作者是一名PHPer,闲暇之余,出于对大数据的好奇,基于 JAVA Servlet 和 python scrapy 做的一个玩具项目,也是为了考验自己在新语言环境下解决问题的能力,从开发到部署用了10天
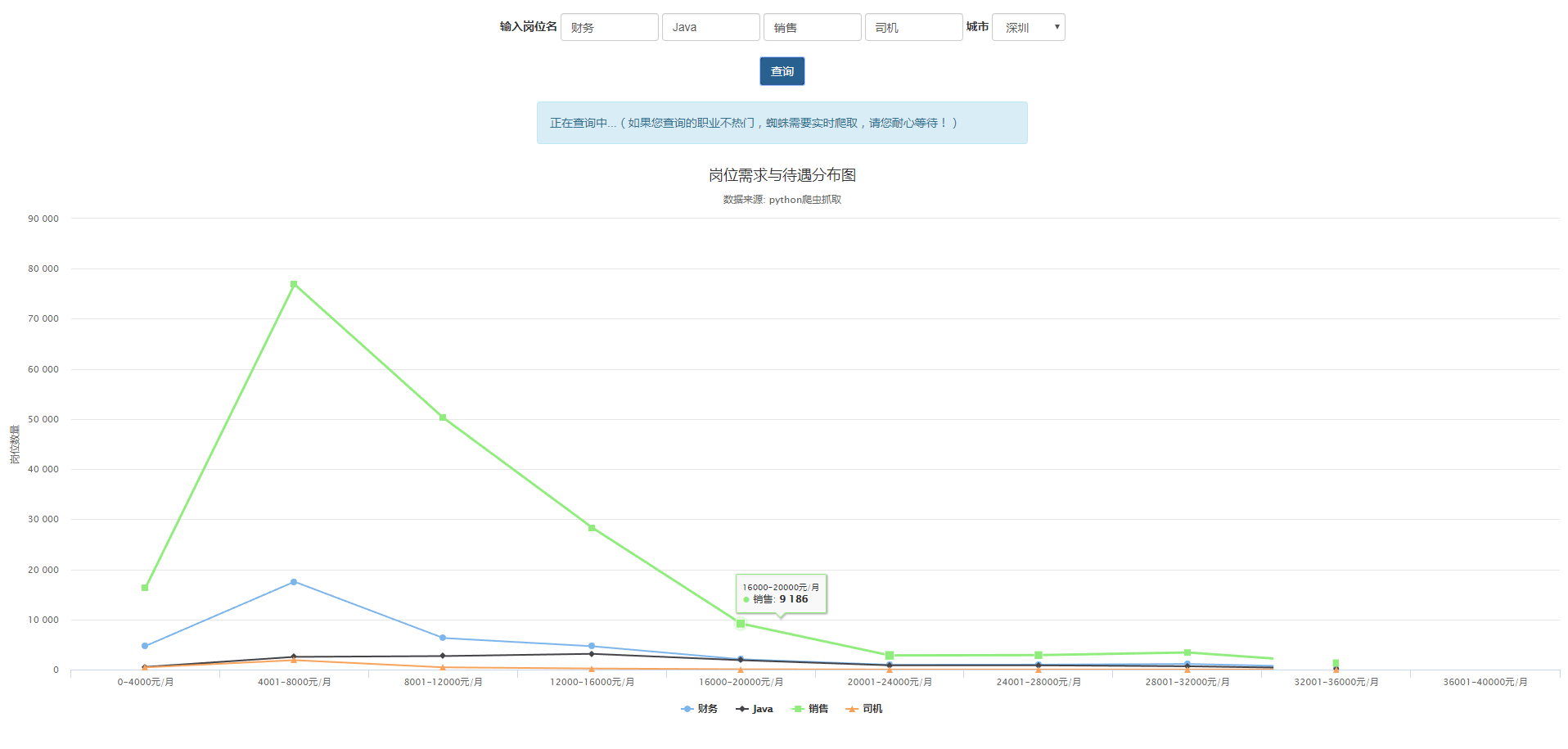
用户输入任何想要查询的多个岗位,选择查询地区,即可知道该地区,岗位的需求数量和待遇分布情况,数据是在真实互联网中抓取,具有一定的参考意义哦 项目演示地址
- 演示平台为:百度云服务器BCC,系统Ubuntu/14.04.1(64bit),Web应用服务器为Tomcat/8.0.47;
- 基于Bootstrap,Highcharts 构建的前端交互界面;
- 基于JAVA Servlet 框架的 RESTful API 后台数据接口;
- 基于python scrapy 框架的网络爬虫从互联网中采集数据;
- 数据库采用Mysql5.5;
- 用户提交查询岗位名称和地区,给到后台java接口,java程序查询数据库,有数据直接返回
- 如果java程序从MySQL中没有查询到,就同时shell命令发起一个爬虫任务,让python程序去网络中抓取,并保存到数据库,然后java程序拿到数据后返回给用户
- java程序会把用户查询的岗位名称保存到MySQL中,python爬虫定时执行,按周期去更新MySQL数据表,这样,既保证了查询的快速响应,也保证了数据的准确实时
- 前端布局优化后,在大中小型屏幕上展示,都美观大方
├── job.sql #数据库SQL
├── python #python scrapy 爬虫
│ └── jobs
│ ├── movie
│ │ ├── __init__.py
│ │ ├── __init__.pyc
│ │ ├── items.py #数据模型
│ │ ├── items.pyc
│ │ ├── middlewares.py
│ │ ├── pipelines.py #保存数据到MySQL
│ │ ├── pipelines.pyc
│ │ ├── settings.py
│ │ ├── settings.pyc
│ │ └── spiders
│ │ ├── __init__.py
│ │ ├── __init__.pyc
│ │ ├── jobs.py #爬取数据
│ │ └── jobs.pyc
│ └── scrapy.cfg
├── pythonJob #cron爬虫定时任务
├── README.md
└── ROOT #tomcat根目录
├── code #java Servlet RESTful 接口源码
│ ├── GetAreasList.java #获取地区列表
│ ├── JobsDistribut.java #获取某地区多个岗位的数量和待遇分布
│ └── MySQLDBCon.java #访问数据库的公共文件
├── view #视图文件
│ ├── highcharts #图表插件
│ ├── Bootstrap #前端视图框架
│ ├── index.html #前端入口
│ ├── jobCharts.js #当前页面JS
│ └── test.html
└── WEB-INF #java编译后的文件和路由配置
├── classes
│ ├── com
│ │ └── dbCon
│ │ └── MySQLDBCon.class
│ ├── GetAreasList.class
│ └── JobsDistribut.class
└── web.xml #路由配置
