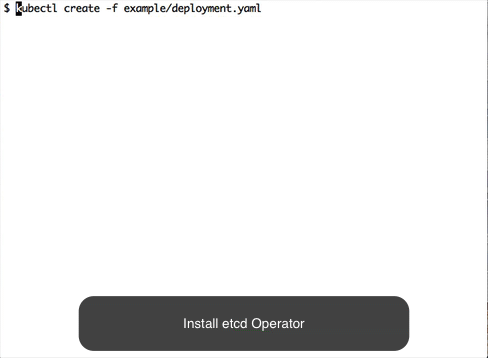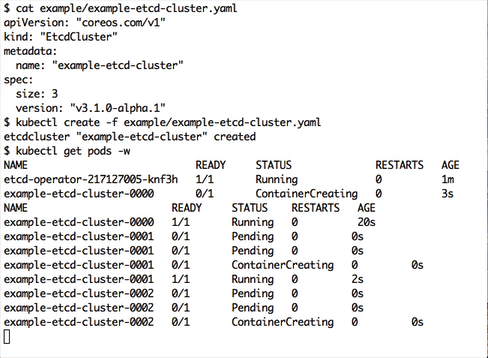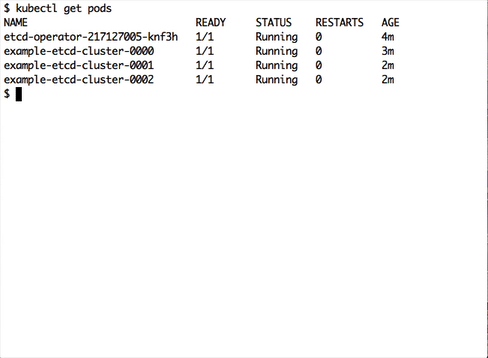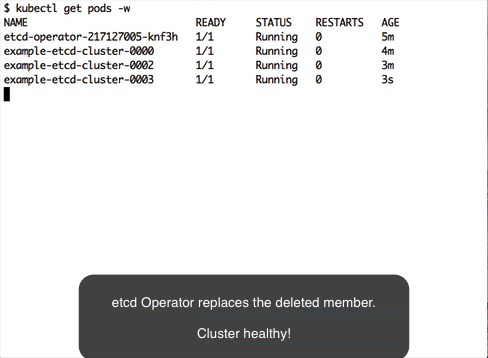
somehow the watcher gets stuck in an error loop, causing the controller to hit the api server constantly and make the cpu load very high.
the size of my cluster is 1.
does it make sense to add a rate limit to the watch loop to prevent accidental high cpu use on the api server?
here are logs with an additional print statement to dump the watch error.
time="2016-10-03T23:01:17Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:17Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:19Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:19Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:22Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:22Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:22Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:22Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:24Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:24Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:27Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:27Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:27Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:27Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:29Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:29Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:32Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:32Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:32Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:32Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:34Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:34Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:37Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:37Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:37Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:37Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:39Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:39Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:42Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:42Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:42Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:42Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:44Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:44Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:47Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:47Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:47Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:47Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:49Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:49Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:52Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:52Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:52Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:52Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:54Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:54Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:01:57Z" level=info msg="Reconciling:"
time="2016-10-03T23:01:57Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:01:57Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:01:57Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:01:59Z" level=info msg="watching at 2639990"
time="2016-10-03T23:01:59Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:02Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:02Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:02Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:02Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:04Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:04Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:07Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:07Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:07Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:07Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:09Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:09Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:12Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:12Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:12Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:12Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:14Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:14Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:17Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:17Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:17Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:17Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:19Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:19Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:22Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:22Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:22Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:22Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:24Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:24Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:27Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:27Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:27Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:27Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:29Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:29Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:32Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:32Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:32Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:32Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:34Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:34Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"
time="2016-10-03T23:02:37Z" level=info msg="Reconciling:"
time="2016-10-03T23:02:37Z" level=info msg="Running pods: etcd-cluster-0000"
time="2016-10-03T23:02:37Z" level=info msg="Expected membership: etcd-cluster-0000"
time="2016-10-03T23:02:37Z" level=info msg="Finish Reconciling"
time="2016-10-03T23:02:39Z" level=info msg="watching at 2639990"
time="2016-10-03T23:02:39Z" level=info msg="etcd cluster event error: &controller.Event{Type:\"ERROR\", Object:cluster.EtcdCluster{TypeMeta:unversioned.TypeMeta{Kind:\"Status\", APIVersion:\"v1\"}, ObjectMeta:api.ObjectMeta{Name:\"\", GenerateName:\"\", Namespace:\"\", SelfLink:\"\", UID:\"\", ResourceVersion:\"\", Generation:0, CreationTimestamp:unversioned.Time{Time:time.Time{sec:0, nsec:0, loc:(*time.Location)(nil)}}, DeletionTimestamp:(*unversioned.Time)(nil), DeletionGracePeriodSeconds:(*int64)(nil), Labels:map[string]string(nil), Annotations:map[string]string(nil), OwnerReferences:[]api.OwnerReference(nil), Finalizers:[]string(nil), ClusterName:\"\"}, Spec:cluster.Spec{Size:0, AntiAffinity:false, Version:\"\", Backup:(*backup.Policy)(nil), HostNetwork:false}}}"