Comments (15)
 NingCY
commented on June 4, 2024
4
NingCY
commented on June 4, 2024
4
@hysts Hi,I tried to run python train.py --config configs/cifar/resnet_preact.yaml and the results still kept the same as @lilujunai :
Traceback (most recent call last):
File "train.py", line 447, in
main()
File "train.py", line 373, in main
model, optimizer, opt_level=config.train.precision)
File "D:\Qiuyu\anaconda\lib\site-packages\apex\amp\frontend.py", line 358, in initialize
return _initialize(models, optimizers, _amp_state.opt_properties, num_losses, cast_model_outputs)
File "D:\Qiuyu\anaconda\lib\site-packages\apex\amp_initialize.py", line 171, in _initialize
check_params_fp32(models)
File "D:\Qiuyu\anaconda\lib\site-packages\apex\amp_initialize.py", line 116, in check_params_fp32
name, buf.type()))
File "D:\Qiuyu\anaconda\lib\site-packages\apex\amp_amp_state.py", line 32, in warn_or_err
raise RuntimeError(msg)
RuntimeError: Found buffer total_ops with type torch.DoubleTensor, expected torch.cuda.FloatTensor.
When using amp.initialize, you need to provide a model with buffers
located on a CUDA device before passing it no matter what optimization level
you chose. Use model.to('cuda') to use the default device.
I think the problem maybe still exists, could you give me some help?
from pytorch_image_classification.
 hysts
commented on June 4, 2024
hysts
commented on June 4, 2024
Hi, @lilujunai
Oh, sorry about that. There seems to be a bug that causes the error when running on a CPU. I'm going to fix it right away.
from pytorch_image_classification.
hysts
commented on June 4, 2024
Now it's fixed. Thanks for reporting the issue.
from pytorch_image_classification.
hysts
commented on June 4, 2024
Hi, @ningce
Maybe it's because of the different versions of NVIDIA apex. Could you try the version that worked in my environment and see if it works? You can install it as follows.
pip uninstall -y apex
pip install git+https://github.com/NVIDIA/apex.git@02a33875970e1b555754dfc4ab85d05595d23764from pytorch_image_classification.
hysts
commented on June 4, 2024
Hi, @dalveasy
You mean you ran the command above but got an error? What is the error message?
from pytorch_image_classification.
NingCY
commented on June 4, 2024
Hi, @hysts , I tried uninstall apex and reinstalled the version you provided, the result remained the same.
I add codes in train.py at about line 372:
optimizer = create_optimizer(config, model)
if config.device != 'cpu':
model.to(config.device)
model, optimizer = apex.amp.initialize(
model, optimizer, opt_level=config.train.precision)
model = apply_data_parallel_wrapper(config, model)
and change optimization level from O0 to O1, and it can be trained:
[2020-10-27 13:50:36] main INFO: Val 0
[2020-10-27 13:51:32] main INFO: Epoch 0 loss nan acc@1 0.1000 acc@5 0.5002
[2020-10-27 13:51:32] main INFO: Elapsed 55.37
[2020-10-27 13:51:32] main INFO: Train 1 0
D:\Qiuyu\anaconda\lib\site-packages\torch\cuda\nccl.py:14: UserWarning: PyTorch is not compiled with NCCL support
warnings.warn('PyTorch is not compiled with NCCL support')
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
D:\Qiuyu\anaconda\lib\site-packages\torch\optim\lr_scheduler.py:123: UserWarning: Detected call oflr_scheduler.step()beforeoptimizer.step(). In PyTorch 1.1.0 and later, you should call them in the opposite order:optimizer.step()beforelr_scheduler.step(). Failure to do this will result in PyTorch skipping the first value of the learning rate schedule. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
"https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate", UserWarning)
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 16384.0
[2020-10-27 13:53:58] main INFO: Epoch 1 Step 100/781 lr 0.010000 loss 2.1310 (nan) acc@1 0.1250 (0.1409) acc@5 0.7188 (0.6077)
However, when it comes to epoch2, the loss displayed is always nan, and loss scale keeps reducing from 32768->16384->...->0 and error occurs:
[2020-10-26 09:41:22] main INFO: MACs : 255.25M
[2020-10-26 09:41:22] main INFO: #params: 1.73M
[2020-10-26 09:41:27] main INFO: Val 0
[2020-10-26 09:42:02] main INFO: Epoch 0 loss nan acc@1 0.1001 acc@5 0.4998
[2020-10-26 09:42:02] main INFO: Elapsed 34.90
[2020-10-26 09:42:02] main INFO: Train 1 0
[2020-10-26 09:43:36] main INFO: Epoch 1 Step 100/390 lr 0.100000 loss 1.9906 (nan) acc@1 0.2500 (0.1845) acc@5 0.7656 (0.6762)
[2020-10-26 09:44:58] main INFO: Epoch 1 Step 200/390 lr 0.100000 loss nan (nan) acc@1 0.2734 (0.2176) acc@5 0.7422 (0.7134)
[2020-10-26 09:46:20] main INFO: Epoch 1 Step 300/390 lr 0.100000 loss 57.8224 (nan) acc@1 0.3672 (0.2394) acc@5 0.7500 (0.7325)
[2020-10-26 09:47:34] main INFO: Epoch 1 Step 390/390 lr 0.100000 loss nan (nan) acc@1 0.2969 (0.2538) acc@5 0.8047 (0.7440)
[2020-10-26 09:47:34] main INFO: Elapsed 332.49
[2020-10-26 09:47:34] main INFO: Val 1
[2020-10-26 09:47:58] main INFO: Epoch 1 loss 1.8652 acc@1 0.3130 acc@5 0.7952
[2020-10-26 09:47:58] main INFO: Elapsed 23.95
[2020-10-26 09:47:58] main INFO: Train 2 390
[2020-10-26 09:49:09] main INFO: Epoch 2 Step 100/390 lr 0.100000 loss nan (nan) acc@1 0.1172 (0.1022) acc@5 0.5781 (0.4984)
[2020-10-26 09:50:18] main INFO: Epoch 2 Step 200/390 lr 0.100000 loss nan (nan) acc@1 0.0938 (0.1010) acc@5 0.4609 (0.4996)
[2020-10-26 09:51:18] main INFO: Epoch 2 Step 300/390 lr 0.100000 loss nan (nan) acc@1 0.1094 (0.1006) acc@5 0.5156 (0.4998)
[2020-10-26 09:52:13] main INFO: Epoch 2 Step 390/390 lr 0.100000 loss nan (nan) acc@1 0.1250 (0.1001) acc@5 0.5469 (0.5002)
[2020-10-26 09:52:13] main INFO: Elapsed 255.32
[2020-10-26 09:52:13] main INFO: Val 2
[2020-10-26 09:52:37] main INFO: Epoch 2 loss nan acc@1 0.1000 acc@5 0.5000
[2020-10-26 09:52:37] main INFO: Elapsed 23.85
[2020-10-26 09:52:37] main INFO: Train 3 780
[2020-10-26 09:54:04] main INFO: Epoch 3 Step 100/390 lr 0.100000 loss nan (nan) acc@1 0.0859 (0.1001) acc@5 0.4219 (0.5073)
So I change training batch size from 128 to 64 and trained for about 120 epochs with no error, but loss become nan sometimes during training without reporting error:
[2020-10-27 08:52:13] main INFO: Train 118 91377
[2020-10-27 08:53:49] main INFO: Epoch 118 Step 100/781 lr 0.001000 loss 0.5874 (nan) acc@1 0.7500 (0.7664) acc@5 0.8750 (0.8781)
[2020-10-27 08:55:14] main INFO: Epoch 118 Step 200/781 lr 0.001000 loss 0.5835 (nan) acc@1 0.7656 (0.7686) acc@5 0.8594 (0.8745)
[2020-10-27 08:56:39] main INFO: Epoch 118 Step 300/781 lr 0.001000 loss 0.5983 (nan) acc@1 0.7656 (0.7693) acc@5 0.8438 (0.8735)
[2020-10-27 08:58:04] main INFO: Epoch 118 Step 400/781 lr 0.001000 loss nan (nan) acc@1 0.7812 (0.7695) acc@5 0.9219 (0.8741)
[2020-10-27 08:59:29] main INFO: Epoch 118 Step 500/781 lr 0.001000 loss 0.5875 (nan) acc@1 0.7969 (0.7702) acc@5 0.8906 (0.8759)
[2020-10-27 09:00:54] main INFO: Epoch 118 Step 600/781 lr 0.001000 loss 1365.0090 (nan) acc@1 0.7500 (0.7698) acc@5 0.8125 (0.8750)
[2020-10-27 09:02:19] main INFO: Epoch 118 Step 700/781 lr 0.001000 loss 16.4159 (nan) acc@1 0.7969 (0.7703) acc@5 0.8906 (0.8760)
[2020-10-27 09:03:28] main INFO: Epoch 118 Step 781/781 lr 0.001000 loss 0.5919 (nan) acc@1 0.7969 (0.7701) acc@5 0.8750 (0.8756)
[2020-10-27 09:03:28] main INFO: Elapsed 674.95
[2020-10-27 09:03:28] main INFO: Val 118
[2020-10-27 09:03:51] main INFO: Epoch 118 loss 1.3860 acc@1 0.7108 acc@5 0.8728
[2020-10-27 09:03:51] main INFO: Elapsed 22.58
[2020-10-27 09:03:51] main INFO: Train 119 92158
[2020-10-27 09:05:26] main INFO: Epoch 119 Step 100/781 lr 0.001000 loss 0.5895 (nan) acc@1 0.7969 (0.7644) acc@5 0.9062 (0.8766)
[2020-10-27 09:06:52] main INFO: Epoch 119 Step 200/781 lr 0.001000 loss 0.5992 (nan) acc@1 0.7656 (0.7673) acc@5 0.9062 (0.8770)
[2020-10-27 09:08:17] main INFO: Epoch 119 Step 300/781 lr 0.001000 loss 0.5801 (nan) acc@1 0.8125 (0.7686) acc@5 0.8906 (0.8771)
[2020-10-27 09:09:43] main INFO: Epoch 119 Step 400/781 lr 0.001000 loss 0.5813 (nan) acc@1 0.7500 (0.7682) acc@5 0.8438 (0.8740)
[2020-10-27 09:11:09] main INFO: Epoch 119 Step 500/781 lr 0.001000 loss nan (nan) acc@1 0.7656 (0.7692) acc@5 0.8594 (0.8747)
[2020-10-27 09:12:35] main INFO: Epoch 119 Step 600/781 lr 0.001000 loss 0.6217 (nan) acc@1 0.7812 (0.7691) acc@5 0.9062 (0.8752)
[2020-10-27 09:14:00] main INFO: Epoch 119 Step 700/781 lr 0.001000 loss 0.6066 (nan) acc@1 0.7344 (0.7695) acc@5 0.8594 (0.8752)
[2020-10-27 09:15:09] main INFO: Epoch 119 Step 781/781 lr 0.001000 loss 2.7433 (nan) acc@1 0.7969 (0.7696) acc@5 0.8750 (0.8751)
[2020-10-27 09:15:10] main INFO: Elapsed 679.20
[2020-10-27 09:15:10] main INFO: Val 119
[2020-10-27 09:15:33] main INFO: Epoch 119 loss 0.8745 acc@1 0.7101 acc@5 0.8722
[2020-10-27 09:15:33] main INFO: Elapsed 23.27
[2020-10-27 09:15:33] main INFO: Train 120 92939
[2020-10-27 09:17:08] main INFO: Epoch 120 Step 100/781 lr 0.001000 loss 0.6229 (nan) acc@1 0.7656 (0.7680) acc@5 0.8906 (0.8766)
[2020-10-27 09:18:34] main INFO: Epoch 120 Step 200/781 lr 0.001000 loss 0.5786 (nan) acc@1 0.7500 (0.7674) acc@5 0.8906 (0.8770)
[2020-10-27 09:19:59] main INFO: Epoch 120 Step 300/781 lr 0.001000 loss 0.5781 (nan) acc@1 0.7812 (0.7668) acc@5 0.8906 (0.8757)
[2020-10-27 09:21:25] main INFO: Epoch 120 Step 400/781 lr 0.001000 loss 0.5776 (nan) acc@1 0.7812 (0.7676) acc@5 0.9062 (0.8763)
[2020-10-27 09:22:50] main INFO: Epoch 120 Step 500/781 lr 0.001000 loss 0.5769 (nan) acc@1 0.7812 (0.7676) acc@5 0.8906 (0.8764)
[2020-10-27 09:24:16] main INFO: Epoch 120 Step 600/781 lr 0.001000 loss 0.5798 (nan) acc@1 0.7969 (0.7677) acc@5 0.8906 (0.8760)
[2020-10-27 09:25:41] main INFO: Epoch 120 Step 700/781 lr 0.001000 loss 0.5864 (nan) acc@1 0.7812 (0.7676) acc@5 0.9062 (0.8759)
[2020-10-27 09:26:50] main INFO: Epoch 120 Step 781/781 lr 0.001000 loss nan (nan) acc@1 0.7500 (0.7677) acc@5 0.7969 (0.8757)
[2020-10-27 09:26:51] main INFO: Elapsed 677.61
[2020-10-27 09:26:51] main INFO: Val 120
[2020-10-27 09:27:14] main INFO: Epoch 120 loss nan acc@1 0.7112 acc@5 0.8726
[2020-10-27 09:27:14] main INFO: Elapsed 23.08
Is this a normal phenomenon? Thanks again!
from pytorch_image_classification.
hysts
commented on June 4, 2024
Hmmm... It's weird. You're using the CPU to train the model, right? In that case, the modification of line 372 doesn't change the behavior, and since Apex is for GPUs, changing the optimization level shouldn't change anything, but it seems Apex is doing something.
According to the log you pasted, I suppose you're running the code on a Windows machine, but they say Windows support of NVIDIA Apex is experimental, so maybe that's the cause of the error.
https://github.com/NVIDIA/apex#windows-support
Is this a normal phenomenon?
I don't think it's normal. If the learning rate is too high or the batch size is too small, the loss could be nan, but that doesn't seem to be the case from the log.
from pytorch_image_classification.
NingCY
commented on June 4, 2024
I train the model on GPU on windows 10, CPU is too slow...
they say Windows support of NVIDIA Apex is experimental, so maybe that's the cause of the error
Yes, I agree with you. Maybe I should switch to linux machine...
Thanks anyway, this project still helps me a lot.
from pytorch_image_classification.
hysts
commented on June 4, 2024
Oh, I assumed you were using CPU because it took 4-5 minutes per epoch according to your log, but that was not the case. Sorry for the confusion.
I've updated the code to add an option to turn off Apex, so this may work. You can turn off Apex by adding use_apex: False to the train section of configs/cifar/resnet_preact.yaml.
from pytorch_image_classification.
NingCY
commented on June 4, 2024
I update the code and adding use_apex: False to the config file, then train and error occured:
Traceback (most recent call last):
File "train.py", line 453, in
main()
File "train.py", line 422, in main
tensorboard_writer)
File "train.py", line 273, in validate
outputs = model(data)
File "D:\Qiuyu\anaconda\lib\site-packages\torch\nn\modules\module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "D:\Qiuyu\anaconda\lib\site-packages\torch\nn\parallel\data_parallel.py", line 149, in forward
"them on device: {}".format(self.src_device_obj, t.device))
RuntimeError: module must have its parameters and buffers on device cuda:0 (device_ids[0]) but found one of them on device: cpu
So I add codes in models/init.py at about28:
else:
if config.device == 'cuda':
model = nn.DataParallel(model)
**model.to("cuda")**
Then it run normally and trained 160 epochs without error:
[2020-10-29 07:03:39] main INFO: Train 159 61620
[2020-10-29 07:04:57] main INFO: Epoch 159 Step 100/390 lr 0.000100 loss 0.5859 (0.5962) acc@1 0.7812 (0.7705) acc@5 0.8516 (0.8754)
[2020-10-29 07:06:03] main INFO: Epoch 159 Step 200/390 lr 0.000100 loss 0.5929 (0.5950) acc@1 0.7734 (0.7695) acc@5 0.8906 (0.8737)
[2020-10-29 07:07:09] main INFO: Epoch 159 Step 300/390 lr 0.000100 loss 0.5937 (0.5952) acc@1 0.7656 (0.7702) acc@5 0.9141 (0.8744)
[2020-10-29 07:08:09] main INFO: Epoch 159 Step 390/390 lr 0.000100 loss 0.5978 (0.5951) acc@1 0.7656 (0.7700) acc@5 0.8359 (0.8746)
[2020-10-29 07:08:09] main INFO: Elapsed 270.63
[2020-10-29 07:08:09] main INFO: Val 159
[2020-10-29 07:08:32] main INFO: Epoch 159 loss 0.9481 acc@1 0.6970 acc@5 0.8694
[2020-10-29 07:08:32] main INFO: Elapsed 22.87
[2020-10-29 07:08:32] main INFO: Train 160 62010
[2020-10-29 07:09:49] main INFO: Epoch 160 Step 100/390 lr 0.000100 loss 0.5906 (0.5954) acc@1 0.7969 (0.7677) acc@5 0.9141 (0.8758)
[2020-10-29 07:10:56] main INFO: Epoch 160 Step 200/390 lr 0.000100 loss 0.5913 (0.5954) acc@1 0.7578 (0.7694) acc@5 0.8750 (0.8732)
[2020-10-29 07:12:02] main INFO: Epoch 160 Step 300/390 lr 0.000100 loss 0.5842 (0.5953) acc@1 0.8047 (0.7695) acc@5 0.9062 (0.8745)
[2020-10-29 07:13:02] main INFO: Epoch 160 Step 390/390 lr 0.000100 loss 0.5968 (0.5949) acc@1 0.7656 (0.7695) acc@5 0.8672 (0.8748)
[2020-10-29 07:13:02] main INFO: Elapsed 270.13
[2020-10-29 07:13:02] main INFO: Val 160
[2020-10-29 07:13:25] main INFO: Epoch 160 loss 0.9458 acc@1 0.6966 acc@5 0.8690
[2020-10-29 07:13:25] main INFO: Elapsed 22.59
[2020-10-29 07:13:25] fvcore.common.checkpoint INFO: Saving checkpoint to experiments\cifar10\resnet_preact\exp20\checkpoint_00160.pth
I checked loss curve in tensorboard, its overall trend is similar to ./figures/cifar10/ResNet-preact-110_basic.png, suddenly down at epoch80 with loss=0.67(far larger than ~0.15 in ./figures/cifar10/ResNet-preact-110_basic.png) and finally stable at 0.59. What could be the reason?
from pytorch_image_classification.
hysts
commented on June 4, 2024
I update the code and adding use_apex: False to the config file, then train and error occured:
Oh, it works on Ubuntu without the line, so it may be due to a difference in environment. As it doesn't change the behavior on Ubuntu even with it, I added it. Thanks for reporting this.
As for the weird behavior of the training, I'm not sure if I get it. Would you post a screenshot of the tensorboard?
Anyway, I guess something is wrong because the validation accuracy seems to be too low. But if you're running the code basically as is, I have no idea what's going on.
from pytorch_image_classification.
NingCY
commented on June 4, 2024
@hysts
Train and val figures are as follows:
Train figures
Val figures
{kind=link}
{kind=link}
Any thoughts are welcome...
from pytorch_image_classification.
hysts
commented on June 4, 2024
Thanks for the screenshots.
Hmm... I don't know why the accuracy is so low. Maybe somehow the transforms are not working properly?
FYI, I ran the training myself, and the tensorboard looks like the screenshots below.
Train:
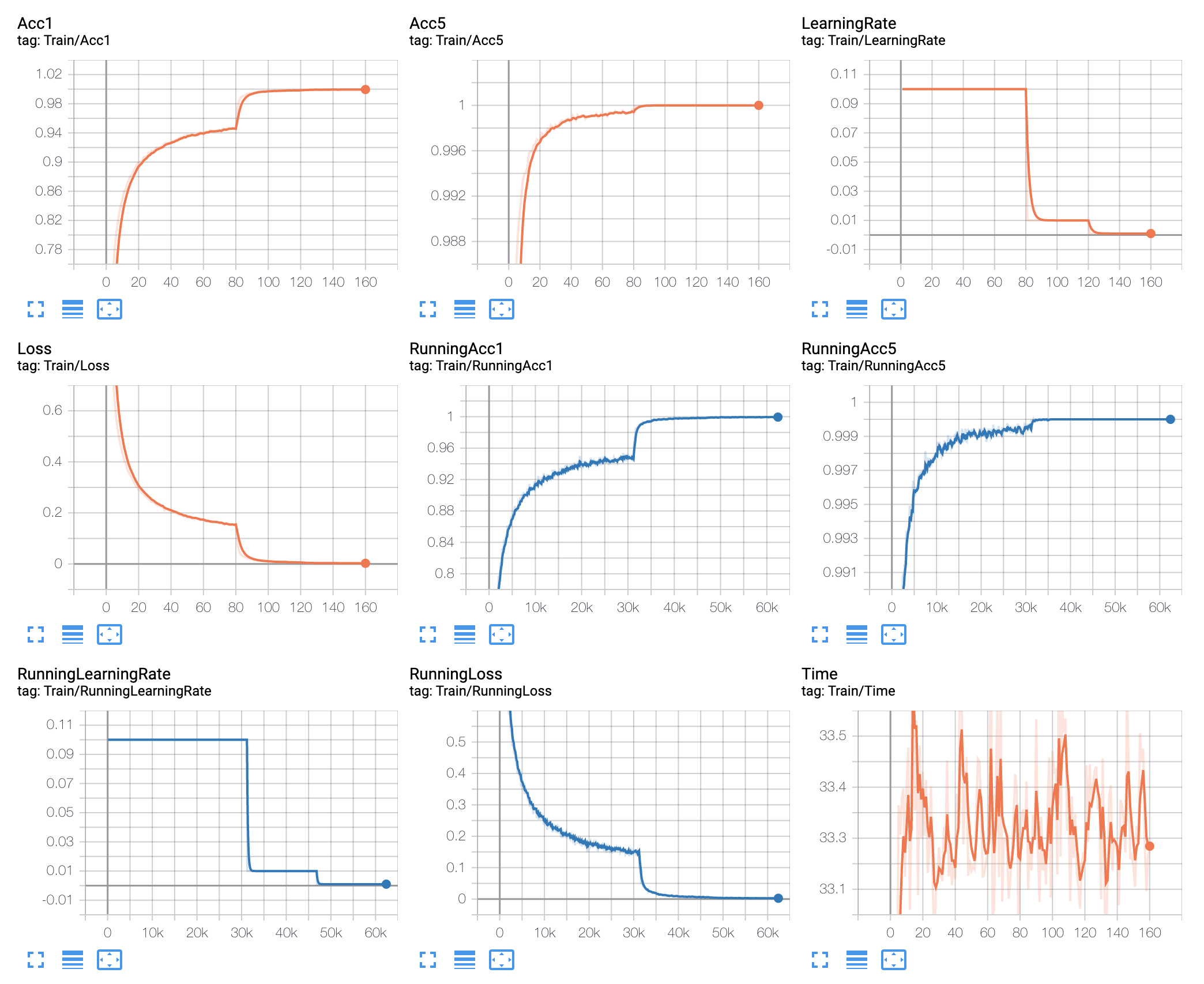
Val:

from pytorch_image_classification.
 chejulien
commented on June 4, 2024
chejulien
commented on June 4, 2024
Hello, so did you guys fixed this problem? I can still see this problem and I am using windows
from pytorch_image_classification.
hysts
commented on June 4, 2024
Hi, @chejulien
Did you try this? #22 (comment)
from pytorch_image_classification.
Related Issues (20)
- how to create the label? HOT 1
- how to train with my own dataset? HOT 2
- Which files that I need to change if I want to test with only an image? HOT 2
- Own DataSet HOT 1
- if n_channels: 1 then RuntimeError HOT 2
- Assertion Error HOT 2
- How could I test my own dataset? HOT 15
- How could I change the code? HOT 3
- Do you use a val/test split? HOT 1
- Do you have training logs? HOT 1
- Slight inaccuracy in VGG model definition? HOT 1
- how to add more algorithm for imagenet from pytorch-image-models HOT 2
- Minor typos HOT 1
- Can you tell me the content of the config.yaml(in #16) when i test my own test dataset with any model HOT 2
- Tset command
- how to train use distributed pattern? HOT 2
- can I run the script without GPU&apex? HOT 1
- 分布式训练怎么设置? HOT 1
- no_weight_decay_on_bn removes weight decay on FC HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from pytorch_image_classification.