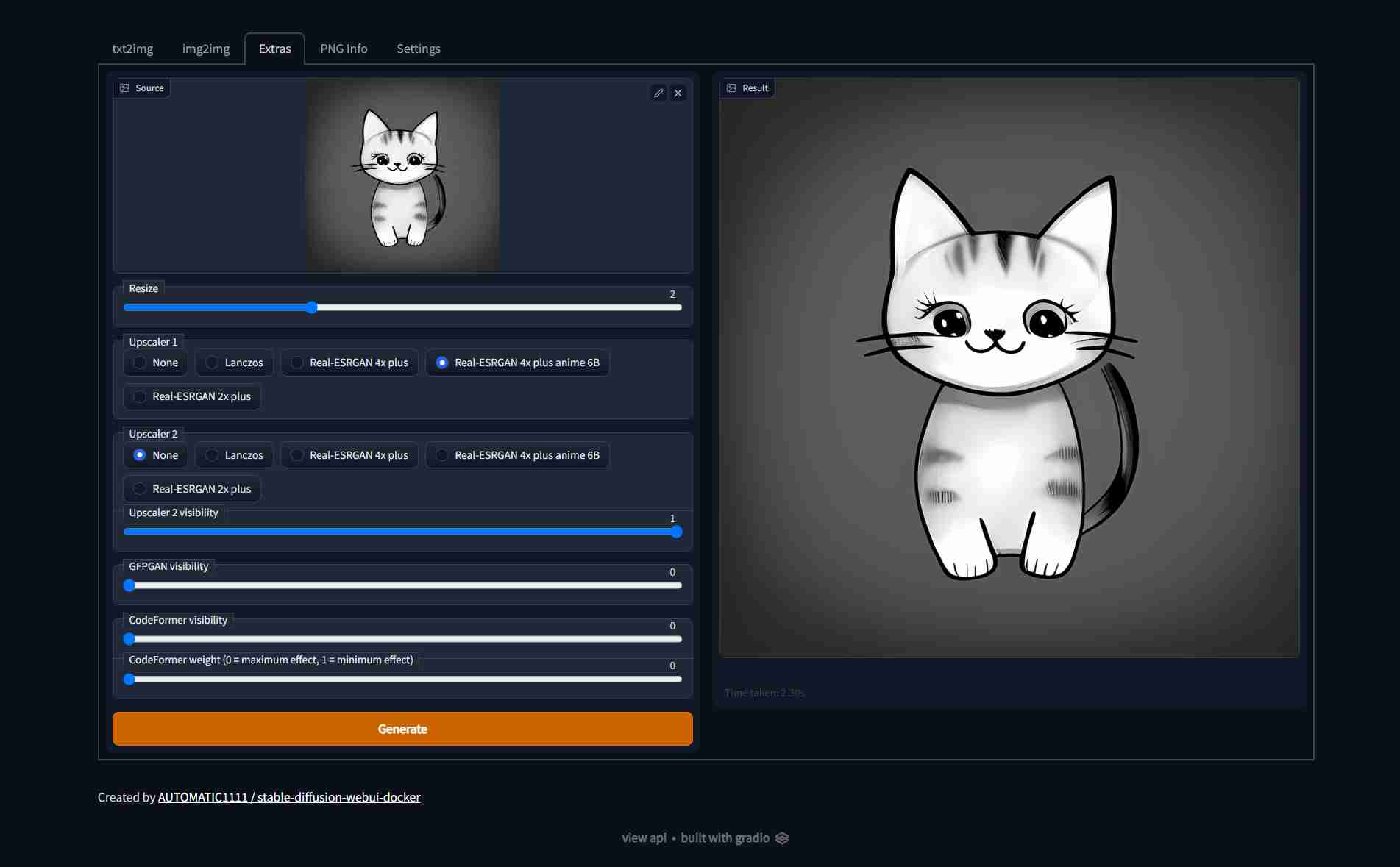
stable-diffusion-webui-docker-master-model-1 | Loaded GFPGAN
stable-diffusion-webui-docker-master-model-1 | Couldn't find metadata on image
stable-diffusion-webui-docker-master-model-1 | Couldn't find metadata on image
stable-diffusion-webui-docker-master-model-1 | Traceback (most recent call last):
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/gradio/routes.py", line 247, in run_predict
stable-diffusion-webui-docker-master-model-1 | output = await app.blocks.process_api(
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/gradio/blocks.py", line 641, in process_api
stable-diffusion-webui-docker-master-model-1 | predictions, duration = await self.call_function(fn_index, processed_input)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/gradio/blocks.py", line 556, in call_function
stable-diffusion-webui-docker-master-model-1 | prediction = await anyio.to_thread.run_sync(
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/anyio/to_thread.py", line 31, in run_sync
stable-diffusion-webui-docker-master-model-1 | return await get_asynclib().run_sync_in_worker_thread(
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
stable-diffusion-webui-docker-master-model-1 | return await future
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/anyio/_backends/_asyncio.py", line 867, in run
stable-diffusion-webui-docker-master-model-1 | result = context.run(func, *args)
stable-diffusion-webui-docker-master-model-1 | File "scripts/webui.py", line 2027, in imgproc
stable-diffusion-webui-docker-master-model-1 | image = processGFPGAN(image,imgproc_gfpgan_strength)
stable-diffusion-webui-docker-master-model-1 | File "scripts/webui.py", line 1732, in processGFPGAN
stable-diffusion-webui-docker-master-model-1 | cropped_faces, restored_faces, restored_img = GFPGAN.enhance(np.array(image, dtype=np.uint8), has_aligned=False, only_center_face=False, paste_back=True)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
stable-diffusion-webui-docker-master-model-1 | return func(*args, **kwargs)
stable-diffusion-webui-docker-master-model-1 | File "/stable-diffusion/src/gfpgan/gfpgan/utils.py", line 108, in enhance
stable-diffusion-webui-docker-master-model-1 | self.face_helper.get_face_landmarks_5(only_center_face=only_center_face, eye_dist_threshold=5)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/facexlib/utils/face_restoration_helper.py", line 139, in get_face_landmarks_5
stable-diffusion-webui-docker-master-model-1 | bboxes = self.face_det.detect_faces(input_img, 0.97) * scale
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/facexlib/detection/retinaface.py", line 205, in detect_faces
stable-diffusion-webui-docker-master-model-1 | loc, conf, landmarks, priors = self.__detect_faces(image)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/facexlib/detection/retinaface.py", line 156, in __detect_faces
stable-diffusion-webui-docker-master-model-1 | loc, conf, landmarks = self(inputs)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
stable-diffusion-webui-docker-master-model-1 | return forward_call(*input, **kwargs)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/facexlib/detection/retinaface.py", line 121, in forward
stable-diffusion-webui-docker-master-model-1 | out = self.body(inputs)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
stable-diffusion-webui-docker-master-model-1 | return forward_call(*input, **kwargs)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/torchvision/models/_utils.py", line 63, in forward
stable-diffusion-webui-docker-master-model-1 | x = module(x)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl
stable-diffusion-webui-docker-master-model-1 | return forward_call(*input, **kwargs)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 447, in forward
stable-diffusion-webui-docker-master-model-1 | return self._conv_forward(input, self.weight, self.bias)
stable-diffusion-webui-docker-master-model-1 | File "/opt/conda/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 443, in _conv_forward
stable-diffusion-webui-docker-master-model-1 | return F.conv2d(input, weight, bias, self.stride,
stable-diffusion-webui-docker-master-model-1 | RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same