earthstar-project / earthstar Goto Github PK
View Code? Open in Web Editor NEWStorage for private, distributed, offline-first applications.
Home Page: https://earthstar-project.org
License: GNU Lesser General Public License v3.0
Storage for private, distributed, offline-first applications.
Home Page: https://earthstar-project.org
License: GNU Lesser General Public License v3.0




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


























































































































I'd like to integrate protocol handlers for EarthStar in Electron apps or other browser-like apps, specifically in my p2p web browser project.
Ideally it should provide read and write access to stuff and have key management handled by the protocol handler.
We talked about this a bit on SSB here: %MbsFkcmbZU/pnx5JS5PpcVDtueMM0xslrzAXpqXfDwE=.sha256
I'd like to propose something that looks like the following psudo code:
GET earthstar://:workspace/path/to/document => JSON blob or whatever
GET earthstar://:workspace/path/prefix?author=example => Array of docs, or maybe a multipart response if it's raw files?
// If this is the first time you're using `name` as an identity
// The browser can prompt the user to initialize it
// If `name` exists but hasn't been used here before, ask permission from user
PUT earthstar://:name@:workspace/path/to/document {content in body}
// You can use whatever strings for methods, so why not invent SYNC? :P
SYNC earthstar://workspace/ {list of peers or pubs in body}
SYNC earthstar://workspace/path/to/document {list of peers or pubs in body}
I think that this could also be adapted for an HTTP API for some sort of daemon where earthstar:// could be repalced with http://somgateway.com/someapi/path/ to point at an HTTP server running either locally or remotely.
I'm interested in making a JS library called earthstar-fetch which will encapsulate this functionality in a similar way to dat-fetch and play around with it before drafting a full standard. A side effect would be that we'd get a fetch-like interface into regular web browsers along side protocol handlers in browsers like Agregore.
The query object specification only has limited ways to match against document fields.
For example, we have lowPath which does <= and highPath which does >. What if we want to do < or >=?
We need to add timestamp range queries too. Do we need a combinatorial explosion of query parameters?
A more systematic way to do this is to combine a field and an operation:
let query = {
timestamp_lte: 15000000000, // timestamp less than or equal to
path_prefix: "/wiki/", // path has prefix
author_in: ["@suzy.bxxxx", "@matt.bxxxxx"], // author in list
content_neq: "", // content !== ""
}Operations:
< lt
<= lte
> gt
>= gte
== === eq // this is the default if no operation is specified
!= !== <> neq
prefix or startsWith
suffix or endsWith
in
Symbols or letters? Spaces or underscores?
{
// which style is better?
timestamp_lte: 15000000,
"timestamp <=", 15000000,
}
This would make for quite a large Query type. Luckily the code doing the query could handle this in a generalized way by splitting the properties at _ instead of hardcoding each combination.
type Query = {
path?: string,
path_lt?: string,
path_lte?: string,
path_gt?: string,
path_gte?: string,
path_eq?: string,
path_neq?: string,
// etc
}
let doQuery = (query: Query) => {
for (let [property, value] of Object.entries(query)) {
let [fieldToQuery, operation] = property.split('_');
// etc
}
}Some query options are not about matching specific fields. These would continue to work in the old way, without an operation in the property name:
limit
includeHistory (pending issue #44 )
now
If we implement #9 we would also need to query the metadata keys and values. Maybe like this?
The metadata we want to search for:
let doc = {
path: "/posts/blah/blah",
author: "@suzy.bxxxxxxx",
...etc...,
metadata: {
category: "gardening",
createdTimestamp: 1500000077,
}
}The query:
let query = {
metadata_category: "gardening",
metadata_createdTimestamp_gt: 1500000000,
}Hey @cinnamon-bun can you add a comparison to how earthstar differs from the gun protocol?
Timestamps should be in microseconds (Date.now() * 1000).
The Validator will reject timestamps that are small enough that they were probably accidentally made in milliseconds (Date.now()).
However, when calling storage.set(doc), the doc's timestamp is bumped forward to be later than the existing docs in that path. This can mask a bad timestamp because it happens before the timestamp validity check.
In storage.set(), check the doc timestamp with the Validator's timestamp check function and fail early if it's a bad timestamp.
In a user interface, two authors could look identical if we only show their shortnames and display names and not their pubkeys.
Give each author a random color that's deterministically derived from their author address.
The function should also accept a salt parameter which could be made different on each device. That way an imposter won't be able to generate a pubkey with a similar looking color because they won't know your salt.
Here's a way I did this in the past. It will need to be adapted to base32.
export let detRandom = (s : string) : number => {
// return random-ish float between 0 and 1, deterministically derived from a hash of the string
let m = md5(s) as string;
return parseInt(m.slice(0, 16), 16) / parseInt('ffffffffffffffff', 16);
};To invite someone to a workspace, you have to tell them:
That's too many things to copy-paste.
How can we combine all those things into a single string?
+gardening.xxxx?privatekey=yyyyyy&pubs=https://mypub.com,https://pub2.com
+gardening.xxxx.yyyyy|https://mypub.com|https://pub2.com
{"workspace":"+gardening.xxxx","privatekey":"yyyyyy","pubs":["https://mypub.com","https://pub2.com"]}
earthstar://gardening.xxx?...
???
This usage of detChoice:
detChoice(author.address, ["alpha", "beta", "gamma"]);Results in the following error:

Am I using it wrong somehow?
And: is this function meant to be used in the browser? Calling it in a client gives me warning messages about how resource-hungry the current tab is.
Hi, I see in the readme you compare to DAT, but it might be best to split out the comparison a bit to be more accurate, since the ecosystem is quite large.
Hyperspace will be the new RPC module for creating applications that are compatible in the dat ecosystem https://github.com/hyperspace-org. This has the same concerns you note with Hypercore, multi-writer is not possible out of the box and it is a bit more complex to do that.
Kappa-db (github.com/kappa-db/) is quite close to Earthstar, but it is less 'batteries-included' and more for customizing database behaviors. I really like the approach earthstar has taken to make these patterns more accessible to the common dev!
Thanks ~K
Make a live sync mode where syncing lasts forever and changes are streamed as they occur.
Augment the existing sync by hooking up the onChange Store event.
Workspace addresses are supposed to be kept secret.
How can peers discover which workspaces they both have (so they can sync them), without disclosing the workspaces they don't have in common?
Example:
Peer1 has W1, W2
Peer2 has W2, W3.
They should discover they both have W2. Peer1 should not learn about W3. Peer2 should not learn about W1.
Share the hashes of the workspace addresses?
sha256(workspaceAddress + nonce1 + nonce2)The hashes they have in common correspond to the workspaces they both have.
The hashes that are unique to one peer will reveal no information to the other peer.
A MitM won't learn the workspace addresses even if they know both of the nonces.
Alice: hey, here's a nonce, give me your workspace hashes.
--> GET /workspaceHashes?nonceA=foo
Bob: ok, I made my own nonce too, here's the result
<-- {
nonceA: "foo", nonceB: "bar",
workspaceHashes: [
// sha(workspace + nonceA + nonceB)
"bq49f8jq0o4f9jqf",
"b098ja0jhahahfa3",
]
}
Alice: now I can compute the same hashes from
my own workspace list, and now I know which
workspaces we have in common.
The peers will learn the number of workspaces they each have. 🤷 They could add random fake entries to the list, but you could still collect a statistical sample and infer the real number.
The nonce prevents a replay attack by making the hashes specific to one particular sync session.
(Related: #9 Metadata or multiple fields on items)
Right now you can "delete" a key by setting an empty value. Instead, make a special value to represent a tombstone.
Figure out: should API calls like keys() list tombstone keys or not?
[issue updated march 2021]
Currently there are 3 implementations of the IStorage interface:
Browsers limit localStorage to 5mb per origin, so we can't have larger workspaces in the browser yet.
The solution is:
Sadly, IndexedDb uses an async API so we had to update the entire Earthstar system to support async calls. This is done now and we're ready to start on IndexedDb.
If some peers have inaccurate clocks, their messages won't be able to sync around the network because they'll be "from the future".
Removing the "from the future" limit allows malicious peers to create documents that can't be overwritten by anyone else, because they have a timestamp of MAX_INT.
"From the future" is currently set to "10 minutes". Make this configurable and disable-able.
Apps that loosen this restriction should either:
/wiki/[email protected].../FlowersFUTURE_CUTOFF_MINUTES. Also allow null to disable it.min(now, myPreviousHighestTimestampAcossAllMyDocuments). This will help if their clock gets reset to 1970Unfortunately DAG backlinks don't work well in Earthstar because you might have gaps in your documents, so we have to use timestamps or version vectors, which are both vulnerable to MAX_INT type attacks. I don't have a solution to that except using the wall clock as a limit to force the numbers to grow slowly instead of jumping right to MAX_INT.
I also just learned about bloom clocks and I think they have the same vulnerability.
See timestamps.md for much more detail
The crypto needs of Earthstar can be filled by 2 swappable implementations so far:
Benchmark
See also #4 Change crypto library for smaller browserify bundle - there are other libraries to try also
For example, everyone's going to make apps that save to /todo/... but use incompatible data formats.
What is this part of the path called? It's a Layer name, or data format, or app name?
Recommend avoiding generic words. Name it todoodle or something instead of todo to avoid accidental collisions.
Recommend publishing Layer code as separate packages. That way other apps can use your data.
Make a registry of these format names. ...as a document in this repo, along with links to the Layer packages on npm.
Version the data. /todoodle-v1.2.3/...?
We need a format for this version that will be compatible with path prefix searches -- the separator character has to be carefully chosen, maybe - is not the best choice. You might want to query for /todoodle-, /todoodle-v1, /todoodle-v.1.2, etc.
Normally path prefix searches end with / to make sure you get a specific folder, e.g. /todo/ to make sure you don't also get /todoooo by mistake. So we might want to use / as the version separator to avoid clashes with another format called /todoodle-doo which happens to include a dash...
Should we use semantic versioning that matches the NPM package version for the Layer code?
Or maybe a simpler version number with just one integer, like we do with our document formats? Sometimes the code changes but the data format stays the same...
We have to think about forwards and backwards compatibility. New data and old code vs. old data and new code.
This query field is implemented in the memory Storage, but not sqlite.
The different ways of querying by author are subtle, we need a diagram :)
// If including history, find paths where the author ever wrote, and return all history for those paths by anyone
// If not including history, find paths where the author ever wrote, and return the latest doc (maybe not by the author)
participatingAuthor?: AuthorAddress,
//// If including history, find paths with the given last-author, and return all history for those paths
//// If not including history, find paths with the given last-author, and return just the last doc
//lastAuthor?: AuthorAddress,
// If including history, it's any revision by this author (heads and non-heads)
// If not including history, it's any revision by this author which is a head
versionsByAuthor?: AuthorAddress,Also enable the tests at https://github.com/earthstar-project/earthstar/blob/master/src/test/storage.test.ts#L602-L607
The validator methods that start with _ are useful to apps, but the _ suggests they are supposed to be treated as private methods.
_checkAuthorCanWriteToPath(doc.author, doc.path);
_checkTimestampIsOk(doc.timestamp, doc.deleteAfter, now);
_checkPathIsValid(doc.path)
etcRemove the _.
These were originally private because they might be specific to a certain validator format and I was thinking ahead to handling multiple, different validator classes.
I'm still not quite sure how to handle that, but for now they can be public.
Related to #6 (Replication filters)
It should be possible to drop local content that matches or doesn't match a query. You would want to do this if you've just blocked someone, or if unfollowing someone means you want fewer people in your local database.
This isn't a delete message that will propagate, we're just forgetting local data.
Sometimes we need to query items in several ways but the path only allows us to choose one access pattern.
Example: We might need to search for social media posts by author, by timestamp, by tag, by thread, etc etc.
Author and timestamp are already core database fields, but what about tag and thread? We could try to embed them into the paths for querying, but we have to choose one access pattern:
/posts/thread1/postA
or
/posts/tagX/postA
...or we have to write two items, one in each place, which could get separated or out of sync with each other.
Each item would have a k-v dictionary of metadata in addition to its regular path and content. Content and metadata will remain just strings. No nesting within metadata.
{
path: '...',
timestamp: 150000000,
content: 'hello world',
metadata: {
tag: 'X',
thread: '1',
}
}
Move all this data inside content, which is now an object instead of a string.
Probably still limit all of the fields to contain strings with no nesting? Or maybe just atomic values (string / boolean / null / number)?
{
path: '...',
timestamp: 150000000,
content: {
text: 'hello world',
tag: 'X',
thread: '1',
}
}
{
content: {
'tag/gardening': true,
'tag/flowers': true,
}
}
The deleteAfter field in a Document is optional and not nullable.
deleteAfter?: number,This seems to be awkward in GraphQL? Earthstar-graphql returns documents with deleteAfter: null.
Another optional field is also coming soon, workplaceSignature, for invite-only workspaces.
We could make the fields required and nullable.
deleteAfter: number | null,I actually prefer this since it makes the documents more self-documenting -- as a programmer, you won't ever be surprised by a document with a field you haven't seen before.
I had made them optional to save space, but it's only 17 bytes extra per document to make them required and null.
During a sync, apps should be able to specify filters for incoming and outgoing data. This could use the same QueryOpts type we already have.
Pseudocode:
syncer.setIncomingSyncFilters([
{ pathPrefix: 'wiki/' },
{ pathPrefix: 'about/' },
]);
syncer.setOutgoingSyncFilters([
{ author: '@aaa' }, // only upload our own data
]);
syncr.sync(url);When you supply multiple filters they get OR'd together. In other words, we send things that match ANY filter.
When starting a sync, we'll send the incoming filters to the other peer so they can avoid sending us things we don't want. We'll also apply the incoming filters on our end in case the other peer didn't pay attention.
And data we send will be filtered by the outgoing filters. This lets you only upload data of people you trust (yourself, or people you follow, or not blocked people).
Questions to resolve
Related conversations
https://github.com/cinnamon-bun/earthstar-wiki/blob/master/src/sync.ts
Unclear exactly how this will fit into the existing IStorage class.
Afterwards, remove the similar code from earthstar-wiki and earthstar-cli.
In SSB, data is limited to spread N hops across the network of peers. This is tracked using the social graph (following).
In Earthstar we can't count the number of hops because we don't have a social graph (no following mechanism, yet). Instead we have two classes of peer: users and pubs. Pubs are unattended peers that are not closely associated with a single user.
Pubs are passive buckets for users to put or get data from. The only way for data to spread from pub to pub is via a user who syncs with both pubs.
Users can also sync directly with each other.
So data zigzags between users and pubs as it spreads:
pub pub pub
/ \ / \ /
user user --- user
A workspace's data could spread widely across pubs and users, far beyond the people who are actually using it.
There are a few ways a workspace could get onto a new peer, and no ways for workspaces to get forgotten by a peer.
Any 2 peers should be allowed to sync a workspace if they both know its address. This problem is all about discovering and adding new workspaces.
The sync protocol could:
Users should:
Pubs could:
Do we need harder rules to limit the spread? E.g. a workspace's data could somehow include an allowlist of pubs that are allowed to host it, and we hope that all peers will respect that list and not spread it further?
(see also: #49 simple encryption)
A document's path can contain sensitive information. We'd like to encrypt an entire document including the path, and put a different less sensitive path on the outside.
This plan requires a more complex Store class.
Outer wrapper layer. The path will probably be a random value chosen by the app, like a UUID.
{
path: 'encrypted/abcad-29a3a-bbda9-2294a',
content: 'xxxxxxxxx...encrypted...data...xxxxxxxx'
timestamp
author
format
workspace
etc
}
Once the content is decrypted, it contains another document, the inner layer:
{
path: 'wiki/Ladybug',
content: 'Ladybugs are a kind of small beetle',
....timestamp etc might be missing here, inherited from the outer layer
}
Details
Stores decrypt items as they arrive.
When apps query the database they can see the outer documents AND the inner documents?
When syncing, we only send the outer documents.
When applying sync filters, we look at the outer path only. This allows untrusted pubs to sync without decrypting anything.
The outer path still needs to contain access control information like a tilde and author pubkey [email protected], because untrusted pubs need to know that.
Recipients
Encrypted data can be encrypted for an author (using their public key), for everyone in a closed workspace (using the workspace key), or for some other kind of key that an app added to the Store's keychain somehow.
Figure out
Make a protocol / stream handler that accomplishes a sync over a duplex stream. This might be easier after we have RPC.
(Related: #14 set up RPC)
(Related: #15 Sync over duplex stream)
Add the ability to sync over a hyperswarm connection.
Document versions with the same path are related to each other. When querying, sometimes we want to handle them as a group and sometimes individually.
We only have one query parameter for this, includeHistory, and it doesn't let us do everything we want.
(vocabulary: a "head" is the latest document at a path)
We might want to...
This complexity will hit any kind of query that can match only certain document versions in a path. We previously ran into this with querying by author. At the time I solved that by adding 3 ways to query by author:
participatingAuthor: match author anywhere in history; includeHistory happens after that
versionsByAuthor: includeHistory happens first, then match author in each version one by one
lastAuthor: only match author on latest doc version; includeHistory expands after that
This is confusing. Is there a more general way to specify how to handle history when querying?
Right now anyone can write to a workspace if they know its address.
Let's add a second kind of workspace which has a pubkey in its address. Every item posted in this kind of workspace must be signed by the workspace private key AND the author private key. This will be enforced by the feed format validator class.
So to write you need to know the workspace private key. You can give the workspace secret to someone to invite them.
This doesn't encrypt messages (yet) so it doesn't limit who can read, only who can write. Once we have encryption, authors can encrypt their messages to the workspace pubkey.
Currently workspace addresses have this format:
"+" NAME "." B32
+gardening.bzwo4h3 // hard to guess randomness, any length
+gardening.baweoijca48jao93jl39cajl94j3 // public key, 53 characters
B32 is a base32-encoded buffer that holds randomness that's hard to guess, or a public key.
There isn't yet a good way to tell if the B32 is a key or not. For now we can check if it's 53 characters long (a key) or shorter (random).
It'd be nice to also have an "invite format" that includes the private key.
workspaceSignature field to validator class, and check for valid workspace signature thereAttempted to make new db with cli, documentation has a different command than the code btw, but more concerningly I ran into an error: workspace address does not start with "@".
adding a @ does not fix it
in https://github.com/cinnamon-bun/earthstar/blob/master/src/util/addresses.ts:
if (!addr.startsWith('//')) { return { workspaceParsed: null, err: 'workspace address does not start with "@"' }; }
the error message does not match the test
Get tooling in place to run all the tests in a browser environment.
(Before this, do #14 Set up RPC)
Make a class that looks like a Store but actually calls out across the network to a remote Store.
Right now sync happens over an HTTP REST API.
Generalize this using some RPC framework so it can happen over other transports too.
JSON-RPC is a good choice.
(First, probably do #14 set up RPC)
Right now we sync by sending everything. Instead, do something like:
hash(list of individual item hashes)This could obviously recurse further into the 1000 items, but there are tradeoffs:
We can't pre-compute the hashes because replication filters might choose a different subset of items each time.
This should eventually support #6 Replication filters.
This is duplicated by #49
Expose something like private-box in the API so apps can easily encrypt values.
Use case is something like this:
earthstar.set({
key: 'secrets!',
value: encryptSecretBox(myData, somePubkey),
});
let mySecret = decryptSecretBox(earthstar.get('secrets!'), someSecretKey)The Store doesn't know anything about this, it's just a helper function for apps.
This doesn't help with encrypting keys, see #11 for that.
This should be implemented as a function in the Crypto class, in each of the interchangeable implementations.
Remember that we use base32 to encode our private and public keys.
(Related: #3 Benchmark the crypto libraries)
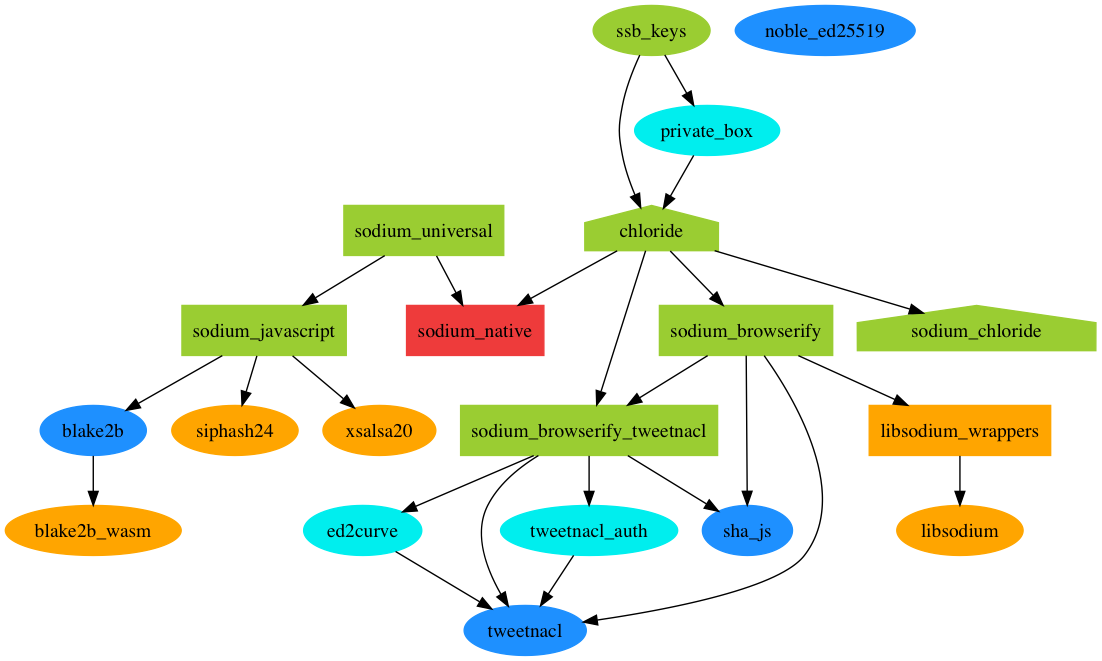
The crypto needs of Earthstar can be filled by 2 swappable implementations so far:
Chloride takes up 1.5mb when browserified.
We can
chloride/small which is probably slower, see the chloride readme for infonoble-ed25519 is nice -- small and pure JS -- but has an async API and we need a sync one. It's only async because it depends on a browser API to do sha512 async'ly. We could fork noble-25519 and make a sync version that depends on some other sha512 library.
We could also try some other crypto library such as sodium-universal. See https://github.com/cinnamon-bun/browser-crypto-diagram
The crypto backend is swappable here, but it's hardcoded:
https://github.com/earthstar-project/earthstar/blob/master/src/crypto/crypto.ts#L1-L2
It would be better to let apps decide which one they wanted, and hopefully a tree-shaking bundler would know to omit the ones not being used.

Allow documents to be (optionally) immutable, meaning you can't overwrite them with newer versions.
Paths could contain a special marker which will be replaced with the document's hash:
/moderation-actions/{id}
will get expanded to
/moderation-actions/#xxxxxxHashOfItemxxxxxx
Because it's hard/impossible to create hash collisions, nobody will be able to create another document version with the same hash, so this document version can never be overwritten with a newer one.
This splits the idea of paths into two:
Documents that are being signed or sent across the wire only have Path Templates. The path templates are kept forever as part of the original item. They are not used for path lookups and queries (?)
Expanded paths are derived state, computed by the Storage when receiving documents. They are used for all kinds of path lookups and queries.
We'll need to reserve a few characters for this, both for the Path Templates and the Expanded Paths.
You must not be able to create an Expanded Path directly, so in this example # would have to be disallowed from Path Templates.
Once we have these two kinds of path, we can add another expansion which is a shorthand for the author's own key:
/~@@/about/name
expands to
/[email protected]/about/name
This is just an optimization to save space from repeating the author's full address all the time. It might not be worth the extra complexity.
If the Syncer tries to talk to a GraphQL pub, it gets a 400 error response and dies while trying to parse JSON. Then it never finishes the sync lifecycle and goes back to an idle state.
Probably need to catch an error during JSON decoding.
(Uncertain if we want to support GraphQL pubs here in the core package or not; but at least it should fail cleanly)
Write specification documents for...
Solid:
In flux:
Speculative:
Workspace names need to be case sensitive to preserve their base58 secrets.
URL locations are supposed to be NOT case sensitive, and some URL parsers will lowercase them for you.
This matters if we want to make our own URL scheme like earthstar:// without fighting the URL parser.
Switch workspace and author addresses to lowercase base32 encoding.
Secrets will be 52 chars long instead of 44. This isn't significantly worse.
See this comment for details.
We can't completely trust the timestamps authors put into their documents.
They could put a very old timestamp. This doesn't break the core replication or conflict resolution parts of Earthstar, but it could matter in a user interface.
Storage implementations should record the time each document was locally received.
This would let apps say "Author claimed to send this in 1974. Message received 3 days ago". There's no way to know if that gap is from dishonesty or a propagation delay, but it could help users to know.
This is a kind of metadata about a document, not part of the document itself where it would have to be included in the author's signature. This would not be sent during syncing.
All the Storage methods return Documents, so I don't know where to put this additional data.
We could also record...
"Deleted documents" are docs with content: "".
We need to preserve them behind the scenes, as tombstones.
Sometimes we want them (when syncing), and sometimes not (when showing things in a UI).
earthstar-graphql has rough support for sync filters, and this feature has been a little hairy to implement.
As of writing, earthstar-graphql's sync filters are shaped like this:
{
pathPrefixes: string[],
versionsByAuthors: []
}The idea is that the peer/pub will return documents that match ANY of these rules.
However, querying documents works like this:
workspace.documents({
pathPrefix: "/something"
versionsByAuthor: "@test.1234"
})And the documents returned must match ALL of the queries.
What this means is that implementing sync filters is a little bit hairy. Here's earthstar-graphql's implementation: https://github.com/earthstar-project/earthstar-graphql/blob/master/src/util.ts#L253
It calls the documents method once for each member of each property in the sync filters, and then puts all the different lists together. This method would probably get a little more unwieldy once more properties are supported.
Could there be ways to query a workspace's documents a bit more like how sync filters operate, i.e. using OR logic, and supporting lists for each property? A new method on IStorage, or a (breaking) change to documents?
It would be nice to have ephemeral documents that get deleted after a given date. This helps with privacy and reduces storage needs.
deleteAfter: <timestamp>.! in their path, and regular docs don't. Add tests too.close(), kill that recurring task.Define a standard format for about info such as
Something like
about/~@xxxxxxxx/name = "Alex"
about/~@xxxxxxxx/info = "Here's some stuff about me"
about/~@xxxxxxxx/icon = "...base64 string of a low res image..."
about/~@xxxxxxxx/relationship/@aaaaaa = "follow" | "block" ???
The new sync implementation uses SSE. This is natively supported in browsers but not in Node.
Practically, earthstar-cli won't be able to do live pull syncing until this is fixed.
Use a polyfill library such as
Document signatures should depend on the hash of the content, not the content itself.
This would let you:
Add contentHash field
contentHash field to documentssha256(content)contentHash and not content when hashing a documentAllow content to be null
content to be null, meaning it's missing (note, empty documents are still content: "")nullincludeContent: boolean (include or omit the content itself in the returned docs)hasContent: boolean (find docs with missing content, or existing content)This issue is duplicated by #10
Users have public keys, let's send them some private messages! Or eventually, encrypt messages to the workspace public key so only people with the workspace private key can read it (e.g. the members of the invite-only workspace).
#11 Fully wrapped encrypted documents
Just encrypt the content and nothing else. The path and author will be exposed.
The recipient could be specified in the path so they know where to look for messages, or we could make recipients scan through everything looking for documents they can decrypt.
The encryption can probably be done with some function in Chloride. For multi-recipient messages we can use private-box
Potential crypto modules we can use:
crypto.tsThis code uses a variety of paradigms for reporting errors. Variously:
Choose and standardize on one style.
Here are some options:
https://github.com/earthstar-project/earthstar/blob/master/ignore/errorstyles.ts
Criteria:
Some Storage implementations might need to do clean-up operations when closing.
Add a close() method to the IStorage interface.
Authors have a shortname and a display name.
(Is it shortname, short name, or shortName?)
Workspaces have a... name and a... pubkey || suffix?
profile.json, rename longname to displayNameshortname to shortName?A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.