Comments (7)
 janosh
commented on June 12, 2024
1
janosh
commented on June 12, 2024
1
Yes, I've wanted that in atomate1 too!
from atomate2.
 utf
commented on June 12, 2024
1
utf
commented on June 12, 2024
1
@utf I think pydantic does have a concept of optional vs required fields.
Yep, but I believe "optional field" just means the value can be None or an empty dict or list etc. Technically, all fields in the atomate2 task documents are already optional.
from atomate2.
utf
commented on June 12, 2024
Interesting - the main point of having a schema is so that you can enforce a structure for task documents. I.e., you can guarantee each document will have every field. This was actually an issue for MP, i.e. some calculations parsed using older versions of pymatgen didn't have all the correct fields in the database, which meant you have to add a lot of checks in the builders.
I'm not sure dropping empty keys is actually possible with pydantic models as their primary goal is to enforce a schema.
Can I ask why this is an issue for you?
from atomate2.
janosh
commented on June 12, 2024
@utf I think pydantic does have a concept of optional vs required fields.
@arosen93 When you say MongoDB, do you mean the Compass app? If so, a feature I have found somewhat helpful in this regard is to define projections incl. only the fields you care about and then store them as favorite queries so you don't need to retype them every time.
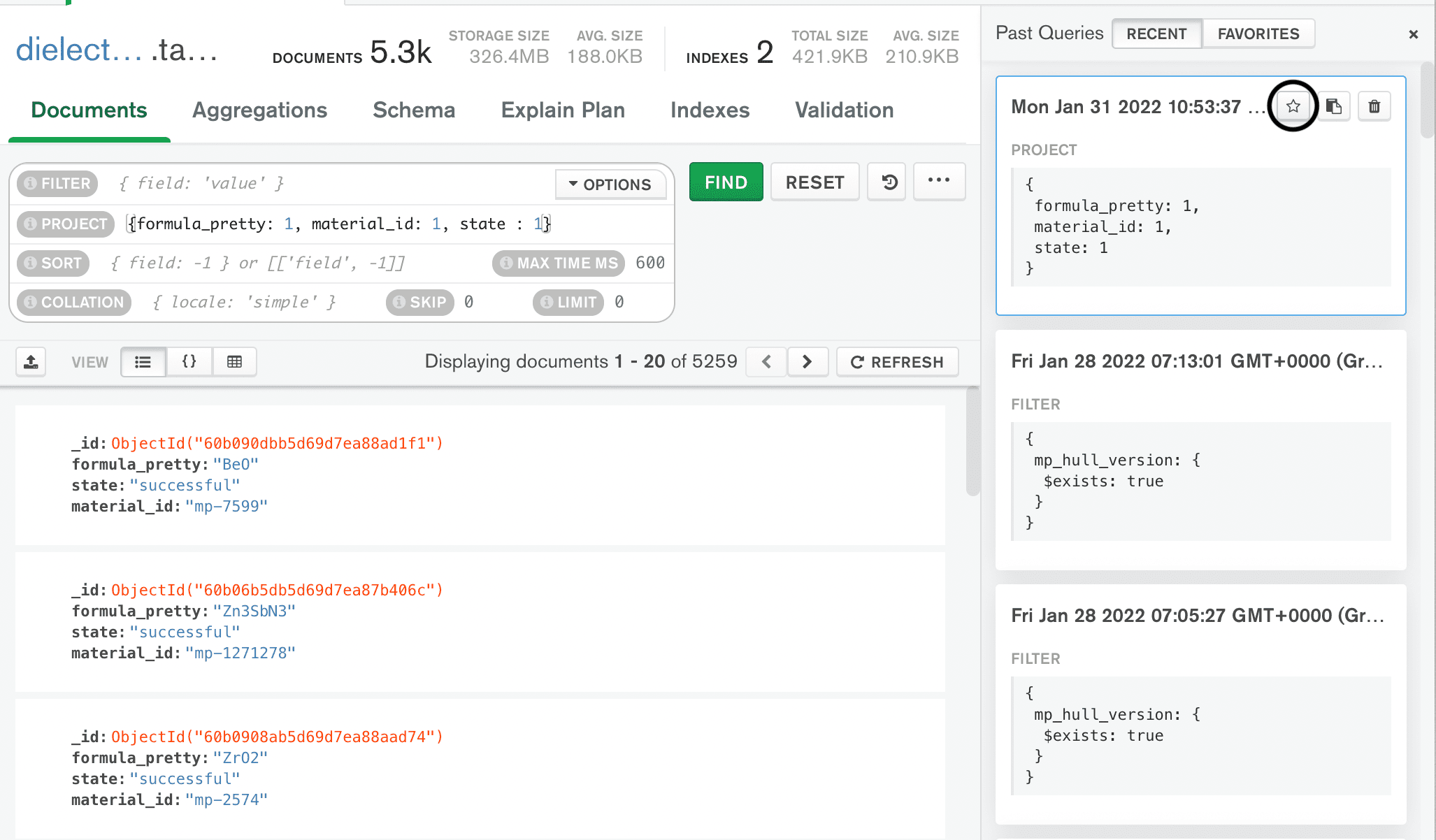
from atomate2.
utf
commented on June 12, 2024
Actually, maybe this is what you want: https://pydantic-docs.helpmanual.io/usage/exporting_models/#modeldict
There are a couple of options to Model.dict():
- exclude_unset: whether fields which were not explicitly set when creating the model should be excluded from the returned dictionary; default False. Prior to v1.0, exclude_unset was known as skip_defaults; use of skip_defaults is now deprecated
- exclude_defaults: whether fields which are equal to their default values (whether set or otherwise) should be excluded from the returned dictionary; default False
I think Model.dict(exclude_defaults) should do the trick. I guess this could be added somewhere in jobflow rather than atomate2?
from atomate2.
 Andrew-S-Rosen
commented on June 12, 2024
Andrew-S-Rosen
commented on June 12, 2024
Thank you for this very useful background and discussion!
I'm not sure dropping empty keys is actually possible with pydantic models as their primary goal is to enforce a schema.
I suppose one could use something like delattr, but I definitely get what you mean.
Can I ask why this is an issue for you?
It's not so much an issue as an inconvenience. When I pull up a dataset in Studio3T, which is my program of choice, each deposited set of calculation results is full of null entries. Visually, it makes it a little bothersome to scroll through. I'm a very visual person and can't remember how schemas are structured for the life of me, so I'm always referring to Studio3T for how my dataset is structured. I thought it'd be nice to have it be "cleaner", albeit at the expense of not having the same keys for all documents. I can see how that might be an issue downstream for some (I haven't run into a scenario like that yet, but maybe one day I will).
There are a couple of options to Model.dict():
This is fantastic! Yes, I think this is the best solution. Actually, my original solution was going to be to suggest to add a function like clean_dict() (rather than modifying the pydantic model directly) that operates the same way as .dict() but cleaner. Seems like there's already a route for that. Thanks for the find.
I think Model.dict(exclude_defaults) should do the trick. I guess this could be added somewhere in jobflow rather than atomate2?
exclude_defaults seems slightly different. For instance, if one were to set the default value of True then it wouldn't be stored in the returned dict unless it's set to False, whereas my main concern is regarding all the null entries. Here, it would generally have that effect though because the defaults are generally (always?) None.
Anyway, given the points here, I think it makes sense to not modify this in Atomate2 directly. It could be modified with a kwarg in Jobflow, as you suggested.
from atomate2.
Andrew-S-Rosen
commented on June 12, 2024
I'm closing this issue because I agree it's better suited for Jobflow.
from atomate2.
Related Issues (20)
- Dealing with large structures in the phonon workflow for forcefields HOT 5
- BUG: WAVECAR deletion HOT 8
- Discussion: sigma value in NSCF calculation
- BUG: custom CHGNET model in PhononFlow throws `jsanitize` error HOT 27
- BUG:ValueError: dictionary update sequence element #0 has length 1; 2 is required HOT 1
- FEATURE: GW workflow with VASP HOT 4
- BUG: pip install atomate2 does not automatically install phonopy and seekpath HOT 2
- Feature: add an additional step to the LOBSTER workflow to reduce run times
- Improve failed perturbations handling in elastic workflow HOT 1
- Feature: Easy switch between GPU/CPU for forcefields HOT 6
- BUG:Could not resolve reference HOT 3
- MLPs are not working in the test suite HOT 4
- The need for `contextlib.redirect_stdout` for MLFF MD
- Import MP input sets directly from Pymatgen HOT 1
- BUG: `RecursionError` with `VaspMaker.input_set_generator.get_input_set`
- BUG: Potential incompatibility with "old" MP GGA workflow w.r.t. k-points in GGA static calculations HOT 2
- `ElasticMaker` shouldn't use submaker as default factory by design HOT 3
- BUG: Documentation currently does not show all the subpackages and modules available in atomate2
- BUG: `MAGMOM` not preserved in r2SCAN workflow HOT 2
- BUG: `pydantic` `UserWarning` from `LobsterTaskDocument`
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from atomate2.