getodk / roadmap Goto Github PK
View Code? Open in Web Editor NEWODK is an open, inclusive, meritocratic, and consensus-based project. Anyone can help set the direction of this project and these documents describe where the project is headed. ✨🗺✨
ODK is an open, inclusive, meritocratic, and consensus-based project. Anyone can help set the direction of this project and these documents describe where the project is headed. ✨🗺✨
Goals and tradeoffs need to be enumerated. Who do we want to be able to do this? Only devs? Anyone? Do we want to track who does this? Any other requirements?
The current challenges are:
Collect changes by @alxndrsn: https://github.com/alxndrsn/collect/tree/multi-brand
Sample branded project by @alxndrsn: https://github.com/alxndrsn/medic-flavoured-collect
Pros:
Cons:
Try to get non-Nafundi people to contribute to core code.
Consortia for pursuing funding and how would something like that work? Letters of support or some such from end-users like Red Cross?
The original thread on the forum
The initial specification written in Google Docs
As a supervisor, I would like to collect location coordinates in the background to provide evidence that data was collected in a particular place.
The reason of this feature is to avoid bad data. For example, you might notice an enumerator who as been poorly trained collect location in the morning, then go home and fill in the survey data whenever.
The idea is to extend the form audit log to add location to the log if location-mode is set as parameters in the audit row of the XLSForm, we will choose the most accurate point recorded in the age window.
In the ideal case for location-interval=10 and location-age=60, 6 points will be collected and we choose the most accurate one to write the log. But location-interval is not guaranteed and so there may be more points or less points.
If location-interval and location-age are not set, defaults will be set by the application based on the mode. If either is set, the value will override the defaults.
Currently an audit.csv file has the following structure:
| event | node | start | end |
|---|---|---|---|
| question | /data/name | 1523403169208 | 1523403170733 |
Location will be recorded in three columns: latitude, longitude, accuracy in the audit log that is attached to Collect's submissions.
New structure of an audit.csv file:
| event | node | start | end | latitude | longitude | accuracy |
|---|---|---|---|---|---|---|
| question | /data/name | 1523403169208 | 1523403169208 | 27.1080 | 11.19574 | 20 |
New columns will be added only if the audit row of the XLSForm contains background parameters otherwise they are not needed.
When you have an existing form with audit that did not have location enabled and you change that form to add location, three new columns will be added.
In the XForms spec audit is placed in the meta block under the orx namespace. It uses a binary data type. See getodk/xforms-spec#94
<orx:meta>
<orx:audit/>
</orx:meta>
<bind nodeset="/orx:meta/orx:audit" type="binary"/>We will add the following bind attributes in the odk namespace to the specification. Both attributes are required to enable location audits and location-age must be greater than or equal to location-interval.
<bind nodeset="/orx:meta/orx:audit" type="binary"
odk:location-mode="balanced" odk:location-interval="10" odk:location-age="60" />We prepend "location-" to the tags to ensure that there are no future conflicts with mode, interval and age.
The tentative pyxform specification is as follows.
| type | name | parameters |
|---|---|---|
| audit | audit | location-mode=balanced location-age=60 |
When Collect opens the form, we will request location updates from the location provider every desired interval seconds. Location updates will be started in onCreate() method and paused when the app is in the background (onStop() method) to avoid battery draining.
At the time of the audit event (e.g., view question, form save etc.) occurs, Collect will check the cache for the location.
If a user disables/enables location or revokes/grants the permission after starting a form an appropriate event will be logged:
| event | node | start | end | latitude | longitude | accuracy |
|---|---|---|---|---|---|---|
| location disabled | 1523403169208 | |||||
| location enabled | 1523403269301 | |||||
| location permission revoked | 1523403469758 | |||||
| location permission granted | 1523403669354 |
We will not exit a form if a user disables location or revokes the permission.
To ensure enumerators are aware that this sensitive data is being gathered...
On first launch of the form, we use a dialog to get consent.
We use the above strategy because if we just ask a yes/no consent question and the user says no, we have no easy way of re-enabling. That is, a yes/no question takes what we expect to be an occasional disabling and turns it into a permanent disable. Using permissions or location providers solves that problem.
The caveat is that this not the easiest thing for users to do. Further, disabling location for the device means no other location apps will work. And revoking permissions means that any required location questions (e.g., geopoint) will not work.
On subsequent launches of the form, we use a snackbar (see image below) to show background location collection status.

This will serve as a reminder to the enumerator that their location is tracked for that specific form. In the case where the enumerator is not the one to open a form for the first time, they will still see the snackbar and have an opportunity to exit the form or turn off location is required for safety or other reasons. Even though Android does show that location is being accessed, it's not clear by which app. The snackbar is clearly associated with Collect.
If location is enabled/disabled during data collection, then we show the snackbar on return to Collect. If this is hard to do, we will show the snackbar on return to Collect (so no need to check enabled/disabled).
GSOC people require significant coaching and don't always stick around. Need, for example, good Android or NodeJS contributors that can independently tackle complex issues. Our social networks might be one place to find people.
Update the Export user interface in Briefcase to allow the selection of multiple forms, each one with a separate export directory, export type, private key, etc.
User Stories
It is clear that Data visualization and reporting is a key point for any kind of user (business or research oriented):
https://www.nature.com/articles/d41586-018-01322-9?utm_source=twt_na&utm_medium=social&utm_campaign=naturemarketing
As an administrator, I want to be able to see some statistics about the survey conducted
As a surveyor, I want to know how I perform, my basic statistic, some advanced statistic defined by the admin maybe as a feedback for the data collection done connecting as a viewer maybe to Aggregate.
Proposed Implementation
It should be easy enough to include some basic statistics in Aggregate itself (show the number of submissions in total/by deviceId, by date, etc etc…).
Advanced reports and data visualization shouldn’t lay directly on Aggregate.
Data should be pushed directly to reporting tools.
There are quite a lot of possibilities about open source tool for reporting or data visualization available:
Data from Aggregate should be pushed to one or more of that tools and get some statistics/visualization.
Admin could choose some default graphs/statistics always available to surveyor, then surveyor could push all dataset to one or more tool and get interactive graphs or statistics.
Ongoing summer internship project.
(needs governance doc?)
Do we need more than the above?
We need to put together a community-driven road map. We've setup this repo and this issue tracker as a first step, but it's not clear it's the best way. If you have ideas about the best way to build a road map as a community, please add your feedback!
Change Validate errors to warnings.
https://forum.opendatakit.org/t/disabling-validates-static-type-checking/19523
See the forum table of contents
As a health worker, I want to be able to collect a medical record every time a patient visits my health facility, so that I can keep track of the patient's progress over time
As a census taker, I want to visit a village every year and record population data
As a vaccine delivery driver, I want to keep track of the quantities of vaccines that I deliver to cold storage facilities during my weekly deliveries
As a regional vaccine administrator, I want to download CSV files that show the quantities of vaccine that have been delivered to all the cold storage facilities in my region over the last six months
For the sake of this explanation, I'm going to use the following terminology:
The simplest solution is probably to have two separate forms, one to collect the details of an entity ("the Entity Form") and one to collect the details of each visit ("the Record Form"). A Record must have one (and only one) Entity associated with it. An Entity can have multiple Records associated with it.
Forms for creating entities must have a certain field (or fields) marked as an "identifying field". This would be for example a patient's name and DOB, or a village name and region, or a cold storage facility name and ID number. These identifying fields can then be used as labels in the CSV file that the Record Form uses to enable a data collector to choose the linked Entity. Entity Forms can also have fields marked as "filter fields". These will be used to reduce the number of options shown in the list of Entities (see Getting Entity lists onto devices below).
Forms for creating records must have one attribute called entity_type_id; this attribute can only contain the UUID of an Entity Form. They must also have one field called entity_id. This field should be of type select_one_external (see Getting Entity lists onto devices below).
The first question in a Record Form should be a selection of the associated Entity. This question should be of type select_one_external. The values will then be loaded into the form from an external CSV file that is downloaded from the server. The CSV file should have the following format:
list_name,name,label,<filter_field_1>,<filter_field_2>,...
entities,<instanceID>,<identifying field value>,<filter field 1 value>,<filter field 2 value>,...
entities,<instanceID>,<identifying field value>,<filter field 1 value>,<filter field 2 value>,...
...
More on external CSV files in X(LS)Forms.
These CSV files should be generated automatically by ODK Central, and updated every time a new Entity Form is submitted. It should then be possible to use the automatic form update functionality to keep the CSV file up to date. [Question: if a media file is updated - in this case the CSV - does that count as an updated form? or would ODK Central have to automatically make a new version of the form each time it updates the CSV file?]
A common use case is to create an Entity and then immediately create a Record for that Entity. In an offline scenario, this is not possible with the spec so far. It is there therefore necessary to add a mechanism for adding Entities locally, within ODK Collect. Every time the Entity form is completed, the data should be written to a local CSV file (or a local database?). There should then be a mechanism whereby the local CSV file is merged with the downloaded CSV file whenever the Record Form is opened.
It might make sense to clean up the local CSV file every time a new CSV file is downloaded from the server, but it's questionable whether this will be necessary (one reason: if an Entity is deleted on the server, it will still be in the local CSV and the merge will make it available in the form).
It would make sense to build some duplication detection and resolution into ODK Central. Ideally, it would only possible to do data collection on entities that have come from Central, so that they will always have to go through this de-duping, but this is obviously not acceptable if I want to register a patient and then make a case report on them in a totally offline setting. I could see a possible solution using a kind of tombstone for de-duped entities, so that a process might look like this:
dd6c32a4 using Form Add6c32a4 is now marked as "pending" on my device, which means I can submit case reports against it, but it's not on Centraldd6c32a4 using Form Bdd6c32a4 is an exact duplicate of an existing patient, 19f44a40, who already has case reports19f44a40dd6c32a4 is replaced in Central with a tombstone that refers to 19f44a40dd6c32a4 will be switched to refer to 19f44a40dd6c32a4For the specifics of the de-duping process, I would probably use a combination of approaches. First you need to find possible matches, probably using a trigram algorithm (or possible Levenshtein distances) on identifying fields such as name, village, etc. There's a really good trigram module for Postgres. This is then combined with matches on other fields (e.g. date of birth or geopoint) to calculate a similarity score. You can then figure out values and say something like "if it's over 95%, just merge them automatically" and "if it's over 80%, flag them as probable dupes", and provide a simple interface that displays the data with yes/no buttons. I've done something like this for de-duping patient lists in DRC and it worked pretty well.
Many form designs include repeat groups that may not be filled out in a linear fashion. For such forms, the ability to easily jump from repeat item to repeat item would be a big usability gain.
Imagine a form for a household with 10 members. The enumerator wishes to first list everyone's name, and then survey the members one by one, often jumping around the list in a non-linear way. Getting the names at the beginning is important because people may come and go.
Currently, doing this via the jump screen is somewhat painful.
Now that we have the ability to dynamically name repeat items things are somewhat better, but still, if you are on a question in one of the repeat items, to go to a different item, you need to tap: Jump > Go Up > Expand Arrow > Desired Item > Desired Question. That's 5 taps for each jump, and each is in a different part of the screen, meaning a lot of finger targeting and moving and cognitive load! If you're doing this a lot, that's a lot!
To remedy this we're suggesting 3 separate changes:
Currently the jump screen with repeat groups looks like this:

Specifically:
So there is a somewhat strange combination of two techniques for browsing a hierarchy: 1) tree view, 2) screen-by-screen drill-down.
I would argue that #2 is the more common approach in mobile UIs. Think of the Android settings screen, the iPod interface, etc. Therefore I'm proposing we change things so that tapping the repeat group opens a new screen to show repeat items instead of expanding.
This approach can be seen in these mockups. (You can ignore the question icons and other fancy stuff for now and just focus on the navigation from top level down into a repeat group item and back up.)
Check out this diagram:

I think this is the implicit mental model of ODK Collect -- the left-right swipe motion moves through a long a linear list of questions (those grouped into a single screen are field-lists or grids). Going to the jump screen is kind of like moving 'up' from the base-level question view. This is reinforced by the label of the button 'Go Up' in the jump screen footer. You can go all the way 'up' to the top level of the jump screen, or all the way 'down' to the question view.
Right now, moving up through the hierarchy is cumbersome because to get from a question to the top level via a repeat group you have to:
So you have to tap three different things just to get to the list of items in the repeat.
If, instead, we:
THEN
Moving up the hierarchy is as simple as repeatedly pressing that icon.
Our mockups convey this idea. e.g.

Cuz why not!? See the mockups for where these would be located.
This would make it much easier to add/remove/manage repeat items.
(In future it would also be nice to prompt the user to enter an answer to a key question (e.g. person name) right when they click the 'add' button, but that's for another day.)
That's it! Thanks all for considering!
PS: Note to Helene, others: I know earlier we had discussed skipping the question list for groups that contain only field-list. That is still a possibility, but I realized it may not be as useful given that for non-trivial forms it's hard to have a field-list only repeat group because conditions and multi-level select-ones don't work in field-lists. So that solution won't work for us I think. I also think it might be a bit confusing and inconsistent. I prefer making it easily to quickly move up the hierarchy instead of just skipping things outright.
Collect 1.16 adds SMS submissions but the process is too manual to fit the needs of users who’ve tried it. Typically, users want submissions to fall back to SMS without user intervention if Internet is not available.
From Server settings, a user can set what the manual send button on Send Finalized Form does and set an SMS destination phone number.
From Form management settings, a user can auto-send to an HTTP server. There is no way to trigger an auto-send via SMS.



As a supervisor or enumerator, I need to be able to identify that I want SMS submission attempted after an Internet submission fails.
Conceptually, the desired flow on send is:

Sending an SMS should only be attempted if the form has SMS tags and an SMS hasn't been sent before. That is, only one SMS should ever be sent by this workflow. The user can still trigger a resend manually if the send button sends over SMS.

Typical settings combinations
Default
Nothing happens automatically. To send a form, the user taps the Send button on the Send Finalized Form screen and the submission(s) are sent over HTTP.
Manual send button sends over: Wifi/Cellular (recommended)
Wifi/Cellular auto send: Off
Fall back to SMS: Off
HTTP autosend
When a user finishes filling a form, that form sends immediately over HTTP if an Internet connection is available. Otherwise, it is enqueued and sends when a connection becomes available. The user can also go to Send Finalized Form and try sending form(s) manually.
Manual send button sends over: Wifi/Cellular (recommended)
Wifi/Cellular auto send: Wifi, cellular or both
Fall back to SMS: Off
SMS-only
Nothing happens automatically. To send a form, the user taps the Send button on the Send Finalized Form screen and the submission(s) are sent over SMS.
Manual send button sends over: SMS
Wifi/Cellular auto send: Off
Fall back to SMS: Off
Phone number must be set in Server settings
Auto send with SMS Fallback
When a user finishes filling a form, that form sends immediately over HTTP if an Internet connection is available. If the connection is not available or the connection fails, and the form contains SMS tags and an SMS hasn't been sent, an SMS is sent. Then the form is enqueued for HTTP submission and sends when a connection becomes available.
Manual send button sends over: any
Wifi/Cellular auto send: Wifi/Cellular or Both
Fall back to SMS: on
Phone number must be set in Server settings
Currently, forms that have been sent via SMS or via Internet have the same SUBMITTED status in the database. Additionally, auto-send does not do a true enqueue, it simply sends anything that doesn’t have a SUBMITTED status. This means there’s no way to sequence an Internet submission after an SMS submission -- the filled form looks like it’s been sent already. To support this sequencing, introduce an SMS_SUBMITTED status. Filled forms that have the SMS_SUBMITTED status will still be queued for auto send over Internet.
By default, the Send Finalized Form screen only shows unsent forms. Once a form is sent, it disappears from that screen (but can be shown using the sent and unsent view option from the overflow menu). With the introduction of the SMS_SUBMITTED status and workflows that may involve submitting first over SMS and then over Internet we need to rethink the most appropriate forms to show in the Send Finalized Form interface.
If the manual send button is configured to send over SMS and autosend is off, hide SMS_SUBMITTED forms because they are considered fully submitted. In all other cases, show SMS_SUBMITTED forms on the unsent screen because they still need to be sent over Internet.
What this specification proposes is not a true auto-send because there is no retry so it seems potentially misleading to include there. It also seems this would result in 6 options: Wifi only, Cellular only, Wifi or Cellular and those same ones with SMS retry options.
As an administrator, I want to be able to specify that surveyors should be using the latest version of the relevant form so that I have some assurance about the quality of data that is being collected
As a surveyor, I want to know that I am using the latest version of the form that I am filling so that I don't waste time with unnecessary questions
As a surveyor, I don't want to have to care about form versions so that I can focus on the process of data collection
It's easy enough to ascertain the latest version of a given form by making a call (e.g. to /formList, but there might be a better endpoint?) to an Aggregate server. For this reason, it would make sense to implement this as a "pull" in Collect, rather than trying to do any kind of push from Aggregate.
ODK Collect should poll the endpoint every X seconds (600?), checking whether the returned version number is higher than that of the forms that are currently stored on the device. This polling should only occur when the application is running in the foreground. Future implementations might explore the possibility of having this run as a background service (payoff: complexity + data usage vs timeliness of updates).
Two measures that could be implemented to save network traffic:
/formList should be madeHowever it is suggested that too much premature optimisation should be avoided; once the feature is implemented, we can assess the impact and decide whether traffic-reduction measures are necessary.
There should be a new option, "Check for new form versions when the app is in the background", which should be set to false by default. If set to true, there should be an additional frequency option with values of 15, 30 or 60 minutes. If these times end up being absolute (e.g if "60 minutes" translates to "on the hour"), a random number of up to 600 seconds should be added, to avoid a synchronised hammering of the server.
There should be another new option added to ODK Collect called "Automatically download new versions of forms when they become available", which should be set to false by default.
If this option is false and a new version of one (or more) of the forms on the device is available, we should show an alert saying something like, "A new version (v20180306) of the form Household Survey is available. You currently have v20180218. Download and install the new version?" [Yes/No]
In the (fairly unlikely) case that there are multiple form updates available, multiple alerts should be shown, one per updated form.
If the "Check for new form versions when the app is in the background" option is set to true but the "Automatically download new versions of forms when they become available" option is set to false, users should receive one (and only one) Android notification informing them that a new form version is available. This notification should say something like, "A new version of the form
If the "Automatically download new versions of forms when they become available" option is set to true, the forms should be downloaded and installed without informing the user.
Older versions of forms should be kept on the device so that filled forms that were created with an older version can still be viewed, but they should not be shown in the UI: only the latest version of each available form should be displayed and selectable.
If there are no filled forms on the device that were created with an obsolete version of a form, and a newer version of that form has been downloaded to the device, then the obsolete version can safely be removed.
Add an appearance "image-map" to select_one and select_multiple questions with an SVG image label. This will enable diagrams with individual parts (e.g., a map, a body) to be used as selects.
Ongoing internship project.
https://forum.opendatakit.org/t/internship-project-odk-briefcase-export-automation/11755
Give forms the ability to recall previously entered values when filling out the same base form multiple times on the same device. This behavior would be opt-in only.
Keywords: recall, autofill, autocomplete, preload, memory, template
As a census taker, I write the current street name on a napkin so I can remember it for each house I visit.
As a natural disaster responder, I enter the exact same earthquake date every time I interview someone from the same area.
As a forest surveyor, I type in my team name and choose a region code every time I log a new tree. Sometimes I make typos.
There have been numerous discussions in the past; I've tried to summarize and consolidate the conclusions here in the creation of this proposal. The "motivation" above is also inspired directly from these discussions.
"Case Management" is related, but separate and much more complex. Linked here because there may be some overlap in ideas:
The cache is a simple SQLite or Shared Preferences key/value store that maps from the [form ID + question ref] to the [last saved value for that question].
The cache is updated whenever a form is saved. Any question in the form that is intended to be cached will be re-cached on save, whether or not that specific question has been edited since the last save.
When filling out a new form instance, the question value is loaded and set from the cache at a specific point in time, depending on which option is being considered (see options below).
The cache would be cleared if you clear app data via system settings, but not if you merely delete the form instance from your device.
To designate a question as being cached, there are multiple options:
XForms bind attribute: e.g. jr:preload="last-saved"
jr:preload options hereXPath function: e.g. lastSaved()
once() calculation for one-time updatesonce(lastSaved() + 1)once()XForms appearance: e.g. appearance="save-recent"
a will still include options for ant and cat but will filter out dog)x next to each item to clear it from memoryOptions that have previously been discussed but are insufficient to fully address these needs:
Options A/B/C are not mutually exclusive, but for the sake of simplicity I think we should keep the initial feature as minimal as possible.
I'm personally in favor of option A alone. It's simple, flexible, and hard to make mistakes when designing forms that utilize it (e.g. forgetting to use once() in option B could lead to major frustrations).
Names I've considered for options A and B:
lastSavedlastValuecachedprevInstanceI personally like lastSaved best because it's clear and specific: assign the value from the form that was most recently saved (as opposed to any other value, such as last viewed, last changed, or last finalized).
Names I've considered for option C:
save-recentshow-recentrecently-usedautocompletelast-savedI personally like save-recent as an appearance because it implies the two-way nature: answers are saved and shown in the future. Setting this option both enables caching and shows the recent values to the user.
Again, I'm personally in favor of only implementing option A for now, but options B and C are also possibilities, and are not mutually exclusive. I'd love to hear your feedback.

Mockup of new UI
Add an icon to the start of each row in form lists. This includes:
The icons will change depending on the form/instance state to make it more clear to users what state the form is in:
| Icon | Icon description | Form state | Screens it appears on |
|---|---|---|---|
 |
0/3 checked boxes | Blank | Fill Blank Form Get Blank Form Delete: Blank Forms |
 |
2/3 checked boxes | Incomplete | Edit Saved Form Delete: Saved Forms |
 |
Package | Finalized | Edit Saved Form Send Finalized Form Delete: Saved Forms |
 |
Message | Sending via SMS* | Edit Saved Form Send Finalized Form Delete: Saved Forms |
 |
Cloud check | Submitted | Send Finalized Form View Sent Form Delete: Saved Forms |
 |
Cloud exclamation | Failed to submit | Send Finalized Form Delete: Saved Forms |
* The SMS icon is optional; the current Send Finalize Form UI includes this icon, but it's redundant with the progress bar. It can either be kept for consistency or removed for simplicity.

Existing screen
The only icons that are currently used to indicate form state are on the Send Finalized Form screen (screenshot above). We took the existing "check", "sms", and "error" icons from there and added the clipboard to unify them into the icon set for this proposal.
The new icons use Material Design's blue/green/red/amber 500 for icon colors, which is consistent with the existing blue icons and status bar color.
If you want to examine the code, icons are currently used in InstanceUploaderAdapter.
For regular submissions:
case STATUS_SUBMISSION_FAILED:
R.drawable.exclamation;
case STATUS_SUBMITTED:
R.drawable.check;
default:
R.drawable.pencil;For SMS submissions:
case Activity.RESULT_OK:
R.drawable.check;
case RESULT_QUEUED:
case RESULT_OK_OTHERS_PENDING:
case RESULT_SENDING:
case RESULT_MESSAGE_READY:
R.drawable.message_text_outline;
default:
R.drawable.exclamation;The following are all the possible states for form instances (public vars from InstanceProviderAPI):
The following are all the possible states for SMS submissions (public vars from SmsService):
The table at the beginning covers each of these states.
I am proposing that we create a template for the specifications that are added here! It can be something with the same structure as the PR template used in Collect that allows us to standardize the details that are provided with each spec that's being created.
deprecate unneeded tools, consolidate existing functions in single tool, ...
Docs are hard for people to get started when contributing due to needing technical context and also skill writing in a particular fashion.
https://forum.opendatakit.org/t/gsod-remove-barriers-to-entry-for-contributors-and-users/19577
Background
When exporting a form from Aggregate or through Briefcase, variable names (column headers of the csv file) are not simply the one specified by the user on designing the form, but the eventual groups name the variable belong to, are automatically added before the actual name given to the variable.
In complex forms, with nested groups, this could lead in very long and complex names of column headers of the exported csv file.
These complex names bring complexity in the analysis and generate headache to data managers.
The reason of generating these complex names when exporting data from Aggregate is due to the XForm specs that give the possibility to have variables with same name inside different groups.
Most ODK users use XLSForms or Build to create their forms that will not allow duplicated variable names but data managers at the end need to manually (or with a specific manipulation post export) remove the group names for analysing the data. I
Goal
a) Add an option to Briefcase to export without group names.
b) Add and option to Aggregate to export to Google Sheets without group names.
These two options will work for forms that have been created with XLSForm and Build or with forms created manually (xml) without duplicated variable names.
In case of manually written xml files with duplicated variable names, a pop up could be shown to users after parsing the file, informing that due to duplicated variable names this kind of export can not be executed.
ODK lets users define spatial fields (GEOPOINT, GEOTRACE, and GEOSHAPE) in their forms. Data in these fields is exported into CSV and JSON files in a way that commonly requires post-processing by users to make it compatible with downstream GIS software.
Typically, users want to use exported data directly in their third-party software apps.
Provide Aggregate and Briefcase with a new GeoJSON data export format
As a data manager, I would like to export data from Briefcase and Aggregate that I can more easily import into GIS or other downstream tools.
Exported GeoJSON data structure
Aggregate

Briefcase

GeoJSON output data structure
We will export a root FeatureCollection that will include all spatial data from all submissions of a form.
Each GeoJSON object will have the following properties:
key, containing the instance ID
Example: uuid:a8433b64-7b76-412f-b376-d48c6f0083a9
Locate the related submission by matching the key property on the GeoJSON object with the KEY column on the main output export file.
field, containing the field name
Examples:
some_field (field at root level)
uuid:a8433b64-7b76-412f-b376-d48c6f0083a9/some_group[42]/some_field:
some_field field in the 42th instance of the some_group repeat group from a particular instance
Locate the related CSV row by matching the field property on the GeoJSON object with the KEY column on the corresponding repeat output export file.
empty, containing yes if the submission doesn't have an answer for that field, no otherwise
This will let users filter GeoJSON data
valid containing yes if the value was valid, no otherwise
This will let users know which submissions and fields are experiencing problems
When a submission has no value for a spatial field, or the value is invalid, it will have the corresponding GeoJSON object type (Point, LineString, or Polygon) and will have a null geometry property
GEOPOINT fields will be encoded as Point GeoJSON objects:
GEOTRACE fields will be encoded as LineString GeoJSON objects
GEOSHAPE fields will be encoded as Polygon objects
Regarding exported GeoJSON data
Regarding the Briefcase UI
The GeoJSON output file could be provided as an extra output of the normal CSV export:
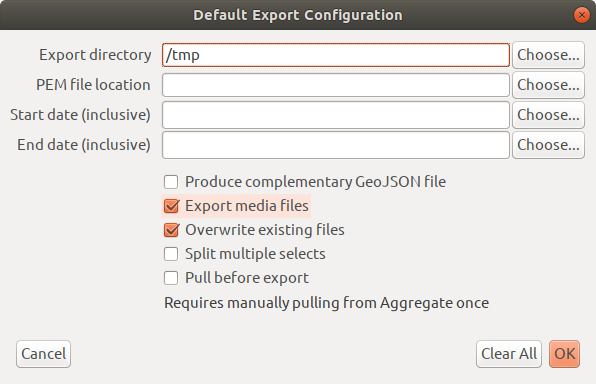
See the "Produce complementary GeoJSON file" checkbox
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.