ferrisoxide / brocade.io Goto Github PK
View Code? Open in Web Editor NEWOpen GTIN / barcode & product database
Home Page: https://www.brocade.io
License: GNU Affero General Public License v3.0
Open GTIN / barcode & product database
Home Page: https://www.brocade.io
License: GNU Affero General Public License v3.0
Logidze might be a better solution for maintaining an audit trail than the exisiting PaperTrail gem. It uses triggers to maintain the delta, and stores the data inside the affected record. It should be faster and simpler than PaperTrail.
Not an urgent issue, as we only have ~200 actual changes recorded for products. But it might become important going forward.
Add a file to guide security reporting, etc. See https://krebsonsecurity.com/2021/09/does-your-organization-have-a-security-txt-file/
Allow logged in users to edit product details.
Will have to provide some default property names (e.g. Trans Fat) and present assumed / default units.
It looks like the concept of federated product data pools is already covered in the GS1 standards, under the general banner of GSDN (Global Data Synchronization Network).
It'd be worth investing some time into looking at the standards and seeing how they fit into the overall goals of Brocade. See:
https://www.gs1.org/services/gdsn
https://en.wikipedia.org/wiki/Global_Data_Synchronization_Network
Is this something we need to be aware of?
Hi,
emails can not be send, I get repeatably the following error:
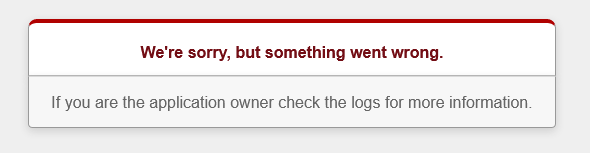
Due to this email addresses can not be verificated and new users, e.g. me, can not sign up.
Regards,
Syndesi
In preparation for write-access to the API, add support for bearer tokens - to be passed in the header when authenticating.
Read-only access will not require a token - at least not for now.
As part of all this we'll need to make a call on validating EAN. As per #27, assuming EAN-14 (and padding EAN-13 codes) is probably the way to go.
The original Datakick API allowed any client - authenticated or not - to add or update items.
This creates risk, as bad-faith third parties could easily pollute the database with poor quality - or incorrect - data.
We don't want to block read access for anyone, but we probably need to have some control over incoming data.
In this model reading is open but writing back to the database requires some kind of authentication - either as a logged in user in the HTML interface or using some kind of token system when accessing via the API.
This requires a decision on type of token. The standards-based JSON Web Tokens are probably the preferred option. An alternative is a simple access key / secret pair. These are less secure, but possibly easier for library authors to use.
In this model any user - authenticated or not - can make changes, but those changes remain in an "unvalidated" state until an authenticated user (or some automated process) marks them as valid.
The review process for changes would require community involvement, though we could use feedback from the manual process to train an AI system (TensorFlow or the like) - moving towards a more automated review process.
Either proposal probably also requires a mechanism to report exisiting bad data. Again, this could be used to train an AI system and help it spot bad data.
Will need to provide text for defining the legal side of things, including:
Explain the intent of brocade.io
Google Analytics - at least via MS Edge - reports a net::ERR_BLOCKED_BY_CLIENT error and doesn't appear to work anymore.
We don't really need this as we're not actively tracking use of the app. We may as well remove the Google Analytics script - if we need to provide any kind of analytics in the future I'd rather ones that are useful to end users directly.
Hi folks
To address some data quality concerns - some dirty data that was already in the system, some that has been added by people testing - I'm going to be turning off write access for a while. The system will remain readable.
I'm considering implementing a protocol that allows changes to be posted but not immediately available - e.g. a log of "changes" that can either be reviewed manually or otherwise quality assured before being integrated into the main data. This isn't clear in my head just yet, but if anyone has any thoughts on this I'd appreciate if we can share ideas.
My goal is to have more people involved in the decision making - at least in the long term, as there are many problems to solve on the way to building out a distributed system.
Apologies for not responding to questions and issues in a timely manner. I'll try to be more on the ball from here on in.
-Tom
I think that it would make sense to add leading zeros to the barcode if it is shorter than 14 digits. Otherwise searching for the more common variants of EAN-8, EAN-13 or the GTIN counterparts doesn't lead to a result...
As far as I remember this was also the default behavior of datakick's API.
e.g. the following doesn't work as expected, as it's a EAN-13 barcode:
https://www.brocade.io/api/items/4012200328002
but padded with a leading zero to form a EAN-14 the correct item is returned:
https://www.brocade.io/api/items/04012200328002
If you don't think that this addition makes sense in this repository, I can as well change it in my downstream library 😄
Import data from http://product-open-data.com/download
NB This could interesting, as the dump file is for MySQL
Already baked into the app is the notion of a property set, basic collections of facts about a product.
Each property set defines the name, type and potentially the title of product information elements:
NUTRITION_FACTS = {
serving_size: { type: :text },
servings_per_container: { type: :text },
calories: { type: :number },
fat_calories: { type: :number, title: 'Calories from Fat' },
...
This scheme is a bit clumsy and likely to become more complicated as more complex types are added. There is also no way currently in the system to validate data against property sets.
Rather than build out a complete type system, use the existing standards and tooling around JSON Schema. Under this model, a property set definition would look something like this:
{
"$id": "https://brocade.io/nutrition-facts.schema.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Nutrition Facts",
"type": "object",
"properties": {
"servingSize": {
"type": "string",
"description": "Details of typical serving portion"
},
....
"calories": {
"type": "integer",
"description": "Number of calories per serving"
},
....
There are numerous resources for validating JSON data, including multiple ruby gems:
We can probably push a lot of this down to the database level, validating / typing data within PostgreSQL itself:
GS1 publishes standard property definitions for different product types and industries. Rather than invent our our, we should defer to the GS1 standards for property name and type information.
For example, the published Australasian_Liquor_Industry attributes includes a liquorAge integer type attribute.
| Attribute Name | Definition | Example | Rationale | Data Type |
|---|---|---|---|---|
| liquorAge | How old in years - 1 to 100 for premium spirits, some fortified & liqueursco | 15 | Required by the Australasian Liquor Industry for Local Data Synchronisation requirements | integer |
Other attributes include enums (alcoholicStrengthDescription), floats (standardDrinks) and a number of attributes that are constrained by various rules - potentially mappable to JSON Schema regex type definitions.
If we were to record data for alcoholic products - at least for the Australian market - we would map all these into a specific JSON Schema document for validating data.
This may be an edge case, but there might be reasons to provide translations of property names. Rather than bake this into the schemas, we can push this off to Rails' I18N mechanism, translating based on keys, e.g.
calories: 'calorías'Need to have a CI solution in place. Investigate use of Github Actions as a first call.
CI solution will need to:
bundle auditand report on failure if any of these fail.
Stretch target is to merge to master and deploy on success, but that's not super critical at this stage.
Hi, thanks for this repo.
Can I get access to all products database, without an api, just to simply download it in a csv format for example.
Thanks
Rails 7 alpha 2 is out now. Edgy, but let's upgrade anyway. By the time Rails 7 hits release-candidate (or release) we'll be looking at building out our own formal release.
Post the update to Rails 7, we've more options re serving up JS, CSS, etc. The sign-on screen can do with some work, as the general "below the fold" content.
Swap to css bundling w/ tailwind for simplicity.
Present nutrition-related properties in a sensible collection, as per the original Datakick style:

NB "Percent of daily values" text at the bottom is derived /assumed and not part of the stored properties values.
NB Default units are not present in the data (and have to be assumed) - e.g. 'Trans Fat' (or trans_fat) is measured in g, whereas Cholesterol is measured in mg. In neither case is the unit stored in the data, with the properties stored as { "trans_fat":0.0, "cholesterol":0 }.
NB Some values are grouped and tallied, e.g. Saturated Fat, Trans Fat, etc are grouped and tallied as 'Total Fats'. The total value is present in the stored properties (as fat) - see * Example JSON Data* below.
NB Total calories and Calories from Fat are reported separately. This data is present in the stored properties (as fat) - see * Example JSON Data* below.
{"gtin14":"00000000079983","brand_name":"Trader Joe's","name":"Pistachios - Dry Roasted & Salted","size":"16 oz (1 lb) 454 g","ingredients":"Pistachios, Salt\r\n\r\nFACILITY PROCESSES OTHER TREE NUTS","serving_size":"1/4 cup nuts without shells (30 g / about 1/2 cup with shells)","servings_per_container":"about 8","calories":180,"fat_calories":120,"fat":14.0,"saturated_fat":1.5,"trans_fat":0.0,"polyunsaturated_fat":2.5,"monounsaturated_fat":10.0,"cholesterol":0,"sodium":160,"carbohydrate":9,"fiber":3,"sugars":3,"protein":6,"images":[]}
Per email from @ajwtech, a debugger breakpoint has been left in properties_controller.js, causing the website to halt if viewed using developer tools.
This needs to be removed.
Partially addressed in #37, we need to document the API formally. The OpenAPI / Swagger model is an accepted set of processes and standards, so we'll use this as a starting point.
NB The rswag gem has already been added to the project, for the purposes of documenting and testing the API. We'll continue to expand use of this.
Per original Datakick style, present country of origin - possibly with a flag symbol as well (see "US" mark):

NB The country of origin can be derived from the GTIN itself - under some conditions at least.
Time to add bundle-audit to the mix. Fix any reported static security issues.
Occasionally a search returns a server side error when results are not found or times out. Seems to happen mainly when a new search is submitted.
Query
https://www.brocade.io/api/items?query=peanux

Review data captured by consensualknowledge.net, in particular the resources they have gathered here:
https://consensualknowledge.net/shopping-advisor-and-other-uses-of-knowledge-base-about-products/
Maybe look to reach out to them, see if there are ways or reasons to collaborate.
Check UI against WCAG, etc standards. Remedy as necessary.
Currently search works on the whole word(s). Searching using "?query=gree" under Datakick will return everything with "gree" in the data (e.g. _Gree_n Tea, _Gree_k Yogurt). The same search on Brocode.io doesn't return anything, as it's looking for the literal word 'gree'.
Is this accurate? I kept looping through records to try understand the API behavior and data structure/types.
This information might be helpful for those consuming the API.
links - First Headerhttps://www.brocade.io/api/items?page=20&query=peanut+butter; rel="last", https://www.brocade.io/api/items?page=2&query=peanut+butter; rel="next"
links - Following Headers include the previous andhttps://www.brocade.io/api/items?page=1&query=peanut+butter; rel="first", https://www.brocade.io/api/items?page=1&query=peanut+butter; rel="prev",
per-page & totalper-page - Results per page = 100
total - Total number records = 1912
total / per-page = Total Pages 19.12 rounded up = 20. Total is also found in Header - links last
**Key DataType**
ProductID int
gtin14 string
brand_name string
name string
fat string
size string
fiber string
sodium string
sugars string
protein string
calories string
potassium string
cholesterol string
ingredients string
carbohydrate string
fat_calories string
serving_size string
saturated_fat string
trans_fat string
monounsaturated_fat string
polyunsaturated_fat string
servings_per_container string
pages string
author string
format string
publisher string
alcohol_by_volume double
alcohol_by_weight double
volume_fluid_ounce double
volume_ml double
weight_g double
weight_ounce double
unit_count double
class clsProducts
{
constructor()
{
this.gtin14 = '';
this.brand_name = '';
this.name = '';
this.fat = '';
this.size = '';
this.fiber = '';
this.sodium = '';
this.sugars = '';
this.protein = '';
this.calories = '';
this.potassium = '';
this.cholesterol = '';
this.ingredients = '';
this.carbohydrate = '';
this.fat_calories = '';
this.serving_size = '';
this.saturated_fat = '';
this.trans_fat = '';
this.monounsaturated_fat = '';
this.polyunsaturated_fat = '';
this.servings_per_container = '';
this.pages = '';
this.author = '';
this.format = '';
this.publisher = '';
this.alcohol_by_volume = null; //Double
this.alcohol_by_weight = null; //Double
this.volume_fluid_ounce = null; //Double
this.volume_ml = null; //Double
this.weight_g = null; //Double
this.weight_ounce = null; //Double
this.unit_count = null; //Double
}
}
public class Products
{
public string gtin14 { get; set; }
public string brand_name { get; set; }
public string name { get; set; }
public string fat { get; set; }
public string size { get; set; }
public string fiber { get; set; }
public string sodium { get; set; }
public string sugars { get; set; }
public string protein { get; set; }
public string calories { get; set; }
public string potassium { get; set; }
public string cholesterol { get; set; }
public string ingredients { get; set; }
public string carbohydrate { get; set; }
public string fat_calories { get; set; }
public string serving_size { get; set; }
public string saturated_fat { get; set; }
public string trans_fat { get; set; }
public string monounsaturated_fat { get; set; }
public string polyunsaturated_fat { get; set; }
public string servings_per_container { get; set; }
public string pages { get; set; }
public string author { get; set; }
public string format { get; set; }
public string publisher { get; set; }
public double? alcohol_by_volume { get; set; }
public double? alcohol_by_weight { get; set; }
public double? volume_fluid_ounce { get; set; }
public double? volume_ml { get; set; }
public double? weight_g { get; set; }
public double? weight_ounce { get; set; }
public double? unit_count { get; set; }
}
Having investigated various approaches to secure access to the API, I've opted to go with OAuth2. This may make integration more complex than a simple token-based solution, but I'm erring on the side of a more secure mechanism. There are numerous implementations of OAuth2 clients in the languages people seem to using to integrate.
I'll also be opting for Github as the first OAuth ID provider, as most users - at least initially - will also have Github accounts.
NOTE Related to #33
I threw this together this weekend. Can't wait for the ability to edit and add new records from the API. This is the initial working version.
https://github.com/MrRedBeard/brocade.io-Mobile-App
Investigate https://store.unspsc.org/ as a possible alternative taxonomy - though this does appear to require a subscription or purchase of the dataset
The lack of any formal structure in the data has always bothered me, as we basically store everything in one blob of JSON data. In the general case this is fine, but when products/items have very definite properties (e.g. a Book has an author, food items have calories, etc) it gets harder to ensure that the data makes sense - or is consumable in a repeatable way.
Brocade.io to start using JSON-LD as the base model for all data presented via the API, using schemas published by third-parties like https://schema.org.
For instance, if we adopt the "Product" type from schema.org, we can structure product information that is both human-readable and easily processed by applications:
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "Lite Italian Dry Salami",
"gtin": "00073007107096",
"countryOfAssembly": "USA"
"brand": {
"@type": "Brand",
"name": "Columbus"
},
"material": "processed meat"
}JSON-LD also enables us to add a graph for extended attributes, e.g. if nutritional information is available for a product we can use the NutritionInformation type to present these attributes in a structured manner:
{
"@context": "https://schema.org/",
"@type": "Product",
"name": "Lite Italian Dry Salami",
"@graph": [
{
"@type": "NutritionInformation",
"calories": "214 kcal",
"servingSize": "28 g",
...
}
},
...
}Other types from schema.org can be used as applicable (e.g. Book, Movie), etc. We can also make use of schemas published by other third parties - or our own custom types - as required and potentially "future proof" the underlying data model.
We can also use the type information in the frontend, using schema types to determine the best way to present data like nutritional information in a table-like format (see #11). We can also use to insert Microdata into the HTML to nest metadata suitable for search engines, web scrapers and the like to consume.
We can mitigate the second problem by processing individual products on demand and progressively update data. The problem of parsing data requires a bit more thought and investigation, but it looks like a solvable problem.
Add support for logging who/what against changes in the database (ala Papertrail or similar)
NB This is affiliate with Open Food Facts, using similar technology throughout: https://world.openbeautyfacts.org/data
Investigate OAI-PMH as a potential mechanism for distributing requests.
http://www.openarchives.org/OAI/openarchivesprotocol.html#Introduction
It's probably not a solution, but will at least help surface meta data concerns (e.g. use of Dublin Core, etc).
Import data from https://github.com/papyrussolution/UhttBarcodeReference
NB
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.