aaaaaaaty / blog Goto Github PK
View Code? Open in Web Editor NEW趁还能折腾的时候多读书——前端何时是个头
趁还能折腾的时候多读书——前端何时是个头








































































































































































































由于昨天掘金上线了自己的小盾牌,感觉非常酷有木有!相关文章在这里。
就是下面这个:)
嗯上面那个是这篇文章现在的喜欢数嘻嘻~
然而这个是分享到掘金的文章才可以生成这样一个盾牌,可是我的文章在专栏里我也想要一个放到github的博客里怎么破!所以我决定自己写一个工具好了。我希望它可以实现:
欢迎关注我的博客,不定期更新中——
看起来还是很好看的嘛!
PS:关于小盾牌这个图标的生成是使用的shield.io这个网站的功能,会生成有一段url,里面是返回的svg图像,替换url参数就可以实现更新盾牌数据了。下文会直接对其进行数据更新。
<p align="center">
<a href=""><img id="like" src="https://img.shields.io/badge/掘金-1.7k喜欢-blue.svg" alt="Build Status"></a>
<a href=""><img id="read" src="https://img.shields.io/badge/掘金-37.6k阅读-blue.svg" alt="Build Status"></a>
</p>
在自己的md中添加这种代码就可以预先放置一些盾牌了,之后再进行更新数据的操作。
这是获取个人主页数据的请求:
有兴趣的同学们可以自己在控制台中浏览,可以看到这是一个get请求,需要的参数都包在其中了,故作者便厚颜无耻的直接将这个url复制过来用了..主要是因为掘金涉及了token验证,不清楚怎么签名的不太好实现自动化得抓取,所以为了最快速得可以做出来这个小工具,作者暂时直接将这个url拿来使用了。之后的事情就简单了:
const superagent = require('superagent')
superagent.get(juejinUrl)
.end((err, obj) => {
var msg = obj.body.d
var totalCollectionsCount = msg.totalCollectionsCount //喜欢数
var totalViewsCount = msg.totalViewsCount //阅读数
console.log('实时喜欢数:' + totalCollectionsCount)
console.log('实时阅读数:' + totalViewsCount)
changeReadMe(totalCollectionsCount, totalViewsCount)
})
通过superagent简单请求到数据后做一个筛选就得到了我们需要的数据。PS:你也可以使用原生api请求,无所谓的。
const cheerio = require('cheerio')
const fileName = './README.md'
const readAble = fs.createReadStream(fileName)
//创建可读流
var body = ''
readAble.on('data', (chunk) => {
body += chunk
})
readAble.on('end', () => {
$ = cheerio.load(body)
var regLike = $('#like').attr('src'),
regRead = $('#read').attr('src')
body = body.replace(regLike, 'https://img.shields.io/badge/掘金-'+ (like / 1000).toFixed(1)+'k喜欢-blue.svg')
body = body.replace(regRead, 'https://img.shields.io/badge/掘金-'+ (read / 1000).toFixed(1)+'k阅读-blue.svg')
fs.writeFile(fileName, body, (err) => {
if (err) throw err;
var updateRan = 'update' + Number(Math.random().toString().split('.')[1])
console.log('文件:'+ fileName +' 已经更新')
});
})
首先创建一个可读流,读出其中的数据body,通过cheerio来解析一下body,查到我们需要更新的两段url里面的数据。将之前获取到的实时数据进行替换,再重新写入文档。
const { spawnSync} = require('child_process')
spawnSync('git', ['add', '-A'])
spawnSync('git', ['commit', '-m'+updateRan])
spawnSync('git', ['push'])
通过调用child_process模块中的spawnSync会同步执行上面的命令,已达到推送数据的效果。
PS:没有使用异步是为了简易,情况复杂或者计算量大阻塞线程的情况还是应该全部异步执行。
最终我们是通过命令行的形式来执行这个“自动化”更新数据的流程,形式如下:
node juejin.shields.js xxx true
其中的第一个参数是我们自己在控制台中看到的get请求的url,其中包裹了查询参数。第二个参数是是否开启git推送,还是只是在本地更新自己的文档,默认为false。命令行获取参数的方式是通过process.argv,有兴趣的童鞋自行打印一下就明白了。
源码地址
PS: 这个命令可以封装进类似PM2的守护进程的工具中,自己设定个定时器就可以定时更新盾牌数据咯,只不过token有可能过期?233。同时这个demo比较简单,很多功能不齐全,希望定制化的小伙伴自己拷走代码自己改改~
不定时更新中——
有问题欢迎在issues下交流。
本次的分享一段代码来重新认识在V8的垃圾回收机制。
欢迎关注我的博客,不定期更新中——
var theThing = null
var replaceThing = function () {
var originalThing = theThing
var unused = function () {
if (originalThing)
console.log("hi")
}
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log(someMessage)
}
};
};
// setInterval(replaceThing, 1000)
1、首先打开一个空白的html,以防其他变量干扰。
2、将这段代码输入到命令行中,并运行一次replaceThing()
3、打印堆快照:

4、在window/:file// window/下找到在控制台打印的变量

可以看出此时的someMethod虽然没有在函数体中留有对originalThing的引用,但事实是函数运行后someMethod被输出到了全局,其内部有着对originalThing的引用导致其不会得到释放。可想而知如果继续运行replaceThing,那么originalThing会被赋值为theThing同时其中的someMethod还保有着上一次originalThing对象引用,从而形成了一个循环引用,内部变量全都不会被释放掉从而导致内存的增长。运行多次后打印快照可看到如下结果:
从打印快照的结果不难理解之前所说的由于循环引用而导致内部变量释放不掉从而内存占用过多的事实。
我们可以知道在这个最关键的someMethod方法中并没有对originalThing的引用!只有unused方法引用了originalThing,但unused方法又没有形成闭包。那么到底是哪里疏漏了呢?
来看下来自meteor-blog的解释:
Well, the typical way that closures are implemented is that every function object has a link to a dictionary-style object representing its lexical scope. If both functions defined inside replaceThing actually used originalThing, it would be important that they both get the same object, even if originalThing gets assigned to over and over, so both functions share the same lexical environment. Now, Chrome’s V8 JavaScript engine is apparently smart enough to keep variables out of the lexical environment if they aren’t used by any closures - from the Meteor blog.
原文出自Node.js Garbage Collection Explained
个人认为关键在于这句话:
If both functions defined inside replaceThing actually used originalThing, it would be important that they both get the same object, even if originalThing gets assigned to over and over, so both functions share the same lexical environment.
那么个人理解为:someMethod与unused方法定义在了同一个父级作用域内也就是同一个函数内,那么这两个方法将共享相同的作用域,可见unused持有了对originalThing引用,即便它没有被调用,同时someMethod形成闭包导出到全局,这个时候someMethod会一直保持,同时由于共享了作用域则强制originalThing不被回收。故而导致最后的内存泄漏。也就是我们在上图中看到的someMethod方法在context中嵌套包含了originalThing对象,导致内存增长的结果。
不定时更新中——
有问题欢迎在issues下交流。
本次分享一个用canvas粒子渲染文字的“完整”版实现,功能包括:随机粒子缓动动画,粒子汇聚、发散,并拼出你想要的文字。本文继续上面一节基于canvas使用粒子拼出你想要的文字的基础效果,完善了在文字拼接过程中的粒子效果。
欢迎关注我的博客,不定期更新中——
自上次的分享基于canvas使用粒子拼出你想要的文字,我们实现了一个可配置的用粒子拼出想要的文字效果,不过这个效果是静态的,就像这样:

这次我们试图对它进行了一些完善,让其可以尽量完整的实现我们的诉求。
惯例直接看下效果图:

这是一个事先配置好的动画效果用来展示一下粒子的完整运动轨迹。在这个例子中我们做了以下几件事:
故本次我们讨论的重点则围绕缓动动画与粒子的汇聚与散开进行展开
先来分析一下整体的实现思路
1、首先为了增加粒子的重用性,不需要每次拼新的文字都new一堆新的粒子。故选择维护了两个数组进行存放相应粒子。即随机缓动数组与展示效果数组
2、初始化一定数目粒子,粒子位置随机,半径随机,加入到随机粒子数组
3、对加入到随机粒子数组中的对象执行缓动动画
4、监听事件被触发,清空展示粒子数组,将当前页面所有粒子全部加入到随机粒子数组,同时更新粒子状态,让每个粒子重新出现在各个随机位置
5、当拼接文字开始,每次需要绘制一个粒子到拼接的地点时则从随机粒子数组中pop出一个粒子对象,更新粒子的位置等信息,push到展示粒子数组中,如果随机粒子数组数量不够,则新建对象添加到展示粒子数组。
6、展示粒子数组中的粒子收集完毕后,遍历数组依次渲染到指定位置
新的监听事件被触发重复以上的4、5、6步骤
就像下面这样:

观察其中一个粒子的动画行为可以发现缓动动画实现核心点在于:起始速度快,之后速度逐步递减,直至停下。
所以速度是与起始点与中点距离相关的,距离越大,速度越快,反之亦然。那么我们的速度就可以表示为:相对路程 ✖️ 缓动系数(一个小数),即可使每一帧的位移距离从大到小,速度从快至慢。
首先初始化了一些随机的粒子:
for(var i = 0; i < 100; i++) {
var option = {
radius: ~~(Math.random() * 3) + 1,
x: ~~ (Math.random() * canvas.width),
y: ~~ (Math.random() * canvas.height),
color: 'rgba(255, 255, 255, 0.5'
}
var bubble = new Bubble(option)
circleArr.push(bubble)
}
之后再绘制粒子缓动:
var dis = ~~ Math.sqrt(Math.pow(Math.abs(this.x - this.randomX), 2) + Math.pow(Math.abs(this.y - this.randomY), 2)),
ease = 0.05
...
if( dis > 0) {
//当粒子在向目标点移动的过程中,由缓动系数与距离控制速度
if(this.x < this.randomX) {
this.x += dis * ease
} else {
this.x -= dis * ease
}
if(this.y < this.randomY) {
this.y += dis * ease
} else {
this.y -= dis * ease
}
} else {
//达到目标点后更新下一个目标点
this.randomX += ~~(Math.random() * (Math.random() > 0.5 ? 5 : -5) * 2)
this.randomY += ~~(Math.random() * (Math.random() > 0.5 ? 5 : -5) * 2)
}
ctx.beginPath()
ctx.arc(this.x, this.y, this.originRadius, 0, 2 * Math.PI, false)
ctx.fillStyle = 'rgba(255, 255, 255, 0.5)'
ctx.fill()
}
...
每一个粒子都会经历由随机粒子 => 展示粒子 => 随机粒子的过程,在这其中我们需要控制好,粒子的坐标,由于在文字与随机移动的切换中,均为缓动效果实现。故我们不单单要在每个状态改变的时候维持好下一个状态下该粒子的坐标,还应该同步保持一个坐标的副本。由于需要通过两个状态下的坐标值算出需要移动的距离,并且这个距离是固定的,所以在状态切换的过程中不能改变这两个坐标值,但是粒子时刻在动,故我们需要一个坐标副本来实时表示当前的粒子坐标位置。
...
if(this.isWord) { //如果该粒子当前是文字
var disLastPosition = ~~ Math.sqrt(Math.pow(Math.abs(this.lastX - this.randomX), 2) + Math.pow(Math.abs(this.lastY - this.randomY), 2))
var ease = 0.05
if (disLastPosition > 0) {
if (this.lastX < this.randomX) {
this.lastX += disLastPosition * ease
} else {
this.lastX -= disLastPosition * ease
}
if (this.lastY < this.randomY) {
this.lastY += disLastPosition * ease
} else {
this.lastY -= disLastPosition * ease
}
} else {
this.lastX = this.randomX
this.lastY = this.randomY
this.x = this.lastX //更新x,y值
this.y = this.lastY
this.isWord = false
}
ctx.beginPath()
ctx.arc(this.lastX, this.lastY, this.originRadius, 0, 2 * Math.PI, false)
ctx.fillStyle = 'rgba(255, 255, 255, 0.5)'
ctx.fill()
return
}
...
此时我们使用lastX,lastY属性来作为前一个坐标值的变量,在计算出位移距离后,通过改变lastX,lastY来实现粒子的动画效果,当粒子到达指定位置后再更新x,y的坐标为新的坐标。
至此我们大体完成了一个完整的粒子文字特效,当然和一些线上炫酷的🌰不能比,不过大体是那么个意思,代码细节部分有兴趣的同学可以参照源码(见最后),或者自己实现一版玩玩~
源代码见:这里
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
首先关于为什么会有这一篇随笔以及为什么是这个时间点有
这篇随笔算是我在阿里的这一年多得时间里对工作包括对生活、社会的认知的一个我个人认为更深入的感悟吧,同时借着马上就要到的2020届校招(已经2020届了,00后还会远么)有些话也是希望可以帮助即将步入社会的新人更加适应一下环境,毕竟我也是亲身经历,没准后面大家就会感同身受了
其次介绍下我自己,我本身是17届一所211大学非cs专业毕业以前端岗位进入的第一家公司,毕业半年之后通过社招来的阿里,18年9月由于个人选择转型做了服务端。如果关心我之前的经历可以看下我之前的一篇随笔,事实证明我当时的很多想法,在那个时间节点和状态下还算是政治正确的。
接下来就是以这个背景来阐述一下从学生时代在到阿里这几年我对未来的一个认知变化,与我而言我认为是个人的几次蜕变。
反观我的大学生涯,大一玩了一年很嗨,到了大二开始认识到貌似找工作不容易,好的工作更难,开始努力自学,从零学编程,期间经历了很多的痛苦,到大三找到了实习直到大四拿到第一家公司的offer。
从结果来看貌似很顺利,但是整个过程里面包括我的大学班主任,我的父母都会有一种不认同的状态,他们觉得大四再找工作不行么?为啥要翘课实习?但是他们不知道的是,如果你的目标是一线互联网公司如BAT(那时候TMD还没起来)这些都是大三就开始实习生招聘(春招),还有大三下的校招(秋招),真的等到大四黄花菜都凉了。所以这其中就有一个很大的问题,那就是现在的学校里面的老师和老一辈的父母对现如今真正的社会状态,里面公司的整个节奏,人才需求指标等等都是存在信息差的。
而这个信息差我觉得是从高中就开始了,我相信99%的高中老师高考之前都说过,“你们高考完就自由啦!大学随便玩啦!”就这样我们的前18年都是在为了上大学拼命,等你拼了命上了一个不错的大学,还真就会有人觉得“啊!解放了!”还真的就放飞自我了,而同时大学的环境你们懂得,老师其实也不怎么管你,你们自己学对不对。而就从前18年的认知即“上了大学就人生圆满”加上后面4年的学校的无为而治,导致没有人真正的告诉过学生,现在的社会真的需要什么样的人才(我目前只说互联网公司)。
大学四年下来我觉得真的蛮遗憾的,老师们只教课,却没有教我们怎么做人,人格教育真是现今高校缺失的很大一部分。其实大学才是人生的开始,因为前18年我说实话我自认为当时的我心智真的不成熟,不利于太早接触社会,而大学真的是一个完美的过渡场,而谁能渡过真的不是985、211的人就比普通学校的人容易,反而又是拉平了一个起跑线的机会。
为什么呢?其实学历固然重要,但是学历真的只是你前18年的成果,即第一块敲门砖。第二块是什么?是你后面四年的成长和收获。
如果一个公司只看第一块敲门砖,绝对不能长久。18岁的时候考不上清华就不能成功么?马老师就不是清华的对吧,当然这不是绝对的!清华有清华的好处毋庸置疑(但是你要明白我想阐述的重点在哪里)。我们不能左右其他公司的选择,至少阿里在我看来对于应届生第二块敲门砖格外重要,以开发为例(毕竟我就是一员)至少我看到的清北交复各种学生肯定少不了吧,第二块敲门砖(技术能力,在学校期间产出)不行,一样也是gg。而同样一个技术产出还不错的同学但是只是二本,一样发出了offer。所以不是说学历不重要,只不过在这背后的能力也同样关键。这就很好的可以诠释为啥我觉得有些同学蛮可惜的,前18年打了一手好牌,名校毕业但是在校期间放飞自我没有产出那除非你是富二代不需要打工,在打工的里面至少刚毕业这一遭你还真就没有那个二本但是后续发力的同学来的起点高了一些,而这一切的一切都是在我们自己手上,这四年时间完全是我们可以自己把控的。只不过是被我诟病很久的高校的人格教育缺失问题导致其实每个人都可以在大一入学的第一天就认识到这个社会的不友好,你非不见棺材不落泪,那就只能后续的时间慢慢再追赶了!不是说回头是岸么,只是早一天明白,早一天可以快跑而已。
所以这么看下来我也是幸运的,我及时在大二遏制了放飞自我的自己然后疯狂的补习,一路狂奔。即便到了今天我都遗憾大一为什么没有好好珍惜,一年时间很短但也真的宝贵。
其实这个意思很好理解,从第一家公司入职了阿里(阿里是世界级的这个应该没有争议吧,我价值观贼正)。那为什么这个叫蜕变呢?其实到过阿里工作包括BT的人员其实很多的,有这样一份工作经历其实算不上蜕变,但是与我而言我认为是我极大的缩短了从一名普通开发跻身阿里的一个时间。从毕业后到拿到offer(p6)前后也只有半年左右,了解的人都知道如果是校招进入阿里到晋升最快是1年,由于晋升期和毕业季有重合迟则是会导致普遍是2年晋升,这还不算社招进来的难度等等。所以说与我而言的蜕变是我小步快跑给自己省了1年多的时间,而也就是这段经历,包括在这期间我所付出的努力,在我当时那个层面上来说真的是强行脱离舒适区,逼迫自己,给自己施压,确保自己“拔苗助长”,关于为什么要强行脱离舒适区,让自己蜕变背后的原因有很多,有兴趣可以参考文章一开始的那篇随笔。但我想说的是,进阿里前后,带给我的认知冲击简直天壤之别。这次脱离舒适区一定是前20多年浓墨重彩的一笔。
来阿里我是以前端title进来的,前半年一直跟一个项目直到项目gg。在这期间我其实一边熟悉集团整个技术体系、业务的架构同时每天也在反思,我发现单纯做前端我会很慌。为什么?因为我看不到技术层面的“全貌”。
我所在的部门是营销平台,里面有非常核心的商家招商体系,选品体系,搭建与投放体系。这些全部都是经历了多次双11,还有各种S级大促之后沉淀的产物,里面都有非常繁复的逻辑和业务背景在里面。里面的很多思考包括知识如果你没有真正的对接,只是和自己的服务端对接,知道一个大概的逻辑我当时认为我是无法独立owner一个业务的(事实证明是的),因为说实话业务的本质在于后端,前端相比较来说还是UI层面的强大能力这个无可厚非,但是当你深入到一个业务,你要和产品、运营去共创的时候你至少要知道你能做什么,和你做不到什么。哪些是你的业务范围哪些是别人的业务边界,应该找谁来对接这个事情,这些都是需要后端能力来补足的。
因为阿里主打是做业务中台,沉淀通用化的能力,这些能力的边界,适用范围其实至少你要有过实战经验,才能真的说的清道的明。也正是基于这个原因包括我自己本身也对服务端有憧憬,所以后面陆陆续续转型做了服务端开发。
而那段期间为什么也叫蜕变呢,很简单我本身就不是CS出身,已经是半路出家了,现在又要再次从零开始,而且这个从零还不是以学生身份。白天还是要正常工作,我只有到了晚上再去自己补习,一路狂补。那段日子每天到两点是肯定的,不过也正是又一次把自己逼出了舒适区,让自己至少从业务产品的角度看到一个技术方案脑子里是有一个清晰全貌的。当然这个全貌不是整个电商线全链路,交易详情下单那些仍不是我的业务范畴。不过我相信哪天我去做交易了,我想看全貌的心不会变,不管是难上几倍,不然我会慌哈哈。
而其实当我在自己的产品上有了技术全貌的认知,我发现我还是很慌?那么这个时候为什么会慌呢?从我的措辞就能看出来了其实,我在描述的时候说的是“技术全貌”。但其实我在18年S1答辩的时候我很清晰的记得我跟老板说,我想转服务端,因为我想看“产品全貌”,我觉得只有前端、服务端整个技术体系都了解之后,我就知道产品全貌了。
然而当我真的做了服务端,把一个产品摸清楚了之后,我发现技术也只是一部分。因为一个产品从诞生到后面的迭代,少不了产品同学的顶层设计,运营同学的各种输出包括但不限于流量来源对接,玩法,权益,货品等等,最终才是产品的落地和迭代需要的技术手段。所以我慌了因为我只是帮产品运营“实现”了各种各样的功能,但是这些功能对于这个产品的作用是什么?为什么要怎么做?仍然是不清楚的。所以我慌了,这就是为啥我现在只说我只看到了“技术全貌”,其实离真正的产品全貌还差了很多。
但也正是明白了这部分认知缺失之后,我才明白为什么老板一直要求我们要有业务感觉,要紧贴业务。因为说白了我们不管是开发、产品还是运营于公司而言都是带着不同技能的人,我们这些人是不能直接给公司创造价值的,只有我们运用各自的技能,最终落地了一个产品,帮助公司赚钱,那才是价值。
所以这也正是为什么一直都要强调,“不要当资源“,为啥不要当资源,因为资源是别人用你帮他创造了公司价值,公司会对他的所作所为认可而不认可你。或者说如果我们不是资源,开发的同学在这个产品落地迭代的过程中通过自己的业务感觉运用自己的能力更好的创造了最终的产品价值,给公司带来更大的收益,那么你就3.75了,明年你晋升对不对。
故反过来看在来阿里之前,包括作为学生的时候那个时候我其实很喜欢钻研代码,这个没毛病,但是你的代码到底是奇技淫巧,还是能给公司创造价值这个就不好说了,因为码农没有什么高级的,产品也没什么高级的,最终都是为公司带来价值才高级。
早期的我过早的给自己设定了边界,比如啊五年后我要当架构师,其实我当时都不知道架构师是做啥的。比如我也为自己35岁还是程序员而焦虑过,老了写不动代码了咋办,等等。然而这些都找错了方向。
我该焦虑的是应该我怎么为一个公司即便以后我自己是老板给自己打工,那也是为自己的团队持续创造价值。只有在社会里作为社会人给社会持续创造价值,才是个人价值。如果能做到那么其实也就没有35岁焦虑了。
虽然我今年24(还没过25生日)还没有体会过中年危机,处于隐形贫困人口挣得不少月月光的那种,但是我相信存在中年危机的人一定是不能创造35岁该有价值的人。我不管是开发还是产品还是各个行业,一定都一样。为什么大家要年轻人?还不是你工资高,产出性价比不够么。用你的工资堆两个年轻人,当资源,老板来指挥肯定能发挥更大的功效。
所以这次的蜕变对于我而言我认为是**层面的蜕变,我现在不慌了,我觉得我的未来大有可为,开发?产品?运营?都只是过程指标,我只需要找到持续创造价值的方式就好了。
至少我是那种,不能停下脚步的人
最后的最后,说了这么多,我的成长都是我的团队带给我的!所以过来总没错!
坐标:杭州
团队:淘系技术部-营销平台
服务端、客户端社招校招都可以!
内推请发我邮箱:[email protected]
本次记录一段突然令我困惑的css代码。主要是由于css一直掌握的不好同时突然出现了一种很常见的浮动情况但是并不能用已有的认知来解释,故从规范中寻找答案。
欢迎关注我的博客,不定期更新中——
The float CSS property specifies that an element should be placed along the left or right side of its container, allowing text and inline elements to wrap around it. The element is removed from the normal flow of the web page, though still remaining a part of the flow (in contrast to absolute positioning).
看完这段话我其实还是有困惑的。主要的困惑是“部分流动性”怎么讲?不是已经脱离文档流了么?按照之前我对float的理解,我认为一般浮动是两种情况:
<div class="red left"></div>
<div class="green"></div>
<div class="red left"></div>
<div class="green">As much mud in the streets as if the waters had but newly retired from the face of the earth, and it would not be wonderful to meet a Megalosaurus, forty feet long or so, waddling like an elephantine lizard up Holborn Hill.</div>
</body>
这就是我之前对于关于浮动定义出的特性所理解的关于“脱离文档流”以及“文字环绕”的理解。至于“保持部分流动性”这种东西我以为离我很远我也就没有在意。直到。。
<div class="left"></div>
<div class="center">
some content fits or there are no more floats present.
</div>

这是一段很平常的代码。。浮动元素脱离文档流,下面的元素不认识它了就顶替了它的位置,同时文字可以识别,故有了环绕效果。
当我把这两个元素倒置了一下之后。。
<div class="center">
some content fits or there are no more floats present.
</div>
<div class="left"></div>

我一直的理解都是,浮动元素脱离了文档流!但是为什么现在没有出现在顶点呢?而这也正是我之前对于MDN解读中遗漏的一小部分导致的。(其实我认为是MDN没说清楚。。那么写愚钝的我并没不能反应过来是什么意思。)
though still remaining a part of the flow (in contrast to absolute positioning).
其实文档中已经说的很明确了。我遗漏了浮动的部分流动性。而这部分流动性到底是什么?来看下我找了“很久”的规范怎么说:

规范中对于浮动的定义比MDN多了些什么?顺序!来看下规范里提到浮动元素如何定位:
我遗漏的关键点就在于:部分流动性指浮动元素会先按照正常流进行布局。
从而可以知道之前下图这样的结果是为什么了。
因为浮动元素是先根据normal flow进行布局,再脱离文档流。脱离之后只能向左或者向右了。确实那个时候上面的元素不认识浮动元素了,但是浮动元素已经定位过了,只能左右动。
至此我们就可以知道,浮动元素确实脱离了文档流,但其和绝对定位不同的地方在于的部分流动性指的是,它会先根绝正常文档流进行布局。之后再脱离文档流,自由翱翔。不像绝对定位,你文档流爱谁谁,我只关心上级的relative/absolute在哪里:)
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次分享一下通过广度优先搜索解决八数码问题并展示其最短路径的动画效果。
欢迎关注我的博客,不定期更新中——
该效果为从[[2, 6, 3],[4, 8, 0],[7, 1, 5]] ==> [[[1, 2, 3],[4, 5, 6],[7, 8, 0]]]的效果展示

配置方式如下:
var option = {
startNode: [
[2, 6, 3],
[4, 8, 0],
[7, 1, 5]
],
endNode: [
[1, 2, 3],
[4, 5, 6],
[7, 8, 0]
],
animateTime: '300' //每次交换数字所需要的动画时间
}
var eightPuzzles = new EightPuzzles(option)
百度一下可以百度出来很多介绍,在此简单说明一下八数码问题所要解决的东西是什么,即将一幅图分成3*3的格子其中八个是图一个空白,俗称拼图游戏=。=,我们需要求解的就是从一个散乱的状态到恢复原状最少需要多少步,以及每步怎么走。
我们可以抽象为现有数字0-8在九宫格中,0可以和其他数字交换。同时有一个开始状态和结束状态,现在需要求解出从初始到结束所需要的步数与过程。
网上有很多算法可以解决八数码问题,本次我们采用最容易理解也是最简单的广度优先搜索(BFS),虽然是无序搜索并且浪费效率,不过我们还是先解决问题要紧,优化的方式大家可以接着百(谷)度(歌)一下。比如A*之类的,因为作者也不太会(逃。

现在我们已知广搜的相关概念,那么如何结合到八数码问题中呢?
当你明白了**之后,我们将其转化为代码思路既可以表示为如下步骤:
看起来一切都很美好是不是?但是我们仍然忽略了一个问题,很关键。
如果真的像拼图一样,从一个已知状态打散到另一个状态,那么肯定是可以复原的。但是我们现在的配置策略是任意的,从而我们需要判断起始状态是否可以达到结束状态。判断方式是通过起始状态和结束状态的逆序数是否同奇偶来判断。
逆序数:在一个排列中,如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数,那么它们就称为一个逆序。一个排列中逆序的总数就称为这个排列的逆序数。一个排列中所有逆序总数叫做这个排列的逆序数。
如果起始状态与结束状态的逆序数的奇偶性相同,则说明状态可达,反之亦然。至于为什么,作者尝试通过简单的例子来试图说明并推广到整个结论:
//起始状态为[[1,2,3],[4,5,6],[7,8,0]]
//可以看做字符串123456780
//结束状态为[[1,2,3],[4,5,6],[7,0,8]]
//可以看做字符串123456708
这个变换只需要一步,即0向左与8进行交换。那么对于逆序数而言,0所在的位置是无关紧要的,因为它比谁都小,不会导致位置变化逆序数改变。所以0的横向移动不会改变逆序数的奇偶性。
//起始状态为[[1,2,3],[4,5,6],[7,8,0]]
//可以看做字符串123456780
//结束状态为[[1,2,3],[4,5,0],[7,8,6]]
//可以看做字符串123450786
这个变换同样只需要一步,即0向上与6进行交换。我们已知0的位置不会影响逆序数的值。那么现在我们只需要关注6的变化。6从第6位置变为第9位置,导致7与8所在位置之前的逆序数量出现了变化。7、8都比6大,则整体逆序数量会减少2,但是逆序数-2仍然保持了奇偶性。与此同时我们可以知道,当0纵向移动的时候,中间的两个数(当前例子7、8的位置)只会有三种情况。要不都比被交换数大(比如7、8比6大)要不一个大一个小,要不都小。如果一大一小,则逆序数仍会保持不变,因为总量上会是+1-1;都小的话则逆序数会+2,奇偶性同样不受到影响。故我们可以认为,0的横向与纵向移动并不会改变逆序数的奇偶性。从而我们可以在一开始通过两个状态的逆序数的奇偶性来判断是否可达。
EightPuzzles.prototype.isCanMoveToEnd = function(startNode, endNode) {
startNode = startNode.toString().split(',')
endNode = endNode.toString().split(',')
if(this.calParity(startNode) === this.calParity(endNode)) {
return true
} else {
return false
}
}
EightPuzzles.prototype.calParity = function(node) {
var num = 0
console.log(node)
node.forEach(function(item, index) {
for(var i = 0; i < index; i++) {
if(node[i] != 0) {
if (node[i] < item) {
num++
}
}
}
})
if(num % 2) {
return 1
} else {
return 0
}
}
EightPuzzles.prototype.solveEightPuzzles = function() {
if(this.isCanMoveToEnd(this.startNode, this.endNode)) {
var _ = this
this.queue.push(this.startNode)
this.hash[this.startNodeStr] = this.startNode
while(!this.isFind) {
var currentNode = this.queue.shift(),
currentNodeStr = currentNode.toString().split(',').join('') //二维数组变为字符串
if(_.endNodeStr === currentNodeStr) { //找到结束状态
var path = []; // 用于保存路径
var pathLength = 0
var resultPath = []
for (var v = _.endNodeStr; v != _.startNodeStr; v = _.prevVertx[v]) {
path.push(_.hash[v]) // 顶点添加进路径
}
path.push(_.hash[_.startNodeStr])
pathLength = path.length
for(var i = 0; i < pathLength; i++) {
resultPath.push(path.pop())
}
setTimeout(function(){
_.showDomMove(resultPath)
}, 500)
_.isFind = true
return
}
result = this.getChildNodes(currentNode) //获得节点子节点
result.forEach(function (item, i) {
var itemStr = item.toString().split(',').join('')
if (!_.hash[itemStr]) { //判断是否已存在该节点
_.queue.push(item)
_.hash[itemStr] = item
_.prevVertx[itemStr] = currentNodeStr //记录节点的父节点
}
})
}
} else {
console.log('无法进行变换得到结果')
}
}
EightPuzzles.prototype.calDom = function(node) { //根据当前状态渲染各数字位置
node.forEach(function(item, index) {
item.forEach(function(obj, i) {
$('#' + obj).css({left: i * (100+2), top: index* (100 + 2)})
})
})
}
EightPuzzles.prototype.showDomMove = function(path) {
var _ = this
path.forEach(function(item, index) { //每次状态改变调用一次渲染函数
setTimeout(function(node) {
this.calDom(node)
}.bind(_, item), index * _.timer)
})
}
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
这次使用react&redux,来模拟了一个购票app,需要关注的是本次全部数据均为mock实现,不涉及后台。同时其中不会涉及react与redux的语法,只关注到一些模拟原生效果的实现理念。没有接触过react的童鞋们可以关注下阮一峰老师的react入门教程,至于redux,redux中文文档上面也有着详细的说明。不过作者对redux也很感兴趣,打算学习一波源码后(如果整个明白了),可能也会出一个分享,届时欢迎前来交流~ #github地址,捂脸求star
本应用全部运行在开发模式下,开启了devserver,没有进行过生产环境测试,如果出现问题大家可以留言~
git clone https://github.com/Aaaaaaaty/react_movie
cd react_movie
cnpm i || npm i
将./data及./src/images 文件 拷贝进dist //项目依赖的图片及假数据
npm start
本次分享的重点是一个基于react的选座组件demo。作者在开发这个组件的时候有观察过微信和支付宝内嵌的影院选座功能。但是无奈看不到代码,一切纯平臆想,说错勿喷。个人感觉微信里面外包的微票儿内的选座模块里面的手势功能为原生浏览器自带的缩放,那么控制上会相对粗暴,缩放上面相对没有支付宝精细。而支付宝上面不仅缩放手感好同时包含了左上方小窗预览功能,可谓用户体验良好(我不是阿里脑残粉hhhhh,虽然事实如此?),所以作者并没有感觉出来这个是混合开发的组件还是原生的还是什么的。。。好了bb了半天,现在轮到作者自己来实现一个了。
很可惜chrome的模拟器下无法演示手势的操作。其实这里面实现了缩放功能,以及在选座界面放大的时候左侧上方的预览图中的红色标示线则会相应的缩小来指出你选中的范围在整个影院中的位置。这次作者使用了react来书写这个组件,所有的移动缩放全部通过js计算,在真机测试中页面会有些许卡顿。不过作者相信如果进行防抖和节流的优化,在手机浏览器中的体验应该可以更优秀一些。
// ./dist/data/filmSeat.json
{
"seatId":"0000002-1-1",
"rowId": 1, //行index
"columnId": 1, //列index
"xAxis":3, //行绝对定位
"yAxis":1, //列绝对定位
...
"isSold":false //是否卖出(用于渲染座位颜色)
}
在这里需要注意的是:行和列的index值与其绝对定位的区别。我们在电影院中座位摆放的地理位置是千奇百怪的,但是索引序号一定是从1到X。从而就有了如上的四个属性。在渲染座位布局的时候一定是采用xAxis & yAxis 才能达到展示影厅座位排布的效果。如果还有点懵请看上图的演示中的座位的排布。
在这里我们先假设要渲染一个占设备视口80%宽的区域来摆放我们的座椅。那么由此就会有一个问题就是我们不确定座椅的数量。故座椅的宽是不能定死的(方便起见,让座椅为正方形,宽高相等),即宽度应为 视口宽*80% / 座椅数量。
当然如果座椅太少那么就会导致宽太大这种情况这些极端条件如果有兴趣可以后期再进行判断
// ./src/Components/FilmSeat/FilmSeat.js
let list = seatList.map((item, index) => {
let style = {
position: 'absolute',
left: `${seatWidth * item.xAxis + seatWidth / 2 }rem`,
top: `${seatWidth * item.yAxis}rem`, // 根据数据中的绝对定位来动态渲染座位位置
width: `${seatWidth}rem`
}
return (
<img key={ 'seatId' + index }
style={ style }
src={ `.\/images\/${isSoldUrl[index]}.png` }
onTouchTap={ this.changeSeat.bind(this, isSoldUrl, index, item) }
className={ styles.seatItem }></img> // 每个座位都是一张小图
)
})
// ./src/Components/FilmSeat/FilmSeat.js
<div ...
onTouchStart={ this.onTouchStart.bind(this) }
onTouchMove={ this.onTouchMove.bind(this) }
onTouchEnd={ this.onTouchEnd.bind(this) }>
对于手势操作,采用了浏览器的三个原生触摸事件。下面主要说明如何使用react实现一个原生的拖拽效果:
// ./src/Components/FilmSeat/FilmSeat.js
onTouchStart(e) { //三个事件均会传入event事件
e.preventDefault()
let { left, top... } = this.state
...
if(e.touches.length === 1) { //判断是否为一个手指触摸
let startX = e.touches[0].clientX //得到起始横坐标
let startY = e.touches[0].clientY //得到起始纵坐标
state = {
startX: startX,
startY: startY,
lastDisX: left, //记录上一次横轴偏移量
lastDisY: top, //记录上一次纵轴偏移量
...
}
}
...
this.setState(state)
}
onTouchMove(e) {
e.preventDefault()
let { startX, startY ... } = this.state
if(e.touches.length === 1) {
let moveX = e.touches[0].clientX //记录当前的位置
let moveY = e.touches[0].clientY
let disX = moveX - startX + lastDisX //记录现在手指相对屏幕左侧距离
let disY = moveY - startY + lastDisY
...
this.setState({
moveX: moveX,
moveY: moveY,
left: disX,
top: disY,
})
} else if(e.touches.length === 2) {
...
}
}
onTouchEnd(e) {
e.preventDefault()
...
//主要做一些拖拽完成之后的判断,重置初始值等等
}
总结来说核心思路是, e.touches[0].clientX/Y可以提供手指在屏幕中的绝对距离,我们滑动中可以记录到滑动了的相对距离。那么在下次滑动前就需要记录下上一次的相对距离,下次滑动时就要加上上次的距离。不然每次重新拖拽就会从0,0点重新开始。
通过效果图我们可以知道,在组件中同时需要渲染座位的选取,下方弹出/关闭座位信息等效果。虽然效果多样但是基本可以看为两个状态即座位是否选中,这就使用到了redux来作为状态管理。通过redux来抽象出公共状态,让不同的效果渲染都基于同一个状态,从而达到效果联动。
// ./src/Container/FilmChooseSeat.js
changeSeatConf(item, isSoldUrl, type) {
const { changeFilmBuySeatList } = this.props // 拿到store中传出来的方法
let data = {
item: item, //座位信息
isSoldUrl: isSoldUrl, //所有座位颜色列表
type: type
}
changeFilmBuySeatList(data)
}
render() {
let { filmSeatList, filmBuyList, location } = this.props
...
return (
<div>
<FilmSeatTitle location={ location }/>
<FilmSeat filmSeatList={ filmSeatList } //选座拖拽区域
filmBuyList={ filmBuyList }
animationTime={ 200 }
changeSeatConf={ this.changeSeatConf.bind(this) }/>
//通过这个函数将组件中事件传递到container中,
//由container发起action来进行改变state
<FilmSeatSale filmBuyList= { filmBuyList } //选座信息
filmSeatList={ filmSeatList }
changeSeatConf={ this.changeSeatConf.bind(this) }/>
</div>
)
}
// ./src/Redux/Store/Store.js
export const mapStateToProps =(state)=> {
return {
...
filmSeatList:state.filmChooseSeatReducer.filmSeatList,//电影座位列表
filmBuyList:state.filmChooseSeatReducer.filmBuyList,//电影选座列表
}
}
export const mapDispatchToProps=(dispatch)=> {
return {
...
getFilmSeatList:(url,data)=>dispatch(FilmChooseSeatActions.fetchFilmSeatList(url,data)),//获取电影座位列表
changeFilmBuySeatList:(data)=>dispatch(FilmChooseSeatActions.changeFilmBuySeatList(data))//选中座位购票
}
}
发起action后,在reducer中改变维护的filmBuyList 数组状态,就可以同时渲染好整个界面的变化。
// ./src/Redux/Reducer/FilmChooseSeatReducer.js
export const filmBuyList = (state = {item:[],isSoldUrl:{},type:''}, action={})=>{
switch(action.type){
case FilmChooseSeatActions.CHANGE_FILM_BUYSEAT:
let _state = Object.assign({}, state)
if(action.text.type === 'add') {
_state.item.push(action.text.item)
} else {
let index = _state.item.indexOf(action.text.item)
_state.item.splice(index, 1)
}
_state.isSoldUrl = action.text.isSoldUrl
_state.type = action.text.type
return _state
default:
return state
}
}
当完成了大图的渲染以及选座状态切换的工作之后,只需要复制一份大图的渲染的那段jsx修改css样式就可以完成一个预览小图。在这期间你不需要做任何事就可以看到小图上面同样会存在选座状态的切换,这就是状态管理的好处。只要你的界面效果和状态进行了绑定,那么在之后的工作中你就不需要再去关注效果而只需要关注状态是否正确即可。在这其中唯一有一点问题的地方是预览图中红色提示框的缩放和大图的缩放是成反比的。大图放大预览图中的红色框应该缩小,同时大图可拖拽的范围应该和红框的移动范围有一个比例系数。在这次的实现中作者用了 scaleNum这个状态来控制其缩放的系数,有兴趣的童鞋可以自己尝试一下如何计算一个正确的系数来保证大图和预览图缩放后红框移动距离和大图拖拽范围的匹配。
本次分享一下我学习到的有关依赖注入的梳理与总结。试图生动形象得解释出来其内部的**与实现流程。
欢迎关注我的博客,不定期更新中——
第一次听到这个说法是在angular的时候,我们都知道angular内部大量使用了依赖注入。虽然我到现在也没玩过:),不过这并不影响我们来探究一下它。
首先试图形象的说明一下(个人观点、有问题欢迎指正):有那么一群人,这群人的职业是程序员。他们除了工作不想费力气去做别的事。除了上班剩下的只有买吃的和买格子衫。具体吃什么和格子衫什么样子他们并不关心。那么也许我们可以提供一个公共服务,来专门为程序员提供吃的和格子衫。程序员不需要关心我们怎么做吃的和去哪里买格子衫,他们只需要告诉我们他们需要就可以了,买好之后我们自然会给他们送到。这样就可以避免每个程序员还要花费心思独自的去吃东西和买格子衫,省去了大把时间就可以更好的投入到工作中了。
刚刚那段说法可以抽象为下面这张简易示意图:

按照上面图的流程中我们可以知道我们需要实现这么几件事:
//假装提供一些服务
var services = {
A: () => {console.log(1)},
B: () => {console.log(2)},
C: () => {console.log(3)}
}
// 目标函数
function Service(A, B) {
A()
B()
}
目前的注册方式采用在形参的方式来传递,我们不需要关心A、B是怎么实现的,我们只需要知道这些代表着吃的和格子衫就可以了:)
// 获取func的参数列表(依赖列表)
getFuncParams = function (func) {
var matches = func.toString().match(/^function\s*[^\(]*\(\s*([^\)]*)\)/m);
if (matches && matches.length > 1)
return matches[1].replace(/\s+/, '').split(',');
return [];
}
实现原理为将传入的目标函数进行正则匹配,匹配出形参。这其中的关键点在于这段正则表达式:
/^function\s*[^\(]*\(\s*([^\)]*)\)/m
其中\(\s*([^\)]*
通过括号来提取匹配到function后面参数括号的内部内容,也就是可以得到参数字符串。这里面是运用了括号的提取数据的规则来获取的信息,规则如下:
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
console.log( string.match(regex) );
// => ["2017-06-12", "2017", "06", "12", index: 0, input: "2017-06-12"]
结果数组中第一个元素为匹配结果,之后为括号内的数据,由此我们便可知道,这段正则通过括号的使用,获取到了整个形参作为一个字符串,之后再通过split进行拆分就得到了我们想要的结果。
//简易实现
setFuncParams = function (params) {
for (var i in params) {
params[i] = services[params[i]];
}
return params;
}; //依次对应服务中的项进行查找返回结果。
// 注射器
function Activitor(func, scope) {
return () => {
func.apply(scope || {}, setFuncParams(getFuncParams(func)));
}
}
// 实例化Service并调用方法
var service = Activitor(Service);
service();//1 2
至此我们便完整地实现了一个很简单的依赖注入的模式,源码在这里。非常简单,同时也没有做很多的判断。不过核心的思路还是梳理了出来。自己闷头琢磨了半天,有不对的地方欢迎斧正~ PS:下面的几篇参考资料写的都很好,其中颜海镜老师的JavaScript里的依赖注入很有深意,拜读了很久,也分享给大家。
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
想问下阿里实习只要全a么如果三次面试两次a一个b➕会要么

我看到你那边绘制得到的是[X,Y] 但是物体移动好像只有一个数据
本次分享一下通过实现kmp算法的动画效果来试图展示kmp的基本思路。
欢迎关注我的博客,不定期更新中——
字符串匹配是计算机科学中最古老、研究最广泛的问题之一。一个字符串是一个定义在有限字母表∑上的字符序列。例如,ATCTAGAGA是字母表∑ = {A,C,G,T}上的一个字符串。字符串匹配问题就是在一个大的字符串T中搜索某个字符串P的所有出现位置。
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息。时间复杂度O(m+n)。
在js中字符串匹配我们通常使用的是原生api,indexOf;其本身是c++实现的不在这次的讨论范围中。本次主要通过动画演示的方式展现朴素算法与kmp算法对比过程的异同从而试图理解kmp的基本思路。
PS:在之后的叙述中BBC ABCDAB ABCDABCDABDE为主串;ABCDABD为模式串

演示地址
上方为朴素算法即按位比较,下方为kmp算法实现的字符串比较方式。kmp可以通过较少的比较次数完成匹配。
从上图的效果预览中可以看出使用朴素算法依次比较模式串需要移位13次,而使用kmp需要8次,故可以说kmp的思路是通过避免无效的移位,来快速移动到指定的地点。接下来我们关注一下kmp是如何“跳着”移动的:

与朴素算法一致,在之前对于主串“BBC ”的匹配中模式串ABCBABD的第一个字符均与之不同故向后移位到现在上图所示的位置。主串通过依次与模式串中的字符比较我们可以看出,模式串的前6个字符与主串相同即ABCDAB;而这也就是kmp算法的关键。
我们先从下图来看朴素算法与kmp中下一次移位的过程:

朴素算法雨打不动得向后移了一位。而kmp跳过了主串的BCD三个字符。从而进行了一次避免无意义的移位比较。那么它是怎么知道我这次要跳过三个而不是两个或者不跳呢?关键在于上一次已经匹配的部分ABCDAB
我们已知此时主串与模式串均有此相同的部分ABCDAB。那么如何从这共同部分中获得有用的信息?或者换个角度想一下:我们能跳过部分位置的依据是什么?
第一次匹配失败时的情形如下:
BBC ABCDAB ABCDABCDABDE
ABCDABD
D != 空格 故失败
为了从已匹配部分提取信息。现在将主串做一下变形:
ABCDABXXXXXX... X可能是任何字符
我们现在只知道已匹配的部分,因为匹配已经失败了不会再去读取后面的字符,故用X代替。
那么我们能跳过多少位置的问题就可以由下面的解得知答案:
//ABCDAB向后移动几位可能能匹配上?
ABCDABXXXXXX...
ABCDABD
答案自然是如下移动:
ABCDABXXXXXX...
ABCDABD
因为我们不知道X代表什么,只能从已匹配的串来分析。
故我们能跳过部分位置的依据是什么?
答:已匹配的模式串的前n位能否等于匹配部分的主串的后n位。并且n尽可能大。
举个例子:
//第一次匹配失败时匹配到ABCDDDABC为共同部分
XXXABCDDDABCFXXX
ABCDDDABCE
//寻找模式串的最大前几位与主串匹配到的部分后几位相同,
//可以发现最多是ABC部分相同,故可以略过DDD的匹配因为肯定对不上
XXXABCDDDABCFXXX
ABCDDDABCE
现在kmp的基本思路已经很明显了,其就是通过经失败后得知的已匹配字段,来寻找主串尾部与模式串头部的相同最大匹配,如果有则可以跨过中间的部分,因为所谓“中间”的部分,也是有可能进入主串尾与模式串头的,没进去的原因即是相对位置字符不同,故最终在模式串移位时可以跳过。
上面是用通俗的话来述说我们如何根据已匹配的部分来决定下一次模式串移位的位置,大家应该已经大体知道kmp的思路了。现在来引出官方的说法。
之前叙述的在已匹配部分中查找主串头部与模式串尾部相同的部分的结果我们可以用部分匹配值的说法来形容:
例如ABCDAB
很容易发现部分匹配值为2即AB的长度。从而结合之前的思路可以知道将模式串直接移位到主串AB对应的地方即可,中间的部分一定是不匹配的。移动几位呢?
答:匹配串长度 - 部分匹配值;本次例子中为6-2=4,模式串向右移动四位
function pmtArr(target) {
var pmtArr = []
target = target.split('')
for(var j = 0; j < target.length; j++) {
//获取模式串不同长度下的部分匹配值
var pmt = target
var pmtNum = 0
for (var k = 0; k < j; k++) {
var head = pmt.slice(0, k + 1) //前缀
var foot = pmt.slice(j - k, j + 1) //后缀
if (head.join('') === foot.join('')) {
var num = head.length
if (num > pmtNum) pmtNum = num
}
}
pmtArr.push(j + 1 - pmtNum)
}
return pmtArr
}
function mapKMPStr(base, target) {
var isMatch = []
var pmt = pmtArr(target)
console.time('kmp')
var times = 0
for(var i = 0; i < base.length; i++) {
times++
var tempIndex = 0
for(var j = 0; j < target.length; j++) {
if(i + target.length <= base.length) {
if (target.charAt(j) === base.charAt(i + j)) {
isMatch.push(target.charAt(j))
} else {
if(!j) break //第一个就不匹配直接跳到下一个
var skip = pmt[j - 1]
tempIndex = i + skip - 1
break
}
}
}
var data = {
index: i,
matchArr: isMatch
}
callerKmp.push(data)
if(tempIndex) i = tempIndex
if(isMatch.length === target.length) {
console.timeEnd('kmp')
console.log('移位次数:', times)
return i
}
isMatch = []
}
console.timeEnd('kmp')
return -1
有了思路后整体实现并不复杂,只需要先通过模式串计算各长度的部分匹配值,在之后的与主串的匹配过程中,每失败一次后如果有部分匹配值存在,我们就可以通过部分匹配值查找到下一次应该移位的位置,省去不必要的步骤。
所以在某些极端情况下,比如需要搜索的词如果内部完全没有重复,算法就会退化成遍历,性能可能还不如传统算法,里面还涉及了比较的开销。
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次试图浅析探索Nodejs的Stream模块中对于Readable类的一部分实现(可写流也差不多)。其中会以可读流两种模式中的paused mode即暂停模式的表现形式来解读源码上的实现,为什么不分析flowing mode自然是因为这个模式是我们常用的其原理相比暂停模式下相对简单(其实是因为笔者总是喜欢关注一些边边角角的东西,不按套路出牌=。=),同时核心方法都是一样的,一通百通嘛,有兴趣的童鞋可以自己看下完整源码。
欢迎关注我的博客,不定期更新中——
首先先明确为什么Nodejs要实现一个stream,这就要清楚关于生产者消费者问题的概念。
生产者消费者问题(英语:Producer-consumer problem),也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了共享固定大小缓冲区的两个线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
简单来说就是内存问题。与前端不同,后端对于内存还是相当敏感的,比如读取文件这种操作,如果文件很小就算了,但如果这个文件一个g呢?难道全读出来?这肯定是不可取的。通过流的形式读一部分写一部分慢慢处理才是一个可取的方式。PS:有关为什么使用stream欢迎大家百(谷)度(歌)一下。
现在我们将自己实现一个可读流,以此来方便观察之后数据的流动过程:
const Readable = require('stream').Readable;
// 实现一个可读流
class SubReadable extends Readable {
constructor(dataSource, options) {
super(options);
this.dataSource = dataSource;
}
// 文档提出必须通过_read方法调用push来实现对底层数据的读取
_read() {
console.log('阈值规定大小:', arguments['0'] + ' bytes')
const data = this.dataSource.makeData()
let result = this.push(data)
if(data) console.log('添加数据大小:', data.toString().length + ' bytes')
console.log('已缓存数据大小: ', subReadable._readableState.length + ' bytes')
console.log('超过阈值限制或数据推送完毕:', !result)
console.log('====================================')
}
}
// 模拟资源池
const dataSource = {
data: new Array(1000000).fill('1'),
// 每次读取时推送一定量数据
makeData() {
if (!dataSource.data.length) return null;
return dataSource.data.splice(dataSource.data.length - 5000).reduce((a,b) => a + '' + b)
}
//每次向缓存推5000字节数据
};
const subReadable = new SubReadable(dataSource);
至此subReadable便是我们实现的自定义可读流。
先来看下整体的流程:
可读流会通过_read()方式从资源读取数据到缓存池,同时设置了一个阈值highWaterMark,标记数据到缓存池大小的一个上限,这个阈值是会浮动的,最小值也是默认值为16384。当消费者监听了readable事件之后,就可以显式调用read()方法来读取数据。
通过注册readable事件以此来触发暂停模式:
subReadable.on('readable', () => {
console.log('缓存剩余数据大小: ', subReadable._readableState.length + ' byte')
console.log('------------------------------------')
})
可以发现当注册readable事件后可对流会从底层资源推送数据到缓存直到达到超过阈值或者底层数据全部加载完。
调用read(n); n = 1000;
首先修改资源池大小data: new Array(10000).fill('1')(方便打印数据),执行read(1000)每次读取1000字节资源读取资源:
subReadable.on('readable', () => {
let chunk = subReadable.read(1000)
if(chunk)
console.log(`读取 ${chunk.length} bytes数据`);
console.log('缓存剩余数据大小: ', subReadable._readableState.length + ' byte')
console.log('------------------------------------')
})
结果执行了两次读取数据,同时如果每次读取的字节少于缓存中的数据,则可读流不会再从资源加载新的数据。
无参调用read()
subReadable.on('readable', () => {
let chunk = subReadable.read()
if(chunk)
console.log(`读取 ${chunk.length} bytes数据`);
console.log('缓存剩余数据大小: ', subReadable._readableState.length + ' byte')
console.log('------------------------------------')
})

直接调用read()后,会逐步读取完全部资源,至于每次读取多少下文会统一探讨。
以上我们依次尝试了在实现可读流后触发暂停模式会发生的事情,接下来作者将会对以下几个可能有疑问的点进行探究:
_read()方法并在其中调用push()read()与传入固定数据的区别_read()方法并在其中调用push()Readable.prototype._read = function(n) {
this.emit('error', new errors.Error('ERR_STREAM_READ_NOT_IMPLEMENTED'));
}; //只是定义接口
Readable.prototype.read = function(n) {
...
var doRead = state.needReadable;
if (doRead) {
this._read(state.highWaterMark);
}
}
当我们调用subReadable.read()便会执行到上面的代码,可以发现,源码中
对于_read()只是定义了一个接口,里面并没有具体实现,如果我们不自己定义那么就会报错。同时read()中会执行它通过它调用push()来从资源中读取数据,并且传入highWaterMark,这个值你可以用也可以不用因为_read()是我们自己实现的。
Readable.prototype.push = function(chunk, encoding) {
...
return readableAddChunk(this, chunk, encoding, false, skipChunkCheck);
};
从代码中可以看出,将底层资源推送到缓存中的核心操作是通过push,通过语义化也可以看出push方法中最后会进行添加新数据的操作。由于之后方法中嵌套很多,不一一展示,直接来看最后调用的方法:
// readableAddChunk最后会调用addChunk
function addChunk(stream, state, chunk, addToFront) {
...
state.buffer.push(chunk); //数据推送到buffer中
if (state.needReadable)//判断此属性值来看是否触发readable事件
emitReadable(stream);
maybeReadMore(stream, state);//可能会推送更多数据到缓存
}
我们可以看出,方法调用的最后确实执行了资源数据推送到缓存的操作。与此同时在会判断needReadable属性值来看是否触发readable回调事件。而这也为之后我们来分析为什么注册了readable事件之后会执行一次回调埋下了伏笔。最后调用maybeReadMore()则是蓄满缓存池的方法。
先来看下源码里是如何绑定的事件:
Readable.prototype.on = function(ev, fn) {
if (ev === 'data') {
...
} else if (ev === 'readable') {
const state = this._readableState;
state.needReadable = true;//设定属性为true,触发readable回调
...
process.nextTick(nReadingNextTick, this);
}
};
function nReadingNextTick(self) {
self.read(0);
}
//之后执行read(0) => _read() => push() => addChunk()
// => maybeReadMore()
maybeReadMore()中当缓存池存储大小小于阈值时则会一直调用read(0)不读取数据,但是会一直push底层资源到缓存:
function maybeReadMore_(stream, state) {
...
if (state.length < state.highWaterMark) {
stream.read(0);
}
}
上文提到过,绑定事件后会开始推送数据至缓存池,最后会执行到addChunk()方法,内部通过needReadable属性来判断是否触发readable事件。当你第一次绑定事件时会执行state.needReadable = true;,从而在最后推送数据后会执行触发readable的操作。
read()与传入特定数值的区别区别在执行read()方法的时候,会将参数n传入到下面这个函数中由它来计算现在应该应该读取多少数据:
function howMuchToRead(n, state) {
if (n <= 0 || (state.length === 0 && state.ended))
return 0;
if (state.objectMode)
return 1;
if (n !== n) {
// Only flow one buffer at a time
if (state.flowing && state.length)
return state.buffer.head.data.length;
else
return state.length;
}
// If we're asking for more than the current hwm, then raise the hwm.
if (n > state.highWaterMark)
state.highWaterMark = computeNewHighWaterMark(n);
if (n <= state.length)
return n;
// Don't have enough
if (!state.ended) { //传输没有结束都是false
state.needReadable = true;
return 0;
}
return state.length;
}
当直接调用read(),n参数则为NaN,当处于流动模式的时候n则为buffer头数据的长度,否则是整个缓存的数据长度。若为read(n)传入数字,大于当前的hwm时可以发现会重新计算一个hwm,与此同时如果已缓存的数据小于请求的数据量,那么将设置state.needReadable = true;并返回0;
第一次试图梳理源码的思路,一路写下来发现有很多想说但是又不知道怎么连贯的理清楚=。= 既然代码细节也有些说不清,不过最后还是进行一个核心思路的提炼:
源码的边界情况比较多。作者如果哪里说错了请指正=。=
PS:源码地址
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次分享一个简易路径替换工具。功能很简单,重点在于掌握:
源码地址:https://github.com/Aaaaaaaty/Blog/tree/master/fsPathSys

PS:后端支持匹配js、css、img、background-image的url的对应路径并进行分别替换,当前只是展示方便,前端只传递一个路径将所有匹配的源路径替换为目标路径。
整体来说可能会遇到的难点在于对正则的使用,以及完成替换后将压缩的文件夹传回本地。以前没怎么写过正则正好借此机会来学习一波,同时对于文件夹(注意不是文件传输!)传输踩了一下坑。毕竟大部分时间做静态服务器我们是只需要返回单个文件不需要以一个文件夹的形式来返回到前端。
在nodejs文档中发现原生api貌似只支持gzip的解压缩,故引入了第三方插件unzip来解决。
let inp = fs.createReadStream(path)
let extract = unzip.Extract({ path: targetPath })
inp.pipe(extract)
extract.on('error', () => {
cons('解压出错:' + err);
})
extract.on('close', () => {
cons('解压完成');
})
这个插件有一点坑的地方在于它没有说明如何监听'close'、'error'等事件。还是我去看源码里面发现要通过上面的形式来调用才能成功:)
通过fs模块的stat方法来判断当前路径是文件还是文件夹来决定是否继续遍历。
function fsPathSys(path) { //遍历路径
let stat = fs.statSync(path)
if(stat.isDirectory()) {
fs.readdir(path, isDirectory) //读文件夹
function isDirectory(err, files) {
if(err) {
return err
} else {
files.forEach((item, index) => {
let nowPath = `${path}/${item}`
let stat = fs.statSync(nowPath)
if(!stat.isDirectory()) {
...somthing going on
} else {
fsPathSys(nowPath)
}
})
}
}
}
else {
...
}
}
正则的重点则在于如何匹配到需要的地方,以及替换的顺序也需要有所考量。
本次需要匹配的地方有四个:
由于目标地址前的关键字src、href可能在不同的标签中,同时最初的想法就是有可能不同类型的文件的存放地址是不同的。故采用的匹配原则是先将script、link、img、background提取出来,然后再分别匹配src、href、url关键字。
//body:要替换的文本
let data = [
{
'type': 'script',
'point': targetUrl
},
{
'type': 'link',
'point': targetUrl
},
{
'type': 'img',
'point': targetUrl
},
{
'type': 'background',
'point': targetUrl
}
]
data.forEach((obj, i) => {
if(obj.type === 'script' || obj.type === 'link' || obj.type === 'img') {
let bodyMatch = body.match(new RegExp(`<${obj.type}.*?>`, 'g'))
if(bodyMatch) {
bodyMatch.forEach((item, index) => {
let itemMatch = item.match(/(src|href)\s*=\s*["|'].*?["|']/g)
if(itemMatch) {
itemMatch.forEach((data, i) => {
let matchItem = data.match(/(["|']).*\//g)[0].replace(/\s/g, '').slice(1)
if(!replaceBody[matchItem]) {
replaceBody[matchItem] = obj.point
}
})
}
})
}
} else if(obj.type === 'background') {
let bodyMatch = body.match(/url\(.*?\)/g)
if(bodyMatch) {
bodyMatch.forEach((item, index) => {
let itemMatch = item.match(/\(.*\//g)[0].replace(/\s/g, '').slice(1)
if(!replaceBody[itemMatch]) {
replaceBody[itemMatch] = obj.point
}
})
}
}
})
其中关于正则的使用可以参考这篇文章JS正则表达式完整教程(略长) 真的是非常详细,我就不班门弄斧了。总的来说上面的代码得到了一个对象,replaceBody。这个对象的key是要替换的路径,value是替换后的路径:

细心的童鞋可能会发现,如果现在直接遍历这个对象进行替换是不是就能大功告成了呢?肯定不是的:)因为替换要有先后顺序,不然会有大麻烦。
例如我们将要替换'../css/'以及'./css/',如果我们先替换后者那么之前的'../css/中的'./css/'也会被换掉从而整体替换失败这并不是我们想要的结果。
目前的做法是将对象中的key排序,长的在前,之后再进行替换。这样至少不会出现上面所提到的情况。
Object.keys(replaceBody).sort((a,b) => b.length - a.length) //对对象排序
另外还需要注意一个小点即在替换'.'的时候,由于'.'在正则中表示通配符。那么此时需要先将所有的'.'替换为'.'再进行下面的操作。
考虑到现在要传回前端的是一个文件夹,故要对其进行压缩。采用开启子进程的方式来编写shell命令来压缩文件夹。(node的zlib模块我没找到怎么来压缩文件夹。。有知道的同学欢迎分享)
let dirName = `${filePath}.tar.gz`
exec(`tar -zcvf ${dirName} ${filePath}`, (error, stdout, stderr) => {
if (error) {
cons(`exec error: ${error}`);
return;
}
let out = fs.createReadStream(dirName)
res.writeHead(200, {
'Content-type':'application/octet-stream',
'Content-Disposition': 'attachment; filename=' + dirName.match(/ip_.*/)[0]
})
out.pipe(res)
})
这里的重点是将压缩包用流的形式读取出来如果不在返回头加入'Content-Disposition'字段,返回的文件将是那种类似buffer流的形式,没有了文件夹层级结构等等。。查阅了资料才发现是因为这个头的缘故。
Content-disposition 是 MIME 协议的扩展,MIME 协议指示 MIME 用户代理如何显示附加的文件。
本次实现这个小工具,使作者正则还有文件在后端的压缩解压以及http传输中的细节有了新的认识。源代码在git上欢迎clone~
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次尝试浅析Node.js中的EventEmitter模块的事件机制,分析在Node.js中实现发布订阅模式的一些细节。完整Node.js源码点这里。
欢迎关注我的博客,不定期更新中——
大多数 Node.js 核心 API 都采用惯用的异步事件驱动架构,其中某些类型的对象(触发器)会周期性地触发命名事件来调用函数对象(监听器)。例如,net.Server 对象会在每次有新连接时触发事件;fs.ReadStream 会在文件被打开时触发事件;流对象 会在数据可读时触发事件。所有能触发事件的对象都是 EventEmitter 类的实例。
Node.js中对EventEmitter类的实例的运用可以说是贯穿整个Node.js,相信这一点大家已经是很熟悉的了。其中所运用到的发布订阅模式,则是很经典的管理消息分发的一种方式。在这种模式中,发布消息的一方不需要知道这个消息会给谁,而订阅的一方也无需知道消息的来源。使用方式一般如下:
const EventEmitter = require('events');
class MyEmitter extends EventEmitter {}
const myEmitter = new MyEmitter();
myEmitter.on('event', () => {
console.log('触发了一个事件A!');
});
myEmitter.emit('event');
//触发了一个事件A!
当我们订阅了'event'事件后,可以在任何地方通过emit('event')来执行事件回调,EventEmitter相当于一个中介,负责记录都订阅了哪些事件并且触发后的回调是什么,当事件被触发,就将回调一一执行。
从源码中看下EventEmitter类的是如何实现发布订阅的。
首先我们梳理一下实现这个模式需要的步骤:
在生成空对象的方式中,一般容易想到的是直接进行赋值空对象即 var a = {};,Node.js中采用的方式为var a = Object.create(null),使用这种方式理论上是应该对对象的属性存取的操作更快,出于好奇作者对这两种方式做了个粗略的对比:
var a = {}
a.test = 1
var b = Object.create(null)
b.test = 1
console.time('{}')
for(var i = 0; i < 1000; i++) {
console.log(a.test)
}
console.timeEnd('{}')
console.time('create')
for(var i = 0; i < 1000; i++) {
console.log(b.test)
}
console.timeEnd('create')


打印结果显示出来貌似直接用空对象赋值与通过Object.create的方式并没有很大的性能差异,并且还没有谁一定占了上风,就目前该空对象用来存储注册的监听事件与回调来看,如果直接用{}来初始化this._events性能方面影响也许不大。不过这一点只是个人观点,暂时还并不能领会Node里面如此运用的深意。
EventEmitter.prototype.addListener = function addListener(type, listener) {
return _addListener(this, type, listener, false);
};
EventEmitter.prototype.on = EventEmitter.prototype.addListener;
添加监听者的方法为addListener,同时on是其别名。
if (!existing) {
// Optimize the case of one listener. Don't need the extra array object.
existing = events[type] = listener;
++target._eventsCount;
} else {
if (typeof existing === 'function') {
// Adding the second element, need to change to array.
existing = events[type] =
prepend ? [listener, existing] : [existing, listener];
} else {
// If we've already got an array, just append.
if (prepend) {
existing.unshift(listener);
} else {
existing.push(listener);
}
}
...
}
如果之前不存在监听事件,则会进入第一个判断内,其中type为事件类型,listener为触发的事件回调。如果之前注册过事件,那么回调函数会添加到回调队列的头或尾。看如下打印结果:
myEmitter.on('event', () => {
console.log('触发了一个事件A!');
});
myEmitter.on('event', () => {
console.log('触发了一个事件B!');
});
myEmitter.on('talk', () => {
console.log('触发了一个事件CS!');
// myEmitter.emit('talk');
});
console.log(myEmitter._events)
//{ event: [ [Function], [Function] ], talk: [Function] }
myEmitter实例的_events方法就是我们存储事件与回调的对象,可以看到当我们依次注册事件后,回调会被推到 _events对应key的value中。
在触发的emit函数中,会根据触发时传入参数的多少执行不同的函数:(参数不同直接执行不同的函数,这个操作应该会让性能更好,不过作者没有测试这点)
switch (len) {
// fast cases
case 1:
emitNone(handler, isFn, this);
break;
case 2:
emitOne(handler, isFn, this, arguments[1]);
break;
case 3:
emitTwo(handler, isFn, this, arguments[1], arguments[2]);
break;
case 4:
emitThree(handler, isFn, this, arguments[1], arguments[2], arguments[3]);
break;
// slower
default:
args = new Array(len - 1);
for (i = 1; i < len; i++)
args[i - 1] = arguments[i];
emitMany(handler, isFn, this, args);
}
以emitMany为例看下内部触发实现:
var isFn = typeof handler === 'function';
function emitMany(handler, isFn, self, args) {
if (isFn)
//handler类型为函数,即对这个事件只注册了一个监听函数
handler.apply(self, args);
else {
//当对同一事件注册了多个监听函数的时候,handler类型为数组
var len = handler.length;
var listeners = arrayClone(handler, len);
for (var i = 0; i < len; ++i)
listeners[i].apply(self, args);
}
}
function arrayClone(arr, n) {
var copy = new Array(n);
for (var i = 0; i < n; ++i)
copy[i] = arr[i];
return copy;
}
源码中实现了arrayClone方法,来复制一份同样的监听函数,再去依次执行副本。个人对这个做法的理解是,当触发当前类型事件后,就锁定需要执行的回调函数队列,否则当触发回调过程中,再去推入新的回调函数,或者删除已有回调函数,容易造成不可预知的问题。
如果回调事件只有一个那么直接删除即可,如果是数组就像之前看到的那样注册了多组对同样事件的监听,就要涉及从数组中删除项的实现。在这里Node自己实现了一个spliceOne函数来代替原生的splice,并且说明其方式比splice快1.5倍。下面是作者进行的简易粗略,不严谨的运行时间比较:

上面做了一个很粗略的运算时间比较,同样是对长度为1000的数组第100项进行删除操作,并且代码运行在chrome浏览器下(版本号61.0.3163.100)node源码中自己实现的方法确实比原生的splice快了一些,不过结果只是一个参考毕竟这个对比很粗略,有兴趣的童鞋可以写一组benchmark来进行对比。
源码的边界情况比较多。在这里只做一个相对简单的流程浅析,哪里说明有误欢迎指正~
PS:相关实例源码:https://github.com/Aaaaaaaty/Blog/blob/master/node/event.js
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次分享一下从HTML5与PromiseA+规范来迅速理解一波事件循环中的microtask 与macrotask。
欢迎关注我的博客,不定期更新中——
——何时完结不确定,写多少看我会多少!这是已经更新的地址:
这个系列旨在对一些人们不常用遇到的知识点,以及可能常用到但不曾深入了解的部分做一个重新梳理,虽然可能有些部分看起来没有什么用,因为平时开发真的用不到!但个人认为糟粕也好精华也罢里面全部蕴藏着JS一些偏本质的东西或者说底层规范,如果能适当避开舒适区来看这些小细节,也许对自己也会有些帮助~文章更新在我的博客,欢迎不定期关注。
先来看段代码
setTimeout(function() {
console.log('setTimeout1');
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
})
}, 0);
setTimeout(function() {
console.log('setTimeout2');
Promise.resolve().then(function() {
console.log('promise3');
}).then(function() {
console.log('promise4');
})
}, 0);
从这段代码中我们发现里面有两个定时器setTimeout,每个定时器中还嵌套了Promise。我相信熟悉microtask 与macrotask任务队列的童鞋能很快的知晓答案,这个东西给我的感觉就是清者自清。
/* 请在新版chrome中打印结果
setTimeout1
promise1
promise2
setTimeout2
promise3
promise4
*/
不做解释直接看下规范中怎么说的:
There must be at least one browsing context event loop per user agent, and at most one per unit of related similar-origin browsing contexts. An event loop has one or more task queues.
一个浏览器环境下只能有一个事件循环,同时循环中是可以存在多个任务队列的。
同时我们接着看规范中对event-loop执行过程是如何规定的:
1.Let oldestTask be the oldest task on one of the event loop's task queues.
2.Set the event loop's currently running task to oldestTask.
3.Run oldestTask.
4.Set the event loop's currently running task back to null.
5.Remove oldestTask from its task queue.
6.Microtasks: Perform a microtask checkpoint.
7.Update the rendering
其中的task queues,就是之前提到的macrotask,中文可以翻译为宏任务。顾名思义也就是正常的一些回调执行,比如IO,setTimeout等。简单来说当事件循环开始后,会将task queues最先进栈的任务执行,之后移出,进行到第六步,做microtask的检测。发现有microtask的任务那么会依照如下方式执行:
While the event loop's microtask queue is not empty:
//当microtask队列中还有任务时,按照下面执行
1.Let oldestMicrotask be the oldest microtask on the event loop's microtask queue.
2.Set the event loop's currently running task to oldestMicrotask.
3.Run oldestMicrotask.
4.Set the event loop's currently running task back to null.
5.Remove oldestMicrotask from the microtask queue.
从这段规范可以看出,当执行了一个macrotask后会有一个循环来检查microtask队列中是否还存在任务,如果有就执行。这说明执行了一个macrotask(宏任务)之后,会执行所有注册了的microtask(微任务)。
一起看起来很正常对吧?
那么如果微任务“嵌套”了呢?就像一开始作者给出的那段代码一样,promise调用了很多次.then方法。这种情况文档中有做出规定么?有的。
If, while a compound microtask is running, the user agent is required to execute a compound microtask subtask to run a series of steps, the user agent must run the following steps:
1.Let parent be the event loop's currently running task (the currently running compound microtask).
2.Let subtask be a new task that consists of running the given series of steps. The task source of such a microtask is the microtask task source. This is a compound microtask subtask.
3.Set the event loop's currently running task to subtask.
4.Run subtask.
5.Set the event loop's currently running task back to parent.
简单来说如果有“嵌套”的情况,注册的任务都是microtask,那么就会一股脑得全部执行。
通过上面对文档的解读我们可以知道以下几件事:
那么还剩一件事情就是什么任务是macrotask,什么是microtask?
这张图来源一篇翻译PromisA+的文章,里面所提到的关于任务的分类。
但是!我对于setImmediate与process.nextTick的行为持怀疑态度。理由最后说!不过在浏览器运行环境中我们不需要关系上面那两种事件。
在本文一开始就提出,这段代码要在新版chrome中运行才会得到正确结果。那么不在chrome中呢?
举个例子,别的作者不一一测试了,这是safari中的结果。我们可以看到顺序被打乱了。so为什么我执行了一样的代码结果却不同?
个人认为若出现结果不同的情况是由于不同执行环境(chrome, safari, node .etc)将回调需要执行的任务所划分到的任务队列与PromiseA+规范中所提到的任务队列中的任务划分准则执行不一致导致的。也就是Promise可能被划分到了macrotask中。有兴趣深入了解的童鞋可以看下这篇tasks-microtasks-queues-and-schedules.
细心的童鞋可能发现我一直强调的js运行环境是浏览器下的事件循环情况。那么node中呢?
setTimeout(function() {
console.log('setTimeout1');
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
})
}, 0);
setTimeout(function() {
console.log('setTimeout2');
Promise.resolve().then(function() {
console.log('promise3');
}).then(function() {
console.log('promise4');
})
}, 0);
还是这段代码,打印出来会不会有区别?多打印几次结果一样么?为什么会这样?
我只能理解到node通过libuv实现事件循环的方式与规范没有关系,但具体为什么会打印出不同的效果。。求大神@我
不定时更新中——
有问题欢迎在issues下交流。
请问一下基于JS的深度优先搜索生成动画怎么解啊
传说中的增长黑客集中营!负责大淘系用户增长,探索手淘的增长方法论及增长平台,打造智能数据驱动用户增长引擎,支撑集团多APP矩阵增长!不论在集团,还是在淘系,用户增长战役都是最重要的战役,重要到财报C位!


(1)技术岗:
校招官网会统一有相关介绍
请移步:https://campus.alibaba.com/index.htm
由于负责招人的同学平时工作也比较忙,同时微信的回复也会不及时以及遗漏消息。本次答疑采用邮件的形式,对应岗位接口的同学会在每天特定时间去回复大家的问题。如果有遗漏第二天再发一次邮件即可。相关问题发送到【[email protected]】
本次的分享是一个基于HTML5标签实现的一个自定义视频播放器。其中实现了播放暂停、进度拖拽、音量控制及全屏等功能。
欢迎关注我的博客,不定期更新中——
画面卡顿请看这个地址
https://user-gold-cdn.xitu.io/2017/7/17/633441b3b7e1a7988d45174fbb3bd6f8?imageView2/0/w/1280/h/960
点我查看源码仓库。
我相信一定会有些没有接触过制作自定义播放器的童鞋对于标签的认识会停留在此。
<video controls="controls" autoplay="autoplay">
<source src="movie.ogg" type="video/ogg" />
</video>
其中controls属性经过设定,会在界面中显示一个浏览器自带的控制条。如果对于UI没有要求的需求,其内置控制器已经可以满足大部分的需求。当然了如果是这样你们也不会看到这篇分享了=。=
那么实现一个自定义功能的播放器关键就在于,我们不使用原生的控制器,将其隐藏掉之后,在下方同样的位置通过html、css来模拟所需样式,同时通过js来调用vedio标签所暴露给我们的接口函数及属性,以及检测用户的操作行为来同步的模拟UI与视频播放数据的相应变化。
myVid=document.getElementById("video1");
//控制视频开关
myVid.play() //播放
myVid.pause() //暂停
//模拟视频进度条
myVid.currentTime=5; //返回或设定当前视频播放位置
myVid.duration // 返回视频总长度
//模拟视频音量
myVid.volume //音量
//获取视频当前状态后判断何时从loading切换为播放
myVid.readyState
//0 = HAVE_NOTHING - 没有关于音频/视频是否就绪的信息
//1 = HAVE_METADATA - 关于音频/视频就绪的元数据
//2 = HAVE_CURRENT_DATA - 关于当前播放位置的数据是可用的,但没有足够的数据来播放下一帧/毫秒
//3 = HAVE_FUTURE_DATA - 当前及至少下一帧的数据是可用的
//4 = HAVE_ENOUGH_DATA - 可用数据足以开始播放
在所有实现中的关键点,较为繁琐的是对于进度条的模拟。其中使用了video标签中的currentTime以及duration属性,通过当前播放时间与总播放时间的比值,就可以计算出进度条相对于总长的位置。同时用户通过拖拽进度条所最后设置的长度也可以用来反向推算出此时视频应该播放的位置。
//核心代码示例
var dragDis = 0
var processWidth = xxx //拖拽条总长
$('body').mousedown(function(e) {
startX = e.clientX
dragDis = startX - leftInit //leftInit为拖拽条起始点距屏幕左侧的距离
dragTarget.css({ //拖拽按钮
left: dragDis
})
dragProcess.css({ //进度条(蓝色进度条)
width: dragDis
}) // 令进度条和拖拽按钮渲染在同一位置
videoSource.pause()
}).mousemove(function(e) {
moveX = e.clientX
disX = moveX - startX
var left = dragDis + disX
if(left > processWidth) {
left = processWidth
} else if(left < 0) {
left = 0
}
dragTarget.css({
left: left
})
dragProcess.css({
width: left
})
}).mouseup(function(e) {
videoSource.play()
videoSource.currentTime = $('蓝色拖拽条').width() / processWidth * duration //拖拽后计算视频的正确播放位置
})
同理音量的控制与其上行为基本一致,故在源码中作者将音量与进度部分通过不同元素进行判断是进行进度还是音量的拖拽控制。
function ifState() {
var state = videoSource.readyState
if(state === 4) { //状态为4即可播放
videoPlayer()
} else {
$('.play-sym-wrapper').remove()
$('body').append('<div class="play-sym-wrapper"><img class="play-sym" src="./images/loading.gif"></div>')
//添加loading动画
setTimeout(ifState, 10)
}
}
setTimeout(ifState, 10)
核心的控制部分已经说完了,有兴趣的同学可以去源码的html中点击播放,其中被迫有很多零碎的需求,比如点击暂停,保存音量等等。整个视频播放器的基础功能实现的还算完善。
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
事情的起因是这段看起来不像代码的代码:

有兴趣的同学可以自己先尝试下!
([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[+[]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[+[]]+([][[]]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()([][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()(([]+{})[+[]])[+[]]+(!+[]+!![]+!![]+!![]+!![]+!![]+!![]+[])+(!+[]+!![]+!![]+!![]+!![]+!![]+!![]+[]))+([]+{})[+!![]]+(!![]+[])[+!![]]+(![]+[])[!+[]+!![]]+([][[]]+[])[!+[]+!![]]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[+[]]+([][[]]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()([][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])()(([]+{})[+[]])[+[]]+(!+[]+!![]+[])+(+!![]+[]))
作者对着这段代码足足看了一下午,我只想说这不是什么深奥的黑魔法。一点点看下来你就知道其中的原理了。最后会有一段作者自己封装的代码叫nb.js(源码在这里),它实现了输入数字字母后自动生成这种玄学代码片段。就像这样:

欢迎关注我的博客,不定期更新中——
——何时完结不确定,写多少看我会多少!这是已经更新的地址:
这个系列旨在对一些人们不常用遇到的知识点,以及可能常用到但不曾深入了解的部分做一个重新梳理,虽然可能有些部分看起来没有什么用,因为平时开发真的用不到!但个人认为糟粕也好精华也罢里面全部蕴藏着JS一些偏本质的东西或者说底层规范,如果能适当避开舒适区来看这些小细节,也许对自己也会有些帮助~文章更新在我的博客,欢迎不定期关注。
什么意思?比如:f。看到f你会想到哪个关键字?同时这个关键字是要在类型转换的机制下能够被打印出来的。如果类型转换你还不是很了解,可以先读下这篇来理解一下:从[] == ![]看隐式强制转换机制。我相信很多同学可以想到是false这个关键字。那么我们的思路就有了也就是要让代码实现'false'[0]这件事,这个认识统一之后我相信下面的代码一定不难理解了:
[[[] == []] + []][+![]][+![]]
//过程理解为
[] == [] => false
[[] == []] => [false]
[[[] == []] + []] => ['false'], [+![]] => [0]
[[[] == []] + []][+![]] => 'false'
[[[] == []] + []][+![]][+![]] => 'false'[0] => 'f'
其中大体形式可以理解为:['false'][0][0] => 'f'
是不是瞬间觉得也不过如此?
当你知道可以用上面的方式来获取自己需要的字母之后,接下来要做的是思考一下你能从关键字中获取哪些字母呢,作者总结了以下你可以通过关键字获得的字母:
([][[]]+[]) => 'undefined'
+[1+[[][0]+[]][0][3]+400][0]+[] => 'Infinity'
[[[] == []] + []][+![]] => 'false'
[[[] != []] + []][+![]] => 'true'
([]+{}) => "[object Object]"
感兴趣的同学自己打印下就明白为什么了。
接下来要说的是剩下的字母怎么办?当然了你仍然可以通过试图寻找关键字的方式来获取字母。但是如果标点我也想要呢?或者说26个字母我都想要怎么办?
具体点来说对于“hello world!”这段字符串来看,至少“w”,"!"的获取方法通过关键字的形式我们是无从下手的。
unescape() 函数可对通过 escape() 编码的字符串进行解码。但是已经废弃了
是的现在已经不建议如此使用了,但是浏览器下基本还是支持这个函数的。通过这个函数我们可以通过ascll码来直接得到我们需要的字符:
unescape('%77') => 'w'
如此看来,除了我们可以快速得得到一些关键字字母外,用这个方法我们便可以实现任意字母的组合。而作者封装的nb.js也是基于这两者来实现输出黑魔法字符串的。
那么现在的问题是如果通过字符串来执行unescape('%77')这段代码?
在这里也不绕弯子了,作者打印了很多次之后才发现是如此调用的:
[]['sort']['constructor']('return unescape')
因为JS调用方法不光是“.”调用,通过[]也是可以调用的。同时通过return unescape,返回了一个匿名函数形成了闭包。故调用的时候采用如下方式:
[]['sort']['constructor']('return unescape')()('%77') => 'w'
至于为什么这段代码写出来如此长是因为上面的每一个字母都是一点点拼出来的,也行好上面通过关键字的方式可以得到这些字母=。=不然的话——
所以经过上面的分析你会发现,除了字符串长度感人之外,这种通过拼接字符串可以返回函数并且执行的方式还真是蛮炫酷的。为了达到装逼的效果。作者决定封装一个支持字母和数字的函数,当你传入普通的字符串之后,会返回带有黑魔法气息的冗长字符串,尽情拿去装x吧,不客气~
var baseAlibrary = {
'a': '[[[] == []][0]+[]][0][1]',
'b': null,
'c': '[[][[[][0] + []][0][4]+[[][0] + []][0][5]+[[][0] + []][0][1]+[[][0] + []][0][2]]+[]][0][3]',
'd': '([][[]]+[])[+!![]+!![]]',
'e': '([][[]]+[])[+!![]+!![]+!![]]',
'f': '([][[]]+[])[+!![]+!![]+!![]+!![]]',
'g': null,
...
'0': '(+![])',
'1': '(+!![])',
'2': '(+!![]+!![])',
...
',': null,
'!': null,
}
var ascll = { //ascll表可自行配置, 新添加后需要在上面对象中配置相同key,只是value为null
'A': '41',
'B': '42',
...
}
将简单的字母转换方式直接存储下来,如果需要的字符无法从基础对象获取,就记为null,并在ascll表中写入相关转码方式。
var result = ''
var unescapeStr = '[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+([][[]]+[])[+[]]+([][[]]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(![]+[])[!+[]+!![]+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+([]+[][(![]+[])[!+[]+!![]+!![]]+([]+{})[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][([]+{})[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]]+(![]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+[]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+([]+{})[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+([][[]]+[])[!+[]+!![]+!![]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!![]]+([][[]]+[])[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!+[]+!![]]+([]+{})[+!![]]+([]+{})[!+[]+!![]+!![]+!![]+!![]]+(+{}+[])[+!![]]+(!![]+[])[+[]]+([][[]]+[])[!+[]+!![]+!![]+!![]+!![]]+([]+{})[+!![]]+([][[]]+[])[+!![]])())[!+[]+!![]+!![]]+([][[]]+[])[!+[]+!![]+!![]])'
//将[]['sort']['constructor']('return unescape')的黑魔法形式存储起来之后直接调用
function changeAscll(ascllItem) {
var ascllResult = ''
var middleValue = ''
ascll[ascllItem].split('').forEach(function(item) {
if(isNaN(item)) { //ascll中遇到字母则需要再次进行unescape转码
var str = ''
ascll[item].split('').forEach(function(data) {
str += '+[' + baseAlibrary[data] + ']'
})
middleValue += '+' + unescapeStr + '()('+ baseAlibrary['%']+'+' + str.slice(1) + ')'
} else {
middleValue += '+[' + baseAlibrary[item] + ']'
}
})
ascllResult += '+' + unescapeStr + '()('+ baseAlibrary['%']+'+' + middleValue.slice(1) + ')'
return ascllResult
}
function getUnEscape(str) {
}
strArr.forEach(function(item) {
Object.keys(baseAlibrary).forEach(function(obj, i) {
if(item.toLocaleLowerCase() === obj) {
if(!baseAlibrary[item]) {
Object.keys(ascll).forEach(function(ascllItem) {
if(obj === ascllItem) {
var cbValue = changeAscll(ascllItem).slice(1)
result += '+' + cbValue
}
})
} else {
result += '+' + baseAlibrary[obj]
}
}
})
})
console.log(result.slice(1))
也就是一开始大家看到的:
作者将函数绑定在了this上,通过this.reallyNb()即可得到你想要的~
PS:代码请部署在服务器中再打开页面,否则个别字母通过location方法会取不到,主要就是t,p。不过这个问题之后作者会将其以ascll表的方式存储,就没有环境限制了。只是作者嫌弃那样做打印的字符串太长了~
不定时更新中——
有问题欢迎在issues下交流。
由于原生的Canvas最高只支持到三阶贝塞尔曲线,那么我想添加多个控制点怎么办呢?(即便大部分复杂曲线都可以用3阶贝塞尔来模拟)与此同时,关于贝塞尔控制点的位置我们很难非常直观的清楚到底将控制点设置为多少可以形成我们想要的曲线。本着解决以上两个痛点同时社区内好像并没有N阶的解决方案(js版)故这次作者非常认真的开源了bezierMaker.js!
bezierMaker.js理论上支持N阶贝塞尔曲线的生成,同时提供了试验场供开发者可以自行添加并拖拽控制点最终生成一组绘制动画。非常直观的让开发者知道不同位置的控制点所对应的不同生成曲线。
如果你喜欢这个作品欢迎Star,毕竟star来之不易。。
项目地址:这里✨✨✨
欢迎关注我的博客,不定期更新中——
在绘制复杂的高阶贝塞尔曲线时无法知道自己需要的曲线的控制点的精确位置。在试验场中进行模拟,可以实时得到控制点的坐标值,将得到的点坐标变为对象数组传递进BezierMaker类就可以生成目标曲线


<script src="./bezierMaker.js"></script>
上面的效果图为试验场的使用,当你通过试验场获得控制点的准确坐标之后,就可以调用bezierMaker.js进行曲线的直接绘制。
/**
* canvas canvas的dom对象
* bezierCtrlNodesArr 控制点数组,包含x,y坐标
* color 曲线颜色
*/
var canvas = document.getElementById('canvas')
//3阶之前采用原生方法实现
var arr0 = [{x:70,y:25},{x:24,y:51}]
var arr1 = [{x:233,y:225},{x:170,y:279},{x:240,y:51}]
var arr2 = [{x:23,y:225},{x:70,y:79},{x:40,y:51},{x:300, y:44}]
var arr3 = [{x:333,y:15},{x:70,y:79},{x:40,y:551},{x:170,y:279},{x:17,y:239}]
var arr4 = [{x:53,y:85},{x:170,y:279},{x:240,y:551},{x:70,y:79},{x:40,y:551},{x:170,y:279}]
var bezier0 = new BezierMaker(canvas, arr0, 'black')
var bezier1 = new BezierMaker(canvas, arr1, 'red')
var bezier2 = new BezierMaker(canvas, arr2, 'blue')
var bezier3 = new BezierMaker(canvas, arr3, 'yellow')
var bezier4 = new BezierMaker(canvas, arr4, 'green')
bezier0.drawBezier()
bezier1.drawBezier()
bezier2.drawBezier()
bezier3.drawBezier()
bezier4.drawBezier()

当控制点少于3个时,会适配使用原生的API接口。当控制点多于2个后,由我们自己实现的函数进行描点绘制。
绘制贝塞尔曲线的核心点在于贝塞尔公式的运用:

这个公式中的P0-Pn代表了从起点到各个控制点再到终点的各点与占比t的各种幂运算。
BezierMaker.prototype.bezier = function(t) { //贝塞尔公式调用
var x = 0,
y = 0,
bezierCtrlNodesArr = this.bezierCtrlNodesArr,
//控制点数组
n = bezierCtrlNodesArr.length - 1,
self = this
bezierCtrlNodesArr.forEach(function(item, index) {
if(!index) {
x += item.x * Math.pow(( 1 - t ), n - index) * Math.pow(t, index)
y += item.y * Math.pow(( 1 - t ), n - index) * Math.pow(t, index)
} else {
//factorial为阶乘函数
x += self.factorial(n) / self.factorial(index) / self.factorial(n - index) * item.x * Math.pow(( 1 - t ), n - index) * Math.pow(t, index)
y += self.factorial(n) / self.factorial(index) / self.factorial(n - index) * item.y * Math.pow(( 1 - t ), n - index) * Math.pow(t, index)
}
})
return {
x: x,
y: y
}
}
对所有点进行遍历同时根据当前占比t的值(0<=t<=1),计算出当前在贝塞尔曲线上的点坐标x,y。t的取值作者分成了100份,即每次运算t+=0.01。此时算出的x,y即所求的贝塞尔曲线分成了100份之后的某一点。当t值从0~1遍历100次后生成100个x,y对应坐标,依次描点画线即可模拟出高阶贝塞尔曲线。
对于贝塞尔公式的推导作者会在之后的文章中专门说明,现在你只需要知道我们通过贝塞尔公式计算出实际贝塞尔曲线被等分成了100份的各点,用直线连接各点后即可模拟出类曲线。
这个部分相关代码可以参考这里
整体思路是用递归的方式来将每个一层控制点当做1阶贝塞尔函数来计算下一层控制点并对应连线。具体逻辑作者会留到深入讲解贝塞尔曲线公式原理的时候一起梳理一下试验场的动画生成原理~
作者一直想开源一些东西(但是菜,也没啥能写的),然而平时会用到的都被人写了,再造轮子也没别人写得好。这次也算是发现了一个貌似空白一些的区域。所以非常郑重的决定开源。贝塞尔的高级运用在gayhub中大多是安卓的实现,前端领域中还有很多地方可以更多的展开,欢迎讨论~ 多多批评!
项目地址:这里✨✨
试验场地址:一定进来玩✨✨✨
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次尝试通过流程图的形式并结合两个例子来重新理解一下JavaScript中的参数传递。
欢迎关注我的博客,不定期更新中——
借用红宝书的一句话:
ECMAScript中所有函数的参数都是按值传递的
这个值如果是简单类型,那么就是其本身。如果是引用类型也就是对象传递的就是指向这个对象的地址。故我们可以认为参数传递全部都是值传递,那么具体怎么理解呢?看下例子:
var obj = {
n: 1
};
function foo(data) {
data = 2;
console.log(data); //2
}
foo(obj);
console.log(obj.n) // 1
先不说为什么原因,我们就通过画图的方式来走一遍流程,我相信应该就能理解其中的参数传递了。切记传递引用类型传递的是指针!

首先执行var obj = {n: 1}; ,可以看作在栈的001地址中存入了一个指向{n:1}的指针*p
接下来为声明function foo 此时会创建函数执行上下文,产生一个变量对象,其中声明了形参data,由于函数没有执行,当前值为undefined。我们记data地址为022。关于更多变量对象的知识可以参考冴羽老师的这篇JavaScript深入之变量对象,本文不深入研究关于AO相关,你只需要知道在声明这个函数的时候里面的形参已经被创建出来了。
执行foo(obj) 其中会进行参数传递,其中将obj中存储的*p拷贝给处在022地址的data,那么此时它们就指向了同一个对象,如果某一个变量更改了n的值,另一个变量中n的值也会更改,因为其中保存的是指针。
进入函数内部,顺序执行data = 2;此时002地址存储了基本类型值,则直接存储在栈中,从而与堆中的{n:1}失去了联系。从而打印console.log(data) // 2 ,最后发现初始开辟的{n:1}对象没有过更改,故而 console.log(obj.n) // 1仍然打印1。
var obj = {n:1};
(function(obj){
console.log(obj.n); //1
obj.n=3;
var obj = {n:2};
console.log(obj.n) //2
})(obj);
console.log(obj.n) //3
整体来看这个例子中出现了同名覆盖的问题。不太了解代码如何执行的流程,可能会因为同名的关系而有些混乱,不过没关系。只要按照上一个例子的流程图中的执行过程,一定可以得出正确的结果。
声明变量obj,地址为011其中存入指向{n:1}的指针*p
声明函数,虽然同为obj变量名,但是形参obj为AO中的属性,不会与全局造成覆盖,其拥有新的地址记作022,在未执行前其值为undefined。
函数立即执行,此时将全局obj赋值给形参obj,我们忽略这个重复命名的问题,其实就是将011中的 指针*p拷贝了一份给了022。同时执行第一个console.log(obj.n)结果即为1。
执行obj.n=3,此时为函数的形参即022中的obj来改变了对象内n的值。
最关键的一步:var obj = {n:2}; 由于对象命名的关系可能很多童鞋就会有点懵,但依然按照同样的方式来分析即可,由于使用了var那么就是新声明一个对象,从而会在栈中压入新的地址记作033,其中存入了新的指针指向了新的对象{n:2}。从而之后打印的console.log(obj.n)结果则应是新开辟的对象中的n的值。
最后打印 console.log(obj.n) //3很显然,全局的对象有过一次更改其值为3。
至此我们走完了上述两段代码涉及变量的所有“心路历程”,由于作者不是科班出身,这个图中对于堆栈以及变量重名的描述可能不是非常的准确,有差错的地方还望不吝赐教~重点是能理解我希望表达的意思就好。总的来说关键点就在于传参的过程中存在一次值的拷贝,同时如果赋值对象是引用类型传入的是指针,明白这两点之后再加上之前流程图的分析相信再遇到类似的问题都可以有较为一致的思路了。
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
昨天和一个童鞋聊到很晚,才意识到现在又是新的一轮校招季了,他像当时的我一样,自己出于喜欢学习了前端,但又不知自己处在了什么水平,也由于知识、眼界的限制不知道路在哪里(真的前端发展到现在知识面太广)而担惊受怕。在和他交谈的同时也回想起当时的自己,像我一个普通的本科生从接触到决定其作为自己未来很多很多年的职业,殊不知要经历些什么才能下定了决心一往无前。时间很快,离我上次参加面试也经过了一年多的时间,在工作里也在不停的对于以往只在面试中“背”过的知识有了些新的认识,同时那些面试题在我之后的工作中也让我受益匪浅,并且从中可能又多了些心得。故借此写一个分享,分享一些以前遇到的题目以及可能包括之后在工作中对其的一些新认识。希望可以帮助到有志在前端领域有所建树的童鞋们。#另有些分享欢迎关注我的github
例如:增删改查dom节点属性
冒泡、捕获的原理;stopPropagation、preventDefault
比如这篇关于事件的基础知识的文章,红包书中的解释大家需要多多理解。
要知道委托是方便,但是什么时候必须要委托呢?是当你动态添加节点的时候,你之前为该节点所绑的事件是无法在之后的节点也进行绑定的。所以要通过委托来进行绑定。
一篇关于事件委托的文章
多列布局的几种方式就不赘述了,只是在这个问题后结合现实需求就可能会有了一些新的布局方式。下面来看这张图:
可能有些同学会说,可以给一个右边距然后将元素4,8的右边距去掉。这件事本身很容易但是我们要考虑到这个页面如果放到线上就可能会进行模板嵌套。在模板中这些元素都是诸如以下方式渲染出来的
for( i in 元素数组) {
return <div class="xxx"> 元素数组[i] </div>
}
在这种情况下我们不太可能去一一控制第几个元素你把右边距给我去了对吧。所以也由这道面试题,引发了一个新的认识即margin负边距。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width">
<title>JS Bin</title>
<style>
body,ul,li{ padding:0; margin:0;}
ul,li{ list-style:none;}
.container{ height:210px; width:460px; border:5px solid #000;}
ul{ height:210px; overflow:hidden; margin-right:-20px;}/*一个负的margin-right,相当于把ul的宽度增加了20px*/
li{ height:100px; width:100px; background:#09F; float:left; margin-right:20px; margin-bottom:10px;}
</style>
</head>
<body>
<div class="container">
<ul>
<li>子元素1</li>
<li>子元素2</li>
<li>子元素3</li>
<li>子元素4</li>
<li>子元素5</li>
<li>子元素6</li>
<li>子元素7</li>
<li>子元素8</li>
</ul>
</div>
</body>
</html>
对于负边距可以看看这篇文章
盒模型有几种?MDN下对盒模型的讲解
必会!自己好好写个demo,简直太好用。要不是有兼容性问题...不过一切都会变好的
万古不变的话题,但要关注的是需求中到底知不知道高度和宽度,实现起来有什么不一样的地方。
这个基础部分推荐一本书《你不知道的JavaScript》,里面的叙述很详尽,其中关于this的用法我觉得总结的很到位。
这个算法不是二叉树什么红黑树那种算法,那些和前端也确实没啥关系。前端层面最需要关注的其实就是对于后端返回的json进行解析的操作。从中获取到需要的数据。也就是对于对象和数组的操作居多。大概会有以下的一些算法:
随着es6、es7语法的不断变革,API的不断更新,我们有了越来越多的快捷操作手段,同时老版本的浏览器在不断退出市场,但是直到现在还没有完全退出。而如果想进一线公司,兼容性是个无法避免的问题。你不能说在ie6下就不能开百度吧?
不过像应届生真的直接问兼容性问题的几率应该没那么大,即便问了可能也是背的没有什么意义。毕竟我的电脑里都没有ie我怎么测?但是兼容性的考察可以以polyfill的方式来进行,这点也非常考验开发人员的功底。比如bind的实现;
对不起,推荐一下我写的对bind的重新学习Javascript之bind;在对bind自己实现的过程中,会涉及原型链继承等概念的运用,使用这种方式顺带着还问了你基础知识,何乐不为。
抛个砖引个玉:
这个效果要关注的核心就是三个函数
touchStart、touchMove、touchEnd
如果有兴趣深入的同学可以试试看写一个拖拽排序,github上也有很多关于其的开源项目。MDN上关于touch事件的介绍
2. 轮播
轮播可以说是最常见的基础实现了,轮播也分为很多种,移动端&PC端,滚动&淡入淡出,一屏&多屏,有限&无限循环,同时使用原生手法和使用框架如react下面的实现思路又不尽相同。在这里可以做一个小的总结,轮播图的核心思路可以定义为对于整个轮播图其横轴坐标的控制(假设轮播图横向滑动)。那么这个值就定义为left,对于原生手段开发而言我们需要关注轮播图当前的索引(即第几张图)和left之间的关系,通过各种判断来实现其left值的反复变化。相当于我们需要关注索引与left之间的关系,是一个强耦合的形式。如果采用react而言(因为作者只用react写过)索引是可以与left进行解耦的,通过使用state来绑定索引值的变化,然后left会自行根据state进行改变,从而使开发者只需要关注索引值,也就是轮播图的url数组中各个url其索引值的改变。#纸上得来终觉浅这部分届时作者会出一个分享来对比通过原生或框架来实现轮播图思路中的异同。
效果实现有太多种可能,这种demo无法做到各个都知道,但我们可以掌握分析问题的方式。个人认为判断一个程序员功底的方式之一是看其多久可以从一个需求中发现问题的本质然后庖丁九牛般一步步分析出思路。
根据28原则,个人感觉可以先学习
let const
解构
() => {}
Promise
class
async
...etc
主要是是否自己在实践中使用了ES6?如果使用了ES6那么必定要对webpack&gulp有些了解,可以自己尝试着配置一份webpack,打包一下less|sass,ES6试试,在自己配置的时候一定收获匪浅
必须要了解的,也是在工作中和后端工程师交涉的时候不可避免的一个环节。那么其和https的关系是?可以来看看这篇文章https时代来了,你却还一无所知?
很重要。至少jsonp给明白吧,还有其背后的原理。自己写一个jsonp?核心是通过script标签的src去请求跨域的服务器,传递其一个callback回调函数,后端在这个回调函数中塞入需要的数据。
私密与不私密的关系,限制于不限制大小的关系。注意jsonp走的是GET请求,这一点你从network里是可以看到的。
最后推荐一篇不错的讲解从前端到后端的科普文
在淘宝上买件东西,背后发生了什么?
仁者见仁智者见智了。可以从express玩起,这方面我也不太擅长就闭嘴了。。
推荐朴灵大大的《Nodejs深入浅出》
另分享一篇有关域名的文章
浅谈域名发散与域名收敛
大佬三只手 react vue angular以及必会的jq
先分享下作者自己使用其中两个框架写的小实践
jq已经十年了,你有看过它的源码么,对不起我也没有...以后我会看的。对于jq个人感觉如果你把它写到了简历里,如果面试官想问你那么问的一定会深入一些。因为那些大佬用的最熟的可能就是jq。在这里抛砖引玉一些可能忽略掉的地方。诸如:jq上的事件委托、bind&on各种绑定事件的区别、jq对象与原生对象间的关联转换等等
如果学习过react、vue、angular三者之一我认为肯定在面试中会有一定的优势,因为如果你使用了这种框架来进行开发,那么一定会涉及到打包编译es6包括可能使用node做后端等等的尝试,同时现在很多大公司也正是使用这些技术来实现需求,所以如果你了解一下那么肯定是有好处的。区别可能就是自己的实践从量级、优化上还远远不足于线上产品。但是有过组件化或者双向绑定技术的实践对你之后面向正规开发会容易上手很多。毕竟做开发虽然我们的梦想是造轮子但是第一层境界也只是站在巨人的肩膀上使用工具感受工具带来的魅力而已。记得阿里去年有一道题让我手动实现一个angular的依赖注入。对不起我没用过angular...
去年一次电面,一位阿里的工程师对于我写的移动端react版本的轮播图组件上提出了一个我开发时候思考过的的一个问题。就是当手指滑动后,该张图片应该还有一个滚动动画,那么这个动画如何判断其滚动完成呢。其实这件事情如果熟悉原生开发或者有过RN开发经验一定不是难事,原生下面会有一个生命周期函数来告诉你滚动已经停止了,但是这件事情在网页上来说不是那么好断定。
我在那个组件中由于可能带来的兼容性原因加上没想到更好的实现方式,所以选择了比较粗略的定时器方式。大致用法为
this.setState({
... //这个状态下动画正在执行,预计300ms
},() => {
setTimeout(() =>{
//断定动画结束执行之后的操作
}, 300)
})
为什么说是粗略呢?这个时候就应该重新关注一下setTimeout事件到底是如何执行的,定时和定时器中的操作一定是定时器到时间了里面就一定执行么,答案是否定的想了解setTimeout运行机制可以看下这篇你所不知道的setTimeout,函数真正执行的时间和定时器定的时间其实没有关系。总的来说定时器定的时间只是在那个时间点把你的事件扔进事件回调队列中,如果前面排着的事件计算量复杂,那么真到你那个定时器函数执行的时候也许黄花菜都凉了。所以“慎用定时器”,然而我...haveto?
有关-webkit-animation请戳这里
回想起来阿里的工程师面试还是很厉害的,虽然可能和我做的东西太常见有关,不过我觉得能从别人的项目中一下子找到实现的一些痛点的经验,也必定是要长期累月进行积累后才能游刃有余吧。
写的很匆忙,但也算回顾了一年多工作中间的小心得吧。希望可以有所帮助大家多多交流。
最后分享一句从冴羽老师文章中看到的话,我个人觉得很有道理:
“曾经团队邀请过 Nodejs 领域一个非常著名的大神来分享,这里便不说是谁了。当知道是他后,简直是粉丝的心情。但是课讲得确实一般,也许是第一次讲,准备不是很充足吧,以至于我都觉得我能讲得比他好,但是有两次,让我觉得这是真正的大神。一次就是,当有同事问到今年有什么流行的前端框架吗?这些框架有怎样的适用场景?该如何抉择?我以为大神一定会回答当时正火的 React、以及小鲜肉 Vue 之类,然后老生常谈的比较一番,但是他回答道:“I dont't care!因为这些并不重要,真正重要的是底层,当你了解了底层,你就能很轻松的明白这些框架的原理,当你明白了原理,这些框架又有什么意思呢?”
本次分享一下并不是很常用的按位非运算符~的原理以及一点点用法。
欢迎关注我的博客,不定期更新中——
——何时完结不确定,写多少看我会多少!这是已经更新的地址:
这个系列旨在对一些人们不常用遇到的知识点,以及可能常用到但不曾深入了解的部分做一个重新梳理,虽然可能有些部分看起来没有什么用,因为平时开发真的用不到!但个人认为糟粕也好精华也罢里面全部蕴藏着JS一些偏本质的东西或者说底层规范,如果能适当避开舒适区来看这些小细节,也许对自己也会有些帮助~文章更新在我的博客,欢迎不定期关注。
看下规范里面的定义的~:
产生式 UnaryExpression : ~ UnaryExpression 按照下面的过程执行:
令 expr 为解释执行 UnaryExpression 的结果。
令 oldValue 为 ToInt32(GetValue(expr))。
返回 oldValue 按位取反的结果。结果为 32位 有符号整数。
总结一下即将数字进行抽象Toint32操作,再进行按位取反。那么再来看下关于Toint32:

数字进行Toint32操作会转化成32位有符号数,第一位为符号位,后面31位为表示整数数值。最后对数字进行按位取反即可得到~转换后的结果。
//以18为例子,进行Toint32抽象操作
//将18表示为二进制形式
0 000 0000 0000 0000 0000 0000 0001 0010
//|符号位|| 数值部分 |
//按位取反
1 111 1111 1111 1111 1111 1111 1110 1101
//|符号位|| 数值部分 |
可以发现现在将18进行了按位非操作之后这个数变成了一个负数,同时我们可以看到这么多个1。。感觉这个负数很大啊?所以~18会是一个很大的负数么?我们打印看下:

好像和预料中的有些出入?
我们可以直接打印看下:

然而这并不是我们想要的,会有这个结果是因为ECMAScript采用了这样简单的方式来避免开发者接触一些底层的操作,真实的存储二进制负数的方式应该是采用补码的形式。而也正是由于补码的操作我们才能解释为什么~18 === -19
生成补码的三个步骤:
确定该数字的非负版本的二进制表示(例如,要计算 -18的二进制补码,首先要确定 18 的二进制表示)
求得二进制反码,即要把 0 替换为 1,把 1 替换为 0
在二进制反码上加 1
我们先不管为什么负数要用补码来存储,先来看下~18 === -19是如何而来的。
根据上述计算-19的补码步骤:
//将19表示为二进制形式
0 000 0000 0000 0000 0000 0000 0001 0011
//|符号位|| 数值部分 |
//按位取反
1 111 1111 1111 1111 1111 1111 1110 1100
//|符号位|| 数值部分 |
//反码加一
1 111 1111 1111 1111 1111 1111 1110 1100
1
--------------------------------------------
1 111 1111 1111 1111 1111 1111 1110 1101
//同时 18的按位取反表示为:
1 111 1111 1111 1111 1111 1111 1110 1101
所以我们可以看到,由于补码为按位取反并+1,~ 为按位取反,那么也就可以说明为什么~18 === -19 同时我们也可以得出结论即:
因为计算机在做二进制运算的时候,不希望考虑运算数的符号,全部希望执行加法操作来得出正确结果,由此引入了补码的概念。比如我们试图用4-2的结果与4+2的补码结果比对来进行说明:
4 - 2 =>
0100 - 0010 = 0010
4 + (-2) =>
0010 + 1110 = 0010(相加超过位数,溢出自动丢失)
哨位值一般可以表示失败的意思。例如js中的哨位值如-1,当你执行indexOf操作时,如果找不到目标则返回-1,同时~-1 = 0,由此我们可以将代码转变为:
if(str.indexOf('js') != -1) => if(~indexOf('js'))
那么为什么不使用>=0或者!= -1这种操作呢,在《你不知道的JavaScript》一书中,将之成为“抽象渗漏”,意思是在代码中暴露了底层实现细节,我们可以选择屏蔽掉细节。故 ~ 可以和indexOf进行配合判断真假值,核心思路就是运用了~x === -(x+1)
我们现在知道~ 会进行按位取反的过程中会进行Toint32抽象操作,在这个过程中会将浮点数去掉,只对前面32位整数进行处理。故我们可以使用~进行以下操作:
~~3.12 = 3
同时需要注意由于~的特性,小数点后面的部分是直接被干掉的,而不是会进行Math.floor之类的四舍五入操作。
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
在之前的这篇文章中我们提到了对于贝塞尔公式的运用。本次分享一下如何推导贝塞尔公式以及附一个简单的🌰即小球跟随曲线轨迹运动。
欢迎关注我的博客,不定期更新中——

对于如何绘制连续的贝塞尔曲线可以参照这篇文章:基于canvas使用贝塞尔曲线平滑拟合折线段
在本例中生成的曲线由以上文章中的源码提供。
上面这张图是贝塞尔曲线的完整公式,看起来一脸懵逼=。=,因为这是N阶的推导公式,本次我们以一二阶贝塞尔公式的推导来理解一下这个推导公式的由来。先来看下网上流传已久的几张贝塞尔动图:



在这三张图中最重要的部分是我们需要理解变量t。t的取值范围是0-1。从上面的gif中也可以看出来似乎曲线的绘制过程就是t从0到1的过程。嗯其实就是这样的。t的真实含义是什么呢?
在p0p1、p1p2、p2p3等等的起点到控制点再到终点的连线中,每段连线都被分割成了两部分(仔细看动图中的黑色、绿色、蓝色圆点),各段连线中两部分的比值都是相同的,比值范围是0到1,而这个比值就是t
来看下面的一阶贝塞尔曲线示意图:

pt是p0p1上的任意一点,p0pt / ptp1 = t。从而我们可以引出下面的推导

此时t为时间,v为速度。我们可以看做从p0到p1的距离等于固定速度乘以固定时间

故到p上某一点的时间为固定的速度乘以某个时间值。同时固定的速度已经已经可以表示为上面的推导公式。此时等式右边就形成了t(0,1) / t;即相当于某个时间值 / 固定时间值,即产生了我们一开始所强调的变量t,其取值范围为[0,1]。从而下面的等式也就比较好理解了。
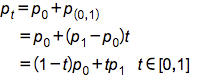
至此一阶贝塞尔曲线我们已经推到了出来,其中变量为起点、终点与比值t。
来看下面这张图:
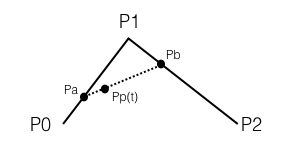
其中Pp(t)的经过路径就是我们所求的二阶贝塞尔曲线,那么其实我们也可以将其从一阶进行演变:
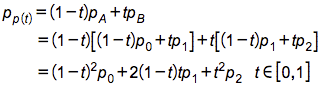
我们先将pa、pb两个点所连线段当做一阶曲线,之后再由两端一阶曲线分别表示pa、pb,最后就得到了我们的二阶曲线公式。仔细观察就能发现这和我们最初的完整公式是相同的:
其中n选择不同数值时就可以得出不同阶的曲线公式。同时从上面的推导过程也可以知道,不论是几阶曲线,我们都可以完全由一阶来表示,而这个“表示”的过程就是我们在上面看到的形成动画中那些辅助线。故可以感受下作者自己写的曲线形成动画中的效果,每段辅助线均由一阶曲线形成:
当我们知道曲线的公式有何而来之后,如何让小球沿着曲线运动就很好理解了。我们生成的每段曲线都是可以用公式表示出来的,也正因如此我们就可以得到每个t值时的曲线坐标点。从而知道物体的绘制坐标。
//核心逻辑
LinearGradient.prototype.drawBall = function() {
var self = this
var item = ctrlNodesArr[ctrlDrawIndex]
//存储了各段曲线的控制点
//各段曲线均为三阶贝塞尔,故下面计算x,y值代入到了三阶公式中
var ctrlAx = item.cAx,//各个控制点
ctrlAy = item.cAy,
ctrlBx = item.cBx,
ctrlBy = item.cBy,
...
if(item.t > 1) {
ctrlDrawIndex++ //当一段曲线的t>1说明曲线已经走到头
}else {
self.ctx.clearRect(0, 0, self.width, self.height)
item.t += 0.05
var ballX = ox * Math.pow((1 - item.t), 3) + 3 * ctrlAx * item.t * Math.pow((1 - item.t), 2) + 3 * ctrlBx * Math.pow(item.t, 2) * (1 - item.t) + x * Math.pow(item.t, 3)
var ballY = oy * Math.pow((1 - item.t), 3) + 3 * ctrlAy * item.t * Math.pow((1 - item.t), 2) + 3 * ctrlBy * Math.pow(item.t, 2) * (1 - item.t) + y * Math.pow(item.t, 3)
//代入三阶贝塞尔曲线公式算出小球的坐标值
self.ctx.beginPath()
self.ctx.arc(ballX, ballY, 5, 0, Math.PI * 2, false)
self.ctx.fill()
}
if(ctrlDrawIndex !== ctrlNodesArr.length) {
window.requestAnimationFrame(newMap.drawBall.bind(self))
}
}
demo地址:这里✨✨
源码地址:欢迎star
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次的分享是一个基于jQuery实现的一个移动端射箭类小游戏。主要实现了目标物、障碍物的随机渲染,以及中箭效果的判定等。
欢迎关注我的博客,不定期更新中——
点我查看源码仓库。
...
//基础属性
defaultOption = {}
//绘制整体画面
function drawGame(defaultOption){}
//障碍物、目标物类
function Hinder(){}
Hinder.prototype.xxx
function Target(){}
Target.prototype.xxx
//循环渲染
function eventLoopHinder(){}
function eventLoopTarget(){}
//过期去除障碍物、目标物
function clearHinder(){}
function clearTarget(){}
//触摸射箭事件监听
function touchEvent(){}
...
通过以上的结构划分及效果图的展示我们可以大概了解到,这个游戏主要涉及的三个较为关键的地方就是:
故接下来作者会介绍下实现思路,至于具体细节有兴趣的同学可以在issues下交流。
对于目标物作者用了下面的类来表示:
//以下代码只作为例子说明,与源码有较大删改
//为了方便表示 random 为一个假想的随机值
function Target(id, nowTime, width, score, x, y, time) {
this.id = id //id即唯一标示
this.nowTime = nowTime //当前时间
this.score = score //代表分数
this.width = width || random // 可随机一个宽度
this.x = x || random //可随机一个x坐标
this.y = y || random //可随机一个y坐标
this.time = time || random //可随机一个过期时间
}
在上面的示例代码中我们可以知道,通过new Target()可以得到一个位置随机,大小随机,过期时间等等均为随机的一个目标物。当然这个随机作者在代码中做过限定,都是在一个特定的范围内随机出来的。那么在这期间唯一需要我们控制的,应该就是出现的位置了,为什么这么说呢,因为出现的位置不应该重合。而如果只凭这个类中的属性来部署目标物,势必会各种重合。
简单看下实现过程:
//targetArray为存放目标物对象的数组,每次new出实例后均会放入该数组
Target.prototype.draw = function(newTarget) {
var img = new Image(),
...
img.onload = function() {
...
targetArray.forEach(function(obj, index) {
var x = obj.x - newTarget.x,
y = obj.y - newTarget.y,
dis = Math.sqrt(x*x + y*y)
if(dis < newTarget.width / 2 + obj.width / 2) {
isOk = false //那么这个对象就不要渲染了
}
if(isOk) {
//渲染该对象到dom
}
})
...
}
}
var newTarget = new Target(id, nowTime, width, scoreTarget)
newTarget.draw(newTarget)
当new出一个目标物后,在调用draw方法时将其传入到方法中。之后遍历存放目标物对象的数组,暂且将目标物想象成圆,通过两圆圆心距离与半径之和的比来判定要不要将其插入dom节点进行展示。如果童鞋们想要更精确的检测“碰撞”的方式,可以将游戏在canvas画布中进行实现。canvas中getImageData方法可以获取图像的像素点,通过两对象其像素点是否重合可以更为精准的判断。
关于障碍物的飞行采用了css中的transition来进行控制:
function setTransition(property, timing, speed) {
return {
'transition-property': property,
'-moz-transition-property': property,
'-webkit-transition-property': property,
'-o-transition-property': property,
'transition-timing-function': timing,
'-moz-transition-timing-function': timing,
'-webkit-transition-timing-function': timing,
'-o-transition-timing-function': timing,
'transition-duration': speed + 's',
'-moz-transition-duration': speed + 's',
'-webkit-transition-duration': speed + 's',
'-o-transition-duration': speed + 's',
}
}
Hinder.prototype.draw = function() {
var img = new Image(),
...
img.onload = function() {
...
$(img).css(setTransition('left', 'linear', this.speed))
...
}
}
通过一个较通用的方法返回一个可配置的transition动画对象,在障碍物类的原型方法中动态改变其css样式,其中动画的持续时间设定为障碍物的速度属性。这样来达到每个新生成的障碍物有着不同的飞行速度。
由于整个游戏会一直跑循环来快速的生成新的目标和障碍物。同时会维护一个存储目标和障碍物对象的数组,当有需求如碰撞检测时需要遍历整个数组。那么这么操作就意味着我们的数组不能太大不然会极大地占用内存。同时当障碍物移出屏幕后理应清理掉这个节点,释放内存。故作者用两个定时器来跑两个检测对象过期的方法:
function clearTarget() { //清理过期目标
var nowTime = new Date().getTime()
targetArray.forEach(function(item, index) {
if(item.time + item.now < nowTime) {
//当生成对象时间+持续时间 > 当前时间即为过期
$('#' + item.id).remove()
targetArray.splice(index, 1)
}
})
targetTimer = setTimeout(clearTarget, xxx)
}
function clearHinder() { //清理过期障碍
hinderArray.forEach(function(item, index) {
if(item.shot) {
if('障碍物移出屏幕') {
$('#' + item.id).remove()
hinderArray.splice(index, 1)
}
}
})
setTimeout(clearHinder, xxx)
}
同样是采用粗略计算,采用弓箭的中心点和目标物/障碍物水平线两侧的点,如下图的(X2, Y2)的连线,与水平线的夹角来判断。
从图上可以看出按照上面的方法来判断的话。图中的α角是一个最小角。最大角应是目标对象水平线上左侧的点到弓箭中心点连线与水平线的夹角。故作者将计算当前对象与弓箭的夹角方法放到了对象原型中,以便射箭后遍历对象判断角度使用。
//yMax, yMin, xMax, xMin 为方便展示使用。具体数值从上图可以很快求出
Target.prototype.angle = function() {
var anglemax = Math.atan2(yMax, xMax)
var anglemin = Math.atan2(yMin, xMin)
function angleCal(angle) { //转化为°数
return (angle / Math.PI * 180) < 0 ? angle / Math.PI * 180 - 90 : angle / Math.PI * 180
}
var angleMax = angleCal(anglemax)
var angleMmin = angleCal(anglemin)
return {
max: angleMax,
min: angleMmin
}
}
需注意的是里面使用了Math.atan2(y, x)方法。注意里面参数顺序哦=。=
不知道尝试了这个游戏的童鞋有没有注意到,当点击了某一个方向后,箭会顺着这个方向射出,并且会沿途判断有没有射中什么东西,如果射中了那么就要停在那个对象身上,没射中就无所谓了。那么这一点的实现我们就不能是使用如目标物身上绑定监听事件来解决了。那么现在再来看这个图:
(X1, Y1)为点击的位置,沿着这个方向延伸就会延伸到(X2, Y2),那么应该是射中了,这个时候需要渲染箭到(X2, Y2)这个点。如何实现呢,其实图中已经有了结果。X2为当前对象的left + width, X1为触摸点的client.X, Y1为画布高 - client.Y - 弓箭高/2;那么结果是不是已经很明了了呢。再加上之前的角度我们已经有原型方法计算过,可以通过css中的rotate使得射出的箭改变方向,那么至此这个需求也算是基本完成。
本次原本打算采用canvas来做这个游戏,但是初步尝试之后发现可能由于绘制得太频繁,手机显示出来效果实在是。。当然也因为作者对这种小游戏的实现经验不足。只借此分享一个小case,欢迎指正。
本次是一个基础不能再基础的复习贴。旨在了解人人皆知的浮动,以及通过clear与bfc清除浮动的一些规范上的解释。
PS:下文没有css样式,全部通过语义化class来表示,因为我发现po一大堆css真是“又臭又长”还懒得看=。=
欢迎关注我的博客,不定期更新中——
float CSS属性指定一个元素应沿其容器的左侧或右侧放置,允许文本和内联元素环绕它。该元素从网页的正常流动中移除,尽管仍然保持部分的流动性(与绝对定位相反)。
基础效果大家都是熟悉的不能再熟悉了,在这些特性中有一点要牢记就是元素从页面常规流中移除了,其他元素无法感知到它的存在,但是文本和内联元素可以环绕它。可以看下两个例子来复习一下float产生的效果:
<div class="border">
<div class=" div red left"></div>
<div>
As much mud in the streets as if the waters had
but newly retired from the face of the earth,
and it would not be wonderful
to meet a Megalosaurus, forty feet long or so,
waddling like an elephantine lizard up Holborn Hill.
</div>

我们会发现,虽然红div下面是一个div是块级元素但由于浮动元素特性,导致下面的div中的文字产生了环绕效果,好像可以感知红div边界一样。这也算是保持了部分的流动性,因为如果我们像下面这样写,结果就有所区别了:
<div class="border">
<div class=" div red absolute"></div>
<div>
As much mud in the streets as if the waters had
but newly retired from the face of the earth,
and it would not be wonderful
to meet a Megalosaurus, forty feet long or so,
waddling like an elephantine lizard up Holborn Hill.
</div>

绝对定位的元素同样脱离了文档流,但是它真是完完全全脱离了,连文字都不认识它了哦。
同样,如果浮动元素下面的元素不是文字的话,效果就会和我们平时所见的那样:
<div class="border">
<div class=" div red left"></div>
<div class="div2 green"></div>
</div>

最常见的情况:普通的文档流的元素并不能感知到float的存在。从而也就会引发很经典的浮动导致父元素高度塌陷的问题:
<div class="border">
<div class=" div red left"></div>
<div class=" div green left"></div>
<div class="div blue left"></div>
</div>

很经典的问题:父元素高度没了!那么我们要怎么做?恢复父元素高度咯!
刚接触前端的时候就开始学清除浮动,清除浮动。但是清除浮动的这个核心clear,到底做了什么?
clear CSS 属性指定一个元素是否可以在它之前的浮动元素旁边,或者必须向下移动(清除浮动) 在它的下面。clear 属性适用于浮动和非浮动元素。
划重点:clear只是指定了一个元素是放在之前浮动元素旁边还是另起一行。这个和我们父元素没高度看似好像没啥关联。但是这么用了貌似就恢复了父级高度即清除浮动。看下示例代码:
<div class="border">
<div class=" div red left"></div>
<div class=" div green left clear"></div>
<div class="div blue left"></div>
</div>

上面的例子确实用到了clear,但是父级高度并没有恢复。原因在于其中每个元素都设置了浮动。而clear也只是让其中一个元素并不在上一个浮动元素旁边,而是换行了,但这并不是我们想要的效果。因为clear做的并不是真的清除了浮动,只是“换了个行”。浮动本身还是存在的,全部脱离文档流。故上图中的父级高度仍然为0。
看下这个例子
<div class="border">
<div class=" div red left"></div>
<div class=" div green clear"></div>
<div class="div blue left"></div>
</div>

可以看到在绿div中设置了clear但是没有设置float,我们恢复了父级的高度。从而说明“清除浮动”背后所做的,恢复父级高度,就是在浮动元素下方安插一个正常文档流的元素,这样父元素计算高度的时候会对其进行包裹,那么高度自然就计算出来了。
以此我们就可以了解到,市面上对于清除浮动(恢复父级高度)的方式,如果用到了clear,其核心思路就是安插一个正常文档流节点在最后,并且换行。原因自然是不换行(clear)的话,正常文档流感知不到浮动存在,计算的高度会少浮动元素的高度。
通过clear的方式确实可以恢复父级高度,那么还有没有别的方式呢?好的bfc。
一个块格式化上下文(block formatting context) 是Web页面的可视化CSS渲染出的一部分。它是块级盒布局出现的区域,也是浮动层元素进行交互的区域。
对于bfc的细节就不细说了,百度上有很多介绍的都很一致的文章了,随意看一篇。大体来说,bfc创建了一个自己的块,不干扰别人,别人不干扰它,同时这次关于恢复父级高度,我们只需要用到下图关于bfc的一个特性就可以了:

附规范地址(https://www.w3.org/TR/CSS2/visudet.html#root-height)
简单来说就是,触发了bfc的元素,在计算高度的时候包括浮动元素。那么结果就很明了了。我们只需要对父级元素触发bfc就好了,触发方式如下:
举一个最基本的overflow的例子:
<div class="border overflow">
<div class=" div red left"></div>
<div class="div green left"></div>
</div>

很明显高度一定会恢复。
在最初接触前端的时候,一直可能会被清除浮动误导,以为clear就是清除了浮动,但其实clear并没有这个操作。要知道我们所做的一切都是围绕如何恢复父级元素的高度来做的就好,至于方法已经说过啦,就是面试前背的一大堆。
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次分享一下在一次jQuery赋值样式失效的结果中来分析背后原因的过程。在翻jQuery源码的过程中,感觉真是还不能说自己只是会用jQuery,我好像连会用都达不到(逃
欢迎关注我的博客,不定期更新中——
$('#' + id).css({"left": "200"})

我只是单纯的想控制一个left值,大家都懂,但是竟然失败了,打印出的元素属性中可以看到left为"";我其实一开始没想到可能是jQuery本身的原因导致的,我先考虑的是我这个元素是不是当前要赋值的?js的问题?等等。。干想了半天,认为可能还是本身的写法问题。所以进行了如下实验:
$('#' + id).css({"left": 200})
看起来是字符串和数字的区别!omg,从来没想过字符串和数字的效果竟然会不一致。。你以为事情已经结束了?no,看下面这个:
$('#' + id).css({"width": "200"})
好的为什么,width设定字符串就可以被添加px后缀,left就不可以??
现在我们可以总结一下通过jQuery.fn.css方法来设定元素属性的时候会有一些不一致的情况,以width和left为例子(因为属性很多,不一致的情况很多,了解原理即可):
从而可以抛出由一开始的奇怪现象的底层问题:为什么通过jQuery.fn.css方法设定样式时,string类型的值在某些属性上无法生效?
jQuery的源码相比react、vue相比应该是很直接的了,就是一个js。(不过我仍然看不懂?
首先引入一个没有压缩过的jQuery,里面保留了所有的注释和代码结构,很方便大家阅读
https://cdn.bootcss.com/jquery/3.3.1/jquery.js
先找到我们本次设定样式的方法jQuery.fn.css:
jQuery.fn.extend( {
css: function( name, value ) {
return access( this, function( elem, name, value ) {
var styles, len,
map = {},
i = 0;
if ( Array.isArray( name ) ) {
styles = getStyles( elem );
len = name.length;
for ( ; i < len; i++ ) {
map[ name[ i ] ] = jQuery.css( elem, name[ i ], false, styles );
}
return map;
}
return value !== undefined ?
jQuery.style( elem, name, value ) :
jQuery.css( elem, name );
}, name, value, arguments.length > 1 );
}
} );
如何通过浏览器来调试源码呢?(因为直接看源码太繁琐了,通过debug的形式可以看到每次的调用栈)我们可以通过console.log的形式,在这段源码中将console写入,之后在控制台中就可以看到对应源码的调用:

进入jQuery.style之后就会来到最终产生区别的地方:
style: function( elem, name, value, extra ) {
...
hooks = jQuery.cssHooks[ name ] || jQuery.cssHooks[ origName ];
if ( value !== undefined ) {
type = typeof value;
if ( type === "string" && ( ret = rcssNum.exec( value ) ) && ret[ 1 ] ) {
value = adjustCSS( elem, name, ret );
type = "number";
}
...
if ( type === "number" ) {
value += ret && ret[ 3 ] || ( jQuery.cssNumber[ origName ] ? "" : "px" );
}
...
if ( !hooks || !( "set" in hooks ) ||( value = hooks.set( elem, value, extra ) ) !== undefined ) {
//此时的value到底是200还是200px;只有添加了后缀才能赋值成功
if ( isCustomProp ) {
style.setProperty( name, value );
} else {
style[ name ] = value;
}
}
}
...
},
源码中可以看到在传入的value中确实对string和number做了区分;而不是我之前所认为的,string应该和number差不多:)如果传入number类型,便会为其添加px后缀;但是这仍然没有解释为什么left和width均传入string而结果不同的问题。重点在于这句话:
hooks = jQuery.cssHooks[ name ] || jQuery.cssHooks[ origName ];
...
if ( !hooks || !( "set" in hooks ) ||
( value = hooks.set( elem, value, extra ) ) !== undefined ) {
...
}
在value是string类型,到最终赋值之前,还会经过value = hooks.set( elem, value, extra ) ) !== undefined的判断,也就是说如果hooks.set方法存在,我们还有一次通过这个方法来将string类型的value进行后缀补全的机会。而这个hooks是由jQuery.cssHooks得到的,那么jQuery.cssHooks是什么:

从源码中可以看出,cssHooks中包含了属性的一些方法,其中left只有get;width有get和set。再结合上面的判断条件就可以推断出,由于width存在了set方法,在其方法中对string类型的value完成了后缀的补齐,而left则不行从而形成了文中一开始的“神奇”现象。
直接向 jQuery 中添加钩子,用于覆盖设置或获取特定 CSS 属性时的方法,目的是为了标准化 CSS 属性名或创建自定义属性。
$.cssHooks 对象提供了一种通过定义函数来获取或设置特定 CSS 值的方法。可以用它来创建新的 cssHooks 用于标准化 CSS3 功能,例如,盒子阴影(box shadows)及渐变(gradients)。例如,某些基于 Webkit 的浏览器会使用 -webkit-border-radius 来设置对象的 border-radius,然而,早先版本的 Firefox 则使用 -moz-border-radius。cssHook 就可以将这些不同的写法进行标准化,从而让 .css() 可以使用统一的标准化属性名(border-radius 或对应的 DOM 属性写法 borderRadius)。
该方法除了提供了对特定样式的处理可以采用更加细致的控制外,$.cssHooks 同时还扩展了 .animate() 方法上的属性集。
简单来说,jQuery给我们暴露了一个钩子,我们可以自己定义方法比如set,来实现针对某个属性的特定行为。所以出现left和width的问题就是有没有set这个钩子方法。so。。我们还剩最后一个问题:
为什么width要对其设定钩子函数?
答案可以从其set方法来窥探一下:
set: function( elem, value, extra ) {
var matches,
styles = getStyles( elem ),
isBorderBox = jQuery.css( elem, "boxSizing", false, styles ) === "border-box",
subtract = extra && boxModelAdjustment(
elem,
dimension,
extra,
isBorderBox,
styles
);
// Account for unreliable border-box dimensions by comparing offset* to computed and
// faking a content-box to get border and padding (gh-3699)
if ( isBorderBox && support.scrollboxSize() === styles.position ) {
subtract -= Math.ceil(
elem[ "offset" + dimension[ 0 ].toUpperCase() + dimension.slice( 1 ) ] -
parseFloat( styles[ dimension ] ) -
boxModelAdjustment( elem, dimension, "border", false, styles ) -
0.5
);
}
// Convert to pixels if value adjustment is needed
if ( subtract && ( matches = rcssNum.exec( value ) ) &&
( matches[ 3 ] || "px" ) !== "px" ) {
elem.style[ dimension ] = value;
value = jQuery.css( elem, dimension );
}
return setPositiveNumber( elem, value, subtract );
}
从这个钩子函数中我们可以看出,要对width做特殊处理是因为css的盒模型有好几种,content-box|border-box|inherit分别代表“不包括padding、border、margin” | “包含border和padding” | “继承”;故为了统一外界的调用,隐藏这些背后的判断,从而增加了这个set方法。顺带着在其中把px补全了。同时left这种没什么需要兼容的故没有设定set方法。
虽然cssHooks不常用(我反正从来没用过,现在对于标准化格式有很多其他的方法来做,cssHooks的钩子感觉还是有些复杂了),但这次通过页面上一个很小的问题从而引发思考并且试图深挖一些的过程还是值得总结下来的。虽然我们不是造轮子的人,但理解别人的轮子也是比“会用”好一些的;更何况看了cssHooks我感觉我都不会用jQuery:)
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
这不是一篇分析源码的文章——因为作者也没有怎么看源码。本文主要分析jQuery中到底是如何进行构造原型链的。思路是通过逆推来抛出问题再用正推的方式来分析解决问题。欢迎关注作者博客,不定期更新中——
首先你知道jQuery有两种使用方法吧?
一种是jQuery('#xxx');一种是new jQuery('#xxx');
这两种方式都会返回一个实例。其原型链应该有一大堆方法。比如:jQuery('#xxx').css;jQuery('#xxx').attr;jQuery('#xxx').html...等等。
并且我们应该认识到jQuery这个函数一方面返回了一个实例,另一方面其本身也是构造函数(因为 new jQuery),那么其原型链也应该指向了那一大堆方法。我们一步步打印一下来验证下猜测:
console.log(jQuery) // 来看下jQuery函数体
function ( selector, context ) {
// The jQuery object is actually just the init constructor 'enhanced'
// Need init if jQuery is called (just allow error to be thrown if not included)
return new jQuery.fn.init( selector, context );
} //小技巧,可以引入没有压缩过的jQuery进行学习,这样备注,变量名会抱持原样。
好的果然没猜错,我们看到了一个构造函数为jQuery.fn.init 。通过new这个构造函数就可以采用第一种jQuery()的形式来生成实例。接下来验证下jQuery.fn.init的prototype属性上是不是有我们猜测的一大堆方法。
console.log(Object.keys(jQuery.fn.init.prototype))
// ["jquery","constructor","init","show","hide","toggle","on","one", "off","detach","remove","text","append", ...]
从结果中也可以知道我们的推测是正确的。在jQuery.fn.init的prototype中有着封装的方法可供实例调用。
验证了无new构造实例的形式之后再来看下对于jQuery同时应该是个构造函数的猜测。
console.log(Object.keys(jQuery.prototype))
//["jquery","constructor","init","show","hide","toggle","on","one", "off","detach","remove","text","append", ...]
console.log(jQuery.prototype === jQuery.fn.init.prototype) //true
可以看出jQuery也确实是一个构造函数其prototype和jQuery.fn.init的一样都指向了那一大堆方法。
让我们再看下这段代码:
function ( selector, context ) {
// The jQuery object is actually just the init constructor 'enhanced'
// Need init if jQuery is called (just allow error to be thrown if not included)
return new jQuery.fn.init( selector, context );
}
这里面返回的构造函数jQuery.fn.init我们可以看成是调用了jQuery.fn的init方法。同时细心的同学们应该可以观察到,在jQuery.fn.init.prototype中也有个方法叫init!。那么是不是。。让我们打印一下我们的猜测:
console.log(jQuery.fn.init.prototype.init === jQuery.fn.init) //true
发现了么同学们!既然jQuery.fn可以调用jQuery.fn.init其原型链上的方法,那么一定有:
jQuery.fn.init.prototype === jQuery.fn // true
好的现在大家可能有种似懂非懂的感觉?来看下面这张图来总结下我们的发现。
通过前文加上我们上图的展示,原型链的关系已经很明了了。在原型链上绑定了很多很多方法确定无疑。与此同时有三个东西指向了该原型链即:
jQuery.fn === jQuery.fn.init.prototype //true
jQuery.fn.init.prototype === jQuery.prototype //true
在完成这三个的指向之后就可以满足我们起初的需求:
当然了jQuery里面还有方法是绑定在jQuery本身的,绑定在原型链上的方法通过jQuery('#xxx').xxx调用,这个是相对某个元素的方法,绑定在jQuery本身的方法通过$.xxx调用,这个是某种特定的静态方法。我们现在只是讨论基础的jQuery在最外层构建时这些prototype属性都是怎么关联的。想深入了解的欢迎去读源码——
再回过头来看上文提到的三个需求:
如果让你来写一个你怎么写?ok,我们一步一步来
//v1.0
var j = function(selector){
return new init(selector);
}
var init = function() {...}
//v2.0
//即fn.init的原型应该是j.prototype
var fn = {}
var xxx = function() {}
fn.init = function(selector) {console.log(selector)}
var j = function(selector){
return new fn.init(selector);
}
xxx.prototype = {
setColor: function(color){console.log(color)}
...
}
fn.init.prototype = xxx.prototype
var a = new j(1) //1
a.setColor('red') // red
//v3.0
var xxx = function() {}
var j = function(selector){
return new j.fn.init(selector); //借用j.fn来找到原型链方法,不然找不到
}
j.fn = xxx.prototype = { //j本身是构造函数
init: function(selector) {
console.log(selector)
},
setColor: function(color) {
console.log('setColor:' + color)
}
}
j.fn.init.prototype = j.fn
var a = new j(1)
a.setColor('red')
//v3.0
//将xxx替换为j,那么j当做构造函数后其原型链也指向了那一堆方法
var j = function(selector){
return new j.fn.init(selector); //借用j.fn来找到原型链方法,不然找不到
}
j.fn = j.prototype = { //j本身是构造函数
init: function(selector) {
console.log(selector)
},
setColor: function(color) {
console.log('setColor:' + color)
}
}
j.fn.init.prototype = j.fn
var a = new j(1)
a.setColor('red')
至此我们便写好了一个jQuery初级版原型链的一个构建。里面很多操作更多的是为了让暴露的变量尽可能的少,所以在原型链构件上有一种循环赋值的赶脚哈哈哈。有兴趣的同学可以继续研究。
本次分享一下使用canvas来进行视频播放并且添加弹幕功能。
欢迎关注我的博客,不定期更新中——
示例源码见:源码地址

可以看到上方为一段视频,下面是用canvas来重新绘制的视频,并且支持动态的添加弹幕。
canvas中的drawImage方法绘制图片所需要的数据源不单单是某张图片,同样可以是使用视频的某一帧来进行绘制。就像这样:
var video = document.getElementById('video')
var canvas = document.getElementById('canvas');
var ctx = canvas.getContext('2d');
var ctx.drawImage(video, 0, 0, width, height);//当视频开始播放后触发这个方法可以开始绘制视频
因为canvas提供了getImageData && putImageData方法使得操作者可以动态得来更改每一帧图像的显示状态,如果你知道它应该怎么变:)
比如像MDN中提到的可以对上面这段视频中的黄色背景进行色调的变化:mdn示例地址
this.ctx1.drawImage(this.video, 0, 0, this.width, this.height);
let frame = this.ctx1.getImageData(0, 0, this.width, this.height);
let l = frame.data.length / 4;
for (let i = 0; i < l; i++) {
let r = frame.data[i * 4 + 0];
let g = frame.data[i * 4 + 1];
let b = frame.data[i * 4 + 2];
if (g > 100 && r > 100 && b < 43)
frame.data[i * 4 + 3] = 0; //将视频黄色部分的透明度进行了变化
}
this.ctx2.putImageData(frame, 0, 0);
视频中效果截图如下:

更多关于canvas的图像操作可以参考下面这两篇文章:
基于canvas的图像处理可以实现很强大的功能,比如滤镜啊之类的~
腾讯的Aolly Team团队出品的AlloyImage - 基于HTML5技术的专业图像处理库就是个很好的范例。作者就搞不明白那些高深的东西了,什么拉普拉斯算子,各种算子:)
弹幕功能分为两部分:
通过维护一个弹幕数组来实时去渲染每一个弹幕字条的应有位置。而何时更新这个数组,为了解耦作者使用了发布订阅的方式来进行数组的更新。当然这里并不是一定要使用这种模式,只不过作者刚刚学习完所以拿来用一下而已。千万别喷我:)
var Event = (function(){
var list = {},
listen,
trigger,
remove;
listen = function(key,fn){ /收集监听事件
if(!list[key]) {
list[key] = [];
}
list[key].push(fn);
};
trigger = function(){/触发后依次执行回调
var key = Array.prototype.shift.call(arguments),
fns = list[key];
if(!fns || fns.length === 0) {
return false;
}
for(var i = 0, fn; fn = fns[i++];) {
fn.apply(this,arguments);
}
};
remove = function(key,fn){
var fns = list[key];
if(!fns) {
return false;
}
if(!fn) {
fns && (fns.length = 0);
}else {
for(var i = fns.length - 1; i >= 0; i--){
var _fn = fns[i];
if(_fn === fn) {
fns.splice(i,1);
}
}
}
};
return {
listen: listen,
trigger: trigger,
remove: remove
}
})();
//调用方式
Event.listen('data', addNewWord)
$('#submit').click(function() { //点击发送后便触发data事件
var data = $('input').val()
Event.trigger('data', {
value: data,
})
})
function addNewWord (data) {
var newWord = new Barrage(this.canvas, this.ctx, data) //构建新的弹幕实例
wordObj.push(newWord)
},
声明了一个弹幕的构造函数,内部包含了其各种属性并且在原型链中添加了draw方法来进行绘制:
function Barrage(canvas, ctx, data) {
this.width = canvas.width
this.height = canvas.height
this.ctx = ctx
this.color = data.color || '#'+Math.floor(Math.random()*16777215).toString(16) //随机颜色
this.value = data.value
this.x = this.width //x坐标
this.y = Math.random() * this.height
this.speed = Math.random() + 0.5
this.fontSize = Math.random() * 10 + 12
}
Barrage.prototype.draw = function() {
if(this.x < -200) {
return
} else {
this.ctx.font = this.fontSize + 'px "microsoft yahei", sans-serif';
this.ctx.fillStyle = this.color
this.x = this.x - this.speed
this.ctx.fillText(this.value, this.x, this.y)
}
}
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
aaaa
本次分享一下在canvas中将绘制出来的折线段的棱角“磨平”,也就是通过贝塞尔曲线穿过各个描点来代替原有的折线图。
欢迎关注我的博客,不定期更新中——
先来看下Echarts下折线图的渲染效果:
一开始我没注意到其实这个折线段是曲线穿过去的,只认为是单纯的描点绘图,所以起初我实现的“简(丑)易(陋)”版本是这样的:
不要关注样式,重点就是实现之后才发现看起来人家Echarts的实现描点非常的圆滑,也由此引发了之后的探讨。怎么有规律的画平滑曲线?
先来看下最终模仿的实现:
因为我也不知道Echarts内部怎么实现的(逃
看起来已经非常圆润了,和我们最初的设想十分接近了。再看下曲线是否穿过了描点:
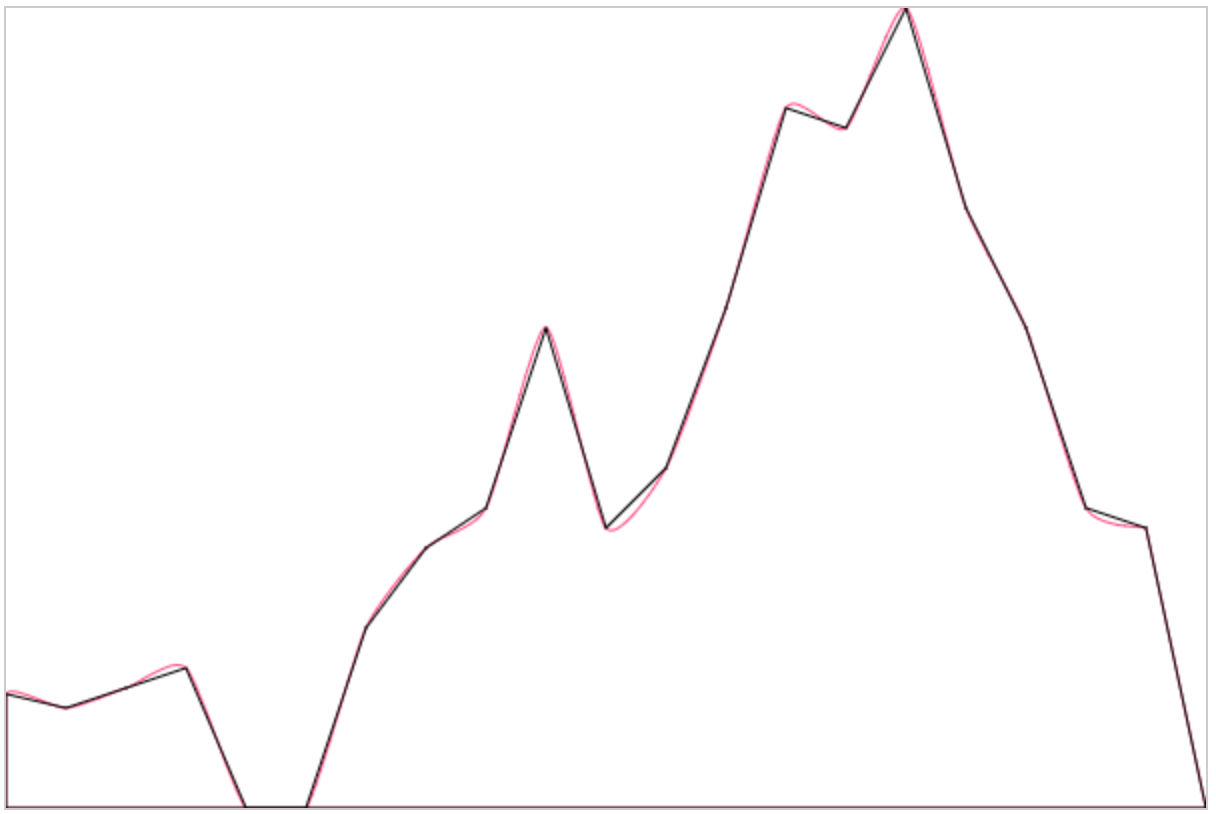
好的!结果很明显现在来重新看下我们的实现方式。
var data = [Math.random() * 300];
for (var i = 1; i < 50; i++) { //按照echarts
data.push(Math.round((Math.random() - 0.5) * 20 + data[i - 1]));
}
option = {
canvas:{
id: 'canvas'
},
series: {
name: '模拟数据',
itemStyle: {
color: 'rgb(255, 70, 131)'
},
areaStyle: {
color: 'rgb(255, 158, 68)'
},
data: data
}
};
首先初始化一个构造函数来放置需要用到的数据:
function LinearGradient(option) {
this.canvas = document.getElementById(option.canvas.id)
this.ctx = this.canvas.getContext('2d')
this.width = this.canvas.width
this.height = this.canvas.height
this.tooltip = option.tooltip
this.title = option.text
this.series = option.series //存放模拟数据
}
绘制折线图:
LinearGradient.prototype.draw1 = function() { //折线参考线
...
//要考虑到canvas中的原点是左上角,
//所以下面要做一些换算,
//diff为x,y轴被数据最大值和最小值的取值范围所平分的等份。
this.series.data.forEach(function(item, index) {
var x = diffX * index,
y = Math.floor(self.height - diffY * (item - dataMin))
self.ctx.lineTo(x, y) //绘制各个数据点
})
...
}
贝塞尔曲线的关键点在于控制点的选择,这个网站可以动态的展现控制点不同而绘制的不同的曲线。而对于控制点的计算。。作者还是选择了百度一下毕竟数学不好:),这篇文章对于将多个点使用贝塞尔曲线连接时各个控制点的计算。具体算法有兴趣的同学可以深入了解下,现在直接说下计算控制点的结论。
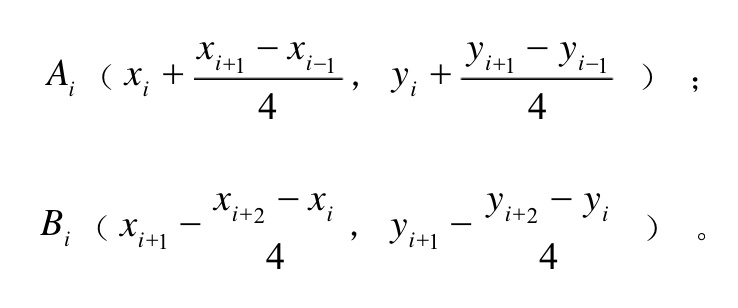
上面的公式涉及到四个坐标点,当前点,前一个点以及后两个点,而当坐标值为下图展示的时候绘制出来的曲线如下所示:

不过会有一个问题就是起始点和最后一个点不能用这个公式,不过那篇文章也给出了边界值的处理办法:

所以在将折线换成平滑曲线的时候,将边界值以及其他控制点计算好之后代入到贝塞尔函数中就完成了:
//核心实现
this.series.data.forEach(function(item, index) { //找到前一个点到下一个点中间的控制点
var scale = 0.1 //分别对于ab控制点的一个正数,可以分别自行调整
var last1X = diffX * (index - 1),
last1Y = Math.floor(self.height - diffY * (self.series.data[index - 1] - dataMin)),
//前一个点坐标
last2X = diffX * (index - 2),
last2Y = Math.floor(self.height - diffY * (self.series.data[index - 2] - dataMin)),
//前两个点坐标
nowX = diffX * (index),
nowY = Math.floor(self.height - diffY * (self.series.data[index] - dataMin)),
//当期点坐标
nextX = diffX * (index + 1),
nextY = Math.floor(self.height - diffY * (self.series.data[index + 1] - dataMin)),
//下一个点坐标
cAx = last1X + (nowX - last2X) * scale,
cAy = last1Y + (nowY - last2Y) * scale,
cBx = nowX - (nextX - last1X) * scale,
cBy = nowY - (nextY - last1Y) * scale
if(index === 0) {
self.ctx.lineTo(nowX, nowY)
return
} else if(index ===1) {
cAx = last1X + (nowX - 0) * scale
cAy = last1Y + (nowY - self.height) * scale
} else if(index === self.series.data.length - 1) {
cBx = nowX - (nowX - last1X) * scale
cBy = nowY - (nowY - last1Y) * scale
}
self.ctx.bezierCurveTo(cAx, cAy, cBx, cBy, nowX, nowY);
//绘制出上一个点到当前点的贝塞尔曲线
})
由于我每次遍历的点都是当前点,但是文章中给出的公式是计算会知道下一个点的控制点算法,故在代码实现中我将所有点的计算挪前了一位。当index = 0时也就是初始点是不需要曲线绘制的,因为我们绘制的是从前一个点到当前点的曲线,没有到0的曲线需要绘制。从index = 1开始我们就可以正常开始绘制,从0到1的曲线,由于index = 1时是没有在他前面第二个点的故其属于边界值点,也就是需要特殊进行计算,以及最后一个点。其余均按照正常公式算出AB的xy坐标代入贝塞尔函数即可。
一直想实现一个聊天应用demo,尝试一下Socket.IO这个框架,同时看到网上的教程很多关于使用node开发聊天应用的demo都是聊天室形式的,也就是群聊,很少有实现私聊的。所以想自己实现一次。另外还尝试了在上传头像的时候接入腾讯云的万象优图API来上传下载注册用户的头像,事实证明确实蛮好用的=。=,只不过那个部署接口的服务器不知道什么时候就会没钱租了,所以可能并不能跑通上传功能T T。github地址
Vue.js是一款在2014年2月开源的前端MVVM开发框架,其内容核心为为开发者提供简洁的API,并且通过实现高效的数据绑定来构建一个可复用的组件系统。
Node.js是一个基于Chrome JavaScript运行时建立的平台, 用于方便地搭建响应速度快、易于扩展的网络应用。Node.js 使用事件驱动, 非阻塞I/O 模型而得以轻量和高效,非常适合在分布式设备上运行数据密集型的实时应用。
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
Socket.IO是一个完全由JavaScript实现、基于Node.js、支持WebSocket的协议用于实时通信、跨平台的开源框架。
Socket.IO除了支持WebSocket通讯协议外,还支持许多种轮询(Polling)机制以及其它实时通信方式,并封装成了通用的接口,并且在服务端实现了这些实时机制的相应代码。
Socket.IO会根据浏览器对通讯机制的支持情况,选择最佳方式实现网络实时通信。
因浏览器的安全限制,在input中提交的文件是不能获得文件的真实地址的这就导致无法直接通过地址来得到所需要的预览图。故可以使用一个HTML5API,FileReader对象。https://developer.mozilla.org/zh-CN/docs/Web/API/FileReader
腾讯云接口的部署分为两个部分,一个是自己服务器做鉴权服务,另一个是腾讯服务器来存储图片。由图可以看到第一步需要从自己服务器中获取上传头像的地址,这一步就是鉴权服务,详细代码可以参照腾讯云官方文档。之后的如何上传到腾讯云也是使用官方的接口。文档相对详细,同时如果出现bug还可以发起工单向tx的工程师咨询。那次我的bug那边的工程师晚上11点给我打电话来解决=。=,所以如果你有一个程序员老公/老婆,请好好珍惜
本次私聊和群聊的界面由同一个组件复用,在前端页面需要判断渲染私聊还是群聊消息。同时后端也需要判断是群聊还是私聊消息模式。
通讯的前端逻辑如下所示:
通讯的后端逻辑如下所示:
// client.js 前端部署socket.io
import io from 'socket.io-client'
const CHAT={
...
init:function(username){
//连接websocket后端服务器
this.socket = io.connect('http://127.0.0.1:3000',{'force new connection': true})
this.socket.on('open', function() {
console.log('已连接')
})
this.socket.emit('addUser', username)
}
}
export default CHAT
// server/bin/www 后端部署socket.io
var io = require('socket.io')(server)
io.on('connection', function(socket){
...
socket.emit('open')
...
})
socket.on("disconnect", function () {
console.log("客户端断开连接.")
delete '某一个对应socket对象'
//每次都要删除该socket连接 否则断开重连还是这个socket但是client端socket已经改变
})
部署之后前后端均可使用emit和on来发送和监听自定义事件。socket.io文档
2. 前端区分渲染私聊群聊
// src/component/talk.vue
<div v-for="msgObj in CHAT.msgArr" track-by="$index">
<div class="talk-space self-talk"
v-if="CHAT.msgArr[$index].fromUser == username && CHAT.msgArr[$index].toUser == $route.query.username"
track-by="$index">
<div class="talk-content">
<div class="talk-word talk-word-self">{{ msgObj.msg }}</div><i class="swip"></i>
</div>
</div>
<div v-else></div>
<div class="talk-space user-talk"
v-if="CHAT.msgArr[$index].toUser == username && CHAT.msgArr[$index].fromUser == $route.query.username"
track-by="$index">
<div class="talk-content">
<div v-if="CHAT.msgArr[$index].fromUser =='群聊'" class="talk-all">{{ msgObj.trueFrom }}</div>
<div class="talk-word talk-word-user">
{{ msgObj.msg }}
<i class="swip-user"></i>
</div>
</div>
</div>
可以看到在CHAT.msgArr维护了一个公共消息队列,这个队列里面有群聊也有私聊的消息。同时每一个数组对象里面都含有fromUSer,toUser方法,来作为记录发送消息的人和接受消息的人的区分。再配合路由中携带的用户名来判断该消息应该渲染在界面的左侧还是右侧。同时由于群聊中虽然用户所面对的聊天对象是“群聊”,但是在渲染左侧“群聊”发送的消息时,仍然应该渲染出真实的用户名即msgObj.trueFrom字段。
3.后端通讯逻辑
// server/bin/www
io.on('connection', function(socket){
var toUser = {}
var fromUser = {}
var msg = ''
socket.emit('open')
socket.on('addUser', function(username) {
if(!onlineUsers.hasOwnProperty(username)) {
onlineUsers[username] = socket
onlineCount = onlineCount + 1
}
user = username
console.log(onlineUsers[username].id) //建立连接后 用户点击不同通讯录都是建立同样的socket对象
console.log('在线人数:',onlineCount)
socket.on('sendMsg', function(obj) {
toUser = obj.toUser
fromUser = obj.fromUser
msg = obj.msg
time = obj.time
if (toUser == '群聊') { //判断为群聊模式
obj.fromUser = '群聊'
obj.toUser = user
obj.trueFrom = fromUser //携带真实发送方
for (user in onlineUsers) { //遍历所有对象,区分自己和其他用户
if( user != fromUser ) { //接收方
onlineUsers[user].emit('to' + user, obj)
} else { //发送方
obj.toUser = '群聊'
obj.fromUser = user
onlineUsers[fromUser].emit('to' + fromUser, obj)
}
}
}
else if(toUser in onlineUsers) { //私聊模式
onlineUsers[toUser].emit('to' + toUser, obj)
onlineUsers[fromUser].emit('to' + fromUser, obj)
} else {
console.log(toUser + '不在线')
onlineUsers[fromUser].emit('to' + fromUser, obj)
}
})
socket.on("disconnect", function () {
console.log("客户端断开连接.")
//遇到的坑 每次都要删除该socket连接 否则断开重连还是这个socket但是client端socket已经改变
delete onlineUsers[fromUser]
})
})
})
效果如下图:
这是一个最最最基本的聊天demo实现,也是我第一次自己写一个小分享。ui方面借用了网页版wx的部分样式。同时代码中仍然存在一些“不可预知”的bug,比如聊天消息显示有时候会出问题但是并没有好的方法来排查,主要是第一次使用vue来做前端框架,里面的html和js分离我还是不能很习惯,在debug方面做得还不够好,毕竟用了很久的react..嗯这都不是理由,所以欢迎交流心得,bug可提issues,虽然我可能...
最后po一个github地址:https://github.com/Aaaaaaaty/vue-im
博客地址:https://github.com/Aaaaaaaty/Blog
本次分享一下在作者上一次“失利”即拿到毕业证第二天突然“收到”阿里社招面试通知失败之后,通过分析自己的定位与实际情况,做出的未来一到两年的规划。以及本次社招的面试经历(但这部分不是重点,每个人的面试经历都是不一样的。千人千面嘛)
PS:当然了计划赶不上变化,半年后一次内推的机会“稀里糊涂”得就通过了。。
欢迎关注我的博客,不定期更新中——
上一次面试挂了后,我便对自己的情况进行了总结:
于此同时我个人认为通过面试的最重要关键点:一定要有一个亮点打动你的面试官!
亮点就是在某个层面的深入研究成果:)
PS: 只是针对刚工作的伙伴,高p请放过我
个人理解亮点可以是两方面:
在公司的项目中中,源于业务并高于业务的沉淀。正如同之前我总结个人情况中提到。如果你的简历里面主要介绍了react的项目。那么这其中会存在两个互补的研究即项目与react(同理还有vue与项目等等,为啥不是单独的react、vue;因为这只是个框架,结合框架解决实际问题才是最重要的,框架真的太多了,但业务都是相似的):
(1)业务的难点,如何解决,更好的思路?针对业务的优化?等等业务层面的深挖。
(2)针对react你都了解多少?如果你对其了解只停留在api的阶段,那应该是凉凉了。。源码?设计**?至少给知道diff怎么回事,setState到底是同步的还是异步的,以及为什么要这么处理?等等很多。
核心思路就是通过你的业务与对技术相结合的深度挖掘来打动你的面试官
第二点我是针对自己做的,因为结合我之前的分析可以发现我其实不具备1的条件,即没有主力业务。在你的业务量极小的时候,你是没有业务驱动的需求去让你挖掘那些背后的优化与更好的解决方案的。也许你会说那你也可以读react源码啊。但是,我读了源码不能反哺到业务中又有什么用呢?不知道如何解决实际的问题,仍然没有做到1的要求即项目与某框架的技术的结合沉淀。故针对我个人情况我选择了如下方式:
(1)由于自己其实没有别人那么忙,我就强制自己每周周末坚持沉淀自己,并产出技术文章,不论是哪个方面的(因为我真的做不到1中的事情,我只好多学习多产出)。通过撰写博客引起更多人的关注,同时也可以让面试官侧面了解我,毕竟一次面试能决定的东西太少了。
(2)在这个过程中我找到适合自己的路,选择一个较脱离主要业务(react之类的)的技术方向来进行一定程度的研究(我选的是canvas与node)。核心思路还是你要自己有自己的沉淀并以此试图打动面试官(逃
这是我半年来关于canvas与node的一些学习与记录:
2017.12月末,师哥突然跟我说现在部门有机会要不要试试,我本来是想拒绝的,因为距离上次被拒只差了半年,加上我现在工作经验满打满算也就一年,其中还有半年实习。。好的一面就来了:),由于这篇文章不是纯粹的面经也不是纯粹的技术文章,同时很多面试题都是有答案的,故大家有兴趣自行百度下面面试题,作者不过多说明。
一面其实就是我的师哥。。所以严格来说就是一次交流,没有技术上的问题;因为我的朋友圈其实已经发了很多我自己的玩具代码了估计师哥心里也是有数的:)
主要介绍了目前团队所做的业务、相关的理念等等。更多的就是互相了解情况,我大概说了一下我这边做的事基本也就结束了。
二面是师哥的老大,也是未来我如果入职的上司。其实这才算是一面。他更多的是来对我了解一些基础情况与一些技术**(他本身是java)聊得很快也就20分钟:
面试官好像和豆瓣有些渊源,上来就问我你是不是克军团队的,我说我不是。。
穿插了一个笔试,就一道题:写一个js的通用事件绑定函数
交叉面充分说明了,没有主力业务的可怕=。=,因为你不能光写你的作品吧?你总给写公司的业务,但是这个业务吧你又没有需求把它优化到别人的标准,或者说根本没有优化:)
来到了北京的一个工作点,准备视频面,我之后才反应过来我其实已经被hr面过了。。因为跟在老板身边是个男的。。
至此完成了对自己这边年来的准备的一个回顾与面试经验的分享。面经不是重点每个人都是不一样的,更重要的应该是如何在当前的工作中找到自己应该努力的方向,并且持续地发光发热,让别人认可你,打动他们。
PS:目前是待发offer状态,之后如果hc没有问题,背调没有问题,体检没有问题,我就可以奔赴2000公里外的杭州了。当然了结果很重要,但过程更令人回味更多。
PPS: 这一切都是个人感悟,说的不对的,不严谨的,欢迎一起分享你的想法,在码梦的路上,一去不归。
PPPS:由于只毕业半年,我估计可能是p5(但是社招p5基本无hc),p6就太赚了,不过这都是后话,静候佳音
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
记得以前在人人上看到一个分享,讲解基于js的截图方案,详细的不记得了,只记得还挺有意思的貌似用了canvas?所以这次打算自己写一个分享给大家作者的思路。这只是一个很简陋的小demo如有bug请提issues。按照惯例po代码地址;以及作者博客的github仓库,不定期更新中——
由于快捷键可能导致的冲突故希望开始快捷键可以不限定快捷键数量,所以在第一个参数中采用了数组的形式进行传递。
function screenShot(quickStartKey, EndKey) {
//兼容性考虑不使用...扩展字符串
var keyLength = quickStartKey.length
var isKeyTrigger = {}
var cantStartShot = false
...
quickStartKey.forEach(function(item) { //遍历参数数组
isKeyTrigger[item] = false //默认数组中所有键都没有触发
})
$('html').on('keyup', function(e) {
var keyCode = e.which
if(keyCode === EndKey) {
...
} else if(!cantStartShot) {
isKeyTrigger[keyCode] = true
var notTrigger = Object.keys(isKeyTrigger).filter(function(item) {
return isKeyTrigger[item] === false //查看有没有需要触发的快捷键
})
if(notTrigger.length === 0) { //没有需要触发的快捷键即可以开始截图
cantStartShot = true
beginShot(cantStartShot)
}
}
})
如果采用原生的方法可以参照MDN下对于在canvas中绘制DOM的介绍。里面最棘手的地方是你需要创建一个包含XML的SVG图像涉及到的元素为 <foreignObject>。如何能计算出当前浏览器显示的DOM并且将其提取出来其实是最繁琐的。好的其实作者也没有好的思路手动实现一个=。=,所以选择了这个html2canvas库来完成这件事。大致调用方式如下:
function beginShot(cantStartShot) {
if(cantStartShot) {
html2canvas(document.body, {
onrendered: function(canvas) {
//得到与界面一致的canvas图像
}
})
}
}
这个地方的实现本来打算使用原生canvasAPI,但是里面涉及到一个问题就是在鼠标按下开始拖拽后,canvas要实时绘制,这里面就要引出一个类似于PS图层的概念,每当mousemove的时候都画出一个当前的截图框,但是当下一次触发mousemove的时候就删掉上一个截图框。以此来模拟实时的绘制过程。无奈作者没有找到使用canvas原生API的方法,如果有的话一定告诉我如何对画出的图做出标记。在这里作者使用了一个基于Jq的canvas的库叫做Jcanvas,里面给出了图层的概念,即在一个图层上只能画一张图,同时可以给图层标记名称。这就满足了作者的需求,实现如下:
$('#' + canvasId).mousedown(function(e) {
$("#"+canvasId).removeLayer(layerName) //删除上一图层
layerName += 1
startX = that._calculateXY(e).x //计算鼠标位置
startY = that._calculateXY(e).y
isShot = true
$("#"+canvasId).addLayer({
type: 'rectangle', //矩形
...
name:layerName, //图层名称
x: startX,
y: startY,
width: 1,
height: 1
})
}).mousemove(function(e) {
if(isShot) {
$("#"+canvasId).removeLayer(layerName)
var moveX = that._calculateXY(e).x
var moveY = that._calculateXY(e).y
var width = moveX - startX
var height = moveY - startY
$("#"+canvasId).addLayer({
type: 'rectangle',
...
name:layerName,
fromCenter: false,
x: startX,
y: startY,
width: width,
height: height
})
$("#"+canvasId).drawLayers(); //绘制
}
})
var canvasResult = document.getElementById('canvasResult')
var ctx = canvasResult.getContext("2d");
ctx.drawImage(copyDomCanvas, moveX - startX > 0 ? startX : moveX, moveY - startY > 0 ? startY : moveY, width, height, 0, 0, width, height )
var dataURL = canvasResult.toDataURL("image/png");
其中通过drawImage截取了图像,再使用toDataURL方法将图像转换为了base64编码
function downloadFile(el, fileName, href){
el.attr({
'download':fileName,
'href': href
})
}
...
downloadFile($('.ok'), 'screenShot' + Math.random().toString().split('.')[1] || Math.random() + '.png', dataURL)
// 传入按键对象、图像保存随机名、base64编码的图像
其中用到了a标签的download属性,当用户点击之后就可以直接进行下载。
<script src="https://cdn.bootcss.com/jquery/3.2.1/jquery.min.js"></script>
<script src="https://cdn.bootcss.com/jcanvas/16.7.3/jcanvas.min.js"></script>
<script src="https://cdn.bootcss.com/html2canvas/0.5.0-beta4/html2canvas.min.js"></script>
screenShot([16, 65], 27) // 开始快捷键设置为shift+a;退出键为ESC
文中最恶心的地方(DOM写入canvas、canvas设置图层)分别采用了两个库来进行实现,后续作者还会陆续关注如何使用原生API来实现这些操作,虽然个人认为自己写还是有点。。
近期读到了alsotang的node教程,对一些基础知识又有了些新认识,故重新梳理了一下,分享出来。这里是教程地址。
本次使用了superagent、cheerio来爬取知乎的发现页文章列表,通过async来控制并发数来动态获取延时加载的文章。源码地址,以及作者的blog欢迎关注,不定期更新中——
// Spider.js
var http = require('http')
const server = http.createServer((req, res) => {
...
}).listen(9090)
nodejs封装了HTTP模块可以让我们快速的搭建一个基础服务,由上面代码可以看出其实一句话就可以解决问题。至于想深入HTTP模块可参照文档。至此我们可以通过
node Spider.js
来开启服务器,这里推荐使用nodemon其自动监听代码修改并自启动还是很方便的。
var baseUrl = 'http://www.zhihu.com/node/ExploreAnswerListV2'
superagent.get(baseUrl)
.set({
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Referrer': 'www.baidu.com'
})
.query({
params: JSON.stringify(params)
})
.end(function(err, obj) {
if(err) return null
res.end(JSON.stringify(obj))
//res是一个可写流里面传递的参数类型为string或buffer
//故使用JSON.stringify()
})
superagent采用了链式调用的形式其API用法一目了然。我们都知道现在的大列表都会实行懒加载,即用户下拉到一定程度再去请求新的列表,所以我们的爬虫也应该用某种规则来获取那些一开始进入页面没有获取到的文章列表。我们来看下知乎发现页下的network,当页面向下滚动的时候会加载新的文章,这个时候会发一个新的请求:
首先可以看到这是一个get请求,请求的key为params,后面携带了一个对象。作者多拉了几次页面发现了其中加载规律,每次加载都会是5篇文章。同时offset为0、5、10...由此我们可以通过动态生成offset拼接参数来请求,就可以理论上拿到n多的文章信息。在此作者犯了个小错误,一开始书写参数的时候作者是这么写的:
offset = 0、5、10...
var params = {
'offset':offset,
'type':'day'
}
superagent.get(baseUrl)
.query({
params: params
})
.end(function(err, obj) {
...
})
};
这样写在请求中会变成什么情况呢?
是不是哪里怪怪的?我们发现这么写的话浏览器会解析这个参数。。本身的样子应该是:
这个对象转变成了字符串,也就是调用了JSON.stringify()方法来将对象进行变换。我知道作者比较愚钝,以后不会再犯这种低级。。特此分享!
const cheerio = require('cheerio')
...
const server = http.createServer((req, res) => {
...
superagent.get(baseUrl)
...
.end(function(err, obj) {
if(err) return null
var $ = cheerio.load(obj.text)
//有兴趣可以打印obj看看里面都有什么;
//text属性中有着html信息;
var items = []
var baseUrl = 'https://www.zhihu.com'
$('.explore-feed').each(function (index, el) {
var $el = $(el)
var tittle = $el.find('h2 a').text().replace(/[\r\n]/g, '')
var href = url.resolve(baseUrl, $el.find('h2 a').attr('href'))
var author = $el.find('.author-link').text()
items.push({
title: tittle,
href: href,
author: author
})
})
res.end(JSON.stringify(items))
})
}).listen(9090)
通过cheerio.load()方法将返回的html封装为jQ形式,之后就可以使用jQ的语法对立面的html操作了,whatever u want.
现在的需求是我们希望可以动态的爬取页面信息,那么肯定就要发很多请求。在这里有两种选择。我们可以一次性去请求,也可以控制请求数来执行。在这里我们采用控制并发数的方式进行请求。原因主要在于浏览器通常会有安全限制不会允许对同一域名有过大的并发数毕竟早期服务器受不了这种操作,很脆弱;再由于有些网站会检测你的请求,如果并发数过多会觉得是恶意爬虫啥的之类的把你的IP封掉,所以乖乖的控制下并发数吧。
本次使用了这个为解决异步编程的弊端即回调地狱所推出的一个流程控制库,让开发人员可以有着同步编程的体验来进行异步开发,这样也顺应了人的思维模式。这里推荐一个github仓库这里面有着对async库使用的demo,简直好用到爆炸?借用其中一个例子:
var arr = [{name:'Jack', delay:200}, {name:'Mike', delay: 100}, {name:'Freewind', delay:300}, {name:'Test', delay: 50}];
async.mapLimit(arr,2, function(item, callback) {
log('1.5 enter: ' + item.name);
setTimeout(function() {
log('1.5 handle: ' + item.name);
if(item.name==='Jack') callback('myerr');
else callback(null, item.name+'!!!');
}, item.delay);
}, function(err, results) {
log('1.5 err: ', err);
log('1.5 results: ', results);
});
//57.797> 1.5 enter: Jack
//57.800> 1.5 enter: Mike
//57.900> 1.5 handle: Mike
//57.900> 1.5 enter: Freewind
//58.008> 1.5 handle: Jack
//58.009> 1.5 err: myerr
//58.009> 1.5 results: [ undefined, 'Mike!!!' ]
//58.208> 1.5 handle: Freewind
//58.208> 1.5 enter: Test
//58.273> 1.5 handle: Test
可以看出mapLimit核心的操作就是先放入需要异步操作的数据,再设定并发数;然后在第一个func中对其进行遍历执行,当执行完成后调用callback,最后所有callback会汇总到第二个func中。有兴趣的同学可以去阅读文档,async对异步操作的封装还是很完善的。
var superagent = require('superagent')
var cheerio = require('cheerio')
var http = require('http')
var url = require('url');
var async = require('async')
const server = http.createServer((req, res) => {
var count = 0;
var fetchUrl = function (offset, callback) {
count++;
console.log('当前并发数:', count) //测试并发数
var baseUrl = 'http://www.zhihu.com/node/ExploreAnswerListV2'
var params = {
'offset':offset,
'type':'day'
}
superagent.get(baseUrl)
.set({
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'Referrer': 'www.baidu.com'
})
.query({
params: params
})
.end(function(err, obj) {
if(err) return null
var $ = cheerio.load(obj.text)
var items = []
var baseUrl = 'https://www.zhihu.com'
$('.explore-feed').each(function (index, item) {
// item = this, $(this)转换为jq对象
var tittle = $(this).find('h2 a').text().replace(/[\r\n]/g, '') //去掉空格
var href = url.resolve(baseUrl, $(this).find('h2 a').attr('href'))
var author = $(this).find('.author-link').text()
items.push({
title: tittle,
href: href,
author: author
})
})
res.end(JSON.stringify(items))
count--
console.log('释放了并发数后,当前并发数:', count)
callback(null, JSON.stringify(items))
})
};
var offsets = [];
for(var i = 0; i < 13; i++) {
offsets.push(i * 5); //生成很多offset参数值
}
async.mapLimit(offsets, 5, function (offset, callback) {
fetchUrl(offset, callback);
}, function (err, result) {
res.writeHead(200, { 'Content-Type': 'text/plain; charset=utf8' });
//记得加上编码utf-8 有乱码别找我
res.end(JSON.stringify(result))
});
}).listen(9090)
再看下后端console下对并发数的检测:
以及爬取到的文章列表:
一直希望可以学好node,但总是由于各种原因被阻挠,现在准备开始细细学习一下原生的API(至于怎么实现的。。对不起这辈子注定无缘c++。脑子真的不够),以后会不定期更新到blog中对于一些node基础知识的理解。基础真的很重要。
在平时的前端开发中我们经常会遇到这种操作。明明我代码更新了,咋刷出来还是以前的呢?是不是缓存了?快清下缓存看看!你看页面是304,怪不得没更新!等等很多情况。作者起初也不是很了解,因为这个不由前端来控制,都是后端的操作。故这次使用node也来写一个控制缓存的服务来真正搞明白这里的道道。欢迎关注我的博客,不定期更新中——
在说这个服务如何写之前我们先要明白浏览器缓存到底是个啥。来看下这个简略示意图:
可以看到浏览器的缓存机制分为两个部分。1、当前缓存是否过期?2、服务器中的文件是否有改动?
这是判断是否启用缓存的第一步。如果浏览器通过某些条件(条件之后再说)判断出来,ok现在这个缓存没有过期可以用,那么连请求都不会发的,直接是启用之前浏览器缓存下来的那份文件:
图中看到这个css文件缓存没有过期,被浏览器直接通过缓存读取了出来,注意这个时候是不会向浏览器请求的! 如果过期了就会向服务器重新发起请求,但是不一定就会重新拉取文件!
如果服务器发现这个文件改变了那么你肯定不能再用以前浏览器的缓存了,那就返回个200并且带上新的文件:
同时如果发现虽然那个缓存虽然过期了,可你在服务器端的文件没有变过,那么服务器只会给你返回一个头信息(304),让你继续用你那过期的缓存,这样就节省了很多传输文件的时间带宽啥的。看下图:
过期了的缓存需要请求一次服务器,若服务器判断说这个文件没有改变还能用,那就返回304。浏览器认识304,它就会去读取过期缓存。否则就真的传一份新文件到浏览器。
在刚才的叙述中作者没有提到具体的判断过期及变动的实现方式,这也是为了可以让童鞋们现有一个整体的概念,无关乎代码,至少通过上面一段讲述,可以认识到“哦浏览器的缓存是这样一个流程”,就够了。下面我们来看下具体的如何操作:
主要的方式有两种,这两种都是设定请求头中的某一个字段来实现的:1、Expires;2、Cache-Control。由于Cache-Control设置后优先级比前者高,这次作者就先说下通过Cache-Control来控制缓存。
可以看到Cache-Control字段有很多值,其他的值有兴趣的同学可以自己尝试,现在作者要说最后一个值max-age;如果在请求头中设定了
var maxAgeTime = 60 //过期时间
res.writeHead(200, {
"Cache-Control": 'max-age=' + maxAgeTime
})
那么在60s内,如果再去请求这个文件的话,是不会发起请求的。因为还没有过期呢!唯一例外是如果这个文件是你在浏览器地址栏输入的地址来请求的(比如你请求localhost:3030/static/style.css),当你刷新的时候就会让当前的这个文件所设定的过期时间失效,直接去请求服务器来看是返回个304还是返回新文件。一般这么请求的都是我们常说的入口文件,入口文件一刷新就会重新向服务器请求,但是入口文件里面所引入的文件如js,css等不会随着刷新而另过期时间失效。除非你单找出来那个引入链接,通过浏览器地址栏去查询它并刷新 :)。
常用的方式为Etag和Last-Modified,思路上差不多,这里作者只介绍Last-Modified的用法。
Last-Modified方式需要用到两个字段:Last-Modified & if-modified-since。
先来看下这两个字段的形式:
可以看出其实形式是一样的,就是一个标准时间。那么怎么用呢?来看下图:
当第一次请求某一个文件的时候,就会传递回来一个Last-Modified 字段,其内容是这个文件的修改时间。当这个文件缓存过期,浏览器又向服务器请求这个文件的时候,会自动带一个请求头字段If-Modified-Since,其值是上一次传递过来的Last-Modified的值,拿这个值去和服务器中现在这个文件的最后修改时间做对比,如果相等,那么就不会重新拉取这个文件了,返回304让浏览器读过期缓存。如果不相等就重新拉取。
本次使用了Cache-Control&Last-Modified来做为缓存机制的判断条件。当然还有多种方式可以使用,希望了解更全面的同学可以去读读这篇文章:Web浏览器的缓存机制
总结前两个部分可以得出以下的流程图,现在再看这张图应该还是很明了的了。
var http = require("http")
var fs = require("fs")
var url = require("url")
http.createServer(function(req,res){
var pathname = url.parse(req.url).pathname
var fsPath = __dirname + pathname
fs.access(fsPath, fs.constants.R_OK, function(err){ //fs.constants.R_OK - path 文件可被调用进程读取
if(err) {
console.log(err) //可返回404,在此简略代码不再演示
}else {
var file = fs.statSync(fsPath) //文件信息
var lastModified = file.mtime.toUTCString()
var ifModifiedSince = req.headers['if-modified-since']
//传回Last-Modified后,再请求服务器会携带if-modified-since值来和服务器中的Last-Modified比较
var maxAgeTime = 3 //设置超时时间
if(ifModifiedSince && lastModified == ifModifiedSince) { //客户端修改时间和服务端修改时间对比
res.writeHead(304,"Not Modified")
res.end()
} else {
fs.readFile(fsPath, function(err,file){
if(err) {
console.log('readFileError:', err)
}else {
res.writeHead(200,{
"Cache-Control": 'max-age=' + maxAgeTime,
"Last-Modified" : lastModified
})
res.end(file)
}
})
}
}
})
}).listen(3030)
代码很简单,看注释即可。这只是一个微小的服务,我们只是关注在文件缓存的方面。
本次的分享是一次作者也不知道如何获得的“社招”经历。今年7月1号作者终于拿到了期盼了好久好久的毕业证。感觉自己已经上班一年多了,但是一直是拿实习工资,真是苦不堪言。由于作者是个阿里脑残粉,在校招的时候因为自己2b的操作(以后不管你们在哪里,问你去不去杭州都说去,记住了么)离阿里又远了一步。所以前段时间更新了下简历就抱着试试看的想法乱投了一波。当然了结果肯定是都挂了:),我猜因为工作年限不够吧,不对,身为大四的我,没有工作年限:)。故这次突然收到面试通知(我真的不记得我是怎么投的简历了),也是很惊喜的。虽然知道肯定是没戏的,社招一般p6起吧。我这种小白...所以
欢迎关注我的博客,不定期更新中——
这个地方虽然我一直在bb,不过在面试官看来可能都是小打小闹吧。以及这种问题我相信每个人面试都会被问到,那么答案也就因人而异咯。我一直在bb的其实是我这篇文章基于react的影院购票应用里面的选座组件,有兴趣的童鞋欢迎交流。我知道很low,但是能力有限=。=
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>layout_box</title>
<link rel="stylesheet" type="text/css" href="../css/layout_box.css">
</head>
<style>
html,body{ margin: 0px;width: 100%; }
#left,#right{
width: 200px;
height: 200px;
background-color: #ffe6b8;
position: absolute;
}
#left{left:0px;}
#right{right: 0px;}
#center{margin:2px 210px ;background-color: #eee;height: 200px; }
</style>
<body>
<div id = "left">我是左边</div>
<div id = "right">我是右边</div>
<div id = "center">我是中间</div>
</body>
</html>
这是当时我给出的,使用绝对布局的方式来达到效果。同样采用float也可以,只不过那样要改变三个div的顺序,如果保证顺序的话,即3个节点依次为左中右。采用float应该不太行。同样如果不涉及兼容低版本的情况下,flex是最方便的,有兴趣可以去看阮一峰老师的一篇文章:Flex 布局教程:语法篇。
//这是我按照当时的思路,重新完善了一下能实现的版本。当时太紧张了了=。=,并不能保证那个代码一定跑起来了
function cal(str) {
let target = '',
arrStore = []
target = typeof str === 'number' ? str.toString() : str
target = target.split('').reverse()
for(let i = 0; i < target.length; i++) {
arrStore.unshift(target[i])
if((i + 1) % 3 === 0) {
if(i+1 !== target.length) arrStore.unshift(',')
}
}
return arrStore.join('')
}
cal(123456789) //"123,456,789"
不管效率如何也算是实现了这个功能..主要思路就是先将字符串反转,并且变为数组。之后遍历数组,将数字插入到新数组的最前面。同时每到3的倍数时候在数组前插入逗号,最后调用join方法将数组合并为字符串。
function Klass(name) {
this.name = name
}
Klass.prototype.hello = function() {
return this.name
}
var a = new Klass('world')
a.hello() // 'world'
这个问题我猜是考察一下this的指向问题?在原型链中的this是指向new出来的实例的。故this.name === a.name,即world
个人认为这个问题可以归结为,函数为普通函数调用和用作构造器调用时的区别。而最大的区别就是在普通函数调用时其内部this指向了全局对象。如果是浏览器中运行那么这个对象就是window。如果用作构造器调用,如 var a = new A(),此时A中的this会指向通过new调用出来的实例化对象。简单来说就是下面这个例子:
function A(name, id) {
this.name = name
this.id = id
}
function B(name, id) {
this.name = name
this.id = id
}
var a = new A(1,2)
var b = B(1,2)
console.log(a) // {id: 2,name: 1}, this === a
console.log(b) // undefined
console.log(window.name) // '1'
console.log(window.id) // 2
由此就可以引发关于javaScript中this的指向问题。其实this的指向大概可分为以下四种情况:
其中作为普通函数和构造器调用的情况作者已经做了简要说明,下面再简单介绍下另外两种情况。掌握这四种情况之后,在之后的开发中再碰到关于this的bug就可以有一个大概的排查方向了
var obj = {
a: 1,
getA: function() {
console.log(this === obj)
console.log(this.a)
}
}
obj.getA()
这三者的异同在此暂不赘述,你只要知道这三个方法的第一个传入的参数,将会是调用这个方法中的this的新指向。
var obj = {
a: 1,
getA: function() {
console.log(this)
console.log(this.a)
}
}
var obj2 = {
a: 2
}
obj.getA.call(obj2) // this === obj2, a===2
看到了么,调用call之后,其第一个参数也就是obj2成为了调用者obj中this的新指向。另外对于bind的一些用法和模拟bind可以看下我的这篇文章Javascript之bind
有关this的文章有兴趣的同学可以去读一读《你不知道的Javascript》,里面对于this有着详细的介绍。
首先我们先来看看cookie是什么?
Cookie 是在 HTTP 协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie 是由 Web 服务器保存在用户浏览器(客户端)上的小文本文件,它可以包含有关用户的信息。无论何时用户链接到服务器,Web 站点都可以访问 Cookie 信息。
这是在控制台中看到cookie
简单来说cookie的存在就是为了短时间存储一定信息的存在。这个信息可以用来进行登陆验证,来判断当前用户是否进行过登陆等等的身份验证以致服务器返回不同的数据等等。至于为什么说是短时间的,是因为这种将信息存储在浏览器本地的方式本身就有安全性问题。所以设置过期时间会令其在一段时间后自动消失。由上图可以看到Expires/Max-Age就是过期时间字段。这里面涉及了有关服务器缓存相关的内容。有兴趣的童鞋可以参考下我这篇文章基于node的微小服务——细说缓存与304。
说了这么多我觉得脱离这个问题,我们怎么实现一个cookie?以下代码参考了朴灵大大的《深入浅出NodeJs》,同时这份代码地址
//通过cookie来验证用户登录
const http = require('http')
const url = require('url')
let server = http.createServer((req, res) => {
req.cookie = cookieParse(req.headers.cookie) //解析请求头中的cookie
isLogin(req, res)
}).listen(9090)
let isLogin = (req, res)=> {
if(req.cookie.isLogin) { //判断cookie中是否有isLogin字段
res.writeHead(200)
res.end('hello world again')
} else { //没有该字段,证明没有登陆或cookie过期
let option = {
'Path': '/',
'Max-Age': 3,
}
res.setHeader('Set-Cookie', setCookie('isLogin', true, option))
res.writeHead(200)
res.end('hello world first')
}
}
let cookieParse = (cookie) => { //解析cookie
let cookieResult = {}
if(!cookie) return cookieResult
let cookieList = cookie.split(';')
cookieList.forEach((item) => {
let keyValue = item.split('=')
let key = keyValue[0]
cookieResult[key] = keyValue[1]
})
return cookieResult
}
let setCookie = (name, value, option) => { //设置cookie
option = option || {}
let cookieValue = [name + '=' + value]
Object.keys(option).forEach((item) => {
cookieValue.push(item + '=' + option[item])
})
return cookieValue.join(';')
}
实现的核心思路为:没有特殊设置时,浏览器发起请求时在请求头中会带入指向这个domain的cookie,此时就可以判断这个cookie中是否有你需要的字段来判断你的需求。
本次面试大概只有40分钟左右。虽然回答的时候觉得基本都达出来了,不过趁着周末沉淀一下,发现之前面试时实现的代码还是有些问题的。还是因为经验不够吧。毕竟我才拿了几天毕业证:),这个时候就要告诉自己我还小,才22:)
在之前的这篇bezierMaker.js——N阶贝塞尔曲线生成器的文章中我们提到了对于高阶贝塞尔公式的绘制与生成。不过更多的童鞋看到后可能会不知道其使用场景是什么。故作者本次分享一下基于bezierMaker.js实现的将静态图片按照自定义曲线轨迹扭曲图片并合称为动态效果。
欢迎关注我的博客,不定期更新中——
之前的描述可能不是很清楚我们直接看下效果图:
首先加载一张图:

然后通过bezierMaker.js提供的试验场功能来绘制一段曲线,进行图片扭曲:

最后拟合为动态图:

再来一个竖直方向的扭动:

其中较为核心的实现即横向与纵向对一维图像数据的切分。其中横向相对简单,细节如下:

如上图所示,在原始图像的数据中的数据形式为一维数组的形式,而对其进行拆分则是一个从中不断截取与提取数据的过程。横向拆分较为简单,只需要确定每一行开始的位置即可,截取的数量就是一行的元素数。同时纵向拆分则需要多加一步,我们需要计算每一层数组中的每一个数,像上图一般拆分第每列数组时首先要遍历图的宽得到每一列的索引,再遍历图的高,通过高✖️宽✖️4 + 宽 ✖️ 4算出当前值在原数据中的位置。当拆分成功数组后,将数组依次移位,移位数为之前曲线与基准线的偏移量决定。
//pg.js
//按行拆分
bezierArr.forEach(function (obj, index) {
if (_.imgStartY < obj.y && _.imgStartY + _.imgHeight > obj.y && type === 'row') {
var diffX = parseInt(obj.x - _.baseX, 10) //计算偏移量
var dissY = parseInt(obj.y - _.imgStartY, 10)
var rowNum = dissY
imgDataSlice = _.imgData.data.slice((rowNum) * _.imgWidth * 4, rowNum * _.imgWidth * 4 + _.imgWidth * 4) //按层切片
...
}
})
//按列拆分
for (var i = 0; i < _.imgWidth; i++) {
imgDataSlice = []
for (var j = 0; j < _.imgHeight; j++) {
var index = j * _.imgWidth * 4 + i * 4
var sliceArr = _.imgData.data.slice(index, index + 4)
imgDataSlice = imgDataSlice.concat(Array.from(sliceArr))
}
if(_.imgChangeObj[i]) {
for (var k = 0; k < Math.abs(_.imgChangeObj[i].diffY * 4); k++) {
imgDataSlice = _.arraymove(_.imgChangeObj[i].diffY, imgDataSlice)
}
for (var p = 0; p < imgDataSlice.length / 4; p++) {
arr[p * _.imgWidth * 4 + i * 4] = imgDataSlice[p * 4]
arr[p * _.imgWidth * 4 + i * 4 + 1] = imgDataSlice[p * 4 + 1]
arr[p * _.imgWidth * 4 + i * 4 + 2] = imgDataSlice[p * 4 + 2]
arr[p * _.imgWidth * 4 + i * 4 + 3] = imgDataSlice[p * 4 + 3]
}
}
}
核心的数组拆分移位再合并的逻辑相对分散,知道思路即可有兴趣的同学欢迎戳源码~
核心**为从我们的原始形态到最终态的两张静态图我们已经得到了。现在我们需要做的是添加几张过渡态。在这里面有两种方式:
作者一开始使用了第一种方式,但是有一个明显的缺陷及通过按比例直接偏移会导致拆分出来的每层的偏移每次都是相同的,那么就会出现锯齿现象。因为图像扭曲可能上一层在这一次移位的时候偏移5合适可是你仍然偏移了总量的1/3导致与下一层的图像不匹配从而出现锯齿。故重新选择了第二种方式,由重新计算各中间态图像的控制点再来移位图像数据,图像的呈现情况就改善了很多。
由于操作图像数据量比较大,故在尝试demo的时候如果遇到ui卡顿那是正在计算中,并没有引入webworker之类的所以请稍等一会就会出现结果=。=
PS:demo使用步骤
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次分享一个提供设计稿与前端页面进行像素对比的node服务,旨在为测试或者前端人员自己完成一个辅助性测试。相信我,在像素级别的对比下,网页对设计稿的还原程度一下子就会凸显出来。。如果哪位童鞋用这个功能测了某位前端小哥哥的页面发现了问题,请不要说是我提供的这个工具=。=
欢迎关注我的博客,不定期更新中——

本次用到了以下两个库作为辅助工具:
所以整个服务我们应该已经有了大题的思路即通过casperjs来进入某个网站截取某个页面,再将其与设计图进行比对得出结果。

通过上图我们应该能整理出一个大概的流程:
这其中有一个问题可能会有人注意到就是:为什么在casperjs中对目标网站截图了不能直接把信息传回服务器中,而是选择了再去打开一个表单页面通过表单的形式来提交信息?
答:首先我对casperjs和node了解都不那么深入,我理解的是首先casperjs不是一个node模块,它是跑在操作系统中的,我尚且没有发现怎么在casperjs中建立与node服务的通信,如果有方法一定要告诉我,因为我真的不太了解casper!其次由于无法建立通信,我只能退而求其次,通过casper快速打开一个我写好的表单页面并且填写好图片信息传回服务器,这么做是可以完成最初的诉求。所以就有了上面from.html那段的操作。
因为涉及到index.html与form.html页面的返回,故需要实现一个超级简易的静态服务器。代码如下:
const MIME_TYPE = {
"css": "text/css",
"gif": "image/gif",
"html": "text/html",
"ico": "image/x-icon",
"jpeg": "image/jpeg",
"jpg": "image/jpg",
"js": "text/javascript",
"json": "application/json",
"pdf": "application/pdf",
"png": "image/png",
"svg": "image/svg+xml",
"swf": "application/x-shockwave-flash",
"tiff": "image/tiff",
"txt": "text/plain",
"wav": "audio/x-wav",
"wma": "audio/x-ms-wma",
"wmv": "video/x-ms-wmv",
"xml": "text/xml"
}
function sendFile(filePath, res) {
fs.open(filePath, 'r+', function(err){ //根据路径打开文件
if(err){
send404(res)
}else{
let ext = path.extname(filePath)
ext = ext ? ext.slice(1) : 'unknown'
let contentType = MIME_TYPE[ext] || "text/plain" //匹配文件类型
fs.readFile(filePath,function(err,data){
if(err){
send500(res)
}else{
res.writeHead(200,{'content-type':contentType})
res.end(data)
}
})
}
})
}
const multiparty = require('multiparty') //解析表单
let form = new multiparty.Form()
form.parse(req, function (err, fields, files) {
let filename = files['file'][0].originalFilename,
targetPath = __dirname + '/images/' + filename,
if(filename){
fs.createReadStream(files['file'][0].path).pipe(fs.createWriteStream(targetPath))
...
}
})
通过创建可读流读出文件内容,再通过pipe写入到制定路径下即可保存上传来的图片。
const { spawn } = require('child_process')
spawn('casperjs', ['casper.js', filename, captureUrl, selector, id])
casperjs.stdout.on('data', (data) => {
...
})
通过spawn可以创建子进程来启动casperjs,同样也可以使用exec等。
const system = require('system')
const host = 'http://10.2.45.110:3033'
const casper = require('casper').create({
// 浏览器窗口大小
viewportSize: {
width: 1920,
height: 4080
}
})
const fileName = decodeURIComponent(system.args[4])
const url = decodeURIComponent(system.args[5])
const selector = decodeURIComponent(system.args[6])
const id = decodeURIComponent(system.args[7])
const time = new Date().getTime()
casper.start(url)
casper.then(function() {
console.log('正在截图请稍后')
this.captureSelector('./images/casper'+ id + time +'.png', selector)
})
casper.then(function() {
casper.start(host + '/form.html', function() {
this.fill('form#contact-form', {
'diff': './images/casper'+ id + time +'.png',
'point': './images/' + fileName,
'id': id
}, true)
})
})
casper.run()
代码还是比较简单的,主要过程就是打开一个页面,然后在then中传入你的操作,最后执行run。在这个过程里我不太知道如何与node服务通信,故选择了再开一个页面。。想深入研究的可以去看casperjs的官网非常详尽!
function complete(data) {
let imgName = 'diff'+ new Date().getTime() +'.png',
imgUrl,
analysisTime = data.analysisTime,
misMatchPercentage = data.misMatchPercentage,
resultUrl = './images/' + imgName
fs.writeFileSync(resultUrl, data.getBuffer())
imgObj = {
...
}
let resEnd = resObj[id] // 找回最开始的res返回给页面数据
resEnd.writeHead(200, {'Content-type':'application/json'})
resEnd.end(JSON.stringify(imgObj))
}
let result = resemble(diff).compareTo(point).ignoreColors().onComplete(complete)
这其中涉及到了一个点,即我现在所得到的结果要返回给最初的请求里,而从一开始的请求到现在我已经中转了多次,导致我现在找不到我最初的返回体res了。想了很久只能暂时采用了设定全局对象,在接收最初的请求后将请求者的ip和时间戳设定为唯一id存为该对象的key,value为当前的res。同时整个中转流程中时刻传递id,最后通过调用resObj[id]来得到一开始的返回体,返回数据。这个方法我不认为是最优解,但是鉴于我现在想不出来好方法为了跑通整个服务不得已。。如果有新的思路请务必告知!!
官网下载: phantomjs-2.1.1-macosx.zip
解压路径:/User/xxx/phantomjs-2.1.1-macosx
添加环境变量:~/.bash_profile 文件中添加
export PATH="$PATH:/Users/xxx/phantomjs-2.1.1-macosx/bin"
terminal输入:phantomjs --version
能看到版本号即安装成功
brew update && brew install casperjs
cnpm i resemblejs //已写进packjson可不用安装
brew install pkg-config cairo libpng jpeg giflib
cnpm i canvas //node内运行canvas
git clone https://github.com/Aaaaaaaty/gui-auto-test.git
cd gui-auto-test
cnpm i
cd pxdiff
nodemon server.js
打开http://localhost:3033/index.html
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
本次的分享是一个基于canvas的更新图片特效实现。其中主要涉及canvas中getImageData()、putImageData()、toDataURL()方法的使用。效果请看下面。
欢迎关注我的博客,不定期更新中——
PS:请在本地服务器中打开页面,因谷歌浏览器中会有跨域问题,如需node静态服务器可以参照这个地址
显示不出来可看这个地址
https://user-gold-cdn.xitu.io/2017/7/6/0a5e704e63e2d410ea8b5d21565ba4dd?imageView2/0/w/1280/h/960
点我查看源码仓库
//当点击按钮时传递底图的宽高
var img = new Image()
img.src = 'xxx'
img.onload = function() {
$('.btn').click(function() {
...
var that = this
var imgSize = {
realHeight: that.height,
realWidth: that.width
}
changeImg(imgSize, img)
})
}
var changeImg = function(imgSize, oldImg) {
var img = $(oldImg),
offset = img.offset(),
imgLeft = offset.left,
imgTop = offset.top,
canvasId = 'canvas'
$('body').append('<canvas id='+ canvasId +' width='+ imgSize.realWidth+' height='+ imgSize.realHeight +'></canvas>')
$('#'+ canvasId).css({
'position': 'absolute',
'left': imgLeft,
'top': imgTop,
'z-index': 1
})
...
}
首先来介绍下getImageData()、putImageData()这两个方法
CanvasRenderingContext2D.getImageData() 返回一个ImageData对象,用来描述canvas区域隐含的像素数据,这个区域通过矩形表示,起始点为(sx, sy)、宽为sw、高为sh。
CanvasRenderingContext2D.putImageData() 是 Canvas 2D API 将数据从已有的 ImageData 对象绘制到位图的方法。
这其中的重点则是ImageData对象是什么。不妨我们打印一下看看:
可以看出一个2乘2的画布占4个像素,其中打印了一个长度为16的一维数组,结合文档中的讲解我们可以知道,其中每一个像素均有4位分别为rgba,故通过getImageData()我们可以得到一个拍平了的rgba数组,那么当我们动态的去改变一些东西的时候整个图像的色值透明度就会引起相应的变化,想想还有些小激动呢。同时putImageData()就很好理解了。当我们改变完像素数值后通过这个方法再反馈到画布上。
//核心代码
//通过sin函数画出曲线
var imgData = content.getImageData(0, 0, width, height)
for(var i = 0; i < width / 10; i+=0.1 ) {
x=Math.round(i*10)
y=Math.round(Math.sin(i - t) * scale + initY)
//scale为曲线幅度,initY为初始位置
for(var k = 0; k < y; k++) {
var sym = x * 4 + k * width * 4
//每个像素4位,sym表示当前为第几个像素的第一位
imgData.data[sym + 3] = 0 //令该像素点变透明
//imgData.data[sym + 3]会到达该像素点的透明度位即第四位
}
}
content.putImageData(imgData, 0, 0, 0, 0, width, height)
其中initY为sin曲线的纵坐标位置,那么当动态减小这个iniY时图像渲染的曲线会一点点向上,同时透明的区域便一点点变小,同时改变t值会另曲线横向移动,以此来形成最后的波浪形并缓缓向上的效果。
oldImg.src = oCanvas.toDataURL('image/png')
$(oCanvas).remove()
通过toDataURL()方法,可以使画布转换成base64形式的img图片,将其替换到旧图片的url中便可以实现图片的更新特效。
不定时更新中——
有问题欢迎在issues下交流。
本次分享一下通过ES5规范来总结如何准确的计算“==”的执行结果。由于规范是枯燥无味的,所以作者试图总结了其中的规律,并希望可以让读完这篇文章的读者不再去“死记硬背”==的结果是什么,而是通过几次简单的计算便心有成竹的得出结论!
欢迎关注我的博客,不定期更新中——
——何时完结不确定,写多少看我会多少!这是已经更新的地址:
这个系列旨在对一些人们不常用遇到的知识点,以及可能常用到但不曾深入了解的部分做一个重新梳理,虽然可能有些部分看起来没有什么用,因为平时开发真的用不到!但个人认为糟粕也好精华也罢里面全部蕴藏着JS一些偏本质的东西或者说底层规范,如果能适当避开舒适区来看这些小细节,也许对自己也会有些帮助~文章更新在我的博客,欢迎不定期关注。
2 == true //false
2 == false //false
[] == false //true
"0" == false //true
[] == ![] //true 神奇吧
我相信大部分的童鞋看着这种等式一般的反应都是xxx是真值,可以转换为true。xxx是假的所以是false!好的摒弃这种想法吧,不然也不会出现这么多神奇的结果了,我们需要做的是通过一步步计算来得出结论。
这部分知识属于真·死记硬背,因为你问我为什么,我只能说规范就是这么定义的。
为什么提到假值,而不是真值是因为真值真的是太!多!了!但是假值只有以下这么几个:
除此以外别的值做强制类型转换的时候都是真值,so记住就好。
PS:有兴趣的同学可以试试new Number(0) 之类的通过对象包装的假值的结果,不过这并不常用故不属于本次讨论范畴。
! 这个运算符,会进行显式强制转化,将结果转化为布尔值即true或false。例如:
![] //false
!1 //false
!0 //true
以此类推来进行显式的强制转换
参考规范11.9.3节抽象相等比较算法可得出
undefined == null 为true的结论。
PS:本次计算规则为抽象相等比较算法的总结,细节可参考上文11.9.3节规范。

这是规范9.1节的内容,简单来说你只需要知道如果某个对象([], {})之类的要进行隐式类型转换,那么里面会顺序执行两个操作。即x.valueOf().toString()。这里有一个不常用的点要注意。我说的是对象类型进行“隐式”类型转化,如果是显式则不是如此。看下例子:
var a = {
valueOf: () => 1,
toString: () => 233
}
a + "" // 1
String(a) // 233
隐式转化是按照先valueOf后toString的顺序执行,如果显式调用会直接执行oString,不过显式调用在js中覆盖率没有隐式的多,知道即可。
这个部分相信有问题的同学百度一下就好。数字的比大小,字符串比大小。里面需要小心的就是NaN != NaN 以及 对象如何比较大小?([1] != [1])
如果x,y其中一个是布尔值,那么对这个布尔值进行toNumber操作。发现问题了么童鞋们,来看下面代码:
42 == true // false
不了解规范的会认为,42是真值啊!42会转换为true!你别说如if(42){}这个42确实是真值。但是我们现在在讨论“==”下的转换,那么请记住规范规定了:类型不同时若一方是布尔值,是对布尔值进行类型转化即true => 1,之后我们就可以理解为什么42不等于true了因为 1!= 42
将字符串的一方进行toNumber()操作,这个不难理解哈
将对象进行ToPrimitive()操作。如何操作见上文。
true => 一方为布尔值:true => 1
2 != 1
true => 一方为布尔值:false => 0
2 != 0
1、[]为对象: ToPrimitive([]) => [].valueOf().toString() => ""
2、false为布尔:false => 0
3、等式变为:"" == 0
4、一方为数字,一方为字符
Number("") => 0
=> 0 == 0
1、false为布尔:false => 0
2、等式变为:"0" == 0
3、一方为数字,一方为字符
Number("0") => 0
=> 0 == 0
1、左侧[]为对象: ToPrimitive([]) => [].valueOf().toString() => ""
2、右侧![]先进行显式类型转换:false(除了上文提到的假值剩下都是真值)
3、等式变为: "" == false
4、一方为布尔:false => 0
5、等式变为:"" == 0
5、一方为数字,一方为字符
Number("") => 0
=> 0 == 0
所以你会发现这些看起来神奇的效果,不过是一步步按照规则进行强制转换罢了。希望以后大家再遇到这种神奇等式的时候不要靠记忆谁是谁,而是一步步推算你会发现结果也不过如此,扮猪吃老虎罢了~
不定时更新中——
有问题欢迎在issues下交流。
本次分享一下使用canvas实现粒子效果拼出你想要的文字。
欢迎关注我的博客,不定期更新中——
不久之前看到大搜车团队出品的easy mock产品的界面中有一个使用粒子拼出“mock so easy”的效果,感觉非常有意思,就像下面这样:

当然了,这个easy mock的界面中还有粒子汇聚、散开、以及缓动等效果,这些在之后的文章中会不定时的更新实现思路。
我当时看到这个效果的时候是一段单一的英文,不知道源码能不能支持自己配置需要的字符,故想自己实现一个可以配置的版本。
PS:突然想到作者之前也封装过一个输入一段英文,输出一段可表示该字母的“黑魔法代码”:效果就像下面这样:
缘由也是网上有人用这种黑魔法代码拼出了单词,但是并不是“可配置”的,也就不能想要啥就是啥,故才有了作者的一版封装实现,文章如下:(相关代码在原文中提及

你可以任意输入你能想到的字符,只要打得进去:)
示例:

emmmm作者目前想到的办法是:降低像素数
来看下这个“非常粗略”的示意图:

这是当我在页面输入“an"之后展示的隐藏的canvas的截图,我将其放入到了ps中并放大,我们可以清晰地看到该图是由一个个很小的像素点通过每个像素点不同的颜色最终绘制出来的。而我们要做的就是用更少的“像素点”来绘制同样的内容。也就是原来100✖️100像素的图,我们如果用25✖️25来表示,那么每个像素点就会粗很多,同时粒度也会更加宽泛,之后我们如果将像素点变为圆形,最后我们就可以得到如文章开头提到的那样,由一个个粒子“拼”出了效果。
总的来说就是通过将输入的信息转化为图片后,读取图片的像素信息,同时粗略的将图片分块,遍历每块区域中的像素点判断该块是否需要画一个粒子。届时所有区域遍历完毕就可以用比像素点少很多的粒子来大体表示每一个输入的字符。那么具体实现过程如下:
function loadCanvas(value) {
var fontSize = 100,
width = calWordWidth(value, fontSize),
canvas = document.createElement('canvas')
canvas.id = 'b_canvas'
canvas.width = width
canvas.height = fontSize
var ctx = canvas.getContext('2d')
ctx.font = fontSize + "px Microsoft YaHei"
ctx.fillStyle = "orange"
ctx.fillText(value, 0, fontSize / 5 * 4) //轻微调整绘制字符位置
getImage(canvas, ctx) //导出为图片再导入到canvas获取图像数据
}
function getImage(canvas, ctx) {
var image = new Image()
image.src = canvas.toDataURL("image/jpeg") //canvas导出
image.onload = function() {
...
}
}
var imageData = ctx.getImageData(0, 0, this.width, this.height)
var dataLength = imageData.data.length
var diff = 4 //按4✖️4划分区域,可自行改变尝试
var newCanvas = document.getElementById('canvas')
var newCtx = newCanvas.getContext('2d')
for (var j = 0; j < this.height; j += diff) { //height为canvas高
for (var i = 0; i < this.width; i += diff) {//width为canvas宽
var colorNum = 0
for (var k = 0; k < diff * diff; k++) {
var row = k % diff
var col = ~~(k / diff)
let r = imageData.data[((j + col) * this.width + i + row) * 4 + 0]
let g = imageData.data[((j + col) * this.width + i + row) * 4 + 1]
let b = imageData.data[((j + col) * this.width + i + row) * 4 + 2]
if (r < 10 && g < 10 && b < 10) colorNum++
//如果满足此条件说明当前为背景色黑色(canvas转出来的图片背景并不是纯黑的
}
if (colorNum < diff * diff / 3 * 2) {
//黑色背景占比小于一定程度说明此处应该画粒子,占比度可自行调整
var option = {
x: i,
y: j,
radius: 6,
color: '#fff'
}
var newBubble = new Bubble(option)
newBubble.draw(newCtx) //画粒子
}
}
}
源代码见:https://github.com/Aaaaaaaty/Blog/blob/master/canvas/canvasImitateWord/main.js
本次只实现了可配置拼出字符的功能,粒子动态上没加入特效,其他效果实现思路之后可能会不定时更新——
惯例po作者的博客,不定时更新中——
有问题欢迎在issues下交流。
最近开始重新学习一波js,框架用久了有些时候觉得这样子应该可以实现发现就真的实现了,但是为什么这么写好像又说不太清楚,之前读了LucasHC以及冴羽的两篇关于bind的文章感觉自己好像基础知识都还给体育老师了哈哈哈,所以危机感爆棚,赶紧重头复习一遍。本次主要围绕bind是什么;做了什么;自己怎么实现一个bind,这三个部分。其中会包含一些细节代码的探究,往下看就知道。
bind()方法创建一个新的函数, 当被调用时,将其this关键字设置为提供的值,在调用新函数时,在任何提供之前提供一个给定的参数序列。
var result = fun.bind(thisArg[, arg1[, arg2[, ...]]])
result(newArg1, newArg2...)
没看懂没事接着往下看。
从上面的介绍中可以看出三点。首先调用bind方法会返回一个新的函数(这个新的函数的函数体应该和fun是一样的)。同时bind中传递两个参数,第一个是this指向,即传入了什么this就等于什么。如下代码所示:
this.value = 2
var foo = {
value: 1
}
var bar = function() {
console.log(this.value)
}
var result = bar.bind(foo)
bar() // 2
result() // 1,即this === foo
第二个参数为一个序列,你可以传递任意数量的参数到其中。并且会预置到新函数参数之前。
this.value = 2
var foo = {
value: 1
};
var bar = function(name, age, school) {
console.log(name) // 'An'
console.log(age) // 22
console.log(school) // '家里蹲大学'
}
var result = bar.bind(foo, 'An') //预置了部分参数'An'
result(22, '家里蹲大学') //这个参数会和预置的参数合并到一起放入bar中
我们可以看出在最后调用result(22, '家里蹲大学')的时候,其内部已经包含了在调用bind的时候传入的 'An'。
一句话总结:调用bind,就会返回一个新的函数。这个函数里面的this就指向bind的第一个参数,同时this后面的参数会提前传给这个新的函数。调用该新的函数时,再传递的参数会放到预置的参数后一起传递进新函数。
this.value = 2
var foo = {
value: 1
};
var bar = function(name, age, school) {
console.log(name) // 'An'
console.log(age) // 22
console.log(school) // '家里蹲大学'
console.log(this.value) // 1
}
Function.prototype.bind = function(newThis) {
var aArgs = Array.prototype.slice.call(arguments, 1) //拿到除了newThis之外的预置参数序列
var that = this
return function() {
return that.apply(newThis, aArgs.concat(Array.prototype.slice.call(arguments)))
//绑定this同时将调用时传递的序列和预置序列进行合并
}
}
var result = bar.bind(foo, 'An')
result(22, '家里蹲大学')
这里面有一个细节就是Array.prototype.slice.call(arguments, 1) 这句话,我们知道arguments这个变量可以拿到函数调用时传递的参数,但不是一个数组,但是其具有一个length属性。为什么如此调用就可以将其变为纯数组了呢。那么我们就需要回到V8的源码来进行分析。#这个版本的源码为早期版本,内容相对少一些。
function ArraySlice(start, end) {
var len = ToUint32(this.length);
//需要传递this指向对象,那么call(arguments),
//便可将this绑定到arguments,拿到其length属性。
var start_i = TO_INTEGER(start);
var end_i = len;
if (end !== void 0) end_i = TO_INTEGER(end);
if (start_i < 0) {
start_i += len;
if (start_i < 0) start_i = 0;
} else {
if (start_i > len) start_i = len;
}
if (end_i < 0) {
end_i += len;
if (end_i < 0) end_i = 0;
} else {
if (end_i > len) end_i = len;
}
var result = [];
if (end_i < start_i)
return result;
if (IS_ARRAY(this))
SmartSlice(this, start_i, end_i - start_i, len, result);
else
SimpleSlice(this, start_i, end_i - start_i, len, result);
result.length = end_i - start_i;
return result;
};
从源码中可以看到通过call将arguments下的length属性赋给slice后,便可通过 start_i & end_i来获得最后的数组,所以不需要传递进slice时就是一个纯数组最后也可以得到一个数组变量。
被用作构造函数时,this应指向new出来的实例,同时有prototype属性,其指向实例的原型。
this.value = 2
var foo = {
value: 1
};
var bar = function(name, age, school) {
...
console.log('this.value', this.value)
}
Function.prototype.bind = function(newThis) {
var aArgs = Array.prototype.slice.call(arguments, 1)
var that = this //that始终指向bar
var NoFunc = function() {}
var resultFunc = function() {
return that.apply(this instanceof that ? this : newThis, aArgs.concat(Array.prototype.slice.call(arguments)))
}
NoFunc.prototype = that.prototype //that指向bar
resultFunc.prototype = new NoFunc()
return resultFunc
}
var result = bar.bind(foo, 'An')
result.prototype.name = 'Lsc' // 有prototype属性
var person = new result(22, '家里蹲大学')
console.log('person', person.name) //'Lsc'
var NoFunc = function() {}
...
NoFunc.prototype = that.prototype //that指向bar
resultFunc.prototype = new NoFunc()
return resultFunc
通过上面代码可以看出,that始终指向bar。同时返回的函数已经继承了that.prototype即bar.prototype。为什么不直接让返回的函数的prototype属性resultFunc.prototype 等于为bar(that).prototype呢,这是因为任何new出来的实例都可以访问原型链。如果直接赋值那么new出来的对象可以直接修改bar函数的原型链,这也就是是原型链污染。所以我们采用继承的方式(将构造函数的原型链赋值为父级构造函数的实例),让new出来的对象的原型链与bar脱离关系。
如何判断当前this指向了哪里呢,通过第一点我们已经知道,通过bind方法返回的新函数已经有了原型链,剩下需要我们做的就是改变this的指向就可以模拟完成了。通过什么来判断当前被调用是以何种姿势呢。答案是instanceof 。
instanceof 运算符用来测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性。
// 定义构造函数
function C(){}
function D(){}
var o = new C();
// true,因为 Object.getPrototypeOf(o) === C.prototype
o instanceof C;
// false,因为 D.prototype不在o的原型链上
o instanceof D;
从上面可以看出,instanceof可以判断出一个对象是否是由这个函数new出来的,如果是new出来的,那么这个对象的原型链应为该函数的prototype.
所以我们来看这段关键的返回的函数结构:
var resultFunc = function() {
return that.apply(this instanceof that ?
this :
newThis,
aArgs.concat(Array.prototype.slice.call(arguments)))
}
在这其中我们要先认清this instanceof that 中的this是bind函数被调用后,返回的新函数中的this。所以这个this可能执行在普通的作用域环境,同时也可能被new一下从而改变自己的指向。再看that,that始终指向了bar,同时其原型链that.prototype是一直存在的。所以如果现在这个新函数要做new操作,那么this指向了新函数,那么 this instanceof that === true, 所以在apply中传入this为指向,即指向新函数。如果是普通调用,那么this不是被new出来的,即新函数不是作为构造函数,this instanceof that === false就很显而易见了。这个时候是正常的bind调用。将调用的第一个参数作为this的指向即可。
if (!Function.prototype.bind) {
Function.prototype.bind = function(oThis) {
if (typeof this !== 'function') {
// closest thing possible to the ECMAScript 5
// internal IsCallable function
throw new TypeError('Function.prototype.bind - what is trying to be bound is not callable');
}
var aArgs = Array.prototype.slice.call(arguments, 1),
fToBind = this,
fNOP = function() {},
fBound = function() {
return fToBind.apply(this instanceof fNOP
? this
: oThis,
aArgs.concat(Array.prototype.slice.call(arguments)));
};
if (this.prototype) {
// Function.prototype doesn't have a prototype property
fNOP.prototype = this.prototype;
}
fBound.prototype = new fNOP();
return fBound;
};
}
可以看到,其首先做了当前是否支持bind的判定,不支持再实行兼容。同时判断调用这个方法的对象是否是个函数,如果不是则报错。
同时这个模拟的方法也有一些缺陷,可关注MDN上的Polyfill部分
模拟bind实现最大的一个缺陷是,模拟出来的函数中会一直存在prototype属性,但是原生的bind作为构造函数是没有prototype的,这点打印一下即可知。不过这样子new出来的实例没有原型链,那么它的意义是什么呢。如果哪天作者知道了意义会更新在这里的=。= 如果说错的地方欢迎指正,一起交流哈哈。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.






















