adeshpande3 / lstm-sentiment-analysis Goto Github PK
View Code? Open in Web Editor NEWSentiment Analysis with LSTMs in Tensorflow
License: MIT License
Sentiment Analysis with LSTMs in Tensorflow
License: MIT License




























































































































































NotFoundError (see above for traceback): Key rnn/basic_lstm_cell/kernel not found in checkpoint
[[Node: save_4/RestoreV2_4 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save_4/Const_0_0, save_4/RestoreV2_4/tensor_names, save_4/RestoreV2_4/shape_and_slices)]]
Hi,
I'd like to be able to run this code in batch, not as a Jupyter notebook. So I wrote some python code (call it "batch.py") that I wanted to run as "python batch.py":
numDimensions = 300
maxSeqLength = 250
batchSize = 24
lstmUnits = 64
numClasses = 2
iterations = 100000
import numpy as np
wordsList = np.load('wordsList.npy').tolist()
wordsList = [word.decode('UTF-8') for word in wordsList] #Encode words as UTF-8
wordVectors = np.load('wordVectors.npy')
import tensorflow as tf
tf.reset_default_graph()
labels = tf.placeholder(tf.float32, [batchSize, numClasses])
input_data = tf.placeholder(tf.int32, [batchSize, maxSeqLength])
data = tf.Variable(tf.zeros([batchSize, maxSeqLength, numDimensions]),dtype=tf.float32)
data = tf.nn.embedding_lookup(wordVectors,input_data)
lstmCell = tf.contrib.rnn.BasicLSTMCell(lstmUnits)
lstmCell = tf.contrib.rnn.DropoutWrapper(cell=lstmCell, output_keep_prob=0.25)
value, _ = tf.nn.dynamic_rnn(lstmCell, data, dtype=tf.float32)
weight = tf.Variable(tf.truncated_normal([lstmUnits, numClasses]))
bias = tf.Variable(tf.constant(0.1, shape=[numClasses]))
value = tf.transpose(value, [1, 0, 2])
last = tf.gather(value, int(value.get_shape()[0]) - 1)
prediction = (tf.matmul(last, weight) + bias)
correctPred = tf.equal(tf.argmax(prediction,1), tf.argmax(labels,1))
accuracy = tf.reduce_mean(tf.cast(correctPred, tf.float32))
sess = tf.InteractiveSession()
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('models'))
But when I do "python batch.py" it crashes with an error that seems to indicate it could not restore the morel properly, even though it did it just fine in Jupyter notebook:
Use the retry module or similar alternatives.
2018-05-04 19:44:18.196624: I tensorflow/core/platform/cpu_feature_guard.cc:140] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2018-05-04 19:44:18.544015: W tensorflow/core/framework/op_kernel.cc:1273] OP_REQUIRES failed at save_restore_v2_ops.cc:184 : Not found: Key rnn/basic_lstm_cell/bias not found in checkpoint
Traceback (most recent call last):
File "/anaconda2/envs/py36base/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1327, in _do_call
return fn(*args)
File "/anaconda2/envs/py36base/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1312, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "/anaconda2/envs/py36base/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1420, in _call_tf_sessionrun
status, run_metadata)
File "/anaconda2/envs/py36base/lib/python3.6/site-packages/tensorflow/python/framework/errors_impl.py", line 516, in __exit__
c_api.TF_GetCode(self.status.status)) tensorflow.python.framework.errors_impl.NotFoundError: Key rnn/basic_lstm_cell/bias not found in checkpoint
[[Node: save/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save/Const_0_0, save/RestoreV2/tensor_names, save/RestoreV2/shape_and_slices)]]
I am not sure what I can do to run this in batch? Could you please help?
Thank you!
With my trained model I am able to get the correct sentiment out of short sentences such as "The movie sucked" but i assumed that if i passed in the entire contents of one of the review files, especially one it trained on, then it should also get the right sentiment, however it is woefully inaccurate.
What am i missing here? Can i not pass an arbitrary length (up to 250) block of text such as the content of any one of the files into getSentenceMatrix()?
For example, if i copy the code from the training script that runs the testing loop but instead use batches from the training set, as below:
ids = np.load(os.path.join( local_path, 'idsMatrix.npy'))
iterations = 10
for i in range(iterations):
nextBatch, nextBatchLabels = getTrainBatch();
print("Accuracy for this batch:", (sess.run(accuracy, {input_data: nextBatch, labels: nextBatchLabels})) * 100)
The results are less than stellar, especially as its using the training data:
Accuracy for this batch: 58.3333313465
Accuracy for this batch: 45.8333343267
Accuracy for this batch: 45.8333343267
Accuracy for this batch: 50.0
Accuracy for this batch: 50.0
Accuracy for this batch: 45.8333343267
Accuracy for this batch: 45.8333343267
Accuracy for this batch: 62.5
Accuracy for this batch: 50.0
Accuracy for this batch: 50.0
I can't seem to understand one line of code from the helper functions:
arr[i] = ids[num-1:num]
Why not just:
arr[i] = ids[num-1]
or:
arr[i] = ids[num]
Thank you.
Hi Adit,
How to get access to wordsList.npy & wordVectors.npy dataset?
Thanks
Mahesh
Nice job! Can you please add entity-level sentiment similar to https://github.com/charlesashby/entity-sentiment-analysis
which uses
https://github.com/charlesashby/CharLSTM
?
Thanks
First I'd like to say a big thanks for sharing this. I came to this repo from O'Reilly website and both the article and video are great. I've been reading the code and there're couple of things I hope to discuss:
Also in the placeholder definitions the first dim can be simply written as None to take any batch sizes.
Normally the dropout prob is defined as another input tensor and can be modified through feeddict in testing/prediction.
Was this done on purpose?
Hi,
I am getting error when I am trying to train the model.
Below is the error.
Traceback (most recent call last):
File "D:/Projects/ML/DeepL/NLPLSTM/lstm/lst.py", line 234, in
nextBatch, nextBatchLabels = getTrainBatch()
File "D:/Projects/ML/DeepL/NLPLSTM/lstm/lst.py", line 170, in getTrainBatch
arr[i] = ids[num-1:num]
ValueError: could not broadcast input array from shape (0,250) into shape (250)
Code:
def getTrainBatch():
labels = []
arr = np.zeros([batchSize, maxSeqLength])
for i in range(batchSize):
if i % 2 == 0:
num = randint(1,11499)
labels.append([1,0])
else:
num = randint(13499,24999)
labels.append([0,1])
arr[i] = ids[num-1:num]
return arr, labels
From the code, large embedding loockup table causes an error.
The code below,
data = tf.nn.embedding_lookup(vector_array, input_data)
got this value error.
ValueError: Cannot create a tensor proto whose content is larger than 2GB
variable vector_array on the code is numpy array, and it contains about 14 million unique tokens and 100 dimension word vectors for each word.
Do you have anything to avoid that?
thank you.
Hi Adit, You seem to put all positive comments together, then why do you append [1,0] for all even lines?
def getTrainBatch():
labels = []
arr = np.zeros([batchSize, maxSeqLength])
for i in range(batchSize):
if (i % 2 == 0):
num = randint(1,11499)
# why append [1,0] when i is even? 👇
labels.append([1,0])
else:
num = randint(13499,24999)
labels.append([0,1])
arr[i] = ids[num-1:num]
return arr, labelsmissing files: wordsList.npy, wordVectors.npy
import numpy as np
wordsList = np.load('wordsList.npy').tolist()
wordsList = [word.decode('UTF-8') for word in wordsList] #Encode words as UTF-8
wordVectors = np.load('wordVectors.npy')
FileNotFoundError Traceback (most recent call last)
in ()
1 import numpy as np
----> 2 wordsList = np.load('wordsList.npy').tolist()
3 wordsList = [word.decode('UTF-8') for word in wordsList] #Encode words as UTF-8
4 wordVectors = np.load('wordVectors.npy')
C:\ProgramData\Anaconda3\lib\site-packages\numpy\lib\npyio.py in load(file, mmap_mode, allow_pickle, fix_imports, encoding)
368 own_fid = False
369 if isinstance(file, basestring):
--> 370 fid = open(file, "rb")
371 own_fid = True
372 elif is_pathlib_path(file):
FileNotFoundError: [Errno 2] No such file or directory: 'wordsList.npy'
when I run the code without using the idsMatrix provided, the correct rate will not increase with the number of iterations increase. I get the idsMatrix By myself, but it doesn't work. When I use the idsMatrix provided, it work well, the correct rate will increase with the number of iterations increase. I don't know why, I try to compare the idsMatrix provided with the idsMatrix created by myself, but I can't find what wrong!
I got an error on building docker image, when i exec the command
docker build -t="@yourname/tensorflow_1.1.0_py3"
(I've replaced @yourname) It shows
`"docker build" requires exactly 1 argument.
See 'docker build --help'.
Usage: docker build [OPTIONS] PATH | URL | - [flags]
Build an image from a Dockerfile`
And I've checked my tensorflow version, It is 1.4.1.
Pls help me to check out what went wrong, thanks.
@adeshpande3 @Sean10
Hello, i'm trying to train the model on my own dataset but i get error here :
arr[i] = ids[num-1:num]
because one i turn it to a comment it works fine but if let this instruction work i get this error :
---------------------------------------------------------------------------
InvalidArgumentError Traceback (most recent call last)
~/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in _do_call(self, fn, *args)
~/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in _run_fn(session, feed_dict, fetch_list, target_list, options, run_metadata)
1328 if self._explicit_graph is not None:
-> 1329 self._default_graph = graph.as_default()
1330 self._default_graph.enforce_nesting = False
~/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/errors_impl.py in __exit__(self, type_arg, value_arg, traceback_arg)
InvalidArgumentError: indices[23,4] = 27689 is not in [0, 27689)
[[Node: embedding_lookup = Gather[Tindices=DT_INT32, Tparams=DT_FLOAT, _class=["loc:@embedding_lookup/params_0"], validate_indices=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](embedding_lookup/params_0, _arg_Placeholder_1_0_1)]]
During handling of the above exception, another exception occurred:
InvalidArgumentError Traceback (most recent call last)
<ipython-input-143-7d1cd0569df3> in <module>()
6 #Next Batch of reviews
7 nextBatch, nextBatchLabels = getTrainBatch();
----> 8 sess.run(optimizer, {input_data: nextBatch, labels: nextBatchLabels})
9
10 #Write summary to Tensorboard
~/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in run(self, fetches, feed_dict, options, run_metadata)
893 # Set up a graph with feeds and fetches for partial run.
894 def _setup_fn(session, feed_list, fetch_list, target_list):
--> 895 self._extend_graph()
896 with errors.raise_exception_on_not_ok_status() as status:
897 return tf_session.TF_PRunSetup(session, feed_list, fetch_list,
~/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in _run(self, handle, fetches, feed_dict, options, run_metadata)
1126 ```python
1127 # Build a graph.
-> 1128 a = tf.constant(5.0)
1129 b = tf.constant(6.0)
1130 c = a * b
~/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in _do_run(self, handle, target_list, fetch_list, feed_dict, options, run_metadata)
~/anaconda3/lib/python3.6/site-packages/tensorflow/python/client/session.py in _do_call(self, fn, *args)
InvalidArgumentError: indices[23,4] = 27689 is not in [0, 27689)
[[Node: embedding_lookup = Gather[Tindices=DT_INT32, Tparams=DT_FLOAT, _class=["loc:@embedding_lookup/params_0"], validate_indices=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](embedding_lookup/params_0, _arg_Placeholder_1_0_1)]]
Caused by op 'embedding_lookup', defined at:
File "/home/adel/anaconda3/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/adel/anaconda3/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/adel/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py", line 16, in <module>
app.launch_new_instance()
File "/home/adel/anaconda3/lib/python3.6/site-packages/traitlets/config/application.py", line 658, in launch_instance
app.start()
File "/home/adel/anaconda3/lib/python3.6/site-packages/ipykernel/kernelapp.py", line 477, in start
ioloop.IOLoop.instance().start()
File "/home/adel/anaconda3/lib/python3.6/site-packages/zmq/eventloop/ioloop.py", line 177, in start
super(ZMQIOLoop, self).start()
File "/home/adel/anaconda3/lib/python3.6/site-packages/tornado/ioloop.py", line 888, in start
handler_func(fd_obj, events)
File "/home/adel/anaconda3/lib/python3.6/site-packages/tornado/stack_context.py", line 277, in null_wrapper
return fn(*args, **kwargs)
File "/home/adel/anaconda3/lib/python3.6/site-packages/zmq/eventloop/zmqstream.py", line 440, in _handle_events
self._handle_recv()
File "/home/adel/anaconda3/lib/python3.6/site-packages/zmq/eventloop/zmqstream.py", line 472, in _handle_recv
self._run_callback(callback, msg)
File "/home/adel/anaconda3/lib/python3.6/site-packages/zmq/eventloop/zmqstream.py", line 414, in _run_callback
callback(*args, **kwargs)
File "/home/adel/anaconda3/lib/python3.6/site-packages/tornado/stack_context.py", line 277, in null_wrapper
return fn(*args, **kwargs)
File "/home/adel/anaconda3/lib/python3.6/site-packages/ipykernel/kernelbase.py", line 283, in dispatcher
return self.dispatch_shell(stream, msg)
File "/home/adel/anaconda3/lib/python3.6/site-packages/ipykernel/kernelbase.py", line 235, in dispatch_shell
handler(stream, idents, msg)
File "/home/adel/anaconda3/lib/python3.6/site-packages/ipykernel/kernelbase.py", line 399, in execute_request
user_expressions, allow_stdin)
File "/home/adel/anaconda3/lib/python3.6/site-packages/ipykernel/ipkernel.py", line 196, in do_execute
res = shell.run_cell(code, store_history=store_history, silent=silent)
File "/home/adel/anaconda3/lib/python3.6/site-packages/ipykernel/zmqshell.py", line 533, in run_cell
return super(ZMQInteractiveShell, self).run_cell(*args, **kwargs)
File "/home/adel/anaconda3/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 2698, in run_cell
interactivity=interactivity, compiler=compiler, result=result)
File "/home/adel/anaconda3/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 2802, in run_ast_nodes
if self.run_code(code, result):
File "/home/adel/anaconda3/lib/python3.6/site-packages/IPython/core/interactiveshell.py", line 2862, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-131-51213839a5e4>", line 2, in <module>
data = tf.nn.embedding_lookup(wordVectors,input_data)
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/embedding_ops.py", line 325, in embedding_lookup
if weights.dtype != embeddings.dtype:
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/embedding_ops.py", line 150, in _embedding_lookup_and_transform
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/embedding_ops.py", line 54, in _gather
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/array_ops.py", line 2585, in gather
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/gen_array_ops.py", line 1864, in gather
Etc.
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py", line 787, in _apply_op_helper
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 3160, in create_op
self._old_stack = self._graph._control_dependencies_stack
File "/home/adel/anaconda3/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 1625, in __init__
TypeError: If `op_type` is not a string.
InvalidArgumentError (see above for traceback): indices[23,4] = 27689 is not in [0, 27689)
[[Node: embedding_lookup = Gather[Tindices=DT_INT32, Tparams=DT_FLOAT, _class=["loc:@embedding_lookup/params_0"], validate_indices=true, _device="/job:localhost/replica:0/task:0/device:CPU:0"](embedding_lookup/params_0, _arg_Placeholder_1_0_1)]]
i use the pre-trained model to predict the sentiment of texts in the traing_data/positiveReviews and training_data/negativeReviews floders, but outputs are always positive.
BTW, i found one line missing in Pre-Trained LSTM.ipynb in the function getSentenceMatrix():
if(indexCounter < maxSeqLength):
Hello,
I am wanting to freeze your model into a .PB file and then later reload that when i want to pass my own sentences. I am familiar with image training where operations are named (e.g 'input' and 'final_result') and i feed the necessary tensors.
However in your model there are no named operations and the testing script does a lot of heavy lifting with restoration and loading of vector files.
Is it possible to just load a PB file and pass in a sentence? And if so then what do I pass that sentence in to and then what tensor do i need as a result?
Basically i am trying to get this running on TF mobile, so only using the Java/C# library, all my other models i have just frozen to PB, restored and fed the correct tensor in, got the results and i am wanting to do the same here but not sure what the absolute minimum requirement is.
I have a tensorflow LSTM model for predicting the sentiment. I build the model with the maximum sequence length 150. (Maximum number of words) While making predictions, i have written the code as below:
batchSize = 32
maxSeqLength = 150
def getSentenceMatrix(sentence):
arr = np.zeros([batchSize, maxSeqLength])
sentenceMatrix = np.zeros([batchSize,maxSeqLength], dtype='int32')
cleanedSentence = cleanSentences(sentence)
cleanedSentence = ' '.join(cleanedSentence.split()[:150])
split = cleanedSentence.split()
for indexCounter,word in enumerate(split):
try:
sentenceMatrix[0,indexCounter] = wordsList.index(word)
except ValueError:
sentenceMatrix[0,indexCounter] = 399999 #Vector for unkown words
return sentenceMatrix
input_text = "example data"
inputMatrix = getSentenceMatrix(input_text)
In the code i'm truncating my input text to 150 words and ignoring remaining data.Due to this my predictions are wrong.
cleanedSentence = ' '.join(cleanedSentence.split()[:150]) I know that if we have lesser length than sequence length we can pad with zero's. What we need to do if we have more length. Can you suggest me the best way to do this. Thanks in advance.
Working through the tutorial while trying to implement the same general architecture for a multiclass classifier. Is there anything specific that needs to be changed to make it work other than setting the numClasses variable and setting the label vectors appropriately? Mainly wondering if the value = tf.transpose(value, [1, 0, 2]) operation after setting the weight matrix and bias needs to be changed in any way? Thanks in advance.
Hey man
First and foremost Truly nice article and presentation . I am really new to NN and I understood what you have written in your blogpost till the point data get integerised. Although I am not able to understand what is happening after that and why.
Also you mentioned that label placeholder represents set of values either [1,0] or [0,1] depending on weather training set is positive or negative. Although if its either positive or negative why cant we use just one dimensional array here viz either [1] or [0] ?
May I request you to please give me some insight as to what is happening in there and how integerizing the token solves the problem ?
Thanks
Samir
First, thanks for your tutorial. I'm new to NLP and DL. You explained things well.
Here is my problem:
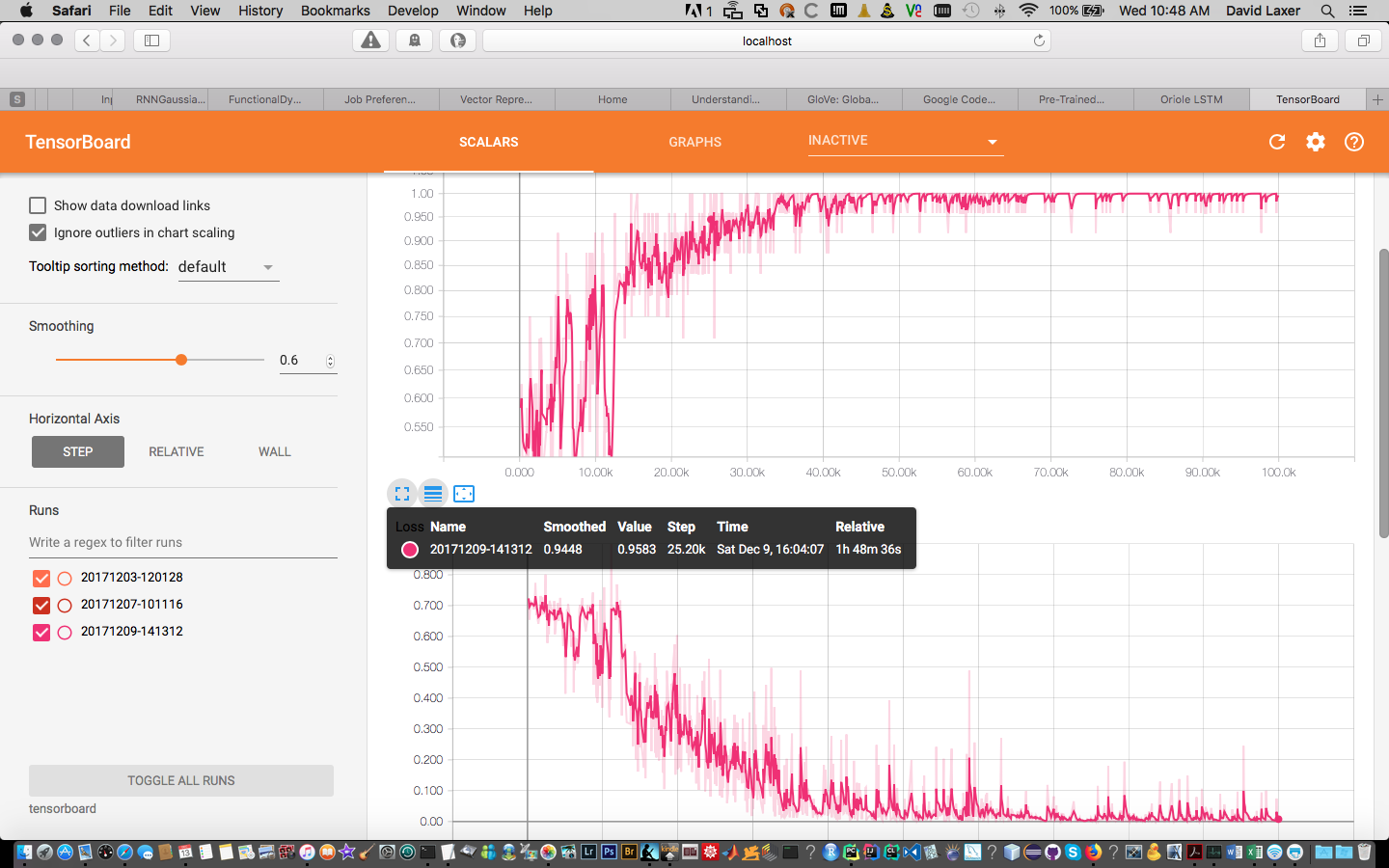
Using the provided code, I trained the network (didn't use pre-trained model). The model’s accuracy and loss curves during training can be found below. It seems that the model learned well.

But the model doesn't perform well on the testing data:
Accuracy for this batch: 33.33333432674408
Accuracy for this batch: 58.33333134651184
Accuracy for this batch: 37.5
Accuracy for this batch: 54.16666865348816
Accuracy for this batch: 50.0
Accuracy for this batch: 58.33333134651184
Accuracy for this batch: 45.83333432674408
Accuracy for this batch: 50.0
Accuracy for this batch: 37.5
Accuracy for this batch: 62.5
Is this overfitting? How to improve this?
I read some issues, and it seems that there are many things to do: early stopping / tuning hyper-parameters / Removing LSTM ...
Which one should I try first?
Hi, first thing: your project is very interesting.
Second: I got an error at the execution at
summary = sess.run( merged , {input_data: nextBatch, labels: nextBatchLabels})
Do you have any ideas how to fix it ?
Thank you in advance
Traceback (most recent call last):
File "Oriole+LSTM.py", line 220, in
summary = sess.run( merged , {input_data: nextBatch, labels: nextBatchLabels})
File "C:\Anaconda\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py", line 789, in run
run_metadata_ptr)
File "C:\Anaconda\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py", line 984, in _run
self._graph, fetches, feed_dict_string, feed_handles=feed_handles)
File "C:\Anaconda\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py", line 410, in init
self._fetch_mapper = _FetchMapper.for_fetch(fetches)
File "C:\Anaconda\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py", line 227, in for_fetch
(fetch, type(fetch)))
TypeError: Fetch argument None has invalid type <class 'NoneType'>
Please, add license.
Hi,

When I run the below code I got the IndexError: index 250 is out of bounds for axis 0 with size 250
I can not convert to the ids matrix as described in the tutorial.
My python version is Python 3.5.2
P.S. Thank you so much for the awesome tutorial. The tutorial is really explaining the concepts very well 👍
Hi adesh. This is really nice article to get going with LSTM. I have wrote a small code in importing the positive and negative files . The positive files loaded are 12500 and the negative files loaded are just 4973. I am little confused on why this is happening. Please refer the screenshot.
I am facing little difficulty on understanding the train test split function. Could you please shed light on that.
Thanks

Hi, first of all, thanks for putting this project up. It's extremely helpful for what I need to do.
Now to the question: I'm running through these notebooks and in the "Pre-Trained LSTM" you have two examples, one, of a positive sentiment and the other of a negative sentiment. However, I noticed that if I were to say ""That movie was not terrible" then it will still be classified as "Negative sentiment" and similarly, if I were to say "That movie was not the best one I have ever seen" then it is still classified as "Positive sentiment."
What would be your recommendation for negation handling? I did find this: negation-handling-in-sentiment-analysis, but in case you've done anything wrt to this example I would be interested in seeing it.
Thanks!
I wonder if the reason you're using wordslist is because you can only get wordvectors from id, or you can't get a tensor if you transfer wordvector in advance.
First of all Thanks for the oriole tutorial, I really enjoyed it.
I noticed that you truncate all the reviews to 250 words, I assume this is for convenience. Would it be better to use all of the use the entire text of the reviews? Do you know of any resources you could point me to that would show me ways of implementing that?
I appreciate your help.
Thanks,
Michael
Can it be applied for 3 different class, Not the one provided??
saver.restore(sess, tf.train.latest_checkpoint('/tmp/models'))
INFO:tensorflow:Restoring parameters from /tmp/models\pretrained_lstm.ckpt-90000
NotFoundError (see above for traceback): Key rnn/basic_lstm_cell/kernel not found in checkpoint
[[Node: save_1/RestoreV2_4 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/cpu:0"](_arg_save_1/Const_0_0, save_1/RestoreV2_4/tensor_names, save_1/RestoreV2_4/shape_and_slices)]]
I'm running on Tensorflow version: 1.4.0
Anaconda Python 3.6
OS X 10.11.6
No GPU
I trained the models in my own environment:
iterations = 10
for i in range(iterations):
nextBatch, nextBatchLabels = getTestBatch();
print("Accuracy for this batch:", (sess.run(accuracy, {input_data: nextBatch, labels: nextBatchLabels})) * 100)
Accuracy for this batch: 87.5
Accuracy for this batch: 75.0
Accuracy for this batch: 83.3333313465
Accuracy for this batch: 95.8333313465
Accuracy for this batch: 83.3333313465
Accuracy for this batch: 91.6666686535
Accuracy for this batch: 91.6666686535
Accuracy for this batch: 79.1666686535
Accuracy for this batch: 87.5
Accuracy for this batch: 79.1666686535
Any ideas why the accuracy varies so much for each batch?
I tried running against the pre-trained model, but tensorflow 1.4.0 can't process the file.
Here's my tensorboard output:
Hi! I'm not very expert in Python; when code is running, there is a error:
Traceback (most recent call last):
File "C:/Python36/SentimentAnalysisWithLSTM.py", line 187, in
saver.restore(sess, tf.train.latest_checkpoint('models'))
File "C:\Python36\lib\site-packages\tensorflow\python\training\saver.py", line 1557, in restore
raise ValueError("Can't load save_path when it is None.")
ValueError: Can't load save_path when it is None.
I don't understand what is the problem.
hi, i am new in this area.while running the following code:
sess = tf.InteractiveSession()
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('models'))
NotFoundError Traceback (most recent call last)
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py in _do_call(self, fn, *args)
1322 try:
-> 1323 return fn(*args)
1324 except errors.OpError as e:
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py in _run_fn(session, feed_dict, fetch_list, target_list, options, run_metadata)
1301 feed_dict, fetch_list, target_list,
-> 1302 status, run_metadata)
1303
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\errors_impl.py in exit(self, type_arg, value_arg, traceback_arg)
472 compat.as_text(c_api.TF_Message(self.status.status)),
--> 473 c_api.TF_GetCode(self.status.status))
474 # Delete the underlying status object from memory otherwise it stays alive
NotFoundError: Key rnn/basic_lstm_cell/kernel/Adam_1 not found in checkpoint
[[Node: save/RestoreV2_14 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save/Const_0_0, save/RestoreV2_14/tensor_names, save/RestoreV2_14/shape_and_slices)]]
[[Node: save/RestoreV2_7/_19 = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device_incarnation=1, tensor_name="edge_52_save/RestoreV2_7", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"]]
During handling of the above exception, another exception occurred:
NotFoundError Traceback (most recent call last)
in ()
1 sess = tf.InteractiveSession()
2 saver = tf.train.Saver()
----> 3 saver.restore(sess, tf.train.latest_checkpoint('models'))
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py in restore(self, sess, save_path)
1664 if context.in_graph_mode():
1665 sess.run(self.saver_def.restore_op_name,
-> 1666 {self.saver_def.filename_tensor_name: save_path})
1667 else:
1668 self._build_eager(save_path, build_save=False, build_restore=True)
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py in run(self, fetches, feed_dict, options, run_metadata)
887 try:
888 result = self._run(None, fetches, feed_dict, options_ptr,
--> 889 run_metadata_ptr)
890 if run_metadata:
891 proto_data = tf_session.TF_GetBuffer(run_metadata_ptr)
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py in _run(self, handle, fetches, feed_dict, options, run_metadata)
1118 if final_fetches or final_targets or (handle and feed_dict_tensor):
1119 results = self._do_run(handle, final_targets, final_fetches,
-> 1120 feed_dict_tensor, options, run_metadata)
1121 else:
1122 results = []
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py in _do_run(self, handle, target_list, fetch_list, feed_dict, options, run_metadata)
1315 if handle is None:
1316 return self._do_call(_run_fn, self._session, feeds, fetches, targets,
-> 1317 options, run_metadata)
1318 else:
1319 return self._do_call(_prun_fn, self._session, handle, feeds, fetches)
~\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\client\session.py in _do_call(self, fn, *args)
1334 except KeyError:
1335 pass
-> 1336 raise type(e)(node_def, op, message)
1337
1338 def _extend_graph(self):
NotFoundError: Key rnn/basic_lstm_cell/kernel/Adam_1 not found in checkpoint
[[Node: save/RestoreV2_14 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save/Const_0_0, save/RestoreV2_14/tensor_names, save/RestoreV2_14/shape_and_slices)]]
[[Node: save/RestoreV2_7/_19 = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device_incarnation=1, tensor_name="edge_52_save/RestoreV2_7", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"]]
Caused by op 'save/RestoreV2_14', defined at:
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\runpy.py", line 193, in _run_module_as_main
"main", mod_spec)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel_launcher.py", line 16, in
app.launch_new_instance()
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\traitlets\config\application.py", line 658, in launch_instance
app.start()
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel\kernelapp.py", line 478, in start
self.io_loop.start()
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\zmq\eventloop\ioloop.py", line 177, in start
super(ZMQIOLoop, self).start()
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tornado\ioloop.py", line 888, in start
handler_func(fd_obj, events)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tornado\stack_context.py", line 277, in null_wrapper
return fn(*args, **kwargs)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\zmq\eventloop\zmqstream.py", line 440, in _handle_events
self._handle_recv()
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\zmq\eventloop\zmqstream.py", line 472, in _handle_recv
self._run_callback(callback, msg)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\zmq\eventloop\zmqstream.py", line 414, in _run_callback
callback(*args, **kwargs)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tornado\stack_context.py", line 277, in null_wrapper
return fn(*args, **kwargs)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel\kernelbase.py", line 283, in dispatcher
return self.dispatch_shell(stream, msg)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel\kernelbase.py", line 233, in dispatch_shell
handler(stream, idents, msg)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel\kernelbase.py", line 399, in execute_request
user_expressions, allow_stdin)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel\ipkernel.py", line 208, in do_execute
res = shell.run_cell(code, store_history=store_history, silent=silent)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\ipykernel\zmqshell.py", line 537, in run_cell
return super(ZMQInteractiveShell, self).run_cell(*args, **kwargs)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\IPython\core\interactiveshell.py", line 2728, in run_cell
interactivity=interactivity, compiler=compiler, result=result)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\IPython\core\interactiveshell.py", line 2850, in run_ast_nodes
if self.run_code(code, result):
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\IPython\core\interactiveshell.py", line 2910, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "", line 2, in
saver = tf.train.Saver()
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py", line 1218, in init
self.build()
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py", line 1227, in build
self._build(self._filename, build_save=True, build_restore=True)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py", line 1263, in _build
build_save=build_save, build_restore=build_restore)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py", line 751, in _build_internal
restore_sequentially, reshape)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py", line 427, in _AddRestoreOps
tensors = self.restore_op(filename_tensor, saveable, preferred_shard)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py", line 267, in restore_op
[spec.tensor.dtype])[0])
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\ops\gen_io_ops.py", line 1020, in restore_v2
shape_and_slices=shape_and_slices, dtypes=dtypes, name=name)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\op_def_library.py", line 787, in _apply_op_helper
op_def=op_def)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\ops.py", line 2956, in create_op
op_def=op_def)
File "C:\Users\TURNO\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\framework\ops.py", line 1470, in init
self._traceback = self._graph._extract_stack() # pylint: disable=protected-access
NotFoundError (see above for traceback): Key rnn/basic_lstm_cell/kernel/Adam_1 not found in checkpoint
[[Node: save/RestoreV2_14 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/device:CPU:0"](_arg_save/Const_0_0, save/RestoreV2_14/tensor_names, save/RestoreV2_14/shape_and_slices)]]
[[Node: save/RestoreV2_7/_19 = _Recvclient_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device_incarnation=1, tensor_name="edge_52_save/RestoreV2_7", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:GPU:0"]]
First of all, I want to thank you for this great project. I have problems in understanding this part:
WH is a matrix that stays the same across all time steps, and the weight matrix WX is different for each input.
I think this information isn't true according to Andrej Karpathy's great post.
The above specifies the forward pass of a vanilla RNN. This RNN’s parameters are the three matrices W_hh, W_xh, W_hy
Correct me if I am wrong.
Thanks in advance.
Hi,
I am trying to understand your code but having a bit confusion, you have added all the positive negative sentences in single ids and saved and loaded from there.
At the end, it calculate the accuracy after training the NN, i want to know how to check the text polarity either its positive or negative upon given the sentence
Thanks,
Shan
includes invalid characters for a local volume name,. If you intended to pass a host directory, use absolute path
https://stackoverflow.com/q/54457535/9646274?sem=2
edit - I've downgraded TensorFlow from 1.2 to 1.1 and the issue no longer occurs
When running the section of code:
sess = tf.InteractiveSession()
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('models'))
I get the following errors:
tensorflow/core/framework/op_kernel.cc:1158] Not found: Key rnn/basic_lstm_cell/kernel/Adam_1 not found in checkpoint
tensorflow/core/framework/op_kernel.cc:1158] Not found: Key rnn/basic_lstm_cell/kernel/Adam not found in checkpoint
tensorflow/core/framework/op_kernel.cc:1158] Not found: Key rnn/basic_lstm_cell/bias not found in checkpoint
tensorflow/core/framework/op_kernel.cc:1158] Not found: Key rnn/basic_lstm_cell/bias/Adam not found in checkpoint
tensorflow/core/framework/op_kernel.cc:1158] Not found: Key rnn/basic_lstm_cell/bias/Adam_1 not found in checkpoint
tensorflow/core/framework/op_kernel.cc:1158] Not found: Key rnn/basic_lstm_cell/kernel not found in checkpoint
I'm on macOS 10.12 and have the same issue with both Python 3.5 and 3.6. It occurs when running python from command line or with jupyter.
Hey Adit, firstly, thank you for the article, this has been extremely useful in my research into sentiment analysis.
Would you mind clarifying 1 point for me, apologies if this is something obvious that I've missed.
In the pre-trained notebook the output from the sess.run is ...
[[-3.4586341 9.232184 ]
[-2.0720391 -4.6618977 ]
[ 1.36504 0.50249183]
[ 2.5868893 -0.28297684]
[-0.7046647 -3.8239028 ]
...]
Would you be able to explain how these numbers relate to the final sentiment analysis. I understand that the higher of the two numbers is the predicted sentiment, however I'm interested to know what the ranges of these numbers are and how we can use them to reason further about the sentiment.
I was expecting both values to be between 0 - 1, and we could therefore deduce a percentage of the probable predicted sentiment. As this isn't the case, is there any light you can shed on the significance of the value of these numbers?
Do you have any intuition as to how this model could be served using Tensorflow Serving? The part I'm struggling with relates to converting the incoming serialized data (that was encoded as a sentence, say "That movie was the best one I have ever seen.") back into a regular string to be passed into getSentenceMatrix(), to then be passed through the network.
All examples of Serving in action are using text images, the file I am (sort of) replicating is: https://github.com/tensorflow/serving/blob/master/tensorflow_serving/example/inception_saved_model.py.
In particular this part:
# Input transformation.
serialized_tf_example = tf.placeholder(tf.string, name='tf_example')
feature_configs = {'image/encoded': tf.FixedLenFeature(shape=[], dtype=tf.string),
}
tf_example = tf.parse_example(serialized_tf_example, feature_configs)
jpegs = tf_example['image/encoded']
images = tf.map_fn(preprocess_image, jpegs, dtype=tf.float32)
# ^ Essentially this step but relating to strings instead of an image (.jpeg)
Any help is much appreciated! Thank You!!

Using the code on Windows 10 with Python v3.5.4 & TensorFlow v1.1
But it always gives Sentiment as Negative respective of the text.
Actually, for text like "That movie was the best one I have ever seen" & "I am very happy today" the sentiment should be positive right? But the code gives negative sentiment as the output
Hi Adesh,
I am getting the following warning.
Warning (from warnings module):
File "C:\Users\UM255003\AppData\Local\Programs\Python\Python36\lib\site-packages\tensorflow\python\ops\embedding_ops.py", line 134
if params is None or params in ((), []):
FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
Following is the code
import numpy as np
import tensorflow as tf
from os import listdir
from os.path import isfile, join
InPath = 'glove.6B.50d.txt'
wordsList = []
wordVector = []
file = open(InPath,'r',encoding='utf-8')
for line in file.readlines():
row = line.strip().split(' ')
wordsList.append(row[0])
wordVector.append(row[1:])
print('Loaded Glove')
file.close()
wordVectors = np.asarray(wordVector)
print('Loading Done')
print(len(wordsList))
print(wordVectors.shape)
maxSeqLength = 10 #Maximum length of sentence
numDimensions = 300 #Dimensions for each word vector
firstSentence = np.zeros((maxSeqLength), dtype='int32')
firstSentence[0] = wordsList.index("i")
firstSentence[1] = wordsList.index("thought")
firstSentence[2] = wordsList.index("is")
firstSentence[3] = wordsList.index("movie")
firstSentence[4] = wordsList.index("was")
firstSentence[5] = wordsList.index("incredible")
firstSentence[6] = wordsList.index("and")
firstSentence[7] = wordsList.index("inspiring")
print(firstSentence.shape)
print(firstSentence)
print(wordVectors)
with tf.Session() as sess:
print(tf.nn.embedding_lookup(wordVectors,firstSentence))
Can you please specify why I am getting the error.
P.S: I am new to tensor flow :)
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.