databrickslabs / migrate Goto Github PK
View Code? Open in Web Editor NEWOld scripts for one-off ST-to-E2 migrations. Use "terraform exporter" linked in the readme.
License: Other
Old scripts for one-off ST-to-E2 migrations. Use "terraform exporter" linked in the readme.
License: Other










































































































































Import cannot re-create admins group:
Creating group: admins
Error: b'{"schemas":["urn:ietf:params:scim:api:messages:2.0:Error"],"detail":"Group with name admins already exists.","status":"409"}\n'
therefore it should not be exported.
Having to switch between CLIs just to configure tokens may not be needed.
Since integration with click we can simply just add:
from databricks_cli.configure.cli import configure_cli
cli.add_command(configure_cli, name='configure')This should pull in the configure command into this cli but also be compatible with the CLI at the same time.
Let me know if anyone has concerns of both tools having the configure command.
Cannot import clusters after export --clusters:
➜ migrate-sample databricks-migrate import --profile sandbox --clusters
Executing action: 'start importing databricks objects' at time: 2020-10-02 11:23:59.949141
Executing action: 'import instance profiles' at time: 2020-10-02 11:23:59.951035
Duration to execute function 'import instance profiles': 0:00:00.426867
Executing action: 'import instance pools' at time: 2020-10-02 11:24:00.378298
Error: TypeError: create_instance_pool() got an unexpected keyword argument 'instance_pool_id'
The workspace databricks REST API supports an overwrite option for workspace artifacts
But the arguments passed to import objects from a prior export are defaults and in such a case, the "overwrite" flag remains false.
An --overwrite option would be quite beneficial here.
Looks like it is needed to add "import re" to HiveClient.py
File "/home/hadoop/databricks/migrate/dbclient/HiveClient.py", line 48, in get_path_option_if_available
params = re.search(r'((.*?))', stmt).group(1)
NameError: name 're' is not defined
Error output:
➜ databricks-migrate export --profile sandbox --workspace --download
Executing action: 'start exporting databricks objects' at time: 2020-10-02 11:16:41.704741
Executing action: 'export workspace object configs' at time: 2020-10-02 11:16:41.706632
Duration to execute function 'export workspace object configs': 0:00:33.061810
Executing action: 'download workspace objects' at time: 2020-10-02 11:17:14.769287
Duration to execute function 'download workspace objects': 0:00:00.971945
Duration to execute function 'start exporting databricks objects': 0:00:34.038299
➜ databricks-migrate import --profile sandbox-e2 --workspace
Executing action: 'start importing databricks objects' at time: 2020-10-02 11:17:33.095767
Executing action: 'import all the workspace objects' at time: 2020-10-02 11:17:33.097597
Uploading: Test.dbc
Uploading: r.dbc
Uploading: python.dbc
Uploading: scala.dbc
Uploading: sql.dbc
Error: b'{"error_code":"RESOURCE_DOES_NOT_EXIST","message":"Path (/Users/[email protected]) doesn\'t exist."}'
RE is not being imported on dbclient/HiveClient but it's being used in line 47.
migrate/dbclient/HiveClient.py
Line 47 in 31d3f32
When exporting databases from the metastore, the table definitions generated do not have constraints such as 'is not null' defined for columns that have them in the original.

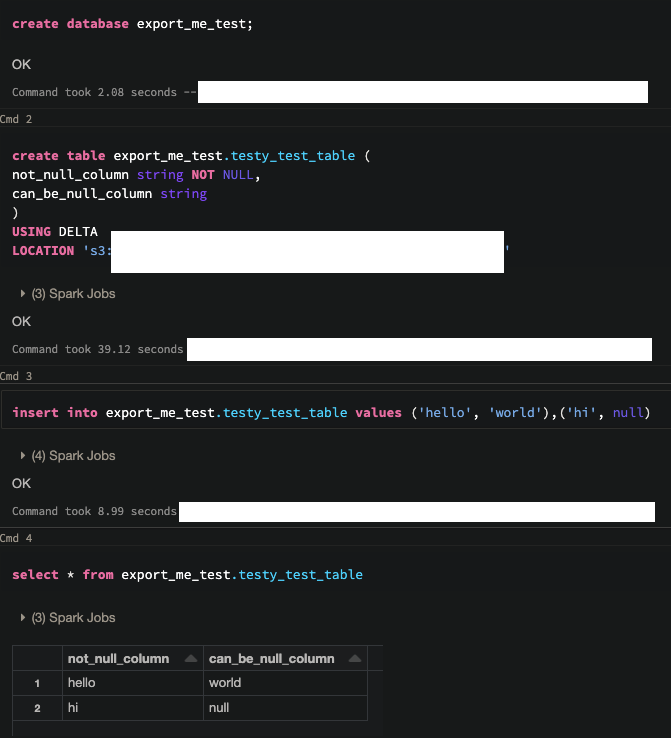
When applying metastore DDL during view creation, it could fail because the underlying table does not exist.
We should follow an order of operation:
Workaround: Users can work around this issue by running the import twice.
First pass will create the tables, second pass will skip failed tables and be able to create the views.
Attempt to export custom CSV file formats that use ^A as a delimiter.
Hi, we had an azure dev-ops pipeline working fine and recently our migration pipeline is failing with the following error on exporting metadata. It is using cluster with the 7.3 LTS runtime. The pipeline has worked successfully before and also works using the templated cluster
Azure Dev-ops error:
ERROR:
AttributeError: namespace
{"resultType": "error", "summary": "<span class="ansi-red-fg">AttributeError: namespace", "cause": "---------------------------------------------------------------------------\nValueError Traceback (most recent call last)\n/databricks/spark/python/pyspark/sql/types.py in getattr(self, item)\n 1594 # but this will not be used in normal cases\n-> 1595 idx = self.fields.index(item)\n 1596 return self[idx]\n\nValueError: 'namespace' is not in list\n\nDuring handling of the above exception, another exception occurred:\n\nAttributeError Traceback (most recent call last)\n in \n----> 1 all_dbs = [x.namespace for x in spark.sql("show databases").collect()]; print(len(all_dbs))\n\n in (.0)\n----> 1 all_dbs = [x.namespace for x in spark.sql("show databases").collect()]; print(len(all_dbs))\n\n/databricks/spark/python/pyspark/sql/types.py in getattr(self, item)\n 1598 raise AttributeError(item)\n 1599 except ValueError:\n-> 1600 raise AttributeError(item)\n 1601 \n 1602 def setattr(self, key, value):\n\nAttributeError: namespace"}
2021-03-15T16:33:09.1574639Z
----------------------------- Driver Log ---------------------------------------------
ValueError Traceback (most recent call last)
/databricks/spark/python/pyspark/sql/types.py in getattr(self, item)
1594 # but this will not be used in normal cases
-> 1595 idx = self.fields.index(item)
1596 return self[idx]
ValueError: 'namespace' is not in list
During handling of the above exception, another exception occurred:
AttributeError Traceback (most recent call last)
in
----> 1 all_dbs = [x.namespace for x in spark.sql("show databases").collect()]; print(len(all_dbs))
in (.0)
----> 1 all_dbs = [x.namespace for x in spark.sql("show databases").collect()]; print(len(all_dbs))
/databricks/spark/python/pyspark/sql/types.py in getattr(self, item)
1598 raise AttributeError(item)
1599 except ValueError:
-> 1600 raise AttributeError(item)
1601
1602 def setattr(self, key, value):
AttributeError: namespace
I ran export_db.py --workspace no problem, but export_db.py --download hits a snag saying:
. . .
Downloading: /Users/[email protected]/Completed Work/Dave Testing/Threading testing
Get: https://bethesda2.cloud.databricks.com/api/2.0/workspace/export
Traceback (most recent call last):
File "./migrate/export_db.py", line 297, in <module>
main()
File "./migrate/export_db.py", line 81, in main
num_notebooks = ws_c.download_notebooks()
File "/Users/neil.best/Documents/GitHub/BethesdaNet/zmi-bi-databricks/migrate/dbclient/WorkspaceClient.py", line 229, in download_notebooks
dl_resp = self.download_notebook_helper(notebook_path, export_dir=self.get_export_dir() + ws_dir)
File "/Users/neil.best/Documents/GitHub/BethesdaNet/zmi-bi-databricks/migrate/dbclient/WorkspaceClient.py", line 256, in download_notebook_helper
save_filename = save_path + os.path.basename(notebook_path) + '.' + resp.get('file_type')
TypeError: must be str, not NoneType
That last notebook name had a trailing space:
'.../Threading testing ' 👈
The workaround was to fix it at the source and in the migrate log.
%sql desc database foo_s3 will show the LOCATION.
Check if this is the default location or a custom location for the warehouse / database.
If so, create the database w/ the location.
whenever instance profiles could not be imported, application should log a warning and not stop completely, allowing operation resume in the later steps.
➜ migrate-sample databricks-migrate import --profile sandbox-e2 --users
Executing action: 'start importing databricks objects' at time: 2020-10-02 10:56:43.340801
Executing action: 'import instance profiles' at time: 2020-10-02 10:56:43.343152
Importing arn: arn:aws:iam::xxx:instance-profile/yyy
Error: b'{"error_code":"DRY_RUN_FAILED","message":"Verification of the instance profile failed. AWS error: Value (arn:aws:iam::xxx:instance-profile/yyy) for parameter iamInstanceProfile.arn is invalid. Invalid IAM Instance Profile ARN"}'
Add this MLFlow experiment & repository capability or refer visitors to:
https://github.com/amesar/mlflow-export-import
While doing the Jobs import (python export_db.py --profile DEMO --jobs -> python import_db.py --profile NEW-DEMO --jobs) I ran into:
Traceback (most recent call last):
File "import_db.py", line 219, in <module>
main()
File "import_db.py", line 105, in main
jobs_c.import_job_configs()
File "/home/terry/databricks/migrate/dbclient/JobsClient.py", line 110, in import_job_configs
cluster_conf = job_settings['new_cluster']
KeyError: 'new_cluster'
Looking at the code, it seems that it parses the JSON from the jobs.log file and expects there to be a 'new_cluster' key, which for MULTI_TASK may not be the case.
For reference, here's what my multi-task job's JSON looked like:
{
"job_id": 1234,
"settings": {
"name": "Example:::1234",
"email_notifications": {
"on_failure": ["[email protected]"],
"no_alert_for_skipped_runs": true
},
"timeout_seconds": 0,
"schedule": {
"quartz_cron_expression": "51 30 23 * * ?",
"timezone_id": "Australia/Brisbane",
"pause_status": "UNPAUSED"
},
"max_concurrent_runs": 1,
"format": "MULTI_TASK"
},
"created_time": 1628241879369,
"creator_user_name": "[email protected]"
}databricks secrets list-scopes --profile bethesda2returns:
Scope Backend KeyVault URL
--------------------------------------------- ---------- --------------
adaptive-planning-scope DATABRICKS N/A
BI/Databricks/ForumUsers DATABRICKS N/A
. . .
Secrets migration:
python ./migrate/export_db.py --secrets \ (zmi-bi-databricks)
--profile bethesda2 \
--cluster-name "E2 migration" \
--set-export-dir workflow/results/migrate/bethesda2/secretsdies like this:
Get: https://bethesda2.cloud.databricks.com/api/2.0/secrets/list
Traceback (most recent call last):
File "./migrate/export_db.py", line 297, in <module>
main()
File "./migrate/export_db.py", line 183, in main
sc.log_all_secrets(args.cluster_name)
File "/Users/neil.best/Documents/GitHub/BethesdaNet/zmi-bi-databricks/migrate/dbclient/SecretsClient.py", line 46, in log_all_secrets
with open(scopes_logfile, 'w') as fp:
FileNotFoundError: [Errno 2] No such file or directory: 'workflow/results/migrate/bethesda2/secrets/secret_scopes/BI/Databricks/ForumUsers'
Export directory contains only:
find workflow/results/migrate/bethesda2/secrets -type fworkflow/results/migrate/bethesda2/secrets/secret_scopes/adaptive-planning-scope
The first scope succeeded but it looks like those slashes in the scope name need to be escaped or translated somehow for it to proceed.
I am exporting a Standard databricks azure cluster to another Standard databricks azure cluster. I am getting the below error:
Traceback (most recent call last):
File "import_db.py", line 219, in
main()
File "import_db.py", line 97, in main
cl_c.import_cluster_configs()
File "/home//migrate/dbclient/ClustersClient.py", line 269, in import_cluster_configs
acl_args = {'access_control_list' : self.build_acl_args(data['access_control_list'])}
KeyError: 'access_control_list'
ACL_clusters.log file showed the following error:
{"error_code": "INTERNAL_ERROR", "message": "FEATURE_DISABLED: ACLs for cluster are disabled or not available in this tier", "http_status_code": 500}
Is there a way to import without ACL?
got some updates from (who is leading Databricks-GCP migration efforts):
1. Users/Groups - successfully migrated, but saw the command failed at the end:
Importing group admins :
Traceback (most recent call last):
File "import_db.py", line 219, in <module>
main()
File "import_db.py", line 41, in main
scim_c.import_all_users_and_groups()
File "/Users/pnaik/Source/Databricks_Migration/migrate/dbclient/ScimClient.py", line 437, in import_all_users_and_groups
self.import_groups(group_dir)
File "/Users/pnaik/Source/Databricks_Migration/migrate/dbclient/ScimClient.py", line 403, in import_groups
old_email = old_user_emails[m['value']]
KeyError: '100000'
2. Notebook - download gave the below error:
Downloading: /Conviva3D/DataManagement/BugsAndProblems/B&P-01-20160628-Cannot-Save-PbRl.scala
Get: https://conviva.cloud.databricks.com/api/2.0/workspace/export
Downloading: /Conviva3D/DataManagement/BugsAndProblems/Clone of B&P-01-20160628-Cannot-Save-PbRl.scala
Get: https://conviva.cloud.databricks.com/api/2.0/workspace/export
Traceback (most recent call last):
File "export_db.py", line 297, in <module>
main()
File "export_db.py", line 81, in main
num_notebooks = ws_c.download_notebooks()
File "/Users/pnaik/Source/Databricks_Migration/migrate/dbclient/WorkspaceClient.py", line 229, in download_notebooks
dl_resp = self.download_notebook_helper(notebook_path, export_dir=self.get_export_dir() + ws_dir)
File "/Users/pnaik/Source/Databricks_Migration/migrate/dbclient/WorkspaceClient.py", line 256, in download_notebook_helper
save_filename = save_path + os.path.basename(notebook_path) + '.' + resp.get('file_type')
TypeError: can only concatenate str (not "NoneType") to str
Looks like API response parsing needs a tuning in https://github.com/databrickslabs/migrate/blob/master/dbclient/WorkspaceClient.py @mwc
Credentials must not be logged in clear text, otherwise it's a security risk.
databricks-migrate test_connection --profile sandbox
Testing connection at https://XXX/api/2.0 with headers: {'Authorization': 'Bearer XXX', 'Content-Type': 'text/json', 'user-agent': 'databricks-cli-0.11.0-test_connection-e372c092-0488-11eb-8cb1-a683e7c44a96'}
Export table acls
Delta tables will fail to import due to TBLPROPERTIES and OPTIONS keywords that are not required during replay of the table DDL.
The fix will strip these properties during the import without affecting the export data.
Add export of all secret scopes and secrets
databricks-migrate import --profile sandbox --clusters --libs --skip-failed --workspace
Executing action: 'start importing databricks objects' at time: 2020-10-02 11:38:19.551181
Executing action: 'import all the workspace objects' at time: 2020-10-02 11:38:19.554536
Uploading: Test.dbc
Error: b'{"error_code":"RESOURCE_ALREADY_EXISTS","message":"Path (/Test) already exists."}'
access credentials should not appear in clear text anywhere
We should skip hidden files like the .DS_store files that are generated on macs using the Finder app.
We have done most of the migration and it was quite smooth but the migration of the Metastore is giving us trouble. Though most of the tables got migrated properly, the views are not when the view has dependency on another view. You can find below an example error:
Importing view XYZdatalakeproduction.last_moe_XYZ_assignment_submissions_current_academic_year_view - Not found
ERROR:
<span class="ansi-red-fg">AnalysisException</span>: View `XYZdatalakeproduction`.`last_XYZ_assignments_submissions_view` already exists. If you want to update the view definition, please use ALTER VIEW AS or CREATE OR REPLACE VIEW AS
{'resultType': 'error', 'summary': '<span class="ansi-red-fg">AnalysisException</span>: View `XYZdatalakeproduction`.`last_XYZ_assignments_submissions_view` already exists. If you want to update the view definition, please use ALTER VIEW AS or CREATE OR REPLACE VIEW AS', 'cause': '---------------------------------------------------------------------------\nAnalysisException Traceback (most recent call last)\n<command--1> in <module>\n----> 1 with open("/dbfs/tmp/migration/tmp_import_ddl.txt", "r") as fp: tmp_ddl = fp.read(); spark.sql(tmp_ddl)\n\n/databricks/spark/python/pyspark/sql/session.py in sql(self, sqlQuery)\n 775 [Row(f1=1, f2=\'row1\'), Row(f1=2, f2=\'row2\'), Row(f1=3, f2=\'row3\')]\n 776 """\n--> 777 return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped)\n 778 \n 779 def table(self, tableName):\n\n/databricks/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py in __call__(self, *args)\n 1302 \n 1303 answer = self.gateway_client.send_command(command)\n-> 1304 return_value = get_return_value(\n 1305 answer, self.gateway_client, self.target_id, self.name)\n 1306 \n\n/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)\n 121 # Hide where the exception came from that shows a non-Pythonic\n 122 # JVM exception message.\n--> 123 raise converted from None\n 124 else:\n 125 raise\n\nAnalysisException: View `XYZdatalakeproduction`.`last_XYZ_assignments_submissions_view` already exists. If you want to update the view definition, please use ALTER VIEW AS or CREATE OR REPLACE VIEW AS'}
After using the databricks Migration tool, I thought I could help others by adding in some additional information to the readme file.
Import --users should throw a clear error if there's an instance profile failure.
We need to throw the error once the command completes.
Notebooks can be time consuming to import, and it restarts from the beginning in the event of a failure.
The better approach is to keep a log of successful imports / and an index to start off where we left off.
Some job schedules are paused on purpose prior to migration and should remain as such. My reading of pause_all_jobs() here says that pause_status is toggled blindly according to only the option given and the current state in the --profile workspace; no other state is considered. My customer pointed this out to me immediately as unhelpful.
Fails to import freshly databricks-migrate export --profile sandbox-e2 --workspace:
databricks-migrate import --profile sandbox-e2 --workspace
Executing action: 'start importing databricks objects' at time: 2020-10-02 11:13:18.874860
Executing action: 'import all the workspace objects' at time: 2020-10-02 11:13:18.877754
Error: FileNotFoundError: [Errno 2] No such file or directory: 'logs/artifacts/Users'
After executing attached Databricks_Manish.txt
script in workspaces , For us it seems like something is wrong with notebook count logic. could you please investigate ?
Add option to support TLD in the workspace APIs.
Cannot export metastore:
databricks-migrate export --profile sandbox --metastore
Executing action: 'start exporting databricks objects' at time: 2020-10-02 11:29:51.939548
Executing action: 'export metastore configs' at time: 2020-10-02 11:29:51.941965
Error: FileNotFoundError: [Errno 2] No such file or directory: '/usr/local/lib/python3.8/site-packages/databricks_migrate/migrations/../data/aws_cluster.json'
This is just a suggestion to add ML Flow support by merging this implementation into the migration tool: https://github.com/amesar/mlflow-export-import
When a user executes a command like this.
python export_db.py --profile demo --azure --export-home [email protected] --workspace-acls
It throws the error below. When the workspace-acls option is not used, no ACLs are exported.
Traceback (most recent call last):
File "export_db.py", line 297, in <module>
main()
File "export_db.py", line 72, in main
ws_c.log_all_workspace_acls()
File "/databricks/driver/git1/migrate/build/lib/dbclient/WorkspaceClient.py", line 388, in log_all_workspace_acls
self.log_acl_to_file('notebooks', workspace_log_file, 'acl_notebooks.log', 'failed_acl_notebooks.log')
File "/databricks/driver/git1/migrate/build/lib/dbclient/WorkspaceClient.py", line 364, in log_acl_to_file
with open(read_log_path, 'r') as read_fp, open(write_log_path, 'w') as write_fp, \
FileNotFoundError: [Errno 2] No such file or directory: 'azure_logs/user_workspace.log'
whenever there's a pending library on starting cluster, it doesn't get export them to migration logs.
Add an option to filter clusters by user / group.
I can not find proper set up instructions for this package to install on Ubuntu and set up databricks configuration to connect to workspace and run commands. Examples are documented in limited sense.
Add support for secrets import and permissions
failed_metastore log below:
{"resultType": "error", "summary": "java.lang.UnsupportedOperationException: Parquet does not support decimal. See HIVE-6384", "cause": "---------------------------------------------------------------------------\nPy4JJavaError Traceback (most recent call last)\n in \n----> 1 ddl_str = spark.sql("show create table default.campaign_master_table").collect()[0][0]\n\n/databricks/spark/python/pyspark/sql/session.py in sql(self, sqlQuery)\n 834 [Row(f1=1, f2=u'row1'), Row(f1=2, f2=u'row2'), Row(f1=3, f2=u'row3')]\n 835 """\n--> 836 return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped)\n 837 \n 838 @SInCE(2.0)\n\n/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py in call(self, *args)\n 1255 answer = self.gateway_client.send_command(command)\n 1256 return_value = get_return_value(\n-> 1257 answer, self.gateway_client, self.target_id, self.name)\n 1258 \n 1259 for temp_arg in temp_args:\n\n/databricks/spark/python/pyspark/sql/utils.py in deco(*a, **kw)\n 61 def deco(*a, **kw):\n 62 try:\n---> 63 return f(*a, **kw)\n 64 except py4j.protocol.Py4JJavaError as e:\n 65 s = e.java_exception.toString()\n\n/databricks/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)\n 326 raise Py4JJavaError(\n 327 "An error occurred while calling {0}{1}{2}.\n".\n--> 328 format(target_id, ".", name), value)\n 329 else:\n 330 raise Py4JError(\n\nPy4JJavaError: An error occurred while calling o218.sql.\n: java.lang.UnsupportedOperationException: Parquet does not support decimal. See HIVE-6384\n\tat org.apache.hadoop.hive.ql.io.parquet.serde.ArrayWritableObjectInspector.getObjectInspector(ArrayWritableObjectInspector.java:102)\n\tat org.apache.hadoop.hive.ql.io.parquet.serde.ArrayWritableObjectInspector.(ArrayWritableObjectInspector.java:60)\n\tat org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe.initialize(ParquetHiveSerDe.java:113)\n\tat org.apache.hadoop.hive.metastore.MetaStoreUtils.getDeserializer(MetaStoreUtils.java:339)\n\tat org.apache.hadoop.hive.ql.metadata.Table.getDeserializerFromMetaStore(Table.java:288)\n\tat org.apache.hadoop.hive.ql.metadata.Table.checkValidity(Table.java:194)\n\tat org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java:1017)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl.org$apache$spark$sql$hive$client$HiveClientImpl$$getRawTableOption(HiveClientImpl.scala:420)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$tableExists$1.apply$mcZ$sp(HiveClientImpl.scala:424)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$tableExists$1.apply(HiveClientImpl.scala:424)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$tableExists$1.apply(HiveClientImpl.scala:424)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$withHiveState$1.apply(HiveClientImpl.scala:331)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$retryLocked$1.apply(HiveClientImpl.scala:239)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl$$anonfun$retryLocked$1.apply(HiveClientImpl.scala:231)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl.synchronizeOnObject(HiveClientImpl.scala:275)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:231)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:314)\n\tat org.apache.spark.sql.hive.client.HiveClientImpl.tableExists(HiveClientImpl.scala:423)\n\tat org.apache.spark.sql.hive.client.PoolingHiveClient$$anonfun$tableExists$1.apply(PoolingHiveClient.scala:275)\n\tat org.apache.spark.sql.hive.client.PoolingHiveClient$$anonfun$tableExists$1.apply(PoolingHiveClient.scala:274)\n\tat org.apache.spark.sql.hive.client.PoolingHiveClient.withHiveClient(PoolingHiveClient.scala:112)\n\tat org.apache.spark.sql.hive.client.PoolingHiveClient.tableExists(PoolingHiveClient.scala:274)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$tableExists$1.apply$mcZ$sp(HiveExternalCatalog.scala:903)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$tableExists$1.apply(HiveExternalCatalog.scala:903)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$tableExists$1.apply(HiveExternalCatalog.scala:903)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$withClient$1$$anonfun$apply$1.apply(HiveExternalCatalog.scala:144)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog.org$apache$spark$sql$hive$HiveExternalCatalog$$maybeSynchronized(HiveExternalCatalog.scala:105)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog$$anonfun$withClient$1.apply(HiveExternalCatalog.scala:142)\n\tat com.databricks.backend.daemon.driver.ProgressReporter$.withStatusCode(ProgressReporter.scala:372)\n\tat com.databricks.backend.daemon.driver.ProgressReporter$.withStatusCode(ProgressReporter.scala:358)\n\tat com.databricks.spark.util.SparkDatabricksProgressReporter$.withStatusCode(ProgressReporter.scala:34)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:140)\n\tat org.apache.spark.sql.hive.HiveExternalCatalog.tableExists(HiveExternalCatalog.scala:902)\n\tat org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.tableExists(ExternalCatalogWithListener.scala:147)\n\tat org.apache.spark.sql.catalyst.catalog.SessionCatalog.tableExists(SessionCatalog.scala:445)\n\tat org.apache.spark.sql.catalyst.catalog.SessionCatalog.requireTableExists(SessionCatalog.scala:205)\n\tat org.apache.spark.sql.catalyst.catalog.SessionCatalog.getTableMetadata(SessionCatalog.scala:458)\n\tat com.databricks.sql.DatabricksSessionCatalog.getTableMetadata(DatabricksSessionCatalog.scala:80)\n\tat org.apache.spark.sql.execution.command.ShowCreateTableCommand.run(tables.scala:1014)\n\tat org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)\n\tat org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)\n\tat org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)\n\tat org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:218)\n\tat org.apache.spark.sql.Dataset$$anonfun$6.apply(Dataset.scala:218)\n\tat org.apache.spark.sql.Dataset$$anonfun$54.apply(Dataset.scala:3501)\n\tat org.apache.spark.sql.Dataset$$anonfun$54.apply(Dataset.scala:3496)\n\tat org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1$$anonfun$apply$1.apply(SQLExecution.scala:112)\n\tat org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:233)\n\tat org.apache.spark.sql.execution.SQLExecution$$anonfun$withCustomExecutionEnv$1.apply(SQLExecution.scala:98)\n\tat org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835)\n\tat org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:74)\n\tat org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:185)\n\tat org.apache.spark.sql.Dataset.org$apache$spark$sql$Dataset$$withAction(Dataset.scala:3496)\n\tat org.apache.spark.sql.Dataset.(Dataset.scala:218)\n\tat org.apache.spark.sql.Dataset$$anonfun$ofRows$2.apply(Dataset.scala:91)\n\tat org.apache.spark.sql.Dataset$$anonfun$ofRows$2.apply(Dataset.scala:88)\n\tat org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835)\n\tat org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:88)\n\tat org.apache.spark.sql.SparkSession$$anonfun$sql$1.apply(SparkSession.scala:693)\n\tat org.apache.spark.sql.SparkSession$$anonfun$sql$1.apply(SparkSession.scala:688)\n\tat org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:835)\n\tat org.apache.spark.sql.SparkSession.sql(SparkSession.scala:688)\n\tat sun.reflect.GeneratedMethodAccessor232.invoke(Unknown Source)\n\tat sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)\n\tat java.lang.reflect.Method.invoke(Method.java:498)\n\tat py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)\n\tat py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:380)\n\tat py4j.Gateway.invoke(Gateway.java:295)\n\tat py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)\n\tat py4j.commands.CallCommand.execute(CallCommand.java:79)\n\tat py4j.GatewayConnection.run(GatewayConnection.java:251)\n\tat java.lang.Thread.run(Thread.java:748)", "table": "default.campaign_master_table"}
Hi!
I used this tool recently to migrate some larger user homes with nearly a thousand notebooks. I noticed that the whole download/upload part is singe-threaded as the rest of the application. This makes the process very slow, for me it took more than an hour to download a single user home, compared to a few (<6) minutes when I parallelized the download part. It was something like this:
from joblib import Parallel, delayed
...
def download_notebooks(self, ws_log_file='user_workspace.log', ws_dir='artifacts/'):
...
responses = Parallel(n_jobs=16)(delayed(self.download_notebook_helper)(nd, self.get_export_dir() + ws_dir) for nd in fp)
for dl_resp in responses:
if 'error_code' not in dl_resp:
num_notebooks += 1
# param notebook_path changed to notebook_data
def download_notebook_helper(self, notebook_data, export_dir='artifacts/'):
...
# moved from the original invocation in download_notebooks
notebook_path = json.loads(notebook_data).get('path', None).rstrip('\n')
...This could be done in multiple places where a lot of API requests are issued. Some of these are a bit harder to parallelize as they're recursive (like log_all_workspace_items), but that's also not impossible I think.
I'm not a python professional or neither someone who fully understands all parts of the tool now so I cannot really open a meaningful PR from this, but I'd be very happy if such improvements could be done.
Thanks!
Launch the import cluster w/ a specific IAM role.
Add support for mapping multiple emails to new case sensitive emails.
There's a common case where the profile name changes with the account id for migrating to new AWS accounts.
APIs allow duplicate names so we should handle that w/ the migration.
Cannot export jobs:
databricks-migrate export --profile sandbox --jobs
Executing action: 'start exporting databricks objects' at time: 2020-10-02 11:27:08.517580
Executing action: 'export job configs' at time: 2020-10-02 11:27:08.520545
Error: KeyError: 'jobs'
We should skip applying ACLs for users workspace that no longer exist.
Need to consider if this is overall faster / slower vs a brute force approach of applying the ACLs + getting an error.
The job doesn't fail today, it just throws an error and keeps going. Therefore it would be an enhancement for improved UX.
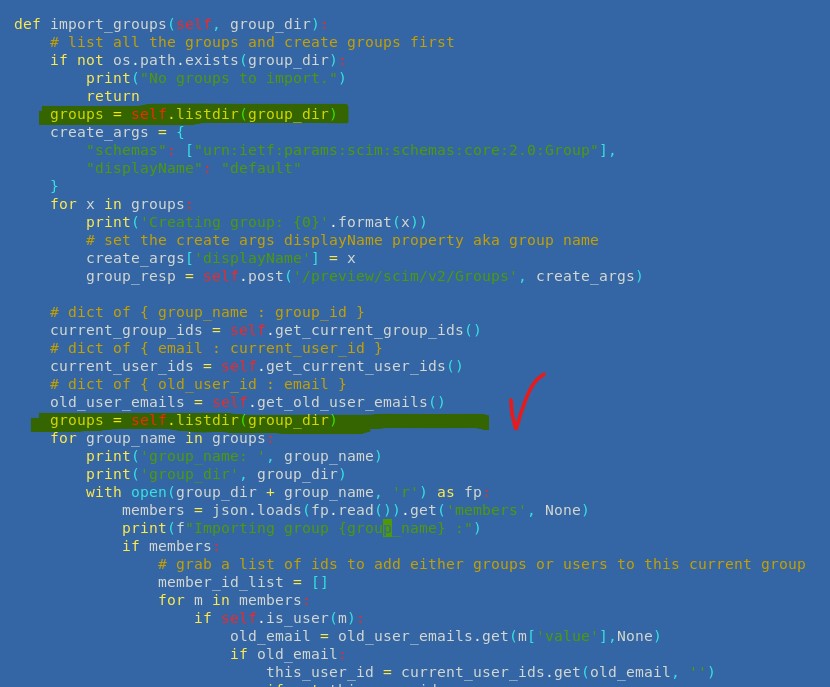
Groups are created while import of ./groups folder (ScimClient.py - import_groups) using iteration over groups = self.listdir(group_dir), here "groups" is a generator object
But then there is another iteration over the same generator "group", which should import group membership for users. But generator has already iterated over all files in ./groups folder, so no iteration happens, so no group membership for users is impported.
I just reinitalized a generator before next iteration and it worked for me:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.