Edge computing is a distributed computing paradigm that brings computation and data storage closer to the sources of data. This is expected to improve response times and save bandwidth.
Edge AI refers to the deployment of artificial intelligence (AI) algorithms and models directly on edge devices, such as mobile phones, Internet of Things (IoT) devices, and other smart sensors.
By processing data locally on the device rather than relying on cloud-based algorithms, edge AI enables real-time decision-making and reduces the need for data to be transmitted to remote servers. This can lead to reduced latency, improved data privacy and security, and reduced bandwidth requirements.
Edge AI has become increasingly important as the proliferation of edge devices continues to grow, and the need for intelligent and low-latency decision-making becomes more pressing.
1.2.1. Blogs About Edge AI 2. Our Survey (To be released) 2.1 The Taxonomy of the Discussed Topics
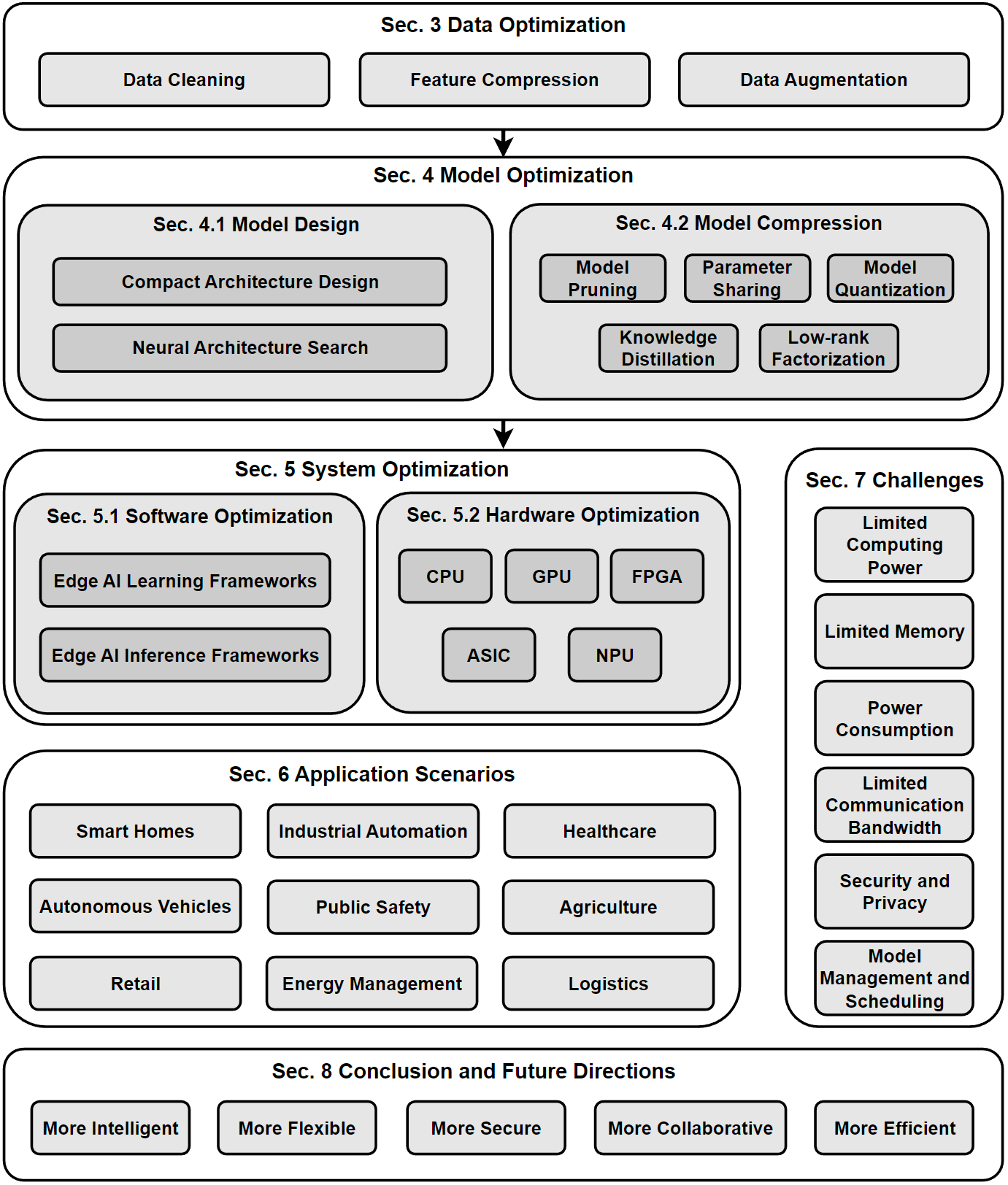
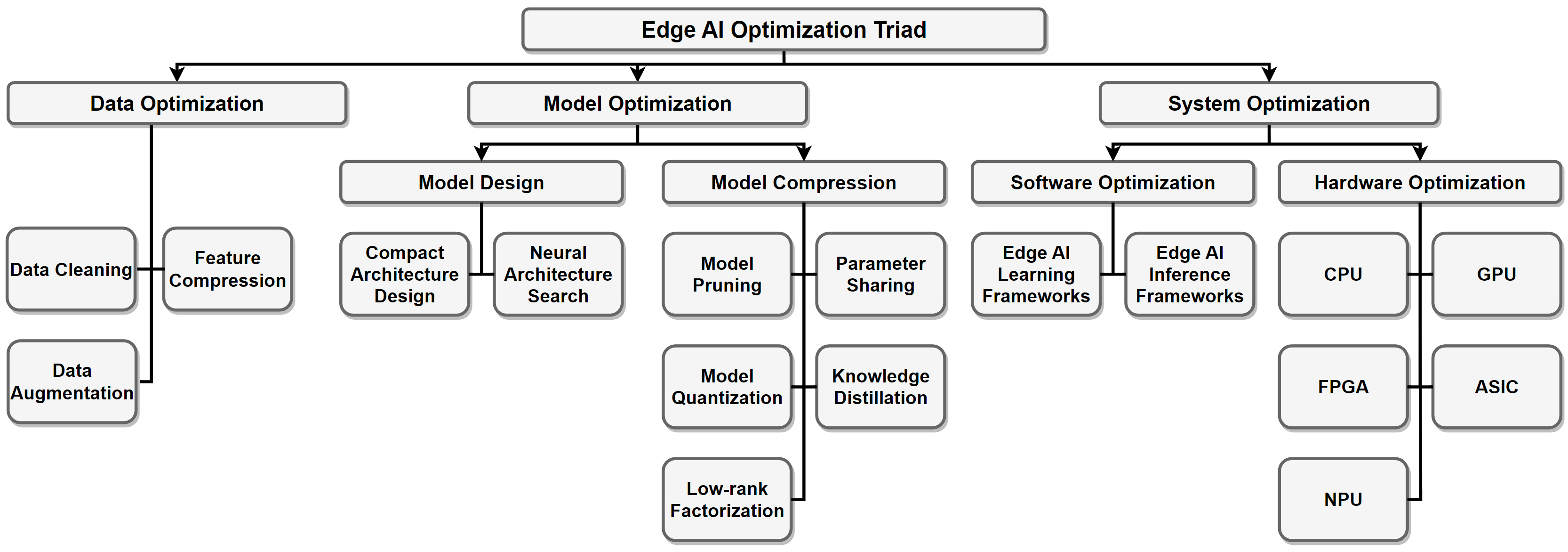
2.2 Edge AI Optimization Triad We introduce a data-model-system optimization triad for edge deployment.
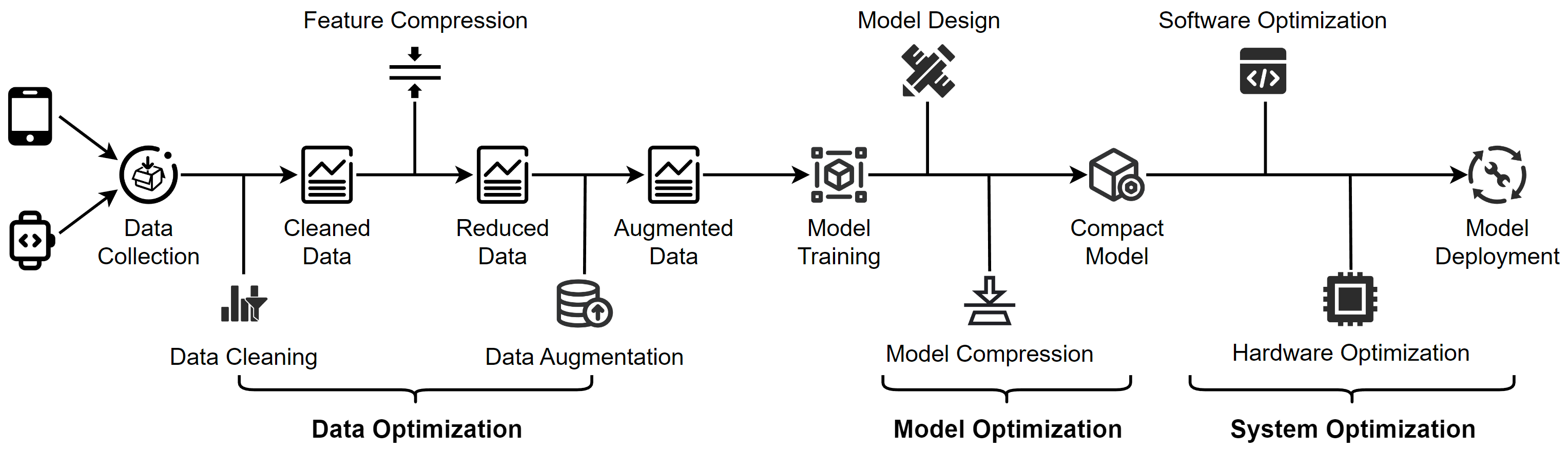
2.3 The Edge AI Deployment Pipeline An overview of edge deployment. The figure shows a general pipeline from the three aspects of data, model and system. Note that not all steps are necessary in real applications.
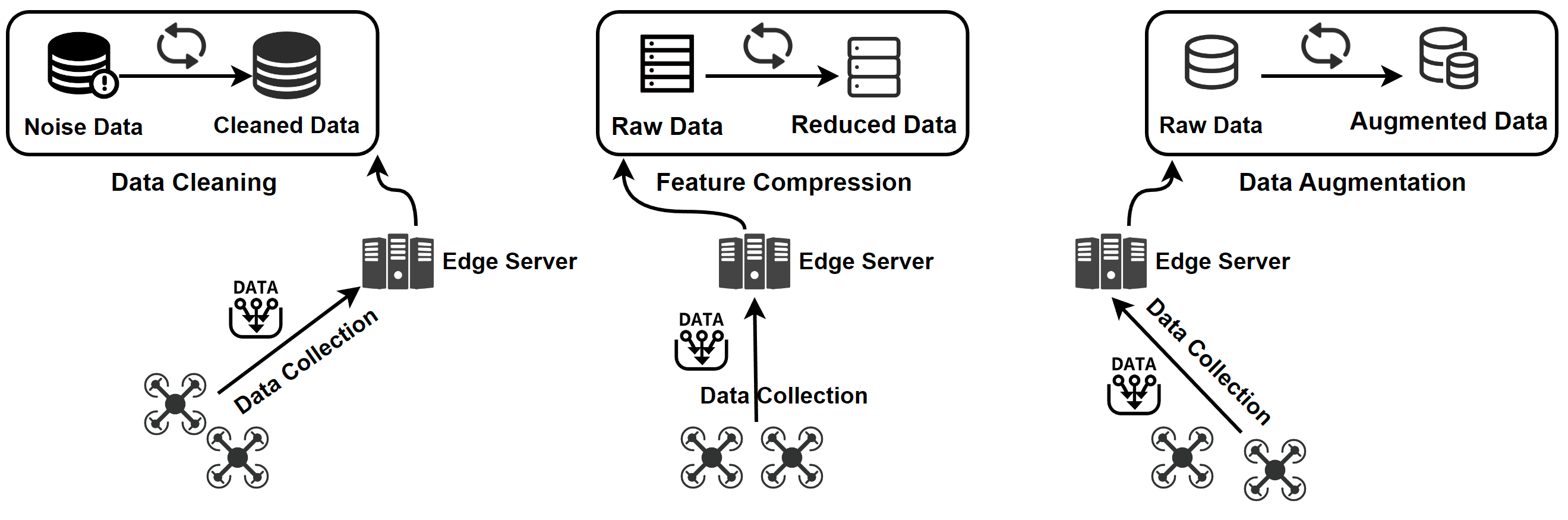
3. The Data-Model-System Optimization Triad An overview of data optimization operations. Data cleaning improves data quality by removing errors and inconsistencies in the raw data. Feature compression is used to eliminate irrelevant and redundant features. For scarce data, data augmentation is employed to increase the data size.
3.1.2. Feature Compression 3.1.2.1. Feature Selection
Title & Basic Information
Affiliation
Code
Accessible melanoma detection using smartphones and mobile image analysis[J]. IEEE Trans. on Multimedia, 2018. Singapore University of Technology and Design
--
ActID: An efficient framework for activity sensor based user identification[J]. Computers & Security, 2021. University of Houston-Clear Lake
--
Descriptor Scoring for Feature Selection in Real-Time Visual Slam[C] ICIP, 2020. Processor Architecture Research Lab, Intel Labs
--
Edge2Analysis: a novel AIoT platform for atrial fibrillation recognition and detection[J]. IEEE Journal of Biomedical and Health Informatics, 2022. Sun Yat-Sen University
--
Feature selection with limited bit depth mutual information for portable embedded systems[J]. Knowledge-Based Systems, 2020. CITIC, Universidade da Coruña
--
Seremas: Self-resilient mobile autonomous systems through predictive edge computing[C] SECON, 2021. University of California, Irvine
--
A covid-19 detection algorithm using deep features and discrete social learning particle swarm optimization for edge computing devices[J]. ACM Trans. on Internet Technology (TOIT), 2021. Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System
--
3.1.2.2. Feature Extraction
Title & Basic Information
Affiliation
Code
Supervised compression for resource-constrained edge computing systems[C] WACV, 2022. University of California, Irvine
Code
"Blessing of dimensionality: High-dimensional feature and its efficient compression for face verification." CVPR, 2013. University of Science and Technology of China
--
Toward intelligent sensing: Intermediate deep feature compression[J]. TIP, 2019. Nangyang Technological University
--
Selective feature compression for efficient activity recognition inference[C] ICCV, 2021. Amazon Web Services
--
Video coding for machines: A paradigm of collaborative compression and intelligent analytics[J]. TIP, 2020. Peking University
--
Communication-computation trade-off in resource-constrained edge inference[J]. IEEE Communications Magazine, 2020. The Hong Kong Polytechnic University
Code
Edge-based compression and classification for smart healthcare systems: Concept, implementation and evaluation[J]. ESWA, 2019. Qatar University
--
EFCam: Configuration-adaptive fog-assisted wireless cameras with reinforcement learning[C] SECON, 2021. Nanyang Technological University
--
Edge computing for smart health: Context-aware approaches, opportunities, and challenges[J]. IEEE Network, 2019. Qatar University
--
DEEPEYE: A deeply tensor-compressed neural network for video comprehension on terminal devices[J]. TECS, 2020. Shanghai Jiao Tong University
--
CROWD: crow search and deep learning based feature extractor for classification of Parkinson’s disease[J]. TOIT, 2021. Taif University
--
"Deep-Learning Based Monitoring Of Fog Layer Dynamics In Wastewater Pumping Stations", Water research 202 (2021): 117482. Deltares
--
Distributed and efficient object detection via interactions among devices, edge, and cloud[J]. IEEE Trans. on Multimedia, 2019. Central South University
--
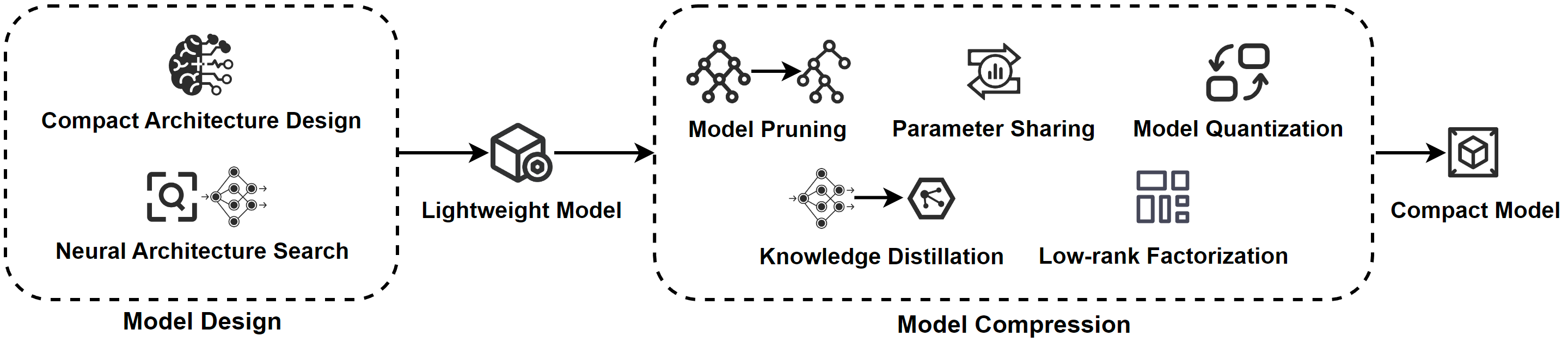
An overview of model optimization operations. Model design involves creating lightweight models through manual and automated techniques, including architecture selection, parameter tuning, and regularization. Model compression involves using various techniques, such as pruning, quantization, and knowledge distillation, to reduce the size of the model and obtain a compact model that requires fewer resources while maintaining high accuracy.
3.2.1.1. Compact Architecture Design
Title & Basic Information
Affiliation
Code
Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arXiv, 2017. Google Inc.
Code
Mobilenetv2: Inverted residuals and linear bottlenecks[C] CVPR, 2018. Google Inc.
Code
Searching for mobilenetv3[C]// ICCV, 2019. Google Inc.
Code
Rethinking bottleneck structure for efficient mobile network design[C] ECCV, 2020. National University of Singapore
Code
Mnasnet: Platform-aware neural architecture search for mobile[C] CVPR, 2019. Google Brain
Code
Shufflenet: An extremely efficient convolutional neural network for mobile devices[C] CVPR, 2018. Megvii Inc (Face++)
Code
Shufflenet v2: Practical guidelines for efficient cnn architecture design[C] ECCV, 2018. Megvii Inc (Face++)
Code
Single path one-shot neural architecture search with uniform sampling[C] ECCV, 2020. Megvii Inc (Face++)
Code
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J]. arXiv, 2016. DeepScale∗ & UC Berkeley
Code
Squeezenext: Hardware-aware neural network design[C] CVPR Workshops. 2018. UC Berkeley
Code
Ghostnet: More features from cheap operations[C] CVPR, 2020. Noah’s Ark Lab, Huawei Technologies
Code
Efficientnet: Rethinking model scaling for convolutional neural networks[C] ICML, 2019. Google Brain
Code
Efficientnetv2: Smaller models and faster training[C] ICML, 2021. Google Brain
Code
Efficientdet: Scalable and efficient object detection[C] CVPR, 2020. Google Brain
Code
Condensenet: An efficient densenet using learned group convolutions[C] CVPR, 2018. Cornell University
Code
Condensenet v2: Sparse feature reactivation for deep networks[C] CVPR, 2021. Tsinghua University
Code
Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation[C] ECCV, 2018. University of Washington
Code
Espnetv2: A light-weight, power efficient, and general purpose convolutional neural network[C] CVPR, 2019. University of Washington
Code
Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search[C] CVPR, 2019. UC Berkeley
Code
Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions[C] CVPR, 2020. UC Berkeley
Code
Fbnetv3: Joint architecture-recipe search using predictor pretraining[C] CVPR, 2021. Facebook Inc. & UC Berkeley
--
Pelee: A real-time object detection system on mobile devices[J]. NeurIPS, 2021. University of Western Ontario
Code
Going deeper with convolutions[C] CVPR, 2015. Google Inc.
Code
Batch normalization: Accelerating deep network training by reducing internal covariate shift[C] ICML, 2015. Google Inc.
Code
Rethinking the inception architecture for computer vision[C]// CVPR, 2016. Google Inc.
Code
Inception-v4, inception-resnet and the impact of residual connections on learning[C] AAAI, 2017. Google Inc.
Code
Xception: Deep learning with depthwise separable convolutions[C] CVPR, 2017. Google, Inc.
Code
Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer[J]. arXiv, 2021. Apple
Code
Lite transformer with long-short range attention[J]. arXiv, 2020. Massachusetts Institute of Technology
Code
Coordinate attention for efficient mobile network design[C] CVPR, 2021. National University of Singapore
Code
ECA-Net: Efficient channel attention for deep convolutional neural networks[C] CVPR, 2020. Tianjin University
Code
Sa-net: Shuffle attention for deep convolutional neural networks[C] ICASSP, 2021. Nanjing University
Code
Triplet Attention: Rethinking the Similarity in Transformers[C] KDD, 2021. Beihang University
Code
Resnest: Split-attention networks[C] CVPR, 2020. Meta
Code
3.2.1.2. Neural Architecture Search (NAS)
Title & Basic Information
Affiliation
Code
FTT-NAS: Discovering fault-tolerant convolutional neural architecture[J]. TODAES), 2021. Tsinghua University
Code
An adaptive neural architecture search design for collaborative edge-cloud computing[J]. IEEE Network, 2021. Nanjing University of Posts and Telecommunications
--
Binarized neural architecture search for efficient object recognition[J]. IJCV, 2021. Beihang University
--
Multiobjective reinforcement learning-based neural architecture search for efficient portrait parsing[J]. IEEE Trans. on Cybernetics, 2021. University of Electronic Science and Technology of China
--
Intermittent-aware neural architecture search[J]. ACM Transactions on Embedded Computing Systems (TECS), 2021. Academia Sinica and National Taiwan University
Code
Hardcore-nas: Hard constrained differentiable neural architecture search[C] ICML, 2021. Alibaba Group, Tel Aviv, Israel
Code
MemNAS: Memory-efficient neural architecture search with grow-trim learning[C] CVPR, 2020. Beijing University of Posts and Telecommunications
--
Pvnas: 3D neural architecture search with point-voxel convolution[J]. TPAMI, 2021. Massachusetts Institute of Technology
--
Toward tailored models on private aiot devices: Federated direct neural architecture search[J]. IoTJ, 2022. Northeastern University, Qinhuangdao
--
Automatic design of convolutional neural network architectures under resource constraints[J]. TNNLS, 2021. Sichuan University
--
Title & Basic Information
Affiliation
Code
Supervised compression for resource-constrained edge computing systems[C] WACV, 2022. University of Pittsburgh
--
Train big, then compress: Rethinking model size for efficient training and inference of transformers[C] ICML, 2020. UC Berkeley
--
Hrank: Filter pruning using high-rank feature map[C]// CVPR, 2020. Xiamen University
Code
Clip-q: Deep network compression learning by in-parallel pruning-quantization[C] CVPR, 2018. Simon Fraser University
--
Sparse: Sparse architecture search for cnns on resource-constrained microcontrollers[J]. NeurIPS, 2019. Arm ML Research
--
Deepadapter: A collaborative deep learning framework for the mobile web using context-aware network pruning[C] INFOCOM, 2020. Beijing University of Posts and Telecommunications
--
SCANN: Synthesis of compact and accurate neural networks[J]. IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems, 2021. Princeton University
--
Directx: Dynamic resource-aware cnn reconfiguration framework for real-time mobile applications[J]. IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems, 2020. George Mason University
--
Pruning deep reinforcement learning for dual user experience and storage lifetime improvement on mobile devices[J]. IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems, 2020. City University of Hong Kong
--
SuperSlash: A unified design space exploration and model compression methodology for design of deep learning accelerators with reduced off-chip memory access volume[J]. IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems, 2020. Information Technology University
--
Penni: Pruned kernel sharing for efficient CNN inference[C] ICML, 2020. Duke University
Code
Fast operation mode selection for highly efficient iot edge devices[J]. IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems, 2019. Karlsruhe Institute of Technology
--
Efficient on-chip learning for optical neural networks through power-aware sparse zeroth-order optimization[C] AAAI, 2021. University of Texas at Austin
--
A Fast Post-Training Pruning Framework for Transformers[C]// NeurIPS UC Berkeley
Code
Radio frequency fingerprinting on the edge[J]. TMC, 2021. Northeastern University, Boston
--
Exploring sparsity in image super-resolution for efficient inference[C] CVPR, 2021. National University of Defense Technology
Code
O3BNN-R: An out-of-order architecture for high-performance and regularized BNN inference[J]. TPDS, 2020. Boston University
--
Enabling on-device cnn training by self-supervised instance filtering and error map pruning[J]. TCAD, 2020. University of Pittsburgh
--
Dropnet: Reducing neural network complexity via iterative pruning[C] ICML, 2020. National University of Singapore
Code
Edgebert: Sentence-level energy optimizations for latency-aware multi-task nlp inference[C] MICRO-54, 2021. Harvard University
Code
Fusion-catalyzed pruning for optimizing deep learning on intelligent edge devices[J]. TCAD, 2020. Chinese Academy of Sciences
--
3D CNN acceleration on FPGA using hardware-aware pruning[C] DAC, 2020. Northeastern University, MA
--
Width & depth pruning for vision transformers[C] AAAI, 2020. Institute of Computing Technology, Chinese Academy of Sciences
--
Prive-hd: Privacy-preserved hyperdimensional computing[C] DAC, 2020. UC San Diego
--
NestFL: efficient federated learning through progressive model pruning in heterogeneous edge computing[C] MobiCom, 2022. Purple Mountain Laboratories, Nanjing
--
3.2.2.2. Parameter Sharing
Title & Basic Information
Affiliation
Code
Deep k-means: Re-training and parameter sharing with harder cluster assignments for compressing deep convolutions[C] ICML, 2018. Texas A&M University
Code
T-basis: a compact representation for neural networks[C] ICML, 2020. ETH Zurich
Code
"Soft Weight-Sharing for Neural Network Compression." International Conference on Learning Representations. University of Amsterdam
Code
ShiftAddNAS: Hardware-inspired search for more accurate and efficient neural networks[C] ICML, 2022. Rice University
Code
EfficientTDNN: Efficient architecture search for speaker recognition[J]. IEEE/ACM Trans. on Audio, Speech, and Language Processing, 2022. Tongji University
Code
A generic network compression framework for sequential recommender systems[C] SIGIR, 2020. University of Science and Technology
Code
Neural architecture search for LF-MMI trained time delay neural networks[J]. IEEE/ACM Trans. on Audio, Speech, and Language Processing, 2022. The Chinese University of Hong Kong
--
Structured transforms for small-footprint deep learning[J]. NeurIPS, 2015. Google, New York
--
3.2.2.3. Model Quantization
Title & Basic Information
Affiliation
Code
Fractrain: Fractionally squeezing bit savings both temporally and spatially for efficient dnn training[J]. NeurIPS, 2020. Rice University
Code
Edgebert: Sentence-level energy optimizations for latency-aware multi-task nlp inference[C] MICRO-54, 2021. Harvard University
--
Stochastic precision ensemble: self-knowledge distillation for quantized deep neural networks[C] AAAI, 2021. Seoul National University
--
Q-capsnets: A specialized framework for quantizing capsule networks[C] DAC, 2020. Technische Universitat Wien (TU Wien)
Code
Fspinn: An optimization framework for memory-efficient and energy-efficient spiking neural networks[J]. TCAD, 2020. Technische Universität Wien
--
Octo: INT8 Training with Loss-aware Compensation and Backward Quantization for Tiny On-device Learning[C] USENIX Annual Technical Conference. 2021. Hong Kong Polytechnic University
Code
Hardware-centric automl for mixed-precision quantization[J]. IJCV, 2020. Massachusetts Institute of Technology
--
An automated quantization framework for high-utilization rram-based pim[J]. TCAD, 2021. Capital Normal University
--
Exact neural networks from inexact multipliers via fibonacci weight encoding[C] DAC, 2021. Swiss Federal Institute of Technology Lausanne (EPFL)
--
Integer-arithmetic-only certified robustness for quantized neural networks[C] ICCV, 2021. University of Southern California
--
Bits-Ensemble: Toward Light-Weight Robust Deep Ensemble by Bits-Sharing[J]. TCAD, 2022. McGill University
--
Similarity-Aware CNN for Efficient Video Recognition at the Edge[J]. TCAD, 2021. University of Southampton
--
Data-Free Network Compression via Parametric Non-uniform Mixed Precision Quantization[C] CVPR, 2022. Huawei Noah's Ark Lab
--
3.2.2.4. Knowledge Distillation
Title & Basic Information
Affiliation
Code
Be your own teacher: Improve the performance of convolutional neural networks via self distillation[C] ICCV, 2019. Tsinghua University
Code
Dynabert: Dynamic bert with adaptive width and depth[J]. NeurIPS, 2020. Huawei Noah’s Ark Lab
Code
Scan: A scalable neural networks framework towards compact and efficient models[J]. NeurIPS, 2019. Tsinghua University
Code
Content-aware gan compression[C] CVPR, 2021. Princeton University
--
Stochastic precision ensemble: self-knowledge distillation for quantized deep neural networks[C] AAAI, 2021. Seoul National University
--
Cross-modal knowledge distillation for vision-to-sensor action recognition[C] ICASSP, 2022. Texas State University
--
Learning efficient and accurate detectors with dynamic knowledge distillation in remote sensing imagery[J]. IEEE Trans. on Geoscience and Remote Sensing, 2021. Chinese Academy of Sciences
--
On-Device Next-Item Recommendation with Self-Supervised Knowledge Distillation[C] SIGIR, 2022. The University of Queensland
Code
Personalized edge intelligence via federated self-knowledge distillation[J]. TPDS, 2022. Huazhong University of Science and Technology
--
Mobilefaceswap: A lightweight framework for video face swapping[C] AAAI, 2022. Baidu Inc.
--
Dynamically pruning segformer for efficient semantic segmentation[C] ICASSP, 2022. Amazon Halo Health & Wellness
--
CDFKD-MFS: Collaborative Data-Free Knowledge Distillation via Multi-Level Feature Sharing[J]. IEEE Trans. on Multimedia, 2022. Beijing Institute of Technology
Code
Learning Efficient Vision Transformers via Fine-Grained Manifold Distillation[J]. NeurIPS, 2022. Beijing Institute of Technology
Code
Learning Accurate, Speedy, Lightweight CNNs via Instance-Specific Multi-Teacher Knowledge Distillation for Distracted Driver Posture Identification[J]. IEEE Trans. on Intelligent Transportation Systems, 2022. Hefei Institutes of Physical Science (HFIPS), Chinese Academy of Sciences
--
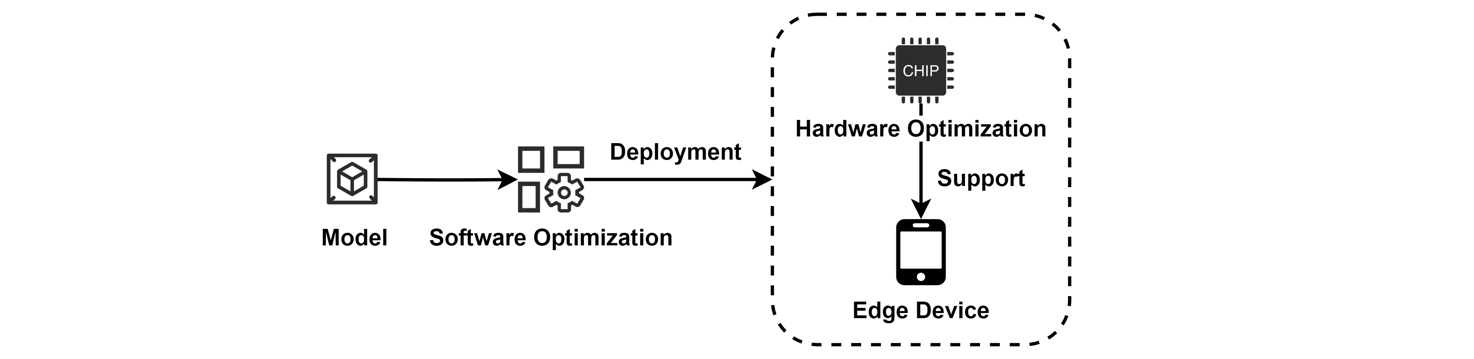
3.2.2.5. Low-rank Factorization An overview of system optimization operations. Software optimization involves developing frameworks for lightweight model training and inference, while hardware optimization focuses on accelerating models using hardware-based approaches to improve computational efficiency on edge devices.
3.3.1. Software Optimization
Title & Basic Information
Affiliation
Code
Hidet: Task-mapping programming paradigm for deep learning tensor programs[C] ASPLOS Conference, 2023. University of Toronto
Code
SparkNoC: An energy-efficiency FPGA-based accelerator using optimized lightweight CNN for edge computing[J]. Journal of Systems Architecture, 2021. Shanghai Advanced Research Institute, Chinese Academy of Sciences
--
Re-architecting the on-chip memory sub-system of machine-learning accelerator for embedded devices[C] ICCAD, 2016. Institute of Computing Technology, Chinese Academy of Sciences
--
A unified optimization approach for cnn model inference on integrated gpus[C] ICPP, 2019. Amazon Web Services
Code
ACG-engine: An inference accelerator for content generative neural networks[C] ICCAD, 2019. University of Chinese Academy of Sciences
--
Edgeeye: An edge service framework for real-time intelligent video analytics[C] EDGESYS Conference, 2018. University of Wisconsin-Madison
--
Haq: Hardware-aware automated quantization with mixed precision[C] CVPR, 2019. Massachusetts Institute of Technology
--
Source compression with bounded dnn perception loss for iot edge computer vision[C] MobiCom, 2019. Hewlett Packard Labs
--
A lightweight collaborative deep neural network for the mobile web in edge cloud[J]. TMC, 2020. Beijing University of Posts and Telecommunications
--
Enabling incremental knowledge transfer for object detection at the edge[C] CVPR Workshops, 2020. Arizona State university
--
DA3: Dynamic Additive Attention Adaption for Memory-Efficient On-Device Multi-Domain Learning[C] CVPR, 2022. Arizona State University
--
An efficient GPU-accelerated inference engine for binary neural network on mobile phones[J]. Journal of Systems Architecture, 2021. Sun Yat-sen University
Code
RAPID-RL: A Reconfigurable Architecture with Preemptive-Exits for Efficient Deep-Reinforcement Learning[C] ICRA, 2022. Purdue University
--
A variational information bottleneck based method to compress sequential networks for human action recognition[C] WACV, 2021. Indian Institute of Technology Delhi
--
EdgeDRNN: Recurrent neural network accelerator for edge inference[J]. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 2020. University of Zürich and ETH Zürich
--
Structured pruning of recurrent neural networks through neuron selection[J]. Neural Networks, 2020. University of Electronic Science and Technology of China
--
Dynamically hierarchy revolution: dirnet for compressing recurrent neural network on mobile devices[J]. arXiv, 2018. Arizona State University
--
High-throughput cnn inference on embedded arm big. little multicore processors[J]. TCAD, 2019. National University of Singapore
--
SCA: a secure CNN accelerator for both training and inference[C] DAC, 2020. University of Pittsburgh
--
NeuLens: spatial-based dynamic acceleration of convolutional neural networks on edge[C] MobiCom, 2022. New Jersey Institute of Technology
--
Weightless neural networks for efficient edge inference[C] PACT, 2022. The University of Texas at Austin
Code
O3BNN-R: An out-of-order architecture for high-performance and regularized BNN inference[J]. TPDS, 2020. --
Blockgnn: Towards efficient gnn acceleration using block-circulant weight matrices[C] DAC, 2021. Peking University
--
{Hardware/Software}{Co-Programmable} Framework for Computational {SSDs} to Accelerate Deep Learning Service on {Large-Scale} Graphs[C] FAST, 2022. KAIST
--
Achieving full parallelism in LSTM via a unified accelerator design[C] ICCD, 2020. University of Pittsburgh
--
Pasgcn: An reram-based pim design for gcn with adaptively sparsified graphs[J]. TCAD, 2022. Shanghai Jiao Tong University
--
3.3.2. Hardware Optimization
Title & Basic Information
Affiliation
Code
Ncpu: An embedded neural cpu architecture on resource-constrained low power devices for real-time end-to-end performance[C] MICRO, 2020. Northwestern Univeristy, Evanston, IL
--
Reduct: Keep it close, keep it cool!: Efficient scaling of dnn inference on multi-core cpus with near-cache compute[C] ISCA, 2021. ETH Zurich
--
FARNN: FPGA-GPU hybrid acceleration platform for recurrent neural networks[J]. TPDS, 2021. Sungkyunkwan University
--
Apgan: Approximate gan for robust low energy learning from imprecise components[J]. IEEE Trans. on Computers, 2019. University of Central Florida
--
An FPGA overlay for CNN inference with fine-grained flexible parallelism[J]. TACO, 2022. International Institute of Information Technology
--
Pipelined data-parallel CPU/GPU scheduling for multi-DNN real-time inference[C] RTSS, 2019. University of California, Riverside
--
Deadline-based scheduling for GPU with preemption support[C] RTSS, 2018. University of Modena and Reggio Emilia Modena
--
Energon: Toward Efficient Acceleration of Transformers Using Dynamic Sparse Attention[J]. TCAD, 2022. Peking University
--
Light-OPU: An FPGA-based overlay processor for lightweight convolutional neural networks[C] FPGA, 2022. University of california, Los Angeles
--
Fluid Batching: Exit-Aware Preemptive Serving of Early-Exit Neural Networks on Edge NPUs[J]. arXiv, 2022. Samsung AI Center, Cambridge
--
BitSystolic: A 26.7 TOPS/W 2b~ 8b NPU with configurable data flows for edge devices[J]. IEEE Trans. on Circuits and Systems I: Regular Papers, 2020. Duke University
--
PL-NPU: An Energy-Efficient Edge-Device DNN Training Processor With Posit-Based Logarithm-Domain Computing[J]. IEEE Trans. on Circuits and Systems I: Regular Papers, 2022. Tsinghua University
--
4. Important Surveys on Edge AI (Related to edge inference and model deployment)
Convergence of edge computing and deep learning: A comprehensive survey. IEEE Communications Surveys & Tutorials, 22(2), 869-904.
Deep learning with edge computing: A review. Proceedings of the IEEE, 107(8), 1655-1674.
Machine learning at the network edge: A survey. ACM Computing Surveys (CSUR), 54(8), 1-37.
Edge intelligence: The confluence of edge computing and artificial intelligence. IEEE Internet of Things Journal, 7(8), 7457-7469.
Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proceedings of the IEEE, 107(8), 1738-1762.
Edge intelligence: Empowering intelligence to the edge of network. Proceedings of the IEEE, 109(11), 1778-1837.