备注:博文一般不更新,只更新
demo目录下的各种实验。
- 博客园 程序猿小卡
- 知乎 程序猿小卡
- 掘金 程序猿小卡
- 微博 @程序猿小卡_casper
- 站酷 chyingp
程序猿小卡的博客
Home Page: https://www.chyingp.com












































































































































































IMWebConf 2017演讲主题如下:
slide传送门请点击这里下载

为了提高页面的性能,通常情况下,我们希望资源尽可能地早地并行加载。这里有两个要点,首先是尽早,其次是并行。
通过data-main方式加载要尽可能地避免,因为它让requirejs、业务代码不必要地串行起来。下面就讲下如何尽可能地利用浏览器并行加载的能力来提高性能。
最简单的优化,下面的例子中,通过两个并排的script标签加载require.js、main.js,这就达到了require.js、main.js并行加载的目的。
但这会有个问题,假设main.js依赖了jquery.js、anonymous.js(如下代码所示),那么,只有等main.js加载完成,其依赖模块才会开始加载。这显然不够理想,后面我们会讲到如何避免这种情况,下面是简单的源码以及效果示意图。
demo.html
<!DOCTYPE html>
<html>
<head></head>
<body>
<h1>main.js、anynomous.js串行加载</h1>
<script type="text/javascript" src="js/require.js"></script>
<script type="text/javascript" src="js/main.js"></script>
</body>
</html>
js/main.js:
require(['js/anonymous'], function(Anonymous) {
alert('加载成功');
});
js/anonymous.js:
define(['js/jquery'], function() {
console.log('匿名模块,require直接报错了。。。');
return{
say: function(msg){
console.log(msg);
}
}
});
最终效果:

正常情况下,假设页面里有如下几个<script>标签,现代浏览器就会并发请求文件,并顺序执行。但在requirejs里,如果这样做的话,可能会遇到一些意料之外的情况。如下所示,四个并排的标签,依次请求了require.js、jquery.js、anonymous.js、main.js。
demo.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>demo</title>
</head>
<body>
<h1>requirejs并行加载例子</h1>
<script type="text/javascript" src="js/require.js"></script>
<script type="text/javascript" src="js/jquery.js"></script>
<script type="text/javascript" src="js/anonymous.js"></script>
<script type="text/javascript" src="js/main.js"></script>
</body>
</html>预期中,资源会并行加载,但实际上,你会在控制台里看到下面的错误日志。

为什么呢?对于requirejs来说,上面的js/anonymous.js是一个匿名的模块,requirejs对它一无所知。当你在main中告诉requirejs说我要用到js/anonymous这个模块时,它就傻眼了。所以,这里就直接给你报个错误提个醒:不要这样写,我不买账。
那么,及早并行加载的路是否走不通了呢?未必,请继续往下看。
简单改下上面的例子,比如这样,然后。。它就行了。。
<script type="text/javascript" src="js/require.js"></script>
<script type="text/javascript" src="js/jquery.js"></script>
<script type="text/javascript" src="js/main.js"></script>原因很简单。因为jquery把自己注册成了命名模块。requirejs于是就认得jquery了。
if ( typeof define === "function" && define.amd && define.amd.jQuery ) {
define( "jquery", [], function () { return jQuery; } );
}上面我们看到,给模块起个名字,将匿名模块改成命名模块(named module),就开启了我们的并行加载之旅。从这点看来,起名字真的很重要。
那么我们对之前的例子进行简单的改造。这里用了个小技巧,利用命名模块js/name-module.js来加载之前的匿名模块js/anonymous.js。可以看到,requirejs不报错了,requirejs跟name-module.js也并行加载了。
demo.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>demo</title>
</head>
<body>
<h1>并行加载requirejs、jquery</h1>
<script type="text/javascript" src="js/require.js"></script>
<script type="text/javascript" src="js/jquery.js"></script>
<script type="text/javascript" src="js/name-module.js"></script>
<script type="text/javascript" src="js/main.js"></script>
</body>
</html>js/name-module.js
define('name-module', 'js/anonymous', [], function() {
return {
say: function(msg){
alert(msg);
}
};
});
最终效果图:

如果你能耐着性子看到这一节,说明少年你已经发现了上一节很明显的一个问题:尽管name-module.js并行加载了,但anonymou.js其实还是串行加载,那做这个优化还有什么意义?

没错,如果最终优化效果这样的话,那是完全无法接受的。不卖关子,这个时候就要请出我们的requirejs打包神器r.js。通过打包优化,将anonymous.js、name-module.js打包生成一个文件,就解决了串行的问题。
1、安装打包工具
npm install -g requirejs
2、创建打包配置文件,注意,由于jquery.js比较通用,一般情况下会单独加载,所以从打包的列表里排除
{
"appDir": "./", // 应用根路径
"baseUrl": "./", //
"dir": "dist", // 打包的文件生成到哪个目录
"optimize": "none", // 是否压缩
"modules": [
{
"name": "js/name-module",
"exclude": [
"jquery" // 将jqury从打包规则里排除
]
}
]
}3、运行如下命令打包
r.js -o ./build.js
4、打包后的name-module,可以看到,匿名模块也被打包进去,同时被转换成了命名模块
define('js/anonymous',['jquery'], function() {
console.log('匿名模块,require直接报错了。。。');
return{
say: function(msg){
console.log('anonymous: '+msg);
}
}
});
define('js/name-module', ['js/anonymous'], function() {
return {
say: function(msg){
alert('name module: '+msg);
}
};
});
5、再次访问demo.html,很好,就是我们想要的结果
上面主要提供了及早并行加载的思路,但在实际利用requirejs打包的过程中,还会遇到一些需要小心处理的细节问题,当然也有一些坑。后面有时间再总结一下。
下载难 /(版本)管理难
YUI Compressor:https://github.com/yui/yuicompressor
Google Closure:https://code.google.com/p/closure-compiler/downloads/list
jshint:http://www.jshint.com/
其他:。。。
环境依赖、平台依赖
YUI Compressor:JDK
fiddler/qzmin:win平台
sass/compass:ruby
配置使用难:
系统参数设置
工具自己的命令、参数
grunt
曾经grunt是: 命令行工具+构建工具+脚手架工具+预定义任务
The Grunt command line interface.
Note: The job of the grunt command is to load and run the version of Grunt you have installed locally to your project, irrespective of its version.
The JavaScript Task Runner
Grunt-init is a scaffolding tool used to automate project creation.
步骤一:安装package
npm install
步骤二:运行任务
文件合并
grunt dist
js文件校验
grunt jshint
Gruntfile.js:必要
Grunt任务的主入口文件,主要作用在于任务的定义与配置
package.json
项目组件依赖的描述文件,非必要
方式一:grunt.initConfig
grunt.initConfig({
clean: {
dev: [ 'dev/' ],
},
jshint: {
all: ['dist/js/**/*.js']
}
});
方式二:grunt.config 接口
grunt.config.set('jshint', {
all: ['dist/js/**/*.js']
});
grunt.task.run('jshint');
根据任务类型:
根据任务位置:
任务定义
grunt.task.registerTask('hello', '一个无聊的demo', function() {
console.log( '大家好,我是grunt任务!');
});
运行任务
grunt hello
任务内部
grunt.registerMultiTask('inline', "同样是很无聊的demo", function() {
var files = this.filesSrc; // 用户
files.forEach(function(filepath){
console.log( '输出文件路径:'+ filepath );
};
});
任务配置
grunt.initConfig({
'inline': {
test: {
src: [$config.distPath+'**/*.html']
}
}
});
运行任务
grunt inline
最常见,Gruntfile.js里定义,可满足绝大部分项目的需求
grunt.task.registerTask('hello', '一个无聊的demo', function() {
console.log( '大家好,我是grunt任务!');
});
定义方式跟内部任务基本没区别,在Grungfile.js之外定义,用到的时候显式加载即可
加载插件:
grunt.loadNpmTasks('grunt-cdn');
加载自定义任务
grunt.task.loadTasks('proj-task/core');
grunt-inline作用:将html页面里的声明了__inline标记的<script>、<link>、<img>等变成内联资源,即:
例子:下面这段script标签,声明了__inline,构建阶段会被行内脚本替换
构建前
<script type="text/javascript" src="modules/common/js/nohost.js?__inline"></script>
构建后
<script>
void function(){setTimeout(function(){var b=document.cookie.match(/(^| )nohost_guid=([^;]*)(;|$)/);if(!b?0:decodeURIComponent(b[2])){var b="/nohost_htdocs/js/SwitchHost.js?random="+Math.random(),c=function(a){try{eval(a)}catch(b){}window.SwitchHost&&window.SwitchHost.init&&window.SwitchHost.init()},a=window.ActiveXObject?new ActiveXObject("Microsoft.XMLHTTP"):new XMLHttpRequest;a.open("GET",b);a.onreadystatechange=function(){4==a.readyState&&((200<=a.status&&300>a.status||304===a.status||1223===a.status||
0===a.status)&&c(a.responseText),a=null)};a.send(null)}},1500)}();
</script>
首先我们看下官方教程里参考教程:http://gruntjs.com/creating-plugins
下载脚手架工具grunt-init
npm install -g grunt-init
安装grunt插件模板
git clone git://github.com/gruntjs/grunt-init-gruntplugin.git ~/.grunt-init/gruntplugin
在任意空目录下运行grunt-init gruntplugin
运行npm install初始化开发环境
声明所有权:其实就是修改package.json里的name、version等字段
通过npm publish发布插件
。。。(待填坑)
Only pass through changed files
This keeps an in-memory cache of files (and their contents) that have passed through it. If a file has already passed through on the last run it will not be passed downstream. This means you only process what you need and save time + resources.
从App组件可以把数据直接传递到Title组件,假如我想从Title组件传递数据到App组件的话,该怎么做呢?
万望解答,谢谢
这里假设本文读者对FIS已经比较熟悉,如还不了解,可猛击官方文档。
虽然FIS整体的源码结构比较清晰,不过讲解起来也是个系统庞大的工程,笔者尽量的挑重点的讲。如果读者有感兴趣的部分笔者没有提到的,或者是存在疑惑的,可以在评论里跑出来,笔者会试着去覆盖这些点。
下笔匆忙,如有错漏请指出。
如在开始剖析FIS的源码前,有三点内容首先强调下,这也是解构FIS内部设计的基础。
1、 FIS支持三个命令,分别是fis release、fis server、fis install。当用户输入fis xx的时候,内部调用fis-command-release、fis-command-server、fis-command-install这三个插件来完成任务。同时,FIS的命令行基于commander这个插件构建,熟悉这个插件的同学很容易看懂FIS命令行相关部分源码。
2、FIS以fis-kernel为核心。fis-kernel提供了FIS的底层能力,包含了一系列模块,如配置、缓存、文件处理、日志等。FIS的三个命令,最终调用了这些模块来完成构建的任务。参考 fis-kernel/lib/ 目录,下面对每个模块的大致作用做了简单备注,后面的文章再详细展开。
lib/
├── cache.js // 缓存模块,提高编译速度
├── compile.js // (单)文件编译模块
├── config.js // 配置模块,fis.config
├── file.js // 文件处理
├── log.js // 日志
├── project.js // 项目相关模块,比如获取、设置项目构建根路径、设置、获取临时路径等
├── release.js // fis release 的时候调用,依赖 compile.js 完成单文件编译。同时还完成如文件打包等任务。├── uri.js // uri相关
└── util.js // 各种工具函数3、FIS的编译过程,最终可以拆解为细粒度的单文件编译,理解了下面这张图,对于阅读FIS的源码有非常大的帮助。(主要是fis release这个命令)
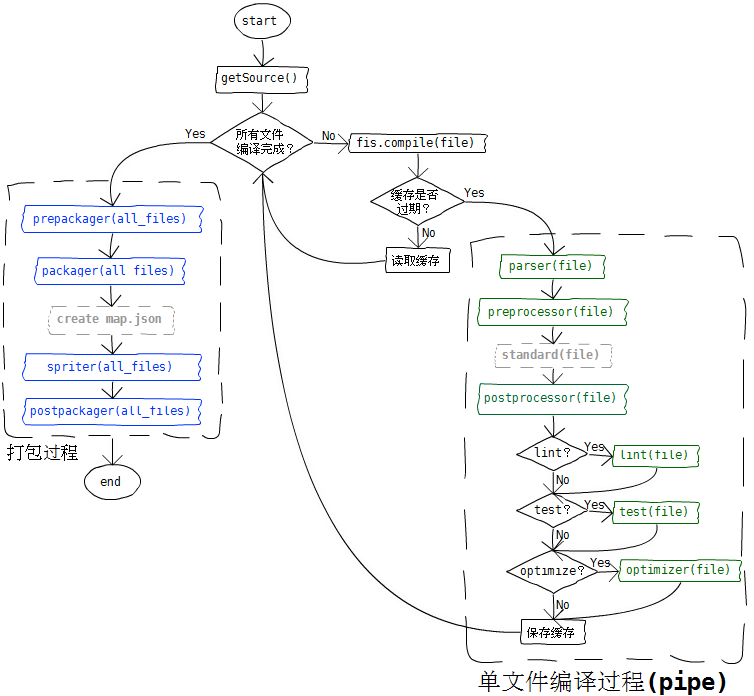
开篇的描述可能比较抽象,下面我们来个实际的例子。通过这个简单的例子,我们可以对FIS的整体设计有个大致的印象。
下文以fis server open为例,逐步剖析FIS的整体设计。其实FIS比较精华的部分集中在fis release这个命令,不过fis server这个命令相对简单,更有助于我们从纷繁的细节中跳出来,窥探FIS的整体概貌。
假设我们已经安装了FIS。好,打开控制台,输入下面命令,其实就是打开FIS的server目录
fis server open
从package.json可以知道,此时调用了 fis/bin/fis,里面只有一行有效代码,调用fis.cli.run()方法,同时将进程参数传进去。
#!/usr/bin/env node
require('../fis.js').cli.run(process.argv);
接下来看下../fis.js。代码结构非常清晰。注意,笔者将一些代码给去掉,避免长串的代码影响理解。同时在关键处加了简单的注释
// 加载FIS内核
var fis = module.exports = require('fis-kernel');
//项目默认配置
fis.config.merge({
// ...
});
//exports cli object
// fis命令行相关的对象
fis.cli = {};
// 工具的名字。在基于fis的二次解决方案中,一般会将名字覆盖
fis.cli.name = 'fis';
//colors
// 日志友好的需求
fis.cli.colors = require('colors');
//commander object
// 其实最后就挂载了 commander 这个插件
fis.cli.commander = null;
//package.json
// 把package.json的信息读进来,后面会用到
fis.cli.info = fis.util.readJSON(__dirname + '/package.json');
//output help info
// 打印帮助信息的API
fis.cli.help = function(){
// ...
};
// 需要打印帮助信息的命令,在 fis.cli.help() 中遍历到。 如果有自定义命令,并且同样需要打印帮助信息,可以覆盖这个变量
fis.cli.help.commands = [ 'release', 'install', 'server' ];
//output version info
// 打印版本信息
fis.cli.version = function(){
// ...
};
// 判断是否传入了某个参数(search)
function hasArgv(argv, search){
// ...
}
//run cli tools
// 核心方法,构建的入口所在。接下来我们就重点分析下这个方法。假设我们跑的命令是 fis server open
// 实际 process.argv为 [ 'node', '/usr/local/bin/fis', 'server', 'open' ]
// 那么,argv[2] ==> 'server'
fis.cli.run = function(argv){
// ...
};
我们来看下笔者注释过的fis.cli.run的源码。
fis -h或者fis --help,打印帮助信息fis -v或者fis --version,打印版本信息fis-command-server//run cli tools
fis.cli.run = function(argv){
fis.processCWD = process.cwd(); // 当前构建的路径
if(hasArgv(argv, '--no-color')){ // 打印的命令行是否单色
fis.cli.colors.mode = 'none';
}
var first = argv[2];
if(argv.length < 3 || first === '-h' || first === '--help'){
fis.cli.help(); // 打印帮助信息
} else if(first === '-v' || first === '--version'){
fis.cli.version(); // 打印版本信息
} else if(first[0] === '-'){
fis.cli.help(); // 打印版本信息
} else {
//register command
// 加载命令对应的插件,这里特指 fis-command-server
var commander = fis.cli.commander = require('commander');
var cmd = fis.require('command', argv[2]);
cmd.register(
commander
.command(cmd.name || first)
.usage(cmd.usage)
.description(cmd.desc)
);
commander.parse(argv); // 执行命令
}
};
通过fis.cli.run的源码,我们可以看到,fis-command-xx插件,都提供了register方法,在这个方法内完成命令的初始化。之后,通过commander.parse(argv)来执行命令。
整个流程归纳如下:
fis server openfis-command-server三个命令相关的插件中,fis-command-server的代码比较简单,这里就通过它来大致介绍下。
根据惯例,同样是抽取一个超级精简版的fis-command-server,这不影响我们对源码的理解
var server = require('./lib/server.js'); // 依赖的基础库
// 命令的配置属性,打印帮助信息的时候会用到
exports.name = 'server';
exports.usage = '<command> [options]';
exports.desc = 'launch a php-cgi server';
// 对外暴露的 register 方法,参数的参数为 fis.cli.command
exports.register = function(commander) {
// 略过若干个函数
// 命令的可选参数,格式参考 commander 插件的文档说明
commander
.option('-p, --port <int>', 'server listen port', parseInt, process.env.FIS_SERVER_PORT || 8080)
.action(function(){
// 当 command.parse(..)被调用时,就会进入这个回调方法。在这里根据fis server 的子命令执行具体的操作
// ...
});
// 注册子命令 fis server open
// 同理,可以注册 fis server start 等子命令
commander
.command('open')
.description('open document root directory');
};
好了,fis server open 就大致剖析到这里。只要熟悉commander这个插件,相信不难看懂上面的代码,这里就不多做展开了,有空也写篇科普文讲下commander的使用。
如序言所说,欢迎交流探讨。如有错漏,请指出。
先上例子,下面代码的作用是:对每个选中的div元素,都给它们添加一个red类
$('div').each(function(index, elem){
$(this).addClass('red');
});
上面用的的.each,即jQuery.fn.each,其内部是通过jQuery.each实现的
先贴一下类官方API说明,非常简单,只有两点需要注意
this指的是当前操作的dom元素/**
* @description 对jQuery对象中,匹配的的每个dom元素执行一个方法
* @param {Number} index 当前处理元素在集合中的位置
* @param {DOMElement} Element 当前处理的dom元素
*/
.each( function(index, Element) )
下面举两个简单的例子
给页面所有的div元素添加red类
$('div').each(function(index, elem){
$(this).addClass('red');
});
给页面前5个div元素添加red类
$('div').each(function(index, elem){
if(index>=5) return false; // 跳出循环
$(this).addClass('red');
});
如上,用法挺简单,不赘述,详细可查看 http://api.jquery.com/each/
内部是通过jQuery.each实现的,下面就讲下jQuery.each的源码,讲完jQuery.each的源码,jQuery.fn.each的源码就很简单了
略。。。
同样是先上一个简单的例子
$.each([52, 97], function(index, value) {
alert(index + ': ' + value + ':' + this);
});
输出内容如下:
0: 52-52
1: 97-97
同样是有两个注意点
this,是集合中的元素,即下面的 valueOfElementfalse,可以跳出循环/**
* @description 对集合(数组或对象)中的每个元素,执行某个操作
* @param {Number|String} indexInArray 元素在集合中对应的位置(如集合为数组,则为数字;如集合为对象,则为键值)
* @param {AnyValue} valueOfElement 集合中的元素
*/
jQuery.each( collection, callback(indexInArray, valueOfElement) )
$.each( ['one,'two','three', 'four'], function(index, value){
if(index >= 2) return false;
alert( "Index:" + index + ", value: " + value );
});
从官网直接copy来的例子,凑合着看
$.each( { name: "John", lang: "JS" }, function(k, v){
alert( "Key: " + k + ", Value: " + v );
});
// args is for internal usage only
each: function( obj, callback, args ) {
var value,
i = 0,
length = obj.length,
isArray = isArraylike( obj ); // obj是不是类似数组的对象,比如 {'0':'hello', '1':'world', 'length':2},其实就是为jQuery对象服务啦
if ( args ) { // args,其实没发现这个参数有什么实际作用~~直接跳过看else里面的内容即可,除了callback传的参数不同外无其他区别
if ( isArray ) {
for ( ; i < length; i++ ) {
value = callback.apply( obj[ i ], args );
if ( value === false ) {
break;
}
}
} else {
for ( i in obj ) {
value = callback.apply( obj[ i ], args );
if ( value === false ) {
break;
}
}
}
// A special, fast, case for the most common use of each
} else {
if ( isArray ) { // 处理数组
for ( ; i < length; i++ ) {
value = callback.call( obj[ i ], i, obj[ i ] );
if ( value === false ) {
break;
}
}
} else { // 处理对象
for ( i in obj ) {
value = callback.call( obj[ i ], i, obj[ i ] ); // value 为callback的返回值
if ( value === false ) { // 注意这里,当value===false的时候,直接跳出循环了
break;
}
}
}
}
return obj;
},
的确很简单,只要理解了jQuery.each应该就没问题了,没什么好讲的~
each: function( callback, args ) {
return jQuery.each( this, callback, args );
},
与jQuery.extend、jQuery.fn.extend一样,虽然 jQuery.each、jQuery.fn.each代码很简单,但也扮演了相当重要的作用,jQuery里大量用到了这两个方法,举例:
jQuery.each("Boolean Number String Function Array Date RegExp Object Error".split(" "), function(i, name) {
class2type[ "[object " + name + "]" ] = name.toLowerCase();
});
所以,少年好好掌握each吧~~
以下代码来自hbs官方demo,app.js,可以看到,依赖于express
// 3rd party
var express = require('express');
var hbs = require('hbs');
var app = express();
// set the view engine to use handlebars
app.set('view engine', 'hbs');
app.set('views', __dirname + '/views');
app.use(express.static(__dirname + '/public'));
var blocks = {};
hbs.registerHelper('extend', function(name, context) {
var block = blocks[name];
if (!block) {
block = blocks[name] = [];
}
block.push(context.fn(this)); // for older versions of handlebars, use block.push(context(this));
});
hbs.registerHelper('block', function(name) {
var val = (blocks[name] || []).join('\n');
// clear the block
blocks[name] = [];
return val;
});
app.get('/', function(req, res){
res.render('index');
});
app.listen(3000);
通过断点,可以看到,express最后调用了hbs.__express(filename, options, cb)。其中
flename:编译的模版路径
options:编译模版时,传入的数据。以及express内部的一些配置,挂在options.settings上
cb:回调方法,参数为模版编译出来的文本内容
那么,事情就很简单了。只需要人工调用 hbs.__express(filename, options, cb) 这个方法就可以了。
var hbs = require('hbs'),
Handlebars = require('handlebars'),
fs = require('fs'),
path = require('path'),
grunt = require('grunt');
var views = path.resolve('views'),
dest = path.resolve('dest'),
filename = path.resolve(views, 'index.hbs'),
destname = path.resolve(dest, 'index.html'),
settings = {
views: views
},
options = {
title: 'hbs without express',
nick: 'casper',
settings: settings
};
var blocks = {};
hbs.registerHelper('extend', function(name, context) {
var block = blocks[name];
if (!block) {
block = blocks[name] = [];
}
block.push(context.fn(this)); // for older versions of handlebars, use block.push(context(this));
});
hbs.registerHelper('block', function(name, context) {
var len = (blocks[name] || []).length;
var val = (blocks[name] || []).join('\n');
// clear the block
blocks[name] = [];
if(!len){
return context.fn(this);
}else{
return val;
}
});
hbs.__express(filename, options, function(err, res){
grunt.file.write(destname, res);
});
作为一个互联网前端老鸟,这么些年下来,做过的项目也不少。从最初的我的QQ中心、QQ圈子,到后面的QQ群项目、腾讯课堂。从几个人的项目,到近百号人的项目都经历过。
这期间,实现了很多的产品需求,也积累了一些经验。这里稍作总结,希望能给新入行的前端小伙伴们一些参考。
要说如何做好一个需求,展开来讲,可以写好几篇文章,这里只挑重点来讲。
最基本的,就是把握好3W:what、when、how。
what:做什么?when:完成时间?how:如何完成?为了下文不至于太过枯燥,这里进行需求场景的模拟,下文主要围绕这个“需求”,从what、when、how 三个点展开来讲。
假设现在有个论坛的项目,产品经理小C提了个需求 “给论坛增加评论功能” 。作为 前端工程师 的小A接到需求后,该如何高质量的完成这个需求。
备注:此时我们脑海里浮现的应该是下面这张图。

可能有同学要拍案而起了:Are you kidding me?不就加个评论功能吗,我还能不知道该做啥?
答案很残酷:是的。
根据过往经验,不少前端同学,包括一些前端老司机,做需求的时候,的确不知道自己究竟要做什么。导致这种情况发生的原因有哪些呢?
说到产品需求不明确,前端的兄弟们估计可以坐一起开个诉苦大会,因为实在太常见了。典型的有“拍脑门需求”、“一句话需求”、“贴个图求照抄需求”。
回到之前的例子:给论坛增加个评论功能。
别看连原型图都贴出来了,其实这就是个典型的“需求不明确”。比如:
也许经过一番确认,最终的需求会是下图所示。遇到这种情况,一定要做好需求确认,避免后期无意义的返工和延期。

再次强调一下,无论何时,一定要做好需求确认。再有经验、再负责的产品经理,也几乎不可能提出“100%明确”的需求。
同样,回到上面的需求。
现在已经确认了,需要支持富文本输入、需要展示评论,这就够了吗?其实不够,还有很多需求细节需要进一步确认。比如:
可以、需要确认的内容太多,这里就不赘述。
看到这里,读者朋友们应该明白,为什么前面会说,几乎不存在“100%明确”的需求。
很多需求细节,同时也跟技术实现细节强相关,不能苛求产品经理都考虑到。这种情况下,作为开发者的我们应该主动找出问题,并与产品经理一起将细节敲定下来。

一个同时有前端、后端参与的需求,精简后的需求生命周期,大概是这样的:
需求提出-->开发-->联调-->提交测试->需求发布
一个需求的实际发布时间,大部分时候取决于实际的开发工作量。如何评估开发工作量呢?最基本的,就是明确“做什么”,这也就是上一小节强调的内容。
这里我们假设:
3天,小B的开发工作量是3天。9月1号投入开发那么,是不是9月3号下班前需求就可以发布了?
答案显然是:不能。
要得出一个靠谱的完成时间,至少需要明确以下内容:
最终,需求的完成时间点可能如下:(跟预期的出入很大)

对于需求完成时间的评估,实际情况远比上面说的要更复杂。比如需要考虑节假日、成员休假、多个需求并行开发、需求存在外部依赖项等。以后有机会再展开来讲。
完成需求容易,如果要高质量完成,那就需要费点功夫了。同样的,只挑一些重要的来讲
这块的重要性,再怎么强调也不为过。前面已经讲过了,这里不再赘述。
作为一名合格的前端工程师,对自己的开发质量负责,这是最基本的要求。
要时常问自己:
严格把控开发、自测、提测质量,这不但是能力,更是一种负责任的态度。如果能做到这点,不单节省大家的时间,还可以让其他人觉得自己比较“靠谱”。
备注:以下截图,是笔者之前一个需求的自测用例(非完整版)。同样是评论功能,自测用例将近50个。

风险意识非常重要。在需求完成的过程中,经常会有各种意外的小插曲出现。对于前端同学,常见的有:
上面列举的项,都可能导致需求发布delay,要时刻要保持警惕。一旦出现可能可能导致delay的风险,要及时做好同步,准备好应对措施。
打个比方:
前面说到,小A 评估了3天的开发工作量。等到开发的第2天,发现之前工作量评估少了,至少需要4天才能完成。
这个时候,该怎么办呢?
相信不少同学都是这样处理的:咬咬牙,加加班,4天的活3天干,实在完不成了再说。
这样处理潜在的问题不小:
更好的处理方式是:及时跟项目组成员同步风险,并落实确认相应解决方案。比如适当调整排期、砍掉部分优先级不高的功能等。
对于一个职场人能力的评判,“解决问题”的能力,是很重要的一个评估标准。解决问题的能力如何体现呢?
举个例子,提测过程中,出现了不少bug,对于小A来说,该怎么办呢?这里分两种情况:
第一种情况很简单,自己的坑自己填,抓紧时间改bug,并做好事总结,降低后续需求的bug率。
第二种情况呢?如果小B比较配合,主动快速修复bug,那没什么好说的。但万一不是呢?
遇到这种情况,小A可能会想:“又不是我的bug,干嘛操那份闲心,需求如果delay的话,那也是小B的问题,跟我无关。”
可能不少同学的想法跟小A一样,这在笔者看来,略显消极,处理方式显得不够“职业化”。
为什么呢?
同在一个项目组,得要有团队意识、整体意识。需求延期,首先是所有需求相关人的责任,是要一起打板子的。然后,才会对具体的责任人进行问责。
回到前面的场景,小A更好的处理方式是:做好沟通工作,主动推进问题解决。
这一点非常重要,但又是容易被忽略的一点。需求发布上线,是个重要的里程碑,但并不意味着需求的终点,还得时刻关注以下事项:
只管功能开发,一旦需求上线,立刻做甩手掌柜,同样是缺乏责任意识的表现。试想一下,如果你是团队的老大,你会放心把重要的需求交给一个“甩手掌柜”吗。
本文中,笔者主要从一个前端工程师的角度出发,谈了一些“高质量完成需求”的经验。里面提到的不少内容,放到其他岗位也是适用的。鉴于篇幅原因,很多细节都是点到为止,并没有深入展开。
方法论再多,最终还是需要人去落实。作为一名前端工程师,加强责任意识,主动承担,勤于总结,做社会主义合格的接班人。
by:程序猿小卡,from:企鹅IMWEB团队.
本文对fis进行概要性的介绍,由于篇幅原因,不会涉及太多使用、设计上的细节。想要了解更多,可参考官方文档。本文内容梗概:
FIS是专为解决前端开发中自动化工具、性能优化、模块化框架、开发规范、代码部署、开发流程等问题的工具框架。
专注于前端构建,无需进行任何配置轻松应付常见需求。

三条命令,满足大部分的构建需求(每个命令带有数量不等的参数)
fis install:命令安装fis仓库提供的各种 组件、框架、示例、素材、配置等 开发资源。fis release:命令用于编译并发布的你的项目,拥有多个参数调整编译发布操作。fis server:命令可以启动一个本地调试服务器用于预览fis release产出的项目。node搭建,可运行于windows、mac、linux等平台

npm install -g fis # 安装fis
npm install -g lights # fis采用lights管理资源;要求node版本在v0.10.27以上假设项目如下,这里主要展示几种能力:
fis-first-demo/
└── src
├── css
│ └── main.css
├── img
│ ├── avatar.png
│ └── saber.jpeg
├── index.html
├── js
│ ├── lib.js
│ ├── main.js
│ └── util.js
└── saber.png运行如下命令
fis release -o
fis server start先看看运行结果

<script type="text/javascript" src="js/lib.js?__inline"></script>下面图片,release后生成到/static/avatar.png
<img class="avatar" src="img/avatar.png" width="115" height="115" />配置文件fis-conf.js
fis.config.merge({
roadmap : {
path : [
{
//所有的js文件
reg : '**.js',
//发布到/static/xxx目录下
release : '/static/$&'
},
{
//所有的css文件
reg : '**.css',
//发布到/static/xxx目录下
release : '/static/$&'
},
{
//所有img目录下的.png,.gif文件
reg : /^\/img\/(.*\.(?:png|gif))/i,
//发布到/static/xxx目录下
release : '/static/$1'
}
]
}
});.clear{clear: both;}
.intro{margin: 10px;}
.intro .avatar{float: left;}
.intro .wording{float: left; margin-left: 10px;}优化后
.clear{clear:both}.intro{}.intro .avatar{float:left}.intro .wording{float:left}fis server start --type node按照配置粒度划分,fis的配置主要包括几项:
settings两者需要进行区分map.json,如需实际打包,可根据这份表自行定制打包方案。
下面是来自官方的例子,挺详细就不展开了:http://fis.baidu.com/docs/api/fis-conf.html
//fis-conf.js
fis.config.merge({
modules : {
parser : {
//coffee后缀的文件使用fis-parser-coffee-script插件编译
coffee : 'coffee-script',
//less后缀的文件使用fis-parser-less插件编译
//处理器支持数组,或者逗号分隔的字符串配置
less : ['less'],
//md后缀的文件使用fis-parser-marked插件编译
md : 'marked'
}
},
roadmap : {
ext : {
//less后缀的文件将输出为css后缀
//并且在parser之后的其他处理流程中被当做css文件处理
less : 'css',
//coffee后缀的文件将输出为js文件
//并且在parser之后的其他处理流程中被当做js文件处理
coffee : 'js',
//md后缀的文件将输出为html文件
//并且在parser之后的其他处理流程中被当做html文件处理
md : 'html'
}
}
});//配置字符串全部转换为ascii字符
fis.config.merge({
settings : {
optimizer : {
'uglify-js' : {
output : {
ascii_only : true
}
}
}
}
});首先需要理解fis的单文件编译过程:
个人总结:http://www.cnblogs.com/chyingp/p/fis-plugins-optimize.html
官方文档:http://fis.baidu.com/docs/more/fis-base.html

fis-optimizer-test配置:
fis.config.merge({
modules : {
optimizer : {
//js后缀文件会经过fis-optimizer-test插件的压缩优化
js : 'test'
}
}
});插件源码:
/*
* fis插件示例
* http://www.cnblogs.com/chyingp/p/fis-plugins-optimize.html
*/
'use strict';
module.exports = function(content, file, conf){
return content+'\nvar nick ="程序猿小卡"';
};fis release -o就可以看到效果了
console.log('inline file');
function hello(argument) {
var nick = 'casper';
var age = 26;
}
var nick ="casper" // 这货就是fis-optimizer-test加上的前面提到过,fis的打包只是生成一份映射表map.json,具体的打包方案需要用户自行定制。
比如在index.html里声明依赖
<!--
@require demo.js
@require "demo.css"
-->编译后生成
{
"res" : {
"demo.css" : {
"uri" : "/static/css/demo_7defa41.css",
"type" : "css"
},
"demo.js" : {
"uri" : "/static/js/demo_33c5143.js",
"type" : "js",
"deps" : [ "demo.css" ]
}
},
"pkg" : {}
}打包配置如下:
//fis-conf.js
fis.config.merge({
pack : {
//打包所有的demo.js, script.js文件
//将内容输出为static/pkg/aio.js文件
'pkg/aio.js' : ['**/demo.js', /\/script\.js$/i],
//打包所有的css文件
//将内容输出为static/pkg/aio.css文件
'pkg/aio.css' : '**.css'
}
});生成的表map.json
{
"res": {
"demo.css": {
"uri": "/static/css/demo_7defa41.css",
"type": "css",
"pkg": "p1"
},
"demo.js": {
"uri": "/static/js/demo_33c5143.js",
"type": "js",
"deps": [
"demo.css"
],
"pkg": "p0"
},
"index.html": {
"uri": "/index.html",
"type": "html",
"deps": [
"demo.js",
"demo.css"
]
},
"script.js": {
"uri": "/static/js/script_32300bf.js",
"type": "js",
"pkg": "p0"
},
"style.css": {
"uri": "/static/css/style_837b297.css",
"type": "css",
"pkg": "p1"
}
},
"pkg": {
"p0": {
"uri": "/static/pkg/aio_5bb04ef.js",
"type": "js",
"has": [
"demo.js",
"script.js"
],
"deps": [
"demo.css"
]
},
"p1": {
"uri": "/static/pkg/aio_cdf8bd3.css",
"type": "css",
"has": [
"demo.css",
"style.css"
]
}
}
}官方介绍
1、简单的一个配置即可成为另外一个工具
2、自定义插件+规范+... 一个解决诸多问题的解决方案FIS具有高扩展性,可以通过配置进行各种目录结构等的定制,同时FIS拥有足够数量的插件,用户可以下载这些插件,配置使用。也可以按照自己的需求开发定制插件。可能有些人会问,如果插件多了后该如何维护。其实,FIS具有可包装性。比如现在市面上的fis-plus、gois、jello、spt等都是包装了FIS,可以使用这种包装性,把多个插件以及FIS包装成为新的一个工具。这就是为什么FIS会定义为工具框架的原因。
上面的介绍来自官方文档。对于为何需要二次开发,个人的看法是:
诸多问题,这里除了项目本身的需求,还有工具本身可能存在的问题,如fis、fis插件的升级、多版本并存问题(fis是全局安装的,升个级,所有项目跑不转了这可摊上大事了。。),drwxr-xr-x 10 nobody staff 340 7 2 23:14 colors
drwxr-xr-x 7 nobody staff 238 7 2 23:14 commander
drwxr-xr-x 7 nobody staff 238 7 2 23:14 fis-command-install
drwxr-xr-x 11 nobody staff 374 7 2 23:14 fis-command-release
drwxr-xr-x 9 nobody staff 306 7 2 23:14 fis-command-server
drwxr-xr-x 9 nobody staff 306 7 2 23:14 fis-kernel
drwxr-xr-x 8 nobody staff 272 7 2 23:14 fis-optimizer-clean-css
drwxr-xr-x 8 nobody staff 272 7 2 23:14 fis-optimizer-png-compressor
drwxr-xr-x 8 nobody staff 272 7 2 23:14 fis-optimizer-uglify-js
drwxr-xr-x 7 nobody staff 238 7 2 23:14 fis-packager-map
drwxr-xr-x 7 nobody staff 238 7 2 23:14 fis-postprocessor-jswrapper
drwxr-xr-x 8 nobody staff 272 7 2 23:14 fis-spriter-cssspritesfis-hello远比想象中要容易,直接看官方文档吧:http://fis.baidu.com/docs/dev/solution.html
经常有人拿grunt、fis进行对比,其实两者并不是同一层面的内容。grunt是前端构建工具,而fis则是前端集成解决方案。
举个不是很恰当的例子,就拿http协议、浏览器的关系来说吧。
这里就讲fis相对于grunt的优势吧。
写得匆忙,如有错漏敬请指出 :)
一些链接:
官网:http://fis.baidu.com/
getting started:http://fis.baidu.com/docs/beginning/getting-started.html
项目配置:http://fis.baidu.com/docs/api/fis-conf.html
插件开发:http://fis.baidu.com/docs/dev/plugin.html
解决方案封装:http://fis.baidu.com/docs/dev/solution.html
前面已经已fis server open为例,讲解了FIS的整体架构设计,以及命令解析&执行的过程。下面就进入FIS最核心的部分,看看执行fis release这个命令时,FIS内部的代码逻辑。
这一看不打紧,基本把fis-kernel的核心模块翻了个遍,虽然大部分细节已经在脑海里里,但是要完整清晰的写出来不容易。于是决定放弃大而全的篇幅,先来个概要的分析,后续文章再针对涉及的各个环节的细节进行展开。
fis-command-release老规矩,献上精简版的 release.js,从函数名就大致知道干嘛的。release(options)是我们重点关注的对象。
'use strict';
exports.register = function(commander){
// fis relase --watch 时,就会执行这个方法
function watch(opt){
// ...
}
// 打点计时用,控制台里看到的一堆小点点就是这个方法输出的
function time(fn){
// ...
}
// fis release --live 时,会进入这个方法,对浏览器进行实时刷新
function reload(){
//...
}
// 高能预警!非常重要的方法,fis release 就靠这个方法走江湖了
function release(opt){
// ...
}
// 可以看到有很多配置参数,每个参数的作用可参考对应的描述,或者看官方文档
commander
.option('-d, --dest <names>', 'release output destination', String, 'preview')
.option('-m, --md5 [level]', 'md5 release option', Number)
.option('-D, --domains', 'add domain name', Boolean, false)
.option('-l, --lint', 'with lint', Boolean, false)
.option('-t, --test', 'with unit testing', Boolean, false)
.option('-o, --optimize', 'with optimizing', Boolean, false)
.option('-p, --pack', 'with package', Boolean, true)
.option('-w, --watch', 'monitor the changes of project')
.option('-L, --live', 'automatically reload your browser')
.option('-c, --clean', 'clean compile cache', Boolean, false)
.option('-r, --root <path>', 'set project root')
.option('-f, --file <filename>', 'set fis-conf file')
.option('-u, --unique', 'use unique compile caching', Boolean, false)
.option('--verbose', 'enable verbose output', Boolean, false)
.action(function(){
// 省略一大堆代码
// fis release 的两个核心分支,根据是否有加入 --watch 进行区分
if(options.watch){
watch(options); // 有 --watch 参数
} else {
release(options); // 这里这里!重点关注!没有 --watch 参数
}
});
};
release(options); 做了些什么用伪代码将逻辑抽象下,主要分为四个步骤。虽然最后一步才是本片文章想要重点讲述的,不过前三步是第四步的基础,所以这里还是花点篇幅介绍下。
findFisConf(); // 找到当前项目的fis-conf.js
setProjectRoot(); // 设置项目根路径,需要编译的源文件就在这个根路径下
mergeFisConf(); // 导入项目自定义配置
readSourcesAndReleaseToDest(options); // 将项目编译到默认的目录下
下面简单对上面几个步骤进行一一讲解。
由于这两步之间存在比较紧密的联系,所以这里就放一起讲。在没有任何运行参数的情况下,比较简单
fis-conf.js,直到找到位置fis-conf.js,则以它为项目配置文件。同时,将项目的根路径设置为fis-conf.js所在的目录。fis-conf.js,则采用默认项目配置。同时,将项目的根路径,设置为当前命令运行时所在的工作目录。从fis release的支持的配置参数可以知道,可以分别通过:
--file:指定fis-conf.js的路径(比如多个项目公用编译配置)--root:指定项目根路径(在A工作目录,编译B工作目录)由本小节前面的介绍得知,--file、--root两个配置参数之间是存在联系的,有可能同时存在。下面用伪代码来说明下
if(options.root){
if(options.file){
// 项目根路径,为 options.root 指定的路径
// fis-conf.js路径,为 options.file 指定的路径
}else{
// 项目根路径,为 options.root 指定的路径
// fis-conf.js路径,为 options.root/fis-conf.js
}
}else{
if(options.file){
// fis-conf.js路径,为 options.file 指定的路径
// 项目根路径,为 fis-conf.js 所在的目录
}else{
// fis-conf.js路径,为 逐层向上遍历后,找到的 fis-conf.js 路径
// 项目根路径,为 fis-conf.js 所在的目录
}
}
合并项目配置文件。从源码可以清楚的看到,包含两个步骤:
fis-conf.js创建缓存。除了配置文件,FIS还会为项目的所有源文件建立缓存,实现增量编译,加快编译速度。缓存的细节后面再讲,这里知道有这么回事就行。// 如果找到了 fis-conf.js
if(conf){
var cache = fis.cache(conf, 'conf');
if(!cache.revert()){
options.clean = true;
cache.save();
}
require(conf); // 加载 fis-conf.js,其实就是合并配置
} else {
// 还是没有找到 fis-conf.js
fis.log.warning('missing config file [' + filename + ']');
}
通过这个死长的伪函数名,就知道这个步骤的作用了,非常关键。根据当前项目配置,读取项目的源文件,编译后输出到目标目录。
编译过程的细节,下一节会讲到。
项目编译发布的细节,主要是在release这个方法里完成。细节非常的多,主要在fis.release()这个调用里完成,基本上用到了fis-kernel里所有的模块,如release、compile、cache等。
伪代码流程如下:fis-command-release/release.js
var collection = {}; // 跟total一样,key=>value 为 “编译的源文件路径”=》"对应的file对象"
var total = {};
var deploy = require('./lib/deploy.js'); // 文件部署模块,完成从 src -> dest 的最后一棒
function release(opt){
opt.beforeEach = function(file){
// 用compile模块编译源文件前调用,往 total 上挂 key=>value
total[file.subpath] = file;
};
opt.afterEach = function(file){
// 用compile模块编译源文件后调用,往 collection 上挂 key=>value
collection[file.subpath] = file;
};
opt.beforeCompile = function(file){
// 在compile内部,对源文件进行编译前调用(好绕。。。)
collection[file.subpath] = file;
};
try {
//release
// 在fis-kernel里,fis.release = require('./lib/release.js');
// 在fis.release里完成除了最终部署之外的文件编译操作,比如文件标准化等
fis.release(opt, function(ret){
deploy(opt, collection, total); // 项目部署(本例子里特指将编译后的文件写到某个特定的路径下)
});
} catch(e) {
// 异常处理,暂时忽略
}
}
fis.release()前面说了,细节非常多,后续文章继续展开。。。
今晚跟团队的小伙伴们碰了下项目中的前端模块规范,这里备忘下,主要包含几点内容
首先来个整体的文件概览,后面会逐项强调下上面说到的几点
/**
* @fileoverview 前端模块规范的范例,主要注意的几点内容
* 1、模块依赖声明
* 2、模块常见调用example
* 3、API注释
* @author 程序猿小卡
* @date 2014.04.02
* @example
* 1、显示登陆弹窗
* Login.show({
* parentNode: document.body, // 父节点
* onClose: function(){} // 弹窗关闭时的回调方法
* });
* 2、关闭登陆弹窗
* Login.hide();
*/
(function (root, factory) {
// 模块规范之:依赖声明
if (typeof define === 'function' && define.amd) {
// @备注 模块的兼容性写法,这里为支持AMD规范的写法,其中,DB为依赖模块
define(['DB'], factory);
} else {
// @备注 不支持AMD的写法,直接将全局模块DB作为依赖的模块参数传入
root['Login'] = factory(root['DB']);
}
}(this, function (DB) {
// 模块规范之:变量命名
var _isShow = false; // 私有变量,以下划线 _ 开头
var MAX_HEIGHT = 400; // 常量,字母全大写,以下划线 _ 连接
/**
* @ignore
* @description 模块规范之:内部私有方法声明
* 1、不用下划线开头
* 2、驼峰命名
*/
function getRandomId(){
}
/**
* @namespace
*/
var exports = {
/**
* @description 显示登录框
* @param {Object} options 配置参数
* @param {DOMElement} options.parentNode 父节点
* @param {Function} options.onClose 弹窗关闭后的回调方法
* @return undefined
*/
show : function(options){
// 模块规范之:方法内部变量
var idOfWin = 'login_' + (new Date() - 0); // 方法内部的局部变量,普通变量命名规则即可,驼峰命名
var $container = $(options.parentNode); // jQuery对象,以$开头
// 具体实现细节略过...
},
/**
* @description 隐藏登录框
* @return undefined
*/
hide: function(){
// 具体实现细节略过
}
};
return exports;
}));有的项目用到requirejs进行模块的依赖管理,而有的项目没有。针对这个问题,下面是个兼容的依赖声明解决方案(非原创)
(function (root, factory) {
// 模块规范之:依赖声明
if (typeof define === 'function' && define.amd) {
// @备注 模块的兼容性写法,这里为支持AMD规范的写法,其中,DB为依赖模块
define(['DB'], factory);
} else {
// @备注 不支持AMD的写法,直接将全局模块DB作为依赖的模块参数传入
root['Login'] = factory(root['DB']);
}
}(this, function (DB) {
var exports = {
// 各种方法
};
return exports;
}));一个模块对外暴露的接口可能有很多个,但常用的一般就那么几个。在完善API注释的情况下,如果能够在文件头提供常见的调用示例,那会节省模块调用者不少的时间。这个也不费事,就几行注释搞定的事情。
* @example
* 1、显示登陆弹窗
* Login.show({
* parentNode: document.body, // 父节点
* onClose: function(){} // 弹窗关闭时的回调方法
* });
* 2、关闭登陆弹窗
* Login.hide();
*/接口注释的重要性不用强调了,这块业界也已经有了比较成熟的规范,可以参考 文档,这里只贴个简单的例子
/**
* @description 显示登录框
* @param {Object} options 配置参数
* @param {DOMElement} options.parentNode 父节点
* @param {Function} options.onClose 弹窗关闭后的回调方法
* @return undefined
*/
show : function(options){
// 模块规范之:方法内部变量
var idOfWin = 'login_' + (new Date() - 0); // 方法内部的局部变量,普通变量命名规则即可,驼峰命名
var $container = $(options.parentNode); // jQuery对象,以$开头
// 具体实现细节略过...
},老生长谈的东西,没有固定标准,只有推荐规范,具体要看符不符合项目、团队实际。现在暂定的有
_isShowMAX_HEIGHTgetRandomIdshowidOfWin$开头进行区分,比如$container例子如下:
// 模块规范之:变量命名
var _isShow = false; // 私有变量,以下划线 _ 开头
var MAX_HEIGHT = 400; // 常量,字母全大写,以下划线 _ 连接
// 模块规范之:内部私有方法声明
function getRandomId(){
}
var exports = {
show : function(options){
// 模块规范之:方法内部变量
var idOfWin = 'login_' + (new Date() - 0); // 方法内部的局部变量,普通变量命名规则即可,驼峰命名
// 模块规范之:jQuery对象
var $container = $(options.parentNode); // jQuery对象,以$开头
// 具体实现细节略过...
}
};@todo review casperchen 2014.06.21:需要review的代码本来是想写个如何编写gulp插件的科普文的,突然探究欲又发作了,于是就有了这篇东西。。。翻了下源码看了下gulp.src()的实现,不禁由衷感慨:肿么这么复杂。。。
首先我们看下gulpfile里面的内容是长什么样子的,很有express中间件的味道是不是~
我们知道.pipe()是典型的流式操作的API。很自然的,我们会想到gulp.src()这个API返回的应该是个Stream对象(也许经过层层封装)。本着一探究竟的目的,花了点时间把gulp的源码大致扫了下,终于找到了答案。
gulpfile.js
var gulp = require('gulp'),
preprocess = require('gulp-preprocess');
gulp.task('default', function() {
gulp.src('src/index.html')
.pipe(preprocess({USERNAME:'程序猿小卡'}))
.pipe(gulp.dest('dest/'));
});
此处有内容剧透,如有对剧透不适者,请自行跳过本段落。。。
gulp.src() 的确返回了定制化的Stream对象。可以在github上搜索
ordered-read-streams这个项目。大致关系是:
ordered-read-streams --> glob-stream --> vinyl-fs --> gulp.src()
首先,我们看下require('gulp')返回了什么。从gulp的源码来看,返回了Gulp对象,该对象上有src、pipe、dest等方法。很好,找到了我们想要的src方法。接着往下看
参考:https://github.com/gulpjs/gulp/blob/master/index.js#L62
gulp/index.js
var inst = new Gulp();
module.exports = inst;从下面的代码可以看到,gulp.src方法,实际上是vfs.src。继续
参考:https://github.com/gulpjs/gulp/blob/master/index.js#L25
gulp/index.js
var vfs = require('vinyl-fs');
// 省略很多行代码
Gulp.prototype.src = vfs.src;接下来我们看下vfs.src这个方法。从vinyl-fs/index.js可以看到,vfs.src实际是vinyl-fs/lib/src/index.js。
参考:https://github.com/wearefractal/vinyl-fs/blob/master/index.js
vinyl-fs/index.js
'use strict';
module.exports = {
src: require('./lib/src'),
dest: require('./lib/dest'),
watch: require('glob-watcher')
};那么,我们看下vinyl-fs/lib/src/index.js。可以看到,gulp.src()返回的,实际是outputStream这货,而outputStream是gs.create(glob, options).pipe()获得的,差不多接近真相了,还有几步而已。
参考:https://github.com/wearefractal/vinyl-fs/blob/master/lib/src/index.js#L37
vinyl-fs/lib/src/index.js
var defaults = require('lodash.defaults');
var through = require('through2');
var gs = require('glob-stream');
var File = require('vinyl');
// 省略非重要代码若干行
function src(glob, opt) {
// 继续省略代码
var globStream = gs.create(glob, options);
// when people write to use just pass it through
var outputStream = globStream
.pipe(through.obj(createFile))
.pipe(getStats(options));
if (options.read !== false) {
outputStream = outputStream
.pipe(getContents(options));
}
// 就是这里了
return outputStream
.pipe(through.obj());
}我们再看看glob-stream/index.js里的create方法,最后的return aggregate.pipe(uniqueStream);。好的,下一步就是真相了,我们去ordered-read-streams这个项目一探究竟。
参考:https://github.com/wearefractal/glob-stream/blob/master/index.js#L89
glob-stream/index.js
var through2 = require('through2');
var Combine = require('ordered-read-streams');
var unique = require('unique-stream');
var glob = require('glob');
var minimatch = require('minimatch');
var glob2base = require('glob2base');
var path = require('path');
// 必须省略很多代码
// create 方法
create: function(globs, opt) {
// 继续省略代码
// create all individual streams
var streams = positives.map(function(glob){
return gs.createStream(glob, negatives, opt);
});
// then just pipe them to a single unique stream and return it
var aggregate = new Combine(streams);
var uniqueStream = unique('path');
// TODO: set up streaming queue so items come in order
return aggregate.pipe(uniqueStream);真相来了,我们看下ordered-read-streams的代码,可能刚开始看不是很懂,没关系,知道它实现了自己的Stream就可以了(nodejs是有暴露相应的API让开发者对Stream进行定制的),具体可参考:http://www.nodejs.org/api/stream.html#stream_api_for_stream_implementors
代码来自:https://github.com/armed/ordered-read-streams/blob/master/index.js
ordered-read-streams/index.js
function OrderedStreams(streams, options) {
if (!(this instanceof(OrderedStreams))) {
return new OrderedStreams(streams, options);
}
streams = streams || [];
options = options || {};
if (!Array.isArray(streams)) {
streams = [streams];
}
options.objectMode = true;
Readable.call(this, options);
// stream data buffer
this._buffs = [];
if (streams.length === 0) {
this.push(null); // no streams, close
return;
}
streams.forEach(function (s, i) {
if (!s.readable) {
throw new Error('All input streams must be readable');
}
s.on('error', function (e) {
this.emit('error', e);
}.bind(this));
var buff = [];
this._buffs.push(buff);
s.on('data', buff.unshift.bind(buff));
s.on('end', flushStreamAtIndex.bind(this, i));
}, this);
}参考:https://github.com/armed/ordered-read-streams/blob/master/index.js
兜兜转转一大圈,终于找到了gulp.src()的源头,大致流程如下,算是蛮深的层级。代码细节神马的,有兴趣的同学可以深究一下。
ordered-read-streams --> glob-stream --> vinyl-fs --> gulp.src()
以下是官方定义,反正我是没看懂。google了下,大家都称之“前端UI开发框架”,勉强这么叫着吧。可以看下这篇文章对react的介绍,本文更多的是覆盖react的入门实践。
A JAVASCRIPT LIBRARY FOR BUILDING USER INTERFACES
本文提到的例子可以在这里找到:github链接
getting-started.html里的例子比较简单,首先引入 react.js、JSXTransformer.js,然后通过 React.render() 方法即可。语法细节什么的可以先不管。
需要注意的点是,最后一段script标签,上面声明了 type="text/jsx",也就是说并不是通常的直接解析执行的脚本,JSXTransformer.js 会对其进行预编译后再执行。
<!DOCTYPE html>
<html>
<head>
<title>getting started</title>
<script src="build/react.js"></script>
<script src="build/JSXTransformer.js"></script>
</head>
<body>
<div id="example"></div>
<script type="text/jsx">
React.render(
<h1>Hello, world!</h1>,
document.getElementById('example')
);
</script>
</body>
</html>
好了,看下效果吧。

根据以往养成的好习惯,直觉的感觉到,这里应该将组件的定义跟 html 页面分离,不然以后页面肯定就乱糟糟了。示例请查看 separate-file.html
修改后的html文件,瞬间清爽很多。同样需要注意 type="text/jsx"
<!DOCTYPE html>
<html>
<head>
<title>demo</title>
<script src="build/react.js"></script>
<script src="build/JSXTransformer.js"></script>
</head>
<body>
<div id="example"></div>
<script type="text/jsx" src="js/helloworld.js"></script>
</body>
</html>
处理后的 helloworld.js,其实内容一点变化都没有
React.render(
<h1>Hello, world!</h1>,
document.getElementById('example')
);
好了,查看效果。双击 separate-file.html,这时看到页面是空白的,同时控制台还有错误信息。

肿么办呢?相信有经验的兄弟知道咋整了。这里偷个懒,直接用fis起个本地服务器。在2015.04.09-react/ 根路径下运行
fis server start
fis release
然后访问 http://127.0.0.1:8080/separate-file.html。well done

之前提到,JSXTransformer.js 会对标志 type="text/jsx" 的script 进行预编译后再执行,那么在浏览器端很可能就会遇到性能问题(没验证过)。React 的开发团队当然也考虑到这个问题了,于是也提供了server端的编译工具。
请查看 server-build-without-transform.html 。这里我们已经把 JSXTransformer.js 的依赖去掉。相对应的,我们需要在server端做一定的编译工作。
<!DOCTYPE html>
<html>
<head>
<title>demo</title>
<script src="build/react.js"></script>
<!-- <script src="build/JSXTransformer.js"></script> -->
</head>
<body>
<div id="example"></div>
<script src="js-build/helloworld.js"></script>
</body>
</html>
挺简单的,安装 react-tools,然后运行相应命令即可
npm install -g react-tools
jsx --watch js/ js-build/
可以看到,js/helloworld.js 已经被编译成 js-build/helloworld.js。我们看下编译后的文件

编译后的文件。可以看到,都是浏览器可以理解的语法。你也可以一开始就这样编写,不过保证你会抓狂。
React.render(
React.createElement("h1", null, "Hello, world!"),
document.getElementById('example')
);
下面定义一个极简的_组件_ 来做说明,示例代码可以查看 define-a-component.html。从代码可以看到:
React.createClass() 来定义一个组件,该方法需要定义 render 方法来返回组件对应的 dom 结构React.render() 来调用组件。该方法传入两个参数,分别是 对应的组件,父级节点。<!DOCTYPE html>
<html>
<head>
<title>getting started</title>
<script src="build/react.js"></script>
<script src="build/JSXTransformer.js"></script>
</head>
<body>
<div id="example"></div>
<script type="text/jsx">
var HelloComponent = React.createClass({
render: function(){
return (
<div>
<h1>Hello World</h1>
<p>I am Hello World Component</p>
</div>
);
}
});
React.render(
<HelloComponent />,
document.getElementById('example')
);
</script>
</body>
</html>
示例效果如下:

刚接触React组件定义的同学,可能会踩中下面的坑。比如把前面的组件定义改成。区别在于去掉了组件最外层的包裹节点 <div>
var HelloComponent = React.createClass({
render: function(){
return (
<h1>Hello World</h1>
<p>I am Hello World Component</p>
);
}
});
再次访问 http://127.0.0.1:8080/define-a-component.html 会有如下错误提示。错误信息比较明确了,不再赘述,乖乖加上包裹节点就好了

在定义一个组件时,我们通常会暴露一定的配置项,提高组件的可复用性。这里简单示范下如何实现,具体代码可查看 using-properties.html。
关键代码如下,还是比较直观的。使用组件时,就跟使用浏览器内置的组件那样给属性赋值。在组件定义的内部代码实现中,通过 this.props.xx 来取到对应的值即可。
<script type="text/jsx">
var HelloComponent = React.createClass({
render: function(){
return (
<div>
<h1>Title is: {this.props.title}</h1>
<p>Content is: {this.props.content}</p>
</div>
);
}
});
React.render(
<HelloComponent title="hello" content="world" />,
document.getElementById('example')
);
</script>
推荐看下 Thinking in React 这篇文章。要实现文中提到的 搭积木式的开发模式,组件的嵌套使用是必不可少的。下面示范下,具体代码查看 compose-components.html。
<!DOCTYPE html>
<html>
<head>
<title>demo</title>
<script src="build/react.js"></script>
<script src="build/JSXTransformer.js"></script>
</head>
<body>
<div id="example"></div>
<script type="text/jsx">
var Title = React.createClass({
render: function(){
return (
<h1>This is Title</h1>
);
}
});
var Content = React.createClass({
render: function(){
return (
<p>This is Content</p>
);
}
});
// Article组件包含了 Title、Content 组件
var Article = React.createClass({
render: function() {
return (
<div class="article">
<Title />
<Content />
</div>
);
}
});
React.render(
<Article />,
document.getElementById('example')
);
</script>
</body>
</html>
在React的体系中,组件的UI会随着组件状态的变化(state)进行更新。从围观的代码层面来说,是 setState() 方法被调用时,组件的UI会刷新。简单例子可以参考 update-if-state-chagne.html。例子可能不是很恰当,就表达那么个意思。
其中有两个方法简单介绍下:
getInitialState:返回组件的初始状态。componentDidMount:当组件渲染完成后调用的方法。ps:React的组件更新机制是最大的亮点之一。看似全量刷新,实际内部是基于Virtual DOM机制的局部刷新,开发者无需再编写大量的重复代码来更新局部的dom节点。
Virtual DOM以及局部刷新实现机制,这里就不展开了,可参考 http://calendar.perfplanet.com/2013/diff/
<!DOCTYPE html>
<html>
<head>
<title>demo</title>
<script src="build/react.js"></script>
<script src="build/JSXTransformer.js"></script>
</head>
<body>
<div id="example"></div>
<script type="text/jsx">
var HelloComponent = React.createClass({
getInitialState: function(){
return {
title: 'title1',
content: 'content1'
};
},
componentDidMount: function(){
var that = this;
setTimeout(function(){
that.setState({
title:'title2',
content:'content2'
});
}, 2000);
},
render: function(){
return (
<div>
<h1>Title is: {this.state.title}</h1>
<p>Content is: {this.state.content}</p>
</div>
);
}
});
React.render(
<HelloComponent />,
document.getElementById('example')
);
</script>
</body>
</html>
访问  ,刚打开时,展示如下
,刚打开时,展示如下

2000ms后,界面刷新。

已经有人写过了,这里直接附上参考链接:http://calendar.perfplanet.com/2013/diff/
TODO 待填坑
之前挖了个坑,准备写篇gulp插件编写入门的科普文,之后迟迟没有动笔,因为不知道该肿么讲清楚Stream这货,毕竟,gulp插件的实现不像grunt插件的实现那么直观。
好吧,于是决定单刀直入了。文中插件示例可在这里找到:https://github.com/chyingp/gulp-preprocess
我们来看看下面的gruntfile,里面用到了笔者刚写的一个gulp插件gulp-preprocess。好吧,npm publish的时候才发现几个月前就被抢注了。为什么星期天晚上在 http://npmjs.org/package/ 上没有搜到 TAT
这个插件基于preprocess这个插件,插件使用方法请自行脑补。本文就讲解下如何实现 gulp-preprocess 这个插件
var gulp = require('gulp'),
preprocess = require('gulp-preprocess');
gulp.task('default', function() {
gulp.src('src/index.html')
.pipe(preprocess({USERNAME:'程序猿小卡'}))
.pipe(gulp.dest('dest/'));
});
我们来看下最关键的几行代码。可以看到,上文的 preprocess() 的作用就是返回一个定制的 Object Stream ,这是实现gulp的流式操作必需的,其他gulp插件也大同小异。
gulp-preprocess/index.js
module.exports = function (options) {
return through.obj(function (file, enc, cb) {
// 主体实现忽略若干行
});
};
接着,看下具体实现。实际上代码很短
首先,引入插件的依赖项。其中:
'use strict';
var gutil = require('gulp-util');
var through = require('through2');
var pp = require('preprocess');
其次,定义gulp-preprocess的主体代码。没错,就是下面这么短的代码。代码结构也比较清晰,下面还是简单做下分解介绍。
module.exports = function (options) {
return through.obj(function (file, enc, cb) {
if (file.isNull()) {
this.push(file);
return cb();
}
if (file.isStream()) {
this.emit('error', new gutil.PluginError(PLUGIN_NAME, 'Streaming not supported'));
return cb();
}
var content = pp.preprocess(file.contents.toString(), options || {});
file.contents = new Buffer(content);
this.push(file);
cb();
});
};
还是直接上代码,在关键位置加上注释。对 through2 不熟悉的童鞋可以参考这里
module.exports = function (options) {
return through.obj(function (file, enc, cb) {
// 如果文件为空,不做任何操作,转入下一个操作,即下一个 .pipe()
if (file.isNull()) {
this.push(file);
return cb();
}
// 插件不支持对 Stream 对直接操作,跑出异常
if (file.isStream()) {
this.emit('error', new gutil.PluginError(PLUGIN_NAME, 'Streaming not supported'));
return cb();
}
// 将文件内容转成字符串,并调用 preprocess 组件进行预处理
// 然后将处理后的字符串,再转成Buffer形式
var content = pp.preprocess(file.contents.toString(), options || {});
file.contents = new Buffer(content);
// 下面这两句基本是标配啦,可以参考下 through2 的API
this.push(file);
cb();
});
};
要把gulp插件内部实现的原理讲透不是件容易的事情,因为实现还是比较复杂的,首先需要对Buffer、Stream 有一定的了解,包括如何通过Node暴露的API对Stream进行定制化。可以参考笔者的另一篇随笔《gulp.src()内部实现探究》,虽然也只是讲了很小的一部分。
原文链接:http://rmurphey.com/blog/2012/04/12/a-baseline-for-front-end-developers/
前几天我为一个项目写README文档,我希望其他开发者能够看到这个项目,并从中学到一些东西。突然我意识到,若放在几年前,我写作的过程中随口提到的Node,npm,Homebrew,git,测试还有产品构建,会把我魂都吓没了。
曾经有段时间,一个前端开工程师基本的工作流程是:编辑文件,本地测试下(尽我们可能做到最好),然后通过FTP上传到服务器。我们评价一个前端工程师的水平,是通过他是否能够兼容IE6,或者取得跨浏览器的像素级的一致。很多社区的成员——包括我在内——缺少传统的编程经验。HTML、CSS和JavaScript——通常指jQuery——是自学的技能。
这些事情在过去的几年里发生了变化。可能是因为大家开始认真的看待前端开发者的工作,或者是因为浏览器开发商开始臭味相投(趋向一致?原句getting their shit together),又或者是前端开发者自己——同样,包括我在内——开始看到软件开发变得完善的曙光。
不管怎么说,我们看到前端开发的重点,从繁琐转向了重视工具化。想要成为一名成功的前端开发者,你需要掌握一套新的基础技能,而不满足要求的前端开发者会感觉到落后越来越多,而那些正在分享他们知识的工程师们觉得这些事情是自然而然的。
下面提到的一些内容是我希望人们能够熟悉的,除此之外还有一些相关的资源,如果你觉得你需要在成长的道路上加速的话。(感谢Paul Irish,Mike Taylor,Angus Croll,以及Vlad Fillppov的贡献)
这个不用多说,但仅仅知道一个javascript库再也不够了。我并不是说你需要知道如何用原生的JavaScript实现一个JavaScript库的所有特性,但你需要知道,什么时候的确需要用库,同时,在不需要用库的时候,有能力用简单而古老的JavaScript完成你的工作。
这意味着,你已经读过《JavaScript语言精粹》—— 希望不止一次。你理解像对象、数组这样的数据结构;函数,包括如何、为什么你需要~call和apply他们;掌握原型继承;掌握javascript的异步操作。
如果你的原生JS比较弱,这里有一些资源可以帮到你:
如果你没访问过Github,你绝对无法参与到这个资源丰富的开源社区中来,它已经在前端开发技术领域呈现欣欣向荣之势。克隆一个分支然后跑一下应该成为你的习惯,同时你需要知道在多人协作的项目中如何使用分支。
需要提升你的git技能?
通过在页面塞几个script或style标签来管理依赖的日子已经一去不复返了。即使你还没能能够将RequireJS引入你的工作流程中去,也应该找时间在自己的个人项目,或像Backbone Boilerplate这样的项目里试下它,因为它能给我们带来许多好处。RequireJS能够让你开发的JS、CSS文件保持模块化、粒度足够细,而在产品上线前可以通过配套的优化工具进行文件压缩、合并。
AMD听起来很吓人?再也没有借口什么也不干了。至少,你应该知道存在像UglifyJS、Closure Compiler这样的工具,它们能够在你的产品上线前,对你的代码进行智能压缩和合并。
如果你还在写原生的CSS —— 也就是说,目前没有用像Sass或者Stylus这样的CSS预处理器 —— RereireJS也能够帮你保持你的CSS文件模块化。在一个基础样式文件里使用@import声明来加载相关依赖文件,然后对这个基础文件运行ReqireJS Optimizer来构建实际生产环境所要用到的文件。
在过去的几年里,基于浏览器的开发工具已经大大得到了提升,如果你知道怎么利用好它们的话,它们能够大大提高你的开发体验。(提示:如果你还在使用alert调试代码的话,你会浪费很多时间)
你或许需要确定一款浏览器,你主要使用它的开发者工具 —— 近来我比较倾向于使用Google Chrome开发者工具 —— 但不要立即抛弃其他浏览器的开发者工具,因为他们经常会根据开发者的反馈来添加有用的特性。特别值得一提的是,Opera的Dragonfly的某些功能让它的开发者工具与众不同,比如(尚在实验中的)CSS分析器,可用户自定义的键盘快捷键,无需USB连接的远程调试,以及能够保存并使用自定义的调色板。
说到命令行,适应它(being comfortable with it)再也不是可选项了——如果你没有准备好坐到终端窗口前,并亲自动手敲命令行的话,你一路上会错过非常多的东西。我并不是说你必须在终端上完成所有事情——我不会抢走你的git GUI(图形化用户操作界面),虽然我的确觉得最终你离开它会更好——但不管做什么项目,你最好一直开着你的命令行终端。下面几个命令行任务是你必须不假思索就必须能够完成的:
ssh 登录另一台机器或服务器scp 拷贝文件到另一台机器或服务器ack或者grep 找到文件名包含某个字符串或符合某种模式的文件find 定位文件名符合某种模式的文件git 至少能够用它完成如下事情:add,commit,status和pullbrew 通过Homebrew 来安装文件npm 安装Node包gem 安装Ruby包如果有些命令你用得比较多,你可以编辑.bashrc或者.profile或者.zshrc或者其他,然后创建alias,这样你就不用像之前那样敲很多字符。你也可以添加alias到你的~/.gitconfig文件里。Gianni Chiappetta的dofiles是个不错的范例。
注意:如果你在Windows上开发,我不知道如何帮助你,除了建议使用Cygwin。在Windows上参与前端开源社区的活动比较麻烦,当然我说的不一定正确。相反的,MacBook Air便宜、强大,而且不可思议地便携,而且总是会有Ubuntu或者各种*nix。
在不久之前,对于前端的XHR请求,服务器典型的应答方式是返回一段HTML文本。但在过去的12到18个月间,前端开发社区看到了曙光,要求服务端返回单纯的数据。将数据转成HTML是件麻烦的事情,如果处理得不好的话,可维护性会相当糟糕。这就是前端模版库诞生的目的:你仅需要维护一套模板,在需要的时候提供数据,就能够将模板转换成HTML。在模板库的选择上需要帮助?Garann Mean的template chooser能够给你指明方向。
Paul Irish前些天注意到,前端开发者编写的代码,跟最终在生产环境部署的差别开始变得很大。通过CSS预处理器写出来的代码就是很好的例子。仍然有不少人坚持说原生的CSS才是唯一的出路,但它们离我们越来越近(but they are starting to come around)。这些工具提供了一些CSS属性按理来说早就该有的特性,包括——变量、数学运算、逻辑、混合(mixin),它们能够帮你从一堆冗余的特性前缀中解放出来。
编写模块化、松耦合代码的乐趣之一就是,你的代码变得很容测试。如果你用了Grunt这样的工具,创建一个包含测试用例的项目再简单不过了。虽然Grunt集成了QUnit,但是还有许多测框架供你选择——Jasmine和Mocha是我喜欢的两个测试框架——框架的选择取决于你的个人偏好,以及你项目的结构(the mark up of the rest of your stack)。
如果你的代码是模块化、松耦合的,测试是件有趣的事情。然而,对于那些组织糟糕的代码,测试不单困难,有时甚至不可能的。换句话说,强迫自己编写测试用例——甚至可能在你正式编码之前——有助于帮你理清你的思路以及你的代码组织。后续当你重构你的代码的时候,它也能让你充满自信。
流程自动化的一个例子:通过Grunt创建内置单元测试的项目。前端开发的现状是,我们有一大堆重复性的工作需要做,但有个朋友曾经告诉我,一个好的开发者是个“懒惰”的开发者:首要的一点是,如果你发现自己做同一件同样的事件超过三次,那么是时候将它变成自动化的。
像make这样的工具已经存在很长一段时间,主要用来帮我们解决上述问题,但也有类似rake、grunt以及其他类似的工具。如果你想把跟需要跟文件系统打交道的任务变成自动化,学习一门JavaScript以外的语言非常有帮助,因为当你仅仅想要处理文件时,Node的异步特性会让事情变得更加麻烦。也有许多针对特定任务的自动化工具——部署,构建,代码质量保证,还有其他。
如果你曾经被缺失分号,或多一个逗号这样的问题困扰过, 你就知道这样小的代码缺陷可以浪费你多少时间。这就是为什么你正在类似JSHint这样的工具里运行你的代码,没错吧?它不仅可配置,而且有很多方式可以将它集成到你的编辑器或构建流程中去。
唉,没有针对前端开发的手册,但MDN触手可及。好的前端开发者会在任何搜索查询里加上mdn前缀,比如mdn javascript arrays,避免搜到像w3schools那样的盈利性组织的内容。
阅读上面这些东西没办法让你成为一个专家,哪怕是变得更有经验些——在某件事情上做得更好的唯一途径就是做那件事。祝你好运。
基于任务的命令行构建工具(针对JavaScript项目)
前端的工具算得上是五花八门,在介绍如何Grunt之前,首先我们得反问自己:
作为一名开发人员,我们见过了不少功能胡里花哨但并不实用的工具。但是,我们很少会因为一个工具功能很强大而去使用它。更多地,是因为在工作中我们遇到了一些问题,而某个工具刚好帮我们解决了这些问题。
假设我们有个叫IMWEB_PROJ的项目,该项目主要包含两个功能模块,分别是moduleA、moduleB。回想一下,作为一名前端开发人员,从功能开发到产品正式上线,我们的工作流程是什么样的:
正式进入编码工作前,得做些准备工作:
HelloProj,index.html为主入口;根目录下面再另外新建三个目录/js、/css、/img,分别用来存放js文件、css文件、图片热火朝天地编码,产品终于即将上线,上线前的准备工作同样不能马虎
concat——JS文件合并,合理减少请求数,提升加载速度cssmin——CSS文件合并,合理减少请求数,提升加载速度JSHint检查下JS代码规范性——避免进行类似隐式全局变量这样的坑里Uglyfy压缩文件——减少文件尺寸,提升用户侧加载速度QUnit单元测试——提高项目可维护性,结合递归测试可尽早发现潜在问题上面的场景是不是很眼熟?重复而枯燥的工作占据了我们太多的时间,忘了谁说过,当重复做一件事超过三次,就应该考虑将它自动化。
Grunt正是为了解决上述问题而诞生,它将上面提到的项目结构生成、JSHint检查、文件合并、文件压缩、单元测试等繁琐的工作变成一个个可自动化完成的任务,一键搞定。
当然有,而且不少,Ant、Yeoman、Modjs等、Fiddler+willow+qzmin等,先不展开
参考链接:http://gruntjs.com/getting-started
使用Grunt通常分两种场景:
Grunt以及Grunt的插件,都是通过npm进行安装和管理,所以首先得安装node环境,不赘述,见 http://nodejs.org/
注意:为了解决多版本并存的问题,从0.4.x版本开始,每个项目需独立安装Grunt及对应插件,版本分别如下:
0.4.x>=0.8.0grunt从版本0.3.X到0.4.x,变化比较大,主要是为了解决Grunt多版本共存的问题,有兴趣的童鞋可以了解下。如果之前安装了0.3.x版本,需先进行卸载
npm uninstall -g grunt
grunt-cli的主要作用是让我们可以运行Grunt命令,加上-g,则可以在任意目录下运行,不展开
npm install -g grunt-cli
grunt-init是个脚手架工具,它可以帮你完成项目的自动化创建,包括项目的目录结构,每个目录里的文件等。具体情况要看你运行grunt-init指定的模板,以及创建过程中你对问题的回答,下文会简单讲到这个功能。先运行下面命令安装grunt-init,
npm install -g grunt-init
下面我们先通过安装jQuery Plugin模板,来展示Gurnt模板的安装,项目的创建,以及一个Grunt项目的目录结构
运行下面命令查看官方维护的Grunt模板
grunt-init --help
运行下面命令安装jQuery模板
git clone [email protected]:gruntjs/grunt-init-jquery.git ~/.grunt-init/jquery
在上一步中我们已经安装好了jQuery模板,接着运行下面命令,安装jQuery项目
grunt-init jquery
按照引导回答下面问题,完成项目的创建
Please answer the following:
[?] Project name (test) DemoJQuery
[?] Project title (DemojQuery)
[?] Description (The best jQuery plugin ever.) just for test
[?] Version (0.1.0) 1.0.0
[?] Project git repository (git://github.com/root/test.git)
[?] Project homepage (https://github.com/root/test)
[?] Project issues tracker (https://github.com/root/test/issues)
[?] Licenses (MIT)
[?] Author name (none) 程序 猿 小卡
[?] Author email (none)
[?] Author url (none) http://chyingp.cnblogs.com
[?] Required jQuery version (*) 1.9.0
[?] Do you need to make any changes to the above before continuing? (y/N) N
项目目录结构如下:
//项目目录结构
-rw-r--r-- 1 root staff 1670 5 9 15:13 CONTRIBUTING.md
-rw-r--r-- 1 root staff 559 5 9 15:13 DemoJQuery.jquery.json
-rw-r--r-- 1 root staff 2184 5 9 15:13 Gruntfile.js
-rw-r--r-- 1 root staff 1053 5 9 15:13 LICENSE-MIT
-rw-r--r-- 1 root staff 543 5 9 15:13 README.md
drwxr-xr-x 5 root staff 170 5 9 15:13 libs
-rw-r--r-- 1 root staff 423 5 9 15:13 package.json
drwxr-xr-x 4 root staff 136 5 9 15:13 src
drwxr-xr-x 5 root staff 170 5 9 15:13 test
从上面的目录结构,大致可以看出各个目录、文件的作用,其中我们需要注意的是两个文件Gruntfile.js、package.json,下面会稍微详细介绍到:
其他其他文件非Grunt项目必须的,可以暂时不去看它
首先运行下面命令,安装所需node模块,耐心等候安装完即可
npm install
运行下面命令
grunt
输出如下
Running "jshint:gruntfile" (jshint) task
>> 1 file lint free.
Running "jshint:src" (jshint) task
>> 1 file lint free.
...
方式一:运行下面命令,通过逐步回答问题的方式创建基础的package.json文件
npm init
方式二:创建空的package.json文件,拷贝下面内容,根据需要进行修改
{ "name": "HelloProj",
"version": "0.1.0",
"devDependencies": {
"grunt": "~0.4.1",
"grunt-contrib-jshint": "~0.1.1",
"grunt-contrib-nodeunit": "~0.1.2"
}
}
创建完package.json,运行如下命令,安装所需插件
npm install
运行如下命令,安装最新版的Grunt
npm install grunt --save-dev
Gruntfile.js的配置文件格式并不复杂,不过刚开始看的时候会有些云里雾里,直接拿官方范例进行修改即可。参考链接:http://gruntjs.com/sample-gruntfile
module.exports = function(grunt) {
// 项目配置信息
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: { //压缩文件
build: {
src: 'src/<%= pkg.name %>.js',
dest: 'build/<%= pkg.name %>.min.js'
}
},
concat: { //合并文件
js:{
src: ['js/moduleA.js', 'js/moduleB.js'],
dest: 'dist/js/moduleA-moduleB.js'
},
css:{
src:['dist/css/moduleA.css', 'dist/css/moduleB.css'],
dest: 'dist/css/moduleB.css'
}
}
});
// 加载uglify插件,完成压缩任务
grunt.loadNpmTasks('grunt-contrib-uglify');
// 加载concat插件,完成文件合并任务
grunt.loadNpmTasks('grunt-contrib-concat');
// 默认任务,如果运行grunt命令,且后面没有指定任务,或为defalut时,运行这个
grunt.registerTask('default', ['concat', 'uglify']);
};
其实这种方式还是有点麻烦,Grunt团队还是比较人性化的,针对Gruntfile,还提供了一个单独的plugin,让我们免去重复劳动之苦,后面再讲
下载链接:https://github.com/gruntjs/grunt-init-jquery
打开下载下来的示例目录,可以看到如下内容:
-rwxr-xr-x@ 1 casperchen staff 877 2 18 09:00 README.md
-rwxr-xr-x@ 1 casperchen staff 138 2 18 09:00 rename.json
drwxr-xr-x@ 10 casperchen staff 340 2 18 09:00 root
-rwxr-xr-x@ 1 casperchen staff 3521 2 18 09:00 template.js
简单介绍下里面内容:
template.js 主模板文件,非常重要!里面主要内容有:项目创建时需要回答的问题,项目依赖的Grunt模块(根据这个生成package.json)rename.json 针对当前模板的目录/文 件重命名规则,不赘述root/ 重要!在这个目录里的文件,通过该模板生成项目结构时,会将root目录下的文件都拷贝到项目中去init.writePackageJSON将之前下载的grunt-init-jquery-master重命名为imweb_template,然后就开始我们的模板自定义之旅了!鉴于这块的内容实在太多,就不详细讲解,直接贴上修改后的文件,可以更为直观,如需深入了解,可查看相关链接
下面是template.js最常包含的一些内容,主要包括:
exports.description 模板简单介绍信息exports.notes 开始回答项目相关问题前,控制台打印的相关信息exports.after 开始回答项目相关问题前,控制台打印的相关信息init.process 项目创建的时候,需要回答的问题init.writePackageJSON 生成package.json,供Grunt、npm使用 /*
* 模板名字
* https://gruntjs.com/
*
* 版权信息
* Licensed under the MIT license.
*/
'use strict';
// 模板简单介绍信息
exports.description = '创建IMWEB专属模板,带文件合并压缩哦!';
// 开始回答项目相关问题前,控制台打印的相关信息
exports.notes = '这段信息出现位置:回答各种项目相关的信息之前 ' +
'\n\n'+
'逐个填写就行,如果不想填的会可以直接enter跳过';
// 结束回答项目相关问题后,控制台打印出来的信息
exports.after = '项目主框架已经搭建好了,现在可以运行 ' +
'\n\n' +
'1、npm install 安装项目依赖的node模块\n'+
'2、grunt 运行任务,包括文件压缩、合并、校验等\n\n';
// 如果运行grunt-init运行的那个目录下,有目录或文件符合warOn指定的模式
// 则会跑出警告,防止用户不小心把当前目录下的文件覆盖了,一般都为*,如果要强制运行,可加上--force
// 例:grunt-init --force imweb_template
exports.warnOn = '*';
// The actual init template.
exports.template = function(grunt, init, done) {
init.process({type: 'IMWEB'}, [
// 项目创建的时候,需要回答的问题
init.prompt('name'),
init.prompt('title'),
init.prompt('description', 'IMWEB项目骨架'),
init.prompt('version', '1.0.0'),
init.prompt('author_name'),
init.prompt('author_email'),
], function(err, props) {
props.keywords = [];
// 需要拷贝处理的文件,这句一般不用改它
var files = init.filesToCopy(props);
// 实际修改跟处理的文件,noProcess表示不进行处理
init.copyAndProcess(files, props, {noProcess: 'libs/**'});
// 生成package.json,供Grunt、npm使用
init.writePackageJSON('package.json', {
name: 'IMWEB-PROJ',
version: '0.0.0-ignored',
npm_test: 'grunt qunit',
node_version: '>= 0.8.0',
devDependencies: {
'grunt-contrib-jshint': '~0.1.1',
'grunt-contrib-qunit': '~0.1.1',
'grunt-contrib-concat': '~0.1.2',
'grunt-contrib-uglify': '~0.1.1',
'grunt-contrib-cssmin': '~0.6.0',
'grunt-contrib-watch': '~0.2.0',
'grunt-contrib-clean': '~0.4.0',
},
});
// All done!
done();
});
};
reame.json的作用比较简单,定义了从root目录将文件拷贝到实际项目下时的路径映射关系,以key:value的形式声明。以下面的为例子,"src/"相对于root的路径,而"js/"则是相对于实际项目的路径。
ps:当value为false时,key对应的文件不会被拷贝到项目中去
{
"src/*.js": "js/*.js",
"test/test.html": "test/test.html"
}
进入修改后的root目录,可以看到很多文件,其中我们需要关注的有Gruntfile.js、README.md:
-rwxr-xr-x@ 1 casperchen staff 2408 5 10 09:34 Gruntfile.js
-rwxr-xr-x@ 1 casperchen staff 605 2 18 09:00 README.md
drwxr-xr-x 4 casperchen staff 136 5 9 20:31 css
drwxr-xr-x@ 8 casperchen staff 272 5 9 20:44 js
drwxr-xr-x@ 5 casperchen staff 170 2 18 09:00 libs
drwxr-xr-x@ 5 casperchen staff 170 2 18 09:00 test
对Gruntfile.js文件进行修改,如下,熟悉qzmin配置文件的童鞋应该很容易看懂
'use strict';
module.exports = function(grunt) {
// Project configuration.
grunt.initConfig({
// Metadata.
pkg: grunt.file.readJSON('package.json'),
banner: '/*! <%= pkg.title || pkg.name %> - v<%= pkg.version %> - ' +
'<%= grunt.template.today("yyyy-mm-dd") %>\n' +
'* Copyright (c) <%= grunt.template.today("yyyy") %> <%= pkg.author.name %>;' +
' */\n',
// 任务配置信息
clean: { // Grunt任务开始前的清理工作
files: ['dist']
},
concat: { //文件压缩
js_and_css: {
files: {
// js文件合并
'dist/js/base.js': ['js/simple.js', 'js/badjs.js', 'js/nohost.js'],
'dist/js/main.js': ['js/moduleA.js', 'js/moduleB.js' 'js/main.js'],
// css文件合并
'dist/css/style.css': ['css/reset.css', 'css/moduleA.css', 'css/moduleB.css']
}
}
},
uglify: { //js文件压缩
js: {
files: {
'dist/js/base.min.js': ['dist/js/base.js'],
'dist/js/main.min.js': ['dist/js/main.js']
}
}
},
cssmin:{ //CSS文件压缩
css: {
files: {
'dist/css/style.min.css': ['dist/css/style.css']
}
}
},
qunit: { //单元测试,范例中未启用
files: ['test/**/*.html']
},
jshint: { //文件校验,范例中未启用
gruntfile: {
options: {
jshintrc: '.jshintrc'
},
src: 'Gruntfile.js'
},
src: {
options: {
jshintrc: 'js/.jshintrc'
},
src: ['js/**/*.js']
},
test: {
options: {
jshintrc: 'test/.jshintrc'
},
src: ['test/**/*.js']
}
},
watch: { //watch任务,实时监听文件的变化,并进行编译
gruntfile: {
files: '<%= jshint.gruntfile.src %>',
tasks: ['jshint:gruntfile']
},
src: {
files: '<%= jshint.src.src %>',
tasks: ['jshint:src', 'qunit']
},
test: {
files: '<%= jshint.test.src %>',
tasks: ['jshint:test', 'qunit']
}
},
});
// 加载各种grunt插件完成任务
grunt.loadNpmTasks('grunt-contrib-clean');
grunt.loadNpmTasks('grunt-contrib-concat');
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-cssmin');
grunt.loadNpmTasks('grunt-contrib-qunit');
grunt.loadNpmTasks('grunt-contrib-jshint');
grunt.loadNpmTasks('grunt-contrib-watch');
// 默认任务
grunt.registerTask('default', ['clean', 'concat', 'uglify', 'cssmin']);
//grunt.registerTask('default', ['jshint', 'qunit', 'clean', 'concat', 'uglify']);
};
花了一点时间把imweb_proj配置好,现在终于到了实际运作阶段了,跟之前的步骤差不多。假设我们当前在目录HelloProj下,且imweb_template在HelloProj根目录下。下面为HelloProj目录下内容
drwxr-xr-x@ 8 casperchen staff 272 5 10 00:59 imweb_template
操作步骤可参照jQuery Plugin示例:如何运行一个现有的Grunt项目,下面直接上命令
grunt-init --force imweb_template/
npm install
grunt
下面为运行grunt命令后控制台输出的信息
Running "clean:files" (clean) task
Cleaning "dist"...OK
Running "concat:js_and_css" (concat) task
File "dist/js/base.js" created.
File "dist/js/main.js" created.
File "dist/css/style.css" created.
Running "uglify:js" (uglify) task
File "dist/js/base.min.js" created.
Uncompressed size: 96927 bytes.
Compressed size: 7609 bytes gzipped (34814 bytes minified).
File "dist/js/main.min.js" created.
Uncompressed size: 926 bytes.
Compressed size: 93 bytes gzipped (305 bytes minified).
Running "cssmin:css" (cssmin) task
File dist/css/style.min.css created.
Done, without errors.
可以看到HelloProj目录下的内容发生了改变,enjoy yourself
-rw-r--r-- 1 root staff 2398 5 10 14:39 Gruntfile.js
-rw-r--r-- 1 root staff 605 5 10 14:37 README.md
drwxr-xr-x 6 root staff 204 5 10 14:37 css
drwxr-xr-x 4 root staff 136 5 10 14:39 dist
drwxr-xr-x@ 8 casperchen staff 272 5 10 00:59 imweb_template
drwxr-xr-x 10 root staff 340 5 10 14:37 js
drwxr-xr-x 5 root staff 170 5 9 20:17 libs
drwxr-xr-x 10 casperchen staff 340 5 10 09:28 node_modules
-rw-r--r-- 1 root staff 458 5 10 14:37 package.json
drwxr-xr-x 4 root staff 136 5 9 20:17 src
drwxr-xr-x 5 root staff 170 5 9 20:17 test
上面对Grunt进行了入门介绍,下面简单说下Ant、aven
由于时间问题,这里没有对Grunt、Ant、Mod进行详细的对比,来个todo吧,qzmin也包含在内
// @todo 待填坑
假设页面有下面这么个标签,$('#ddd').attr('nick')、$('#ddd').prop('nick')分别会取得什么值?
<div id="test" nick="casper" class="dddd"></div>
没什么关子好卖,答案如下:
$('#test').attr('nick'); // "casper"
$('#test').prop('nick'); // undefined
再看看下面这几行代码:
$('#test')[0].nick = 'chyingp';
$('#test').attr('age'); // "casper"
$('#test').prop('nick'); // "chyingp"
看到这里应该知道这两个方法的区别了。其实从方法名也可以大致猜出来,.attr()、.prop()分别取的是节点的attribute值、property值。
至于attribute、property的区别,还真不知道怎么解释,有分别翻译成“特性”、“属性”的,这两个词看完后还是有头雾水。我就干脆直接理解成:
怎么方便怎么记吧。为方便区分,下文统一用特性来代指attribute,用属性来表示property。
attribute、property令人费解的地方在于:
1、一些常用attribute,比如id、class、value等,在设置attribute值的时候(直接写标签里,或通过setAttribute方法),会创建对应的property,部分情况下是同名的,比如id
document.getElementsByTagName('div')[0].id; // "casper"
document.getElementsByTagName('div')[0].getAttribute('id'); // "casper"
2、如1提到的,对某个attribute,创建了对应的property,但却用了不同的名称,比如class,对应的property为className
document.getElementsByTagName('div')[0].className; // "dddd"
document.getElementsByTagName('div')[0]['class']; // undefined
所以导致下面代码的诡异之处:
$('test').attr('class', 'dddd'); //有效
$('test').attr('className', 'dddd'); //无效
$('test').prop('class', 'dddd'); //无效
$('test').prop('className', 'dddd'); //有效
假设页面有这么个复选框,假设它的初始状态为选中
不知道有多少人曾经想我一样,被下面的代码弄得有些抓狂:false、null、"" 轮番上阵,复选框依旧保持“选中”状态$('#box')[0].setAttribute('checked', false);
$('#box')[0].getAttribute('checked', false); // 'false'
再试试下面这行代码估计更要抓狂了,T-T
$('#box')[0].checked; // true
好吧,如checkbox的checked属性,它的值为Boolean类型,特点是:
1)只要特性checked在标签里出现了,不管值是什么,复选框就会被选中。此时属性checked为true,否则为false;
2)后续修改特性checked的值,不会导致checkbox的选中状态改变;
3)后续修改属性checked的值,会导致checkbox的选中状态改变;
简单demo如下:
<input type="checkbox" id="box" checked="checked" />
<script>
document.getElementById('box').setAttribute('checked', false);
document.getElementById('box').getAttribute('checked'); // "false"
document.getElementById('box').checked; // true
document.getElementById('box').checked = false; // 复选框选中态消失
</script>
也可以参考jQuery官网的demo:http://api.jquery.com/attr/
.attr()内部是通过jQuery.attr()实现的,.prop()实现类似,所以这里只简单讲一下jQuery.attr()的实现,如下:
其中,大部分的特性值可通过getAttribute、setAttribute进行获取/设置,部分特殊的,比如href、src、checked等,需要调用相应的hook(钩子,很奇怪的名字)的get、set方法几i女性获取/设置值。
可以参照 http://api.jquery.com/attr/ 对.attr() 这个API的讲解,并结合断点调试来理解下面的源码。体力活,不赘述~~
attr: function( elem, name, value ) {
// 这里一坨代码可以先直接忽视,不影响下面主要逻辑,...代表被忽略的代码
// ...
// All attributes are lowercase
// Grab necessary hook if one is defined
if ( notxml ) {
name = name.toLowerCase();
// 这里几种情况:
// 1、一些特殊的特性,如href、width等=>attrHooks
// 2、一些值为Boolean的属性,如checked等=>boolHook
// 3、其他:nodeHook,主要是针对IE6/7的bug
hooks = jQuery.attrHooks[ name ] || ( rboolean.test( name ) ? boolHook : nodeHook );
}
if ( value !== undefined ) { //设置节点特性,包括:
//$(node).attr('nick','casper')
//或 $(node).attr({'nick':'casper', 'age':100})
//或 $(node).attr('nick', null)
if ( value === null ) { // 删除
jQuery.removeAttr( elem, name );
} else if ( hooks && notxml && "set" in hooks && (ret = hooks.set( elem, value, name )) !== undefined ) {
return ret; // 一些特殊的特性,比如href、src等,有专门的set方法
} else { // 普通的setAttribute
elem.setAttribute( name, value + "" );
return value;
}
} else if ( hooks && notxml && "get" in hooks && (ret = hooks.get( elem, name )) !== null ) {
// 获取特性值,且该特性有对应的hook~
return ret;
} else { // 普通的获取特性值
// In IE9+, Flash objects don't have .getAttribute (#12945)
// Support: IE9+
if ( typeof elem.getAttribute !== core_strundefined ) {
ret = elem.getAttribute( name );
}
// Non-existent attributes return null, we normalize to undefined
return ret == null ?
undefined :
ret;
}
}
参考连接:
从jQuery的源码中可以看到,jQuery.extend和jQuery.fn.extend其实是同指向同一方法的不同引用
jQuery.extend = jQuery.fn.extend = function() {
瞄了下它的代码,其实不复杂,但是在jQuery中扮演了极其重要的作用
jQuery.extend 对jQuery本身的属性和方法进行了扩展
jQuery.fn.extend 对jQuery.fn的属性和方法进行了扩展
// 扩展jQuery对象本身,此处添加了jQuery.noConflict方法
jQuery.extend({
noConflict: function(deep){
//实现细节略
},
//..
})
// 扩展jQuery.fn,此处添加 jQuery.fn.data方法
jQuery.fn.extend({
data: function( key, value ) {
//实现细节略
},
//...
})
下面会举例说明extend的常见使用方法,最后面的时候简单提下extend方法内部一些实现细节
代码如下
jQuery.extend({nick: 'casper'});
打印下
console.log(jQuery.nick); //输出:'casper'
代码如下,将obj2的的属性/方法拷贝到obj1上,需要注意的有两点
var obj1 = {nick: 'casper'},
obj2 = {nick: 'chyingp', age: 25};
var obj3 = jQuery.extend(obj1, obj2);
打印下
console.log( JSON.stringify(obj1) ); // 输出 {"nick":"chyingp","age":25}
console.log( JSON.stringify(obj3) ); // 输出 {"nick":"chyingp","age":25}
如下代码,obj1.scores 的值是个指向对象的引用,当obj2中存在同名应用时,默认obj2中的同名引用会覆盖obj1中那个
var obj1 = { nick: 'casper', scores: { math: 100, English: 100 } },
obj2 = { scores: { hitory: 100 } },
obj3 = jQuery.extend(obj1, obj2);
打印下
console.log( JSON.stringify(obj1) ); // 输出 {"nick":"casper","scores":{"hitory":100}}
还是实例三的代码,不同的是,第一个参数改成true,表明这是深拷贝
var obj1 = { nick: 'casper', scores: { math: 100, English: 100 } },
obj2 = { scores: { hitory: 100 } },
obj3 = jQuery.extend( true, obj1, obj2 );
打印下
console.log( JSON.stringify(obj1) ); // 输出 {"nick":"casper","scores":{"math":100,"English":100,"hitory":100}}
如下代码,给jQuery.fn添加 say 方法~
jQuery.fn.extend({
say: function(){
console.log("hello, I'm "+this.attr('id'));
}
});
打印下
$('#casper').say(); // 输出 hello, I'm casper
直接上代码
jQuery.extend = jQuery.fn.extend = function() {
var src, copyIsArray, copy, name, options, clone,
target = arguments[0] || {}, // 常见用法 jQuery.extend( obj1, obj2 ),此时,target为arguments[0]
i = 1,
length = arguments.length,
deep = false;
// Handle a deep copy situation
if ( typeof target === "boolean" ) { // 如果第一个参数为true,即 jQuery.extend( true, obj1, obj2 ); 的情况
deep = target; // 此时target是true
target = arguments[1] || {}; // target改为 obj1
// skip the boolean and the target
i = 2;
}
// Handle case when target is a string or something (possible in deep copy)
if ( typeof target !== "object" && !jQuery.isFunction(target) ) { // 处理奇怪的情况,比如 jQuery.extend( 'hello' , {nick: 'casper})~~
target = {};
}
// extend jQuery itself if only one argument is passed
if ( length === i ) { // 处理这种情况 jQuery.extend(obj),或 jQuery.fn.extend( obj )
target = this; // jQuery.extend时,this指的是jQuery;jQuery.fn.extend时,this指的是jQuery.fn
--i;
}
for ( ; i < length; i++ ) {
// Only deal with non-null/undefined values
if ( (options = arguments[ i ]) != null ) { // 比如 jQuery.extend( obj1, obj2, obj3, ojb4 ),options则为 obj2、obj3...
// Extend the base object
for ( name in options ) {
src = target[ name ];
copy = options[ name ];
// Prevent never-ending loop
if ( target === copy ) { // 防止自引用,不赘述
continue;
}
// Recurse if we're merging plain objects or arrays
// 如果是深拷贝,且被拷贝的属性值本身是个对象
if ( deep && copy && ( jQuery.isPlainObject(copy) || (copyIsArray = jQuery.isArray(copy)) ) ) {
if ( copyIsArray ) { // 被拷贝的属性值是个数组
copyIsArray = false;
clone = src && jQuery.isArray(src) ? src : [];
} else { 被拷贝的属性值是个plainObject,比如{ nick: 'casper' }
clone = src && jQuery.isPlainObject(src) ? src : {};
}
// Never move original objects, clone them
target[ name ] = jQuery.extend( deep, clone, copy ); // 递归~
// Don't bring in undefined values
} else if ( copy !== undefined ) { // 浅拷贝,且属性值不为undefined
target[ name ] = copy;
}
}
}
}
// Return the modified object
return target;
};
jQuery.extend / jQuery.fn.extend方法本身很简单,但在jQuery整体设计中的作用非常重要,理解了jQuery.extend(obj)、jQuery.fn.extend(obj) 分别是对jQuery本身、jQuery.fn 进行扩展,对后续的源码分析会很有帮助,除此之外,没了~~
chrome开发者工具很好很强大,此处省略三千字,进入主题。下面主要分两部分内容:
从下图可以看到,chrome开发者工具主要由下面几部分组成:
前面已经提到了fis release命令大致的运行流程。本文会进一步讲解增量编译以及依赖扫描的一些细节。
首先,在fis release后加上--watch参数,看下会有什么样的变化。打开命令行
fis release --watch
不难猜想,内部同样是调用release()方法把源文件编译一遍。区别在于,进程会监听项目路径下源文件的变化,一旦出现文件(夹)的增、删、改,则重新调用release()进行增量编译。
并且,如果资源之间存在依赖关系(比如资源内嵌),那么一些情况下,被依赖资源的变化,会反过来导致资源引用方的重新编译。
// 是否自动重新编译
if(options.watch){
watch(options); // 对!就是这里
} else {
release(options);
}
下面扒扒源码来验证下我们的猜想。
源码不算长,逻辑也比较清晰,这里就不上伪代码了,直接贴源码出来,附上一些注释,应该不难理解,无非就是重复**文件变化-->release(opt)**这个过程。
在下一小结稍稍展开下增量编译的细节。
function watch(opt){
var root = fis.project.getProjectPath();
var timer = -1;
var safePathReg = /[\\\/][_\-.\s\w]+$/i; // 是否安全路径(参考)
var ignoredReg = /[\/\\](?:output\b[^\/\\]*([\/\\]|$)|\.|fis-conf\.js$)/i; // ouput路径下的,或者 fis-conf.js 排除,不参与监听
opt.srcCache = fis.project.getSource(); // 缓存映射表,代表参与编译的源文件;格式为 源文件路径=>源文件对应的File实例。比较奇怪的是,opt.srcCache 没见到有地方用到,在 fis.release 里,fis.project.getSource() 会重新调用,这里感觉有点多余
// 根据传入的事件类型(type),返回对应的回调方法
// type 的取值有add、change、unlink、unlinkDir
function listener(type){
return function (path) {
if(safePathReg.test(path)){
var file = fis.file.wrap(path);
if (type == 'add' || type == 'change') { // 新增 或 修改文件
if (!opt.srcCache[file.subpath]) { // 新增的文件,还不在 opt.srcCache 里
var file = fis.file(path);
opt.srcCache[file.subpath] = file; // 从这里可以知道 opt.srcCache 的数据结构了,不展开
}
} else if (type == 'unlink') { // 删除文件
if (opt.srcCache[file.subpath]) {
delete opt.srcCache[file.subpath]; //
}
} else if (type == 'unlinkDir') { // 删除目录
fis.util.map(opt.srcCache, function (subpath, file) {
if (file.realpath.indexOf(path) !== -1) {
delete opt.srcCache[subpath];
}
});
}
clearTimeout(timer);
timer = setTimeout(function(){
release(opt); // 编译,增量编译的细节在内部实现了
}, 500);
}
};
}
//添加usePolling配置
// 这个配置项可以先忽略
var usePolling = null;
if (typeof fis.config.get('project.watch.usePolling') !== 'undefined'){
usePolling = fis.config.get('project.watch.usePolling');
}
// chokidar模块,主要负责文件变化的监听
// 除了error之外的所有事件,包括add、change、unlink、unlinkDir,都调用 listenter(eventType) 来处理
require('chokidar')
.watch(root, {
// 当文件发生变化时候,会调用这个方法(参数是变化文件的路径)
// 如果返回true,则不触发文件变化相关的事件
ignored : function(path){
var ignored = ignoredReg.test(path); // 如果满足,则忽略
// 从编译队列中排除
if (fis.config.get('project.exclude')){
ignored = ignored ||
fis.util.filter(path, fis.config.get('project.exclude')); // 此时 ignoredReg.test(path) 为false,如果在exclude里,ignored也为true
}
// 从watch中排除
if (fis.config.get('project.watch.exclude')){
ignored = ignored ||
fis.util.filter(path, fis.config.get('project.watch.exclude')); // 跟上面类似
}
return ignored;
},
usePolling: usePolling,
persistent: true
})
.on('add', listener('add'))
.on('change', listener('change'))
.on('unlink', listener('unlink'))
.on('unlinkDir', listener('unlinkDir'))
.on('error', function(err){
//fis.log.error(err);
});
}
增量编译的要点很简单,就是只发生变化的文件进行编译部署。在fis.release(opt, callback)里,有这段代码:
// ret.src 为项目下的源文件
fis.util.map(ret.src, function(subpath, file){
if(opt.beforeEach) {
opt.beforeEach(file, ret);
}
file = fis.compile(file);
if(opt.afterEach) {
opt.afterEach(file, ret); // 这里这里!
}
opt.afterEach(file, ret)这个回调方法可以在 fis-command-release/release.js 中找到。归纳下:
collection中去。deploy进行增量部署。(带着collection参数)opt.afterEach = function(file){
//cal compile time
// 略过无关代码
var mtime = file.getMtime().getTime(); // 源文件的最近修改时间
//collect file to deploy
// 如果符合这几个条件:1、文件需要部署 2、最近修改时间 不等于 上一次缓存的修改时间
// 那么重新编译部署
if(file.release && lastModified[file.subpath] !== mtime){
// 略过无关代码
lastModified[file.subpath] = mtime;
collection[file.subpath] = file; // 这里这里!!在 deploy 方法里会用到
}
};
关于deploy ,细节先略过,可以看到带上了collection参数。
deploy(opt, collection, total); // 部署~
在增量编译的时候,有个细节点很关键,变化的文件,可能被其他资源所引用(如内嵌),那么这时,除了编译文件之身,还需要对引用它的文件也进行编译。
原先我的想法是:
看了下FIS的实现,虽然大体思路是一致的,不过是反向操作。从资源引用方作为起始点,递归式地对引用的资源进行编译,并添加到资源依赖表里。
假设项目结构如下,仅有index.html、index.cc两个文件,且 index.html 通过 __inline 标记嵌入 index.css。
^CadeMacBook-Pro-3:fi a$ tree
.
├── index.css
└── index.html
index.html 内容如下。
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" type="text/css" href="index.css?__inline">
</head>
<body>
</body>
</html>
假设文件内容发生了变化,理论上应该是这样
理论是直观的,那么看下内部是怎么实现这个逻辑的。先归纳如下,再看源码
__inline内嵌的资源,并通过cache.addDeps(file)添加到deps里。index.html,发现index.html本身没有变化,但deps发生了变化,那么,重新编译部署index.html。好,看源码。在compile.js里面,cache.revert(revertObj)这个方法检测文件本身、文件依赖的资源是否变化。
if(file.isFile()){
if(file.useCompile && file.ext && file.ext !== '.'){
var cache = file.cache = fis.cache(file.realpath, CACHE_DIR), // 为文件建立缓存(路径)
revertObj = {};
// 目测是检测缓存过期了没,如果只是跑 fis release ,直接进else
if(file.useCache && cache.revert(revertObj)){ // 检查依赖的资源(deps)是否发生变化,就在 cache.revert(revertObj)这个方法里
exports.settings.beforeCacheRevert(file);
file.requires = revertObj.info.requires;
file.extras = revertObj.info.extras;
if(file.isText()){
revertObj.content = revertObj.content.toString('utf8');
}
file.setContent(revertObj.content);
exports.settings.afterCacheRevert(file);
} else {
看看cache.revert是如何定义的。大致归纳如下,源码不难看懂。至于infos.deps这货怎么来的,下面会立刻讲到。
// 如果过期,返回false;没有过期,返回true
// 注意,穿进来的file对象会被修改,往上挂属性
revert : function(file){
fis.log.debug('revert cache');
// this.cacheInfo、this.cacheFile 中存储了文件缓存相关的信息
// 如果还不存在,说明缓存还没建立哪(或者被人工删除了也有可能,这种变态情况不多)
if(
exports.enable
&& fis.util.exists(this.cacheInfo)
&& fis.util.exists(this.cacheFile)
){
fis.log.debug('cache file exists');
var infos = fis.util.readJSON(this.cacheInfo);
fis.log.debug('cache info read');
// 首先,检测文件本身是否发生变化
if(infos.version == this.version && infos.timestamp == this.timestamp){
// 接着,检测文件依赖的资源是否发生变化
// infos.deps 这货怎么来的,可以看下compile.js 里的实现
var deps = infos['deps'];
for(var f in deps){
if(deps.hasOwnProperty(f)){
var d = fis.util.mtime(f);
if(d == 0 || deps[f] != d.getTime()){ // 过期啦!!
fis.log.debug('cache is expired');
return false;
}
}
}
this.deps = deps;
fis.log.debug('cache is valid');
if(file){
file.info = infos.info;
file.content = fis.util.fs.readFileSync(this.cacheFile);
}
fis.log.debug('revert cache finished');
return true;
}
}
fis.log.debug('cache is expired');
return false;
},
之前多次提到deps这货,这里就简单讲下依赖扫描的过程。还是之前compile.js里那段代码。归纳如下:
process(file)这个方法对文件进行处理。里面进行了一系列操作,如文件的“标准化”处理等。在这个过程中,扫描出文件的依赖,并写到deps里去。下面会以“标准化”为例,进一步讲解依赖扫描的过程。
if(file.useCompile && file.ext && file.ext !== '.'){
var cache = file.cache = fis.cache(file.realpath, CACHE_DIR), // 为文件建立缓存(路径)
revertObj = {};
// 目测是检测缓存过期了没,如果只是跑 fis release ,直接进else
if(file.useCache && cache.revert(revertObj)){
exports.settings.beforeCacheRevert(file);
file.requires = revertObj.info.requires;
file.extras = revertObj.info.extras;
if(file.isText()){
revertObj.content = revertObj.content.toString('utf8');
}
file.setContent(revertObj.content);
exports.settings.afterCacheRevert(file);
} else {
// 缓存过期啦!!缓存还不存在啊!都到这里面来!!
exports.settings.beforeCompile(file);
file.setContent(fis.util.read(file.realpath));
process(file); // 这里面会对文件进行"标准化"等处理
exports.settings.afterCompile(file);
revertObj = {
requires : file.requires,
extras : file.extras
};
cache.save(file.getContent(), revertObj);
}
}
在process里,对文件进行了标准化操作。什么是标准化,可以参考官方文档。就是下面这小段代码
if(file.useStandard !== false){
standard(file);
}
看下standard内部是如何实现的。可以看到,针对类HTML、类JS、类CSS,分别进行了不同的能力扩展(包括内嵌)。比如上面的index.html,就会进入extHtml(content)。这个方法会扫描html文件的__inline标记,然后替换成特定的占位符,并将内嵌的资源加入依赖列表。
比如,文件的<link href="index.css?__inline" />会被替换成 <style type="text/css"><<<embed:"index.css?__inline">>>。
function standard(file){
var path = file.realpath,
content = file.getContent();
if(typeof content === 'string'){
fis.log.debug('standard start');
//expand language ability
if(file.isHtmlLike){
content = extHtml(content); // 如果有 <link href="index1.css?__inline" /> 会被替换成 <style type="text/css"><<<embed:"index1.css?__inline">>> 这样的占位符
} else if(file.isJsLike){
content = extJs(content);
} else if(file.isCssLike){
content = extCss(content);
}
content = content.replace(map.reg, function(all, type, value){
// 虽然这里很重要,还是先省略代码很多很多行
}
}
然后,在content.replace里面,将进入embed这个分支。从源码可以大致看出逻辑如下,更多细节就先不展开了。
content = content.replace(map.reg, function(all, type, value){
var ret = '', info;
try {
switch(type){
case 'require':
// 省略...
case 'uri':
// 省略...
case 'dep':
// 省略
case 'embed':
case 'jsEmbed':
info = fis.uri(value, file.dirname); // value ==> ""index.css?__inline""
var f;
if(info.file){
f = info.file;
} else if(fis.util.isAbsolute(info.rest)){
f = fis.file(info.rest);
}
if(f && f.isFile()){
if(embeddedCheck(file, f)){ // 一切合法性检查,比如有没有循环引用之类的
exports(f); // 编译依赖的资源
addDeps(file, f); // 添加到依赖列表
f.requires.forEach(function(id){
file.addRequire(id);
});
if(f.isText()){
ret = f.getContent();
if(type === 'jsEmbed' && !f.isJsLike && !f.isJsonLike){
ret = JSON.stringify(ret);
}
} else {
ret = info.quote + f.getBase64() + info.quote;
}
}
} else {
fis.log.error('unable to embed non-existent file [' + value + ']');
}
break;
default :
fis.log.error('unsupported fis language tag [' + type + ']');
}
} catch (e) {
embeddedMap = {};
e.message = e.message + ' in [' + file.subpath + ']';
throw e;
}
return ret;
});
更多内容,敬请期待。
前端的童鞋对jQuery绝对不会陌生,有不少刚入门的筒子,在不知JS为何物的时候,就已经在用jQuery了。这也应该归功于前端恶劣的生存环境:各自为政的浏览器厂商,依旧严峻的兼容性问题,并不好用的原生API。。。
使用jQuery的理由有很多,喜欢它的理由也很多,优雅的接口,丰富的插件,完善的文档等。作为一名有进取心的前端攻城狮,大家心理或多或少都有一个框架梦,总用它人写的库,内心总归有些那么不是滋味。
那好吧,干脆自己写一个,“师夷长技以自强”嘛,于是热火朝天地开工,一个又一个小JQ就这样横空出世。再精心挑选上好的测试用例证明自己的库比其他库更牛逼,当然,jQuery基本都在对比之列。
此处省略三千字。。下面开始进入jQuery源码分析之路
好吧,这里的jQuery指的并不是“jQuery库”,而是jQuery这个对象。首先用你习惯使用的编辑器打开jQuery-1.9.1.js,最好能够支持代码高亮和智能折叠。好家伙,源码加注释共9500++行,怪吓人的。没错,这是每个有志学习jQuery源码的童鞋需要过的第一道坎。其实,完全没有必要害怕,将多余的噪音去掉,其实jQuery就是下面几行代码而已:
(function( window, undefined ) {
var jQuery = function( selector, context ) {
// The jQuery object is actually just the init constructor 'enhanced'
return new jQuery.fn.init( selector, context, rootjQuery );
};
window.jQuery = window.$ = jQuery;
})( window );
我们更为常用的美元符号$,其实就是jQuery的同名对象,而jQuery是个方法,它的作用是返回一个jQuery对象,更确切地来说,是jQuery.fn.init对象。至于为什么会返回jQuery.fn.init对象,可以小小参考下之前写的另一篇文章【jquery学习笔记】美元背后的一点小技巧
$('#casper').addClass('handsome‘)这行代码的作用不用多说:给ID为casper的dom节点添加一个名为handsome的class。很简单的一句代码,拆成两部分来看:
$('#casper') 返回一个jQuery对象,该对象的属性’0‘包含了选中的dom节点=> $('#casper')[0] === document.getElementById('casper').addClass('handsome') 给选中的dom节点添加handsome类,addClass为jQuery的prototype方法于是我们把之前的那个简陋的骨架再丰满下,整个jQuery的骨架就基本出来了,里面的代码关键点在源码骨架后面会逐个进行讲解
(function( window, undefined ) {
var
jQuery = function( selector, context ) {
// The jQuery object is actually just the init constructor 'enhanced'
return new jQuery.fn.init( selector, context, rootjQuery );
};
//各种原型属性
jQuery.fn = jQuery.prototype = {
constructor: jQuery,
init: function( selector, context, rootjQuery ) {
//...
},
...
};
jQuery.fn.init.prototype = jQuery.fn;
//extend方法,用来扩展jQuery,或jQuery.fn
jQuery.extend = jQuery.fn.extend = function() {
//...
};
jQuery.fn.extend({
addClass: function( value ) {
//...
return this; //返回this,链式调用的秘密
}
});
window.jQuery = window.$ = jQuery;
})( window );
没什么好讲,jQuery.prototype为jQuery的原型方法,这里用jQuery.fn来代替jQuery.prototype,只是为了少写几个字符,平常写插件时就是在这东东上面做修改
很好很绕的一个语句,上面说了$(’#casper‘)返回的其实是个jQuery.fn.init对象。所以,这里的作用,是让jQuery.fn上的方法都成为jQuery.fn.init对象的原型方法。
这个语句应该让很多刚接触jQuery源码的人感到困惑,包括我(=_=),可以试jQuery.fn.init.prototype.init.prototype.init...,如果你愿意可以一直写下去。
下面这段代码很短很关键,别看它很简单,jQuery众多强大的接口就是这样通过jQuery.fn.extend一个一个扩展出来的,不赘述
jQuery.fn.extend({
addClass: function( value ) {
本文对jQuery源码核心结构进行了粗略的介绍,当然jQuery实际的源码要比这个复杂得多,但只要掌握了上面的要点,后续的分析就会轻松很多。jQuery源码之所以比较难看懂,是因为里面有许多为了解决糟糕的浏览器兼容性问题而引进的hack。
万事开头难,这是笔者jQuery源码解析的开篇之作,网络上这类的文章很多,而且有些写的很不错,这里写作的原因,一来总结,二来备忘。
未完待续。
选择一门模版语言时,可能会考虑的几点
注意到hbs,似乎满足大部分的需求:https://github.com/donpark/hbs
demo地址:https://github.com/chyingp/blog/tree/master/demo/2015.04.01-hbs/getting-started
目录结构如下:
.
├── app.js
├── node_modules
├── package.json
└── views
看下app.js内容,还是比较容易理解的。模版views/index.hbs没什么好说的,语法跟handlbars一样
var express = require('express'),
hbs = require('hbs'),
app = express();
app.set('view engine', 'hbs'); // 用hbs作为模版引擎
app.set('views', __dirname + '/views'); // 模版所在路径
app.get('/', function(req, res){
res.render('index', {title: 'hbs demo', author: 'chyingp'});
});
app.listen(3000);
demo地址:https://github.com/chyingp/blog/tree/master/demo/2015.04.01-hbs/inherit-from-layout
如果稍微看过hbs源码可以知道,hbs默认会到views下找layout.hbs这个模版,将这个模板作为基本骨架,来渲染返回的页面。
以getting-started里的例子来说,比如用户请求 http://127.0.0.1:3000,那么,处理步骤如下
views/index.hbs,进行编译,并将编译的结果保存为 Aviews/layout.hbs,如果
layout.hbs进行编译,其中{{{body}}}标签替换成 A,并返回最终编译结果B直接看例子。目录机构如下,可以看到多了个layout.hbs。
.
├── app.js
├── node_modules
│ ├── express
│ └── hbs
├── package.json
├── public
│ └── style.css
└── views
├── index.hbs
├── layout.hbs
└── profile.hbs
layout.hbs的内容如下:
<!DOCTYPE html>
<html>
<head>
<title>{{title}}</title>
<link rel="stylesheet" type="text/css" href="/style.css">
</head>
<body>
{{{body}}}
</body>
</html>
相应的,index.hbs调整为
<h1>Demo by {{author}}</h1>
<p>{{author}}: welcome to homepage, I'm handsome!</p>
再次访问 http://127.0.0.1:3000,可以看到返回的页面

demo地址:https://github.com/chyingp/blog/tree/master/demo/2015.04.01-hbs/inherit-and-override
在项目中,我们会有这样的需求。页面的基础骨架是共享的,但某些信息,每个页面可能是不同的,比如引用的css文件、meta标签等。那么,除了上面提到的“继承”之外,还需要引入类似“覆盖”的特性。
hbs官方其实就提供了demo https://github.com/donpark/hbs/blob/master/examples/extend/ ,感兴趣的同学可以去围观下。可以看到,在app.js里面加入了下面的 helper function`,这就是实现”覆盖“ 的关键代码了。
var blocks = {};
hbs.registerHelper('extend', function(name, context) {
var block = blocks[name];
if (!block) {
block = blocks[name] = [];
}
block.push(context.fn(this)); // for older versions of handlebars, use block.push(context(this));
});
hbs.registerHelper('block', function(name) {
var val = (blocks[name] || []).join('\n');
// clear the block
blocks[name] = [];
return val;
});
此外,layout.hbs需要做点小改动。里面比较明显的变化是加入了下面的block标记
{{{block "stylesheets"}}}
{{{block "scripts"}}}
那么,可以在index.hbs里对这些标记的内容进行覆盖(或者说自定义),包括其他的模版,如果有需要,都可以对这两个`block进行覆盖。
{{#extend "stylesheets"}}
<link rel="stylesheet" href="/css/index.css"/>
{{/extend}}
let the magic begin
{{#extend "scripts"}}
<script>
document.write('foo bar!');
</script>
{{/extend}}
那么问题来了。如果有这样的需求:所有的页面,都引用 style.css,只有 index.hbs 引用 index.css,那么上面的改动还不足以满足这个需求。
其实,只需要改几行代码就可以实现了,扩展性点个赞。改动后的app.js如下
var blocks = {};
hbs.registerHelper('extend', function(name, context) {
var block = blocks[name];
if (!block) {
block = blocks[name] = [];
}
block.push(context.fn(this)); // for older versions of handlebars, use block.push(context(this));
});
// 改动主要在这个方法
hbs.registerHelper('block', function(name, context) {
var len = (blocks[name] || []).length;
var val = (blocks[name] || []).join('\n');
// clear the block
blocks[name] = [];
return len ? val : context.fn(this);
});
学习jQuery源码,第一步是了解jQuery整体核心代码结构。第二步,当然就是了解无比强大无所不能的美元$。根据平常使用jQuery的经验,你会发现,几乎所有的语句都是以美元开头的,比如:
$(function(){
console.log('dom ready 啦!!');
});
又比如:
$('#casper').addClass('handsome');
当然还有其他。。。翻开jQuery的源码你会发现,里面就一行代码:
jQuery = function( selector, context ) {
// The jQuery object is actually just the init constructor 'enhanced'
return new jQuery.fn.init( selector, context, rootjQuery ); //就是这货
},
于是,我们接下来的任务就是一探jQuery.fn.init的究竟:里面究竟是什么东东,能够让美元符号$如此强大以至于无处不在。
老规矩,打开编辑器,定位到jQuery.fn.init这个方法。如果是用sublime的话,可以试下ctrl+r,然后输入init,第一个出来的搜索结果就是。
相信很多童鞋跟我的第一反应是:oh my god!将近90行代码!不过还可以接受啦,工作中还见别人写过300++行的方法,想想90行也算不得可怕。
然而,当你再往下看,可能就会有种想死的心——怎么这么多if、else!
不卖关子之所以会有那么多if、else,是因为——$有将近10种用法,文章最开头列举的不过是最常见的两种用法而已。
以下为jQuery.fn.init的源码,瞄一眼感受下这代码的可怕就可以了,可以暂时忽略其中的实现细节,安心进入下一节。
init: function( selector, context, rootjQuery ) {
var match, elem;
// HANDLE: $(""), $(null), $(undefined), $(false)
if ( !selector ) {
return this;
}
// Handle HTML strings
if ( typeof selector === "string" ) {
if ( selector.charAt(0) === "<" && selector.charAt( selector.length - 1 ) === ">" && selector.length >= 3 ) {
// Assume that strings that start and end with <> are HTML and skip the regex check
match = [ null, selector, null ];
} else {
match = rquickExpr.exec( selector );
}
// Match html or make sure no context is specified for #id
if ( match && (match[1] || !context) ) {
// HANDLE: $(html) -> $(array)
if ( match[1] ) {
context = context instanceof jQuery ? context[0] : context;
// scripts is true for back-compat
jQuery.merge( this, jQuery.parseHTML(
match[1],
context && context.nodeType ? context.ownerDocument || context : document,
true
) );
// HANDLE: $(html, props)
if ( rsingleTag.test( match[1] ) && jQuery.isPlainObject( context ) ) {
for ( match in context ) {
// Properties of context are called as methods if possible
if ( jQuery.isFunction( this[ match ] ) ) {
this[ match ]( context[ match ] );
// ...and otherwise set as attributes
} else {
this.attr( match, context[ match ] );
}
}
}
return this;
// HANDLE: $(#id)
} else {
elem = document.getElementById( match[2] );
// Check parentNode to catch when Blackberry 4.6 returns
// nodes that are no longer in the document #6963
if ( elem && elem.parentNode ) {
// Handle the case where IE and Opera return items
// by name instead of ID
if ( elem.id !== match[2] ) {
return rootjQuery.find( selector );
}
// Otherwise, we inject the element directly into the jQuery object
this.length = 1;
this[0] = elem;
}
this.context = document;
this.selector = selector;
return this;
}
// HANDLE: $(expr, $(...))
} else if ( !context || context.jquery ) {
return ( context || rootjQuery ).find( selector );
// HANDLE: $(expr, context)
// (which is just equivalent to: $(context).find(expr)
} else {
return this.constructor( context ).find( selector );
}
// HANDLE: $(DOMElement)
} else if ( selector.nodeType ) {
this.context = this[0] = selector;
this.length = 1;
return this;
// HANDLE: $(function)
// Shortcut for document ready
} else if ( jQuery.isFunction( selector ) ) {
return rootjQuery.ready( selector );
}
if ( selector.selector !== undefined ) {
this.selector = selector.selector;
this.context = selector.context;
}
return jQuery.makeArray( selector, this );
},
上面提到,$的用法有将近10种,也就是说,jQuery.fn.init这一个函数需要处理的情况有将近10种。那究竟都是哪些情况呢?如果想从它的源码直接看出来的话,那最好放弃。当然并不是说此路不通,只不过有更好的方法而已。
jQuery之所以这么受欢迎,其中一个原因是它的文档很齐全,这个时候果断可以去看它的API文档,请猛击这里
jQuery的API文档里面很详细地将各种情况都列了出来,可以看到,里面共列举了三大种、八小种情况。至于每种情况的作用、参数、返回值,可自行查看API说明,这里不赘述。
jQuery( selector [, context ] )
jQuery( selector [, context ] )
jQuery( element )
jQuery( elementArray )
jQuery( object )
jQuery( jQuery object )
jQuery()
jQuery( html [, ownerDocument ] )
jQuery( html [, ownerDocument ] )
jQuery( html, attributes )
jQuery( callback )
jQuery( callback )
上面我们已经将$的n种用法非常详细地列举出来了,但这只是第一步,因为对着jQuery.fn.init错综复杂的逻辑分支,你有可能依旧手忙脚乱,不知如何下手。里面比较明显能够看出来的是下面这几种情况:
jQuery()
jQuery( element )
jQuery( callback )
除了上面这三种情况外,其他五种情况依旧无法在代码里直观地看出来。那么肿么办呢?其实我也没有特别好的方法,但可以将自己的经验分享一下,分两步:
好,于是我们开始编写用例,下面提到的用例都基于下面的html片段
<div id="id_container" class="container">
<div class="header"></div>
</div>
直接上具体的用例。对于这些用例的具体分析会在下面再讲到。
//
$('#id_container')
$('.container')
//
$('.header', $('#id_container')[0])
$('.header', $('#id_container'))
//
$(document.getElementsByTagName('div'))
$(document.getElementsByTagName('div')[0])
$($('.header'))
$({name:'casper', age:25})
//
$('<div class="content"><span>casper</span></div>')
$('<div class="content"><span>casper</span></div>', document)
$('<div></div>', {'class':'content'})
$('<div/>', {'class':'content'})
//
$(function(){
console.log('$(callback)');
});
灰常简单,直接返回this(jQuery对象)
init: function( selector, context, rootjQuery ) {
var match, elem;
// HANDLE: $(""), $(null), $(undefined), $(false)
if ( !selector ) {
return this;
}
这个很简单,直接跑进下面这个分支然后就return了
else if ( jQuery.isFunction( selector ) ) {
return rootjQuery.ready( selector );
}
同样很简单,跑到这个分支里去了
else if ( selector.nodeType ) {
this.context = this[0] = selector;
this.length = 1;
return this;
}
这个比较费解,似乎前面所有的if、else都不符合,没错,其实只有下面这么句话
return jQuery.makeArray( selector, this );
跳过代码细节,先了解下面的背景知识,看下面的代码。对于$(selector)返回的jQuery对象,上面都会附加一个selector属性,作用不介绍。
$('.header').selector
于是乎,华丽丽地跑进下面这个分支,其实作用就是:创建一个jQuery对象,并将参数jQuery对象里的dom节点拷贝到新创建的jQuery对象里
if ( selector.selector !== undefined ) {
this.selector = selector.selector;
this.context = selector.context;
}
return jQuery.makeArray( selector, this );
这个的话,情况比较多,分开讲
init: function( selector, context, rootjQuery ) {
//各种省略
} else { //先跑到这个分支里去鸟
match = rquickExpr.exec( selector ); //这里,match==['#casper', undefined, 'casper']
}
//各种省略
// HANDLE: $(#id) //然后跑到这个分支了,其实源码的注释这里也说了~~
} else {
elem = document.getElementById( match[2] );
// Check parentNode to catch when Blackberry 4.6 returns
// nodes that are no longer in the document #6963
if ( elem && elem.parentNode ) {
// Handle the case where IE and Opera return items
// by name instead of ID
if ( elem.id !== match[2] ) {
return rootjQuery.find( selector );
}
// Otherwise, we inject the element directly into the jQuery object
this.length = 1;
this[0] = elem;
}
this.context = document;
this.selector = selector;
return this;
}
// HANDLE: $(expr, $(...))
} // 下面全部省略
//首先进入这个分支
match = rquickExpr.exec( selector ); //['#casper', undefined, 'casper']
//然后进入这个分支
} else {
return this.constructor( context ).find( selector );
}
//先进入这个分支
match = rquickExpr.exec( selector ); // match==null
//然后进入这个分支~
else if ( !context || context.jquery ) {
return ( context || rootjQuery ).find( selector );
// HANDLE: $(expr, context)
// (which is just equivalent to: $(context).find(expr)
}
//首先进入这里
match = rquickExpr.exec( selector ); // match==null
//然后进入这里
// HANDLE: $(expr, context)
// (which is just equivalent to: $(context).find(expr)
} else {
return this.constructor( context ).find( selector );
}
//首先进入这里
match = rquickExpr.exec( selector ); // match==null
//然后进入这里
// HANDLE: $(expr, $(...))
} else if ( !context || context.jquery ) {
return ( context || rootjQuery ).find( selector );
具体例子jQuery('<div></div>', {style: 'background:red;'}),或者jQuery('<div/>', {style: 'background:red'})
//首先进入这里
// Handle HTML strings
if ( typeof selector === "string" ) {
if ( selector.charAt(0) === "<" && selector.charAt( selector.length - 1 ) === ">" && selector.length >= 3 ) {
// Assume that strings that start and end with <> are HTML and skip the regex check
match = [ null, selector, null ]; //[null, '<div></div>', null]
}
//然后进入这里
// Match html or make sure no context is specified for #id
if ( match && (match[1] || !context) ) {
// HANDLE: $(html) -> $(array)
if ( match[1] ) {
context = context instanceof jQuery ? context[0] : context; // context == {style:{background:red}}
//先把创建好的dom借点复制到this里
// scripts is true for back-compat
jQuery.merge( this, jQuery.parseHTML(
match[1],
context && context.nodeType ? context.ownerDocument || context : document,
true
) );
//然后将{style: 'background:red'}等属性添加到创建好的dom节点上
// HANDLE: $(html, props)
if ( rsingleTag.test( match[1] ) && jQuery.isPlainObject( context ) ) {
for ( match in context ) {
// Properties of context are called as methods if possible
if ( jQuery.isFunction( this[ match ] ) ) {
this[ match ]( context[ match ] );
// ...and otherwise set as attributes
} else {
this.attr( match, context[ match ] );
}
}
}
return this;
// HANDLE: $(#id)
}
这个应该是我们经常用到的。。。
//首先华丽丽进入这个分支
if ( typeof selector === "string" ) {
if ( selector.charAt(0) === "<" && selector.charAt( selector.length - 1 ) === ">" && selector.length >= 3 ) {
// Assume that strings that start and end with <> are HTML and skip the regex check
match = [ null, selector, null ];
}
//然后进入这个分支
// Match html or make sure no context is specified for #id
if ( match && (match[1] || !context) ) {
//在进入这个分支
// HANDLE: $(html) -> $(array)
if ( match[1] ) {
context = context instanceof jQuery ? context[0] : context;
// scripts is true for back-compat
jQuery.merge( this, jQuery.parseHTML(
match[1],
context && context.nodeType ? context.ownerDocument || context : document,
true
) );
// 木有赋值
return this;
好了,万恶的美元$就先介绍到这里,第二部的源码详解本来还想把代码路径全部标出来,这样更方便观众围观。不过markdown给改变代码的字体颜色不知道咋整将就吧,且听下回分解
基于nodejs的实时web APP开发框架。

简单的说,你可以用js搞定客户端、服务端的开发。另外,客户端、服务端的界限被极大的模糊。客户端的界面跟服务端的数据是双向绑定的,修改服务端的数据,用户界面会随着更新;你也可以在客户端直接修改服务端的数据库。
系统的归纳下,对于(前端)开发者来说,可能比较吸引人的点。
demo请点击,参照官方demo进行的仿写,进一步进行了简化。也可直接参考官方demo
meteor的入门demo还是比较好上手的。跟着ste by step的教程走,基本就可以捣鼓出一个像样的TODO LIST的demo了,所以这里也不打算细讲,只是挑一些重点备忘下。
首先,安装meteor,然后通过meteor create这个命令创建一个新项目。
meteor create meteor-todo-list
创建好的项目结构如下。

大致包含以下内容。有点像传统的web页面,1个HTML页面,再加1个css文件、1个js文件。
.
├── .meteor // 项目依赖的package,在这个小demo里我们可以先忽略
├── meteor-todo-list.css // 页面相关的css
├── meteor-todo-list.html // 页面入口文件
└── meteor-todo-list.js // 页面主逻辑
打开html页面,你会发现只有head、body、template三个标签。如果接触过模版引擎的同学会有中熟悉之感。其中:
head、body两个标签中的内容,最终会被嵌入到输出给终端用户的HTML页面中。template则定义了页面需要用到的模版,有点向web component规范看齐的意味。举例来说,head标签中内容如下
<head>
<title>程序猿小卡的meteor demo</title>
</head
我们访问页面就可以看到title为程序猿小卡

至于body标签,如果对handlebars熟悉的同学,大致就知道是干嘛用的了。{{>create}}引入定义好的模版,该模版的name为create。{{#each tasks}}则是对数据进行遍历,至于数据源,下面会提到。
<body>
{{>create}}
<div class="todo-items">
{{#each tasks}}
{{>task}}
{{/each}}
</div>
</body>
我们再来看看这段模版。name为create,就可以在页面里方便的通过create这个名字来引用这段模版(包括模版嵌套)。而模版数据会在 meteor-todo-list.js 小节提到。
<template name="create">
<div class="">
<input type="text" placehodler="输入todo项" class="js-text" />
<button class="js-add">创建</button>
</div>
</template>
打开meteor-todo-list.js,会看到一行显眼的代码。正如meteor官方介绍所说,meteor应用的代码可以同时跑在客户端、服务端。有些场景下,某些代码只适合跑在客户端,那么,就可以用下面的判断。
if( Meteor.isClient ){
//...
}
meteor-todo-list.html里其实就一堆模版。相应的,需要为这些模版提供数据。数据大都是存在数据库的,那么就需要有数据库操作。
除了数据之外,还要处理用户交互,那么就涉及到事件绑定。
数据在meteor应用了扮演了极为重要的角色,作为实时双向更新的引用,meteor服务端数据的修改,会导致客户端界面的更新。同时,客户端用户操作导致的数据更新,也会实时同步到服务端。
比如这段代码,意思就是,模版body用到的tasks数据,就是这个同名方法的返回值。
Template.body.helpers({
tasks: function(){
return Tasks.find({});
}
});
比如页面有这么一段无聊的模版,那么就可以通过Template.nonsense.helpers来注册nonsense这段模版需要用到的数据。我们的页面里其实没有name为body的模版,这是因为内部做了特殊处理,body、head标签默认当模板对待了。
<template name="nonsense">
<p>hello {{nick}}</p>
</template>
下面来讲数据库操作,这里用到了人民大众热爱已久的mongodb。
首先,我们我们创建collections,对应的是一系列的文档集合,下面我们做的就是对这个文档集合进行操作,比如增、删、改、查,这四大操作demo里都覆盖到了。
var Tasks = new Mongo.Collection("tasks");
举个例子,返回所有的task数据,类似mysql里的select *。
return Tasks.find({});
插入一条task。
Tasks.insert({text: value, createdAt: new Date()});
其余操作类似,这里不赘述,更多细节参考官方文档。
相当直观。以下面代码为例。更多细节参考官方文档
Template.create.events表示为 create 这个模版渲染出来的节点绑定事件。click .js-add表示:为.js-add这个选择器匹配中的节点监听click事件。event就是常规的事件对象。而template相当于模版自身的引用,可以通过template.$(selector)来选中模版内部的子节点。(类似backbone内部节点操作的设计) Template.create.events({
'click .js-add': function(event, template){
var $input = template.$('.js-text'),
value = $input.val();
Tasks.insert({text: value, createdAt: new Date()});
$input.val('');
}
});
没什么好讲的,跳过。。。
DDP是 分布式数据协议 (Distributed Data Protocol)的简称,meteor双向实时更新机制的底层依赖的就是这东东。官方协议
粗略瞄了下协议,大致有两个特点:
实际看看例子。在chrome控制台下,切到WebSocket这个tab,就会看到不断的有收发包。部分是用户操作发出(如删除操作),部分是用于保持通信状态的心跳包。(可以这样翻译吧。。)

协议比较长,内容本身倒是不复杂,有兴趣的自行围观。。。
meteor有自己的包管理机制,也有个专门的社区在维护 https://atmospherejs.com/ 。关于这个,有空再单独拎出来讲讲。

同样没什么好讲的,直接贴上官方文档地址 https://www.meteor.com/try/7 ,有空再贴几章截图。。
TODO demo:https://github.com/chyingp/meteor-todo-list
官网:https://www.meteor.com/
入门教程:https://www.meteor.com/install
DDP协议:https://github.com/meteor/meteor/blob/devel/packages/ddp/DDP.md
**grunt-inline**是楼主之前写的一个插件,主要作用是把页面带了__inline标记的资源内嵌到html页面去。比如下面的这个script标签。
<script src="main.js?__inline"></script>技术难度不高,主要就是通过正则将符合条件的script标签等匹配出来。当时就在想:
如果有那么一个插件,能够帮我们完成html解析就好了!
没错,真有——cheerio。感谢当劳君的推荐 =。=
直接引用某前端同学的翻译。
为服务器特别定制的,快速、灵活、实施精益(lean implementation)的jQuery核心
举个最简单的栗子,更多API说明请参考官方文档
var cheerio = require('cheerio'),
$ = cheerio.load('<h2 class="title">Hello world</h2>');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> <h2 class="title welcome">Hello there!</h2>首先看下我们的目录结构。其中,src里的是源文件,dest目录里是编译生成的文件。可以猛击这里下载demo。
├── demo.js
├── package.json
├── dest
│ └── index.html
└── src
├── index.html
└── main.js
我们看下src/index.html,里面的main.js就是我们最终要内嵌的目标。let's go
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>cheerio demo</title>
</head>
<body>
<h1>cheerio demo</h1>
<script src="main.js?__inline"></script>
</body>
</html>在控制台敲如下命令,就会生成dest/index.html。下一节我们会讲下demo.js的实现
npm install
node demo.js
dest/index.html如下。
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>cheerio demo</title>
</head>
<body>
<h1>cheerio demo</h1>
<script>/**
* Created by a on 14-7-15.
*/
var Main = {
say: function(msg){
console.log(msg);
}
};</script>
</body>
</html>直接上demo.js的代码,一切尽在不言中。如果想更近一步,完成css资源、img资源的内嵌,非常简单,参照script内嵌的那部分代码就可以了。需要压缩代码?赶紧用uglifyjs啦,so easy,这里就不占用篇幅讲这个了。
/**
* Created by a on 14-7-15.
*/
var cheerio = require('cheerio'), // 主角 cheerio
fs = require('fs'),
url = require('url'),
path = require('path');
var from = 'src/index.html', // 源文件
to = 'dest/index.html', // 最终生成的文件
content = fs.readFileSync(from),
$ = cheerio.load(content), // 加载源文件
fd = 0;
// 选取 src/index.html 里所有的script标签,并将带有 __inline 标记的内嵌
$('script').each(function(index, script){
var script = $(this),
src = script.attr('src'),
urlObj = url.parse(src),
dir = path.dirname(from),
pathname = path.resolve(dir, urlObj.pathname),
scriptContent = '';
// 关键步骤:__inline 检测!(ps:非严谨写法)
if(urlObj.search.indexOf('__inline')!=-1){
scriptContent = fs.readFileSync(pathname);
script.replaceWith('<script>'+ scriptContent +'</script>');
}
});
// 创建dest目录
if(!fs.exists(path.dirname(to))){
fs.mkdirSync(path.dirname(to));
}
// 将处理完的文件写回去
fd = fs.openSync(to, 'w');
fs.writeFileSync(to, $.html());
fs.closeSync(fd);没什么好写的其实,求勘误~
描述:读取文件
{String} filename 文件名
{Object} options 可选配置项
{Function} callback 文件读取结束时的回调
jQuery**提供了四个操作class的方法,除了toggleClass外,其他从方法名就可以知道方法是干嘛的,下文会分别举具体例子
.addClass(className):添加className
.removeClass(className):删除className
.hasClass(className):是否有className
.toggleClass(className):如果没有className,则添加className;如果有,则删除className
3种用法,直接上例子
$('#aa').addClass('green'); // 添加green类
$('#cc').addClass('red green'); // 添加red green类
// index:元素在集合中的位置,从0开始
// className:元素当前className
// 返回值:添加到元素上的class
$('div').addClass(function(index, className){
if(index>1){
return 'red';
}else{
return 'green';
}
});
$('#aa').removeClass('green'); // 添加green类
$('#aa').removeClass('red green'); // 添加red green类
$('#aa').removeClass(); // 删除所有class
// index:元素在集合中的位置,从0开始
// className:元素当前className
// 返回值:从元素上删除的class
$('div').removeClass(function(index, className){
if(index>1){
return 'red';
}else{
return 'green';
}
});
1种用法,直接上例子;下面例子中需要注意的是:只要集合中的任意一个元素(div)有red类,它就返回true
$('div').hasClass('red'); // 是否存在div,它有red类
## .toggleClass:切换类
$('div').toggleClass('red'); // 切换red类
$('div').toggleClass('red green'); // 切换red、green类,相当于连续调两次toggleClass,分别传入red、green
var flag = false;
$('div').toggleClass('red', flag); // 如果flag为true,添加red类;否则,删除red类
$('div').toggleClass(function(index, className){ // 参数参照 .addClass
if(index>1){
return 'red'; // 这里返回的类会被拿去toggle~~~
}else{
return 'green';
}
});
$('div').toggleClass(function(index, className, flag){ // 跟上面的区别在于多了一个flag,其实就是本例子最后一个参数false
if(index>1){
return 'red';
}else{
return 'green';
}
}, false);
class操作的源码比较简单,字符串查找、相加、替换神马的,只要了解基本的正则,熟悉jQuery.fn.each就问题不大,这里就略过了~~~有问题的可以在下面丢个回复~~~ :)
jQuery官方文档:http://api.jquery.com/category/manipulation/class-attribute/
stream-handbook:https://github.com/substack/stream-handbook
node-glob:https://github.com/isaacs/node-glob
gaze:https://github.com/shama/gaze
autoprefixer:https://github.com/ai/autoprefixer
request,下载文件so easy:https://github.com/mikeal/request
node-liftoff:更简单地创建命令行工具?
https://github.com/tkellen/node-liftoff
可用的中间件:middleware
基础校验:basic-auth-connect
日志:morgan
cokie解析:cookie-parser
body解析:body-parse
中文文档
实时例子 - gihub地址
将html转成Jade
API文档
命令行参考
官方文档:https://github.com/gulpjs/gulp/blob/master/docs/README.md
插件编写:https://github.com/gulpjs/gulp/blob/master/docs/writing-a-plugin/README.md
through2:https://github.com/rvagg/through2
vinyl:https://github.com/wearefractal/vinyl
简单的gulp插件gulp-markdown:https://github.com/sindresorhus/gulp-markdown
History.js:https://github.com/browserstate/history.js
npm的包安装分为本地安装(local)、全局安装(global)两种,从敲的命令行来看,差别只是有没有-g而已,比如
npm install grunt # 本地安装
npm install -g grunt-cli # 全局安装
这两种安装方式有什么区别呢?从npm官方文档的说明来看,主要区别在于(后面通过具体的例子来说明):
本地安装
全局安装
比如运行下面命令
npm install grunt --save-dev那么,就会在当前目录下发现一个node_modules目录,进去后能够看到grunt这个包
casperchenMacBookPro:testUsemin casperchen$ ll
total 200
drwxr-xr-x 16 casperchen staff 544B 12 14 23:17 node_modules
进入node_modules
casperchenMacBookPro:node_modules casperchen$ ll
total 0
drwxr-xr-x 16 casperchen staff 544B 12 5 00:49 grunt
直接来个例子,我们在项目根目录下创建test.js,里面的内容很简单
var grunt = require('grunt');
grunt.log.writeln('hello grunt');然后在控制台运行test.js
node test.js
然后就会看到如下输出
casperchenMacBookPro:testUsemin casperchen$ node test.js
hello grunt
运行如下命令
npm install -g grunt-cli
然后进入/usr/local/bin目录,就会发现grunt-cli已经被放置在下面了
casperchenMacBookPro:bin casperchen$ pwd
/usr/local/bin
casperchenMacBookPro:bin casperchen$ ll grunt
lrwxr-xr-x 1 root admin 39B 8 18 21:43 grunt -> ../lib/node_modules/grunt-cli/bin/grunt
可见,全局模块的真实安装路径在/usr/local/lib/node_modules/下,/usr/local/bin下的可执行文件只是软链接而已
实现细节在上面其实就讲到了,通过在``/usr/local/bin`下创建软链接的方式实现。这里不赘述
下面就直接看下,当我们在项目目录下运行grunt task(task为具体的grunt任务名,自行替换)时,发生了什么事情。这里要借助node-inspector。
首先,没接触过node-inspector的童鞋可以参考之前的文章了解下
运行如下命令开启调试
node-inspector &
见到如下输出
casperchenMacBookPro:tmp casperchen$ node-inspector &
[1] 14390
casperchenMacBookPro:tmp casperchen$ Node Inspector v0.6.1
info - socket.io started
Visit http://127.0.0.1:8080/debug?port=5858 to start debugging.
接着,在当前任务下运行grunt任务
^CcasperchenMacBookPro:testUsemin casperchen$ node --debug-brk $(which grunt) dev
debugger listening on port 5858
接着,打开chrome浏览器,输入网址http://127.0.0.1:8080/debug?port=5858,就会自动进入断点调试状态
。从一旁显示的tips可以看到,全局命令grunt其实就是/usr/local/lib/node_modules/grunt-cli/bin/grunt
按下F8接着往下跑,就会进如Gruntfile.js,此时的grunt,是本地安装的一个node包。全局命令跟本地的包名字一样,挺有迷惑性的。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.


