879479119 / 879479119.github.io Goto Github PK
View Code? Open in Web Editor NEW个人博客,主要是源码阅读笔记一类的,博文都在issue里面
个人博客,主要是源码阅读笔记一类的,博文都在issue里面















































































本文是Dan Abramov发表于Medium文章的部分译文,只截取了其中部分内容,仅供学习交流,主要作为本人其他博客的素材使用,禁止转载
React Hto Loader是我第一个比较知名的开源项目,据我所知,这是第一个可以实现让使用者无需重新挂载组件组件或是丢失组件state的工具,在刚开始的时候我只是做出了一个Demo用于在台上进行演示,不过在之后我发现了大家对这个工具的巨大热情,所以我花费了几周的时间开发出了这个工具。
在创建这个特别的项目之前,我曾想到直接使用webpack提供的HMR来替换项目中的根节点并且重新渲染我们的整个React树。
但是需要注意的是HMR根本不是为React定制的。James Long在这片文章中说的很不错。简单来说他只是一个「当新版本的模块可以使用过后,调用设置好的回调函数,让我们便于对新模块做一些处理」的作用。这件事情会发生在你每次保存修改好的文件的时候。
一个纯粹的HMR来实现热加载就像是这样的:
var App = require('./App')
var React = require('react')
var ReactDOM = require('react-dom')
// Render the root component normally
var rootEl = document.getElementById('root')
ReactDOM.render(<App />, rootEl)
// Are we in development mode?
if (module.hot) {
// Whenever a new version of App.js is available
module.hot.accept('./App', function () {
// Require the new version and render it instead
var NextApp = require('./App')
ReactDOM.render(<NextApp />, rootEl)
})
}只要你按照类似上面的配置处理好了你的react引用,那么只要出现了文件的修改,你的应用状态就可以直接刷新而不用刷新浏览器界面啦。
这样的实现是最纯粹的,没有用到React-Hot-Loader,React-Transform,没有对你的模块做任何有关语义化的改变,只是做到了监听变化,适时地插入新的<script/>标签用于引入模块,并且调用一个回调函数而已
内部的模块改变也会被外界的hot.accept捕捉到,如果只是在子组件中发生了变化而其上没有设置accept来捕捉这次的变化的话,它将会往上冒泡直到被捕捉进行回调的处理(就像上文一样),否则会给用户抛出一个警告。
因为我们是在App中进行了热模块的处理,也就是说我们在App中使用的子孙组件都会被重新挂载处理。
举个栗子,我们有一个Button组件被UserProfile和NavBar使用,并且这两个组件都被App引用。
因为index是唯一一个引入了App的模块,并且他其中还配置了module.hot.accept('./App', callback)的处理操作,webpack会生成一个包含了我们所有被影响的module的「update bundle」给他处理(就是我们的XXX.hot-update.js文件)
当发现一个升级的App的时候,直接就能重新渲染React啦,
// Whenever a new version of App.js is available
module.hot.accept('./App', function () {
// Require the new version and render it instead
var NextApp = require('./App')
ReactDOM.render(<NextApp />, rootEl)
})不过这是我们想要的结果吗?当然,不完全是
新版本的module其实就是放在script中重新执行的模块罢了!由于App的重新运行,他的Class定义和之前的class不是同一个了,只是从我们的理解上来说觉得他们是一个class的不同版本而已
对于React来说,你所做的只是在渲染一个全新的组件,所以他会帮你把旧的组件给卸载掉,因为他没有办法帮你把这个已经存在的组件实例的class替换一下!官方的接口实际上都是创建新节点的create相关接口
所以啦~其实React必须这样做才能够应用上新的组件
James Kyle近期指出我们应用可以使用维护单一状态树,就像Redux一样。在这样的应用里,我们重要的数据状态往往是存在Redux中的,所以并不需要去想着维护在每个组件中的state(可能是一些展示类的需求)。
受到他的启发,我准备了这个PR来移除了Redux应用中对state的维护,转而使用纯净的HMR。James同样建议使用isolated-core来应对这种情况,我还没有查看过,但是如果你对这个实现感兴趣的话我建议你去看看这个demo。
通过这种方式,你甚至可以把状态存储到localStorage里面,就连刷新页面也不能阻止你保留以前的状态,岂不是美滋滋。
总之,如果你是使用Redux来存储几乎所有有价值的信息的话,那么我强烈建议你就使用HMR就好了,这样已经完全够用并且很简洁。但是我们还有些用户需要在组件自身中存储比较复杂的状态,那我们还是得继续研究下去了
现在你知道这中间会出现哪些问题了,我想出来了两个法子或许能解决这个问题
这个方法可能更适合React的长期发展,但是目前官方还没有提供合适的接口来完成相关工作(合并state到React组件上,替换实例而不卸载DOM和执行生命周期函数)即使我们通过内部的API解决了上面的问题,我们仍然还有其他问题需要解决
再举个例子,我们的组件常常订阅了Flux/Reudx的Store或者是在componentDidMount中会有其他带来副作用的操作。就算我们可以悄悄的把旧的实例换成新的(不破坏DOM和state),还会出现事件绑定无法转移的问题
为了为我们的实例添加上订阅,在替换过程中,我们需要将生命周期函数重新执行一下子。但是这样就会出现componentDidMount执行两次的情况,鬼知道会做出什么动作,是自己写的代码还能尽量避免,但是使用三方的库时就没那么好说了
最终来说,如果状态的订阅能够脱离生命周期存在或者说React不再那么依赖class和实例,这个方法也可能有实现的方式;当然上面所说的其实也是我认为的React的一些改进方向吧
这个方法是我在React Hot Loader和React Transform中使用的方法,这是一个相当有入侵性的方法,他会改变我们代码结构。不过实际上他现在还是工作的非常好在当前版本和以后的一段时间看来。
主要是路就是把每个组件放到一个Proxy里面,在这里说的Proxy并不是指的ES2015中的那个,我想用的是HOC就能够实现这个功能(口嫌体正直,现在的版本就是直接用的Proxy)
这样的代理可以正常的工作,把我们的实际用到的组件放到里面包起来,进行了更改只需要HOC把新的组件更新一个并把State放过去
一个大家经常误会的问题:React Hot Loader其实并不是一个webpack中使用的loader(错的)
她是一个loader,因为loader做的就是对我们的代码进行transform的操作,把我们的代码进行格式化变形,像json-loader把json处理为js文件,style-loader也处理成js文件这样子。
相似的,React Hot Loader也是一个编译时转换(compile time transform),并且所做的也不是简单的加上一段代码这么简单,他会找到所有module.exports导出的Component把他们放入想对应的代理中,并把外面这层代理给返回出去。
通过这样的方法,当App在渲染NavBar的时候,他实际上渲染的是<NavBarProxy/>,render会通过调用NavBar#render()的方法进行实际的渲染,保证内部的模块时刻是最新的
代理的对象通过拼凑出来的uid(文件名+组件名)存储在某个全局的对象中,当一次更新进行时,与之匹配的Proxy就会吸收新版本的class,并且进行重新的渲染
从module.exports中寻找组件开始看起来非常合理,这是符合我们平时一般的开发习惯的,但是随着前端的不断发展,慢慢的这么做开始不能覆盖另一些出现较多的情况了
不过,就算只是让开发者把所有的组件都export出来都还是不够的,他们在文件内部的相互依赖,我们没有办法通过简单的改变module.exports进行改变。
听到这里肯定有很多人会说了:随便啦,就用一个全局存储就好了嘛,管那么多组件内的状态干嘛,肯定不会有多大用处。。。。或许我真该信了你们的邪
这可是个大问题,我们现在的系统非常依赖webpack的打包和HMR机制,如果不是用的webpack,我们要支持rollupheFIS一类的工具该咋办呢?(译者:巧了吗这不是,你只针对webpack我不知道又得改多少东西)所以还是尽量脱离这个系统,便于别人移植的时候不用做那么多的修改
差不多就是那段时间我写下了这篇博客 The Death of React Hot Loader,我在寻找方法来解决上述的一些问题
Babel似风暴一样影响了整个前端的生态圈,我正好也需要某种静态分析的工具来定位组件(甚至没有被export出去)并给他们外面包上一层代理。babel看起来正合适
除此之外,我刚好还在想个法子实现错误处理。我们的组件如果在render中发生错误每次都会直接导致渲染失败进入一个错误的state状态并变得无法更新,我想通过babel更加优雅的处理这个问题
所以我想到:咦,为什么不写一个babel插件来定位组件的位置,并把他们直接的按照我们定义好的模式来进行变换呢?如果别人在这个基础上也来开发其他的卡法工具不会也很酷吗?比如说在页面上对应组件显示性能热力图什么的
这就是React Transform要做的事情了
我不确定哪些功能是以后还需要进行使用和维护的,所以我在React Transform下面创建了很多独立的模块:
render()函数通过try/catch包起来并展示一个可自定义的组件而不是任其发展上述的实现是一个双刃剑,好的方面可以让我们更加利于实验开发,但坏处又是大大的增加了普通开发者的使用成本,有些东西其实没必要向他们暴露出来,比如:「proxies」,「HMR」,「hot middleware」,「error catcher」等等
我还想着Babel6能够尽快出来,然后做一个presets,那就可以把我们的默认配置直接封装好放到上面了。然而Babel6比我预期的发布时间晚太多了(不过毕竟工程量那么大,能做出来我也很感激了)
React Transform比我想象中还快的流行开来,并且现在在boilerplate中的完整配置需要尽快处理掉。不然会给用户带来一些误解。事实上我们在Redux中的使用让情况变得更糟糕了
在Babel6升级并发布了官方的preset之后,模块化就不再是一个问题了,事实上还变成了一件好事,我们针对不同的环境可以只取到需要的部分(比如React Naive)。这也是给我上了一课,在将某个东西进行模块化的时候,你必须提供一个好的默认值,如果有人想要搞明白其中的原理他们必定会自己去看其中的东西
有时候问题总是对立的,你没办法同时兼顾两面
React-Hot-Loader可以找到你在文件中导出的组件,但是看不到文件中的本地组件,以下图为例,能够对useSheet的高阶组件做一层代理处理,但是没办法对Counter进行处理,文件一刷新Counter中的状态就会丢失
// React Hot Loader doesn’t see it
// React Transform sees it
class Counter extends Component {
constructor(props) {
super(props)
this.state = { counter: 0 }
this.handleClick = this.handleClick.bind(this)
}
handleClick() {
this.setState({
counter: this.state.counter + 1
})
}
render() {
return (
<div className={this.props.sheet.container} onClick={this.handleClick}>
{this.state.counter}
</div>
)
}
}
const styles = {
container: {
backgroundColor: 'yellow'
}
}
// React Hot Loader sees it
// React Transform doesn’t see it
export default useSheet(styles)(Counter)React Transform 通过了静态分析,在文件中寻找继承自React.Component的组件或者是通过React.createClass创建的组件的操作,"修复"了这一问题
猜猜我们忘了什么什么东西,输出去的高阶组件啊!在这个例子里面,React Transform会保存Counter组件的状态,并且热替换他的render和handleClick方法,但是任何styles的改变都不会得到回应因为他不知道useSheet也会返回一个需要代理的组件
通常人们发现这个问题是在使用Redux的时候,这里就是因为没有把connect处理后的组件做代理,导致了selector和action creator都不会被替换了
通过寻找继承或者是createClass创建的对象并不困难。然而这有一个潜在的问题,我相信你一定不想看到这个确实出现的错误。
在React 0.14之后,这个问题变得愈发难以处理。任何返回ReactElement的函数都有可能是一个组件。但是你没办法保证,所以只能启发式的搜寻。比如说,你可以说顶底作用域中使用Pascal命名的,使用JSX的并且接受两个参数以下的或许能够被称为组件?这样能避免问题吗?或许是不能的
这样甚至比以前更糟糕了,你还得告诉React Transform那些是组件。如果React推出了新的组件定义方法怎么办?我们再把Transform重写一遍吗?
最后,其实我们觉得通过静态分析吧他们包起来已经足够了。你必须得处理无尽的导出函数和class,包括:default的啊,有名字的啊,函数声明啦,createClass调用啦等等等等。每种情况你都得想个法子进行处理避免遗漏。
对于函数式组件的提供支持是目前呼声最高的一个特性,但是我现在不能这么搞,毕竟这个东西的工作量太大了,会给我自己的和其他维护者带来巨大的压力,并且还存在着一些边缘情况有潜在的风险
那。。是否应该选择放弃呢?
我仍然觉得React Hot Loader和React Transform是很成功的项目,尽管他们内部有些缺点而且有些局限。我仍然相信热加载总有一天能够实现,我们不应该停止继续尝试。讲真,这是我在这几个月以来第一次对热加载感觉到乐观。
React Naive在React Transform上面封装了一个hot reloading的实现。现在已经足够稳定了,但是我也相信我们以后会有更好更简单的解决方案
以下开始介绍目前实现的解决方案
这是最直接的一个方案。正如James Kyle建议,如果你把状态存在Redux这样的东西里,其实不需要考虑在Reload的时候保留DOM,考虑一下就那么用或者试试isolated-core这样的,这会让你的项目简单很多!
当React Native在使用fork的一份React封装的时候,配置这些东西是很有用处的,但是现在直接使用的是react这个package了,他其中也实现了HMR的一部分需要的功能,所以配置也不那么有意义
Browserify也有一个HMR Plugin,但是还是有bug,但我还是觉得项目中能够简单开启HMR配制已经很好了。我觉着要求其他环境像React Native一样提供polyfill是相当不公的
React计划封装一套官方的工具API来让我们更方便使用,像是观察profile或者是更方便在用户端实现无需通过某种手段来包裹就能监测组件。事实上,通过DevTools提供的API来做这些事情会可靠的多,毕竟这些代码在实际运行的时候肯定会被剥离出去。
这就是我不乐意作为三方进行深度定制库的原因了,只要相应的系统发生一些改变就可能推倒重来,所以我们还是继续研究热加载吧
React15封装了一个内部接口用于控制错误的状态(这个接口在目前已经在16中有了对应的生命周期函数),实际上最有效的使用方法就是把她,作为一个类似于React Native那样的错误显示屏功能了,我们以后可能会将这个和hot reload结合起来(确实是的)
我觉着吧,这是我在写React Transform的时候犯的最大的一个错误。之前十月份的时候Sebastian Markbåge就给我说过她不是很看好我这种Babel-Plugin的写法,但是我没有完全理解她的建议直到我这几天重新在思考的时候才发现,其实距离更好的写法只有一尺之隔
找到组件并把他们包起来确实有很难做,并伴有很大的风险。很有可能会破坏你的代码结构。但是从另一方面想,标记他们却是相对安全的,设想我们没有直接在组件中进行操作,而是将他们标记起来,在文件的最下方进行远程处理,大大减弱了入侵性。
比方说,我们可以为顶层中的function和class还有export出去的东西做这样的操作:
class Counter extends Component {
constructor(props) {
super(props)
this.state = { counter: 0 }
this.handleClick = this.handleClick.bind(this)
}
handleClick() {
this.setState({
counter: this.state.counter + 1
})
}
render() {
return (
<div className={this.props.sheet.container} onClick={this.handleClick}>
{this.state.counter}
</div>
)
}
}
const styles = {
container: {
backgroundColor: 'yellow'
}
}
const __exports_default = useSheet(styles)(Counter)
export default __exports_default
// generated:
// register anything that *remotely* looks like a React component
register('Counter.js#Counter', Counter)
register('Counter.js#exports#default', __exports_default) // every export tooregister具体是要干啥?我的想法是检查一下至少先检查一下是不是一个function,如果是的话那就利用React Proxy对她做一层代理操作。但是!她!不会立即替换你的class或者是function!这才是关键点,这个代理只是会乖乖的把东西存好,然后一直等着你用React.createElement的时候再说(懒)
如果调用React.createElement,那么你传入的就肯定是一个Class没得跑了,不管之前声明了什么乱七八糟的,最后一定是传过来的一个组件。
现在看来,只要我们的React Proxy是支持所有类型的组件的,那我们的热加载就是OK的。这也是为虾米我们需要为React.createElement做一些monkeypatch(简单的说就是单纯修饰一下这个方法)让这个过程可以触发操作,看起来就像是这样:
import createProxy from 'react-proxy'
let proxies = {}
const UNIQUE_ID_KEY = '__uniqueId'
export function register(uniqueId, type) {
Object.defineProperty(type, UNIQUE_ID_KEY, {
value: uniqueId,
enumerable: false,
configurable: false
})
let proxy = proxies[uniqueId]
if (proxy) {
proxy.update(type)
} else {
proxy = proxies[id] = createProxy(type)
}
}
// Resolve when elements are created, not during type definition!
const realCreateElement = React.createElement
React.createElement = function createElement(type, ...args) {
if (type[UNIQUE_ID_KEY]) {
type = proxies[type[UNIQUE_ID_KEY]].get()
}
return realCreateElement(type, ...args)
}有了React Proxy对我们的组件做了一些里里外外的代理(递归),我们可以做到和现在的React Transform有大致相同的表现啦,并且同时还能解决下面这样一些问题
总得而言,谢谢大家的资磁,我们定将继往开来,一往无前继续开发(懒得翻译了,我编得)
另外新版本也可以看看这里 Say hi to React Hot Loader 3
原文来自:Medium - Dan Abramov - Hot Reloading in React
为了图简单,文章中省略了很多的链接,有人看的话评论下我会补充上去,没有就算了哈哈
自己看源码的时候做的一些简单的笔记,感兴趣可以看一下,不保证完全正确
如果要看完整解析请还是看别人家的资料吧(这家的太烂了)


全部使用的都是flow进行类型检查,这样的对比ts有什么好处呢?根据尤雨溪本人所说,这样的做法是为了避免使用ts带来的巨大工作量,flow可以对每个文件单独进行改动,难度较低一些,而且相对于全部推翻重做风险低很多
在对设置项option进行设置的时候,首先对内部模块进行了优化,因为其并不需要设置这些 配置项,然后对配置项执行了mergeOptions的方法,此放方法较为复杂,首先进行了数据的扁平化

可以看到也没有做函数式的操作,都是通过共享参数直接传进去处理(奇妙)
随即进行了递归操作,对子元素的配置项进行了遍历(应该是之后添加上去的)
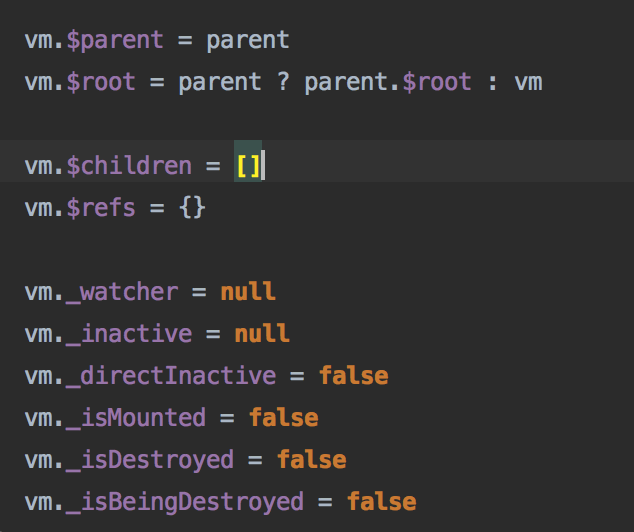
其他函数也是大同小异,从注释中可以看出,这个init是对根节点做的特异化的init,很多是为了给vue这个tree中的子元素提供一个上下文环境
在生命周期中,可以看到在data和prop之前还有一个通过inject属性注入的东西,可以添加下这个属性试一试
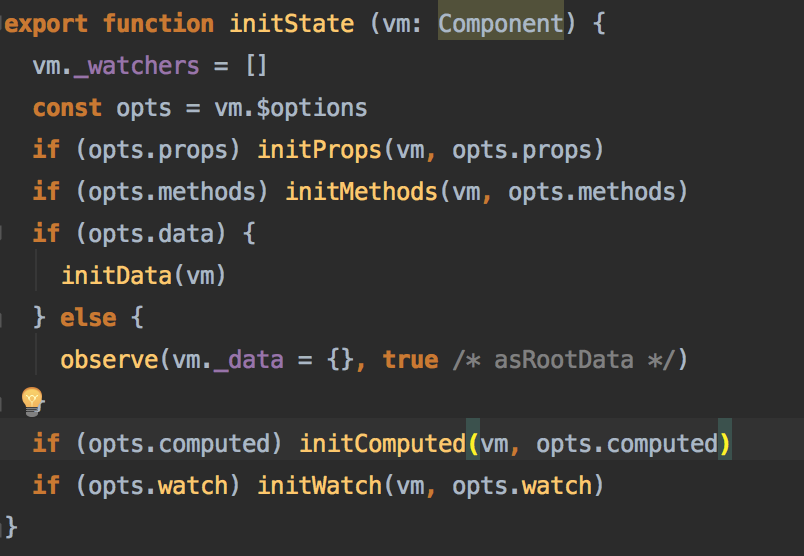
initState方法中对对象中的属性都进行了处理,prop,method,data,computed,watch都做了初始化
对于props,他是一个对象,vue对其中的属性都进行缓存处理,缓存的优势表现在转化成数组过后操作会更加便捷,并且性能也会更好
在这个过程中,会对每一个prop的可用性进行判断,同时使用比较核心的 **defineReactive **方法对这个属性进行响应式处理(监听他的变化,并做出改变)
在defineReactive方法中,首先创建一个Dep对象的实例,这个对象拥有作为监视器,可以在上面挂载多个订阅方法,(directive 指令)
在创建过后对属性进行校验,获取对象的描述符,如果发现当前配置的属性configable被设置为false,那么直接跳过这个属性
在对属性进行观察时,如果是数组则会一层层递归深入,但是如果是类数组元素呢?测试一下
Vue.extend方法会在vue对象的原型链上加上属性,所以在这个地方是自定义的属性的话会通过代理直接挂载到vm的_props属性上面,而并不是直接的vm对象
注:每个属性都会新创建一个dep对象,这个dep对象上可以挂载多个订阅者,事件的通知就是通过在set中调用其上的notify方法实现的,这个方法依次调用订阅的函数,并且递归的传递给它的子元素
props处理完成过后,method依次直接被挂载到vm上面
data属性初始化的时候会先判定是否是一个函数,如果是函数的话则使用起执行过后返回的值作为data挂载,如果这个时候不是返回的一个对象也会报错;在执行操作完成后属性都会被放到_data上面,如果与props产生冲突则发出一个警告
对于一个正常元素,会把data上的元素都用observe处理,绑定到一个观察者上面,同时相应的vmCount也会 +1
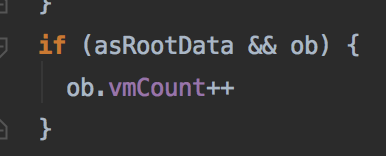
值得注意的是如果data属性为空时,这里会把他认为是一个根元素,并且把vmCount的数字加一,这里的ob指的是数据的观察者
Watcher对象有一个lazy选项,可以惰性求值,即在constructor函数中先不求出结果,过后需要的时候再来
Watcher对象有两个用处:一个是用在这里,还有用途是在指令的时候用到
Watcher和Observer有什么区别呢?同是检测数据变化?
根据其优先级来看不可重复的顺序:Props > data > computed > watch
在进行了以上的initState步骤过后,会执行provide的初始化,这个东西在官方文档中没有写到,不知道是拿来干嘛的,现在只知道是把provide属性安装到了_provided上面
完成这一步过后调用created的回调函数,执行相关操作
此时我们的组件也已经初始化完成,如果在性能测试下可以通过mark函数打印出这一段所花费的时间
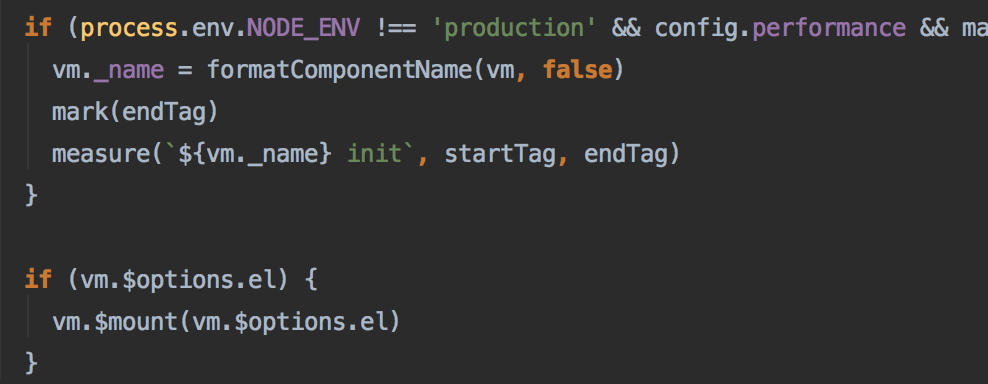
再过后直接通过mount方法把组件挂载到对应元素上,如果没有就等待手动执行
对$data和$props做好了setter的设置,用户试图更改直接打出警告并且不会返回任何值
对$set方法进行了统一设置,函数中表明,在对其进行改动的时候会去拿到对应的target,并且把target上面的ob对象进行触发操作,如果没有的话,则使用createReactive方法新创建一个观察者绑定上去
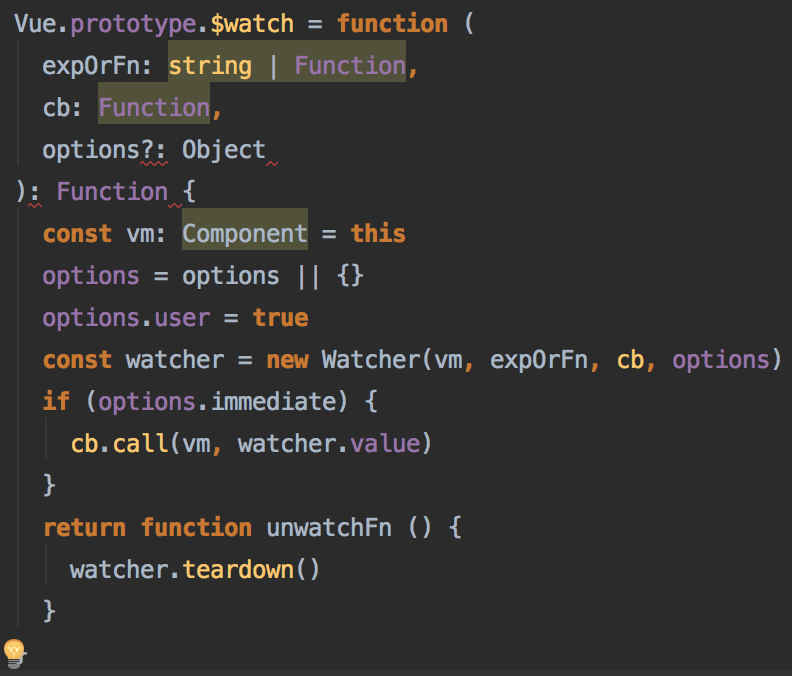
同时如果设置了immediate属性的话,回调函数会立即执行
在teardown函数中,只会对正在工作的(即active === true)的watcher进行解绑,由于这个操作非常耗时(一个一个的通过removeSub移除),所以在销毁元素时的直接跳过了这部分操作。
实现了一个基本的事件系统,意外的是没有组件的父元素子元素之间传递,不知道这一步是在哪里完成的
基本的$on, $once, $off, $emit功能都加了上去,挂载到了_events属性上面的一个对象,通过事件名字分组,在调用时依次执行
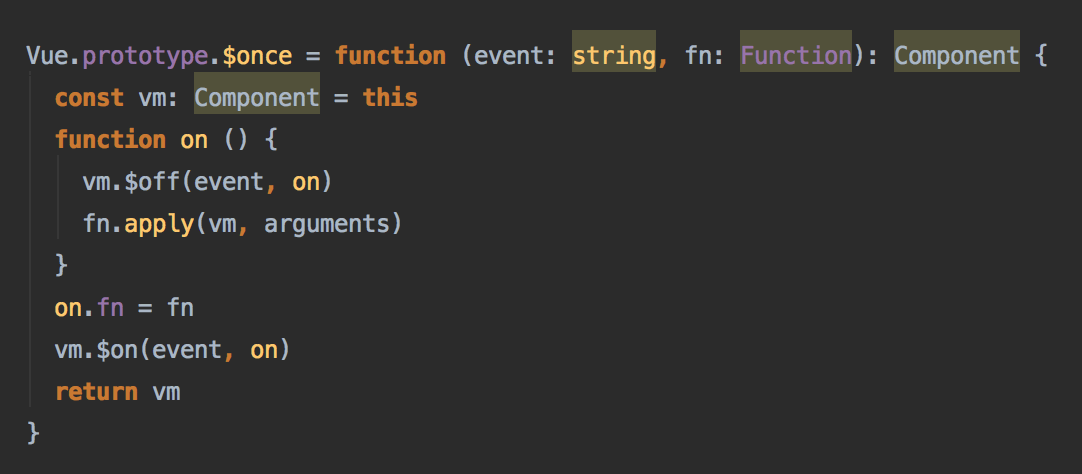
这里出现了一个很重要的_vnode属性,应该存储的是这个节点挂载的信息,
当第一次挂载时(第一次render也是调用了这个方法),会使用__patch__方法,在$el元素上渲染我们的元素,这一点和react非常相似
还有一个相似的地方就是,vue中也存在高阶组件的概念,通过比较自身vnode和父节点的_vnode如果相同,则认为其是高阶组件


$forceUpdate干了什么?其实只做了一个操作,就是把所有watcher重新计算一次,(watcher中保存的是所有watch的表达式,那computed是不会受影响咯?)
由于销毁操作会消耗一定时间,并且可能重复调用导致出现一些东西undefined的问题,所以有一个名叫_isBeingDestroyed的属性保存了是否正在被删除,就像前面说过的一样,这个变量还被用在removeSub中做优化

卸载时候总得来说做了几项工作:
vm._data.__ob__.vmCount --做了一些降级处理,本来是想用microTask的,如果前两个不能用最后还是会换成在marco中工作的setTimeout函数放到下一个task处理
在这一步中,操作和返回的元素并不是真实的DOM节点,而是名为vnode的vue节点,如果出现了错误的情况,可能会返回一个空的vnode
同时,为了节省代码大小,也是蛮拼的
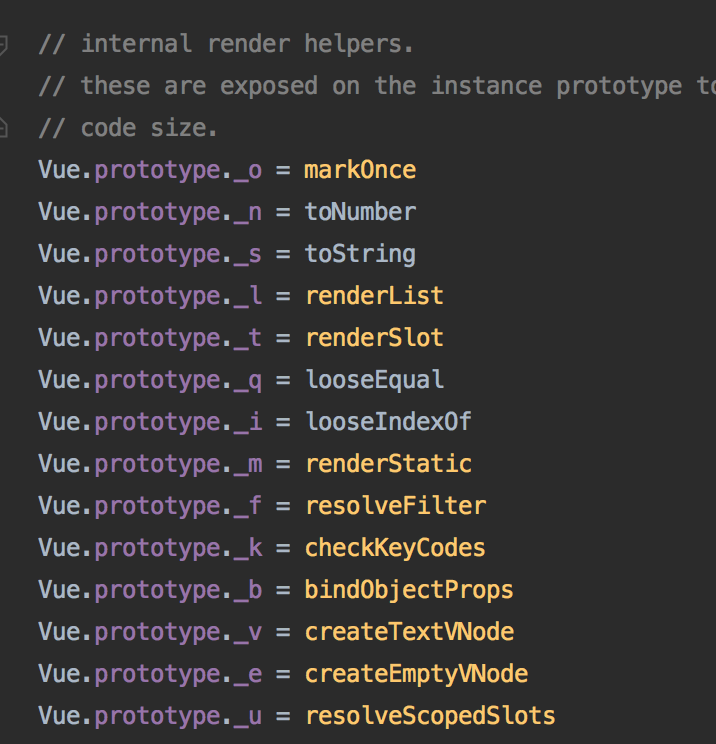
这些操作都是针对指令做的
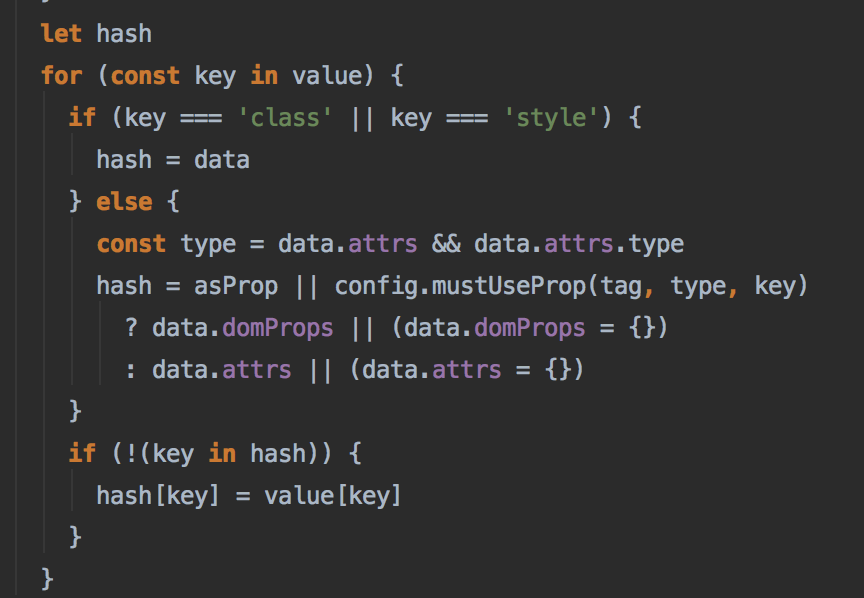
style是一个对象还可以理解,那么class也单独提出来的原因是什么呢?根据属性的设置,可以选择设定为props还是dom上的attribute
在很多函数中都会发现没有直接通过{}创建对象,而是使用的Object.create(null),个人觉得应该是有两个原因,第一是如果用{}可以在原型链上添加别的属性,影响数据处理,还有一点是可以省一定的内存空间
cache函数可以缓存纯函数操作的结果,注意这里的要求一定要是纯函数!其他函数的话会跟执行的环境有关,导致缓存的结果不可信
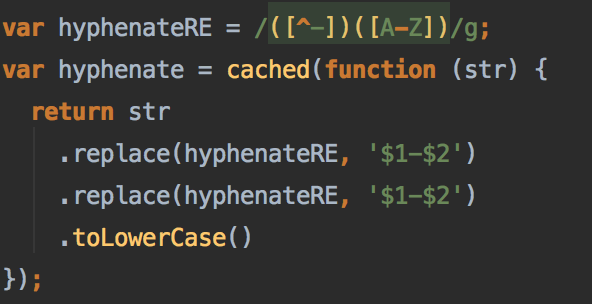
把驼峰表达式转化成连接线连接的函数也很有意思
这个函数应该也是做了很多考虑的,由于设置的匹配每次会匹配两个连续的,所有有必要执行两次
同时没有用网上流传的/([a-z\d])([A-Z])/g类似的方法也是极大的增强了兼容性,像ABCDE这种奇葩的也可以转化成为a-b-c-d-e
在2.3.4版本的158行代码可以看到作者提到:Simple bind, faster than native,作者表示自定义的简单封装的bind还要比原生的bind函数更快,怎么搞的chrome实现的bind这么不争气吗
将类数组转化为数组的方法中没有使用slice等操作,说起来你可能不信,他是一个一个遍历的,应该是处于兼容性的考虑(但是这样会不会出现一个问题:本来是稀疏数组类似的元素结果相对应的值全部变为了undefined,用in操作符变得无法检测了)
looseEqual方法对比两个对象没有使用递归遍历的方法,直接使用的JSON.stringify方法变换后对比,没有考虑特殊数字等的问题
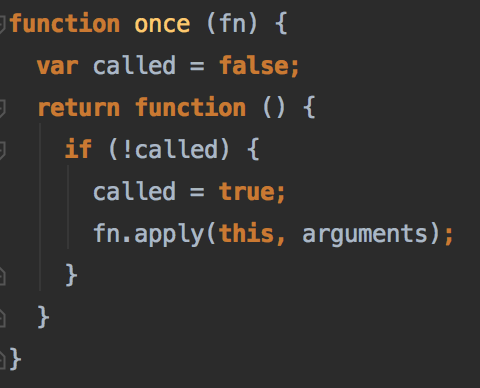
once函数的实现,非常经典,利用了闭包的特性
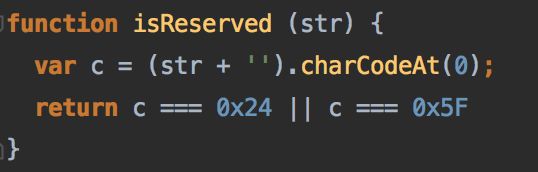
有一个变量uid$1是用来唯一标识它的
他还有一个静态的属性target,他是一个数组,其中存储的是Watcher,调用depend方法会把二者连起来
在创建时会把他和一个新创建的dep连接起来,她还会把属性自身上的__ob__设置为自己(但是自己并没有返回值)
当然上面的方法是针对于对象的,那数组的话就是单独拿出来对上面的方法进行修改,添加上了监视功能
对数组原型上的方法进行了改造,涉及到push,pop,shift,unshift,splice,sort,reverse调用这些方法都会触发dep的notify事件
对于在属性传递时,可能出现向组件子元素传递一些嵌套元素被freeze的元素的情形,这个时候便不能对其进行监听,所以出现了shouldConvert这样的属性标识避免被监视
官方文档里面说的props是只能传递一个数组进去,但是实际上传对象进去都可以,他只会把键取出来拼到另一边
有时候会出现跨域(iframe)的问题,这个时候默认的window不是指向一个地方的,有可能导致平时使用的一些类型对比函数出现错误,使用字符串转化后比较就要稳妥一些
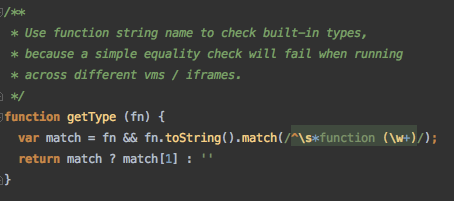
这个函数只是会把传入的Number对象等转化为字符串,这是针对跨iframe做的处理
在对属性进行处理时,面对几种符号开头的事件会有特殊处理方式& - passive不会被阻止,~ - 只执行一次,! - 捕获阶段执行执行
vue自带了异步加载组件的功能,利用的是resolveAsyncComponent函数(vue.runtime.common.js:1963),第一个参数就是一个组件经过处理的factory工厂函数,我们在配置时设置的超时都在这里作用
里面有个forceRender函数会对factory所在的上下文遍历进行forceUpdate,这里的上下文当然也是过后传进去的,即需要加载组件地方的上下文
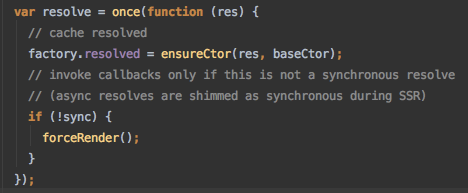
同时这里的设计也有需要注意的一点就是对SSR的处理,在进行异步操作之前先将同步操作标识sync设置为true,然后进行(异步或同步的)加载操作,在marcotask中继续向下将sync置为false,这时候变为要求异步加载;用处在哪里?
若之前里面的加载是异步的话,变量变为false会保证异步加载完成后forceRender执行;如果是同步的话实际上到改变sync值的那一步已经加载好了资源,这个时候直接返回加载好的组件就行了;
此篇博客紧承上一篇,上片讨论了我们的webpack整个处理单个文件的流程,这一节主要说一说webpack的文件打包问题,其实本身是比较简单的,但是有异步块和html-plugin的加入,使这个步骤变得尤为复杂,这里先介绍几个重要的概念:
Module,模块,我们的入口文件就是一个模块
Block,一个新的资源块,我们在最后进行打包的时候,块里的东西会被打包成一个新的资源
Dependency,依赖而已,所有依赖如果不进行处理会被打包到一起,然后通过她们存好的ID在最后使用的时候拿出来使用
Variables,不知道干什么用,暂时的使用中一直为空,最近才发现他会给我们的代码里面注入一些IIFE函数,这个过程叫做variable injection(变量注入)绑定一些需要计算的特殊值,比如global,process这一类,直接替换不太好,这是最终打包时的部分代码,可以看到我们的variable最后会被处理成为一个立即执行的函数,拼接出来的字符串参数在这里是module和global

在下面的call中参数进行拼凑时,通过我们的sourceId得到需要引入的对应资源

这样便形成了一个封闭的作用域,拿来干嘛呢?这里就是实际的演示了,他把我们的模块代码整个放到了这个IIFE中间,提供了变量环境,而且这里被包裹的还是lodash。。。他怎么会用到global?这个global又是在解析语法树的时候记录下来的吗
上一节中,我们成功的对每个文件进行了处理,并通过了process的方法对所有入口文件以及他们的依赖文件进行了处理,获得了最初的依赖文件列表,现在我们就可以对资源的依赖进行优化处理,本片的内容将从webpack/lib/Compiler.js:510的断点开始逐步的对源码进行分析
在seal之前,由于一轮compilition已经执行完成,先调用finish方法进行收尾处理与之对应的是我们注册的finish-modules事件,
这里我们首先看到的又是index.ejs这个老朋友,由于他是单独的文件经过了loader处理没有获得额外的处理函数的依赖,所以最终这里看到的module实际上是它的js外壳包起来的ejs文件,此阶段也还没有进行资源hash的注入等等
这里有一个FlagDependencyExportsPlugin进行了操作,听名字可能就听出来了,他是对我们资源中的export使用进行一个标志的作用,和我们最终做出的tree shaking效果可能是相关的
调用seal事件处理
处理我们的preparedChunk,这个东西是我们刚好在进行addEntry的时候添加上的不知道你们还记不记得,中途就没有添加过新的,所以讲道理,一个entry是只用一个的,但是这里使用了一个数组不知道有什么用意

然后把这个入口模块添加到了block里面,过后打包也是从block里面拿数据,block里面的东西会被打包成为单独的文件,但是还是工作在之前的上下文中,这里可以通过看一下这里的import即是我们之前在路由文件中通过import函数设置引入的动态加载路由资源
进入到processDependenciesBlockForChunk函数,就开始处理我们之前做好准备的block了,这里这是一个不断处理依赖的过程,但是没有使用递归的做法,毕竟文件太多了,不断的进行递归会浪费很多空间,取而代之的是使用queue进行记录,处理过程中不断把新的需要处理的模块放到queue里面等待下一步处理
在每一步的处理中
首先处理variable,这个东西简直罕见,不过它也是依赖模块,像这个地方的他就是在替换浏览器环境的时候用到的变量依赖,可能会再之后的处理用,像是一些polyfill可能就是这样的工作方式

然后是dependency,向当前的chunk上添加module,并且这个module的集合还是个set,也就是相同的模块是不会再添加进去了,所以这里如果是新的模块的话会给之前的queue上面push一项新的资源上去
最后处理block资源,会添加新的block资源,并且按照一个Map,如果父模块是新的block,则为他开辟一个项目,把我们的模块和对应的依赖放进去最后得到一个Map类型的chunkDependencies,在我们这里处理应该是只有入口模块,在底下的dep数组中挂载剩下的异步block才对,但是事与愿违
处理完这一波循环依赖过后,本身的依赖树结构变得扁平化,之前一层一层的模块通过dependency连接起来作为一个树的结构,而现在变成了顶层最终的几个chunk

可以看到我们最终在这个入口(entry)设置中拿到了9个chunk,她们都有_modules属性,我们的所有依赖都是放到这里面的,是用的一个Set进行存储,其中的依赖关系则是通过origins和reason等标识进行模块间关系的连接的
还可以将我们的入口chunk和异步加载的chunk进行一些对比(上面的是入口文件),下面的chunk中出现的origins就是指向我们之前的router那个module
这个图里也可以看到,两个chunk实际上按照自己的路子搜集了所有的依赖,结果导致了_modules的文件数量都达到了一千多个,这就是我们常使用的CommonChunk插件需要处理的地方了,稍后进行讨论

这轮处理我们成功的把主要的入口module和异步加载的模块区分开了,然后开始按照类似的逻辑处理我们的第一个入口模块
这个时候拿到chunkDependencies进行处理,这就是之前那个存储block的东西,但是有个很奇怪的地方,就是这里面居然只有三个chunk,而不是和上面的一样是9个也不是只有一个入口模块,这就让人无从下手了(我异步加载的模块并不是一样的,而且这些模块之间没有没相互依赖)

喜闻乐见进行第二次处理,首先取出一个chunk拿到对应的存储在value中的deps,对每一个项目添加上了他们的parent,但是有个组件就是用来removeParent的
在RemoveParentModulesPlugin这个插件中,针对每个module都做了处理,看看这些模块在哪些chunk之中有被使用到,把他们所存在的chunks按照id记录下来,并改变她们的reason为几种统一的chunk组合数组。这样就做到了每个module知道了自己被哪些chunk使用,但是从之前的单一reason到现在的多reason具体不知道有什么用(恩。。可能是为作用域提升做准备)
然后嘛,移除空的模块,不需要多解释
然后这层处理就算完啦,主要进行了模块的依赖梳理和拆分,并为他们添加上了指向父节点的指针(话说之前不是有origins吗)
对模块进行排序工作,不过只是按照索引进行排序罢了,那个按照出现概率进行排序处理的插件不是在这里工作的
又是那个flag的插件进行了处理,但是只是把所有模块的used设置为了true,还有为一些被依赖的module设置上他们的usedExports为true
ChunkConditions插件用于监视模块上是否有chunkCondition函数,并返回他的执行结果,如果有模块的此函数返回了false,那么将会重写这个模块(重写即是重新添加进入parent的链接以及reason等的设置)并且还会返回true,到至此过程不断执行直至condition全部OK
RemoveParentModulesPlugin这个插件的作用有点玄乎,看样子是对每个chunk进行处理,看对于多个chunk中都有的某一些module,会直接把他们的reason设置为主要的入口chunk,而后把当前chunk中的module移除掉(话说这个事情不是应该Common来做吗)
然后移除所有空的模块,再就是移除重复的模块了(话说一直用set神他妈还会有重复的)
因为这些优化处理的插件都是放在一个while循环中的,所以如果对于他这种等幂操作做的一些优化就是利用自己的文件路径名做了一个标志位,检查确认只执行一次就好了
由于我们在设置中取好了名字叫vender,那么这个地方就会直接从产生的chunk中拿到这个要处理的chunk资源,也就是说这里实际上拿到的还是chunk中依赖的内容,而不是全部的node_modules中的内容,那么为什么会出现基本上所有node包中的资源都被打包到vender里面的情况呢?因为我们这里做的minChunk函数实际上是对有所依赖的chunk才做到了过滤的这里有两个概念,一个是target,一个是affected,其中target就死我们设置好的用来存储提取公共文件的一个chunk,而affected是我们其他需要被提取资源的包,经过一些筛选最终得到的是我们的index模块,然后这里也理所当然的对所有index的依赖进行筛选,导致最后所有的node_modules里面的资源都被放到vender中

在vender中添加了过后,当然还要把原来chunk中的依赖全部移除掉,也就是简单的删除操作
删除了不用我说,也会给新的CommonChunk添加上哪些被删除模块的链接,经典的操作,给双方都添加上指针
然后最后再把我们的index的parent指向vender,毕竟现在index中的资源已经完全依赖vender了,然后处理了entry,也添加上了新的依赖
返回true,导致在进行一次优化,不过我们在开始的时候会做判断,这个插件相当于不会再执行功能了
然后进行各种优化,比如出现的概率大的放到前面,这里还是做了module和chunk两种优化,也是有毛病,就像我们的react项目中可以知道react的使用次数最多,那么他就被放到了最钱前面,紧随其后的是echart等
HashedModuleIdsPlugin插件为我们的模块计算出它的id,默认是通过md5进行计算,解出来的是base64的,而且计算的参数也仅仅只是通过模块的libId进行hash,而这个libhash只是相对位置,连绝对的都不是,所以算下来这个东西能够当成单个文件的hash了
applyModuleId,到这里你可能会想,诶之前不是已经设置好每个元素的id了吗,为什么还要搞这么个函数专门处理,我们在上一个生成id的时候实际上得到的id是根据我们的设置进行了截断的,实际上拿到的hash碰撞的概率非常大,我们看看下面这个筛选的处理就可以知道,1885个模块里面竟然又3个重复的id,这种时候就要特殊处理了

执行sortItemsWithModuleIds依据id进行排序,不只是最外面的chunk,就连reason里的id也会被重新排序,也是蛮逗的,这里直接用的是id做比较并没有判断类型,也就是说把数字和字符串会混到一起,就算你是class也会拿valueOf出来比较,想想还是蛮刺激的,不过其实比较完成也没有太特殊的用途就这么随意一点也好
中间一些处理recordId的我忽略掉了
然后开始处理hash了,这里的hash具体使用了哪些参数和长度是多少呢
可以在此阶段添加hashSalt即噪声,给hash值添加一些特征
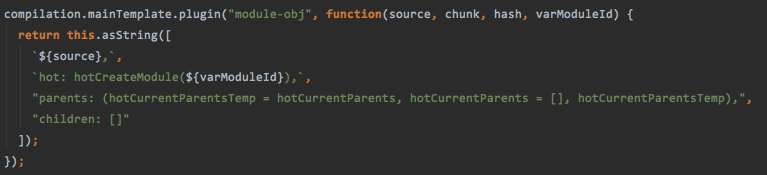
进入mainTemplate的处理函数中,添加了一些字符串参数和数字参数,并且调用了mainTemplate的hash插件,但是她们的执行过程并不是保证我们最后生成的文件中能够有结果的hash值,便于请求对应的资源文件,而是仅仅在hash的过程中添加了一些干扰的路径参数等
最终一轮hash下来,chunk会得到自己的renderHash,而compilation会得到一个针对编译过程的hash,这个hash就跟我们的所有资源扯上关联啦,所以每次都是新的
创建模块资源咯~
说到底,这里就是在拼接字符串的过程,但是其实我们使用的应用模块中有时require有时webpack_require是怎么来的呢,到处都看到的requireFn为什么不直接设置成为require或者加上webpack的形式呢
先调用bootstrap的插件,执行封装头的过程,这里首先会拿到HotModule的一些插件处理,主要是插入模块热替换的一些工具,相关源码在/webpack/lib/HotModuleReplacement.runtime.js中,下次讲模块热替换会进行专门的分析
在此紧要关头,又触发了hot-bootstrap的操作,NodeMainTemplatePlugin也来凑热闹,拿到了我们默认设置的热替换资源json文件名和操作的update的js文件名字,然后顺势又把asset-path的事件给调用了,把我们的模式文件名化为了表达式的存在,便于过后直接进行替换存储
如[name].[chunk].js变成了"" + chunkId + "." + hotCurrentHash + ".hot-update.js"类似的样子
然后取出并返回我们的模板函数内容,这里的模板函数没有使用字符串的方式进行存储,而是直接使用的获取函数toString的方式拿到其中的内容,再对一些特殊变量名的位置进行替换,岂不是美滋滋(模板有两种一种同步一种异步)
把我们刚才得到的hot资源还有源码资源等全部合并压缩为字符串,我们暂且就叫这一部分叫bootstrap吧
Main中处理了大部分和web-requi这个变量相关的值,并且设置了通过_esMoudle来确定是ES6模块还是COMMONjs模块,过后再看是否需要default把需要的模块导出
这里是通过defineProperity的方法定义的getter,但是这样也导致了我们的模块如果不做特殊处理,不能够兼容上古浏览器。而且还有一点值得注意的是过度使用定义对象属性的方法会导致较大的性能损失
NodeMain又要放什么洋屁呢?chunk太少了没放出来
Hot,看起来只是利用wr来设置了一下自己的相关变量挂载对象而已,回忆起来其实好多模块都是拿过去干这个事

Main,创建一个ConcatSource用于拼接资源,可以看到下面这一段决定了整个文件的结构,首先是我们拼装好的bootstrap(bootstrap里面存上了我们启动模块的id,可以用于流程的发起工作),然后就是紧随其后的参数了,想必大家也都知道,这些参数就是我们的所有模块了,不过一直不知道为什么webpack毛病老是要在前面加星号的注释

然后就是依次处理每个module了,通过ModuleTemplate的render方法进行处理,在其中搜集他的资源,按照经典的从大到小的顺序搜寻chunk,block,dependency。在这个处理过程中又出现了variable,之前一次看到的时候以为他是充当了一个代替变量的作用,这次呢,看样子实际上好像是被注入到了我们最外层的wrapper函数中当做参数使用诶!
承接上文现在执行module方法,EvalSourceMapDevToolModuleTemplatePlugin分别取出了我们资源的source和map,注意webpack中有很多地方都是喜欢用reduce对资源进行处理,没发现对性能有多大的提升,只不过让你少在外面建立一个对象,看起来更优雅

我们仔细看看创建sourceMap的最终操作
const footer = self.sourceMapComment.replace(/\[url\]/g, `data:application/json;charset=utf-8;base64,${new Buffer(JSON.stringify(sourceMap), "utf8").toString("base64")}`) +
`\n//# sourceURL=webpack-internal:///${module.id}\n`; // workaround for chrome bug发现这里其实针对chrome的bug做了些处理,才有了现在这种猎奇的webpack-internal:///格式的路径名字,所以以后看到不要惊慌了,1版本的时候是对应文件的,升级到3就不是了,想知道具体是什么BUG可以去issue找找
这里由于我们当时设置的sourceMap就是eval-cheap的所以最后得到的代码内容也就变成了上面一个eval全部抱起来,下面一个sourceMap的base64link而已
处理完成模块的封装我们就来渲染吧,执行render事件,千万不要搞糊了,这些事件名称很多重复的,但是他们是针对不同的Tapable组件作用的,比如现在执行这个就是绑定在MainTeplate上面
FunctionModuleTemplatePlugin闪亮登场,就是她把我们的每个模块单独分装起来的,比较短就直接贴代码了,可以看到wr这个参数要添加上去还是得花些功夫,因为只有在需要用到那些加载函数相关的时候才会用到,如果一个模块已经不依赖别的模块的话,那么再把他添加上是没有意义的,还有就是上面的module和exports有时会按照需求变成webpack打头的;记得之前说的use strict吗?,需要的话就在这里统一加上了

全部都拼凑好啦!至此,模块构建完成!剩下的就只是把他们打包放到文件中!
这些文章写的都有点水,看看图个乐子吧
说在前面:
这些文章均是本人花费大量精力研究整理,如有转载请联系作者并注明引用,谢谢
本文的受众人群不是webpack的小白,仅适合有一定基础的前端工程师以及需要对webpack进行研究但是在阅读源码的过程中有些小的细节不明白时进行查阅理解使用,学艺不精,文章中很多地方可能有理解上的问题希望在评论区指正
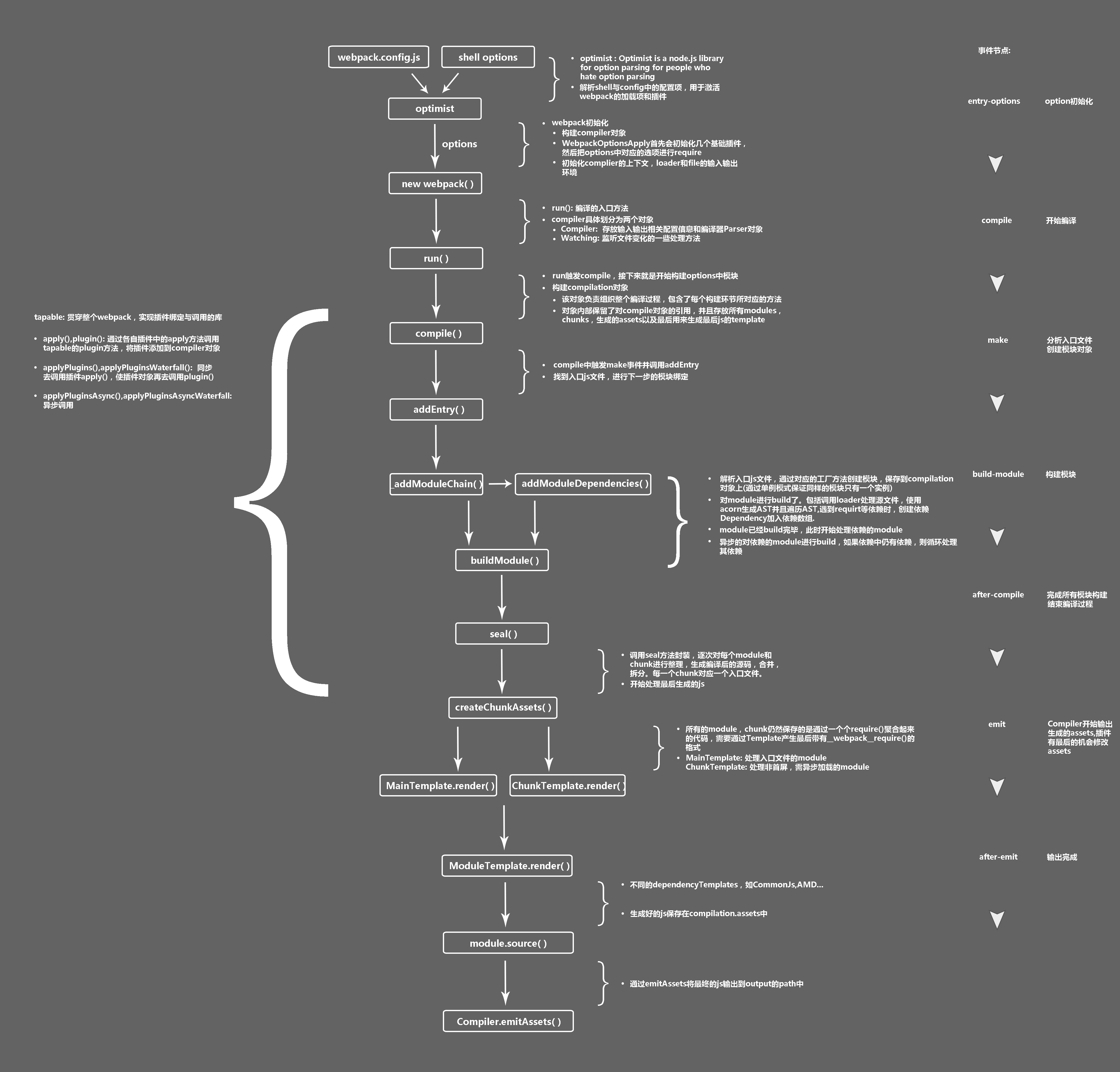
webpack整个系统中的核心组件基本都是继承自Tapable这个class的,内部维护一个插件对象,key是我们指定了流程中会运行的钩子事件名,value则是一个列表_plugins数组,里面存放着在key的对应时间能够以特定的方式执行的插件们。这里所说的特定方式可以是同步,异步,高阶函数,bail等等,各个地方的用法各有不同。
我们的插件主要通过自身的apply方法插入进去,同时因为核心组件都是Tapable的,所以可能会在apply中继续看到apply方法,就不用惊讶了
webpack首先利用optimist对我们的命令行参数进行格式化处理,得到的对象可以拿到很多参数,然后与我们的webpack.config.js进行合并,当然webpack其实还默认支持别名的配置文件「webpackfile.js」,这两个配置文件都是直接可以通过node自身的require进行引入的,不要把她们和webpack的打包中的require搞混淆了
通过创建webpack实例过后,我们一般将得到的对象命名为compiler,可以对她进行run操作,进行此操作过后的对象便会开始下面那张的图中的构造过程,下面我将进行尽可能详细的描述,便于读者在开发过程中对于整个插件系统有完整的了解
进行run操作后,开始了一系列的准备工作,这个时候
首当其冲的执行,进行了对于文件系统的设置,inputFileSystem是我们手动设置的,如果对于平时的构建操作,她会选用普通的文件系统,而对于使用dev-server的时候来说,其中使用到的dev-middleware就是一套实现了对应文件系统接口的库,其内部使用了memory-fs这个库进行对内存中的虚拟文件进行管理的操作。
webpack在很多地方参考了rollup,但是rollup却没有选择文件系统这样的操作,只能读入固定的文件系统,而写出的时候我们能够拿到代码,当然是可以写到内存里面也是没毛病
然后进入run流程中,这个时候第一个插件就开始工作了,不过为什么我没配置插件还有插件进行工作?之前也说到compiler对象是一个Tapable对象,自身不会带有太多执行逻辑,更多的是表明了业务流程,所以其实这里的插件是我们的内置插件—CachePlugin,她和我们整个系统资源缓存相关的,还有一个RecordId也是和缓存相关的
进入此阶段检查缓存过后(实际上是通过stat查看某个位置的文件是否存在),会调用readRecords的方法检查之前的记录recordsInputPath是否存在,由于是第一次编译所以当然是没有的
检查完成两项缓存正式进入compile函数进行编译阶段的处理
这个阶段中最重要的对象就是compilition了,但是构建她需要一个参数,我们会在进入compile阶段时通过newCompilationParams方法给她提供相应的normalMoudle和contextMoudle等的上下文工厂函数,还有一个重要的compilcationDep存贮相应的依赖便于以后收集依赖进行打包以及代码处理(整个打包过程会有大量的Dep关键词出现,每一次都是不同的依赖分析,但是最终还是会被放到一个名叫dependencies的数组中,另外其实入口模块的依赖就是她自己,相当于作为了打包起点)

工厂函数的构造过程中,将rule的匹配设置以及loader处理等全部拿给了这些工厂函数进行存储,设置为对应的ruleSet对象(之前我找了好久没找到,原来藏在这里),这个ruleSet和我们之后的loader处理密切相关
进入这个事件,传进去的修饰参数竟然是nmf(normal-module-factory),现在还没有构造compilition,同时因为她也是继承自Tapable,所以有一些插件也会被插到nmf上面,另一个context是没有编译实体的,仅提供一个上下文环境。
上面可能说的有点糊,理一理,我们都知道webpack进行打包的时候会找到指定名字的文件然后添加依赖打包进去,但是这是知道明确文件名的时候做的操作(normal)。如果不知道具体的文件名,比如
require('./module'+number)的时候,webpack系统实际上不能确定你用了哪一个,只能够把可能用上的包全部打包进去,这个时候会用到的就是context进行处理说了上面一圈有什么用?实际上如果我们需要打包某个文件下的所有以jpg结尾的图片,就可以使用这种方法或者是
require.context进行处理,全部打包进去,详情就看文档吧
平淡无奇没有操作
创建了新的对象,同样是一个插件系统对象,所有的插件键值都存储在_plugins属性中
由于终于出现了complication对象,就算没有什么要做的但是需要尽早注册自己事件的插件就在这个阶段登场注册了,比如我们的CommonsChunkPlugin直接给优化阶段注册了一个就走了
然后是JSONP相关的插件,她主要处理的是异步加载脚本的时候动态添加script标签的事情,她也只是把插件插到了template上面,而不是compilation,这里绑定的处理大都会在最后打包的时候用到,所以hot-chunk其实和chunk区别不大,主要体现在加载方式不同,包裹不同而已

根据我的配置,这个阶段足足有38个插件,其中大部分还是来自wepack自身,由于使用Tapable带来的高度解耦,让人感觉webpack的核心是空的,只是一个走流程的架子,完全没有实际的业务逻辑


RequireJsStuff, requirejs相关变量配置,如require.config
API,配置相关缩写,如果有需要可以直接在代码中写这些接口进行使用,同时处理后的代码可以根据这个进行比对

ConstPlugin,处理if语句和?:语句以及被设置为__resourceQuery的地方(这个东西她是在我们的require请求后面带的那一堆query参数require('./a.js?sock:8000'),比如我们在使用devServer的时候会加上上请求端口等,打包的时候就可以通过她获取到)
UseStrict, 由于use strict只能放在脚本最前面才起效,并且ast中解析出来的comment是放在别的位置的,所以把旧的use strict杀掉,过后统一一起加上
RequireInclude,简直鸡肋,没有什么实际用途
RequireEnsure,人如其名,会在parse阶段加入插件进行处理
RequireContext,可以用来加载一整个文件目录下的资源呢,不过还是主要用在了contextModule上面
ImportPlugin,用做处理System.import,还有import-call?什么鬼
SystemPlugin,向外提供System这个屌对象
EnsureChunkCondition,利用set进行筛选,清理输入模块中重复的部分,这里的ensure是确认,不是require.ensure里面那个
RemoveParentModule,em。提取公共module,过后会讲到
RemoveEmptyChunks,正如名字一样
MergeDuplicateChunksPlugin,合并重复的chunk
Flagincluded
Occationaly
FlagDep
TemplatePath,过程中可以拿到结果的资源path和hash值,这对于html插件来说是很有意义的
RecordId,
。。。。。。。
首先是html-webpack-plugin
html的插件会在这里执行,我们就可以跟着她进行分析了,需要注意的是她把catch放在了then的前面,只是处理前面的操作抛出的错误,更有针对性
runAsChild过后没有相应的事件处理了,其实也就是在子compiler中执行了compile方法,开出来的新的异步执行空间,具体请去看插件之中的源码
这里会createChildCompiler产生一个新的compiler,作用是能够得到父级的loader设置等等(issue说的)
同时也在原来的基础上增加了一些插件,比如比较重要的new LibraryTemplatePlugin('HTML_WEBPACK_PLUGIN_RESULT', 'var'),还有改变了平台成为node,之后在代码进行处理的时候会根据这个名字再把她消除掉

html插件通过向外面提供一些「接口」,也可以被定制,我们早就说过,这些东西都是插件,现在的子compiler也不例外,我们这里下面写的这个事件就是一个钩子,使用她的插件
 make阶段只是添加了这个新的compiler和一些异步任务,真正的使用还在emit的时候
make阶段只是添加了这个新的compiler和一些异步任务,真正的使用还在emit的时候
这里有一点关于WEBPACK的特点就是js 的在处理的时候得到的source是一堆js代码,并不是我们最终输出的html,这里把她拿到vm中去执行一下才能拿到我们要的东西(HTML字符串),毕竟子compiler也只是打包而已,得到的代码还是要执行才能有相应的结果
最终执行返回的结果还是null,只不过会在asset中注册上要新创建的html文件
nml使用的是和compiler里面不同的parser,规则也会有不同的地方
然后是single-entry-plugin
这个阶段会用到我们之前在config文件或者是手动配置时的entry参数,看看会不会是单个入口文件
细心一些才能发现,之前在html插件中,插入了一个single-entry-plugin,并且把入口设置成了我们之前的html或者ejs等模板文件,导致我们在第一次进入此插件的时候会发现是那个模板文件
通过之前的Map获取到相对应的moduleFactory来创建模块,这里得到的是一个nmf普通模块
现在出现了一个特别变量semaphore,她是一个信标,本来是在多线程中使用的资源控制使用的,(其实这里的资源说的是并行处理的数目)默认情况下是100的可用资源量,如果资源不足时就让过后的请求挂起等待,这里的acquire方法就去申请一个资源,然后进入了首个Module的create方法
nmf自身有一个处理函数被插入进去,并且ExternalModuleFactory在nmf上面插入了一个处理函数,
由于是两个连续的过程调用,通过函数式的处理返回了一个回调方法factory,直接使用factory对我们的ejs文件进行封装
external的模块都是nodejs的内部模块,这些模块不能拿来打包
然后是multiple-entry-plugin
这里出现了我们设置的第一个index,多入口文件,进入multiple开始进行处理,其实内部还是把multiple的每一项,转化成为了单独的SingleEntry,并且所有的id都是从100000开始计数的
然后通过Map获取到对应的moduleFactory是Multiple的,并开始执行create方法,create后会相同的执行addMoudle的操作,但是这次和之前的html有不同,因为她有明确的依赖关系,能够正确进入处理函数得到结果
如何获取module的id呢?module中的identifier方法会返回出表现当前module特性的字符串包含「multi」「path」等等,把她的索引缓存到_modules里面,如果下次又出现了了相同id的模块则直接退出
不过缓存又是放到另一个地方的,即cache里面,这里面缓存module的key就是在id前面加上一个m,或者是其她定义的缓存分组(这个机制暂时不知道有什么用),在添加进缓存完成后返回true表示成功添加新模块
非常重要的一项操作,loader的应用和AST的解析都是在这一步进行的,可以说除去打包优化的所有重要功能都是在这里进行的
build-module的时候只是sourceMap的插件把useSourceMap开启了,然后没了
正式调用module的build方法,比较重要的是传递了设置和相关的文件系统
不过mutiple的处理很水,直接什么也没做就构造完成了,把built置成了true
处理完成一个模块后释放之前的标识semaphore,又回到了100个的默认值
现在才是真操作,processModuleDependencies将做递归操作,为每一个模块的依赖进行获取和处理
然后又进入了nmf的create函数里面,现在又是before-resolve,这次和ejs那次不一样,能够拿到的是nmf的plugin,不过这次能够执行操作了
factory是通过waterfall将插件组合成为一个函数对结果进行处理,resolver也是一样的道理将所有操作合成为一个函数进行处理
在resolver里面把request进行了拆分,得到最终的资源文件所在位置和需要使用到的loaders,并行的执行两步操作,一步是resolveRequestArray用于一个一个的检查这个模块上应用上了哪些loaders的扩展,一个接一个的进行执行

在进行实实在在的doResolve操作的时候使用到了一个操作栈的概念,每一次处理得文件会按照一定规律将名字缓存起来,放到函数上面作为属性保存;

最后进行runMormal做最普通的处理,然后添加了很多生命周期栈,应该说这里面的操作都是在为编译的实际过程做准备,并且做了一堆准备工作过后最后还主要是返回了package.json里面的东西回去继续异步处理
NormalModuleFactory.js:100
然后从第一个参数中提取到刚才我们分析出来需要使用的loader,再到ruleSet对象中跑一遍,先是exec然后_run方法,进行一个个的规则匹配工作,看看当前文件到底要使用哪些loader
这里需要分辨一下,这个地方的是按照webpack.config.js里面的规则,正则表达式来进行匹配的,但是我们说的上面的那一次resolver处理实际上是对类似于require('index.js?babel-loader')这种形式进行的操作

经过一系列的匹配我们知道了现在需要的只有babel-loader进行处理,所以返回一个result,如果我们有enforce的需要,会把loader挂载到对应的时机上面处理,但是实际执行的时候并行执行了三种loader
然后她又来到了我们之前执行过的resolveRequestArray方法,就是从request中取出需要使用的loader那一步用到的东西。(NormalModuleFactory.js:247)
当处理完的时候进入回调的时候神TM的results中得到的loader又变成了空数组!合着我辛辛苦苦拿到的loader最后又喂了狗(未解之谜,正常的流程操作在下面,请接着看)
从伤痛之中走出来发现,底下执行回调函数的时候并没有直接执行,而是放到了nextTick里面,过后试一下拿出来会怎么样
由于回调回去会用到解析器进行词法分析,这里调用了getParser方法尝试拿到一个解析器,如果没有现成的的话就创建一个新的,顺便把她缓存下来之后使用
进入创建解析器的函数,我们会发现她创建好新的对象过后会把自身上安装上插件「二元计算」「typeof计算」等等,另外还发现在处理字符串的split,substr等操作函数时,会有特别的处理,由此可见其实在这一步里面parser其实会做少量的字符串优化
创建完成之后,得到了parser她也是继承自Tapable的,那么我们其她组件也可以慢慢发挥自己的作用了,通过把自己在parse阶段要做的处理apply上去,比如之前说的import和require.ensure等等就是在这里找到指定的表达式进行替换处理的
按照旧例梳理一下有哪些插件应用到了这上面,详细的作用不做梳理,不然能讲一年:
HotModuleReplacement,主要是做模块热替换的处理(这玩意儿都能讲一个专题)
把__webpack_hash__变成webpack_require.h()对照前面的看看这个函数具体会变成什么作用
把module.hot的计算值根据开发环境还是什么的进行替换,这里的模块热替换也可以去看看相关的知识点,她的依赖图谱也是一个树形的结构,牵一发而动全身,如果本层没有处理这个更新那么会向上一层传递
调用module.hot.accept的时候,会根据里面的参数进行转换,这个地方再次引入了插件。。。简直了。。如果带参数就是callback,没有就是withoutCallback,居然是在HarmonyImportDependencyParser里面引入的两个处理模块
if (module.hot) {
module.hot.accept('./print.js', function() {
console.log('Accepting the updated printMe module!');
printMe();
})
}这里做的处理就是吧前面的request收集起来,做成包的依赖
module.hot.decline….

DefinePlugin,把我们在plugin中设置好的表达式进行替换就是了
主要的处理是在can-rename中进行的,不过一般不好保证这个插件能比较完美的执行
如果出现循环替换的怎么办,a->b,b->a,这样的情况下,直接返回原本代码的计算值

NodeSource,就是处理global,process,console,Buffer,setImmediate这几个
那么global是怎么替换的呢,就像下面这样,把她用来替换,不过这里面这个(1,eval)我是真没搞懂,还有webpack里面的(0,module)都很trick的感觉


那么其她呢?其实都是依赖的node-libs-browser这个package里面的内容,不过其实有些模块还是没有实现的,当然都是无可避免的,比如dns,cluster这一类,简单看看console的实现,其她自行查阅

Compatibility,主要是针对browserify做的一些处理,不过我没有用过这个东西,她好像是require后面可以带上两个参数同时添加上一个新的ConstDependecy
HarmonyModules,里面包含了好几个插件
HarmonyDetectionParser主要是在program阶段,处理是import和export等语句,如果有这两个关键字出现的话,就把这个模块当成HarmonyCompatibility依赖处理,添加进入依赖列表,注意这个module是从parser.state.module中取出来的
HarmonyImportDependencyParser,根据import寻找依赖,把找到的依赖通过HarmonyImportDependency添加进依赖列表中;如果有import specifier好像会换成imported var过后会有另一个插件来处理,把她变成HarmonyImportSpecifierDependency的依赖,这个specifier应该说的是引入部分模块那种操作
HarmonyExportDependencyParser,对export做了类似的处理,不过有点看不懂
上面这些注册的调用是在哪里执行的呢?当然就是在parser处理得过程中啦,由于名字都是一一对应的所以我们只需要简单的搜索一下就能知道「import specifier」是在Parser.js:656开始进行处理的,可以往回观察她的逻辑

AMD,安装了两个插件,第一个处理了所有和require相关的依赖加载(复杂异常)有很多的parser类似于「call require:amd:array」这种应该是parser阶段做的特殊处理;第二个是处理define加载相关解析操作的,和前一个差的不多;剩下的就是对typeof等等的一些处理了
COMMONJs,就是处理module.exports这种啦,当然还有require,同样为了保证给require赋值时不导致undefine的尴尬,插件会加上一个var require;
NodeStuff,有什么用呢?当然就是把文档中所写的那些nodeAPI给替换掉啊,浏览器环境可是没有什么__dirname这种东西的,当然还有module相关的什么id,loaded之类的东西
RequirejsStuff,有些小用处
让require.config和requirejs.config返回undefined
把require.version换成0.0.0,这样我们可以看看当前的系统是不是使用的webpack打包咯~,毕竟只有requirejs参与的话这里就会是她的版本了
require.onError是加载错误的回调函数,会转变成webpack.oe,请对照之前说的列表看看怎么操作的,不过有了import可以用catch处理这个也没那么重要了
API,还是官方文档里写的那些表达式的处理,__wepack_require__我们上面说的oe也在这里面哦
Const,主要是处理表达式的true或者false,进行表达式的计算直接替换做优化,另外还有一个__resourceQuery是和热加载相关的

UseStrict,处理的时候添加了一个空的ConstDependency,和一个issue有关,不这样处理位置可能不对issue:1970
Require.include,没鸟用,下一个
Require.ensure,除了基本的typeof处理等,加载了一个插件RequireEnsureDependenciesBlockParser处理异步加载,她最多的处理参数可以达到4个。。而处理的逻辑里面会发现,这次操作并没有把当前得到的模块添加到parser的依赖上面,而是直接赋值了一个给parser.state.current
RequireContext,好东西啊,不过不常用,之后再解释
Import,这个import和之前的Harmony插件有什么区别呢?区别就是这个import其实是webpack里面那个System.import 和 import函数,进来处理的时候呢,首先会把她的第一个参数进行计算处理,然后判断这个东西计算出来是不是一个字符串,如果是直接可以计算出是某个确定的字符串的话,那我们就可以直接引入相对应的模块
1. 从源码才看出来,其实这个加载支持几种方式,有lazy模式只是其中一种,她还可以是eager和weak的方式
2. 当是其她两种方式的时候会加入对应type的Dependency,但是如果是lazy模式下面则会作为一个新的block添加,这个block继承自AsyncDependenciesBlock,就是平时的异步模块
3. 但如果不是字符串的时候怎么办呢,这个时候创建的就是我们的ContextDependency了,这个东西会根据我们已经知道的模块信息进行模块查找,匹配的都打包到一起i(未验证)
System,处理System这个变量,不知道有什么鸟用,现在她上面其实只有import一个方法,对她的set,get,register都做了报错处理
parser.state.dependendies好像是一个特别重要的东西
另外要注意的是我们现在调用的是nmf的createParser,所以只会有类似于params.mormalModuleFactory.plugin("parser")这种才会在这个步骤进行注册操作,其她如hot或者chunk这一类的会在自己的周期中进行注册
至此,parser创建完毕,返回回去
然后创建一个真正的NomalModule对象,进行一些没有实际插件工作的操作,过后再次进入到我们的doBuild过程中,调用runLoader的方法使用loadLoader加载我们将要使用的loader
进入loadLoader函数中,首先会检查是否有System这个对象,以及System.import这个东西,但是讲道理这个东西应该是在我们将要处理的文件中出现的东西,为什么会在我们的工具代码中出现呢?这点暂时不得而知,不过有可能是因为这一段代码也有可能被打包进入我们的工程文件,然后通过webpack进行处理;在发现没有这种方法将资源引入过后,webpack会选择使用require的方式把loader加载进来(注意这里的require是node的require,即同步加载的require :loaderRunner/lib/loadLoader.js:2)
在这过后调用iteratePitchingLoaders方法,不断递归的检查还有没有其她的loader加入(pitch指的就是我们的loader是否是从这个位置开始执行,所以如果当pitch为undefined的时候会导致她不断的递归处理,直到到达最前面一个loader或者是刚好是pitch的loader)
这里我们只有一个ejs的loader,那么就会进入processResource中开始对资源进行处理
还记得之前说的use strict加入了一个constDependency吗,其实这玩意儿没什么用,她不会添加新的依赖,给人感觉只是一个干净的占位符,不过另外还有其她类型的依赖,她们就是有各种各样的特殊作用了
其实啊,这些依赖呢,本身就是存储了相应的位置信息,还有需要添加的模板,她们都有一个非常重要的属性Template,
这个东西能够在最后加入进文档的时候把她们的内容进行添加操作
继续进行prewalk的处理,这里我们简单的举一些例子,比如第一次进来的var Sockjs首先会进行一个var-XXX的绑定操作,然后才是var Sockjs的操作,所以要是真正开发的时候这里面的解析顺序还是非常值得注意的问题,在处理完成过后就会在defination数组之中加入我们新创建的变量名字,以便后续的处理过程使用。

进行完成prewalk过后就是我们的walk操作,在这一步中
在回调函数中,由于完成了一个文件的解析处理,这里我们把semaphore还回去一个,即释放回去一个资源,同时由于这里的递归参数被设置为了true,我们会继续寻找已处理模块的依赖(注意这里的模块概念,我们的input设置的一个键名即对应了一个chunk,而不是只数组的每个值对应一个模块)
突然发现这个block的单位值得拿出来说一说,在这个地方添加依赖的时候首先就是会执行addDependenciesBlock,这样算是把整个模块当成是一个block来处理了,然后再处理里面的子block和dependencies等等,全部添加进去

既然有入口,那么肯定就免不了循环的寻找依赖了,现在又会调用我们之前使用过的addModuleDependencies方法,进行依赖的寻找,以及所依赖模块的依赖递归处理
单独说一下NullFactory,她会处理我们之前提到的ConstDependency,整个create函数毛也没干直接就执行了回调函数,暂时没发现有什么用,所以你也知道ConstDependency只是占位了
不过如果是碰到正常的模块的话比如说Coomonjs的依赖,她在map中其实对应的就是一个普通的nmf,这个时候就会把这个模块普普通通的进行像之前解析入口文件一样的操作
由于之前的模块在node_module里面,成功的避开了设置好的经历loader处理的过程,所以这里先单独拿出来说过后补上去
可以看到这次好不容易啊,我们的loaders数目终于变成了1,总算是可以进行babel的处理了,还有需要注意的问题就是这个东西她不知道是又开了一个进程还是怎么的,如果别的地方打了断点是进不来的,花了好多时间尝试,inspect的机制也有待了解
终于可以正式进行处理了好兴奋,这里也会把我们的输入参数进行格式化(其实就是拿到的文件资源buffer,webpack也是很聪明的,如果不使用buffer这样的原始内存空间,那么项目的大小和资源大小就会收到限制了)
然后我们一直说的处理BOM头,这个BOM头究竟是个啥,其实她就是0xFEFF,我们在第一个字符找到了她要记得清除哦,不然鬼知道会解析出来的什么鬼东西
然后进入了神秘的runSyncOrAsync函数,可能执行同步或者异步操作,看来就是拿给我们的loader来做决定了
进来插件里面当然会礼貌性的检查一下我们有没有.babelrc的配置文件,不过并没有主动的找,而是看我们有没有设置
由于我们的loader要执行异步操作,这里便先执行一下webpack要求的this.async方法,主要就是跑回去把isSync变成了false,下次检查的时候就知道这个不是同步处理了
我们发现loader的默认缓存路径是在node_module/.cache/babel-loader里面,而且由于没有使用外部的fs系统,她的内容是确实的存在在硬盘中的,检查目录的时候也是用的mkdirp确定目录存在
在进行debug操作的时候要记得把之前的缓存删掉不然会直接拿到旧的数据
反正终于通过read方法拿到了我们需要的文件,这个时候就尝试调用transform方法进行转化工作,这里的编译函数就是index.js:38中的transpile函数,可以看到很多用void 0而不是undefined,除了代码压缩的时候我还少有看到这么干的
babel-core的代码看起来贼难受,本身也是从es6的代码转化过来的,这算是自举了?23333333
总之嘛,算是把她解析好了看看处理完成什么样子,算是包含了注释单独抽出来,ast树结构,这个babel解析的树肯定还是和之前说的那个有些不一样的,解析出来的代码code,我们的sourceMap,以及在处理过程中得到的所有token居然也保留了下来,这个时候返回我们处理的结果,但是只返回了code,map和metadata这就让人很难受了啊,如果这个语法树要是能够直接拿去给检查依赖用多好省了不少时间
返回出来的结果把她缓存到我们之前说过的目录里面,以便下次使用加快编译
我们留意一下编译出来的代码,会发现每处外部加载包被调用之前都会有(0, XXX)的写法,到现在还没发现到底拿来干嘛
看了一下存下来的metadata发现她还是存下来了import进去的依赖,看来过后还是可以使用的嘛
然后会让metaData的订阅者们首先处理一下这些依赖,讲道理我们也可以在这里做些手脚,不过现在发现是没有东西进行操作
最终执行回调退出过程,这次还是没有吧metadata带走!所以metadata还是没能翻身!
回到我们熟悉的runSyncOrAsync的回调之中LoaderRunner.js:233再次执行iterateNormalLoaders,为什么会这样呢?当然是因为还是要去这个韩束里面判断我们是否还有loader要对她进行处理咯,事实证明是没有的,有空我们看看less文件怎么办
随着调用栈的不断退出!我们终于又回到了doBuild中,开始了新一轮解析AST的征程!是不是有毛病!
说了一下babel是这样处理的,那么其她资源文件是怎么做的呢?
less文件的处理会把文件进行转码最终变成字符串传给下游,css和style等组件并不会直接把资源做多大的处理,她们更多的是添加依赖进去module里面,这些添加的依赖是一些工具函数,最终会帮助资源进行封装工作
这里可以做一下思考为什么webpack的设计者会让实际上越后处理资源的loader放到列表的前面呢?
另外还有一点就是css从某个版本开始没有直接使用字符串存放我们的css资源了,取而代之的是使用了base64的字符串,如果支持的情况下会使用atob的方式对资源进行解码,这样处理好像是对于sourceMap更加方便
【1】淘宝FED-细说 webpack 之流程篇 http://taobaofed.org/blog/2016/09/09/webpack-flow/
【2】zsx的博客 https://blog.zsxsoft.com/post/28
由于前端资源的特殊性,首屏有大量的优化都是体现在网络上的,在网络优化中有非常多文章进行说明,这里我就不再赘述了。但是其中有一个非常有意思的点,就是14KB的问题,大家基本都听说过,但是却很少知道其中的道理,我在网上也没看到很详细的解释,所以提出来说一下。
为什么首屏的html资源要限制在14KB以内呢?
最普遍的说法(各种博客):
反正是14kb可以最好的利用网络带宽,可以让html在一次就传输完所以最快咯~
详细的说法(谷歌开发者文档):
鉴于 TCP 评估连接状况的方式(即 TCP 慢启动),新的 TCP 连接无法立即使用客户端和服务器之间的全部有效带宽。因此,在通过新连接进行首次往返的过程中,服务器最多只能发送 10 个 TCP 数据包(约 14KB),然后必须等待客户端确认已收到这些数据,才能增大拥塞窗口并继续发送更多数据。
另外还需注意的是,10 个数据包 (IW10) 这一限值源自 TCP 标准的最近一次更新:您应确保自己的服务器已升级到最新版本,以便能够充分利用这次更新。否则,这一限值可能会降低到 3-4 个数据包!
考虑到 TCP 的这种行为,请务必优化您的内容,以尽可能减少为传输必要数据(以完成网页的首次呈现)而需进行的网络往返的次数。理想情况下,ATF 内容应小于 98KB,这样浏览器才能在 3 次网络往返之后即可显示网页内容,以便为服务器响应延迟和客户端呈现留出充足的时间预算。
看到上面的一段我们其实已经大概明白了,原来是因为慢启动的存在导致我们第一屏只能发送14kb的内容,那为什么是1.4kb * 10这么计算呢?在旧版本的服务器上又是指的哪个版本之前呢?这里我们分两块说
TCP网络通信占了我们日常使用的网络通信的绝大部分,网络环境质量变化都十分复杂,同时为了避免流量攻击等行为,TCP实际上有一些防止拥塞的策略,主要是依靠四个算法来实现:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复
我们现在只说slow start这一个,剩下的读者可以自行搜索阅读
慢启动在1988年就由TCP-Tahoe 提出了,主要目的就是为了避免新加入的连接直接把带宽打满,也可以避免一些恶意行为。
先好好补一下计算机网络的概念:
MTU: Maximum Transmission Unit,是指一种通信协议的某一层上面所能通过的最大数据包大小(以字节为单位)。最大传输单元这个参数通常与通信接口有关(网络接口卡、串口等)。
MSS: Maximum Segment Size,是传输控制协议(TCP)的一个参数,以字节数定义一个计算机或通信设备所能接受的分段的最大数据量。 它并不会计算 TCP 或 IP 协议头的大小。
从算法上来说原理(不论系统实现),慢启动的算法如下(cwnd全称Congestion Window):
1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(去参考文章里面看)
所以,我们可以看到,如果网速很快的话,ACK也会返回得快,RTT也会短,那么,这个慢启动就一点也不慢。但是我们首屏注重的就是第一个横线,在这么看来只有1个MSS肯定是不够使的,下图说明了这个过程。
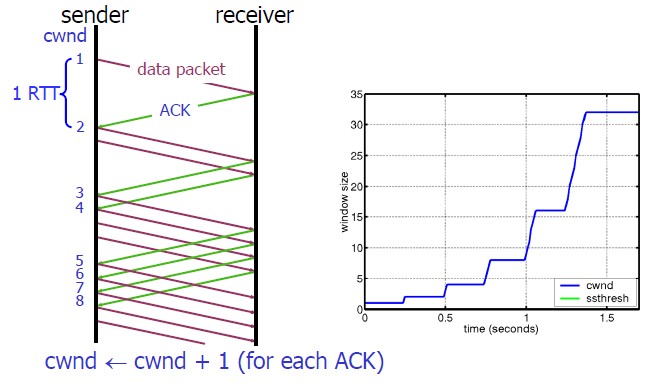
上面的是理论的算法,实际上我们工作中就不是从1开始慢慢增长了,需要提一下的是一篇Google的论文《An Argument for Increasing TCP’s Initial Congestion Window》Linux 3.0后采用了这篇论文的建议——把cwnd 初始化成了 10个MSS。
而Linux 3.0以前,比如2.6,Linux采用了RFC3390,cwnd是跟MSS的值来变的,如果MSS< 1095,则cwnd = 4;如果MSS>2190,则cwnd=2;其它情况下,则是3。
不得不说隔了这么几十年了,互联网技术还是还是会随着硬件能力的增长不断更新的,现在就是10个MSS起步了,那么Linux 3.0这个我们用不用担心呢?其实不用,3.0已经是2011年07月22日发行的了,以我们常用的centOS 7.2为例,他的内核版本已经是3.10了,不用担心
我们已经知道了1.4K * 10之中的10是从哪里来的了,10就是指的10个MSS,那1.4k就是这个MSS的最大大小了吧。熟悉计算机网络的同学肯定已经知道是怎么回事了
因为我们一般认为终端用户使用的网络MTU是1500Byte来的,由于那相当于是我们数据链路层能够传输的大小了,我们实际能传输的IP数据包内容肯定是比他少的,简单的算一算
一个TCP包(数据段)的荷载 <= MSS < MTU
PPPoE首部6,PPP协议2
数据链路层最大data为1500-8=1492
IPv4首部最少20,IPv6首部40,TCP首部最少20
MSS最大为1492-20-20=1452
现在得到了MSS最大是1.452K这个结果,正是与我们预期一致的,Q.E.D
整个探索过程很多东西都是与网络相关,可见计算机基础和网络对于一个工程师的重要性,虽然日常工作很少实际用到底层的原理,但是学习一下打好基础还是很有价值的。。笔者对计算机网络并不能算很熟悉,文中若有错误还请多指正!
转载请注明出处及作者,同时感谢下列作者
[TCP的那些事儿(下) 陈皓]https://coolshell.cn/articles/11609.html
[goolge 移动网络分析]https://developers.google.com/speed/docs/insights/mobile
[TCP/IP数据包结构详解 水沐清華]https://blog.csdn.net/prsniper/article/details/6762145
[TCP一次数据包最大负载是多少?wind5o]https://segmentfault.com/a/1190000012962389%
昨天在webpack这个Issue上面有人提到了个很有趣的问题,大概是说了3版本的webpack生成的代码是如何做到的引入了新的模块。比如像下面这样:
import foo from "module";
foo(1, 2); // <- called without this (undefined/global object)打包处理后会被转化成如下的样子:
var __WEBPACK_IMPORTED_MODULE_1__module__ = __webpack_require__(1);
Object(__WEBPACK_IMPORTED_MODULE_1__module__.foo)(1, 2);
// ^ called without this (undefined/global object)这背后的原因是webpack必须把保留潜在的语义上的this给函数foo。如果你是像下面这样生成代码的话
var __WEBPACK_IMPORTED_MODULE_1__module__ = __webpack_require__(1);
__WEBPACK_IMPORTED_MODULE_1__module__.foo(1, 2);
// ^ called this = __WEBPACK_IMPORTED_MODULE_1__module__在foo里面用到this的地方会被绑定到__WEBPACK_IMPORTED_MODULE_1__module__上,这样一来就和我们上面的ESM语义是不相符的了。很显然还有很多其他不同的方法来实现这一效果,Tobias Koppers研究了这其中的很多细节,尝试了多种方法,最终决定使用Object constructor来做
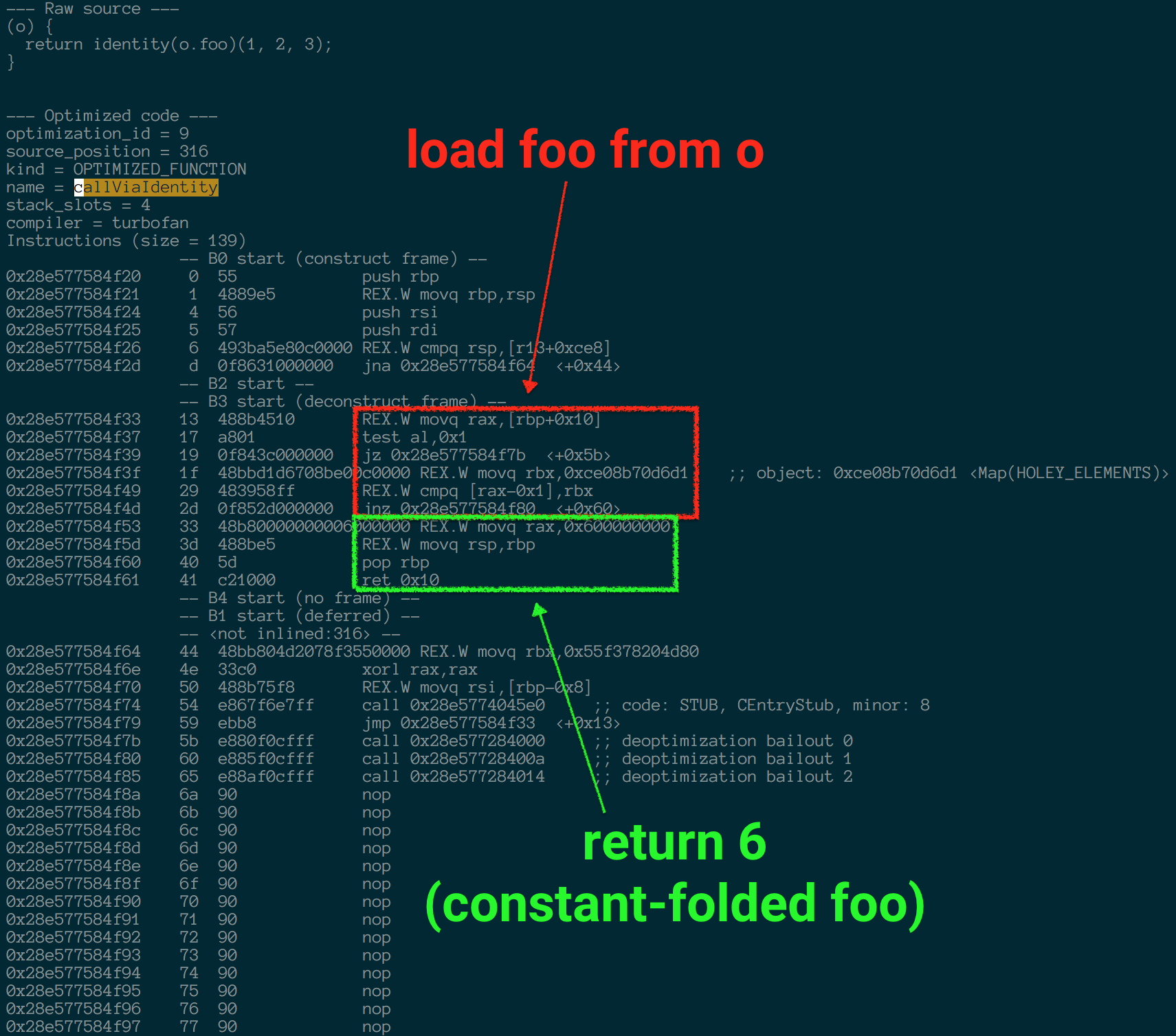
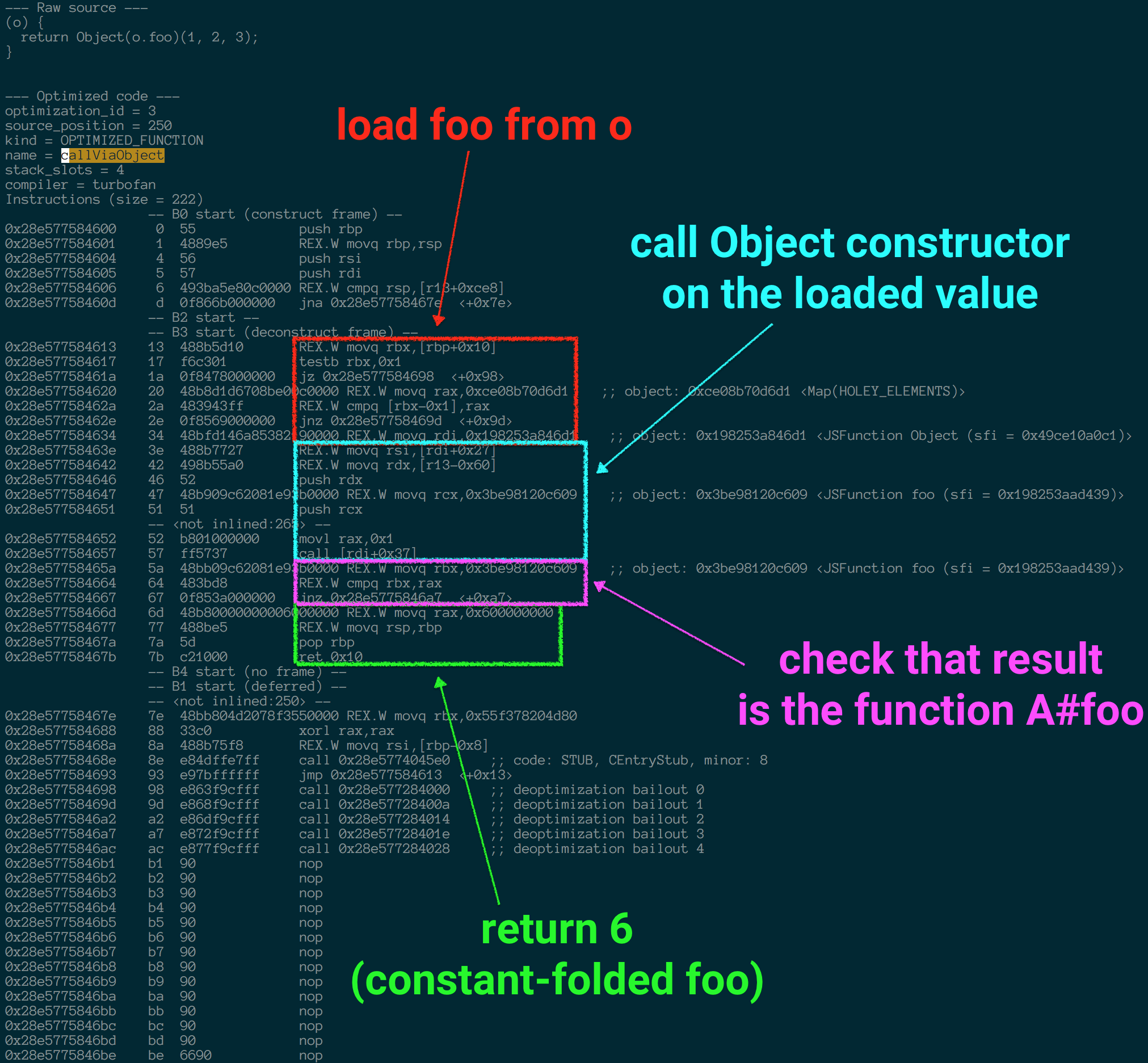
不幸的是 事实上对象构造函数在某些情况下仍然带来了一些不必要的损失,因为直到现在TurboFan(V8底层)还没有搞清楚怎么一回事,我简单的写了个benchmark
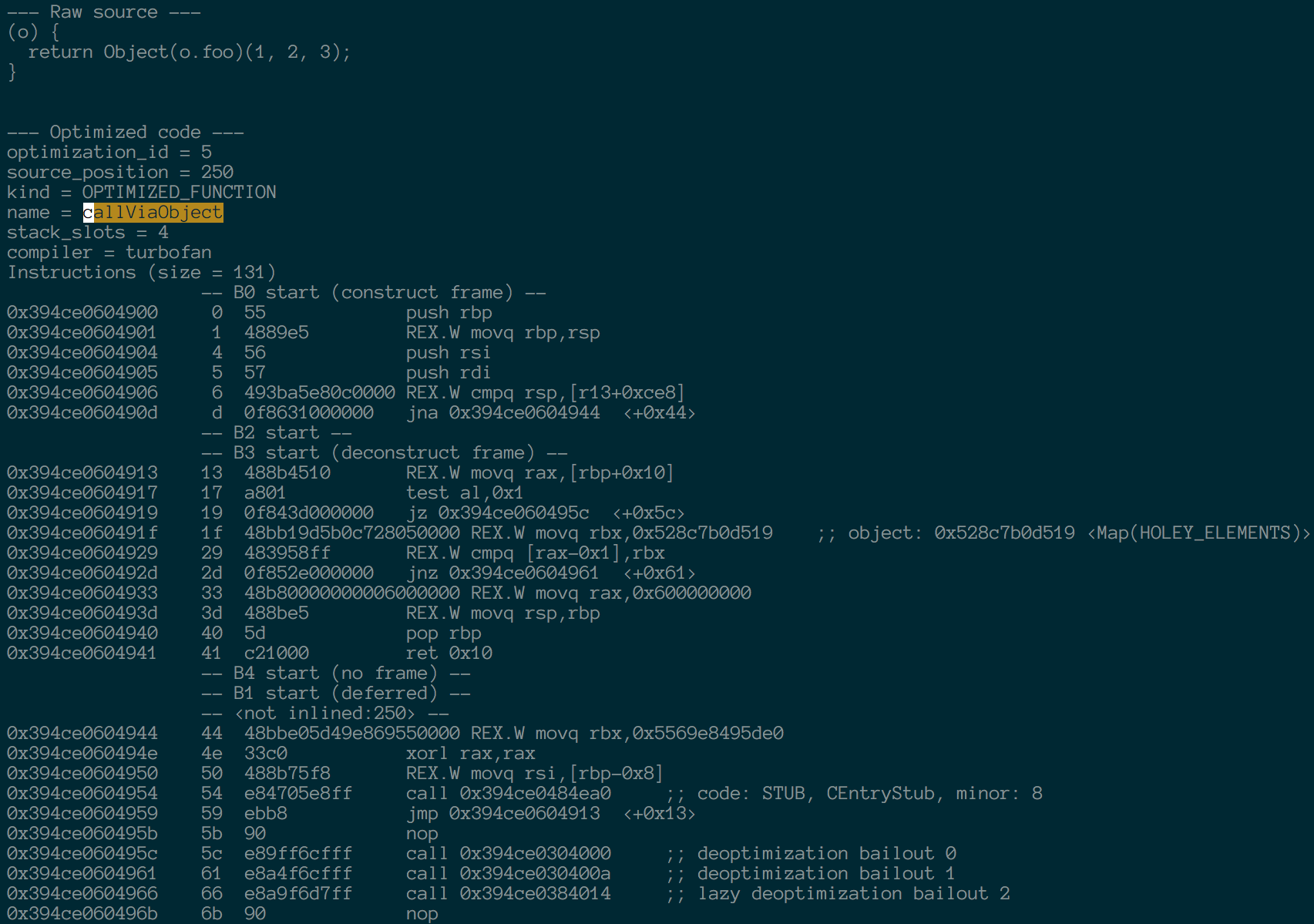
const identity = x => x;
function callDirect(o) {
const foo = o.foo;
return foo(1, 2, 3);
}
function callViaCall(o) {
return o.foo.call(undefined, 1, 2, 3);
}
function callViaObject(o) {
return Object(o.foo)(1, 2, 3);
}
function callViaIdentity(o) {
return identity(o.foo)(1, 2, 3);
}
var TESTS = [
callDirect,
callViaObject,
callViaCall,
callViaIdentity
];
class A { foo(x, y, z) { return x + y + z; } };
var o = new A;
var n = 1e8;
function test(fn) {
var result;
for (var i = 0; i < n; ++i) result = fn(o);
return result;
}
// Warmup.
for (var j = 0; j < TESTS.length; ++j) {
test(TESTS[j]);
}
// Measure.
for (var j = 0; j < TESTS.length; ++j) {
var startTime = Date.now();
test(TESTS[j]);
console.log(TESTS[j].name + ':', (Date.now() - startTime), 'ms.');
}在V8.5.5(使用Crankshaft的最新版本)和V8.6.1(当前使用TurboFan的beta版本)中,从结果看来webpack的选择是正确的做法??
$ ./d8-5.8.283.38 bench-object-constructor.js
callDirect: 598 ms.
callViaObject: 1352 ms.
callViaCall: 645 ms.
callViaIdentity: 663 ms.
$ ./d8-6.1.534.15 bench-object-constructor.js
callDirect: 560 ms.
callViaObject: 1322 ms.
callViaCall: 613 ms.
callViaIdentity: 561 ms.使用identity函数的版本达到了最好的效果(最接近直接调用的结果,目前webpack无法实现)。其次就是使用Function.proptype.call的方式了,然后使用Object constructor的方式就是最慢的了,是直接执行的2.3倍耗时
导致这一事件的原因是TurboFan和Crankshaft在执行callViaIdentity的时候将identity函数进行了内联(不知道C++ inline的自己去面壁),因此几乎完全没有造成什么额外的消耗
但是调用Object constructor的时候没有被内联(我也看不懂汇编,不过明显看到多出来的步骤吧)
在这种情况下,在o.foo的环境中调用Object constructor相当于是一个noop函数(不知道的去面壁),就跟调用identify函数一样。我们可以在规范中找到相应的描述
ToObject抽象操作是js中对象的定义操作(closures就是普通的js对象)。所以我们就是得教会处理TurboFan这样的调用
Object(value)当能够证明这个value是个object的时候。这就足以满足webpack的情况了,因为这里传递给Object constructor的是从module中拿到的对象,他们是始终被V8引擎所跟踪的,所以TurboFan能够追溯到module.hot的来源就是某个常量对象。所以能够添加一些Object constructor相关的黑魔法到TurboFan上面来解决这个issue
$ out/Release/d8 bench-object-constructor.js
callDirect: 562 ms.
callViaObject: 564 ms.
callViaCall: 615 ms.
callViaIdentity: 564 ms.可以看到上面性能上有了的提升,或多或少的改变了些代码
并且webpack3生成的打包资源,也不回因为这些问题而有那么大差异了
嘛,其实全文读下来你会发现没说什么东西,而且现在的新版本上这几种操作的速度基本一致了。不过这也让我们知道了不断深挖的重要性
代码的智能提示其实是一个在开发中会比较少碰到的问题,更多的我们是在使用编辑器的时候很自然而然的就用上了这项功能,但是也没有仔细想过其中的原理到底是什么。
笔者之前做过补全的工作,但是受限于时间和能力,选择了将hue的自动补全功能迁移到其他平台的工作,完成相关工作之后看到 黄子毅的这篇文章,也是另辟蹊径,是另一种自己从头开始做的做法。今天简单的说下自己看到hue中的自动补全是如何完成的。
大家可以先行阅读上面那篇文章,其实是有一个比较通用的点,就是把我们光标位置设计为一个特殊字符。其实如果要自己想出这个结论的话还是需要一些时间的。
这一点为什么重要?因为我们解析的时候是要构造一个树状的结构,所以不可能把前半部分和后半部分的文本分开进行构建,在lexer处理的时候都可能出现问题,就算能够成功的解析在后续构建语法树时也有极大可能会出现结构上的问题。
相较与黄同学的从底层的解析一层层做起,我们选择的方法是使用直接的jison方案进行解析。hue的jison文件
jison本身就是js版本的bison和flex的合集,他是其在js上的一层实现,我们可以用它完成编译器的前端工作(此前端非彼前端)。
他的语法这里就不赘述了,网上有很多教程,因为我们要做的是SQL的自动补全,整体的语法还是比较简单的,主要的也就create,insert,select这几种DML,DDL。
要写出整个解析语法的解析规则还是一个体力活。在书写的过程中也要对编译原理有足够的了解,不然会收到编译器的大量警告和报错。由于解析的过程会有很多递归的操作,所以写的时候要小心自己写下的的语法规则。如果有不确定的地方可以去看看一些开源的方案的代码或者antlr等。
不过上面说的是如何生成AST,如果我们的规则不符合标准的语法结构咋办呢,比如像自动补全的情况?这时候我们可以把光标当成一个特殊符号,在每一个结构中进行独立的补全处理配置。
上面这话啥意思,我们一般的解析规则是
select a from b;jison会把这个SQL按照这种规则进行解析(简化),得到一个树状的结构
SelectStatement
| \
SelectList FromSource
| |
SelectItem FromItem
| |
{ value: 'a' } { value: 'b' }
如果我们是在输入过程中,那么内容很有可能就变成了
select from b;这样的结构,我们不知道我们的指针在哪里,解析肯定是不能成功的,并且不符合我们预先定义的语法结构,我们就需要在其中加入我们的指针位置,让他和我们的内容一起解析,在指针的位置做特殊处理。
select | from b; 现在我们就可以进行解析了,但是是通过专门的editing的规则进行匹配。
所谓的editing规则,其实就是在我们完整的语法解析结构中加入了光标的语句,代表了我们当前正在编辑这句话。不过这也引出了一个点,就是在多个指针同时操作文本时可能出现问题,这是在提示时需要注意的。
SelectStatement_Edit
| \
SelectList_Edit FromSource
| |
①SelectItem_Edit FromItem
| |
{ text: '' } { value: 'b' }
由于我们在匹配到固定结构时是可以做一些js的操作的。比如在①的位置,我们就能拿到设置一条函数在匹配到这条规则时进行执行。构建语法树时对应的可能是些转化处理,并把子节点插到一个节点上再向上传递。
对应到智能补全的时候,我们要做的就是在这个函数中添加上我们需要的补全类型和当前字段的状态了。比如在①这里,我们可以简单的设计一个函数handleColumn,通过调用handleColumn(text, position),来注册一个固定的autocomplete的逻辑,也可以异步的做一些获取库表信息的操作了。对应到hue中的代码 就是这里
至此,解析器就能够简单的针对每个位置做到一个解析并提示了。
笔者的记录比较粗糙,只是提供一种思路,如果想要看具体的实现还是建议阅读hue或者其他有代码自动提示功能项目的源代码,由于hue项目的结构组织复杂,并且现在有多个版本,前端项目并不好直接在本地跑起来,可能开发上会有些问题,只建议了解一下相关思路,有任何问题欢迎在issue下面讨论。
引用
https://github.com/dt-fe/weekly/blob/master/85.%E7%B2%BE%E8%AF%BB%E3%80%8A%E6%89%8B%E5%86%99%20SQL%20%E7%BC%96%E8%AF%91%E5%99%A8%20-%20%E6%99%BA%E8%83%BD%E6%8F%90%E7%A4%BA%E3%80%8B.md
https://github.com/cloudera/hue/blob/release-4.0.0/desktop/core/src/desktop/static/desktop/js
上一次说了webpack打包的原理,但是仅仅是打包而已,没有涉及到服务器和中间件还有热加载相关的东西,这次就来聊一聊
我们写这篇博客是有一个目标的,就是想着把dev-server应用到rollup上面重新实现一次,不过碍于二者的打包方式以及输出资源的方式都有所不同,这里我们就先看看dev-server源代码的执行方式,看搞清楚他们的原理之后会不会有方法将他们组合起来
webpack-dev-server简写为DSwebpack-dev-middleware简写为DMwebpack-hot-middleware简写为HMEventEmitter简写为EE服务端
客户端
收到socket链接发送过来的hash值,更新了自己目前的hash值,不过并没有下载json文件
(其实我想问这里真的能够保证两次的顺序吗?)收到ok,或者error等,这里只讨论ok
通知其他的iframe和worker等,发送OK消息并清除错误显示屏overlay,之后重新加载reloadApp
利用hotEmitter的共享实例,发送出一个『webpackHotUpdate』的事件,注意这里在客户端是由webpack的polyfill实现的
发出的事件会被dev-server中的代码接收到,执行check操作,取回并检查我们的json文件
初次进入到这里,或者是没有完全搞明白webpack的目录结构的同学可能会很懵逼,这个module.hot.check方法是哪里那进来的啊混蛋?!其实要知道这个首先得知道我们的module不能当成一个普通的对象来看待,她和require一样都是webpack和我们文件沟通的桥梁,很多时候webpack会在她上面动一些手脚
这里就是通过上面的方法,在module对象上面添加上我们的对象和参数等,我们看到这里的hot被设置成为执行一个函数的返回值,发现这个函数在HotModuleReplacement.runtime.js中
这里面有我们的check,decline,accept等方法,也即是我们在代码中执行的那些方法的实际实现
仔细看看hotCheck方法的实现,把状态变成check,并执行hotDownloadManifest去取我们的描述json文件,返回一个Promise
这个下载方法在不同环境又有不同实现方式,我们现在心里只有浏览器!所以只看浏览器的!
不过也只是自己发了一个request请求而已,拿到那一段json,从这里可以看出,其实现在已经没有必要管古代的浏览器了,直接使用的XMLHttprequest,然后去服务端拿数据
服务端
[hash].hot-update.json的请求,进行回复
进入dev-server收到请求,但是交由dev-middleware进行处理
对于这一次请求我们得到的路径是/Users/rocksama/project-name/public/9c531a0d5c8a256697b3.hot-update.json,可以确定是我们在那个目录下是没有那个文件的
在memory-js寻寻觅觅,终于找到了我们的文件,读出来,并把它返回给我们
这个json文件是什么时候写入的呢?是在additional-chunk-assets阶段,在内存中存储了一个json文件,c代表的是变化的chunk是哪个,h代表的是hash值,而经常还会看到l代表的是是否需要重新加载,比如只是改了个空格肯定就不会有变化啦
那么这个c中的值是囊个计算出来的呢?之前也说过我们的文件变化过后,会导致重新编译,(重新编译不一定hash变化,这个hash值是AST相关,不是纯粹的与文件内容相关联的)这个时候会拿之前编译后留下的record中记录的hash和我们现在模块的hash,进行对比看哪些module发生变化
知道module后就好办了,往上面找到引用了他的父chunk,就能得到哪些是需要进行更新的了
把我们做好的json串放到虚拟文件系统中,等着前端来请求,美滋滋(不过好像没看到删除操作)
客户端
客户端拿到json文件,对其中的c字段进行检查,对于需要改变的chunk请求对应的新的js
注意这里重新请求的是chunk,为什么不是module呢?我知道个屁
在不同环境下利用hotDownloadUpdateChunk下载新的chunk文件
添加一个新的hot-update.js的文件script到head里面进行下载工作
我们的hot-chunk又是在哪里生成的呢?之前不是compiler一直都watch着吗,这一轮的complication执行下来得到的hot资源就是通过Jsonp的插件在render的时候进行的格式化然后插入到我们的内存中的
webpackJsonp,但是在现在这里是用的是webpackHotUpdate,并且这两个东西你无法直接在源码中找到对应名字的函数,他们是挂在window上面的,所以在中途还被改了个名字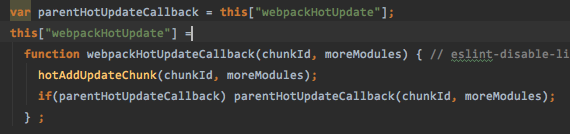
hotUpdateDownloaded方法开始执行,标记现在的状态为ready,并把之前下载manifest的deffer给置为null清空了;忽略特殊情况开始处理apply的事件
用getAffectedStuff处理后,从更改的节点往上找到拿到被影响的模块,最终返回几个列表,这样就能开始我们的替换工作啦,同时方法执行最后会返回一个对象
return {
type: "accepted",
moduleId: updateModuleId, // 当前hot的module的id
outdatedModules: outdatedModules, // 被影响的module的id
outdatedDependencies: outdatedDependencies // 存在根节点和当前module的关系?不懂不敢乱说
};这次处理由于只有这么一个模块发生了修改,而且没有把本次的热加载往上冒泡(可能是因为dva的作用,我们这个页面实际上没有hot相关配置),所以直接得到了accepted的许可,如果有设置则执行onAccepted方法。继续往后把doApply设置为true接着往下执行
当doApply为true时会往outdatedModules中添加不重复的module元素id,用于一会儿的移除并更新操作
改变标记位,进入dispose阶段,进入对过期模块的清理工作,但是只是从installedMoudules的列表中把他们delete掉了,和node还需要清除cache不一样,简单删除掉就好了;当然除了把自身卸载掉还有之前说的dependency也需要处理,我不是很清楚就不再赘述了
删除完成进入apply阶段,将新的代码模块都应用上去,这里终于发现我们的dependency其实是设置好了module.hot.accept的模块,拥有这个配置的模块会将回调函数放到_acceptedDependencies里面存好,过后边开始执行hot中的操作,比如利用ReactDOM重新挂载,或者重新加载模块等,具体操作以dva为例,请前往dva部分查看
处理完更新过后,有错误就触发fail标识,不然直接进入idle的空闲状态
调用栈一直退出直到check中,进行收尾工作打印操作正确与否的日志
这下面的内容属于笔记性质的了,还是需要配合源代码食用,而且质量不高很容易造成消化不良的症状,请酌情使用
本是同根生,所以webpack还是使用了yargs进行参数的处理,其他还有optimist和commander等等,大家都大同小异,而且诶个人使用下来还是yargs舒服而且相对活跃,那这就是用他的原因吗?
其实我倒觉得是因为两个包都用一样的yargs会保证npm下载的时候更快更稳啦~
之后会对里面拿到的参数进行格式化(convert)处理,这里有个选项直接会导致他的输出统一变成bundle.js,当然这也是为了方便DS读取固定且单一的路径

对设置的参数进行处理,如果设置了stdin的参数的话会打开输入流,是用来后面直接读取资源数据?方便管道处理?
之后还有其他初始化,比如这个读取证书的操作,DS实际上是支持https的,不过少有用到,跟着研究一下
DS是真的皮,如果-p参数带来的端口刚好是默认端口号的话,他反而会先尝试去使用在文件中设置的值
// Kind of weird, but ensures prior behavior isn't broken in cases
// that wouldn't throw errors. E.g. both argv.port and options.port
// were specified, but since argv.port is 8080, options.port will be
// tried first instead.
options.port = argv.port === DEFAULT_PORT ?
defaultTo(options.port, argv.port):
defaultTo(argv.port, options.port);如果我们没有在任何地方设置好服务启动端口的话,那就会通过portfinder从8080一直往上面找,直到找到一个可以用的端口,但是如果指定了某一个值就没那么好玩了,不行的话直接GG
听名字就知道不是什么好事,他会在我们webpack的配置中添加上两个entry,其中一个是我们必要的DS客户端,就是干响应新数据啊,发起链接这些事情的
但是另一个就要分两种情况了,但是都是和热加载有关的文件,可能是only-dev-server也可能是dev-server。有个什么区别呢?区别在于webpack/hot/dev-server 在 HMR 更新失败之后会刷新整个页面,如果你想查看错误自己刷新页面, 可以改用 webpack/hot/only-dev-server
那么我们就很愉快的拿到了两个入口,看看这次测试是什么样子
/Users/you/project/node_modules/webpack-dev-server/client/index.js?http://0.0.0.0:8080,后面的query字符串会在webpack处理之后变成我们的熟人__resourceQuery说一句题外话,不知道大家觉得下面这种写法有没有什么问题呢,
path.resolve(__dirname, 'project/main.js?http://0.0.0.0:8888'),试一试打印出来就知道问题在哪里了哈哈
webpack/hot/dev-server,一般都是用hot,所以相当于默认的就是这个相关:github-issue
创建一个新的webpack实例,拿到我们的compiler
创建一个新的Server,美滋滋,就是简单的express服务器加上我们的相关中间件
设置好相关的插件,分别在compile,invalid,done阶段向客户端的socket连接发送信息告知详情,done的时候会整个发送stat过去,就是我们的分析数据摘要,包含了请求资源json和补丁js文件的hash值等等,另外这几个里面只有process的过程是按需的,根据process的设置启动
创建express服务器,拿到所有的请求,先把host过滤一遍,不知道意义何在;添加上我们的中间件DM
他会把我们的文件存到虚拟系统里,你别无选择,如果input的时候是虚拟系统就直接用那个,没有就新建一个memory-fs的实例拿来存取东西
给done,invalid,watch-run,run阶段添加上一些管理函数
开始调用compiler的watch方法对文件进行监视
创建一个Watcher对象,进行初始化,由于fs其实还是扫描文件是否发生变化,所有有一个时间间隔,这里默认的值是200ms
试图读取record的缓存记录,但是很可惜,什么都没有那么直接执行_go,跟我们之前所说的的compile差不多,不过是里面和正统的webpack打包对比起来,有一些生命周期发生了变化,比如不会有什么资源存储,本来的run变身为watch-run等
首先会进行一次编译操作,然后回到我们的onCompiled函数,这样构成了一个闭环,不断的做递归,每次检查我们的资源有没有变化
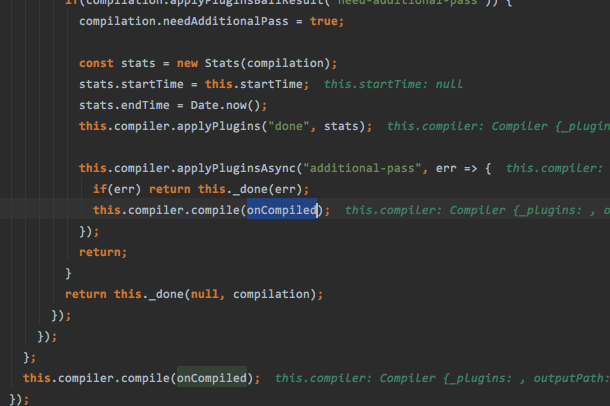
在_done方法的回调中,进行相关的状态发送,不只是hash,还可能出现still-ok,errors的情况,浏览器端会给出相应的反映
本来以为会在某个插件中卡住一直等待文件状态刷新,但是其实这个东西是webpack自己的方法watch,如果发现我们的文件发改变进入invalidate方法,把之前的watcher扔掉(watcher实际上一个Watchpack对象,这个对象还是webpack的大佬们定制的,毫无疑问继承自EventEmitter)
给线程绑定上两个信号的监听,虽然只有这么几种信号,但是姑且也算是一种通信方式吧
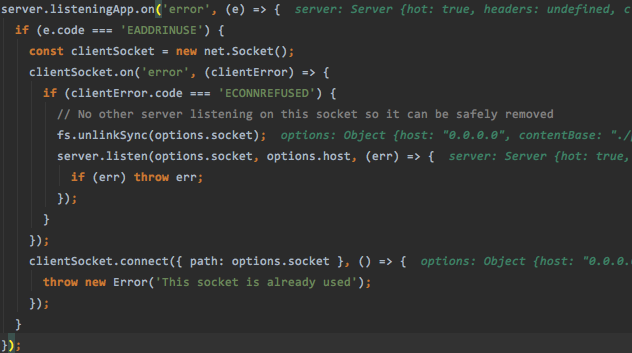
SIGINT——程序终止(interrupt)信号, 在用户键入INTR字符(通常是Ctrl-C)时发出,用于通知前台进程组终止进程。SIGTERM——程序结束(terminate)信号, 与SIGKILL不同的是该信号可以被阻塞和处理。通常用来要求程序自己正常退出,shell命令kill缺省产生这个信号。如果进程终止不了,我们才会尝试SIGKILL。SIGKILL——用来立即结束程序的运行. 本信号不能被阻塞、处理和忽略。如果管理员发现某个进程终止不了,可尝试发送这个信号。(所以理所当然这里没有监听他)我们现在已经有了一个express的服务器,不过还没有启动(只是一个实例,没有监听端口),那剩下来要做的就是创建我们的socket服务,实现双向数据传输
如果我们配置了socket,那就直接使用我们配置的socket而不是重新起一个sockjs的实例来处理,因为是继承自EventEmitter,所以监听error事件,如果出现了端口占用的情况,则创建一个新的socket连接,要是再拒绝了链接那就再重新尝试连接一次,然后抛出错误,真是坚韧不拔啊
app这个属性中存储的是我们的express服务器,用于接收来自我们页面的所有http请求,用作分发处理,中间代理等等
listeningApp中存储的是一个新的httpServer,如果没有启用https的话会很简单直接是把之前的express服务器拿过来启动就好,但是如果是https的话会用到spdy这个库进行创建
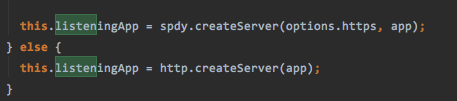
spdy相当于是HTTP2的前身,有chrome指定的协议,但是根据wiki,在2015年9月,Google 已经宣布了计划,移除对SPDY的支持,拥抱 HTTP/2,并将在Chrome 51中生效。那为什么还会用SPDY?多半是在这个库里面设置成了能用HTTP2就直接使用,不再深究,扯太远了
执行server的listen方法,处理监听操作
listening事件,并添加once的监听放入我们设置的回调函数承接上文的利用sockjs创建一个新的socket服务器,我们探究一下其中的原理
看一下默认的配置呢,优先使用websocket咯,完全没毛病;jsessionid是什么?socket连接怎么会能用这种浪费流量的东西?好吧其实是拿给域名服务商看的
Some hosting providers enable sticky sessions only to requests that have JSESSIONID cookie set. This setting controls if the server should set this cookie to a dummy value. By default setting JSESSIONID cookie is disabled. More sophisticated behaviour can be achieved by supplying a function.
还有个sockjs_url这个就比较有意思了,这里的默认值是sockjs挂在线上CDN的sockjs-client库,我们会对他进行替换,只是换成本地的资源,没有一丁点变化
this.options = {
prefix: '',
response_limit: 128 * 1024,
websocket: true,
faye_server_options: null,
jsessionid: false,
heartbeat_delay: 25000,
disconnect_delay: 5000,
log: function(severity, line) {
return console.log(line);
},
sockjs_url: 'https://cdn.jsdelivr.net/sockjs/1.0.1/sockjs.min.js'
};那么我们现在要看sockjs的启动得去哪里找呢?hey,还记得之前在每个entry中添加的两个文件吗,现在就去看看他们做了什么
这里用到的sockjs不是之前直接设置的打包好的sockjs,而是在这里重新做的一次引用require('sockjs'),就目前看来这样会导致我们引入多余的js文件,我们一会儿看看打包出来的文件是什么样子。没准儿最后有什么奇妙的方法修复了
里面有个getCurrentScriptSource方法能够拿到现在正在执行的script脚本,本来是有一个document.currentScript应该能够获取到,但是没有浏览器支持,所以现在拿到正在执行的脚本的方法比较笨,就是直接拿到最后一个script标签;
有人会问了,我要是在这段JS里面动态添加上script标签可咋办,而且webpack本来就是用JSONP加载资源,这样岂不是要拿错?(记得补上)
对象里面定义了我们响应socket信息时可能会接受到的所有信号,看看都坐了些啥
const onSocketMsg = {
hot: function msgHot() {
hot = true;
log.info('[WDS] Hot Module Replacement enabled.');
},
invalid: function msgInvalid() {
log.info('[WDS] App updated. Recompiling...');
// fixes #1042. overlay doesn't clear if errors are fixed but warnings remain.
if (useWarningOverlay || useErrorOverlay) overlay.clear();
sendMsg('Invalid');
},
hash: function msgHash(hash) {
currentHash = hash;
},
'still-ok': function stillOk() {
log.info('[WDS] Nothing changed.');
if (useWarningOverlay || useErrorOverlay) overlay.clear();
sendMsg('StillOk');
},
'log-level': function logLevel(level) {
const hotCtx = require.context('webpack/hot', false, /^\.\/log$/);
const contextKeys = hotCtx.keys();
if (contextKeys.length && contextKeys['./log']) {
hotCtx('./log').setLogLevel(level);
}
switch (level) {
case INFO:
case ERROR:
log.setLevel(level);
break;
case WARNING:
// loglevel's warning name is different from webpack's
log.setLevel('warn');
break;
case NONE:
log.disableAll();
break;
default:
log.error('[WDS] Unknown clientLogLevel \'' + level + '\'');
}
},
overlay: function msgOverlay(value) {
if (typeof document !== 'undefined') {
if (typeof (value) === 'boolean') {
useWarningOverlay = false;
useErrorOverlay = value;
} else if (value) {
useWarningOverlay = value.warnings;
useErrorOverlay = value.errors;
}
}
},
progress: function msgProgress(progress) {
if (typeof document !== 'undefined') {
useProgress = progress;
}
},
'progress-update': function progressUpdate(data) {
if (useProgress) log.info('[WDS] ' + data.percent + '% - ' + data.msg + '.');
},
ok: function msgOk() {
sendMsg('Ok');
if (useWarningOverlay || useErrorOverlay) overlay.clear();
if (initial) return initial = false; // eslint-disable-line no-return-assign
reloadApp();
},
'content-changed': function contentChanged() {
log.info('[WDS] Content base changed. Reloading...');
self.location.reload();
},
warnings: function msgWarnings(warnings) {
log.warn('[WDS] Warnings while compiling.');
const strippedWarnings = warnings.map(function map(warning) { return stripAnsi(warning); });
sendMsg('Warnings', strippedWarnings);
for (let i = 0; i < strippedWarnings.length; i++) { log.warn(strippedWarnings[i]); }
if (useWarningOverlay) overlay.showMessage(warnings);
if (initial) return initial = false; // eslint-disable-line no-return-assign
reloadApp();
},
errors: function msgErrors(errors) {
log.error('[WDS] Errors while compiling. Reload prevented.');
const strippedErrors = errors.map(function map(error) { return stripAnsi(error); });
sendMsg('Errors', strippedErrors);
for (let i = 0; i < strippedErrors.length; i++) { log.error(strippedErrors[i]); }
if (useErrorOverlay) overlay.showMessage(errors);
},
error: function msgError(error) {
log.error(error);
},
close: function msgClose() {
log.error('[WDS] Disconnected!');
sendMsg('Close');
}
};这里面的sendMsg等方法都是用来通知其他页面的,利用的就是postMessage,其他页面只需要监听message事件并做出响应就好了,如果当前的工作环境是在WebWorker中那就不发消息通知。
self.postMessage({
type: 'webpack' + type,
data: data
}, '*')但是这样发送消息会发送到所有的页面上去,也就是说我们如果有两个应用同时在调试的话,那么其中的iframe都会收到这些个消息并且打印到控制台
除了发送消息展示结果,更重要的就是刷新我们的引用了,reloadApp方法就是拿来做此事的。
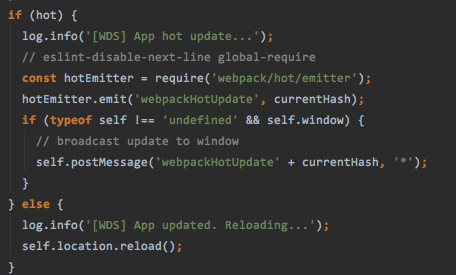
拿到资源还是广昭天下,给大家说说这次拿到的hash值,可以新添加上JSONP去请求新的资源,请求的时候是怎么请求的呢?这里就要详细的说一说了
都知道我们的webpack不止能用于browser中,也可能存在于worker或者是直接的node环境中使用,如果我们是一套同构代码的话,那么也会碰上不同环境下异步模块的处理问题,这里来看下不同环境是怎么做到的
为了方便大家找到,直接在webpack目录里面找到这几个文件就行了,直接搜索hotDownloadUpdateChunk这个方法找到相关线索
这里的几个文件都存在着这个函数的不同实现方式,而且他们都有一个runtime的中间名,实际上这一点代表了他们是会被作为插入的模块打包到我们的运行时环境中的,而不是在打包的时候执行的代码,那就来看看看看每一种实现
逻辑部分,很多是HotReplacement的插件和插入进去的runtime做的,我们现在观察一下这两个文件
最主要的文件:/webpack/lib/HotModuleReplacementPlugin.js
其他运行时环境的:/webpack/lib/node/NodeMainTemplatePlugin.js等相似的名字
该插件做了几件事
引入我们的runtime文件,并且把里面的代码拿出来进行一些必要的代码替换(会被替换的字段写到了文件中最上方的global注释里面,可以参考看一看)
/*global $hash$ $requestTimeout$ installedModules $require$ hotDownloadManifest hotDownloadUpdateChunk hotDisposeChunk modules */
就像这样子,其中以$$框起来的变量会在本次处理的时候被替换掉,具体的逻辑是
return this.asString([
source, // 其他地方的源代码
"",
hotInitCode // 我们引入的runtime文件代码
.replace(/\$require\$/g, this.requireFn) // 替换成__webapck_require__
.replace(/\$hash\$/g, JSON.stringify(hash)) // 当前的hash数字
.replace(/\$requestTimeout\$/g, requestTimeout) // 超时时间(默认10000)
.replace(/\/\*foreachInstalledChunks\*\//g, chunk.chunks.length > 0 ? "for(var chunkId in installedChunks)" : `var chunkId = ${JSON.stringify(chunk.id)};`)
]);发现在这个过程里面还有很多变量没有被替换是怎么回事?他们是在哪里定义的?installedModules这种,还有其他相关的函数
我们这里是用的是dva的babel-plugin,至于为什么没有使用在loader和plugin中添加操作,可以看看redux作者,同时也是react-hot-loader的作者写的一篇博客,详细的阐述了判断一个东西是不是组件有多少困难
最终选择了到babel的层面来注入代码也是有原因的,对于dva来说他是把hmr的兼容操作进行了一层封装放到了整个系统内部作为一个插件,将onHmr的入口留给webpack进行hash的注入
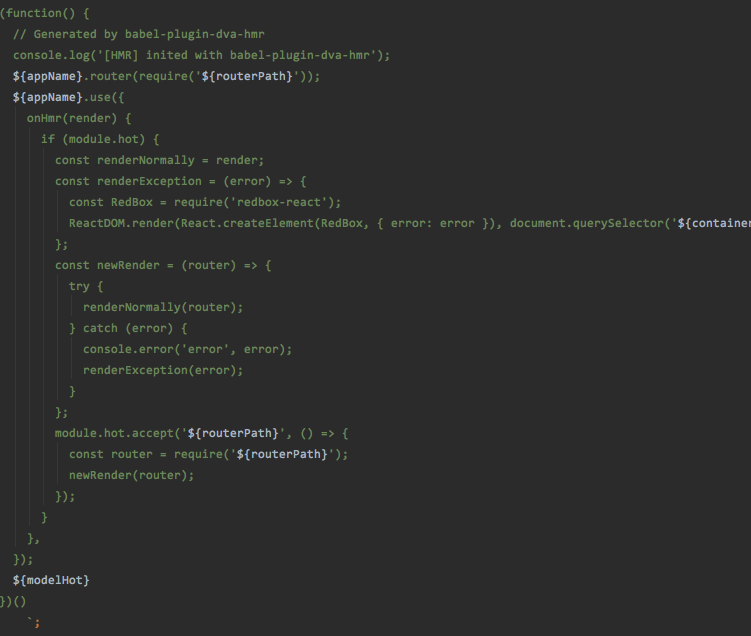
紧接上文,我们提到把存在module.hot.accept的模块称之为dependency,对应到dva里面就是我们在上面展示的这一段代码了,他会出现在我们使用app.router的地方,把每一个路由中的内容做了一个热处理
这里的render实际上。。。只是重新挂载了一次到dom上面,是我设置有错吗??这个东西应该做到的其实是保留当前的store中的状态,重新挂载更新的组件啊!
我们来看看performance中记录的是怎样的情景(部分,过深处的调用栈也是差不多),看看这么整个重新挂载dom树会有哪些动作

从上图中可以发现这样重新挂载到DOM节点上面实际上是会导致我们的项目整个重新来过;我们逐个山峰进行分析
不知道这个插件的可以先看一下要做哪些配置,这也是我们从无到有解析的一个起点 ——> https://github.com/gaearon/react-hot-loader
看了上面的dva-hmr是不是有点沮丧。这也能叫热加载?感觉就比刷新页面少了个加载其他资源的步骤,其实要求也不要那么高,这只是dva顺手做的一个功能而已,我们具体来看看 Dan Abramov是怎么做的吧,如何才能做到保留我们组件的状态和store的状态
ReactDOM.render原来不是我想的那样,把所有组件卸载了然后重新挂载,根据官方解释,其实是做一次更新,那前面dva怎么搞成了这样
If the React element was previously rendered into
container, this will perform an update on it and only mutate the DOM as necessary to reflect the latest React element.
为了便于于dva做一个对比,我们看一下他的函数调用图谱(部分)是怎么样的
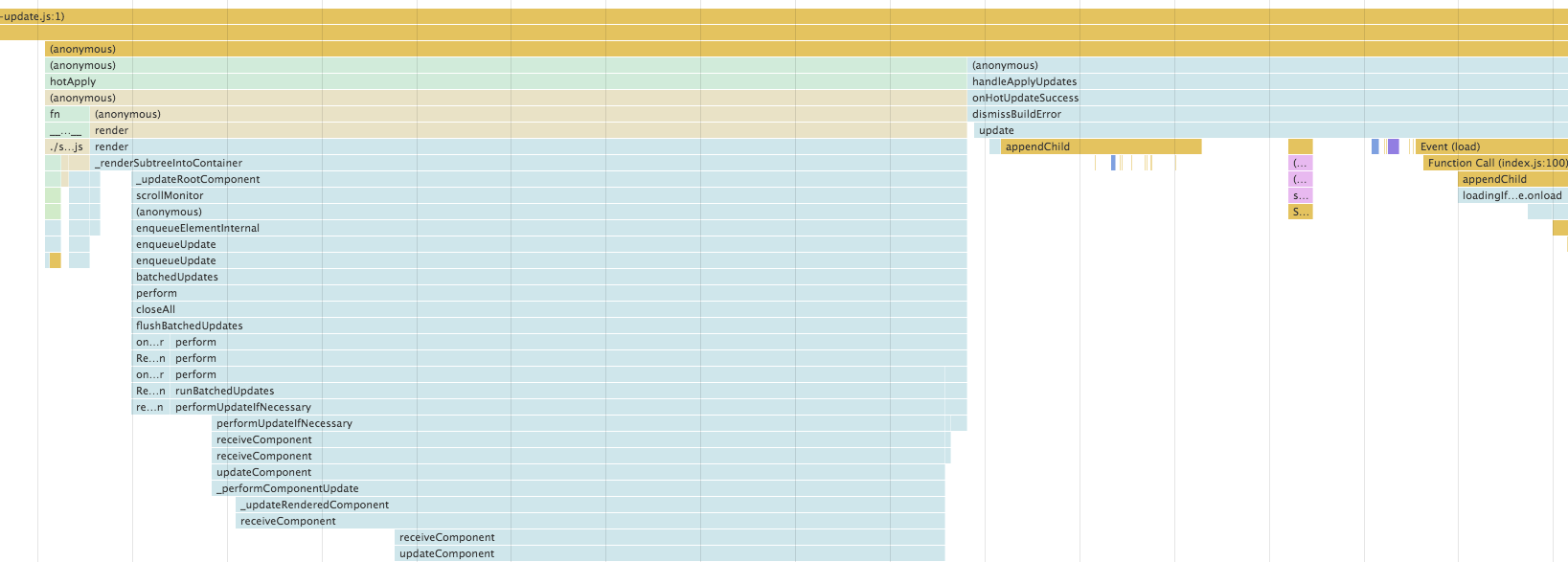
可以看到和之前的全部unmount再进行mount不一样,这里都是在update我们的组件了,这个操作是和我们文档中的ReactDOM是完全相符合的,算下来其实是dva有点奇葩,她底层也是使用的ReactDOM.render,不过我们的react-hot-loader是利用了AppContainer在我们的组件最外层包裹上了一层,才达到这样的效果
根据AppContainer的源码,其主要是有一个展示编码错误的功能,还有就是手动对所有子元素进行深度强制更新(forceUpdate),当他的props发生改变的时候便会触发这一操作,而这一动作的触发想必也一定是和我们的热更新资源有关了
关于react-hot-loader我之前翻译了一篇相关文章,请跳转继续阅读
不知道你看完有没有想到我上面所写的目标的答案?欢迎下方留言~
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.