Comments (17)
 Sun-Ziyi
commented on July 23, 2024
1
Sun-Ziyi
commented on July 23, 2024
1
问题解决https://blog.csdn.net/c28732149/article/details/88222862
终于可以close this indeed!!!
from randomcnn-voice-transfer.
 mazzzystar
commented on July 23, 2024
mazzzystar
commented on July 23, 2024
你plot一下就知道是什么了。我的理解:
energy其实就是每帧各频率的值,你可以理解为傅里叶变换各正弦曲线的系数。
音调取决于基频(Fundamental frequency), 即你看到频谱图最亮的那条频率。音色取决于非基频的其他部分,也称泛音。
抱歉此部分代码找不到了,工作其实很容易理解:
Dataset: arctic
speaker1, audio1 记作 S1, A1
speaker1, audio2 记作 S2, A2
设想我们可以将Content和Style完全分离,训练一个网络同时优化两个模块,优化:
loss_content = min(dist(S1A1, S2A1) + dist(S1A2, S2A2))
loss_style = min(dist(S1A1, S1A2) + dist(S2A1, S2A2))
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
谢谢大佬!
但是对于代码实践方面,我还是存在疑惑:
我大概明白了你的“优化Content和Style的loss模块”,但是可否直接在你这篇代码的输入input上做修改呢?
CONTENT_FILENAME = basepath + "boy18.wav" STYLE_FILENAME = basepath + "girl52.wav"
把内容语音的input改为多个不同人说的boy18.wav内容(boy18-1.wav、boy18-2.wav、boy18-3.wav)
把风格语音的input改为同一个人girl52说的不同内容(girl52-1.wav、girl52-2.wav、girl52-3.wav)
由于小弟Python不精,不知该如何修改
from randomcnn-voice-transfer.
mazzzystar
commented on July 23, 2024
其实就是选择一种网络结构,然后构建这content和style模块,训练网络就行。对于一段新audio,经过已经训练好的网络得到content feature和style feature,再用style transfer的**做就行了。
网络构建可以看看PyTorch官网吧。
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
谢谢!
from randomcnn-voice-transfer.
mazzzystar
commented on July 23, 2024
@Sun-Ziyi
刚看到这篇可能和你想做的比较像
https://researchdemopage.wixsite.com/tts-gan
https://openreview.net/forum?id=ByzcS3AcYX
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
@mazzzystar
thank you!
但是这篇好像处理的是语音的“情绪”,我想弄的是transfer A's style to B。
style:比如王菲空灵的风格、邓丽君甜蜜柔软的风格......
大神,可以帮我个忙吗?我真的很想学习下“我之前也尝试过类似的方法,即用不同说话人、相同内容的语音样本,计算一个loss来抹去speaker information,然后用同一个人的不同句子,计算另一个loss抹去content information,但训练效果并不好。”您的这篇代码,您可否再编编程?就相当于你这篇代码的番外了。
由于我既不是通信专业的、在数学本专业上又只会看看理论,代码着实让我头大啊。
!!!好人一生平安!!!
from randomcnn-voice-transfer.
mazzzystar
commented on July 23, 2024
Sorry实在非常抱歉。本repo也是我在之前labs里做的,目前已经工作压力也不小,难挤出时间再去尝试新想法且也有其他想法待尝试,未来再看看能否继续试试吧。
不过目前我仍然在做声音的style transfer,可以给你建议一些其他方法:
- 比如VQ-VAE(https://avdnoord.github.io/homepage/vqvae) 或者其他
representation learning的方法,这种方法的核心**是提取speaker说话中比较通用的音素信息(比如"你好"的音素信息可以是,'ne1 yi2 he1 ao3'),然后增加speaker ID信息用来做reconstruction。
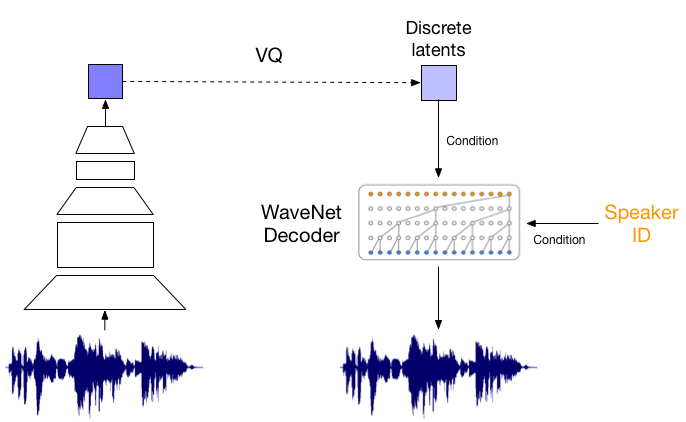
- 或者尝试基于语音合成(TTS)来做。
部分工作其实是可以在github看到开源版本的。
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
@mazzzystar
谢谢你:)
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
@mazzzystar ,不好意思,我又有问题想请教你了:)
前面说到我想用三个不同speakers说的同一句语音作为_内容语音_ ,同一个speaker说的3句不同内容的语音作为_风格语音_,具体如下:
content_chen.wav
content_sun.wav
content_zhou.wav
我把以上语音用Adobe AU的混缩语音功能得到content_csz.wav:实际上是chen\sun\zhou三人同时说同一内容的语音
style_1.wav
style_2.wav
style_3.wav
我把以上语音用Adobe AU的混缩语音功能得到style.wav:实际上是卷福(target speaker)一人同时说3句不同内容的语音
然后我把content_csz.wav和style.wav作为input,得到了如下错误:
(但是当我把content_chen.wav和style_1.wav\content_sun.wav和style_1.wav\content_zhou.wav和style_1.wav......作为input则没有错误,程序可以得到相应结果)
E:\aaa-sunziyi\test\venv\Scripts\python.exe "E:/aaa-sunziyi/test/3-1 randomCNN-voice-transfer-master/train.py"
Traceback (most recent call last):
File "E:/aaa-sunziyi/test/3-1 randomCNN-voice-transfer-master/train.py", line 17, in <module>
a_content, sr = wav2spectrum(CONTENT_FILENAME)
File "E:\aaa-sunziyi\test\3-1 randomCNN-voice-transfer-master\utils.py", line 8, in wav2spectrum
x, sr = librosa.load(filename)
File "E:\aaa-sunziyi\test\venv\lib\site-packages\librosa\core\audio.py", line 119, in load
with audioread.audio_open(os.path.realpath(path)) as input_file:
File "E:\aaa-sunziyi\test\venv\lib\site-packages\audioread\__init__.py", line 116, in audio_open
raise NoBackendError()
audioread.NoBackendError
Process finished with exit code 1
from randomcnn-voice-transfer.
mazzzystar
commented on July 23, 2024
我没用过混缩语音功能,是将3个声音重叠在一起么?
这个错误主要是librosa.load对某些修改过的wav格式不支持,需要:
sudo apt-get install libav-tools
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
@mazzzystar 是的(3个声音重叠);请问sudo apt-get install libav-tools这串代码放在哪个py.文件呢?train.py or utils.py or model.py???
from randomcnn-voice-transfer.
mazzzystar
commented on July 23, 2024
额。。这是linux安装lib包文件的命令。
Windows的话,你找找看有没有libav-tools这个包,安装就好
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
@mazzzystar

没找到啊
还有其他解决方法吗???
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
@mazzzystar 我还想跟你分享一个现象:

图中的content_chen + style_2.wav是由content_chen.wav和style_2.wav生成的
图中的content_chen + style_3.wav是由content_chen.wav和style_3.wav生成的
style_2.wav和style_3.wav是同一个人说的不同内容的语音(style_2.wav时长 > style_3.wav时长)
我很奇怪:
- content_chen + style_2.wav和content_chen + style_3.wav听起来是没有区别的
- content_chen + style_2.wav和content_chen + style_3.wav时间长度不一样,分别与style_2.wav、style_3.wav时长相同
- 在你的例子中, 内容语音boy18.wav的时长 < 风格语音girl52.wav的时长,这是生成良好的生成语音的必要条件吗?但是在我的实验过程中,content_chen + style_2.wav(content_chen.wav的时长 < style_2.wav的时长)和content_chen + style_3.wav(content_chen.wav的时长 > style_2.wav的时长),结果却是1.2.中所阐述的:content_chen + style_2.wav和content_chen + style_3.wav听起来是没有区别的,但是时间长度却不一样
很想听听大神的见解 :D
from randomcnn-voice-transfer.
mazzzystar
commented on July 23, 2024
我是指,Windows平台下的libav-tools包,你Google 搜索"libav-tools windows"下载安装就行。
此外长度不是必要的。我之前那两段不一样,但是我用无声信息(silence)强制补齐成一样了,但不需要一致。而且我不明白你把三段声音重叠在一起的目的是什么?
from randomcnn-voice-transfer.
Sun-Ziyi
commented on July 23, 2024
"把三段声音重叠在一起"类似于RGB图片形式,就是想试试结果是什么样的(满足下好奇心,hahhh)。
然而没找到libav-tools。。。
from randomcnn-voice-transfer.
Related Issues (20)
- bad result i git!!
- Is it possible to retain a model of the voice conversion? HOT 2
- Some unclear details. HOT 1
- can't optimize a non-leaf Tensor HOT 1
- required os and python versions? HOT 3
- Input output??? HOT 1
- Question: difference between this repo and others? HOT 1
- Why does it have so much noise and vibration, how can we remove it ? HOT 10
- Bad very long time to train compare the original project DmitryUlyanov
- no voice
- RuntimeError: CUDA error: unspecified launch failure HOT 1
- AttributeError: module 'librosa' has no attribute 'output' HOT 1
- Any updates to this? HOT 2
- when I run train, some problems came out: HOT 9
- How to Train this repo, can you please eloborate ? HOT 4
- Installation Environment HOT 2
- import torch error HOT 7
- RuntimeError: CUDA out of memory HOT 1
- Phase restoration algorithm HOT 2
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from randomcnn-voice-transfer.