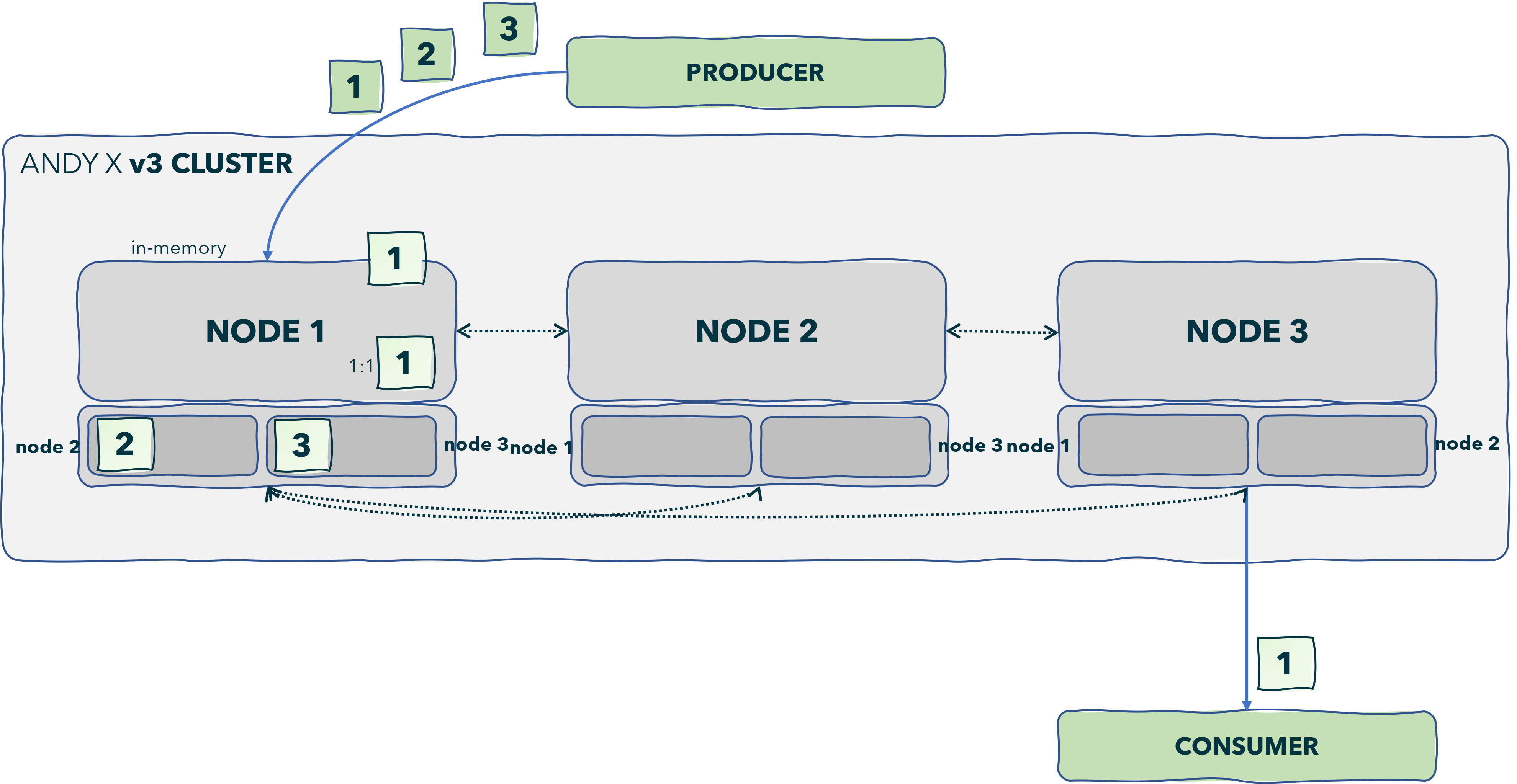
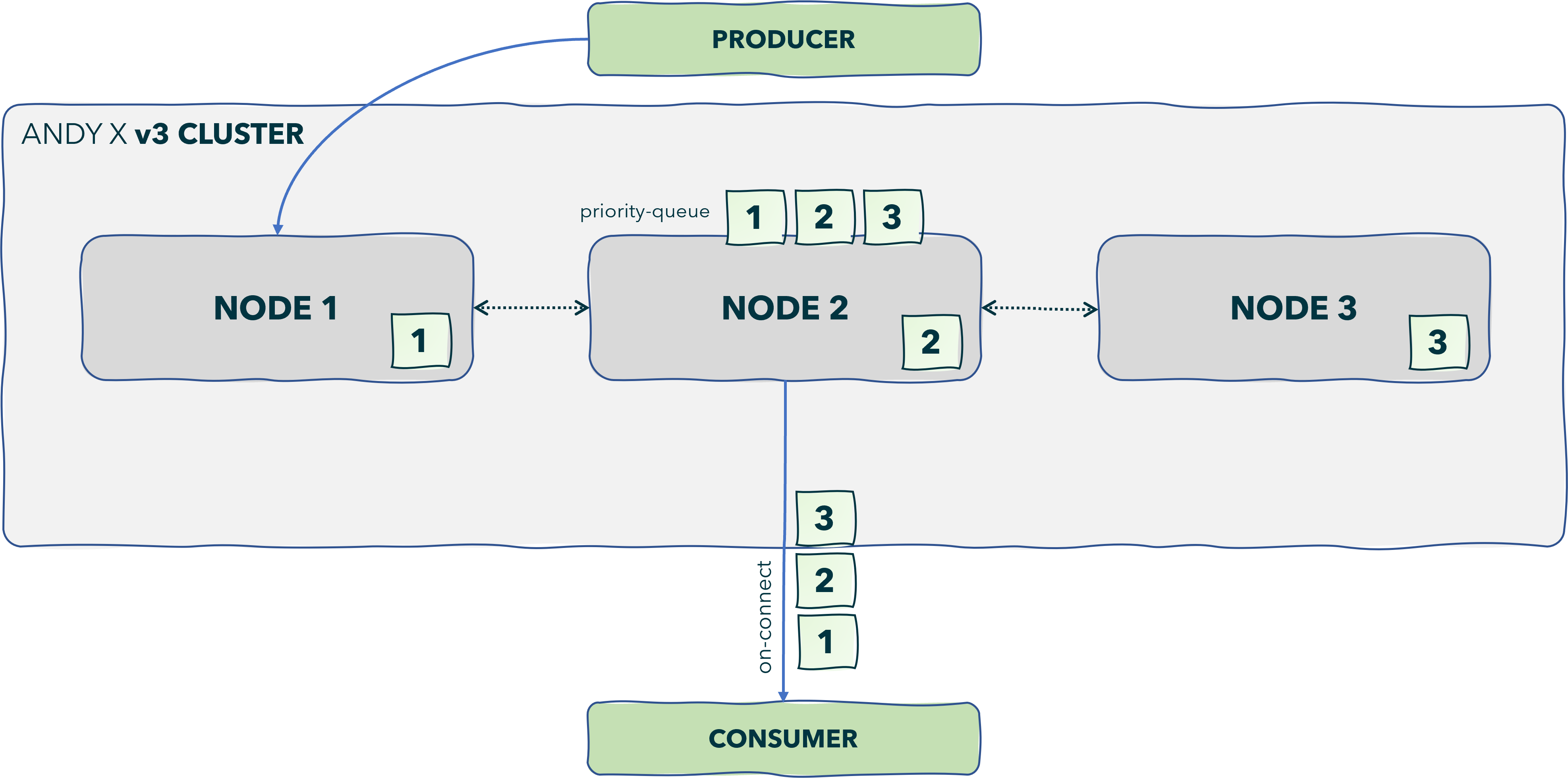
Andy X is an open-source distributed streaming platform designed to deliver the best performance possible for high-performance data pipelines, streaming analytics, streaming between microservices and data integrations.
Follow the Getting Started instructions how to run Andy X.
For local development and testing, you can run Andy X within a Docker container, for more info click here
Some of the best ways to contribute are to try things out, file issues, join in design conversations, and make pull-requests.
Security issues and bugs should be reported privately, via email, [email protected]. You should receive a response within 24 hours.
These are some other repos for related projects:
- Andy X Portal - Dashboard for Andy X Node
- Andy X Cli - Manage all resources of Andy X
Andy X can be easily deployed on a docker container using docker-compose, for more info click here
This project has adopted the code of conduct defined by the Contributor Covenant to clarify expected behavior in our community.
For more information, see the .NET Foundation Code of Conduct.
Let's do it together! You can support us by clicking on the link below!