Data Analyst for Trajectory Data
The project aims to explore the optimization of different Density-Based Clustering Methods to evaluate the aggregation of observed paths from trajectories
K-means is a centroid-based clustering method, valued for its simplicity and ability to manage large datasets. It partitions input data into clusters based on similarity but requires a pre-defined cluster count 'K' and can be sensitive to its value and outliers.
Hierarchical Clustering measures the distance between data points and suits hierarchical data like taxonomies (e.g., animals -> mammals, birds). It's flexible in cluster count but can struggle with outliers and noise.
Density-based clustering prioritizes density over distance. DBSCAN is notable, excelling with spatial data like our geographical dataset. It doesn't need a fixed cluster count, handles non-spherical shapes, and prevents outliers.
In conclusion, density-based clustering is favored for our dataset due to outlier resilience. While K-means and Hierarchical methods are simpler, they're sensitive to noise and outliers. Given our spatial data, density-based methods are the better fit.
Density-Based Clustering methods used:
- DBSCAN: The cluster does not have to be spherical shapes to be identified, and the number of clusters does not have to be pre-defined. Moreover, it is insensitive to outliers. However, DBSCAN is sensitive to its two required parameters, and fine-tuning them takes time and requires deep understanding on the dataset. In addition, it does not perform well over clusters with different densities.
- OPTICS: It excels at detecting clusters of varying densities and can manage larger datasets compared to DBSCAN. Additionally, the epsilon parameter is relatively straightforward to set with a default value, simplifying parameter tuning. Conversely, OPTICS demands more memory due to its use of a priority queue (Min Heap) to identify the next closest data point during processing. It falters if density drops between clusters are absent.
- HDBSCAN: It places emphasis solely on densely concentrated points, capable of creating significant clusters even with low-density components. Additionally, it necessitates just one parameter. However, HDBSCAN's efficacy diminishes beyond 50 to 100 dimensions. Furthermore, insufficient data size can lead to indistinct cluster separation.
Centroid-Based Clustering method used:
- K-means: K-means is the centroid-based clustering, which requires one parameter, however it is sensitive the its own required parameter and sensitive to outliers.
Results of comparison
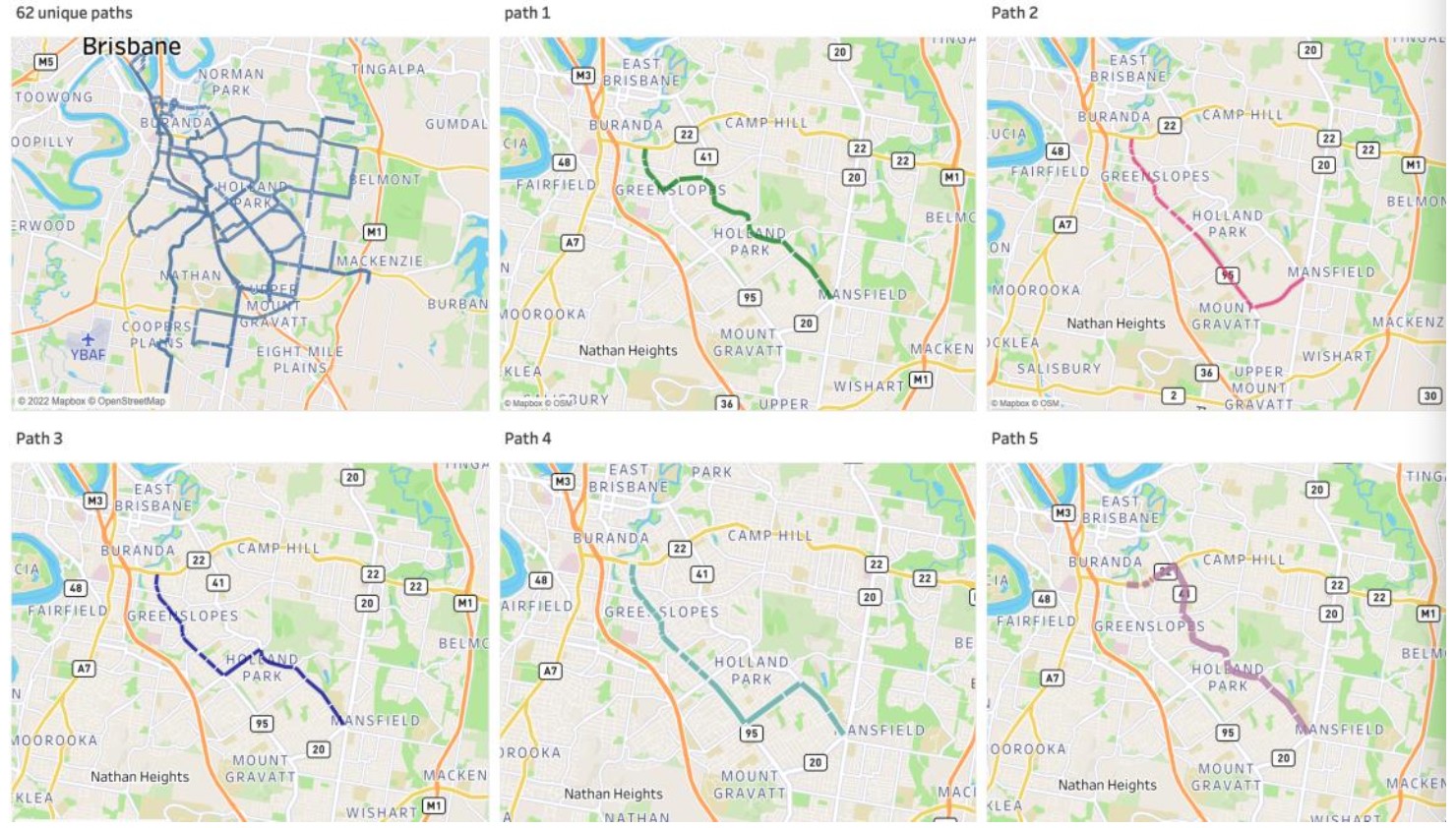
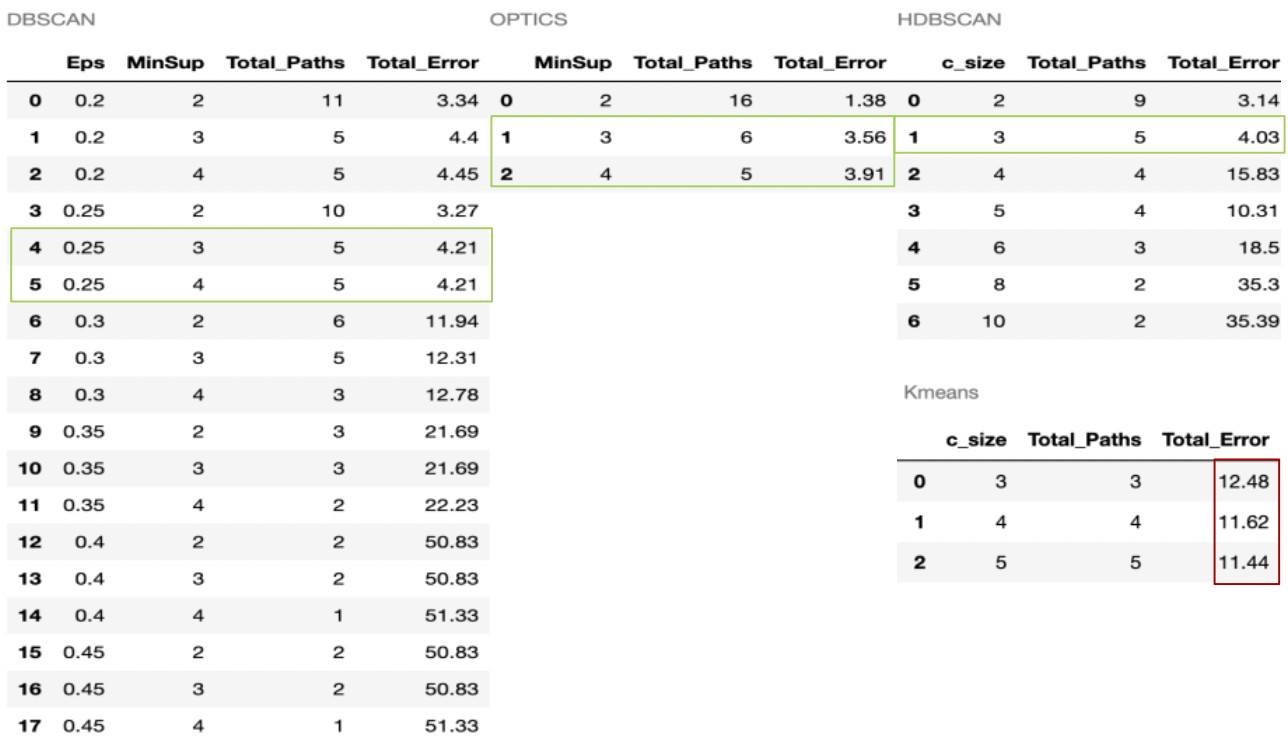
The DBSCAN outcome is produced after 18 iterations, owing to the complexity in defining and fine-tuning the necessary hyperparameters for optimal results. Consequently, when Eps equals or exceeds 0.3, the error escalates notably from about 4.21% to 11.94%, eventually reaching 51.33%. OPTICS, requiring one fewer parameter than DBSCAN, yields excellent results in just three iterations, demonstrating a reasonable path count and minimal errors.
HDBSCAN demands a sole parameter, the minimum cluster size, delivering optimal outcomes when set to three; resulting in five paths and a 4.03% inaccuracy. In contrast, the K-means output exhibits significantly higher overall error due to its inability to effectively manage outliers or noise.
Utilizing Tableau to present the selected paths