CHAMELEON is a Deep Learning Meta-Architecture for News Recommender Systems [1]. It has being developed as part of the Doctoral research of Gabriel de Souza Pereira Moreira, at the Brazilian Aeronautics Institute of Technology (ITA).
The initial version (v1.0) of CHAMELEON source code allows reproducibility of the experiments reported in a paper [2] published at the DLRS'18, co-located with ACM RecSys'18.
The version v1.7.3 was released for reproducibility of the experiments reported in our papers at the INRA'19, co-located with ACM RecSys'19 [3], and at the IEEE Access journal [4]. The version v1.7.3 includes metrics for item coverage, novelty and diversity, and item-cold start, an optimized instantiation of CHAMELEON meta-architecture and experiments with two datasets are made available: G1 (Globo.com) and Adressa. Furthermore, a recent baseline using Graph Neural Networks (SR-GNN) was included and some additional instantiations of the ACR module were implemented, using GRUs for both supervised and unsupervised training (Sequence Denoising Autoencoder) of the Article Content Embeddings.
[1] Gabriel de Souza Pereira Moreira, Felipe Ferreira, and Adilson Marques da Cunha. 2018. CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems. In Proceedings of Doctoral Symposium of the 12th ACM RecSys'18, October 6, 2018, Vancouver, BC, Canada. ACM, New York, NY, USA, 9 pages. https://doi.org/10.1145/3240323.3240331
[2] Gabriel de Souza Pereira Moreira, Felipe Ferreira, and Adilson Marques da Cunha. 2018. News Session-Based Recommendations using Deep Neural Networks. In 3rd Workshop on Deep Learning for Recommender Systems (DLRS 2018), October 6, 2018, Vancouver, BC, Canada. ACM, New York, NY, USA, 9 pages. https://doi.org/10.1145/3270323.3270328
[3] Gabriel de Souza Pereira Moreira, Dietmar Jannach, and Adilson Marques da Cunha. 2019. On the Importance of News Content Representation in Hybrid Neural Session-based Recommender Systems. In 7th International Workshop on News Recommendation and Analytics (INRA 2019), in conjunction with RecSys 2019, September 19, 2019, Copenhagen, Denmark. https://arxiv.org/abs/1907.07629
[4] Gabriel de Souza Pereira Moreira, Dietmar Jannach, and Adilson Marques da Cunha. 2019. Contextual Hybrid Session-based News Recommendation with Recurrent Neural Networks. IEEE Access, v. 7, p. 169185-169203, 2019. https://doi.org/10.1109/ACCESS.2019.2954957
[5] Gabriel de Souza Pereira Moreira, 2019. CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems. Doctoral Thesis, Instituto Tecnológico de Aeronáutica (ITA), Brazil. https://arxiv.org/abs/2001.04831
This implementation uses Python 3 (with Pandas, Scikit-learn and SciPy modules) and TensorFlow 1.12. CHAMELEON modules were implemented using TF Estimators and Datasets.
The CHAMELEON modules training and evaluation can be performed either locally (GPU highly recommended) or using Google Cloud Platform ML Engine managed service.
The experiments reported in the papers [3], [4] and [5] use the following datasets:
-
Globo.com (G1) dataset - Globo.com is the most popular media company in Brazil. This dataset was originally shared by us in [2]. With this work, we publish a second version, which includes contextual information. The dataset comprises about 1 million user sessions, composed of 3 million clicks on 46,033 different articles. This dataset used was kindly shared by Globo.com for this research.
-
SmartMedia Adressa dataset - This dataset contains approximately 20 million page visits from a Norwegian news portal [91]. In our experiments we used 16 days of the full dataset, which is available upon request, and includes article text and click events of about 2 million users and 13,000 articles.
You must download these dataset to be able to run the commands to pre-process, train, and evaluate the session-based algorithms for next-click recommendation within user sessions.
The objetive of the CHAMELEON is to provide accurate contextual session-based recommendations for news portals. It is composed of two complementary modules, with independent life cycles for training and inference: the Article Content Representation (ACR) and the Next-Article Recommendation (NAR) modules, as shown in Figure 1.
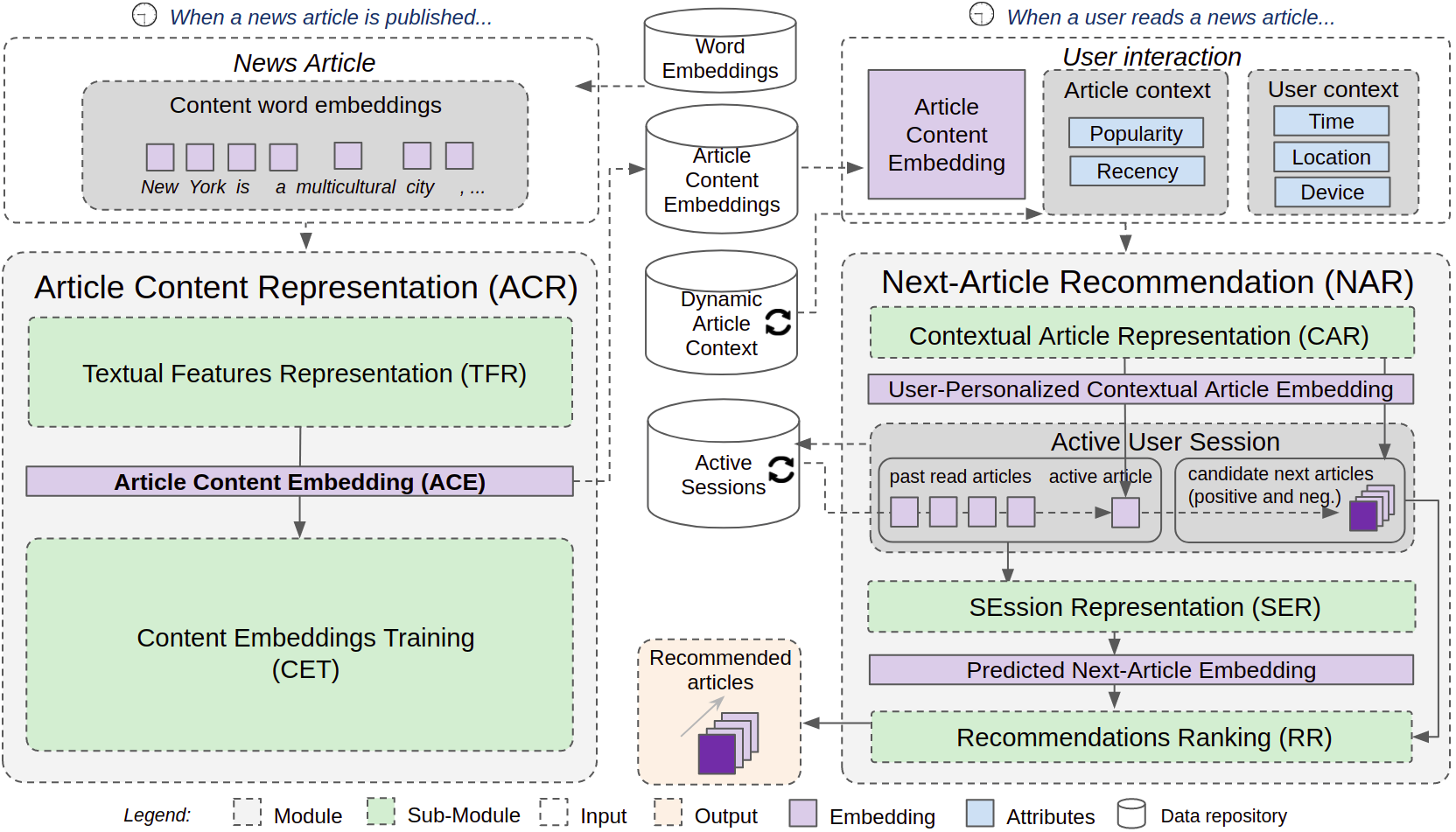
Fig. 1 - CHAMELEON - a Deep Learning Meta-Architecture for News Recommender Systems
The CHAMELEON is a meta-architecture, in the sense of a reference architecture that collects together decisions relating to an architecture strategy. It might be instantiated as different architectures with similar characteristics that fulfill a common task, in this case, news recommendations.
The ACR module is responsible to extract features from news articles text and metadata and to learn a distributed representations (embeddings) for each news article context.
The ACR module learns an Article Content Embedding for each article independently from the recorded user sessions. This is done for scalability reasons, because training user interactions and articles in a joint process would be computationally very expensive, given the typically large amount of daily user interactions in a typical news portal. Instead, the internal model is trained for a side classification task (e.g. predicting target metadata attributes of an article).
The input for the *ACR *module is the article textual content, represented as a sequence of word embeddings (e.g., word2vec, GLoVE).
The ACR module is composed of two sub-modules: Textual Features Representation (TFR) and Content Embeddings Training (CET). The TFR sub-module is responsible to learn relevant features directly from the article textual content, and can be instantiated using CNN and RNNs, for example.
The CET sub-module is responsible to train the Article Content Embeddings (ACE) for a side task. It can be instantiated as a supervised or unsupervised learning model. In the supervised approach, the side task is to predict articles' metadata attributes, such as articles categories. In the unsupervised approach, the task is to reconstruct the original article text from the learned ACE, as an sequence autoencoder.
After training, the Article Content Embeddings for news articles (NumPy matrix) are persisted into a Pickle dump file, for further usage by NAR module.
It was not possible to share the articles' textual content for Globo.com dataset due to licensing reasons. Although, it is not necessary to run the ACR module pre-processing and training commands (presented in the following subsections), since the trained Article Content Embeddings (articles_embeddings.pickle) and Article Metadata (articles_metadata.csv) were already been provided with the dataset.
The creators of the Adressa dataset can make available the full textual content of articles upon request. After download their data, you must follow this steps:
-
As Adressa has provided a large dataset, the first pre-processing step is performed using Spark.
- Create a Spark cluster (dataproc_preprocessing/create_cluster.sh) on GCP Dataproc
- Open a Jupyter session (dataproc_preprocessing/browse_cluster.sh)
- Upload the preprocessing notebook (dataproc_preprocessing/nar_preprocessing_addressa_01_dataproc.ipynb), adjust the GCS path where the Adressa dataset was uploaded and run the notebook.
- Download the sessions JSON lines and the pickle with nar_encoders_dict, exported by the notebook, to be used by the 2nd step of pre-processing
- Destroy the Spark cluster (dataproc_preprocessing/destroy_cluster.sh)
-
Run the 2nd pre-processing step (run_acr_preprocessing_adressa.sh)
-
Run the training and evaluation script (run_acr_training_adressa_local.sh), to generate the Article Content Embeddings with the ACR module.
Here is an example of the command to pre-process articles text and metadata for the ACR module for Adressa dataset. P.s. Again, you will not be able to run the corresponding pre-processing script for the G1 dataset, as described in the previous section.
It allows to specify the path of a CSV containing articles text and metadata (input_articles_csv_path), the path of pre-trained word embeddings and exports articles data into TFRecords format into output_tf_records_path, including the dictionaries that mapped tokenized words to sequences of int (output_word_vocab_embeddings_path) and metadata the categorical features encoders (output_label_encoders).
The word embeddings (input_word_embeddings_path parameter) must be in Gensim format, either in binary or plain text format. For Globo.com dataset, we used pre-trained Portuguese word embeddings (skip-gram model (300 dimensions), available here and for Adressa dataset we used Norwegian word-embeddings (skip-gram model with 100 dimen- sions (model #100), available here).
#!/bin/bash
cd acr_module && \
DATA_DIR="[REPLACE BY THE ADRESSA ARTICLES DATASET PATH]" && \
python3 -m acr.preprocessing.acr_preprocess_adressa \
--input_articles_folder_path ${DATA_DIR}/data/contentdata \
--input_word_embeddings_path ${DATA_DIR}/word_embeddings/w2v_skipgram_no_lemma_aviskorpus_nowac_nbdigital/model.txt \
--vocab_most_freq_words 100000 \
--max_words_length 1000 \
--output_word_vocab_embeddings_path ${DATA_DIR}/pickles/acr_word_vocab_embeddings.pickle \
--output_label_encoders ${DATA_DIR}/pickles/acr_label_encoders.pickle \
--output_tf_records_path "${DATA_DIR}/articles_tfrecords/adressa_articles_*.tfrecord.gz" \
--output_articles_csv_path "${DATA_DIR}/adressa_articles.csv" \
--articles_by_tfrecord 1000The ACR module can be trained either locally (example below) or using GCP ML Engine (run_acr_training_gcom_mlengine.sh).
The path of pre-processed TFRecords is informed in train_set_path_regex parameter, as well as the other ACR exported assets (input_word_vocab_embeddings_path and input_label_encoders_path). The trained Article Content Embeddings (NumPy matrix), with the dimensions specified by acr_embeddings_size, are exported (Pickle dump file) after training to output_acr_metadata_embeddings_path, for further usage by the NAR module.
You can train using an supervised or unsupervised instantiation of the ACR module by changing the --training_task parameter ("metadata_classification" or "autoencoder") and change the feature extraction using the --text_feature_extractor parameter ("CNN", "GRU").
DATA_DIR="[REPLACE BY THE ADRESSA ARTICLES DATASET PATH]" && \
JOB_PREFIX=adressa && \
JOB_ID=`whoami`_${JOB_PREFIX}_`date '+%Y_%m_%d_%H%M%S'` && \
MODEL_DIR='/tmp/chameleon/addressa/jobs/'${JOB_ID} && \
echo 'Running training job and outputing to '${MODEL_DIR} && \
python3 -m acr.acr_trainer_adressa \
--model_dir ${MODEL_DIR} \
--train_set_path_regex "${DATA_DIR}/articles_tfrecords/adressa_articles_*.tfrecord.gz" \
--input_word_vocab_embeddings_path ${DATA_DIR}/pickles/acr_word_vocab_embeddings.pickle \
--input_label_encoders_path ${DATA_DIR}/pickles/acr_label_encoders.pickle \
--output_acr_metadata_embeddings_path ${DATA_DIR}/pickles/acr_articles_metadata_embeddings_supervised_cnn.pickle \
--batch_size 8 \
--truncate_tokens_length 300 \
--training_epochs 1 \
--learning_rate 3e-4 \
--dropout_keep_prob 1.0 \
--l2_reg_lambda 1e-5 \
--text_feature_extractor "CNN" \
--training_task "metadata_classification" \
--cnn_filter_sizes "3,4,5" \
--cnn_num_filters 128 \
--rnn_units 512 \
--rnn_layers 1 \
--rnn_direction "unidirectional" \
--acr_embeddings_size 250The Next-Article Recommendation (NAR) module is responsible for providing news articles recommendations for active sessions. Due to the high sparsity of users and their constant interests shift, these CHAMELEON instantiations leverages only session-based contextual information, ignoring possible users’ past sessions.
The inputs for the NAR module are: (1) the pre-trained Article Content Embedding of the last viewed article; (2) the contextual properties of the articles (recent popularity and recency); and (3) the user context (e.g. time, location, and device). These inputs are combined by Fully Connected layers to produce a User-Personalized Contextual Article Embedding, whose representations might differ for the same article, depending on the user context and on the current article context (popularity and recency).
These NAR module instantiations uses Recurrent Neural Networks (RNN) to model the sequence of articles read by users in their sessions, represented by their User-Personalized Contextual Article Embeddings. For each article of the sequence, the RNN outputs a Predicted Next-Article Embedding – the expected representation of a news content the user would like to read next in the active session.
The NAR module is composed by three sub-modules: Contextual Article Representation (CAR), SEssion Representation (SER), and Recommendations Ranking (RR). You can find more details about those sub-modules in [3].
In most deep learning architectures proposed for RS, the neural network outputs a vector whose dimension is the number of available items. Such approach may work for domains were the items number is more stable, like movies and books. Although, in the dynamic scenario of news recommendations, where thousands of news stories are added and removed daily, such approach could require full retrain of the network, as often as new articles are published.
For this reason, instead of using a softmax cross-entropy loss, the NAR module is trained to maximize the similarity between the Predicted Next-Article Embedding and the User-Personalized Contextual Article Embedding corresponding to the next article actually read by the user in his session (positive sample), whilst minimizing its similarity with negative samples (articles not read by the user during the session). With this strategy to deal with item cold-start, a newly published article might be immediately recommended, as soon as its Article Content Embedding is trained and added to a repository.
The following example commands are for the Globo.com dataset. For the Adressa dataset, you want to use run_nar_preprocessing_adressa.sh for pre-processing and run_nar_train_adressa_local.sh for training and evaluation.
The NAR module expects TFRecord files containing SequenceExamples of user sessions's context and clicked articles.
The following example command (run_nar_preprocessing_gcom.sh) takes the path of CSV files, containing users sessions split by hour (input_clicks_csv_path_regex), and outputs the corresponding TFRecord files.
cd nar_module && \
DATA_DIR="[REPLACE WITH THE PATH TO UNZIPPED GCOM DATASET FOLDER]" && \
python3 -m nar.preprocessing.nar_preprocess_gcom \
--input_clicks_csv_path_regex "${DATA_DIR}/clicks/clicks_hour_*" \
--number_hours_to_preprocess 384 \
--output_sessions_tfrecords_path "${DATA_DIR}/sessions_tfrecords/sessions_hour_*.tfrecord.gz"The NAR module is trained and evaluated according to the following Temporal Offline Evaluation Method, described in [2]:
- Train the NAR module with sessions within the active hour.
- Evaluate the NAR module with sessions within the next hour, for the task of the next-click prediction.
The following baseline methods (described in more detail in [4]) are also trained and evaluated in parallel, as benchmarks for CHAMELEON:
- Neural methods: GRU4Rec, SR-GNN
- Association Rules-based methods: Co-occurrent (CO), Sequential Rules (SR)
- Neighborhood-based methods: Item-kNN, Vector Multiplication Session-Based kNN (V-SkNN)
- Other methods: Recently Popular (RP), Content-Based (CB)
The choosen evaluation metrics were Hit-Rate@N and MRR@N for accuracy, COV for catalog coverage, ESI-R and ESI-RR for novelty, and EILD-R and EILD-RR for diversity, described in [4].
The train_set_path_regex parameter expects the path (local or GCS) where the sessions' TFRecords were exported. It also expects the path of the articles metadata CSV (acr_module_articles_metadata_csv_path) and the Pickle dump file with the Article Content Embeddings (acr_module_articles_content_embeddings_pickle_path).
It is necessary to specify a subset of files (representing sessions started in the same hour) for training and evaluation (train_files_from to train_files_up_to). The frequency of evaluation is specified in training_hours_for_each_eval (e.g. training_hours_for_each_eval=5 means that after training on 5 hour's (files) sessions, the next hour (file) is used for evaluation.
To reproduce the experiments of [3] (only for the Adressa dataset, as the articles text for the G1 dataset could not be provided), where different techniques of content representation are compared, you can generate the ACEs using the ACR supervised implementations using "acr_module/scripts/run_acr_training_*classification.sh" (CNN or GRU) and the unsupervised implementation using "run_acr_training*_autoencoder.sh". The files to generate the ACEs using baseline techniques reported in the paper (LSA, doc2vec, W2V*TF-IDF) are available at "acr_module/acr/preprocessing/". After generating the ACE (numpy array dumped using Pickle), you can test them with the NAR module to evaluate the effect of that content representation in the recommendation quality, setting the path of the Pickle file using the "--acr_module_resources_path" hyperparamenter.
To reproduce the experiments of [4], where additional features are used as inputs to the NAR module, you must change the following parameters according to the Input Configurations (IC) reported in the paper: enabled_articles_input_features_groups, enabled_clicks_input_features_groups, enabled_internal_features.
To reproduce the experiments reported in [4] with the novelty regularization in loss function, change the parameter novelty_reg_factor.
The disable_eval_benchmarks parameter disables training and evaluation of benchmark methods (useful for speed up).
The NAR module can either be trained locally or using GCP ML Engine, as following examples.
cd nar_module && \
DATA_DIR="[REPLACE WITH THE PATH TO UNZIPPED GCOM DATASET FOLDER]" && \
JOB_PREFIX=gcom && \
JOB_ID=`whoami`_${JOB_PREFIX}_`date '+%Y_%m_%d_%H%M%S'` && \
MODEL_DIR='/tmp/chameleon/jobs/'${JOB_ID} && \
echo 'Running training job and outputing to '${MODEL_DIR} && \
python3 -m nar.nar_trainer_gcom \
--model_dir ${MODEL_DIR} \
--train_set_path_regex "${DATA_DIR}/sessions_tfrecords/sessions_hour_*.tfrecord.gz" \
--train_files_from 0 \
--train_files_up_to 72 \
--training_hours_for_each_eval 5 \
--save_results_each_n_evals 1 \
--acr_module_articles_metadata_csv_path ${DATA_DIR}/articles_metadata.csv \
--acr_module_articles_content_embeddings_pickle_path ${DATA_DIR}/articles_embeddings.pickle \
--batch_size 64 \
--truncate_session_length 20 \
--learning_rate 3e-5 \
--dropout_keep_prob 1.0 \
--reg_l2 1e-5 \
--softmax_temperature 0.1 \
--recent_clicks_buffer_hours 1.0 \
--recent_clicks_buffer_max_size 20000 \
--recent_clicks_for_normalization 2000 \
--eval_metrics_top_n 6 \
--CAR_embedding_size 1024 \
--rnn_units 255 \
--rnn_num_layers 1 \
--train_total_negative_samples 30 \
--train_negative_samples_from_buffer 3000 \
--eval_total_negative_samples 30 \
--eval_negative_samples_from_buffer 3000 \
--eval_negative_sample_relevance 0.02 \
--enabled_articles_input_features_groups "category" \
--enabled_clicks_input_features_groups "time,device,location,referrer" \
--enabled_internal_features "item_clicked_embeddings,recency,novelty,article_content_embeddings" \
--novelty_reg_factor 0.0 \
--disable_eval_benchmarksWhen training the NAR module in GCP ML Engine, two parameters are specially important:
- use_local_cache_model_dir - TensorFlow logs and summaries are usually large and saving them directly to GCS considerally slows down the training/evaluation process. When this parameter is present, TF model logs to a local folder in the worker machine.
- save_results_each_n_evals - The frequency (number of evaluation loops) in which TF logs saved locally are uploaded to a GCS path (model_dir).
P.s. As the proposed Temporal Offline Evaluation Method assumes that hours are trained and evaluated in sequence, a single ML Engine worker with GPU is used (scale-tier=basic-gpu) to avoid leaking from future sessions (due to the asynchronous training when more than one worker is used).
cd nar_module && \
PROJECT_ID="[REPLACE BY THE GCP PROJECT ID. e.g. 'chameleon-test']" && \
DATA_DIR="[REPLACE BY THE GCS PATH OF GCOM DATASET. e.g. gs://chameleon_datasets/gcom]" && \
JOB_PREFIX=gcom_nar && \
JOB_ID=`whoami`_${JOB_PREFIX}_`date '+%Y_%m_%d_%H%M%S'` && \
MODEL_DIR="[REPLACE BY THE GCS PATH TO OUTPUT NAR MODEL RESULTS. e.g. gs://chameleon_jobs/gcom/nar_module/${JOB_ID}]" && \
JOBS_STAGING_DIR="[REPLACE BY A GCS PATH FOR STAGING. e.g. gs://mlengine_staging/" && \
echo 'Running training job '${JOB_ID} && \
gcloud --project ${PROJECT_ID} ml-engine jobs submit training ${JOB_ID} \
--package-path nar \
--module-name nar.nar_trainer_gcom \
--staging-bucket ${JOBS_STAGING_DIR} \
--region us-central1 \
--python-version 3.5 \
--runtime-version 1.12 \
--scale-tier basic-gpu \
--job-dir ${MODEL_DIR} \
-- \
--model_dir ${MODEL_DIR} \
--use_local_cache_model_dir \
--train_set_path_regex "${DATA_DIR}/sessions_tfrecords/sessions_hour_*.tfrecord.gz" \
--train_files_from 0 \
--train_files_up_to 385 \
--training_hours_for_each_eval 5 \
--save_results_each_n_evals 1 \
--acr_module_articles_metadata_csv_path ${DATA_DIR}/articles_metadata.csv \
--acr_module_articles_content_embeddings_pickle_path ${DATA_DIR}/articles_embeddings.pickle \
--batch_size 256 \
--truncate_session_length 20 \
--learning_rate 1e-4 \
--dropout_keep_prob 1.0 \
--reg_l2 1e-5 \
--softmax_temperature 0.1 \
--recent_clicks_buffer_hours 1.0 \
--recent_clicks_buffer_max_size 20000 \
--recent_clicks_for_normalization 2000 \
--eval_metrics_top_n 10 \
--CAR_embedding_size 1024 \
--rnn_units 255 \
--rnn_num_layers 2 \
--train_total_negative_samples 50 \
--train_negative_samples_from_buffer 3000 \
--eval_total_negative_samples 50 \
--eval_negative_samples_from_buffer 3000 \
--eval_negative_sample_relevance 0.02 \
--content_embedding_scale_factor 6.0 \
--enabled_articles_input_features_groups "category" \
--enabled_clicks_input_features_groups "time,device,location,referrer" \
--enabled_internal_features "item_clicked_embeddings,recency,novelty,article_content_embeddings" \
--novelty_reg_factor 0.0 \
--disable_eval_benchmarks




























































































































