Comments (19)
 kwcckw
commented on May 30, 2024
1
kwcckw
commented on May 30, 2024
1
I'm thinking to use augraphy to further improve the work in old document restoration, since those documents are quite rare and it would be helpful if we are able to produce some synthetic samples to further aid in their model training process.
Example of old document restoration:
https://arxiv.org/pdf/2001.08742.pdfDo you guys think this is a good idea?
I tried to create some old documents by using different fonts and papers. Here are the current results:









Is this real enough? Or do let me know if you think there's any area of improvement.
One of the constraint right now is the page is in perfect condition, it would be nice if we can create some teared paper effect.
from augraphy.
 proofconstruction
commented on May 30, 2024
1
proofconstruction
commented on May 30, 2024
1
I think this should be a "pipeline level" demo where we apply several augmentations to produce a more relatable real life application. So eventually we can have several predefined pipelines (sort of utility class), each with different purpose, for example photocopy machine effect, old document effect, and etc (can't think of more now).
I like this idea, and I think we can use the pipelines for the Reproducing Archetypes work as the predefined ones. Once we get those working well, we can add them to augraphy.default.prebuilt or something, so users can select one of those or the default_augraphy_pipeline containing all augmentations.
from augraphy.
kwcckw
commented on May 30, 2024
I'm thinking to use augraphy to further improve the work in old document restoration, since those documents are quite rare and it would be helpful if we are able to produce some synthetic samples to further aid in their model training process.
Example of old document restoration:
https://arxiv.org/pdf/2001.08742.pdf
Do you guys think this is a good idea?
from augraphy.
kwcckw
commented on May 30, 2024
I added a demo here using google colab:
https://colab.research.google.com/drive/1g0hDeneIGcy0sYtIzZSnNmZfesFdu5Sn?usp=sharing
from augraphy.
 jboarman
commented on May 30, 2024
jboarman
commented on May 30, 2024
Thanks @kwcckw
Can you update that notebook to use gdown?
Once you've compiled all the files into a Google Drive folder, then you will need to file IDs for each file: https://clay-atlas.com/us/blog/2021/07/01/python-en-gdown-package-download-file-google-drive/
If we are sharing more than a few files, then it might be best to ZIP the files together first so that it's a single file to be downloaded and unpacked within the notebook.
from augraphy.
kwcckw
commented on May 30, 2024
Thanks @kwcckw
Can you update that notebook to use
gdown?Once you've compiled all the files into a Google Drive folder, then you will need to file IDs for each file: https://clay-atlas.com/us/blog/2021/07/01/python-en-gdown-package-download-file-google-drive/
If we are sharing more than a few files, then it might be best to ZIP the files together first so that it's a single file to be downloaded and unpacked within the notebook.
Thanks, i will look into this and apply the changes accordingly.
from augraphy.
kwcckw
commented on May 30, 2024
I added a new example with gdown, now user will be able to download files and run the same thing from their end. Is there anyone can try this out and let me know if this is run-able?
Link: https://colab.research.google.com/drive/1IDkfmKKajMb2dlchW-rWN6kmrnGk2TWX?usp=sharing
i just tried with another account and with a new copy of notebook, so far there's isn't any issue yet and please let me know if you guys facing any problem to run the notebook.

from augraphy.
jboarman
commented on May 30, 2024
Can you remove all dependency on connecting to a personal Google Drive (outside of using gdown I mean)?
For example, we should be able to just use the local folder on the Colab server instead mounting the “My Drive” reference.
from augraphy.
kwcckw
commented on May 30, 2024
Can you remove all dependency on connecting to a personal Google Drive (outside of using
gdownI mean)?For example, we should be able to just use the local folder on the Colab server instead mounting the “My Drive” reference.
Alright, at this point i'm not aware of such function yet, let me check again.
from augraphy.
kwcckw
commented on May 30, 2024
Here's the updated notebook which is able to run without connecting to any gdrive, but you still need to login to your google account to run it:
https://colab.research.google.com/drive/1MXNhPQ_37aiPmAOkfKNCDhKnlaPc1zDt?usp=sharing
Also if the code is updated in the pip installation , then we can skip the section to download the zip file too.
from augraphy.
kwcckw
commented on May 30, 2024
I added new notebook on the example of pipeline for photocopy paper, and I've updated the previous example on old document to use the code directly from the repo. So right now there's 2 examples from my end:
-
Photocopy paper:
https://colab.research.google.com/drive/1hLHyyvNi-cRRDOcqtPnZPCw4j25oZMDG?usp=sharing -
Old document:
https://colab.research.google.com/drive/1MXNhPQ_37aiPmAOkfKNCDhKnlaPc1zDt?usp=sharing
from augraphy.
 tbrettallen
commented on May 30, 2024
tbrettallen
commented on May 30, 2024
I'm having an issue running this notebook. I've attached the issue I've run into in the image below.
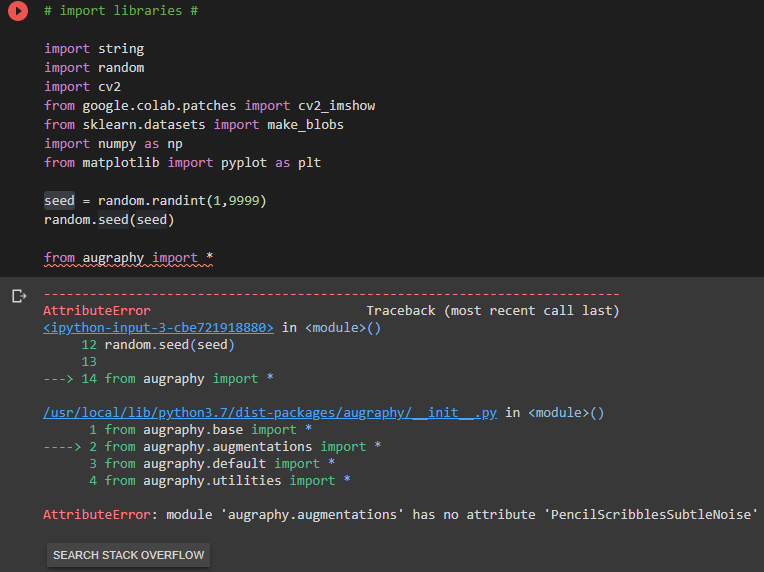
from augraphy.
kwcckw
commented on May 30, 2024
I'm having an issue running this notebook. I've attached the issue I've run into in the image below.
Sorry, it should be caused by a typo in the init file. Now i updated the code and tested it. It should be having no issue to run now.
from augraphy.
proofconstruction
commented on May 30, 2024
I get a type error running this.

from augraphy.
kwcckw
commented on May 30, 2024
I get a type error running this.
Sorry, this notebook is still pending update, since it is using the previous badphotocopy code. I will post here again when it is updated.
from augraphy.
kwcckw
commented on May 30, 2024
Sorry, this notebook is still pending update, since it is using the previous badphotocopy code. I will post here again when it is updated.
@proofconstruction I just updated the notebook, please try again and let me know if you facing any issue to run the notebook.
from augraphy.
proofconstruction
commented on May 30, 2024
These look really good!
Is the "Photocopy machine" code now part of BadPhotoCopy?
The "Synthetic old documents" code can probably become a new augmentation, or maybe a utility class. We should add a new Issue to discuss this.
from augraphy.
kwcckw
commented on May 30, 2024
These look really good!
Is the "Photocopy machine" code now part of
BadPhotoCopy?The "Synthetic old documents" code can probably become a new augmentation, or maybe a utility class. We should add a new Issue to discuss this.
I think this should be a "pipeline level" demo where we apply several augmentations to produce a more relatable real life application. So eventually we can have several predefined pipelines (sort of utility class), each with different purpose, for example photocopy machine effect, old document effect, and etc (can't think of more now).
from augraphy.
proofconstruction
commented on May 30, 2024
Closed with PR #154
from augraphy.
Related Issues (20)
- Create Baseline Performance Benchmark; Apply Initial Optimizations Using Numba HOT 2
- Create Example Using Dataloader for PyTorch and TensorFlow HOT 1
- Add Python 3.11 Support, Drop Python 3.7 HOT 2
- Images Broken in PyPI Listing HOT 2
- Reflected Light from Camera Flash or other Bright Sources HOT 1
- Add Color Shifting / 3D Blur Effect HOT 4
- Improve PageBorder effect HOT 1
- Add support for bounding box, keypoints and mask. HOT 1
- Add `InkColorSwap` to Replace the Color Used for Lettering in a Document HOT 1
- Add `InkMottling` Augmentation to Ensure Ink is Non-Uniform HOT 1
- Add support for image with alpha layer. HOT 1
- Color range in InkBleed is not working HOT 1
- Update to Paper Factory HOT 1
- Confusion on `Geometric` Augmentation HOT 2
- Memory leak in AugmentationSequence HOT 4
- Training becomes very slow with these transforms. HOT 10
- ColorPaper cant generate different color in the cycle running HOT 2
- DirtyScreen doesnt work and crashes jupyterlabs HOT 2
- stucked when I process image in the cycle HOT 5
- Default pipeline generates many "unreadable" documents HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from augraphy.