Comments (11)
 theEricMa
commented on May 26, 2024
1
theEricMa
commented on May 26, 2024
1
Yes, the screenshot means batch size = 4 per GPU for sure. The training is configurable in config/otavatar.yaml, you can change the batch size there.
from otavatar.
theEricMa
commented on May 26, 2024
@szh-bash Please refer to the log and check if there is a message as follows: No checkpoint found at iteration 2000. I suspect you did not load the weight correctly. If there is any other question, please let me know.
from otavatar.
 szh-bash
commented on May 26, 2024
szh-bash
commented on May 26, 2024
@szh-bash Please refer to the log and check if there is a message as follows: No checkpoint found at iteration 2000. I suspect you did not load the weight correctly. If there is any other question, please let me know.
Yes there is

This is a screenshot of the file information in the folder, what should i do?

from otavatar.
szh-bash
commented on May 26, 2024
After i print (pot, model_path, latest_checkpoint_path) in load_checkpoint() from "trainers/base.py" (line 242),

got these outputs.
snapshot_save_iter: 100
snapshot_save_epoch: 5
snapshot_save_start_iter: 100
snapshot_save_start_epoch: 0
image_save_iter: 100
eval_epoch: 1000000000
start_eval_epoch: 1000000000
max_epoch: 2000
max_iter: 1000000000
logging_iter: 10
image_to_tensorboard: True
which_iter: 2000
resume: False
checkpoints_dir: result
name: config/otavatar.yaml
phase: test
gen:
type: models.triplane::TriPlaneGenerator
param:
z_dim: 512
w_dim: 512
c_dim: 25
channel_base: 32768
channel_max: 512
mapping_kwargs:
num_layers: 2
rendering_kwargs:
depth_resolution: 48
depth_resolution_importance: 48
ray_start: 2.25
ray_end: 3.3
box_warp: 1
avg_camera_radius: 2.7
avg_camera_pivot: [0, 0, 0.2]
image_resolution: 512
disparity_space_sampling: False
clamp_mode: softplus
superresolution_module: models.superresolution.SuperresolutionHybrid8XDC
c_gen_conditioning_zero: False
c_scale: 1.0
superresolution_noise_mode: none
density_reg: 0.25
density_reg_p_dist: 0.004
reg_type: l1
decoder_lr_mul: 1.0
sr_antialias: True
num_fp16_res: 0
sr_num_fp16_res: 4
sr_kwargs:
channel_base: 32768
channel_max: 512
fused_modconv_default: inference_only
conv_clamp: None
img_resolution: 512
img_channels: 3
inference:
depth_resolution: 48
depth_resolution_importance: 48
ray_start: 2.25
ray_end: 3.3
box_warp: 1
image_resolution: 512
disparity_space_sampling: False
clamp_mode: softplus
superresolution_module: training.superresolution.SuperresolutionHybrid8XDC
c_gen_conditioning_zero: False
c_scale: 1.0
superresolution_noise_mode: none
density_reg: 0.25
density_reg_p_dis: 0.004
reg_type: l1
decoder_lr_mul: 1.0
sr_antialias: True
checkpoint: pretrained/ffhqrebalanced512-64.pth
dis:
type: discriminators.dummy
data:
name: dummy
type: data.dataset::HDTFDataset
num_workers: 1
path: ./datasets/hdtf_lmdb_inv
resolution: 512
semantic_radius: 13
frames_each_video: 2
train:
batch_size: 4
distributed: True
prefetch_factor: 1
val:
batch_size: 4
distributed: True
prefetch_factor: 1
cross_id: True
cross_id_target: WRA_EricCantor_000
test_data:
name: dummy
type: datasets.images
num_workers: 0
test:
is_lmdb: False
roots:
batch_size: 1
trainer:
model_average: False
model_average_beta: 0.9999
model_average_start_iteration: 1000
model_average_batch_norm_estimation_iteration: 30
model_average_remove_sn: True
image_to_tensorboard: False
hparam_to_tensorboard: False
distributed_data_parallel: pytorch
delay_allreduce: True
gan_relativistic: False
gen_step: 1
dis_step: 1
type: trainers.decouple_by_invert::FaceTrainer
use_sr: True
sr_iters: 10
accum_ratio:
G: 0.95
Warp: 0.95
inversion:
iterations: 100
warp_lr_mult: 100
asynchronous_update: successively
warp_update_iters: 10
loss_weight:
mask_rate: 1
inverse: 1.0
refine: 1.0
local: 10.0
TV: 1.0
monotonic: 1.0
pixel: 1
id: 1.0
p_norm: 0.0
a_norm: 0.0
a_mutual: 0.0
vgg_param_lr:
network: vgg19
layers: ['relu_1_1', 'relu_2_1', 'relu_3_1', 'relu_4_1', 'relu_5_1']
use_style_loss: True
num_scales: 2
style_to_perceptual: 250
vgg_param_sr:
network: vgg19
layers: ['relu_1_1', 'relu_2_1', 'relu_3_1', 'relu_4_1', 'relu_5_1']
use_style_loss: True
num_scales: 4
style_to_perceptual: 250
init:
type: xavier
gain: 0.02
cudnn:
deterministic: False
benchmark: True
pretrained_weight:
inference_args:
distributed: True
results_dir: ./eval_results
w_samples: 600
warp_optimizer:
type: adamw
lr: 0.001
refine_only: False
adam_beta1: 0.5
adam_beta2: 0.999
lr_policy:
iteration_mode: True
type: step
step_size: 10000
gamma: 0.2
weight_decay: 1
inverse_optimizer:
type: adam
lr: 0.01
adam_beta1: 0.9
adam_beta2: 0.999
gen_optimizer:
type: adam
lr: 0.0001
adam_beta1: 0.9
adam_beta2: 0.9999
sr_only: False
lr_policy:
iteration_mode: True
type: step
step_size: 10000
gamma: 0.2
camera_optimizer:
type: adamw
lr: 0.01
adam_beta1: 0.9
adam_beta2: 0.9999
warp:
type: models.controller::VideoCodeBook
param:
descriptor_nc: 256
mapping_layers: 3
mlp_layers: 5
if_use_pose: True
if_plus_scaling: False
if_short_cut: True
directions: 20
checkpoint: None
local_rank: 0
device: 0
logdir: result/config/otavatar.yaml
result/config/otavatar.yaml/*_iteration_000002000_checkpoint.pt
[]
No checkpoint found at iteration 2000.
It appears that there is an issue with the "model_path" variable and i found there existed a folder at "./result/cofng/otavatar.yaml/". What could be causing this problem and how can it be thoroughly resolved?
After moving epoch_00005_iteration_000002000_checkpoint.pt to "./result/config/otavatar.yml/", "No checkpoint found at iteration 2000." disappeared.

So is the logic that inference.py will create folder "./result/$name$" and we need to make sure model "*_iteration_$which_iter$_checkpoint.pt" be put in there?

Now it seems to be working normally.

BTW is it normal for the eyes to be out of sync and how to facilating trainning speed cause it seems no speed-up after changing "--nproc_per_node=1" to "--nproc_per_node=2" (both are 57s/iter on 3090 x1 or x2)
export CUDA_VISIBLE_DEVICES=0
python -m torch.distributed.launch --nproc_per_node=1 --master_port 12346 train_inversion.py \
--config ./config/otavatar.yaml \
--name otavatar
export CUDA_VISIBLE_DEVICES=0,1
python -m torch.distributed.launch --nproc_per_node=2 --master_port 12346 train_inversion.py \
--config ./config/otavatar.yaml \
--name otavatar
from otavatar.
theEricMa
commented on May 26, 2024
@szh-bash 1) Thanks for pointing out the typo! I will fix it in the readme. 2) According to our experiment, the eye synchronization is non-trival to achieve. Our explanation is: first, EG3D (as well as other GAN) is trained on FFHQ which does not have sufficient eye-closing faces, so closing eyes are not feasible with barely latent manipulation; second, as you may see in our pesudo-code in the paper, we only finetune EG3D with 1e-4 lr for 2000 iterations, so there is minor modification on the model weights. Maybe other mechnism e.x. dense image warping can achieve natural eye synchronization, but it is beyond the scope of our paper. 3) "--nproc_per_node=2" makes the 2 gpus training the model with the same batchsize, therefore the total batchsize is doubled.
from otavatar.
szh-bash
commented on May 26, 2024
@theEricMa Thank you for the detailed explanation, best wishes!
from otavatar.
szh-bash
commented on May 26, 2024
@theEricMa Hi, I found the model i trained behaviour bad than pretrain model, is the reason that 6 epoch(pretrain model) is better than 1 epoch?
But i got nan after 2290 iters in epoch 0, how to train 5 epoch?

from otavatar.
theEricMa
commented on May 26, 2024
Hi, may I know how much GPU is used for the training? Mine is 4 A100s (80GB mem), so the batchsize is 8(per GPU) * 4 (GPU num) = 32, therefore the 2000 iters will spend more than 1 epoch. If you cannot support batchsize=8 per GPU, please try more GPUs. Larger batchsize leads to more stable training.
By the way, training with limit GPU resoursce would be feasible with gradient accumulation, if you prefer this way, please modify the code here by first making this function takes the iteration number also as input, and the both optimizers do .step() only when iteration number % <accumulate_size> == 0
from otavatar.
szh-bash
commented on May 26, 2024
How to check current batchsize(per GPU)? Does this log mean batchsize=4 per GPU?
Training on 3090s (24GB mem) x2|x4|x8 showed same batchsize here.

from otavatar.
 ldz666666
commented on May 26, 2024
ldz666666
commented on May 26, 2024
I also come up with this problem.
I have run the training experiment for serveral times, each time the loss becomes nan in epoch 0 or epoch 1.
4x A100, batch_size = 8 or 4, how to fix this ?


from otavatar.
theEricMa
commented on May 26, 2024
You can try the following modification:
- Decrease the
style_to_perceptualfor bothvgg_param_lrandvgg_param_sr. It is used for supervising the 'style' consistency using Gram matrices but is not the most important loss term. You can even choose to not use it by setting bothuse_style_lossto False.

- in the
optimize_parameters()function from trainers/decouple_by_invert.py, change the summation of all the loss terms into the following, so as to isolate the nan term.
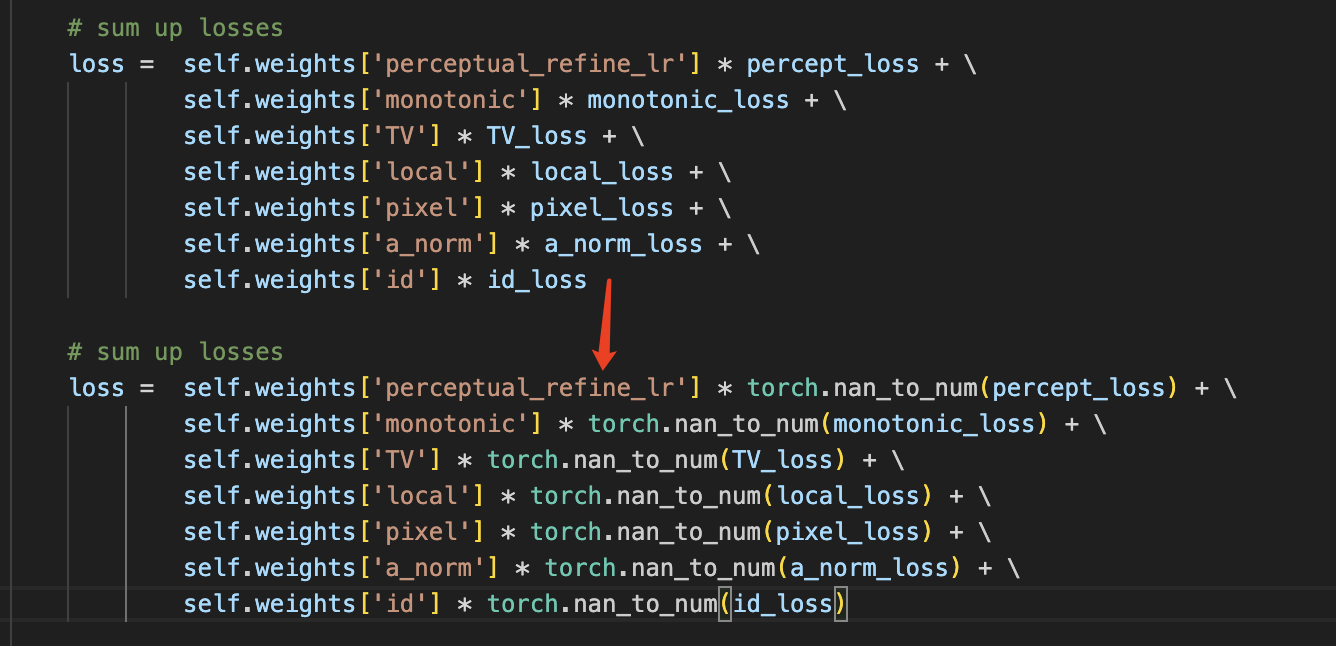
Please contact me if both operations do not work.
from otavatar.
Related Issues (20)
- Quantitative Evaluation HOT 12
- Difference between code and paper HOT 1
- ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -9) local_rank: 0 (pid: 150437) of binary: /data1/anconda3/envs/otavatar/bin/python HOT 2
- When do you plan to upload the data preprocessing script? HOT 1
- Could you please upload the remaining preprocessing scripts?
- Can you please tell on what operating system is this code running ? HOT 1
- How to makes face animation with specified image HOT 4
- About downloading processed data HOT 2
- Question about 'FaceTrainer' object has no attribute 'net_G_module'
- question about emotion code , ws_stdv HOT 4
- No arcface_resnet18.pth found in arcface-pytorch HOT 1
- question about data.utils.process_camera_inv HOT 1
- About training consumption and inference speed HOT 1
- License file HOT 1
- Makes face animation with specified image HOT 3
- About requirement.yaml
- metric code about cross-identity reenactment HOT 1
- pretrained data HOT 1
- ModuleNotFoundError: No module named 'third_part' HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from otavatar.