
This crawler takes an webaddress as input and then extracts all emails from that website by sequentially visiting every url in that domain.
·
Email-Crawler-Lead-Generatorrt Bug
·
Request Feature
The Email Crawler makes sure that it only visits the urls in same domain and doesnot save duplicate emails.It also keeps the log of urls visited and dumps them at the end of crawling
To get a local copy up and running follow these simple steps.
- Clone the Email-Crawler-Lead-Generator
git clone https://github.com/nOOBIE-nOOBIE/Email-Crawler-Lead-Generator.git- Install dependencies
pip install -r requirements.txtIf you have python2 and python3 both installed. You might need to do.
pip3 install -r requirements.txtSimply pass the url as an argument
python email_crawler.py https://medium.com/If you have python2 and python3 both installed. You might need to do.
python3 email_crawler.py https://medium.com/➜ email_crawler python3 email_crawler.py https://medium.com/
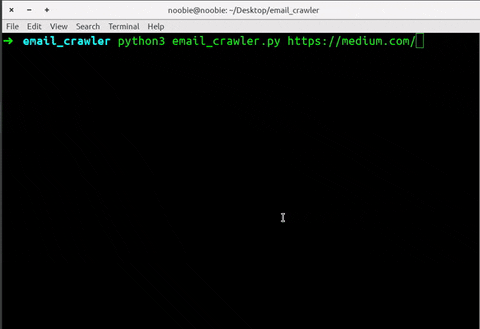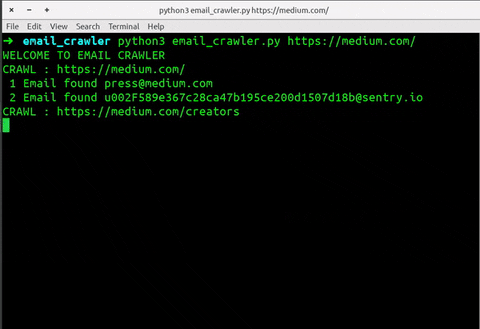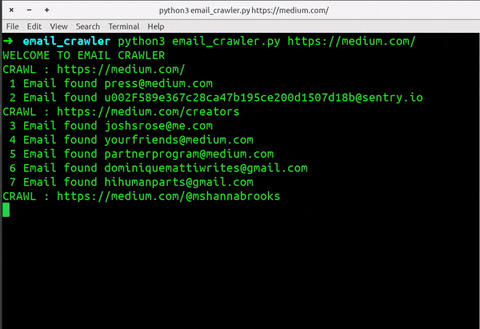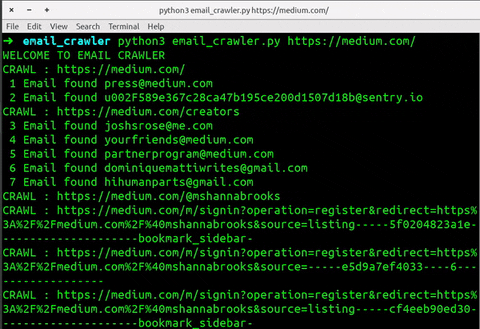
WELCOME TO EMAIL CRAWLER
CRAWL : https://medium.com/
1 Email found [email protected]
2 Email found [email protected]
CRAWL : https://medium.com/creators
3 Email found [email protected]
4 Email found [email protected]
5 Email found [email protected]
6 Email found [email protected]
7 Email found [email protected]
CRAWL : https://medium.com/@mshannabrooks
CRAWL : https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40mshannabrooks&source=listing-----5f0204823a1e---------------------bookmark_sidebar-
CRAWL : https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40mshannabrooks&source=-----e5d9a7ef4033----6------------------
See the open issues for a list of proposed features (and known issues).
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Distributed under the MIT License. See LICENSE for more information.
Amit Upreti - @amitupreti
Project Link: https://github.com/nOOBIE-nOOBIE/Email-Crawler-Lead-Generator


































































































