Comments (11)
 kosloot
commented on May 28, 2024
1
kosloot
commented on May 28, 2024
1
still puzzling...
Somehow its seems that programs get slower with increasing size of the OUTPUT files.
Checked this with 'mblem' too.
First thought: 'pv' get in the way. But also without pv is slows down.
Next guess: using cout and redirecting slows it down.
So I added an output parameter to mblem, to write directly to a file.
But to no avail... at least, nor really.
But for output files < 1.5 Gb it seems reasonable. So splitting seems the way to go.
Bit still....
This is nerve-wrecking....
from frog.
kosloot
commented on May 28, 2024
1
Hi,
thanks for the update.
to start of: I am surprised about the numbers files you mention. We are used to processing 1000 files per hour or so. So probably your files are very, very large?
The idea of thread starving might be interesting to look at, but:
drum-roll...
I am working on a re-implementation of Frog, aiming at speed, memory footprint and less locking.
So fixing the current Frog is not a high priority.
The work is going well, but slow. A first release is scheduled a month (or two...) form now.
Feel free to checkout the new_datastructure branch of frog and test it.
You will also need the foliareader branch for libfolia then.
NO WARRANTY
from frog.
kosloot
commented on May 28, 2024
Well, i am not sure what is happening here, but my first guess is that the process gets low on memory.
Do you have enough RAM to run this kind of large input?
frog will construct a large FoLiA document, covering the whole input. I wouldn't be surprised if it needs 50G of RAM or more.
This is the result of an unfortunate design decision long ago.
For the time being, it might be a solution to split the input file into smaller parts.
You also might experiment with the -n option (one sentence per line)
or the --threads option, setting it to 1
from frog.
 gmjonker
commented on May 28, 2024
gmjonker
commented on May 28, 2024
Frog is currenly using 577MB of memory, see screenshot.
I will try the -n and --threads=1.
If it doesn't help, I will split indeed.
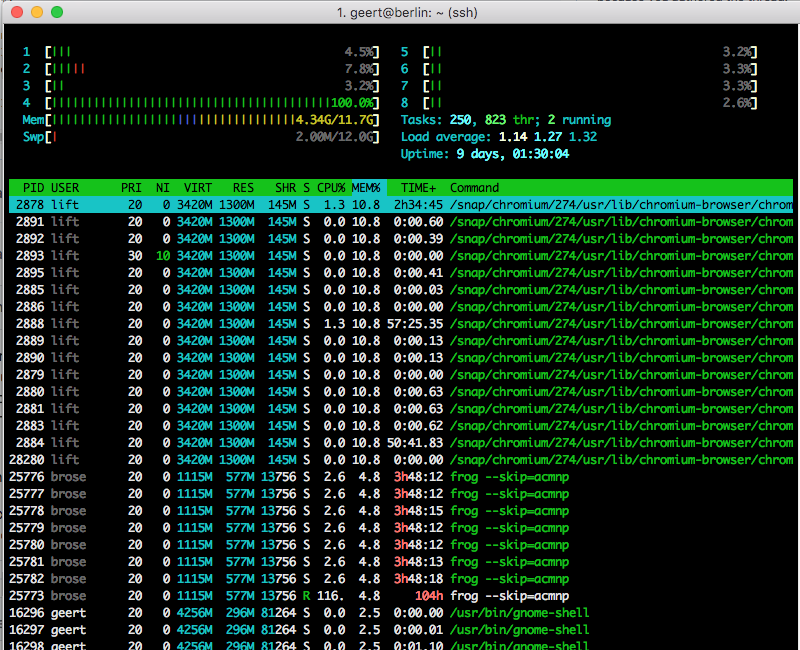
from frog.
kosloot
commented on May 28, 2024
Hmm, this is strange.
it might be that Frog is deadlocking on the threads.
is it producing any output?
if you have the rights, you could try 'strace -p 25773'
if the only thing it shows is a futex-wait then your are probably lost.
Side note:
Is this problem reproducible? Or just once in a while?
Is all else fails, is it possible to give me the offensive file?
from frog.
gmjonker
commented on May 28, 2024
Frog is still producing output, but just very slowly.
The behaviour is always the same.
I should also mention that I'm running frog in proycon/lamachine
I'm now testing with --threads=1
from frog.
kosloot
commented on May 28, 2024
hmm. OK. getting out of clues then....
Is the 2.5 Gb available for me? for analyzing.
from frog.
gmjonker
commented on May 28, 2024
--threads=1 doesn't help.
from frog.
 asharkinasuit
commented on May 28, 2024
asharkinasuit
commented on May 28, 2024
An update perhaps: I've been running frog 0.15 (based on ucto 0.13.2, libfolia 1.13, timbl 6.4.12, ticcutils 0.19, mbt 3.3.2) for the past several days on the COW corpus. I knew there was no way that was all fitting in memory, so I split it into files of 10k sentences each and asked frog to run on them using frog --testdir=. -n --skip=cmnp --xmldir=. --nostdout (just to be complete; the point is probably the -n --threads stuff, but I can say I only need the lemmas and didn't want to slow things down with a parse.)
I let it run over the weekend and it looks like it processed about 80 files on Friday, 70 on Saturday and 40 on Sunday. The new clue to the problem I would contribute is that it started with 8 threads, but this morning I found it using only one thread (by CPU usage anyway). Memory is not a problem on the machine I'm using, but maybe the threads are dying or getting killed for some reason? Not sure this relates to the above problems, since there apparently threads don't help, but maybe this is still worth looking into.
PS Sorry I didn't check to see if threads died or just CPU use reduced; I can let it run this week and check when it slows down again.
from frog.
asharkinasuit
commented on May 28, 2024
Yea the files are just under a megabyte each, 10k sentences a pop. I suppose we'll see how it goes when the new version comes out.
from frog.
kosloot
commented on May 28, 2024
Well, the new implementation is around for quite a while now. Don't know if it made any difference.
But at the moment work on Frog is on a hold. except for real bugs.
If work will ever be picked up is dependent on real demand, accompanied by some currency.
So closing this issue for now.
from frog.
Related Issues (20)
- Frog Chunker creates invalid FoLiA HOT 2
- released frog (0.29) depends on unreleased libfolia (2.15) HOT 2
- Building on Ubuntu 22.04 LTS Pop!_OS HOT 1
- Token annotation error for XML output with non-standard rules HOT 3
- segmentation fault when invoked with a missing [[tokenizer]] section in the configuration HOT 5
- Server mode creates only 1 paragraph HOT 2
- Add JSON output as an alternative to 'tabbed' format HOT 3
- Frog breaks while processing large amount of txt data HOT 11
- Keep the deep_morph structure intact when resolving MWU's HOT 1
- Simplify option and configuration handling
- MWU output when no Parser is selected HOT 7
- Update debian package for v0.20
- Python Frog HOT 2
- Frog (through python-frog) accumulates a huge number of temporary files HOT 11
- Praktische vragen rondom grote datasets HOT 7
- Bug: frog server; frog-:connection lost unexpected : write to client failed HOT 2
- Segfault on FoLiA in to FoLiA out (speech data with events and utterances) HOT 7
- New release? HOT 3
- frog lemmatizer with --deep-morph misses a morpheme in FoLiA output
- [Docker] Initialization fails for nld-vnn and dum HOT 7
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from frog.