Comments (10)
 vinid
commented on June 2, 2024
vinid
commented on June 2, 2024
Hello!
yea the vocab is needed to reconstruct the bag of words representation, it is the thing we use to build the topics.
On the other hand, you can pass any custom bag of words representation
from contextualized-topic-models.
 raymondsim
commented on June 2, 2024
raymondsim
commented on June 2, 2024
Thanks for your reply.
The encoder I am using is BART encoder which uses BPE tokenization so many of the words have "Ġ" in front of it, when training topic model, my plan is to remove this character from all vocabs so that the topic model can learn with the vocab better.
Will this be an issue that the vocab list is not 100% the same as vocab.json in the encoder I used?
from contextualized-topic-models.
vinid
commented on June 2, 2024
which text_for_bow will you be giving to the model?
from contextualized-topic-models.
raymondsim
commented on June 2, 2024
For now, I used preprocessed documents.
from contextualized-topic-models.
vinid
commented on June 2, 2024
preprocessed how? these have to correspond to the vocab. if you use BART tokenizer there should not be any issue
from contextualized-topic-models.
raymondsim
commented on June 2, 2024
I used WhiteSpacePreprocessingStopwords as shown in the example in colab.
So I guess what you mean is I should use BART tokenizer for data preprocessing here?
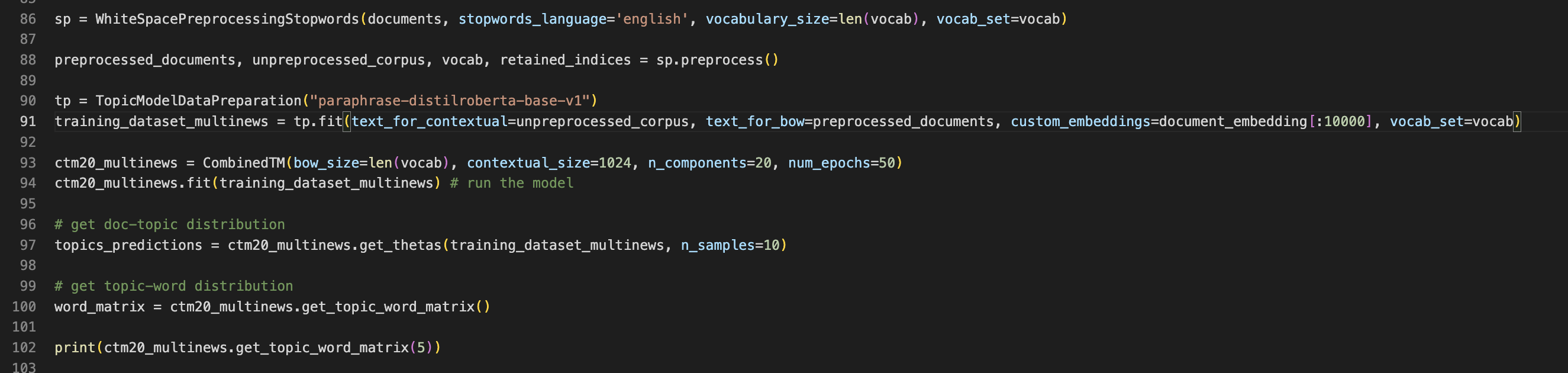
from contextualized-topic-models.
vinid
commented on June 2, 2024
you need to define your own preprocessing pipeline and data preparation yes :)
from contextualized-topic-models.
raymondsim
commented on June 2, 2024
After I modified the vocab list by removing some special characters, the index still remains unchanged and that's why I thought providing vocab list from the encoder to WhiteSpacePreprocessingStopwords would be sufficient.
And if I use the BART tokenizer for preprocessing pipeline, that means the vocab will have some special characters like "Ġ", will that affect the performance of topic model? Or is it okay as long as they are consistent?
Do you mind providing some pointers on how I can integrate BART tokenizer into preprocessing.py?
Thanks in advance :)
from contextualized-topic-models.
vinid
commented on June 2, 2024
And if I use the BART tokenizer for preprocessing pipeline, that means the vocab will have some special characters like "Ġ", will that affect the performance of topic model? Or is it okay as long as they are consistent?
it depends on what are you using this.
at a high-level, CTM takes in input two things:
-
a sentence
-
a preprocessed sentence
-
is fed to the contextualized embedders and 2) is fed to a "bow" generator. The bow uses whitespace to detect what counts as a word.
at a more in-depth level, CTM takes in input two things:
- an embedded representation coming from the contextualized embeddings
- an embedded representation combing that is the bag of words.
You can decide where to operate wrt your goals.
You can use your own custom embeddings and a bag of words based on the text you like. You can use BART tokenizer, but this is not mandatory:
You can still use BART embeddings for what we referred to as 1) and standard whitespace-based BoW representations for what we referred to as 2).
You can preprocess text with BART and represent text using sentences like "The new desi Ġgn is fun", but you will end up with topics that contain words with that character.
I am not sure what you are trying to achieve, but I'd simply follow this procedure and use your own embedder. For example, assuming you have your text_for_contextual and text_for_bow.
vectorizer = CountVectorizer() #from sklearn
train_bow_embeddings = vectorizer.fit_transform(text_for_bow)
train_contextualized_embeddings = MY_BART_EMBEDDER(text_for_contextual)
vocab = vectorizer.get_feature_names_out()
id2token = {k: v for k, v in zip(range(0, len(vocab)), vocab)}from contextualized-topic-models.
vinid
commented on June 2, 2024
let me know if this helps
from contextualized-topic-models.
Related Issues (20)
- Inference with the last version in master HOT 2
- How to create 'miscellaneous' topic from this model HOT 1
- Numpy error evalation scores HOT 17
- OSError: [Errno 22] Invalid argument HOT 5
- representation embedding HOT 18
- How to work with Large dataset? HOT 14
- Large Dataset HOT 4
- How to Find coherence of this Topic and Model? HOT 1
- GPU and CPU usage HOT 2
- [help] Required versions HOT 4
- Perplexity HOT 3
- AttributeError: 'CountVectorizer' object has no attribute 'get_feature_names' HOT 2
- Loading own embedding & division by zero error HOT 7
- Testing with custom embedding HOT 7
- More time spent for finding smaller number of topics HOT 5
- Add patience to reduce LR as CTM argument HOT 1
- Bug: Minor bug when constructing the model directory path
- Running cythonize failed! HOT 2
- Variable naming issues HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from contextualized-topic-models.