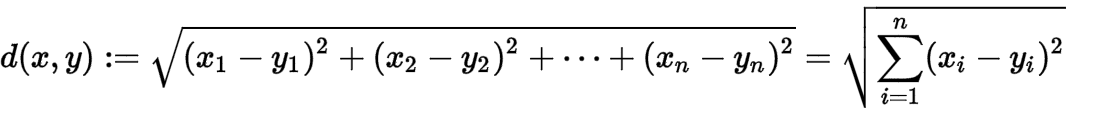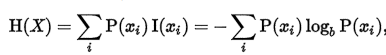导语
在笔者的上一篇文章中[1],使用了 k-NN 算法来识别手写字数据集,它的缺点是浪费存储空间且执行效率低。本文将使用决策树算法来解决同样的问题。相对 k-NN 算法,它更节约存储空间且执行效率更高。更重要的是,实施决策树算法的过程将训练算法并得到知识 —— 这是开发机器学习程序的一般步骤。一旦理解了这个工作流程,才有可能利用好机器学习这把利剑。
在本文中,笔者将训练一个决策树模型并使用该模型来识别手写字数据集。从中读者将可以了解到:如何构建学习模型?模型经过训练后学习到了怎样的知识?学习到的知识怎么表示和存储?又该如何利用这些学到的知识来解决同类的问题?
本文适合以下背景的读者阅读:
- 了解 MNIST 数据集[2];
- 使用 Javascript 作为编程语言的开发者;
- 不需要具备算法能力和高数的背景:全文只有一道数学公式;
- 加上示例代码,全文总共 460 行,大约需要 20 分钟的阅读时间。
作者学识有限,如有疏漏,敬请指正。
生活中的决策
在开始构建决策树之前,必须了解决策树的工作原理。更详细的内容可以从参考资料的链接[2]中获得。
一个例子是,如何教育一个学龄前的儿童辨认猫和老虎?

- 我们会拿来一些示例照片,对照这些照片根据某些特征来训练小孩,告他 A 是猫,B 是老虎;
- 这些特征可能是,表面的颜色、耳朵的形状、体积的大小等等;
- 我们总是希望儿童能快速辨认出猫和老虎,毕竟假如他们真的遇到了老虎,则需要和老虎保持一定的距离;
- 其中一种筛选方法就是决策模型:把认为最重要的特征先进行甄别,然后到次要的,再到次次要的,以此来加速决策过程并得出判定。
作为一个示例,这里假设将识别老虎分为 2 个特征,分别是耳朵的形状和体积大小,那么已知的数据可能是这样的:
| Index |
Shape of the ear |
Size |
Animal |
| 1 |
Triangle |
Small |
Cat |
| 2 |
Triangle |
Small |
Cat |
| 3 |
Triangle |
Big |
Tiger |
| 4 |
Circular |
Small |
Tiger |
| 5 |
Circular |
Big |
Tiger |
在程序中将使用数组的形式来表示上列数据,我把它称为「抓虎的数据集」:
const dataSet = [
['Triangle', 'Small', 'Cat'],
['Triangle', 'Small', 'Cat'],
['Triangle', 'Big', 'Tiger'],
['Circular', 'Small', 'Tiger'],
['Circular', 'Big', 'Tiger'],
];
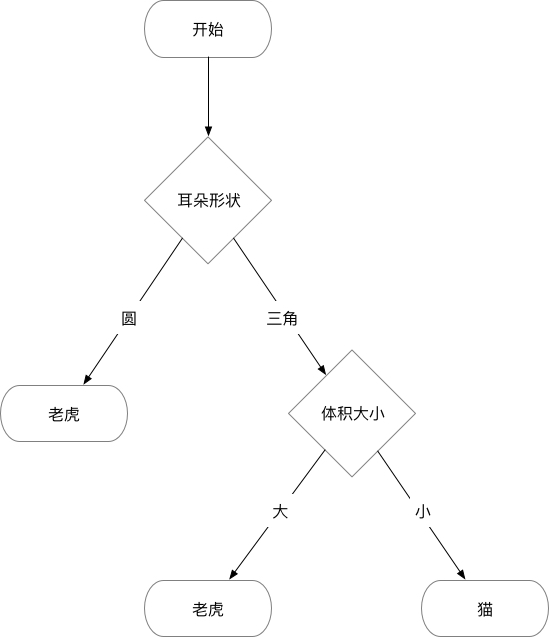
根据已有的数据集(经验),猫和老虎的决策树则是这样:
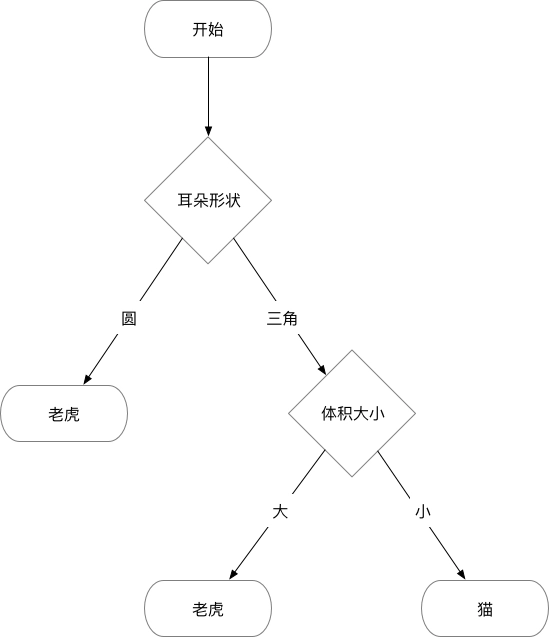
这就是决策树的工作原理了。因为属于分类算法,所以决策树也可以推演到 MNIST 数据集的识别中。把 728 个点作为特征,对应的数字作为分类目标即可应用决策树算法。当然决策树算法不适合解决 MNIST 数据集这类特征为数值型的问题,但是因为它易于理解和实现,人们在通过解释后都有能力去理解决策树所表达的意义,因此作为机器学习中训练模型的算法来进行入门则非常合适。
那么决策树模型在程序中应该如何构建和表示呢?
构建决策树
决策树的构建过程就是在训练数据集中不断划分数据集,直到找到目标分类的过程。在此过程中需要找到最好的数据集划分方式,递归地不断划分数据集,直到所有的分类都属于同一类目或没有多余特征时停止生长。可以结合上一章节的「抓虎」的决策树进行理解。
找出最佳特征来划分数据
不难看出,构建决策树的关键问题是如何找出最佳的特征来划分数据集。先要回答问题是,假设我按照某个特征将数据集一分为二,那么有 N 种划分方式,哪一种才算做「最好的划分方式」?这就得引入香农熵的概念。
香农熵
划分数据集的大原则是:将无序的数据变得更加有序。
在「抓虎」的决策树中,耳朵的形状是最佳的划分特征,因为根据它来划分后的数据集更加有序了(混杂项更少)。度量集合有序程度的其中一种方法就是香农熵。香农熵是信息论中的内容,有兴趣的读者可以从参考资料的链接[4]中获得更详细的内容。在此只需要知道的是,香农熵越低则集合越有序。
香农熵的计算公式是:
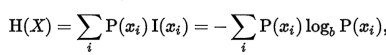
根据公式,在程序中实现计算香农熵的代码:
function calcShannonEnt(dataSet) {
const labelCounts = {};
for (let featVec of dataSet) {
const currentLabel = featVec[featVec.length - 1];
if (Object.keys(labelCounts).indexOf(currentLabel) === -1) {
labelCounts[currentLabel] = 1;
} else {
labelCounts[currentLabel]++;
}
}
let shannonEnt = 0.0;
const numEntries = dataSet.length;
for (let i in labelCounts) {
const x = labelCounts[i];
const probability = x / numEntries; // p(x)
shannonEnt = shannonEnt - probability * log2(probability); // -Σp*log(p)
}
return shannonEnt;
}进行一些测试将会有助于理解香农熵的含义:
// 注意:初始化时数据集里面只有 2 个目标分类(yes or no)
const dataSet = [
[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 0 'no']
];
console.log(calcShannonEnt(dataSet)); // 0.9709505944546686
dataSet[0][dataSet[0].length - 1] = 'maybe'; // 混合更多的分类
console.log(calcShannonEnt(dataSet)); // 1.3709505944546687 (香农熵变大,说明数据集更无序了)
根据特征划分数据集
实现一个函数,根据特征来划分数据集:
function splitDataSet(dataSet, index, value) {
const retDataSet = [];
for (let featVec of dataSet) {
if (featVec[index] === value) {
let reducedFeatVec = featVec.slice(0, index);
reducedFeatVec = reducedFeatVec.concat(featVec.slice(index + 1));
retDataSet.push(reducedFeatVec);
}
}
return retDataSet;
}拿「抓虎」的数据集进行测试,看看划分后的数据长什么样?
console.log(splitDataSet(dataSet, 0, 'Triangle'));
// Triangle [ [ 'Small', 'Cat' ], [ 'Small', 'Cat' ], [ 'Big', 'Tiger' ] ]
console.log(splitDataSet(dataSet, 0, 'Circular'));
// Circular [ [ 'Small', 'Tiger' ], [ 'Big', 'Tiger' ] ]
从结果上看,成功地按照某个特征值把数据划分了出来。
组合计算熵的算法和划分数据集的函数,就可以找出最佳的数据划分特征项。以下是代码实现:
function uniqueDataSetColumn(dataSet, i) {
const uniqueValues = [];
dataSet.forEach((element) => {
const value = element[i];
if (uniqueValues.indexOf(value) === -1) {
uniqueValues.push(value)
}
});
return uniqueValues;
}
function chooseBestFeatureToSplit(dataSet) {
const numberFeatures = dataSet[0].length;
let baseEntropy = calcShannonEnt(dataSet);
let bestInfoGain = 0.0;
let bestFeature = -1;
// 对比每个特征划分数据的熵,找出最佳划分特征
for (let i = 0, length = numberFeatures - 1; length > i; i++) {
const uniqueValues = uniqueDataSetColumn(dataSet, i);
// 计算熵
let newEntropy = 0.0;
uniqueValues.forEach((value) => {
const subDataSet = splitDataSet(dataSet, i, value);
const probability = subDataSet.length / dataSet.length;
newEntropy += probability * calcShannonEnt(subDataSet);
});
const infoGain = baseEntropy - newEntropy;
if (infoGain > bestInfoGain) {
bestInfoGain = infoGain;
bestFeature = i;
}
}
return bestFeature;
}将该函数在「抓虎」的数据集进行测试,这个数据集的第一划分依据是什么特征?
console.log(chooseBestFeatureToSplit(dataSet));
如无意外,程序将输出 0。耳朵的形状是最佳的划分特征,证明程序达到了我们预想的效果。
递归构建决策树
将上面的函数结合起来,再不断地进行递归就可以构建出决策树模型。什么时候应该停止递归?有 2 种情况:
- 当所有的分类都属于同一类目时,停止划分数据 —— 该分类即是目标分类;
- 划分的数据集中没有其他特征时,停止划分数据 —— 根据出现次数最多的类别作为目标分类。
构建树的入参是什么?
- 训练数据集 —— 从训练数据中提取决策知识;
- 特征的标签 —— 用于绘制决策树每个节点。
以下是代码实现:
// 辅助函数,根据出现次数最多的类别作为目标分类
function majority(classList) {
const classCount = {};
for (let vote of classList) {
if (Object.keys(classCount).indexOf(vote) === -1) {
classCount[vote] = 1;
} else {
classCount[vote]++;
}
}
let predictedClass = '';
let topCount = 0;
for (const voteLabel in classCount) {
if (classCount[voteLabel] > topCount) {
predictedClass = voteLabel;
topCount = classCount[voteLabel];
}
}
return predictedClass;
}
function createTree(dataSet, featureLabels) {
const classList = dataSet.map((elements) => elements[elements.length - 1]);
// 当所有的分类都属于同一类目时,停止划分数据
let count = 0;
classList.forEach((classItem) => {
if (classItem === classList[0]) {
count++;
}
});
if (count == classList.length) {
return classList[0]
}
// 数据集中没有其他特征时,停止划分数据,根据出现次数最多的类别作为返回值
if (dataSet[0].length === 1) {
return majority(classList);
}
// 1. 找到最佳划分数据集的特征
const bestFeat = chooseBestFeatureToSplit(dataSet);
const bestFeatLabel = featureLabels[bestFeat];
const myTree = {[bestFeatLabel]: {}};
// 2. 获得特征的枚举值
const uniqueValues = uniqueDataSetColumn(dataSet, bestFeat);
// 3. 根据特征值划分数据(创建子节点)
uniqueValues.forEach((value) => {
const newDataSet = splitDataSet(dataSet, bestFeat, value);
const subLabels = featureLabels.filter((label, key) => key !== bestFeat);
// 4. 递归划分
myTree[bestFeatLabel][value] = createTree(newDataSet, subLabels)
});
return myTree;
}自此就完成了学习模型的构建。
训练算法得到知识
将已有的数据集使用决策树模型进行训练,将会得到怎样的知识?
以「抓虎」为例,运行以下代码:
const tree = createTree(dataSet, ['Shape', 'Size']);
// {"Shape":{"Triangle":{"Size":{"Small":"Cat","Big":"Tiger"}},"Circular":"Tiger"}}可见,能得到的知识是针对数据集学习到的特征权重顺序排列,是层层筛选决策的依据。
为了更加直观和易于理解,可以将数据可视化(关于如何进行数据可视化不是本文的内容),它大概长这样:
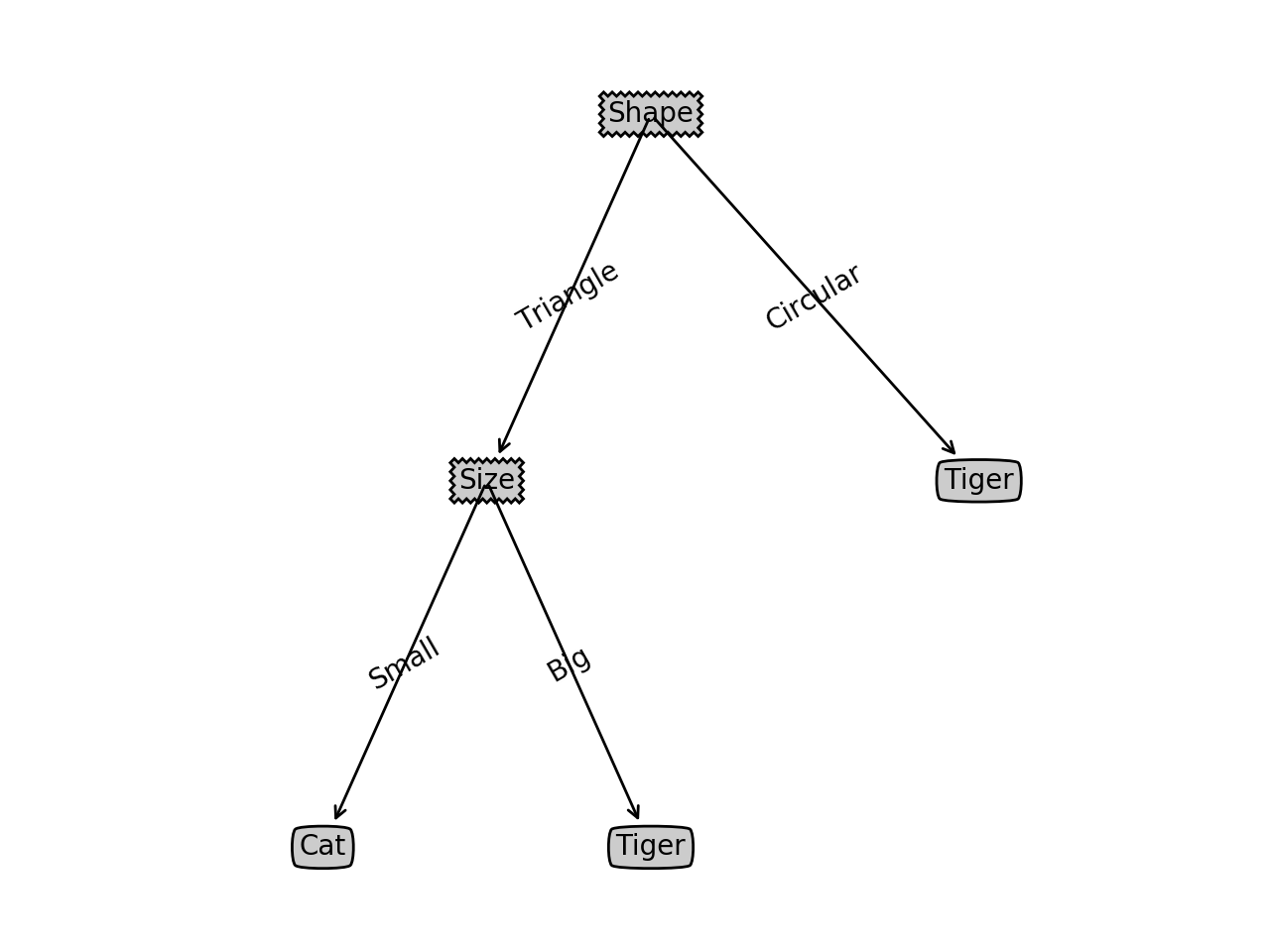
在程序中加入知识的存储和提取函数,方便利用已有的知识进行推理。所以再声明 2 个辅助函数:
function storeTree(inputTree, filename) {
fs.writeFileSync(filename, JSON.stringify(inputTree));
}
function grabTree(filename) {
return JSON.parse(fs.readFileSync(filename, 'utf8'))
}使用已有的知识进行推理
只需要写一个解析树的函数就可以将学习到决策知识推理到同类的数据集中。以下是代码实现:
function classify(inputTree, featureLabels, testVec) {
const firstStr = Object.keys(inputTree)[0];
const secondElement = inputTree[firstStr];
const featIndex = featureLabels.indexOf(firstStr);
const key = testVec[featIndex];
const valueOfFeat = secondElement[key];
if (typeof valueOfFeat === 'object') {
return classify(valueOfFeat, featureLabels, testVec);
} else {
return valueOfFeat;
}
}以「抓虎」为例,下次见到一个耳朵形状是三角形,体积较小的动物,根据我们之前学习到的知识,它应该是猫还是老虎?
console.log(classify(tree, ['Shape', 'Size'], ['Triangle', 'Small']));
// Cat
如无意外,将会输出 "Cat"。
应用到 MNIST 数据集
最后,组合上面的函数,将其应用到 MNIST 数据集的识别中。
值得注意的是,在数据准备环节需要一些工作以适应上文构建的算法:
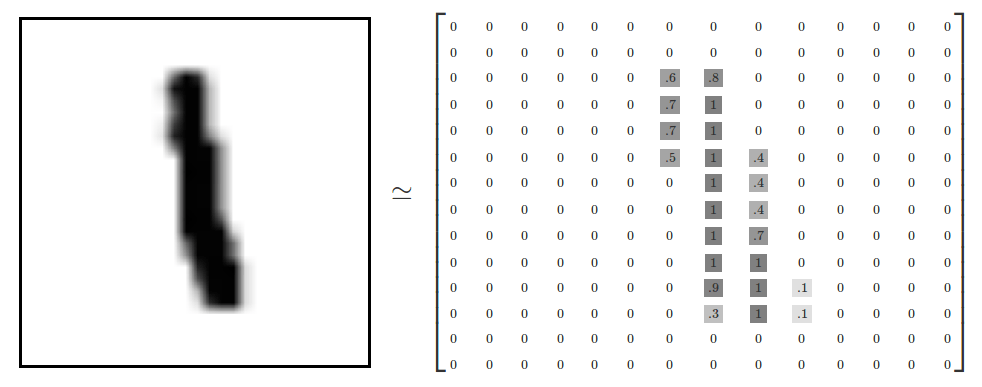
- 将特征由数值型转化为标称型,这里我用了 0 / 1;
- 将分类值由 one-hot 向量转化为具体的数字。
准备数据
const mnist = require('mnist');
const fs = require('fs');
const path = require('path');
const trainingCount = 8000;
const testCount = 2000;
const {training, test} = mnist.set(trainingCount, testCount);
fs.writeFileSync(path.join(__dirname, 'mnist_trainingData.json'), JSON.stringify(training));
fs.writeFileSync(path.join(__dirname, 'mnist_testData.json'), JSON.stringify(test));学习阶段
const mnist = require('mnist');
const path = require('path');
const fs = require('fs');
// 1. 加载数据
const trainingData = JSON.parse(fs.readFileSync(path.join(__dirname, 'mnist_trainingData.json'), 'utf8'));
// 2. 准备数据
let data = [];
trainingData.forEach(({input, output}) => {
// 将分类值由 one-hot 向量转化为具体的数字
const number = String(output.indexOf(output.reduce((max, activation) => Math.max(max, activation), 0)));
// 数值型特征转换为标称型
data.push(toZeroOne(input).concat([number]));
});
// 特征的标签
const labels = mnist[0].get().map((number, key) => `number_${key}`);
// 3. 分析数据:在命令行中检查数据,确保它的格式符合要求
console.log('data', JSON.stringify(data[0]));
console.log('labels', JSON.stringify(labels));
// 4. 训练算法
const startTime = Date.now();
const tree = createTree(data, labels);
console.log('tree', JSON.stringify(tree));
console.log(`Spend: ${(Date.now() - startTime) / 1000}s`);
// 存储学到的知识
storeTree(tree, path.join(__dirname, 'mnist_tree.txt'));在笔者的电脑上大概运行了 10 分钟:

看起来运行时间很长,那怎么能说比 k-NN 算法更有效率?!
其实这是训练阶段的耗时,而训练阶段往往是离线处理,有大量的手段可以优化这部分的性能。
应用阶段
const mnist = require('mnist');
const path = require('path');
const fs = require('fs');
// 1. 加载测试数据
const testData = JSON.parse(fs.readFileSync(path.join(__dirname, 'mnist_testData.json'), 'utf8'));
const testCount = testData.length;
// 获取先前学习的知识
const tree = grabTree(path.join(__dirname, './mnist_tree.txt'));
const labels = mnist[0].get().map((number, key) => `number_${key}`);
// 2. 测试算法
let errorCount = 0;
const startTime = Date.now();
testData.forEach(({input, output}, key) => {
const number = output.indexOf(output.reduce((max, activation) => Math.max(max, activation), 0));
const predicted = classify(tree, labels, toZeroOne(input));
const result = predicted == number;
console.log(`${key}. number is ${number}, predicted is ${predicted}, result is ${result}`);
if (!result) {
errorCount++;
}
});
console.log(`The total number of errors is: ${errorCount}`);
console.log(`The total error rate is: ${errorCount / testCount}`);
console.log(`Spend: ${(Date.now() - startTime) / 1000}s`);
// 3. 使用算法
const number = 8;
console.log('Result is', classify(tree, labels, toZeroOne(mnist[number].get())));如无意外,终端命令行中将输出以下结果:

在同样的数据集中,笔者上一篇文章构建的 k-NN 算法,运行时长是 325 秒,错误率是 0.05。这组数据该如何解读?笔者认为:
- 决策树的在预测阶段计算量非常小,所以执行效率非常高;
- 本文做特征处理时丢失了很多信息,数值型特征转换到 0/1 的方式太过于粗暴。
使用决策树算法来识别 MNIST 数据集效果很不理想,不过从中可以看到构建一个机器学习应用的完整过程。
参考资料
- 机器学习,Hello World from Javascript!
- MNIST 数据集
- 决策树
- 香农熵
- 本文示例代码
文章封面图由 Igor Ovsyannykov 发表在 Unsplash