camsong / blog Goto Github PK
View Code? Open in Web Editor NEW✍️Front-end Development Thoughts
✍️Front-end Development Thoughts
2019 农历新年即将到来,是时候总结一下团队过去一年的技术沉淀。过去一年我们支撑的数据相关业务突飞猛进,其中两个核心平台级产品代码量分别达到30+万行和80+万行,TS 模块数均超过1000个,协同开发人员增加到20+人。由于历史原因,开发框架同时基于 React 和 Angular,考虑到产品的复杂性、人员的短缺和技术背景各异,我们尝试了各种方法打磨工具体系来提升开发效率,以下是节选的5项主要方法。
从2013年React发布至今已近6个年头,前端框架逐渐形成 React/Vue/Angular 三足鼎立之势。几年前还在争论单向绑定和双向绑定孰优孰劣,现在三大框架已经不约而同选择单向绑定,双向绑定沦为单纯的语法糖。框架间的差异越来越小,加上 Ant-Design/NG-ZORRO/ElementUI 组件库的成熟,选择任一你熟悉的框架都能高效完成业务。
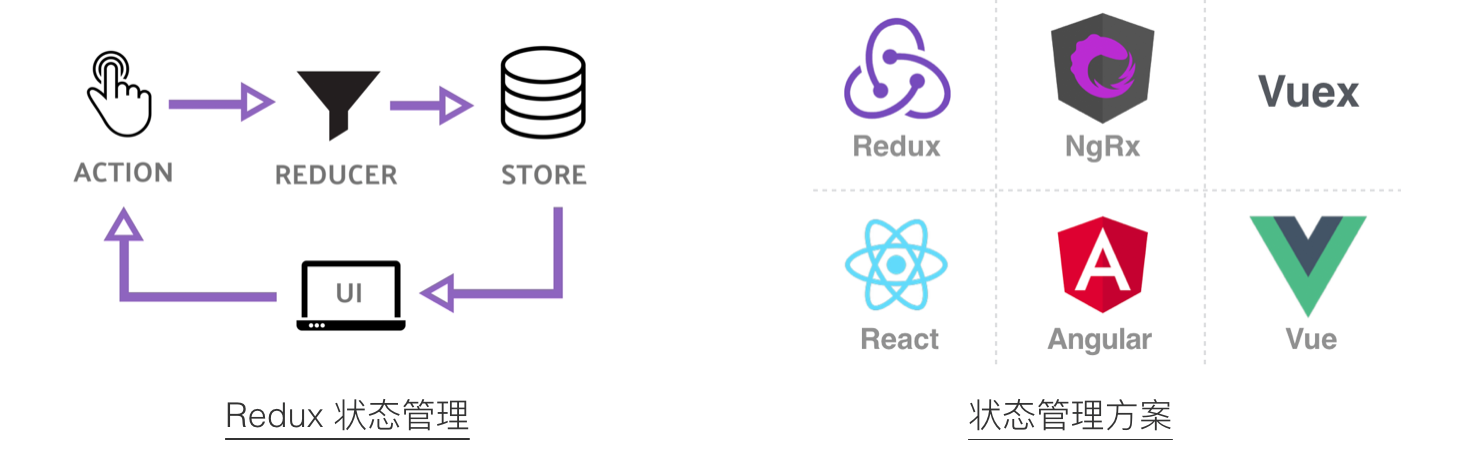
那接下来核心问题是什么?我们认为是状态管理。简单应用使用组件内 State 方便快捷,但随着应用复杂度上升,会发现数据散落在不同的组件,组件通信会变得异常复杂。我们先后尝试过原生 Redux、分形 Fractal 的思路、自研类 Mobx 框架、Angular Service,最终认为 Redux 依旧是复杂应用数据流处理最佳选项之一。
庆幸的是除了 React 社区,Vue 社区有类似的 Vuex,Angular 社区有 NgRx 也提供了几乎同样的能力,甚至 NgRx 还可以无缝使用 redux-devtools 来调试状态变化。
无论如何优化,始终要遵循 Redux 三原则:
| 原则 | 方法 | 引发的问题 |
|---|---|---|
| Single source of truth | 组件 Stateless,数据来源于 Store | 如何组织 Store? |
| State is read-only | 只能通过触发 action 来改变 State | action 数量膨胀,大量样板代码 |
| Changes are made with pure functions | Reducer 是纯函数 | 副作用如何处理,大量样板代码 |
这三个问题我们是通过自研 iron-redux 库来解决,以下是背后的思考:
如何组织 Action?
FetchTypes 类型来自动生成对应到 3 个 action如何组织 Store/Reducer?
最终我们得到如下扁平的状态树。虽庞大但有序,你可以快速而明确的访问任何数据。
[Redux 状态树]
如何减少样板代码?
使用原生 Redux,一个常见的请求处理如下。非常冗余,这是 Redux 被很多人诟病的原因
const initialState = {
loading = true,
error = false,
data = []
};
function todoApp(state = initialState, action) {
switch (action.type) {
case DATA_LOADING:
return {
...state,
loading: true,
error: false
}
case DATA_SUCCESS:
return {
...state,
loading: false,
data: action.payload
}
case DATA_ERROR:
return {
...state,
loading: false,
error: true
}
default:
return state
}
}使用 iron-redux 后:
class InitialState {
data = new AsyncTuple(true);
}
function reducer(state = new InitialState(), action) {
switch (action.type) {
/** 省略其它 action 处理 */
default:
return AsyncTuple.handleAll(prefix, state, action);
}
}代码量减少三分之二!!
主要做了这2点:
AsyncTuple 类型,就是 {data: [], loading: boolean, error: boolean} 这样的数据结构;AsyncTuple.handleAll 处理 LOADING/SUCCESS/ERROR 这 3 种 action,handleAll 的代码很简单,使用 if 判断 action.type 的后缀即可,源码在这里。曾经 React 和 Angular 是两个很难调和的框架,开发中浪费了我们大量的人力。通过使用轻量级的 iron-redux,完全遵循 Redux 核心原则下,我们内部实现了除组件层以外几乎所有代码的复用。开发规范、工具库达成一致,开发人员能够无缝切换,框架差异带来的额外成本降到很低。
TypeScript 目前可谓大红大紫,根据 2018 stateofjs,超过 50% 的使用率以及 90% 的满意度,甚至连 Jest 也正在从 Flow 切换到 TS。如果你还没有使用,可以考虑切换,绝对能给项目带来很大提升。过去一年,我们从部分使用 TS 变为全面切换到 TS,包括我们自己开发的工具库等。
TS 最大的优势是它提供了强大的静态分析能力,结合 TSLint 能对代码做到更加严格的检查约束。传统的 EcmaScript 由于没有静态类型,即使有了 ESLint 也只能做到很基本的检查,一些 typo 问题可能线上出了 Bug 后才被发现。
下图是一个前端应用常见的4层架构。代码和工具全面拥抱 TS 后,实现了从后端 API 接口到 View 组件的全链路静态分析,具有了完善的代码提示和校验能力。
[前后端协作简图]
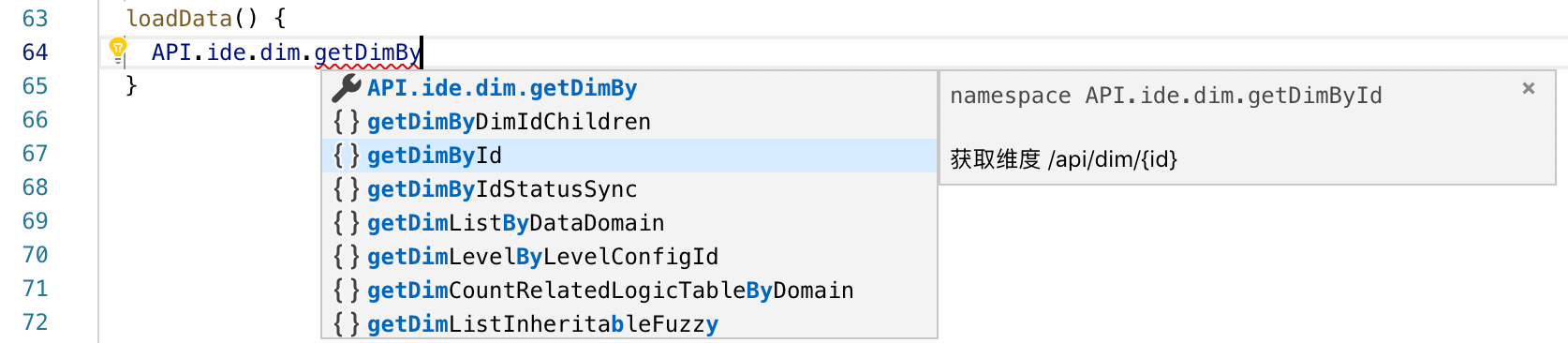
除了上面讲的 iron-redux,我们还引入 Pont 实现前端取数,它可以自动把后端 API 映射到前端可调用的请求方法。
Pont 实现原理:(法语:桥) 是我们研发的前端取数层框架**。对接的后端 API 使用 Java Swagger,Swagger 能提供所有 API 的元信息,包括请求和响应的类型格式。Pont 解析 API 元信息生成 TS 的取数函数,这些取数函数类型完美,并挂载到 API 模块下。最终代码中取数效果是这样的:
Pont 实现的效果有:
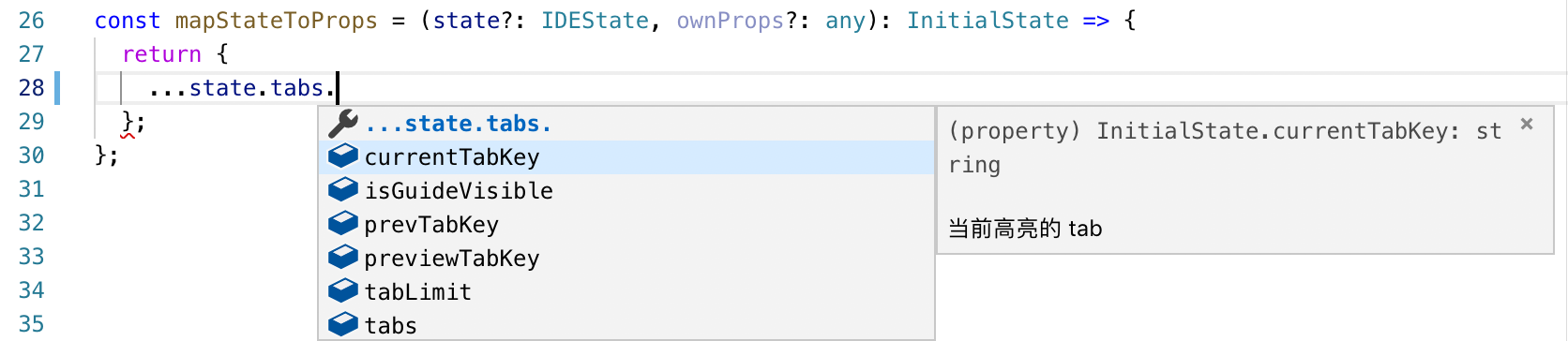
另外 iron-redux 能接收到 Pont 接口响应数据格式,并推导出整个 Redux 状态树的静态类型定义,Store 中的数据完美的类型提示。效果如下:
最终 TS 让代码更加健壮,尤其是对于大型项目,编译通过几乎就代表运行正常,也给重构增加了很多信心。
2015 年我们就开始实践 CSS Modules,包括后来的 styled-components 等,到 2019 年 css-in-js 方案依旧争论不休,虽然它确实解决了一些 CSS 语言天生的问题,但同时增加了不少成本,新手不够友好、全局样式覆盖成本高涨、伪类处理复杂、与antd等组件库结合有坑。与此同时 Sass/Less 社区也在飞速发展,尤其是 Stylelint 的成熟,可以通过技术约束的手段来避免 CSS 的 Bad Parts。
.home-page{ .top-nav {/**/}, .main-content{ /**/ } }。如果有多个顶级类,可以使用 Stylelint rule 检测并给出警告。// src/styles/variables.js
module.exports = {
// 主颜色
'primary-color': '#0C4CFF',
// 出错颜色
'error-color': '#F15533',
// 成功颜色
'success-color': '#35B34A',
};// webpack.config.js
const styleVariables = require('src/styles/variables');
// ...
{
test: /\.scss$/,
use: [
'style-loader',
'css-loader?sourceMap&minimize',
{
loader: 'sass-loader',
options: {
data: Object.keys(styleVariables)
.map(key => `\$${key}: ${styleVariables[key]};`)
.join('\n'),
sourceMap: true,
sourceMapContents: true
}
}
]
}
//...在 scss 文件中,可以直接引用变量
// page.scss
.button {
background: $primary-color;
}2019 年,你几乎不可能再开发出 React/Angular/Vue 级别的框架,也没必要再造 Ant-Design/Ng-Zorro 这样的轮子。难道就没有机会了吗?
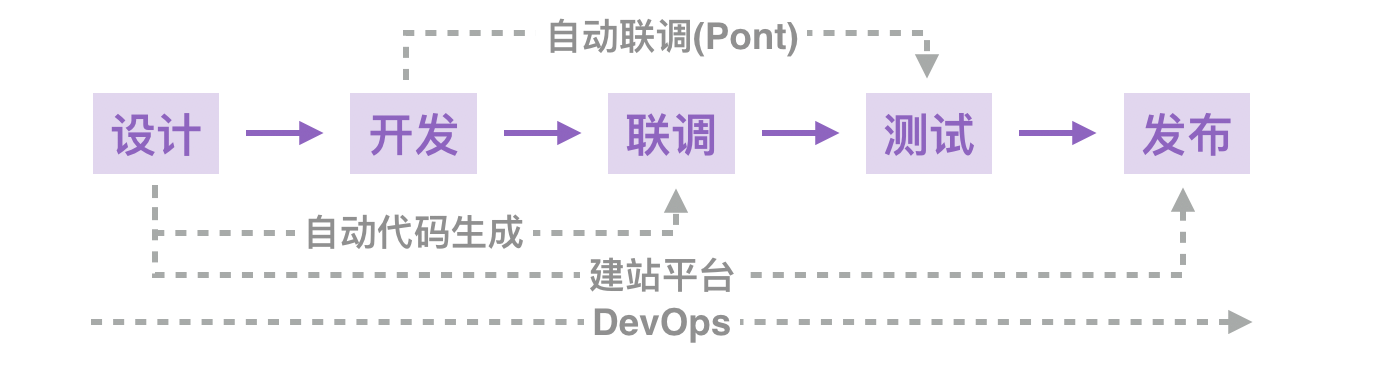
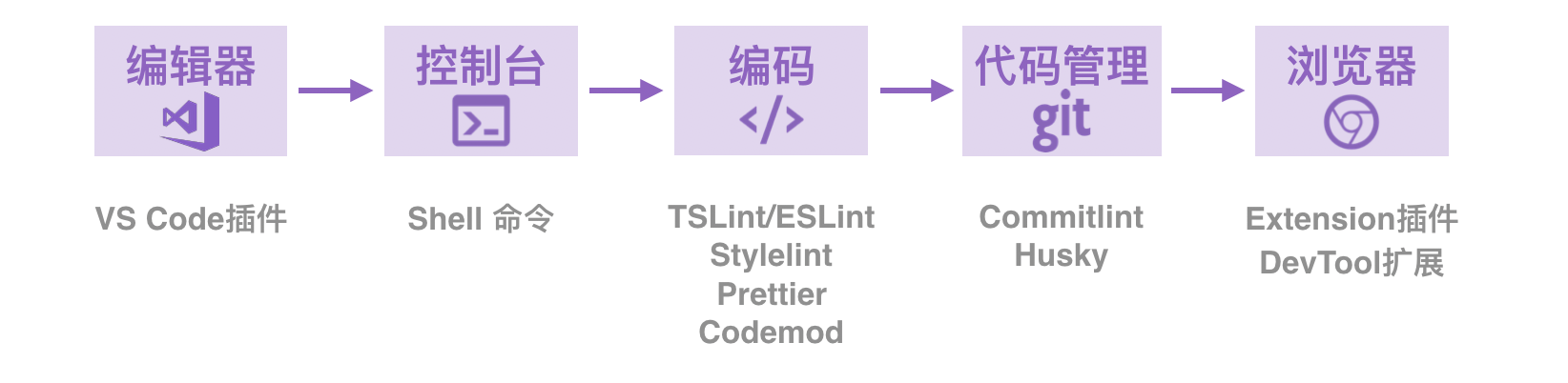
当然有,结合你自身的产品开发流程,依旧有很多机会。下面是常规项目的开发流程图,任何一个环节只要深挖,都有提升空间。如果你能通过工具减少一个或多个环节,带来的价值更大。
单拿其中的【开发】环节展开,就有很多可扩展的场景:
一个有代表性的例子是,我们开发了国际化工具 kiwi。它同样具有 TS 的类型完美,非常强大的文案提示,另外还有:
除了以上三点,未来还计划开发浏览器插件来检查漏翻文案,利用 Husky 在 git 提交前对漏翻文案自动做机器翻译等等。
未来如果你只提供一个代码库,那它的价值会非常局限。你可以参照上面的图表,开发相应的扩展来丰富生态。如果你是新手,推荐学习下编译原理和对应的扩展开发规范。
过去的一年,我们一共进行了 1200+ 多次 Code Review(CR),很多同事从刚开始不好意思提 MR 到后来追着别人 Review,CR 成为每个人的习惯。通过 CR 让项目中任何一行代码都至少被两人触达过,减少了绝大多数的低级错误,提升了代码质量,这也是帮助新人成长最快的方式之一。
【其中一个项目MR截图】
Code Review 的几个技巧:
以上5点当然不是我们技术的全部。除此之外我们还实践了移动端开发、可视化图表/WebGL、Web Worker、GraphQL、性能优化等等,但这些还停留在术的层面,未来到一定程度会拿出来分享。
如果你也准备或正在开发复杂的前端应用,同时团队人员多样技术背景各异,可以参考以上5点,使用 Redux 实现规范清晰可预测的状态管理,深耕 TypeScript 来提升代码健壮性和可维护性,借助各种 Lint 工具回归简单方便的 CSS,不断打磨自己的开发工具来保证开发规范高效,并严格彻底实行 Code Review 促进人的交流和提升。
Links
为什么 Number.MAX_VALUE 最多只有 2^1023
Math.pow(2, 1023)
> 8.98846567431158e+307
Math.pow(2, 1024)
> Infinity
Number.MAX_VALUE
> 1.7976931348623157e+308根据下图,我认为最大因该是 1023(最大的 E) + 53 = 1076 次方

Originally posted by @stupidehorizon in #9 (comment)
React Conf 是 React 官方主办的年度盛会,2020年因为疫情没有举行,今年的更加被期待。今年也是第一次线上举办,同往年我熬夜看完 Keynote。整个大会一共19个主题,5个半小时(包括1个小时茶歇),其中有将近40%的女性演讲,内容涵盖 React 18新特性,未来前瞻,以及生态的内容,接下来是我的一些感受。(完整回放链接:https://www.youtube.com/watch?v=8dUpL8SCO1w)
PS: 为了方便回看,截图尽量保留了播放进度条

首先第一个重点介绍的 Suspense,它并不是新特性,React 16.6 就已经引入,现在主要是用来和 React.lazy做组件延迟加载,这次介绍的重点是用 Suspense 来做取数。它最大的优势是把取数和loading处理的关注点分离。

对我而言,Suspense 能够把取数这类异步操作变成同步代码开发一样的体验。确实能提高代码的可读性和可维护性。Suspense 本身并不处理取数,需要和取数库搭配使用,目前 Relay 官方支持,swr 也已经支持,我最期待的 redux-toolkit 也有了支持计划。
然后开始讲比 Suspense 更底层的 Concurrent。

React 引入的并发最开始叫 Concurrent mode,也就是走新旧二选一的“模式”,确定把 mode 改成 feature 目的是你可以在想要的时候开启,不开启依旧是旧模式。这样对于大型应用就可以逐步升级。

React 18中所有新特性就这一页就可以概括。

彩蛋:千亿美金市值大佬 Shopify 创始人兼 CEO Tobi 直播写 React Hydrogen【这大概是最富有的前端开发者】 https://youtu.be/FPNZkPqUFIU
还有一个上页 PPT 没有讲的内容是 useSyncExternalStore。它是用来解决 Concurrent 下并发渲染数据撕裂(Tearing)的问题。

开发第三方 Store 类库的时候会遇到这个问题,解决的方法是使用 useSyncExternalStore。

总之,这也是引入 Concurrent 之后带来的新问题。目前 React-Redux V8 alpha 基于 useExternalStore 实现,并用 TypeScript 重写。 https://github.com/reduxjs/react-redux/releases/tag/v8.0.0-alpha.0
第一环节最后一场是黄玄带来的 React Forget 分享,有点 One More Thing 的味道。

非常精准的解决了 React 引入 Hooks 后 memo 满天飞的痛点。是否要 memo 是争议很久的问题。可以不写,但会导致很多不必要的渲染导致性能问题。所以为了性能考虑有些人会建议一股脑全都 memo,React Forget 的解决思路是用编译器分析源代码,把数据和函数都放到内置的 memoCache[] 中来自动 memo,减少多余渲染,这真的是一个好主意!

但我觉得想法很理想,做起来困难重重。本来不希望 memo 的自动加了怎么办,搜索一下代码中有多少处使用了 eslint-disable-next-line react-hooks/exhaustive-deps 来避免 useMemo 检测依赖。老项目如果添加如何做全面的测试,出问题如何排查。
目前 React Forget 还处在探索阶段,黄玄说未来也有可能“失败”,但这个特性还是很期待的,期望 React 团队能找到的解决办法。

这个图很全面,React 19 的重点的方向表达清晰。对于 data fetching 和 SSR 会非常重视。
// before
const container = document.getElementById('root');
ReactDOM.render(<App />, container);
// after
const container = document.getElementById('root');
const root = ReactDOM.createRoot(container);
root.render(<App/>);只需要删2行,加3行,一共5行代码搞定。
一杯咖啡的时间全部搞定,至于依赖库的升级花费多少时间,就看你咖啡时间的长短。
实际上,我最好奇的是:

这个分享介绍了 React Workgroup 建立的过程,方法,做了哪些事情。
感兴趣的可以去关注下他们 github 的讨论区,很专业也很热闹 https://github.com/reactwg/react-18/discussions
经常有人说前端概念太多,学不动了。React 一直很关照初学者。

目前 React doc 有 200万的 MAU,开发者众多。
React 这几年编码方式经过多次变化,React.createClass -> class -> hooks
未来都会转向 hooks,但原来的文档组织方式的问题已经难改变。
于是进干脆进行了一次彻底的基于 hooks 的重写,并在文档中加入可实时修改运行的代码,还有一些小测验。读起来非常利于新手由浅入深 https://beta.reactjs.org/

Relay 从发布后吸引了很多的关注,后来一直不温不火。但并没有停止更新。
上面分享者说 Facebook 使用了 Relay 后处理网络数据的时间减少了 10 倍。(到底是开发时间还是执行时间,我没有搞清楚)

当然,出来讲了,肯定有大的更新。因为旧的 GraphQL 不够模块化,他们基于 Rust 做了重写!性能提升 5倍!95%的分位值提升了 7倍!
比较特别的点是请来了 Facebook Messenger 团队和 微软一起来分享。

Messenger 旧的应用是 Electron,他们把它迁移到了 React Native,过程中复用了大量的代码,并没有重写。最终打包体积减少了 80%,冷启动时间减少 60%。
关于微软,已经不是曾经的微软,现在变得很开放。比较好奇的是为什么微软会选择 React Native?

原因如上,JS 是目前使用人数做多的语言!React.js 是最流行的前端开发框架!
微软使用 RN 的场景主要是 Office 中的评论模块、XBox console、Power Apps。
不是纯粹的拿来主义,微软维护了 react-native-windows react-native-macos。
RN 完美吗?

RN 在计划新一轮的重写,从 async 变成 sync,重分利用 concurrent 的优势。
Keynote 的最后的环节 Andrew Clark 分享了 React 的多平台愿景。除了老生常谈的“Learn once write anywhere”,“React is more than a library. React is a paradigm for building user interfaces”。今年做了一个概括,我总结为以下的 PPT(Andrew 并没有 ppt):

React 过去和将来的工作都是围绕如何移除错误的选择(Rejecting false choices),以此来让用户无需选择就有最好的体验。实际上围绕3组角色和场景的选择:
很美好的愿景,包括 小程序、Flutter 实际上都围绕类似的目标在尝试。但笔者认为,在跨端技术演进的过程中,各个端为了保持自己的优势也在不断演化,这会是一个不断促进的过程,可能没有终点。
这次大会几乎所有技术点都是围绕 Concurrent,这是从阻塞渲染到可中断渲染进化的彻底性的改变/重写。整个过程大概思路是从 DOM Rendering(Fiber、transition/deferredValue)、Data Fetching(Suspense)、SSR(Server Component、Streaming SSR)、跨端(React Native)所有这一切都变成 Concurrent。目前看来 DOM Rendering 已经重构完成,接下来的新版本重点会围绕 Suspense 取数层和 SSR。
相比以往,本次大会能看出 React 对 SSR 非常重视。我在2016年的项目中有引用过 SSR,当时还没有 Next.js 这类框架,当时为了做 SSR 对前端组件做了大量改造,还引入 Node 服务增加了很多运维成本,是一次失败的尝试。现在已经 2022,不知道 SSR 现在体验如何,不做评论。
对 Concurrent 的大力投入,看得出 React 对用户体验和性能极致的追求。
GraphQL 使用 Rust 重写引擎性能提升了 5 倍,React Native 计划重写为 Synchronous,而且印象中 RN 每年讲都是在重写。每次重写既大胆又能找到恰当的理由,这也是一种技术文化吧。
重写重构的时间都是以年为单位的,React Concurren 从最初 Fiber 引入开始,在 2016 年开始构思 Fiber,花了2年重写 reconciler 并在2018年 React 16 发布,然后 16.6 版本发布 Suspense,这是挖了一个更大的坑,到现在只支持 Relay,接下来 Suspense 还有几年的路要走。
经历过 Angular 1.x 到 2.0,Vue 2.0 到 3.0 升级的人会觉得 React 这些年来升级平滑的不可思议。平滑升级是 React 追求的目标,但 React 并没有为了平滑而不敢添加功能,实际上这几年在 Hooks,Concurrent 的引入上非常的大胆。能做到平滑,是因为 React Team 背后做了很多的工作,包括大会上介绍的 React Working Group 让社区深度参与 API 制定,Facebook 内部大量的 Dogfooding,以及内核 API 非常克制保持极简,还有一开始就选择函数式编程这个非常成熟的方向。
企业级的应用大多开始后就没有终点,逻辑复杂,维护者会几经转手。像我们瓴羊的几个平台级产品代码量已经/未来都会是几百万行。长期来看,技术的升级成本是最大的成本之一,因此 React 依旧是企业应用开发首选。
什么都没变,也好像什么都变了,这就是 React Conf 给我带来的最大感受。
VS Code 作为目前使用人数绝对 Top1 的 IDE/Editor(Stackoverflow 2021 调研有 71% 的开发者使用),一定是做对了一些关键的事情才达到今天的规模,如果想做好一个技术性的产品或工具,细细研究,一定能有所收获。
本文最初是回答知乎热帖 “Visual Studio Code 可以翻盘成功主要是因为什么?”,稍作补充。
用 VS Code 之父 Erich Gamma 的话讲:VS Code 的成功是 “An Overnight Success”,一夜成名。当然这是作者在调侃。
作为一个工具类产品,细节是魔鬼,不存在一招鲜吃遍天。VS Code 也不例外,打磨了10年,从2011年前身的 Monaco,2013年后团队差点被解散,2015年改名 VS Code 后发布,此后一直是稳步增长。
我个人是最初使用了 6 年 Vim(Ruby + JS),然后是切换到 Sublime,短暂的 Atom,到最后使用 VS Code 一直到现在。
大环境上,编辑器是很热门也是传统的赛道,VS Code 本有很多机会泯然众人,但各种原因让它最后一骑绝尘。
接下来一起扒一扒 VS Code 的发展历史。

VS Code 之父 Erich Gamma 作为设计模式 “四人帮” 作者之一,软件模式发展的先驱。开发了 Java 圈的单元测试框架 JUnit,更辉煌的是,在 IBM 主导开发了 Eclipse IDE 编辑器,当年最流行的 编辑器/IDE。可是,Erich Gamma 觉得有点不太对,未来属于 Web,他想在 Web 上打造像桌面端一样的开发体验。
在那个 IE 6 浏览器很香、jQuery 是最先进前端框架的年代,大佬果然是大佬,比一般人往后看10年。
同时 IBM 也江河日下,这个时候微软抛出橄榄枝,“入伙吧,未来是云时代,来做 Azure 的 Web 端编辑器”。Azure 刚于2010年发布,需要一个 web 端的编辑器。
双方一拍即合!(过程当然并不像预料的那样一帆风顺)
因为有 Eclipse IDE 的开发经验,很快撸了一个 Web 端的编辑器。
猜测是因为 Erich 喜欢去摩纳哥旅游,起名叫 "Monaco"。这是一个 纯 Web 的 Editor,VS Code 前身。也是目前 VS Code 使用的 Editor。很快提供给 Azure 用户使用。
Monaco 的特点就是“快“。性能吊打 Ace 和 CodeMirror。我们团队孵化的 “SQL 编辑器” 也是基于 Monaco。
这也是 VS Code 至今的原则:不使用任何 UI Framework,这是为了追求极致的性能,尽可能接近 DOM,做到每一个性能损耗点都能完全控制。
JS 语言设计的时候太过仓促,留下很多怪癖,且动态类型导致很多问题在运行时才能发现,开发像 VS Code 这样的项目难堪重任。想一下:如果没有 TS 的类型校验,重构一个大型的 JS 项目将会是怎样的灾难!(这一点做 Quick BI 开发的时候深有体会,如果没有 TS 的帮助,我们不可能发展这么快。)
这一次,幸运又一次降临在 Erich。他是同事兼好基友 Anders Hejlsberg 开发了 TypeScript。从 2011 年 Monaco 就使用 TS,感觉越用越好,2013 年决定全面切到 TypeScript。
更巧合的是:据说 Anders Hejlsberg 有一个怪癖,喜欢在一个文件内写所有代码,所以大文件特别多,他也是 Monaco 的重度用户,有他的加持,Monaco 性能更进一步。
因为转到了 TypeScript,给 VS Code 的快速发展打下来坚守的技术基础。
开发了 3 年的工具,虽然性能逆天,但致命的缺点是月活只有 3000 用户!
“你到底为公司创造了什么价值?” Erich 也面临灵魂拷问。
算了一下,用户数至少 x10 倍才能养活团队。但做 Web Editor 大概也只能这些用户,继续搞 Monaco 还是换一个新赛道?怎么办?
2014年,微软开始全面转型到生产力工具和云优先。从只考虑 Windows 平台到要考虑 MacOS、Linux、Windows 跨平台,并全面拥抱开源。
但微软缺少一个跨平台的开发工具,尤其是这个时候 Web 开发者开始迅速增长。
Erich 意识到机会来了。
但 2014 年的浏览器还是不够给力,前端项目越来越重,需要大量的文件处理。不是一个 Monaco 在线编辑器可以搞定的。
Erich 面临艰难选择:继续发展挚爱的 Web 编辑器 Monaco 还是改到 Desktop 版的 Editor/IDE???
最终:结果大家都知道了,Erich 选择了开发者更能接受的 Desktop Editor/IDE。
方法也简单,用 Electron 包壳 Monaco。
并改了个网红潜质的名字 “Visual Studio Code“,蹭了 Visual Studio 的热度,根正苗红,几个月就搞好了。
为了给尽可能多的 MS 人使用,提升业务价值,VS Code 选择在 BUILD 大会上正式发布。
当时最成功的一个 demo 是演示 Linux 下调试 .NET 应用。
但当时很多功能停留在 Demo 上,比如很多人期待的 Extension 扩展 API,是在 6 个月后上线的。
开发过 VS Code 插件的朋友应该很熟悉 LSP,可以扩展其他语言支持。

第一个使用 LSP 接入支持的就是 Java。在一个 Hackathon 上完成启动。
2017 年开始做 open in VS Code,到后来就是 VS Code Remote。
这样本地只需要一个低配置的浏览器,调试器和命令行都执行的远端服务器上,真正实现多人完全相同的环境下云开发。
因为涉及到跨平台,微软的 WSL(Windows Subsystem for Linux) 帮了大忙,解决了不同操作系统文件系统的差异,不然单是简单的文件路径匹配就是很麻烦的事情。在这之前,Windows 最被开发者吐槽的是差劲的 Shell 支持,虽然有 powershell 但距离 Linux 的 shell 还是差距很大。WSL 通过在 Windows 中运行 Linux 子系统,可以接近 Linux 原生性能执行各种 bash、grep、ls 操作。
VS Code Desktop 版本深度依赖了各种 Node.js File API。所以即使是 JS 开发的 Electron 应用移植到 Web 也是需要花不少时间。

2020年终于发布纯 Web 版的 VS Code。
也是在 2020 年,出现很多在线的 IDE/Editor 开发工具,低代码工具满天飞,很多是基于 VS Code 代码改造。
VS Code 之所以成功,有很多因素。除了 LSP 这个大杀器,我们无法直接照搬,很多方面我们在做产品的时候可以借鉴。
我们总是容易高估短期,低估长期。
Be patient, be persistent, be fit, be willing to pivot, be lucky.
本文大部分内容来自 Erich 的演讲,推荐观看: VS Code Day Keynote with Erich Gamma
Shared mutable state is the root of all evil(共享的可变状态是万恶之源)
-- Pete Hunt
有人说 Immutable 可以给 React 应用带来数十倍的提升,也有人说 Immutable 的引入是近期 JavaScript 中伟大的发明,因为同期 React 太火,它的光芒被掩盖了。这些至少说明 Immutable 是很有价值的,下面我们来一探究竟。
JavaScript 中的对象一般是可变的(Mutable),因为使用了引用赋值,新的对象简单的引用了原始对象,改变新的对象将影响到原始对象。如 foo={a: 1}; bar=foo; bar.a=2 你会发现此时 foo.a 也被改成了 2。虽然这样做可以节约内存,但当应用复杂后,这就造成了非常大的隐患,Mutable 带来的优点变得得不偿失。为了解决这个问题,一般的做法是使用 shallowCopy(浅拷贝)或 deepCopy(深拷贝)来避免被修改,但这样做造成了 CPU 和内存的浪费。
Immutable 可以很好地解决这些问题。
Immutable Data 就是一旦创建,就不能再被更改的数据。对 Immutable 对象的任何修改或添加删除操作都会返回一个新的 Immutable 对象。Immutable 实现的原理是 Persistent Data Structure(持久化数据结构),也就是使用旧数据创建新数据时,要保证旧数据同时可用且不变。同时为了避免 deepCopy 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing(结构共享),即如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。请看下面动画:
目前流行的 Immutable 库有两个:
Facebook 工程师 Lee Byron 花费 3 年时间打造,与 React 同期出现,但没有被默认放到 React 工具集里(React 提供了简化的 Helper)。它内部实现了一套完整的 Persistent Data Structure,还有很多易用的数据类型。像 Collection、List、Map、Set、Record、Seq。有非常全面的map、filter、groupBy、reduce``find函数式操作方法。同时 API 也尽量与 Object 或 Array 类似。
其中有 3 种最重要的数据结构说明一下:(Java 程序员应该最熟悉了)
与 Immutable.js 学院派的风格不同,seamless-immutable 并没有实现完整的 Persistent Data Structure,而是使用 Object.defineProperty(因此只能在 IE9 及以上使用)扩展了 JavaScript 的 Array 和 Object 对象来实现,只支持 Array 和 Object 两种数据类型,API 基于与 Array 和 Object 操持不变。代码库非常小,压缩后下载只有 2K。而 Immutable.js 压缩后下载有 16K。
下面上代码来感受一下两者的不同:
// 原来的写法
let foo = {a: {b: 1}};
let bar = foo;
bar.a.b = 2;
console.log(foo.a.b); // 打印 2
console.log(foo === bar); // 打印 true
// 使用 immutable.js 后
import Immutable from 'immutable';
foo = Immutable.fromJS({a: {b: 1}});
bar = foo.setIn(['a', 'b'], 2); // 使用 setIn 赋值
console.log(foo.getIn(['a', 'b'])); // 使用 getIn 取值,打印 1
console.log(foo === bar); // 打印 false
// 使用 seamless-immutable.js 后
import SImmutable from 'seamless-immutable';
foo = SImmutable({a: {b: 1}})
bar = foo.merge({a: { b: 2}}) // 使用 merge 赋值
console.log(foo.a.b); // 像原生 Object 一样取值,打印 1
console.log(foo === bar); // 打印 false可变(Mutable)数据耦合了 Time 和 Value 的概念,造成了数据很难被回溯。
比如下面一段代码:
function touchAndLog(touchFn) {
let data = { key: 'value' };
touchFn(data);
console.log(data.key); // 猜猜会打印什么?
}在不查看 touchFn 的代码的情况下,因为不确定它对 data 做了什么,你是不可能知道会打印什么(这不是废话吗)。但如果 data 是 Immutable 的呢,你可以很肯定的知道打印的是 value。
Immutable.js 使用了 Structure Sharing 会尽量复用内存,甚至以前使用的对象也可以再次被复用。没有被引用的对象会被垃圾回收。
import { Map} from 'immutable';
let a = Map({
select: 'users',
filter: Map({ name: 'Cam' })
})
let b = a.set('select', 'people');
a === b; // false
a.get('filter') === b.get('filter'); // true上面 a 和 b 共享了没有变化的 filter 节点。
因为每次数据都是不一样的,只要把这些数据放到一个数组里储存起来,想回退到哪里就拿出对应数据即可,很容易开发出撤销重做这种功能。
后面我会提供 Flux 做 Undo 的示例。
传统的并发非常难做,因为要处理各种数据不一致问题,因此『聪明人』发明了各种锁来解决。但使用了 Immutable 之后,数据天生是不可变的,并发锁就不需要了。
然而现在并没什么卵用,因为 JavaScript 还是单线程运行的啊。但未来可能会加入,提前解决未来的问题不也挺好吗?
Immutable 本身就是函数式编程中的概念,纯函数式编程比面向对象更适用于前端开发。因为只要输入一致,输出必然一致,这样开发的组件更易于调试和组装。
像 ClojureScript,Elm 等函数式编程语言中的数据类型天生都是 Immutable 的,这也是为什么 ClojureScript 基于 React 的框架 --- Om 性能比 React 还要好的原因。
No Comments
No Comments
这点是我们使用 Immutable.js 过程中遇到最大的问题。写代码要做思维上的转变。
虽然 Immutable.js 尽量尝试把 API 设计的原生对象类似,有的时候还是很难区别到底是 Immutable 对象还是原生对象,容易混淆操作。
Immutable 中的 Map 和 List 虽对应原生 Object 和 Array,但操作非常不同,比如你要用 map.get('key') 而不是 map.key,array.get(0) 而不是 array[0]。另外 Immutable 每次修改都会返回新对象,也很容易忘记赋值。
当使用外部库的时候,一般需要使用原生对象,也很容易忘记转换。
下面给出一些办法来避免类似问题发生:
$$ 开头。Immutable.fromJS 而不是 Immutable.Map 或 Immutable.List 来创建对象,这样可以避免 Immutable 和原生对象间的混用。Immutable.is两个 immutable 对象可以使用 === 来比较,这样是直接比较内存地址,性能最好。但即使两个对象的值是一样的,也会返回 false:
let map1 = Immutable.Map({a:1, b:1, c:1});
let map2 = Immutable.Map({a:1, b:1, c:1});
map1 === map2; // false为了直接比较对象的值,immutable.js 提供了 Immutable.is 来做『值比较』,结果如下:
Immutable.is(map1, map2); // trueImmutable.is 比较的是两个对象的 hashCode 或 valueOf(对于 JavaScript 对象)。由于 immutable 内部使用了 Trie 数据结构来存储,只要两个对象的 hashCode 相等,值就是一样的。这样的算法避免了深度遍历比较,性能非常好。
后面会使用 Immutable.is 来减少 React 重复渲染,提高性能。
另外,还有 mori、cortex 等,因为类似就不再介绍。
Object.freeze 和 ES6 中新加入的 const 都可以达到防止对象被篡改的功能,但它们是 shallowCopy 的。对象层级一深就要特殊处理了。
这个 Cursor 和数据库中的游标是完全不同的概念。
由于 Immutable 数据一般嵌套非常深,为了便于访问深层数据,Cursor 提供了可以直接访问这个深层数据的引用。
import Immutable from 'immutable';
import Cursor from 'immutable/contrib/cursor';
let data = Immutable.fromJS({ a: { b: { c: 1 } } });
// 让 cursor 指向 { c: 1 }
let cursor = Cursor.from(data, ['a', 'b'], newData => {
// 当 cursor 或其子 cursor 执行 update 时调用
console.log(newData);
});
cursor.get('c'); // 1
cursor = cursor.update('c', x => x + 1);
cursor.get('c'); // 2熟悉 React 的都知道,React 做性能优化时有一个避免重复渲染的大招,就是使用 shouldComponentUpdate(),但它默认返回 true,即始终会执行 render() 方法,然后做 Virtual DOM 比较,并得出是否需要做真实 DOM 更新,这里往往会带来很多无必要的渲染并成为性能瓶颈。
当然我们也可以在 shouldComponentUpdate() 中使用使用 deepCopy 和 deepCompare 来避免无必要的 render(),但 deepCopy 和 deepCompare 一般都是非常耗性能的。
Immutable 则提供了简洁高效的判断数据是否变化的方法,只需 === 和 is 比较就能知道是否需要执行 render(),而这个操作几乎 0 成本,所以可以极大提高性能。修改后的 shouldComponentUpdate 是这样的:
注意:React 中规定
state和props只能是一个普通对象,所以比较时要比较对象的key,谢谢 @chenmnkken 指正。
import { is } from 'immutable';
shouldComponentUpdate: (nextProps = {}, nextState = {}) => {
const thisProps = this.props || {}, thisState = this.state || {};
if (Object.keys(thisProps).length !== Object.keys(nextProps).length ||
Object.keys(thisState).length !== Object.keys(nextState).length) {
return true;
}
for (const key in nextProps) {
if (!is(thisProps[key], nextProps[key])) {
return true;
}
}
for (const key in nextState) {
if (thisState[key] !== nextState[key] && !is(thisState[key], nextState[key])) {
return true;
}
}
return false;
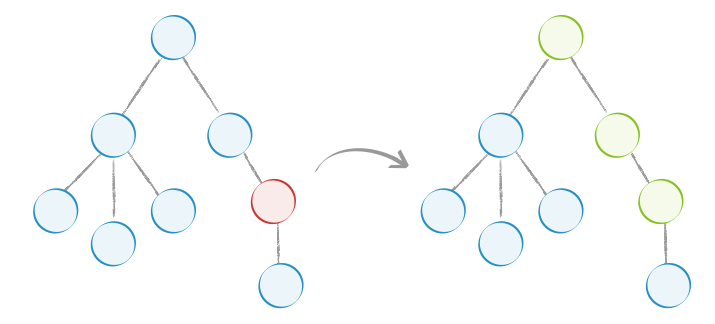
}使用 Immutable 后,如下图,当红色节点的 state 变化后,不会再渲染树中的所有节点,而是只渲染图中绿色的部分:
你也可以借助 React.addons.PureRenderMixin 或支持 class 语法的 [pure-render-decorator](felixgirault/pure-render-decorator · GitHub) 来实现。
React 建议把 this.state 当作 Immutable 的,因此修改前需要做一个 deepCopy,显得麻烦:
import '_' from 'lodash';
const Component = React.createClass({
getInitialState() {
return {
data: { times: 0 }
}
},
handleAdd() {
let data = _.cloneDeep(this.state.data);
data.times = data.times + 1;
this.setState({ data: data });
// 如果上面不做 cloneDeep,下面打印的结果会是已经加 1 后的值。
console.log(this.state.data.times);
}
}使用 Immutable 后:
getInitialState() {
return {
data: Map({ times: 0 })
}
},
handleAdd() {
this.setState({ data: this.state.data.update('times', v => v + 1) });
// 这时的 times 并不会改变
console.log(this.state.data.get('times'));
}上面的 handleAdd 可以简写成:
handleAdd() {
this.setState(({data}) => ({
data: data.update('times', v => v + 1) })
});
}由于 Flux 并没有限定 Store 中数据的类型,使用 Immutable 非常简单。
现在是实现一个类似带有添加和撤销功能的 Store:
import { Map, OrderedMap } from 'immutable';
let todos = OrderedMap();
let history = []; // 普通数组,存放每次操作后产生的数据
let TodoStore = createStore({
getAll() { return todos; }
});
Dispatcher.register(action => {
if (action.actionType === 'create') {
let id = createGUID();
history.push(todos); // 记录当前操作前的数据,便于撤销
todos = todos.set(id, Map({
id: id,
complete: false,
text: action.text.trim()
}));
TodoStore.emitChange();
} else if (action.actionType === 'undo') {
// 这里是撤销功能实现,
// 只需从 history 数组中取前一次 todos 即可
if (history.length > 0) {
todos = history.pop();
}
TodoStore.emitChange();
}
});Redux 是目前流行的 Flux 衍生库。它简化了 Flux 中多个 Store 的概念,只有一个 Store,数据操作通过 Reducer 中实现;同时它提供更简洁和清晰的单向数据流(View -> Action -> Middleware -> Reducer),也更易于开发同构应用。目前已经在我们项目中大规模使用。
由于 Redux 中内置的 combineReducers 和 reducer 中的 initialState 都为原生的 Object 对象,所以不能和 Immutable 原生搭配使用。
幸运的是,Redux 并不排斥使用 Immutable,可以自己重写 combineReducers 或使用 redux-immutablejs 来提供支持。
上面我们提到 Cursor 可以方便检索和 update 层级比较深的数据,但因为 Redux 中已经有了 select 来做检索,Action 来更新数据,因此 Cursor 在这里就没有用武之地了。
Immutable 可以给应用带来极大的性能提升,但是否使用还要看项目情况。由于侵入性较强,新项目引入比较容易,老项目迁移需要评估迁移。对于一些提供给外部使用的公共组件,最好不要把 Immutable 对象直接暴露在对外接口中。
如果 JS 原生 Immutable 类型会不会太美,被称为 React API 终结者的 Sebastian Markbåge 有一个这样的提案,能否通过现在还不确定。不过可以肯定的是 Immutable 会被越来越多的项目使用。
如果你觉得本文对你有帮助,请点击右上方的 Star 鼓励一下,或者点击 Watch 订阅
近年来,阿里数据中台产品发展迅速。核心产品之 Quick BI 连续 2 年成为国内唯一入选 Gartner 魔力象限的国产 BI。Quick BI 单一代码仓库源码突破了 100万行。整个开发过程涉及到的人员和模块都很多,因为下面分享的一些原则,产品能一直做到快速迭代。
先分享几个关键数据:
很多人会问,这么多代码,为什么不切分代码库?还不赶快引入微前端、Serverless 框架?你们就不担心无法维护,启动龟速吗?
实际情况是,从第一天开始,就预估到会有这么大的代码量。启动时间也从最初的几秒钟到后面越来越慢5~10分钟,再优化到近期的5秒钟。整个过程下来,团队更感受到 Monorepo(单一代码仓库)的优势。
这个实践想说明:
2019年4月30号,晴朗的下午,刚好是喜迎五一的前一天,发挥集体智慧,投票选出满意的仓库名。最开始是做 Quick BI 的底座,后来底座越来越大,把上层业务代码也吸纳进来。
commit 769bf68c1740631b39dca6931a19a5e1692be48d
Date: Tue Apr 30 17:48:52 2019 +0800
A New Era of BI Begins在开工之前,对单一仓库(Monorepo)和多仓库(Polyrepo)团队内做了很多的讨论。
曾经我也很喜欢 Polyrepo,为每个组件建立独立 repo 独立 npm,比如2019年前,单是表单类的编辑器组件就有 43 个:
本以为这样可以做到 完美的解耦、极致的复用??
但实际上:
最终我们把所有这些组件都合并到一个仓库,其实像 Google/Facebook/Microsoft 这些公司内部都很推崇 Monorepo。
但我们不是原教旨主义的 Monorepo,没必要把不相关的产品代码硬放到一起。在实线团队内部,单个产品可以使用 Monorepo,会极大降低协同成本。但开始的时候,团队内还是有很多疑问。
100 万行代码的体积有多大?
先来猜一下:1GB?10GB?还是更多?
首先,按照公式计算一下:
代码的体积 = 源码的体积 + .git 的体积 + 资源文件(音视频、图片、其他文件)
i. 我们一起来算一下源码的体积:
一般建议每行小于 120 字符,我们取每行 100 个字符来算,100 万行就是:
100 * 1000,000 = 100,000,000 B
转换之后就是 100 MB!
那我们的仓库实际多大呢?
只有 85 MB!也就是平均每行 85 个字符。
ii. 再来算一下 .git的体积:
.git里记录了所有代码的提交历史、branch 和 tag 信息。会很大体积吧?
实际上 Git 底层做了很多的优化:1. 所有 branch 和 tag 都是引用;2. 对变更是增量存储;3. 变更对象存储的时候会使用 zlib 压缩。(对于重复出现的样板代码只会存储一次,对于规范化的代码压缩比例极高)。
按照我们的经验,.git记录 10,000 次 commit 提交只需要额外的 1~3 个代码体积即可。
iii. 资源文件大小
Git 做了很多针对源码的优化,但视频和音频这类资源文件除外。我们最近使用 BFG 把另一个产品的仓库从 22GB 优化到 200MB,降低 99%!而且优化后代码的提交历史和分支都得到了保留(因为 BFG 会编辑 Git 提交记录,部分 commit id 会变化)。
以前 22 GB 是因为仓库里存放视频、发布的 build 文件和 sourcemap 文件,这些都不应该放到源码仓库。
小结一下,百万行代码体积一般在 200MB ~ 400MB 之间。那来估算下 1000 万行代码占用体积是多少?
乘以十也就是 2GB ~ 4GB 之间。这对比 node_modules随随便便几个 G 来说,并不算什么,很容易管理。
补充个案例,Linux 内核有 2800 万行,使用 Monorepo,数千人协同。据说当时 Linus 就是为了管理 Linux 的源码而开发出 Git。
听到有些团队讲,代码十几万行,启动 10+分钟,典型的“巨石”项目,已经很难维护了。赶紧拆包、或者改微前端。可能团队才 3 个人却拆了 5 个项目,协同起来非常麻烦。
我们做法有3个:
尤其是 Webpack 切换到 Vite 以后,最终项目冷启动时间由 2-5分钟 优化到 **5秒 **内。
热编译时间由原来 5秒 优化到 1秒 内,Apple M1 电脑基本都是 500ms 以内。
传统的软件工程**追求 DRY,但并不是越 DRY 越好。
每写一行代码,都产生了相应代价:维护的成本。为了减少代码,我们有了可复用的模块。但是代码复用有一个问题:当你以后想要修改的时候它就会成为一个障碍。
对于像 Quick BI 这样长期迭代的产品,绝大部分需求都是对原有功能的扩展,所以写出易维护的代码最重要。因此,团队不鼓励使用 magic 的特技写法;不单纯追求代码复用率,而是追求更易于修改;鼓励在未来模块下线的时候易于删除的编码方式。
对于确实存在复用的场景,我们做了拆包。Monorepo 内部我们拆了多个 package(后面有截图),比如其他产品需要 BI 搭建,可以复用 @alife/bi-designer,并借助于 Tree-Shaking 做到依赖引入的最小化。
这样的体验要保持并不容易,开发中还有很多问题要解决:
Monorepo 不是银弹,对于不成熟的团队反而可能是炸弹。因为每个人每次提交都有摧毁整个产品的风险。
要产生价值,需要团队在 协同、技术文化、工程化、质量保障等方面达到深度认可。
拆包的主要原因有2个,给外部复用以及减少打包后的体积(Tree Shaking 做的不够)。对于小闭环的团队,直接使用子目录让业务快跑就够用了,架构上更简单。
内部拆分多个子包,每个子包对应一个子文件,可以单独发布 npm,见下图:
内部包管理的核心原则是:
对于开源 npm 的引入,需要更慎重。大部分 npm 的维护时长不超过x年,即使像 Moment.js 这样曾经标配的工具库也会终止维护。可能有 20% 的 npm 是没人维护。但未来如果你的线上用户遇到问题,你就需要靠自己啃源码,陷入被动。所以我们的原则是,引入开源 npm 要架构组评审通过才行。
互相 Code Review 能帮助新人快速成长,同时也是打造团队技术文化的方式。
过去几年一直在团队内推行 100% CR,但这还不够。机械的执行很容易把 CR 流于形式,去年开始探索分场景来做。
目前我们的 Code Review 主要分为3个场景:
过去几年,一万两千多次 Code Review 积累的经验有很多,主要是:
这个过程首先要感谢阿里 Def 工程化团队的支持,代码的增加在不断挑战打包机性能和灵活性的边界,Def 都能快速支持。
一般团队都会有开发规范,但能做到自动化工具检查的规范才是好规范。
语法检查器是推动规范落地的重要方法,ESLint 可以做增量,优化后 git commit 的 pre-hooks 依旧很快。但 TS type check 因为不支持增量就比较慢了,放到本地体验就不好,需要搭配 CI/CD 来使用。
Webpack 的优势是插件丰富,打包产物兼容性好,页面打开快速,但开发模式启动慢、极慢,而 Vite 恰恰切中了这个痛点,开发模式启动快、飞快。
最近,我们做到了 Webpack 和 Vite 混合的模式,使用了两者的优点。
开发环境使用 Vite 快速调试,生产环境依旧使用 Webpack 打包出稳定兼容性好的产物。
风险是开发和生产编译产物不一致,这一块需要上线前回归测试避免。
对于数据类产品而言,性能的挑战除了来自于 Monorepo 后构建产物的变大,还有大数据量对渲染计算带来的挑战。
性能优化可以分为3个环节:
另外还有性能检测工具,定位性能卡点。计划做代码性能门闩,代码提交前如果发现包体积增大发出提醒。
身在数据中台,我对数据的业务价值深信不疑。但对于开发本身而言,很少深度使用过数据。
所以 S1 重点探索了开发体验的数字化。通过采集大家的开发环境和启动耗时数据来做分析【不统计其他数据避免内卷】。发现很多有意思的事情,比如有个同学热编译 3~5 分钟,他以为别人也是这样慢,严重影响了开发效率,当从报表发现数据异常后十分钟帮他解决。
另外一个例子,为了保持线上打包产物的一致性,推动团队做 Node.js 版本统一,以前都是靠钉,钉多少次都无法知道效果如何。有了报表以后就一目了然。
目前整个数据化的流程跑通,初步尝到甜头。未来还有很多好玩的分析可以做。
每行代码都会留下成本。长远考虑,效率最高的方法就是一次做好。
苏世民说“做大事和做小事的难度是一样的。 两者都会消耗你的时间和精力”。既然如此,不妨把代码一次写好。代码中如果遗留 “TODO” 可能就永远 TO DO。客观来讲,一次做好比较难,首先是每个人认为的“好”标准不同,背后是个人的技术能力、体验的追求、业务的理解。
技术架构和组织结构有很大关系,选择适合组织的技术架构更重要。
如果一个组织是分散的,使用 Monorepo 会有很大的协同成本。组织如果是内聚的,Monorepo 用好能极大提效。
工程化和架构底座是团队的事情,靠个人很难去推动。
短期可以靠战役靠照搬,长期要形成文化才能持续迭代。
组织沟通成本高应该通过组织来解,通过技术来解的力量是渺小的。技术可以做的是充分发挥工具的优势,让变化快速发生。
这是借用Alan Perlis的一句话。
对于一个简单的架构,总会有人会想办法把它做复杂。踩了坑,下决心重构,成功则回归简单,失败就会被新的简单模式颠覆。架构就是这样不断的在做复杂和做简单中交替着螺旋式演进。
踩坑本身也是有价值的,不然新人总是按捺不住还会再踩一次。做复杂很容易,但保持简单需要远见和克制。没有经历过过程的磨练,别人的解药对你可能是毒药。
架构不会一成不变,Quick BI 的图表最开始直接使用 D3、ECharts 简单快速,后来非常多定制化的功能逐渐复杂到难以扩展,于是基于 G2 自研 bi-charts 后架构又一次变简单,每一次重构都是对架构中各个元素的重新思考和整合,能够以更简单高效的方式支持业务。
百万行代码没什么可怕,是一个正常的节点,仍然可以像几万行代码那样敏捷。
现在 Quick BI 已经向千万行迈进,向世界一流 BI 的目标迈进。需要考虑研发效率、质量管控、组织协同、工程化、体验性能多方面的优化。以上内容限于篇幅。BI 数据分析业务开发涉及的技术挑战非常多,因为数据分析天生就要与海量数据打交道,在大数据量渲染和导出上我们在不断的探索;洞察丰富异样的数据,可视化及复杂表格方面有极其多样的需求,可视化能力不仅是技术,还变成业务本身;手机平板电视等多端展示,跨端适配需要融入到每个功能点。未来还希望能够把数据分析打造成一个引擎,能够快速集成到技术产品和商业流程中。
目前的开发模式并不完美,你有任何方面的建议,欢迎交流。
我在使用fetch-jsonp的时候,使用IE9用来获取数据时,获取不到数据啊,
我是利用redux来管理react的state,这是action.js中的获取所有用户的action
============下面的代码=======
import fetchJsonp from 'fetch-jsonp';
import 'fetch-detector';
import 'fetch-ie8';
require('es6-promise').polyfill();
export const USERFETCHSUCCESS="USERFETCHSUCCESS";
export const USERFETCHERR="USERFETCHERR";
/==========================获取用户信息reducers+++++++++++++++++++++++++/
//请求用户数据成功
export function UserFetchSucess(json,singal){
return {
type:USERFETCHSUCCESS,
json,
singal
}
}
//请求用户数据失败
export function UserFetchErr(singal){
return {
type:USERFETCHERR,
singal
}
}
//请求用户数据
export function UserFetchData(){
return dispatch=>{
return fetchJsonp('/sys/userAction/selectAllUser')
.then(res=>{return res.json()})
.then(data=>{
dispatch(UserFetchSucess(data,1))
})
.catch( err=>{dispatch(UserFetchErr(2))})
}
}
=-======================求各位大神指教==========
我是一个应届毕业生,很喜欢react技术,但是苦于没有人来指导,我遇到这个问题已经很久了。
CSS 是前端领域中进化最慢的一块。由于 ES2015/2016 的快速普及和 Babel/Webpack 等工具的迅猛发展,CSS 被远远甩在了后面,逐渐成为大型项目工程化的痛点。也变成了前端走向彻底模块化前必须解决的难题。
CSS 模块化的解决方案有很多,但主要有两类。一类是彻底抛弃 CSS,使用 JS 或 JSON 来写样式。Radium,jsxstyle,react-style 属于这一类。优点是能给 CSS 提供 JS 同样强大的模块化能力;缺点是不能利用成熟的 CSS 预处理器(或后处理器) Sass/Less/PostCSS,:hover 和 :active 伪类处理起来复杂。另一类是依旧使用 CSS,但使用 JS 来管理样式依赖,代表是 CSS Modules。CSS Modules 能最大化地结合现有 CSS 生态和 JS 模块化能力,API 简洁到几乎零学习成本。发布时依旧编译出单独的 JS 和 CSS。它并不依赖于 React,只要你使用 Webpack,可以在 Vue/Angular/jQuery 中使用。是我认为目前最好的 CSS 模块化解决方案。近期在项目中大量使用,下面具体分享下实践中的细节和想法。
CSS 模块化重要的是要解决好两个问题:CSS 样式的导入和导出。灵活按需导入以便复用代码;导出时要能够隐藏内部作用域,以免造成全局污染。Sass/Less/PostCSS 等前仆后继试图解决 CSS 编程能力弱的问题,结果它们做的也确实优秀,但这并没有解决模块化最重要的问题。Facebook 工程师 Vjeux 首先抛出了 React 开发中遇到的一系列 CSS 相关问题。加上我个人的看法,总结如下:
!important,甚至 inline !important 和复杂的选择器权重计数表,提高犯错概率和使用成本。Web Components 标准中的 Shadow DOM 能彻底解决这个问题,但它的做法有点极端,样式彻底局部化,造成外部无法重写样式,损失了灵活性。css-loader 提供了这种能力。上面的问题如果只凭 CSS 自身是无法解决的,如果是通过 JS 来管理 CSS 就很好解决,因此 Vjuex 给出的解决方案是完全的 CSS in JS,但这相当于完全抛弃 CSS,在 JS 中以 Object 语法来写 CSS,估计刚看到的小伙伴都受惊了。直到出现了 CSS Modules。
CSS Modules 内部通过 ICSS 来解决样式导入和导出这两个问题。分别对应 :import 和 :export 两个新增的伪类。
:import("path/to/dep.css") {
localAlias: keyFromDep;
/* ... */
}
:export {
exportedKey: exportedValue;
/* ... */
}但直接使用这两个关键字编程太麻烦,实际项目中很少会直接使用它们,我们需要的是用 JS 来管理 CSS 的能力。结合 Webpack 的 css-loader 后,就可以在 CSS 中定义样式,在 JS 中导入。
// webpack.config.js
css?modules&localIdentName=[name]__[local]-[hash:base64:5]加上 modules 即为启用,localIdentName 是设置生成样式的命名规则。
/* components/Button.css */
.normal { /* normal 相关的所有样式 */ }
.disabled { /* disabled 相关的所有样式 */ }/* components/Button.js */
import styles from './Button.css';
console.log(styles);
buttonElem.outerHTML = `<button class=${styles.normal}>Submit</button>`生成的 HTML 是
<button class="button--normal-abc53">Submit</button>注意到 button--normal-abc53 是 CSS Modules 按照 localIdentName 自动生成的 class 名。其中的 abc53 是按照给定算法生成的序列码。经过这样混淆处理后,class 名基本就是唯一的,大大降低了项目中样式覆盖的几率。同时在生产环境下修改规则,生成更短的 class 名,可以提高 CSS 的压缩率。
上例中 console 打印的结果是:
Object {
normal: 'button--normal-abc53',
disabled: 'button--disabled-def884',
}CSS Modules 对 CSS 中的 class 名都做了处理,使用对象来保存原 class 和混淆后 class 的对应关系。
通过这些简单的处理,CSS Modules 实现了以下几点:
使用了 CSS Modules 后,就相当于给每个 class 名外加加了一个 :local,以此来实现样式的局部化,如果你想切换到全局模式,使用对应的 :global。
.normal {
color: green;
}
/* 以上与下面等价 */
:local(.normal) {
color: green;
}
/* 定义全局样式 */
:global(.btn) {
color: red;
}
/* 定义多个全局样式 */
:global {
.link {
color: green;
}
.box {
color: yellow;
}
}对于样式复用,CSS Modules 只提供了唯一的方式来处理:composes 组合
/* components/Button.css */
.base { /* 所有通用的样式 */ }
.normal {
composes: base;
/* normal 其它样式 */
}
.disabled {
composes: base;
/* disabled 其它样式 */
}import styles from './Button.css';
buttonElem.outerHTML = `<button class=${styles.normal}>Submit</button>`生成的 HTML 变为
<button class="button--base-daf62 button--normal-abc53">Submit</button>由于在 .normal 中 composes 了 .base,编译后会 normal 会变成两个 class。
composes 还可以组合外部文件中的样式。
/* settings.css */
.primary-color {
color: #f40;
}
/* components/Button.css */
.base { /* 所有通用的样式 */ }
.primary {
composes: base;
composes: primary-color from './settings.css';
/* primary 其它样式 */
}对于大多数项目,有了 composes 后已经不再需要 Sass/Less/PostCSS。但如果你想用的话,由于 composes 不是标准的 CSS 语法,编译时会报错。就只能使用预处理器自己的语法来做样式复用了。
CSS Modules 的命名规范是从 BEM 扩展而来。BEM 把样式名分为 3 个级别,分别是:
综上,BEM 最终得到的 class 名为 dialog__confirm-button--highlight。使用双符号 __ 和 -- 是为了和区块内单词间的分隔符区分开来。虽然看起来有点奇怪,但 BEM 被非常多的大型项目和团队采用。我们实践下来也很认可这种命名方法。
CSS Modules 中 CSS 文件名恰好对应 Block 名,只需要再考虑 Element 和 Modifier。BEM 对应到 CSS Modules 的做法是:
/* .dialog.css */
.ConfirmButton--disabled {
}你也可以不遵循完整的命名规范,使用 camelCase 的写法把 Block 和 Modifier 放到一起:
/* .dialog.css */
.disabledConfirmButton {
}注:CSS Modules 中没有变量的概念,这里的 CSS 变量指的是 Sass 中的变量。
上面提到的 :export 关键字可以把 CSS 中的 变量输出到 JS 中。下面演示如何在 JS 中读取 Sass 变量:
/* config.scss */
$primary-color: #f40;
:export {
primaryColor: $primary-color;
}/* app.js */
import style from 'config.scss';
// 会输出 #F40
console.log(style.primaryColor);CSS Modules 是对现有的 CSS 做减法。为了追求简单可控,作者建议遵循如下原则:
composes 组合来实现复用上面两条原则相当于削弱了样式中最灵活的部分,初使用者很难接受。第一条实践起来难度不大,但第二条如果模块状态过多时,class 数量将成倍上升。
一定要知道,上面之所以称为建议,是因为 CSS Modules 并不强制你一定要这么做。听起来有些矛盾,由于多数 CSS 项目存在深厚的历史遗留问题,过多的限制就意味着增加迁移成本和与外部合作的成本。初期使用中肯定需要一些折衷。幸运的是,CSS Modules 这点做的很好:
如果我对一个元素使用多个 class 呢?
没问题,样式照样生效。
如何我在一个 style 文件中使用同名 class 呢?
没问题,这些同名 class 编译后虽然可能是随机码,但仍是同名的。
如果我在 style 文件中使用伪类,标签选择器等呢?
没问题,所有这些选择器将不被转换,原封不动的出现在编译后的 css 中。也就是说 CSS Modules 只会转换 class 名和 id 选择器名相关的样式。
但注意,上面 3 个“如果”尽量不要发生。
在 className 处直接使用 css 中 class 名即可。
/* dialog.css */
.root {}
.confirm {}
.disabledConfirm {}import classNames from 'classnames';
import styles from './dialog.css';
export default class Dialog extends React.Component {
render() {
const cx = classNames({
[styles.confirm]: !this.state.disabled,
[styles.disabledConfirm]: this.state.disabled
});
return <div className={styles.root}>
<a className={cx}>Confirm</a>
...
</div>
}
}注意,一般把组件最外层节点对应的 class 名称为 root。这里使用了 classnames 库来操作 class 名。
如果你不想频繁的输入 styles.**,可以试一下 react-css-modules,它通过高阶函数的形式来避免重复输入 styles.**。
好的技术方案除了功能强大炫酷,还要能做到现有项目能平滑迁移。CSS Modules 在这一点上表现的非常灵活。
当生成混淆的 class 名后,可以解决命名冲突,但因为无法预知最终 class 名,不能通过一般选择器覆盖。我们现在项目中的实践是可以给组件关键节点加上 data-role 属性,然后通过属性选择器来覆盖样式。
如
// dialog.js
return <div className={styles.root} data-role='dialog-root'>
<a className={styles.disabledConfirm} data-role='dialog-confirm-btn'>Confirm</a>
...
</div>// dialog.css
[data-role="dialog-root"] {
// override style
}因为 CSS Modules 只会转变类选择器,所以这里的属性选择器不需要添加 :global。
前端项目不可避免会引入 normalize.css 或其它一类全局 css 文件。使用 Webpack 可以让全局样式和 CSS Modules 的局部样式和谐共存。下面是我们项目中使用的 webpack 部分配置代码:
module: {
loaders: [{
test: /\.jsx?$/,
loader: 'babel'
}, {
test: /\.scss$/,
exclude: path.resolve(__dirname, 'src/styles'),
loader: 'style!css?modules&localIdentName=[name]__[local]!sass?sourceMap=true'
}, {
test: /\.scss$/,
include: path.resolve(__dirname, 'src/styles'),
loader: 'style!css!sass?sourceMap=true'
}]
}/* src/app.js */
import './styles/app.scss';
import Component from './view/Component'
/* src/views/Component.js */
// 以下为组件相关样式
import './Component.scss';目录结构如下:
src
├── app.js
├── styles
│ ├── app.scss
│ └── normalize.scss
└── views
├── Component.js
└── Component.scss
这样所有全局的样式都放到 src/styles/app.scss 中引入就可以了。其它所有目录包括 src/views 中的样式都是局部的。
CSS Modules 很好的解决了 CSS 目前面临的模块化难题。支持与 Sass/Less/PostCSS 等搭配使用,能充分利用现有技术积累。同时也能和全局样式灵活搭配,便于项目中逐步迁移至 CSS Modules。CSS Modules 的实现也属轻量级,未来有标准解决方案后可以低成本迁移。如果你的产品中正好遇到类似问题,非常值得一试。
这是我在前端精度专栏发的一篇文章。精读的文章是:Here's why Client-side Rendering Won

我为什么要选这篇文章呢?
十年前,几乎所有网站都使用 ASP、Java、PHP 这类做后端渲染,但后来随着 jQuery、Angular、React、Vue 等 JS 框架的崛起,开始转向了前端渲染。从 2014 年起又开始流行了同构渲染,号称是未来,集成了前后端渲染的优点,但转眼间三年过去了,很多当时壮心满满的框架(rendr、Lazo)从先驱变成了先烈。同构到底是不是未来?自己的项目该如何选型?我想不应该只停留在追求热门和拘泥于固定模式上,忽略了前后端渲染之“争”的“核心点”,关注如何提升“用户体验”。
原文分析了前端渲染的优势,并没有进行深入探讨。我想以它为切入口来深入探讨一下。
明确三个概念:「后端渲染」指传统的 ASP、Java 或 PHP 的渲染机制;「前端渲染」指使用 JS 来渲染页面大部分内容,代表是现在流行的 SPA 单页面应用;「同构渲染」指前后端共用 JS,首次渲染时使用 Node.js 来直出 HTML。一般来说同构渲染是介于前后端中的共有部分。
前端渲染的优势
后端渲染的优势
以上服务端优势其实只有首屏性能和 SEO 两点比较突出。但现在这两点也慢慢变得微不足道了。React 这类支持同构的框架已经能解决这个问题,尤其是 Next.js 让同构开发变得非常容易。还有静态站点的渲染,但这类应用本身复杂度低,很多前端框架已经能完全囊括。
本次提出独到观点的同学有:@javie007 @杨森 @流形 @camsong @Turbe Xue @淡苍 @留影 @FrankFang @alcat2008 @xile611 @twobin @黄子毅 精读由此归纳。
大家对前端和后端渲染的现状基本达成共识。即前端渲染是未来趋势,但前端渲染遇到了首屏性能和SEO的问题。对于同构争议最多,在此我归纳一下。
前端渲染主要面临的问题有两个 SEO、首屏性能。
SEO 很好理解。由于传统的搜索引擎只会从 HTML 中抓取数据,导致前端渲染的页面无法被抓取。前端渲染常使用的 SPA 会把所有 JS 整体打包,无法忽视的问题就是文件太大,导致渲染前等待很长时间。特别是网速差的时候,让用户等待白屏结束并非一个很好的体验。
同构恰恰就是为了解决前端渲染遇到的问题才产生的,至 2014 年底伴随着 React 的崛起而被认为是前端框架应具备的一大杀器,以至于当时很多人为了用此特性而放弃 Angular 1 而转向 React。然而近3年过去了,很多产品逐渐从全栈同构的理想化逐渐转到首屏或部分同构。让我们再一次思考同构的优点真是优点吗?
首先确定你的应用是否都要做 SEO,如果是一个后台应用,那么只要首页做一些静态内容宣导就可以了。如果是内容型的网站,那么可以考虑专门做一些页面给搜索引擎
时到今日,谷歌已经能够可以在爬虫中执行 JS 像浏览器一样理解网页内容,只需要往常一样使用 JS 和 CSS 即可。并且尽量使用新规范,使用 pushstate 来替代以前的 hashstate。不同的搜索引擎的爬虫还不一样,要做一些配置的工作,而且可能要经常关注数据,有波动那么可能就需要更新。第二是该做 sitemap 的还得做。相信未来即使是纯前端渲染的页面,爬虫也能很好的解析。
其实同构并没有节省前端的开发量,只是把一部分前端代码拿到服务端执行。而且为了同构还要处处兼容 Node.js 不同的执行环境。有额外成本,这也是后面会具体谈到的。
由于 SPA 打包生成的 JS 往往都比较大,会导致页面加载后花费很长的时间来解析,也就造成了白屏问题。服务端渲染可以预先使到数据并渲染成最终 HTML 直接展示,理想情况下能避免白屏问题。在我参考过的一些产品中,很多页面需要获取十几个接口的数据,单是数据获取的时候都会花费数秒钟,这样全部使用同构反而会变慢。
把原来放在几百万浏览器端的工作拿过来给你几台服务器做,这还是花挺多计算力的。尤其是涉及到图表类需要大量计算的场景。这方面调优,可以参考 walmart的调优策略。
个性化的缓存是遇到的另外一个问题。可以把每个用户个性化信息缓存到浏览器,这是一个天生的分布式缓存系统。我们有个数据类应用通过在浏览器合理设置缓存,双十一当天节省了 70% 的请求量。试想如果这些缓存全部放到服务器存储,需要的存储空间和计算都是很非常大。
前端代码在编写时并没有过多的考虑后端渲染的情景,因此各种 BOM 对象和 DOM API 都是拿来即用。这从客观层面也增加了同构渲染的难度。我们主要遇到了以下几个问题:
由于前端代码使用的 window 在 node 环境是不存在的,所以要 mock window,其中最重要的是 cookie,userAgent,location。但是由于每个用户访问时是不一样的 window,那么就意味着你得每次都更新 window。
而服务端由于 js require 的 cache 机制,造成前端代码除了具体渲染部分都只会加载一遍。这时候 window 就得不到更新了。所以要引入一个合适的更新机制,比如把读取改成每次用的时候再读取。
export const isSsr = () => (
!(typeof window !== 'undefined' && window.document && window.document.createElement && window.setTimeout)
);原因是很多 DOM 计算在 SSR 的时候是无法进行的,涉及到 DOM 计算的的内容不可能做到 SSR 和 CSR 完全一致,这种不一致可能会带来页面的闪动。
前端代码由于浏览器环境刷新一遍内存重置的天然优势,对内存溢出的风险并没有考虑充分。
比如在 React 的 componentWillMount 里做绑定事件就会发生内存溢出,因为 React 的设计是后端渲染只会运行 componentDidMount 之前的操作,而不会运行 componentWillUnmount 方法(一般解绑事件在这里)。
前端可以做非常复杂的请求合并和延迟处理,但为了同构,所有这些请求都在预先拿到结果才会渲染。而往往这些请求是有很多依赖条件的,很难调和。纯 React 的方式会把这些数据以埋点的方式打到页面上,前端不再发请求,但仍然再渲染一遍来比对数据。造成的结果是流程复杂,大规模使用成本高。幸运的是 Next.js 解决了这一些,后面会谈到。
这个 store 是必须以字符串形式塞到前端,所以复杂类型是无法转义成字符串的,比如function。
总的来说,同构渲染实施难度大,不够优雅,无论在前端还是服务端,都需要额外改造。
再回到前端渲染遇到首屏渲染问题,除了同构就没有其它解法了吗?总结以下可以通过以下三步解决
现在流行的路由库如 react-router 对分拆打包都有很好的支持。可以按照页面对包进行分拆,并在页面切换时加上一些 loading 和 transition 效果。
首次渲染的问题可以用更好的交互来解决,先看下 linkedin 的渲染
有什么感受,非常自然,打开渲染并没有白屏,有两段加载动画,第一段像是加载资源,第二段是一个加载占位器,过去我们会用 loading 效果,但过渡性不好。近年流行 Skeleton Screen 效果。其实就是在白屏无法避免的时候,为了解决等待加载过程中白屏或者界面闪烁造成的割裂感带来的解决方案。
部分同构可以降低成功同时利用同构的优点,如把核心的部分如菜单通过同构的方式优先渲染出来。我们现在的做法就是使用同构把菜单和页面骨架渲染出来。给用户提示信息,减少无端的等待时间。
相信有了以上三步之后,首屏问题已经能有很大改观。相对来说体验提升和同构不分伯仲,而且相对来说对原来架构破坏性小,入侵性小。是我比较推崇的方案。
我们赞成客户端渲染是未来的主要方向,服务端则会专注于在数据和业务处理上的优势。但由于日趋复杂的软硬件环境和用户体验更高的追求,也不能只拘泥于完全的客户端渲染。同构渲染看似美好,但以目前的发展程度来看,在大型项目中还不具有足够的应用价值,但不妨碍部分使用来优化首屏性能。做同构之前 ,一定要考虑到浏览器和服务器的环境差异,站在更高层面考虑。
Next.js 是时下非常流行的基于 React 的同构开发框架。作者之一就是大名鼎鼎的 Socket.io 的作者 Guillermo Rauch。它有以下几个亮点特别吸引我:
全家桶式的的解决方案。简洁清晰的目录结构,这一点 Redux 等框架真应该学一学。不过全家桶的方案比较适合全新项目使用,旧项目使用要评估好成本

题图:达摩院文生图大模型绘制的一张照片
2022 年是科技圈艰难的一年,很少有振奋人心的消息。惊喜的是年底 OpenAI 开放的 ChatGPT,一下点燃了整个科技圈,体验后感觉有点像人脑,智能化程度惊艳。
曾经我和朋友常调侃人工智能就是“有多少人工,就有多少智能”,ChatGPT 打破了这种印象。这里少有“人工”的痕迹,更像是“人脑”。AI 就像从远处开来的火车,听腻了每年总有人说它来了、要来了、真的要来了,这一次感觉它从我旁边呼啸而过~
春节期间我围绕 ChatGPT、编程语言、大数据、前端听了很多播客 Podcasts,脑海里一直在想,如此强大的 AI 能力,会给工作带来什么变化?作为工程师,工作机会是否会面临来自 AI 的威胁或者替代,我们应该如何在工作中更好地使用 AI?以下是我的观察和理解,本文不是硬核的 AI 技术解读,更多是从产品和应用角度阐述,我会先分享4个我认为内容较好的外部输入,然后是个人观点探讨。
ChatGPT 是现在的当红炸子鸡,但 AI 的进化不是一蹴而就,还有很多上层和周边的 AI 明星产品和概念,各自用一句话介绍下:
https://www.bilibili.com/video/BV1qY411X71q/
推荐指数:⭐⭐⭐⭐⭐

Sam Altman 是 ChatGPT 背后公司 OpenAI 的联合创始人兼 CEO,前任 YC 总裁。采访时间是 2023年1月份,应该是 Sam Altman 最新的公开分享。共有2部分:
第1部分是关于 Sam 的投资,他个人投资了 400+ 公司,有核聚变发电设备的 Helion,超音速飞行器,这部分和 AI 无关,可以简单略过。
第2部分推荐一定要看一下。里面讲了很多 AI 宏观内容,主持人的问题很直接,关于商业竞争、盈利模式、创业建议的问题。包括 ChatGPT、AGI 、GPT 4、微软的合作、谷歌的竞争、OpenAI 盈利模式、AI 监管。
内容总结如下:
如何看待学生用 ChatGPT 写作业(甚至有人获奖)?:这无法避免,要学会向前看。
Sam 的风格和 Elon Musk 完全不同。Sam 是尽可能降低人们预期,然后发布产品后打破预期。Elon 是不断展望,破裂以后再展望最迟明年。但共同点是,做的事情都很技术突破性。
https://guiguzaozhidao.fireside.fm/20220148
推荐指数:⭐⭐⭐⭐
主讲者都在 AI 圈多年创业或经验,OpenAI 的务实程度,模型迭代速度超过预期。讲了大模型、数据和算力这3个 AI 底层能力的相辅相成,一些 ChatGPT 内部的 transformer、训练方法。ChatGPT 用了更好的监督数据,让模型更符合人类的认知。以及在工业和商业上规模化落地的可能,ChatGPT 不仅是文本上的突破,未来也可以基于财务、营销、制造做一些智能的应用。(AI 对现有产品来讲,是一个新的能力维度,比如我们在做 Quick BI 时深刻感知到,无论仪表板多么精美,多少模板都不够,必须要 know how,结合制造、互联网、金融、零售等行业做特色的解决方案)。
From Turbo Pascal to Delphi to C# to TypeScript, an interview with PL legend Anders Hejlsberg
https://www.bilibili.com/video/BV1YG411L774
推荐指数:⭐⭐⭐⭐⭐

TS 是我最喜欢的语言,VS Code 是最受程序员欢迎的 Editor,前者是 Anders 创造,后者有他的深度参与。
Anders 有 40 年的编程经验,创造了一个又一个传奇,Delphi、C#、TypeScript 之父。视频只有20多分钟,很多传奇故事被一句带过。
几个有趣的经历:
对于 AI 对编程的影响,Anders 除了 “Surprise” 并没有太多反馈,看来现在大家都还在接受的过程中。但 AI 毫无疑问会降低在不同语言间切换的成本,在不同平台上更容易转换到对应的语言。
视频中提到了 Language 是否有必要统一问题,是否有必要做一个跨 Language 的层,实际上没有必要。因为 Language 实际上是和 Platform 绑定,我们在谈 Language 实际上是在谈背后的 Platform,比如想到 Java 就对应 Server、想到 Swift 就对应 iOS、想到 Python 就对应算法模型,在 Platform 不打通的情况下把 Java 和 Swift 互相转毫无意义,但 Platform 打通牵涉太多内容,不切实际。所以程序员在预见的将来还是需要和不同的 Language 打交道,我想有了 ChatGPT 这类能力之后,Language 给开发者带来的门槛会降低,会有越来越多的开发者可以使用不同 Language 在不同 Platform 间自由切换。
此外,由于 ChatGPT 有了大量开发者用户,编程语言的设计者也会考虑面向 ChatGPT 的可理解性做优化,因此描述性强的编程语言会有优势,新兴的编程语言或框架因为缺少数据训练不占优势。
https://www.xiaoyuzhoufm.com/episode/638013b518554643b70ab197
推荐指数:⭐⭐⭐⭐⭐
Vercel 工程师的一期节目,比较轻松。Shu Ding 是 Vercel 早期的员工,也是 SWR 的作者。Vercel 目前竟然已经到了 400 人。
讲了一些小故事,印象深刻:
以上是我看过听过感觉比较好的内容推荐。接下来是我的个人观点,和上面不是一一对应,欢迎讨论。
不能一味去夸 ChatGPT,我尝试了 ChatGPT 的边界场景,发现仍有一些不足/缺点,这些是潜在的机会。
ChatGPT 会降低 AI 的使用门槛,让前端工程师更容易开发智能应用。也会改变前端的开发方式、用户体验。
只要你描述清楚需求,写代码,那是小菜一碟。甚至还可以帮你优化代码。
我随手找了一段拼凑代码给 ChatGPT 来优化。
帮我优化下这段代码,ChatGPT 能够熟练使用 React hooks,并做性能调优:

它居然还可以给你解释为什么这么优化!

我感觉像是在和一个熟悉 React 开发规范、《Unix 编程艺术》《设计模式》《Clean Code》的同学在结对编程。
AI 就像一个强大的结对编程助手,可以帮你检查编码的问题。
比如我们团队 Code review 发现有很多 React hooks 滥用的问题,我看了前端圈很多大会的 topic,感觉讲的并不适用我们的场景,很多实践没有我们团队深入。
实际上这个问题最好的答案就在 React 官方文档内。我们团队把它浓缩成了几个简单的规则:
我们一直很重视团队的工程化工具建设,能用工具解决的绝不停留在规范。但以上的规则很难用现有的工具检测出来,真正检测需要理解代码语义。这就是 ChatGPT 可以带来的底层能力变化。
ChatGPT 会让编程语言的上手门槛大幅降低,前后端的融合更加容易。因此新一代的全栈开发会流行。注重性能和开发效率。比如 Next.js 框架。敏捷开发类框架曾经我最喜欢的是 Ruby on Rails,主要是开发确实快,遗憾是 Ruby 弱类型语言没有 TypeScript 这么鲁棒性好。希望 Next.js 能快速达到 Ruby on Rails 的生态,同时能真正解决前后端同构渲染的问题。
这是对产品和前端的一大挑战和机会。
对于 2B 复杂系统,目前主流的交互方式还是报表展现类、交互分析类、表单流程类、可视化搭建类。但回到客户需求,用户的真实需求是从数据中得到一些 insight,辅助决策。引入 ChatGPT 这类能力后,整个数据开发和分析的流程会大幅缩短。
并且,在问题明确的场景下,通过 Chat 聊天来寻找答案会很快速,可以很容易扩展到语音问答。

虽然 AI 能回答很多问题,绘出很精美的图片。但 如果你不能发现问题,他无法给你答案。
我们会不断地感受到好问题比答案更重要。借助 AI 的能力,普通人一步步体会到了爱因斯坦的洞见。
面对 AI 的冲击,不必担心 AI 会抢掉你的饭碗。如果停止学习,饭碗迟早会丢。抢掉饭碗的何止AI...
另外担心也没用,我们应该成为快速使用 AI 的一波人,这一轮受益最大的会是能快速利用 AI 提高工作效率的人,你不用别人会用。
有了场景以后,你还需要掌握一些技巧,来发挥 AI 的潜能:
1、提出更好的问题,花时间重点理解客户需求,并设计你的方案。最终限制你的还是你的想象力。AI 可以捏造出美丽的照片和代码,但没有你的想法就缺少意义,没有价值。你的竞争力有如何准确地捕获出用户需求,如何深入理解业务,如何协同上下游。
2、学习一些 prompt,准确描述你的想法,会帮助你大幅提效。比如 awesome-chatgpt-prompts 这个 Github 仓库可以帮你学习各种 prompt,如果你是开发者,可以在 camsong/chatgpt-engineer-prompts 找到一些编程相关的使用技巧。
3、开放的态度,遇到新的 AI 周边工具去了解,去使用,为己所用。
总之,AI 可以作为强大的生产力工具,会缩小不同编程语言间的差异,让开发者更容易在不同平台间切换来完成任务。前端工程师升级为终端工程师之后,未来能力边界会进一步扩大。大数据潜力进一步挖掘,数据处理能力更被重视,数据开发的门槛进一步降低。接下来会是 AI 上层应用井喷的一段时间,会有更简洁的用户交互,各行各业最终都会有 AI 深度结合的解决方案,未来可期。
componentDidMount 而不是 didMount 或 mounted 呢?类似的还有超长的 dangerouslySetInnerHTML 有考虑过键盘的感受吗。其实这是一种古老的命名策略,给不鼓励使用的方法设置非常长的方法名,来尽量避免使用。生命周期方法都是给你应急或与外部组件对接用的,如果能避免就尽量不用。class Button extends React.Component {
static propTypes = {
type: PropTypes.oneOf(['success', 'normal']),
onClick: PropTypes.func,
};
static defaultProps = {
type: 'normal',
};
handleClick() {
}
render() {
let { className, type, children, ...other } = this.props;
const classes = classNames(className, 'prefix-button', 'prefix-button-' + type);
return <span className={classes} {...other} onClick={::this.handleClick}>
{children}
</span>;
}
}长痛不如短痛,如果你预料到业务未来会比较复杂的话,还是早点使用 Redux 吧。但即使使用了 Redux 并不是说只有一种选择,基于它上面的生态非常丰富。Redux 是一个重**轻实现的框架,理解**非常关键。
下图是我画的 Redux 操作流程图

有几点明确一下:
type 来区分
connect 方法把 Store 中数据按需绑定到 View 上,是最核心方法之一,有很多的细节,建议看下源码使用 Redux 时,最可能遇到了是这些问题
好的数据组织方式评判方法很简单:一眼就知道这个数据是哪个页面、哪个模块、大致做什么的。
现在大多是单页面应用,而且每个页面(Page)包含多个模块(我喜欢叫卡片 Card),所以这个数据树至少会包含 page 和 card 两层。在我开发的一个应用中,是这样来规划的

左边是页面大致的结构,包含可能多页面复用的全局筛选器(Global Filter),当前页面的多个卡片。所以在设计 Store 结构的时候就分了 page 和 card 两层,card 下面才是业务数据。为了让全局筛选器统一管理,单独在顶层开辟了 filters 分支。
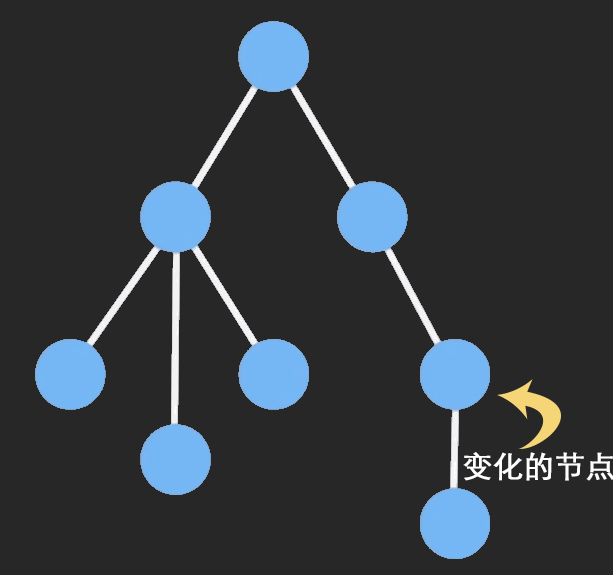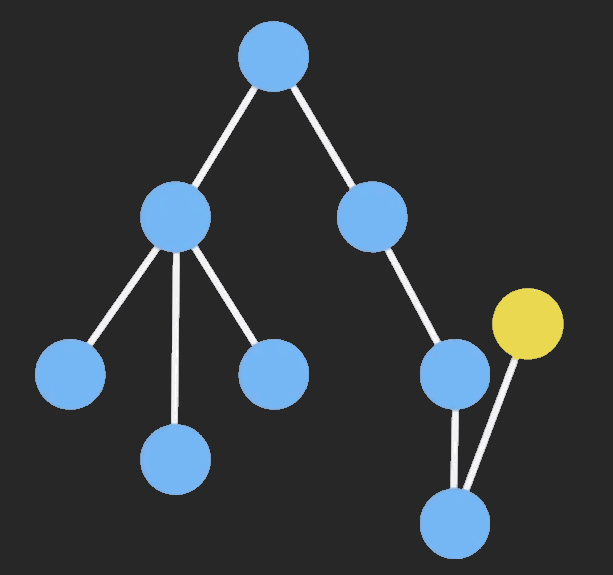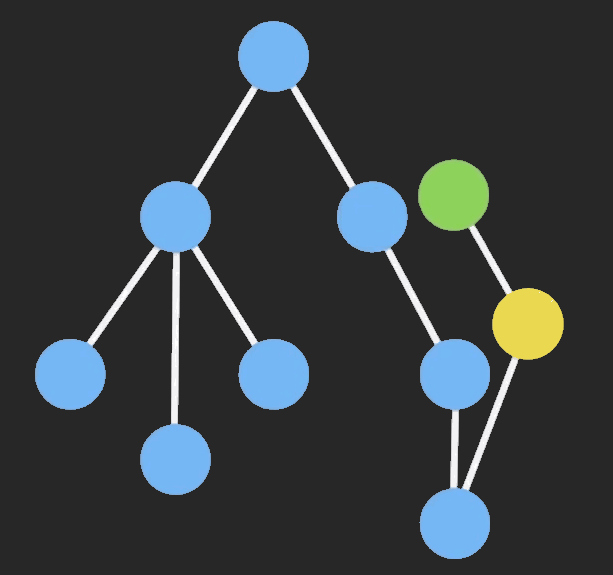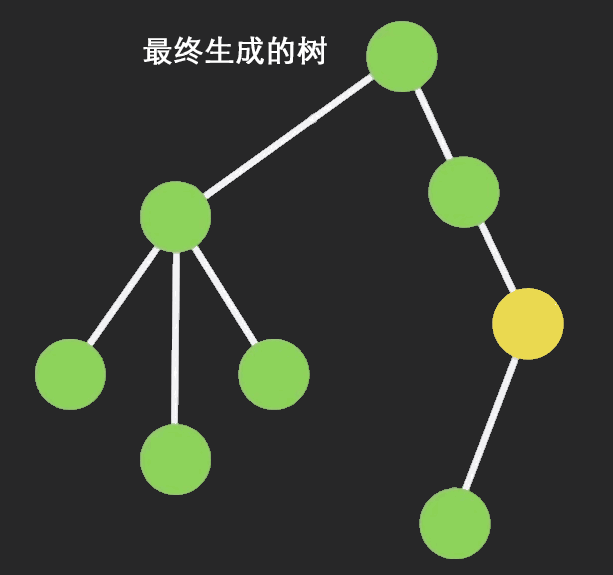
只要你使用了 immutable 的数据结构后,做 Redux 性能优化非常简单。由于 connect 默认开启了 pure render 模式,所以让需要数据的组件来 connect 数据性能最好,也就是** connect at lower level**。下图演示了在不同位置 connect 导致 render 的差异。

第一棵树中红色结点数据变化后
connect 所有数据,然后 props 形式把数据往下传,渲染结果如第二棵树,从顶层直到数据改变的组件都会渲染connect,其它地方就不需要关心这块数据,结果只有改变数据的组件被渲染,结果如第三棵树另外你还可以对 Component 添加 pure-render-decorator 来提升组件渲染性能。对于速度慢的函数使用 Memoization 来提升性能,常见的有 lodash.memoize
首先要清楚,不要用了复用性而牺牲了开发的便利性,而且复用在最初是比较高效的,但可能随意业务的扩展,本来相同的东西变得不同,这时候最初的复用反而给未来增加了成本。我不是不鼓励复用,只是不建议把它摆在太高的位置。
View 的复用比较简单,只要保证 view 的纯粹,在 connect 之前可以当作标准的 react 组件任意复用。如果想把 view, action, reduer 做为一个整体的业务模块来考虑复用,是比较难的。但这其实是最能提升效率的。如果你也遇到这样的场景,可以试下这个方法。

generateView 方法,接收页面名(page)和卡片名(card)来生成 view 和 actiongenerateReducer 方法,接收同样的页面名(page)和卡片名(card)来生成 reducer示例代码如下:
// generateFooView.js
export default function generateFooView({ pageName, cardName = 'overview' }) {
const NAMESPACE = `${pageName}/${cardName}/`;
const LOAD = NAMESPACE + 'LOAD';
function load(url, params) {
return {
type: LOAD,
};
}
@connect((state) => {
return {
[cardName]: state[pageName][cardName],
};
}, {
load,
})
class Overview extends Component {
render() {}
}
}// generateFooReducer.js
export default function generateFooReducer({ pageName, cardName = 'overview' }) {
const NAMESPACE = `${pageName}/${cardName}/`;
const LOAD = NAMESPACE + 'LOAD';
const initialState = {
isLoading: false,
data: [],
};
// 导出 reducer
return function OverviewReducer(state = initialState, action) {
switch (action.type) {
case LOAD:
return {
...state,
isLoading: true
};
default:
return state;
}
};
}以上四点业务层的经验是我一年多以来感受比较深的。还有目录组织、路由等一些细节问题,可参考的资料很多就不赘述了。
原发于知乎专栏:https://zhuanlan.zhihu.com/ne-fe
众所周知,JavaScript 浮点数运算时经常遇到会 0.000000001 和 0.999999999 这样奇怪的结果,如 0.1+0.2=0.30000000000000004、1-0.9=0.09999999999999998,很多人知道这是浮点数误差问题,但具体就说不清楚了。本文帮你理清这背后的原理以及解决方案,还会向你解释JS中的大数危机和四则运算中会遇到的坑。
首先要搞清楚 JavaScript 如何存储小数。和其它语言如 Java 和 Python 不同,JavaScript 中所有数字包括整数和小数都只有一种类型 — Number。它的实现遵循 IEEE 754 标准,使用 64 位固定长度来表示,也就是标准的 double 双精度浮点数(相关的还有float 32位单精度)。计算机组成原理中有过详细介绍,如果你不记得也没关系。
这样的存储结构优点是可以归一化处理整数和小数,节省存储空间。
64位比特又可分为三个部分:

实际数字就可以用以下公式来计算:

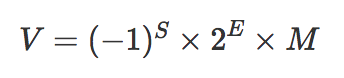
注意以上的公式遵循科学计数法的规范,在十进制是为0<M<10,到二进行就是0<M<2。也就是说整数部分只能是1,所以可以被舍去,只保留后面的小数部分。如 4.5 转换成二进制就是 100.1,科学计数法表示是 1.001*2^2,舍去1后 M = 001。E是一个无符号整数,因为长度是11位,取值范围是 0~2047。但是科学计数法中的指数是可以为负数的,所以再减去一个中间数 1023,[0,1022]表示为负,[1024,2047] 表示为正。如4.5 的指数E = 1025,尾数M为 001。
最终的公式变成:

所以 4.5 最终表示为(M=001、E=1025):

(图片由此生成 http://www.binaryconvert.com/convert_double.html)
下面再以 0.1 例解释浮点误差的原因, 0.1 转成二进制表示为 0.0001100110011001100(1100循环),1.100110011001100x2^-4,所以 E=-4+1023=1019;M 舍去首位的1,得到 100110011...。最终就是:

转化成十进制后为 0.100000000000000005551115123126,因此就出现了浮点误差。
0.1+0.2=0.30000000000000004?计算步骤为:
// 0.1 和 0.2 都转化成二进制后再进行运算
0.00011001100110011001100110011001100110011001100110011010 +
0.0011001100110011001100110011001100110011001100110011010 =
0.0100110011001100110011001100110011001100110011001100111
// 转成十进制正好是 0.30000000000000004x=0.1 能得到 0.1?恭喜你到了看山不是山的境界。因为 mantissa 固定长度是 52 位,再加上省略的一位,最多可以表示的数是 2^53=9007199254740992,对应科学计数尾数是 9.007199254740992,这也是 JS 最多能表示的精度。它的长度是 16,所以可以使用 toPrecision(16) 来做精度运算,超过的精度会自动做凑整处理。于是就有:
0.10000000000000000555.toPrecision(16)
// 返回 0.1000000000000000,去掉末尾的零后正好为 0.1
// 但你看到的 `0.1` 实际上并不是 `0.1`。不信你可用更高的精度试试:
0.1.toPrecision(21) = 0.100000000000000005551可能你已经隐约感觉到了,如果整数大于 9007199254740992 会出现什么情况呢?
由于 E 最大值是 1023,所以最大可以表示的整数是 2^1024 - 1,这就是能表示的最大整数。但你并不能这样计算这个数字,因为从 2^1024 开始就变成了 Infinity
> Math.pow(2, 1023)
8.98846567431158e+307
> Math.pow(2, 1024)
Infinity那么对于 (2^53, 2^63) 之间的数会出现什么情况呢?
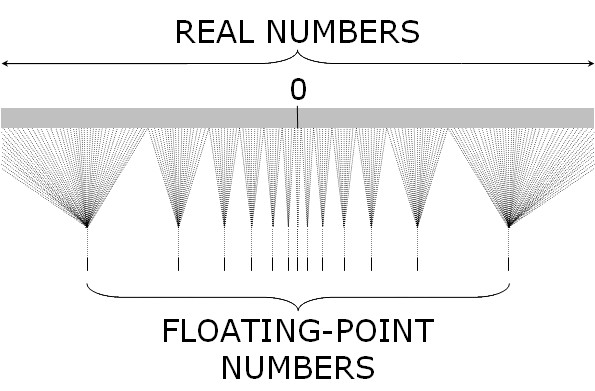
(2^53, 2^54) 之间的数会两个选一个,只能精确表示偶数(2^54, 2^55) 之间的数会四个选一个,只能精确表示4个倍数下面这张图能很好的表示 JavaScript 中浮点数和实数(Real Number)之间的对应关系。我们常用的 (-2^53, 2^53) 只是最中间非常小的一部分,越往两边越稀疏越不精确。
在淘宝早期的订单系统中把订单号当作数字处理,后来随意订单号暴增,已经超过了
9007199254740992,最终的解法是把订单号改成字符串处理。
要想解决大数的问题你可以引用第三方库 bignumber.js,原理是把所有数字当作字符串,重新实现了计算逻辑,缺点是性能比原生的差很多。所以原生支持大数就很有必要了,现在 TC39 已经有一个 Stage 3 的提案 proposal bigint,大数问题有望彻底解决。在浏览器正式支持前,可以使用 Babel 7.0 来实现,它的内部是自动转换成 big-integer 来计算,要注意的是这样能保持精度但运算效率会降低。
toPrecision vs toFixed数据处理时,这两个函数很容易混淆。它们的共同点是把数字转成字符串供展示使用。注意在计算的中间过程不要使用,只用于最终结果。
不同点就需要注意一下:
toPrecision 是处理精度,精度是从左至右第一个不为0的数开始数起。toFixed 是小数点后指定位数取整,从小数点开始数起。两者都能对多余数字做凑整处理,也有些人用 toFixed 来做四舍五入,但一定要知道它是有 Bug 的。
如:1.005.toFixed(2) 返回的是 1.00 而不是 1.01。
原因: 1.005 实际对应的数字是 1.00499999999999989,在四舍五入时全部被舍去!
解法:使用专业的四舍五入函数 Math.round() 来处理。但 Math.round(1.005 * 100) / 100 还是不行,因为 1.005 * 100 = 100.49999999999999。还需要把乘法和除法精度误差都解决后再使用 Math.round。可以使用后面介绍的 number-precision#round 方法来解决。
回到最关心的问题:如何解决浮点误差。首先,理论上用有限的空间来存储无限的小数是不可能保证精确的,但我们可以处理一下得到我们期望的结果。
当你拿到 1.4000000000000001 这样的数据要展示时,建议使用 toPrecision 凑整并 parseFloat 转成数字后再显示,如下:
parseFloat(1.4000000000000001.toPrecision(12)) === 1.4 // True
封装成方法就是:
function strip(num, precision = 12) {
return +parseFloat(num.toPrecision(precision));
}为什么选择 12 做为默认精度?这是一个经验的选择,一般选12就能解决掉大部分0001和0009问题,而且大部分情况下也够用了,如果你需要更精确可以调高。
对于运算类操作,如 +-*/,就不能使用 toPrecision 了。正确的做法是把小数转成整数后再运算。以加法为例:
/**
* 精确加法
*/
function add(num1, num2) {
const num1Digits = (num1.toString().split('.')[1] || '').length;
const num2Digits = (num2.toString().split('.')[1] || '').length;
const baseNum = Math.pow(10, Math.max(num1Digits, num2Digits));
return (num1 * baseNum + num2 * baseNum) / baseNum;
}以上方法能适用于大部分场景。遇到科学计数法如 2.3e+1(当数字精度大于21时,数字会强制转为科学计数法形式显示)时还需要特别处理一下。
能读到这里,说明你非常有耐心,那我就放个福利吧。遇到浮点数误差问题时可以直接使用
https://github.com/dt-fe/number-precision
完美支持浮点数的加减乘除、四舍五入等运算。非常小只有1K,远小于绝大多数同类库(如Math.js、BigDecimal.js),100%测试全覆盖,代码可读性强,不妨在你的应用里用起来!
当然写这篇文章是为了招聘!!!
阿里巴巴大数据前端部门诚招前端攻城狮。不要犹豫,万一通过了呢。
简历发过来[email protected]
重磅消息,Redux 1.0 发布,终于可以放心用于生产环境了!
在这个端应用技术膨胀的时代,每天都有一大堆框架冒出,号称解决了 XYZ 等一系列牛 X 的问题,然后过一段时间就不被提起了。但开发的应用还是需要维护的!所以选择框架时不要只顾着自己用着爽,还要想着以后别人接手时的难易度。
因为 Flux 本身约定不够细致,如何做异步、如何做同构这些非常普遍的问题,官方都没有给出详细的说明。还有 store,view 里一大堆重复代码,极速膨胀的 action 等问题。这也难免会冒出一堆“改良”性的轮子。有一些非常闪光,如 Redux,Reflux,Marty。Reflux 和 Marty 基本上只是去掉重复代码并为现有 Store,Action 增加一些灵活性,用起来比原生 Flux 上手更容易,但是总体二者没有跳出 Flux 的**,大量依旧采用“传统”的 mixin 方式实现。如果项目不是很复杂可以试试。至于 Relay,由于需要后端 GraphQL 支持,对于采用 REST 接口开发的遗留项目和前后端分离的大团队来说成本切换有点高。
现在开始说今天的主角 Redux。Redux 由 Flux 演变而来,后来受 Elm 启发,去掉了 Flux 的复杂性,到现在越来越自成一派,甚至已经有了 Angular 的实现。最近开始把团队旧的纯 Flux 开发项目逐步往 Redux 上迁移。Redux 还是秉承了 Flux 单向数据流、Store is the single source of truth 的**,这两点略过。下面谈一下使用 Redux 过程中的其它感受。
Redux 文档非常清晰细致,这一点有助于统一团队编码风格,节省了很多纠结和踩坑的时间。再也不纠结 Ajax 请求到底放哪里了,全部丢到 action(通用的也可以放到 middleware) 里就没错。究竟使用 state 还是 props?组件里全部使用 props,只在顶层组件里使用 state。之前为了灵活或兼容性,Redux 的 provider 提供 Provider decorator 装饰器 和 provider 两种调用用法,现在只建议使用 Provider decorator。Redux 这点设计**和 Python 的非常像:
There should be one, and preferably only one - obvious way to do it.
你会发现用了 Redux 后,整个团队写的代码风格都比较一致,上一次有这种感受是项目由旧的 jQuery 组件迁到 React 的时候。如果有些场景你还是纠结怎么办?去 Redux issues 提个 issue 吧,很快就会有人回复。
前端复杂性在于 view,view 复杂性在于 state 处理。state 复杂是因为包括了 AJAX 返回的数据、当前显示的是哪个 tab 等这些 UI state、表单状态、甚至还有当前的 url 等。Redux 把这些所有的 state 汇总成一个大的对象,起了个名字叫 Store,没错,就是 Flux 里的 Store。只是 Redux 限定一个应用只能有一个 Store。单一 Store 带来的好处是,所有数据结果集中化,操作时的便利,只要把它传给最外层组件,那么内层组件就不需要维持 state,全部经父级由 props 往下传即可。子组件变得异常简单。
只有一个 Store,第一感觉是这个 Store 对象会不会非常大?其实对象大并不可怕,可怕的是对象处理逻辑放到一起。只要把这些处理逻辑按处理内容拆分不就可以了吗?!拆分后的每块处理逻辑就是一个 Reducer。把这些 Reducer 里的每块内容合到一起(用 ES6 的 import 语法)就组成了完整的 Store。Reducer 只是一个纯函数,所以很容易测试。提到 Reducer 不得不提函数式编程,reducer 本质就是做对象格式转换,这点用函数式操作实在太高效了。
(previousState, action) => newState
因为是纯函数,组合多个 reducer 非常简单,参见 https://gist.github.com/gaearon/d77ca812015c0356654f。顺便也移除了 Flux 里最让人诟病的 waitFor 语法。
Redux 的 action 与 Flux 中的类似,都是表达 view 要改变 store 内容的载体。Flux 是通过统一的 Dispatcher 分发 action,Redux 去除了这个 Dispatcher,使用 store 的 store.dispatch() 方法来把 action 传给 store。由于所有的 action 处理都会经过这个 store.dispatch() 方法,Redux 聪明地利用这一点,实现了与 Koa,Ruby Rack 类似的 Middleware 机制。Middleware 可以让你在 dispatch action 后,到达 store 前这一段拦截并插入代码,可以任意操作 action 和 store。很容易实现灵活的日志打印、错误收集、API 请求、路由等操作。我们团队根据预建立的 action 和请求间的映射直接在这里直接发 Ajax 请求,从此麻麻再也不用担心我异步取数据了。
除了这些之外,还有逆天的 DevTools,可以让应用像录像机一样反复录制和重放。
对于同构应用 Redux 也有很好的支持,这一块团队正在调研,等实际上线后再做分享。
当然使用过程中也有一些不顺利的地方,其实主要还是**方面的转变。
这也被称为 Smart Component 和 Dumb Component 之间的选择,组件库开发应尽可能做成 Dumb Component。这一点和传统的 jQuery 类普遍使用命令式语法做组件开发有很大不同。如写一个 Dialog,jQuery 组件一般会提供 dialog.show(), dialog.hide() 方法。但 Redux 要求显示或隐藏应该被当作一个 props,由外部传入来控制。Redux 比 Flux 更严格要求 Store 作为数据来源的惟一性,所以之前能用的组件现在发现直接不能用了。
请求的发起要在 action 里做,但是请求的暂停/启动状态要放到 store 里,会增加一些复杂性,但保证了数据的一致性。其实还是未明确 store 是单一数据源的**。
官方地址:https://github.com/rackt/redux
中文文档:http://github.com/camsong/redux-in-chinese
项目列表:https://github.com/xgrommx/awesome-redux
同构示例:http://react-redux.herokuapp.com/
对了,听说中文文档翻译的还不错,连 Redux 作者 Dan Abramov 都推了,要不你也看看。

前端发展很快,现代浏览器原生 API 已经足够好用。我们并不需要为了操作 DOM、Event 等再学习一下 jQuery 的 API。同时由于 React、Angular、Vue 等框架的流行,直接操作 DOM 不再是好的模式,jQuery 使用场景大大减少。因此我们项目组在双十一后抽了一周时间,把所有代码中的 jQuery 移除。下面总结一下:
jQuery 代表着传统的以 DOM 为中心的开发模式,但现在复杂页面开发流行的是以 React 为代表的以数据/状态为中心的开发模式
应用复杂后,直接操作 DOM 意味着手动维护状态,当状态复杂后,变得不可控。React 以状态为中心,自动帮我们渲染出 DOM,同时通过高效的 DOM Diff 算法,也能保证性能。我们在 React 应用实践中也发现,大部分当你想直接操作 DOM 的时候,就意味着你可能做错了。
重构就是前后端运行同一份代码,后端也可以渲染出页面,这对 SEO 要求高的场景非常合适。由于 React 等流行框架天然支持,已经具有可行性。当我们在尝试把现有应用改成同构时,因为代码要运行在服务器端,但服务器端没有 DOM,所以引用 jQuery 就会报错。这也是要移除 jQuery 的迫切原因。同时不但要移除 jQuery,在很多场合也要避免直接操作 DOM。
由于浏览器的历史原因,曾经的前端开发为了兼容不同浏览器怪癖,需要增加很多成本。jQuery 由于提供了非常易用的 API,屏蔽了浏览器差异,极大地提高了开发效率。这也导致很多前端只懂 jQuery。其实这几年浏览器更新很快,也借鉴了很多 jQuery 的 API,如 querySelector,querySelectorAll 和 jQuery 选择器同样好用,而且性能更优。
前端开发一般不需要考虑性能问题,但你想在性能上追求极致的话,一定要知道 jQuery 性能很差。原生 API 选择器相比 jQuery 丰富很多,如 document.getElementsByClassName 性能是 $(classSelector) 的 50 多倍!
测试链接:http://jsperf.com/jquery-vs-native-api/3
差的浏览器(IE)已经淘汰的差不多了。
If We Didn't Spend So Much on IE Support, We Could Be Taking Vacations on Mars
Christian Alfoni
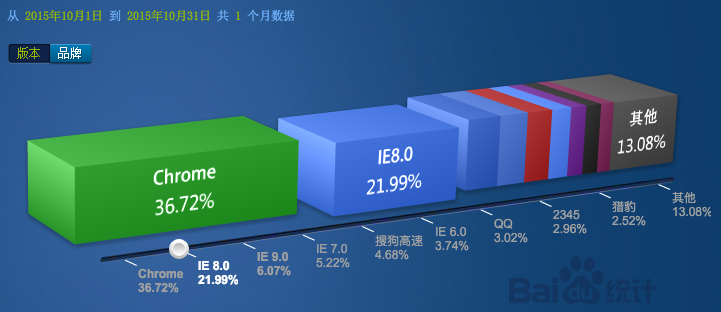
我们的主打产品现在有千万用户,因为我们一直引导用户升级浏览器,上个月统计 IE 9 以下用户只占不到 3%。但为了这 3% 的用户我们前端开发却增加了很多工作量,也限制了我们升级我们的架构,因此放弃支持他们利大于弊。当然这要根据产品来定,比如这是百度统计的国内浏览器占有率,IE8 竟然还有 22%。有些产品可以为了保证用户体验,在旧的浏览器上投入很大成本,甚至做到了极致。其实我觉得产品更应该做的是引导用户升级浏览器。微软也宣布 2016年1月12号停止支持 IE 11 以下浏览器,继续使用旧浏览器就会有安全风险,我们更应该主动引导,只要产品有足够吸引力,大部分用户升级并不困难。
数据来源 百度统计
下面是国际上 IE 占有率,IE8 已经跌出前 10,IE 11 比较多,还好支持他们并不难。
数据来源 W3 Counter
移除 jQuery 可以很顺利,我们把整个过程详细整理了,并开源。
打开 https://github.com/oneuijs/You-Dont-Need-jQuery 对 API 查找替换即可。
同时我们简单封装了一些方法:
刚去了 jQuery 又引了新的库,这不是玩我吗??其实以上两个库很简单,只是常用方法的简单封装,建议你看一下代码。你当然可以不用。
以上的库都用于我们的生产环境,我们会长期维护,保证更新。
代码替换后,当用户用旧浏览器打开时,你还要做一个跳转,把用户定位到提示页面,提示用户下载升级浏览器。IE9 以下浏览器都支持条件判断语句,可以在 </head> 标签结束前添加如下代码做自动跳转
<!--[if lte IE 9]>
<script>if (!/update\.htm/.test(location.href)) window.location = '//abc.com/update.htm'; </script>
<![endif]-->本文并不是强迫你一定要移除 jQuery,jQuery 为支持旧浏览器节省了很多成本。但条件成熟的情况下,移除 jQuery,参照 You Don't Need jQuery 拥抱原生 JavaScript 能同样保证开发效率,也可以给产品带来更好的性能,同时也能提高开发者水平。

原谅我做一次标题党,Ajax 不会死,传统 Ajax 指的是 XMLHttpRequest(XHR),未来现在已被 Fetch 替代。
最近把阿里一个千万级 PV 的数据产品全部由 jQuery 的 $.ajax 迁移到 Fetch,上线一个多月以来运行非常稳定。结果证明,对于 IE8+ 以上浏览器,在生产环境使用 Fetch 是可行的。
由于 Fetch API 是基于 Promise 设计,有必要先学习一下 Promise,推荐阅读 MDN Promise 教程。旧浏览器不支持 Promise,需要使用 polyfill es6-promise 。
本文不是 Fetch API 科普贴,其实是讲异步处理和 Promise 的。Fetch API 很简单,看文档很快就学会了。推荐 MDN Fetch 教程 和 万能的WHATWG Fetch 规范
XMLHttpRequest 是一个设计粗糙的 API,不符合关注分离(Separation of Concerns)的原则,配置和调用方式非常混乱,而且基于事件的异步模型写起来也没有现代的 Promise,generator/yield,async/await 友好。
Fetch 的出现就是为了解决 XHR 的问题,拿例子说明:
使用 XHR 发送一个 json 请求一般是这样:
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.responseType = 'json';
xhr.onload = function() {
console.log(xhr.response);
};
xhr.onerror = function() {
console.log("Oops, error");
};
xhr.send();使用 Fetch 后,顿时看起来好一点
fetch(url).then(function(response) {
return response.json();
}).then(function(data) {
console.log(data);
}).catch(function(e) {
console.log("Oops, error");
});使用 ES6 的 箭头函数 后:
fetch(url).then(response => response.json())
.then(data => console.log(data))
.catch(e => console.log("Oops, error", e))现在看起来好很多了,但这种 Promise 的写法还是有 Callback 的影子,而且 promise 使用 catch 方法来进行错误处理的方式有点奇怪。不用急,下面使用 async/await 来做最终优化:
注:async/await 是非常新的 API,属于 ES7,目前尚在 Stage 1(提议) 阶段,这是它的完整规范。使用 Babel 开启 runtime 模式后可以把 async/await 无痛编译成 ES5 代码。也可以直接使用 regenerator 来编译到 ES5。
try {
let response = await fetch(url);
let data = await response.json();
console.log(data);
} catch(e) {
console.log("Oops, error", e);
}
// 注:这段代码如果想运行,外面需要包一个 async functionduang~~ 的一声,使用 await 后,写异步代码就像写同步代码一样爽。await 后面可以跟 Promise 对象,表示等待 Promise resolve() 才会继续向下执行,如果 Promise 被 reject() 或抛出异常则会被外面的 try...catch 捕获。
Promise,generator/yield,await/async 都是现在和未来 JS 解决异步的标准做法,可以完美搭配使用。这也是使用标准 Promise 一大好处。最近也把项目中使用第三方 Promise 库的代码全部转成标准 Promise,为以后全面使用 async/await 做准备。
另外,Fetch 也很适合做现在流行的同构应用,有人基于 Fetch 的语法,在 Node 端基于 http 库实现了 node-fetch,又有人封装了用于同构应用的 isomorphic-fetch。
注:同构(isomorphic/universal)就是使前后端运行同一套代码的意思,后端一般是指 NodeJS 环境。
总结一下,Fetch 优点主要有:
下面是重点↓↓↓
先看一下 Fetch 原生支持率:

原生支持率并不高,幸运的是,引入下面这些 polyfill 后可以完美支持 IE8+ :
Fetch polyfill 的基本原理是探测是否存在 window.fetch 方法,如果没有则用 XHR 实现。这也是 github/fetch 的做法,但是有些浏览器(Chrome 45)原生支持 Fetch,但响应中有中文时会乱码,老外又不太关心这种问题,所以我自己才封装了 fetch-detector 和 fetch-ie8 只在浏览器稳定支持 Fetch 情况下才使用原生 Fetch。这些库现在 每天有几千万个请求都在使用,绝对靠谱 !
终于,引用了这一堆 polyfill 后,可以愉快地使用 Fetch 了。但要小心,下面有坑:
fetch(url, {credentials: 'include'})竟然没有提到 IE,这实在太不科学了,现在来详细说下 IE
所有版本的 IE 均不支持原生 Fetch,fetch-ie8 会自动使用 XHR 做 polyfill。但在跨域时有个问题需要处理。
IE8, 9 的 XHR 不支持 CORS 跨域,虽然提供 XDomainRequest,但这个东西就是玩具,不支持传 Cookie!如果接口需要权限验证,还是乖乖地使用 jsonp 吧,推荐使用 fetch-jsonp。如果有问题直接提 issue,我会第一时间解决。
由于 Fetch 是典型的异步场景,所以大部分遇到的问题不是 Fetch 的,其实是 Promise 的。ES6 的 Promise 是基于 Promises/A+ 标准,为了保持 简单简洁 ,只提供极简的几个 API。如果你用过一些牛 X 的异步库,如 jQuery(不要笑) 、Q.js 或者 RSVP.js,可能会感觉 Promise 功能太少了。
Deferred 可以在创建 Promise 时可以减少一层嵌套,还有就是跨方法使用时很方便。
ECMAScript 11 年就有过 Deferred 提案,但后来没被接受。其实用 Promise 不到十行代码就能实现 Deferred:es6-deferred。现在有了 async/await,generator/yield 后,deferred 就没有使用价值了。
标准 Promise 没有提供获取当前状态 rejected 或者 resolved 的方法。只允许外部传入成功或失败后的回调。我认为这其实是优点,这是一种声明式的接口,更简单。
always 可以通过在 then 和 catch 里重复调用方法实现。finally 也类似。progress 这种进度通知的功能还没有用过,暂不知道如何替代。
Fetch 和 Promise 一样,一旦发起,不能中断,也不会超时,只能等待被 resolve 或 reject。幸运的是,whatwg 目前正在尝试解决这个问题 whatwg/fetch#27
Fetch 替换 XHR 只是时间问题,现在看到国外很多新的库都默认使用了 Fetch。
最后再做一个大胆预测:由于 async/await 这类新异步语法的出现,第三方的 Promise 类库会逐渐被标准 Promise 替代,使用 polyfill 是现在比较明智的做法。
如果你觉得本文对你有帮助,请点击右上方的 Star 鼓励一下,或者点击 Watch 订阅
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.