draperhxy / notes Goto Github PK
View Code? Open in Web Editor NEW好记性不如烂笔头
好记性不如烂笔头


Java RMI 指的是远程方法调用(Remote Method Invocation)。这是一种机制,能够让在某个 Java 虚拟机上的对象调用另一个 Java 虚拟机中对象的方法。可以用此方法调用的任何对象都必须实现远程接口
Java RMI 不是什么新技术(在 Java 1.1 的时代就有了),但却是非常重要的底层技术,大名鼎鼎的 EJB 就是建立在 RMI 基础之上的,现在还有一些开源的远程调用组件,其底层技术也是 RMI
RMI 在一些小的应用中使用比较合适
RPC 就是远程过程调用协议(Remote Procedure Call Protocol),通过网络从远程计算机上调用某种服务。但这是一种协议,不依赖于操作系统和语言,更像是一种**,而 RMI 则是对这种**的实现。
为了实现对象持久化,在 JVM 退出之后,对象的内部状态也可以被保存。序列化的存在很容易实现在 JVM 中的活动对象与字节数组(流)之间进行转换,使用系列化可以使对象可以被存储,可以被网络传输,在网络的一端将对象序列化成字节数组,经过网络传输到另一端,可以从字节流重新还原成 JVM 中运行状态中的对象。
Java 类中的对象序列化工作通过 ObjectOutputStream 和 ObjectInputStream
ObjectOutputStream(OutputStream out); 写入的是对象非 transient,非 static 属性
void write(Object obj);
ObjectInputStream(InputStream in);
Object readObject(); 从指定流中还原对象信息
对于任何需要被序列化的对象,都必须要实现接口 Serializable,它只是一个标识接口,本身没有任何成员,只是用来标识说明当前的实现类的对象可以被序列化。
这个关键字用来控制哪些变量可以不被序列化,在被反序列化后, transient 变量被设置为初始值,如 int 型的值为 0,引用型的初始值为 null。
例如
private transient String password;假设已经将一个 Student 的对象序列化成字节流通过网络传输到另一端,但是在另一端进行了修改,添加了一个新的属性,但之前的序列化好的对象在反序列化过程中将会导致失败
所以强制添加一个新的属性如下
private static final long serialVersionUID = 1L;这表示了序列化的版本,在没有这个属性的时候, JDK 将会默认生成一个 serialVersionUID,这能保证程序的安全性,限制用户的使用。
SOA
Service-Oriented Architecture 面向服务的架构,将应用程序的不同功能单元(服务)进行拆分,并通过服务之间定义良好的接口和契约联系起来。
“服务”并不仅仅是一个按照标准暴露出 API 的对象,也不是面向对象编程的“放大版”。确实,如同面向对象给过程式编程带来了另一层次的抽象和思维,面向服务也给面向对象编程带来了另一层次的抽象和思维。
确实,面向服务的运动根本不是关于技术的!它是一个面向业务的运动,里头的抽象正是关于企业如何看待自身组织中变化不息的方方面面,以及如何用松耦合的方式将它们组织起来,从而造就出平缓而可预测的成本变动。这就是说我们要重新思考我们看待 IT 能力的方式,而不是简单地以同样的方式暴露出同样的资源,而仅仅是采用了新的接口或者中间件。
一般我们开发程序都避免不了自顶向下和自底向上的两种开发方式(或者两种都有)
从业务过程或者业务模型开始着手,然后将之递归分解成子过程或者子模型,直到达到某些条件,再继续分解就会违反这些条件位置。或者架构师从系统开始着手,从已有的 API 和访问点中暴露出服务的接口,以这些接口为基础创建出新的服务和契约,然后将它们组合起来,直到满足业务过程中的需求
适当的面向服务分析和设计方式应该从以下五个关键方面分别考虑粒度和原子性的问题:服务的可复用性、效率、事务性、可消费性(Consumability)和可见性。一开始从复用的角度看应该成为复合服务的,实际上可能出于事务性的考虑而应该成为原子服务。类似地,出于可见性和安全审查的考虑似乎应该成为细粒度服务的,可能因为效率的关系而应该改用粗粒度。这份服务粒度表格仅仅是一位高效的企业架构师腰带上挂着的又一把工具。
所以决定粒度大小的并不是一成不变的,一个粗粒度的服务在特定的环境下非常适合,并不意味在其他环境也是最好的。服务是跟着他们的应用程序一起演变的。
首先做个知识铺垫,对于 HashMap 的了解更加深入
数组就是在内存中连续申请一片内存用于存储数据,插入取出只需要使用数组的下标就可以了。时间复杂度为 O(1),而其中查找其中的值需要遍历数组,其时间复杂度为 O(n),对于有序数组来说可以使用二分查找等提高查找效率。但对于插入来说,如果要维护好数组的形态,则需要将插入点之后的数据依次向后。
链表是由一个一个结点连接而成,每个结点中都会有一个指针指向与自己类型相同的下一个结点。故插入和删除只要改变前后结点的指针,释放内存,即可删除,操作时间复杂度为 O(1) ,但在内存中的分布并不连续,故我们查找数据的时候只能通过遍历的方式,其时间复杂度为 O(n)。
HashMap 就是结合了数组和链表,查找,插入,删除的效率特别快。不考虑哈希冲突的情况下,时间复杂度几乎为 O(1)。而其的缺陷就是哈希冲突
HashMap 的主体是数组,链表是解决哈希冲突的方案(在 JDK 1.8 后链表中的结点超过八个将会优化成红黑树 ConcurrentHashMap 也进行了红黑树优化)
先来定义哈希函数为 具体位置 = 哈希函数(key)
而数组 table[具体位置] 即可插入,查找,等操作。但如果不同的 key 进行哈希函数运算得到相同的地址造成哈希冲突,通过在后面添加结点使用链表链接来解决哈希冲突。
在 HashMap 底层,运用了很多大量的位运算,可以加快运行速度。且 HashMap 的容量是按照 2 的 X 次幂进行扩充,对于扩充来说,还将之前散列好的数据进行散列,老数组散列成新数组通过位运算,速度也很快,故使用 2 的 X 次幂的策略扩充。
注意 HashMap 的初试容量并不是 16,而是 0,将会在第一次 put 的时候初始化容量为 16(感觉有点杠精的感觉...)
都知道 HashMap 是键值对(key-value)形式,那么什么样的对象才可以作为 key 呢?
那就是不可变对象(String, Integer 等)避免计算哈希值时发生改变。所以我们通常覆写 equal() 还要覆写 hashCode() 方法
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;对于分布不均匀的 HashMap jdk 1.8 会比 jdk 1.7 快
如果在极端情况哈希分布不均匀,jdk 1.8 的红黑树优化将会远远快于 jdk 1.7
还有很多不足,待完善
HashMap 实现原理以及源码分析
HashMap 和 Hashtable 的区别
Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second)
u undoctrl + r redoa 在光标后插入o 在当前行后插入一行O 在当前行前插入一行e 到下一个单词开头w 到下一个单词结尾viw 选中光标所在的单词因为重装电脑,故安装了最新的 IDEA,在配置 tomcat 的时候发现 在 deployment 下没有关于 application context 选项

而在之前的版本是有的
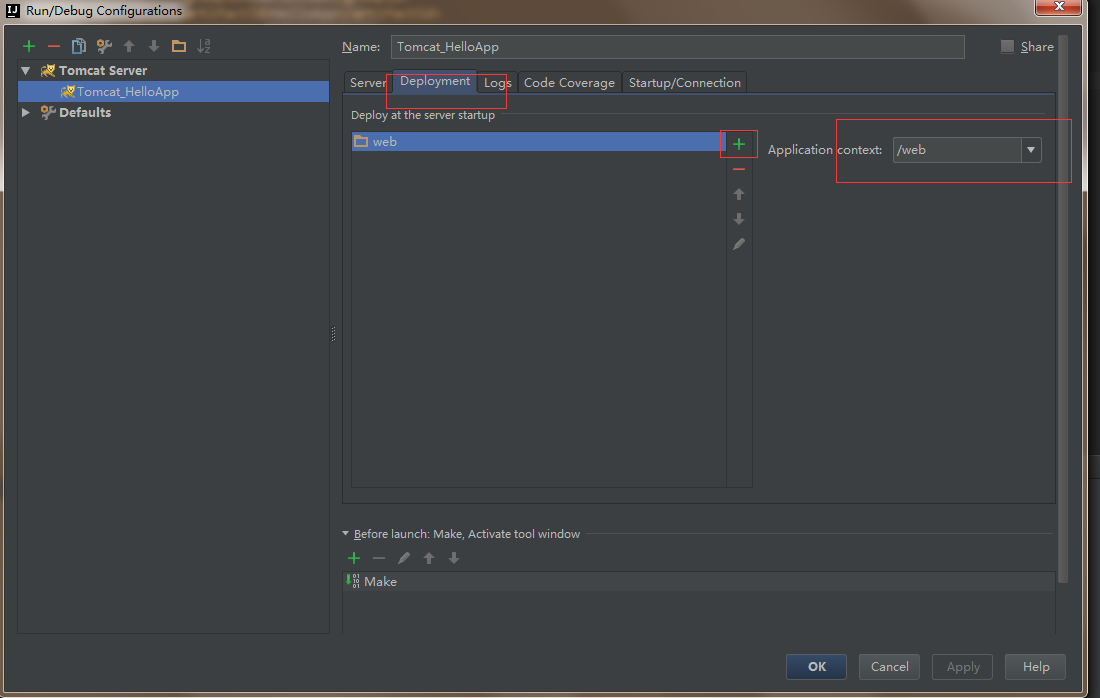
把 tomcat URL 修改了,结果导致项目启动成功,但是页面加载不出来,连 404 都不是,chrome 显示找不到 localhost 的网页
百思不得其解,反复新创项目,试图重现问题,终于在晚上找到了上述的这个原因
我们的 IDEA 只是一个开发环境,到底是什么决定了我们的项目路径,我们以前的配置是怎么解决的
于是在 IDEA 的配置文件,在 .idea/workspace.xml 中 command + r 搜索我们最初初始化的 URL 找到了配置 URL 的位置,如图下所示

而其中的 CONTEXT_PATH 选项才是我们真正的项目路径
所以按照这个修改,就可以解决问题
第二次更新
如果不能解决也需要改一下 find 里面的字符串
<component name="FindInProjectRecents">
<findStrings>
<find>Tuscany</find>
</findStrings>
</component>
对于字符串的拼接速度来说
StringBuilder > String > StringBuffer
因为 StringBuilder 并不会重复创建 String 对象
当我们声明 String str = "a"; 时,将会创建一个 str 对象
继续 str = str + "b" 时
表面来看是修改了 str 对象
但实际上在 jvm 中新建了一个 str 对象将,是之前的 str 和 'b' 拼接而成
所以效率会慢一点
而我们也通常使用下面代码来新建对象
String str = new StringBuilder().append("a").append("b");但他的线程并不安全
然而在 jdk 1.8 以及之后字符串拼接,不再需要 StringBuilder 做优化了,实际上在 Java 底层早已帮我们使用了 StringBuilder
StringBuffer 相较于 StringBuilder 来说,众多方法使用了 synchronized 关键字,故可以保证线程是安全的
参考:
Java中的String,StringBuilder,StringBuffer三者的区别
jdk不同版本对String拼接的优化分析
Java 8中不再需要StringBuilder拼接字符串
第一次启动 Spring Boot,按照 Spring Boot快速入门
结果出现了 Whitelabel Error Page
这么一个简单的项目不应该出现这种问题
后来查到
@SpringBootApplication 将会扫描该注解所在的包,而不是所有的包
所以有以下两种解决方案
一 添加 @componentscan
@SpringBootApplication
@ComponentScan(basePackages = {"com.draper.web"})
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}二 遵循正确的目录结构
com
+- example
+- myapplication
+- Application.java
|
+- customer
| +- Customer.java
| +- CustomerController.java
| +- CustomerService.java
| +- CustomerRepository.java
|
+- order
+- Order.java
+- OrderController.java
+- OrderService.java
+- OrderRepository.java
| \ | @ConfigurationProperties | @value |
|---|---|---|
| 功能 | 批量注入配置文件中的属性 | 单独指定 |
| 松散绑定(松散语法) | 支持 | 不支持 |
| SpEL | 不支持 | 支持 |
| JSR303 数据校验 | 支持 | 不支持 |
Spring Boot
Java 语言在设计之初提供了相对完善的异常处理机制,这种机制大大降低了编写和维护可靠的程序门槛。
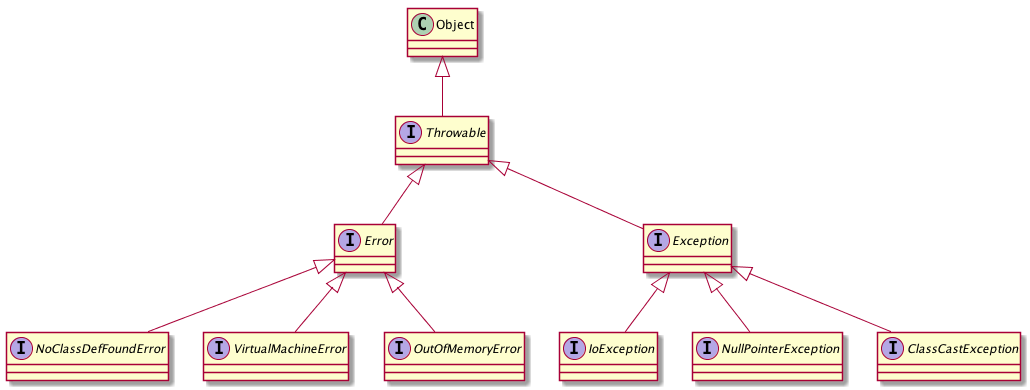
Exception 和 Error 都继承了 Throwable 类,在 Java 中只有 Throwable 类型的实例才可以被抛出 (throw) 或者捕获 (catch),它是异常处理机制的基本组成类型。
Exception 和 Error 体现了 Java 平台设计者对不同异常情况的分类。 Exception 是程序正常运行中,可以预料的意外情况,可能也应该被捕获,进行相应处理。
Error 是指在正常情况下,不太可能出现的情况,绝大部分的 Error 都会导致程序处于非正常的、不可恢复的状态。既然是非正常情况,所以不便于也不需要捕获,常见的如 OutOfMemoryError 之类,都是 Error 的自雷
Exception 又分为可检查 (checked) 异常和不检查 (unchecked) 异常, 可检查异常在源代码里必须显示地进行捕获处理,这是编译器检查的一部分。前面说的 Error 是 Throwable 不是 Exception。
不检查异常就是所谓的运行时异常,类似 NullPointerException、ArrayIndexOutOfBoundsException 之类,通常是可以编码避免的逻辑错误,具体情况需要来判断是否需要捕获,并不会在编译期强制要求
异常处理的代码比较繁琐,而使用 try-catch 语句已经随处可见,但随着语言的发展有了很多新的特性可以使用,例如 try-with-resources、multiple catch,
try (BufferedReader br = new BufferedReader(…);
BufferedWriter writer = new BufferedWriter(…)) {// Try-with-resources
// do something
catch ( IOException | XEception e) {// Multiple catch
// Handle it
} 当我们进行异常处理的时候应该捕获其最小子类的 Exception 而不是通用异常 Exception
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}比如说这里捕获的是 Exception 不能将过多的信息暴露出来
其次不要生吞异常
避免发生奇怪难以诊断的问题出现
还有注意不要使用异常处理机制来改变代码的执行过程
因为 new 一个 Exception 远远比 if swich 的成本要搞得多
在 Java 中这是一种错误机制,从而避免更大的错误
例如 ArrayList 在迭代(list.hasNext())的时候,另外一个操作改变了 ArrayList 的结构,从而抛出异常,避免引起其他的错误。
将 java.util 包替换成 java.util.concurrent 包下的相应实现类
jdk 1.5 内置了三种标准的注解:
@Override 表示当前的方法定义将会覆盖父类中的方法@Deprecated 表示注解将会为 IDE 发出警告,表示使用的代码是不被赞成的代码,将被弃用的代码@SuppressWarnings 关闭不当 IDE 警告消息除此之外还提供了四种注解负责注解的创建
表示该注解可以用于什么地方,其参数为 ElementType 枚举类型的常量
包括有
CONSTRUCTOR 在构造器中声明FIELD 域声明(包括 enum 实例)LOCAL_CARIABLE 局部变量声明METHOD 方法声明PACKAGE 包声明PARAMETER 参数声明TYPE 类、接口(包括注解类型)或 enum 声明表示要在什么级别保存该注解信息,其参数为 RetentionPolicy 枚举类型的常量
包括有
SOURCE 注解将被编译器丢弃CLASS 注解在 class 文件中可用,但会被 VM 丢弃RUNTIME VM 将在运行期间保留注解,因此可以通过反射机制读取注解的信息将注解包含在 Java doc 中
允许子类继承父类中的注解
如果不想思考关于 key 的长度问题或者是想让工作简单点,JJWT 提供了 io.jsonwebtoken.security.Keys 实用类来生成能够满足 JWT 签名足够安全的 key,且能够满足用户想要使用的算法。
如果想要使用足够强壮的 SecretKey,可以使用 JWT HMAC-SHA 算法
SecretKey key = Keys.secretKeyFor(SignatureAlgorithm.HS256);//or HS384 or HS512通过上述代码, JJWT 使用了 JCA 提供的 KeyGenerator 来创建一个安全的随机秘钥,这个秘钥拥有最短的正确长度来满足算法。
如果使用一个现有的编码成的 byte array 的 HMAC SHA SecretKey,可以使用下面代码进行转换
byte[] keyBytes = getSigningKeyFromApplicationConfiguration();
SecretKey key = Keys.hmacShaKeyFor(keyBytes);如果想生成足够强壮的 Elliptic Curve 或 RSA 不对称秘钥对,可以使用 JWT ECDSA 或 RSA 算法,使用 Keys.keyPairFor(SignatureAlgorithm) ,代码如下
KeyPair keyPair = Keys.keyPairFor(SignatureAlgorithm.RS256); //or RS 384, RS512, PS256, PS384, PS512, ES256, ES384, ES512可以使用 秘钥(keyPair.getPrivate()) 来创建 JWS 和公钥 (keyPair.getPublic()) 来解析校验一个 JWS
备注: PS256, ps384 和 PS512 算法需要在运行环境提供 JDK 11 或者兼容的 JCA 实现类 (如 BouncyCastle) ,如果在 JDK 10 或更早版本想要使用这些算法,那就需要 BouncyCastle,其他算法则由 JDK 提供
小明的女朋友最喜欢在网上买买买了,可是钱包里钞票有限,不能想买啥就买啥。面对琳琅满目的物品,她想买尽可能多的种类,每种只买一件,同时总价格还不能超过预算上限。于是她请小明写程序帮她找出应该买哪些物品,并算出这些物品的总价格。
输入规范:
每个输入包含两行。第一行是预算上限。第二行是用空格分隔的一组数字,代表每种物品的价格。所有数字都为正整数并且不会超过10000。
输出规范:
对每个输入,输出应买物品的总价格。
输入示例1:
100
50 50
输出示例1:
100
输入示例2:
188
50 42 9 15 105 63 14 30
输出示例2:
160
package com.draper;
import java.util.Arrays;
import java.util.Scanner;
public class Consume {
public static void main(String[] args) {
System.out.println(solution());
}
private static int solution() {
Scanner scanner = new Scanner(System.in);
Integer total = scanner.nextInt();
scanner.nextLine();
String line = scanner.nextLine();
String[] priceStr = line.split(" ");
// 一件物品都没有
if (priceStr.length == 0) {
return 0;
}
// 只有一件物品
if (priceStr.length == 1) {
if (Integer.valueOf(priceStr[0]) < total) {
return Integer.valueOf(priceStr[0]);
} else {
return 0;
}
}
int[] priceInteger = new int[priceStr.length];
for (int i = 0; i < priceStr.length; i++) {
priceInteger[i] = Integer.valueOf(priceStr[i]);
}
return calculate(total, priceInteger);
}
private static int calculate(int total, int[] prices) {
int sum = 0;
int flag = 0;
Arrays.sort(prices);
for (int i = 0; i < prices.length; i++) {
flag = sum;
if (sum < total) {
if (flag + prices[i] <= total)
sum = flag + prices[i];
}
}
return sum;
}
}李雷和韩梅梅坐前后排,上课想说话怕被老师发现,所以改为传小纸条。为了不被老师发现他们纸条上说的是啥,他们约定了如下方法传递信息:
将26个英文字母(全为大写),外加空格,一共27个字符分成3组,每组9个。也就是ABCDEFGHI是第一组,JKLMNOPQR是第二组,STUVWXYZ是第三组(此处用代表空格)。
然后根据传递纸条那天的日期,改变字母的位置。
先根据月份数m,以整个分组为单位进行循环左移,移动(m-1)次。
然后根据日期数d,对每个分组内的字符进行循环左移,移动(d-1)次。
以3月8日为例,首先移动分组,3月需要循环左移2次,变成:
STUVWXYZ*,ABCDEFGHI,JKLMNOPQR
然后每组内的字符,8日的话需要循环左移7次,最终的编码为:
Z*STUVWXY,HIABCDEFG,QRJKLMNOP
对于要传递信息中的每个字符,用组号和组内序号两个数字来表示。
如果在3月8日传递信息“HAPPY”,那么H位于第2组的第1个,A位于第2组第3个,P位于第3组第9个,Y位于第1组第9个,所以纸条上会写成:
21 23 39 39 19
现在给定日期和需要传递的信息,请输出应该写在纸条上的编码。
输入规范:
每个输入包含两行。第一行是用空格分隔的两个数字,第一个数字是月份,第二个数字是日子。输入保证是一个合法的日期。
第二行为需要编码的信息字符串,仅由A~Z和空格组成,长度不超过1024个字符。
输出规范:
对每个输入,打印对应的编码,数字之间用空格分隔,每个输出占一行。
输入示例1:
1 1
HI
输出示例1:
18 19
输入示例2:
3 8
HAPPY
输出示例2:
21 23 39 39 19
输入示例3:
2 14
I LOVE YOU
输出示例3:
35 25 18 12 29 31 25 23 12 28
package com.draper;
import java.util.Scanner;
public class SecretMessage {
private static String[] base = {"ABCDEFGHI", "JKLMNOPQR", "STUVWXYZ "};
private static String[] str1 = base[0].split("");
private static String[] str2 = base[1].split("");
private static String[] str3 = base[2].split("");
private static String[][] doubleArrays = {str1, str2, str3};
/**
* 主要**是根据原始坐标,按照日期进行相应的计算,然后得出相应的坐标
* 时间复杂度除了计算原始坐标花了时间为 O(n^2)以外,其余均为 O(1)
*
* @param args
*/
public static void main(String[] args) {
System.out.println(solution());
}
/**
* 处理输入输出
*
* @return
*/
public static String solution() {
Scanner scanner = new Scanner(System.in);
String dateStr = scanner.nextLine();
String[] dateStrs = dateStr.split(" ");
Integer month = Integer.valueOf(dateStrs[0]);
Integer day = Integer.valueOf(dateStrs[1]);
String line = scanner.nextLine();
String result = "";
String[] chars = line.split("");
for (String aChar : chars) {
int[] resultIndex = indexOfDate(month, day, aChar);
result = result + " " + resultIndex[0] + "" + resultIndex[1];
}
if (result.startsWith(" "))
result = result.substring(1);
return result;
}
/**
* 根据日期的变化,查找目标字符变化过后的坐标
* 核心**是使用了字符串三次旋转得到字符串左移位后的值
* 但这里只求坐标,所以只要将坐标进行计算
*
* @param month
* @param day
* @param target 目标字符
* @return
*/
public static int[] indexOfDate(int month, int day, String target) {
int[] index = indexOf(doubleArrays, target);
int blockIndex = (index[0] + 1 - (month - 1)) % 3;
if (blockIndex == 0) {
blockIndex = 3;
}
if (blockIndex < 0) {
blockIndex = blockIndex + 3;
}
int spanIndex = (index[1] + 1 - (day - 1)) % 9;
if (spanIndex < 0) {
spanIndex = spanIndex + 9;
}
if (spanIndex == 0) {
spanIndex = 9;
}
return new int[]{blockIndex, spanIndex};
}
/**
* 将三组字符串中,目标字符的原始坐标计算出来
*
* @param arrays 传入基本数组,分为三块,其中每一块是一个 String 数组
* @param target 查找的目标
* @return 原始坐标
*/
public static int[] indexOf(String[][] arrays, String target) {
for (int i = 0; i < arrays.length; i++) {
for (int i1 = 0; i1 < arrays[i].length; i1++) {
if (arrays[i][i1].equals(target)) {
return new int[]{i, i1};
}
}
}
return null;
}
}当我实现一个 TreeMap
TreeMap<Student<int age>,String name>理所当然的认为 TreeMap 的 key,也就是 Student 类需要重写 equal 和 hashCode 方法,来确保键的唯一性
但实际上
treeMap.put(student1, "小米12");
treeMap.put(student2, "小米11");
treeMap.put(student3, "小米45");
treeMap.put(student4, "小米82");
treeMap.put(student5, "小米66");连续 put 五次后得到的 Size 居然为 3
在 debug 过程中,跟随断点查看
在确定唯一性的时候并没有进入 equal 和 hashCode 方法
反而是在 TreeMap 中迟迟停留
而里面有一步
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);这让我想起了我的 compare 方法,好像找到问题了
@Override
public int compareTo(Student o) {
if (this == o) {
return 0;
} else {
if (this.age < o.getAge()) {
return 0;
} else {
return 1;
}
}
}我的比较方法没有返回负值得可能,这就意味着我的 t 对象(指针) 一指再往右边找,直到直接执行下面 else 的内容进行赋值
所以我的 treeMap 中的 Entry 总是被覆盖
所以修改 compare 方法,增加往左搜索的可能解决问题
int num = this.age - o.getAge();
//为0时候,两者相同:
if (num == 0) {
return 0;
//大于0时,传入的参数小:
} else if (num > 0) {
return 1;
//小于0时,传入的参数大:
} else {
return -1;
}上牛客网做了一道剑指offer的算法题 重建二叉树
输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
看了别人的代码,感觉自己真的 ...
贴下自己吧,毕竟花了很长时间解决的
public class Solution {
private static int[] pre = {1, 2, 4, 7, 3, 5, 6, 8};
private static int[] in = {4, 7, 2, 1, 5, 3, 8, 6};
public TreeNode reConstructBinaryTree(int[] pre, int[] in) {
return buildChildTree(null, pre, in);
}
// 寻找根节点值
public static int searchRootValue(int[] pre) {
int root;
if (pre.length == 0) {
return 0;
}
root = pre[0];
return root;
}
// 寻找根节点下标
public static int searchRootIndex(int[] pre, int[] in) {
if (pre == null && in == null
|| pre.length == 0 && in.length == 0) {
return -1;
}
// 只有一个节点,根下标就是 0
if (pre.length == 1 && in.length == 1)
return 0;
int rootValue = searchRootValue(pre);
int index = 0; // 用来标记根节点下标
for (int i = 0; i < in.length; i++) {
if (in[i] == rootValue) {
index = i;
}
}
return index;
}
// 寻找左子树中序数组
public static int[] searchLeftChildInArrays(int[] pre, int[] in) {
if (pre == null && in == null
// 只有一个节点则无法找到其子树
|| pre.length <= 1 && in.length <= 1) {
return null;
}
int rootIndex = searchRootIndex(pre, in);
int[] result = new int[rootIndex];
for (int i = 0; i < rootIndex; i++) {
result[i] = in[i];
}
return result;
}
// 寻找右子树中序数组
public static int[] searchRightChildInArrays(int[] pre, int[] in) {
if (pre == null || in == null
// 只有一个节点则无法找到其子树
|| pre.length <= 1 || in.length <= 1) {
return null;
}
int rootIndex = searchRootIndex(pre, in);
int[] result = new int[in.length - rootIndex - 1];
for (int i = 0; i < (in.length - rootIndex - 1); i++) {
result[i] = in[rootIndex + 1 + i];
}
return result;
}
// 寻找前序根节点的值
public static int searchPreLeftChildRootValue(int[] pre, int[] in) {
int[] leftArrays = searchLeftChildInArrays(pre, in);
int rootValue = 0;
for (int i = 0; i < pre.length; i++) {
for (int j = 0; j < leftArrays.length; j++) {
if (leftArrays[j] == pre[i]) {
rootValue = leftArrays[j];
return rootValue;
}
}
}
return rootValue;
}
// 寻找左子树前序数组
public static int[] searchLeftChildPreArrays(int[] pre, int[] in) {
if (pre == null || in == null ||
pre.length <= 1 || in.length <= 1) {
return null;
}
int length = searchLeftChildInArrays(pre, in).length;
int[] result = new int[length];
for (int i = 0; i < result.length; i++) {
result[i] = pre[i + 1];
}
return result;
}
// 寻找右子树前序数组
public static int[] searchRightChildPreArrays(int[] pre, int[] in) {
if (pre == null || in == null ||
pre.length <= 1 || in.length <= 1) {
return null;
}
int rightLength = searchRightChildInArrays(pre, in).length;
int[] result = new int[rightLength];
for (int i = 0; i < result.length; i++) {
result[i] = pre[pre.length - rightLength + i];
}
return result;
}
// 递归构建一颗树,返回根节点
public static TreeNode buildChildTree(TreeNode father, int[] pre, int[] in) {
if (pre == null && in == null || pre.length == 0 && pre.length == 0) {
return father;
}
int rootValue = searchRootValue(pre);
father = new TreeNode(rootValue);
int[] leftChildPreArrays = searchLeftChildPreArrays(pre, in);
int[] leftChildInArrays = searchLeftChildInArrays(pre, in);
int[] rightChildPreArrays = searchRightChildPreArrays(pre, in);
int[] rightChildInArrays = searchRightChildInArrays(pre, in);
if (leftChildPreArrays != null && leftChildPreArrays.length != 0) {
// printAll(leftChildPreArrays, leftChildInArrays);
TreeNode leftNode = buildChildTree(father, leftChildPreArrays, leftChildInArrays);
father.left = leftNode;
}
if (rightChildPreArrays != null && rightChildPreArrays.length != 0) {
// printAll(rightChildPreArrays, rightChildInArrays);
TreeNode rightNode = buildChildTree(father, rightChildPreArrays, rightChildInArrays);
father.right = rightNode;
}
return father;
}
public static void main(String[] args) {
TreeNode root = new Solution().reConstructBinaryTree(pre, in);
}
public static void printAll(int[] pre, int[] in) {
int index = searchRootValue(pre);
System.out.print("中序根节点值\t");
System.out.println(index);
System.out.print("左子树中序数组\t");
int[] leftChildInArrays = searchLeftChildInArrays(pre, in);
if (leftChildInArrays != null)
for (int child : leftChildInArrays) {
System.out.print(child + " ");
}
System.out.println();
System.out.print("右子树中序数组\t");
int[] rightChildInArrays = searchRightChildInArrays(pre, in);
if (rightChildInArrays != null)
for (int child : rightChildInArrays) {
System.out.print(child + " ");
}
System.out.println();
System.out.print("左子树前序数组\t");
int[] leftChildPreArrays = searchLeftChildPreArrays(pre, in);
if (leftChildPreArrays != null)
for (int child : leftChildPreArrays) {
System.out.print(child + " ");
}
System.out.println();
System.out.print("右子树前序数组\t");
int[] rightChildPreArrays = searchRightChildPreArrays(pre, in);
if (rightChildPreArrays != null)
for (int child : rightChildPreArrays) {
System.out.print(child + " ");
}
System.out.println("\n\n");
}
public static void printTree(TreeNode treeNode) {
if (treeNode == null) {
System.out.println("到结尾了");
}
System.out.println(treeNode.val);
if (treeNode.left != null) {
printTree(treeNode.left);
System.out.println("输出结束");
}
if (treeNode.right != null) {
printTree(treeNode.right);
System.out.println("输出结束");
}
}
}为了减少重复的环境配置工作的一个容器
有了高可用的沙箱机制就离高可用更进了一步
使用Docker的步骤:
1)、安装Docker
2)、去Docker仓库找到这个软件对应的镜像;
3)、使用Docker运行这个镜像,这个镜像就会生成一个Docker容器;
4)、对容器的启动停止就是对软件的启动停止;
Docker 引擎是一个包含以下主要最贱的客户端服务器应用程序
一种服务器,它是一种称为守护进程并且长时间运行的程序
REST API 用于指定程序可以用来与守护进程通信的接口,并指示它做什么
使用 RESTful API 来调用程序的 API
一个有命令行(CLI )工具的客户端
docker 镜像(images) 镜像用来创建 Docker 容器的模板
docker 容器(Container) 容器是独立运行的一个或一组应用
在一台机器上运行多个应用,可以实现负载均衡等,Docker 也可以成为
docker 客户端(Client) 客户端通过命令行或者其他工具使用 Docker
- build 请求守护进程,守护进程构建一个镜像
- pull 拉取
- run 运行
docker 仓库(Registry) Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库
docker 主机(Host) 安装 Docker 程序的机器,用于执行 Docker 守护进程和容器
可以是一个物理机或者虚拟机,Docker 中还可以装 Docker
docker 网络(Network)
docker 数据卷(Data Volumes)
Docker 使用客户端-服务器(C/S)架构模式,使用远程 API 来创建管理 Docker 容器
Docker 容器通过 Docker 镜像来创建
容器与镜像的关系类似于 OOP 中的对象与类
操作系统分为内核和用户空间,对于 Linux 而言,内核启动后,会挂在 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image) 相当于一个 root 文件系统。比如官方镜像 ubuntu:16.04 包含一套完成 Ubuntu 16.04 最小系统的 root 文件系统
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序,库,资源,配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷,环境变量,用户等)。镜像不包含任何动态数据,其内容在构建之后也不会改变。
因为镜像包含操作系统 root 文件系统,其体积也是庞大的,因此在 Docker 设计时,就充分利用 Union FS 技术,将其设计为分层存储的架构。所以严格来说,镜像并非像一个 ISO 那样打包的文件,镜像只是一个虚拟概念,其实际提现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成。
镜像构建时,会以此封层构建,前一层时后一层的基础,每一层构建完就不会发生改变,后一层上的改变只发生在自己这一层。比如删除前一层文件的操作,实际不是删除前一层的文件,而是仅仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看见这个文件,但是实际上该文件会一致跟随镜像。因此在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
分层存储的特征还使得镜像的复用,定制变得更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制所需的内容,构建新的镜像。
(可以理解成 Java 的继承)
镜像(Image) 和容器 (Container) 的关系,就相当于 OOP 中类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间,因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间、甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像在一个独立于宿主的系统下操作一样。这种特性也是容器封装的应用比直接在宿主运行更加安全。也因为这种隔离的特性,许多人会搞混容器和虚拟机
镜像使用的是分层存储,容器也是如此,每一个容器运行时,是以镜像为基础层,在其上创建一个当前容器的存储层,我们可以称这个容器为运行时读写而准备的容器存储层。
容器存储的生存周期和容器一样,容器消亡时,容器存储也随之消亡。因此,任何保存于存储层的信息都会随容器删除而丢失。
按照 Docker 最佳实践的要求,容器不应该向其存储层内写入任何数据,容器存储层要保持无状态化,所有的文件写入操作,都应该使用 数据圈(Volume),或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高
虚拟机的文件存储在放虚拟机的地方,由虚拟机管理,会发生一个重复写的操作,性能明显弱于宿主机,使用 Docker 使用避免重复 IO,使性能接近宿主机。
数据卷的生命周期独立于容器,容器消亡,数据卷不会向往,因此,使用数据卷后,容器删除或者重新运行之后数据却不会丢失。
镜像构建完成后,可以很容易的在当前宿主机上运行,但是,如果需要在其他服务器上使用这个镜像,我们就需要一个集中的存储,分发镜像服务, Docker Registry 就是这样的服务
一个 Docker Registry 中可以包含多个仓库 (Repository);每个仓库可以包含多个标签(Tag),每个标签对应一个镜像。
通常一个仓库包含同一个软件不同版本镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体软件的版本镜像,如果不给出标签,将以 latest 作为默认标签。
最常用的 Registry 公开服务是官方的 DockerHub,这也是默认的 Registry,还有 CoreOS 的 Quay.io
开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令但不包含图形界面,以及镜像维护,用户管理,访问控制。在官方的商业化版本 Docker Trusted Registrty 中提供高级功能。
查看正在运行的程序
rapers-MBP:~ draper$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
11981671e633 ubuntu:16.04 "bash" 3 seconds ago Up 2 seconds adoring_keller如果没有使用 --rm查看所有容器则会如下所示
rapers-MBP:~ draper$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
11981671e633 ubuntu:16.04 "bash" 4 minutes ago Up 4 minutes adoring_keller
a26d7fab4d83 tomcat "catalina.sh run" About an hour ago Exited (130) About an hour ago admiring_swirles
5b660a81eed8 hello-world "/hello" 3 hours ago Exited (0) 3 hours ago sad_heisenbergrapers-MBP:~ draper$ docker rm 5b660a81eed8
5b660a81eed8Drapers-MBP:~ draper$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
11981671e633 ubuntu:16.04 "bash" 14 minutes ago Up 14 minutes adoring_keller
a26d7fab4d83 tomcat "catalina.sh run" About an hour ago Exited (130) About an hour ago admiring_swirles
Drapers-MBP:~ draper$ docker rm --force 11981671e633
11981671e633
Drapers-MBP:~ draper$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a26d7fab4d83 tomcat "catalina.sh run" About an hour ago Exited (130) About an hour ago admiring_swirlesdocker pull ubuntu:16.04一般可以是
docker pull ip:port/reponsitory:tag
docker run -it --rm \
ubuntu:16.04 \
bashit 这是两个参数 -l:交互式操作,-t: 进入终端
--rm 退出容器后将其删除
一般情况下,退出容器不会立即删除,而是手动
docker rm删除
ubuntu:16.04 我们需要启动的镜像
bash 我们需要的交互式终端,指定用 bash
查看镜像,容器,数据卷所占用的空间
docker hub 上面的体积一般是经过压缩的,所以本地的体积会比 docker hub 上大
使用
docker image ls的体积经过了继承,复用,所以实际磁盘消耗大小要比 docker image ls`` 的体积小很多
用于显示虚悬镜像,随着官方镜像维护,旧镜像的名称被取消,原来的镜像标签则会变为 <none>
docker pull 或者 build 会出现这种问题
用于显示中间层镜像
显示顶级镜像
删除镜像,可以用 docker rmi 代替
以下内容仅适用于 Docker CE 18.09 以下版本,在 Docker CE 18.09 版本中默认使用的是
overlay2驱动。
在 Ubuntu/Debian 上有 UnionFS 可以使用,如 aufs 或者 overlay2,而 CentOS 和 RHEL 的内核中没有相关驱动。因此对于这类系统,一般使用 devicemapper 驱动利用 LVM 的一些机制来模拟分层存储。这样的做法除了性能比较差外,稳定性一般也不好,而且配置相对复杂。Docker 安装在 CentOS/RHEL 上后,会默认选择 devicemapper,但是为了简化配置,其 devicemapper 是跑在一个稀疏文件模拟的块设备上,也被称为 loop-lvm。这样的选择是因为不需要额外配置就可以运行 Docker,这是自动配置唯一能做到的事情。但是 loop-lvm 的做法非常不好,其稳定性、性能更差,无论是日志还是 docker info 中都会看到警告信息。官方文档有明确的文章讲解了如何配置块设备给 devicemapper 驱动做存储层的做法,这类做法也被称为配置 direct-lvm。
除了前面说到的问题外,devicemapper + loop-lvm 还有一个缺陷,因为它是稀疏文件,所以它会不断增长。用户在使用过程中会注意到 /var/lib/docker/devicemapper/devicemapper/data 不断增长,而且无法控制。很多人会希望删除镜像或者可以解决这个问题,结果发现效果并不明显。原因就是这个稀疏文件的空间释放后基本不进行垃圾回收的问题。因此往往会出现即使删除了文件内容,空间却无法回收,随着使用这个稀疏文件一直在不断增长。
所以对于 CentOS/RHEL 的用户来说,在没有办法使用 UnionFS 的情况下,一定要配置 direct-lvm 给 devicemapper,无论是为了性能、稳定性还是空间利用率。
或许有人注意到了 CentOS 7 中存在被 backports 回来的 overlay 驱动,不过 CentOS 里的这个驱动达不到生产环境使用的稳定程度,所以不推荐使用。
发现了这个原始资料Docker — 从入门到实践
单台服务器资源的总是有上限的,CPU资源和IO资源我们可以通过主从复制,进行读写分离,把一部分CPU和IO的压力转移到从服务器上。但是内存资源怎么办,主从模式做到的只是相同数据的备份,并不能横向扩充内存;单台机器的内存也只能进行加大处理,但是总有上限的。所以我们就需要一种解决方案,可以让我们横向扩展。最终的目的既是把每台服务器只负责其中的一部分,让这些所有的服务器构成一个整体,对外界的消费者而言,这一组分布式的服务器就像是一个集中式的服务器一样
集群一般有三种类型
每个Redis集群中的节点都需要打开两个TCP连接。一个连接用于正常的给Client提供服务,比如6379,还有一个额外的端口(通过在这个端口号上加10000)作为数据端口,比如16379。第二个端口(本例中就是16379)用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测、配置更新、故障转移授权,等等。客户端从来都不应该尝试和这些集群总线端口通信,它们只应该和正常的Redis命令端口进行通信。注意,确保在你的防火墙中开放着两个端口,否则,Redis集群节点之间将无法通信。
Redis集群中有16384个hash slots,为了计算给定的key应该在哪个hash slot上,我们简单地用这个key的CRC16值来对16384取模。(即:CRC16(key) % 16384)
Redis 允许添加和删除集群节点。比如,如果你想增加一个新的节点D,那么久需要从A、B、C节点上删除一些hash slot给到D。同样地,如果你想从集群中删除节点A,那么会将A上面的hash slots移动到B和C,当节点A上是空的时候就可以将其从集群中完全删除。
因为将hash slots从一个节点移动到另一个节点并不需要停止其它的操作,添加、删除节点以及更改节点所维护的hash slots的百分比都不需要任何停机时间。也就是说,移动hash slots是并行的,移动hash slots不会影响其它操作。
当部分master节点失败了,或者不能够和大多数节点通信的时候,为了保持可用,Redis集群用一个master-slave模式,这样的话每个hash slot就有1到N个副本。
在我们的例子中,集群有A、B、C三个节点,如果节点B失败了,那么5501-11000之间的hash slot将无法提供服务。然而,当我们给每个master节点添加一个slave节点以后,我们的集群最终会变成由A、B、C三个master节点和A1、B1、C1三个slave节点组成,这个时候如果B失败了,系统仍然可用。节点B1是B的副本,如果B失败了,集群会将B1提升为新的master,从而继续提供服务。然而,如果B和B1同时失败了,那么整个集群将不可用。
Java Spring mvc 操作 Redis 及 Redis 集群
一文看懂 Redis5 搭建集群
Redis Spring 配置
Redis Cluster 工具类配置
Redis Cluster 的使用
key 和 value 的最大值为 512MB
CLUSTER INFO
CLUSTER NODES
除了完成基本的功能以外,还要考虑到参数的边界条件,特殊输入(如 null pointer, 空字符串等)
清晰的思路比代码更重要
如果遇到了复杂的问题,就把抽象的问题形象化(画图)具体化(举例),复杂的问题简单化(分解)
问题还有可能在时间效率和空间效率方面存在优化
第一种
通过加一个中间层 proxy 所有请求,使 DB 对客户端不可见,例如 Codis

例如,使用 zhihu/redis-shard 进行客户端分片
MSET、MGET 等多种同事操作多个 key 的命令,需要使用 Hash tag 来保证多个 key 在同一个分片上fnv1a_64、murmur、md5 等多种哈希算法有些文章对此的翻译是随机访问文件,但对于其理解颇为费解,Random 在英文中的翻译有 任意的意思,所以翻译成任意访问文件
RandomAccessFile raf = new RandomAccessFile(new File("a.txt"),"rw");RandomAccessFile 的构造函数中有一个 String 类型的 mode 参数
用来指定打开文件的访问模式
IOExceptionseek 用来移动访问文件的指针,其参数为 long 类型,表示指针的下标
有了这个操作,对于文件的操作就很灵活
比如说在文件后追加内容
raf.seek(raf.length());
raf.write(".......".getBytes());但是要注意对于文件的操作只能追加,不能在中间插入,否则就会将原有的文件覆盖
Scatter 从 Channel 中读取是指在读取的数据 "分散(Scatter)" 到多个 Buffer 中channel.read(arrayBuffer);read() 方法按照 buffer 在数组中的顺序,将从 Channel 中读取的数据写入到 Buffer 中,当一个 Buffer 被写满后, Channel 紧接着向另一个 Buffer 中写
Gather 写入 Channel 将多个 Buffer 中的数据 "聚集(Gather)" 后发送到 Channelchannel.write(arrayBuffer);write() 方法会按照 buffer 在数组中的顺序,将数据写入到 Channel,注意只有 position 和 limit 之间的数据才会被写入,因此如果是一个 Buffer 的容量为 128 byte,但是仅仅包含 58 byte 的数据,那么这 58 byte 中的数据才会被写入到 Channel 中
RandomAccessFile raf1 = new RandomAccessFile("fileA.txt", "rw");
FileChannel fromChannel = raf1.getChannel();
RandomAccessFile raf2 = new RandomAccessFile("fileB.txt", "rw");
FileChannel toChannel = raf2.getChannel();
int position = 0;
long count = fromChannel.size();
// 这两个效果一样
fromChannel.transferTo(position, count, toChannel);
toChannel.transferFrom(fromChannel, 0, count);JVM 内存可以简单分为三个区
成员变量
局部变量
| \ | 成员变量 | 局部变量 | 静态变量 |
|---|---|---|---|
| 定义位置 | 在类中,方法外 | 方法中,或者方法的形参 | 在类中,方法外 |
| 初始化值 | 有默认初始化值 | 无,先定义,赋值后才能使用 | 有默认初始化值 |
| 调用方式 | 对象调用 | 对象调用,类名调用 | |
| 存储位置 | 堆中 | 栈中 | 方法区 |
| 生命周期 | 与对象共存亡 | 与方法共存亡 | 与类共存亡 |
| 别名 | 实例变量 | 类变量 |
git branch 查看分支状况git branch <branch_name> 新建一个新的分支git branch -r 查看远程分支git branch -f <a_branch> <b_branch>|<tag>|<hash> 强制移动前者的引用到后者git branch -d <branch_name> 删除分支git merge --no-ff <branch_name> 不使用fast-forward方式合并,保留分支的commit历史git checkout -b myfeature develop 开始一项功能的开发工作时,基于develop创建分支。git remote add origin <Url> 添加一个远程分支和 Urlgit remote -v 查看远程仓库git diff 查看工作区(working directory)和暂存区(staged)之间差异git diff HEAD 查看工作区(working directory)与当前仓库版本(repository)HEAD版本差异git diff --cached / git diff --staged 查看暂存区(staged)与当前仓库版本(repository)git diff --stat 不查看具体改动,只查看改动了哪些类git log -p 查看日志,并查看每次修改的内容单例模式算是设计模式中最容易理解,也是最容易手写代码的模式了吧。但是其中的坑却不少,所以也常作为面试题来考。本文主要对几种单例写法的整理,并分析其优缺点。很多都是一些老生常谈的问题,但如果你不知道如何创建一个线程安全的单例,不知道什么是双检锁,那这篇文章可能会帮助到你。
当被问到要实现一个单例模式时,很多人的第一反应是写出如下的代码,包括教科书上也是这样教我们的。
public class Singleton {
private static Singleton uniqueInstance;
private Singleton (){}
public static Singleton getInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
}这段代码简单明了,而且使用了懒加载模式,但是却存在致命的问题。当有多个线程并行调用 getInstance() 的时候,就会创建多个实例。也就是说在多线程下不能正常工作。
为了解决上面的问题,最简单的方法是将整个 getInstance() 方法设为同步(synchronized)。
public static synchronized Singleton getInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}虽然做到了线程安全,并且解决了多实例的问题,但是它并不高效。因为在任何时候只能有一个线程调用 getInstance() 方法。但是同步操作只需要在第一次调用时才被需要,即第一次创建单例实例对象时。这就引出了双重检验锁。
双重检验加锁模式(double checked locking pattern),是一种使用同步块加锁的方法。程序员称其为双重检查锁,因为会有两次检查 uniqueInstance == null,一次是在同步块外,一次是在同步块内。为什么在同步块内还要再检验一次?因为可能会有多个线程一起进入同步块外的 if,如果在同步块内不进行二次检验的话就会生成多个实例了。
public static Singleton getSingleton() {
if (uniqueInstance == null) { //Single Checked
synchronized (Singleton.class) {
if (uniqueInstance == null) { //Double Checked
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}这段代码看起来很完美,很可惜,它是有问题。主要在于uniqueInstance = new Singleton()这句,这并非是一个原子操作,事实上在 JVM 中这句话大概做了下面 3 件事情。
但是在 JVM 的即时编译器中存在指令重排序的优化。也就是说上面的第二步和第三步的顺序是不能保证的,最终的执行顺序可能是 1-2-3 也可能是 1-3-2。如果是后者,则在 3 执行完毕、2 未执行之前,被线程二抢占了,这时uniqueInstance已经是非 null 了(但却没有初始化),所以线程二会直接返回 uniqueInstance,然后使用,然后顺理成章地报错。
我们只需要将 uniqueInstance 变量声明成 volatile 就可以了。
public class Singleton {
private volatile static Singleton uniqueInstance; //声明成 volatile
private Singleton (){}
public static Singleton getSingleton() {
if (uniqueInstance == null) {
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}有些人认为使用 volatile 的原因是可见性,也就是可以保证线程在本地不会存有 uniqueInstance 的副本,每次都是去主内存中读取。但其实是不对的。使用 volatile 的主要原因是其另一个特性:禁止指令重排序优化。也就是说,在 volatile 变量的赋值操作后面会有一个内存屏障(生成的汇编代码上),读操作不会被重排序到内存屏障之前。比如上面的例子,取操作必须在执行完 1-2-3 之后或者 1-3-2 之后,不存在执行到 1-3 然后取到值的情况。从「先行发生原则」的角度理解的话,就是对于一个 volatile 变量的写操作都先行发生于后面对这个变量的读操作(这里的“后面”是时间上的先后顺序)。
但是特别注意在 Java 5 以前的版本使用了 volatile 的双检锁还是有问题的。其原因是 Java 5 以前的 JMM (Java 内存模型)是存在缺陷的,即时将变量声明成 volatile 也不能完全避免重排序,主要是 volatile 变量前后的代码仍然存在重排序问题。这个 volatile 屏蔽重排序的问题在 Java 5 中才得以修复,所以在这之后才可以放心使用 volatile。
相信你不会喜欢这种复杂又隐含问题的方式,当然我们有更好的实现线程安全的单例模式的办法。
这种方法非常简单,因为单例的实例被声明成 static 和 final 变量了,在第一次加载类到内存中时就会初始化,所以创建实例本身是线程安全的。
public class Singleton{
//类加载时就初始化
private static final Singleton uniqueInstance = new Singleton();
private Singleton(){}
public static Singleton getInstance(){
return uniqueInstance;
}
}这种写法如果完美的话,就没必要在啰嗦那么多双检锁的问题了。缺点是它不是一种懒加载模式(lazy initialization),单例会在加载类后一开始就被初始化,即使客户端没有调用 getInstance()方法。饿汉式的创建方式在一些场景中将无法使用:譬如 Singleton 实例的创建是依赖参数或者配置文件的,在 getInstance() 之前必须调用某个方法设置参数给它,那样这种单例写法就无法使用了。
我比较倾向于使用静态内部类的方法,这种方法也是《Effective Java》上所推荐的。
public class Singleton {
private static class SingletonHolder {
private static final Singleton uniqueInstance = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.uniqueInstance;
}
}这种写法仍然使用JVM本身机制保证了线程安全问题;由于 SingletonHolder 是私有的,除了 getInstance() 之外没有办法访问它,因此它是懒加载的;同时读取实例的时候不会进行同步,没有性能缺陷;也不依赖 JDK 版本。
用枚举写单例实在太简单了!这也是它最大的优点。下面这段代码就是声明枚举实例的通常做法。
public enum EasySingleton{
INSTANCE;
}我们可以通过EasySingleton.INSTANCE来访问实例,这比调用getInstance()方法简单多了。创建枚举默认就是线程安全的,所以不需要担心double checked locking,而且还能防止反序列化导致重新创建新的对象。但是还是很少看到有人这样写,可能是因为不太熟悉吧。
一般来说,单例模式有五种写法:懒加载、急加载、双重检查加锁锁、静态内部类、枚举。上述所说都是线程安全的实现,文章开头给出的第一种方法不算正确的写法。
就我个人而言,一般情况下直接使用急加载就好了,如果明确要求要懒加载(lazy initialization)会倾向于使用静态内部类,如果涉及到反序列化创建对象时会试着使用枚举的方式来实现单例。
使用 Buffer 一般遵循以下四个步骤
当向 buffer 写入数据时, buffer 会记录下写了多少数据。一旦要读取数据,需要通过 flip() 方法将 Buffer 从写模式切换到读模式(即将 position 从最后一个切换到第一个, 翻转 buffer)。
一旦读完了所有的数据,就需要清空缓冲区,让它可以再次被写入。
有两种方式能够清空缓冲区:
clear() 清空整个缓冲区compact() 清除已经读过的数据。任何未读的数据都被移到缓冲区的起始处,新写入的数据将放到缓冲区未读数据的后面缓冲区本质是一块可以写入数据,然后从中读取数据的内存。这块内存被包装成 NIO Buffer 对象,并提供了一组方法,用来访问该内存。
其中有三个主要的属性
capacitypositionlimitposition 和 limit 的含义取决于 Buffer 处在读模式还是写模式。不管 Buffer 处在什么模式,capacity 的含义总是一样的。
下面有一个图可以让理解一目了然
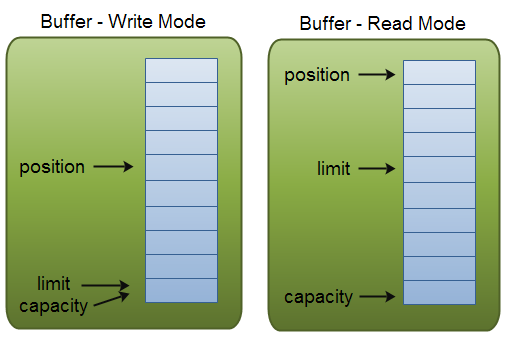
作为一个内存块,Buffer 有一个固定大小值 capacity,你只能往里写 capacity 个 byte,long,char 等类型。一旦 Buffer 满了,组需要清空 (通过读数据,然后调用 compact() 方法,或者 clear 数据才能继续写数据)
当你写数据到 Buffer 中时, position 表示当前的位置。出事的 position 值为 0。当一个 bvte,long 等类型的数据写到 Buffer 后, position 会向前移动到下一个可插入数据的 Buffer 单元,position 最大可为 capaciry - 1
当读取数据时,也是从某个特定的位置读。当将 Buffer 从写模式切换到读模式,position 会被重置为 0,limit 设置为之前的 position
ByteBufferMappedByteBufferCharBufferDoubleBufferFloatBufferIntBufferLongBufferShortBuffer这些 Buffer 代表了不同的数据类型。换句话说可以通过这些类型来操作缓冲区中的字节
其中 MappedByteBuffer 有些特别
要获取一个 Buffer 对象,首先要进行分配。每一个 Buffer 类都有一个 allocate 方法。
// Reads a sequence of bytes from this channel into the given buffer,
// starting at the given file position.
ByteBuffer buffer = ByteBuffer.allocate(48);一般有两种方式写数据到 Buffer 中
int bytesRead = channel.read(buffer);put() 方法写到 Buffer 里buf.put(127);put 有很多版本,例如写到一个指定的位置,或者把一个字节数组写入到 Buffer。
flip() 方法将 Buffer 从写模式切换到读模式。调用 flip() 方法会将 position 设为 0,并将 limit 设置成之前 position 的值,所以 flip 也叫翻转。
一般有两种方式可以从 Buffer 中读取数据
// Writes a sequence of bytes to this channel from the given buffer.
int byte = channel.write(buffer);byte byte = buf.get();使 position 设回 0,所以可以重读 Buffer 中的所有数据。limit 保持不变,仍然表示能从 Buffer 中读取多少个元素
上面有过描述了,再不赘述
通过 mark() 方法来标记这个特殊的 position,然后调用 reset() 方法恢复到这个特殊的 position
当满足下列条件时,表示两个 Buffer 相等
比较两个 Buffer 的剩余元素,如果满足下列条件,则认为一个 Buffer 小于另一个 Buffer
标准的 IO 基于字节流和字符秀进行操作的,而 NIO 是基于通道 (Channel) 和缓冲区 (Buffer) 进行操作,数据总是从通道读取到缓冲区,或者从换中去写入到通道中。
Java NIO 可以让你非阻塞的使用 IO,例如:当前线程从通道读取数据到缓冲区时,线程还可以进行其他事情。当数据被写入到缓冲区时,线程可以继续处理它。从缓冲区写入通道也是类似。
Java NIO 引入选择器的概念,选择器用于监听多个通道的事件,例如连接打开,数据到达等。因此,单个线程可以监听多个数据通道。
Java NIO 基本基于以上三个组件
Channel 有点儿像流,数据可以从 Channel 读取到 Buffer 中,也可以从 Buffer 写到 Channel 中。通道中的数据总是要先读到一个 Buffer,或者总是要从一个 Buffer 中写入。
Channel 有以下四个主要实现
FileChannel 从文件中读写数据DatagramChannel 能通过 UDP 读写网络中的数据SocketChannel 能通过 TCP 读写网络中的数据ServerSocketChannel 可以监听新进来的 TCP 连接,像 Web 服务器那样。对每一个进来的连接都会创建一个 SocketChannel 而 Buffer 有以下几个主要实现
ByteBuffer FileChannel 和 ByteBuffer 的代码实现byte,short,int,long,double,float和char。Selector 允许单个线程出来多个 Channel,如果应用打开了多个连接(通道)连接的流量都很低,使用 Selector 就会很方便。
要使用 Selector,得向 Selector 注册 Channel,然后调用 select() 方法。这个方法一致阻塞到摸个注册的通道有时间就绪。一旦这个方法返回,线程就可以处理这些事件。
Base 64 编码可用于在 HTTP 环境下传递较长的标识信息,具有不可读性。
主要被设计用来把任意序列的 8 字节描述为一种不易被人直接识别的形式。
某些系统中只能使用 ASCII 字符。Base 64 就是用来将非 ASCII 字符的数据转换成 ASCII 字符的一种方法。
Base 64 特别适合在 HTTP, MIME 协议下快速传输数据。
Base 64 是否算加密
是,但防君子不防小人
只是做到一眼看过去并不能识别,但算法很简单,很容易破解
考虑到加密算法效率的问题,如何快速发送 Email,且有效率,使用 Base 64 能有效的转换成 ASCII。且遵循 RFC2046 避免了网关将最高位字节转换成 1,这些才是使用 Base 64 的主要原因
在 Java 中,选择使用 codec 即可使用 Base 64
//base64字符串转byte[]
public static byte[] base64String2ByteFun(String base64Str){
return Base64.decodeBase64(base64Str);
}
//byte[]转base64
public static String byte2Base64StringFun(byte[] b){
return Base64.encodeBase64String(b);
当在浏览器输入一个 github.com 的请求
浏览器会检查后缀是否有 .com 从而判断得出这不是一个搜索关键词,而是一个 Url,如果没有其他的东西,则会赋予一些默认值,例如 http:// ,80 端口以及 GET 方法,无基本的身份认证。
然后请求会先经过本地 DNS 解析或者去下一个节点进行 DNS 解析,直到找到 github.com 负载均衡的 IP 地址。可惜对网络底层不太了解,要不然也能对 TCP/IP 说个一二三四出来。

接下来 github.com 回应说需要使用 https 307 内部重定向。因此原路返回到浏览器,浏览器将协议改为 https,默认使用 443 端口并重新发送,并使用 github 支持的什么协议 (TLS 1.0,1.1,1.2),加密过后发送请求。
github 的负载均衡服务器会将请求放到网络应用防火墙的规则集上进行判断这是否是一个恶意的请求,如果不是则会将准备好的正文放在 http 响应中返回,可能有一些东西是早已经压缩好的。
浏览器会读取 github 的响应头,根据响应头的缓存策略进行缓存,然后将正文解压缩,可能有很多预渲染的内容,内联 CSS,JavaScript 和图像,用来减少网络请求和首次渲染时间。谁知道他们会做什么事情
此时可能还有一些额外的请求,可能本地保存了相关的 Cookie 或者是 OAuth 令牌的本地存储,这些东西都会发送到 github 用来认真我的身份,从而返回我的相关信息,昵称头像之类的...
我想即使是对网络在不熟悉的人都会听说过 OSI 七层模型
从上到下是
我大概也就了解这么多了
全新Chrome Devtool Performance使用指南
这是之前的原文,后来再学习新的技术时,又有了新的理解
在很久之前我就有过疑惑,什么是 Web 服务器,Nginx 和 Tomcat 之间的区别很明显,但是为什么都叫 Web 服务器
Nginx 给我们提供了什么?动静分离,负载均衡,反向代理
Tomcat 为我们提供了什么?一个处理 Web 请求的容器,再说特殊一点就是里面有解析 JSP 变成 Servlet 的 controller 控制层,有我们写的 business service。
但他们都是围绕着 web 为中心,为应用程序提供服务
在看到 TCP/IP 协议的时候,说到一个 socket 概念,即 socket 是 TCP/IP 暴露出来的 API 接口
我们写的程序通常是直接调用 Http,但基于 Http 无状态的特性,对于一些需求并不能很好的满足,例如服务器主动发送请求给客户端,我们都知道客户端发送 http 请求同时会立即有一个 Response 作为服务器的回应,即请求-响应的方式,除此之外,服务器并没有什么其他的机会主动发送给客户端,所以客户端会通过定期轮询访问的方式,不断地向服务器发送请求,服务器返回数据时顺便夹带私货…当然这样会耗费网络流量,客户端 CPU 等资源,基于 Http 有更好的方式,例如 SSE、Comet,这些不是这篇文章的主题,就不多说了。
Http 服务器请求的原理
1、创建一个 ServerSocket,监听并 绑定一个端口
2、一些列客户端来请求这个端口
3、服务器使用 Accept,获得一个来自客户端的 Socket 连接对象
4、启动一个新线程处理连接
不断重复步骤三
这就是 Http 服务器的原理,如果解析的协议是 Redis,那就会变成 Redis 服务器,如果解析的协议时 Ftp 协议,那么就会变成一个 Ftp 服务器、RPC、UDP、 或者 MySQL 的 Proxy 服务器都是同一个原理
Socket 网络编程就和 Win 编程一样,我们调用的是 TCP/IP 的 API,Win 用的是 Windows 系统开放的 API
Http 在 OSI 会话层的协议,底层的实现大部分都是 Socket,除非一些特殊领域。
理解了原理,就比较容易写代码了
网络上教程很多,就不说了,就这样
Java IO 中的管道为运行在同一个 JVM 中的两个线程提供了通信能力。所以管道可以作为数据源以及目标媒介。
在 Java 中,通信的双方应该是运行在同意进程中的不同线程
PipedInputStream pipedInputStream = new PipedInputStream();
PipedOutputStream pipedOutputStream = new PipedOutputStream();
// PipedOutputStream pipedOutputStream = new PipedOutputStream(pipedInputStream);
// 管道建立连接,或者使用构造函数直接连接
pipedInputStream.connect(pipedOutputStream);
new Thread(new Runnable() {
@Override
public void run() {
try {
pipedOutputStream.write("Hello World".getBytes());
pipedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
byte[] arr = new byte[128];
while (pipedInputStream.read(arr) != -1) {
System.out.println(Arrays.toString(arr));
}
pipedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();注意 当使用两个相关联的管道流时,务必将它们分配给不同的线程。read() 和 write() 方法在同一个线程中调用会导致流阻塞,这意味着如果尝试在一个线程中同事进行读和写,可能会导致线程死锁。
实际上线程在大多数情况下会传递完整的对象信息,并非原始的字节数据。但是如果要在线程之间传递字节数据,Java IO 的管道是一个不错的选择。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.


