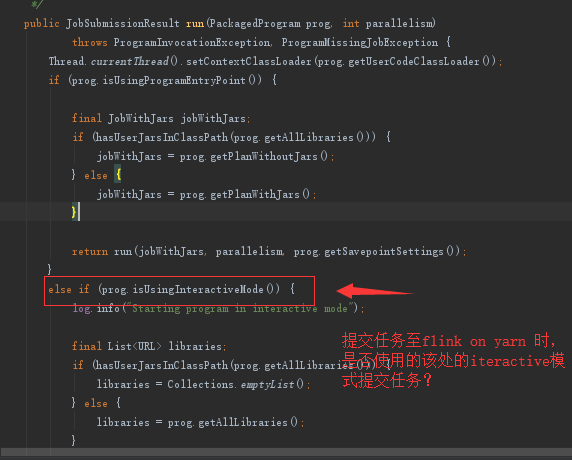
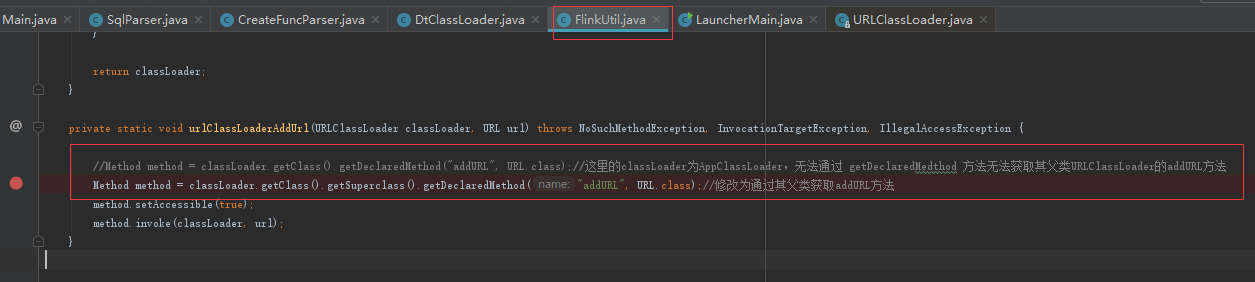
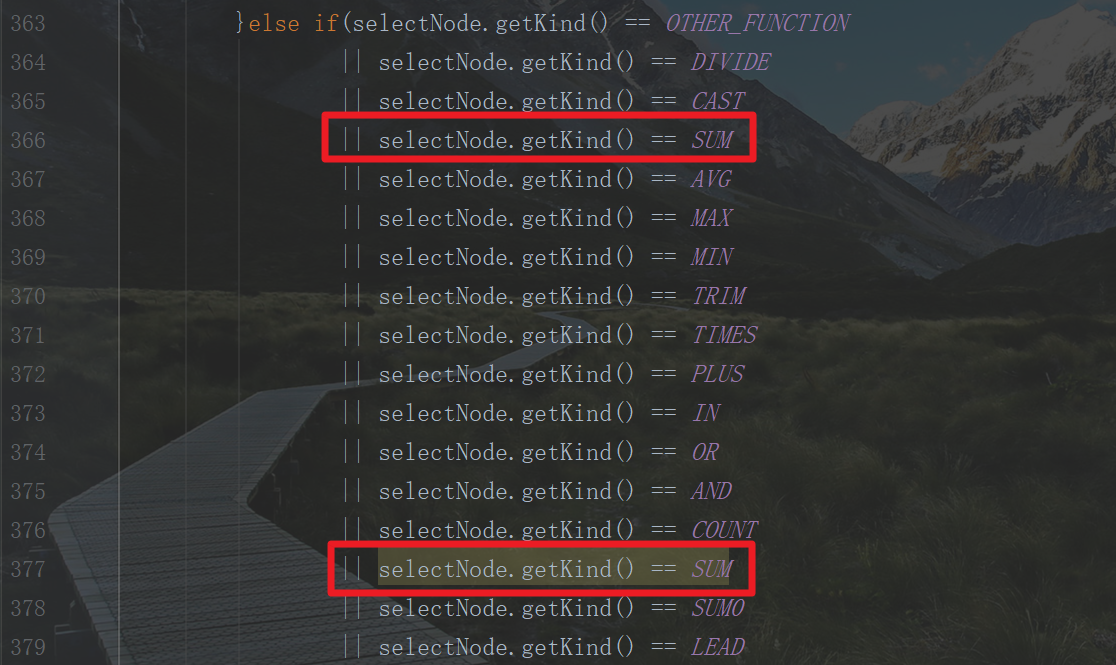
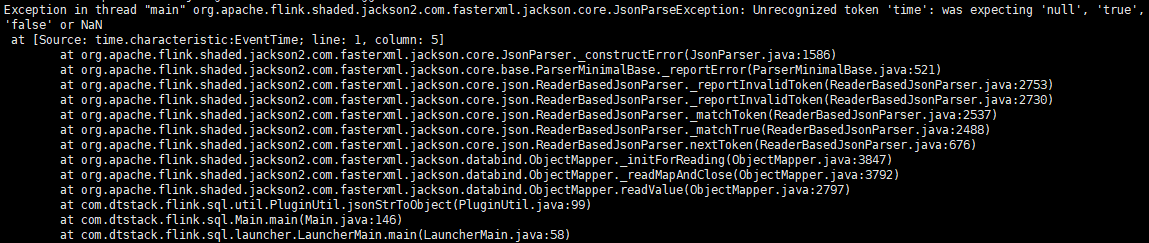
提交任务命令是:
sh ./submit.sh -sql /home/javajzl/testFile/flink/sqlTXT/sideSql.txt -name xctest -remoteSqlPluginPath /opt/modules/flink-1.5.2/plugins -localSqlPluginPath /opt/modules/flink-1.5.2/plugins -mode standalone -flinkconf /opt/modules/flink-1.5.2/conf -confProp {"time.characteristic":"EventTime","sql.checkpoint.interval":10000}
任务节点log错误代码如下:
2018-10-24 20:09:06,928 INFO org.apache.flink.runtime.taskmanager.Task - Creating FileSystem stream leak safety net for task Source: Custom Source -> Map -> to: Row -> from: (NAME, HEIGHT, PROCTIME) -> select: (HEIGHT AS ID, NAME) -> to: Tuple2 -> Sink: Unnamed (1/1) (9b2516f64d0f5245888c0371b273a5b7) [DEPLOYING] 2018-10-24 20:09:06,931 INFO org.apache.flink.runtime.taskmanager.Task - Loading JAR files for task Source: Custom Source -> Map -> to: Row -> from: (NAME, HEIGHT, PROCTIME) -> select: (HEIGHT AS ID, NAME) -> to: Tuple2 -> Sink: Unnamed (1/1) (9b2516f64d0f5245888c0371b273a5b7) [DEPLOYING]. 2018-10-24 20:09:06,935 INFO org.apache.flink.runtime.blob.BlobClient - Downloading 3c2cf29ec019b5fd78c9adc9f5453e4d/p-e1d178b977317e2485c78864825b487fa11da742-d3e1b655109b356b921b0c4d8157ef06 from /192.168.114.128:39276 2018-10-24 20:09:06,989 INFO org.apache.flink.runtime.taskmanager.Task - Registering task at network: Source: Custom Source -> Map -> to: Row -> from: (NAME, HEIGHT, PROCTIME) -> select: (HEIGHT AS ID, NAME) -> to: Tuple2 -> Sink: Unnamed (1/1) (9b2516f64d0f5245888c0371b273a5b7) [DEPLOYING]. 2018-10-24 20:09:06,992 INFO org.apache.flink.runtime.taskmanager.Task - Source: Custom Source -> Map -> to: Row -> from: (NAME, HEIGHT, PROCTIME) -> select: (HEIGHT AS ID, NAME) -> to: Tuple2 -> Sink: Unnamed (1/1) (9b2516f64d0f5245888c0371b273a5b7) switched from DEPLOYING to RUNNING. 2018-10-24 20:09:07,004 INFO org.apache.flink.streaming.runtime.tasks.StreamTask - No state backend has been configured, using default state backend (Memory / JobManager) 2018-10-24 20:09:07,471 INFO org.apache.flink.runtime.taskmanager.Task - Source: Custom Source -> Map -> to: Row -> from: (NAME, HEIGHT, PROCTIME) -> select: (HEIGHT AS ID, NAME) -> to: Tuple2 -> Sink: Unnamed (1/1) (9b2516f64d0f5245888c0371b273a5b7) switched from RUNNING to FAILED. org.apache.flink.streaming.runtime.tasks.StreamTaskException: Could not instantiate chained outputs. at org.apache.flink.streaming.api.graph.StreamConfig.getChainedOutputs(StreamConfig.java:320) at org.apache.flink.streaming.runtime.tasks.OperatorChain.createOutputCollector(OperatorChain.java:278) at org.apache.flink.streaming.runtime.tasks.OperatorChain.<init>(OperatorChain.java:126) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:231) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.ClassNotFoundException: org.apache.flink.table.runtime.types.CRowSerializer at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$ChildFirstClassLoader.loadClass(FlinkUserCodeClassLoaders.java:115) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348)
请问,是否是由于提交任务时plugins插件包没有顺利加载进入项目导致的呢?



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")