This is project as topic: TOEIC(Test of English for International Communication) problem solving using pytorch-pretrained-BERT model. The reason why I used huggingface's pytorch-pretrained-BERT model is for pre-training or to do fine-tune more easily. I've solved the only blank problem, not the whole problem. There are two types of blank issues:
- Selecting Correct Grammar Type.
Q) The teacher had me _________ scales several times a day.
1. play (Answer)
2. to play
3. played
4. playing
- Selecting Correct Vocabulary Type.
Q) The wet weather _________ her from going shopping.
1. interrupted
2. obstructed
3. impeded
4. discouraged (Answer)
- input
{
"1" : {
"question" : "Business experts predict that the upward trend in consumer spending is _ to continue until the end of this year.",
"answer" : "likely",
"1" : "potential",
"2" : "likely",
"3" : "safety",
"4" : "seemed"
}
}- output
=============================
Question : Business experts predict that the upward trend in consumer spending is _ to continue until the end of this year.
Real Answer : likely
1) potential 2) likely 3) safety 4) seemed
BERT's Answer => [likely]
In pretrained BERT, It contains contextual information. So It can find more contextual or grammatical sentences, not clear, a little bit. I was inspired by grammar checker from blog post.
Can We Use BERT as a Language Model to Assign a Score to a Sentence?
BERT uses a bidirectional encoder to encapsulate a sentence from left to right and from right to left. Thus, it learns two representations of each word-one from left to right and one from right to left-and then concatenates them for many downstream tasks.
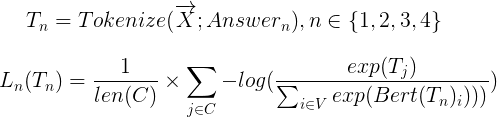
I had evaluated with only pretrained BERT model(not fine-tuning) to check grammatical or lexical error. Above mathematical expression, X is a question sentence. and n is number of questions : {a, b, c, d}. C subset means answer candidate tokens : C of warranty is ['warrant', '##y']. V means total Vocabulary.
There's a problem with more than one token. I solved this problem by getting the average value of each tensor. ex) is being formed as ['is', 'being', 'formed']
Then, we find argmax in L_n(T_n).
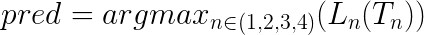
predictions = model(question_tensors, segment_tensors)
# predictions : [batch_size, sequence_length, vocab_size]
predictions_candidates = predictions[0, masked_index, candidate_ids].mean()Fantastic result with only pretrained BERT model
bert-base-uncased: 12-layer, 768-hidden, 12-heads, 110M parametersbert-large-uncased: 24-layer, 1024-hidden, 16-heads, 340M parametersbert-base-cased: 12-layer, 768-hidden, 12-heads , 110M parametersbert-large-cased: 24-layer, 1024-hidden, 16-heads, 340M parameters
Total 7067 datasets: make non-deterministic with model.eval()
| bert-base-uncased | bert-base-cased | bert-large-uncased | bert-large-cased | |
|---|---|---|---|---|
| Correct Num | 5192 | 5398 | 5321 | 5148 |
| Percent | 73.46% | 76.38% | 75.29% | 72.84 |
Start with pip
$ pip install toeicbertRun & Option
$ python -m toeicbert --model bert-base-uncased --file test.json-
-m, --model: bert-model name in huggingface's pytorch-pretrained-BERT :bert-base-uncased,bert-large-uncased,bert-base-cased,bert-large-cased. -
-f, --file: json file to evalution, see json format, test.json.key(question, 1, 2, 3, 4) is required options, but answer not.
_in question will be replaced to[MASK]
{
"1" : {
"question" : "The teacher had me _ scales several times a day.",
"answer" : "play",
"1" : "play",
"2" : "to play",
"3" : "played",
"4" : "playing"
},
"2" : {
"question" : "The teacher had me _ scales several times a day.",
"1" : "play",
"2" : "to play",
"3" : "played",
"4" : "playing"
}
}- Tae Hwan Jung(Jeff Jung) @graykode, Kyung Hee Univ CE(Undergraduate).
- Author Email : [email protected]
Thanks for Hwan Suk Gang(Kyung Hee Univ.) for collecting Dataset(7114 datasets)

