darknet 优化版本:https://github.com/chineseocr/darknet-ocr.git
ocr ctc训练数据集(压缩包解码:chineseocr)
百度网盘地址:链接: https://pan.baidu.com/s/1UcUKUUELLwdM29zfbztzdw 提取码: atwn
gofile地址:http://gofile.me/4Nlqh/uT32hAjbx 密码 https://github.com/chineseocr/chineseocr
- 文字方向检测 0、90、180、270度检测(支持dnn/tensorflow)
- 支持(darknet/opencv dnn /keras)文字检测,支持darknet/keras训练
- 不定长OCR训练(英文、中英文) crnn\dense ocr 识别及训练 ,新增pytorch转keras模型代码(tools/pytorch_to_keras.py)
- 支持darknet 转keras, keras转darknet, pytorch 转keras模型
- 身份证/火车票结构化数据识别
- 新增CNN+ctc模型,支持DNN模块调用OCR,单行图像平均时间为0.02秒以下
- CPU版本加速
- 支持基于用户字典OCR识别
- 新增语言模型修正OCR识别结果
- 支持树莓派实时识别方案
GPU部署 参考:setup.md
CPU部署 参考:setup-cpu.md
git clone https://github.com/pjreddie/darknet.git
mv darknet chineseocr/
##编译对GPU、cudnn的支持 修改 Makefile
#GPU=1
#CUDNN=1
#OPENCV=0
#OPENMP=0
make
修改 darknet/python/darknet.py line 48
root = '/root/'##chineseocr所在目录
lib = CDLL(root+"chineseocr/darknet/libdarknet.so", RTLD_GLOBAL)
模型文件地址:
- 百度网盘:https://pan.baidu.com/s/1gTW9gwJR6hlwTuyB6nCkzQ
other-links:http://gofile.me/4Nlqh/fNHlWzVWo
复制文件夹中的所有文件到models目录
pytorch ocr 转keras ocr
python tools/pytorch_to_keras.py -weights_path models/ocr-dense.pth -output_path models/ocr-dense-keras.h5darknet 转keras
python tools/darknet_to_keras.py -cfg_path models/text.cfg -weights_path models/text.weights -output_path models/text.h5keras 转darknet
python tools/keras_to_darknet.py -cfg_path models/text.cfg -weights_path models/text.h5 -output_path models/text.weights参考config.py文件##下载Anaconda3 python 环境安装包(https://repo.anaconda.com/archive/Anaconda3-2019.03-Linux-x86_64.sh) 放置在chineseocr目录下
##建立镜像
docker build -t chineseocr .
##启动服务
docker run -d -p 8080:8080 chineseocr /root/anaconda3/bin/python app.py
cd chineseocr## 进入chineseocr目录
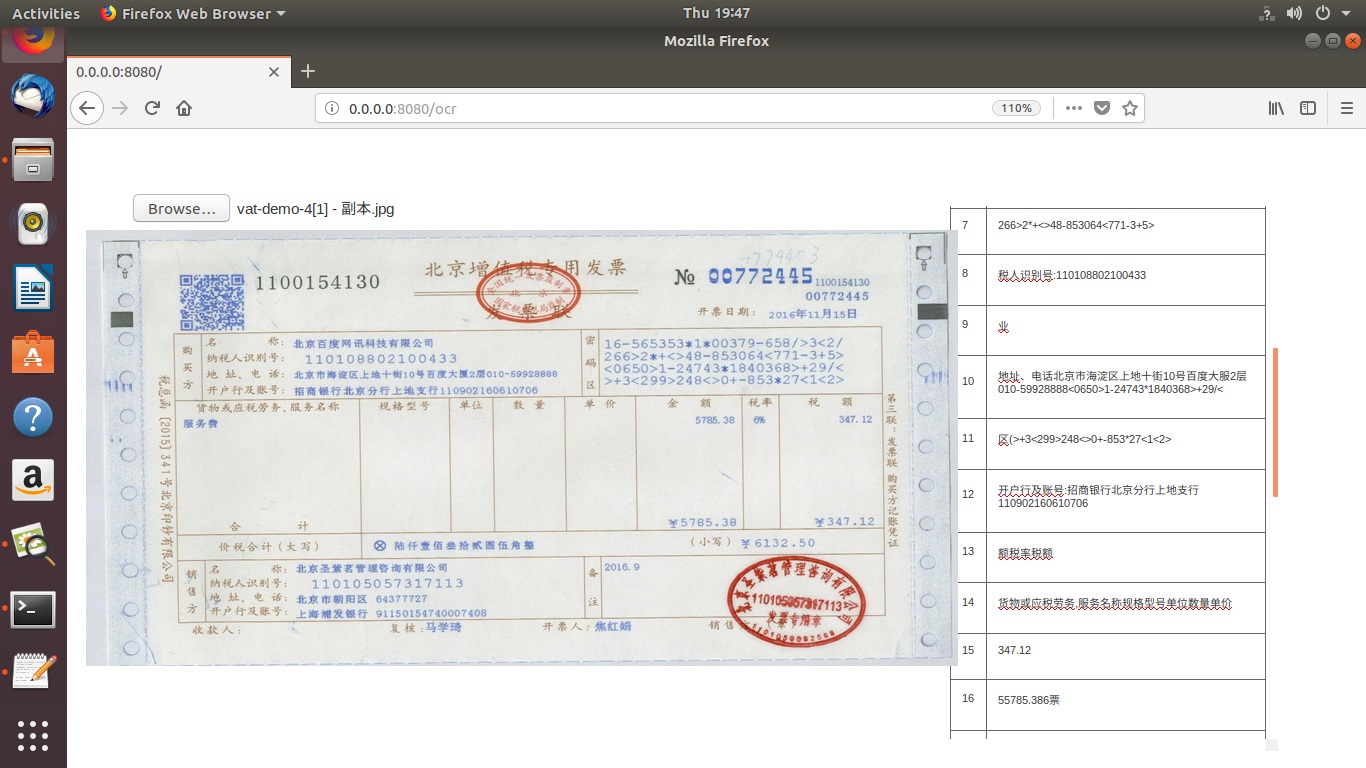
python app.py 8080 ##8080端口号,可以设置任意端口




- yolo3 https://github.com/pjreddie/darknet.git
- crnn https://github.com/meijieru/crnn.pytorch.git
- ctpn https://github.com/eragonruan/text-detection-ctpn
- CTPN https://github.com/tianzhi0549/CTPN
- keras yolo3 https://github.com/qqwweee/keras-yolo3.git
- darknet keras 模型转换参考 参考:https://www.cnblogs.com/shouhuxianjian/p/10567201.html
- 语言模型实现 https://github.com/lukhy/masr