Comments (13)
 EdwinVW
commented on May 12, 2024
EdwinVW
commented on May 12, 2024
Hi @jbonnett92. Thanks for your interest in this project!
The data is being kept up-to-date using events. If you add a customer for instance, a CustomerRegistered event is published by the CustomerManagementAPI to the message-broker (RabbitMQ). This event is picked up by all the services that need customer info and persisted in their local database (in a form that fits the service). This event-driven approach makes the services autonomous. The Invoice service for instance, can do its work and send invoices, even when the CustomerManagementAPI if offline (for maintenance or because of an issue).
So yes data is shared between the services. But the CustomerManagementAPI will always be the system-of-record for customer information. All other services have a read-only "cache" of the data locally. And they store the least amount of fields as possible for them to do their work. This is done to reduce the chance of a change to the customer data-structure having an impact on the local cache. The data will only be created and updated by ingesting events.
Does this answer your question?
from pitstop.
 jbonnett92
commented on May 12, 2024
jbonnett92
commented on May 12, 2024
So this is for redundancy? Does it break the rules of normalisation? Not sure how normalisation applies to multiple databases.
from pitstop.
EdwinVW
commented on May 12, 2024
Not sure I fully understand your question. I used this approach to make every service fully autonomous. So it's primarily for availability. Every service owns its own database and normalization is used within this database.
from pitstop.
EdwinVW
commented on May 12, 2024
Hi @jbonnett92. Did this answer your question?
from pitstop.
jbonnett92
commented on May 12, 2024
Sorry about the late reply, I was on training. Yes that answered the question.
from pitstop.
jbonnett92
commented on May 12, 2024
Do you by chance have any tutorials on implementing the concepts that you've used in this project?
I am new to .NET Core (Though I have been developing Umbraco for the last two years for my job, which is .NET Framework) and I have basic knowledge how microservices work and what not to do. I just can't seem to know where to start implementing. I am fond of the idea of Event Sourcing as we can rollback a particular event at a particular time, also makes tracing an issue far easier.
from pitstop.
EdwinVW
commented on May 12, 2024
No problem @jbonnett92. Thanks for the update.
For me it has been a journey (so no overnight thing). I have learned all the concepts I've put into Pitstop primarily by reading books. These are a couple I can recommend:
- Building Microservices by Sam Newman
- Exploring CQRS and Event Sourcing. This is an older book, but I've really learned CQRS and the event-driven approach from this book. Samples are not .NET Core but it's more about the concepts.
- Patterns, Principles, and Practices of Domain-Driven Design.
I also had the privilege of following a course by Greg Young about CQRS and Event Sourcing in London. That was also an eye-opener for me.
And finally it's been a lot of sparring with fellow software architects about - and experimenting with - the concepts I've picked up from the books and how to implement them. This is why Pitstop exists. It's my go to project for trying new concepts and technology (I'm currently thinking about porting the front-end to Blazor for instance).
I've done some talks on how I've built Pitstop using .NET Core and docker. This will also go into some of the architectural concepts. Maybe this recording will help: Building microservices with .NET Core and docker.
I hope this will get you started.
from pitstop.
jbonnett92
commented on May 12, 2024
Thank you,
I also noticed that in WorkshopManagementAPI repo's you reference databases from other microservices.
Shouldn't you query the service that the database is paired with? Like in this illustration?
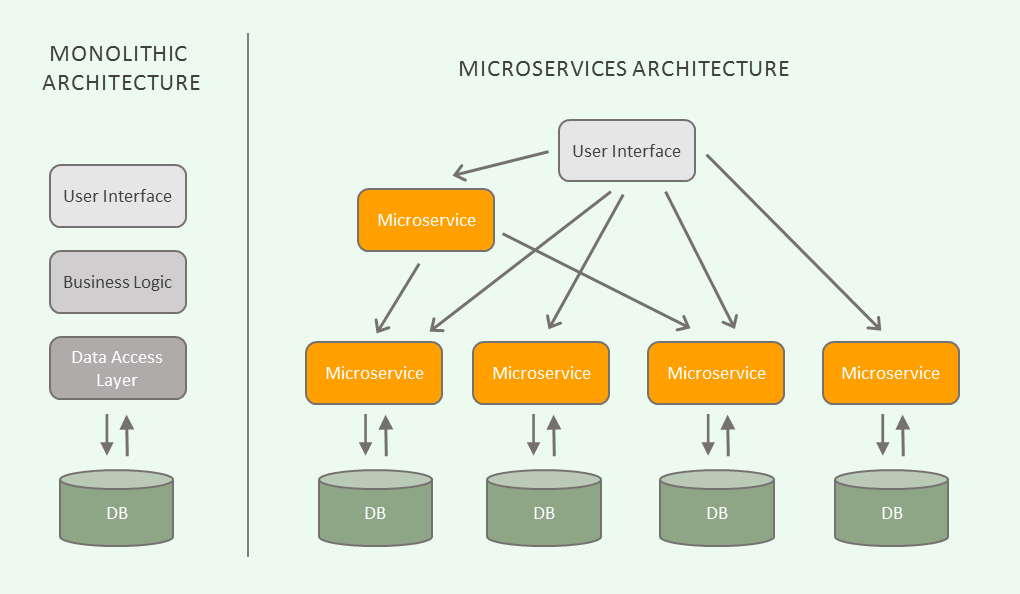
from pitstop.
EdwinVW
commented on May 12, 2024
Yes @jbonnett92, that's how it should be done.
A microservice is a concept and the WorkshopManagement microservice contains 2 components: an API for handling commands (WorkshopManagementAPI) and an eventhandler for ingesting events from other services (WorkshopManagementEventHandler). Both components are part of the implementation of the WorkshopManagement microservice. And hence, both databases are only used within this microservice. This is also how I visualized it in the solution architecture diagram:

from pitstop.
jbonnett92
commented on May 12, 2024
If a service is down when a event is published, and that service did not consume the event, when the service is back online how does the service know that the event wasn't consumed and to consume it?
Please can you add a authentication service? It would be an interesting one to see.
from pitstop.
EdwinVW
commented on May 12, 2024
This is why I use an message broker. The messages will be kept in the queue while the service is down. When the service is started, it will just resume picking up the next message from the queue.
It's on my backlog.
from pitstop.
jbonnett92
commented on May 12, 2024
This may be a problem when you scale up the services, lets say that we create multiple invoice service instances, we publish and even that the invoice service consumes, that means that only one instance can consume using the broker (which in some case is ok, means that it is not doing the same thing twice) though this hurts throughput, even if we manage to get the multiple instances consuming the event, would there be database locking? What would you suggest to this?
My thinking is that RabbitMQ can handle 50k messages in a single queue and if we (for some reason) need more, what route do we take then? It just doesn't seem as scalable as microservices intend to be. I know that RabbitMQ can shard queues, though that also hurts throughput.
Just spitballing some ideas / issues that may come up.
from pitstop.
EdwinVW
commented on May 12, 2024
RabbitMQ handles competing consumers on the queue. So if you would run multiple instances of the invoice service, each instance of the service will get a different message and the load will be balanced that way. This is also a reason to choose for a more sophisticated message-broker.
Database locking could be a problem, but using a retry mechanism (which RabbitMQ offers out of the box) with optimistic concurrency control would be enough here.
If you need very high throughput (way more than necessary for the Pitstop scenario), you should look at a different architecture and use concepts like streaming. Like I said, microservices is a concept that can be implemented in several ways. I've used the setup I've used for Pitstop also for production applications that could handle pretty large workloads. So it depends ;)
from pitstop.
Related Issues (20)
- Where WorkshopManagement database is created HOT 1
- WebApp not working on ARM / M1 pro CPU HOT 2
- Maildev UI not opening in Browser HOT 11
- Stand-Alone SQL to build database HOT 6
- All docker images deployment on Azure HOT 1
- There is a typo under functionality in Domain description on MaintenanceJob....there is a forgotten "be" HOT 2
- Invoice HOT 5
- Future plan HOT 1
- Context map workshop management precision HOT 5
- Do we really need multiple retries policy setup? HOT 2
- Parameter-less constructor HOT 2
- How do I HOT 4
- Get an error in RabbitMQMessagePublisher class
- Wiki mentions running Kubernetes dashboard, but it seems to have moved HOT 1
- Consistency between Db Entity and Event HOT 2
- Issue with microsoft/mssql-server-linux:latest HOT 3
- Questions regarding - Upgrade to .NET Core 3.0 HOT 4
- RabbitMQ Connection approach HOT 2
- Azure SQL is not supported HOT 6
- PSA: Create pitstop databases manually when deploying with azure sql
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from pitstop.