amulet-team / amulet-core Goto Github PK
View Code? Open in Web Editor NEWA Python library for reading and writing the Minecraft save formats. See Amulet for the actual editor.
Home Page: https://www.amuletmc.com/
A Python library for reading and writing the Minecraft save formats. See Amulet for the actual editor.
Home Page: https://www.amuletmc.com/
Describe the bug
It seems that when setting the Text[1-4] properties for a sign, the properties are not saved in the block, causing any text set for a sign to be ignored.
To Reproduce
Use the following example code:
import amulet
from amulet.api.block import Block
from amulet_nbt import TAG_String, TAG_Int
# Load level, which is a superflat creative world made in Minecraft 1.16.2
level = amulet.load_level("<a flat world>")
game_version = ("java", (1, 16, 2))
sign = Block(
namespace="minecraft",
base_name="birch_sign",
properties={
"rotation": TAG_String("2"),
"Text1": TAG_String('{"text":"Hi there","color":"blue"}'),
},
)
level.set_version_block(
192, # x location
4, # y location
166, # z location
"minecraft:overworld", # dimension
game_version,
sign,
)
print(level.get_version_block(192,4,166,"minecraft:overworld", game_version))
# Save and exit
level.save()
level.close()
It will then print the following block data:
(Block(minecraft:birch_sign[rotation="2"]), BlockEntity[minecraft:sign, 0, 0, 0]{NBTFile("":{Text1: "{\"text\":\"\"}", Text2: "{\"text\":\"\"}", Text3: "{\"text\":\"\"}", Text4: "{\"text\":\"\"}"})})
Loading up the map in Minecraft shows the correct sign with the correct rotation, only the text is missing.
Expected behavior
I would have expected the block data to contain "hi there" and the color definition. And the text "hi there" to appear in-game.
Java 1.15 introduced an additional file format for chunks that exceed the 1MB limit for chunk data that is currently present in the Anvil region format. If a chunk is larger than 1MB, then it's chunk data will be saved to an additional file named c.<cx>.<cz>.mcc where <cx> and <cz> denote the chunk coordinates. The chunk data in this new file is still compressed with zlib.
Notable divergences:
.mca file for the region, the chunk data is saved as one byte, with the value 0x82 [1]. This is the indicator that the chunk data is saved in the additional file along with the chunk data length being 1 (this latter fact shouldn't be be the sole indicator, from [1])Changes Needed:
.mca fileSources:
i no know how to launch for test a 1.13.2 minecraft world
Currently palette is a mixture of BlockManager and numpy.ndarray and it is not particularly clear when which one should be used.
Clean this up, add better typing and documentation
Add sub-chunks to chunks where you can save things into the sub-chunks and it will be considered as part of the chunk. Can be used for blocks but is mostly needed for entities.
A proposal by @StealthyExpertX and @ezfe in our MCEdit discord is to rename our version definition directories from 1_12 to java_1_12 and from bedrock to bedrock_<version>
Implement a renderer for our UI, it would be preferred to have good performance while also being understandable and easy to extend to account for possible additions and changes as needed. Currently, we have a prototype written with one library and candidates for other options.
Options so far:
I have also started prototype work on a raycast system to avoid being tied to a physics engine and/or framework in case we decided to switch to a better or more suitable framework. That can be found here
If you think another framework or engine would be more suitable and has Python 3+ bindings (>=3.7 specifically), please post a link to it here so we can take a look at it and add it to the list above!
Hi, when is this going to be officially released with a .exe for Windows.
Running from the source seems to be irritating. Not sure if Numpy and pyglet is extensions or what. So it would be nice if it can be compiled and released in versions like MC-Edit was.
Create an Entity class that will be the parent class for each entity. It should have a boolean parameter of isMovable in its constructor since most entities are movable and have special properties because of it.
It should have empty import and export functions that other entities will override.
have been talking witth gentlegiantJGC about this.
https://github.com/MineInAbyss/deeperworld-converter/blob/master/main.py is code
Describe the bug
When following the install guide in README.md pip will error with a cryptic error message
To Reproduce
Steps to reproduce the behavior:
Expected behavior
App builds succesfully
Screenshots

Desktop (please complete the following information):
Additional context
I am using python and pip version 3
I cannot work out what the actual error is here. Needs more testing
Traceback (most recent call last):
File "C:\Users\gerald.GBOVE-OFFICE\Downloads\Amulet-Converter_v0.2\Amulet-Converter\amulet_map_editor\amulet_wx\world_manager\extensions\convert.py", line 128, in _convert_method
self.world.save(out_world, self._update_loading_bar)
File "lib\site-packages\amulet\api\world.py", line 123, in save
File "lib\site-packages\amulet\api\chunk.py", line 51, in __getitem__
Exception: The item 0 for Selection object does not make sense
We have 2 cases of that.
We can either error which will ruin any operations even if some chunks exist, we can fill with air but it might not be what the users expect.
Using a single cache makes it very hard to use multi process or multi threaded code
Amulet-Core/amulet/api/cache.py
Line 24 in 29ba12c
Proposal to fix is change this to return a new one every time and have caller deal with life cycle.
Currently for chunk translation a Chunk object and a numpy array of blocks are passed around. This is because the chunk array indexes into a global block palette and it is required to determine what the block is.
This is also the case for biomes which have the palette stored in the translator however that palette is not passed into the translator it is just accessed from the translator.
My suggestion is to make a sub-class of the Chunk class that stores within extra attributes for block and biome palette. That way the extra attributes don't need to be passed in as extra inputs to the translation system.
This change would be purely internal and would be converted back to the normal chunk at the end.
There are a number of issues with how we handle dimensions and it needs fixing.
Here is my research so far
Java
forge
1.12
level.dat["forge"]["DimensionData"]["UsedIDs"] = [I;0, 1, 7]
an int array of the biomes that are used.
This relates to the DIM{X} format.
Not sure what the 0 and 1 are for.
boss data
level.dat["Data"]["DimensionData"] = {"7": {"CustomSeed": 0L}}
level.dat["Data"]["Player"]["Dimension"] = 7
-1 = the nether
0 = overworld
1 = the end
1.16
seems to use the vanilla system
vanilla
before 1.16 could not have custom biomes
1.16
level.dat["Data"]["WorldGenSettings"]["dimensions"] = {"namespace:basename": {...}, "minecraft:overworld": {...}, ...}
keys are string dimension ids.
It looks like the dimension data is stored in "./dimensions/namespace/basename"
player "Dimension" is a string
1.17
adds customisable min and max height values in the generator settings
Bedrock has always been numerical. 0, 1, 2 for overworld, nether and end respectively. It doesn't yet have custom dimensions.
The main issue I see is managing the switch between the numerical and namespaced string system.
We will need to look up the dimension in newer versions based on both the numerical and namespaced formats.
This means the translation/interface logic will need reworking so that it has access to this information.
When saving back entity data the dimension entry will need patching to the correct value.
An Item class should be created for use in Entities that have an item parameter. It should include the needed Item properties in it. It can be a data class.
Add support for reading the leveldb world format and recognizing bedrock worlds.
The description and the first line of this method are contradicting each other: the description says the rotation is in radians, while the condition only works if it is in degrees. In both branches of the condition the rotation is passed to transform_matrix which uses radians.
Amulet-Core/amulet/api/selection/box.py
Lines 714 to 725 in 88f700c
I don't know if this method is used anywhere, but I happened to stuble upon this while working on a project of mine.
I guess changing the check to this would be a passable fix (at least it fixed my use case):
if all(math.isclose(abs(r) % (numpy.pi / 2), 0) for r in rotation):The command source /ENV/bin/activate described in README.md section for Linux/Mac at the line that says Activate the environment has an argument pointing to wrong location, where using the slash before path name points to root directory of the system instead of the one in current directory. Removing the slash or adding a dot might fix it. But there comes another prombem: installed pip version does not install requirements in order, even when using the latest version of it (by upgrading it using command It appears the latest version works almost ok. After doing workarounds to make it build properly (installing dependencies manually one by one) the editor finally can be run. Though it fails with another error when all the dependencies are installedpip install --upgrade pip
Describe the solution you'd like
Changing the source command in README.md (by removing the leading slash or adding dot on the first parameter) might help to fix some problems. Other than that the requirement installation order might needed to be fixed too, or if it is a pip bug, this should be reported to the developers. Also fixing the paths needed for runtime might fix the program unable to be run correctly, not mentioning of adding the correct documentation of running to in the README.md.
Use cat requirements.txt | xargs -I{} sh -c 'pip install {}' as a workaround for buggy pip command. or upgrade pip inside env.
Python: 3.7.5
Pip provided by system: 9.0.1
Initial failure running env w/o changing the command line to correct one:
$ python3.7 -m venv ENV
$ LC_ALL=C source /ENV/bin/activate
bash: /ENV/bin/activate: No such file or directory
After fixing that the env can no be entered and pip install -r requirements.txt command can be run. Though the command might fail if cython is not installed (as the pip does not appear to do the installation in correct order). Install cython by running pip install cython inside the env then try the command again.
(ENV) juozas@xubuntu:~/test/Amulet-Core$ pip install -r requirements.txt
Collecting git+git://github.com/Amulet-Team/Amulet-NBT.git (from -r requirements.txt (line 2))
Cloning git://github.com/Amulet-Team/Amulet-NBT.git to /tmp/pip-ezvv2zaf-build
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-ezvv2zaf-build/setup.py", line 5, in <module>
from Cython.Build import cythonize
ModuleNotFoundError: No module named 'Cython'
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-ezvv2zaf-build/
After installing cython the command fails again with another error pointing to numpy that's supposedly missing (it should be installed first, is this a pip bug?)
$ pip install -r requirements.txt
Collecting git+git://github.com/Amulet-Team/Amulet-NBT.git (from -r requirements.txt (line 2))
Cloning git://github.com/Amulet-Team/Amulet-NBT.git to /tmp/pip-fnuu9n92-build
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-fnuu9n92-build/setup.py", line 7, in <module>
import numpy
ModuleNotFoundError: No module named 'numpy'
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-fnuu9n92-build/
Fixed by installing correct version of numpy first then trying again, by running command pip install $(grep -i numpy requirements.txt) . If compilation fails on next attempt to install deps from requirements.txt, install python3.7-dev outside the env then try again. The error should say that Python.h is not found or similar. After that it can be run even though it still might fail during runtime as shown below.
$ python main.py
Traceback (most recent call last):
File "main.py", line 4, in <module>
from amulet.command_line import enhanced_prompt, reduced_prompt, CommandHandler
File "/home/juozas/test/Amulet-Core/amulet/command_line/__init__.py", line 1, in <module>
from .command_api import (
File "/home/juozas/test/Amulet-Core/amulet/command_line/command_api.py", line 12, in <module>
from amulet.api.world_loader import load_world
ModuleNotFoundError: No module named 'amulet.api.world_loader'
The undo point operation takes quite a while to run.
Many users have expressed wanting to be able to disable this.
The undo point was added in as a mechanism to allow users to undo changes but also as a mechanism of freeing RAM.
When a chunk is loaded, Amulet needs to hold a reference to it so that if it is requested again the same chunk object can be returned. From now on we will refer to this as the RAM database.
There needs to be some condition when chunks can be unloaded from the RAM database to free memory, otherwise memory usage will grow over time.
Chunks cannot be unloaded if they have changed otherwise those changes would be lost.
Currently this condition is a manual function that unloads all chunks.
It would be better if chunks were automatically unloaded when they are no longer referenced (and are not changed)
The history database was a mechanism to allow the chunk to be persisted to disk for later loading and unloaded from the RAM database to free up RAM.
When loading a chunk the history database is first checked and if it contains the chunk it is loaded. If not it is loaded from the raw level.
One hurdle to removing the undo point is the behaviour when a chunk is changed but not marked as changed. Currently these changes are discarded but without a backup to revert to those changes will remain.
Should this be the correct behaviour or should a solution be found? Perhaps caching the previous state in RAM.
Changing the undo point behaviour is possible but it is currently a rather core part of how Amulet operates so it can't currently just be disabled.
To remove the undo point we would need to disable the disk caching system and all changed chunks would have to exist purely in RAM. We would also need to make sure that the chunks in RAM were not cleared.
Having a history database on disk allows RAM to be freed so is the best solution for most users with limited RAM.
This is the fastest way to have a history system but requires a lot of RAM
This is the fastest solution but requires a bit of RAM.
Changed chunks cannot be unloaded from the RAM database.
Will have to manage the case where an operation changes a chunk but does not mark it as changed.
#256 Chunk management improvement
#257 Chunk ownership
If I have more thoughts on this I will modify this.
Problem 1: To install all required dependencies, one needs to run pip install -r requirements-dev.txt which might fail on Linux, as some packages tries to write to the system directories which fails due to Permission Denied error.
Problem 2: Using root might cause problems when using versions provided by the package manager, pip might want to uninstall or overwrite them, which might break other system packages and cause even more problems.
Problem 3: The program needs Python 3.7, it doesn't work with Python3.6 or earlier as there are errors shown when one attempts to launch it.
Workaround (on Ubuntu): first install virtualenv and python-3.7 packages them use virtualenv to build python3.7 environment, activate it then install dependencies as follows:
virtualenv -p python3.7 ENV #create new env in directory named ENV, with python 3.7 as default
. ENV/bin/activate #enter (activate) the env
pip install -r requirements-dev.txt
deactivate #exit out of the env
You can use python venv module (python3.7-venv on Debian & Ubuntu) in place of virtualenv program and create an env using command python3.7 -m venv ENV
After installation of deps, you can run the app inside env, each time activating the env using . ENV/bin/activate command and deactivating with deactivate command.
Edit: added information about problems using pip to install deps while on root, also done some re-wording and reorganizing of the description for better readability.
Edit2: Included the alternate method to create virtual environment, when the virtualenv program is not desired, as shown in the changes to README.md made by PR #52
There should be a documentation how to run properly on Linux, such as of using python virtual environment created using virtualenv or other methods, and any other workarounds that also might be possible.
Java's mcc chunks are getting deleted when they shouldn't be.
The issue emanates from here:
Describe the bug
After cloning the project Amulet editor and installing all the python requirements, I don't know why src/main.py doesn't run the program.
To Reproduce
Steps to reproduce the behavior:
Expected behavior
Amulet editor program opens
Screenshots
None.
Desktop (please complete the following information):
Additional context
I don't know how to run this program, If I type in Windows cmd: Amulet-Map-Editor --command-line, it shows: 'Amulet-Map-Editor' is not recognized as an internal or external command,
operable program or batch file.
Hi,
I can't see any indication of which license this code is published under - has that been decided?
Many thanks
Create the world logic to read the entities and add them to an entities list for each sub-chunk. It should be implemented for 1.12 and 1.13 for now.
Greetings. I tried to install the editor yesterday, and I was having a lot of trouble getting it installed. I installed all the prerequisites (numpy, etc.) but after the virtual environment didn't activate. The console said that it wasn't a directory. Also, the documentation link is dead, so I couldn't go to it. Fixing that too would be nice. Thanks for your time and help.
Currently a call to the load_level or load_format method in our core library returns a new instance of the level wrapper.
This has currently been fine because each level tab owns the level associated with it.
The issue happens when something separate to that level tab wants to access that world.
An example of this if a level is opened in a level tab and also in the converter in another level tab.
We should have some sort of caching system that can return a previously opened instance rather than opening it again since this can cause issues.
We would also need to add a system to release the level when it is finished with so it can be closed when everything is finished with it.
We would need to keep the normal close method so that a program can force close the world.
Everything up to now has been fine because only one element should be running at once but we should plan in case we want to allow multiple level tabs to run at once (eg allowing dragging a level tab out of the standard view)
We should discuss the solution to this problem because I am sure my solution will have problems I have not thought of and this may have been solved before.
The code that "owns" the level should close it when it is finished with it.
The __del__ method should also call the close method to make sure it actually gets closed.
Describe the bug
Loading a chunk from world A with get_chunk() and pasting it to world B with put_chunk() doesn't copy entities.
To Reproduce
# Example
lvl_a = load_level("world_a")
lvl_b = load_level("world_b)
chunk = lvl_a.get_chunk(0, 0, "minecraft:overworld")
lvl_b.put_chunk(chunk, "minecraft:overworld)
lvl_b.save()
lvl_b.close()
lvl_a.close()
Expected behavior
The entities in the copied chunk should appear in the target world too.
Desktop (please complete the following information):
Amulet-Core/amulet/level/formats/anvil_world/region.py
Lines 286 to 293 in f81f423
last time i check minecraft code, compress_type may be 3.
Im not sure if this value is still allowed.
We currently support either the 16x16 2D biome representation used in old Java and all of Bedrock or the 4x64x4 representation used in Java 1.16 onwards.
In order to support mods that increase the ceiling height such as the cubic chunks mod (Amulet-Team/Amulet-Map-Editor#12) this would need to be redesigned in the same way that blocks were. This would store the biomes for each sub-chunk as a 4x4x4 numpy array and sparsely storing each sub-chunk.
We would also need another attribute that is the 2D representation and a method to convert between them
This bug was reported by cynodont.
For each block is saved as 5/6/7 bits, our decoding doesn't work well because decoding should behave differently when one block is split between 2 longs.
Add API functions to get entities from a selection, add an entity and remove an entity.
https://github.com/Amulet-Team/Amulet-Map-Editor/blob/impl-entities/src/api/block.py#L157
This line may cause issues when two blocks are created with the same properties but with the properties in different orders.
{'note': '1', 'instrument': 'harp', 'powered': 'false'}
{'instrument': 'harp', 'note': '1', 'powered': 'false'}
These two property dictionaries are the same but are in different orders. In python equating them with == returns True however doing this list comprehension will keep the order they were defined in the dictionary. When the hash of this string is subsequently calculated they will be seen as different objects. Sorting them alphabetically should solve the issue
'instrument=harp,note=1,powered=false'
'note=1,instrument=harp,powered=false'
Implement ChunkLoadError for chunks that exist but cannot be loaded either due to not being supported or erroring during loading of the chunk.
This will enable handling of chunks that cannot be loaded without crashing the program
Add the logic to save chunks after they're changed, currently both for anvil and anvil2.
Currently the Chunk class has two attributes to track when a chunk was changed. There is Chunk.changed and Chunk.changed_time. The former being the bool of the latter.
The original intention of Chunk.changed was to be the only tracker of if the chunk has been changed. When the world is saved these flags would all be set to false. With the introduction of the history manager this became problematic because not all of the chunks would be loaded in memory to reset this flag.
The history manager now tracks which version of the chunk is saved to disk and which version is the current version. If these two values match then the chunk is the same as on disk. The Chunk.changed_time attribute was introduced to track if the chunk had been changed since the last undo point.
In its current form Chunk.changed tracks if the chunk has changed since the world was first opened and setting it to True also updates the Chunk.changed_time attribute.
My suggested change is that we remove Chunk.changed_time and make Chunk.changed track if it has changed since the last undo point. The history manager can be used to save chunks that have changed since the last save and the RAM database can be used to save chunks since the last undo point.
That was kind of rambly
When I tried to convert a world from 1.14.1 bedrock to java 1.14, it didn't convert well, even after trying to load the chunks, the logs sent this error.
"NotImplementedError
2020-02-12 00:51:02,695 - amulet_core - ERROR - Error loading chunk 32 29
Traceback (most recent call last):
File "lib\site-packages\amulet\world_interface\formats_init_.py", line 161, in load_chunk
File "lib\site-packages\amulet\world_interface\formats_init_.py", line 196, in _load_chunk
File "C:\Users\vip\Desktop\Amulet-Converter-V0.1\Amulet-Converter\amulet\world_interface\chunk\interfaces\leveldb\base_leveldb_interface.py", line 112, in decode
chunk.blocks, palette = self._load_subchunks(subchunks)
File "C:\Users\vip\Desktop\Amulet-Converter-V0.1\Amulet-Converter\amulet\world_interface\chunk\interfaces\leveldb\base_leveldb_interface.py", line 267, in _load_subchunks
raise NotImplementedError
NotImplementedError"
This is how the conversion looked like at the end, https://cdn.discordapp.com/attachments/343783861609562113/676805470966644754/unknown.png
Currently we store dimension as an integer but the integer values do not necessarily translate across platforms. (They do not for Java and Bedrock)
To make this easier to handle dimension should be a string internally and the Format class used to translate that to the version specific value.
Unknown dimensions (id non-vanilla ones) should have the name scheme DIM{x} to follow the Java name scheme
The memory footprint for loaded worlds may get out of hand for larger worlds.
Look into creating a feature to allow region files that have not been recently accessed to be unloaded to save memory.
Currently, we load some of the blocks data as needed in commands like get_block but that is not ideal since maybe someone would want to fill an area with a block that was not loaded so far, so we'll need to either load all of the blocks ahead of time (which might be slow) or figure out a way for the API to work for stuff like fill without loading ahead everything.
Formats to add
J1.14
J1.15
B1.14 (chunk format 16)
Loading a chunk with block entities takes quite a while. This is due to having to iterate through all the block entities in the chunk to find the correct block entity for each block entity.
Some faster searching system should be created that allows quick access via coordinates but also allows the coordinates to change.
Describe the bug
A clear and concise description of what the bug is.
When reading a world file using load_level and the calling .get_chunk(x,y), the returned Chunk object stores the signs that are in that chunk in the entity. The signs stored in block_entities do not have text, despite the in-game signs having text.
To Reproduce
from amulet import load_level
# A world with a sign
level = load_level("worlds/test")
# A chunk in the world with a sign
chunk = level.get_chunk(5,6)
for e in c.block_entities:
print(e.nbt)
And output
NBTFile("":{utags: {Text4: "{\"text\":\"\"}", Text3: "{\"text\":\"\"}", Text2: "{\"text\":\"\"}", Text1: "{\"text\":\"\"}"}})
NBTFile("":{utags: {Text4: "{\"text\":\"\"}", Text3: "{\"text\":\"\"}", Text2: "{\"text\":\"\"}", Text1: "{\"text\":\"\"}"}})
NBTFile("":{utags: {Text4: "{\"text\":\"\"}", Text3: "{\"text\":\"\"}", Text2: "{\"text\":\"\"}", Text1: "{\"text\":\"\"}"}})
Expected behavior
NBTFile("":{utags: {Text4: "{\"text\":\"\"}", Text3: "{\"text\":\"THIS SIGN\"}", Text2: "{\"text\":\"TEXT ON\"}", Text1: "{\"text\":\"THERE IS\"}"}})
NBTFile("":{utags: {Text4: "{\"text\":\"\"}", Text3: "{\"text\":\"\"}", Text2: "{\"text\":\"\"}", Text1: "{\"text\":\"THIS ONE TOO\"}"}})
NBTFile("":{utags: {Text4: "{\"text\":\"\"}", Text3: "{\"text\":\"\"}", Text2: "{\"text\":\"\"}", Text1: "{\"text\":\"WHEEE\"}"}})
Screenshots
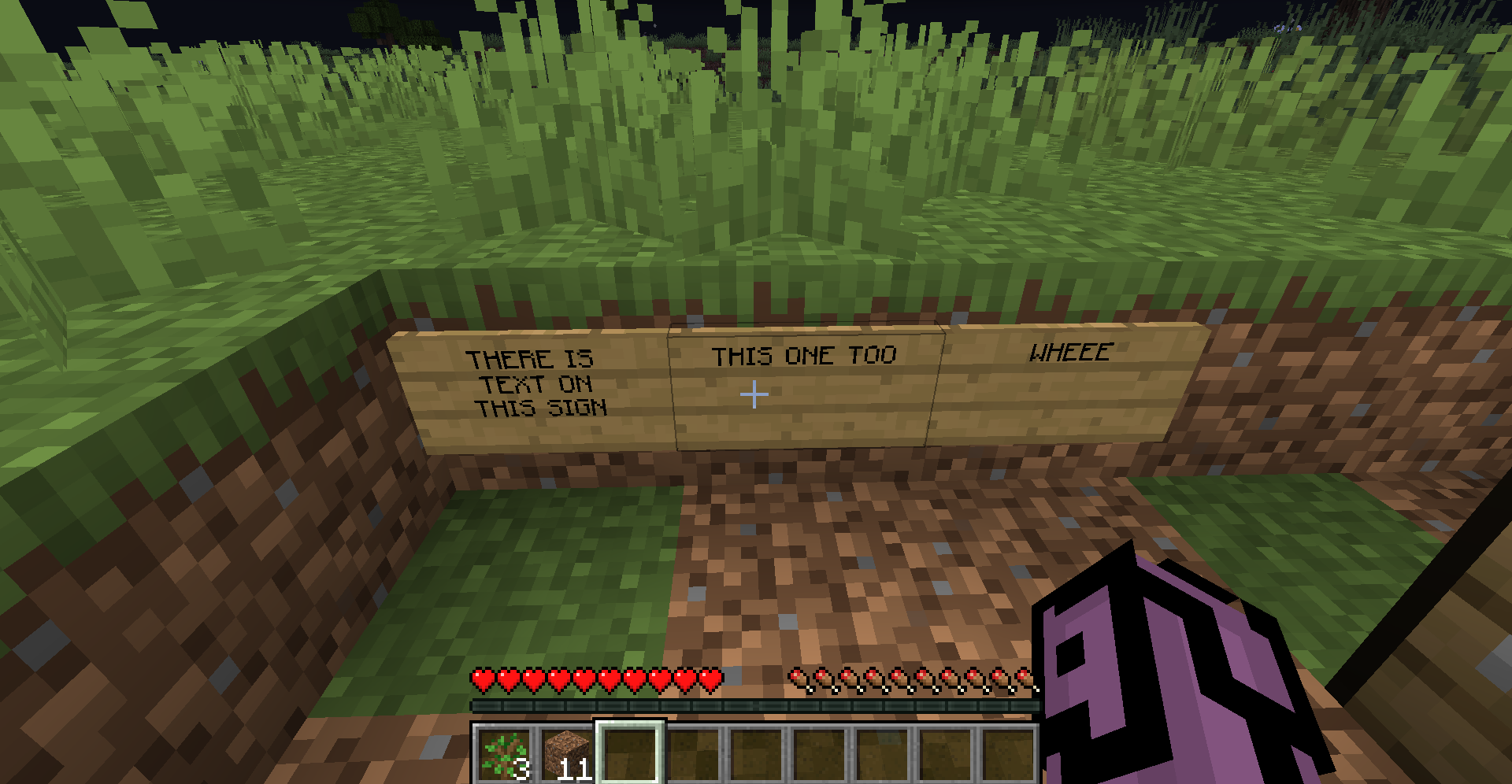
Desktop (please complete the following information):
Use Gradle to download all dependencies , determine what OS platform and build Amulet
Is your feature request related to a problem? Please describe.
Will allow for multi process code.
Describe the solution you'd like
Add flag to dissable checking the lock file
Describe alternatives you've considered
Complex fs shininigans, forked version of libary
Additional context
Add any other context or screenshots about the feature request here.
I'm using 1.14 and would like to test this project
The world class needs a bit of an overhaul.
There are a number of features that are hidden in the world wrapper that should probably be exposed in the world class (eg world name, image and others)
The world class also needs updating to support multiple dimensions. I believe all the code exists in the format wrappers to support it but it isn't currently used.
The format wrapper should also have an open method to explicitly open the world database rather than being done automatically when a chunk is accessed
World methods currently only work in the universal format but with an optional extra input they could also automatically translate the data into a given version for the user
Currently a wrapper program will just call the save method of the world class and will have no idea how far through it is.
The save method (and perhaps other methods) should have a way to tell the calling code what its progress is.
MCEdit did this by save yielding back each time a chunk is saved which meant that you needed to iterate over the generator it created to actually do the saving.
I don't much like this route as it disables the ability to just call world.save()
My proposed method is to have an optional input which would be a callback function which would take current chunk number and total chunk count as inputs. The calling program could optionally give that function but it would still retain the world.save() functionality
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.