The ultimate goal of our research is to reduce the effort of SLR to days of work and make it practical to be conducted frequently.
ai-se / ml-assisted-slr Goto Github PK
View Code? Open in Web Editor NEWAutomated Systematic Literature Review
Automated Systematic Literature Review








 Chen")
The entropy maximization methods do not make a single difference from random sampling!!!



Need to decide whether to use UPDATE or REUSE.
Notice:
Hall -> Wahono, UPDATE is better,

Hall -> Abdellatif, REUSE is better,

Wahono -> Hall, REUSE is better,

However:
Results:
Single repeat results suggest that UPDATE_REUSE will have the merits of both UPDATE and REUSE.
More sophisticated results are expected tomorrow. Will update this issue when results come out.
01/11/2017:
Test to see which is the cost efficient point to stop reading: at X% (X=80,85,90,95,99...) retrieval rate?

80% or 85% retrieval rate seems most cost efficient.
I would choose 90% since we want more completeness and the sacrifice on efficiency is not much.
Any suggestions?

Want bar chart at 80%, 85%, 90%, 95%, 99% for the above?
Semi-automatic selection of primary studies in systematic literature reviews: is it reasonable? (2015): Score Citation Automatic Selection (SCAS), to automate part of the primary study selection activity. (58.2 % cost reduction, 12.98 % error rate.)
VTM 2013, VTM 2011. (Clustering, citation maps), less than half cost reduction (70.14 min -> 54.5 min).
| snowballing | full search | |
|---|---|---|
| recall | 92.86% | 100% |
| precision | 7.55% | 1.42% |
A visual analysis approach to update systematic reviews 2014
Formalizing a systematic review updating process first addressed the difficulty of updating an SLR.
| Hall Paper | IEEExplore | |
|---|---|---|
| Initial Size | 2073 | 8912 |
| Final Size | 136 | 106 |

In the scenario of
Baseline from Biomedical #17
Baseline from Litigation #16
medline database
Byron C. Wallace
Active learning for biomedical citation screening 2010
co-feature (co-testing) for hasty problem (rule based simple model vs SVM, find disagreements)
Semi-automated screening of biomedical citations for systematic reviews 2010
patient AL (random sampling until enough, then start training and uncertainty sampling. Aggressive under-sampling for final model [found incredibly useful in simple experiment])
Who should label what? instance allocation in multiple expert active learning. 2011
Problem: given a panel of experts, a set of unlabeled examples and a budget, who should label which examples?
Solution: inexpensive experts flag difficult examples encountered during annotation for review by more experienced experts.
Active literature discovery for scoping evidence reviews: How many needles are there? 2013
Problem: how to estimate the prevalence of relative docs.
Solution: active learning as to select informative docs to be reviewed (bias introduced), then inverse-weighting to correct bias. (weighting is the prediction probability)
Deploying an Interactive Machine Learning System in an
Evidence-Based Practice Center: abstrackr 2012
TOOL
Modernizing the systematic review process to inform comparative effectiveness: tools and methods. 2013
Overview
Combining crowd and expert labels using decision theoretic active learning 2015
crowd sourcing + expert labeling + active learning
Non - Wallace
Automatic text classification to support systematic reviews in medicine 2014
Compare some supervised text miners for classification of Medical Systematic Review data.
Classifiers: NB, KNN, SVM, Rocchio
Preprocessing: steming, stopword removal, TF, tfidf
Metrics: Macro-F score
Like our BIGDSE16 paper.
Reviewed 350 docs, 160 of them are "relevant". Cost me 1.5 hours.
Hall.csv without true labels, trying to find studies about "software defect prediction".
Just me

The output csv file is here

In the scenario of
Baseline from Biomedical #17
Baseline from Litigation #16
Conclusions drawn:
Two current winners:

Get more data sets to do experiment on. It would be best if one from biomedical, one from litigation.
Newest result in e-discovery:
Scalability of Continuous Active Learning for Reliable High-Recall Text Classification mentioned one technique to tackle the problem.
Presumptive non-relevant examples.
Autonomy and reliability of continuous active learning for technology-assisted review
May be useful for REUSE.
Testing.
Each round, besides all the labeled examples, randomly sample from the unlabeled examples and treat them as negative training examples.
Then train the model.
why we need this technique:
why it works:
why we need this technique:
why it works:
Hall:

Wahono:

Abdellatif:

At least as good as not using it. (worst case result depends on pseudo random, not reliable)
Hall as previous SLR,
on Wahono:

on Abdellatif:

Wahono as previous SLR,
on Hall:

on Abdellatif:

Abdellatif as previous SLR,
on Hall:

on Wahono:

25 repeats, took about 1 day on ncsu hpcc.
| Hall Paper | IEEExplore | |
|---|---|---|
| Initial Size | 2073 | 8912 |
| Final Size | 136 | 106 |


| Wahono Paper | IEEExplore | |
|---|---|---|
| Initial Size | 2117 | 7002 |
| Final Size | 71 | 62 |


Question: is the figure clear enough? or make it double with medians and iqrs on different figs?
P_U_S_A vs. P_U_S_N


P_U_S_A wins.
For last code, A is better than N (aggressive undersampling is useful)
Compare the third code
P_U_S_A vs. P_U_C_A


No clear winner. C is better than S due to its ability to continuous update the model.
Compare the second code
P_U_C_A vs. P_C_C_A


No clear winner, let's keep both.
Compare the first code
P_U_C_A vs. P_C_C_A vs.H_U_C_A vs. H_C_C_A
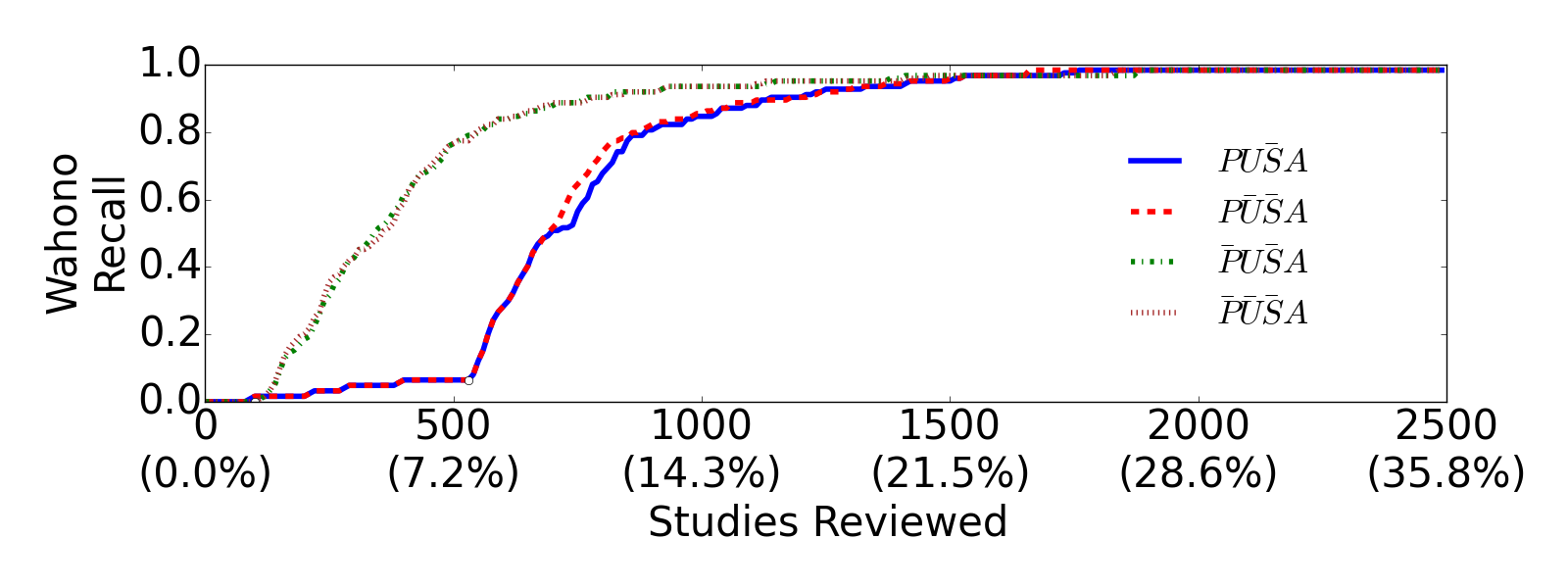

H is better than P.
H_U_C_A and H_C_C_A are similar.
Compare H_U_C_A and H_C_C_A in terms of stability:


H_C_C_A outperforms H_U_C_A in terms of stability.
Comparing to state-of-the-art:
H_C_C_A vs. H_C_C_N vs. P_U_S_A


H_C_C_A outperforms either of the state-of-the-art methods.
Reason: transparency
Expected result:
Injected citemap.csv (provided by George) into elastic search.
Problems:
Supported by https://github.com/ai-se/ML-assisted-SLR/blob/master/no_ES/src/runner.py
LDA on 30 topics (number of topics does not matter much)
Topic weighting for the two data sets:


L1 similarity, as default of LDA:
L2 similarity, make more sense:
LDA on 30 topics
Topic weighting for the two relevant set:


L1 similarity, as default of LDA:
L2 similarity, make more sense:
F score with training size
What is used in the baseline method?
g-means (sqrt(prec*rec)), AUC and PRBEP
add to proposal
"query": { (software OR applicati* OR systems ) AND (fault* OR defect* OR quality OR error-prone) AND (predict* OR prone* OR probability OR assess* OR detect* OR estimat* OR classificat*) }
"filter": {"publicationYear":{ "gte":2000, "lte":2013 }},
{owners.owner=HOSTED}
relativity analytics (TOOL)
tar for smart people, catalyst (BOOK)
CAL: Evaluation of machine-learning protocols for technology-assisted review in electronic discovery 2014
Autonomy and Reliability of Continuous Active Learning for Technology-Assisted Review (1 relevant seed (hasty)) 2015
| Hall Paper | IEEExplore | |
|---|---|---|
| Initial Size | 2073 | 8912 |
| Final Size | 136 | 106 |


| Wahono Paper | IEEExplore | |
|---|---|---|
| Initial Size | 2117 | 7002 |
| Final Size | 71 | 62 |


Stage 1: Random sampling
Stage 2: Build classifier
Stage 3: Prediction
Data Balancing
Baseline from Medicine #17
Baseline from Litigation #16
H_U_C_A (hasty, uncertainty sampling, continuous, aggressive undersampling)
Hasty and continuous suggested by litigation,
Uncertainty sampling and aggressive undersampling suggested by Medicine.
Have reviewed Hall. Retrieved 90%
Want to review Wahono. Want to retrieve 90%. Both set are targeting at defect prediction, but different RQs. (Different review protocols)
Review protocol for Hall:

Review protocol for Wahono:

REUSE: Import only learned model from Hall, featurize just on Wahono. Use imported Hall model to replace random sampling, then start to learn its own model on Wahono.
UPDATE (Partial): Import only labeled data from Hall, combine with Wahono, and re-featurize. It is partial UPDATE since it can save memory without damaging performance as discussed in #31.

UPDATE is actually performing better than REUSE.
Is it because of the data sets? Does there exist data sets where UPDATE performs badly but REUSE stays similarly.
As by the end of April, a total of 232 volunteers have signed up and screened more than 38,000 records identifying 1147 RCTs or quasi-RCTS. Early data on the accuracy of the crowd and the robustness of the algorithm is extremely positive with 99.8% sensitivity and 99.8% specificity.
Crowd labels are collected via Amazon Mechanical Turk.
FN costs 10 times more than FP.
A typical (Mechanical Turk) crowd worker might earn ≈ $1.5 / hour, while a trained physician might earn ≈ $150 /hour.
Whole UPDATE: Import all data from Hall2007-, combine with Hall2007+, and re-featurize. Only retrieve studies from Hall2007+.
Partial UPDATE: Import only labeled data from Hall2007-, combine with Hall2007+, and re-featurize. Only retrieve studies from Hall2007+.

Combining crowd and expert labels using decision theoretic active learning 2015
Strategy:
Two choices each step:
Decision theory for which action to choose.
Performance is measured by an expected loss vs cost curve. Not very convincing to me.
If crowd worker is way cheaper than expert. (Say 1/1000)
Strategy:
In 4, can use "true" label (expert label) to adjust weight of crowd labels, e.g. this crowd worker is unreliable...
If crowd worker is not that cheap
Strategy:
| Hall Paper | IEEExplore | |
|---|---|---|
| Initial Size | 2073 | 8912 |
| Final Size | 136 | 106 |

| Wahono Paper | IEEExplore | |
|---|---|---|
| Initial Size | 2117 | 7002 |
| Final Size | 71 | 62 |

Start with patient active learning (P_U_S_A)
First compare the last code
P_U_S_A vs. P_U_S_N

P_U_S_A wins.
For last code, A is better than N (aggressive undersampling is useful)
Compare the third code
P_U_S_A vs. P_U_C_A

No clear winner. I would prefer C over S, since continuous learning can handle concept drift better.
But let's keep both
Compare the second code
P_U_S_A vs. P_U_C_A vs. P_C_C_A

No clear winner. I prefer C over U since no need to worry about stop rule for U (margin threshold of SVM)
But let's keep all three
Compare the first code
P_U_S_A vs. P_U_C_A vs. P_C_C_A vs. H_U_S_A vs. H_U_C_A vs. H_C_C_A

H is better than P.
But H_C_C_A is a clear loser.
Start aggressive undersampling with only one "relevant" example is a bad idea.
The final winner would be H_U_S_A and H_U_C_A.
I would prefer H_U_C_A for continuous learning to handle concept drift and updating of SLR.
How much effort does it cost for a primary study selection? (N reviewers, T time for each)
Better if details of each step can be provided:
Is there any effort taken (a hidden step) between applying the search string to databases and the initial candidate study list has been collected?
Why ask: I retrieve much more candidate studies with the same search string provided in the SLR paper.
If there is any effort, what is that? How much does it cost? What is the reason behind?
One reason I guess is to reduce the size of initial candidate study list, thus reduce the review cost of primary study selection. If this is true, learning based primary study selection can remove this hidden step since it can search in much larger candidate study list and retrieve above 90% "relevant" with less effort. This may even improve the overall completeness and save the effort of this hidden step.
Target similarity of three data sets: Hall, Wahono, Abdellatif.
Need to stabilize the target similarity.
Tune LDA paremeters (Decision = [alpha, eta]). Don't want to change topic number.
Objective = [iqrs].
Differential evolution, 10 candidates per generation, 10 generations max.
Running on NCSU HPC with single node, 10 threads.
Best decisions: [alpha = 0.3636991597795636, eta = 0.9722983748261428]
Best objectives (iqrs): [0.0064311303948402232, 0.039641889335073899, 0.048358360331471784]
iqrs before tuning: [0.002, 0.129, 0.129]
medians of similarities: [0.98309488776481135, 0.45742986887869136, 0.4108420090949999]
Tuning LDA is essential to get a stabilized similarity score.
Retrieved from IEEE by search string: 6963
Target: 70
Target in IEEE: 37 (23)
Target in IEEE+acm: 25
Target in other: 8
Injected into Elasticsearch: 7002
Pos in Elasticsearch: 62

An extreme one

Systematic literature review (SLR) is the primary method for aggregating and synthesizing evidence in evidence-based software engineering. Such SLR studies need to be conducted frequently since a) researchers should update their SLR result once one or two years to consider latest publications; b) most researchers are constantly studying different research questions in the same or similar topic area. However, SLR studies cannot be conducted frequently due to its heavy cost. In our previous study, with the help of FASTREAD, we succeed to save 90% of the review cost in sacrifice of 10% recall in primary study selection of systematic literature review (SLR). In this paper, we allow researchers to import knowledge from previously completed SLR studies to boost FASTREAD. With knowledge transfering, review effort can be further reduced to 50% of the review effort of FASTREAD with extremely low variance when updating an SLR study while variance can be greatly reduced in the scenario of conducting an SLR on similar or the same topic.
(same as FASTREAD paper)
(Except for the general assumptions)
previously completed an SLR which
import the labeled examples from previous SLR to boost current primary study selection
(Except for the general assumptions)
previously completed an SLR which
import the trained model from previous SLR to boost current primary study selection

[Hall2007-] -> [Hall2007+] -> [Wahono]
FASTREAD on [Hall2007-]

FASTREAD vs UPDATE on [Hall2007+]

FASTREAD vs UPDATE vs REUSE on [Wahono]

UPDATE is better than REUSE in the case of transfering knowledge from Hall to Wahono. Probably because the targets are very consistent. See #33
Need to find a data set which is also in SE SLR, but has different target.
From the following two figures, looks like Hall data set has much larger variance than Wahono.
Hall:
Wahono:

Hall has some bad luck when random sampling. The prevalence of "relevant" is larger than 0.01, the possibility of not getting a single "relevant" when reviewing the first 200 studies is (1-0.99)^(200)=13%. For our 10 repeat experiments, there should be 1 to 2 out of 10 repeats that stay at 0 "relevant" at 200 studies reviewed, which will not cause a big iqr. However, in the experiments shown above, we got 3, and the iqr at 200 is therefore extremely large. On the other hand, in Wahono, with a little bit luck, we always got more than 1 "relevant" studies retrieved at 200 reviewed, which leads to a low iqr.
The Hall should look more like this:

And Wahono should look more like this:

Probably 10 repeats is not enough.
Should we increase it to 25?
Software Analytics to Software Practice: A Systematic Literature Review
Target: software analysis, 19/1726
Hall.csv vs. Abdellatif.csv


START on Hall.csv, then

Just median

Evidence-based software engineering
Evidence-based software engineering for practitioners
First brought to SE community
Guidelines for performing systematic literature reviews in software engineering
The famous GOLDEN guideline
A systematic review of systematic review process research in software engineering
An recent review
Identifying barriers to the systematic literature review process
Same goal. Primary study selection being identified as the top three most difficult, time-consuming, tool support needed phase in SLR.
Tools to Support Systematic Reviews in Software Engineering: A Feature Analysis
Best study for tools
Tools to support systematic literature reviews in software engineering: A mapping study
SLuRp: a tool to help large complex systematic literature reviews deliver valid and rigorous results
SESRA: A Web-based Automated Tool to Support the Systematic Literature Review Process
best and latest tool so far
SLR-Tool: A Tool for Performing Systematic Literature Reviews.
Using GQM and TAM to evaluate StArt-a tool that supports Systematic Review
A Visual Analysis Approach to Update Systematic Reviews
A visual analysis approach to validate the selection review of primary studies in systematic reviews
Hierarchical Clustering does NOT help to balance initial training data.
Possible Reasons:
Fix: (fix 2 first, if results are good, then 1 is not the problem)
Basically try things listed in Fix on LN DiscoveryIQ project.
Then map useful techs into Systematic Literature Review in SE.
Our Task:
Similar task as to LN. How to assist reviews fast retrieve relevant papers by search and active learning.
Checked several 2016 paper conducting Systematic Literature Review, some use CiteSeerX as part of the source.
Souza, Draylson M., Katia R. Felizardo, and Ellen F. Barbosa. "A Systematic Literature Review of Assessment Tools for Programming Assignments." In 2016 IEEE 29th International Conference on Software Engineering Education and Training (CSEET), pp. 147-156. IEEE, 2016.
No learning involved, just searching and filtering.
Evaluate tools used in Systematic Literature Review.

Literature on Systematic Literature Review itself (instead of conducting one)
Zhou, You, He Zhang, Xin Huang, Song Yang, Muhammad Ali Babar, and Hao Tang. "Quality assessment of systematic reviews in software engineering: a tertiary study." In Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering, p. 14. ACM, 2015.
Focuses on how to manage tasks distributed onto several reviewer, how to setup standard rubrics, how to do quality assessment...
Task 2: Technologically Assisted Reviews in Empirical Medicine
As in RQ6, the need of continuous updating SLR is identified in:
Another possible need is to reuse SLR, also identified in the above paper. The goal is to speed up the random selection process for one SLR by applying a model from another similar SLR, e. g., apply the model from Hall to Wahono to speed up the initial seed collection.
Systematic literature review (SLR) is the primary method for aggregating and synthesizing evidence in evidence-based software engineering. Such SLR studies need to be conducted frequently since a) researchers should update their SLR result once one or two years to consider latest publications; b) most researchers are constantly studying different research questions in the same or similar topic area. However, SLR studies cannot be conducted frequently due to its heavy cost. In our previous study, with the help of FASTREAD, we succeed to save 90% of the review cost in sacrifice of 10% recall in primary study selection of systematic literature review (SLR). In this paper, we allow researchers to import knowledge from previously completed SLR studies to boost FASTREAD. With the appropriate knowledge transfering technique, review cost and variances can be further reduced when updating an SLR or initiating an new SLR on similar or related topics.
In our previous study, FASTREAD has effectively reduced the cost of primary study selection in SLR.
However, in FASTREAD, random sampling costs a large amount of review effort and introduces most of the variances as shown above. To further reduce the cost of primary study selection, random sampling step needs to be replaced.
External knowledge needs to be introduced in order to replace random sampling. There are certain scenarios that reviewers are guaranteed to have some knowledge on their SLRs. Such scenarios are when a reviewer has done an SLR using FASTREAD (or has access to all the data of other reviewers conducting an SLR with FASTREAD) and now
We call these two scenarios update SLR and transfer SLR respectively. In both of these scenarios, the knowledge of previously conducted SLR can be imported as external knowledge to boost the primary study selection of the new SLR.
The following of this paper will discuss the use of previous knowledge in such scenarios.
Some literature review, existing SLR update examples, full update vs. snowballing...
Assumptions:
Some literature review, examples.
Assumptions:
UPDATE is designed to transfer knowledge in update SLR scenario where
REUSE is designed to transfer knowledge in transfer SLR scenario where
Partial UPDATE vs. Whole UPDATE: (can be a RQ).
Data: Hall2007- as previous SLR, Hall2007+ as new SLR:
FASTREAD on Hall2007-:
FASTREAD vs. Partial UPDATE vs. Whole UPDATE on Hall2007+:
Depending on the topic similarity of the new SLR and the previous one, different methods might be more suitable:
Data sets:
Similarity measurement: 30 topics LDA, L2 normalization, cosine distance.
Data similarity

data_Hall_Wahono: 0.860254
data_Hall_Abdellatif: 0.726351
data_Abdellatif_Wahono: 0.809703
Target similarity

target_Hall_Wahono: 0.995255
target_Hall_Abdellatif: 0.64379
target_Abdellatif_Wahono: 0.649005
(Data similarity does not necessarily reflect target similarity)
Hall and Wahono are both on defect prediction, and these two have very high target similarity (0.995).
Abdellatif is on software analysis, the target similarity between Abdellatif and the other two are about 0.64.
Hall as previous SLR,
on Wahono:

on Abdellatif:

Wahono as previous SLR,
on Hall:

on Abdellatif:


Abdellatif as previous SLR,
on Hall:


on Wahono:


Conclusions:
FASTREAD on Hall2007- => UPDATE on Hall2007+ => UPDATE on Wahono => REUSE on Adbellatif:

A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

