Comments (8)
 novioleo
commented on April 19, 2024
novioleo
commented on April 19, 2024
@cendelian 抱歉看到晚了。能麻烦print一下错误的时候distance的值么
from pytorchocr.
 dengfenglai321
commented on April 19, 2024
dengfenglai321
commented on April 19, 2024
@cendelian 抱歉看到晚了。能麻烦print一下错误的时候distance的值么
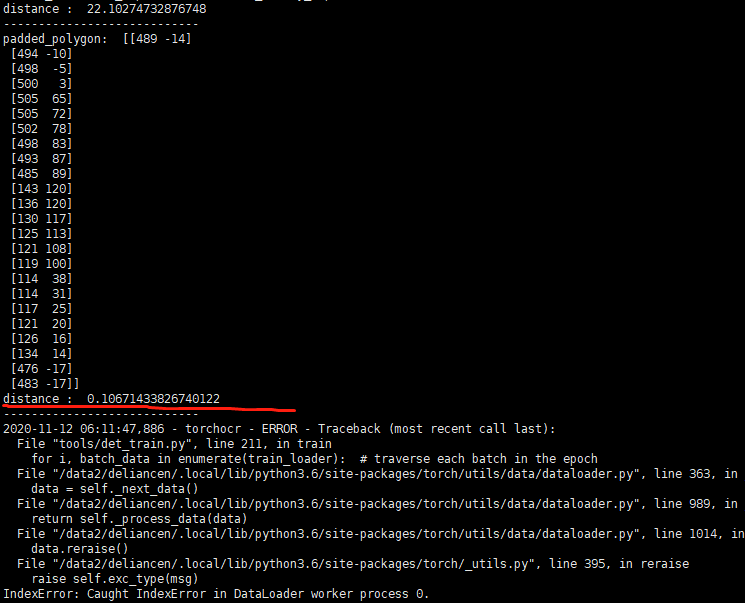
对应的代码如下:
# if padding.Execute(distance) is None:
# print('None')
print('distance : ',distance)
print('----------------------------')
padded_polygon = np.array(padding.Execute(distance)[0])
print('padded_polygon: ',padded_polygon)
cv2.fillPoly(mask, [padded_polygon.astype(np.int32)], 1.0)
请问该怎么解决?
运行时batch :1, numworker:1
from pytorchocr.
novioleo
commented on April 19, 2024
这个是你这个标注数据区域shrink的话太小,小于0了。你可以调整shrink比例,也可以check一下你的这个case的标注情况。
from pytorchocr.
dengfenglai321
commented on April 19, 2024
这个是你这个标注数据区域shrink的话太小,小于0了。你可以调整shrink比例,也可以check一下你的这个case的标注情况。
shrink比例在哪里调?调小还是调大?
还有一样的数据集,我在大佬WenmuZhou / DBNet.pytorch这个项目里就能跑通没有任何错误。
我感觉WenmuZhou / DBNet.pytorch 和WenmuZhou / PytorchOCR这两个项目的文本检测部分都差不多吧
from pytorchocr.
dengfenglai321
commented on April 19, 2024
这个是你这个标注数据区域shrink的话太小,小于0了。你可以调整shrink比例,也可以check一下你的这个case的标注情况。
我使用WenmuZhou / DBNet.pytorch跑一样的数据集,推理发现结果的标注的确比正常文本框要小。。。比如下图:

大佬该怎么调shrink呢?
实在config下调那个shrink_ratio吗?调大?
# db 预处理,不需要修改
'pre_processes': [{'type': 'IaaAugment', 'args': [{'type': 'Fliplr', 'args': {'p': 0.5}},
{'type': 'Affine', 'args': {'rotate': [-10, 10]}},
{'type': 'Resize', 'args': {'size': [0.5, 3]}}]},
{'type': 'EastRandomCropData', 'args': {'size': [640, 640], 'max_tries': 50, 'keep_ratio': True}},
{'type': 'MakeBorderMap', 'args': {'shrink_ratio': 0.4, 'thresh_min': 0.3, 'thresh_max': 0.7}},
{'type': 'MakeShrinkMap', 'args': {'shrink_ratio': 0.4, 'min_text_size': 8}}],
from pytorchocr.
 WenmuZhou
commented on April 19, 2024
WenmuZhou
commented on April 19, 2024
框小了,需要unclip_ratio调大
from pytorchocr.
dengfenglai321
commented on April 19, 2024
框小了,需要unclip_ratio调大
大佬你好,我将unclip_ration调到2.0了 还是报一样的错误
from pytorchocr.
novioleo
commented on April 19, 2024
我觉得是标注的数据有点问题
from pytorchocr.
Related Issues (20)
- 有没有Int版本的模型
- ValueError: num_samples should be a positive integer value, but got num_samples=0
- 如何在ocr识别的字典文件中添加上下标的训练素材
- python tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml HOT 6
- 请问目前转换成onnx格式推理的功能可以使用了吗 HOT 3
- 请问cls的模型有开源参数吗 HOT 2
- 在det模型中,如何调节检测框之间合并的间距阈值
- use the comand to run the train report the warning,any one have the same warning? HOT 1
- 训练ch_PP-OCRv3_rec不收敛,CTCLOSS到50就不降了 HOT 1
- ch_ppocr_mobile_v2.0_cls_train 的 config文件是不是没上传? HOT 3
- cls_mv3 模型权重是不是忘了上传了? 链接里没有 HOT 2
- 为什么新样本首次推理速度都会慢? HOT 4
- 文字识别模型的训练数据来源 HOT 3
- predict部分需要三个模型是什么情况? HOT 2
- 检测模型pth转换为onnx报错,configs\det\ch_PP-OCRv3\ch_PP-OCRv3_det_student.yml,
- 训练好的paddle模型,迁移到torch,又转onnx,进行推理为什么都识别不出来东西 HOT 1
- 大佬你好 ,想问个关于模型大小的问题 HOT 1
- 转trt HOT 1
- onnx2trt HOT 1
- 关于paddleocr库代码中使用这个配置ch_PP-OCRv4_rec_distill.yml进行文本识别训练代码bug HOT 1
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from pytorchocr.