HTTPS for all connections and password encryption for connect strings
- Very low resource requirements for the collector - 1 CPU core can handle ~3k monitored DBs at 1GB RAM usage
- Log parsing capabilities when deployed locally in "push" mode
pgwatch2 can be deployed in various configurations, as all components are "loosely coupled". This means that you can very well reuse your existing PostgreSQL or Grafana installations, adding only pgwatch2 specific components - see here for more information.
Two most common deployment options are:
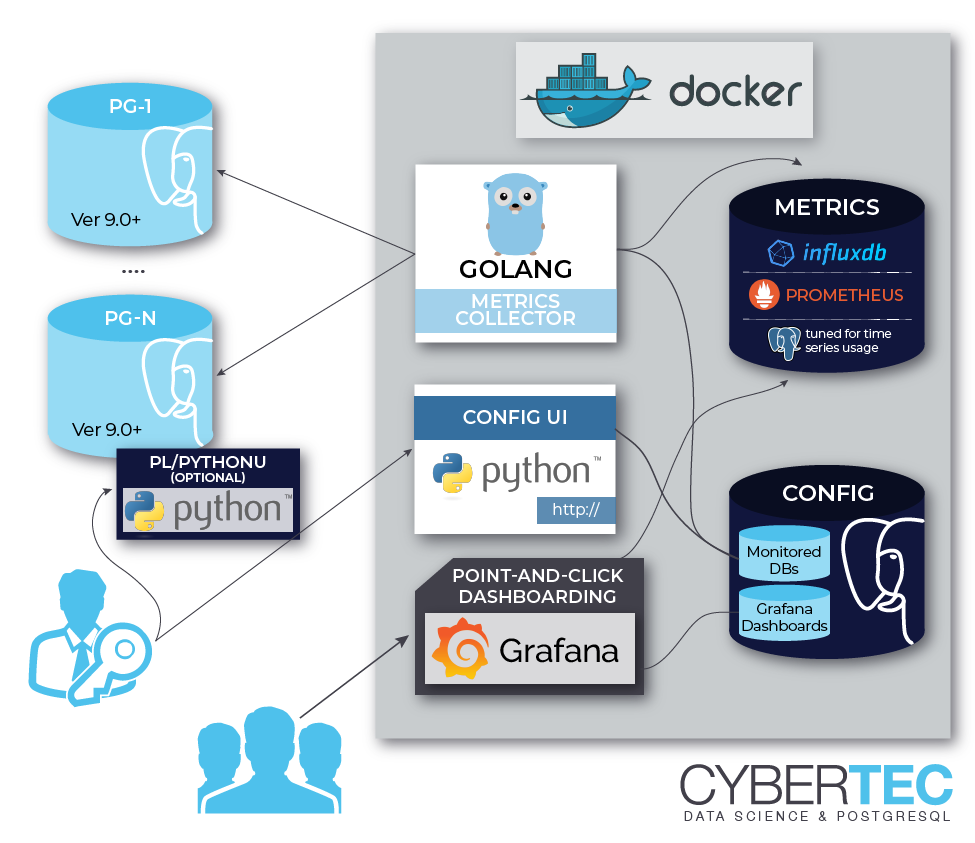
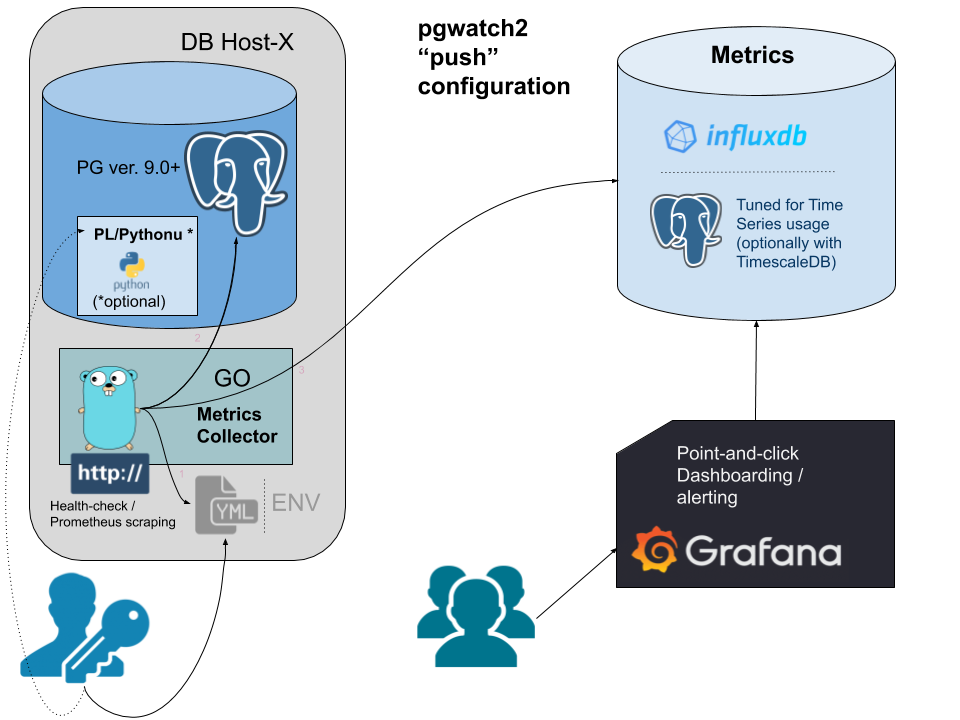
For storing metrics collected by the pgwatch2 daemon there are quite some options available:
- PostgreSQL - v11+ recommended. Multiple storage partitioning layouts available depending on the amount of servers to be monitored.
- PostgreSQL with the TimescaleDB extension - offers good compression and generally recommended when monitoring 100+ databases.
- InfluxDB - Time-Series optimized database. Note that the newly released v2.0 is not yet supported. Good Grafana integration but quite limited query language.
- Prometheus - here the pgwatch2 daemon would not store anything directly but just expose an endpoint for remote scraping / storage via Prometheus.
- Graphite - legacy support for Graphite. Not recommended anymore for new installations as it does not support the "tag" system.
See the documentation for more details.
As a base requirement you'll need a login user (non-superuser suggested) for connecting to your PostgreSQL servers and fetching metrics queries. Using a user named "pgwatch2" is recommended though, as otherwise your might need to adjust some scripts for advanced monitoring options, in case an unpriveleged monitoring account is used. More documentation on that can be found here.
CREATE ROLE pgwatch2 WITH LOGIN PASSWORD 'secret';
-- NB! For very important databases it might make sense to ensure that the user
-- account used for monitoring can only open a limited number of connections (there are according checks in code also though)
ALTER ROLE pgwatch2 CONNECTION LIMIT 3;
GRANT pg_monitor TO pgwatch2; -- system role available for v10+ servers to reduce superuser usage
GRANT CONNECT ON DATABASE mydb TO pgwatch2;
GRANT USAGE ON SCHEMA public TO pgwatch2; -- NB! pgwatch doesn't necessarily require using the public schema though!Additionally, for extra insights on "to be monitored" databases, it's recommended to install and activate the pg_stat_statement contrib extension and enable the track_io_timing parameter in server configuration.
If for security reasons a plain unprivileged database account is used for metrics gathering, this would mean that some protected PostgreSQL internal statistics cannot be fetched. This might be just OK (there's also an "unprivileged" preset), but it's also possible to expose such protected information in a safe and controlled way via a set of predefined SECURITY DEFINER functions. Note that another way to expose most of the protected metrics for Postgres v10+ instances would be to grant the special "pg_monitor" system role to the monitoring user like in the above paragraph.
To be executed on the "to be monitored" database:
psql -h mydb.com -U superuser -f /etc/pgwatch2/metrics/00_helpers/get_stat_activity/$pgver/metric.sql mydb
psql -h mydb.com -U superuser -f /etc/pgwatch2/metrics/00_helpers/get_stat_statements/$pgver/metric.sql mydb
psql -h mydb.com -U superuser -f /etc/pgwatch2/metrics/00_helpers/get_stat_replication/$pgver/metric.sql mydb
NB! By default the "helpers" assume that a role called "pgwatch2" will be used for metrics gathering. If not so, you need to change the SQL definitions. Also note that some helper scripts can refuse to install if the security of the target schema is too "open" for everyone (i.e. to the built-in "public" meta-role) and thus there's potential for misuse.
Similar to above described plain SQL helper functions, one can also create such wrapper functions in any PostgreSQL supported PL-language, like most commonly PL/Python. This will allow to return metrics on any information deemed useful. Main use case though is to extract OS statistics like CPU, RAM, disk utilization and backup status over regular Postgres connections. The pgwatch2 project provides a good set of such wrappers, so that in simpler cases you would not need any additional system monitoring tools.
# first install the Python bindings for Postgres
apt install postgresql-plpython3-XY
# yum install postgresqlXY-plpython3
psql -c "CREATE EXTENSION plpython3u" mydb
psql -f /etc/pgwatch2/metrics/00_helpers/get_load_average/9.1/metric.sql mydb
# psutil helpers are only needed when full set of common OS metrics is wanted
apt install python3-psutil
psql -f /etc/pgwatch2/metrics/00_helpers/get_psutil_cpu/9.1/metric.sql mydb
psql -f /etc/pgwatch2/metrics/00_helpers/get_psutil_mem/9.1/metric.sql mydb
psql -f /etc/pgwatch2/metrics/00_helpers/get_psutil_disk/9.1/metric.sql mydb
psql -f /etc/pgwatch2/metrics/00_helpers/get_psutil_disk_io_total/9.1/metric.sql mydb
Metrics in pgwatch2 are named SQL queries that can return pretty much everything you find useful. Metrics can have different query text versions for different target PostgreSQL versions, also optionally taking into account recovery state (primary / standby) and as of v1.8 also versions of installed extensions. Query output is automatically stored into the metric DB and optionally also indexed if a column's name is prefixed with the "tag_" modifier.
A sample custom metric looks like that:
-- a sample metric
SELECT
(extract(epoch from now()) * 1e9)::int8 as epoch_ns,
extract(epoch from (now() - pg_postmaster_start_time()))::int8 as postmaster_uptime_s,
case when pg_is_in_recovery() then 1 else 0 end as in_recovery_int;From v1.4.0 one can also deploy pgwatch2 gatherer daemons de-centrally without a configuration database, based on YAML config files. This means a more resilient setup (the only point of failure will be the metrics storage DB) and more security, so that even superuser roles can be used on the agents running locally on monitored database. See here for details.
From v1.4.0 it's also possible to run the gatherer daemon in ad-hoc / test mode, by giving a single standard connection string as input, and optionally also specifying the metrics to monitor (a Preset Config name or a custom JSON string). In that case there is no need for the central Postgres "Config DB", nor any YAML files, i.e. the setup can be based purely on environment variables, which can be beneficial for Cloud setups. Details here.
# launching in ad-hoc / test mode
docker run --rm -d --name pw2_temp \
-p 3000:3000 \
-e PW2_ADHOC_CONN_STR="postgresql://postgres:[email protected]:5432/postgres" \
-e PW2_ADHOC_CONFIG=unprivileged cybertec/pgwatch2-postgres
In v1.6.0 support for one of the most popular metrics gathering solutions – Prometheus, was added. When the "datastore" parameter is set to "prometheus" then the pgwatch2 metrics collector doesn't do any normal interval-based fetching but listens on port 9187 (changeable) for scrape requests configured and performed on Prometheus side.
In this mode the pgwatch2 agents should be running on all database hosts separately, not centrally. While technically possible though, it would counter the core idea of Prometheus and would make scrapes also longer, risking timeouts. There's also a separate "Preset Config" named "prometheus". More details.
Cloud deployments of pgwatch2 should be no problem - there are some simple deployment templates provided and also some Helm charts in the "pgwatch2-charts" repository.
Helm setup values should always be reviewed / edited as the defaults are rather for testing purposes. Installation is done by the following command:
cd openshift_k8s
helm install -f chart-values-k8s-pg-storage.yml pgwatch2 helm-chart-k8s-pg-storagePlease have a look at the according (K8s or OpenShift) values.yaml files to get additional information of configurable options.
Feedback, suggestions, problem reports and pull requests are very much appreciated.






![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")















































































































































































