This repo contains the files I used to conduct my analysis of my league of legends matches by using an ETL to extract data from Riot's API. There are two Python files which were used extracted data from Riot's API, transformed the JSON into a pandas dataframe, and Loaded the information into an Amazon MySQL RDS micro instance. The data was then analyzed and visualized using MySQL to query specific information and Tableau to build out a dashboard which can be accessed in the chrome_proxy.exe file or at the link here: https://public.tableau.com/app/profile/aidan2791/viz/LeagueofLegendsPlayerRankedMatchHistoryInsights/Champion#1
The contents of each file are as follows:
- MySQL_queries folder is a folder with 3 different SQL queries for information.
- chrome_proxy.exe is a link to the Tableau Public dashboard I created for this project.
- database_lol.hyper is the database extract used to publish the Tableau Public dashboard, it does not need to be accessed.
- lol_queues.json is a JSON file with queue ids and their corresponding queue names.
- mysql_player_match_history_censored.py is the Python script file that extracts the data and loads it into the Amazon MySQL RDS.
- queue_ids_censored.py is the Python script file that extracts the queue data from lol_queues.json and loads them into the RDS.
I also wrote a medium article which is the same as the rest of this README. It can be found here: https://medium.com/@aidanzhaobrook/data-analysis-etl-league-of-legends-project-4d52678b563c
These past couple of weeks I have been working on an analytics project focused on drawing insights from my League of Legends games. I enjoy playing ranked, but I am not always the best player. My goal with this project is to evaluate my current performance in game, determine what I am doing well, and where I can clean up my execution in order to increase my rank. To do this I will be parsing through my past match history. I do want to add a caveat to my work as a lot of good conclusions can be drawn from data, but there are certain parts of the game that don't show up in my data such as items purchased, decision making, or poorly playing teammates.

The first step, besides playing games of League of Legends, is to access the player information and match history using the Riot API. To do this I applied for an API key and was approved for an API key to make requests to the Riot API. Next I needed to determine what APIs to use to get the information I needed. I ended up finding 3 APIs (Summoner V4, Match V5 - puuid, Match V5 - matches) which would work in tandem to collect match history information for a particular player.
- Summoner V4: is used to find the puuid (a unique player identifier) when inputting the summoner name.
- Match V5 - puuid: will return a list of match id's between 0 and 100 id's long of the most recent matches played by the player's puuid.
- Match V5 - matches: returns a JSON formatted set of match infomation for a given match id.

Next, I created a Python script to access these API's and used the following sequence of steps to write my ETL script that extracts the match data into JSON format, transforms the data into a dataframe, and loads the dataframe as a table into the MySQL Amazon RDS.
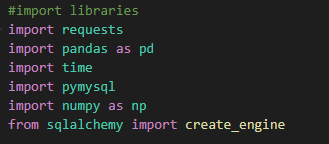
- Starting by importing the needed libraries: requests, pandas, time, pymysql, numpy, and sqlalchemy.
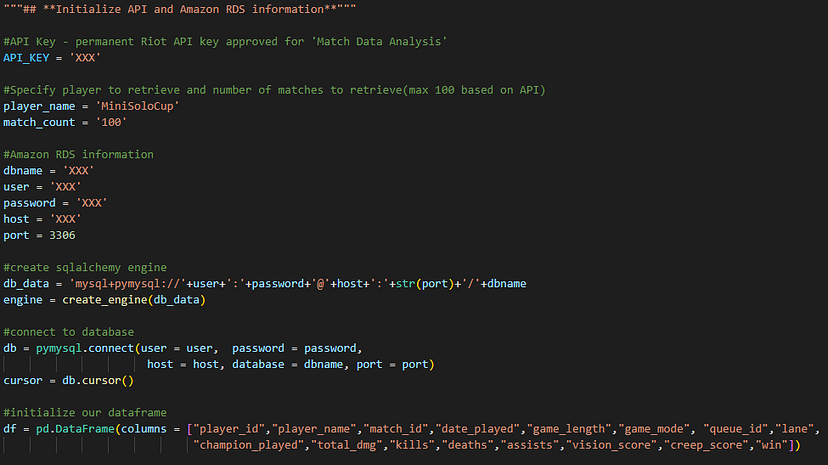
- Initializing the API key, player-match variables, Amazon RDS connection information, the sqlalchemy engine, connecting to the MySQL RDS, and initializing the final dataframe.
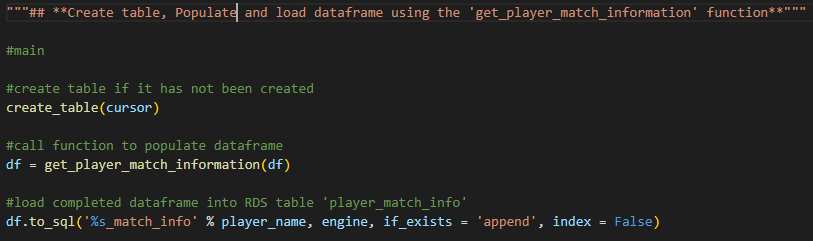
- Then creating the main section where we call the create_table function, get_player_match_information function, and load the dataframe into our MySQL database.

- The first function that is called uses a pymysql cursor to execute SQL code where a table is created if it does not already exist in the form of 'player_name'_match_info where player_name is one of the initialized variables.

- Next the get_player_match function is called in our main script and the empty dataframe (df) is input and the populated dataframe df is expected as the output. The get_player_match function first calls the get_player_id function to retreive the puuid from the Riot API.
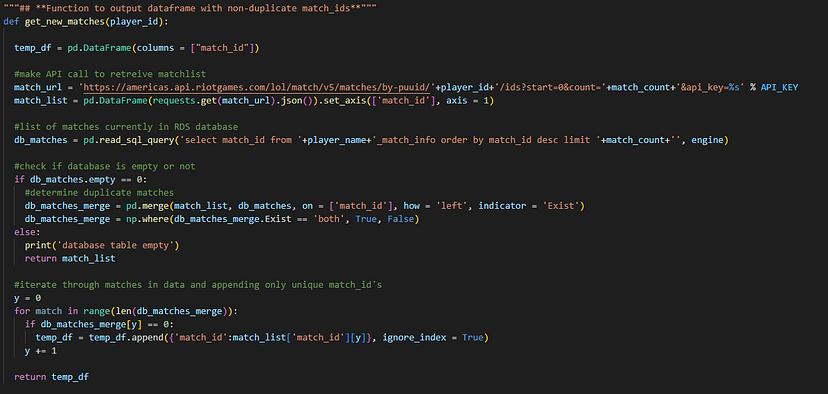
- Our next function is then called, get_new_matches which first uses the puuid to extract the match_list from the Riot API. The db_matches variable is then created and queries our MySQL RDS to compare to the match_list extracted from the Riot API. The if statement checks if the table is empty or not and then the for loop goes through each match in match_list and checks if the id is already in the RDS and only saves the match_ids that are unique to match_list and returns a dataframe containing these ids.

- Lastly our get_player_match_information function checks if the match_list is empty (no new matches were played) and accesses the Riot API for each unique match; Looping through each player until the correct one (based on puuid) is reached and then saving the information to the dataframe and returning it once all matches have been saved.
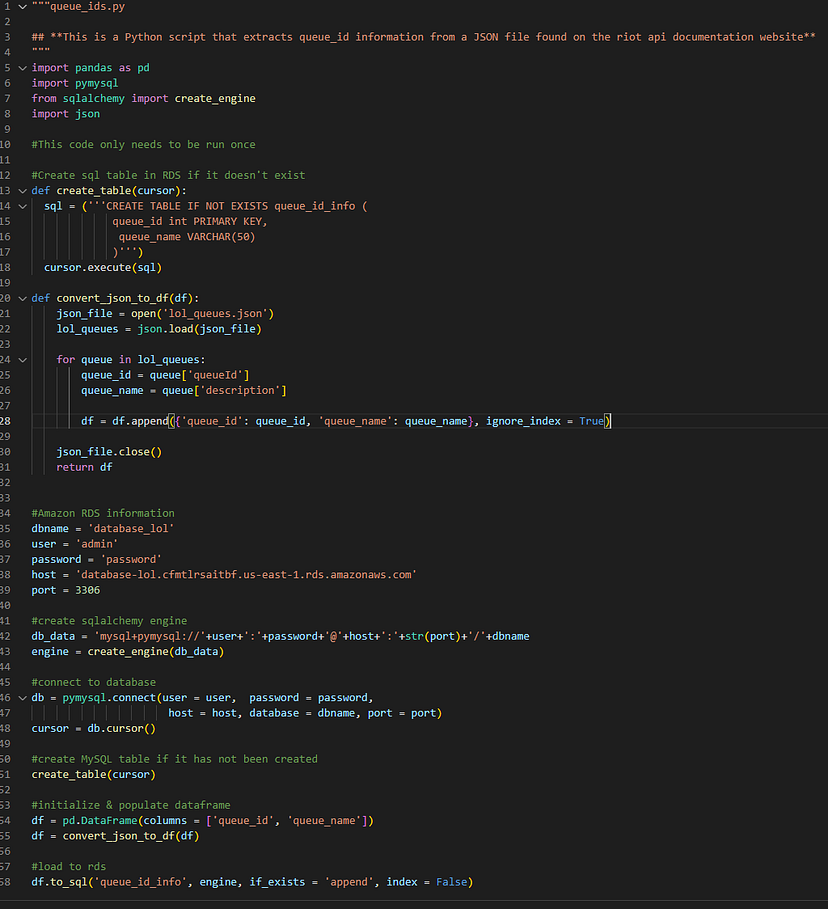
Since the game_mode attribute found in the match information from the Riot API does not distinguish between ranked, casual, or versus AI the queue_id must be used to distinguish between these modes. The script, queue_ids.py, shown above does that by loading a JSON file that Riot provides in their documentation, parsing the queue id with the matching queue name, and then saving it as a dataframe to the MySQL RDS.
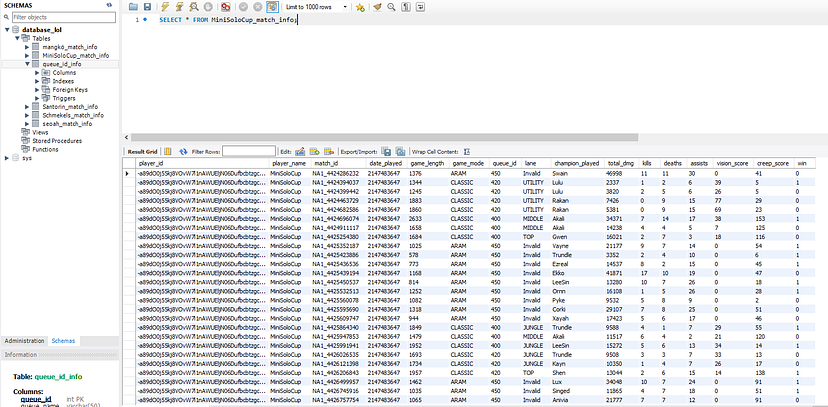
We can see the newly created tables in our RDS by accessing the database using MySQL workbench and do a simply select all query to see our data. This table will be used in the creation of my Tableau dashboard, but we can conduct some queries to determine some player stats.
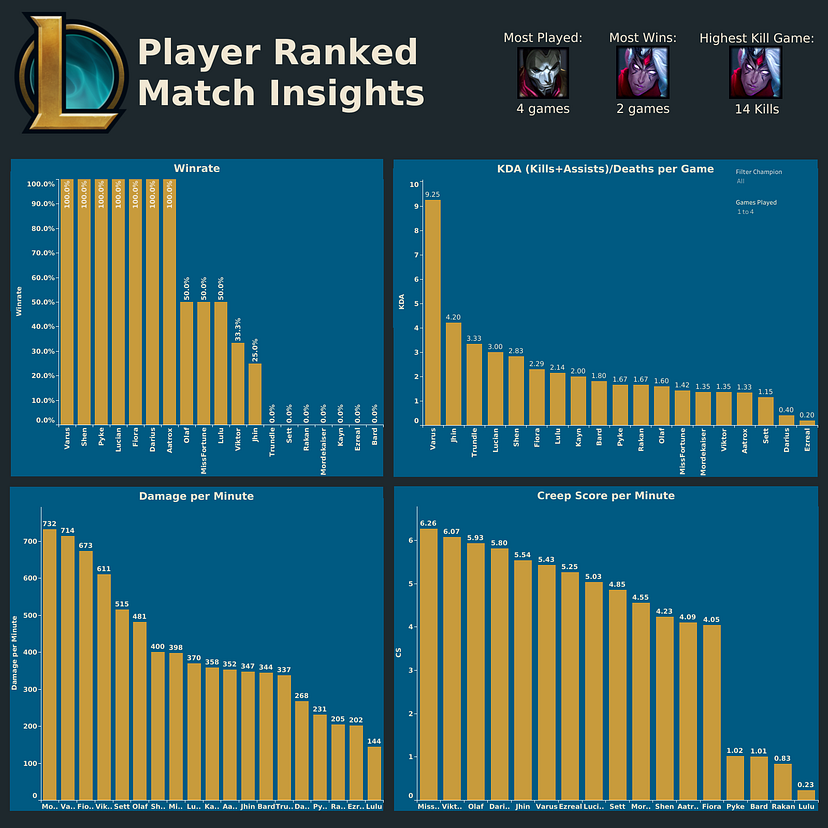
I wanted to include 3 stats onto my dashboard: Champion with the most ranked solo queue games played, Champion with the most ranked solo queue games won, and Champion with the highest kill game in ranked solo. To do this I wrote three separate queries.
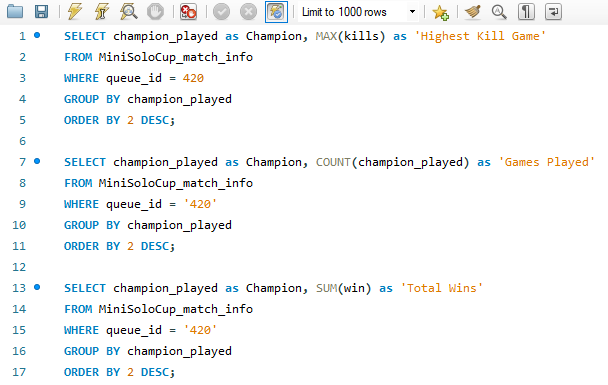
Each query was written to be filtered by the queue id '420' which is the identifier for ranked solo queue matches and were grouped by the champion played. The difference in each query were the aggregate functions that I used: MAX(kills) for highest kill game, COUNT(champion_played) for the highest total games played, and SUM(win) for most wins. These queries returned tables that were ordered by their aggregate function column so that the champion that fit was at the top. I could have put a LIMIT 1 on each query to only see the top champion, but I was curious what the data was for each champion so I did not make that change.
Lastly I connected my Tableau Desktop program with the MySQL RDS to create my final dashboard. I created a relationship between the queue_id_info and MiniSoloCup_match_info data sources in order to filter by the queue name rather than the queue id. I created 4 worksheets to evaluate my creep score (cs) per minute, my kills and assists per death ratio, damage per minute, and win rate for each champion in ranked solo queue using calculated fields.
Using all of the information I have gathered I created and published the finished dashboard to Tableau Public and you may view it here. Using the information and the dashboard we can filter by the champion played as well as the number of matches that were played with that champion.
Based on the stats shown it seems that we have the highest win rate, highest KDA, most wins, and highest kill game with Varus as well as placing second on damage per minute.
Upon completion of this project we can take away that my most successful champion is Varus and that if I want to win and rank up playing as Varus would probably bring me the most success.
Even through the wins with Varus we can see some troubling numbers when taking a look at the creep score per minute. In general killing the in-game 'creeps' guarantees the easiest consistent source of gold income in order to buy items to strengthen your character. However, the ideal cs per minute is around 10 cs/min and good goals to have for the average player are at least 6–7 cs/min if not 8+ cs/min. Not only am I not anywhere near 10 cs/min, but only my top two champions (Miss Fortune and Viktor) are above 6 cs/min which means I am getting 75% or less of consistent income compared to players who can kill the minions better than I can. Seeing this I should focus a little more on killing the in-game 'creeps' so that I don't fall behind other players in terms of income.
The other insight I can draw is that I play a lot of champions, maybe too many. The champions that I have played almost all have varying playstyles, strengths, weaknesses, and difficulty levels. If my goal is to improve and rank up I should focus on a smaller pool of champions that I can try to master.
Going forward I will need to focus on my csing to keep my income high, decrease my champion pool so I can master individual mechanics, and play champions such as Varus.

Through the course of this project I used different skills in data analysis using Python, APIs, Python libraries, AWS RDS, MySQL, and Tableau. While I tried my best there is always opportunity for improvement. Here are ways I think I could have improved my analysis if I had to do it all over again:
- Save more information from the Match V5 API. The JSON file that is extracted has an incredible amount of information in it. If I gave myself more time and really dove deep into each data point I could probably paint an even better picture of how well my play was in each match.
- Extract information from teammates and opponents. League of Legends is a team game after all and every performance is heavily impacted by the other 9 people in the game and it would be useful to extract some information about how well the other players are doing when I am playing a certain champion.
- Something I might actually modify in the future is scheduling my python script to run once a day in order to auto populate the MySQL database as I play more games. Whether it is using DAGS with something like Apache Airflow or something simpler such as a CRON scheduler.
- Play more League of Legends, or perform the analysis on other players. Since I am working full time and prioritize many other things over playing ranked LoL games the sample size I was working with was only 32 total matches total. While that does satisfy the Central Limit Theorem being >30 data points so the conclusions I draw can be statistically significant, It is still a relatively small data set that can be skewed by just a few data points. Even my most played champion, Jhin, only has 4 total games.
Overall I am very happy with the work that I have done and appreciate anyone who has taken the time to read this. Thank you!


