projectphysx / fluidx3d Goto Github PK
View Code? Open in Web Editor NEWThe fastest and most memory efficient lattice Boltzmann CFD software, running on all GPUs via OpenCL.
Home Page: https://youtube.com/@ProjectPhysX
License: Other
The fastest and most memory efficient lattice Boltzmann CFD software, running on all GPUs via OpenCL.
Home Page: https://youtube.com/@ProjectPhysX
License: Other


















































































































































First of all, thank you for your amazing work on this project, very much appriciated.
Is it possible to import a closed .stl geometry and define an inlet/outlet to simulate the flow through that geometry, like for example a pipe? If so, would you have main_setup() example that you could provide?
Thank you
Hello, I assume the only difference between the stationary (Type S) boundaries and the moving boundaries is the fact that for the moving boundary case the velocity of the fluid at the boundary nodes are unequal to zero.
So, if I move a "stationary" boundary by revoxelizing the mesh this is actually representing a "slip" condition, because the absolute velocity of the fluid is zero, but the solid has a nonzero absolute velocity. So, the relative velocity between fluid and solid is nonzero (slip).
On the other hand, if I move a "moving boundary" by revoxelizing the mesh, and set the velocity of the fluid boundary nodes equal to the velocity of the solid boundary, then we would represent the "no slip" condition. This is because the relative velocity between fluid and solid is zero, even though the absolute velocity of both is nonzero.
Is this all correct?
Also in setup.cpp you don't have an example of a moving boundary implementation I don't think, you only move stationary boundaries. You recently posted a video of a moving boundary setup on the F1 car by turning the wheels, can you share a code snippet of how you write the solid velocity in the fluid boundary nodes (after revoxelization)? I'm not sure how I would write the solid velocity to the fluid, especially for a rotating object that doesn't have axial symmetry (like a wheel). After this, I think you would call lbm.update_moving_boundaries.
How to get a transparent background in exported .png images?
Hi
Thank you for a very impressive tool!
I'm trying to setup a calculation for a water jet striking a plate like shown below.
However, I'm not able to get the inlet/outlet working.

How do I setup the solver so that there is a circular inlet boundary on one side where the water-jet can enter and strike the plate on the other side before the water exits on the side of the domain?
Best Regards
Petter
I am running the project in Visual Studio and I am not able to visualize any of the examples I have run. I have uncommented #define WINDOWS_GRAPHICS in defines.h and then uncommented a specific main_setup function in setup.cpp.
Any other changes I should make for windows to visualize? Thank you.
You are welcome to report your benchmark results for the FP32/FP16S/FP16C accuracy levels here.
Especially numbers for AMD GPUs are desired for GCN/RDNA/RDNA2 architectures.
Thank you!
Hi everyone, i'm i high school student and i want to improve myself in cfd. I recently saw FluidX3D and it looks really cool. But i get error when i compile it as WINDOWS_GRAPHICS, i get memory usage error. But i have no idea to how to change the memory that cfd uses. I'm really a beginner so please take it easy.
CFD Windows is just black.
And the console is just gives that error;
Error: Device "NVIDIA GeForce GTX 1050 Ti" does not have enough memory. |
| Allocating another 8680 MB would use a total of 11573 MB / 4095 MB. |
| Press Enter to exit.
Changings I made to the src:
defines.hpp:
comment #define BENCHMARK
uncomment #define WINDOWS_GRAPHICS
setup.cpp :
uncomment Boeing 757 setup
This is what my setup.cpp file looks like;
void main_setup() { // Boeing 757
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
const uint L = 912u;
const float Re = 100000.0f;
const float u = 0.125f;
LBM lbm(L, 2u*L, L/2u, units.nu_from_Re(Re, (float)L, u));
// #############################################################################################################################################################################################
const float size = 1.1f*(float)L;
const float3 center = float3(lbm.center().x, 32.0f+0.5f*size, lbm.center().z);
const float3x3 rotation = float3x3(float3(1, 0, 0), radians(75.0f));
lbm.voxelize_stl(get_exe_path()+"../stl/757.stl", center, rotation, size); // https://www.thingiverse.com/thing:5091064/files
const uint N=lbm.get_N(), Nx=lbm.get_Nx(), Ny=lbm.get_Ny(), Nz=lbm.get_Nz(); for(uint n=0u, x=0u, y=0u, z=0u; n<N; n++, lbm.coordinates(n, x, y, z)) {
// ########################################################################### define geometry #############################################################################################
if(lbm.flags[n]!=TYPE_S) lbm.u.y[n] = u;
if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==0u||z==Nz-1u) lbm.flags[n] = TYPE_E; // all non periodic
} // #########################################################################################################################################################################################
key_4 = true;
Clock clock;
lbm.run(0u);
while(lbm.get_t()<100000u) {
lbm.graphics.set_camera_free(float3(1.0f*(float)Nx, -0.4f*(float)Ny, 2.0f*(float)Nz), -33.0f, 42.0f, 68.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/t/");
lbm.graphics.set_camera_free(float3(0.5f*(float)Nx, -0.35f*(float)Ny, -0.7f*(float)Nz), -35.0f, -35.0f, 100.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/b/");
lbm.graphics.set_camera_free(float3(0.0f*(float)Nx, 0.51f*(float)Ny, 0.75f*(float)Nz), 90.0f, 28.0f, 80.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/f/");
lbm.graphics.set_camera_free(float3(0.6f*(float)Nx, -0.15f*(float)Ny, 0.06f*(float)Nz), 0.0f, 0.0f, 100.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/s/");
lbm.run(28u);
}
write_file(get_exe_path()+"time.txt", print_time(clock.stop()));
lbm.run();
}
Hi.
I borrowed a laptop that has a NVIDIA GeForce RTX 3050 Ti Laptop GPU. I run benchmark.
I put the reslut.
However I have a question. The memory of the NVIDIA GeForce RTX 3050 Ti Laptop GPU seems to be working by seeing the task manager. But the NVIDIA GeForce RTX 3050 Ti Laptop GPU itself did not react by seeing the task manager.
I am struggling with why it occurred. Could you let me know the reason?
Best,


Hello, thank you for making this awesome project available! After getting the star wars tie fighter working, I was looking at how you rotated the mesh before revoxelizing. In setup.cpp you make a matrix called rotation and pass it to the rotate function. Is it possible to also translate the mesh, or is the mesh always constrained to the "center" point that you define when you use read_stl? Perhaps I'm not interpreting this correctly. Translating the mesh would be useful to observe the interaction between two solid geometries within the simulation domain, where the two geometries could be both rotating and translating dynamically. Thanks for any clarification!
I'm trying to do a rough calculation of the maximum airspeed attainable by a particular aircraft. I've completed some force simulations in other sims before, but not one where I have a set amount of available thrust (40 kN) and plan to increase the lbm_u flow speed until the total drag force in the y-axis equals this amount.
The problem is I can't really seem to get the conversion to/from real life to sim units correct in the code (or in my head) as far as I can tell + Primarily I'm not sure of how to determine the real life airspeed based on the lbm_u flow speed.
(The results are also very unstable and can't get the simulation to converge on an accurate value, but one problem at a time 🤔)
I've read right through these other issue threads (#36, #32) relating to force readouts but I think I'm still missing something here. My code and force results are below:
void main_setup() {
// setup the volume and objects
const uint L = 512u; // size of test volume
const uint Nx = to_uint(L * 1.1f); // adjust size of volume x axis
const uint Ny = to_uint(L * 1.1f); // adjust size of volume y axis
const uint Nz = to_uint(L * 0.4f); // adjust size of volume z axis
const float size = 0.5f * (float)L; // scaling of object compared with size of the volume
// setup aircraft parameters
const float knots = 300.0f; // speed through air (only affects Reynolds number I think?)
const float AoA = 0.0f; // angle of attack (°), rotates object in field on x-axis
const float3 center = float3(0.5f * Nx, 0.45f * Ny, 0.55f * Nz); // offset the aircraft position
const float3x3 rotation = float3x3(float3(1, 0, 0), radians(-AoA)); // set the aircraft rotation, check the specified axis
// setting SI units
const float si_x = 18.0f; // characteristic length (m)
const float si_u = knots * 0.5144f; // convert airspeed to SI units (m/s)
const float si_rho = 1.2f; // air density
const float si_nu = 1.48E-5f; // kinematic shear viscosity of air (~sea level)
// setting LBM units
const float lbm_u = 0.12f;
const float lbm_rho = 1.0f; // density in LBM units always 1
const float lbm_x = L;
// set unit conversion factors between SI and LBM units
units.set_m_kg_s(lbm_x, lbm_u, lbm_rho, si_x, si_u, si_rho);
const float lbm_nu = units.nu(si_nu); // kinematic shear viscosity in LBM units
// create LBM object, setup mesh and set flags
LBM lbm(Nx, Ny, Nz, lbm_nu);
// setup mesh
Mesh* mesh = read_stl(get_exe_path() + "../stl/aircraft.stl", lbm.size(), center, rotation, size);
lbm.voxelize_mesh_on_device(mesh);
lbm.flags.read_from_device();
const uint N = lbm.get_N();
for (uint n = 0ull, x = 0u, y = 0u, z = 0u; n < N; n++, lbm.coordinates(n, x, y, z)) {
if (lbm.flags[n] != TYPE_S) lbm.u.y[n] = lbm_u;
if (x == 0u || x == Nx - 1u || y == 0u || y == Ny - 1u || z == 0u || z == Nz - 1u) lbm.flags[n] = TYPE_E;
}
// set overlay options
key_1 = true;
key_2 = false;
key_3 = true;
key_4 = true;
// setup text file output
std::ofstream fout(get_exe_path() + "results.txt");
if (!fout) {
std::cerr << "Could not open file." << std::endl;
}
// run the simulation
lbm.run(0u);
while (lbm.get_t() < 30000u) {
lbm.run(100u);
// calculate the force on the object
lbm.calculate_force_on_boundaries();
lbm.F.read_from_device();
const float3 force = lbm.calculate_force_on_object(TYPE_S);
// write the calculated force to file
fout << to_string(units.si_F(force.y)) << std::endl;
print_info(to_string(units.si_F(force.y)));
}
// close the output file
fout.close();
wait(); // wait for a keypress to close the Program
}#pragma once
//#define D2Q9 // choose D2Q9 velocity set for 2D; allocates 53 (FP32) or 35 (FP16) Bytes/node
//#define D3Q15 // choose D3Q15 velocity set for 3D; allocates 77 (FP32) or 47 (FP16) Bytes/node
//#define D3Q19 // choose D3Q19 velocity set for 3D; allocates 93 (FP32) or 55 (FP16) Bytes/node; (default)
#define D3Q27 // choose D3Q27 velocity set for 3D; allocates 125 (FP32) or 71 (FP16) Bytes/node
#define SRT // choose single-relaxation-time LBM collision operator; (default)
//#define TRT // choose two-relaxation-time LBM collision operator
//#define FP16S // compress LBM DDFs to range-shifted IEEE-754 FP16; number conversion is done in hardware; all arithmetic is still done in FP32
//#define FP16C // compress LBM DDFs to more accurate custom FP16C format; number conversion is emulated in software; all arithmetic is still done in FP32
//#define BENCHMARK // disable all extensions and setups and run benchmark setup instead
//#define VOLUME_FORCE // enables global force per volume in one direction, specified in the LBM class constructor; the force can be changed on-the-fly between time steps at no performance cost
#define FORCE_FIELD // enables computing the forces on solid boundaries with lbm.calculate_force_on_boundaries(); and enables setting the force for each lattice point independently (enable VOLUME_FORCE too); allocates an extra 12 Bytes/node
//#define MOVING_BOUNDARIES // enables moving solids: set solid nodes to TYPE_S and set their velocity u unequal to zero
#define EQUILIBRIUM_BOUNDARIES // enables fixing the velocity/density by marking nodes with TYPE_E; can be used for inflow/outflow; does not reflect shock waves
//#define SURFACE // enables free surface LBM: mark fluid nodes with TYPE_F; at initialization the TYPE_I interface and TYPE_G gas domains will automatically be completed; allocates an extra 12 Bytes/node
//#define TEMPERATURE // enables temperature extension; set fixed-temperature nodes with TYPE_T (similar to EQUILIBRIUM_BOUNDARIES); allocates an extra 32 (FP32) or 18 (FP16) Bytes/node
#define SUBGRID // enables Smagorinsky-Lilly subgrid turbulence model to keep simulations with very large Reynolds number stable
#define INTERACTIVE_GRAPHICS // enable interactive graphics; start/pause the simulation by pressing P; either Windows or Linux X11 desktop must be available; on Linux: change to "compile on Linux with X11" command in make.sh
//#define INTERACTIVE_GRAPHICS_ASCII // enable interactive graphics in ASCII mode the console; start/pause the simulation by pressing P
//#define GRAPHICS // run FluidX3D in the console, but still enable graphics functionality for writing rendered frames to the hard drive
#define GRAPHICS_FRAME_WIDTH 3840 // set frame width if only GRAPHICS is enabled
#define GRAPHICS_FRAME_HEIGHT 2160 // set frame height if only GRAPHICS is enabled
#define GRAPHICS_BACKGROUND_COLOR 0x000000 // set background color; black background (default) = 0x000000, white background = 0xFFFFFF
#define GRAPHICS_U_MAX 0.18f // maximum velocity for velocity coloring in units of LBM lattice speed of sound (c=1/sqrt(3)) (default: 0.15f)
#define GRAPHICS_Q_CRITERION 0.0001f // Q-criterion value for Q-criterion isosurface visualization (default: 0.0001f)
#define GRAPHICS_BOUNDARY_FORCE_SCALE 100.0f // scaling factor for visualization of forces on solid boundaries if VOLUME_FORCE is enabled and lbm.calculate_force_on_boundaries(); is called (default: 100.0f)
#define GRAPHICS_STREAMLINE_SPARSE 47 // set how many streamlines there are every x lattice points
#define GRAPHICS_STREAMLINE_LENGTH 256 // set maximum length of streamlines
// #############################################################################################################
#define TYPE_S 0b00000001 // (stationary or moving) solid boundary
#define TYPE_E 0b00000010 // equilibrium boundary (inflow/outflow)
#define TYPE_T 0b00000100 // temperature boundary
#define TYPE_F 0b00001000 // fluid
#define TYPE_I 0b00010000 // interface
#define TYPE_G 0b00100000 // gas
#define TYPE_X 0b01000000 // reserved type X
#define TYPE_Y 0b10000000 // reserved type Y
#if defined(FP16S) || defined(FP16C)
#define fpxx ushort
#else // FP32
#define fpxx float
#endif // FP32
#ifdef BENCHMARK
#undef UPDATE_FIELDS
#undef VOLUME_FORCE
#undef FORCE_FIELD
#undef MOVING_BOUNDARIES
#undef EQUILIBRIUM_BOUNDARIES
#undef SURFACE
#undef TEMPERATURE
#undef SUBGRID
#undef INTERACTIVE_GRAPHICS
#undef INTERACTIVE_GRAPHICS_ASCII
#undef GRAPHICS
#endif // BENCHMARK
#ifdef SURFACE // (rho, u) need to be updated exactly every LBM step
#define UPDATE_FIELDS // update (rho, u, T) in every LBM step
#endif // SURFACE
#ifdef TEMPERATURE
#define VOLUME_FORCE
#endif // TEMPERATURE
#if defined(INTERACTIVE_GRAPHICS) || defined(INTERACTIVE_GRAPHICS_ASCII)
#define GRAPHICS
#endif // INTERACTIVE_GRAPHICS || INTERACTIVE_GRAPHICS_ASCIIHere's a snippet of the force results output (does anyone know how to get the output to not be scientific notation? Google Sheets doesn't handle these values and I have to resort to MS Excel):
5.45981456E4
7.24956846E4
7.05784989E4
4.87261344E4
5.33241606E4
4.76977920E4
4.39427472E4
4.65264656E4
4.49056340E4
4.15205240E4
4.89547016E4
4.37330200E4
3.41821480E4
5.59037636E4
3.54986192E4
3.03640080E4
6.60130216E4
1.98685264E4
4.37987564E4
5.84950160E4
1.40907776E4
5.30362702E4
4.93470624E4
1.66901088E4
6.21138572E4
3.50296092E4
2.53584744E4
6.05184031E4
2.65506504E4
3.66595888E4
5.78224232E4
2.07870364E4
4.56666420E4
4.79558512E4
2.18530130E4
5.24934960E4
4.20690488E4
2.38719248E4
5.73561760E4
3.04396701E4
3.29020452E4
5.45614432E4
2.86208776E4
3.78154800E4
5.19157028E4
2.27532816E4
4.62905692E4
4.43532228E4
2.78953000E4
4.90866040E4
3.82027696E4
2.95206312E4
5.04203034E4
3.29360580E4
3.73151400E4
4.77963496E4
3.10918498E4
3.99938512E4
4.41328812E4
2.99023864E4
4.72581864E4
3.70907136E4
3.52803944E4
4.51192808E4
3.29675292E4
3.91297720E4
4.56213856E4
3.03644109E4
4.48174240E4
3.93006824E4
3.07123041E4
4.83290144E4
3.47505568E4
3.55810620E4
4.79376888E4
2.96577928E4
3.90675064E4
4.69986776E4
2.75215248E4
4.63786412E4
4.14923382E4
2.75947616E4
4.86272048E4
3.66286016E4
3.10061097E4
5.13841009E4
3.11370969E4
3.47928692E4
5.00028658E4
2.79550312E4
3.98808744E4
4.84784648E4
2.45359184E4
4.63440372E4
4.16207886E4
2.70788336E4
4.90002344E4
3.83687952E4
2.75404432E4
5.26642036E4
3.07034731E4
3.39467932E4
5.09975672E4
2.84062696E4
3.78370336E4
5.01098347E4
2.38102340E4
4.47991560E4
4.50371884E4
2.43556548E4
4.90558720E4
3.96822504E4
2.49006056E4
5.38041876E4
3.20686198E4
3.12109590E4
5.30605126E4
2.81475904E4
3.52483344E4
5.24868106E4
2.32955694E4
4.32908916E4
4.73114536E4
2.31392718E4
4.78467272E4
4.26806164E4
2.36173772E4
5.27146720E4
3.64221096E4
2.72658848E4
5.37688492E4
3.21892882E4
3.15374017E4
5.30127192E4
2.87015728E4
3.51730704E4
5.13758898E4
2.62463404E4
4.04599190E4
4.75241136E4
2.80091504E4
4.12005997E4
4.52993488E4
2.95608160E4
4.34895752E4
4.26450872E4
3.17720150E4
4.10161400E4
4.15983200E4
3.45705508E4
4.11882591E4
4.11889410E4
3.62099792E4
3.64361740E4
4.39449404E4
3.55373500E4
3.74828080E4
4.55044604E4
3.47750972E4
3.48780344E4
4.73938992E4
3.23299218E4
3.82154488E4
4.80530736E4
3.00424647E4
3.91072776E4
4.62211560E4
2.82382848E4
4.31937932E4
4.56638528E4
2.68889168E4
4.58463956E4
4.08407545E4
2.79705000E4
4.83229064E4
3.97819688E4
2.86021256E4
4.94393400E4
3.49910664E4
3.12321615E4
5.04131508E4
3.44256544E4
3.30876518E4
5.02775574E4
2.88833376E4
3.78664400E4
4.77260304E4
3.04172182E4
4.01574278E4
4.58602380E4
2.68378544E4
4.47494124E4
4.18165016E4
3.05465555E4
4.53165436E4
3.94830728E4
2.89034680E4
4.83971688E4
3.50941636E4
3.48705148E4
4.67443224E4
3.39380216E4
3.38679432E4
4.85436392E4
3.05737758E4
4.04101801E4
4.52647828E4
3.02574444E4
4.03174400E4
4.44756936E4
2.88578224E4
4.54932880E4
4.09248829E4
2.99064352E4
4.50767516E4
3.92672752E4
3.06318474E4
4.82059480E4
3.57805896E4
3.25918674E4
4.66934728E4
3.37587928E4
3.48344444E4
4.87301160E4
3.17187286E4
3.70109248E4
4.61975004E4
2.93210528E4
4.05846787E4
4.57513000E4
2.92939016E4
4.27224446E4
4.21224594E4
2.82099104E4
4.62798644E4
3.98973344E4
3.09912205E4
4.61989500E4
3.70167640E4
3.05215764E4
4.95039272E4
3.33795764E4
3.57161308E4
4.69126512E4
3.14432621E4
3.61775900E4
4.83867120E4
2.86830904E4
4.32326270E4
4.34546520E4
2.88929984E4
4.28917074E4
4.26834106E4
2.88632296E4
4.81515312E4
3.75875688E4
3.07526446E4
4.73358968E4
3.54067968E4
3.24639488E4
5.02047062E4
3.08033443E4
3.67542480E4
4.71359352E4
3.03295064E4
Plenty of volume around the aircraft:

Early in the sim (force lines start flailing around further into the simulation):

The results are all over the place and I'm completely stuck now. Can anyone see where I'm going wrong and/or how I can get the results I'm looking for? 😟
The code seems to be in good shape to run on macOS, except for a couple of #ifs.
The changes I had to make:
diff --git a/make.sh b/make.sh
old mode 100644
new mode 100755
index 7bb6217..efd6fc6
--- a/make.sh
+++ b/make.sh
@@ -1,6 +1,7 @@
# command line argument $1: device ID; if empty, FluidX3D will automatically choose the fastest available device
mkdir -p bin # create directory for executable
rm -f ./bin/FluidX3D.exe # prevent execution of old version if compiling fails
-g++ ./src/*.cpp -o ./bin/FluidX3D.exe -std=c++17 -pthread -I./src/OpenCL/include -L./src/OpenCL/lib -lOpenCL # compile on Linux
+#g++ ./src/*.cpp -o ./bin/FluidX3D.exe -std=c++17 -pthread -I./src/OpenCL/include -L./src/OpenCL/lib -lOpenCL # compile on Linux
+g++ ./src/*.cpp -o ./bin/FluidX3D.exe -std=c++17 -pthread -I./src/OpenCL/include -framework OpenCL # compile on macOS
#g++ ./src/*.cpp -o ./bin/FluidX3D.exe -std=c++17 -pthread -I./src/OpenCL/include -L/system/vendor/lib64 -lOpenCL # compile on Android
./bin/FluidX3D.exe $1 # run FluidX3D
diff --git a/src/utilities.hpp b/src/utilities.hpp
index e7916de..09b46d5 100644
--- a/src/utilities.hpp
+++ b/src/utilities.hpp
@@ -3010,7 +3010,7 @@ inline uint hsv_to_rgb(const float3& hsv) {
#include <Windows.h> // for displaying colors and getting console size
#undef min
#undef max
-#elif defined(__linux__)
+#elif defined(__linux__) || defined(__APPLE__)
#include <sys/ioctl.h> // for getting console size
#include <unistd.h> // for getting path of executable
#else // Windows/Linux
@@ -3338,7 +3338,7 @@ inline void print_image_bw(const Image* image, const uint textwidth=0u, const ui
const string ww = string("")+(char)219; // trick to double vertical resolution: use graphic characters
const string bw = string("")+(char)220;
const string wb = string("")+(char)223;
-#elif defined(__linux__)
+#elif defined(__linux__) || defined(__APPLE__)
const string ww = "\u2588"; // trick to double vertical resolution: use graphic characters
const string bw = "\u2584";
const string wb = "\u2580";
@@ -3570,7 +3570,7 @@ inline Image* screenshot(Image* image=nullptr) {
inline void print_color_test() {
#ifdef _WIN32
const string s = string("")+(char)223; // trick to double vertical resolution: use graphic character
-#elif defined(__linux__)
+#elif defined(__linux__) || defined(__APPLE__)
const string s = "\u2580"; // trick to double vertical resolution: use graphic character
#endif // Windows/Linux
print(s, color_magenta , color_black );
% ./make.sh
.-----------------------------------------------------------------------------.
| ______________ ______________ |
| \ ________ | | ________ / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ \_.-" | | "-._/ / |
| \ _.-" _ "-._ / |
| \.-" _.-" "-._ "-./ |
| .-" .-"-. "-. |
| \ v" "v / |
| \ \ / / |
| \ \ / / |
| \ \ / / |
| \ ' / |
| \ / |
| \ / |
| ' (c) Moritz Lehmann |
|----------------.------------------------------------------------------------|
| Device ID 0 | Apple M1 Pro |
|----------------'------------------------------------------------------------|
|----------------.------------------------------------------------------------|
| Device ID | 0 |
| Device Name | Apple M1 Pro |
| Device Vendor | Apple |
| Device Driver | 1.2 1.0 |
| OpenCL Version | OpenCL C 1.2 |
| Compute Units | 16 at 1000 MHz (0 cores, 0.000 TFLOPs/s) |
| Memory, Cache | 10922 MB, 0 KB global / 32 KB local |
| Buffer Limits | 2048 MB global, 1048576 KB constant |
|----------------'------------------------------------------------------------|
| Info: OpenCL C code successfully compiled. |
|-----------------.-----------------------------------------------------------|
| Grid Resolution | 256 x 256 x 256 = 16777216 |
| LBM Type | D3Q19 SRT (FP32/FP32) |
| Memory Usage | CPU 272 MB, GPU 1488 MB |
| Max Alloc Size | 1216 MB |
| Time Steps | 10 |
| Kin. Viscosity | 1.00000000 |
| Relaxation Time | 3.50000000 |
| Reynolds Number | Re < 148 |
|---------.-------'-----.-----------.-------------------.---------------------|
| MLUPs | Bandwidth | Steps/s | Current Step | Time Remaining |
| 1202 | 184 GB/s | 72 | 9997 70% | 0s |
|---------'-------------'-----------'-------------------'---------------------|
| Info: Peak MLUPs/s = 1204
I've been searching around for a few hours in the kernel and making lots of attempts to change parts of the code, but I haven't been able to find a way (if possible) to make the solid object voxels an opaque color (they're currently a grey set of axis lines with the remainder of the cube transparent). In some situations it would be good to prevent the coloured vorticity surfaces from appearing through the object from the other side for the sake of clarity.
I'm guessing there's something in +R(kernel void graphics_q, but is anyone aware of how to achieve this?
I run the exe in A100 40G ,and get the performance as followed , It give only 6105 MLUPS with FP16C but 14563MLUPS withFP16S. This is not consistent with the results in the table in README.


Hi,
Thank your for sharing your CFD code. I have a question to your codes.
After runing your code, I got the date of flags. I coudnt understand this date.
Could you teach me?
Best,
Based on my testing, lbm.calculate_force_on_boundaries only works on a stationary mesh. With the default D3Q19 velocity set, I moved a mesh with mesh->rotate or mesh->translate, then I revoxelize and flag with type S and run for 50 LBM timesteps. Then I call lbm.calculate_force_on_boundaries. I do this repeatedly in a while loop as shown. The simulation diverges after 3 cycles of the while loop where the forces are NaN, and the flow field disappears (I think it might be NaN).
I can remove lbm.calculate_force_on_boundaries and the simulation runs without issues.
When I rotate less per loop (ex: radians(0.01f)) I'm able to do 5-6 while loops but then I still diverge. I think its probably the mid-grid bounce back BC where a large movement of the mesh causes issues with lbm.calculate_force_on_boundaries. However, this BC is obviously working without calculating the forces, so why would calculating the forces break it?
Any idea what's going on? It's strange that if I calculate the forces after the while loop its fine, but when this command is inside the while loop problems occur.
I also tried FP16C, and lbm.calculate_force_on_boundaries works fine for each loop, but the fluid domain looks "unphysical" where the entire domain is turbulence.
You can try this on any mesh:
void main_setup() {
// make a list of all variables you have in SI units (m, kg, s)
const float si_x = 0.25f; // 0.25m cylinder length
const float si_u = 5.0f; //wind speed
const float si_rho = 1.225f; // 1.225kg/m^3 air density
const float si_nu = 1.48E-5f; // 1.48E-5f m^2/s kinematic shear viscosity of air
// set velocity in LBM units, should be between 0.01-0.2
const float lbm_u = 0.1f;
const float lbm_rho = 1.0f; // density in LBM units always has to be 1
const float lbm_x = 256u;
// set unit conversion factors between SI units and LBM units
units.set_m_kg_s(lbm_x, lbm_u, lbm_rho, si_x, si_u, si_rho);
// compute kinematic shear viscosity in LBM units
const float lbm_nu = units.nu(si_nu);
// set grid resolution based on lbm_x
const uint Nx = to_uint(1.25*lbm_x);
const uint Ny = to_uint(2*lbm_x);
const uint Nz = to_uint(lbm_x/2);
LBM lbm(Nx, Ny, Nz, lbm_nu); // create LBM object
// load geometry from stl file, mark all grid points that belong to your geometry with (TYPE_S)
const float size = 1.0f * (float)lbm_x;
float3 center = float3(lbm.center().x, lbm.center().y, lbm.center().z);
const float3x3 rotation = float3x3(float3(0, 0, 1), radians(90.0f));
Mesh* mesh = read_stl("<path to your stl file>", lbm.size(), center, rotation, size);
voxelize_mesh_hull(lbm, mesh, TYPE_S);
// set box boundary conditions
for (uint n = 0u, x = 0u, y = 0u, z = 0u; n < lbm.get_N(); n++, lbm.coordinates(n, x, y, z)) {
if (!(lbm.flags[n] & TYPE_S)) lbm.u.y[n] = lbm_u; // initial velocity
if (x == 0u || x == Nx - 1u || y == 0u || y == Ny - 1u || z == 0u || z == Nz - 1u) lbm.flags[n] = TYPE_E;
if (y == 0u) lbm.u.y[n] = lbm_u; //velocity inlet
}
lbm.run(0u);
while (lbm.get_t() < 50000u) {
for (uint n = 0u; n < lbm.get_N(); n++) lbm.flags[n] &= ~TYPE_S; // clear flags
const float3x3 rotation = float3x3(float3(0.0f, 0.0f, 1.0f), radians(0.9f)); // create rotation matrix to rotate mesh
mesh->rotate(rotation); // rotate mesh
//voxelize_mesh_hull(lbm, mesh, TYPE_S); // alternative but issue still occurs with this
lbm.voxelize_mesh(mesh, TYPE_S);
lbm.flags.write_to_device(); // lbm.flags on host is finished, write to device now
lbm.run(50u);
// calculate forces on boundaries on GPU, then copy force field to CPU memory
lbm.calculate_force_on_boundaries(); //remove this and the simulation runs fine.
// sum force over all boundary nodes marked with TYPE_S
lbm.F.read_from_device();
//transition to si units
const float3 lbm_force = lbm.calculate_force_on_object(TYPE_S);
const float si_force_x = units.si_F(lbm_force.x); // force in Newton
const float si_force_y = units.si_F(lbm_force.y);
const float si_force_z = units.si_F(lbm_force.z);
// print force components
print_info("z force = " + to_string(si_force_z) + " N");
print_info("y force = " + to_string(si_force_y) + " N");
print_info("x force = " + to_string(si_force_x) + " N");
}
}
Hi everyone,
I would like to iterate on an airfoil shape by revoxelising it during a running sim, so that for small changes I don't need as many timesteps to get a result. Restarting it for a tiny change would be a lot slower. To experiment I tested quite large changes (+ 5° AoA) and the airflow looks perfect after some time has passed. I do this by setting everything that is TYPE_S at the moment to be a fluid, then everything that is the new airfoil is TYPE_S and all its values get reset. Then I write everything to the GPU and run more steps.
The airflow looks perfect, like I mentioned, the forces are all over the place. In all the places where it was a fluid at first but is now a solid, it shows a ridiculous amount of drag, so I reduced the scaling factor.
I tried everything I thought could help resetting the forces, but I always get the same results. This is how I try to reset the force:
lbm.voxelize_stl(get_exe_path() + "/stl/NACA-Wide.stl", center, rotation, size, TYPE_S);
lbm.run(1000);
for (int i = 0; i < 10; i++)
{
lbm.run(100);
lbm.calculate_force_on_boundaries();
lbm.F.read_from_device();
const float3 force = lbm.calculate_force_on_object(TYPE_S);// | TYPE_X
print_info(to_string(lbm.get_t()) + " " + to_string(units.si_F(force.z)) + " " + to_string(units.si_F(force.y)));
}
lbm.u.read_from_device();
lbm.F.read_from_device();
lbm.rho.read_from_device();
lbm.flags.read_from_device();
// remove the old airfoil
for (uint n = 0u, x = 0u, y = 0u, z = 0u; n < N; n++, lbm.coordinates(n, x, y, z)) // remove the old airfoil
{
if (lbm.flags[n] == TYPE_S)
{
lbm.u.x[n] = 0.0f;
lbm.u.y[n] = 0.0f;
lbm.u.z[n] = 0.0f;
lbm.rho[n] = 0.0f;
lbm.flags[n] = TYPE_N; // 0b00000000
}
}
rotation = float3x3(float3(1, 0, 0), radians(-5.0f)) * float3x3(float3(0, 0, 1), radians(90.0f)) * float3x3(float3(1, 0, 0), radians(90.0f));
lbm.voxelize_stl(get_exe_path() + "/stl/NACA-Wide.stl", center, rotation, size, TYPE_S); // set new to Solid
//reset stuff
for (uint n = 0u, x = 0u, y = 0u, z = 0u; n < N; n++, lbm.coordinates(n, x, y, z))
{
if (lbm.flags[n] == TYPE_S)
{
lbm.u.x[n] = 0.0f;
lbm.u.y[n] = 0.0f;
lbm.u.z[n] = 0.0f;
lbm.F.x[n] = 0.0f;
lbm.F.y[n] = 0.0f;
lbm.F.z[n] = 0.0f;
lbm.rho[n] = 0.0f;
}
}
lbm.F.reset();
lbm.rho.write_to_device();
lbm.u.write_to_device();
lbm.F.write_to_device();
lbm.flags.write_to_device();
lbm.run();// now run it againAnd this is what it looks like right after the Revoxelisation, The AoA increased by 5°, the holes at the top right and bottom left are where the airfoil used to be.

And here you can see the white boundary forces that are in the inside of the airfoil:

I get the same issue when moving the airfoil, all the nodes that were not solid at first, have ridiculous ammounts of drag.
Has anyone tried revoxelising and getting the forces? And what am I not resetting correctly?
I hope everyone was able to enjoy Christmas,
Cheers Marius
Hi,
Sory I have a question again.
I tyied to compute by msi radeon 7850 however I got some worning and an error.(I could biud your codes) I use windows10, Visual studio 2022, openCL1.2 from Intel® SDK For OpenCL™ Applications and intel CPUs.
Is msi radeon 7850 too old?
Best,
The STL isn't being loaded into lbm for any size greater than .25f*(float)L. The output is simply black with the stats at the bottom right. For size = .25f*(float)L, I can see the STL but it is very small and pixelated.
Is it possible to run in a headless mode if I have a model setup and I am more interested in getting specific output values than the visualization?
Currently taking an exploratory look at the project and running the default test case.
Linux (kernel 5.18.10)
Intel i7 12700k
AMD RX5600xt
Trying both devices, both in LBM 15 and 19 leads to a segfault


g++ version output:
g++ --version
g++ (GCC) 12.1.1 20220707
Copyright (C) 2022 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
I think we are missing si_T, to convert torque from lbm units to si units. Its probably just adding the line
float si_T(const float T) const { return T * kg * sq(m) / sq(s); } //torque si_T = T*[kg*m^2/s^2]
to units.hpp.
Hi, first of all, thanks a lot for making this code available, really cool!
I was running the F1 setup and attempting to get VTK files (velocity only) to get written out during the simulation. I'm using the code below to write VTK files and renders:
key_4 = true;
Clock clock;
lbm.run(0u);
while(lbm.get_t()<50000u) {
lbm.graphics.set_camera_free(float3(1.0f*(float)Nx, -0.4f*(float)Ny, 2.0f*(float)Nz), -33.0f, 42.0f, 68.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/t/");
lbm.graphics.set_camera_free(float3(0.5f*(float)Nx, -0.35f*(float)Ny, -0.7f*(float)Nz), -33.0f, -40.0f, 100.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/b/");
lbm.graphics.set_camera_free(float3(0.0f*(float)Nx, 0.51f*(float)Ny, 0.75f*(float)Nz), 90.0f, 28.0f, 80.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/f/");
lbm.graphics.set_camera_free(float3(0.7f*(float)Nx, -0.15f*(float)Ny, 0.06f*(float)Nz), 0.0f, 0.0f, 100.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/s/");
//lbm.update_fields();
lbm.u_write_host_to_vtk(get_exe_path()+"export/vtk/");
lbm.run(28u);
}
Looking at the renders all is well in the simulation, but the VTK files only contain a non-zero velocity in the Y component (when loading in the VTK file in ParaView), X and Z are all zero:

Also, there seems to be something off in the aspect ratio, as the wheel outlines are not circular (perhaps an incorrect cell size)?

Strike that remark, the input STL model has the wrong aspect ratio. Really weird:

Is what I'm trying to do even supported in the current code?
Thanks in advance for any help.
Hi @ProjectPhysX ,
First of all, thank you for opening your fantastic code.
I got an error that I could not deal with.
I use GeForce 9600GT and I tried "#define USE_OPENCL_1_1" .
In spite of that it dose not calculate anything.
What is problem?
Could you tell me the reason?
My GeForce driver version is 342.01(the newest for my GPU)

Thank you.
I am amazed by the power of LBM. It used to take a couple of days to
reach this level of vortical structure, but now it is just a couple of
hours.
I really appreciate your code and definitely enjoy playing with it.

Ran
Hey I'm new to github so I don't know if these kind of snippets are helpful here or not? If there's a better forum or discord, etc then let me know and I can post there instead. 😊
If anyone wants a way to quickly create videos from the image sequences in between running simulations (so you don't have to cut and paste thousands of PNGs around into folders everywhere) I made this #.bin file and changed some of the FluidX3D code.
It's just a bin file that runs ffmpeg.exe and feeds it the images. Since people are running nvidia gear, the hardware encoding on the video is lightning fast.
The pipetovideo.bin file and ffmpeg.exe can sit anywhere but just needs to be edited to get the folder path correct.
This is the arrangement I use:

The images in the folder have filenames like this (later in the post will show the code I changed to make that happen):

And when pipetovideo.bin runs it creates .mpg videos in the same directory:

My #.bin file needed to have the -pix_fmt yuv444p and high444 inputs there because I've set my png's to write with an alpha channel (rgba) so you may need to change some of the ffmpeg arguments to make it work. If people are interested I'll make it work for the shipped version of FluidX3D:
pipetovideo.bin:
@echo off
for /f "usebackq" %%x in (powershell "get-date -f yyyy-MM-dd-HH-mm-ss") do set timestamp=%%x
if exist "ffmpeg.exe" (
ffmpeg.exe -framerate 60 -i images/%%6d.png -vcodec libx264 -pix_fmt yuv444p -preset slow -profile:v high444 -crf 20 %timestamp%.mp4
) else (
@echo on
echo ffmpeg.exe not found
echo ------------------------------
echo Download a Windows build of FFmpeg from https://www.ffmpeg.org
echo Place the ffmpeg.exe file in this folder and run this script again
echo ------------------------------
pause
)
cmd /k
Then, since Windows can't glob filenames and deal with the non-sequential numbering from FluidX3D, I also had to change the numbering for the output of PNGs in the code. My edits are very clunky because I know nothing much about programming, let alone C++
I added this into lbm at the start:
#include "lbm.hpp"
#include "info.hpp"
#include "graphics.hpp"
#include "units.hpp"
Units units; // for unit conversion
**int framecounter = 0; // initialise the frame counter for sequential output file naming**
And then changed default_filename around a bit:
string LBM::default_filename(const string& path, const string& name, const string& extension) {
string time = "000000"+to_string(framecounter);
time = substring(time, length(time) - 6u, 6u);
framecounter++;
return create_file_extension((path=="" ? get_exe_path()+"export/" : path)+time, extension);
I added another folder level in my setup.cpp to keep the important files separate from the flood of images:
lbm.graphics.write_frame_png(get_exe_path() + "export/images/");
I think there was some other strings added to the filename like "images" and hyphens etc, and I scratched around to find and delete those, but can't remember where they were in the code.
Not posting this as a suggestion for something to add into the original program code, just putting this here as an idea for people who might need help to quickly make videos (or just preview) of their creations 🤷♂️

Hello!
I want to simulate fluid - structure interactions for coastal waves. But have few queries regarding creation of simulation box (domain) and locating stl file in the simulation box. The desired set up would look like as in figure below with a domain size of 6m x 30m x 4m. It is having fluid below 0.75m.

The stl file would look like following image, where blue coordinate symbol represents origin -
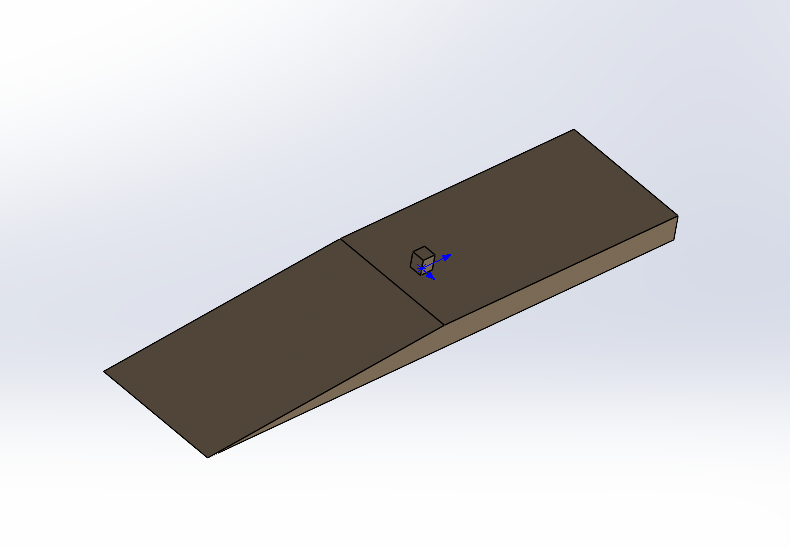
I have used following code -
#include "setup.hpp"
void main_setup() {
const float f = 0.001f;
const float u = 0.276f; // peak velocity of speaker membrane (Need to calculate)
const float frequency = 0.043f; // amplitude = u/(2.0f*pif*frequency);
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
// Actual simulation box dimensions = 6m x 30m x 4m
LBM lbm(60, 300, 40, 0.001); // Nx, Ny, Nx. nu // 1. Can we add more refinement in lattice? I want more resolution in height
const float3 size = float3(6.0f, 30.0f, 4.0f); // 2. Is it related to scaling of stl object?
const float3 center = float3(lbm.center().x, lbm.center().y, size.z / 2.0f); //3. Is it relative position between center of stl and center of simulation box?
lbm.voxelize_stl(get_exe_path() + "../stl/kyoto.stl", center, size);
const ulong N = lbm.get_N(); const uint Nx = lbm.get_Nx(), Ny = lbm.get_Ny(), Nz = lbm.get_Nz(); for (ulong n = 0ull; n < N; n++) {
uint x = 0u, y = 0u, z = 0u; lbm.coordinates(n, x, y, z);
// ########################################################################### define geometry #############################################################################################
if (lbm.flags[n] == TYPE_S) lbm.flags[n] = TYPE_S;
else if (z < 7.5) { // 0.75 m // 4. Is this conversion correct? I want to have fluid below 0.75 m
lbm.flags[n] = TYPE_F;
lbm.rho[n] = units.rho_hydrostatic(f, (float)z, 7.95f);
}
if (x == 0u || x == Nx - 1u || y == 0u || y == Ny - 1u || z == 0u || z == Nz - 1u) lbm.flags[n] = TYPE_S; // all non periodic
if (y == 0u && x > 0u && x < Nx - 1u && z>0u && z < Nz - 1u) lbm.flags[n] = TYPE_E;
}
lbm.run(0u);
while (running) {
lbm.u.read_from_device();
const float uy = u * sin(2.0f * pif * frequency * (float)lbm.get_t());
const float uz = 0.5f * u * cos(2.0f * pif * frequency * (float)lbm.get_t());
for (uint z = 1u; z < Nz - 1u; z++) {
for (uint y = 0u; y < 1u; y++) {
for (uint x = 1u; x < Nx - 1u; x++) {
if (y == 0u) { // only set velocity at inlet
const uint n = x + (y + z * Ny) * Nx;
lbm.u.y[n] = uy;
lbm.u.z[n] = uz;
}
}
}
}
lbm.u.write_to_device();
lbm.run(100u);
}
}
But, when I run the case. The set up appears as below image -

Here, the stl gets scaled up uneven. And also the water level seems not correct.
I have written my doubts in the respective code lines
Thank you for your time and assistance and look forward to hearing back from you!
Unfortunately there is no option to hide the Pull Requests tab, so I'm pinning this issue: I won't do Pull Requests on the main repository. Please don't submit any.
Hi there,
As requested here are the STL's and setup code for the Ornithopter sequence in this Youtube video. You mentioned you'd like to have a look for the purposes of improving the revoxelisation.
Here is the STL sequence in a zip file.
This is the code I used in my setup below. I'm sure anyone who knows C++ can write some much simpler code to reference 125+ meshes instead of the way I've done it, haha. Note that this positioning and rotation etc for this code is for a different STL sequence of a helicopter, so you'll need to adjust the centre point and rotation for the Orni. lbm.update_moving_boundaries() may also be called at the incorrect position in the loop...?
td::atomic_bool revoxelizing = false;
void revoxelize(LBM* lbm, Mesh* mesh) { // voxelize new frames in detached thread in parallel while LBM is running
for (uint n = 0u; n < lbm->get_N(); n++) lbm->flags[n] &= ~TYPE_S; // clear flags
voxelize_mesh_hull(*lbm, mesh, TYPE_S); // voxelize rotated mesh in lbm.flags
revoxelizing = false; // indicate new voxelizer thread has finished
}
void main_setup() { // ORNITHOPTER SETUP
// ######################################################### define simulation box size, viscosity and volume force ####################################
const uint L = 512+128u;
const float knots = 120.0f; // Initial speed of fluid?
const float AoA = -2.0f; // Negative is nose down
const float kmh = knots * 1.852f;
const float si_u = kmh / 3.6f;
const float si_x = 20.0f; //Characteristic Length
const float si_rho = 1.15f; //Air Density
const float si_nu = 1.48E-5f;
const float Re = units.si_Re(si_x, si_u, si_nu); //Reynolds Number
print_info("Re = " + to_string(Re));
const float u = 0.08f;
LBM lbm(L, L*3u/2u , L / 2u, units.nu_from_Re(Re, (float)L, u)); // Proportions of containing box
// #####################################################################################################################################################
const float size = 1.0f * (float)L;
const float3 center = float3(lbm.center().x+0.0f*size, lbm.center().y+(-0.2f)*size, lbm.center().z+0.09f*size);
const float3x3 rotation = float3x3(float3(1, 0, 0), -radians(AoA)); //Set initial orientation of object (CHECK AXIS SET CORRECTLY: x, y, z)
float modelSize = size * 1.0f; //set relative model size here
// *************Allocate ALL of the meshes*************
Mesh* mesh1 = read_stl(get_exe_path() + "../stl/Sequence/1.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh2 = read_stl(get_exe_path() + "../stl/Sequence/2.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh3 = read_stl(get_exe_path() + "../stl/Sequence/3.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh4 = read_stl(get_exe_path() + "../stl/Sequence/4.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh5 = read_stl(get_exe_path() + "../stl/Sequence/5.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh6 = read_stl(get_exe_path() + "../stl/Sequence/6.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh7 = read_stl(get_exe_path() + "../stl/Sequence/7.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh8 = read_stl(get_exe_path() + "../stl/Sequence/8.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh9 = read_stl(get_exe_path() + "../stl/Sequence/9.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh10 = read_stl(get_exe_path() + "../stl/Sequence/10.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh11 = read_stl(get_exe_path() + "../stl/Sequence/11.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh12 = read_stl(get_exe_path() + "../stl/Sequence/12.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh13 = read_stl(get_exe_path() + "../stl/Sequence/13.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh14 = read_stl(get_exe_path() + "../stl/Sequence/14.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh15 = read_stl(get_exe_path() + "../stl/Sequence/15.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh16 = read_stl(get_exe_path() + "../stl/Sequence/16.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh17 = read_stl(get_exe_path() + "../stl/Sequence/17.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh18 = read_stl(get_exe_path() + "../stl/Sequence/18.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh19 = read_stl(get_exe_path() + "../stl/Sequence/19.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh20 = read_stl(get_exe_path() + "../stl/Sequence/20.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh21 = read_stl(get_exe_path() + "../stl/Sequence/21.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh22 = read_stl(get_exe_path() + "../stl/Sequence/22.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh23 = read_stl(get_exe_path() + "../stl/Sequence/23.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh24 = read_stl(get_exe_path() + "../stl/Sequence/24.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh25 = read_stl(get_exe_path() + "../stl/Sequence/25.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh26 = read_stl(get_exe_path() + "../stl/Sequence/26.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh27 = read_stl(get_exe_path() + "../stl/Sequence/27.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh28 = read_stl(get_exe_path() + "../stl/Sequence/28.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh29 = read_stl(get_exe_path() + "../stl/Sequence/29.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh30 = read_stl(get_exe_path() + "../stl/Sequence/30.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh31 = read_stl(get_exe_path() + "../stl/Sequence/31.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh32 = read_stl(get_exe_path() + "../stl/Sequence/32.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh33 = read_stl(get_exe_path() + "../stl/Sequence/33.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh34 = read_stl(get_exe_path() + "../stl/Sequence/34.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh35 = read_stl(get_exe_path() + "../stl/Sequence/35.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh36 = read_stl(get_exe_path() + "../stl/Sequence/36.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh37 = read_stl(get_exe_path() + "../stl/Sequence/37.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh38 = read_stl(get_exe_path() + "../stl/Sequence/38.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh39 = read_stl(get_exe_path() + "../stl/Sequence/39.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh40 = read_stl(get_exe_path() + "../stl/Sequence/40.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh41 = read_stl(get_exe_path() + "../stl/Sequence/41.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh42 = read_stl(get_exe_path() + "../stl/Sequence/42.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh43 = read_stl(get_exe_path() + "../stl/Sequence/43.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh44 = read_stl(get_exe_path() + "../stl/Sequence/44.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh45 = read_stl(get_exe_path() + "../stl/Sequence/45.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh46 = read_stl(get_exe_path() + "../stl/Sequence/46.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh47 = read_stl(get_exe_path() + "../stl/Sequence/47.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh48 = read_stl(get_exe_path() + "../stl/Sequence/48.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh49 = read_stl(get_exe_path() + "../stl/Sequence/49.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh50 = read_stl(get_exe_path() + "../stl/Sequence/50.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh51 = read_stl(get_exe_path() + "../stl/Sequence/51.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh52 = read_stl(get_exe_path() + "../stl/Sequence/52.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh53 = read_stl(get_exe_path() + "../stl/Sequence/53.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh54 = read_stl(get_exe_path() + "../stl/Sequence/54.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh55 = read_stl(get_exe_path() + "../stl/Sequence/55.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh56 = read_stl(get_exe_path() + "../stl/Sequence/56.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh57 = read_stl(get_exe_path() + "../stl/Sequence/57.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh58 = read_stl(get_exe_path() + "../stl/Sequence/58.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh59 = read_stl(get_exe_path() + "../stl/Sequence/59.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh60 = read_stl(get_exe_path() + "../stl/Sequence/60.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh61 = read_stl(get_exe_path() + "../stl/Sequence/61.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh62 = read_stl(get_exe_path() + "../stl/Sequence/62.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh63 = read_stl(get_exe_path() + "../stl/Sequence/63.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh64 = read_stl(get_exe_path() + "../stl/Sequence/64.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh65 = read_stl(get_exe_path() + "../stl/Sequence/65.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh66 = read_stl(get_exe_path() + "../stl/Sequence/66.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh67 = read_stl(get_exe_path() + "../stl/Sequence/67.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh68 = read_stl(get_exe_path() + "../stl/Sequence/68.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh69 = read_stl(get_exe_path() + "../stl/Sequence/69.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh70 = read_stl(get_exe_path() + "../stl/Sequence/70.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh71 = read_stl(get_exe_path() + "../stl/Sequence/71.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh72 = read_stl(get_exe_path() + "../stl/Sequence/72.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh73 = read_stl(get_exe_path() + "../stl/Sequence/73.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh74 = read_stl(get_exe_path() + "../stl/Sequence/74.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh75 = read_stl(get_exe_path() + "../stl/Sequence/75.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh76 = read_stl(get_exe_path() + "../stl/Sequence/76.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh77 = read_stl(get_exe_path() + "../stl/Sequence/77.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh78 = read_stl(get_exe_path() + "../stl/Sequence/78.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh79 = read_stl(get_exe_path() + "../stl/Sequence/79.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh80 = read_stl(get_exe_path() + "../stl/Sequence/80.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh81 = read_stl(get_exe_path() + "../stl/Sequence/81.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh82 = read_stl(get_exe_path() + "../stl/Sequence/82.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh83 = read_stl(get_exe_path() + "../stl/Sequence/83.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh84 = read_stl(get_exe_path() + "../stl/Sequence/84.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh85 = read_stl(get_exe_path() + "../stl/Sequence/85.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh86 = read_stl(get_exe_path() + "../stl/Sequence/86.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh87 = read_stl(get_exe_path() + "../stl/Sequence/87.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh88 = read_stl(get_exe_path() + "../stl/Sequence/88.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh89 = read_stl(get_exe_path() + "../stl/Sequence/89.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh90 = read_stl(get_exe_path() + "../stl/Sequence/90.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh91 = read_stl(get_exe_path() + "../stl/Sequence/91.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh92 = read_stl(get_exe_path() + "../stl/Sequence/92.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh93 = read_stl(get_exe_path() + "../stl/Sequence/93.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh94 = read_stl(get_exe_path() + "../stl/Sequence/94.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh95 = read_stl(get_exe_path() + "../stl/Sequence/95.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh96 = read_stl(get_exe_path() + "../stl/Sequence/96.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh97 = read_stl(get_exe_path() + "../stl/Sequence/97.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh98 = read_stl(get_exe_path() + "../stl/Sequence/98.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh99 = read_stl(get_exe_path() + "../stl/Sequence/99.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh100 = read_stl(get_exe_path() + "../stl/Sequence/100.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh101 = read_stl(get_exe_path() + "../stl/Sequence/101.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh102 = read_stl(get_exe_path() + "../stl/Sequence/102.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh103 = read_stl(get_exe_path() + "../stl/Sequence/103.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh104 = read_stl(get_exe_path() + "../stl/Sequence/104.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh105 = read_stl(get_exe_path() + "../stl/Sequence/105.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh106 = read_stl(get_exe_path() + "../stl/Sequence/106.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh107 = read_stl(get_exe_path() + "../stl/Sequence/107.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh108 = read_stl(get_exe_path() + "../stl/Sequence/108.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh109 = read_stl(get_exe_path() + "../stl/Sequence/109.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh110 = read_stl(get_exe_path() + "../stl/Sequence/110.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh111 = read_stl(get_exe_path() + "../stl/Sequence/111.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh112 = read_stl(get_exe_path() + "../stl/Sequence/112.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh113 = read_stl(get_exe_path() + "../stl/Sequence/113.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh114 = read_stl(get_exe_path() + "../stl/Sequence/114.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh115 = read_stl(get_exe_path() + "../stl/Sequence/115.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh116 = read_stl(get_exe_path() + "../stl/Sequence/116.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh117 = read_stl(get_exe_path() + "../stl/Sequence/117.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh118 = read_stl(get_exe_path() + "../stl/Sequence/118.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh119 = read_stl(get_exe_path() + "../stl/Sequence/119.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh120 = read_stl(get_exe_path() + "../stl/Sequence/120.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh121 = read_stl(get_exe_path() + "../stl/Sequence/121.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh122 = read_stl(get_exe_path() + "../stl/Sequence/122.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh123 = read_stl(get_exe_path() + "../stl/Sequence/123.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh124 = read_stl(get_exe_path() + "../stl/Sequence/124.stl", lbm.size(), center, rotation, modelSize);
Mesh* mesh125 = read_stl(get_exe_path() + "../stl/Sequence/125.stl", lbm.size(), center, rotation, modelSize);
int currentMesh = 1u;
voxelize_mesh_hull(lbm, mesh1, TYPE_S);
const uint N = lbm.get_N(), Nx = lbm.get_Nx(), Ny = lbm.get_Ny(), Nz = lbm.get_Nz(); for (uint n = 0u, x = 0u, y = 0u, z = 0u; n < N; n++, lbm.coordinates(n, x, y, z)) {
// ############################################################## ############# define geometry #############################################################################################
if (lbm.flags[n] != TYPE_S) lbm.u.y[n] = u;
if (x == 0u || x == Nx - 1u || y == 0u || y == Ny - 1u || z == 0u || z == Nz - 1u) lbm.flags[n] = TYPE_E; // all non periodic
} // #########################################################################################################################################################################################
key_4 = true;
Clock clock;
lbm.run(0u);
while (lbm.get_t() < 120000u) {
lbm.update_moving_boundaries(); // This TYPE_S flag update may be in the wrong position
lbm.graphics.write_frame_png(get_exe_path() + "export/images/"); // Take screenshot
// *********** REVOXELISING / ROTATING SECTION ***********
while (revoxelizing.load()) sleep(0.01f); // wait for voxelizer thread to finish (ORIGINAL WAS 0.01f)
lbm.flags.write_to_device(); // lbm.flags on host is finished, write to device now
//Set the STL selection value (0-60) for the Ornithopter
if (currentMesh > 125) currentMesh = 1;
// Select which mesh in the sequence to use - OMG THIS NEEDS TO BE MORE ELEGANT
if (lbm.get_t() > 0u && lbm.get_t() < 80000) { //Set period of time which the revoxeliser is rotating object
revoxelizing = true; // indicate new voxelizer thread is starting
if (currentMesh == 1) {
thread voxelizer(revoxelize, &lbm, mesh1); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 2) {
thread voxelizer(revoxelize, &lbm, mesh2); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 3) {
thread voxelizer(revoxelize, &lbm, mesh3); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 4) {
thread voxelizer(revoxelize, &lbm, mesh4); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 5) {
thread voxelizer(revoxelize, &lbm, mesh5); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 6) {
thread voxelizer(revoxelize, &lbm, mesh6); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 7) {
thread voxelizer(revoxelize, &lbm, mesh7); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 8) {
thread voxelizer(revoxelize, &lbm, mesh8); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 9) {
thread voxelizer(revoxelize, &lbm, mesh9); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 10) {
thread voxelizer(revoxelize, &lbm, mesh10); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 11) {
thread voxelizer(revoxelize, &lbm, mesh11); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 12) {
thread voxelizer(revoxelize, &lbm, mesh12); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 13) {
thread voxelizer(revoxelize, &lbm, mesh13); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 14) {
thread voxelizer(revoxelize, &lbm, mesh14); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 15) {
thread voxelizer(revoxelize, &lbm, mesh15); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 16) {
thread voxelizer(revoxelize, &lbm, mesh16); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 17) {
thread voxelizer(revoxelize, &lbm, mesh17); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 18) {
thread voxelizer(revoxelize, &lbm, mesh18); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 19) {
thread voxelizer(revoxelize, &lbm, mesh19); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 20) {
thread voxelizer(revoxelize, &lbm, mesh20); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 21) {
thread voxelizer(revoxelize, &lbm, mesh21); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 22) {
thread voxelizer(revoxelize, &lbm, mesh22); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 23) {
thread voxelizer(revoxelize, &lbm, mesh23); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 24) {
thread voxelizer(revoxelize, &lbm, mesh24); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 24) {
thread voxelizer(revoxelize, &lbm, mesh24); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 25) {
thread voxelizer(revoxelize, &lbm, mesh25); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 26) {
thread voxelizer(revoxelize, &lbm, mesh26); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 27) {
thread voxelizer(revoxelize, &lbm, mesh27); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 28) {
thread voxelizer(revoxelize, &lbm, mesh28); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 29) {
thread voxelizer(revoxelize, &lbm, mesh29); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 30) {
thread voxelizer(revoxelize, &lbm, mesh30); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 31) {
thread voxelizer(revoxelize, &lbm, mesh31); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 32) {
thread voxelizer(revoxelize, &lbm, mesh32); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 33) {
thread voxelizer(revoxelize, &lbm, mesh33); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 34) {
thread voxelizer(revoxelize, &lbm, mesh34); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 35) {
thread voxelizer(revoxelize, &lbm, mesh35); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 36) {
thread voxelizer(revoxelize, &lbm, mesh36); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 37) {
thread voxelizer(revoxelize, &lbm, mesh37); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 38) {
thread voxelizer(revoxelize, &lbm, mesh38); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 39) {
thread voxelizer(revoxelize, &lbm, mesh39); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 40) {
thread voxelizer(revoxelize, &lbm, mesh40); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 41) {
thread voxelizer(revoxelize, &lbm, mesh41); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 42) {
thread voxelizer(revoxelize, &lbm, mesh42); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 43) {
thread voxelizer(revoxelize, &lbm, mesh43); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 44) {
thread voxelizer(revoxelize, &lbm, mesh44); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 45) {
thread voxelizer(revoxelize, &lbm, mesh45); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 46) {
thread voxelizer(revoxelize, &lbm, mesh46); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 47) {
thread voxelizer(revoxelize, &lbm, mesh47); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 48) {
thread voxelizer(revoxelize, &lbm, mesh48); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 49) {
thread voxelizer(revoxelize, &lbm, mesh49); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 50) {
thread voxelizer(revoxelize, &lbm, mesh50); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 51) {
thread voxelizer(revoxelize, &lbm, mesh51); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 52) {
thread voxelizer(revoxelize, &lbm, mesh52); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 53) {
thread voxelizer(revoxelize, &lbm, mesh53); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 54) {
thread voxelizer(revoxelize, &lbm, mesh54); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 55) {
thread voxelizer(revoxelize, &lbm, mesh55); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 56) {
thread voxelizer(revoxelize, &lbm, mesh56); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 57) {
thread voxelizer(revoxelize, &lbm, mesh57); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 58) {
thread voxelizer(revoxelize, &lbm, mesh58); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 59) {
thread voxelizer(revoxelize, &lbm, mesh59); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 60) {
thread voxelizer(revoxelize, &lbm, mesh60); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 61) {
thread voxelizer(revoxelize, &lbm, mesh61); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 62) {
thread voxelizer(revoxelize, &lbm, mesh62); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 63) {
thread voxelizer(revoxelize, &lbm, mesh63); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 64) {
thread voxelizer(revoxelize, &lbm, mesh64); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
//Split IF function into two for error "Blocks nested too deeply"
if (currentMesh == 65) {
thread voxelizer(revoxelize, &lbm, mesh65); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 66) {
thread voxelizer(revoxelize, &lbm, mesh66); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 67) {
thread voxelizer(revoxelize, &lbm, mesh67); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 68) {
thread voxelizer(revoxelize, &lbm, mesh68); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 69) {
thread voxelizer(revoxelize, &lbm, mesh69); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 70) {
thread voxelizer(revoxelize, &lbm, mesh70); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 71) {
thread voxelizer(revoxelize, &lbm, mesh71); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 72) {
thread voxelizer(revoxelize, &lbm, mesh72); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 73) {
thread voxelizer(revoxelize, &lbm, mesh73); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 74) {
thread voxelizer(revoxelize, &lbm, mesh74); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 75) {
thread voxelizer(revoxelize, &lbm, mesh75); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 76) {
thread voxelizer(revoxelize, &lbm, mesh76); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 77) {
thread voxelizer(revoxelize, &lbm, mesh77); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 78) {
thread voxelizer(revoxelize, &lbm, mesh78); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 79) {
thread voxelizer(revoxelize, &lbm, mesh79); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 80) {
thread voxelizer(revoxelize, &lbm, mesh80); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 81) {
thread voxelizer(revoxelize, &lbm, mesh81); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 82) {
thread voxelizer(revoxelize, &lbm, mesh82); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 83) {
thread voxelizer(revoxelize, &lbm, mesh83); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 84) {
thread voxelizer(revoxelize, &lbm, mesh84); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 85) {
thread voxelizer(revoxelize, &lbm, mesh85); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 86) {
thread voxelizer(revoxelize, &lbm, mesh86); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 87) {
thread voxelizer(revoxelize, &lbm, mesh87); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 88) {
thread voxelizer(revoxelize, &lbm, mesh88); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 89) {
thread voxelizer(revoxelize, &lbm, mesh89); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 90) {
thread voxelizer(revoxelize, &lbm, mesh90); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 91) {
thread voxelizer(revoxelize, &lbm, mesh91); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 92) {
thread voxelizer(revoxelize, &lbm, mesh92); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 93) {
thread voxelizer(revoxelize, &lbm, mesh93); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 94) {
thread voxelizer(revoxelize, &lbm, mesh94); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 95) {
thread voxelizer(revoxelize, &lbm, mesh95); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 96) {
thread voxelizer(revoxelize, &lbm, mesh96); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 97) {
thread voxelizer(revoxelize, &lbm, mesh97); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 98) {
thread voxelizer(revoxelize, &lbm, mesh98); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 99) {
thread voxelizer(revoxelize, &lbm, mesh99); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 100) {
thread voxelizer(revoxelize, &lbm, mesh100); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 101) {
thread voxelizer(revoxelize, &lbm, mesh101); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 102) {
thread voxelizer(revoxelize, &lbm, mesh102); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 103) {
thread voxelizer(revoxelize, &lbm, mesh103); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 104) {
thread voxelizer(revoxelize, &lbm, mesh104); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 105) {
thread voxelizer(revoxelize, &lbm, mesh105); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 106) {
thread voxelizer(revoxelize, &lbm, mesh106); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 107) {
thread voxelizer(revoxelize, &lbm, mesh107); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 108) {
thread voxelizer(revoxelize, &lbm, mesh108); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 109) {
thread voxelizer(revoxelize, &lbm, mesh109); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 110) {
thread voxelizer(revoxelize, &lbm, mesh110); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 111) {
thread voxelizer(revoxelize, &lbm, mesh111); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 112) {
thread voxelizer(revoxelize, &lbm, mesh112); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 113) {
thread voxelizer(revoxelize, &lbm, mesh113); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 114) {
thread voxelizer(revoxelize, &lbm, mesh114); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 115) {
thread voxelizer(revoxelize, &lbm, mesh115); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 116) {
thread voxelizer(revoxelize, &lbm, mesh116); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 117) {
thread voxelizer(revoxelize, &lbm, mesh117); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 118) {
thread voxelizer(revoxelize, &lbm, mesh118); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 119) {
thread voxelizer(revoxelize, &lbm, mesh118); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 120) {
thread voxelizer(revoxelize, &lbm, mesh120); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 121) {
thread voxelizer(revoxelize, &lbm, mesh121); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 122) {
thread voxelizer(revoxelize, &lbm, mesh122); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 123) {
thread voxelizer(revoxelize, &lbm, mesh123); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 124) {
thread voxelizer(revoxelize, &lbm, mesh124); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
else if (currentMesh == 125) {
thread voxelizer(revoxelize, &lbm, mesh125); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
}
currentMesh++;
}
lbm.run(14u); // run LBM in parallel while CPU is voxelizing the next frame;
}
write_file(get_exe_path() + "time.txt", print_time(clock.stop()));
}The simulation with (main_setup code below) seems to blows up between 77000 and 78000 steps. I have changed just the box size and boundary condition. In defines.hpp #define TEMPERATURE and #define SUBGRID are enable. By the way it is not clear where additional parameters for convection, like, thermal diffusivity set.
void main_setup() { // Rayleigh-Benard convection
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
LBM lbm(256u, 128u, 128u, 0.02f, 0.0f, 0.0f, -0.001f, 0.0f, 1.0f, 1.0f);
// #############################################################################################################################################################################################
const uint N=lbm.get_N(), Nx=lbm.get_Nx(), Ny=lbm.get_Ny(), Nz=lbm.get_Nz(); for(uint n=0u, x=0u, y=0u, z=0u; n<N; n++, lbm.coordinates(n, x, y, z)) {
// ########################################################################### define geometry #############################################################################################
lbm.u.x[n] = random_symmetric(0.015f);
lbm.u.y[n] = random_symmetric(0.015f);
lbm.u.z[n] = random_symmetric(0.015f);
if(z==1u) {
lbm.T[n] = 1.75f;
lbm.flags[n] = TYPE_T;
} else if(z==Nz-2u) {
lbm.T[n] = 0.25f;
lbm.flags[n] = TYPE_T;
}
if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==0u||z==Nz-1u) lbm.flags[n] = TYPE_S; // all non periodic
//if(z==0u||z==Nz-1u) lbm.flags[n] = TYPE_S;
} // #########################################################################################################################################################################################
key_4 = true;
Clock clock;
lbm.run(0u);
while(lbm.get_t()<1000000u) {
lbm.graphics.set_camera_free(float3(1.0f*(float)Nx, -0.4f*(float)Ny, 2.0f*(float)Nz), -33.0f, 42.0f, 68.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/t/");
lbm.graphics.set_camera_free(float3(0.5f*(float)Nx, -0.35f*(float)Ny, -0.7f*(float)Nz), -33.0f, -40.0f, 100.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/b/");
lbm.graphics.set_camera_free(float3(0.0f*(float)Nx, 0.51f*(float)Ny, 0.75f*(float)Nz), 90.0f, 28.0f, 80.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/f/");
lbm.graphics.set_camera_free(float3(0.7f*(float)Nx, -0.15f*(float)Ny, 0.06f*(float)Nz), 0.0f, 0.0f, 100.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/s/");
lbm.run(1000u);
}
write_file(get_exe_path()+"time.txt", print_time(clock.stop()));
lbm.run();
} /**/
Hi @ProjectPhysX ,
I would like to know the difference between when I use this option and when I dont use this option.

As long as I use this option, density and velocity arent updated during time marching?
Moreover, could you teach me how I set up this option.
Thank you
Running everything on default settings, there were no streamlines or eddies happening anywhere around the car body, only around the tires. I experimented with grid size and other settings, to no avail.
I know MacOS, especially Intel chips, aren't ideal for the GPU performance but as far as getting to play with FluidX3D before considering buying a dedicated machine for rendering it would be nice to have a MacOS build. Is that a heavy lift?

The warnings look to be simple mistakes ";" or "(" begin expected but I don't know what those files are or what for and there aren't in that file path anyways.
I tried to uncomment "#define USE_OPENCL_1_1" but as I expected it wouldn't work anyways. The kernel.cpp, I didn't even look at it because I didn't change anything.
Hello, I just wanted to point out that some of the setups in setup.cpp enforce a condition that might not be physically accurate:
In your setups, this is often used:
const ulong N=lbm.get_N(); const uint Nx=lbm.get_Nx(), Ny=lbm.get_Ny(), Nz=lbm.get_Nz(); for(ulong n=0ull; n<N; n++) { uint x=0u, y=0u, z=0u; lbm.coordinates(n, x, y, z);
// ########################################################################### define geometry #############################################################################################
if(lbm.flags[n]!=TYPE_S) lbm.u.y[n] = u;
if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==0u||z==Nz-1u) lbm.flags[n] = TYPE_E; // all non periodic
} // #########################################################################################################################################################################################
When you say
if(lbm.flags[n]!=TYPE_S) lbm.u.y[n] = u;
I think this means (please correct me) that during the entire simulation (this is not an IC), the y component of the velocity in every cell that isn't flagged TYPE_S will equal u. This is enforced on the entire volumetric domain. This is not physically accurate because near a solid wall a boundary layer will develop where the y component will gradually approach 0 (no slip wall). A better way:
Enforce this only on the inlet, where all of the boundaries are also TYPE_E:
if (y == 0u) lbm.u.y[n] = u; //inlet
if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==0u||z==Nz-1u) lbm.flags[n] = TYPE_E; // all non periodic
This way, the entire domain is initialized at zero velocity and the y component is free to be whatever the solution wills.
The first way that you've used is probably faster because you initialize the entire domain at a nonzero value. What I've proposed here requires time for the domain to reach a steady value.
To alleviate this issue, it would be nice to be able to initialize the domain at a nonzero velocity, and then allow it to change value. This would mean the first simulation step would use if(lbm.flags[n]!=TYPE_S) lbm.u.y[n] = u;, and then this constraint would be released on any subsequent simulation steps. But, I don't know how to do this.
@ProjectPhysX, Hello.
Can you add the functionality of the program so that it can be used even by beginners who do not know C++. So that the simulation can be configured via UI or json or python *.pyd library. The presence of python binding allows you to embed this engine in 3d editors that support the python api (blender, maya, 3ds max).
When enable interactive graphics in Windows, some error happen. The programme only can execute one loop.
Hello, in the windows graphics on the lower right corner you show simulation time. Simulation time looks like it has units of steps.

Could you possibly report simulation time in seconds instead so that it is easier to compare how close to real time we are?
Is there a way to report simulation time and elapsed (real) execution time? I'm trying to easily differentiate these to see how close they are. Thanks!
Hello there,
First of all, I find your project just incredible, I discovered it 3 days ago and I use it for a car project, but I just need some precision about your code.
lbm.graphics.write_frame_png() function or the lbm.graphics.write_frame() function it just write a black image the root directory and it hasn't got any name, just an extention (.png / .bmp).#define WINDOWS_GRAPHICS and the windows shows up, I press P and nothing happends.Here is the code I use:
defines.hpp
//#define D2Q9 // choose D2Q9 velocity set for 2D; allocates 53 (FP32) or 35 (FP16) Bytes/node
#define D3Q15 // choose D3Q15 velocity set for 3D; allocates 77 (FP32) or 47 (FP16) Bytes/node
//#define D3Q19 // choose D3Q19 velocity set for 3D; allocates 93 (FP32) or 55 (FP16) Bytes/node; (default)
//#define D3Q27 // choose D3Q27 velocity set for 3D; allocates 125 (FP32) or 71 (FP16) Bytes/node
#define SRT // choose single-relaxation-time LBM collision operator; (default)
//#define TRT // choose two-relaxation-time LBM collision operator
//#define VOLUME_FORCE // enables global force per volume in one direction, specified in the LBM class constructor; the force can be changed on-the-fly between time steps at no performance cost
//#define FORCE_FIELD // enables a force per volume for each lattice point independently; allocates an extra 12 Bytes/node; enables computing the forces from the fluid on solid boundaries with lbm.calculate_force_on_boundaries();
#define MOVING_BOUNDARIES // enables moving solids: set solid nodes to TYPE_S and set their velocity u unequal to zero
#define EQUILIBRIUM_BOUNDARIES // enables fixing the velocity/density by marking nodes with TYPE_E; can be used for inflow/outflow; does not reflect shock waves
//#define SURFACE // enables free surface LBM: mark fluid nodes with TYPE_F; at initialization the TYPE_I interface and TYPE_G gas domains will automatically be completed; allocates an extra 12 Bytes/node
//#define TEMPERATURE // enables temperature extension; set fixed-temperature nodes with TYPE_T (similar to EQUILIBRIUM_BOUNDARIES); allocates an extra 32 (FP32) or 18 (FP16) Bytes/node
//#define SUBGRID // enables Smagorinsky-Lilly subgrid turbulence model to keep simulations with very large Reynolds number stable
//#define FP16S
//#define FP16C
#define WINDOWS_GRAPHICS
//#define CONSOLE_GRAPHICS
#define GRAPHICSsetup.cpp
void main_setup() { // Concorde
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
const uint L = 256u;
const float Re = 10000.0f;
const float u = 0.2f;
LBM lbm(L, 3u * L, L, units.nu_from_Re(Re, (float)L, u));
// #############################################################################################################################################################################################
const float size = 1.75f * (float)L;
const float3 center = float3(lbm.center().x, 2.0f + 0.5f * size, lbm.center().z);
const float3x3 rotation = float3x3(float3(1, 0, 0), radians(-10.0f)) * float3x3(float3(0, 0, 1), radians(90.0f)) * float3x3(float3(1, 0, 0), radians(90.0f));
voxelize_stl(lbm, get_exe_path() + "../Tests/Concorde.stl", center, rotation, size); // https://www.thingiverse.com/thing:1176931/files
const uint N = lbm.get_N(), Nx = lbm.get_Nx(), Ny = lbm.get_Ny(), Nz = lbm.get_Nz(); for (uint n = 0u, x = 0u, y = 0u, z = 0u; n < N; n++, lbm.coordinates(n, x, y, z)) {
// ########################################################################### define geometry #############################################################################################
lbm.u.y[n] = u;
if (x == 0u || x == Nx - 1u || y == 0u || y == Ny - 1u || z == 0u || z == Nz - 1u) lbm.flags[n] = TYPE_E; // all non periodic
} // #########################################################################################################################################################################################
lbm.run();
}
So I hope that someone can help me with this problem.
Best regards from France.
But where to check the TFLOPs/s
| ______________ ______________ |
| \ ________ | | ________ / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ _.-" | | "-._/ / |
| \ .-" _ "-. / |
| .-" .-" "-. "-./ |
| .-" .-"-. "-. |
| \ v" "v / |
| \ \ / / |
| \ \ / / |
| \ \ / / |
| \ ' / |
| \ / |
| \ / |
| ' ?Moritz Lehmann |
|----------------.------------------------------------------------------------|
| Device ID 0 | Quadro GV100 |
|----------------'------------------------------------------------------------|
|----------------.------------------------------------------------------------|
| Device ID | 0 |
| Device Name | Quadro GV100 |
| Device Vendor | NVIDIA Corporation |
| Device Driver | 516.59 |
| OpenCL Version | OpenCL C 1.2 |
| Compute Units | 80 at 1627 MHz (5120 cores, 16.660 TFLOPs/s) |
| Memory, Cache | 32767 MB, 2560 KB global / 48 KB local |
| Buffer Limits | 8191 MB global, 64 KB constant |
|----------------'------------------------------------------------------------|
| Info: OpenCL C code successfully compiled. |
|-----------------.-----------------------------------------------------------|
| Grid Resolution | 256 x 256 x 256 = 16777216 |
| LBM Type | D3Q19 SRT (FP32/FP32) |
| Memory Usage | CPU 272 MB, GPU 1488 MB |
| Max Alloc Size | 1216 MB |
| Time Steps | 10 |
| Kin. Viscosity | 1.00000000 |
| Relaxation Time | 3.50000000 |
| Reynolds Number | Re < 148 |
|---------.-------'-----.-----------.-------------------.---------------------|
| MLUPs | Bandwidth | Steps/s | Current Step | Time Remaining |
| 3377 | 517 GB/s | 201 | 9996 60% | 0s |
|---------'-------------'-----------'-------------------'---------------------|
| Info: Peak MLUPs/s = 3442 |
PS D:\Software\FluidX3D> .\FluidX3D-Benchmark-FP32-FP16S-Windows.exe
.-----------------------------------------------------------------------------.
| ______________ ______________ |
| \ ________ | | ________ / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ _.-" | | "-._/ / |
| \ .-" _ "-. / |
| .-" .-" "-. "-./ |
| .-" .-"-. "-. |
| \ v" "v / |
| \ \ / / |
| \ \ / / |
| \ \ / / |
| \ ' / |
| \ / |
| \ / |
| ' ?Moritz Lehmann |
|----------------.------------------------------------------------------------|
| Device ID 0 | Quadro GV100 |
|----------------'------------------------------------------------------------|
|----------------.------------------------------------------------------------|
| Device ID | 0 |
| Device Name | Quadro GV100 |
| Device Vendor | NVIDIA Corporation |
| Device Driver | 516.59 |
| OpenCL Version | OpenCL C 1.2 |
| Compute Units | 80 at 1627 MHz (5120 cores, 16.660 TFLOPs/s) |
| Memory, Cache | 32767 MB, 2560 KB global / 48 KB local |
| Buffer Limits | 8191 MB global, 64 KB constant |
|----------------'------------------------------------------------------------|
| Info: OpenCL C code successfully compiled. |
|-----------------.-----------------------------------------------------------|
| Grid Resolution | 256 x 256 x 256 = 16777216 |
| LBM Type | D3Q19 SRT (FP32/FP16S) |
| Memory Usage | CPU 272 MB, GPU 880 MB |
| Max Alloc Size | 608 MB |
| Time Steps | 10 |
| Kin. Viscosity | 1.00000000 |
| Relaxation Time | 3.50000000 |
| Reynolds Number | Re < 148 |
|---------.-------'-----.-----------.-------------------.---------------------|
| MLUPs | Bandwidth | Steps/s | Current Step | Time Remaining |
| 6149 | 473 GB/s | 367 | 9995 50% | 0s |
|---------'-------------'-----------'-------------------'---------------------|
| Info: Peak MLUPs/s = 6441 |
.-----------------------------------------------------------------------------.
| ______________ ______________ |
| \ ________ | | ________ / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ \ | | | | / / |
| \ _.-" | | "-._/ / |
| \ .-" _ "-. / |
| .-" .-" "-. "-./ |
| .-" .-"-. "-. |
| \ v" "v / |
| \ \ / / |
| \ \ / / |
| \ \ / / |
| \ ' / |
| \ / |
| \ / |
| ' ?Moritz Lehmann |
|----------------.------------------------------------------------------------|
| Device ID 0 | Quadro GV100 |
|----------------'------------------------------------------------------------|
|----------------.------------------------------------------------------------|
| Device ID | 0 |
| Device Name | Quadro GV100 |
| Device Vendor | NVIDIA Corporation |
| Device Driver | 516.59 |
| OpenCL Version | OpenCL C 1.2 |
| Compute Units | 80 at 1627 MHz (5120 cores, 16.660 TFLOPs/s) |
| Memory, Cache | 32767 MB, 2560 KB global / 48 KB local |
| Buffer Limits | 8191 MB global, 64 KB constant |
|----------------'------------------------------------------------------------|
| Info: OpenCL C code successfully compiled. |
|-----------------.-----------------------------------------------------------|
| Grid Resolution | 256 x 256 x 256 = 16777216 |
| LBM Type | D3Q19 SRT (FP32/FP16C) |
| Memory Usage | CPU 272 MB, GPU 880 MB |
| Max Alloc Size | 608 MB |
| Time Steps | 10 |
| Kin. Viscosity | 1.00000000 |
| Relaxation Time | 3.50000000 |
| Reynolds Number | Re < 148 |
|---------.-------'-----.-----------.-------------------.---------------------|
| MLUPs | Bandwidth | Steps/s | Current Step | Time Remaining |
| 5795 | 446 GB/s | 345 | 9991 10% | 0s |
|---------'-------------'-----------'-------------------'---------------------|
| Info: Peak MLUPs/s = 5863
I've been trying some simple D2Q9 2D simulations and find that the sparse streamlines algorithm doesn't work properly. For example, using a value of 2 simply draws streamlines in the bottom half of the simulation box. I haven't tried it with 3D simulations.
Really interesting software. Thanks for making it available.
I am modelling a Car with rotating Tires.
The ground z = 0 has the Flags = TYPE_S with set velocity of u.
The Carbody and the Tires are setup with the the Flag (TYPE_S|TYPE_X)
I need the TYPE_X Flag for the Force readout.
For the Rotations of the Tires I use a similiar procedure as the Demo of the Rotating Fan.
meshTireFR->rotate(float3x3(idk, angular_u*4.0f)); // rotate mesh
lbm.voxelize_mesh_on_device(meshTireFR, TYPE_S | TYPE_X, centerTireFR, float3(0.0f), RotationTire);
lbm.run(1u);
I noticed that if the Tire touches the Ground all Voxels inside the Projection surface of the tire on the Ground are reset with the Flags of the Tire.
This is a picture before the simulation was started. You can see that one of Tires touches the Ground.

After the Rotations of the Tires all the Ground Areas below the Tires have a Purple Rim. Indicating that something off.

i think thats happening because of the new revoxlizing algorithmen.
forgive the concise issue description, i'm under time constraints, i am happy to elaborate if necessary
Hi Moritz,
Following up on the post from mastodon, I wanted to point out a potential bug. Specifically during the voxel creation phase when converting an STL mesh, the converter seems to be creating "fake" geometry.
Example of behaviour:


I'm running the latest version
The file in question is:
And the code being run is:
#include "setup.hpp"
#ifndef BENCHMARK
void main_setup() { // F1 car
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
const uint L = 672u; // 2152u on 8x MI200
const float kmh = 100.0f;
const float si_u = kmh/3.6f;
const float si_x = 2.0f;
const float si_rho = 1.225f;
const float si_nu = 1.48E-5f;
const float Re = units.si_Re(si_x, si_u, si_nu);
print_info("Re = "+to_string(Re));
const float u = 0.08f;
const float size = 1.6f*(float)L;
units.set_m_kg_s(size*2.0f/5.5f, u, 1.0f, si_x, si_u, si_rho);
const float nu = units.nu(si_nu);
print_info("1s = "+to_string(units.t(1.0f)));
LBM lbm(0.6*L, 1.65*L, 0.35*L, nu); // (width, depth, height)
// LBM lbm(L, 2*L, 3*L, nu); //work with L=256u, u=0.08f
// #############################################################################################################################################################################################
const float3 center = float3(lbm.center().x, lbm.center().y, lbm.center().z);
// const float3 center = float3(lbm.center().x, 0.525f*size, 0.116f*size);
lbm.voxelize_stl("/home/felix/cad/RB18_alligned.stl", center, size); // https://addons-redbullracing-com2020.redbull.com/b3993c8955aad441ec69/assets/cars/RB18/model/RB_18_v05.glb
const ulong N=lbm.get_N(); const uint Nx=lbm.get_Nx(), Ny=lbm.get_Ny(), Nz=lbm.get_Nz(); for(ulong n=0ull; n<N; n++) { uint x=0u, y=0u, z=0u; lbm.coordinates(n, x, y, z);
// ########################################################################### define geometry #############################################################################################
//if(lbm.flags[n]!=TYPE_S) lbm.u.y[n] = u;
if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==Nz-1u) lbm.flags[n] = TYPE_E;
if(z==0u) lbm.flags[n] = TYPE_S;
const float3 p = lbm.position(x, y, z);
const float W = 1.05f*(0.312465f-0.179692f)*(float)Nx;
const float R = 1.05f*0.5f*(0.361372f-0.255851f)*(float)Ny;
//rotating bodies
/* const float3 FL = float3(0.247597f*(float)Nx, -0.308710f*(float)Ny, -0.260423f*(float)Nz);
const float3 HL = float3(0.224739f*(float)Nx, 0.210758f*(float)Ny, -0.264461f*(float)Nz);
const float3 FR = float3(-FL.x, FL.y, FL.z);
const float3 HR = float3(-HL.x, HL.y, HL.z);
if((lbm.flags[n]&TYPE_S) && cylinder(x, y, z, lbm.center()+FL, float3(W, 0.0f, 0.0f), R)) {
const float3 uW = u/R*float3(0.0f, FL.z-p.z, p.y-FL.y);
lbm.u.y[n] = uW.y;
lbm.u.z[n] = uW.z;
}
if((lbm.flags[n]&TYPE_S) && cylinder(x, y, z, lbm.center()+HL, float3(W, 0.0f, 0.0f), R)) {
const float3 uW = u/R*float3(0.0f, HL.z-p.z, p.y-HL.y);
lbm.u.y[n] = uW.y;
lbm.u.z[n] = uW.z;
}
if((lbm.flags[n]&TYPE_S) && cylinder(x, y, z, lbm.center()+FR, float3(W, 0.0f, 0.0f), R)) {
const float3 uW = u/R*float3(0.0f, FR.z-p.z, p.y-FR.y);
lbm.u.y[n] = uW.y;
lbm.u.z[n] = uW.z;
}
if((lbm.flags[n]&TYPE_S) && cylinder(x, y, z, lbm.center()+HR, float3(W, 0.0f, 0.0f), R)) {
const float3 uW = u/R*float3(0.0f, HR.z-p.z, p.y-HR.y);
lbm.u.y[n] = uW.y;
lbm.u.z[n] = uW.z;
}
*/ } // #########################################################################################################################################################################################
// key_4 = true;
//Clock clock;
//lbm.run(0u);
//while(lbm.get_t()<=units.t(1.0f)) {
// lbm.graphics.set_camera_free(float3(0.779346f*(float)Nx, -0.315650f*(float)Ny, 0.329444f*(float)Nz), -27.0f, 19.0f, 100.0f);
// lbm.graphics.write_frame_png(get_exe_path()+"export/a/");
// lbm.graphics.set_camera_free(float3(0.556877f*(float)Nx, 0.228191f*(float)Ny, 1.159613f*(float)Nz), 19.0f, 53.0f, 100.0f);
// lbm.graphics.write_frame_png(get_exe_path()+"export/b/");
// lbm.graphics.set_camera_free(float3(0.220650f*(float)Nx, -0.589529f*(float)Ny, 0.085407f*(float)Nz), -72.0f, 21.0f, 86.0f);
// lbm.graphics.write_frame_png(get_exe_path()+"export/c/");
// lbm.run(units.t(0.5f/600.0f)); // run LBM in parallel while CPU is voxelizing the next frame
//}
//write_file(get_exe_path()+"time.txt", print_time(clock.stop()));
lbm.run();
} /**/
#endif // SURFACE
#ifdef TEMPERATURE
/*void main_setup() { // Rayleigh-Benard convection
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
LBM lbm(256u, 256u, 64u, 0.02f, 0.0f, 0.0f, -0.001f, 0.0f, 1.0f, 1.0f);
// #############################################################################################################################################################################################
const ulong N=lbm.get_N(); const uint Nx=lbm.get_Nx(), Ny=lbm.get_Ny(), Nz=lbm.get_Nz(); for(ulong n=0ull; n<N; n++) { uint x=0u, y=0u, z=0u; lbm.coordinates(n, x, y, z);
// ########################################################################### define geometry #############################################################################################
lbm.u.x[n] = random_symmetric(0.015f);
lbm.u.y[n] = random_symmetric(0.015f);
lbm.u.z[n] = random_symmetric(0.015f);
if(z==1u) {
lbm.T[n] = 1.75f;
lbm.flags[n] = TYPE_T;
} else if(z==Nz-2u) {
lbm.T[n] = 0.25f;
lbm.flags[n] = TYPE_T;
}
//if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==0u||z==Nz-1u) lbm.flags[n] = TYPE_S; // all non periodic
if(z==0u||z==Nz-1u) lbm.flags[n] = TYPE_S;
} // #########################################################################################################################################################################################
lbm.run();
} /**/
/*void main_setup() { // TEMPERATURE test
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
LBM lbm(32u, 196u, 60u, 1u, 1u, 1u, 0.02f, 0.0f, 0.0f, -0.001f, 0.0f, 1.0f, 1.0f);
// #############################################################################################################################################################################################
const ulong N=lbm.get_N(); const uint Nx=lbm.get_Nx(), Ny=lbm.get_Ny(), Nz=lbm.get_Nz(); for(ulong n=0ull; n<N; n++) { uint x=0u, y=0u, z=0u; lbm.coordinates(n, x, y, z);
// ########################################################################### define geometry #############################################################################################
if(y==1) {
lbm.T[n] = 1.8f;
lbm.flags[n] = TYPE_T;
} else if(y==Ny-2) {
lbm.T[n] = 0.3f;
lbm.flags[n] = TYPE_T;
}
if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==0u||z==Nz-1u) lbm.flags[n] = TYPE_S; // all non periodic
} // #########################################################################################################################################################################################
lbm.run();
//lbm.run(1000u); lbm.u.read_from_device(); println(lbm.u.x[lbm.index(Nx/2u, Ny/2u, Nz/2u)]); wait(); // test for binary identity
} /**/
/*
#endif // TEMPERATURE
#else // BENCHMARK
#include "info.hpp"
void main_setup() { // benchmark
uint mlups = 0u;
{ // ######################################################## define simulation box size, viscosity and volume force ###########################################################################
//LBM lbm( 32u, 32u, 32u, 1.0f);
//LBM lbm( 48u, 48u, 48u, 1.0f);
//LBM lbm( 64u, 64u, 64u, 1.0f);
//LBM lbm( 96u, 96u, 96u, 1.0f);
//LBM lbm(128u, 128u, 128u, 1.0f);
//LBM lbm(192u, 192u, 192u, 1.0f);
LBM lbm(256u, 256u, 256u, 1.0f);
//LBM lbm(384u, 384u, 384u, 1.0f);
//LBM lbm(464u, 464u, 464u, 1.0f);
//LBM lbm(480u, 480u, 480u, 1.0f);
//LBM lbm(512u, 512u, 512u, 1.0f);
//const uint memory = 4096u; // in MB
//const uint L = ((uint)cbrt(fmin((float)memory*1048576.0f/(19.0f*(float)sizeof(fpxx)+17.0f), (float)max_uint))/2u)*2u;
//LBM lbm(1u*L, 1u*L, 1u*L, 1u, 1u, 1u, 1.0f); // 1 GPU
//LBM lbm(2u*L, 1u*L, 1u*L, 2u, 1u, 1u, 1.0f); // 2 GPUs
//LBM lbm(2u*L, 2u*L, 1u*L, 2u, 2u, 1u, 1.0f); // 4 GPUs
//LBM lbm(2u*L, 2u*L, 2u*L, 2u, 2u, 2u, 1.0f); // 8 GPUs
// #########################################################################################################################################################################################
for(uint i=0u; i<1000u; i++) {
lbm.run(10u);
mlups = max(mlups, to_uint((double)lbm.get_N()*1E-6/info.dt_smooth));
}
} // make lbm object go out of scope to free its memory
print_info("Peak MLUPs/s = "+to_string(mlups));
#if defined(_WIN32)
wait();
#endif // Windows
}*/
#endif // BENCHMARK
How difficult is fixed temperature gradient to implement?
Hello Moritz, this is more of a feature enhancement than an issue. Due to your code's speed, I've realized that it may open doors into applications that have been under-researched.
Context: I am experimenting with getting a semi-real time (maybe 3-4s real time for every 1s simulation time) moving mesh simulation working on a Nvidia A100. This simulation involves fluid-solid interaction with the mid-grid bounce back boundaries you've implemented. During each timestep, FluidX3D sends forces and moments to my rigid body solver (with calculate_torque_on_object), and the rigid body solver calculates the resulting kinematics and sends rotation and translation matrices back to FluidX3d. I'm actually experimenting with the rigid body solver running on the same GPU using IPC. Right now I'm working on a single body pendulum to keep it simple. The end game is to do controller design on rigid body dynamics immersed in fluids. Multiphysics simulations have done similar things before, but combining control theory with fluid dynamics has been a challenge because controllers often involve trial and error. Trial and error on a simulation that takes many hours isn't practical, this is why I’m interested in LBM.
Now concerning the feature enhancement: I started with the tie fighter example where you detach a separate thread and revoxelize a new frame with the rotated mesh on CPU in parallel with LBM running on GPU. However in my scenario with fluid solid interaction we would need to solve the flow field before rotating/moving the mesh because the mesh movement is driven by the fluid and visa versa (in series). On large grids where we can't run close to real time, this isn't a big deal because LBM takes a lot longer than the revoxelization process anyways. However, if I were to try and get a simulation to run close to real time on a smaller grid (say only 4-5 million voxels), the revoxelization process on CPU could become a bottleneck and LBM would need to wait until the revoxelization process is complete in order to start on the next frame.
Do you have any thoughts on placing the revoxelization process onto the GPU as well? The two processes would still run in series with time, but each would be parallelized internally so that the overall process would be faster than doing it in series on CPU. I would appreciate your thoughts!
Hello everyone i'm a Metallurgical and Material Engineer and i wanna do study aerospace engineering as my master degree. That's why i wanna learn CFD things as much as i can and i'm interesting with FluidX3D. Today i tried some sample setups at FluidX3D and i compiled with succes but i couldn't get any render things. I Used Sample STL files (Concorde and 747). How can i get rendered images or videos? Because when compiling is done CMD screen is closing instantly.
My Setup.cpp file is this. I'm using Visual Studio 2022 and it's my first experience with this program. Thanks everyone in advance for their help.
`
#include "setup.hpp"
#include "info.hpp"
#include "lbm.hpp"
#include "graphics.hpp"
void main_setup() { // Star Wars TIE fighter
// ######################################################### define simulation box size, viscosity and volume force ############################################################################
const uint L = 256u;
const float Re = 100000.0f;
const float u = 0.125f;
LBM lbm(L, L*2u, L, units.nu_from_Re(Re, (float)L, u));
// #############################################################################################################################################################################################
const float size = 0.65f*(float)L;
const float3 center = float3(lbm.center().x, 0.6f*size, lbm.center().z);
const float3x3 rotation = float3x3(float3(1, 0, 0), radians(90.0f));
Mesh* mesh = read_stl(get_exe_path()+"../stl/TIE-fighter.stl", lbm.size(), center, rotation, size); // https://www.thingiverse.com/thing:2919109/files
voxelize_mesh_hull(lbm, mesh, TYPE_S);
const uint N=lbm.get_N(), Nx=lbm.get_Nx(), Ny=lbm.get_Ny(), Nz=lbm.get_Nz(); for(uint n=0u, x=0u, y=0u, z=0u; n<N; n++, lbm.coordinates(n, x, y, z)) {
// ########################################################################### define geometry #############################################################################################
if(lbm.flags[n]!=TYPE_S) lbm.u.y[n] = u;
if(x==0u||x==Nx-1u||y==0u||y==Ny-1u||z==0u||z==Nz-1u) lbm.flags[n] = TYPE_E; // all non periodic
} // #########################################################################################################################################################################################
key_4 = true;
Clock clock;
lbm.run(0);
while(lbm.get_t()<1000u) {
lbm.graphics.set_camera_free(float3(1.0f*(float)Nx, -0.4f*(float)Ny, 0.63f*(float)Nz), -33.0f, 33.0f, 80.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/t/");
lbm.graphics.set_camera_free(float3(0.3f*(float)Nx, -1.5f*(float)Ny, -0.45f*(float)Nz), -83.0f, -10.0f, 40.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/b/");
lbm.graphics.set_camera_free(float3(0.0f*(float)Nx, 0.57f*(float)Ny, 0.7f*(float)Nz), 90.0f, 29.5f, 80.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/f/");
lbm.graphics.set_camera_free(float3(2.5f*(float)Nx, 0.0f*(float)Ny, 0.0f*(float)Nz), 0.0f, 0.0f, 50.0f);
lbm.graphics.write_frame_png(get_exe_path()+"export/s/");
while(revoxelizing.load()) sleep(0.01f); // wait for voxelizer thread to finish
lbm.flags.write_to_device(); // lbm.flags on host is finished, write to device now
revoxelizing = true; // indicate new voxelizer thread is starting
thread voxelizer(revoxelize, &lbm, mesh); // start new voxelizer thread
voxelizer.detach(); // detatch voxelizer thread so LBM can run in parallel
lbm.run(28u); // run LBM in parallel while CPU is voxelizing the next frame
}
write_file(get_exe_path()+"time.txt", print_time(clock.stop(1000u)));
`
Hi,
First off I want to say that you have made some great software, very nice to both use and look into. I really appreciate the effort that went into making it.
I was quite surprised by the disparity between the performance that AMD cards reach in the benchmark compared to the NVidia GPUs, so I tried to look into it. I ported the stream_collide kernel to HIP and saw that the performance that can be reached with HIP is much higher, effectively same peak bandwidths ratio as with NVidia GPUs. (If of interest, I can provide that HIP code).
So that lead me to think that something is wrong with AMD's OpenCL runtime, such as kernel launch &synchronization overheads or something of the like.
I saw that in the case of single GPU simulation, there was some synchronization that could be removed in FluidX3D by synchronizing once per run() call instead of once per do_time_step().
By doing so, I can see that the total simulation time gets smaller on AMD GPUs, by roughly a constant amount of time independent of the GPU. For faster GPUs, it means the improvement gets more significant relatively.
Here are some numbers:
| GPU | Grid size | Simulation time before change | Simulation time after change | Improvement |
|---|---|---|---|---|
| Ryzen 5800U | 128^3 | 114s | 108s | 1.05x faster |
| NVidia V100 16GB PCIe | 256^3 | 34.2s | 34.1s | same |
| AMD RX6700xt | 256^3 | 131s | 127s | 1.3x faster |
| AMD MI50 | 256^3 | 50.7s | 48.0s | 1.05x faster |
| AMD MI100 | 256^3 | 34.0s | 32.0s | 1.06x faster |
While the improvement isn't amazing, I guess it is a low effort improvement, and the effect might be more visible for faster GPUs, maybe 10% relatively on MI250x if the time improvement is the same.
Hoping you consider this improvement,
On my side I will continue trying to understand where the disparity between HIP and OpenCL comes from for funsies,
Best regards,
Epliz
Hello, an amazing program you have developed, I appreciate that you published it for free. I'm simulating a high lift airfoil at high Reynolds, which was a nightmare with Ansys fluent. My goal is to obtain the drag and lift coefficients or at least the force at the airfoil, is it possible or implemented in the program? I exported the velocity and force vtk file, but the force vtk when I opened it at OpenFoam it showed nothing. Thanks :)

https://drive.google.com/file/d/1oRb9zjwCpU86CRqfl6DP671Ibxth5gM1/view?usp=sharing (a short clip of the simulation)
Hello, I tried running some models with graphics output, for example the 3D Taylor-Green vortices model. With all the settings at default (#define BENCHMARK commented out), I struggle to receive a graphics output. When using WINDOWS_GRAPHICS, the setup does not compile with the output below. When trying to use CONSOLE_GRAPHICS, the console seems to prepare the space for the output with the pixel counter on the bottom right, but the space stays black. Defining GRAPHICS works, but where is the file output to? In addition, where can the time step or output time step be altered? I use Windows 10 and WSL if it's of importance.
WINDOWS_GRAPHICS output:
$ ./make.sh In file included from ./src/opencl.hpp:14, from ./src/lbm.hpp:4, from ./src/info.cpp:2: ./src/OpenCL/include/CL/cl.hpp:5085:28: warning: ignoring attributes on template argument 'cl_int' {aka 'int'} [-Wignored-attributes] 5085 | VECTOR_CLASS<cl_int>* binaryStatus = NULL, | ^ In file included from ./src/opencl.hpp:14, from ./src/lbm.hpp:4, from ./src/lbm.cpp:1: ./src/OpenCL/include/CL/cl.hpp:5085:28: warning: ignoring attributes on template argument 'cl_int' {aka 'int'} [-Wignored-attributes] 5085 | VECTOR_CLASS<cl_int>* binaryStatus = NULL, | ^ In file included from ./src/opencl.hpp:14, from ./src/lbm.hpp:4, from ./src/main.cpp:2: ./src/OpenCL/include/CL/cl.hpp:5085:28: warning: ignoring attributes on template argument 'cl_int' {aka 'int'} [-Wignored-attributes] 5085 | VECTOR_CLASS<cl_int>* binaryStatus = NULL, | ^ In file included from ./src/opencl.hpp:14, from ./src/lbm.hpp:4, from ./src/setup.hpp:4, from ./src/setup.cpp:1: ./src/OpenCL/include/CL/cl.hpp:5085:28: warning: ignoring attributes on template argument 'cl_int' {aka 'int'} [-Wignored-attributes] 5085 | VECTOR_CLASS<cl_int>* binaryStatus = NULL, | ^ In file included from ./src/opencl.hpp:14, from ./src/lbm.hpp:4, from ./src/shapes.cpp:2: ./src/OpenCL/include/CL/cl.hpp:5085:28: warning: ignoring attributes on template argument 'cl_int' {aka 'int'} [-Wignored-attributes] 5085 | VECTOR_CLASS<cl_int>* binaryStatus = NULL, | ^ C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1ac9): undefined reference to __imp_SetBitmapBits'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1b2a): undefined reference to __imp_SetTextColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1b68): undefined reference to __imp_TextOutA'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1bd8): undefined reference to __imp_TextOutA' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1c45): undefined reference to __imp_TextOutA'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1cae): undefined reference to __imp_SetPixel' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1d20): undefined reference to __imp_SetPixel'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1d33): undefined reference to __imp_GetStockObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1d49): undefined reference to __imp_SelectObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1d88): undefined reference to __imp_SetDCPenColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1df1): undefined reference to __imp_Ellipse'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1e2e): undefined reference to __imp_Ellipse' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1e3c): undefined reference to __imp_GetStockObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1e52): undefined reference to __imp_SelectObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1eaf): undefined reference to __imp_SetDCPenColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1ed1): undefined reference to __imp_MoveToEx' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1eed): undefined reference to __imp_LineTo'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1f6e): undefined reference to __imp_SetDCPenColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1fad): undefined reference to __imp_SetDCBrushColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x1fca): undefined reference to __imp_Polygon' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x2027): undefined reference to __imp_SetDCPenColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x2066): undefined reference to __imp_SetDCBrushColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x208b): undefined reference to __imp_Rectangle'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x2189): undefined reference to __imp_SetDCPenColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x21c8): undefined reference to __imp_SetDCBrushColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x21e5): undefined reference to __imp_Polygon' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x2259): undefined reference to __imp_SetTextColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x2297): undefined reference to __imp_TextOutA' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x377d): undefined reference to __imp_CreateRectRgn'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3793): undefined reference to __imp_SelectClipRgn' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3b3e): undefined reference to __imp_BitBlt'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3b4c): undefined reference to __imp_GetStockObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3b62): undefined reference to __imp_SelectObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3b74): undefined reference to __imp_GetStockObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3b8a): undefined reference to __imp_SelectObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3bc3): undefined reference to __imp_Rectangle' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3bda): undefined reference to __imp_SelectObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x3bf1): undefined reference to __imp_SelectObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4038): undefined reference to __imp_GetStockObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4278): undefined reference to __imp_CreateCompatibleBitmap' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4292): undefined reference to __imp_CreateCompatibleDC'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x42b3): undefined reference to __imp_SelectObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x42cd): undefined reference to __imp_DeleteObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x42db): undefined reference to __imp_GetStockObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x42f1): undefined reference to __imp_SelectObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x42ff): undefined reference to __imp_GetStockObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4315): undefined reference to __imp_SelectObject'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x432d): undefined reference to __imp_SetDCPenColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4345): undefined reference to __imp_SetDCBrushColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x435d): undefined reference to __imp_SetTextAlign' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4375): undefined reference to __imp_SetBkMode'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x438d): undefined reference to __imp_SetPolyFillMode' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4400): undefined reference to __imp_CreateFontA'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text+0x4421): undefined reference to __imp_SelectObject' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text$_ZNK8Triangle4drawEv[_ZNK8Triangle4drawEv]+0x46): undefined reference to __imp_SetDCPenColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text$_ZNK8Triangle4drawEv[_ZNK8Triangle4drawEv]+0x86): undefined reference to __imp_SetDCBrushColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text$_ZNK8Triangle4drawEv[_ZNK8Triangle4drawEv]+0xa7): undefined reference to __imp_Polygon'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text$_ZNK10Quadrangle4drawEv[_ZNK10Quadrangle4drawEv]+0x46): undefined reference to __imp_SetDCPenColor' C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text$_ZNK10Quadrangle4drawEv[_ZNK10Quadrangle4drawEv]+0x86): undefined reference to __imp_SetDCBrushColor'
C:/TDM-GCC-64/bin/../lib/gcc/x86_64-w64-mingw32/10.3.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\Thierry\AppData\Local\Temp\ccmwGO2p.o:graphics.cpp:(.text$_ZNK10Quadrangle4drawEv[_ZNK10Quadrangle4drawEv]+0xa7): undefined reference to __imp_Polygon' collect2.exe: error: ld returned 1 exit status ./make.sh: line 7: ./bin/FluidX3D.exe: No such file or directory
Hi,
First of all, thank you for this amazing software. The performance is out of this world.
I'm trying to simulate a wingsuit at different angles of attack. I was using Ansys Fluent for this but it just takes forever on a PC at home and a limited license, even at a way lower resolution.
I'm having trouble with the force readouts, expected lift and drag at an AoA of 10° is in the hundreds of Newtons. (That’s why I commented out the scientific notation, since 500 is easier to read than 5.0E2). I get 55N drag and 15N lift if I don’t convert to SI, or 6.62E7 N drag and 1.74E7 N lift with units.si_F();
I assume that I made mistake in the setup of the conversion between LBM and SI units. And I find weird that the drag is way bigger that the lift, wingsuits should have a glide ratio of around 3.
Do you see any obvious mistakes in the setup.cpp ?
Cheers and thank you for your work!
Marius
Setup.cpp
void main_setup() {
const uint res = 240; // Grid Resolution
const float AoA = 10.0f; // Angle of Attack [°]
// -- SI units --
const float si_Length = 2.0f; // Characteristic length[m]
const float si_Airspeed = 50.0f; // Airspeed in SI [m/s]
const float si_rho = 1.225f; // 1.225kg/m^3 air density
const float si_nu = 1.48E-5f; // 1.48E-5f m^2/s kinematic shear viscosity of air
// -- LBM units --
const float lbm_x = 1.0f;
const float lbm_u = 0.1f;
const float lbm_rho = 1.0f;
units.set_m_kg_s(lbm_x, lbm_u, lbm_rho, si_Length, si_Airspeed, si_rho);
LBM lbm(res*1.2, res*1.6, res*1.2, units.nu(si_nu));
const float size = 1.0f * (float)res;
const float3 center = float3(lbm.center().x, lbm.center().y, lbm.center().z); // center the model
const float3x3 rotation = float3x3(float3(1, 0, 0), radians(30.0f-AoA)) * float3x3(float3(0, 0, 1), radians(00.0f)) * float3x3(float3(1, 0, 0), radians(90.0f)); // Stl is Y-up -> Rotate by 90° | 30.0f because the model is already tilted
lbm.voxelize_stl(get_exe_path() + "stl/wingsuit.stl", center, rotation, size, TYPE_S); // Import Mesh
const uint N = lbm.get_N(), Nx = lbm.get_Nx(), Ny = lbm.get_Ny(), Nz = lbm.get_Nz();
for (uint n = 0u, x = 0u, y = 0u, z = 0u; n < N; n++, lbm.coordinates(n, x, y, z)) {
if (lbm.flags[n] != TYPE_S) {
lbm.u.y[n] = lbm_u; //All non Solid nodes get the Velocity
}
if (x == 0u || x == Nx - 1u || y == 0u || y == Ny - 1u || z == 0u || z == Nz - 1u) {
lbm.flags[n] = TYPE_E; // Flag Inlets and Outlets
}
}
key_1 = true;// Show Mesh
key_4 = true;// Show Turbulence
lbm.run(1500);// Run
for (int i = 0; i < 10; i++) // Run for 100 Steps, then print the Forces to the Console
{
lbm.run(100);
lbm.calculate_force_on_boundaries();
lbm.F.read_from_device();
const float3 force = lbm.calculate_force_on_object(TYPE_S);
print_info("Step nr : " + to_string(lbm.get_t()));
print_info(/*"Lateral: " + to_string(force.x) +*/ "LBM - Drag: " + to_string(force.y) + " N Lift:" + to_string(force.z) + " N");
print_info(/*"Lateral: " + to_string(force.x) +*/ "SI - Drag: " + to_string(units.si_F(force.y)) + " N Lift:" + to_string(units.si_F(force.z)) + " N");
}
wait(); // wait for a keypress to close the Program
}Console Out:
`
|----------------.------------------------------------------------------------|
| Device ID 0 | NVIDIA GeForce GTX 1080 |
|----------------'------------------------------------------------------------|
|----------------.------------------------------------------------------------|
| Device ID | 0 |
| Device Name | NVIDIA GeForce GTX 1080 |
| Device Vendor | NVIDIA Corporation |
| Device Driver | 522.25 |
| OpenCL Version | OpenCL C 1.2 |
| Compute Units | 20 at 1797 MHz (2560 cores, 9.201 TFLOPs/s) |
| Memory, Cache | 8191 MB, 960 KB global / 48 KB local |
| Buffer Limits | 2047 MB global, 64 KB constant |
|----------------'------------------------------------------------------------|
1 warning generated.
| Info: OpenCL C code successfully compiled. |
Loading "C:/dev/FluidX/bin/stl/wingsuit.stl" with 203691 triangles.
| Info: Voxelizing mesh. This may take a few minutes. |
|-----------------.-----------------------------------------------------------|
| Grid Resolution | 288 x 384 x 288 = 31850496 |
| LBM Type | D3Q27 SRT (FP32/FP32) |
| Memory Usage | CPU 516 MB, GPU 3796 MB |
| Max Alloc Size | 3280 MB |
| Time Steps | 1500 |
| Kin. Viscosity | 0.00000001 |
| Relaxation Time | 0.50000004 |
| Reynolds Number | Re < 2644988928 |
| Volume Force | 0.00000000, 0.00000000, 0.00000000 |
|---------.-------'-----.-----------.-------------------.---------------------|
| MLUPs | Bandwidth | Steps/s | Current Step | Time Remaining |
| Info: Step nr : 1600 |
| Info: LBM - Drag: 62.980694 N Lift:11.393983 N |
| Info: SI - Drag: 77151344.000000 N Lift:13957628.000000 N |
| Info: Step nr : 1700 |
| Info: LBM - Drag: 61.000553 N Lift:11.799897 N |
| Info: SI - Drag: 74725672.000000 N Lift:14454872.000000 N |
| Info: Step nr : 1800 |
| Info: LBM - Drag: 59.884335 N Lift:13.046824 N |
| Info: SI - Drag: 73358304.000000 N Lift:15982358.000000 N |
| Info: Step nr : 1900 |
| Info: LBM - Drag: 59.182091 N Lift:14.444882 N |
| Info: SI - Drag: 72498056.000000 N Lift:17694978.000000 N |
| Info: Step nr : 2000 |
| Info: LBM - Drag: 58.040073 N Lift:15.479063 N |
| Info: SI - Drag: 71099080.000000 N Lift:18961850.000000 N |
| Info: Step nr : 2100 |
| Info: LBM - Drag: 57.142467 N Lift:15.655202 N |
| Info: SI - Drag: 69999520.000000 N Lift:19177620.000000 N |
| Info: Step nr : 2200 |
| Info: LBM - Drag: 55.727894 N Lift:15.647128 N |
| Info: SI - Drag: 68266664.000000 N Lift:19167730.000000 N |
| Info: Step nr : 2300 |
| Info: LBM - Drag: 55.218250 N Lift:15.055589 N |
| Info: SI - Drag: 67642352.000000 N Lift:18443094.000000 N |
| Info: Step nr : 2400 |
| Info: LBM - Drag: 53.899487 N Lift:14.339896 N |
| Info: SI - Drag: 66026864.000000 N Lift:17566372.000000 N |
| Info: Step nr : 2500 |
| Info: LBM - Drag: 54.105560 N Lift:14.259664 N |
| Info: SI - Drag: 66279304.000000 N Lift:17468086.000000 N |
| 1082 | 235 GB/s | 34 | 2500 100% | 0s |
`
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.