dcharlie123 / learning Goto Github PK
View Code? Open in Web Editor NEW整理一些在线的学习资源
整理一些在线的学习资源


32%2->0
16%2->0
8%2->0
4%2->0
2%2->0
1%2->1
从下往上得到:0100000
小数0.6875转二进制(乘以2如果大于1就标1,然后小于0就标0)乘2取整,顺序排列
0.6875 * 2->1
0.375 * 2->0
0.75 * 2->1
0.5 * 2->1
从上到下得到:0.1011
number.toString(2)例如:11.01(二进制)
1*2^1+1*2^0+0*2^-1+1*2^-2=3.25
function converter(string){
let a=0;
let [integer,decimal]=string.split('.')
integer.split('').reverse().forEach((item,index)=>a+=item*Math.pow(2,index))
decimal.split('').forEach((item,index)=>a+=item/Math.pow(2,index+1))
return a
}假如用4位来表示
| 十进制 | 二进制 |
|---|---|
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| ... | ... |
| 7 | 0111 |
像上面这样无法表示负数,所以有了原码:把左边第一位腾出来,存放符号,正数用 0 来表示,负用 1 来表示
原码其实就是数值前面增加了一位符号位(即最高位为符号位),正数时符号位为 0;
负数时符号位为 1(0有两种表示:+0 和 -0),其余位表示数值的大小
负数:
| 十进制 | 二进制 |
|---|---|
| -0 | 1000 |
| -1 | 1001 |
| -2 | 1010 |
| ... | ... |
| -7 | 1111 |
那么这样表示正负相加怎么办1+(-1)如果按上面的二进制0001+1001=1010,查表十进制为-2,明显不对,
所以就有了反码:正数的反码还是等同于原码,反码 的表示方式其实就是用来处理负数的,也就是除符号位不变,其余位置皆取反存储,0 就存 1,1 就存 0。
正数的反码与其原码相同
负数的反码是对其原码除符号位外,皆取反
| 十进制 | 二进制 |
|---|---|
| -0 | 1111 |
| -1 | 1110 |
| -2 | 1101 |
| ... | ... |
| -7 | 1000 |
这时候又有新的问题,(+0)和(-0)这两个相同的值,存在两个不同的二进制表达方式,所以就有了补码:从原来 反码 的基础上,补充一个新的代码 1
正数的补码与其原码相同
负数的补码是在其反码的末位加 1去掉最高进位
| 十进制 | 二进制 |
|---|---|
| -1 | 1111 |
| -2 | 1110 |
| ... | ... |
| -7 | 1001 |
| -8 | 1000 |
所以现在(+4)和(-4)相加,0100 + 1100 =10000,有进位,把最高位丢掉,也就是 0000(0)
在计算机中存储为64位
1 11 52
1: 符号位 0正数 1负数
11: 指数位(阶码) 用来确定范围,阶码 = 阶码真值 + 偏移量 1023,偏移量 = 2^(k-1)-1,k 表示阶码位数
52: 尾数位 用来确定精度
转成十进制表示法为
num = (-1)^s * (1.f) * 2^E
回到问题:
0.2转成二进制:...
0.2 = 2^-3 * 1.10011(0011)// (0011) 表示循环
JS 采用 IEEE 754 双精度版本(64位),六十四位中符号位占一位,整数位占十一位,其余五十二位都为小数位。因为 0.1 和 0.2 都是无限循环的二进制,所以在小数位末尾处需要判断是否进位(规则和十进制里的四舍五入一样)。所以 0.1的二进制表示(0.1 = 2^-4 * 1.10011(0011)) 进位后就变成了 2^-4 * 1.10011(0011 * 12次)010,同理可得0.2的二进制表示 。把这两个二进制加起来得到 2^-2 * 1.0011(0011 * 11次)0100 , 这个值再换算成十进制就是 0.30000000000000004。
Number.EPSILON=(function(){ //解决兼容性问题
return Number.EPSILON?Number.EPSILON:Math.pow(2,-52);
})();
//上面是一个自调用函数,当JS文件刚加载到内存中,就会去判断并返回一个结果,相比if(!Number.EPSILON){
// Number.EPSILON=Math.pow(2,-52);
//}这种代码更节约性能,也更美观。
function numbersequal(a,b){
return Math.abs(a-b)<Number.EPSILON;
}
//接下来再判断
var a=0.1+0.2, b=0.3;
console.log(numbersequal(a,b)); //这里就为true了前端移动端调试:https://juejin.im/entry/5c947f85f265da612d633e95
https://www.imooc.com/article/20870
npm i -g spy-debugger
spy-debugger
第一步:生成证书:
生成CA根证书,根证书生成在 /Users/XXX/node-mitmproxy/ 目录下(Mac)。
spy-debugger initCA
第二步:安装证书:
把node-mitmproxy文件夹下的 node-mitmproxy.ca.crt 传到手机上,点击安装即可。
Spy-debugger启动界面,同样,在手机端刷新页面之后,targets中会有记录
var params=new URLSearchParams(window.location.search)
const obj = {};
for (key of params) {
obj[key[0]] = key[1];
}function parseURL(url) {
var a = document.createElement('a');
a.href = url;
return {
host: a.hostname,
port: a.port,
query: a.search,
params: (function () {
var ret = {},
seg = a.search.replace(/^\?/, '').split('&'),
len = seg.length,
i = 0,
s;
console.log(a.search);
for (; i < len; i++) {
if (!seg[i]) {
continue;
}
s = seg[i].split('=');
ret[s[0]] = s[1];
}
return ret;
})(),
hash: a.hash.replace('#', '')
};
}想让我们自己写的库就可以在浏览器运行又可以node运行,兼容AMD,CMD,commomjs等多种规范。
(function(global,factory){
})(this,(function(){
//逻辑代码
}))(function (global, factory) {
if (typeof exports === 'object' && typeof module !== 'undefined') {
// CommonJS、CMD规范检查
module.exports = factory();
} else if (typeof define === 'function' && define.amd) {
// AMD规范检查
define(factory);
} else {
// 浏览器注册全局对象
global.Hentai = factory();
}
})(this, (function () {
function say() {
console.log('hello hentai');
}
return {
say: say
}
}))让你的插件兼容AMD, CMD ,CommonJS和 原生 JS
使用模块化工具打包自己开发的JS库
前端模块化的前世今生
__dirname: 总是返回被执行的 js 所在文件夹的绝对路径
__filename: 总是返回被执行的 js 的绝对路径
process.cwd(): 总是返回运行 node 命令时所在的文件夹的绝对路径
./ 和 ../ : 在 require() 中使用是跟 __dirname 的效果相同,不会因为启动脚本的目录不一样而改变,在其他情况下跟 process.cwd() 效果相同,是相对于启动脚本所在目录的路径。
RTMP是Macromedia开发的一套视频直播协议,现在属于adobe ,这套方案需要搭建专门的 RTMP 流媒体服务如 Adobe Media Server,并且在浏览器中只能使用 FLASH 实现播放器。它的实时性非常好,延迟很小,但无法支持移动端 WEB 播放是它的硬伤。html5中根据网上资料可用video.js实现播放(//TODO)
HTTP Live Streaming(简称 HLS)是一个基于 HTTP 的视频流协议。这是 Apple 提出的直播流协议。目前,IOS 和 高版本 Android 都支持 HLS。那什么是 HLS 呢?HLS 主要的两块内容是 .m3u8 文件和 .ts 播放文件。
HLS 协议基于 HTTP,而一个提供 HLS 的服务器需要做两件事:
编码:以 H.263 格式对图像进行编码,以 MP3 或者 HE-AAC 对声音进行编码,最终打包到 MPEG-2 TS(Transport Stream)容器之中;
分割:把编码好的 TS 文件等长切分成后缀为 ts 的小文件,并生成一个 .m3u8 的纯文本索引文件;
浏览器使用的是 m3u8 文件。m3u8 跟音频列表格式 m3u 很像,可以简单的认为 m3u8 就是包含多个 ts 文件的播放列表。播放器按顺序逐个播放,全部放完再请求一下 m3u8 文件,获得包含最新 ts 文件的播放列表继续播,周而复始。整个直播过程就是依靠一个不断更新的 m3u8 和一堆小的 ts 文件组成,m3u8 必须动态更新,ts 可以走 CDN。
基于http流式IO传输flv。HTTP-FLV 协议由 Adobe 公司主推,格式极其简单,只是在大块的视频帧和音视频头部加入一些标记头信息,由于这种极致的简洁,在延迟表现和大规模并发方面都很成熟。唯一的不足就是在手机浏览器上的支持非常有限,但是用作手机端 APP 直播协议却异常合适。
我们知道 hls 协议是将直播流分成一段一段的小段视频去下载播放的,所以假设列表里面的包含 5 个 ts 文件,每个 TS 文件包含 5 秒的视频内容,那么整体的延迟就是 25 秒。因为当你看到这些视频时,主播已经将视频录制好上传上去了,所以时这样产生的延迟。当然可以缩短列表的长度和单个 ts 文件的大小来降低延迟,极致来说可以缩减列表长度为 1,并且 ts 的时长为 1s,但是这样会造成请求次数增加,增大服务器压力,当网速慢时回造成更多的缓冲,所以苹果官方推荐的 ts 时长时 10s,所以这样就会大改有 30s 的延迟。参考资料:https://developer.apple.com/library/ios/documentation/NetworkingInternet/Conceptual/StreamingMediaG
视频编码是本系列一个重要的部分,如果把整个流媒体比喻成一个物流系统,那么编解码就是其中配货和装货的过程,这个过程非常重要,它的速度和压缩比对物流系统的意义非常大,影响物流系统的整体速度和成本。同样,对流媒体传输来说,编码也非常重要,它的编码性能、编码速度和编码压缩比会直接影响整个流媒体传输的用户体验和传输成本。而经过 H.264 编码压缩之后,视频大小只有 708 k 、10 Mbps 的带宽仅仅需要 500 ms ,可以满足实时传输的需求,所以从视频采集传感器采集来的原始视频势必要经过视频编码。
封装可以理解为采用哪种货车去运输,也就是媒体的容器。
目前,我们在流媒体传输,尤其是直播中主要采用的就是 FLV 和 MPEG2-TS 格式,分别用于 RTMP/HTTP-FLV 和 HLS 协议。
RTMP 是 Real Time Messaging Protocol(实时消息传输协议)的首字母缩写。该协议基于 TCP,是一个协议族,包括 RTMP 基本协议及 RTMPT/RTMPS/RTMPE 等多种变种。RTMP 是一种设计用来进行实时数据通信的网络协议,主要用来在 Flash/AIR 平台和支持 RTMP 协议的流媒体/交互服务器之间进行音视频和数据通信。支持该协议的软件包括 Adobe Media Server/Ultrant Media Server/red5 等。目前推流协议大部分采用的rtmp协议。在浏览器端基于flv格式(FLV是Flash Video的简写,是一种文件体积小,适合在网络上传输的封包方式。),在浏览器端播放依赖于FLASH。
优点:CDN 支持良好,主流的 CDN 厂商都支持;协议简单,在各平台上实现容易。
缺点:基于 TCP ,传输成本高,在弱网环境丢包率高的情况下问题显著;不支持浏览器推送;Adobe 私有协议,Adobe 已经不再更新。
HLS 全称是 HTTP Live Streaming。这是 Apple 提出的直播流协议。,iOS和 Android 都天然支持这种协议,配置简单,直接使用
video标签即可。
简单讲就是把整个流分成一个个小的,基于 HTTP 的文件来下载,每次只下载一些,前面提到了用于 H5 播放直播视频时引入的一个 .m3u8 的文件,这个文件就是基于 HLS 协议,存放视频流元数据的文件。每一个 .m3u8 文件,分别对应若干个 ts 文件,这些 ts 文件才是真正存放视频的数据,m3u8 文件只是存放了一些 ts 文件的配置信息和相关路径,当视频播放时,.m3u8 是动态改变的,video 标签会解析这个文件,并找到对应的 ts 文件来播放,所以一般为了加快速度,.m3u8 放在 Web 服务器上,ts 文件放在 CDN 上。
.m3u8 文件,其实就是以 UTF-8 编码的 m3u 文件,这个文件本身不能播放,只是存放了播放信息的文本文件。
HTTP-FLV 和 RTMP 类似,都是针对于 FLV 视频格式做的直播分发流。但,两者有着很大的区别。
现在市面上,比较常用的就是 HTTP-FLV 进行播放。但,由于手机端上不支持,所以,H5 的 HTTP-FLV 也是一个痛点。
具体:现代播放器原理
上面封装提到了‘视频文件格式实际上我们常常称作为容器格式’,传到用户端如何将该盒子解开?就需要找到对应的解码器进行解码
由于各大浏览器的对 FLV 的围追堵截,导致 FLV 在浏览器的生存状况堪忧,但是,FLV 凭借其格式简单,处理效率高的特点,使各大视频后台的开发者都舍不得启用,如果一旦更改的话,就需要对现有视频进行转码,比如变为 MP4,这样不仅在播放,而且在流处理来说都有点重的让人无法接受。而 MSE 的出现,彻底解决了这个尴尬点,能够让前端能够自定义来实现一个 Web 播放器,确实完美。(不过,苹果老大爷觉得没这必要,所以,在 IOS 上无法实现。)——《不再碎片化学习,快速掌握 H5 直播技术》
MSE 全称就是 Media Source Extensions。它是一套处理视频流技术的简称,里面包括了一系列 API:Media Source,Source Buffer 等。在没有 MSE 出现之前,前端对 video 的操作,仅仅局限在对视频文件的操作,而并不能对视频流做任何相关的操作。现在 MSE 提供了一系列的接口,使开发者可以直接提供 media stream。
b站开源的flv.js就是基于MSE,解析flv数据,通过MSE封装成fMP4喂给video标签
我们知道 hls 协议是将直播流分成一段一段的小段视频去下载播放的,所以假设列表里面的包含 5 个 ts 文件,每个 TS 文件包含 5 秒的视频内容,那么整体的延迟就是 25 秒。因为当你看到这些视频时,主播已经将视频录制好上传上去了,所以时这样产生的延迟。当然可以缩短列表的长度和单个 ts 文件的大小来降低延迟,极致来说可以缩减列表长度为 1,并且 ts 的时长为 1s,但是这样会造成请求次数增加,增大服务器压力,当网速慢时回造成更多的缓冲,所以苹果官方推荐的 ts 时长时 10s,所以这样就会大改有 30s 的延迟。参考资料:https://developer.apple.com/library/ios/documentation/NetworkingInternet/Conceptual/StreamingMediaG——《h5视频直播扫盲》
根据观察,目前各大直播平台,移动端网页直播用的基本是hls的m3u8格式,例如b站,YouTube,虎牙,斗鱼等,不强调互动性,对流畅度比较高,一般选用HLS,延时在10秒以上。
需要较低延迟(3-5秒),可以选用rtmp和http-flv,但是需要考虑兼容性,依赖flash或MSE意味着放弃部分端;如果需要实时通讯IM,直播答题这些对延迟要求更高的,可能可以考虑webRTC,因为无论是HLS还是RTMP、http-flv都基于TCP。
下一代低延时直播CDN:HLS、RTMP 与UDP +WebRTC
进击的WebRTC:我们为什么需要它?
WebRTC 中文教程
在web移动端hls协议直播是目前兼容性较好的因为其输出的m3u8格式在移动端都能播放(无需插件),如果我们想要移动端和pc端都能播放直播有以下两种解决方法:
<!DOCTYPE html>
<html lang="en">
<head>
<title>Video.js | HTML5 Video Player</title>
<script src="https://cdn.bootcss.com/video.js/7.7.6/video.min.js"></script>
<link href="https://cdn.bootcss.com/video.js/7.7.5/alt/video-js-cdn.min.css" rel="stylesheet">
</head>
<body>
<video id="my-player" class="video-js">
</video>
</body>
<script>
const videojs = window.videojs || _videojs
var player = videojs('my-player', {
width: '360px',
autoplay: true,
controls: true,
// preload: 'auto',
// fluid: false,
// muted: false,
controlBar: {
remainingTimeDisplay: false,
playToggle: {},
progressControl: {},
fullscreenToggle: {},
volumeMenuButton: {
inline: false,
vertical: true
}
},
sources: [{
type: "application/x-mpegURL",
src: "http://ivi.bupt.edu.cn/hls/cctv1hd.m3u8" //你的m3u8地址(必填)
}],
poster: "https://surmon-china.github.io/vue-quill-editor/static/images/surmon-3.jpg",
techOrder: ['html5'],
plugins: {}
}, function () {
console.log(111)
})
</script>
</html>由于水平有限各个协议没有深入学习,只是根据网络上的网站、文档浅显的了解,可能存在错误,欢迎指正。
base64是一种编码方式,为什么叫base64呢。因为它是包含64个字符(大小写26个英文字母52个,0-9数字10个,还有加号+和斜杆/),此外还有等号=用来作为后缀用途。
对照表(from 奇舞周刊)
但,为什么Base64编码算法只支持64个字符呢?
首先,我们先回顾下ASCII码。ASCII码的范围是0-127,其中0-31和127是控制字符,共33个。其余95个,即32-126是可打印字符,包括数字、大小写字母、常用符号等。
早期的一些传输协议,例如邮件传输协议SMTP,只能传输可打印的ASCII字符。这样原本的8bit字节码(0-255)就会超出使用范围,从而导致无法传输。
这时,就产生了Base64编码,它利用6bit字符来表达原本的8bit字符。
想知道为什么base64会大33%,先来看一下base64的原理:它主要是通过6bit字符来表达原本的8bit字符。
举个栗子:看一下Man三个字母转成base64
M->ASCII:77->二进制:01001101
a->ASCII:97->二进制:01100001
n->ASCII:110->二进制:01101110
| 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 |
| 19 | 22 | 5 | 46 | ||||||||||||||||||||
| T | W | F | u | ||||||||||||||||||||
A->ASCII:65->二进制:0100 0001
B->ASCII:66->二进制:0100 0010
C->ASCII:67->二进制:0100 0011
解码的过程比较简单。去掉末尾的等号=。剩下的Base64字符,每8bit组成一个8bit字节,最后剩余不足8位的丢弃即可解码的过程比较简单。去掉末尾的等号=。剩下的Base64字符,每8bit组成一个8bit字节,最后剩余不足8位的丢弃即可
所以 在编码期间,Base64 算法用四个字节替换每三个字节导致大了33%
前端开发中我们经常会把较小的图片转为base64,这种格式的资源我们称为DataURL
Data URL由data:前缀、MIME类型(表明数据类型)、base64标志位(如果是文本,则可选)以及数据本身四部分组成。
npm install --save-dev webpack-bundle-analyzer
webpack配置:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
configureWebpack: {
plugins: [new BundleAnalyzerPlugin()]
}
};routes:[path:'Blogs',name:'ShowBlogs',component:()=>import('./components/ShowBlogs.vue')]webpack配置:
output:{
path:path.join(__dirname,'/../dist'),
filename:'[name].js',
publicPath:defaultSettings.publicPath,
//指定chunkfilename
chunkFilename:'[name].[chunkhash:5].chunk.js'
}用 include 或 exclude 来帮我们避免不必要的转译
module:{
rules:[
{
test:/\.js$/,
exclude:/(node_modules|bower_components)/,
use:[
loader:['cache-loader','babel-loader'],
// options:{
// presets:['@babel/preset-env']
// }
]
}
]
}DLLPlugin,它会到第三方库单独打包到一个文件中,不会和业务代码一起打包,只有第三方库版本发生变化才会重新打包。
用DLLPlugin处理文件要分两步走:
- 基于dll专属配置文件,打开dll库
- 基于webpack.config.js文件,打包业务代码
dll文件const path=require("path"); const webpack = require("webpack"); module.exports={ entry:{ vendor:[ "prop-types", "babel-polyfill", "react", "react-dom" ] }, output: { path: path.join(__dirname, 'dist'), filename: '[name].js', library: '[name]_[hash]', }, plugins: [ new webpack.DllPlugin({ // DllPlugin的name属性需要和libary保持一致 name: '[name]_[hash]', path: path.join(__dirname, 'dist', '[name]-manifest.json'), // context需要和webpack.config.js保持一致 context: __dirname, }), ], }
配置完运行会生成两个文件vendor-manifest.json和vendor.js
下一步修改webpack配置:
const path = require("path");
const webpack= require("webpack");
module.exports={
mode:"production",
entry:{
main:"./src/index.js"
},
output:{
path:path.join(__dirname,'dist/'),
filename:'[name].js'
},
//dll相关配置
plugins:[
new webpack.DllReferencePlugin({
context:__dirname,
//manifest
manifest:require('./dist/vendor-manifest.json');
})
]
}//todo
//todo
npm i -D compression-webpack-plugin
const CompressionWebpackPlugin = require('compression-webpack-plugin');
webpackConfig.plugins.push(
new CompressionWebpackPlugin({
filename: '[path].gz[query]',
algorithm: 'gzip',
test: new RegExp('\\.(js|css)$'),
// 只处理大于xx字节 的文件,默认:0
threshold: 10240,
// 示例:一个1024b大小的文件,压缩后大小为768b,minRatio : 0.75
minRatio: 0.8 // 默认: 0.8
// 是否删除源文件,默认: false
deleteOriginalAssets: false
})
)https://github.com/dcharlie123/webpack4.0/tree/webpack4_new
var data=[{name:"akira",score:100}]
JSON.stringify(data)
JSON.stringify(data,null,4)//第三个参数每行缩进空格的个数
JSON.stringify(data,['name'],4)//只序列化['name']
function replace(key,value){
if(key==='score'){
...
}
}
JSON.stringify(data,replace,4)//第二个参数可以传入函数
JSON.parse()//第二个参数也可以传入一个函数function currying(fn){
let max_length=fn.length,args_arr=[];
let closure=function(...args){
args_arr=args_arr.concat(args);
if(args_arr.length<max_length) return closure;//如果传入参数还未达到要求进行返回
return fn(...args_arr);
}
return closure
} function create(){
var obj=new Object();
Con=[].shift.call(arguments);//取出第一个,获得构造函数
obj.__proto__=Con.prototype;
var ret=Con.apply(pbj,arguments);
return typeof ret === 'object'?ret:obj;//如果返回的是对象优先返回构造函数返回的对象
}var xhr=new XMLHttpRequest();
xhr.open('post','www.xxx.com',true);
xhr.onreadystatechange=function(){
if(xhr.readyState===4){
if(xhr.status >= 200 && xhr.status < 300) || xhr.status == 304){
console.log(xhr.responseText);
}
}
}
postData={"name1":"xxx","name2":"yyy"};
postData=(function(value){
var dataString = "";
for(var key in value){
dataString += key+"="+value[key]+"&";
};
return dataString;
}(postData));
// 设置请求头
xhr.setRequestHeader("Content-type","application/x-www-form-urlencoded");
// 异常处理
xhr.onerror = function() {
console.log('Network request failed')
}
// 跨域携带 cookie
xhr.withCredentials = true;
// 发出请求
xhr.send(postData);instanceof原理
const instanceofMock=(L,R)=>{
if(typeOf L!=='object'){
return false;
}
while(true){
if(L===null){
// 已经遍历到了最顶端
return false;
}
if(R.prototype===L.__proto__){
return true;
}
L = L.__proto__;
}
}call模拟实现
Function.prototype.call2=function(content=window){
content.fn=this;
let args=[...arguments].slice(1);
let result=content.fn(...args);
delete content.fn;
return result;
}class myPromise {
callbacks = [];
state = "pedding";
value = null;
constructor(fn) {
fn(this._resolve.bind(this), this._reject.bind(this));
}
then(onFulfilled, onRejected) {
return new myPromise((resolve, reject) => {
this._handle({
onFulfilled: onFulfilled || null,
onRejected: onRejected || null,
resolve,
reject,
});
});
}
catch(onError) {
return this.then(null, onError);
}
finally(onDone) {
if (typeof onDone !== "function") return this.then();
let Promise = this.constructor;
return this.then(
(value) => Promise.resolve(onDone()).then(() => value),
(reason) =>
Promise.resolve(onDone()).then(() => {
throw reason;
})
);
}
_handle(callback) {
if (this.state == "pedding") {
this.callbacks.push(callback);
return;
}
let cb =
this.state === "fulfilled" ? callback.onFulfilled : callback.onRejected;
//then没有传递,直接把上一个resolve的值resolve下去
if (!cb) {
cb = this.state === "fulfilled" ? callback.resolve : callback.reject;
cb(this.value);
return;
}
let ret;
//捕获onFulfilled或onRejected执行时的异常
try {
//var ret = callback.onFulfilled(this.value);//return xxx
ret = cb(this.value);
cb = this.state === "fulfilled" ? callback.resolve : callback.reject;
} catch (error) {
ret = error;
cb = callback.reject;
} finally {
cb(ret);
}
}
_resolve(value) {
if (value && (typeof value == "object" || typeof value == "function")) {
var then = value.then;
if (typeof then === "function") {
then.call(value, this._resolve.bind(this), this._reject.bind(this));
return;
}
}
this.state = "fulfilled";
this.value = value;
this.callbacks.forEach((callback) => this._handle(callback));
}
_reject(error) {
this.state = "rejected";
this.value = error;
this.callbacks.forEach((callback) => this._handle(callback));
}
}3.按位非~1
转二进制
原码:00000001
反码:11111110
符号位外取反 10000001
末位+1取补码 10000010//-2
公司官网要求首页视频全屏铺满,同事使用object-fit:cover在chrome完成,无奈产品要求适配ie11、edge等浏览器。来看一眼object-fit在caniuse的兼容性列表https://www.caniuse.com/#search=object-fit。。ie完全不支持,edge低版本只支持img标签上的。
position: absolute;
min-width: 100%;
min-height: 100%;
width: auto;
height: auto;
left: 50%;
top: 50%;
-webkit-transform: translate(-50%, -50%);
-moz-transform: translate(-50%, -50%);
-ms-transform: translate(-50%, -50%);
-o-transform: translate(-50%, -50%);
transform: translate(-50%, -50%);测试了一下,ie、edge都可以了
var arr=[12,2,1,3,8,3,6,20,7]function bubbleSort(arr){
let len=arr.length;
for(let i=0;i<len-1;i++){
for(var j=0;j<len-1-i;j++){
if(arr[j]>=arr[j+1]){
//交换位置
[arr[j],arr[j+1]]=[arr[j+1],arr[j]]
}
}
}
return arr;
}function insertSort(arr){
var len=arr.length;
for(var i=1;i<len-1;i++){
var temp=arr[i];
//前面是已排序好的
for(var j=i;j>=0;j--){
if(arr[j-1]>temp){
arr[j]=arr[j-1];//大的往后移
}else{
arr[j]=temp;
break;
}
}
}
return arr;
}function selectionSort(arr){
var len=arr.length;
for(var i=0;i<len-1;i++){
var min=i;
for(var j=i+1;j<len;j++){
if(arr[j]<arr[min]){
min=j
}
}
if(min!==i){
[arr[min],arr[i]]=[arr[i],arr[min]]
}
}
return arr;
}function shellSort(arr) {
const len = arr.length;
let gap = 1;
while (gap < len / 3) {
gap = gap * 3 + 1;
}
while (gap > 0) {
for (let i = gap; i < len; i++) {
const temp = arr[i];
let preIndex = i - gap;
while (arr[preIndex] > temp) {
arr[preIndex + gap] = arr[preIndex];
preIndex -= gap;
}
arr[preIndex + gap] = temp;
}
gap = Math.floor(gap / 2);
}
return arr;
}function QuickSort(arr){
if(arr.length<2) return arr;
var pivot=arr[arr.length-1];
var left=arr.filter((item,i)=>item<=pivot&&i!==(arr.length-1));
var right=arr.filter(item=>item>pivot);
return [...QuickSort(left), pivot, ...QuickSort(right)];
}function MergeSort(arr){
var len=arr.length
if(len<2) return arr;
const mid = Math.floor(len / 2);
const left = arr.splice(0, mid);
const right = arr;
return merge(MergeSort(left),MergeSort(right));
}
function merge(left,right){
var res=[];
while(left.length>0&&right.length>0){
if(left[0]>right[0]){
res.push(right.shift())
}else{
res.push(left.shift())
}
}
return res.concat(left, right);
}function countingSort(array) {
let min = Infinity
for (let v of array) {
if (v < min) {
min = v
}
}
let counts = []
for (let v of array) {
counts[v-min] = (counts[v-min] || 0) + 1
}
let index = 0
for (let i = 0; i < counts.length; i++) {
let count = counts[i]
while(count > 0) {
array[index] = i + min
count--
index++
}
}
return array
}function bucketSort(array, size = 10) {
let min = Math.min(...array)
let max = Math.max(...array)
let count = Math.floor((max - min) / size) + 1
let buckets = []
for (let i = 0; i < count; i++) {
buckets.push([])
}
for (let v of array) {
let num = Math.floor((v - min) / size)
buckets[num].push(v)
}
let result = []
for (bucket of buckets) {
result.push(...insertionSort(bucket))
}
return result
}Array.prototype.map(callbackfn[, thisArg])
Array.prototype.Mymap=function(callbackFn,thisArg){
if(this==null){
throw new TypeError("Cannot read property 'map' of null or undefined")
}
let O = object(this);
let len = O.length>>>0;
if(typeof callbackFn !== 'function'){
throw new TypeError(callbackFn+'is not a function')
}
let T = thisArg;
let A =new Array(len);
let k=0;
while(k<len){
if(k in O){
let kValue=O[k];
let mappedValue=callbackFn.call(T,kValue,k,O);
A[k] = mappedValue
}
k++;
}
return A;
}let a=1
window.a;//undefined
var b=2;
window.b;//2Array.prototype.filter(callbackfn[, thisArg])
Array.prototype.Myfilter=function(callbacFn,thisArg){
if(this==null){
throw new TypeError("Cannot read property 'filter' of null or undefined");
}
if(typeof callbackFn!=="function"){
throw new TypeError(callbackFn+'is not a function');
}
let O=Object(this),len=O.length>>>0,
T=thisArg,A=new Array(len),k=0;
let to=0;
while(k<len){
if(k in O){
let kValue=O[k];
if(callbackFn.call(T,kValue,k,O)){
A[to++]=kValue;
}
}
k++
}
A.length=to;
return A;
} Array.prototype.reduce(callbackfn[, initialValue])
//监听全局错误
window.addEventListener('error', function (e) {
let target = e.target, // 当前dom节点
tagName = target.tagName,
times = Number(target.dataset.times) || 0, // 以失败的次数,默认为0
allTimes = 3; // 总失败次数,此时设定为3
// 当前异常是由图片加载异常引起的
if (tagName.toUpperCase() === 'IMG') {
if (times >= allTimes) {
alert(1)
target.src = 'data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7';
} else {
console.log(times)
target.dataset.times = times + 1;
target.src = '//xxx.xxx.xxx/default.jpg';
}
}
}, true)正则表达式在开发中经常用到,它几乎是每个程序员都必须知道的知识;
正则表达式(Regular Expression) 是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个规则字符串,这个规则字符串用来表达对字符串的一种过滤逻辑。简单来说就是:按照某种规则去匹配符合条件的字符串。正则表达式的规则是 / pattern /flags
在js中可以使用字面量或者new的方式来创建正则表达式
var reg1=/\d/g
var reg2=new RegExp("\d",'g');([{\^$|)?*+.]}
这些元字符在正则使用中都必须在前面加\进行转义
| 修饰符 | 描述 |
|---|---|
| i | 执行对大小写不敏感的匹配 |
| g | 执行全局匹配,查找所有匹配而非在找到第一个匹配后停止 |
| m | 执行多行匹配,会改变 ^和 $的行为 |
| u | 可以匹配4字节的unicode编码 |
| s (ES9) | dotAll模式, .可以匹配换行符 |
[]中某一个字符
| 表达式 | 描述 |
|---|---|
| [abc] | 查找方括号之间的任何字符 |
| [0-9] | 查找任何从 0 至 9 的数字 |
| [a-zA-Z] | 查找大小写26个字母 |
正则中还有一些预定义类:
| 预定义类 | 等价 | 描述 |
|---|---|---|
| \s | [\t\n\x0B\f\r] | 空格 |
| \S | [^\t\n\x0B\f\r] | 非空格 |
| \d | [0-9] | 数字 |
| \D | [^0-9] | 非数字 |
| \w | [a-zA-Z_0-9] | 单词字符 ( 字母、数字、下划线) |
| \W | [^a-zA-Z_0-9] | 非单词字符 |
| . | [^\r\n] | 任意字符,除了回车与换行外所有字符 |
| \f | \x0c \cL | 匹配一个换页符 |
| \n | \x0a \cJ | 匹配一个换行符 |
| \r | \x0d \cM | 匹配一个回车符 |
| \t | \x09 \cI | 匹配一个制表符 |
| \v | \x0b \cK | 匹配一个垂直制表符 |
| \xxx | 查找以八进制数 xxx 规定的字符 | |
| \xdd | 查找以十六进制数 dd 规定的字符 | |
| \uxxxx | 查找以十六进制数 xxxx 规定的 Unicode 字符 |
| 量词 | 描述 |
|---|---|
| n* | 0或多个 |
| n+ | 1或多个 |
| n? | 0或1个 |
| {n} | n个 |
| {n,} | n个以上 |
| {n,m} | n至m个 |
let str=`i am i
i am 2
you are 3
`
str.replace(/^i/gm,'dch')
//如果设置了 RegExp 对象的 Multiline 属性 m, ^ 也匹配 '\n' 或 '\r' 之后的位置
/*
“dch am i
dch am 2
you are 3
"
*/
str.replace(/\d$/gm,'i')
/*
"i am i
i am i
you are i
"
*/分组使用 (),作用是提取相匹配的字符串,使量词作用于分组
/*
表示“或”
*/
"atwotoob".replace(/t(w|o)o/g,"-");
//"a--b"
/*
反向引用
*/
'2018-02-11'.replace(/(\d{4})\-(\d{2})\-(\d{2})/g,'$2/$3/$1')// 02/11/2018
/*
后向引用
*/
//匹配日期格式,表达式中的\1代表重复(\-|\/|.)
var rgx =/\d{4}(\-|\/|.)\d{1,2}\1\d{1,2}/;
rgx.test("2016-03-26")// true
rgx.test("2016-03.26")// false如果不希望捕获某些分组,在分组内加上 ?:即可 比如 (?:tom).(ok)那么这里 $1指的就是ok
前瞻分正向前瞻和负向前瞻;
"read reading".replace(/read/g,'look')//"look looking"
"read reading".replace(/read(?=ing)/g,'look')//"read looking"
"read reading".replace(/read(?!ing)/g,'look')//"look reading"| 名称 | 正则 | 描述 |
|---|---|---|
| 正向后顾 | (?<=) | 前面要有xx |
| 负向后顾 | (?<!) | 前面不能有xx |
正则表达式在匹配的时候默认会尽可能多的匹配,叫贪婪模式。通过在限定符后加 ?可以进行非贪婪匹配 比如 \d{3,6}默认会匹配6个数字而不是3个,在量词 {}后加一个 ?就可以修改成非贪婪模式,匹配3次
'12345678'.replace(/\d{3,6}/,'-')// -78
'12345678'.replace(/\d{3,6}?/,'-')// -45678
'abbbb'.replace(/ab+?/,'-')// -bbb官方定义:Babel 是一个工具链,主要用于将 ECMAScript 2015+ 版本的代码转换为向后兼容的 JavaScript 语法,以便能够运行在当前和旧版本的浏览器或其他环境中。
babel 总共分为三个阶段:解析,转换,生成。
babel自6.0起不再对代码进行转换,只负责解析和生成,它把转化的功能都分解到一个个 plugin 里面。因此当我们不配置任何插件时,经过 babel 的代码和输入是相同的。
babel只是提供了一个“平台”,让更多有能力的plugins入驻这个平台,是这些plugins提供了将 ECMAScript 2015+ 版本的代码转换为向后兼容的 JavaScript 语法的能力。
所谓Preset就是一些Plugin组成的合集,你可以将Preset理解称为就是一些的Plugin整合称为的一个包。
根据官方文档的说法,目前有两类配置文件:项目范围配置 和 文件相对配置。
区别:第一种配置作用整个项目,如果 babel 决定应用这个配置文件,则一定会应用到所有文件的转换。而第二种配置文件只能应用到“当前目录”下的文件中。
babel 在决定一个 js 文件应用哪些配置文件时,会执行如下策略: 如果这个 js 文件在当前项目内,则会递归向上搜索最近的一个 .babelrc 文件(直到遇到package.json),将其与全局配置合并。
babel在编译代码过程中核心的库就是@babel/core这个库。
@babel/core是babel最核心的一个编译库,他可以将我们的代码进行词法分析--语法分析--语义分析过程从而生成AST抽象语法树,从而对于“这棵树”的操作之后再通过编译称为新的代码。
@babel/core其实相当于@babel/parse和@babel/generator这两个包的合体
corejs是JavaScript的模块化标准库,其中包括各种ECMAScript特性的polyfill。我们转换后的代码中引入的polyfill都是来源于corejs。它现有2和3两个版本,目前2版本已经进入功能冻结阶段了,新的功能会添加到3版本中。
@babel/preset-env是一个智能预设,它可以将我们的高版本JavaScript代码进行转译根据内置的规则转译成为低版本的javascript代码。
preset-env内部集成了绝大多数plugin(State > 3)的转译插件,它会根据对应的参数进行代码转译。
需要额外注意的是babel-preset-env仅仅针对语法阶段的转译,比如转译箭头函数,const/let语法。针对一些Api或者ES6内置模块的polyfill,preset-env是无法进行转译的。
@babel/preset-env有三个常用的关键可选项:
es:里面只包含有稳定的ES功能。
proposals:里面包含所有stage阶段的API
stable:它里面包含了,只有稳定的ES功能跟网络标准所以,我们可以这么使用:
当我们只需要垫平某个稳定的ES6+ API,我们可以用es这个文件夹里的polyfill来垫平 (import X from 'es/xx')
当我们需要用到提案阶段的API时,我就用proposals这个文件夹里的polyfill来垫平(import X from 'proposals/xx')
当我们想垫平所有稳定版本的ES6+ API,可以导入用stable文件夹(import 'core-js/stable')
当我们想垫平所有的ES6+ API(包括提案阶段),可以直接import 'core-js'作者:前端切圖仔
链接:https://juejin.cn/post/7197666704435920957
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
通过babelPolyfill通过往全局对象上添加属性以及直接修改内置对象的Prototype上添加方法实现polyfill。

提供了一种不污染全局作用域的 polyfill 的方式
这个插件正式基于 @babel/runtime 可以更加智能化的分析我们的代码,同时 @babel/plugin-transform-runtime 支持一个 helper 参数默认为 true 它会提取 @babel/runtime 编译过程中一些重复的工具函数变成外部模块引入的方式。
关于polyfill,我们先来解释下何谓polyfill。
首先我们来理清楚这三个概念:
babel-prest-env仅仅只会转化最新的es语法,并不会转化对应的Api和实例方法,比如说ES 6中的Array.from静态方法。如果想在低版本浏览器中识别并且运行Array.from方法达到我们的预期就需要额外引入polyfill进行在Array上添加实现这个方法。
其实可以稍微简单总结一下,语法层面的转化preset-env完全可以胜任。但是一些内置方法模块,仅仅通过preset-env的语法转化是无法进行识别转化的,所以就需要一系列类似”垫片“的工具进行补充实现这部分内容的低版本代码实现。这就是所谓的polyfill的作用
Babel中存在几种ployfill解决方案:
npm i core-js@3 regenerator-runtime -S再把.babelrc文件的useBuiltIns设置为false
{
"presets": [
[
"@babel/preset-env",
{
"useBuiltIns": false
}
]
],
"plugins": []
}项目入口代码中引入
import 'core-js/stable';
import 'regenerator-runtime/runtime';但是这样会把所有的 polyfills 全部打入,造成包体积庞大
npm i corejs@3 -S
// 在babelrc文件配置:
{
"presets": [
[
"@babel/preset-env",
{
"targets": {
"chrome": "58" // 按自己需要填写
},
"useBuiltIns": "entry"||"usage",
"corejs": {
"version": 3
}
}
]
],
"plugins": []
}配置中entry和usage的区别:
entry的话还需要在项目入口添加,将会根据浏览器目标环境(targets)的配置,引入全部浏览器暂未支持的polyfill模块,无论在项目中是否使用到。
import 'core-js/stable'
import 'regenerator-runtime/runtime' // babel大于7.18.0不需要手动引入regenerator-runtime这个包无论是 entry 还是 usage 本质上都是通过注入浏览器不支持的 polyfill 在对应的全局对象上增加功能实现,这样无疑是会污染全局环境。
npm i @babel/plugin-transform-runtime -D
npm i @babel/runtime-corejs3 -S.babelrc配置
{
"presets": [
[
"@babel/preset-env"
]
],
"plugins": [
[
"@babel/plugin-transform-runtime",
{
"corejs": 3
}
]
]
}方案的优缺点:
所以,要根据场景来使用不同ployfill方案:
也许你会强调,那么我使用 babel 编译我的第三方模块呢,又或者我在入口处额外单独引入 Promise 的 polyfill 总可以吧。
首先,在入口文件中单独引入 Promise 是假设在已知前提下既是说我了解第三方库代码中使用 Promise 而我的代码中没有 Promise 我需要 polyfil。
这样的情况在多人合作的大型项目下只能说一种理想情况。
其次使用 Babel 编译第三方模块我个人是强烈不推荐的,抛开编译慢而且可能会造成重复编译造成体积过大的问题。
TODO
1.阻塞问题:同个域名只允许同时建立6个TCP持久连接
2.无状态:巨大且重复的字段,几个请求的头部都是相同的都是每次都要发送
3.明文传输
4.只能由客户端发起请求,不支持服务器推送消息
1.二进制传输
HTTP/2 采用二进制格式传输数据,而非HTTP/1.x 里纯文本形式的报文 ,二进制协议解析起来更高效。 HTTP/2 将请求和响应数据分割为更小的帧,并且它们采用二进制编码。
HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
2.Header压缩
HTTP/2并没有使用传统的压缩算法,而是开发了专门的"HPACK”算法,在客户端和服务器两端建立“字典”,用索引号表示重复的字符串,还采用哈夫曼编码来压缩整数和字符串,可以达到50%~90%的高压缩率。
例如下图中的两个请求, 请求一发送了所有的头部字段,第二个请求则只需要发送差异数据,这样可以减少冗余数据,降低开销
3.多路复用:同个域名只需要占用一个TCP连接,并行发送多个请求
4.Server Push 主动推送也遵守同源策略
5.提高安全性
出于兼容的考虑,HTTP/2延续了HTTP/1的“明文”特点,可以像以前一样使用明文传输数据,不强制使用加密通信,不过格式还是二进制,只是不需要解密。
但由于HTTPS已经是大势所趋,而且主流的浏览器Chrome、Firefox等都公开宣布只支持加密的HTTP/2,所以“事实上”的HTTP/2是加密的。也就是说,互联网上通常所能见到的HTTP/2都是使用"https”协议名,跑在TLS上面。HTTP/2协议定义了两个字符串标识符:“h2"表示加密的HTTP/2,“h2c”表示明文的HTTP/2。
原:【仓库】C<-B<-A 【暂存】空 【本地】D
git reset HEAD^:【仓库】B<-A 【暂存】空 【本地】D),使用场景一般是用于丢弃当前已经add的结果git reset --soft HEAD^:【仓库】B<-A 【暂存】C 【本地】D),用于合并commit:将已commit的多条记录回退合并再重新commitgit reset --hard HEAD^:【仓库】B<-A 【暂存】空 【本地】C)原:【仓库】C<-B<-A 【暂存】空 【本地】D
退回记录并生成新记录(执行git revert B:【仓库】B'<-C<-B<-A 【暂存】空 【本地】B'&D)
git commit --amendgit rebase -i HEAD~3https://mp.weixin.qq.com/s/oKMdlo6jsIcMcZW8nzoAUg
https://mp.weixin.qq.com/s/RJGal09q_3vtPywEDmeEeQ
https://juejin.im/post/6869519303864123399
https://juejin.im/post/6844903635533594632
https://juejin.im/post/6844903546104135694
DataURL
data:[][;base64],
base64
blob-》Object URL
URL.createObjectURL(blob)
Blob api
new Blob()
ArrayBuffer与TypedArray
blob-》arrayBuffer/DataURL
fileReader.readAsArrayBuffer(blob)
fileReader.readAsDataURL(blob)
ArrayBuffer->Blob
var arr=new Uint8Array([0x01,0x02,0x03,0x04]);
var blob=new Blob([array]);
Cache-Control: publicpublic意味着资源可以被任意缓存(浏览器,CDN等)Cache-Control: privateprivate意味着资源只能被浏览器缓存Cache-Control: no-storeno-store意味着让浏览器总是去请求服务器以获取资源Cache-Control: no-cache不是“不要缓存”而是让去确认是否是最新的Cache-Control: max-age=60缓存多少秒Cache-Control: s-max-age=60被用在中间缓存(比如CDN),max-age会应用于经过缓存的每一级,如果不想cdn缓存那么久,可以使用s-max-ageCache-Control: must-revalidate缓存在使用它之前必须去验证资源的过期状态Expires: Wed, 25 Jul 2018 21:00:00 GMT如果已经指定了Cache-Control中的max-age指令,那浏览器就会忽略expires (max-age > Expires)强缓存阶段,获取成功浏览器会返回 200 (from disk cache)或是200 OK (from memory cache)
当 Pragma 和 Cache-Control 同时存在的时候,Pragma 的优先级高于 Cache-Control。
Last-Modified: Mon, 12 Dec 2016 14:45:00 GMTAccept-Ranges: bytes
Cache-Control: max-age=3600
Connection: Keep-Alive
Content-Length: 4361
Content-Type: image/png
Date: Tue, 25 Jul 2017 17:26:16 GMT
ETag: "1109-554221c5c8540"
Expires: Tue, 25 Jul 2017 18:26:16 GMT
Keep-Alive: timeout=5, max=93
Last-Modified: Wed, 12 Jul 2017 17:26:05 GMT
Server: Apache
所谓浏览器的行为,指的就是用户在浏览器如何操作时,会触发怎样的缓存策略。主要有 3 种:



counter-reset:count1 0;
声明计数器count1,从0开始
counter-increment: count1 1;
计数器count1每次增加1
content:counter(count1)
我司有一些智库报告,编辑们是以pdf格式给到我们,需要在移动端展示,目前的做法是手动把pdf转成图片,然后用图片展示,且因为移动端h5主要在微信内,用了wxpreviewImage预览图片,可以放大查看,体验还可以。可是每份报告都要去手动转换,一旦报告内容修改又要重新转换并替换图片,有点麻烦。
所以,想到两种解决方案:
引入pdfjs
<script src="https://unpkg.com/[email protected]/build/pdf.js"></script>
<script src="https://unpkg.com/[email protected]/build/pdf.worker.js"></script>直接看代码demo
var loadingTask = pdfjsLib.getDocument({
url: 'http://127.0.0.1:8080/pdfjs/test.pdf',
})
var numPages = 0;
var renderFlag = 0;
loadingTask.promise.then(function (pdf) {
numPages = pdf._pdfInfo.numPages;
console.log('ok')
pdfCreator(pdf, 1)
function pdfCreator(pdf, index) {
console.log(index)
var div = document.createElement('DIV');
var canvas = document.createElement("CANVAS");
var className = 'container the-canvas-' + index;
div.setAttribute('class', className)
canvas.id = 'the-canvas-' + index;
// canvas.setAttribute('style',"transform: scale(0.5, 0.5);transform-origin: 0 0")
div.appendChild(canvas)
document.body.appendChild(div)
pdf.getPage(index).then(function (page) {
// 初始scale数值
var scale = 1;
// 获取PDF在“一倍图”时的尺寸
var viewport = page.getViewport({
scale: scale
});
// 获取body宽度
var width = document.body.clientWidth;
/**
* width / viewport.width > 1
* 视窗 > PDF一倍宽度最终得到scale > 2
* 反之则会得到小于等于1的scale
* 最终再*2是为了得到更清晰的渲染
*/
scale = scale * width / viewport.width*2
// 重新定义scale之后再次getViewport
viewport = page.getViewport({
scale: scale
});
var canvas = document.getElementById('the-canvas-' + index);
var container=document.querySelector('.the-canvas-' + index);
var context = canvas.getContext('2d');
console.log(container)
container.setAttribute('style',"width:"+viewport.width/2+"px;height:"+viewport.height/2+"px");
canvas.setAttribute('style',"width:"+viewport.width/2+"px;height:"+viewport.height/2+"px");
canvas.height = viewport.height;
canvas.width = viewport.width;
var renderContext = {
canvasContext: context,
viewport: viewport
};
page.render(renderContext).promise.then(() => {
renderFlag = index
if (renderFlag < numPages) {
pdfCreator(pdf, renderFlag + 1)
}
});
});
}
})基础:
1.启动start nginx;
2.快速停止或关闭nginx -s stop;
3.正常停止关闭,等待所有的请求完成再停止 nginx -s quit;
4.nginx -t看是否有错误;
5.nginx -s reload 更新Nginx配置文件(重新加载配置文件nginx.conf)
6.nginx -s reopen 重新打开日志文件
静态主机:
动态匹配
location ~* \.(js|css|png|jpg|gif)$ {
add_header Cache-Control no-store;
}
location /api {
# 请求host传给后端
proxy_set_header Host $http_host;
# 请求ip 传给后端
proxy_set_header X-Real-IP $remote_addr;
# 请求协议传给后端
proxy_set_header X-Scheme $scheme;
# 路径重写
rewrite /api/(.*) /$1 break;
# 代理服务器
proxy_pass http://localhost:9000;
}
server {
# 开启gzip 压缩
gzip on;
# 设置gzip所需的http协议最低版本 (HTTP/1.1, HTTP/1.0)
gzip_http_version 1.1;
# 设置压缩级别,压缩级别越高压缩时间越长 (1-9)
gzip_comp_level 4;
# 设置压缩的最小字节数, 页面Content-Length获取
gzip_min_length 1000;
# 设置压缩文件的类型 (text/html)
gzip_types text/plain application/javascript text/css;
}
upstream balanceServer{
server 10.1.22.33:12345;
server 10.1.22.34:12345;
server 10.1.22.35:12345;
}
在server中拦截响应请求,并将请求转发到Upstream中配置的服务器列表。
server{
server_name fe.server.com;
listen 80;
location /api{
proxy_pass http://balanceServer;
}
}
location ~* .(png|gif|jpg|jpeg)${
root /root/static/;
autoindex on;
access_log off;
expires 10h;#设置过期时间为10小时
}
https://codepen.io/dcharlie2016/pen/BaqJdaY
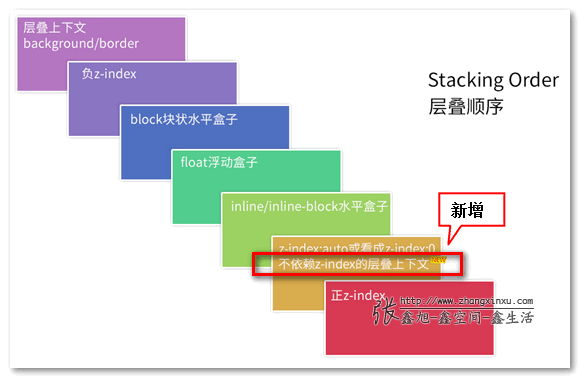
父元素不设置z-index值,伪元素设置负z-index 值,父元素位移效果不使用transform,简单说下原因。
同一个层叠上下文里面, 层叠顺序从后向前依次是: 背景和边框、负z-index、块级盒、浮动盒、行内盒、z-index:0、正z-index.
伪元素相当于子元素,也就是包含在元素内的,二者不在同一个层叠上下文中。
如果想实现层叠效果,需要元素和对应的伪元素在同一层叠上下文中,所以不能让元素创建层叠上下文。以下情况会创建层叠上下文
即便是 position 不为 static 的元素, 如果没有指定一个非 auto 值的 z-index, 该元素就不会建立一个层叠上下文。
元素的transform值不是none。
参考:
https://fatesinger.com/100258
层叠上下文、层叠顺序:
https://www.zhangxinxu.com/wordpress/2016/01/understand-css-stacking-context-order-z-index/
manfn=()=>{
throw new Error("Missing parameter")
}
foo=(bar=manfn())=>{
console.log(bar);
}http://www.ruanyifeng.com/blog/2013/01/javascript_source_map.html
eval
每个 module 会封装到 eval 里包裹起来执行,并且会在末尾追加注释 //@ sourceURL.
source-map
生成一个 SourceMap 文件.
hidden-source-map
和 source-map 一样,但不会在 bundle 末尾追加注释.
inline-source-map
生成一个 DataUrl 形式的 SourceMap 文件.
eval-source-map
每个 module 会通过 eval() 来执行,并且生成一个 DataUrl 形式的 SourceMap .
cheap-source-map
生成一个没有列信息(column-mappings)的 SourceMaps 文件,不包含 loader 的 sourcemap(譬如 babel 的 sourcemap)
cheap-module-source-map
生成一个没有列信息(column-mappings)的 SourceMaps 文件,同时 loader 的 sourcemap 也被简化为只包含对应行的。
[webpack] devtool里的7种SourceMap模式是什么鬼?
打破砂锅问到底:详解Webpack中的sourcemap
前端错误分为JS运行时错误、资源加载错误和接口错误三种。
try-catch只能捕获同步异常
/**
* @param {String} msg 错误信息
* @param {String} url 出错文件
* @param {Number} row 行号
* @param {Number} col 列号
* @param {Object} error 错误详细信息
*/
window.onerror=function(msg, url, lineNo, columnNo, error){
}大多数现代浏览器对window onerror都支持良好。需要注意的点如下:
IE10以下只有行号,没有列号, IE10有行号列号,但无堆栈信息。IE10以下,可以通过在onerror事件中访问window.event对象,其中有errorCharacter,也就是列号了。但不知为何,列号总是比真实列号小一些。
IOS下onerror表现非常统一,包含所有标准信息
安卓部分机型没有堆栈信息
总之,浏览器关于onerror这件事,是这样的一个演化过程,最早因为页面中的js并不会很复杂,所以定位错误只需要一个行号就很容易找到,后面加上了列号,最后又加上了堆栈信息。
当语法错误、静态资源异常、接口异常错误window.onerror无法捕获
window.addEventListener('error', event =>{
console.log('addEventListener error:' + event.target);
}, true); 不同浏览器返回的error对象可能不同,需要兼容处理
没有写catch的Promise中抛出的错误无法被onerror或try-catch捕获。
解决方法:
当promise被reject并且错误信息没有被处理的时候,会抛出一个unhandledrejection
window.addEventListener('unhandledrejection', event =>
{
console.log('unhandledrejection:' + event.reason); // 捕获后自定义处理
});var consoleError = window.console.error;
window.console.error = function () {
alert(JSON.stringify(arguments)); // 自定义处理
consoleError && consoleError.apply(window, arguments);
};Vue.config.errorHandle = function (err, vm, info) {
// handle error
// `info` 是 Vue 特定的错误信息,比如错误所在的生命周期钩子
// 只在 2.2.0+ 可用
}window.onerror和window.addEventListener('error')的异同:相同点是都可以捕获到window上的js运行时错误。区别是1.捕获到的错误参数不同 2.window.addEventListener('error')可以捕获资源加载错误,但是window.onerror不能捕获到资源加载错误
所有http请求都是基于xmlHttpRequest或者fetch封装的。所以要捕获全局的接口错误,方法就是封装xmlHttpRequest或者fetch
参考 从 0 到 1 的前端异常监控项目实战或 JS错误监控总结
function report(error) {
var reportUrl = 'http://xxxx/report';
new Image().src = reportUrl + 'error=' + error;
}在线上由于JS一般都是被压缩或者打包(webpack)过,打包后的文件只有一行,因此报错会出现第一行第5000列出现JS错误,给排查带来困难。sourceMap存储打包前的JS文件和打包后的JS文件之间一个映射关系,可以根据打包后的位置快速解析出对应源文件的位置。
但是出于安全性考虑,线上设置sourceMap会存在不安全的问题,因为网站使用者可以轻易的看到网站源码,此时可以设置.map文件只能通过公司内网访问降低隐患
sourceMap配置devtool: 'inline-source-map'
如果使用了uglifyjs-webpack-plugin 必须把 sourceMap设置为true
https://doc.webpack-china.org...
yarn config set ignore-engines true
如一个2px*2px的图,从右到左从上往下依次是红、白、白、红;Index会用红-1,4;白-2,3记录;而RGB会依次记录:红,白,白,红;PNG-8就是Index,称 索引色,PNG-24和PNG-32为RGB,称直接色
每个前端工程师都应该了解的图片知识(长文建议收藏)
现代图片性能优化及体验优化指南 - 图片类型及 Picture 标签的使用
validate-npm-package-name包来检测包名是否合法npm view packageName查看包是否被占用例如,上面 antd 指定的模块入口 lib/index.js ,当我们在代码用引入 antd 时:import { notification } from 'antd'; 实际上引入的就是 lib/index.js 中暴露出去的模块。
{
"scripts": {
"test": "jest --config .jest.js --no-cache",
"dist": "antd-tools run dist",
"compile": "antd-tools run compile",
"build": "npm run compile && npm run dist"
}
}
webkit,Gecko,EdgeHTML,Trident
用户界面,浏览器引擎,呈现引擎,网络,用户界面后端,js解释器,数据存储。
chrome浏览器每一个标签页都分别对应一个呈现引擎实例,每个标签页都是一个独立的进程。
解析HTML形成DOM Tree,解析CSS,生成style Rules,将DOM Tree和style Rules合并成Render Tree,布局(为每个节点分配一个屏幕的坐标),调用GPU进行绘制,遍历Render Tree的节点并将元素呈现出来,Composite
浏览器会从右往左解析css选择器
.mod-nav h3 span {font-size: 16px;}
从 .mod-nav 开始,遍历子节点 header 和子节点 div
然后各自向子节点遍历。在右侧 div 的分支中
最后遍历到叶子节点 a ,发现不符合规则,需要回溯到 ul 节点,再遍历下一个 li-a,一颗DOM树的节点动不动上千,这种效率很低。
先找到所有的最右节点 span,对于每一个 span,向上寻找节点 h3
由 h3再向上寻找 class=mod-nav 的节点
最后找到根元素 html 则结束这个分支的遍历。
后者匹配性能更好,是因为从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点);而从左向右的匹配规则的性能都浪费在了失败的查找上面。
1.转码,浏览器把接受到的二进制数据根据编码格式转化成HTML字符串
2.parse,把HTML解析成Tokens
3.构建Nodes
var fragment = document.createDocumentFragment();
for (let i = 0;i<10;i++){
let node = document.createElement("p");
node.innerHTML = i;
fragment.appendChild(node);
}
document.body.appendChild(fragment);https://juejin.im/post/6859545317378490376?utm_source=gold_browser_extension
window.addEventListener('resize', function () {
if (
document.activeElement.tagName === 'INPUT' ||
document.activeElement.tagName === 'TEXTAREA' ||
document.activeElement.getAttribute('contenteditable') == 'true'
) {
window.setTimeout(function () {
if ('scrollIntoView' in document.activeElement) {
document.activeElement.scrollIntoView();
} else {
// @ts-ignore
document.activeElement.scrollIntoViewIfNeeded();
}
}, 0);
}
})工程化即系统化、模块化、规范化的一个过程。
工程化解决的问题是,如何提高编码、测试、维护阶段的生产效率。
BEM BEM 即Block Element Modifier;类名命名规则: Block__Element--Modifier
@color-blue-link: #5D7299;
css是web不可或缺的一部分,简单有难懂的
https://zhuanlan.zhihu.com/p/32117359
js设计之初,主要用于处理简单的页面效果和逻辑验证之类的简单工作。
被过于随意的设计,缺乏模块化一直是其缺陷之一。
随着网页功能不断丰富,js越来越大了
//file1.js
var num=1
function a(){
console.log(1)
}
//file2.js
var num=2
function a(){
console.log(2)
}//file1.js
var app={
num:1
a:function(){
console.log(1)
}
}
//file2.js
var app1={
num:2
a:function(){
console.log(2)
}
}但是app.num=3,内部状态可以被外部改变
3. 优化
var app=(function(){
var num=1
var a=function(){
console.log(1)
}
return {
a:a
}
})()// greeting.js 文件
var helloInLang = {
en: 'Hello world!',
es: '¡Hola mundo!',
ru: 'Привет мир!'
};
var sayHello = function (lang) {
return helloInLang[lang];
}
module.exports.sayHello = sayHello;
// hello.js 文件
var sayHello = require('./lib/greeting').sayHello;
var phrase = sayHello('en');
console.log(phrase);//todo
define('a',[],function(){
return 1
})
define('b',['a'],function(a){
return a+2
})
//使用
require(['b'],function(b){
console.log(b)
})
// 定义模块
define(['myModule'],() => {
var name = 'Byron';
function printName(){
console.log(name);
}
return {
printName:printName
}
})
// 加载模块
require(['myModule'],function(my){
my.printName();
})(function(global){
var modlues={};
var define=function(name,deps,fn){
for(var i=0;i<deps.length;i++){
deps[i]=modules[deps[i]]
}
modules[name]=fn.apply(fn,deps)
}
var require=function(name){
return modlues[name]
}
global.define=define,
global.require=require
})(this)CMD sea.js
AMD推崇依赖前置,在定义模块的时候就要声明其依赖的模块. CMD推崇就近依赖,只有在用到某个模块的时候再去require.
es module
//greet.js
function greeting(){
console.log("hello world")
}
export {
greeting
}
//hello.js
import {greeting} from './greeting.js';
greeting()A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.