giscafer / blog Goto Github PK
View Code? Open in Web Editor NEWNext.js + Issues 博客解决方案 https://www.giscafer.com
Home Page: https://www.giscafer.com
License: MIT License
Next.js + Issues 博客解决方案 https://www.giscafer.com
Home Page: https://www.giscafer.com
License: MIT License






















































































































微前端(Micro-Frontend),是将微服务(Micro-Services)理念应用于前端技术后的相关实践,使得一个前端项目能够经由多个团队独立开发以及独立部署,并且该前端项目可能是不同技术栈的结合。
single-spa Microfrontends made easy
angular-pluggable-architecture This is an example of an Angular application that allows to dynamically plug functionality
mooa A independent-deployment micro-frontend Framework for Angular from single-spa.
icestark Micro Frontends solution for large application(面向大型应用的微前端解决方案)
ngx-planet An Angular 7+ Micro Front-end library
qiankun 📦 🚀 Blazing fast, simple and complete solution for micro frontends.
Tencent/wujie 极致的微前端框架
micro-zoe/micro-app 一款轻量、高效、功能强大的微前端框架
文章是学习
《设计模式之美》- 王争的总结
KISS、YAGNI、DRY 原则概念比较简单,主要都是为了让我们写出更简单和合理的代码。越简单的方法,解决复杂问题,越能表现出一个人的技术能力!
英文 Keep it simple and stupid 的缩写,简单的说就是:尽量保持代码简单。
遵循 KISS 原则的话,日常写代码可以这么要求自己:
英文 “You Ain’t Gonna Need It” 的缩写,直白的意思就是:你不会需要它。
当用在软件开发中的时候,它的意思是:不要去设计当前用不到的功能;不要去编写当前用不到的代码。实际上,这条原则的核心**就是:不要做过度设计。
比如前端项目中 package.json 过多的依赖一些没用到的模块,或者是配置一下当前没有用上的配置,编写可能没有用的代码等情况。
要注意的是 YAGNI 不代表在任何情况你不考虑扩展性设计,要明白设计原则中 单一职责、开闭原则、里式替换原则、接口隔离原则、依赖注入原则等都基本是围绕着扩展性、易读性、易维护性等理念的,同样 KISS、YAGNI 也是为了易读性、保持易扩展性。而扩展性是需要在写代码的时候做一些预留的设计,比如将来不久或者可能特换的代码或者配置等。这并不是冲突的,而应该是相辅相成。
KISS重点是如何做(尽量保持简单),YAGNI 是要不要做(当前不需要做的尽量不要做)。
英文“Don’t Repeat Yourself” 的缩写,直白的意思是:不要重复代码。
违法 DRY 原则的代码重复分为三种:实现逻辑重复、功能语义重复、代码执行重复。
区分三个概念:代码复用性(Code Reusability)、 代码复用(Code Reuse)和 DRY 原则
代码复用表示一种行为:我们在开发新功能的时候,尽量复用已经存在的代码。代码的可复用性表示一段代码可被复用的特性或能力:我们在编写代码的时候,让代码尽量可复用。DRY 原则是一条原则:不要写重复的代码。从定义描述上,它们好像有点类似,但深究起来,三者的区别还是蛮大的。
在设计每个模块、类、函数的时候,要像设计一个 外部 API 一样去思考它的复用性。
在第一次写代码的时候,如果当下没有复用的需求,而未来的复用需求也不是特别明确,并且开发科复用代码的成本较高,那我们就不需要考虑代码的复用性。在之后开发新功能的时候,发现可以复用之前写的代码,那我们就重构这段代码,让其变得更加可复用。
记录一些实践内容,给想学习的同学参考
主要内容
一个高效和实用的开发流程规范,可以被用到各种软件开发项目中,并且使用开源工具来协助和自动化大部分任务。关注基本的开发流程规范,有助于开发过程顺利和提高代码质量。
开发流程基本规范内容有:
此部分可以参考文章 一个靠谱的前端开源项目需要什么? 的描述,变更日志见下边章节 Git 提交规范
内容多,单独文章:Git 信息提交规范实践
(1)代码检查工具
团队人员水平不一,或者编码习惯不一致,无规范的情况一定是最开心的啦,人人都可以做到 code with fun 了。但是,实际情况不是这样的,你会看到的是乱七八糟的代码表现,每个人的习惯造成各种代码风格,JS 原本就很灵活,100 人可以有 100 种写法。所以,只有制定并强制执行代码规范,项目的代码质量才有所保证。
代码规范包含语法规则和代码风格等,检查工具 ES6 的话用 ESLint,TypeScript 的话用 TSLint。根据前端工程项目的不同,还有对应的规则模块可以配置,建议优先使用网上流行的大厂规范,如 Google 、Airbnb 等,也有一些标准规范,团队规范建设过程中,可以调整细节,形成自己的一套适合团队的代码规范检查规则。这里有个 RN APP 开发的 ESLint 代码检查配置:React Native ESLint Config,目前其实很多前端库/框架的脚手架已自带代码检查配置生成,这种就比较方便了(如 React \Angular\Vue )。相关的配置对应官方文档和网上资料也很多,不详细介绍。
(2)格式化插件/工具
IDE 中有很多格式化插件,团队协作的话,建议使用统一的格式化插件,然后自定义统一的格式化配置文件,比如 VSCode 编辑器常用的格式化扩展程序 Prettier - Code formatter,通过自定义 .prettierrc 插件格式化配置可以保证同一个工程下,所有同学的格式化风格一致。
然后再配合 husky 做 git 的 pre-commit 时做格式化操作和代码规范校验。保证代码提交前,自动做好代码格式化且代码规范校验通过的。相关文章见 Git 信息提交规范实践
(3)总结
代码规范检查工具优点:
(1)Git 是最好的选择
基于 Git 的简单实用的版本管理规范及流程,包括:代码库的分布、人员角色的划分、代码提交合并流程、代码冲突处理、分支管理。2017 年刚进公司的时候,使用的还是 SVN,年底的时候改用 Git,自搭 Gitlab 作为内部的 git 服务器。
因为常使用 Github,对 Git 相对熟悉一些。所以当时有幸有机会作为分享者去给大部门分享 Git 的基本使用技巧,以及协助公司私服搭建的 Gitlab 落实使用和建设支持。
公司从 SVN 转为 Git 时整理的学习资源:Git 教程指南
(2)代码分支和版本管理
内容多,单独文章:代码分支和版本管理
项目流程规范,是为了保证项目正常进行,并控制好质量和风险,更多的是管理好项目成员之间的相互协作。规范是死的,人是活的,很多时候也需要灵活的去协调,并在实践后不断地完善这个流程。
下图是公司团队的一个项目经理绘制的,拿过来用,作为一个演示说明:
(待整理)
(待整理)
在前后端完全分离开发的项目环境下,影响到开发效率最多的情况是在接口对接阶段。后端交付接口的方式,以及接口文档可能存在经常性变动,或者是交付的接口质量,都会直接影响到前端开发人员接口联调对接的效率。所以我们需要从这以下几个主要的地方去解决问题。
一个项目或者需求,前后端开发协作的顺序:后端设计确定表结构 ——> 后端输出接口文档(确定入参、出参) ——> 后端进行接口开发/前端编写并基于mock开发 (并行开发,互不影响) ——> 联调验证接口,交付测试 。
(1)后端交付接口的方式
前后端分离后,前端为了高效开发,减少后期对接真实接口和环境的工作内容和时间,一般采用 Mock 的方式模拟数据接口,在写页面的时候,就绑定好对应字段和把一些能写的逻辑都写好。在接口不复杂和 Mock 数据结构字段符合的时候,完美的情况,前端在写好页面的时候,就已经对接好了,最后后端接口可行的时候,只需要联通验证即可。
前端在写 Mock 数据的时候,后端需要提供接口的数据结构,所以需要有一个接口文档给到前端,接口文档可以是一些 api 接口和文档管理工具常用的有以下几种。
比较热门的线上工具有:
企业一般都采用自建 API 接口管理工具,比较热门的有:
公司内部使用过的有 swagger 和 yapi ,个人感受来讲,yapi 在使用体验和功能上比 swagger 好很多。
(2)后端接口规范
后端开发人员很多,如果没有制定对应的规范,导致的问题将是不同后端开发人员的习惯不同,背景不同,会有不同的接口风格。比如以下情况:
前端页面查询条件是一个区间:
后端开发人员,不同的人就有不同的想法了,有的人是定义两个字段来接受参数:
orderBeginNum:1,
orderEndNum:222有的则是用数组来接收参数:
orderNumbers:[1,222]同样的情况在前端组件选择 date range 日期区间作为查询条件也是,我见过有定义两个参数的,有定义为一个数组字符串的。这在前端页面开发的时候,可能造成过多余的数组格式转换,如果同一个项目,不同的后端,有不同的风格,那就惨不忍睹了。很多参数格式可以在组件封装的时候统一确定好的,不需要额外的转换格式。所以,对于后端接口参数格式,不管是入参和出参,有一个统一的格式规范是很有必要的。
另外,还有编辑接口的规范,不同背景后端开发人员养成的习惯不一样,有些开发人员认为表单编辑,前端这边编辑修改了什么内容,接口就传什么内容,没有修改过的东西不要传给接口。而有些开发人员和前面说的不同,把所有表单数据都给接口,接口会都 update 数据。这里不同的要求,对于前端会产生不一样的工作量。所以需要统一一种约定,保证接口约定风格和习惯统一。当然,也有特殊的情况,那些情况可以特殊处理。
(3)接口的单元测试
我认为一些重要和关键的接口编写单元测试是很有必要的,不写测试的项目就是耍流氓。没有单元测试,你无法保证某部分代码是否正常,每次都让 QA 去回归?没有测试,在 CI/CD 过程,也不能做到验证。很多后端开发人员会以没有时间为借口,或者是认为没有必要,觉得 Postman 简单请求两下就 OK 了,剩下丢给前端对接的时候帮忙做测试。我觉得,一旦开发人员习惯写测试,写多了,代码质量和单元测试写的速度都会得到较大的提升,并且很多协助编写单元测试的框架和工具,以及 mock 工具等,利用起来,写测试就不会那么困难了吧。
从频繁提交代码、自动化测试(保证测试覆盖) -> 运行本地测试 -> 服务器运行测试 -> 部署到测试环境 -> 交付管理,这些都应该是自动的。CI/CD 可以释放我们的双手,一劳永逸,节约时间和提供效率,本人在公司内部对前端团队的实践部分总结如下:
1.0版本的情况:

前端团队工程化实践(上) PPT
(大图)

JIT: Just-in-Time Compiler
AOT:Ahead-of-Time Compiler
ng build --prod -aot 构建的时候,工程中未使用到的components会报错,如下;删除未引用的文件即可Cannot determine the module for class ImComponent
ERROR in main.19f09357128c495bb8e8.bundle.js from UglifyJs
Unexpected token: name (Wrapper_RouterOutlet) [main.19f09357128c495bb8e8.bundle.js:15,6]
构建如果报错JavaScript heap out of memory
<--- JS stacktrace --->
==== JS stack trace =========================================
Security context: 00000319856CFB61 <JS Object>
1: DoJoin(aka DoJoin) [native array.js:~129] [pc=00000258C3E9F96F] (this=0000031985604381 <undefined>,w=0000012E5C1B5271 <JS Array[688]>,x=688,N=00000319856043C1 <true>,J=0000031985604411 <String[0]: >,I=00000319856B46F1 <JS Function ConvertToString (SharedFunctionInfo 0000031985652DC9)>)
2: Join(aka Join) [native array.js:180] [pc=00000258C330EE12] (this=0000031985604381 <undefined>,...
FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory
package.json设置node内存后执行
"build-aot": "node --max_old_space_size=2192 node_modules/@angular/cli/bin/ng build --aot --prod"
AngularUniversal : https://universal.angular.io/
在工作6年的时间里遇过不少项目重构、项目重写的情况。有从PHP重写到Java,前后端一起重写;有App用 Ionic 重写,也有过同技术栈的老系统重构成新系统,更多的情况是老系统代码混乱,设计较差,业务变化时无法很好的扩展,使得代码在维护和改动时,开发成本剧增。
我认为一个软件的生命周期正常不应该低于3年,如果业务飞速发展,架构设计不够,只能撑2年也还行,这种是例外情况,毕竟业务飞速发展的情况下,软件设计的时候无法预想到更多的扩展情形,这需要非常有业务和技术经验才能做得好系统架构设计。
业务飞速发展也不是重构系统的借口,做好的话就可以避免重构的情况,要做的就是写代码的时候一直在不停的重构……
首先要理解重构和重写的区别,重构不是单纯的指重新开发,重新写代码,而是改进代码与设计。
直白的说重构就是改善现状,使得系统在扩展需求和写代码的时候更快更好、更合理。专业的定义:重构是一种对软件内部结构的改善,目的是在不改变软件的可见行为的情况下,使其更易理解,修改成本更低。
重构的目的是改善代码质量,以便不至于让代码腐化到无可救药的地步。(程序员不愿意去维护的老代码,看到就口吐芬芳…)。项目需求在每日迭代演进,代码不停的堆砌。如果没有人为代码的质量负责,代码总是会往坏味道的方向走,味道变了,发出恶臭后(混乱),项目的维护成本就慢慢的高过重新开发一套新代码的成本,这时候要想再去重构,可能就做不到,做不好,不如重新开发一个新系统。 这时候可能就是重写了。
任何优秀的代码和架构,不是在着手写的时候就可以做好的,都是慢慢迭代出来的。我们无法100%预检未来的需求,也没有足够的精力、时间、资源为遥远的未来买单,这也是避免过度设计。特别是创业公司,应该以最快、最低成本的研发达到业务需求。所以,随着系统的演讲,我们再进行重构代码。
当我们真正遇到问题时,就应该着手重构,而不是说先这样,日后再改(重构),慢慢的就改不动了。重构代码其实对一个程序员的编码能力提升有很大的帮助的。有句话是这么说的:初级工程师在维护代码,高级工程师在设计代码,资深工程师在重构代码。 (这里的级别不是职称,就是个能力的概念)。
重构分为大型重构和小型重构。大型重构指的是对顶层代码的设计的重构,包括:系统、模块、代码结构、类与类之间的关系等的重构,重构的手段有:分层、模块化、解耦、抽象可复用组件等。
小型重构指的是对代码细节的重构,主要是针对类、函数、变量等代码级别的重构,比如规范命名、规范注释、消除超大类或函数、提取重复代码等等。
不管是大型重构和小型重构,都需要用到设计**、原则和模式。
把一个系统当做我们的健康身体,我们不能等到代码烂到一定的程度(身体出现问题)之后才去重构(锻炼、改善饮食、不熬夜)。当身体出现大问题,就不能像健康的身体那样能承受日常生活的压力,日久就会加剧,而锻炼和端正作息的行为的目的就是让身体恢复到健康,这时候的目的就降了一个级别了。以前你身体也健康,也有理想去实现,现在理想变成梦想,理想变成了身体健康。所以,我们需要一开始就要保证身体健康,才能继续的去为了生活、未来目标、理想奋斗。重构就是身体健康的保证。
项目代码拉倒一定程度后,开发效率低,招了很多人,天天加班,出活率低,线上bug频发,领导发飙,管理束手无策,工程师抱怨不断,查bug难。这时候再重构也是比较晚的了,可能也无法解决问题。
和健康生活保障健康一样,日常就需要锻炼、不熬夜、按时吃饭。平时如果不注重代码质量,堆砌烂代码,实在维护不了了就大刀阔斧地重构,甚至重写代码,也不是一种可持续、可演进的方式。
何时重构的答案就是持续重构,日常迭代需求,修改代码的时候,顺手把不符合规范、不好的设计重构一下,这是最好的时机,因为之前的代码可能预想不到此时的业务需求,写得不够,当前需求完善的时候就应该改进该处代码,保证日后的可扩展性、易读性、健壮性等。
项目团队中要把单元测试、Code Review 作为开发的一部分,把持续重构作为开发的一部分,成为一种习惯,对项目、对自己都会很有好处。
大型重构时,需要提前做好重构计划,然后按阶段来进行。每个阶段完成一小部分代码的重构,比如一次最多动一个微服务,做好测试覆盖,上新版本,保留旧版本预后等。控制重构的影响范围,兼容业务和老代码,必要的时候都会写一些类似适配器的过渡代码。
大规模高层次的重构需要有组织和计划,也要有经验和熟悉业务的资深同事来主导。小规模低层次的重构因为影响范围小,改动耗时短,随时有时间都推荐去做,避免堆积后期改不动了。
重构这件事,需要团队中的资深工程师和项目leader负起责任。对代码放任不管时,有人堆砌了烂代码,日后也会更多的烂代码。
保持代码质量最后的方法是打造一种好的技术氛围,以此来驱动大家主动去关注代码质量。
参考资料 《设计模式之美》
近期用 nuxt.js + nightmare 开发的爬虫工具,发布时部署 Linux 系统。由于 Linux 系统没有图像相关的 GUI 界面,需要安装一系列的依赖,所以才遇到坑。
CentOS 和 Ubuntu 系统都不一样的操作,遇到 docker 创建的各种坑(其实就是不熟悉),以及国内服务器 docker build 时下载速度慢,需要镜像更换等,从不会写 Dockerfile 到懂得使用 Docker 部署 nuxt.js 应用的过程,以下是一些操作记录。
config set PUPPETEER_MIRRORS=https://npm.taobao.org/mirrors
npm install puppeteer
pm2 启动 nuxt 的方式
pm2 start npm --name nuxt -- start
Linux
- netstat -aptn |grep -i 3000 # 查看所有 3000 端口使用情况·
- netstat -ntlp # 查看当前所有 tcp 端口MacOS
lsof -i:3000
kill 3000
https://www.myfreax.com/how-to-install-google-chrome-web-browser-on-centos-8/
Ubuntu
segment-boneyard/nightmare#224
https://github.com/mitel/nightmare-docker/blob/master/Dockerfile
https://hoody.tech/blog/detail/27
# 移除所有容器
docker rm $(docker ps -a -q)
# 日记查看
docker logs -f -t --tail 行数 容器名
# 重启 docker
systemctl restart docker
# 进入容器shell
docker exec -it nginx /bin/bash
# 查看时区
date -RUbuntu 安装最新版 nodejs
https://www.jianshu.com/p/e7605f75b767
Ubuntu 安装 docker
https://www.jianshu.com/p/80e3fd18a17e
sudo vim /etc/docker/daemon.json输入
{
"registry-mirrors": ["https://sji1i20h.mirror.aliyuncs.com"]
}重启 docker
sudo systemctl daemon-reload
sudo systemctl restart docker
apt-get 镜像更换
RUN sed -i s@/deb.debian.org/@/mirrors.163.com/@g /etc/apt/sources.list
RUN apt-get clean
RUN apt-get update
其中 s@/deb.debian.org/@/mirrors.163.com/@g 表示将 deb.debian.org 全部替换为 mirrors.163.com 的意思
不写着行,直接系统 设置 sources.list 在 docker 内部不起作用,最会对当前系统执行有效
sources.list 内容为:
deb http://mirrors.163.com/debian/ jessie main non-free contrib
deb http://mirrors.163.com/debian/ jessie-updates main non-free contrib
deb http://mirrors.163.com/debian/ jessie-backports main non-free contrib
deb-src http://mirrors.163.com/debian/ jessie main non-free contrib
deb-src http://mirrors.163.com/debian/ jessie-updates main non-free contrib
deb-src http://mirrors.163.com/debian/ jessie-backports main non-free contrib
deb http://mirrors.163.com/debian-security/ jessie/updates main non-free contrib
deb-src http://mirrors.163.com/debian-security/ jessie/updates main non-free contrib
可以先考虑 备份原来的文件 mv /etc/apt/sources.list /etc/apt/sources.list.bak
FROM node:12.14.0
MAINTAINER giscafer.com
#设置node环境变量为production
ENV NODE_ENV=production
# 配合程序逻辑
ENV container=linux
ENV HOST 0.0.0.0
#创建/app 目录作为部署目录,创建容器实例时,挂载此目录
RUN mkdir -p /app
# docker - apt-get更换国内源解决Dockerfile构建速度过慢
RUN sed -i s@/deb.debian.org/@/mirrors.163.com/@g /etc/apt/sources.list
RUN apt-get clean
RUN apt-get update
# Installing the packages needed to run Nightmare
RUN apt-get install -y \
xvfb \
x11-xkb-utils \
xfonts-100dpi \
xfonts-75dpi \
xfonts-scalable \
xfonts-cyrillic \
x11-apps \
clang \
libdbus-1-dev \
libgtk2.0-dev \
libnotify-dev \
libgconf2-dev \
libasound2-dev \
libcap-dev \
libcups2-dev \
libxtst-dev \
libxss1 \
libnss3-dev \
gcc-multilib \
g++-multilib \
libgnome-keyring-dev
# 把项目复制到镜像里面
COPY . /app
# 指定命令执行的目录为 /app
WORKDIR /app
EXPOSE 3000
# 淘宝镜像
RUN npm config set registry https://registry.npm.taobao.org
# electron 淘宝镜像
RUN npm config set ELECTRON_MIRROR http://npm.taobao.org/mirrors/electron/
RUN npm install
RUN npm run build
#设置容器启动时执行的命令
ENTRYPOINT [ "npm","start" ]
https://hub.docker.com/repository/docker/giscafer/nightmare
FROM giscafer/nightmare:latest
MAINTAINER giscafer.com
#设置node环境变量为production
ENV NODE_ENV=production
# 配合程序逻辑
ENV container=linux
ENV HOST 0.0.0.0
#创建/app 目录作为部署目录,创建容器实例时,挂载此目录
RUN mkdir -p /app
# 把项目复制到镜像里面
COPY . /app
# 指定命令执行的目录为 /app
WORKDIR /app
EXPOSE 3000
# 淘宝镜像
RUN npm config set registry https://registry.npm.taobao.org
# electron 淘宝镜像
RUN npm config set electron_mirror http://npm.taobao.org/mirrors/electron/
RUN rm -rf node_modules
RUN npm install
RUN npm run build
#设置容器启动时执行的命令
ENTRYPOINT [ "npm","start" ]
单纯测试nightmare在linux上docker部署的话参考:Running Nightmare headlessly on Linux
纪录一些网友分享的学习经验,提供给大家参考。
不管是工作还是业余,总会有新人问你是如何学习的,或者是你带团队了,给团队同学进行指导辅导,有些别人实践的经验可以借鉴来作为指导,另外,尽管你自认为是老司机,也应该了解别人的学习方式,借鉴、思考、实践、总结、到演变;知识、技能、学习的方式都应该在不停的进步或改变的路上,你才能走的更远!
说明:以下是前期公司内部试行的简单的代码分支版本流程管理规范,规范其实和运维有很大的关联,随着管理方式和流程的完善,代码版本管理流程也是会改变的。仅供参考!!!
dev-xxx 为开发分支,xxx表示版本,建议使用上线年月日时间串,比如dev-20180612 或 为需求功能点名称,比如dev-xx需求test 为测试分支 (如果存在多版本同时测试,可能存在 test-xxx 分支,意思是多个测试环境,有做压测或者是功能测试的)master 主分支为 uat 回归测试分支(预生产/准生产分支)。(此分支会做分支保护,不允许直接 push 和 只有主程序员可以 merge )prod 为生产发布分支prod-xxx 为生产上线后备份tag图解:
prod 分支创建新开发分支 dev-xxx;fork 主仓库到自己名下,(如果原来已经 fork 过,可以通过更新的方式更新获取到最新的master和dev-xxx代码),切换到分支 dev-xxx 进行开发;fork 仓库,适当时机 PR merge 到 远程项目主仓库对应的 dev-xxx 分支;dev-xxx 分支代码合并提交到 test 分支;(建议是 fork 仓库的分支 dev-xxx 提交到了远程主仓库的 dev-xxx 分支,再用主仓库的远程dev-xxx分支合并到test 分支)test 分支代码通过后,就将 test 分支 PR 合并到 master分支,进行回归测试;uat 测试有 bug,重复(3)(4)(6)步骤;如果 uat 测试失败,运维要回滚 uat 环境和生产一致。uat 测试通过,产品验收通过,则将代码覆盖更新到 prod 分支,进行上线安排,上线出问题还是要有紧急回滚机制。prod 分支版本打标签,如 prod-xxxx(xxx 为上线日期)(一个完整流程到此结束)
当有新需求开发时,一般是经过需求评审后,定下的冲刺迭代版本,评估了开发周期,确认了上线时间。
prod-xxxx 创建一个分支出来,比如取名为 dev-xxxx,然后基于此分支开发同版本的需求上线,要提交 Jenkins 构建的话就 merge 到对应的测试分支。PR 到 test 分支,QA 完成功能测试没问题后,将 test 分支 merge 到 master 分支进行回归测试。prod-xxx 创建分支修改 bug,分支名称为bug-prod-xxx,改完自验没问题需要提交测试的时候,merge 到相应测试分支(如test),Jenkins 构建后验证通过,上线生产。上线完成后,别忘记了备份新生产分支prod-xxxx。然后其他正常使用的分支,需要拉取最新生产分支代码prod-xxxx,保证拥有最新的生产分支代码,避免 bug 又上线了(这个过程在以上把 master 定为准生产分支时规避掉了)。(一)冲突的新需求情景:
2018-06-09 CRM 前端上线了,上线后开发人员备份了生产分支代码为 prod-20180609,第二天,前端开发人员紧接着开发新需求,并且新需求有两个版本,版本一 是在下周上线;版本二 是在月底上上线。版本一和版本二是不同的开发人员,启动开发时间是一样的。这时候,开发人员应该基于 master 分支创建出两个分支,假设为 dev-20180618-需求1 和 dev-20180625-需求2,然后他们都是各自在各自分支里边开发,相互不影响。
master,合并最新生产代码(因为可能会有遗漏,有人改过没更新同步你们的分支),然后再 PR 到 test 分支测试。(二)线上 BUG 情景:
问题来了:上线后第三天,线上用户反馈了 bug,需要紧急修复。
做法:基于远程仓库主分支的版本标签 prod-20180609 创建新分支bug-prod-xxx,在此新分支修改 bug,自测没问题后 PR 到主仓库 test(如果该分支已经被新需求占用,可以创建新分支test-bug,Jenkins 构建选对就好),jenkins构建后 QA 测试,没问题后,将 test 分支 merge到 master 分支,没问题后再覆盖更新到 prod上线,上线完成后,备份新生产分支,打标签prod-xxxx。
(三)公共代码(非需求代码变动)情景:
修改公共代码的同学,需要自己创建一个专门用来改公共代码的分支出来。公共代码或者是公共类库和基础服务等代码改动了,也要和业务代码一样,提测走完测试流程。
本文属于《前端团队工程化记录》 的一小节内容,更多请前往了解。
关于浏览器缓存
浏览器缓存,有时候我们需要他,因为他可以提高网站性能和浏览器速度,提高网站性能。但是有时候我们又不得不清除缓存,因为缓存可能误事,出现一些错误的数据。像股票类网站实时更新等,这样的网站是不要缓存的,像有的网站很少更新,有缓存还是比较好的。今天主要介绍清除缓存的几种方法。
清理网站缓存的几种方法
web服务器设置
通过web服务器设置 Cache-Control 缓存配置,比如nginx等
meta方法
//不缓存
<META HTTP-EQUIV="pragma" CONTENT="no-cache">
<META HTTP-EQUIV="Cache-Control" CONTENT="no-cache, must-revalidate">
<META HTTP-EQUIV="expires" CONTENT="0">
清理form表单的临时缓存
<body onLoad="javascript:document.yourFormName.reset()">
其实form表单的缓存对于我们书写还是有帮助的,一般情况不建议清理,但是有时候为了安全问题等,需要清理一下!
jquery ajax清除浏览器缓存
方式一:用ajax请求服务器最新文件,并加上请求头If-Modified-Since和Cache-Control
,如下:
$.ajax({
url:'www.haorooms.com',
dataType:'json',
data:{},
beforeSend :function(xmlHttp){
xmlHttp.setRequestHeader("If-Modified-Since","0");
xmlHttp.setRequestHeader("Cache-Control","no-cache");
},
success:function(response){
//操作
}
async:false
});
方法二,直接用cache:false,
$.ajax({
url:'www.haorooms.com',
dataType:'json',
data:{},
cache:false,
ifModified :true ,
success:function(response){
//操作
}
async:false
});
方法三:用随机数,随机数也是避免缓存的一种很不错的方法!
URL 参数后加上 ?ran=" + Math.random();//当然这里参数 ran可以任意取了
方法四:用随机时间,和随机数一样。
在 URL 参数后加上 ?timestamp=+ new Date().getTime();
方法五:用php后端清理
在服务端加 header("Cache-Control: no-cache, must-revalidate");等等(如php中)
今天面试官有问到,顺便复习一下,摘自网络原文
update:2016-8-4 20:32:45
远程办公协同工具大合集
在线协作文档可以快速的收集整理不同人员的内容,免去以往收集汇总复制黏贴的步骤,同时也可以将做好的内容通过链接分享出去,简单高效快捷。
石墨文档-多人实时协作Office https://shimo.im/
腾讯文档-支持多人在线编辑Word、Excel和PPT文档 https://docs.qq.com/
金山文档 - https://www.kdocs.cn/welcome
Google 文档 - 在线创建和编辑文档 http://www.google.cn/intl/zh-cn_all/docs/
个人在线学习,企业全员移动学习平台
在线视频会议这个就不用多说了,简单来说就是线上版的开会
钉钉视频会议 https://tms.dingtalk.com/markets/dingtalk/shipinghuiyi
Zoom https://zoom.com.cn/
TalkLine视频会议 https://www.talkline.cn/
灵感零碎资料收集整理工具,创意文案智能搜索工具
有道云笔记 http://note.youdao.com/
幕布 - 极简大纲笔记 https://mubu.com/
ADGuider- 智能AI案例创意文案库搜索工具 https://www.adguider.com/
远程沟通协调、项目管理等
create-react-native-app with GraphQL & Apollo某些问题可以尝试cd android && gradlew clean
见个人 star : https://github.com/stars/giscafer/lists/react-native
https://developers.google.com/web/progressive-web-apps/
国内无需科学上网:https://developers.google.cn/web/progressive-web-apps/
百度的lavas (这里也有PWA文档:https://lavas.baidu.com/pwa/ )
https://github.com/TalAter/awesome-progressive-web-apps
Service Worker 和 Web Worker 的区别也可以了解一下
ng add @angular/pwa即可1、单页面,左侧类似树状导航,右侧是视图的布局;
2、点击左侧树功能节点,右侧切换显示对应功能页面;显示模式有两种,一种是替换展示,新点击的功能替换原来的功能页,展示最新点击的功能页;另一种是追加展示,左侧功能相当于多选,右侧视图展示选择的功能的所有页面,追加显示再最后;
1、angularjs路由无法解决这个问题;使用ng-include页面,动态获取页面的路径,提前注入所有页面的controller。
2、一开始用了字符串拼接,然后$compile一下,使得子页面的controller的$scope作用域被修改,获取不到模型数据。需要注意的是controller的作用域就好了,采用以下方式解决。
<div class="form panel" id="main-view">
<div ng-repeat="template in home.pageTemplates">
<header class="page-header margin-bottom-0 clearfix gray">
<h4 class="panel-title" ng-cloak><span class="fa fa-bars margin-left-10 margin-right-5"></span>{{template.title}}</h4></header>
<div ng-include="template.pageSrc"></div>
</div>
</div>思路来自:http://stackoverflow.com/questions/17801988/dynamically-loading-controllers-and-ng-include
2016-8-31 09:51:42
本文由我收集总结了一些前端面试题,初学者阅后也要用心钻研其中的原理,重要知识需要系统学习、透彻学习,形成自己的知识链。万不可投机取巧,临时抱佛脚只求面试侥幸混过关是错误的!也是不可能的!不可能的!不可能的!
前端还是一个年轻的行业,新的行业标准, 框架, 库都不断在更新和新增,正如赫门在2015深JS大会上的《前端服务化之路》主题演讲中说的一句话:“每18至24个月,前端都会难一倍”,这些变化使前端的能力更加丰富、创造的应用也会更加完美。所以关注各种前端技术,跟上快速变化的节奏,也是身为一个前端程序员必备的技能之一。
最近也收到许多微博私信的鼓励和更正题目信息,后面会经常更新题目和答案到github博客。希望前端er达到既能使用也会表达,对理论知识有自己的理解。可根据下面的知识点一个一个去进阶学习,形成自己的职业技能链。
面试有几点需注意:(来源寒冬winter 老师,github:@wintercn)
前端开发知识点:
HTML&CSS:
对Web标准的理解、浏览器内核差异、兼容性、hack、CSS基本功:布局、盒子模型、选择器优先级、
HTML5、CSS3、Flexbox
JavaScript:
数据类型、运算、对象、Function、继承、闭包、作用域、原型链、事件、RegExp、JSON、Ajax、
DOM、BOM、内存泄漏、跨域、异步装载、模板引擎、前端MVC、路由、模块化、Canvas、ECMAScript 6、Nodejs
其他:
移动端、响应式、自动化构建、HTTP、离线存储、WEB安全、优化、重构、团队协作、可维护、易用性、SEO、UED、架构、职业生涯、快速学习能力
作为一名前端工程师,无论工作年头长短都应该掌握的知识点:
此条由 王子墨 发表在 攻城师的实验室
1、DOM结构 —— 两个节点之间可能存在哪些关系以及如何在节点之间任意移动。
2、DOM操作 —— 如何添加、移除、移动、复制、创建和查找节点等。
3、事件 —— 如何使用事件,以及IE和标准DOM事件模型之间存在的差别。
4、XMLHttpRequest —— 这是什么、怎样完整地执行一次GET请求、怎样检测错误。
5、严格模式与混杂模式 —— 如何触发这两种模式,区分它们有何意义。
6、盒模型 —— 外边距、内边距和边框之间的关系,及IE8以下版本的浏览器中的盒模型
7、块级元素与行内元素 —— 怎么用CSS控制它们、以及如何合理的使用它们
8、浮动元素 —— 怎么使用它们、它们有什么问题以及怎么解决这些问题。
9、HTML与XHTML —— 二者有什么区别,你觉得应该使用哪一个并说出理由。
10、JSON —— 作用、用途、设计结构。
备注:
根据自己需要选择性阅读,面试题是对理论知识的总结,让自己学会应该如何表达。
资料答案不够正确和全面,欢迎欢迎Star和提交issues。
格式不断修改更新中。
更新记录:
2016年3月25日:新增ECMAScript6 相关问题
个人@giscafer整理过一个版本,看这里HTML知识点问题A&Q
Doctype作用?标准模式与兼容模式各有什么区别?
(1)、<!DOCTYPE>声明位于位于HTML文档中的第一行,处于 <html> 标签之前。告知浏览器的解析器用什么文档标准解析这个文档。DOCTYPE不存在或格式不正确会导致文档以兼容模式呈现。
(2)、标准模式的排版 和JS运作模式都是以该浏览器支持的最高标准运行。在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为以防止站点无法工作。
HTML5 为什么只需要写 ?
HTML5 不基于 SGML,因此不需要对DTD进行引用,但是需要doctype来规范浏览器的行为(让浏览器按照它们应该的方式来运行);
而HTML4.01基于SGML,所以需要对DTD进行引用,才能告知浏览器文档所使用的文档类型。
行内元素有哪些?块级元素有哪些? 空(void)元素有那些?
首先:CSS规范规定,每个元素都有display属性,确定该元素的类型,每个元素都有默认的display值,如div的display默认值为“block”,则为“块级”元素;span默认display属性值为“inline”,是“行内”元素。
(1)行内元素有:a b span img input select strong(强调的语气)
(2)块级元素有:div ul ol li dl dt dd h1 h2 h3 h4…p
(3)常见的空元素:
<br> <hr> <img> <input> <link> <meta>
鲜为人知的是:
<area> <base> <col> <command> <embed> <keygen> <param> <source> <track> <wbr>
页面导入样式时,使用link和@import有什么区别?
(1)link属于XHTML标签,除了加载CSS外,还能用于定义RSS, 定义rel连接属性等作用;而@import是CSS提供的,只能用于加载CSS;
(2)页面被加载的时,link会同时被加载,而@import引用的CSS会等到页面被加载完再加载;
(3)import是CSS2.1 提出的,只在IE5以上才能被识别,而link是XHTML标签,无兼容问题;
介绍一下你对浏览器内核的理解?
主要分成两部分:渲染引擎(layout engineer或Rendering Engine)和JS引擎。
渲染引擎:负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核。
JS引擎则:解析和执行javascript来实现网页的动态效果。
最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎。
常见的浏览器内核有哪些?
Trident内核:IE,MaxThon,TT,The World,360,搜狗浏览器等。[又称MSHTML]
Gecko内核:Netscape6及以上版本,FF,MozillaSuite/SeaMonkey等
Presto内核:Opera7及以上。 [Opera内核原为:Presto,现为:Blink;]
Webkit内核:Safari,Chrome等。 [ Chrome的:Blink(WebKit的分支)]
详细文章:浏览器内核的解析和对比
html5有哪些新特性、移除了那些元素?如何处理HTML5新标签的浏览器兼容问题?如何区分 HTML 和
HTML5?
* HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加。
绘画 canvas;
用于媒介回放的 video 和 audio 元素;
本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失;
sessionStorage 的数据在浏览器关闭后自动删除;
语意化更好的内容元素,比如 article、footer、header、nav、section;
表单控件,calendar、date、time、email、url、search;
新的技术webworker, websocket, Geolocation;
移除的元素:
纯表现的元素:basefont,big,center,font, s,strike,tt,u;
对可用性产生负面影响的元素:frame,frameset,noframes;
* 支持HTML5新标签:
IE8/IE7/IE6支持通过document.createElement方法产生的标签,
可以利用这一特性让这些浏览器支持HTML5新标签,
浏览器支持新标签后,还需要添加标签默认的样式。
当然也可以直接使用成熟的框架、比如html5shim;
<!--[if lt IE 9]>
<script> src="http://html5shim.googlecode.com/svn/trunk/html5.js"</script>
<![endif]-->
* 如何区分HTML5: DOCTYPE声明\新增的结构元素\功能元素
简述一下你对HTML语义化的理解?
用正确的标签做正确的事情。
html语义化让页面的内容结构化,结构更清晰,便于对浏览器、搜索引擎解析;
即使在没有样式CSS情况下也以一种文档格式显示,并且是容易阅读的;
搜索引擎的爬虫也依赖于HTML标记来确定上下文和各个关键字的权重,利于SEO;
使阅读源代码的人对网站更容易将网站分块,便于阅读维护理解。
HTML5的离线储存怎么使用,工作原理能不能解释一下?
在用户没有与因特网连接时,可以正常访问站点或应用,在用户与因特网连接时,更新用户机器上的缓存文件。
原理:HTML5的离线存储是基于一个新建的.appcache文件的缓存机制(不是存储技术),通过这个文件上的解析清单离线存储资源,这些资源就会像cookie一样被存储了下来。之后当网络在处于离线状态下时,浏览器会通过被离线存储的数据进行页面展示。
如何使用:
1、页面头部像下面一样加入一个manifest的属性;
2、在cache.manifest文件的编写离线存储的资源;
CACHE MANIFEST
#v0.11
CACHE:
js/app.js
css/style.css
NETWORK:
resourse/logo.png
FALLBACK:
/ /offline.html
3、在离线状态时,操作window.applicationCache进行需求实现。
详细的使用请参考:有趣的HTML5:离线存储
浏览器是怎么对HTML5的离线储存资源进行管理和加载的呢?
在线的情况下,浏览器发现html头部有manifest属性,它会请求manifest文件,如果是第一次访问app,那么浏览器就会根据manifest文件的内容下载相应的资源并且进行离线存储。如果已经访问过app并且资源已经离线存储了,那么浏览器就会使用离线的资源加载页面,然后浏览器会对比新的manifest文件与旧的manifest文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,那么就会重新下载文件中的资源并进行离线存储。
离线的情况下,浏览器就直接使用离线存储的资源。
详细的使用请参考:有趣的HTML5:离线存储
请描述一下 cookies,sessionStorage 和 localStorage 的区别?
cookie是网站为了标示用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。
cookie数据始终在同源的http请求中携带(即使不需要),记会在浏览器和服务器间来回传递。
sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。
存储大小:
cookie数据大小不能超过4k。
sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。
有期时间:
localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
sessionStorage 数据在当前浏览器窗口关闭后自动删除。
cookie 设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭
iframe有那些缺点?
*iframe会阻塞主页面的Onload事件;
*搜索引擎的检索程序无法解读这种页面,不利于SEO;
*iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载。
使用iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript
动态给iframe添加src属性值,这样可以绕开以上两个问题。
Label的作用是什么?是怎么用的?
label标签来定义表单控制间的关系,当用户选择该标签时,浏览器会自动将焦点转到和标签相关的表单控件上。
<label for="Name">Number:</label>
<input type=“text“name="Name" id="Name"/>
<label>Date:<input type="text" name="B"/></label>
HTML5的form如何关闭自动完成功能?
给不想要提示的 form 或某个 input 设置为 autocomplete=off。
如何实现浏览器内多个标签页之间的通信? (阿里)
WebSocket、SharedWorker;
也可以调用localstorge、cookies等本地存储方式;
localstorge另一个浏览上下文里被添加、修改或删除时,它都会触发一个事件,
我们通过监听事件,控制它的值来进行页面信息通信;
注意quirks:Safari 在无痕模式下设置localstorge值时会抛出 QuotaExceededError 的异常;
webSocket如何兼容低浏览器?(阿里)
Adobe Flash Socket 、
ActiveX HTMLFile (IE) 、
基于 multipart 编码发送 XHR 、
基于长轮询的 XHR
页面可见性(Page Visibility API) 可以有哪些用途?
通过 visibilityState 的值检测页面当前是否可见,以及打开网页的时间等;
在页面被切换到其他后台进程的时候,自动暂停音乐或视频的播放;
如何在页面上实现一个圆形的可点击区域?
1、map+area或者svg
2、border-radius
3、纯js实现 需要求一个点在不在圆上简单算法、获取鼠标坐标等等
实现不使用 border 画出1px高的线,在不同浏览器的标准模式与怪异模式下都能保持一致的效果。
<div style="height:1px;overflow:hidden;background:red"></div>
网页验证码是干嘛的,是为了解决什么安全问题。
区分用户是计算机还是人的公共全自动程序。可以防止恶意破解密码、刷票、论坛灌水;
有效防止黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试。
title与h1的区别、b与strong的区别、i与em的区别?
title属性没有明确意义只表示是个标题,H1则表示层次明确的标题,对页面信息的抓取也有很大的影响;
strong是标明重点内容,有语气加强的含义,使用阅读设备阅读网络时:<strong>会重读,而<B>是展示强调内容。
i内容展示为斜体,em表示强调的文本;
Physical Style Elements -- 自然样式标签
b, i, u, s, pre
Semantic Style Elements -- 语义样式标签
strong, em, ins, del, code
应该准确使用语义样式标签, 但不能滥用, 如果不能确定时首选使用自然样式标签。
介绍一下标准的CSS的盒子模型?低版本IE的盒子模型有什么不同的?
(1)有两种, IE 盒子模型、W3C 盒子模型;
(2)盒模型: 内容(content)、填充(padding)、边界(margin)、 边框(border);
(3)区 别: IE的content部分把 border 和 padding计算了进去;
CSS选择符有哪些?哪些属性可以继承?
* 1.id选择器( # myid)
2.类选择器(.myclassname)
3.标签选择器(div, h1, p)
4.相邻选择器(h1 + p)
5.子选择器(ul > li)
6.后代选择器(li a)
7.通配符选择器( * )
8.属性选择器(a[rel = "external"])
9.伪类选择器(a:hover, li:nth-child)
* 可继承的样式: font-size font-family color, UL LI DL DD DT;
* 不可继承的样式:border padding margin width height ;
CSS优先级算法如何计算?
* 优先级就近原则,同权重情况下样式定义最近者为准;
* 载入样式以最后载入的定位为准;
优先级为:
!important > id > class > tag
important 比 内联优先级高
CSS3新增伪类有那些?
举例:
p:first-of-type 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。
p:last-of-type 选择属于其父元素的最后 <p> 元素的每个 <p> 元素。
p:only-of-type 选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。
p:only-child 选择属于其父元素的唯一子元素的每个 <p> 元素。
p:nth-child(2) 选择属于其父元素的第二个子元素的每个 <p> 元素。
:after 在元素之前添加内容,也可以用来做清除浮动。
:before 在元素之后添加内容
:enabled
:disabled 控制表单控件的禁用状态。
:checked 单选框或复选框被选中。
如何居中div?如何居中一个浮动元素?如何让绝对定位的div居中?
div{
width:200px;
margin:0 auto;
}
确定容器的宽高 宽500 高 300 的层
设置层的外边距
.div {
width:500px ; height:300px;//高度可以不设
margin: -150px 0 0 -250px;
position:relative; //相对定位
background-color:pink; //方便看效果
left:50%;
top:50%;
}
position: absolute;
width: 1200px;
background: none;
margin: 0 auto;
top: 0;
left: 0;
bottom: 0;
right: 0;
display有哪些值?说明他们的作用。
block 象块类型元素一样显示。
none 缺省值。象行内元素类型一样显示。
inline-block 象行内元素一样显示,但其内容象块类型元素一样显示。
list-item 象块类型元素一样显示,并添加样式列表标记。
table 此元素会作为块级表格来显示
inherit 规定应该从父元素继承 display 属性的值
position的值relative和absolute定位原点是?
absolute
生成绝对定位的元素,相对于值不为 static的第一个父元素进行定位。
fixed (老IE不支持)
生成绝对定位的元素,相对于浏览器窗口进行定位。
relative
生成相对定位的元素,相对于其正常位置进行定位。
static
默认值。没有定位,元素出现在正常的流中(忽略 top, bottom, left, right z-index 声明)。
inherit
规定从父元素继承 position 属性的值。
CSS3有哪些新特性?
新增各种CSS选择器 (: not(.input):所有 class 不是“input”的节点)
圆角 (border-radius:8px)
多列布局 (multi-column layout)
阴影和反射 (Shadow\Reflect)
文字特效 (text-shadow、)
文字渲染 (Text-decoration)
线性渐变 (gradient)
旋转 (transform)
增加了旋转,缩放,定位,倾斜,动画,多背景
transform:\scale(0.85,0.90)\ translate(0px,-30px)\ skew(-9deg,0deg)\Animation:
请解释一下CSS3的Flexbox(弹性盒布局模型),以及适用场景?
.
用纯CSS创建一个三角形的原理是什么?
把上、左、右三条边隐藏掉(颜色设为 transparent)
#demo {
width: 0;
height: 0;
border-width: 20px;
border-style: solid;
border-color: transparent transparent red transparent;
}
一个满屏 品 字布局 如何设计?
简单的方式:
上面的div宽100%,
下面的两个div分别宽50%,
然后用float或者inline使其不换行即可
经常遇到的浏览器的兼容性有哪些?原因,解决方法是什么,常用hack的技巧 ?
* png24位的图片在iE6浏览器上出现背景,解决方案是做成PNG8.
* 浏览器默认的margin和padding不同。解决方案是加一个全局的*{margin:0;padding:0;}来统一。
* IE6双边距bug:块属性标签float后,又有横行的margin情况下,在ie6显示margin比设置的大。
浮动ie产生的双倍距离 #box{ float:left; width:10px; margin:0 0 0 100px;}
这种情况之下IE会产生20px的距离,解决方案是在float的标签样式控制中加入 ——_display:inline;将其转化为行内属性。(_这个符号只有ie6会识别)
渐进识别的方式,从总体中逐渐排除局部。
首先,巧妙的使用“\9”这一标记,将IE游览器从所有情况中分离出来。
接着,再次使用“+”将IE8和IE7、IE6分离开来,这样IE8已经独立识别。
css
.bb{
background-color:#f1ee18;/*所有识别*/
.background-color:#00deff\9; /*IE6、7、8识别*/
+background-color:#a200ff;/*IE6、7识别*/
_background-color:#1e0bd1;/*IE6识别*/
}
* IE下,可以使用获取常规属性的方法来获取自定义属性,
也可以使用getAttribute()获取自定义属性;
Firefox下,只能使用getAttribute()获取自定义属性。
解决方法:统一通过getAttribute()获取自定义属性。
* IE下,even对象有x,y属性,但是没有pageX,pageY属性;
Firefox下,event对象有pageX,pageY属性,但是没有x,y属性。
* 解决方法:(条件注释)缺点是在IE浏览器下可能会增加额外的HTTP请求数。
* Chrome 中文界面下默认会将小于 12px 的文本强制按照 12px 显示,
可通过加入 CSS 属性 -webkit-text-size-adjust: none; 解决。
超链接访问过后hover样式就不出现了 被点击访问过的超链接样式不在具有hover和active了解决方法是改变CSS属性的排列顺序:
L-V-H-A : a:link {} a:visited {} a:hover {} a:active {}
li与li之间有看不见的空白间隔是什么原因引起的?有什么解决办法?
行框的排列会受到中间空白(回车\空格)等的影响,因为空格也属于字符,这些空白也会被应用样式,占据空间,所以会有间隔,把字符大小设为0,就没有空格了。
为什么要初始化CSS样式。
- 因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异。
- 当然,初始化样式会对SEO有一定的影响,但鱼和熊掌不可兼得,但力求影响最小的情况下初始化。
最简单的初始化方法: * {padding: 0; margin: 0;} (强烈不建议)
淘宝的样式初始化代码:
body, h1, h2, h3, h4, h5, h6, hr, p, blockquote, dl, dt, dd, ul, ol, li, pre, form, fieldset, legend, button, input, textarea, th, td { margin:0; padding:0; }
body, button, input, select, textarea { font:12px/1.5tahoma, arial, \5b8b\4f53; }
h1, h2, h3, h4, h5, h6{ font-size:100%; }
address, cite, dfn, em, var { font-style:normal; }
code, kbd, pre, samp { font-family:couriernew, courier, monospace; }
small{ font-size:12px; }
ul, ol { list-style:none; }
a { text-decoration:none; }
a:hover { text-decoration:underline; }
sup { vertical-align:text-top; }
sub{ vertical-align:text-bottom; }
legend { color:#000; }
fieldset, img { border:0; }
button, input, select, textarea { font-size:100%; }
table { border-collapse:collapse; border-spacing:0; }
absolute的containing block(容器块)计算方式跟正常流有什么不同?
无论属于哪种,都要先找到其祖先元素中最近的 position 值不为 static 的元素,然后再判断:
1、若此元素为 inline 元素,则 containing block 为能够包含这个元素生成的第一个和最后一个 inline box 的 padding box (除 margin, border 外的区域) 的最小矩形;
2、否则,则由这个祖先元素的 padding box 构成。
如果都找不到,则为 initial containing block。
补充:
1. static(默认的)/relative:简单说就是它的父元素的内容框(即去掉padding的部分)
2. absolute: 向上找最近的定位为absolute/relative的元素
3. fixed: 它的containing block一律为根元素(html/body),根元素也是initial containing block
CSS里的visibility属性有个collapse属性值是干嘛用的?在不同浏览器下以后什么区别?
position跟display、margin collapse、overflow、float这些特性相互叠加后会怎么样?
对BFC规范(块级格式化上下文:block formatting context)的理解?
(W3C CSS 2.1 规范中的一个概念,它是一个独立容器,决定了元素如何对其内容进行定位,以及与其他元素的关系和相互作用。)
一个页面是由很多个 Box 组成的,元素的类型和 display 属性,决定了这个 Box 的类型。
不同类型的 Box,会参与不同的 Formatting Context(决定如何渲染文档的容器),因此Box内的元素会以不同的方式渲染,也就是说BFC内部的元素和外部的元素不会互相影响。
css定义的权重
以下是权重的规则:标签的权重为1,class的权重为10,id的权重为100,以下例子是演示各种定义的权重值:
/*权重为1*/
div{
}
/*权重为10*/
.class1{
}
/*权重为100*/
#id1{
}
/*权重为100+1=101*/
#id1 div{
}
/*权重为10+1=11*/
.class1 div{
}
/*权重为10+10+1=21*/
.class1 .class2 div{
}
如果权重相同,则最后定义的样式会起作用,但是应该避免这种情况出现
请解释一下为什么会出现浮动和什么时候需要清除浮动?清除浮动的方式
移动端的布局用过媒体查询吗?
使用 CSS 预处理器吗?喜欢那个?
SASS (SASS、LESS没有本质区别,只因为团队前端都是用的SASS)
CSS优化、提高性能的方法有哪些?
浏览器是怎样解析CSS选择器的?
在网页中的应该使用奇数还是偶数的字体?为什么呢?
margin和padding分别适合什么场景使用?
抽离样式模块怎么写,说出思路,有无实践经验?[阿里航旅的面试题]
元素竖向的百分比设定是相对于容器的高度吗?
全屏滚动的原理是什么?用到了CSS的那些属性?
什么是响应式设计?响应式设计的基本原理是什么?如何兼容低版本的IE?
视差滚动效果,如何给每页做不同的动画?(回到顶部,向下滑动要再次出现,和只出现一次分别怎么做?)
::before 和 :after中双冒号和单冒号 有什么区别?解释一下这2个伪元素的作用。
如何修改chrome记住密码后自动填充表单的黄色背景 ?
你对line-height是如何理解的?
设置元素浮动后,该元素的display值是多少?(自动变成display:block)
怎么让Chrome支持小于12px 的文字?
让页面里的字体变清晰,变细用CSS怎么做?(-webkit-font-smoothing: antialiased;)
font-style属性可以让它赋值为“oblique” oblique是什么意思?
position:fixed;在android下无效怎么处理?
如果需要手动写动画,你认为最小时间间隔是多久,为什么?(阿里)
多数显示器默认频率是60Hz,即1秒刷新60次,所以理论上最小间隔为1/60*1000ms = 16.7ms
display:inline-block 什么时候会显示间隙?(携程)
移除空格、使用margin负值、使用font-size:0、letter-spacing、word-spacing
overflow: scroll时不能平滑滚动的问题怎么处理?
有一个高度自适应的div,里面有两个div,一个高度100px,希望另一个填满剩下的高度。
png、jpg、gif 这些图片格式解释一下,分别什么时候用。有没有了解过webp?
什么是Cookie 隔离?(或者说:请求资源的时候不要让它带cookie怎么做)
如果静态文件都放在主域名下,那静态文件请求的时候都带有的cookie的数据提交给server的,非常浪费流量,
所以不如隔离开。
因为cookie有域的限制,因此不能跨域提交请求,故使用非主要域名的时候,请求头中就不会带有cookie数据,
这样可以降低请求头的大小,降低请求时间,从而达到降低整体请求延时的目的。
同时这种方式不会将cookie传入Web Server,也减少了Web Server对cookie的处理分析环节,
提高了webserver的http请求的解析速度。
style标签写在body后与body前有什么区别?
什么是CSS 预处理器 / 后处理器?
- 预处理器例如:LESS、Sass、Stylus,用来预编译Sass或less,增强了css代码的复用性,
还有层级、mixin、变量、循环、函数等,具有很方便的UI组件模块化开发能力,极大的提高工作效率。
- 后处理器例如:PostCSS,通常被视为在完成的样式表中根据CSS规范处理CSS,让其更有效;目前最常做的
是给CSS属性添加浏览器私有前缀,实现跨浏览器兼容性的问题。
原来公司工作流程是怎么样的,如何与其他人协作的?如何夸部门合作的?
你遇到过比较难的技术问题是?你是如何解决的?
设计模式 知道什么是singleton, factory, strategy, decrator么?
常使用的库有哪些?常用的前端开发工具?开发过什么应用或组件?
页面重构怎么操作?
网站重构:在不改变外部行为的前提下,简化结构、添加可读性,而在网站前端保持一致的行为。
也就是说是在不改变UI的情况下,对网站进行优化,在扩展的同时保持一致的UI。
对于传统的网站来说重构通常是:
表格(table)布局改为DIV+CSS
使网站前端兼容于现代浏览器(针对于不合规范的CSS、如对IE6有效的)
对于移动平台的优化
针对于SEO进行优化
深层次的网站重构应该考虑的方面
减少代码间的耦合
让代码保持弹性
严格按规范编写代码
设计可扩展的API
代替旧有的框架、语言(如VB)
增强用户体验
通常来说对于速度的优化也包含在重构中
压缩JS、CSS、image等前端资源(通常是由服务器来解决)
程序的性能优化(如数据读写)
采用CDN来加速资源加载
对于JS DOM的优化
HTTP服务器的文件缓存
列举IE与其他浏览器不一样的特性?
1、事件不同之处:
触发事件的元素被认为是目标(target)。而在 IE 中,目标包含在 event 对象的 srcElement 属性;
获取字符代码、如果按键代表一个字符(shift、ctrl、alt除外),IE 的 keyCode 会返回字符代码(Unicode),DOM 中按键的代码和字符是分离的,要获取字符代码,需要使用 charCode 属性;
阻止某个事件的默认行为,IE 中阻止某个事件的默认行为,必须将 returnValue 属性设置为 false,Mozilla 中,需要调用 preventDefault() 方法;
停止事件冒泡,IE 中阻止事件进一步冒泡,需要设置 cancelBubble 为 true,Mozzilla 中,需要调用 stopPropagation();
99%的网站都需要被重构是那本书上写的?
网站重构:应用web标准进行设计(第2版)
什么叫优雅降级和渐进增强?
优雅降级:Web站点在所有新式浏览器中都能正常工作,如果用户使用的是老式浏览器,则代码会针对旧版本的IE进行降级处理了,使之在旧式浏览器上以某种形式降级体验却不至于完全不能用。
如:border-shadow
渐进增强:从被所有浏览器支持的基本功能开始,逐步地添加那些只有新版本浏览器才支持的功能,向页面增加不影响基础浏览器的额外样式和功能的。当浏览器支持时,它们会自动地呈现出来并发挥作用。
如:默认使用flash上传,但如果浏览器支持 HTML5 的文件上传功能,则使用HTML5实现更好的体验;
是否了解公钥加密和私钥加密。
一般情况下是指私钥用于对数据进行签名,公钥用于对签名进行验证;
HTTP网站在浏览器端用公钥加密敏感数据,然后在服务器端再用私钥解密。
WEB应用从服务器主动推送Data到客户端有那些方式?
html5提供的Websocket
不可见的iframe
WebSocket通过Flash
XHR长时间连接
XHR Multipart Streaming
<script>标签的长时间连接(可跨域)
对Node的优点和缺点提出了自己的看法?
*(优点)因为Node是基于事件驱动和无阻塞的,所以非常适合处理并发请求,
因此构建在Node上的代理服务器相比其他技术实现(如Ruby)的服务器表现要好得多。
此外,与Node代理服务器交互的客户端代码是由javascript语言编写的,
因此客户端和服务器端都用同一种语言编写,这是非常美妙的事情。
*(缺点)Node是一个相对新的开源项目,所以不太稳定,它总是一直在变,
而且缺少足够多的第三方库支持。看起来,就像是Ruby/Rails当年的样子。
你有用过哪些前端性能优化的方法?
(1) 减少http请求次数:CSS Sprites, JS、CSS源码压缩、图片大小控制合适;网页Gzip,CDN托管,data缓存 ,图片服务器。
(2) 前端模板 JS+数据,减少由于HTML标签导致的带宽浪费,前端用变量保存AJAX请求结果,每次操作本地变量,不用请求,减少请求次数
(3) 用innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能。
(4) 当需要设置的样式很多时设置className而不是直接操作style。
(5) 少用全局变量、缓存DOM节点查找的结果。减少IO读取操作。
(6) 避免使用CSS Expression(css表达式)又称Dynamic properties(动态属性)。
(7) 图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳。
(8) 避免在页面的主体布局中使用table,table要等其中的内容完全下载之后才会显示出来,显示比div+css布局慢。
对普通的网站有一个统一的思路,就是尽量向前端优化、减少数据库操作、减少磁盘IO。向前端优化指的是,在不影响功能和体验的情况下,能在浏览器执行的不要在服务端执行,能在缓存服务器上直接返回的不要到应用服务器,程序能直接取得的结果不要到外部取得,本机内能取得的数据不要到远程取,内存能取到的不要到磁盘取,缓存中有的不要去数据库查询。减少数据库操作指减少更新次数、缓存结果减少查询次数、将数据库执行的操作尽可能的让你的程序完成(例如join查询),减少磁盘IO指尽量不使用文件系统作为缓存、减少读写文件次数等。程序优化永远要优化慢的部分,换语言是无法“优化”的。
http状态码有那些?分别代表是什么意思?
简单版
[
100 Continue 继续,一般在发送post请求时,已发送了http header之后服务端将返回此信息,表示确认,之后发送具体参数信息
200 OK 正常返回信息
201 Created 请求成功并且服务器创建了新的资源
202 Accepted 服务器已接受请求,但尚未处理
301 Moved Permanently 请求的网页已永久移动到新位置。
302 Found 临时性重定向。
303 See Other 临时性重定向,且总是使用 GET 请求新的 URI。
304 Not Modified 自从上次请求后,请求的网页未修改过。
400 Bad Request 服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。
401 Unauthorized 请求未授权。
403 Forbidden 禁止访问。
404 Not Found 找不到如何与 URI 相匹配的资源。
500 Internal Server Error 最常见的服务器端错误。
503 Service Unavailable 服务器端暂时无法处理请求(可能是过载或维护)。
]
完整版
1**(信息类):表示接收到请求并且继续处理
100——客户必须继续发出请求
101——客户要求服务器根据请求转换HTTP协议版本
2**(响应成功):表示动作被成功接收、理解和接受
200——表明该请求被成功地完成,所请求的资源发送回客户端
201——提示知道新文件的URL
202——接受和处理、但处理未完成
203——返回信息不确定或不完整
204——请求收到,但返回信息为空
205——服务器完成了请求,用户代理必须复位当前已经浏览过的文件
206——服务器已经完成了部分用户的GET请求
3**(重定向类):为了完成指定的动作,必须接受进一步处理
300——请求的资源可在多处得到
301——本网页被永久性转移到另一个URL
302——请求的网页被转移到一个新的地址,但客户访问仍继续通过原始URL地址,重定向,新的URL会在response中的Location中返回,浏览器将会使用新的URL发出新的Request。
303——建议客户访问其他URL或访问方式
304——自从上次请求后,请求的网页未修改过,服务器返回此响应时,不会返回网页内容,代表上次的文档已经被缓存了,还可以继续使用
305——请求的资源必须从服务器指定的地址得到
306——前一版本HTTP中使用的代码,现行版本中不再使用
307——申明请求的资源临时性删除
4**(客户端错误类):请求包含错误语法或不能正确执行
400——客户端请求有语法错误,不能被服务器所理解
401——请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
HTTP 401.1 - 未授权:登录失败
HTTP 401.2 - 未授权:服务器配置问题导致登录失败
HTTP 401.3 - ACL 禁止访问资源
HTTP 401.4 - 未授权:授权被筛选器拒绝
HTTP 401.5 - 未授权:ISAPI 或 CGI 授权失败
402——保留有效ChargeTo头响应
403——禁止访问,服务器收到请求,但是拒绝提供服务
HTTP 403.1 禁止访问:禁止可执行访问
HTTP 403.2 - 禁止访问:禁止读访问
HTTP 403.3 - 禁止访问:禁止写访问
HTTP 403.4 - 禁止访问:要求 SSL
HTTP 403.5 - 禁止访问:要求 SSL 128
HTTP 403.6 - 禁止访问:IP 地址被拒绝
HTTP 403.7 - 禁止访问:要求客户证书
HTTP 403.8 - 禁止访问:禁止站点访问
HTTP 403.9 - 禁止访问:连接的用户过多
HTTP 403.10 - 禁止访问:配置无效
HTTP 403.11 - 禁止访问:密码更改
HTTP 403.12 - 禁止访问:映射器拒绝访问
HTTP 403.13 - 禁止访问:客户证书已被吊销
HTTP 403.15 - 禁止访问:客户访问许可过多
HTTP 403.16 - 禁止访问:客户证书不可信或者无效
HTTP 403.17 - 禁止访问:客户证书已经到期或者尚未生效
404——一个404错误表明可连接服务器,但服务器无法取得所请求的网页,请求资源不存在。eg:输入了错误的URL
405——用户在Request-Line字段定义的方法不允许
406——根据用户发送的Accept拖,请求资源不可访问
407——类似401,用户必须首先在代理服务器上得到授权
408——客户端没有在用户指定的饿时间内完成请求
409——对当前资源状态,请求不能完成
410——服务器上不再有此资源且无进一步的参考地址
411——服务器拒绝用户定义的Content-Length属性请求
412——一个或多个请求头字段在当前请求中错误
413——请求的资源大于服务器允许的大小
414——请求的资源URL长于服务器允许的长度
415——请求资源不支持请求项目格式
416——请求中包含Range请求头字段,在当前请求资源范围内没有range指示值,请求也不包含If-Range请求头字段
417——服务器不满足请求Expect头字段指定的期望值,如果是代理服务器,可能是下一级服务器不能满足请求长。
5**(服务端错误类):服务器不能正确执行一个正确的请求
HTTP 500 - 服务器遇到错误,无法完成请求
HTTP 500.100 - 内部服务器错误 - ASP 错误
HTTP 500-11 服务器关闭
HTTP 500-12 应用程序重新启动
HTTP 500-13 - 服务器太忙
HTTP 500-14 - 应用程序无效
HTTP 500-15 - 不允许请求 global.asa
Error 501 - 未实现
HTTP 502 - 网关错误
HTTP 503:由于超载或停机维护,服务器目前无法使用,一段时间后可能恢复正常
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?(流程说的越详细越好)
注:这题胜在区分度高,知识点覆盖广,再不懂的人,也能答出几句,
而高手可以根据自己擅长的领域自由发挥,从URL规范、HTTP协议、DNS、CDN、数据库查询、
到浏览器流式解析、CSS规则构建、layout、paint、onload/domready、JS执行、JS API绑定等等;
详细版:
1、浏览器会开启一个线程来处理这个请求,对 URL 分析判断如果是 http 协议就按照 Web 方式来处理;
2、调用浏览器内核中的对应方法,比如 WebView 中的 loadUrl 方法;
3、通过DNS解析获取网址的IP地址,设置 UA 等信息发出第二个GET请求;
4、进行HTTP协议会话,客户端发送报头(请求报头);
5、进入到web服务器上的 Web Server,如 Apache、Tomcat、Node.JS 等服务器;
6、进入部署好的后端应用,如 PHP、Java、JavaScript、Python 等,找到对应的请求处理;
7、处理结束回馈报头,此处如果浏览器访问过,缓存上有对应资源,会与服务器最后修改时间对比,一致则返回304;
8、浏览器开始下载html文档(响应报头,状态码200),同时使用缓存;
9、文档树建立,根据标记请求所需指定MIME类型的文件(比如css、js),同时设置了cookie;
10、页面开始渲染DOM,JS根据DOM API操作DOM,执行事件绑定等,页面显示完成。
简洁版:
浏览器根据请求的URL交给DNS域名解析,找到真实IP,向服务器发起请求;
服务器交给后台处理完成后返回数据,浏览器接收文件(HTML、JS、CSS、图象等);
浏览器对加载到的资源(HTML、JS、CSS等)进行语法解析,建立相应的内部数据结构(如HTML的DOM);
载入解析到的资源文件,渲染页面,完成。
部分地区用户反应网站很卡,请问有哪些可能性的原因,以及解决方法?
从打开app到刷新出内容,整个过程中都发生了什么,如果感觉慢,怎么定位问题,怎么解决?
除了前端以外还了解什么其它技术么?你最最厉害的技能是什么?
你用的得心应手用的熟练地编辑器&开发环境是什么样子?
Sublime Text 3 + 相关插件编写前端代码
Google chrome 、Mozilla Firefox浏览器 +firebug 兼容测试和预览页面UI、动画效果和交互功能
Node.js+Gulp
git 用于版本控制和Code Review
对前端工程师这个职位是怎么样理解的?它的前景会怎么样?
前端是最贴近用户的程序员,比后端、数据库、产品经理、运营、安全都近。
1、实现界面交互
2、提升用户体验
3、有了Node.js,前端可以实现服务端的一些事情
前端是最贴近用户的程序员,前端的能力就是能让产品从 90分进化到 100 分,甚至更好,
参与项目,快速高质量完成实现效果图,精确到1px;
与团队成员,UI设计,产品经理的沟通;
做好的页面结构,页面重构和用户体验;
处理hack,兼容、写出优美的代码格式;
针对服务器的优化、拥抱最新前端技术。
你怎么看待Web App 、hybrid App、Native App?
你移动端前端开发的理解?(和 Web 前端开发的主要区别是什么?)
你对加班的看法?
加班就像借钱,原则应当是------救急不救穷
平时如何管理你的项目?
先期团队必须确定好全局样式(globe.css),编码模式(utf-8) 等;
编写习惯必须一致(例如都是采用继承式的写法,单样式都写成一行);
标注样式编写人,各模块都及时标注(标注关键样式调用的地方);
页面进行标注(例如 页面 模块 开始和结束);
CSS跟HTML 分文件夹并行存放,命名都得统一(例如style.css);
JS 分文件夹存放 命名以该JS功能为准的英文翻译。
图片采用整合的 images.png png8 格式文件使用 尽量整合在一起使用方便将来的管理
如何设计突发大规模并发架构?
当团队人手不足,把功能代码写完已经需要加班的情况下,你会做前端代码的测试吗?
说说最近最流行的一些东西吧?常去哪些网站?
ES6\WebAssembly\Node\MVVM\Web Components\React\React Native\Webpack 组件化
知道什么是SEO并且怎么优化么? 知道各种meta data的含义么?
移动端(Android IOS)怎么做好用户体验?
清晰的视觉纵线、
信息的分组、极致的减法、
利用选择代替输入、
标签及文字的排布方式、
依靠明文确认密码、
合理的键盘利用、
简单描述一下你做过的移动APP项目研发流程?
你在现在的团队处于什么样的角色,起到了什么明显的作用?
你认为怎样才是全端工程师(Full Stack developer)?
介绍一个你最得意的作品吧?
你有自己的技术博客吗,用了哪些技术?
对前端安全有什么看法?
是否了解Web注入攻击,说下原理,最常见的两种攻击(XSS 和 CSRF)了解到什么程度?
项目中遇到国哪些印象深刻的技术难题,具体是什么问题,怎么解决?。
最近在学什么东西?
你的优点是什么?缺点是什么?
如何管理前端团队?
最近在学什么?能谈谈你未来3,5年给自己的规划吗?
1. 极客标签: http://www.gbtags.com/
2. 码农周刊: http://weekly.manong.io/issues/
3. 前端周刊: http://www.feweekly.com/issues
4. 慕课网: http://www.imooc.com/
5. div.io: http://div.io
6. Hacker News: https://news.ycombinator.com/news
7. InfoQ: http://www.infoq.com/
8. w3cplus: http://www.w3cplus.com/
9. Stack Overflow: http://stackoverflow.com/
10.w3school: http://www.w3school.com.cn/
11.mozilla: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript
实际上变量和函数声明在代码里的位置是不会变的,而且是在编译阶段被 JavaScript 引擎放入内存中,一段 JavaScript 代码在执行之前需要被 JavaScript 引擎编译,编译完成之后,才会进入执行阶段。大致流程为:JavaScript 代码片段 ——> 编译阶段 ——> 执行阶段—>。
编译阶段,每段执行代码会分为两部分,第一部分为变量提升部分的代码,第二部分为执行部分的代码。经过编译后,生成执行上下文(Execution context)和 可执行代码。
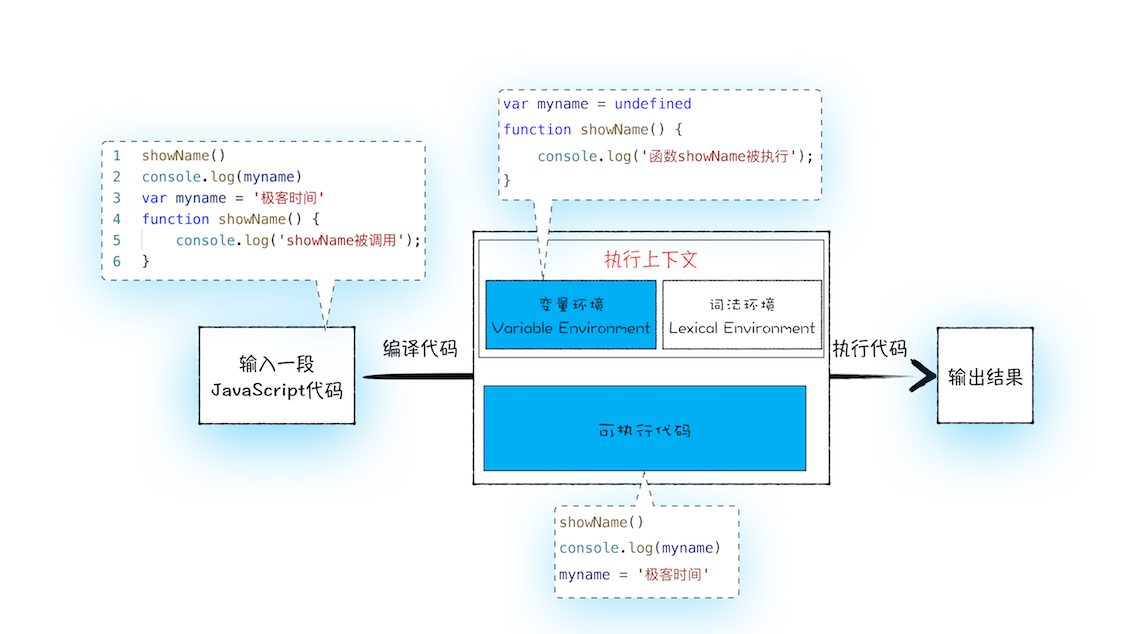
执行上下文 是 JavaScript 执行一段代码时的运行环境,比如调用一个函数,就会进入函数的执行上下文,从而确定该函数执行期间用到的如 this、变量、对象以及函数等。
执行上下文由 变量环境(Variable Environment) 和 **词法环境(Lexical Environment)**对象 组成,变量环境保存了代码中变量提升的内容,包括 var 定义和 function 定义的变量。而词法环境保存 let 和 const 定义块级作用域的变量。
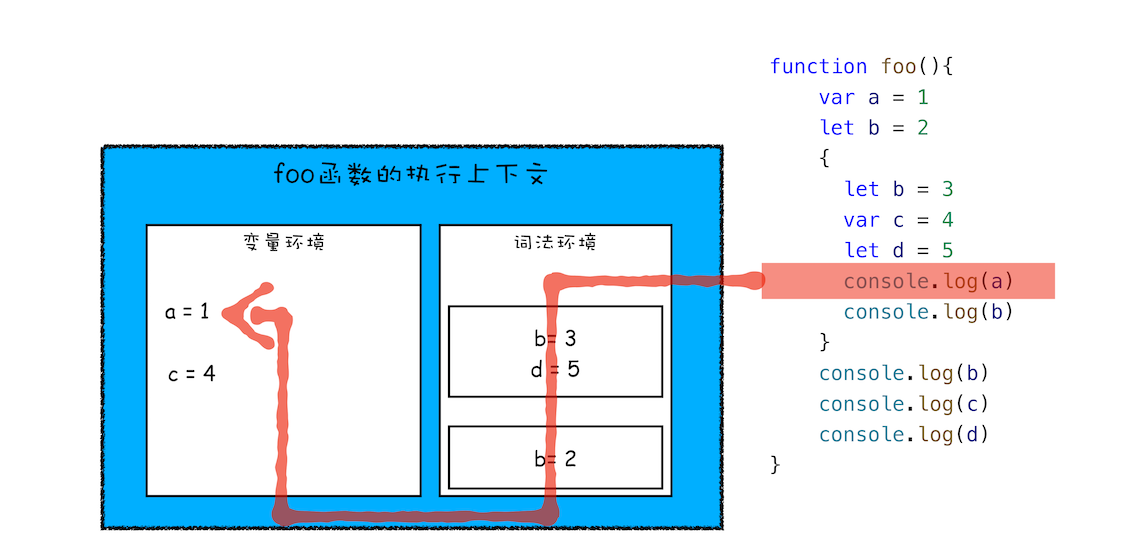
块级作用域就是通过词法环境的栈结构来实现的,而变量提升是通过变量环境来实现,通过这两者的结合,JavaScript 引擎也就同时支持了变量提升和块级作用域了
变量查找过程:沿着词法环境的栈顶向下查询,如果在词法环境中的某个块中查找到了,就直接返回给 JavaScript 引擎,如果没有查找到,那么继续在变量环境中查找。
变量声明提升补充:
var的创建和初始化被提升,赋值不会被提升。
let的创建被提升,初始化和赋值不会被提升。
function的创建、初始化和赋值均会被提升。
调用栈是用来管理函数调用关系的一种数据结构。在函数调用的时候,JavaScript 引擎会创建函数执行上下文,而全局代码下又有一个全局执行上下文,这些执行上下文会使用一种叫栈的数据结果来管理。
所以 JavaScript 的调用栈,其实就是 执行上下文栈 。举例代码执行,入栈如图所示:
var a = 2
function add(b,c){
return b+c
}
function addAll(b,c){
var d = 10
result = add(b,c)
return a+result+d
}
addAll(3,6)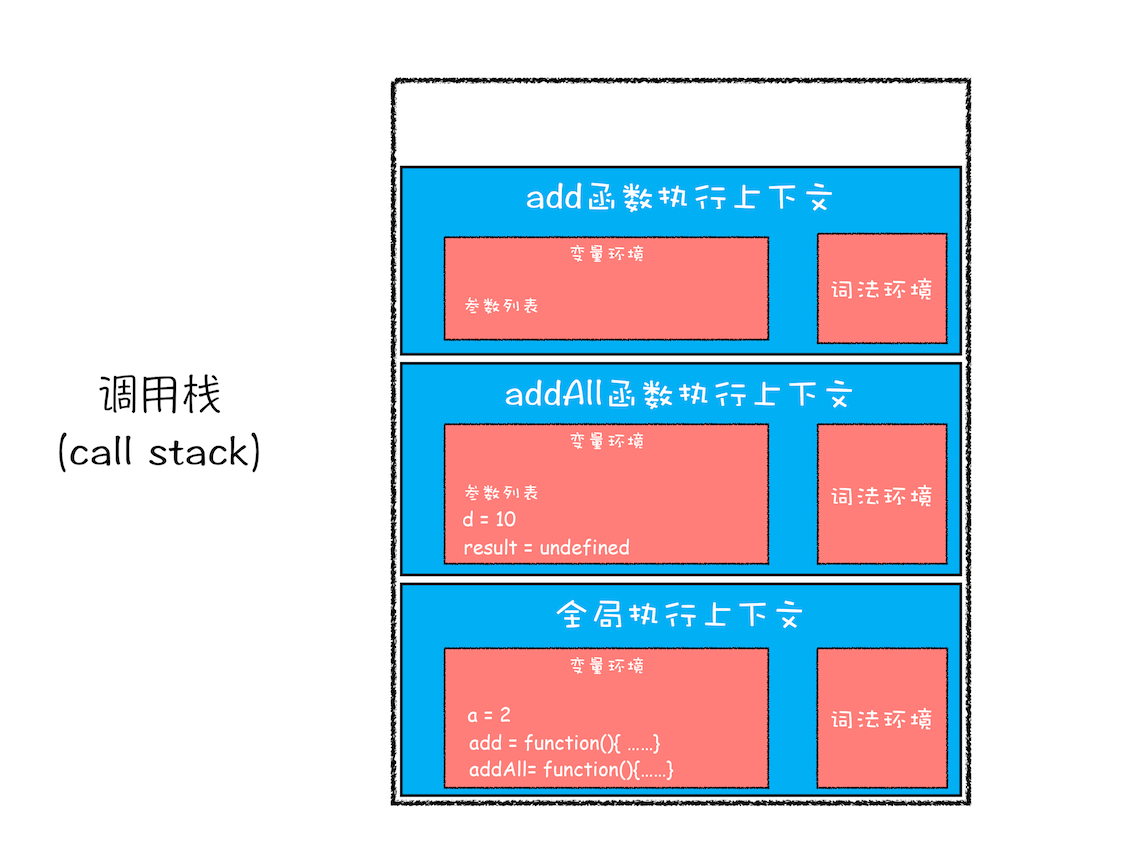
调用栈既然是一种数据结构,所以是存在大小的,超出了栈大小就会出现栈溢出报错,比如斐波那契数列,执行10000次,超过了最大栈调用大小(Maximum call stack size exceeded)。
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(10000) // Maximum call stack size exceeded该函数是递归的,虽然只有一种函数调用,但是还是会一直创建执行上下文压入调用栈中,导致超过最大调用栈大小报错,可以通过 Chrome 调式看到 Call Stack 的情况
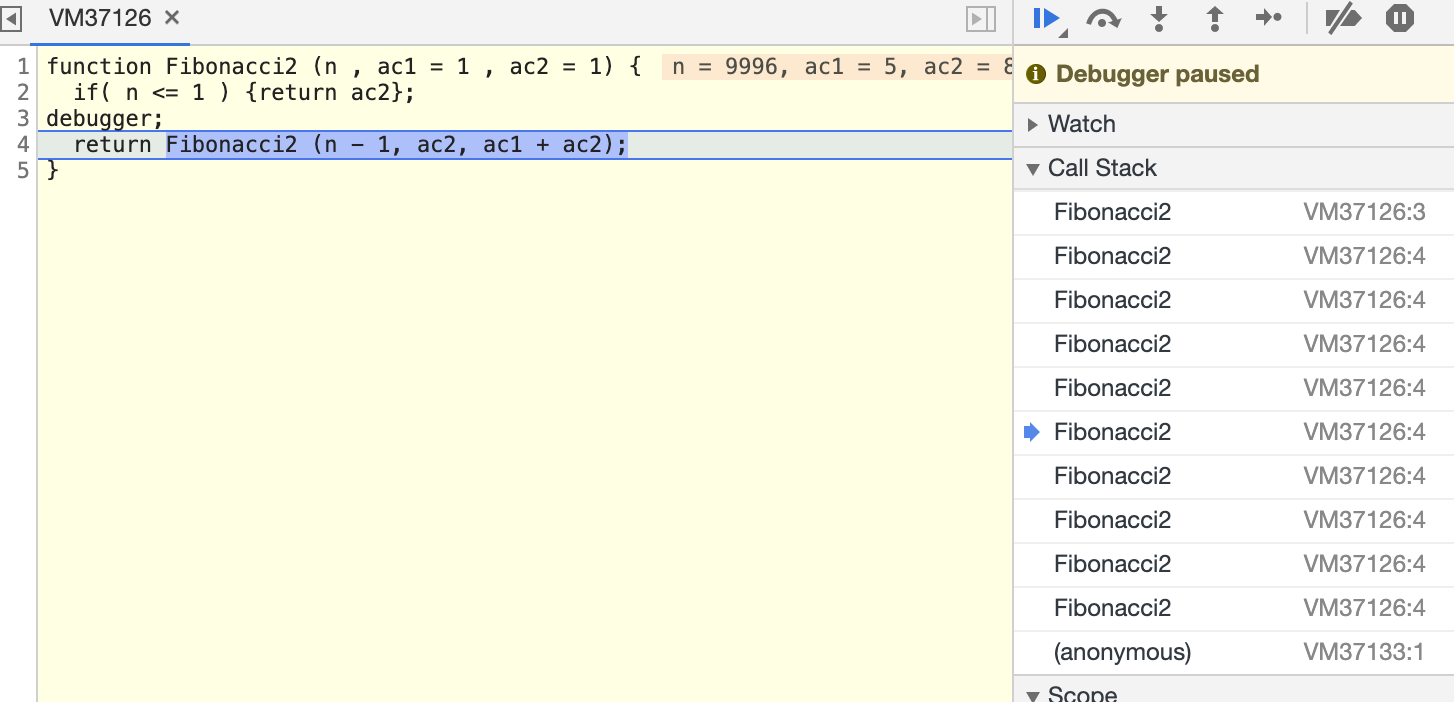
总结:
所以,斐波那契数列函数优化的手段就是使用循环来减少函数调用,从而减少函数执行上下文的创建压入栈的情况,就可以解决栈溢出的报错了。(递归尾部优化无法解决问题,Chrome浏览器还是栈溢出),使用蹦床函数来解决:
function runStack (n) {
if (n === 0) return 100;
return runStack.bind(null, n- 2); // 返回自身的一个版本
}
// 蹦床函数,避免递归
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
trampoline(runStack(1000000))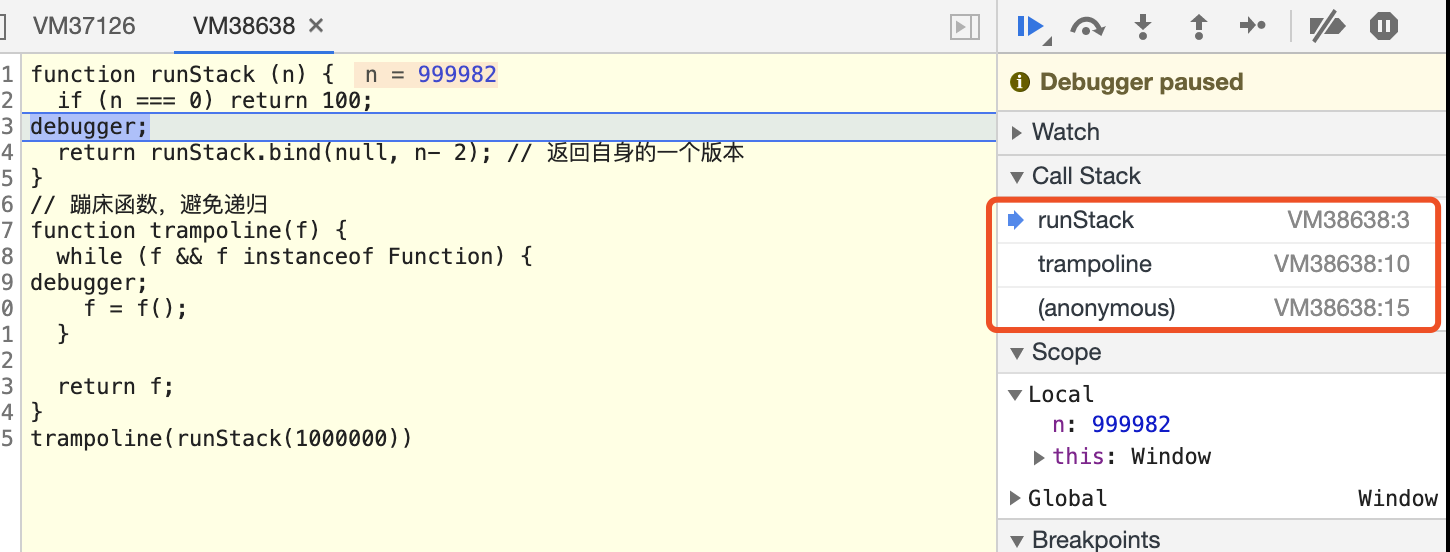
可以看到,调用栈中一直是保持3个执行上下文而已,多余的都及时的pop掉了。
每个执行上下文的变量环境中,都包含了一个外部引用,用来指向外部的执行上下文,我们把这个外部的引用称为 outer。
当一段代码使用一个变量是,JavaScript 引擎首先会在“当前的执行上下文”中查找该变量,如果找不到就会继续在 outer 所指向的执行上下文中查找。我们把这个查找的链条就称为作用域链。
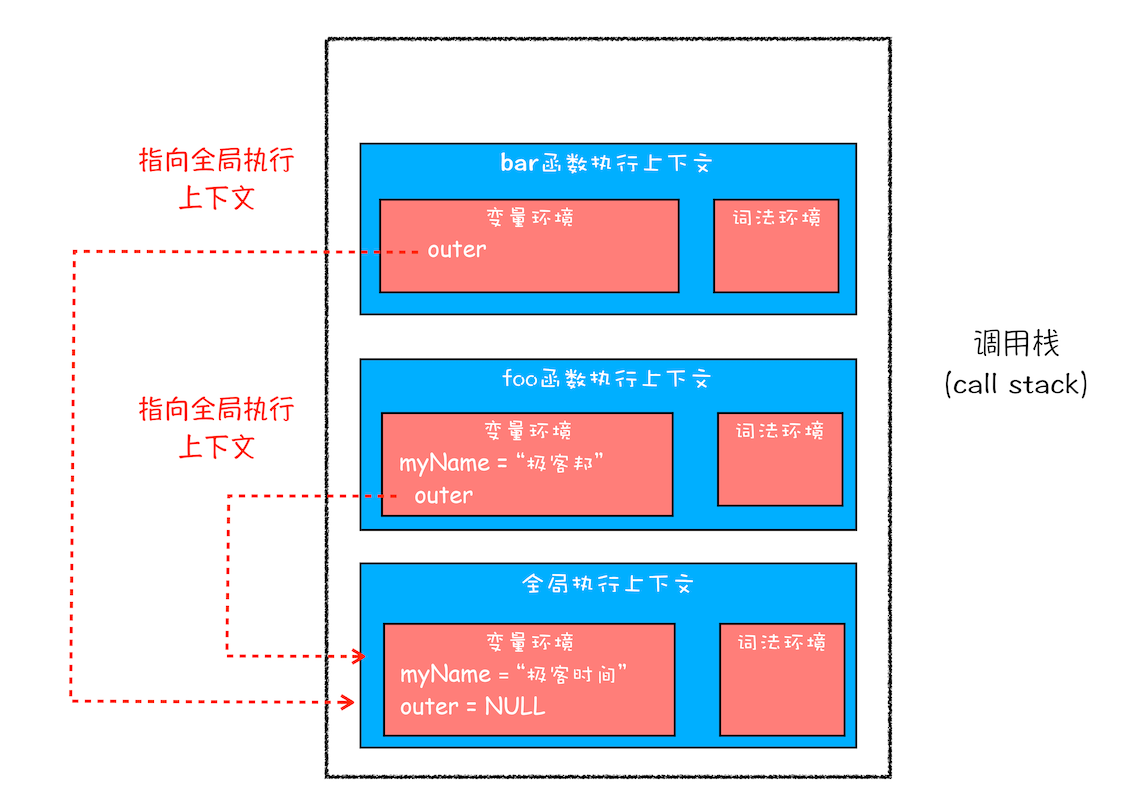
词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。词法作用域是代码阶段决定好的,和函数是怎么调用的没有关系。
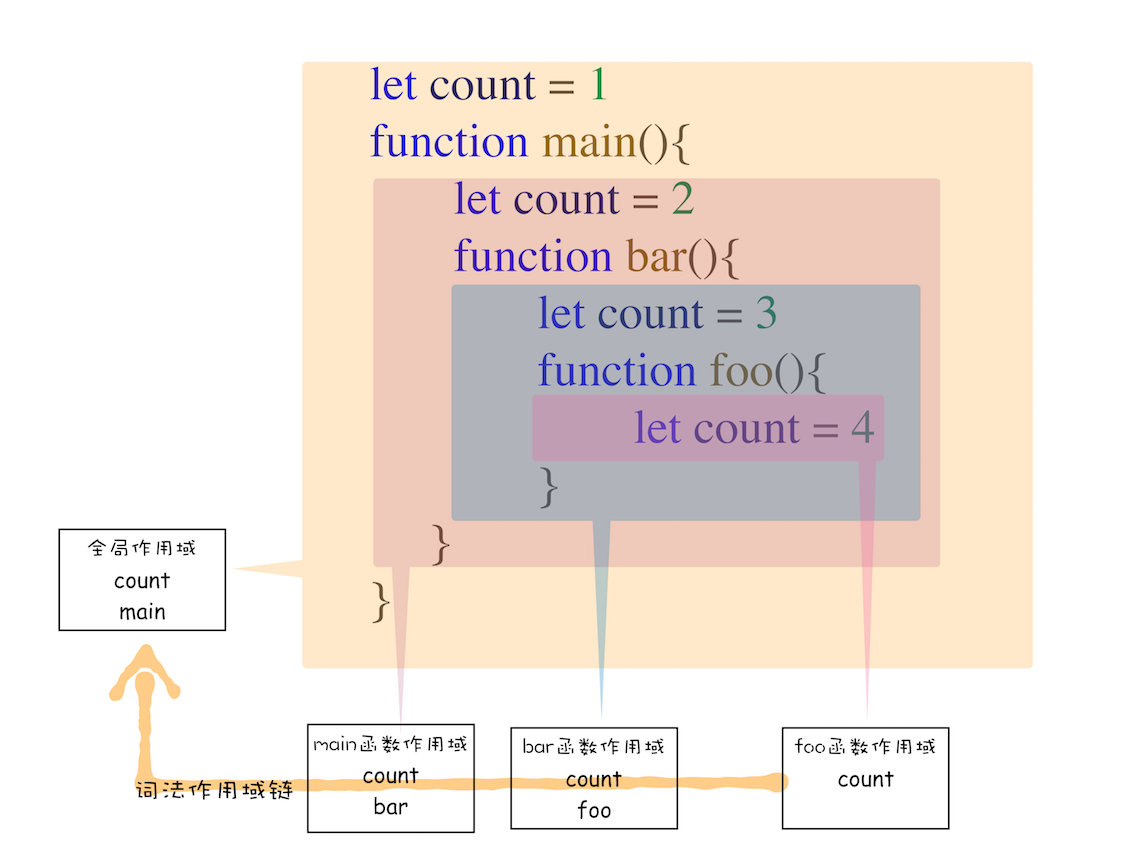
有词法作用域的规则可以知道,内部函数总是可以访问他们的外部函数中的变量,当外部函数执行完毕后,pop stack了,遗留下了外部环境形成的闭包 Closure 环境,该环境内存中还保存着那些可以访问的变量,类似一个专属背包,除了内部函数访问,气氛方式无法访问该专属背包,我们就包这个背包称为外部函数的闭包(那些内部函数引用外部函数的变量依然保存在内存中,我们把这些变量的集合称为闭包)。
如果引用闭包的函数是一个全局变量,那么闭包会一直存在知道页面关闭;如果这个闭包以后不再使用的话,就会造成内存泄漏。
如果引用闭包的函数是一个局部变量,等函数销毁后,下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块的内存。
使用闭包的原则:如果闭包会一直使用,那么他可以作为全局变量而存在;但如果使用频率不高,而且占用内存有比较大的话,那就尽量让它成为一个局部变量。
let a = { name: 'this解释' }
function foo() {
console.log(this.name)
}
foo.bind(a)() // => 'this解释''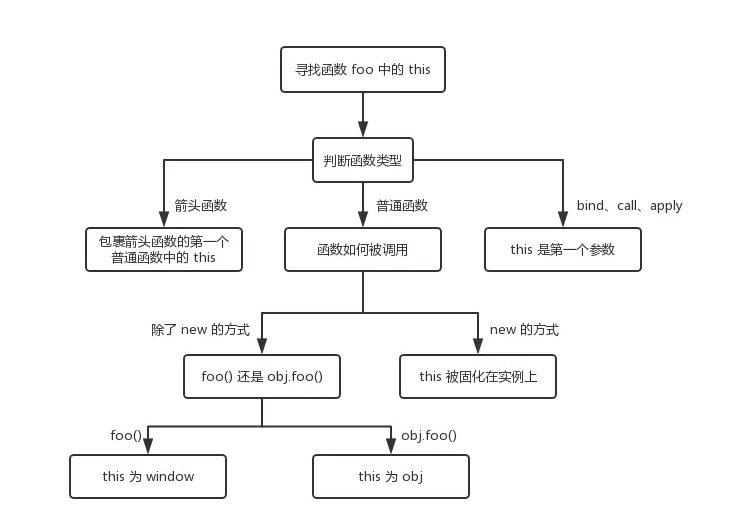
参考资源:《浏览器的工作原理与实践》极客时间-李兵
这个过程以后可能会重复,或者搞成docker,这里先做个记录
全局命令:ln -s 安装路径 /usr/local/bin
下载jdk包,解压到 /usr/local/jdk1.8 下,配置环境变量
export JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
wget http://dl.google.com/android/android-sdk_r24.4.1-linux.tgz
tar xvzf android-sdk_r24.4.1-linux.tgz
mv ./android-sdk-linux ./usr/local/android
编辑环境变量
vim /etc/profile
export ANDROID_HOME=/usr/local/android
export PATH=$ANDROID_HOME/tools:$PATH
export PATH=$ANDROID_HOME/platform-tools:$PATH
source /etc/profileandroid list sdk --all
列出所有的 skd 资源包括 Sdk buildTools,SDK platform 等等
选中所需呀资源的序号,比如3 是 buildtoolsVersion 28.0.3,47是 platform 8.1.0
android update sdk -u -a -t 3,7,15,101,199 (需要资源的序号) 下载
wget https://services.gradle.org/distributions/gradle-3.3-all.zip
unzip ./gradle-3.3-all.zip
编辑环境变量
vim /etc/profile
export GRADLE_HOME=/usr/local/gradle-3.3
export PATH=$PATH:/usr/local/gradle-3.3/bin
source /etc/profile文章是学习
《设计模式之美》- 王争的总结
设计原则是设计模式重要的**和原则,需要清楚原则的定义和原则设计的初衷,能解决哪些问题,有哪些应用场景。本篇是复习5大设计原则 SOLID 的前三个 SRP(单一职责原则)、OCP(开闭原则)、LSP(里式替换原则)。
指:一个类或模块只负责完成一个职责(或者功能)。
如何判断类的职责是否单一?有几条可以参考的判断原则:
误区:避免类的职责在任何时候都设计的越单一。
单一职责原则通过避免设计大而全的类,避免将不相关的功能耦合在一起,来提高类的内聚性,同时,类职责单一,类依赖的和被依赖的其他类也会变少,减少了代码的耦合性,从此来实现代码的高内聚、低耦合。但是如果拆分得过细,实际上会适得其反,反倒会降低内聚性,也会影响代码的可维护性。
对扩展开放,对修改关闭。添加一个新的功能,应该是通过在已有代码基础上扩展代码(新增模块、类、方法、属性等),而非修改已有代码(修改模块、类、方法、属性等)的方式来完成。关于定义,我们有两点要注意。第一点是,开闭原则并不是说完全杜绝修改,而是以最小的修改代码的代价来完成新功能的开发。第二点是,同样的代码改动,在粗代码粒度下,可能被认定为“修改”;在细代码粒度下,可能又被认定为“扩展”。
如何做到 “对扩展开放,对修改关闭?
我们要时刻具备扩展意识、抽象意识、封装意识。在写代码的时候,我们要多花点时间思考一下,这段代码未来可能有哪些需求变更,如何设计代码结构,事先留好扩展点,以便在未来需求变更的时候,在不改动代码整体结构、做到最小代码改动的情况下,将新的代码灵活地插入到扩展点上。
很多设计原则、设计**、设计模式,都是以提高代码的扩展性为最终目的的。特别是 23 种经典设计模式,大部分都是为了解决代码的扩展性问题而总结出来的,都是以开闭原则为指导原则的。最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编程,以及大部分的设计模式(比如,装饰、策略、模板、职责链、状态)。
举例API 接口监控代码 Alert.ts 类
/**
* API 接口监控代码
*/
interface AlertRule {
getMatchedRule(api: string);
}
interface Notification {
notify(level: NotificationEmergencyLevel, msg: string);
}
enum NotificationEmergencyLevel {
URGENCY = 0,
SEVERE = 1,
}
class Alert {
private rule: AlertRule;
private notification: Notification;
constructor(rule: AlertRule, notification: Notification) {
this.rule = rule;
this.notification = notification;
}
public check(
api: string,
requestCount: number,
errorCount: number,
durationOfSecond: number
): void {
const tps = requestCount / durationOfSecond;
if (tps > this.rule.getMatchedRule(api).getMaxTps()) {
this.notification.notify(NotificationEmergencyLevel.URGENCY, '…');
}
if (errorCount > this.rule.getMatchedRule(api).getMaxErrorCount()) {
this.notification.notify(NotificationEmergencyLevel.SEVERE, '…');
}
}
}根据 OCP 改进之后的代码:
/**
* OCP 改进后的API 接口监控代码
*/
interface AlertRule {
getMatchedRule(api: string);
}
interface Notification {
notify(level: NotificationEmergencyLevel, msg: string);
}
enum NotificationEmergencyLevel {
URGENCY = 0,
SEVERE = 1,
}
class Alert {
private alertHandlers: AlertHandler[] = [];
public addAlertHandler(alertHandler: AlertHandler) {
this.alertHandlers.push(alertHandler);
}
public check(apiStatInfo: ApiStatInfo) {
for (const handler of this.alertHandlers) {
handler.check(apiStatInfo);
}
}
}
class ApiStatInfo {
private _api: string;
public get api(): string {
return this._api;
}
public set api(value: string) {
this._api = value;
}
private _requestCount: number;
public get requestCount(): number {
return this._requestCount;
}
public set requestCount(value: number) {
this._requestCount = value;
}
private _errorCount: number;
public get errorCount(): number {
return this._errorCount;
}
public set errorCount(value: number) {
this._errorCount = value;
}
private _durationOfSecond: number;
public get durationOfSecond(): number {
return this._durationOfSecond;
}
public set durationOfSecond(value: number) {
this._durationOfSecond = value;
}
}
abstract class AlertHandler {
protected rule: AlertRule;
protected notification: Notification;
constructor(rule: AlertRule, notification: Notification) {
this.rule = rule;
this.notification = notification;
}
public abstract check(apiStatInfo: ApiStatInfo);
}
class TpsAlertHandler extends AlertHandler {
constructor(rule: AlertRule, notification: Notification) {
super(rule, notification);
}
public check(apiStatInfo: ApiStatInfo) {
const tps = apiStatInfo.requestCount / apiStatInfo.durationOfSecond;
if (tps > this.rule.getMatchedRule(apiStatInfo.api.getMaxTps())) {
this.notification.notify(NotificationEmergencyLevel.URGENCY, '...');
}
}
}
class ErrorAlertHandler extends AlertHandler {
constructor(rule: AlertRule, notification: Notification) {
super(rule, notification);
}
public check(apiStatInfo: ApiStatInfo): void {
if (
apiStatInfo.errorCount >
this.rule.getMatchedRule(apiStatInfo.api.getMaxTps())
) {
this.notification.notify(NotificationEmergencyLevel.SEVERE, '...');
}
}
}
// 重构之后的 Alert 使用举例
class ApplicationContext {
private alertRule: AlertRule;
private notification: Notification;
private alert: Alert;
public initializeBeans() {
this.alertRule = new AlertRule();
this.notification = new Notification();
this.alert = new Alert();
alert.addAlertHandler(
new TpsAlertHandler(this.alertRule, this.notification)
);
alert.addAlertHandler(
new ErrorAlertHandler(this.alertRule, this.notification)
);
}
public getAlert(): Alert {
return this.alert;
}
private static instace: ApplicationContext = new ApplicationContext();
constructor() {
ApplicationContext.instace.initializeBeans();
}
public static getInstance(): ApplicationContext {
return this.instace;
}
}
const apiStatInfo: ApiStatInfo = new ApiStatInfo();
ApplicationContext.getInstance().getAlert().check(apiStatInfo);
If S is a subtype of T, then objects of type T may be replaced with objects of type S, without breaking the program。
子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏。
里式替换原则是用来指导,继承关系中子类该如何设计的一个原则。理解里式替换原则,最核心的就是理解“design by contract,按照协议来设计”这几个字。父类定义了函数的“约定”(或者叫协议),那子类可以改变函数的内部实现逻辑,但不能改变函数原有的“约定”。这里的约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至包括注释中所罗列的任何特殊说明。
理解这个原则,我们还要弄明白里式替换原则跟多态的区别。虽然从定义描述和代码实现上来看,多态和里式替换有点类似,但它们关注的角度是不一样的。多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路。而里式替换是一种设计原则,用来指导继承关系中子类该如何设计,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑及不破坏原有程序的正确性。
以下是违反里式替换原则的情况:
单例模式(Singleton Design Patterns):一个类只允许创建一个实例,单例一般用来处理资源访问冲突、或者是表示一个全局唯一类。
在前端,由于js是单线程的,所以,不会存在锁的情况,不过也可以了解后端是通过锁来解决这个并发问题的。
ts 代码
class SingletonEhan {
private id: number = 0;
private static instance: SingletonEhan = new SingletonEhan();
private SingletonEhan() {}
private static getInstance() {
return SingletonEhan.instance;
}
getId() {
return (this.id += 1);
}
}ts 代码
class SingletonLhan {
private id: number = 0;
private static instance: SingletonLhan;
private SingletonLhan() {}
// java 写的话函数加上 synchronized 锁,导致频繁加锁和解锁并发低
// js 单线程所以不需要考虑此问题
private static getInstance() {
if (!this.instance) {
this.instance = new SingletonLhan();
}
return this.instance;
}
getId() {
return (this.id += 1);
}
}ts 代码
class SingletonLhan2 {
private id: number = 0;
private static instance: SingletonLhan;
private SingletonLhan() {}
private static getInstance() {
if (!this.instance) {
// java 写的话函数加上 synchronized 锁,解决频繁加锁和解锁并发低问题
// js 单线程所以不需要考虑此问题
// synchronized(SingletonLhan2.class){
// if (!this.instance) {
// this.instance = new SingletonLhan();
// }
// }
this.instance = new SingletonLhan();
}
return this.instance;
}
getId() {
return (this.id += 1);
}
}java 代码
public class SingletonInner{
private int id=0;
private constructor(){}
private static class Inner{
private static SingletonInner instance = new SingletonInner();
}
private static SingletonInner getInstance(){
return Inner.instance;
}
public int getId(){
return id+=1;
}
}思考,如果不是用 typescript 来写,es6 写的话不存在 private 属性的东西,如何实现?
—— 闭包
为了保证全局唯一性,除了单例类,还可以用以下方法:
一个单例类只能实例化一个实例对象。
一个线程中单例实例是唯一的,线程间实例不同,可以用 HashMap<线程id,单例实例对象> 来存储区分
一个进程中的单例实例是唯一的,进程中多线程都是使用同一个单例实例对象。进程间不唯一。因为应用程序最新执行单元就是进程起步,进程分配了独立的运行空间,不同进程间的环境和内存是独立隔离开的。
集群是多个服务器或者多个应用程序部署,程序运行环境和内存都是独立的,实际上就是多进程如何保证单例唯一。要使得集群应用的单例是唯一的,需要借助存储共享的能力。
使用共享存储区(比如文件),在进程使用到单例时,从共享存储区读取到内存,并反序列化为对象,然后再使用,使用完成之后还要再存储到外部共享存储区。
为了保证任何时间,进程之间只有一份对象存在,一进程在获取到对象之后,需要对对象进行加锁,避免其他进程再对其读取。并在使用完成这个对象之后,还需要显式的将对象从内存删除,并释放对对象的加锁。
使用HashMap 来控制
Java中单例的唯一性作用的范围不是进程,而是类的加载器
公司项目统一都使用 angular-cli 来搭建工程环境,从 Angular2 到 Angular8 版本都经历了,老项目都基本升级到 Angular4、6,新一点的项目,ng 版本都是7、8了。许多项目构建的速度,一直都是正常的表现,某一两个项目表现的比较异常,这不得不采取相关改进措施。
Angular 生产环境构建打包 ng build --prod 是开启了 AOT (为什么要AOT编译),ng build 构建配置项也比较多,含义介绍见文档:build,常见配置属性设置如下:
"prod": {
"optimization": true,
"outputHashing": "all",
"sourceMap": false,
"extractCss": true,
"namedChunks": false,
"aot": true,
"extractLicenses": true,
"vendorChunk": false,
"buildOptimizer": true,
"fileReplacements": [
{
"replace": "src/environments/environment.local.ts",
"with": "src/environments/environment.prod.ts"
}
]
}同样的配置,在不同的项目,构建时间长短也是不一样的。所以影响项目构建时间的原因可能有:
Tips: 我们构建默认都统一加大了node.js的执行内存
我们有个项目,再上线工单系统的页面之后,多出了10分钟的构建时间,构建时间在 15~20分钟 区间浮动。截图是 Gitlab CI/CD Build Job的(iMac 是8分钟内)

本地iMac的构建速度:

至于为什么 构建参数、配置不变的情况下,iMac 构建会比 gitlab runner(Linux 以及 Windows 系统)快很多,初步单纯认为是硬件性能的影响。我们项目持续集成服务器是 Linux 非 iMac,所以优化的时候,以CI/CD服务器构建效果的速度作为参考。
构建过程最慢的有两个地方分别是79% 和92%的操作:
79% chunk modules optimization ModuleConcatenationPlugin 92% chuck asset optimization 所有慢的构建都在这里浪费时间的,有网友是这么描述:
I've just upgraded my CLI to 1.7.2 (I've double checked the node_modules and --version) and a my build time has gone from about 15 seconds to infinity
It hangs forever at "92% chunk asset optimization", I've waited more than 10 mins before giving up
It's a very small app
理解这两个过程是干了什么,然后再去查找解决方案。官方文档是这么描述着两个属性配置的:
| buildOptimizer=true|false | Enables '@angular-devkit/build-optimizer' optimizations when using the 'aot' option.Default: false |
|---|
| optimization=true|false | Enables optimization of the build output. |
|---|
经实践,修改着两个配置属性为false后,构建就提速多倍,如图

又得必有失,从图中也可以看出来,提速了,但是单个文件代码体积明显提升了,因为关闭了optimization ,输出的文件体积没有做优化。
……未完待续
参考资源:
Author: @giscafer,原文地址:front-end-manual/issues/33 ,
欢迎讨论
pull request推荐 GitHub 使用工具,建议 WebStorm , Sourcetree ,命令行( window 加强 CMD 工具 Cmder ,建议不要下载那个客户端。
整个流程(以下举例,其中我为giscafer用户):
我先 fork 了 crm/crm-platform 的仓库,然后我从我的仓库克隆到本地修改,修改完后提交到我的仓库,然后我再申请 pull request ,crm/crm-platform 同意合并后其实整个过程就完了,但是 crm/crm-platform 经常会有更改就需要我刚那一步在我本地同步一下你的远程仓库,同步后再提交到我的仓库。
具体代码:
# 列出远程仓库 URL
$ git remote -v
# List the current remotes (列出当前远程仓库)
# origin https://git.yourcompany.com/user/crm-platform.git (fetch)
# origin https://git.yourcompany.com/user/crm-platform.git (push)
# 设置一个新的远程仓库
$ git remote add yourcompany [email protected]:crm/crm-platform.git
# 再次列出远程仓库 URL
$ git remote -v
# yourcompany [email protected]:crm/crm-platform.git (fetch)
# yourcompany [email protected]:crm/crm-platform.git (push)
# origin [email protected]:giscafer/crm-platform.git (fetch)
# origin [email protected]:giscafer/crm-platform.git (push)
# 获取上游代码
$ git fetch yourcompany
# 检查你的 fork’s 本地 master 分支,如果不在 master 分支就切换到该分支
$ git checkout master
# Switched to branch 'master'
# 合并来自 yourcompany/master 的更改到本地 master 分支上。
$ git merge yourcompany/master提交合并到 crm/crm-platform 之后,为了保证与主仓库代码的一致性,还需要进行一次本地与远程仓库的手动更新。
名词解析:master(默认开发分支)、origin(默认远程版本库) 、本地分支、远程分支、Fork仓库、远程仓库、远程原仓库
批量删除远程分支,带greenkeeper 前缀的分支:
git branch -a | grep -o "greenkeeper.*" | xargs -I {} git push origin :{}git push scm 「分支名称」:「分支名称」
git branch <new-branch-name> <tag-name>
远程来源主仓库分支最新代码到Fork仓库分支?(「fork 出来的仓库」和「最新版本的原仓库」内容同步更新)添加remote仓库,pull对应分支,再 push 到fork仓库
非主程序员只能用PR方式:本地分支的改动代码push到远程分支对应分支后,再通过PR方式请求合并到原仓库分支。PR之前,建议更新最新代码,避免冲突的可能(就是执行步骤4)
详细阅读文章:Git速查表
Git速查表

比如Github上的开源项目,要严格要求,一个功能点feat或者,一个bug修改,代码修改好,测试没问题,一次性提交修改的文件(只允许一个commit)
举例一个PR中commit两次的操作,然后工程维护者建议修改提交信息重新PR:NG-ZORRO/ng-zorro-antd#78
commit 信息不是乱填的,PR 标题也不是乱填的。可以参考开源工程的一些约束说明:CONTRIBUTING.md
之前在使用 Promise 时最多可能就是 new 一个对象出来,然后使用 then,Promise.all ,Promise.resove 等这些,清楚 Promise 具备的几个状态,但可能很少如深入剖析熟悉 Promise 的实现,所以本文其实也是我深入学习 Promise 做的整理。
Promise 初始动机就是为了解决 JavaScript 回调地狱的问题,我们来看,在没有 Promise 时,我们是如何通过 callback 来处理异步函数问题的。
function readJSON(filename, callback){
fs.readFile(filename, 'utf8', function (err, res){
if (err) return callback(err);
callback(null, JSON.parse(res));
});
}上边的写法有以下问题:
callback 参数带给我们的疑问:输入值是什么,和返回值是什么JSON.parse(res) 抛出异常无法处理我们需要处理 JSON.parse 的异常,并且还要担心 callback 函数的异常,所以我们就有了糟糕的处理错误的代码:
function readJSON(filename, callback){
fs.readFile(filename, 'utf8', function (err, res){
if (err) return callback(err);
try {
res = JSON.parse(res);
} catch (ex) {
return callback(ex);
}
callback(null, res);
});
}除了糟糕的异常处理代码外,callback 回调的参数也是约定多余了。我们需要记住callback的第一个参数是异常原因,第二个是成功结果。 Promises 帮助我们比较自然的处理异常错误,书写更简洁的代码而不是通过 callback 这种参数。
promises 的核心理念是,promise 代表着异步操作的结果值。promise 有三种不同的状态:
pending : promise的初始值fulfillled : promise 操作成功的状态rejected : promise 操作失败的状态一旦 promise 从 pending 转变到 fulfilled 或者 rejected,它就是永久不可变的了。
使用 new Promise 的方式去构建一个 promise 。 通过传入一个真正处理逻辑的还是函数,该函数有两个参数并且会立即执行,第一个参数 是fulfills promise 的函数,第二个参数是 rejects promise 的函数。一旦操作完成,就会调用对应的函数。
重写上面的 readFile 函数:
function readFile(filename, enc){
return new Promise(function (fulfill, reject){
fs.readFile(filename, enc, function (err, res){
if (err) reject(err);
else fulfill(res);
});
});
}使用 promise.done 来等待一个 promise 完成,重写readJSON 函数:
function readJSON(filename){
return new Promise(function (fulfill, reject){
readFile(filename, 'utf8').done(function (res){
try {
fulfill(JSON.parse(res));
} catch (ex) {
reject(ex);
}
}, reject);
});
}这段代码里,已经不存在 callback 这样的奇怪额外的回调参数,但是还存在很多异常处理的代码。(思考如何优化这段代码到更精简的程度)
.then 是可以链式的方式编程的,简单的讲,.then 和 .done 的区别和 .map 与 .forEach 类似,换一种说法, 使用 .then 就是你打算用promise返回的结果去处理任何逻辑,而 .done 则是你不计划处理结果result。
现在,简单重写一下原始的列子:
function readJSON(filename){
return readFile(filename, 'utf8').then(function (res){
return JSON.parse(res);
});
}由于 JSON.parse 是一个函数,我们可以改写成:
function readJSON(filename){
return readFile(filename, 'utf8').then(JSON.parse);
}返回一个 resolved 值为 value 的 promise。
如果 value 类似为promise,讲会执行此 promise 并得到 resolved 结果作为返回 promise 的 resolved 值。这对用来转换其他函数或库创建的 promise 很有用处。
Promise.resolve("Success").then(function(value) {
console.log(value); // "Success"
}, function(value) {
// not called
});
var p = Promise.resolve([1,2,3]);
p.then(function(v) {
console.log(v[0]); // 1
});
var original = Promise.resolve(true);
var cast = Promise.resolve(original);
cast.then(function(v) {
console.log(v); // true
});代码执行环境如果不支持则简单实现:
Promise.resolve = function (value) {
return new Promise(function (resolve) {
resolve(value);
});
};返回与给定的 promise 被拒绝的理由。
Promise.reject(new Error("fail")).then(function(error) {
// not called
}, function(error) {
console.log(error); // Stacktrace
});代码执行环境如果不支持则简单实现:
Promise.reject = function (value) {
return new Promise(function (resolve, reject) {
reject(value);
});
};函数返回一个 Promise ,函数执行后会等待在 iterable 数组中的所有 promises 完成 fulfilled 状态时,返回一个数组结果,该数组元素一一对应每个promise 的结果值。
var promise = Promise.resolve(3);
Promise.all([true, promise]).then(values => {
console.log(values); // [true, 3]
});若执行环境不支持Promise.all,可以通过polyfill实现,实现1:
Promise.all = function (arr) {
// TODO: this polyfill only supports array-likes
// it should support all iterables
var args = Array.prototype.slice.call(arr);
return new Promise(function (resolve, reject) {
if (args.length === 0) return resolve([]);
var remaining = args.length;
function res(i, val) {
if (val && (typeof val === 'object' || typeof val === 'function')) {
var then = val.then;
if (typeof then === 'function') {
var p = new Promise(then.bind(val));
p.then(function (val) {
res(i, val);
}, reject);
return;
}
}
args[i] = val;
if (--remaining === 0) {
resolve(args);
}
}
for (var i = 0; i < args.length; i++) {
res(i, args[i]);
}
});
};实现2:
Promise.all = function (promises) {
var accumulator = [];
var ready = Promise.resolve(null);
promises.forEach(function (promise, ndx) {
ready = ready.then(function () {
return promise;
}).then(function (value) {
accumulator[ndx] = value;
});
});
return ready.then(function () { return accumulator; });
}返回一个 promise,当 iterable 有一个 promise 状态为 resolved 或 rejected,就立马返回。
var p1 = new Promise(function(resolve, reject) {
setTimeout(resolve, 500, "one");
});
var p2 = new Promise(function(resolve, reject) {
setTimeout(resolve, 100, "two");
});
Promise.race([p1, p2]).then(function(value) {
console.log(value); // "two"
// Both resolve, but p2 is faster
});
var p3 = new Promise(function(resolve, reject) {
setTimeout(resolve, 100, "three");
});
var p4 = new Promise(function(resolve, reject) {
setTimeout(reject, 500, "four");
});
Promise.race([p3, p4]).then(function(value) {
console.log(value); // "three"
// p3 is faster, so it resolves
}, function(reason) {
// Not called
});
var p5 = new Promise(function(resolve, reject) {
setTimeout(resolve, 500, "five");
});
var p6 = new Promise(function(resolve, reject) {
setTimeout(reject, 100, "six");
});
Promise.race([p5, p6]).then(function(value) {
// Not called
}, function(reason) {
console.log(reason); // "six"
// p6 is faster, so it rejects
});Promise.race = function (values) {
// TODO: this polyfill only supports array-likes
// it should support all iterables
return new Promise(function (resolve, reject) {
values.forEach(function(value){
Promise.resolve(value).then(resolve, reject);
});
});
};等价于调用 Promise.prototype.then(undefined, onRejected)。
var p1 = new Promise(function(resolve, reject) {
resolve("Success");
});
p1.then(function(value) {
console.log(value); // "Success!"
throw "oh, no!";
}).catch(function(e) {
console.log(e); // "oh, no!"
});
p1.then(function(value) {
console.log(value); // "Success!"
throw "oh, no!";
}).then(undefined, function(e) {
console.log(e); // "oh, no!"
});Promise.prototype['catch'] = function (onRejected) {
return this.then(null, onRejected);
};尚未标准化
var Promise = require('promise');
var p = Promise.resolve('foo');
p.done(function (value) {
console.log(value); // "foo"
});
p.done(function (value) {
throw new Error('Ooops!'); // thrown in next tick
});Promise.prototype.done = function (onFulfilled, onRejected) {
var self = arguments.length ? this.then.apply(this, arguments) : this
self.then(null, function (err) {
setTimeout(function () {
throw err
}, 0)
})
}和 .done 不同的是,.then 会返回一个promise
var p1 = new Promise(function(resolve, reject) {
resolve("Success!");
// or
// reject ("Error!");
});
p1.then(function(value) {
console.log(value); // Success!
}, function(reason) {
console.log(reason); // Error!
});
var p2 = new Promise(function(resolve, reject) {
resolve(1);
});
p2.then(function(value) {
console.log(value); // 1
return value + 1;
}).then(function(value) {
console.log(value); // 2
});finally() 方法返回一个 Promise。在 promise 结束时,无论结果是 fulfilled 或者是 rejected,都会执行指定的回调函数。这为在Promise是否成功完成后都需要执行的代码提供了一种方式。
这避免了同样的语句需要在then()和catch()中各写一次的情况。
var Promise = require('promise');
var p = Promise.resolve('foo');
var disposed = false;
p.then(function (value) {
if (Math.random() < 0.5) throw new Error('oops!');
else return value;
}).finally(function () {
disposed = true; // always called
}).then(function (value) {
console.log(value); // => "foo"
}, function (err) {
console.log(err); // => oops!
});Promise.prototype['finally'] = function (f) {
return this.then(function (value) {
return Promise.resolve(f()).then(function () {
return value;
});
}, function (err) {
return Promise.resolve(f()).then(function () {
throw err;
});
});
}详细见:https://www.promisejs.org/patterns/
源码库为then/promise
从 package.json 可以看到,promise 库的构建入口为 build.js 文件,我们执行构建后,也发现多创建了三个目录 lib、setimmediate、domains ,相关目录的代码文件变动都和 asap 这个模块有关系。

可以看到,这里出来混淆代码之外,还将 asap/raw 模块分别换成了 asap 和 setImmediate
那这个 asap/raw 和 asap 还有 setimmediate 的区别是什么呢?
共同点,都是立即对参数中的函数进行异步调用
不同点:
- asap 比 setimmediate 调用更快,而且调用的时候会阻止其他事件的处理 (默认)。
- asap/raw 和 asap 运行的原理一样,但不处理运行抛出的异常 (换来更多效率), 同时也支持不同域的事件绑定。https://www.npmjs.com/package/asap
- setimmediate 为JS自带的,但它是在当前所有I/O事件完成后去调用,速度上没有ASAP快。
所以 Promise 有额外的 promise/domains (支持domain) 和 promise/setimmediate (支持自定义setimmediate) 供调用。
核心代码是 core.js,所以这里只贴出这里的解析。
'use strict';
var asap = require('asap/raw');
function noop() {}
// States:
//
// 0 - pending
// 1 - fulfilled with _value
// 2 - rejected with _value
// 3 - adopted the state of another promise, _value
//
// once the state is no longer pending (0) it is immutable
// All `_` prefixed properties will be reduced to `_{random number}`
//// build的时候会把所有的预定义的属性转变为 `_{随机数}的形式做混淆,不鼓励直接使用他们,看build.js中的fixup混淆函数就懂了
// at build time to obfuscate them and discourage their use.
// We don't use symbols or Object.defineProperty to fully hide them
// because the performance isn't good enough.
// to avoid using try/catch inside critical functions, we
// extract them to here.
var LAST_ERROR = null; // 记录最新错误
var IS_ERROR = {}; // 错误标记符,什么值都可行,能作为唯一识别参考即可
// 获取then方法
function getThen(obj) {
try {
return obj.then;
} catch (ex) {
LAST_ERROR = ex;
return IS_ERROR;
}
}
// 执行函数fn,并传入参数a,这里目的是做好统一的异常错误处理
function tryCallOne(fn, a) {
try {
return fn(a); // 返回执行结果值
} catch (ex) {
LAST_ERROR = ex;
return IS_ERROR; // 返回异常
}
}
// 执行fn函数并传入参数,目的一样是统一处理好异常
function tryCallTwo(fn, a, b) {
try {
fn(a, b); // 无返回
} catch (ex) {
LAST_ERROR = ex;
return IS_ERROR; // 有异常则返回异常
}
}
module.exports = Promise;
// Promise 构造器
function Promise(fn) {
if (typeof this !== 'object') {
throw new TypeError('Promises must be constructed via new');
}
if (typeof fn !== 'function') {
throw new TypeError('Promise constructor\'s argument is not a function');
}
// 初始化状态等字段
this._deferredState = 0;
this._state = 0;
this._value = null;
this._deferreds = null;
// noop是作为某种情况的控制,不需要再执行 doResolve(传入空函数直接返回)
if (fn === noop) return;
// 开始正常流程处理
doResolve(fn, this);
}
Promise._onHandle = null;
Promise._onReject = null;
Promise._noop = noop;
// 原型链方法 then
Promise.prototype.then = function(onFulfilled, onRejected) {
// 如果this不是Promise 实例,则重新创建一个新的promise
if (this.constructor !== Promise) {
return safeThen(this, onFulfilled, onRejected);
}
// 创建一个空回调逻辑promise对象,用来创建 Handler
var res = new Promise(noop);
handle(this, new Handler(onFulfilled, onRejected, res));
return res;
};
// safeThen 的作用是当调用 then 的时候环境 this 已经不是 Promise 的情况下能够继续安全执行 then
function safeThen(self, onFulfilled, onRejected) {
return new self.constructor(function (resolve, reject) {
var res = new Promise(noop);
res.then(resolve, reject);
handle(self, new Handler(onFulfilled, onRejected, res));
});
}
/**
* 处理器函数,根据state的值来决定要做的事情
* @param {*} self
* @param {*} deferred
*/
function handle(self, deferred) {
// 当我们 resolve 接收到得是一个 promise 或 thenable 对象时,我们进入到 handle 后,会进入while循环,
// 直到 self 指向接收到的 promise,以接收到的 promise 的结果为标准
while (self._state === 3) {
self = self._value;
}
if (Promise._onHandle) { // 外部如果定义了 _onHandle的话这里处理一下
Promise._onHandle(self);
}
if (self._state === 0) {
// 在接收到的 promise 的 state===0 阶段我们会将原始 promise 中拿到得 onFulfilled 以及 onRejected 回调方法(包含在deferred对象中),
// 添加到接收到的 promise 的 _deferreds 中,然后return
if (self._deferredState === 0) {
self._deferredState = 1;
self._deferreds = deferred;
return;
}
if (self._deferredState === 1) {
self._deferredState = 2; // 这里的1,2不像_state的意义,仅仅是作为记录_deferreds的个数,然后在finale里边用到
self._deferreds = [self._deferreds, deferred];
return;
}
self._deferreds.push(deferred);
return;
}
// finale 函数进来的都不为0直接走这里了
handleResolved(self, deferred);
}
/**
* 这个函数执行完,promise 的执行过程就完成了
* @param {*} deferred 这里的deffered中的promise是在then的时候创建的空promise,什么都不会执行(直接进入 finale 无handle情况)
*/
function handleResolved(self, deferred) {
// 异步回调
asap(function() {
var cb = self._state === 1 ? deferred.onFulfilled : deferred.onRejected;
// 对应的回调为空时处理逻辑
if (cb === null) {
if (self._state === 1) {
resolve(deferred.promise, self._value);
} else {
reject(deferred.promise, self._value);
}
return;
}
// 回调不为空,执行回调逻辑
var ret = tryCallOne(cb, self._value);
// cb执行结果与异常处理
if (ret === IS_ERROR) {
reject(deferred.promise, LAST_ERROR);
} else {
resolve(deferred.promise, ret);
}
});
}
function resolve(self, newValue) {
// 这里依照标准的promise执行程序
// Promise Resolution Procedure: https://github.com/promises-aplus/promises-spec#the-promise-resolution-procedure
if (newValue === self) {
// 一个Promise的解决结果不能是自身,不然会出现循环处理的情况
return reject(
self,
new TypeError('A promise cannot be resolved with itself.')
);
}
// 值存在并且类型为对象或者函数时
if (
newValue &&
(typeof newValue === 'object' || typeof newValue === 'function')
) {
// 是否存在then函数
var then = getThen(newValue);
// 这里处理的是获取then的时候异常情况
if (then === IS_ERROR) {
return reject(self, LAST_ERROR);
}
// 结果是promise 对象,则状态跟着这个promise走
if (
then === self.then &&
newValue instanceof Promise
) {
self._state = 3; // 3表示结果还是promise的情况
self._value = newValue;
finale(self);
return;
} else if (typeof then === 'function') {
// 如果结果是一个包含then函数的对象(thenable),则继续走doResolve(基于then函数)
doResolve(then.bind(newValue), self);
return;
}
}
// newValue没什么特殊的,正常逻辑
self._state = 1; // fulfilled 状态
self._value = newValue;
finale(self);
}
function reject(self, newValue) {
self._state = 2;
self._value = newValue;
if (Promise._onReject) {
Promise._onReject(self, newValue);
}
finale(self);
}
/**
* 可以总结出在三种情况下调用了finale:
* 1、_state=3,等待其他promise的结果时
* 2、_state=1,完成的时候
* 3、_state=2,reject的时候
*
* 所以,只有在 promise 结束或者依赖其他 promise 的时候,才会进入finale.
* 功能:该函数主要为了取出之前放入的deffereds,调用handle,走finale逻辑时_state都非0,所以进入handle时,直接走了handleResolved
*/
function finale(self) {
if (self._deferredState === 1) { // 单deffered处理逻辑
handle(self, self._deferreds);
self._deferreds = null;
}
if (self._deferredState === 2) { // 多deffered处理多级
for (var i = 0; i < self._deferreds.length; i++) {
handle(self, self._deferreds[i]);
}
self._deferreds = null;
}
}
// Handler 类构造器,仅是包装 onFulfilled, onRejected, promise到一个实例上,deferred
function Handler(onFulfilled, onRejected, promise){
this.onFulfilled = typeof onFulfilled === 'function' ? onFulfilled : null;
this.onRejected = typeof onRejected === 'function' ? onRejected : null;
this.promise = promise;
}
/**
* Take a potentially misbehaving resolver function and make sure
* onFulfilled and onRejected are only called once.
*
* Makes no guarantees about asynchrony.
*
*/
function doResolve(fn, promise) {
var done = false;
// 同步的直接调用传入的函数,将两个function作为fn的参数传入,也就是外部new Promise时编写的 resolve 和 reject
var res = tryCallTwo(fn, function (value) {
if (done) return;
done = true;
// 处理 resolve 逻辑
resolve(promise, value);
}, function (reason) {
if (done) return;
done = true;
// 处理 reject 逻辑
reject(promise, reason);
});
// 如果fn执行出现异常则直接reject
if (!done && res === IS_ERROR) {
done = true;
reject(promise, LAST_ERROR);
}
}
/* Promise执行流程总结:
- 创建 Promise (new Promise)
- 设置需要执行的函数 (外部的resolve,reject)
- 设置完成的回调 (then调用后,通过handle处理deffered)
- 开始执行函数 (finale)
- 根据执行结果选择回调 (handleResolved) */欢迎交流和指出问题@giscafer
DOM (Document Object Model)是一种通过对象来表示结构化文档的方法,它是一种跨平台的、与语言无关的约定,用于表示HTML、XML和其他格式的数据并与之交互。浏览器通过处理DOM来实现细节,我们可以使用 JavaScript、CSS来与它交互。可以搜索节点并更改它的详细信息,删除或者插入新节点。
DOM 几乎是跨平台和跨浏览器的,那它有什么问题呢?主要问题是 DOM 从来没有为创建动态UI进行优化。
我们通过一张图来看浏览器是如何呈现web页面的:

浏览器中的页面呈现引擎解析HTML网页以创建DOM,同时解析CSS,并将CSS应用于HTML,和DOM组成一个渲染树(Render Tree),这个过程称为Attachment。布局过程(Layout)为每个节点提供精确的坐标,节点在其中进行绘制和展示。我们对DOM进行操作的时候,浏览器就会重复上边的渲染过程。
我们可以使用JavaScript 和像 jQuery这样的库去处理DOM,但它们在解决性能问题方面做得很少。想象一下,像微博、Twitter、Facebook 这种社交平台,页面滚动一定情况后,用户浏览器下将有数万个节点,使这些节点之间进行有效的交互、动态UI是一个巨大的问题。
Shadow DOM 是W3C工作草案标准。该规范描述了将多个DOM树组合成一个层次结构的方法,以及这些树如何在文档中相互交互,从而实现更好的DOM组合
参考:

指不是直接地接触DOM,而是构建它的抽象版本。这样我们使用DOM的某种轻量副本,就可以随意的修改它,然后保存到真正的DOM树种。保存时我们应该进行比较,找出DOM节点差异并更改(重新渲染)应该更改的内容。
它比直接操作DOM快得多,因为它不需要进入真正DOM的所有重量级部分。它工作得很好,但只有当我们以正确的方式使用它的时候。有两个问题需要解决:何时重新渲染DOM以及如何有效的实现它。
何时重新渲染DOM——当数据发送更改并需要更新时。
但我们怎么知道数据被改变了呢?
我们有两个选择:
脏值检测(dirty checking),定期轮询检测,并递归检测数据结构中的所有值。怎么做才能真正快速。
diff算法总结:Virtual DOM 是一种技术和一组库/算法,它允许我们通过避免直接使用DOM和只使用模拟DOM树的轻量级JavaScript对象来提高前端性能。
ReactJS 使用 Observale 来查找修改后的组件,每当在任何组件上调用 setState() 方法时,ReactJS 都会标记该组件为dirty,并重新渲染它。
无论何时调用 setState() 方法,ReactJS 都会从头创建整个 Virtual DOM ,创建整个Virtual DOM非常快,不影响性能。在任何给定的时间,ReactJS 维护两个 Virtual DOM,一个使用更新状态后的Virtual DOM,另一个使用之前(老的)状态的Virtual DOM。
ReactJS 使用 diff 算法 比较两个 Virtual DOM 去查找更新真实DOM(Real DOM)的最小步骤。在两棵树之间寻找最小修改数的复杂度为O(n^3)。但是React使用启发式方法,并带有一些假设,使得问题的复杂度为 O(n)。
ReactJS 使用以下步骤来查找两个Virtual DOM的不同之处:
shouldComponentUpdate() 生命周期方法,用来有效的减少一些没必要的渲染,提升性能Real DOM 哪些需要更新的过程:1、不同的元素类型将产生不同的树;2、开发人员可以通过设置key属性来告知 ReactJS 哪些子元素可能是稳定的。详细见官方文档docs/reconciliationReal DOM执行完所有步骤后,React将重新绘制 Real DOM。这意味着在事件循环期间,只有一次绘制 Real DOM。因此,所有的布局过程只会按时运行,以更新 Real DOM。

归功于VDOM,React Native 可以实现跨平台,详细:Does React Native have a 'Virtual DOM'?
koa中间件response.send、response.rounded、response.json发生了什么事,浏览器为什么能识别到它是一个json结构或是htmlkoa-bodyparser怎么来解析requestExpress 是一个轻量级的 Web Framework,自带Router、路由规则等,早期版本的 Express 还有bodyParser,后期剥离为独立模块作为中间件管理。其中间件模型是基于 callback回调 实现。
中间件 middlewares 是较多Web框架的核心概念,可以根据不同的业务场景,集成到框架中,进而增强框架的服务能力,而框架也是需要提供一套机制来保证中间件有序的执行。
在 Express 中,我们是通过 app.use(middleware()) 的方式注册中间件,见using-middleware文档。use的顺序和规则express都做了控制。我们可以看一下源码进行分析。
express.js
Express 服务实例将 Node.js 的 req 、res 对象传递给 app.handle 函数,使得handle内部具有req 、res 对象的控制权。handle函数还有一个叫 next 的参数, next 在中间件控制权起到了十分重要的作用。
application.js
app.handle中,如果是路由的情况,还会将控制权转给router.handle,并传入res、req、callback,app.use 方法作为 路由的 Router#use() 代理方法添加中间件到路由。
router/index.js
Router#use() 中使用了layer来存放中间件,类似一个等待执行的中间件堆叠层。
router.handle 方法三个参数为 res、req、out,第三个参数变化了名称为out,意思可以理解为这是要原路返回出去的。
这里关键部分在于内部函数 next,next会去查找匹配layer对叠层,如果匹配到,将会通过proto.process_params 来处理,将参数传递给layer层并执行,最后 layer.handle_request 执行的就是路由的handle。
function next(err) {
var layerError = err === 'route'
? null
: err;
……
// find next matching layer
var layer;
var match;
var route;
while (match !== true && idx < stack.length) {
layer = stack[idx++];
match = matchLayer(layer, path);
route = layer.route;
……
}
}整个过程中,next 起到了关键作用——所有的中间件都要执行next,从而把当前的控制权以回调的方式往下面传递。
response.send、response.json发生了什么事,浏览器为什么能识别到它是一个json结构或是htmlresponse.json 本质上也是调用 response.send 方法,所以只需要分析一下response.send 的源码即可。
res.send 中通过判断chunk (body) 的类型,以及Content-Type 的值,来动态设置 Content-Type类型,使得浏览器知道响应的内容是什么类型数据。Express请求响应Content-Type类型常见有:
res.type('.html');
res.type('html');
res.type('json');
res.type('application/json');
res.type('png');body-parser 如何解析request从源码可以看到,body-parser 通过根据请求报文主体的压缩格式Content-Encoding 类型,将获取到请求的内容流进行解析。主要做了以下几点的实现:
text、json、urlencoded,对应主体的格式不同utf8,gbk 等;gzip 、 deflate 、identity 等简单使用,在Express中,通过设置请求为json格式
app.use(bodyParser.json())
app.use(bodyParser.urlencoded({ extended: true }))Koa 是一个新的 web 框架,由 Express 幕后的原班人马打造, 致力于成为 web 应用和 API 开发领域中的一个更小、更富有表现力、更健壮的基石。 通过利用 async 函数,Koa 帮你丢弃回调函数,并有力地增强错误处理。 Koa 并没有捆绑任何中间件, 而是提供了一套优雅的方法,帮助您快速而愉快地编写服务端应用程序。
Koa1.0 是基于 co 实现,通过 Generator/yield 来控制异步(详细了解co模块与tj说:co是async/await的一块垫脚石)。随后 Koa2.0 改用 ES7 中的 async/await 来配合 Promise 实现异步控制。
上下文对象ctx是由 createContext 创建的。主要把一些属性和变量挂载到 context 上,以及request 和 response。对于将 ctx 添加到整个应用程序中使用的属性或方法非常有用,这可能会更加有效(不需要中间件)和/或 更简单(更少的require()),而更多依赖于 ctx ,这可以被认为是一种反模式。
当一个中间件调用 next(),则该函数暂停并将控制传递给定义的下一个中间件。当在下游没有更多的中间件执行后,堆栈展开并且每个中间件恢复执行其上游行为。
Koa 中间件构成实现模块是koa-compose (application源码构成中间件),是一个洋葱圈模型。
compose模块的源码也只有几十行:
/**
* Compose `middleware` returning
* a fully valid middleware comprised
* of all those which are passed.
*
* @param {Array} middleware
* @return {Function}
* @api public
*/
function compose (middleware) {
if (!Array.isArray(middleware)) throw new TypeError('Middleware stack must be an array!')
for (const fn of middleware) {
if (typeof fn !== 'function') throw new TypeError('Middleware must be composed of functions!')
}
/**
* @param {Object} context
* @return {Promise}
* @api public
*/
return function (context, next) {
// last called middleware #
let index = -1
return dispatch(0)
function dispatch (i) {
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
let fn = middleware[i]
if (i === middleware.length) fn = next
if (!fn) return Promise.resolve()
try {
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err)
}
}
}
}从源码可以看出,compose 对中间件进行了递归的操作,最终形成了一个中间件自执行链(只要第一个中间件执行了,随后的中间件都会依次被执行),这与koa1.0 版本基于co 实现一个目的,koa1.0 利用Thunk函数对 generator yield 异步操作封装成达到自执行目的。Koa2 之后,就改用 async/await 配合 promise 来实现了,上边代码就是中间件自执行操作的核心。
每个中间件都被封装成了一个 Promise对象。(这也是可以猜到的,因为 await 配合 Promise 才是最佳的。)
如下例子:
const Koa = require('koa');
const app = new Koa();
app.use(async function m1(ctx, next) {
console.log('m1');
await next(); // 暂停进入下一个中间件
console.log('m1 end');
const rt = ctx.response.get('X-Response-Time');
console.log(`${ctx.method} ${ctx.url} - ${rt}`);
});
app.use(async function m2(ctx, next) {
const start = Date.now();
console.log('m2');
await next(); // 暂停进入下一个中间件
console.log('m2 end');
const ms = Date.now() - start;
ctx.set('X-Response-Time', `${ms}ms`);
});
app.use(async function m3(ctx, next) {
console.log('m3');
ctx.body = 'Hello World!';
});
app.listen(3000);输出结果:
// 请求开始
m1
// m1中await next()进入暂停,进入下一个中间件m2
m2
// m2中await next()进入暂停,进入下一个中间件m3
m3
// 洋葱模型,逆向回去,先m2的
m2 end
// 洋葱模型,逆向回去,m2执行完毕后进行上游m1的
m1 end
GET / - 2ms
// 响应结束
Koa 还提供了异常处理的解决方式,统一的异常处理源码见ctx.onerror,我们可以使用 app.on('error',()=>{}) 来统一错误处理。
参考资料
https://www.zhihu.com/question/38879363
https://www.imooc.com/article/22994
https://www.cnblogs.com/chyingp/p/nodejs-learning-express-body-parser.html
https://juejin.im/post/5a62bab4f265da3e58596f40
Undefined、Null、Boolean、Number、String、Object
Object 是 JavaScript 中所有对象的父对象
数据封装类对象:Object、Array、Boolean、Number 和 String
其他对象:Function、Arguments、Math、Date、RegExp、Error
1.不要在同一行声明多个变量。
2.请使用 ===/!==来比较true/false或者数值
3.使用对象字面量替代new Array这种形式
4.不要使用全局函数。
5.Switch语句必须带有default分支
6.函数不应该有时候有返回值,有时候没有返回值。
7.For循环必须使用大括号
8.If语句必须使用大括号
9.for-in循环中的变量 应该使用var关键字明确限定作用域,从而避免作用域污染。
每个对象都会在其内部初始化一个属性,就是prototype(原型),当我们访问一个对象的属性时,
如果这个对象内部不存在这个属性,那么他就会去prototype里找这个属性,这个prototype又会有自己的prototype,
于是就这样一直找下去,也就是我们平时所说的原型链的概念。
关系:instance.constructor.prototype = instance.__proto__
特点:
JavaScript对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与之相关的对象也会继承这一改变。
当我们需要一个属性的时,Javascript引擎会先看当前对象中是否有这个属性, 如果没有的话,
就会查找他的Prototype对象是否有这个属性,如此递推下去,一直检索到 Object 内建对象。
function Func(){}
Func.prototype.name = "Sean";
Func.prototype.getInfo = function() {
return this.name;
}
var person = new Func();//现在可以参考var person = Object.create(oldObject);
console.log(person.getInfo());//它拥有了Func的属性和方法
//"Sean"
console.log(Func.prototype);
// Func { name="Sean", getInfo=function()}
栈:原始数据类型(Undefined,Null,Boolean,Number、String)
堆:引用数据类型(对象、数组和函数)
两种类型的区别是:存储位置不同;
原始数据类型直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储;
引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定,如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其
在栈中的地址,取得地址后从堆中获得实体
1、构造继承
2、原型继承
3、实例继承
4、拷贝继承
原型prototype机制或apply和call方法去实现较简单,建议使用构造函数与原型混合方式。
function Parent(){
this.name = 'wang';
}
function Child(){
this.age = 28;
}
Child.prototype = new Parent();//继承了Parent,通过原型
var demo = new Child();
alert(demo.age);
alert(demo.name);//得到被继承的属性
}
javascript创建对象简单的说,无非就是使用内置对象或各种自定义对象,当然还可以用JSON;但写法有很多种,也能混合使用。
1、对象字面量的方式
person={firstname:"Mark",lastname:"Yun",age:25,eyecolor:"black"};
2、用function来模拟无参的构造函数
function Person(){}
var person=new Person();//定义一个function,如果使用new"实例化",该function可以看作是一个Class
person.name="Mark";
person.age="25";
person.work=function(){
alert(person.name+" hello...");
}
person.work();
3、用function来模拟参构造函数来实现(用this关键字定义构造的上下文属性)
function Pet(name,age,hobby){
this.name=name;//this作用域:当前对象
this.age=age;
this.hobby=hobby;
this.eat=function(){
alert("我叫"+this.name+",我喜欢"+this.hobby+",是个程序员");
}
}
var maidou =new Pet("麦兜",25,"coding");//实例化、创建对象
maidou.eat();//调用eat方法
4、用工厂方式来创建(内置对象)
var wcDog =new Object();
wcDog.name="旺财";
wcDog.age=3;
wcDog.work=function(){
alert("我是"+wcDog.name+",汪汪汪......");
}
wcDog.work();
5、用原型方式来创建
function Dog(){
}
Dog.prototype.name="旺财";
Dog.prototype.eat=function(){
alert(this.name+"是个吃货");
}
var wangcai =new Dog();
wangcai.eat();
5、用混合方式来创建
function Car(name,price){
this.name=name;
this.price=price;
}
Car.prototype.sell=function(){
alert("我是"+this.name+",我现在卖"+this.price+"万元");
}
var camry =new Car("凯美瑞",27);
camry.sell();
全局函数无法查看局部函数的内部细节,但局部函数可以查看其上层的函数细节,直至全局细节。
当需要从局部函数查找某一属性或方法时,如果当前作用域没有找到,就会上溯到上层作用域查找,
直至全局函数,这种组织形式就是作用域链。
它的功能是把对应的字符串解析成JS代码并运行;
应该避免使用eval,不安全,非常耗性能(2次,一次解析成js语句,一次执行)。
由JSON字符串转换为JSON对象的时候可以用eval,var obj =eval('('+ str +')');
null 表示一个对象被定义了,值为“空值”;
undefined 表示不存在这个值。
typeof undefined
//"undefined"
undefined :是一个表示"无"的原始值或者说表示"缺少值",就是此处应该有一个值,但是还没有定义。当尝试读取时会返回 undefined;
例如变量被声明了,但没有赋值时,就等于undefined
typeof null
//"object"
null : 是一个对象(空对象, 没有任何属性和方法);
例如作为函数的参数,表示该函数的参数不是对象;
注意:
在验证null时,一定要使用 === ,因为 == 无法分别 null 和 undefined
再来一个例子:
null
Q:有张三这个人么?
A:有!
Q:张三有房子么?
A:没有!
undefined
Q:有张三这个人么?
A:没有!
参考阅读:undefined与null的区别
// event(事件)工具集,来源:github.com/markyun
markyun.Event = {
// 页面加载完成后
readyEvent : function(fn) {
if (fn==null) {
fn=document;
}
var oldonload = window.onload;
if (typeof window.onload != 'function') {
window.onload = fn;
} else {
window.onload = function() {
oldonload();
fn();
};
}
},
// 视能力分别使用dom0||dom2||IE方式 来绑定事件
// 参数: 操作的元素,事件名称 ,事件处理程序
addEvent : function(element, type, handler) {
if (element.addEventListener) {
//事件类型、需要执行的函数、是否捕捉
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent('on' + type, function() {
handler.call(element);
});
} else {
element['on' + type] = handler;
}
},
// 移除事件
removeEvent : function(element, type, handler) {
if (element.removeEventListener) {
element.removeEventListener(type, handler, false);
} else if (element.datachEvent) {
element.detachEvent('on' + type, handler);
} else {
element['on' + type] = null;
}
},
// 阻止事件 (主要是事件冒泡,因为IE不支持事件捕获)
stopPropagation : function(ev) {
if (ev.stopPropagation) {
ev.stopPropagation();
} else {
ev.cancelBubble = true;
}
},
// 取消事件的默认行为
preventDefault : function(event) {
if (event.preventDefault) {
event.preventDefault();
} else {
event.returnValue = false;
}
},
// 获取事件目标
getTarget : function(event) {
return event.target || event.srcElement;
},
// 获取event对象的引用,取到事件的所有信息,确保随时能使用event;
getEvent : function(e) {
var ev = e || window.event;
if (!ev) {
var c = this.getEvent.caller;
while (c) {
ev = c.arguments[0];
if (ev && Event == ev.constructor) {
break;
}
c = c.caller;
}
}
return ev;
}
};
[1, NaN, NaN] 因为 parseInt 需要两个参数 (val, radix),
其中 radix 表示解析时用的基数。
map 传了 3 个 (element, index, array),对应的 radix 不合法导致解析失败。
1. 我们在网页中的某个操作(有的操作对应多个事件)。例如:当我们点击一个按钮就会产生一个事件。是可以被 JavaScript 侦测到的行为。
2. 事件处理机制:IE是事件冒泡、Firefox同时支持两种事件模型,也就是:捕获型事件和冒泡型事件;
3. ev.stopPropagation();(旧ie的方法 ev.cancelBubble = true;)
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,通过另一个函数访问这个函数的局部变量,利用闭包可以突破作用链域,将函数内部的变量和方法传递到外部。
闭包的特性:
1.函数内再嵌套函数
2.内部函数可以引用外层的参数和变量
3.参数和变量不会被垃圾回收机制回收
//li节点的onclick事件都能正确的弹出当前被点击的li索引
<ul id="testUL">
<li> index = 0</li>
<li> index = 1</li>
<li> index = 2</li>
<li> index = 3</li>
</ul>
<script type="text/javascript">
var nodes = document.getElementsByTagName("li");
for(i = 0;i<nodes.length;i+= 1){
nodes[i].onclick = function(){
console.log(i+1);//不用闭包的话,值每次都是4
}(i);
}
</script>
执行say667()后,say667()闭包内部变量会存在,而闭包内部函数的内部变量不会存在
使得Javascript的垃圾回收机制GC不会收回say667()所占用的资源
因为say667()的内部函数的执行需要依赖say667()中的变量
这是对闭包作用的非常直白的描述
function say667() {
// Local variable that ends up within closure
var num = 666;
var sayAlert = function() {
alert(num);
}
num++;
return sayAlert;
}
var sayAlert = say667();
sayAlert()//执行结果应该弹出的667
use strict是一种ECMAscript 5 添加的(严格)运行模式,这种模式使得 Javascript 在更严格的条件下运行,
使JS编码更加规范化的模式,消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为。
默认支持的糟糕特性都会被禁用,比如不能用with,也不能在意外的情况下给全局变量赋值;
全局变量的显示声明,函数必须声明在顶层,不允许在非函数代码块内声明函数,arguments.callee也不允许使用;
消除代码运行的一些不安全之处,保证代码运行的安全,限制函数中的arguments修改,严格模式下的eval函数的行为和非严格模式的也不相同;
提高编译器效率,增加运行速度;
为未来新版本的Javascript标准化做铺垫。
使用instanceof (待完善)
if(a instanceof Person){
alert('yes');
}
1、创建一个空对象,并且 this 变量引用该对象,同时还继承了该函数的原型。
2、属性和方法被加入到 this 引用的对象中。
3、新创建的对象由 this 所引用,并且最后隐式的返回 this 。
var obj = {};
obj.__proto__ = Base.prototype;
Base.call(obj);
hasOwnProperty
javaScript中hasOwnProperty函数方法是返回一个布尔值,指出一个对象是否具有指定名称的属性。此方法无法检查该对象的原型链中是否具有该属性;该属性必须是对象本身的一个成员。
使用方法:
object.hasOwnProperty(proName)
其中参数object是必选项。一个对象的实例。
proName是必选项。一个属性名称的字符串值。
如果 object 具有指定名称的属性,那么JavaScript中hasOwnProperty函数方法返回 true,反之则返回 false。
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。
它是基于JavaScript的一个子集。数据格式简单, 易于读写, 占用带宽小
如:{"age":"12", "name":"back"}
JSON字符串转换为JSON对象:
var obj =eval('('+ str +')');
var obj = str.parseJSON();
var obj = JSON.parse(str);
JSON对象转换为JSON字符串:
var last=obj.toJSONString();
var last=JSON.stringify(obj);
[].forEach.call($$("*"),function(a){a.style.outline="1px solid #"+(~~(Math.random()*(1<<24))).toString(16)}) 能解释一下这段代码的意思吗?defer和async、动态创建DOM方式(用得最多)、按需异步载入js
ajax的全称:Asynchronous Javascript And XML。
异步传输+js+xml。
所谓异步,在这里简单地解释就是:向服务器发送请求的时候,我们不必等待结果,而是可以同时做其他的事情,等到有了结果它自己会根据设定进行后续操作,与此同时,页面是不会发生整页刷新的,提高了用户体验。
(1)创建XMLHttpRequest对象,也就是创建一个异步调用对象
(2)创建一个新的HTTP请求,并指定该HTTP请求的方法、URL及验证信息
(3)设置响应HTTP请求状态变化的函数
(4)发送HTTP请求
(5)获取异步调用返回的数据
(6)使用JavaScript和DOM实现局部刷新
同步的概念应该是来自于OS中关于同步的概念:不同进程为协同完成某项工作而在先后次序上调整(通过阻塞,唤醒等方式).同步强调的是顺序性.谁先谁后.异步则不存在这种顺序性.
同步:浏览器访问服务器请求,用户看得到页面刷新,重新发请求,等请求完,页面刷新,新内容出现,用户看到新内容,进行下一步操作。
异步:浏览器访问服务器请求,用户正常操作,浏览器后端进行请求。等请求完,页面不刷新,新内容也会出现,用户看到新内容。
(待完善)
jsonp、 iframe、window.name、window.postMessage、服务器上设置代理页面
页面编码和被请求的资源编码如果不一致如何处理?
模块化开发怎么做?
立即执行函数,不暴露私有成员
var module1 = (function(){
var _count = 0;
var m1 = function(){
//...
};
var m2 = function(){
//...
};
return {
m1 : m1,
m2 : m2
};
})();
(待完善)
AMD 规范在这里:https://github.com/amdjs/amdjs-api/wiki/AMD
CMD 规范在这里:seajs/seajs#242
Asynchronous Module Definition,异步模块定义,所有的模块将被异步加载,模块加载不影响后面语句运行。所有依赖某些模块的语句均放置在回调函数中。
区别:
1. 对于依赖的模块,AMD 是提前执行,CMD 是延迟执行。不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。CMD 推崇 as lazy as possible.
2. CMD 推崇依赖就近,AMD 推崇依赖前置。看代码:
// CMD
define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
// 此处略去 100 行
var b = require('./b') // 依赖可以就近书写
b.doSomething()
// ...
})
// AMD 默认推荐
define(['./a', './b'], function(a, b) { // 依赖必须一开始就写好
a.doSomething()
// 此处略去 100 行
b.doSomething()
// ...
})
(1) defer,只支持IE
(2) async:
(3) 创建script,插入到DOM中,加载完毕后callBack
documen.write和 innerHTML的区别
document.write只能重绘整个页面
innerHTML可以重绘页面的一部分
DOM操作——怎样添加、移除、移动、复制、创建和查找节点?
(1)创建新节点
createDocumentFragment() //创建一个DOM片段
createElement() //创建一个具体的元素
createTextNode() //创建一个文本节点
(2)添加、移除、替换、插入
appendChild()
removeChild()
replaceChild()
insertBefore() //在已有的子节点前插入一个新的子节点
(3)查找
getElementsByTagName() //通过标签名称
getElementsByName() //通过元素的Name属性的值(IE容错能力较强,会得到一个数组,其中包括id等于name值的)
getElementById() //通过元素Id,唯一性
.call() 和 .apply() 的区别?
例子中用 add 来替换 sub,add.call(sub,3,1) == add(3,1) ,所以运行结果为:alert(4);
注意:js 中的函数其实是对象,函数名是对 Function 对象的引用。
function add(a,b)
{
alert(a+b);
}
function sub(a,b)
{
alert(a-b);
}
add.call(sub,3,1);
*jQuery是一个js库,主要提供的功能是选择器,属性修改和事件绑定等等。
*jQuery UI则是在jQuery的基础上,利用jQuery的扩展性,设计的插件。
提供了一些常用的界面元素,诸如对话框、拖动行为、改变大小行为等等
jQuery中没有提供这个功能,所以你需要先编写两个jQuery的扩展:
$.fn.stringifyArray = function(array) {
return JSON.stringify(array)
}
$.fn.parseArray = function(array) {
return JSON.parse(array)
}
然后调用:
$("").stringifyArray(array)
*基于Class的选择性的性能相对于Id选择器开销很大,因为需遍历所有DOM元素。
*频繁操作的DOM,先缓存起来再操作。用Jquery的链式调用更好。
比如:var str=$("a").attr("href");
*for (var i = size; i < arr.length; i++) {}
for 循环每一次循环都查找了数组 (arr) 的.length 属性,在开始循环的时候设置一个变量来存储这个数字,可以让循环跑得更快:
for (var i = size, length = arr.length; i < length; i++) {}
Zepto的点透问题如何解决?
jQueryUI如何自定义组件?
需求:实现一个页面操作不会整页刷新的网站,并且能在浏览器前进、后退时正确响应。给出你的技术实现方案?
如何判断当前脚本运行在浏览器还是node环境中?(阿里)
通过判断Global对象是否为window,如果不为window,当前脚本没有运行在浏览器中
移动端最小触控区域是多大?
jQuery 的 slideUp动画 ,如果目标元素是被外部事件驱动, 当鼠标快速地连续触发外部元素事件, 动画会滞后的反复执行,该如何处理呢?
把 Script 标签 放在页面的最底部的body封闭之前 和封闭之后有什么区别?浏览器会如何解析它们?
移动端的点击事件的有延迟,时间是多久,为什么会有? 怎么解决这个延时?(click 有 300ms 延迟,为了实现safari的双击事件的设计,浏览器要知道你是不是要双击操作。)
知道各种JS框架(Angular, Backbone, Ember, React, Meteor, Knockout...)么? 能讲出他们各自的优点和缺点么?
Underscore 对哪些 JS 原生对象进行了扩展以及提供了哪些好用的函数方法?
解释JavaScript中的作用域与变量声明提升?
那些操作会造成内存泄漏?
内存泄漏指任何对象在您不再拥有或需要它之后仍然存在。
垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
setTimeout 的第一个参数使用字符串而非函数的话,会引发内存泄漏。
闭包、控制台日志、循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
JQuery一个对象可以同时绑定多个事件,这是如何实现的?
Node.js的适用场景?
(如果会用node)知道route, middleware, cluster, nodemon, pm2, server-side rendering么?
解释一下 Backbone 的 MVC 实现方式?
什么是“前端路由”?什么时候适合使用“前端路由”? “前端路由”有哪些优点和缺点?
知道什么是webkit么? 知道怎么用浏览器的各种工具来调试和debug代码么?
如何测试前端代码么? 知道BDD, TDD, Unit Test么? 知道怎么测试你的前端工程么(mocha, sinon, jasmin, qUnit..)?
前端templating(Mustache, underscore, handlebars)是干嘛的, 怎么用?
简述一下 Handlebars 的基本用法?
简述一下 Handlerbars 的对模板的基本处理流程, 如何编译的?如何缓存的?
用js实现千位分隔符?(来源:前端农民工,提示:正则+replace)
function commafy(num) {
num = num + '';
var reg = /(-?d+)(d{3})/;
if(reg.test(num)){
num = num.replace(reg, '$1,$2');
}
return num;
}
检测浏览器版本版本有哪些方式?
功能检测、userAgent特征检测
比如:navigator.userAgent
//"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36"
What is a Polyfill?
polyfill 是“在旧版浏览器上复制标准 API 的 JavaScript 补充”,可以动态地加载 JavaScript 代码或库,在不支持这些标准 API 的浏览器中模拟它们。
例如,geolocation(地理位置)polyfill 可以在 navigator 对象上添加全局的 geolocation 对象,还能添加 getCurrentPosition 函数以及“坐标”回调对象,
所有这些都是 W3C 地理位置 API 定义的对象和函数。因为 polyfill 模拟标准 API,所以能够以一种面向所有浏览器未来的方式针对这些 API 进行开发,
一旦对这些 API 的支持变成绝对大多数,则可以方便地去掉 polyfill,无需做任何额外工作。
做的项目中,有没有用过或自己实现一些 polyfill 方案(兼容性处理方案)?
比如: html5shiv、Geolocation、Placeholder
我们给一个dom同时绑定两个点击事件,一个用捕获,一个用冒泡。会执行几次事件,会先执行冒泡还是捕获?
Object.is() 与原来的比较操作符“ ===”、“ ==”的区别?
两等号判等,会在比较时进行类型转换;
三等号判等(判断严格),比较时不进行隐式类型转换,(类型不同则会返回false);
Object.is 在三等号判等的基础上特别处理了 NaN 、-0 和 +0 ,保证 -0 和 +0 不再相同,
但 Object.is(NaN, NaN) 会返回 true.
Object.is 应被认为有其特殊的用途,而不能用它认为它比其它的相等对比更宽松或严格。
Low-Code 一词早在 2014 年就由 Forrester 提出了。(见 wikipedia)。
你 Google 搜关键词 “Low-code development platform” 可以找到很多关于 Low-Code 的内容。类似的词有** Pro-Code(纯代码)、Less Code(少写代码)、No-Code(无代码、自动化)**。Low-Code 应该介于 Less Code 与 No-Code 之间。
低代码开发平台能够实现业务应用的快速交付。也就是说,不只是像传统开发平台一样“能”开发应用而已,低代码开发平台的重点是开发应用更“快”。更重要的是,这个快的程度是颠覆性的:根据Forrester在2016年的调研,大部分公司反馈低代码平台帮助他们把开发效率提升了5-10倍。而且我们有理由相信,随着低代码技术、产品和行业的不断成熟,这个提升倍数还能继续上涨。
低代码开发平台能够降低业务应用的开发成本。一方面,低代码开发在软件全生命周期流程上的投入都要更低(代码编写更少、环境设置和部署成本也更简单);另一方面,低代码开发还显著降低了开发人员的使用门槛,非专业开发者经过简单的IT基础培训就能快速上岗,既能充分调动和利用企业现有的各方面人力资源,也能大幅降低对昂贵专业开发者资源的依赖。
更多介绍>> 文章:什么是低代码平台?
搜索相关类别的开源项目,可以利用 Github 主题分类的筛选方式,比如 https://github.com/topics/low-code-development-platform,可以点击 Star 关注这类主题,日后 Github 会在你的个人主页推送相关的流行项目。
阿里的物料平台、前端解决方案,详细介绍见 关于飞冰
试用感受:大而全。可以整合自己的物料,根据飞冰的规范、定制自己的物料生态。飞冰出来好几年了,但也未见很多团队去使用开来,有可能是大家使用源码自答了私服?团队太小,不适合使用,团队大了,自身业务和设计也有自己的特色,用不起来,不如自己搭建物料平台。没有自研能力的时候,可以去试用看是否能借飞冰来提升研发效能或者是沉淀自己的物料资源。
Budibase是一个开源的低代码开发平台
试用感受:暂未体验,不过看官方感觉挺不错
阿里巴巴集团统一表单解决方案。
试用感受:是一个表单框架,主要是阿里业务中后台表单的沉淀,对于大众也比较试用,表单组件库以及schema表单都支持,是写代码的表单方案。
百度开源的前端低代码框架,通过 JSON 配置就能生成各种页面。
**试用感受:**通过 JSON 配置就能生成各种后台页面,极大减少开发成本,甚至可以不需要了解前端。在一些只注重数据处理和展示的平台中,少定制化的情况下比较适合试用。
n8n是一个可扩展的工作流自动化工具。通过 Fair-code 的代码分发模式,可以自托管,并允许您添加自己的自定义功能代码逻辑和应用程序。n8n 基于节点的方法使它具有高度通用性,使您能够将任何东西连接到所有东西。
**试用感受:**可以自己去看个2分钟的视频 https://www.youtube.com/watch?v=3w7xIMKLVAg , 这类项目适合结合 DevOps 去实践。
支持多UI组件,Angular 技术栈,团队持续维护
组件可视化拖拽,页面搭建,源码生成工具,自由拖拽嵌套,可实现任何真实开发中的复杂页面,所见即所得,可完美还原UI设计,多平台展示支持。
试用感受:支持手机和PC两种平台,生成源码 react + antd 的源码可直接使用,组件基本满足开发场景,对于没有物料市场、模板工程、脚手架的团队,可以说是一个方便的工具。
类似易企秀的H5制作、建站工具、可视化搭建系统。
试用感受:H5 页面完善度不错,可以支持多页H5编辑,是一个可以直接使用的开源项目。
基于vue2 + koa2的 H5制作工具。让不会写代码的人也能轻松快速上手制作H5页面。类似易企秀、百度H5等H5制作、建站工具。
试用感受:H5页面只做,基本满足要求,可存储模板,组件和细节完善的话是可以使用到业务场景中的一个项目。
基于vue的高扩展在线网页制作平台,可自定义组件,可添加脚本,可数据统计。
试用感受:比上边几个同类H5好很多,还有组件商城。
核心目标仅有一条“提升研发效率”,目前提供基于vue、element-ui组件库中后台项目的实践,实时输出源代码。
感受:后续团队内部的物料平台搭建,可以考虑参考。
几年前,为了提供团队内的研发效率,自己也研究过类似的小应用。比如基于 json schema 实现表单页面自动生成并产出源代码的学习工程: ngx-form-builder
现在 Low-Code 的流行,越来越多的开源项目可以参考学习。是否能被自己所用,还需要结合公司的产品业务、团队的情况去看,类似的时候,进行开源项目的改造也是可以探索一下研发效能的提升。
最近项目要搞一个可视化大屏编辑器,就是那种数据大屏,通过编辑器拖和编辑实现。也因为自己之前学习了解一些Low-Code平台的东西,才能短时间内在技术上可以hold住。短时间=几周实现一个编辑器,疯了吗?我都觉得疯了,项目时间不合理,只能硬着头往前赶。
开发不到一周的编辑器雏形:

推荐阅读:
「可视化搭建系统」——从设计到架构,探索前端领域技术和业务价值 - Lucas HC的文章 - 知乎 https://zhuanlan.zhihu.com/p/164558106
从 Flux 到 Redux ,还有 Vux 、Mobx 等,前端数据流和状态存储的控制库很多,也很强大,适用于复杂的项目中对数据状态的管理和组件之间的通信控制。另外加入响应式编程的 RxJS 的话,就变得更强大了……
本篇和上边的各种都无感,只是分析如何实现一个极简的全局变量存储和支持订阅状态属性变化。
lodash 有 _.set(obj,key,value) 和 _.get(obj,key) 这些方法。如下
_.set(obj,key,value)
var object = { 'a': [{ 'b': { 'c': 3 } }] };
_.set(object, 'a[0].b.c', 4);
console.log(object.a[0].b.c);
// => 4
_.set(object, ['x', '0', 'y', 'z'], 5);
console.log(object.x[0].y.z);
// => 5_.get(obj,key)
var object = { 'a': [{ 'b': { 'c': 3 } }] };
_.get(object, 'a[0].b.c');
// => 3
_.get(object, ['a', '0', 'b', 'c']);
// => 3
_.get(object, 'a.b.c', 'default');
// => 'default'下边自己实现模拟类似的 set/get 方法,定义名为 Store 的类 :
(1)Store.set 方法实现类似 _.set 效果

(2)Store.get 方法实现类似 _.get 效果

export const data = {}; // 管理全局数据
export const observers = {}; // 管理所有Observer实例
export const uuid = () => {
return Math.random()
.toString(16)
.substr(2);
};
export class Observer {
id: string;
key: string;
fn: Function;
constructor(id: string, key: string, fn: Function) {
this.id = id || uuid();
this.key = key;
this.fn = fn;
}
// 模拟解除监听
unsubscribe() {
delete observers[this.id];
}
}Store.set 和 Store.get 函数的第一个参数 obj 都移除,变成内部直接使用 data;subscribe 静态函数,实现订阅效果import { Observer, uuid, observers, data } from "./observer";
class Store {
// 模拟lodash(或underscore)的函数 _.set()
static set(key, val) {
if (!key) {
return;
}
if (typeof key !== "string") {
return;
}
let props = key.split(".");
let value = data;
for (let i = 0; i < props.length - 1; i++) {
const prop = props[i];
if (!value[prop]) {
value[prop] = {};
}
value = data[prop];
}
value[props[props.length - 1]] = val;
}
// 模拟lodash(或underscore)的函数 _.get()
static get(key) {
if (!key) {
return;
}
if (typeof key !== "string") {
return;
}
const props = key.split(".");
let value;
for (let i = 0; i < props.length; i++) {
const prop = props[i];
if (i === 0 && !data[prop]) {
return undefined;
}
if (!value) {
value = data[prop];
} else {
value = value[prop];
}
}
return value;
}
// 订阅
static subscribe(key, fn) {
const id = uuid();
const ob = new Observer(id, key, fn);
observers[id] = ob;
const val = this.get(key);
if (val !== null && val !== undefined) {
fn(val);
}
return ob;
}
}
// test set()
Store.set("sex", "male");
Store.set("name.first", "Nickbing");
Store.set("name.last", "Lao");
console.log(data);
// 输出:{ sex: 'male', name: { first: 'Nickbing', last: 'Lao' } }
// test get()
console.log(Store.get("sex")); // 输出:male
console.log(Store.get("name.last")); // 输出:Lao
// test subscribe()
Store.subscribe('name', (res) => {
console.log(`subscribe的结果:${JSON.stringify(res)}`)
})
// 输出:subscribe的结果:{"first":"Nickbing","last":"Lao"}到此,已实现的内容有:
订阅监听效果就是属性值发生变化,就会触发 subscribe 函数的调用,所以我们需要修改 Store.set 这个静态方法,使得值设置变化时,触发 subscribe 绑定的回调函数调用。
// 模拟lodash(或underscore)的函数 _.set()
static set(key, val) {
if (!key) {
return;
}
if (typeof key !== "string") {
return;
}
let props = key.split(".");
let value = data;
for (let i = 0; i < props.length - 1; i++) {
const prop = props[i];
if (!value[prop]) {
value[prop] = {};
}
value = data[prop];
}
value[props[props.length - 1]] = val;
// 新增
// 触发已有的订阅回调
for (let id in observers) {
const observer = observers[id];
if (key.indexOf(observer.key) === 0 || key === observer.key) {
if (observer.fn) {
observer.fn(val);
}
}
}
}新增 updated 函数,主动触发更新所有监听 key 的回调:
static updated(key: string) {
for (const id in observers) {
if (key.indexOf(observers[id].key) === 0) {
observers[id].fn(Store.get(observers[id].key));
}
}
}通过上边步骤,依次实现了
源码参考:le5le-store
如果要执行规范,工具是一定要有的。通过工具来限制开发人员的习惯的,一方面保证所有人参与项目都强制按照统一的规范来操作,另一方面是如果你没有工具去强制执行规范,不是每个人都会自觉遵守,行为规范没法统一的话,规范也就没有多少存在的意义了。
我们对如何格式化 git 提交消息有非常精确的规则。这样可以查看更易读的消息,这些消息在查看项目历史记录时很容易理解。规范提交信息后,我们可以通过工具将 git commit 消息来生成 {工程项目} 更改日志,每次版本发布都会有一个清晰的日记列表。
每个提交消息由 header, body 和 footer。 标头具有特殊格式,包括 type, scope 和 subject:
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>
所述 header 是必须的,而 scope 的报头的是可选的。
提交消息的任何行都不能超过100个字符!这允许在GitHub以及各种git工具中更容易阅读消息。
页脚应包含 closing reference to an issue (如果有).
(更多见 samples)
docs(changelog): update change log to beta.5
fix(release): need to depend on latest rxjs and zone.js
The version in our package.json gets copied to the one we publish, and users need the latest of these.
如果提交恢复先前的提交,则它应该以 revert: ,然后是还原提交的标头开头。在正文中它应该说:This reverts commit <hash>.,其中哈希是被还原的提交的SHA。
必须是以下之一:
范围应该是受影响的模块的名称(文件夹名称或其他有意义的单词),并且应该以模块为前缀:(由读取由提交消息生成的更改日志的人员感知
以下是一些例子:
“使用模块名称”规则目前有一些例外:
style, test 以及 refactor 所做的更改 (e.g. style: add missing semicolons)该主题包含对变更的简洁描述:
就像 subject 一样, 使用命令式,现在时: "change" 而非 "changed" 和 "changes"。
body 应该包括改变的动机,并将其与之前的行为进行对比。
页脚应包含有关 Breaking Changes任何信息,也是引用此提交 Closes GitHub问题的地方。.
Breaking Changes 应该以 BREAKING CHANGE: 带有空格或两个换行符的单词开头。然后将其余的提交消息用于此目的。
详细的解释请看这里 document.
以下是前端工程的提交日记举例:
利用 husky (哈士奇来看门) 可以阻止一些不规范 的 git commit, git push 操作。使用方式见官方文档,比较详细。
以下是个人在项目的实践,package.json中加入 :
"husky": {
"hooks": {
"commit-msg": "node ./scripts/git/commit-msg.js -E HUSKY_GIT_PARAMS",
"pre-commit": "pretty-quick --staged"
}
}git commit 之前会触发 pre-commit hooks,执行脚本 pretty-quick --staged ,用来自动格式化代码。格式化代码统一一个格式化工具,缩进等(可能会和编辑器配置文件.editorconfig配合使用),保证整个项目在代码提交到仓库之前,都是统一的格式化风格,这样就不存在多个开发人员改一个文件,缩进时影响到很多代码行的问题了,对 CR 时体验较好。所以,这个步骤也是必不可少的。
1、需要安装两个模块:
npm i --save-dev prettier pretty-quick2、配置规则文件 .prettierrc 和 忽略文件 .prettierignore
.prettierrc
{
"singleQuote": true,
"printWidth": 120,
"tabWidth": 2,
"useTabs": false,
"overrides": [
{
"files": ".prettierrc",
"options": {
"parser": "json"
}
}
]
}.prettierignore
**/*.svg
**/test.ts
**/*.less
coverage/
publish/
schematics/
**/template/*
**/i18n/*
首次安装环境时,可以测试看效果

git commit 时,会触发 commit-msg hooks,执行脚本 node ./scripts/git/commit-msg.js -E HUSKY_GIT_PARAMS
脚本可以参考 Angular 工程的 commit-msg.js来自定义规范要求,也可以直接使用commitlint,当 git message 不符合规范的时候,提交时检测不通过会有如下提示:


通过 commit-msg 和 pre-commit 两个hooks,就可以阻止了开发人员不认真填写 git message 的行为了。更多hooks 可以看 git_hooks,根据自己的需要配置不同的脚本行为即可
conventional-changelog 可以通过命令行生成 CHANGELOG.md 文件
"changelog": "conventional-changelog -p angular -i CHANGELOG.md -s -r 0"
通常情况线下,我们会在 master 分支进行如下的版本发布操作:
- git pull origin master
- 根据 pacakage.json 中的 version 更新版本号,更新 changelog
- git add -A, 然后 git commit
- git tag 打版本操作
- push 版本 tag 和 master 分支到仓库
其中2,3,4则是 standard-version 工具会自动完成的工作,配合本地的 shell 脚本,则可以自动完成一系列版本发布的工作了。
手工打标签发布的话如:
git tag -a v1.1.0 -m "chore(release): 1.1.0"
git push --follow-tags origin master以上这些动作都可以通过脚本来统一处理,运行脚本文件即可。
git message 规范化很重要,对版本更新信息的汇总管理,代码问题出现时,可能很好的追踪和查看修改记录,团队协作的情况下,是有必要进行管理的,吃过亏你就知道错了。Github上的开源项目,一般都会有很多相似规范的约束,这也是全球开源项目维护者、贡献者的协作的保障。有参与过开源项目 NG-ZORRO/ng-zorro-antd 的bug修改,这方面感受较多,建议开发者多了解或者有机会参与一些工程较规范的项目贡献。
Author: @giscafer
欢迎讨论
参考资料
Angular 1.x和ES6的结合
xufei/blog#29
Angular1.x + ES6 开发风格指南
kuitos/kuitos.github.io#34
类似angularjs中的ng-include,或者是动态创建html,再$compile编译一下。这些语法在ng2+已经被去掉,去掉原因如下:
Something like ng-include can not be supported for several reasons:
- In Angular 2 directives are declared on per component. Having ng-include would mean that the same ng-include would behave differently depending where it is included. The same goes for variable declarations.
- It is a security risk, in the sense of you may point it to a user input.
- It prevents Angular from doing offline compilation, hence speed / size improvements.
The solution is that you need to wrap your templates into components, and then you can lazy load the components. This will work with offline compilation, does not have security concerns and still allows for offline compilation.
Blog
https://blog.lacolaco.net/post/dynamic-component-creation-in-angular-2/
NgComponentOutlet(含代码举例)
http://stackoverflow.com/questions/36325212/angular-2-dynamic-tabs-with-user-click-chosen-components/36325468#36325468
Issues
Final statement about ngInclude alternative
Proposal: Declarative Dynamic Components

本文部分内容和截图内容都来自以下第五届前端早早聊大会分享:
《如何实现用户行为的动态采集与分析》
《如何结合组件设计前端埋点策略》
《如何面向场景做监控数据分析》
《如何针对 APP 自建前端监控体系》
《如何搭建一套多端错误监控平台》
《如何基于错误日志进行分析和告警》
《如何基于数据和堆栈映射快速定位问题》
《如何设计前端实时分析及报警系统》
会议详细见:https://www.yuque.com/zaotalk/conf/425
本文是会议总结文章,可能会有点大乱炖的感觉。
监控步骤:定制规范,埋点 > 采集 > 计算 > 分析
面向场景做监控:
(super position model)
采集方式有:进入、离开、点击、滚屏、代码植入
data-utm-c="区块ID"data-utm-click="坑位ID1"
举例生成的配置文件:
事件委托到 document,一般的事件类型:mousedown、touch、scroll、keydown
设置埋点参数:进入页面的时候,可以在URL 后边加入生成唯一标识的串联ID,在链接点击跳转时,可以依据标识上报。
< href="http://giscafer.com?utm=项目ID.页面ID.区块ID.坑位index.串联ID"监听 scroll 事件处理一些需要上报的场景,要处理好触发次数。
使用 Send Beacon 避免离开页面时请求被终止,保证数据上报正常发送。缺陷:IE浏览器不支持。IE的话改用 <Img> 发送发送。
比如商场的收藏、加购、spm链接跳转等这种逻辑下自动采集数据
手动埋点,事件触发上报等
任何页面都可以拆分成组件(React 的**:已组件的方式考虑UI构建),所以监控可以结合组件来做。当组件渲染异常时,可以监控到哪个地方出问题。比如聚合组件在业务组件中的统计效能:曝光量、点击转化率、加载性能、渲染性能、数据性能、应用次数、失败次数、代码质量。

个人觉得可以用相关的技术点来解决前端可能影响到页面性能的问题,比如:Web Worker、requestIdleCallback 等,但后端的服务稳定性是否能保证需要关注吗?
除了 Send Beacon 外,可以考虑 Service Worker 来配合做?页面奔溃前定时器处理做标记,下次打开页面对比对应值来判断是否页面奔溃过。
记录但不处理,不进行报警
数据分析本质就是将监控到的数据可视化展示,或是转化为大家可以理解的概念,指标数据。使用过站长统计、比如 Google Analytics 和 百度统计、CNZZ 等,他们的统计管理后台,展示给“站长”可视化的指标数据就是通过数据分析得来的。
实现思路/方案:
得到指标分析得结果,可以用来分析存在的问题,改善网站,通过转化率来促进义务。,也可以研究用户习惯和发现趋势,提供一些自定义设置功能帮助更好的做到分析。
将监控数据通过各种图表工具来展示分析结果。
**
详细见 《如何针对 APP 自建前端监控体系》PPT
eg: 常规任务
稳定性、一致性、扩展性、安全性和成本综合考虑
AOP 面向切面编程,改写原有行为
Q: 为什么用 1x1 像素 gif 图?
监听/劫持 原始方法,获取需要上报的数据,在错误发生时触发触发函数会用 gif 上报。
数据特征:
详情见会议PPT
ES——>获取数据——> 数据预处理——>数据聚合(为了存储小、查询快)
Node 端使用 process 对象监听 uncaughtException、unhandledRejection 事件,捕获未处理的 JS异常 和 Promise 异常。
使用 **系统提供 **的机制,实现 Thread.UncauhtExceptionHandler 接口,通过 uncaughtException 方法获取崩溃错误信息,在应用初始化时替换掉默认的崩溃回调。
使用 系统提供 的错误捕获机制,注册了 Objective-C 异常和 POSIX signal 的处理钩子,在发生奔溃的时候可以通过钩子函数记录崩溃的信息。在下次启动APP 的时候再上报。
更多见会议分享PPT
http://stackoverflow.com/questions/22408790/angularjs-passing-data-between-pages
作者:Ye Huang
链接:http://www.zhihu.com/question/33565135/answer/69651500
来源:知乎
Angular页面传参有多种办法,根据不同用例,我举5种最常见的:
PS: 在实际项目中,请参照angular-styleguide优化您的代码。
1. 基于ui-router的页面跳转传参
(1) 在AngularJS的app.js中用ui-router定义路由,比如现在有两个页面,一个页面(producers.html)放置了多个producers,点击其中一个目标,页面跳转到对应的producer页,同时将producerId这个参数传过去。
.state('producers', {
url: '/producers',
templateUrl: 'views/producers.html',
controller: 'ProducersCtrl'
})
.state('producer', {
url: '/producer/:producerId',
templateUrl: 'views/producer.html',
controller: 'ProducerCtrl'
})
(2) 在producers.html中,定义点击事件,比如ng-click="toProducer(producerId)",在ProducersCtrl中,定义页面跳转函数 (使用ui-router的$state.go接口):
.controller('ProducersCtrl', function ($scope, $state) {
$scope.toProducer = function (producerId) {
$state.go('producer', {producerId: producerId});
};
});
(3) 在ProducerCtrl中,通过ui-router的$stateParams获取参数producerId,譬如:
.controller('ProducerCtrl', function ($scope, $state, $stateParams) {
var producerId = $stateParams.producerId;
});
2. 基于factory的页面跳转传参
Demo: http://jsfiddle.net/k3phygpz/869/
举例:你有N个页面,每个页面都需要用户填选信息,最终引导用户至尾页提交,同时后一个页面要显示前面所有页面填写的信息。这个时候用factory传参是比较合理的选择(下面的代码是一个简化版,根据需求可以不同定制):
.factory('myFactory', function () {
//定义参数对象
var myObject = {};
/**
* 定义传递数据的setter函数
* @param {type} xxx
* @returns {*}
* @private
*/
var _setter = function (data) {
myObject = data;
};
/**
* 定义获取数据的getter函数
* @param {type} xxx
* @returns {*}
* @private
*/
var _getter = function () {
return myObject;
};
// Public APIs
// 在controller中通过调setter()和getter()方法可实现提交或获取参数的功能
return {
setter: _setter,
getter: _getter
};
});
3. 基于factory和$rootScope.$broadcast()的传参
(1) 举例:在一个单页中定义了nested views,你希望让所有子作用域都监听到某个参数的变化,并且作出相应动作。比如一个地图应用,某个$state中定义元素input,输入地址后,地图要定位,同时另一个状态下的列表要显示出该位置周边商铺的信息,此时多个$scope都在监听地址变化。
PS: $rootScope.$broadcast()可以非常方便的设置全局事件,并让所有子作用域都监听到。
.factory('addressFactory', ['$rootScope', function ($rootScope) {
// 定义所要返回的地址对象
var address = {};
// 定义components数组,数组包括街道,城市,国家等
address.components = [];
// 定义更新地址函数,通过$rootScope.$broadcast()设置全局事件'AddressUpdated'
// 所有子作用域都能监听到该事件
address.updateAddress = function (value) {
this.components = angular.copy(value);
$rootScope.$broadcast('AddressUpdated');
};
// 返回地址对象
return address;
}]);
(2) 在获取地址的controller中:
// 动态获取地址,接口方法省略
var component = {
addressLongName: xxxx,
addressShortName: xx,
cityLongName: xxxx,
cityShortName: xx,
countryLongName: xxxx,
countryShortName: xx,
postCode: xxxxx
};
// 定义地址数组
$scope.components = [];
$scope.$watch('components', function () {
// 将component对象推入$scope.components数组
components.push(component);
// 更新addressFactory中的components
addressFactory.updateAddress(components);
});
(3) 在监听地址变化的controller中:
// 通过addressFactory中定义的全局事件'AddressUpdated'监听地址变化
$scope.$on('AddressUpdated', function () {
// 监听地址变化并获取相应数据
var street = address.components[0].addressLongName;
var city = address.components[0].cityLongName;
// 通过获取的地址数据可以做相关操作,譬如获取该地址周边的商铺,下面代码为本人虚构
shopFactory.getShops(street, city).then(function (data) {
if(data.status === 200){
$scope.shops = data.shops;
}else{
$log.error('对不起,获取该位置周边商铺数据出错: ', data);
}
});
});
4. 基于localStorage或sessionStorage的页面跳转传参
注意事项:通过LS或SS传参,一定要监听变量,否则参数改变时,获取变量的一端不会更新。AngularJS有一些现成的WebStorage dependency可以使用,譬如gsklee/ngStorage · GitHub,grevory/angular-local-storage · GitHub。下面使用ngStorage来简述传参过程:
(1) 上传参数到localStorage - Controller A
// 定义并初始化localStorage中的counter属性
$scope.$storage = $localStorage.$default({
counter: 0
});
// 假设某个factory(此例暂且命名为counterFactory)中的updateCounter()方法
// 可以用于更新参数counter
counterFactory.updateCounter().then(function (data) {
// 将新的counter值上传到localStorage中
$scope.$storage.counter = data.counter;
});
(2) 监听localStorage中的参数变化 - Controller B
$scope.counter = $localStorage.counter;
$scope.$watch('counter', function(newVal, oldVal) {
// 监听变化,并获取参数的最新值
$log.log('newVal: ', newVal);
});
5. 基于localStorage/sessionStorage和Factory的页面传参
由于传参出现的不同的需求,将不同方式组合起来可帮助你构建低耦合便于扩展和维护的代码。
举例:应用的Authentication(授权)。用户登录后,后端传回一个时限性的token,该用户下次访问应用,通过检测token和相关参数,可获取用户权限,因而无须再次登录即可进入相应页面(Automatically Login)。其次所有的APIs都需要在HTTP header里注入token才能与服务器传输数据。此时我们看到token扮演一个重要角色:(a)用于检测用户权限,(b)保证前后端数据传输安全性。以下实例中使用GitHub - gsklee/ngStorage: localStorage and sessionStorage done right for AngularJS.和GitHub - Narzerus/angular-permission: Simple route authorization via roles/permissions。
(1)定义一个名为auth.service.js的factory,用于处理和authentication相关的业务逻辑,比如login,logout,checkAuthentication,getAuthenticationParams等。此处略去其他业务,只专注Authentication的部分。
(function() {
'use strict';
angular
.module('myApp')
.factory('authService', authService);
/** @ngInject */
function authService($http, $log, $q, $localStorage, PermissionStore, ENV) {
var apiUserPermission = ENV.baseUrl + 'user/permission';
var authServices = {
login: login,
logout: logout,
getAuthenticationParams: getAuthenticationParams,
checkAuthentication: checkAuthentication
};
return authServices;
////////////////
/**
* 定义处理错误函数,私有函数。
* @param {type} xxx
* @returns {*}
* @private
*/
function handleError(name, error) {
return $log.error('XHR Failed for ' + name + '.\n', angular.toJson(error, true));
}
/**
* 定义login函数,公有函数。
* 若登录成功,把服务器返回的token存入localStorage。
* @param {type} xxx
* @returns {*}
* @public
*/
function login(loginData) {
var apiLoginUrl = ENV.baseUrl + 'user/login';
return $http({
method: 'POST',
url: apiLoginUrl,
params: {
username: loginData.username,
password: loginData.password
}
})
.then(loginComplete)
.catch(loginFailed);
function loginComplete(response) {
if (response.status === 200 && _.includes(response.data.authorities, 'admin')) {
// 将token存入localStorage。
$localStorage.authtoken = response.headers().authtoken;
setAuthenticationParams(true);
} else {
$localStorage.authtoken = '';
setAuthenticationParams(false);
}
}
function loginFailed(error) {
handleError('login()', error);
}
}
/**
* 定义logout函数,公有函数。
* 清除localStorage和PermissionStore中的数据。
* @public
*/
function logout() {
$localStorage.$reset();
PermissionStore.clearStore();
}
/**
* 定义传递数据的setter函数,私有函数。
* 用于设置isAuth参数。
* @param {type} xxx
* @returns {*}
* @private
*/
function setAuthenticationParams(param) {
$localStorage.isAuth = param;
}
/**
* 定义获取数据的getter函数,公有函数。
* 用于获取isAuth和token参数。
* 通过setter和getter函数,可以避免使用第四种方法所提到的$watch变量。
* @param {type} xxx
* @returns {*}
* @public
*/
function getAuthenticationParams() {
var authParams = {
isAuth: $localStorage.isAuth,
authtoken: $localStorage.authtoken
};
return authParams;
}
/*
* 第一步: 检测token是否有效.
* 若token有效,进入第二步。
*
* 第二步: 检测用户是否依旧属于admin权限.
*
* 只有满足上述两个条件,函数才会返回true,否则返回false。
* 请参看angular-permission文档了解其工作原理https://github.com/Narzerus/angular-permission/wiki/Managing-permissions
*/
function checkAuthentication() {
var deferred = $q.defer();
$http.get(apiUserPermission).success(function(response) {
if (_.includes(response.authorities, 'admin')) {
deferred.resolve(true);
} else {
deferred.reject(false);
}
}).error(function(error) {
handleError('checkAuthentication()', error);
deferred.reject(false);
});
return deferred.promise;
}
}
})();
(2)定义名为index.run.js的文件,用于在应用载入时自动运行权限检测代码。
(function() {
'use strict';
angular
.module('myApp')
.run(checkPermission);
/** @ngInject */
/**
* angular-permission version 3.0.x.
* https://github.com/Narzerus/angular-permission/wiki/Managing-permissions.
*
* 第一步: 运行authService.getAuthenticationParams()函数.
* 返回true:用户之前成功登陆过。因而localStorage中已储存isAuth和authtoken两个参数。
* 返回false:用户或许已logout,或是首次访问应用。因而强制用户至登录页输入用户名密码登录。
*
* 第二步: 运行authService.checkAuthentication()函数.
* 返回true:用户的token依旧有效,同时用户依然拥有admin权限。因而无需手动登录,页面将自动重定向到admin页面。
* 返回false:要么用户token已经过期,或用户不再属于admin权限。因而强制用户至登录页输入用户名密码登录。
*/
function checkPermission(PermissionStore, authService) {
PermissionStore
.definePermission('ADMIN', function() {
var authParams = authService.getAuthenticationParams();
if (authParams.isAuth) {
return authService.checkAuthentication();
} else {
return false;
}
});
}
})();
(3)定义名为authInterceptor.service.js的文件,用于在所有该应用请求的HTTP requests的header中注入token。关于AngularJS的Interceptor,请参看AngularJS。
(function() {
'use strict';
angular
.module('myApp')
.factory('authInterceptorService', authInterceptorService);
/** @ngInject */
function authInterceptorService($q, $injector, $location) {
var authService = $injector.get('authService');
var authInterceptorServices = {
request: request,
responseError: responseError
};
return authInterceptorServices;
////////////////
// 将token注入所有HTTP requests的headers。
function request(config) {
var authParams = authService.getAuthenticationParams();
config.headers = config.headers || {};
if (authParams.authtoken) config.headers.authtoken = authParams.authtoken;
return config || $q.when(config);
}
function responseError(rejection) {
if (rejection.status === 401) {
authService.logout();
$location.path('/login');
}
return $q.reject(rejection);
}
}
})();
主流的有:
ant+YUI Tool——>grunt——> fis3/gulp——>rollup/webpack/parcel
基本的包括 entry、output、mode、module、plugins 几种

const path = require('path');
module.exports = {
entry: {
index: './src/index.js',
search: './src/search.js',
},
output: {
path: path.join(__dirname, 'dist'),
filename: '[name].bundle.js',
},
mode: 'production',
};Loaders 是 webpack 的核心概念。webpack 开箱即用只支持 JS 和 JSON 两种文件类型,通过 Loaders 去支持其它文件类型并且把它们转化成有效的模块,并且可以添加到依赖图中。
Loaders 本身是一个函数,接受源文件作为参数,返回转换的结果。
列举部分,更多见 loaders
babel-loader 转换 ES6\ES7 等 JS 新特性语法css-loader 支持.css 文件的加载和解析less-loader 将 less 文件转换成 cssts-loader 将 TS 转换成 JSfile-loader 进行图片、文字等的打包raw-loader 将文件以字符串的形式导入thread-loader 多进程打包 JS 和 CSSmodule: {
rules: [
// test 指定匹配规则,use 指定使用的 loader 名称
{ test: /\.txt$/, use: 'raw-loader' },
];
}Plugins 用于 bundle 文件的优化,资源管理和环境变量注入,作用域整个构建过程。
列举部分,更多见 plugins
CommonsChunkPlugin 将 chunks 相同的模块代码提取成公共 jsCleanWebpackPlugin 清理构建目录ExtractTextWebpackPlugin 将 CSS 从 bundle 文件中提取成一个独立的 CSS 文件CopyWebpackPlugin 将文件或者文件夹拷贝到构建的输出目录HTMLWebpackPlugin 创建 html 文件去承输出的 bundleUglifyjsWebpackPlugin 压缩 JSZipWebpackPlugin 将打包出的资源生成一个 zip 包在配置文件中的 plugins 数组里将定义好的插件放入即可。
Mode 用来指定当前的构建环境是: production 、development 还是 none , 对应 node.js 中的 process.env.NODE_ENV。
设置 mode 可以使用 webpack 内置的函数,默认设置为 production
详细见:https://webpack.js.org/configuration/mode/
1、 --watch 监听文件改动,构建命令改为 webpack --watch
缺点:构建后需要手动刷新浏览器页面才能看到效果
2、文件监听的原理分析
轮询判断文件的最后编辑时间是否变化,某个文件发生了变化,并不会立刻告诉监听者,而是先缓存起来,等 aggregateTimeout
module.exports = {
// 默认 false, 也就是不开启
watch: true,
watchOptions: {
// 默认为空,不监听的文件或者文件夹,支持正则匹配
ignored: /node_modules/,
// 监听到变化发生后等300ms再去执行,默认 300ms
aggregateTimeout: 300,
// 判断文件是否发生变化是通过不停的询问系统指定文件有没有变化实现的,默认每秒问1000次
poll: 1000,
},
};HotModuleReplacementPlugin 插件配合// webpack.config.js 主要内容
plugins: [new webpack.HotModuleReplacementPlugin()],
devServer: {
contentBase: './dist',
hot: true,
}
// package.json script 脚本的配置
"dev": "webpack-dev-server --open"const express = require('express');
const webpack = require('webpack');
const webpackDevMiddleware = require('webpack-dev-middleware');
const app = express();
const config = require('./webpack.config.js');
const compiler = webpack(config);
app.use(
webpackDevMiddleware(compiler, {
publicPath: config.output.publicPath,
})
);
app.listen(3000, function() {
console.log('Example app listening on port 3000!\n');
});
概述过程:
(启动阶段 1、2、A、B)源代码文件经过 Webpack Compiler 编译后,生成 bundle,然后 Bundle Server 提供 bundle 文件在浏览器中访问;
(热更新阶段 1、2、3、4)文件变化后,还是经过 Webpack Complier 进行编译,然后将变化的代码传给 HMR Server,HMR Server(服务端) 和 HMR Runtime(客户端) 一直通信,当有代码更新(通知过了 HMR Runtime 后),HMR Server 会将更新的代码模块以 JSON 的形式发送给 HMR Runtime,然后 HMR Runtime 进行一个代码的更新,而不需要刷新浏览器页面。
css 文件一般用 contenthash 来实现,js 则使用 chunkhash, 图片资源用 hash。相关配置和输出结果如下:
'use strict';
const path = require('path');
const MiniCssExtractPlugin = require('mini-css-extract-plugin'); // 提取css 为文件(和 style-loader互斥)
module.exports = {
entry: {
index: './src/index.js',
search: './src/search.js',
},
output: {
path: path.join(__dirname, 'dist'),
filename: '[name]_[chunkhash:8].js',
},
mode: 'production',
module: {
rules: [
{
test: /.js$/,
use: 'babel-loader',
},
{
test: /.css$/,
use: [MiniCssExtractPlugin.loader, 'css-loader'],
},
{
test: /.less$/,
use: [MiniCssExtractPlugin.loader, 'css-loader', 'less-loader'],
},
{
test: /.png|.jpg|.jpeg|.gif$/, // /.(png|jpg|gif|jpeg)$/
use: [
{
loader: 'file-loader',
options: {
name: '[name]_[hash:8][ext]',
},
},
],
},
],
},
plugins: [
new MiniCssExtractPlugin({
filename: '[name]_[contenthash:8].css',
}),
],
};Built at: 03/25/2020 6:30:13 PM
Asset Size Chunks Chunk Names
index_443df551.js 1.01 KiB 0 [emitted] [immutable] index
search_650a0e60.js 129 KiB 1 [emitted] [immutable] search
search_6dd0097b.css 57 bytes 1 [emitted] [immutable] search
webpack_365b2ee8png 253 KiB [emitted] [big]内置插件 uglifyjs-webpack-plugin
使用 optimize-css-assets-webpack-plugin,同时使用 cssnano 预处理器处理 CSS
plugins: [
new OptimizeCSSAssetsPlugin({
assetNameRegExp: /\.css$/g,
cssProcessor: require('cssnano'),
}),
];修改 htm-webpack-plugin,设置压缩参数
plugins: [
new HtmlWebpackPlugin({
template: path.join(__dirname, 'src/search.html'),
filename: 'search.html',
chunks: ['search'],
inject: true,
minify: {
html5: true,
collapseWhitespace: true,
preserveLineBreaks: false,
minifyCSS: true,
minifyJS: true,
removeComments: false,
},
}),
];浏览器内核和对应 CSS3 属性前缀:
使用 autoprefixer 插件(配合 prostcss-loader 使用),根据 Can I Use 规则 (https://caniuse.com)
{
test: /.less$/,
use: [
MiniCssExtractPlugin.loader,
'css-loader',
'less-loader',
{ // +++ 新增内容
loader: 'postcss-loader',
options: {
plugins: () => [
require('autoprefixer')({
// 浏览器支持的最新的两个版本、使用人数>1%、IOS 版本兼容到8
overrideBrowserslist: ['last 2 version', '>1%', 'ios 8'],
})
]
},
},
],
},使用 px2rem-loader
页面渲染时计算根元素的 font-size 值
lib-flexible 库viewpoint 得到更多的浏览器支持后,可以使用 viewpoint 代替 lib-flexible , px 到 vw 的转换插件
module.exports = {
module: {
rules: [
{
test: /\.less$/,
use: [
'style-loader',
'css-loader',
'less-loader',
{
// +++
loader: 'px2rem-loader',
options: {
remUnit: 75, // 1rem 代表多少 px
remPrecision: 8, // 小数点保留位数
},
},
],
},
],
},
};还需要将 lib-flexible 内联到 html head 头部,为了页面渲染的时候提早计算到根元素的 font-size 的大小。
raw-loader 内联 html
${require('raw-loader!babel-loader!./meta.html')}raw-loader 内联 JS
<script>
${require('raw-loader!babel-loader!./node_modules/lib-flexible/flexible.js')}
</script>基本实现思路:每个页面对应一个 entry,一个 html-webpack-plugin。缺点:每次新增或删除页面都需要改 webpack 配置。
解决方案:动态获取 entry 和设置 html-webpack-plugin 数量,利用 glob.sync
entry: glob.sync(path.join(__dirname,'./src/*/index.js')),source map 类型关键词:
tree-shaking 利用了 DCE 的特点做优化:
if(false){// 这里边的代码}1、现象:webpack 构建后的带存在大量的闭包代码
eg:
假如现在有两个文件分别是 util.js:
export default 'Hello,Webpack';和入口文件 main.js:
import str from './util.js';
console.log(str);以上源码用 Webpack 打包后输出中的部分代码如下:
// 模块初始化函数,为了兼容各种浏览器
[
function(module, __webpack_exports__, __webpack_require__) {
var __WEBPACK_IMPORTED_MODULE_0__util_js__ = __webpack_require__(1);
console.log(__WEBPACK_IMPORTED_MODULE_0__util_js__['a']);
},
function(module, __webpack_exports__, __webpack_require__) {
__webpack_exports__['a'] = 'Hello,Webpack';
},
];2、会导致什么问题?
3、结论
import 会被转换成 __webpack_require4、进一步分析 webpack 的模块机制
分析:

原理:将所有的模块的代码按照引用顺序放到一个函数作用域里,然后适当的重命名一些变量以防止变量名冲突
对比:通过 scope hoisting 可以减少函数声明代码和内存开销
// 在开启 Scope Hoisting 后,同样的源码输出的部分代码如下
[
function(module, __webpack_exports__, __webpack_require__) {
var util = 'Hello,Webpack';
console.log(util);
},
];webpack v4 在将 mode 设置为 production 会默认开启 scope hoisting ,且必须是 ES6 语法,CJS 不支持(这点和 tree-shaking 一样)。
下边介绍后边三者
要求:基于 Node 库的 imagemin 或者 tinypng API
使用:配置 image-webpack-loader
背景:babel-polyfill 打包后体积 88.49k。
构建体积优化:动态 Polyfill。如 polyfill.io
polyfill service 原理:识别 User Agent,下发不同的 Polyfill,不加载多余的已支持的特性

推荐使用 terser-webpack-plugin,设置参数 parallel
思路:将 react、react-dom 基础包通过 cdn 引入,不大于 bundle 中
方法:使用 html-webpack-externals-plugin
问题:业务包多的时候,这种方式会在页面中引入很多 script 标签
思路:将 react、react-dom、redux、react-redux 基础包和业务基础包打包成一个文件
方法:使用 DLLPlugin 进行分包,DllReferencePlugin 对 manifest.json 引用
// webpack.dll.js
const webpack = require('webpack');
module.exports = {
context: process.cwd(),
// resolve: {
// extensions: ['.js', ''],
// },
entry: {
libaray: ['react', 'react-dom'],
},
output: {
filename: '[name]_[chunkhash].dll.js',
path: path.join(__dirname, 'build/library'),
library: '[name]',
},
plugins: [
new webpack.DllPlugin({
name: '[name]_[chunkhash]',
path: path.join(__dirname, 'build/library/[name].json'),
}),
],
};然后 webpack.prod.js 中添加 DllReferencePlugin 插件,指定 manifest json
new webpack.DllReferencePlugin({
manifest: require('./build/library/library.json'),
});缓存思路:
?cacheDirectory=true)cache:true)目的:尽可能的少构建模块,比如 babel-loader 不解析 node_module。
demo代码:https://github.com/giscafer/webpack-study
内容为极客时间《玩转Webpack》学习笔记
用于学习和实践过程参考的文章(不会刻意去整理记录,但学习过程中会持续更新)
CSP 和 SRI 可以预防XSS攻击和数据包嗅探攻击。
来自MDN 的介绍
内容安全策略(Content-Security-Policy) 是一个额外的安全层,用于检测并削弱某些特定类型的攻击,包括 跨站脚本 (XSS) 和数据注入攻击等。无论是数据盗取、网站内容污染还是散发恶意软件,这些攻击都是主要的手段。
CSP 被设计成完全向后兼容(除CSP2 在向后兼容有明确提及的不一致; 更多细节查看这里 章节1.1)。不支持 CSP 的浏览器也能与实现了 CSP 的服务器正常合作,反之亦然:不支持 CSP 的浏览器只会忽略它,如常运行,默认为网页内容使用标准的同源策略。如果网站不提供 CSP 头部,浏览器也使用标准的同源策略。
为使 CSP 可用, 你需要配置你的网络服务器返回 Content-Security-Policy HTTP头部 ( 有时你会看到一些关于 X-Content-Security-Policy 头部的提法, 那是旧版本,你无须再如此指定它)。
HTTP Response Headers ,举例:

除此之外, <meta> 元素也可以被用来配置该策略, 例如
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; img-src https://*; child-src 'none';">"Content-Security-Policy":策略字符串
资源限制可以精细到 img、font、style、frame等粒度。
Content-Security-Policy: default-src 'self'
一个网站管理者想要所有内容均来自站点的同一个源 (不包括其子域名),详细 Content-Security-Policy/default-src
Content-Security-Policy: default-src 'self'; img-src *; media-src media1.com media2.com; script-src userscripts.example.com
在这里,各种内容默认仅允许从文档所在的源获取, 但存在如下例外:
允许使用 eval() 以及相似的函数来从字符串创建代码。必须有单引号。
更多策略见 CSP directives
知乎


子资源完整性(SRI) 是允许浏览器检查其获得的资源(例如从 CDN 获得的)是否被篡改的一项安全特性。它通过验证获取文件的哈希值是否和你提供的哈希值一样来判断资源是否被篡改。
很多时候我们使用CDN多个站点之间共享了脚本和样式,以便提高网站性能节省宽带。然而也存在风险,如果攻击者获取了CDN的控制权,就可以将任意内容恶意注入到CDN文件中,从而攻击了加载此CDN资源的站点。所以就需要 SRI 来确保Web应用程序获得的文件未经过第三方注入或者其他形式的修改来降低被攻击的风险。
将文件内容通过 base64 编码 后的哈希值,写入你所引用的 <script> 或 <link> 标签的 integrity 属性值中即可启用子资源完整性功能。浏览器在加载此内容执行之前,会判断该文件的哈希值是否和 integrity 预期的一致,只有一致才会执行。
SRI Hash Generator 是一个在线生成 SRI 哈希值的工具。
<script src="https://example.com/example-framework.js"
integrity="sha384-oqVuAfXRKap7fdgcCY5uykM6+R9GqQ8K/uxy9rx7HNQlGYl1kPzQho1wx4JwY8wC"
crossorigin="anonymous"></script>你可以根据内容安全策略(CSP)来配置你的服务器使得指定类型的文件遵守 SRI。这是通过在 CSP 头部 添加 require-sri-for 指令实现的:
Content-Security-Policy: require-sri-for script;
这条指令规定了所有 JavaScript 都要有 integrity 属性,且通过验证才能被加载。
所以,只要文件变化了,浏览器就不会执行,有效避免了脚本攻击。
参考链接
之前一直用公司的 Mac , 环境直接安装没啥问题,自己入手的 mbp 就遇到一些问题,记录一下。
Basher 允许您直接从 github(或其他站点)快速安装 shell 软件包。 basher 无需为每个软件包寻找特定的安装说明并弄乱您的路径,而是将为所有软件包创建一个中心位置并为您管理其二进制文件。
https://github.com/basherpm/basher
sudo vi /etc/sudoers
找到:
# root and users in group wheel can run anything on any machine as any user
root ALL = (ALL) ALL
%admin ALL = (ALL) ALL
修改为:
# root and users in group wheel can run anything on any machine as any user
#root ALL = (ALL) ALL
#%admin ALL = (ALL) ALL
root ALL = (ALL) NOPASSWD: NOPASSWD: ALL
%admin ALL = (ALL) NOPASSWD: NOPASSWD: ALL~/.bash_profile 文件环境变量& source 了也不生效Terminal 可能使用的是 zsh (看终端title是否有这个后缀),zsh加载的是 ~/.zshrc文件,而 ‘.zshrc’ 文件中并没有定义任务环境变量
vim ~/.zshrc 创建文件~/.zshrc 文件最后,增加一行:source ~/.bash_profilesource ~/.zshrc 各环境文件补充说明:MAC OSX环境变量$PATH
避免误删文件无法恢复
brew install rmtrash
echo "alias rm='rmtrash'" >> ~/.bash_profile
source ~/.bash_profilegyp: No Xcode or CLT version detected macOS Catalina | Anansewaa
sudo rm -rf $(xcode-select -print-path)
xcode-select --install
1.bash_profile Alias
alias proxy='export https_proxy=http://127.0.0.1:1087 export http_proxy=http://127.0.0.1:1087 export all_proxy=socks5://127.0.0.1:1087'
alias unproxy='unset https_proxy unset http_proxy unset all_proxy'
alias ip='curl cip.cc'bash_profile 设置加入HTTP 和 HTTPS
2.ClashX 配置文件
在ClashX的配置文件中加入 - 'DOMAIN-SUFFIX,cip.cc,Proxy'
这一步的设置是可以走规则判断,不用使用全局模式
直接使用mm单位设置为A4大小的宽度最好,如: style = "width:210mm; "
也可以设置为: style ="width:794px; "
当然打印总要有边,所以padding空白: style ="width:754px; padding: 20px; "
单位换算:
1 inch = 2.54 cm 1mm = 96 px 1 cm = 37.79528 px
CI/CD 是 Gitlab 提供的一整套持续集成、持续交付解决方案。
概念:「持续集成(Continuous Integration)」、「持续交付(Continuous Delivery)」和「持续部署(Continuous Deployment)」,概念理解详细见文章:简单理解持续集成、持续交付、持续部署 与 谈谈持续集成,持续交付,持续部署之间的区别
近期在抽空把团队工程化这块做好,CI/CD只是其中的九牛一毛。在运维文开同学协助配合下,以公司某项目前端工程做试验,实现了 CI 的过程,本质上CD也是支持了的,主要是看CD这个过程怎么做更好。自动触发了构建操作,还是直接使用构建后的 artifacts 直接部署,走不走Jenkins后续方案等……下边简单介绍一下。
前提:服务器部署配置了 Runner 。 如图,搞了一个共享型的 Runner,十几个前端工程都可以基于此 Runner 执行CI脚本。因为Runner是共享的,所以gitlab-ci.yml 中的 docker 镜像 image 建议保证每个项目不一致,这样就可以共同使用一个 Runner 来并行执行多个项目CI,本质上在不同的 docker 镜像中运行脚本,这样就不会冲突了。Runner: gitlab-runner

下边是举例 Angular 前端工程 在 Gitlab 上实践的 CI 脚本,目前只做了代码检查和自动构建过程检测。实现自动化检查代码是否规范,前端限制了一些代码拼写规范、console.log禁用、alert禁用 等 tslint的约束,这些都可以在工程下自定义维护规则。aot构建是为了进一步检查一些编译问题。只要两者通过,Jenkins 构建100%是无差错的。
配置:
# GitLab CI/CD 前端 Angular 持续集成实践 : https://github.com/giscafer/front-end-manual/issues/27
# 因为共享Runner,这里不建议一样的版本号,避免同时运行的时候,相同docker镜像会出问题
image: node:latest
# image: node:10.4.1
# 变量定义
# https://docs.gitlab.com/ee/ci/variables/#using-predefined-environment-variables
variables:
NODE_MODULES_VERSION: 'ng-starter-web-1.0.0' # node_modules版本号,每次升级依赖改一下这里的数值
CURRENT_BRANCH: $CI_COMMIT_REF_NAME
# 缓存目录文件
# key是唯一值,重名会覆盖上一次的缓存
cache:
key: '$NODE_MODULES_VERSION'
paths:
- node_modules/
stages:
- init
- lint
- build
# - deploy
install_packages:
stage: init
cache:
key: '$NODE_MODULES_VERSION'
paths:
- node_modules/
script:
# 打印一下当前是什么分支而已
- echo "NODE_MODULES_VERSION=$NODE_MODULES_VERSION"
- echo "CURRENT_BRANCH=$CURRENT_BRANCH"
# 设置 npm 的源,会快一些
- npm config set registry http://registry.npm.taobao.org/
# 安装所有依赖,也就是 node_modules
- npm install --silent
lint_code:
stage: lint
# 定义缓存
cache:
key: '$NODE_MODULES_VERSION'
# 下面的配置指示,我们当前只拉取缓存,不上传,这样会节省不少时间
policy: pull
# 指定要缓存的文件/文件夹
paths:
- node_modules/
script:
- npm run lint
only:
- /^dev.*$/ # dev分支下只做lint语法检查
build:
stage: build
cache:
key: '$NODE_MODULES_VERSION'
policy: pull
paths:
- node_modules/
script: npm run aot:test
# artifacets 是打包你指定的文件或者文件夹,然后你可以通过 gitlab 的页面进行下载的
artifacts:
# artifacets 的名字
name: '$CI_COMMIT_REF_NAME-dist'
# artifacets 的过期时间,因为这些数据都是直接保存在 Gitlab 机器上的,过于久远的资源就可以删除掉了
expire_in: 60 mins
# 制定需要打包的目录,这里我把 dist 目录给打包了,准备发布到服务器
paths:
- dist/
only:
- master
#
## 部署任务
# deploy:
# stage: deploy
# # 该命令指定只有 master 分支才能够执行当前任务
# only:
# - master
# # 部署脚本,在下面的代码中,我用到了很多类似 ${AMAZON_PEM} 的变量,由于我们的私钥、Ip 都算是不宜公开显示的信息,
# # 所以我用到了 Gitlab 的变量工具,在 repo 的 Setting > CI/CD > Secret variables 中,这些变量值只有项目管理员才有权限访问
# script:
# - 'ls -la'
# - 'ls -Rl dist'
# - 'echo "${AMAZON_PEM}" > amazon.pem'
# - 'chmod 600 amazon.pem'
# - 'scp -o StrictHostKeyChecking=no -i amazon.pem -r dist/* ${AMAZON_NAME_IP}:/usr/share/nginx/html/'
Angular gitlab-ci.yml 配置还可以参考:https://stackoverflow.com/questions/46269681/gitlab-ci-failing-with-angular-cli
配置中有几个关键点需要了解,如:
variables用户可以自定义变量或者读取Gitlab系统自带的变量,用来动态在脚本中获取,也可以根据变量写一下if语句来执行不同的逻辑,如下:
build:
stage: build
script:
- |
if [ "$CI_COMMIT_REF_NAME" = "$ci_defined_secret_variable_deploy_branch" ]; then
echo "build ran and conditional was true"
fi
except:
- master
stagetwo:
stage: deploy
script:
- |
echo "stage two ran"
only:
variables:
- $CI_COMMIT_REF_NAME == $ci_defined_secret_variable_deploy_branch下图是某工程下的构建配置

定义 stage,stage 可以简单的理解为“步骤”,会顺序执行,如果上一步错了,那不会继续执行下一步,比如像上边定义的,第一步先 lint 检查代码规范,第二步构建。完整的阶段划分应该为:第一步先初始化,第二步检查代码规范,第三步进行单元测试,第四步构建,第五步就直接将项目部署到服务器
GitLab CI/CD提供了一种 缓存机制,可用于在运行作业时节省时间。
定义全局的缓存策略,如上所说,每个不同的 stage,CI 都会重新启动一个新的容器,所以我们之前 stage 中的文件都会消失,在前端开发中,就意味着每个 stage 都要重新完整装一次 node_modules,这样的时间和网络成本都不低,所以我们选择将这些文件缓存下来。
但是,缓存也要讲究实效性,例如我在第二次的提交中增加了一个库,那第二次的 CI 就不能再重复使用上一次的 node_modules 缓存了,在 .gitlab-ci.yml 中,我们通过设置 cache 的 key 来区分不同的缓存,从配置中可以看到,通过自定义变量 NODE_MODULES_VERSION 来标识 node_modules 的版本,决定是否下载新的依赖,每次工程修改依赖版本或者新增模块时,维护一下这个NODE_MODULES_VERSION 版本号就可以了。可以通过监听package.json 文件版本更新,然后脚本自动修改NODE_MODULES_VERSION版本号。如脚本:compare-pk.js
# 变量定义
# https://docs.gitlab.com/ee/ci/variables/#using-predefined-environment-variables
variables:
NODE_MODULES_VERSION: 'ng-starter-web-1.0.0' # node_modules版本号,每次升级依赖改一下这里的数值
CURRENT_BRANCH: $CI_COMMIT_REF_NAME剩下就是 Job 来定义脚本了,以上的东西都是给 Job 来使用的。下边举例详细说明:
# 这个是某个任务的名称,你可以随意起名
install_packages:
# 指定该任务所属的步骤,每到一个步骤,该步骤所对应的所有任务都会并行执行
stage: init
# 指定要缓存的文件以及文件夹
cache:
# 这个属性是 gitlab 比较新版本里面加的特性,意思是在这一步,我只上传这个缓存,我不会拉取该缓存
policy: push
# 指定缓存的内容,在下面我缓存了 node_modules 这个文件夹,你还可以在下面继续添加文件或者文件夹
paths:
- node_modules/
# 该任务要运行的脚本,顺序执行
# 都是 bash 命令
# 默认当前目录就是 repo 的根目录
script:
# 打印一下当前是什么分支而已
- echo "CURRENT_BRANCH=$CURRENT_BRANCH"
# 设置 npm 的源,会快一些
- 'npm config set registry "https://registry.npm.taobao.org"'
# 安装所有依赖,也就是 node_modules
- "npm install"无缓存做一个lint检查需要约 8 分钟

有缓存则约一分半

更多配置项介绍见官方文档yaml/README
PR: pull request 或 merge request
每次提交或者 PR 都会自动触发 job:lint ,PR 在代码lint或者测试没有通过的情况下,是默认无法合并的(按钮禁用,权限大的用户才能跳过检查,但不建议,除非你想出错)。
更方便的是,PR 可以设置为脚本执行通过后自动合并,当然如果需要 CR (code review) 的话,可以设置为手动合并。 如果连测试都没有通过的代码,就没有必要 CR 了。

可以在 master 分支做持续交付操作(CD), 主要就是自动化构建;将构建成功结果物,通过脚本来部署即可。如果还有后期的自动化接口或者组件测试,部署后执行测试,如果失败则回滚。按理是测试成功的代码,部署后就一般没有问题,除非是环境和数据引起的问题。
因为 master 分支是 dev 或者 test 分支 PR 合并过来的,所以他们的测试和代码检查一般都通过了的,当然,合并之前也会重新执行一次代码检查和测试,最后才会走构建的job。
Gitlab 的 Pipeline 下可以看到每次提交触发Job的执行状态,可以对执行日记查看,对应job执行成功或失败都可以发生通知给开发者。
持续交付在持续集成的基础上,将集成后的代码署到更贴近真实运行环境的「类生产环境」中。比如,我们完成单元测试后,可以把代码部署到连接数据库的 Staging 环境中更多的测试。如果代码没有问题,可以继续手动部署到生产环境中。
从频繁提交代码、自动化测试(保证测试覆盖) -> 运行本地测试 -> 服务器运行测试 -> 部署到测试环境 -> 交付管理
而这些都应该是自动的,所以你需要知道的东西有: 如何编写测试(Junit、Qunit、BDD、TDD..)、自动化测试(Selenium..)、版本管理(git)、配置(feature toggle)、依赖管理、部署脚本等等。
从0起做好持续交付并不容易,涉及很多东西,从简单的做起吧。自动触发了构建操作,目前如何自动部署,走不走 Jenkins 后续方案讨论再定。可以保留 Jenkins 手动构建(出问题可以规避),也可以有自动化构建部署两种方案都有
后边又尝试了Gitlab Pages的CI/CD,构建后上传到远程服务器:
image: node:10.4.1
variables:
NODE_MODULES_VERSION: 'wiki-web-1.0.0' # node_modules版本号,每次升级依赖改一下这里的数值
CURRENT_BRANCH: $CI_COMMIT_REF_NAME
# 缓存目录文件
# key是唯一值,重名会覆盖上一次的缓存
cache:
key: '$NODE_MODULES_VERSION'
paths:
- node_modules/
stages:
- build
- deploy
build:
stage: build
cache:
paths:
- node_modules/
script:
- npm install --silent
- npm run build
artifacts:
name: 'dist'
expire_in: 60 mins
paths:
- dist
# - docs/.vuepress/dist
only:
- master
deploy:
stage: deploy
environment:
name: Production
before_script:
# - sed -i '/jessie-updates/d' /etc/apt/sources.list
# https://superuser.com/questions/1423486/issue-with-fetching-http-deb-debian-org-debian-dists-jessie-updates-inrelease/1424377#1424377
- printf "deb http://archive.debian.org/debian/ jessie main\ndeb-src http://archive.debian.org/debian/ jessie main\ndeb http://security.debian.org jessie/updates main\ndeb-src http://security.debian.org jessie/updates main" > /etc/apt/sources.list
- apt-get update -qq && apt-get install -y -qq sshpass
script:
- cd dist/
- ls
- sshpass -V
- export SSHPASS=$USER_PASS
- sshpass -e scp -P 端口 -o stricthostkeychecking=no -r . root@IP:/data/git_cd
# - sshpass -e scp -o stricthostkeychecking=no -r . [email protected]:/var/www/html
# - rsync -avz --delete -e"ssh -p 端口" ./ root@ip:/data/git_cd
when: on_success
only:
- master
是一个基于 vuepress 的工程,CI 自动构建后,会将打包后的 dist文件夹 上传到 artifacts , CD 操作的时候从这里那就好了。

构建生成的附件可以通过 sshpass 或 rsync 将附件上传到远程服务器。相关文章可以参考:
Android 和 IOS CI 环境搭建参考:
以上是网友的分享文章,前半部分工作主要是搭建 Runner 和 docker 环境,有更快速的方式来搭建。我在搭建 android 环境时,使用了共享性 Runner,image选用的是开源社区的 react-native-community/ci-sample docker 镜像,然后配置对应的执行脚本即可。越过了繁琐的 android 环境搭建,这就是 docker 的好处了。


常用的有以下几种:
详情了解:http://dockone.io/article/8173
分享两个来自 ProcessOn 网友分享的 Jenkins CI/CD 流程图:


把Runner搞成共享型的,前端的工程就不需要重复配置Runner了,后续逐步的改善即可。一个完整的ci配置应该包含这些过程:第一步先初始化,第二步检查代码规范,第三步进行单元测试,第四步构建,第五步就直接将项目部署到服务器。

整合 DevOps,CI/CD 实现是必须的,目前市场和工具方案都特别成熟,个人认为,小团队或者大团队都有必要去学习掌握,以便改善团队的效能问题。一切能脚本自动化的工作,都不应该人工参与。无论如何,频繁部署、快速交付以及开发测试流程自动化都将成为未来软件工程的重要组成部分。
欢迎讨论~
推荐:
文章是学习
《设计模式之美》- 王争的总结
面向对象编程中,抽象类和接口是经常被用到的语法概念,也是面向对象四大特性,和很多设计模式、设计**、设计原则编程实现的基础。比如使用接口来实现面向对象的抽象特性、多态特性和基于接口而非实现的设计原则,使用抽象类来实现面向对象的继承特性和模板设计模式等。
抽象类其实就是一种特殊的不能被实例化的类,只能被子类继承,继承关系是一种 is-a 的关系。接口时一种 has-a 关系,表示具有某些功能,还可以叫为协议(contract)。
TypeScript 和 Java 一样使用关键词 abstract 来定义抽象类,举例:
/**
* 抽象类
*/
abstract class Logger {
private name: string;
private enabled: boolean;
constructor(name: string, enabled: boolean) {
this.name = name;
this.enabled = enabled;
}
public log(message: string): void {
if (!this.enabled) {
return;
}
this.doLog(message);
}
protected abstract doLog(message: string): void;
}
// 抽象类子类,输出到日记文件
// Non-abstract class 'FileLogger' does not implement inherited abstract member 'doLog' from class 'Logger'.ts(2515)
class FileLogger extends Logger {}下面看一下 TypeScript 的接口例子代码:
// 模拟代码,定义类型
interface RpcRequest {}
// Filter 接口
interface Filter {
doFilter(req: RpcRequest): void;
}
// 接口实现:鉴权过滤器
class AuthencationFilter implements Filter {
doFilter(req: RpcRequest): void {
// 省略逻辑
}
}
// 接口实现:限流过滤器
class RateLimitFilter implements Filter {
doFilter(req: RpcRequest): void {
// 省略逻辑
}
}
// 过滤器使用 demo
class Applicaption {
private filters: Array<Filter> = [];
public handleRpcRequest(req: RpcRequest) {
try {
for (const filter of this.filters) {
filter.doFilter(req);
}
} catch (error) {
// 省略
}
}
}抽象类不能实例化,需要子类去继承,所以,抽象类的存在就是为了类继承来使用的,而类继承更多是为了代码复用而生,故认为抽象类是为了更好的解决代码复用问题。
一般的类继承不是也可以解决代码复用的问题了吗?是的,但是会存在一些约束性的问题。假设上面 的抽象类 Logger 是普通的类,一样有 doLog 方法,但子类继承 Logger 时,没有强制让子类去重写父类的doLog 方法,这时候就达不到我们要的多态效果了。此外,Logger 类还可以被直接实例化,这时候new 出来的实例调用的 doLog 方法是空的。
而抽象类就可以很优雅的解决这样的继承问题。
接口时对行为的一种抽象,相当于一组协议或者契约,你可以联想类比一下 API 接口,调用者只关注抽象的接口,不需要了解具体的实现,具体的实现代码对调用者透明。接口实现了约定和实现相分离,降低代码间的耦合性,提供代码的可扩展性。
应用“基于接口而非实现编程”的原则,可以将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低耦合性,提供扩展性。
越抽象、越顶层、越脱离具体某一实现的设计,越能提高代码的灵活性,越能应对未来的需求变化。好的代码设计,不仅能应对当下的需求,而且在将来需求发生变化的时候,仍然能够在不破坏原有代码设计的情况下灵活应对。
先看一下 AliyunImageStore 类
/**
* 图片存储
*/
class AliyunImageStore {
public createBucketIfNotExisting(bucketName: string): void {
// bucket创建逻辑
}
public generateAccessToken(): string {
// 根据 accesskey、secrectkey 生成 access token
const accessToken = '';
return accessToken;
}
public uploadToAliyun(
image: Blob,
bucketName: string,
accessToken: string
): string {
// 上传图片到阿里云,返回图片url
const url = '';
return url;
}
public downloadFromAliyun(url: string, accessToken: string) {
// 从阿里云下载图片
}
}上边代码没有遵从“基于接口而非实现原则” :
uploadToAliyun()就不符合要求,应该抽象命名为 upload()。重构代码后:
// 重构
interface ImageStore {
update(image: Blob, bucketName: string): string;
download(url: string): Blob;
}
class AliyunImageStore implements ImageStore {
update(image: Blob, bucketName: string): string {
this.createBucketIfNotExisting(bucketName);
const accessToken: string = this.generateAccessToken();
// 上传到阿里云得到图片url
return '';
}
download(url: string): Blob {
const accessToken: string = this.generateAccessToken();
// 从阿里云下载图片……
return;
}
public createBucketIfNotExisting(bucketName: string): void {
// bucket创建逻辑
}
public generateAccessToken(): string {
// 根据 accesskey、secrectkey 生成 access token
const accessToken = '';
return accessToken;
}
}
class PrivateImageStorae implements ImageStore {
update(image: Blob, bucketName: string): string {
this.createBucketIfNotExisting(bucketName);
// 上传到私有云,返回图片url……
return;
}
download(url: string): Blob {
// 从私有云下载图片……
return;
}
public createBucketIfNotExisting(bucketName: string): void {
// bucket创建逻辑
}
}继承主要有三个作用:is-a 关系表示、支持多态、代码复用。这三个特性都可以通过组合、接口、委托三个技术手段来达成。利用组合可以解决层次过深、过复杂的继承关系影响代码可维护性的问题。
抽象类和接口,都是面向对象编程中是实现面向对象编程四大特性的基础。但在编程中,需要合理的分析设计与抽象,使用最佳的方案来实现代码,最终的目的还是为了代码的易读性、易扩展、易维护等。只有清除的了解抽象类和接口的区别,以及使用场景,才能更好的运用。也是设计模式、设计原则中的重要基础。
Why we chose Angular 2 over React for our enterprise software development work
React vs Angular: An In-depth Comparison
日常运维的最佳拍档
显示文件的头部内容,默认前10行
# 显示前10行内容
$ head README.md
# 或者显示多个文件
$ head README.md package.json
# -n 指定显示行数
$ head -n 100 README.md显示文件的末尾部分,默认后10行
| 参数 | 描述 |
|---|---|
| -n | 指定显示末尾行数 |
| -f | 实时监听并打印文件变化, 文件删除后不在监听 |
| -F | 实时监听并打印文件变化, 文件删除后继续监听 |
| -c | 指定显示文件最后N个字符 |
# 默认显示末尾10行
$ tail README.md
# -n 指定显示末尾20行
$ tail -n 20 README.md
# 实时监听README.md文件变化
$ tail -f README.md
# 根据文件名进行追踪, 如果删除后创建相同的文件名会继续追踪
$ tail -F README.md
# 显示文件的最后10个字符
$ tail -c 10 README.md查看文件全部内容,如果文件太大,头部部分内容会被截掉。
# 查看 README.md 文件全部内容
$ cat README.md
$ cat README.md README2.md # 多个文件
# -n 每一行显示行号包括空行
$ cat -n README.md
# -b 只在有内容的行显示行号
$ cat -b README.md同样用来打印内容,与 cat 命令不同的是打印内容会自动加上行号, 但 nl 命令可以对行号做特别的定制,主要针对行号有特别高要求的用户。
cat -n)cat -b)# 打印内容并输出行号, 除了空号
# 等价于 cat -b README.md
$ nl README.md
# 空行同样打印行号
$ nl -b a README.md分页查看文件内容, 每次查看一屏, 每屏能显示多少内容取决于终端大小。
与 cat 命令不同,cat 只能一次显示全部内容,如果内容太多部分会被截取掉。
快捷键:
空格 或 PageUp - 查看下一屏内容B 或 PageDown - 查看上一屏内容回车 - 查看下一行内容Q - 退出$ more README.md
# 从第10行开始显示
$ more +10 README.md
# 显示查看进度
$ more -d README.md # --More--(17%)[Press space to continue, 'q' to quit.]创建一个空文件, 如果文件存在只会修改文件的创建时间
$ touch README.mdmake directory, 创建目录。
# 在当前目录下创建 temp 目录
$ mkdir temp
# 创建多层目录
$ mkdir -p temp/temp2/temp3
# 基于权限创建
$ mkdir -m 777 temp创建临时目录或文件,Linux使用 /tmp 目录来存放不需要永久保留的文件,大多数Linux发行版配置了系统在启动时自动删除 /tmp 目录的所有文件。
默认情况下, mktemp 会在本地目录中创建一个文件,只要指定一个文件名模板就行,模板可以包含任意文本文件名,在文件名末尾加上 6 个X就行了。
# 创建本地临时文件, 会在当前目录下创建一个叫 log.XXXXXX, XXXXXX是一个随机字符码,保证文件名在目录中是唯一的。
$ mktemp log.XXXXXX # log.J3awfb
# -t, 在 /tmp 目录创建临时文件, 返回绝对路径地址
$ mktemp -t log.XXXXXX # /tmp/log.G5g9dX
# -d 创建临时目录, 这样就能用该目录进行任何需要的操作了,比如创建其他的临时文件
$ mktemp -d dir.XXXXXX删除指定目录或文件
注: 使用此命令需要非常小心, 一但删除无法恢复
# 删除当前目录下的 1.txt 文件
$ rm 1.txt
# -i 删除前询问是否真的要删除,因为一旦删除无法恢复
$ rm -i README.md
# 这条命令比较常用, 强制删除目录或文件
# -r 如果是目录递归删除, -f 强制删除 不发出任何警告
$ rm -rf ./src删除指定空目录
注:rmdir 实际上用得并不多,因为不是很灵活,基本上使用 rm 代替
# 删除当前 temp 空目录, 如果不是空目录会发出警告
$ rmdir temp
# -p 参数可以删除多层空目录, 发现temp3是空目录删除掉,然后接着往父级找如果还是空目录继续删除...
$ rmdir -p temp1/temp2/temp3
# -i 删除前询问确认删除
$ rmdir -i temp指定某个目录下查找文件
# 在当前目录递归搜索文件名为 README.md 文件
$ find . -name README.md
# 也可以指定多个目录,比如 src1 src2目录
$ find src1 src2 -name README.md
# 通过通配符进行查找, 必须用引号括着, 这里查找所有后缀为 .md 文件
$ find . -name "*.md"
$ find . -iname "*.md" # 忽略文件大小写
# 排除文件,只要加 ! , 排除掉所有 .md 后缀的文件
$ find . ! -name "*.md"
# 根据类型进行过滤搜索
# f 普通文件, l 符号连接
# d 目录, c 字符设备
# b 块设备, s 套接字, p Fifo
$ find . -type f
# 限定目录递归深度
$ find . -maxdepth 3 # 最大为3个目录
$ find . -mindepth 3 # 最小为3个目录
# 查找文件大小大于 25k 文件
$ find /root -size +25k
# 查找10天前文件 -mtime 修改时间、 -ctime 创建时间、 -atime 访问时间
$ find /root -mtime +10搜索文件,与 find 命令很像,但更快,因为是从数据库里查找, 通常每天会进行数据更新。
# 搜索 README.md 相关文件
$ locate README.md
# 忽略大小写
$ locate -i README.md显示当前目录下的文件和目录,输出的列表是按字母排序 (某些发行版可能不一样)。
| 参数 | 描述 |
|---|---|
| -l | 显示目录列表的详细信息 |
| -h | 显示文件大小,需要和 -l 参数一起使用 |
| -a | 列出所有文件,包括隐藏文件 |
| -F | 显示文件类型 |
| -i | 查看inode编号, 每个文件都有唯一的编号 |
| -S | 以文件大小进行排序 |
| -t | 以文件修改时间排序 |
| -r | 输出结果倒序排列 |
# 显示当前目录列表
$ ls
# 列出指定目录下的列表
$ ls ./src
# 显示目录列表的详细信息
$ ls -l
# 显示目录列表详细信息和大小
$ ls -lh
# 列出所有文件包括隐藏文件
$ ls -a
# -F 可以显示类型,用以区分是文件还是目录
# 后缀为 ”/“ 代表是目录,”*“ 为可执行文件,没有则为文件
$ ls -F
# 过滤文件列表, * 代表0个或多个字符, ? 代表一个字符
$ ls javasc*
# -i 查看inode编号, 每一个文件或目录都有一个唯一的编号,这个数字由内核分配给文件系统中的每一个对象
$ ls -i文件权限说明,当敲入 ls -la 最左侧会出现10个字符:
$ ls -la
-rw-r--r-- 1 root root 0 Jan 3 11:01 master-stderr.log[-][rwx][r-x][r--] 转换为 1 234 567 890
- 文件权限的位置是不会改变的,有权限则显示,无权限则 - 显示。
是Print Working Directory的缩写, 显示当前工作目录
$ pwd统计文件的行数、字数、字节数, 常见用于统计代码行数
# 统计字节数
$ wc -c README.md
# 统计行数
$ wc -l README.md
# 统计字数
$ wc -w README.md
# 统计字符数
$ wc -m README.md用于修改文件属性, 这项指令可改变存放在ext2文件系统上的文件或目录属性。
| 参数 | 描述 |
|---|---|
| a | 让文件或目录仅供附加用途 |
| b | 不更新文件或目录的最后存取时间 |
| c | 将文件或目录压缩后存放 |
| d | 将文件或目录排除在倾倒操作之外 |
| i | 不得任意更动文件或目录 |
| s | 保密性删除文件或目录 |
| S | 即时更新文件或目录 |
| u | 预防意外删除 |
| -R | 递归处理,将指令目录下的所有文件及子目录一并处理 |
| -v<版本编号> | 设置文件或目录版本 |
| -V | 显示指令执行过程 |
| +<属性>` | 开启文件或目录的该项属性 |
| -<属性>` | 关闭文件或目录的该项属性 |
| =<属性>` | 指定文件或目录的该项属性 |
# 锁定该文件, 防止文件被修改或删除
$ chattr +i README.md
# -i 解锁文件
$ chattr -i README.md
# 可以使用 lsattr 查看赋予的属性
$ lsattr README.md
----i--------e-- README.md合并N个文件的列,相当于追加文件内容。
# 1.txt 和 2.txt 合并输出
$ paste 1.txt 2.txt
# 1.txt 2.txt 合并后保存为 3.txt
$ paste 1.txt 2.txt > 3.txt用于显示文件或目录的状态信息
stat logs
# File: ‘logs/’
# Size: 16384 Blocks: 32 IO Block: 4096 directory
# Device: fd01h/64769d Inode: 669067 Links: 5
# Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
# Access: 2020-07-07 17:24:23.941816812 +0800
# Modify: 2020-07-12 11:46:55.567707577 +0800
# Change: 2020-07-12 11:46:55.567707577 +0800
# Birth: -强大的文本搜索工具,被称为Linux命令三剑客之老三。
命令用法:grep [option] pattern file...
| 参数 | 描述 |
|---|---|
| -i | 忽略大小写 |
| -n | 打印匹配行号 |
| -c | 打印匹配成功的次数 |
| --color | 高亮打印匹配文本 |
| -o | 只打印匹配到的内容 |
| -v | 反向查找 |
| -E | 正则查找 |
| -w | 匹配单词 |
| -r | 从目录下递归搜索 |
# 从 README.md 文件中搜索 linux 关键字
$ grep "linux" README.md
$ grep "linux" README.md README2.md # 多个文件搜索
# 高亮打印匹配文本
$ grep "linux" README.md --color
# -o 只打印匹配到的内容
$ grep -o "linux" README.md --color
# -n 打印匹配的行号
$ grep -n "linux" README.md
# -c 只打印成功匹配的次数
$ grep -c "linux" README.md
# -r 递归搜索目录文件
$ grep -r "linux" ./src
# 使用 glob 风格表达式搜索
# 等价于 grep -E "[0-9]" README.md
$ egrep "[0-9]"sed(stream editor) 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用 sed 命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。
sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
命令格式:sed options script file...
选项
| 参数 | 描述 |
|---|---|
| -e script | 在处理输入时,将script中指定的命令添加到已有的命令中 |
| -f file | 在处理输入时,将file中指定的命令添加到已有的命令中 |
| -n | 不产生命令输入,使用print命令来完成输出 |
| -i | 直接编辑文件并保存 |
| -i.bak | 备份文件并编辑保存 |
来个简单的例子:
$ cat test.txt
i like apple
i like apple
i like apple
i like apple
$ sed 's/apple/banana/' test.txt
i like banana
i like banana
i like banana
i like banana运行上面例子结果就会马上显示出来。
命令解释: sed 's/要替换的内容/替换后的内容/' 文件名, s(substitute)替代
如果需要执行多个命令时只要指定 -e 选项就可以了:
# 多个命令使用分号分隔
$ sed 's/apple/banana/; s/i/I/' test.txt
I like banana
I like banana
I like banana
I like banana当需要执行大量命令时使用 -e 选项就有点鸡助了, 这时候可以将命令存储在一个单独文件中,然后在执行时指定 -f 选项读取。
$ cat cmd.sed
s/apple/banana/
s/i/I/
# 执行
$ sed -f cmd.sed test.txt在执行 sed 时指定 -i 选项可以直接编辑文件并保存。
$ sed -i 's/apple/banana/' test.txt如果是在 mac 上运行会报错:
那是因为 mac 强制要求备份
sed: 1: "test.txt": undefined label '.txt'# 指定备份后缀 .bak 执行后将生成一个 test.txt.bak 文件
$ sed -i '.bak' 's/apple/banana/' test.txt
# 或者指定 -i.bak 选项, 会默认保存备份文件, 不需要指定备份后缀
$ sed -i.bak 's/apple/banana/' test.txts命令最后有一个可选的 flags s/pattern/replacement/flags, 有4种可用的标记:
1、数字:
表明只替换每行中第二次出现的匹配模式。
$ cat test.txt
i like apple apple
i like apple apple
$ sed 's/apple/banana/2' test.txt
i like banana apple
i like banana apple2、g:
在替换时如果不带 g 标记只会替换每行中第一次出现匹配模式。
$ cat test.txt
i like apple apple
i like apple apple
# 没有带 g 标记
$ sed 's/apple/banana/' test.txt
i like banana apple
i like banana apple
# 带 g 标记
$ sed 's/apple/banana/g' test.txt
i like banana banana
i like banana banana3、p:
p 替换标记会打印与替换命令中指定的模式匹配的行,通常会与 -n 选项一起使用才能发挥更好的作用。
-n 选项会禁止 sed 编辑器输出,但p替换标记会输出修改过的行,将两者配合使用的效果就是只输出被替换命令修改过的行。
$ cat test.txt
i like apple apple
i like apple apple
$ sed -n 's/apple/banana/p' test.txt
i like banana apple
i like banana apple4、w:
将命令替换的结果写入到文件中
$ sed 's/apple/banana/w 1.txt' test.txt当遇到需要匹配反斜杠 / 时就很麻烦了,需要做转义:
# 将 /bin/sh 替换为 /bin/bash
$ sed 's/\/bin\/sh/\/bin\/bash/' test.txt如果有大量这种反斜杠可读性就变差了, 还好 sed 提供了感叹号作为字符串分隔符:
# 感叹号是一个占位符, 代表的是 / 反斜杠
$ sed 's!/bin/sh!/bin/bash!' test.txt默认情况下 sed 命令会作用于所有行,如果只想作用于某些行,比如第10行到100行,则必须用行寻址(Line Addressing)。
有两种形式的行寻址:
1、数字方式的行寻址:
以数字 2 表示只处理第2行
$ sed '2s/apple/banana/' test.txt
i like apple
i like banana
i like apple
i like apple
i like apple以区间来表示,第2行到3行
$ sed '2,3s/apple/banana/' test.txt
i like apple
i like banana
i like banana
i like apple
i like apple从某行开始的所有行, 用美元符号 $ 表示末尾行
$ sed '2,$s/apple/banana/' test.txt
i like apple
i like banana
i like banana
i like banana
i like banana2、以文本模式过滤出行
如果只想作用于 B 开头的行, 则可以使用文本模式过滤, 支持正则表达式。
格式: /pattern/command
$ cat README.md
A: Good
B: Bad
A: Good
B: Bad将所有 B 开头的 Bad 改成 Good!
$ sed '/B/s/Bad/Good!/' test.txt
A: Good
B: Good!
A: Good
B: Good!3、多个命令使用相同行寻址
要将多个命令使用相同行寻址可以使用分隔符:
$ sed '1,$s/Bad/Luck/;1,$s/Good/Nice!/' test.txt
A: Nice!
B: Luck
A: Nice!
B: Luck这只是其中一种办法,更好的办法是使用花括号将多条命令组合在一起:
$ sed '1,${
s/Bad/Luck/
s/Good/Nice!/
}' test.txt
# 打印:
A: Nice!
B: Luck
A: Nice!
B: Luck只在多个命令使用相同寻址才使用花括号。
删除行使用 d 命令来执行, 使用该命令需要小心,如果不指定行寻址会删除所有行。
只指定 d 命令将删除所有行
$ sed 'd' test.txt
# 上面并不会删除所有行,你需要指定 -i 直接编辑
$ sed -i 'd' test.txt上面已经介绍过通过数字方式寻址行,同样适用删除:
# 只删除第一行
$ sed '1d' test.txt或者通过数字区间
# 删除1-3行
$ sed '1,3d' test.txt
# 删除第一行以及后面所有行
$ sed '1,$d' test.txt可以通过 -n 参数来打印指定的行内容
打印 10-20 行内容:
$ sed -n '10,20p' README.md打印第一行内容:
$ sed -n '1p' README.md进入指定目录
# 进入当前 src 目录
$ cd src
# 回到上一次目录
$ cd -
# 返回上一级目录
$ cd ..
$ cd ../../.. # 返回多级
# 进入家目录
$ cd ~
$ cd # 或者不带任何参数
# 将上一个命令的参数作为cd参数使用
$ cd !$
# 模糊匹配目录,有时目录名很长一个一个敲效率就很低
# * 代表0个或多个字符, ? 代表一个字符
$ cd javasc*拷贝文件或目录
# 将当前 README.md 文件拷贝到上一层
$ cp ./README.md ../README.md
# -a 将原文件属性一同拷贝, 修改时间、创建时间等
$ cp -a ./README.md ../README.md
# -r 用于递归拷贝目录
$ cp -r home ../home
# -i 如果目标文件存在会询问用户是否需要覆盖
$ cp -i README.md README.mdmv 有2个用途:
注:实际上 mv 是用来移动文件或目录,只不过有类似重命名的功能而已。
# 将 README.md 重命名为 README-2.md, 如果 README-2.md 存在会直接覆盖。
$ mv README.md README-2.md
# 将 README.md 移动到上一层目录
$ mv README.md ../README.md
# -i 交互式操作,如果目标文件存在则进行询问是否覆盖
$ mv -i README.md ../README.md
# -f 如果出现同名直接覆盖
$ mv -f 1.txt 2.txtopen 命令可在 linux / mac 具有可视化界面下进行文本编辑、打开应用程序等功能。
| 参数 | 描述 |
|---|---|
| -n | 即使该应用程序已经在运行,也要打开它的新实例。(适用于Mac) |
| -e | 使用默认编辑器打开文件 |
| -a | 用指定的应用程序来打开指定的文件 |
# 在mac下用Finder打开当前目录
$ open .
# 用默认应用程序打开文件
$ open README.md
# 用默认编辑器打开文件
$ open -e README.md
# 如果是一个URL用默认浏览器打开页面
$ open https://github.com/xjh22222228/linux-manual.git
# 指定某个应用程序打开某个文件, 如果不指定文件默认直接打开程序
$ open -a /Applications/Google\ Chrome.app README.md在当前Shell环境中从指定文件读取和执行命令, 通常用于重新执行环境。
它有个别名 . 点操作符号。
# 等价 . ~/.bash_profile
$ source ~/.bash_profile实际上大部分开发者都没搞懂 source 命令。 可以把它理解为编程语言中的 import, java/python/js 都有这个,就是用来导入文件。
下面演示 source 用于 shell 脚本中
util.sh
#!/bin/bash
getName() {
echo "Linux"
}main.sh
#!/bin/bash
# 加载文件
source ./util.sh
# 这样就可以调用 util 文件中的函数了
echo $(getName)生成目录树结构, 通常用于描述项目结构。
# 递归当前目录下所有文件并生成目录树
$ tree
# .
# ├── LICENSE
# ├── README.md
# └── media
# └── poster.jpg
# -I 忽略某些目录
$ tree -I "node_modules|.git|.svn"
# 只显示目录
$ tree -d
# 指定要递归的目录层级
$ tree -L 3将某一个文件在另外一个位置建立并产生同步的链接。 当不同的2个目录需要同时引用某一个文件时此命令就派上用场了。
软链接也可以叫符号链接:
硬链接:
共同点:
# 默认创建硬链接
$ ln 1.md 2.md
# -s 创建软链接, 2.md 就相当于副本
$ ln -s 1.md 2.md
# -f 强制执行创建
$ ln -f README.md ./src/a.md查看文件类型, 比如文件、目录、二进制、符号链接等
# 输出 README.md: ASCII text
$ file README.md
# index.html: HTML document, UTF-8 Unicode text, with very long lines, with no line terminators
$ file index.html将文本内容以行为单位进行排序。
| 参数 | 描述 |
|---|---|
| -c | 检查文件是否已排序,若已经排序则什么都不输出 |
| -r | 以倒序来排序 |
| -b | 忽略每行开头的空格 |
| -o | 将排序结果输出到文件 |
| -u | 排序并去重,每行都是唯一的 |
| -n | 按照数值大小排序 |
# 排序并打印到终端
$ sort README.md
# 排序并去重将结果输出到 u.md 文件,可以用来替代 uniq 命令
$ sort -u README.md -o u.mduniq 命令用于检查或删除文件中重复出现的行内容。
# 将 1.txt 文件重复内容过滤后输出到 2.txt 文件
$ uniq 1.txt 2.txt
# -c 在左边显示每行重复次数
$ uniq -c 1.txt
# -d 只显示重复行内容
$ uniq -d 1.txtuniq 命令有个问题,只能过滤相邻的内容,比如:
111
111
222
333
222结果: 222 也重复但是不是相邻
111
222
333
222解决办法是配合使用 sort 命令, 原理是先排序为相邻再去重(实际上只用 sort 命令就能解决):
$ sort 1.txt | uniq > 2.txt将一个文件切割成数个文件, 对于大文件来说非常实用。
# 将 README.md 文件每10行分割成一个文件
$ split -10 README.md
# -b 按字节分割
$ split -b 100000 README.md
# 指定分割后的文件名前缀为 READ ,分割后会自动在文件名后随机加上编号
$ split -b 100000 README.md READvi 编辑器是Unix系统最初的编辑器,在GNU项目将vi编辑器移植到开源世界时,他们决定对其做一些改进,开发人员也就将它重命名为 vi improved。
vim(vi improved) 是 vi 的升级版,所以只需要知道 vim 即可, 是一个非强大的文本编辑器,学习成本不低,需要长期使用才能记牢每一个指令操作。
这是一份速查表,使用的时候注意区分大小写。
vim 的快捷键指令非常多,只列出一些实用性便于记忆。
打开文件
# 最简单的打开文件方式, 如果文件不存在会开辟一段新的缓冲区域来编辑。
$ vim README.md
# 打开文件并定位到最后一行
$ vim + README.md
# 打开文件并定位到某一行, +号后面指定行数
$ vim +100 README.md
# 打开多个文件
# :bn 切换下一个文件
# :bp 切换上一个文件
# :ls 列出所有已经打开的文件
# :b2 切换到第2个文件, 2是个任意数字
$ vim 1.txt 2.txt光标定位插入
| 快捷键 | 描述 |
|---|---|
| i | 在当前光标位置插入 |
| I | 在当前光标行第一个字符插入 |
| a | 在当前光标后一个字符插入 |
| A | 光标到当前行最后一个字符插入 |
| H | 光标到第一行第一个字符 (是以终端大小来计算,不是原文本的第一行) |
| M | 光标到中间第一行 (是以终端大小来计算) |
| L | 光标到最后行第一个字符 (是以终端大小来计算) |
| E | 将光标定位到右边的空格 |
| o | 在当前光标下一行插入 |
| O | 在当前光标上一行插入 |
| :n | 将光标定位到 n 行 |
撤销
| 快捷键 | 描述 |
|---|---|
| u | 撤销上一次编辑内容 |
| U | 撤销当前光标整行内容 |
| Ctrl + r | 还原初始文件状态 |
| e! | 撤销所有修改,恢复打开文件时的状态 |
删除
| 快捷键 | 描述 |
|---|---|
| dd | 删除当前行 |
| dj | 删除上一行 |
| dk | 删除下一行 |
| :1,$d | 删除所有行 |
拷贝/粘贴
| 快捷键 | 描述 |
|---|---|
| yy | 拷贝当前行 |
| p | 在当前光标粘贴上一次拷贝的内容 |
搜索
| 快捷键 | 描述 |
|---|---|
| :/text | 从上往下查找 text,按 n 向下搜索, 按 N 想前搜索 |
| :?text | 从下往上查找 text,按 n 向下搜索, 按 N 想前搜索 |
替换
要想匹配 / 需要反斜杠进行转义: \/
| 快捷键 | 描述 |
|---|---|
| :s/old/new | 找到old第一次出现的地方并用new来替换 |
| :s/old/new/g | 找到所有old出现的地方并用new来替换(当前屏幕) |
| :%s/old/new/g | 替换整个文件中的所有old |
| :%s/old/new/gc | 替换整个文件中的所有old,但在每次出现时询问是否替换 |
| :n,ms/old/new/g | 替换行号n和m之间的所有old |
退出
先按 ESC 键然后再操作后面的快捷键。
| 快捷键 | 描述 |
|---|---|
| :w | 写入但不退出 |
| :w! | 强制保存,但不退出 |
| :q! | 退出但不保存 |
| :wq | 保存写入内容并退出 |
| :w file | 将当前文件内容保存到 file 文件中 |
| :qa! | 退出所有文件并不做保存,比如打开了多个文件 |
设置
| 快捷键 | 描述 |
|---|---|
| :set ignorecase | 忽略大小写查找 |
| :set noignorecase | 不忽略大小写查找 |
| :set hlsearch | 高亮搜索结果 |
| :set nohlsearch | 关闭高亮搜索显示 |
| :set hlsearch | 高亮搜索结果 |
| :set number | 显示行号 |
| :set nonumber | 不显示行号 |
程序以挂起方式运行。
nohup 命令会自动将 STDOUT(标准输出)和STDERR(标准错误)的消息重定向到一个名为 nohup.out 文件。
# 例如运行一个 node.js 程序
$ nohup node main.js
# 在当前目录会出现 nohup.out 文件,里面包含了 Hello World
$ nohup echo "Hello World"通常用于监听1个命令的运行结果、定时执行命令
# 每5秒执行一次 tail 命令, 如果不指定-n 默认为2秒
$ watch -n 5 "tail README.md"
# -d 高亮显示变化内容
$ watch -n 5 -d "tail README.md"测试目标地址是否可连接、延迟度
# 测试 github.com 连通性, 按 ctrl + C 停止
$ ping github.com
# ping 5次后断开
$ ping -c 5 xiejiahe.com
# 每5秒ping 一次
$ ping -i 5 xiejiahe.com查找某个命令存储在哪个位置, 输出绝对路径, which 会在环境变量 $PATH 设置的目录里去查找。
注: 可以通过 echo $PATH 查看设置的目录。
只有内建命令才会正常打印,判断是否内建命令可以通过 type 检查。
$ which top # /usr/bin/top
# 查找pwd发现会找不到,因为 pwd 是shell内置命令
$ which pwd
# 打印多个命令
$which ls vi将系统关机或重启操作。
# 什么参数都不加,默认会在1分钟后关机
$ shutdown
# 在将系统的服务停掉之后就重新开机
$ shutdown -r now
# 关闭系统并切断电源
$ shutdown -h now # 立即关机, 实际上调用 init 0
# 把前一个关机或重启取消掉
$ shutdown -c
# 设定一个时间关机, "&" 符号表示后台模式,让出CLI
$ shutdown -h 05:33 &
$ shutdown +5 "5分钟后关机" # 5分钟后关机,同时送出警告信息给登入用户:有点类似 shutdown 命令, 用于重新启动系统。
# 重启系统
$ reboot
# -f 强制重启
$ reboot -f
# 用于模拟重新启动系统,不会真实重启,数据会写入 /var/log/wtmp
$ reboot -w
# 在重新启动之前关闭所有网络界面
$ reboot -i查看系统负载信息, 此命令非常简单,没有太多的参数。
# 21:51:53 当前时间
# up 750 days, 13:24 当前系统运行的天数,小时,分钟 (从上次开机起计算)
# 1 user 当前系统登录用户数
# load average: 0.08, 0.07, 0.06 一分钟、5分钟、15分钟平均负载, 这3个值不能大于CPU个数,如果大于了说明系统负载高,性能低。
$ uptime # 21:51:53 up 750 days, 13:24, 1 user, load average: 0.08, 0.07, 0.06周期性执行任务, 通常用于定时执行作业。
# 列出该用户设置
$ crontab -l
# 编辑该用户设置
$ crontab -e
# 删除该用户设置
$ crontab -r* * * * * 分别含义:
* * * * *
┬ ┬ ┬ ┬ ┬
│ │ │ │ │
│ │ │ │ │
│ │ │ │ └───── 一周中的某一天 (0 - 7) 0或7代表是星期日
│ │ │ └────────── 月份 (1 - 12)
│ │ └─────────────── 一个月的某一天 (1 - 31)
│ └──────────────────── 小时 (0 - 23)
└───────────────────────── 分钟 (0 - 59)18 18 * * * 指令* * * * */1 指令00 12 1 * * 指令每个月的最后一天就比较麻烦了, 需要配合 date 命令和 if 流程语句来实现,
这里 if 语句检查明天的日期是不是01,如果是今天就是最后一天,
每天中午12点检查今天是不是最后一天
00 12 * * * if [ `date +%d -d tomorrow` = 01 ] ; then ; 要执行的指令0 0 * * 1,2,3,4,5,6 指令0 23-8/1 * * * 指令在指定时间执行指令,at 命令时间参数相当复杂,只需要了解常用即可。
| 参数 | 描述 |
|---|---|
| -d | 删除已经设定的任务, atrm 别名 |
| -v | 显示任务将被执行的时间 |
| -c | 打印任务的内容到标准输出 |
| -f | 指定文件读取任务 |
设定任务, 执行后进入交互输入要执行的指令, 按 Ctrl+D 完成并退出。
# 三天后的下午 5点
$ at 5pm+3 days
# 明天上午 11点11分
$ at 11:11 tomorrow
# 今天上午 11点11分
$ at 11:11
# 当前时间之后1分钟
# year 年
# month 月
# day 日
# hours 小时
# minutes 分钟
$ at now +1 minutes
# 也可以通过管道执行,免去交互
echo "ls" | at 11:11指定文件运行脚本
$ at 11:11 -f /opt/script.sh查看当前任务队列
$ atq
2 Sat Jan 30 11:46:00 2021 a root查看指定任务内容
# 2为编号
$ at -c 2删除已经设定的任务
# 1 是编号, 通过 atq 查看
$ at -d 1
# 等价
$ atrm 1打印系统信息
| 参数 | 描述 |
|---|---|
| -a | 打印系统所有信息 |
| -r | 打印系统版本 |
| -n | 打印网络节点主机名称 |
| -p | 打印处理器名称 |
| -m | 打印主机的硬件架构名称 |
# 不带任何参数打印当前操作系统内核名称
$ uname # Linux , 等价于 uname -s
# 打印系统所有信息
$ uname -a
# -r 打印系统版本 , 如果次版本号都是偶数,说明是一个稳定版
$ uname -r # 3.10.0-514.26.2.el7.x86_64
# 打印网络节点主机名称
$ uname -n # Yin.local
# 打印处理器名称
$ uname -p # i386
# 打印主机的硬件架构名称
$ uname -m # x86_64配置或显示系统网卡的网络参数
# 显示所有网络参数信息
$ ifconfig
# 配置网卡IP地址
$ ifconfig eth0 192.168.1.111用来定位指令的二进制程序、源代码文件和man手册页等相关文件的路径。
注意:whereis 是从数据库里查找的,因此特别快,默认情况下一星期更新一次数据,所以有时会查找删除的数据或者刚建立的数据无法找到问题。
# 查找 nginx
$ whereis nginx # nginx: /usr/sbin/nginx /usr/lib64/nginx /etc/nginx /usr/share/nginx /usr/share/man/man8/nginx.8.gz /usr/share/man/man3/nginx.3pm.gz
# -b 指定只查找二进制
$ where -b nginx # nginx: /usr/sbin/nginx /usr/lib64/nginx /etc/nginx /usr/share/nginx
# -m 指定查找说明文件 man
$ whereis -m nginx # nginx: /usr/share/man/man8/nginx.8.gz /usr/share/man/man3/nginx.3pm.gz修改文件或目录权限
chmod [参数选项] [mode, 八进制或符号表示] files...
u 符号代表当前用户。g 符号代表和当前用户在同一个组的用户,以下简称组用户。o 符号代表其他用户。a 符号代表所有用户。r 符号代表读权限以及八进制数4。w 符号代表写权限以及八进制数2。x 符号代表执行权限以及八进制数1。X 符号代表如果目标文件是可执行文件或目录,可给其设置可执行权限。s 符号代表设置权限suid和sgid,使用权限组合u+s设定文件的用户的ID位,g+s设置组用户ID位。t 符号代表只有目录或文件的所有者才可以删除目录下的文件。+ 符号代表添加目标用户相应的权限。- 符号代表删除目标用户相应的权限。= 符号代表添加目标用户相应的权限,删除未提到的权限。| 权限 | 二进制值 | 八进制值 | 描述 |
|---|---|---|---|
| --- | 000 | 0 | 没有任何权限 |
| --x | 001 | 1 | 只有执行权限 |
| -w- | 010 | 2 | 只有写入权限 |
| -wx | 011 | 3 | 有写入和执行权限 |
| r-- | 100 | 4 | 只有读取权限 |
| r-x | 101 | 5 | 有读取和执行权限 |
| rw- | 110 | 6 | 有读取和写入权限 |
| rwx | 111 | 7 | 有全部权限 |
# README.md 文件设为所有用户可读取
$ chmod a+r README.md
# -R 递归目录下所有文件
$ chmod a+r src/
# 也可以用八进制符号表示
# 3个数字分别为 x,y,z 表示User、Group、及Other的权限。
# r=4, w=2, x=1
$ chmod 777 README.md # 等价于 chmod a=rwx README.md全名list open files, 列出当前系统已经被打开的文件。
## 打印所有打开文件的的列表
$ lsof
# 查看指定端口被占用情况
$ lsof -i:8080
# -p 列出指定进程号所打开的文件
$ lsof -p 6112用来变更文件或目录的拥有者或所属群组
# 将 README.md 文件拥有者设为 byroot
$ chown byroot README.md
# 使用-R递归处理文件
$ chown -R byroot src/
# 改变所属群组, 拥有者设为 byroot 群组设为 byrootgroup
$ chown byroot:byrootgroup README.md系统服务管理器指令, 通常用来设置某个服务器默认开机启动或关闭。
命令:systemctl [command] [unit]
# 立即启动服务
$ systemctl start nginx.service
# 立即停止服务
$ systemctl stop nginx.service
# 重启服务,stop 后 start
$ systemctl restart nginx.service
# 重新载入服务, 一般情况下重新载入新的配置
$ systemctl reload nginx.service
# 下次开机时默认启动服务
$ systemctl enable nginx.service
# 下次开机时不会启动服务
$ systemctl disable nginx.service
# 查看某个服务状态信息
$ systemctl status nginx.service
# 当前服务是否正在运行中
$ systemctl is-active nginx.service
# 查看服务开机有没有默认启动
$ systemctl is-enable nginx.service管理操作系统服务的命令, 是Redhat Linux兼容的发行版中用来控制系统服务的实用工具,它以启动、停止、重新启动和关闭系统服务,还可以显示所有系统服务的当前状态。
# 启动 docker 服务
$ service docker start
# 查看 docker 状态
$ service docker status
# 停止 docker 服务
$ service docker stop
# 重新启动 docker 服务
$ service docker restart
# 查看所有服务状态
$ service --status-all显示内存使用情况
| 参数 | 描述 |
|---|---|
| -h | 自动按大小转换对应单位进行格式化显示 |
| -b | 字节单位显示 |
| -k | KB单位显示 |
| -m | MB单位显示 |
| -g | GB单位显示 |
| -s <秒> | 每S秒监控内存使用情况 |
解释:
$ free
# 输出以下, 默认以字节为单位
total used free shared buff/cache available
Mem: 1882192 485312 448424 704 948456 1204660
Swap: 0 0 0
# MB单位显示
$ free -m
# 10秒执行一次查询
$ free -s 10type 命令有2个作用:
普及:内建命令和外部命令的区别:内建命令不会衍生出子进程,而外部命令会衍生出一个子进程然后执行命令, 所以内建命令执行效率要高。
# cd is a shell builtin 表示这是shell内建命令
$ type cd
# ps is hashed (/usr/bin/ps) 表示这是一个外部命令
$ type ps设置命令别名,用于简化较长的命令。
# 列出所有已设置的别名
$ alias
# 设置别名
$ alias ll='ls -l'删除别名
# 删除所有别名
$ unalias -a
# 删除指定别名
$ unalias ll测试某条命令执行所需花费时间
# time 后面跟着要测试的命令
# 输出: 0.02s user 0.01s system 0% cpu 6.233 total
$ time curl https://github.com/xjh22222228/linux-manual显示当前运行在后台模式中的所有用户的进程(作业)
| 参数 | 描述 |
|---|---|
| -l | 打印进程的PID和作业号以及作业命令 |
| -n | 只列出上次shell发出的通知后改变了状态的作业 |
| -p | 只列出作业的PID(进程ID) |
| -r | 只列出运行中的作业 |
| -s | 只列出已停止的作业 |
# 先来启一个后台作业进程, & 符号表示后台运行
$ sleep 100 &
# 查看后台作业
$ jobs # 输出:[1]+ Running sleep 3 &相关命令 &
& 符号表示后台运行, 只要在命令后面加上 & 符号即可。
如果一个命令运行的时间非常长,比如处理文件、HTTP请求时就可以在后台运行,这样就可以让出shell继续执行其他命令。
# 模拟了休眠100秒并在后台运行
$ sleep 100 &你可以通过 jobs 命令来查看后台作业。
screen 命令可以在当前窗口创建多个窗口。
场景:比如我们在当前Shell窗口中运行 python main.py 后就不能操作其他了,除非使用 nohup 等命令挂载到后台。 screen 命令则可以解决此问题。
screen 命令有些发行版Linux会自带,有些则没有,安装:
$ yum install screen -y| 参数 | 描述 |
|---|---|
| -ls | 列表当前所有session窗口 |
| -S | 新建窗口时指定名字 |
| -r | 回到指定名字Session窗口 |
最简单的创建一个新窗口就是直接敲 screen
$ screen最好的方式是指定 -S 给一个Session名字,以便知道这个窗口是干什么的:
$ screen -S python列表所有Session窗口
$ screen -ls
There is a screen on:
18772.python (Attached)
1 Socket in /var/run/screen/S-root.杀死Session窗口, 18722 是Session Id, 通过 screen -ls 可以找到
$ screen -S 18722 -X quit回到指定名字的Session窗口
$ screen -r python
# 只有一个session情况下允许不指定名字
$ screen -r退出并杀死当前窗口,也可以按 Ctrl+D
$ exit只有在 screen session 窗口中使用
| 参数 | 描述 |
|---|---|
| Ctrl+a x | 锁定当前窗口,需要密码才能解开 |
| Ctrl+a d | 暂时离开当前窗口 |
操作:按住 Ctrl+a 然后放, 再按 x。
查看当前系统进程状态。
ps 命令非常复杂,且参数极多,由于 ps 历史问题,参数风格支持了三种 UNIX/BSD/``GNU` 这里不详细的介绍,感兴趣可以自行了解。
| 参数 | 描述 |
|---|---|
| -A | 显示所有进程 |
| -N | 显示与指定参数不符的所有进程 |
| -a | 显示除控制进程和无终端进程外的所有进程 |
| -d | 显示除控制进程外的所有进程 |
| -e | 显示所有进程 |
| -C cmdlist | 显示包含在cmdlist列表中的进程 |
| -G grplist | 显示组ID在grplist列表中的进程 |
| -U userlist | 显示属主的用户ID在userlist列表中的进程 |
| -g grplist | 显示会话或组ID在grplist列表中的进程 |
| -p pidlist | 显示PID在pidlist列表中的进程 |
| -s sesslist | 显示会话ID在sesslist列表中的进程 |
| -t ttylist | 显示终端ID在ttylist列表中的进程 |
| -u userlist | 显示有效用户ID在userlist列表中的进程 |
| -F | 显示更多额外输出(相对-f参数而言) |
| -O format | 显示默认的输出列以及format列表指定的特定列 |
| -M | 显示进程的安全信息 |
| -c | 显示进程的额外条调度器信息 |
| -l | 显示长列表 |
| -o format | 仅显示由format指定的列表 |
| -y | 不要显示进程标记(process tag, 表明进程状态的标记) |
| -Z | 显示安全标签(security context)信息 |
| -H | 用层级格式来显示进程(树状,用来显示父进程) |
| -n namelist | 定义了WCHAN列显示的值 |
| -w | 采用宽输出模式,不限宽显示 |
| -L | 显示进程中的线程 |
| -V | 显示PS命令的版本号 |
# 显示所有进程信息
$ ps -A
# 显示指定用户进程信息
$ ps -u root
# 显示所有进程信息包括命令行
$ ps -ef # -e 等价于 -A , 即等价于 ps -Af
# 这是 BSD 风格参数,列出所有正在内存中的进程
$ ps aux
# 配合 grep 查询指定进程
$ ps -ef | grep nginxpstree命令以树状图的方式展现进程之间的派生关系。
$ pstree -a
# 输出信息:
├─AliSecGuard
├─assist_daemon
│ └─7*[{assist_daemon}]
├─atd -f
├─auditd -n
│ └─{auditd}
├─crond -n
├─dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
├─dhclient -H debug010000002015 -1 -q -lf /var/lib/dhclient/dhclient--eth0.lease -pf /var/run/dhclient-eth0.pid eth0
├─frps -c ./frps.ini
│ └─2*[{frps}]
├─nginx
│ └─nginx
├─ntpd -u ntp:ntp -g
├─polkitd --no-debug
│ └─5*[{polkitd}]
├─rsyslogd -n
│ └─2*[{rsyslogd}]
├─sshd -D
│ └─sshd
│ └─bash
│ └─pstree -a
├─systemd-journal
├─systemd-logind
├─systemd-udevd
└─tuned -Es /usr/sbin/tuned -l -P
└─4*[{tuned}]$ pstree -p
# 输出信息:
systemd(1)─┬─AliSecGuard(9347)─┬─{AliSecGuard}(9348)
├─agetty(474)
├─agetty(475)
├─assist_daemon(1356)─┬─{assist_daemon}(1370)
│ ├─{assist_daemon}(1371)
│ ├─{assist_daemon}(1372)
│ ├─{assist_daemon}(1870)
│ ├─{assist_daemon}(1871)
│ ├─{assist_daemon}(1872)
│ └─{assist_daemon}(1873)
├─atd(459)
├─auditd(368)───{auditd}(375)
├─crond(455)
├─dbus-daemon(440)
├─dhclient(680)
├─nginx(9605)───nginx(9608)
├─ntpd(766)
├─polkitd(448)─┬─{polkitd}(489)
│ ├─{polkitd}(490)
│ ├─{polkitd}(491)
│ ├─{polkitd}(492)
│ └─{polkitd}(493)
├─rsyslogd(740)─┬─{rsyslogd}(769)
│ └─{rsyslogd}(770)
├─sshd(4007)───sshd(21896)───bash(21898)───pstree(21921)
├─systemd-journal(326)
├─systemd-logind(445)
├─systemd-udevd(350)
└─tuned(743)─┬─{tuned}(1004)
├─{tuned}(1006)
├─{tuned}(1009)
└─{tuned}(1011)实时查看系统执行中的程序, top 命令跟 ps 命令相似,但它是实时的。
默认情况下 top 命令启动时会按照 %CPU 值对进程排序。
| 名称 | 描述 |
|---|---|
| PID | 进程的ID |
| USER | 进程的优先级 |
| PR | 进程的优先级 |
| NI | 进程的谦让度值 |
| VIRT | 进程占用的虚拟内存总量 |
| RES | 进程占用的物理内存总量 |
| SHR | 进程和其他进程共享的内存总量 |
| S | 进程的状态(D=可中断的休眠状态,R在运行状态,S休眠状态,T跟踪状态或停止状态,Z=僵化状态) |
| %CPU | 进程使用的CPU时间比例 |
| %MEM | 进程使用的内存占可用内存的比例 |
| TIME+ | 自进程启动到目前为止的CPU时间总量 |
| COMMAND | 进程所对应的命令行名称,也就是启动的程序名 |
# 实时监听进程变化
# PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
# 1 root 20 0 125124 3612 2428 S 0.0 0.2 0:04.88 systemd
$ top
# 显示2条
$ top -n 2
# 显示指定的进程信息
$ top -pid <pid>
# 查看进程所有的线程
$ top -H -p <pid>查看网络系统状态信息
参数说明:
| 参数 | 描述 |
|---|---|
| a或--all | 显示所有连线中的Socket |
| A<网络类型>或--<网络类型> | 列出该网络类型连线中的相关地址 |
| c或--continuous | 持续列出网络状态 |
| C或--cache | 显示路由器配置的快取信息 |
| e或--extend | 显示网络其他相关信息 |
| F或--fib | 显示FIB |
| g或--groups | 显示多重广播功能群组组员名单 |
| h或--help | 在线帮助 |
| i或--interfaces | 显示网络界面信息表单 |
| l或--listening | 显示监控中的服务器的Socket |
| M或--masquerade | 显示伪装的网络连线 |
| n或--numeric | 直接使用IP地址,而不通过域名服务器 |
| N或--netlink或--symbolic | 显示网络硬件外围设备的符号连接名称 |
| o或--timers | 显示计时器 |
| p或--programs | 显示正在使用Socket的程序识别码和程序名称 |
| r或--route | 显示Routing Table |
| s或--statistics | 显示网络工作信息统计表 |
| t或--tcp | 显示TCP传输协议的连线状况 |
| u或--udp | 显示UDP传输协议的连线状况 |
| v或--verbose | 显示指令执行过程 |
| V或--version | 显示版本信息 |
| w或--raw | 显示RAW传输协议的连线状况 |
| x或--unix | 此参数的效果和指定"-A unix"参数相同 |
| -ip或--inet | 此参数的效果和指定"-A inet"参数相同 |
# 列出所有占用端口
$ netstat -ntlp
# 显示所有网络状况
$ netstat -a
# 显示所有tcp网络状况
$ netstat -at
# 显示所有udp网络状况
$ netstat -au
# 配合grep命令查看某个端口被占用情况
$ netstat -ap | grep 8080结束程序,kill 命令只支持进程id杀死,不支持进程名称。
| 信号 | 名称 | 描述 |
|---|---|---|
| 1 | HUP | 挂起 |
| 2 | INT | 中断 |
| 3 | QUIT | 结束运行 |
| 9 | KILL | 无条件终止 |
| 11 | SEGV | 段错误 |
| 15 | TERM | 尽可能终止 |
| 17 | STOP | 无条件停止运行,但不终止 |
| 18 | TSTP | 停止或暂停,但继续在后台运行 |
| 19 | CONT | 在STOP或TSTP之后恢复执行 |
注:程序进程 id 可通过 top 等命令查看。
# 杀死 pid 为88 进程,不带参数默认等价 kill -15
$ kill 88
# 无条件终止进程,以下是等价,可以用进程名称信号
$ kill -KILL 88
$ kill -9 88
# 显示信号
$ kill -l
# 杀死指定用户的所有进程
$ kill -u nginx杀死进程,可以杀死多个进程,比 kill 要强大, 支持通过进程名称杀死, 还支持通配符。
# 杀死以tcp进程名称开头的所有进程
$ killall tcp*给系统添加新用户
注:
passwd 命令进行更改。| 参数 | 描述 |
|---|---|
| -c comment | 给新用户添加备注 |
| -d home_dir | 为主目录指定一个名字(如果不想用登录名作为主目录名的话) |
| -e expire_date | 用YYYY-MM-DD格式指定一个账户过期的日期 |
| -f inactive_days | 指定这个账户密码过期后多少天这个账户被禁用;0表示密码已过期就立即禁用,1表示禁用这个功能 |
| -g initial_group | 指定用户登录组的GID或组名 |
| -G group | 指定用户除登录组之外所属的一个或多个附加组 |
| -k | 必须和-m一起使用,将/etc/skel目录的内容复制到用户的HOME目录 |
| -m | 创建用户的HOME目录 |
| -M | 不创建用户的HOME目录(当默认设置里要求创建时才使用这个选项) |
| -n | 创建一个与用户登录名同名的新租 |
| -r | 创建系统账户 |
| -p passwd | 为用户账户指定默认密码 (需要使用openssl把明文进行加密后设置,否则无效) |
| -s shell | 指定默认的登录shell |
| -u uid | 为账户指定唯一的UID |
| 参数 | 描述 |
|---|---|
| -b default_home | 更改默认的创建用户HOME目录的位置 |
| -e expiration_date | 更改默认的心账户的过期日期 |
| -f inactive | 更改默认的心用户从密码过期到账户被禁用的天数 |
| -g group | 更改默认的组名称或GID |
| -s shell | 更改默认的登录shell |
# -D, 查看默认值
$ useradd -D
# 输出:
GROUP=100 # 新用户会被添加到GID为100的公共组
HOME=/home # 新用户的HOME目录将位于 /home/loginname
INACTIVE=-1 # 新用户账户密码在过期后不会被禁用
EXPIRE= # 新用户账户未被设置过期日期
SHELL=/bin/bash # 新用户账户将bash shell作为默认shell
SKEL=/etc/skel # 系统会将/etc/skel目录下的内容复制到用户的HOME目录下
CREATE_MAIL_SPOOL=yes # 系统为该用户账户在mail目录下创建一个用于接收邮件的文件
# 创建一个 test 用户, -m 创建 /home/test 目录
$ useradd -m test
# 创建一个用户并设置密码
$ useradd -m test # 不指定-p,因为需要加密那样很麻烦
$ passwd test # 通过passwd修改指定用户密码添加新用户后可以执行 cat /etc/passwd 查看用户列表。
删除用户
# 删除用户,默认会从 /etc/passwd 文件中删除用户信息,而不会删除系统中属于该账户的任何文件
$ userdel 用户名
# -r 用来删除用户目录, 之前创建的 /home/用户名 就不存在了, 使用-r参数需要小心,要检查是否有重要文件。
$ userdel -r 用户名修改用户密码, 只有 root 用户才有权限修改别人的密码。
使用 passwd 一般用于修改单个用户密码,如果想批量修改那么需要 chpasswd 命令。
# 如果不指定用户名,修改的是自己当前用户密码, 回车后输入新密码
$ passwd
# 修改指定用户密码,比如test用户
$ passwd test类似 passwd 命令也是用于修改用户密码,但它支持批量修改用户。
chpasswd 命令从标准输入自动读取登录名和密码对(由冒号分割)列表,给密码加密。
# 利用输入重定向从文本中读取
$ chpasswd < users.txt
# 从标准输入读取
$ echo 'test:fff33300..a' | chpasswduser.txt 内容:
test:helloworld0123..
test1:fff33300..
admin:youyouyou00..11chsh 命令用于修改默认用户登录 shell。
修改后重新启动Shell即可生效(exit/logout),或重新启动系统。
# 必须使用完整路径,不能使用shell名
$ chsh -s /bin/zsh查看当前 Shell
$ echo $SHELL # /bin/zsh列出当前所有已安装的Shell
$ cat /etc/shells
# /bin/bash
# /bin/csh
# /bin/dash
# /bin/ksh
# /bin/sh
# /bin/tcsh
# /bin/zsh主要用于更改账号的个人信息。这些信息保存在 /etc/passwd 下。
默认情况下如果不提供参数将进入问答式逐一设置。
| 参数 | 描述 |
|---|---|
| -f | 真实姓名 |
| -h | 家中电话 |
| -o | 办公地址 |
| -p | 办公室电话 |
# 修改 root 账号信息
$ chfn root
# Changing finger information for root.
# Name [xiejiahe]:
# Office [ZhuHai]:
# Office Phone [13xxxxxxxxx]:
# Home Phone [13xxxxxxxxx]: $ chfn -f rootusermod 命令是用于账号修改工具中最强大的一个,它能用来修改 /etc/passwd 文件中的大部分字段。
注意:确保需要修改的用户已下线。
| 参数 | 描述 |
|---|---|
| -l | 修改用户账号的登录名 |
| -p | 修改账号的密码 |
| -L | 锁定账号,使用户无法登录 |
| -U | 解除锁定,使用户能登录 |
| -l | 修改用户账号的登录名 |
| -d | 修改用户登录时的目录 |
| -c | 修改用户备注信息 |
| -s | 修改用户登录时默认shell |
| -u | 修改用户的UID |
# 将 root 登录名修改为 root123
$ usermod -l root root123
# 锁定 test 账号
$ usermod -L test
# 当用户登录时目录为 /etc 下
$ usermod -d /etc root
# 修改UID
$ usermod -u 888 root显示当前登录系统的所有用户的用户列表
$ users
# xiejiahe
# root
# admin显示当前所有用户登录信息
# 显示当前登录系统的用户
$ who
xiejiahe console Jun 15 21:38
xiejiahe ttys001 Jun 15 21:44
xiejiahe ttys002 Jun 15 21:44
xiejiahe ttys003 Jun 15 21:44
xiejiahe ttys004 Jun 15 21:44
xiejiahe ttys005 Jun 15 21:44
# 显示登录账号名和总人数
$ who -q
# 显示上次系统启动时间
$ who -b # reboot ~ Jun 15 21:38查看当前登入系统的用户信息, 有哪些用户正在登陆, 以及他们正在执行的程序。
此命令与 who 相似,默认情况下比 who 命令输出内容更详细。
$ w
# 输出
22:44:33 up 748 days, 14:16, 1 user, load average: 0.04, 0.03, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 183.11.111.11 22:40 1.00s 0.03s 0.00s w显示用户最近登录信息
$ last # root pts/0 183.58.247.64 Sun Jan 5 13:57 - 14:28 (00:30)
# 指定显示条目数
$ last -n 1切换到其他用户。
# 切换到 root 身份
$ su -
# 切换到 admin 身份
$ su admin
# -c 执行完指令后切换回原身份
$ su -c ls admin可以通过以下指令查找当前系统用户列表
$ cat /etc/passwd显示自身的用户名称, 此命令等价于 id -un
$ whoami
# root列出全局环境变量, 有个 env 命令很像,但 printenv 可以打印变量的值。
普及:所有系统环境变量都是大写字母,用于区分普通用户的环境变量。
# 列出所有全局环境变量
$ printenv
# 也可以显示指定全局环境变量的值, 等价于 echo $HOME
$ printenv HOME # /root列出所有全局变量、局部变量和普通用户定义的变量,按照字母顺序对结果进行排序。
注意:所有系统全局变量都是大写,用户定义的环境变量全部采用小写,这是标准规范。
$ set
# OPTIND=1
# OSTYPE=linux-gnu
# PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
# PIPESTATUS=([0]="0")
# ...导出环境变量, 可以把一个局部变量导出成全局环境变量
注意:export 只有在当前Shell有效,退出后将失效
# 先声明一个局部环境变量
$ my_var='Hello'
# 然后将其导出全局环境变量
$ export my_var删除环境变量
注意:unset 只在当前shell删除环境变量,假如环境变量设置在 ~/.bash_profile 等文件中用户重新启动依然生效。如果是在子进程删除全局环境变量只在子进程有效,不会影响父进程。
# 删除 HOME 环境变量,前面不需要带 $ 符号
$ unset HOME归档数据,将目录或文件归档为 .zip 格式, zip 不是Linux中的标准归档工具, 是为了支持 windows 而存在。
# 归档文件
$ zip README.zip README.md
# 归档目录需要 -r 递归处理
$ zip -r temp.zip temp
# -S 包含系统隐藏文件
$ zip -r -S temp.zip temp
# 指定归档效率 1-9
$ zip -r -9 temp.zip temp
# -j 消除文件夹, 这样解压后只有 README.md 文件而不是带有 src 文件夹
$ zip -j temp.zip src/README.md提取 zip 归档的文件或目录
# 将 demo.zip 提取到当前目录下
$ unzip demo.zip
# 列表 demo.zip 文件内容,但不提取
$ unzip -v demo.zip
# -d 指定将文件提取到 src 目录下
$ unzip demo.zip -d srcGNU 压缩/解压工具,用 Lempel-Ziv编码,格式为 .gz, 压缩后原文件将被删除
注意:gzip 不能用于压缩整个目录, 只能用于压缩一个文件, 如果需要压缩整个目录可以考虑使用 zip 命令。
# 压缩 README.md 文件, 压缩完成后 README.md 文件会被删除
$ gzip README.md # README.md.gz
# 递归压缩目录下的所有文件, 每个文件都会被压缩为 .gz 然后删除
$ gzip -r ./logs
# 加 -v 显示压缩执行过程
$ gzip -rv ./logs
# 压缩 .tar 后缀文件
$ gzip -r src.tar # 压缩后为 src.tar.gz
# -d 解压gzip压缩后的文件,解压后 .gz 文件会被删除
$ gzip -d README.md.gz
$ gzip -dr ./logs # 或者递归解压目录下所有 .gz采用 Burrows-Wheeler 块排序文本压缩算法和霍夫曼编码,将文件压缩成 .bz2 格式,也可用于解压 .bz2
# 压缩 README.md 文件
$ bzip2 README.md # 不保留源文件 README.md.bz2
$ bzip2 -k README.md # -k 保留源文件
# 解压
$ bzip2 -d README.md.bz2 # 源文件将被删除
$ bzip2 -dk README.md.bz2 # -k 保留源文件
$ bzip -dt README.md.bz2 # -t --test 测试解压, 实际不解压,模拟整个解压过程归档数据,是Linux中标准归档工具。
| 参数 | 描述 |
|---|---|
| -A | 将一个已有tar归档文件追加到另一个已有tar归档文件 |
| -c | 创建一个新的tar归档文件 |
| -d | 检查归档文件和文件系统的不同之处 |
| -r | 追加文件到已有tar归档文件结尾 |
| -t | 列出已有tar归档文件的内容 |
| -u | 将比tar归档文件中已有的同名文件新的文件追加到该tar归档文件中 |
| -x | 从已有的tar归档文件中提取文件 |
| -f | 输出结果到文件或设备file |
# -c 创建一个归档文件
$ tar -cvf demo.tar src/
# -x 提取归档文件内容
$ tar -xvf demo.tar
$ tar -xvf demo.tar.gz # tar命令是可以提取 gzip 压缩后的文件计算和校验文件报文摘要
# 计算文件md5
$ mmd5sum README.md # d41d8cd98f00b204e9800998ecf8427e README.md
# 校验文件, 查看文件是否被篡改过
$ md5sum README.md > README.md5 # 计算文件md5并保存在 README.md5 , 保存的文件名和后缀可以随意命名
$ md5sum -c README.md5 # -c 从指定的文件读取md5并校验, 会从当前目录寻找 README.mdbase64 编码/解码文件或标准输入输出
# 编码字符串
$ printf "hello world"|base64 # aGVsbG8gd29ybGQ=
# 解码字符串
$ printf aGVsbG8gd29ybGQ=|base64 -d # hello world
# 编码文件, 将结果保存在 decode.txt
$ base64 README.md > decode.txt
# 从标准输入中读取已经进行base64编码的内容进行解码
$ base64 -d decode.txt远程连接服务器工具
命令:ssh [-p port] [user@]hostname [command]
| 参数 | 描述 |
|---|---|
| -p | 指定端口号 |
| -t | 强制分配为终端 |
# 最简单的连接方式
$ ssh [email protected]
# 指定端口号连接
$ ssh -p 23 [email protected]
# 执行远程服务器命令, 比如创建目录
$ ssh [email protected] "mkdir -p /home/test"
# 在远程服务器执行本地脚本
$ ssh [email protected] < shell.sh用于从网络下载文件到本地
# 下载某个文件
$ wget https://www.xiejiahe.com/robots.txt
# 指定下载后文件名
$ wget -O ro.txt https://www.xiejiahe.com/robots.txt
# 断开续传,一般用于大文件,防止重新下载
$ wget -c https://www.xiejiahe.com/robots.txt
# 使用后台下载, 对于大文件非常有用
$ wget -b https://www.xiejiahe.com/robots.txt
$ tail -f wget-log # 查看后台下载进度curl 是一个非常强大的网络传输工具, 利用URL规则在命令行下工作的文件传输工具。
| 参数 | 描述 |
|---|---|
| -s, --silent | 不输出错误和进度信息, 只显示正常结果 |
| -o, --output | 将结果输出到文件中 |
| -O, --remote-name | 下载文件到本地,并将URL最后部分当做文件名 |
| -L | HTTP请求跟随服务器重定向 |
| -I, --head | 显示HTTP响应报文 |
| -H | 设置请求头 |
| -X | 指定HTTP请求方法,大写字母 |
| -d | HTTP请求实体内容 |
| --cookie | 指定发送cookie |
| -v | 打印整个传输过程 |
| -F, --form | 上传文件 |
| -u | 指定用户名密码授权 |
| --progress | 显示进度条 |
| -f, --fail | 连接失败时不显示http错误 |
| --retry | 请求重试 |
注意:参数不分前后
$ curl https://github.com/xjh22222228/linux-manual$ curl -s https://github.com/xjh22222228/linux-manual# 将响应内容保存到 1.txt 文件
$ curl https://github.com/xjh22222228/linux-manual -o 1.txt# 文件名为 linux-manual
$ curl https://github.com/xjh22222228/linux-manual -O$ curl https://github.com/xjh22222228/linux-manual --progress$ curl -L https://github.com/xjh22222228/linux-manual$ curl -I https://github.com/xjh22222228/linux-manual$ curl -H 'Content-Type: application/json' -H 'Content-Type: application/json' https://github.com/xjh22222228/linux-manual$ curl -X POST https://github.com/xjh22222228/linux-manual$ curl -X POST -d '{"key":"value"}' https://github.com/xjh22222228/linux-manual$ curl --cookie "age=18;name=xjh" https://github.com/xjh22222228/linux-manual$ curl -v https://github.com/xjh22222228/linux-manual# file 是字段名, =@ 必须存在
$ curl https://example.com/upload -F "file=@/home/demo.png"$ curl -u root:password ftp://demo/README.md请求失败时设置重试次数
$ curl http://example.com --retry 3加密的方式在本地主机和远程主机之间复制文件
注:需要有读写权限,否则会无法操作。
# 从远程主机下载文件到本地
$ scp [email protected]:/root/file.zip /home/file.zip
# 从远程主机下载目录到本地,需要 -r 递归
$ scp -r [email protected]:/root/dir /home/dir
# 从本地主机上传文件到远程主机
$ scp /home/file.zip [email protected]:/root/file.zip
# # 从本地主机上传目录到远程主机,需要 -r 递归
$ scp -r /home/dir [email protected]:/root/dirrsync 命令是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件。rsync使用所谓的“rsync算法”来使本地和远程两个主机之间的文件达到同步,这个算法只传送两个文件的不同部分,而不是每次都整份传送,因此速度相当快。
rsync 非常强大,可以用来替代 cp / mv / scp 等命令。
| 参数 | 描述 |
|---|---|
| -r | 递归拷贝子目录 |
| -a | 递归拷贝子目录,但同步元数据信息,比如修改时间,创建时间,权限等 |
| -n | 模拟执行结果 |
| -v | 显示执行过程 |
| -z | 压缩传输 |
| --exclude | 排除文件 |
| --include | 包含文件 |
| --progress | 显示传输进度信息 |
| --link-dest | 指定增量备份的基准目录 |
source 有没有斜杠影响同步结果:
# 无斜杠, dst 目录下只有 source目录
$ rsync -r source dst
# 有斜杠, dst 目录下包含 source 所有文件,没有source目录
$ rsync -r source/ dst# -r 表示递归拷贝子目录,将 source 拷贝到 dst 目录下
$ rsync -r source dst # dst 目录下就有 source
# 可以将多个source 拷贝到指定目录下
$ rsync -r source1 source2 dst
# -a替代-r, 同步元数据信息,比如修改时间,创建时间,权限等
$ rsync -a source dst# 本地同步到远程, 本地 docs 目录同步到远程 home/docs 下
$ rsync -rv ~/docs [email protected]:/home/docs
# 远程同步到本地, 将远程 /home/docs 目录同步到本地 ~/docs 下
$ rsync -rv [email protected]:/home/docs ~/docsrsync 最大的特点就是支持增量备份,所谓增量备份指的是只同步有变动的文件。
rsync 默认就是增量备份的,但可以添加 --link-dest 参数指定基准目录进行比较,找出有变动的文件。
# --link-dest 后面跟着基准目录,然后会跟 source 进行一一比较,找出变动的文件进行同步
$ rsync -a --link-dest compare source dest# 排除文件
$ rsync -r --exclude=".git" source dst
# 大括号指定多个排除模式
$ rsync -r --exclude={".git", ".svn"} source dst
# 包含文件
$ rsync -r --include="src/" source dst
# 大括号指定多个包含模式
$ rsync -r --include={"src/", "tests/"} source dst查看已挂载的磁盘使用情况。
| 名称 | 描述 |
|---|---|
| Filesystem | 设备的设备位置文件 |
| Size | 能容纳多少个1024字节大小的块 |
| Used | 已用了多少个1024字节大小的块 |
| Avail | 还有多少个1024字节大小的块可用 |
| Use% | 已用空间所占的比例 |
| Mounted on | 设备挂载到了哪个挂载点上 |
# 显示每个有数据的已挂载文件系统
# Filesystem 1K-blocks Used Available Use% Mounted on
# /dev/vda1 41151808 1853208 37185168 5% /
$ df
# 格式化大小,以kb以上进行显示
$ df -h
# 查看全部文件系统信息
$ df -a显示文件或目录所占用的磁盘空间
| 参数 | 描述 |
|---|---|
| -m | 以mb单位显示大小 |
| -h | 自动格式化单位,以 K, M, G为单位 |
| -s | 只显示总大小,列出最后累计的值 |
| -c | 显示当前所有已列出文件总大小 |
| -b | 以 bytes 为单位显示大小 |
# 默认显示当前目录的所有文件、目录、和子目录的磁盘使用情况
$ du
# 查看指定文件所占用磁盘空间
$ du README.md
# 查看指定目录所占用磁盘空间, 输出的最后一行是累计总大小
$ du src
# -h 以K,M,G为单位,提高信息的可读性。
$ du -h src
20K src
# -s 只显示总大小,列出最后累计的值
$ du -s src
# 显示当前所有已列出文件总大小
$ du -c基于RPM的软件包管理器, 特点安装快捷,命令简洁好记。
# 安装
$ yum install 包名
# 指定 -y 安装时自动全部 yes
$ yum -y install 包名
# 查找包
$ yum search 包名
# 显示所有已安装的包
$ yum list
# 升级包
$ yum update 包名
# 只删除软件包而保留配置文件和数据文件
$ yum remove 包名
# 删除软件和它的所有配置文件
$ yum erase 包名
# 清除缓存
$ yum clean all
# 显示安装包信息
$ yum info 包名
# 检查可更新的包程序
$ yum check-updateapt-get命令 是Debian Linux发行版中的APT软件包管理工具。所有基于Debian的发行都使用这个包管理系统。
# 安装一个docker软件
$ apt-get install docker
# 卸载软件,保留配置文件
$ apt-get remove docker
# 卸载软件并删除配置文件
$ apt-get –purge remove docker
# 更新所有已安装的软件包
$ apt-get upgrade
# 删除软件备份,主要用来释放空间
$ apt-get clean| 目录名 | 描述 |
|---|---|
| / | 虚拟目录的根目录,通常不会在这里存储文件 |
| /bin | 二进制目录,存放许多用户级的GNU工具 |
| /boot | 启动目录,存放启动文件 |
| /dev | 设备目录,Linux在这里创建设备节点 |
| /etc | 系统配置文件目录 |
| /home | 主目录,Linux在这里创建用户目录 |
| /lib | 库目录,存放系统和应用程序的库文件 |
| /media | 媒体目录,可移动媒体设备的常用挂载点 |
| /mnt | 挂载目录,另一个可移动媒体设备的常用挂载点 |
| /opt | 可选目录,常用于存放第三方软件包和数据文件 |
| /proc | 进程目录,存放现有硬件及当期进程的相关信息 |
| /root | ROOT用户的主目录 |
| /sbin | 系统二进制目录,存放许多GNU管理员级工具 |
| /run | 运行目录,存放系统运作时的运行时数据 |
| /srv | 服务目录,存放本地服务的相关文件 |
| /sys | 系统目录,存放系统硬件信息的相关文件 |
| /tmp | 临时目录,可以在该目录中创建和删除临时工作文件 |
| /usr | 用户二进制目录,大量用户级的GNU工具和数据文件都存储在这里(Unix Software Resource) |
| /var | 可变目录,用以存放经常变化的文件,比如日志文件 |
将命令输出的内容发送到一个文件中叫做 输出重定向 。 使用 > 大于号。
下面展示了几个例子
# 例子一:
$ echo "Hello World" > log.txt
# 例子二:
$ ps -ef > ps.txt
# 例子三:
$ history > a.txt有时不想覆盖文件而是追加内容,比如日志,可以使用 >> 2个大于号。
$ echo "H" >> log.txt和输出重定向正好相反,将文件的内容定向到命令。
# 统计input.txt文本行数
$ wc -l < input.txt # 等价于 wc -l input.txt还有一种叫内联重定向,比较少见,但也挺有用。 使用2个 << 小于号。然后跟着一个开头标记和结尾标记。
# 统计行数,输出2
$ wc -l << EOF
第一行
第二行
EOF开头标记必须和结尾标记一致,标记名称可以是任何字符串。
下面这个也是可以的。
# 输出2
$ wc -l << Hello
第一行
第二行
Hello将一个命令的输出作为另一个命令的输入称为管道。 管道用 | 符号表示。
# 将 ls 输出内容作为 wc 输入
$ ls | wc
# 执行一个脚本,这没有什么意义,只是一个例子
$ echo "./bash.sh" | bash输出字符串或者变量
| 参数 | 描述 |
|---|---|
| -n | 打印时不加换行符 |
| -e | 解析字符 |
注: 一般情况下字符串不必加双引号, 如果包含转义字符就必须要加
# 在终端输出 Hello World
$ echo "Hello World"
$ echo Hello World # 也可以不加双引号
$ echo "Hello\nWorld" # 必须加双引号, 否则无法转义
# 打印系统环境变量,如果变量不存在输出为空
$ echo $PATH
# > 输出重定向,将内容输出到文件中
$ echo Hello World > 1.txt
# -n 不换行, 默认情况下会换行
$ echo -n Hello; echo World
# -e 解析字符, 比如让字体输出颜色
$ echo -e "\033[1;32m绿色\033[0m"
$ echo -e "\n换行\n" # 解析 \n 作为换行显示或设置系统时间日期
| 格式化符号 | 描述 |
|---|---|
| %% | 百分号 |
| %a | 当地缩写的工作日名称(例如,Sun) |
| %A | 当地完整的工作日名称(例如,Sunday) |
| %b | 当地缩写的月份名称(例如,Jan) |
| %B | 当地完整的月份名称(例如,January) |
| %c | 当地的日期和时间(例如,Thu Mar 3 23:05:25 2005) |
| %C | 世纪,和 %Y 类似,但是省略后两位(例如,20) |
| %d | 一月中的一天(例如,01) |
| %D | 日期,等价于 %m/%d/%y |
| %e | 一月中的一天,格式使用空格填充,等价于 %_d |
| %F | 完整的日期;等价于 %+4Y-%m-%d |
| %g | ISO标准计数周的年份的最后两位数字 |
| %G | ISO标准计数周的年份,通常只对 %V 有用 |
| %h | 等价于 %b |
| %H | 小时,范围(00..23)24小时制 |
| %I | 小时,范围(00..12)12小时制 |
| %j | 一年中的一天,范围(001..366) |
| %k | 小时,使用空格填充,范围(0..23),等价于 %_H |
| %l | 小时,使用空格填充,范围(1..12),等价于 %_I |
| %m | 月,范围(01..12) |
| %M | 分钟,范围(00..59) |
| %n | 换行符 |
| %N | 纳秒,范围(000000000..000000000) |
| %p | 用于表示当地的AM或PM,如果未知则为空白 |
| %P | 类似于 %p ,但用小写表示 |
| %q | 季度,范围(1..4) |
| %r | 当地以12小时表示的时钟时间(例如,11:11:04 PM) |
| %R | 24小时每分钟;等价于 %H:%M |
| %s | 自协调世界时1970年01月01日00时00分以来的秒数 |
| %S | 秒数,范围(00..60) |
| %t | 水平制表符 |
| %T | 时间;等价于 %H:%M:%S |
| %u | 一周中的一天(1..7),1代表星期一 |
| %U | 一年中的第几周,周日作为一周的起始(00..53) |
| %V | ISO标准计数周,该方法将周一作为一周的起始(01..53) |
| %w | 一周中的一天(0..6),0代表星期天 |
| %W | 一年中的第几周,周一作为一周的起始(00..53) |
| %x | 当地的日期表示(例如,12/31/99) |
| %X | 当地的时间表示(例如,23:13:48) |
| %y | 年份后两位数字,范围(00..99) |
| %Y | 年份 |
| %z | +hhmm格式的数值化时区格式(例如,-0400) |
| %:z | +hh:mm格式的数值化时区格式(例如,-04:00) |
| %::z | +hh:mm:ss格式的数值化时区格式(例如,-04:00:00) |
| %:::z | 数值化时区格式,相比上一个格式增加':'以显示必要的精度(例如,-04,+05:30) |
| %Z | 时区缩写(如EDT) |
| - | (连字符) 不要填充相应的字段。 |
| _ | (下划线) 使用空格填充相应的字段。 |
| 0 | (数字0) 使用数字0填充相应的字段。 |
| + | 用数字0填充,未来年份大于4位数字则在前面加上'+'号。 |
| ^ | 允许的情况下使用大写。 |
| # | 允许的情况下将默认的大写转换为小写,默认的小写转换为大写。 |
# 显示当前时间
$ date
# 格式化当前时间
$ date +"%Y-%m-%d %H:%M.%S" # 2020-07-01 00:00.00
# 设置系统时间
$ date -s # 设置当前时间, 须root
$ date -s "2020-07-01 00:00:00" # 设置指定时间查看指令帮助手册
man 信息说明
| 名称 | 描述 |
|---|---|
| NAME | 显示命令名和一段简短的描述 |
| SYNOPSIS | 命令的语法 |
| CONFI GURATION | 命令配置信息 |
| DESCRIPTION | 命令的一般性描述 |
| OPTIONS | 命令选项描述 |
| EXIT STATUS | 命令的退出状态指示 |
| RETURN VALUE | 命令的返回值 |
| ERRORS | 命令的错误消息 |
| ENVIRONMENT | 描述所使用的环境变量 |
| FILES | 命令用到的文件 |
| VERSIONS | 命令的版本信息 |
| CONFORMING TO | 命令所遵从的标准 |
| NOTES | 其他有帮助的资料 |
| BUGS | 提供提交BUG的途径 |
| EXAMPLE | 展示命令的用法 |
| AUTHORS | 命令开发人员的信息 |
| COPYRIGHT | 命令源代码的版权状况 |
| SEE ALSO | 与该命令类型的其他命令 |
# 查看 ls 指令帮助手册
$ man ls
# 可以通过数字来阅读某一部分内容, 比如阅读第一部分
$ man 1 ls
# -a 在所有手册中查找
$ man -a ls
# -k, 搜索关键字, 如果忘记了完整的命令可以通过关键字搜索出来,比如 nginx
$ man -k ngi将目前动作延迟一段时间, 通常用于脚本当中
时间参数, 这是可选的,默认s:
# 5秒后输出 Hello
$ sleep 5s; echo Hello下面是一段 Shell 脚本, 延迟10秒后再去请求
#!/bin/bash
sleep 10s
curl https://www.xiejiahe.com/列出当前系统使用过的命令,通常保存在 ~/.bash_history 文件中,注意的是只有在Shell退出时才写入到文件。
如果是在 mac 下运行会有差异。
# 列出当前使用过的命令
$ history
# 指定要显示的条数, mac 下不支持
$ history 50
# 清除历史命令
$ history -c # 清空历史命令
$ history -d 编号 # 清除指定编号
# -a 强制写入到 ~/.bash_history 文件中而不用等shell退出才写入
$ history -a执行历史命令, 在 mac 下运行需要回车确认。
# 指定编号, 例如运行 1001 编号的命令
$ !1001
# 执行历史最后一条命令
$ !!永久清除历史记录, 默认情况下只执行 hisotry -c 只会清除当前Shell:
# 先把 .bash_history 文件所有内容删除,然后再次强制写入
$ sed -i "d" ~/.bash_history && history -a给命令传递参数的一个过滤器,也是组合多个命令的一个工具, 将左侧的标准输出放进右侧标准输入。
此命令可以将多次操作简便为一次操作。
# 统计代码
$ find -name "*.js" | xargs wc -l # 等价于 wc -l a.js b.js c.js ...
# 批量下载文件
$ cat download.txt | xargs wget显示当前日历, 别名 ncal 以纵向显示。
$ cal
# 输出
June 2020
Su Mo Tu We Th Fr Sa
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30
# 显示临近3个月, -3 是固定不能更改数字
$ cal -3
# 打印今天是今年的第几天
$ cal -j
# 输出:今天日期会高亮显示
October 2020
Su Mo Tu We Th Fr Sa
275 276 277
278 279 280 281 282 283 284
285 286 287 288 289 `290` 291
292 293 294 295 296 297 298
299 300 301 302 303 304 305
# 打印今年1月-12月份日历
$ cal -y执行数学运算,expr 命令比较鸡助,通常在 shell 脚本当中看到。但在shell脚本也不建议用。
expr 后面每个表达式都要有一个空格,否则是不合法。
注:expr 只支持整数运算,这是一个限制。
# 3
$ expr 1 + 2
$ expr 1+2 # 这样是不行的
# 在浮点数计算时会丢失小数, 这里等于 2
$ expr 5 / 2bash计算器,用来执行数学运算, 与 expr 不同,因为 expr 命令不支持浮点数运算,所以可以用 bc 命令替代。
bash计算器实际上是一种编程语言,它允许在命令行中输入浮点表达式,然后解释并计算该表达式。最后返回结果。
bc 大多数情况下是在 shell 脚本中使用。
# 敲 bc 然后回车进入交互式, 输入 quit 退出
$ bc
scale=2 # 保留几位小数,默认是0
5 / 2
# 输出 2.50在指定时长范围内执行命令,并在规定时间结束后停止进程。
意思是在规定时间内必须完成,否则停止进程。
# 模拟超过3秒, 因为sleep阻塞5秒所以在3秒内无法完成,则停止进程
$ timeout 3 sleep 5
# 比如打包, 1分钟内要打包完成,否则停止进程
$ timeout 60 npm run build退出当前登录Shell, 或使用快捷键 Ctrl + D。
等价命令 logout
$ exit打印目录或者文件的基本名称。
# 输出:index.html
$ basename /www/index.html
# 输出:www
$ basename /www/read 命令从标准输入(键盘)或另一个文件描述符中接收输入。 通常用在Shell脚本, 在收到输入后,read命令会将数据存放进一个变量。
| 参数 | 描述 |
|---|---|
| -t | 指定输入字符的最大等待时间 |
| -p | 提示信息 |
| -s | 隐藏输入,比如密码信息 |
| -n | 限制输入字符的最大长度 |
| -r | 不对 \ 进行转义, \ 会正常打印 |
# 最简单用法, data 是自定义变量名,用户输入内容并回车后结束
$ read data # echo $data 会打印用户输入的内容
# -p 指定提示符
$ read -p 确认要删除吗? data
# -t 指定超时(秒)
$ read -t 5 -p 确认要删除吗? data
# —s 隐藏用户输入,比如密码,实际上是将文本颜色设置成背景颜色一样
$ read -s -p "请输入您的密码:" datatee命令相当于管道的一个T型接头,它将从 STDIN标准输入 过来的数据同时发往两处,一处是 STDOUT ,另一处是tee命令指定的文件名。
tee 命令通常用于 shell 脚本当中。
# date内容打印到屏幕上并且重定向输出到 date.txt 文件中
$ date | tee date.txt
# -a 以追加方式,默认情况下会覆盖输出文件内容
$ date | tee -a date.txttee 命令只是一个语法糖,如果不用 tee 可以这样做:
# 1、将date结果保存到 var 变量中
$ var=$(date)
# 2、将结果打印到屏幕上 STDOUT
$ echo $var
# 3、将结果重定向到文件
$ echo $var > date.txt用于清除当前终端所有信息,本质上只是向后翻了一页,往上滚动还能看到之前的操作信息
注:笔者用得比较多的是 command + K 可以完全清除终端所有操作信息。
$ clear部分内容从《Linux命令行与Shell脚本编程大全》和 互联网 进行整理出来, 如有错误,欢迎指正,谢谢!
文章是学习
《设计模式之美》- 王争的总结
主要复习主流编程范式(编程风格)面向对象和面向过程,其中面向对象编程是最主流的。区别面向对象和面向过程两种编程范式,以及抽象类和接口的区别,和如何通过普通类模拟抽象类和接口。
面向对象编程OOP (Object Oriented Programming) 有两个重要和基础的概念:类(class)和 对象(object)。如果不按照严格的定义来说,大部分编程语言都是面向对象编程语言,比如 Java、C++、Go、Python、C#、Ruby、JavaScript、Objective-C、Scala、PHP、Perl 等。
面向对象编程是一种编程范式或编程风格。它以类或对象为组织代码的基本单元,并将 封装、抽象、继承、多态 四个特性,作为代码设计和实现的基石。
面向对象编程语言是支持类或对象的语法机制,并有现成的语法机制,能方便地实现面向对象编程四大特性(封装、抽象、继承、多态)的编程语言。
面向对象编程经常和 面向对象分析(OOA) 和面向对象设计(OOD) 放在一块讨论,OOA、OOD、OOP 三个连一起就是面向对象分析、设计、编程(实现),正好是面向对象软件开发要经历的三个阶段。
面向过程编程也是一种编程范式或风格。它以过程(可以理解为方法、函数、操作)作为组织代码的基本单元,以数据(可以理解为成员变量、属性)与方法相分离为最主要的特点。面向过程风格是一种流程话的编程风格,通过拼接一组顺序执行的方法来操作数据完成一项功能。
面向过程编程语言首先是一种编程语言。它最大的特点是不支持类和对象两个语法概念,不支持丰富的面向对象编程特性(比如继承、多态、封装),仅支持面向过程编程。比如 Basic、Pascal、C 等。
1.OOP 更加能够应对大规模复杂程序的开发
2.OOP 风格的代码更易复用、易扩展、易维护
3.OOP 语言更加人性化、更加高级、更加智能
/**
* 滥用 getter setter 举例
*/
class ShoppingCart {
private _itemsCount: number;
public get itemsCount(): number {
return this._itemsCount;
}
public set itemsCount(value: number) {
this._itemsCount = value;
}
private _totalPrice: number;
public get totalPrice(): number {
return this._totalPrice;
}
public set totalPrice(value: number) {
this._totalPrice = value;
}
private _items: Array<any> = [];
public get items(): Array<any> {
return this._items;
}
public set items(value: Array<any>) {
this._items = value;
}
public addItem(item) {
this.items.push(item);
this.itemsCount++;
this.totalPrice += item.getPrices();
}
}代码中,_itemCount 、_totalPrice 、 _items 是私有属性,但是没有得到封装的作用,它们都有 setter 方法,外部使用的时候都可以通过 setter 来改变属性值,这使得 _itemCount 、_totalPrice 可能会和实际的 _items 个数不一致的数据风险,照成错乱。
另外 get items 外部也可以直接得到 items,从而可以直接操作 items.clear() 或 items=[] 的方式置空数组,导致 _itemCount 、_totalPrice 不一致。所以需要封装提供一个 clear 方法给外部使用,不暴露 _items 给外部操作
为了解决上边的问题,我们修改一下 ShoppingCart 类
/**
* 调整后
*/
class ShoppingCart {
private _itemsCount: number = 0;
public get itemsCount(): number {
return this._itemsCount;
}
private _totalPrice: number = 0;
public get totalPrice(): number {
return this._totalPrice;
}
private _items: Array<any> = [];
public get items(): Array<any> {
return [...this._items]; // 简单效果,实际不是这样,为了外部获取items不能改掉内部的_items
}
public addItem(item) {
this.items.push(item);
this._itemsCount++;
this._totalPrice += item.getPrices();
}
public clear() {
this._items = [];
this._itemsCount = 0;
this._totalPrice = 0;
}
}在面向对象编程中,比如 Java 使用全局变量和方法的情况,有单例类对象、静态成员变量、常量、静态方法等。常量是一种非常常见的全局变量,比如代码中的配置参数,一般都设置为常量,放到一个 Constants 类中。静态方法的话就常放在 Utils 类。静态方法将方法和数据分离,破坏了封装的特性,是典型的面向过程风格。
项目中,一种常见的 Constants 定义的方式如下。
// local
export const APP_NAME = '中台管理系统';
export const DEFAULT_AVATAR =
'https://wpimg.wallstcn.com/f778738c-e4f8-4870-b634-56703b4acafe.gif';
export const TOKEN_KEY = '_login_token';
// request
export const REQ_RESEND_MAX_COUNT = 1;
export const REQ_RESEND_COUNT_EXCEED_CODE = 4000001;
export const REQ_RESEND_COUNT_EXCEED_MSG = '重发次数超出上限';
export const REQ_OVERTIME_DURATION = 10 * 1000;
export const RES_SUCCESS_DEFAULT_CODE = 2000; // 处理成功
export const RES_NOT_FOUND_CODE = 3000; // 处理失败
export const RES_UNAUTHORIZED_CODE = 4010; // token过期
export const RES_PERMISSION_DENIED_CODE = 4100; // 权限不足
export const RES_INVALID_PARAMS_CODE = 4000; // 参数错误
export const RES_SECRET_INCORRECT_CODE = 4200; // 秘钥错误
export const RES_SERVER_EXCEPTION_CODE = 5000; // 服务器异常
// notification
export const ERR_MESSAGE_SHOW_DURATION = 3 * 1000;我们把程序中用到的常量都会集中的放到这个 Constants 中,如果项目越来越庞大,配置项的常量越来岳多,这个文件众的常量数量就会越来越大,对于查找和修改某个常量也是比较费劲。在 Java 中,你修改了 Constants 类还会增加编译时间。
改进 Constants 设计的话可以拆解为功能更加单一的多个“类”,比如跟 MySQL 配置相关的常量放到 MySQLConstants 类中;跟 Redis 配置相关的常量,放到 RedisConstants 类中。当然,还有一种设计方式是,在对应的用到常量的类中定义常量,比如有个 RedisConfig 类,这时候 Redis 配置相关的常量就放到这里。
同理,Utils 也进行归类细分。如果是后端可以有 IOUtils、StringUtils、FileUtils 类,前端的话如 DomUtils、DateUtils 等,避免全部都放在叫 utils.ts 的文件中,这个文件的代码里随着开发时间会一直增加,对使用体验和易维护性都是减分的。前端的话通常也可以根据特定的功能性去命名 utils 文件,比如是一个事件代理相关的Uitls功能就命名为 event.ts ,某些操作也可以单独创建一个文件,因为前端目前使用模块化 import 的方式导入,也是比较方便,比如滚动代码,命名为 scrollTo.ts
MVC 三层结构是面向过程风格的编码方式。传统的 MVC 结构范围 Model 层、Controller 层、View 层。为了做前后端分离,三层结构在后端开发中被分为 Controller 层、Service 层、 Repository 层。Controller 层负责暴露接口给前端调用,Service 层负责核心业务逻辑,Repository 层负责数据读写。而每一层中,有会定义相应的 VO (View Object)、BO(Business Object)、Entity。一般情况下,VO、BO、Entity 中只会定义数据,不会定义方法,所有操作这些业务逻辑都定义在对应的 Controller 类、Service类、Repository 类中。这就是典型的面向过程的编程风格。
这种开发模式又叫作基于贫血模型的开发模式。
面向对象编程要比面向过程编程难一些。在 OOP 类的设计需要技巧和设计经验,需要思考如何封装合适的数据和方法到一个类里,如何设计类之间的关系和交互等设计问题。
在生活中,去完成一个任务,我们一般都会思考,应该做什么、后做什么,如何一步一步地顺利执行一系列操作,最后完成整个任务 。面向过程编程风格恰恰符合人的这种流程化思维方式。而面向对象编程风格正好相反。它是一种自底向上的思考方式。它不是先去执行流程来分解任务,而是将任务翻译成一个一个的小的模块(类),设计类之间的交互,最后按照流程将类组装起来,完成整个任务。
面向对象编程的四大特性 封装、抽象、继承、多态 使得其更适合更复杂类型的程序开发,利用这些特性编写出来的代码,更加易扩展、易复用、易维护,也更加人性化、高级和智能。
在MVC里,View是可以直接访问Model的!从而,View里会包含Model信息,不可避免的还要包括一些业务逻辑。 MVC模型关注的是Model的不变,所以,在MVC模型里,Model不依赖于View,但是 View是依赖于Model的。不仅如此,因为有一些业务逻辑在View里实现了,导致要更改View也是比较困难的,至少那些业务逻辑是无法重用的。
MVVM在概念上是真正将页面与数据逻辑分离的模式,它把数据绑定工作放到一个JS里去实现,而这个JS文件的主要功能是完成数据的绑定,即把model绑定到UI的元素上。
有人做过测试:使用Angular(MVVM)代替Backbone(MVC)来开发,代码可以减少一半。
此外,MVVM另一个重要特性,双向绑定
http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html

基于Gitlab 的 CI/CD 流程搞好后,需要将CI Job或流水线的执行状态通知到给相关QA或者开发人员,整个大前端组,项目系统工程数量>15个,所以有必要聚合CI/CD相关自动化流水线信息,将相关需要关注的信息通过机器人自动推送到群里。
工作上常用群的话选择有微信群,钉钉,QQ群等。微信现在限制了2018年之后注册的新用户无法通过脚本走API登录,很难搞到2016年注册的小号,因此只能选择钉钉群和QQ群了,因为我司不用钉钉,有自己的OA系统,所以就尝试了酷Q的机器人推送方案。下面将详细介绍实现过程。
DingTalk (钉钉) 提供了群机器人,提供 WebHook 来实现,特别的方便,消息发送还支持各种格式的模板,比如text、link、markdown等,增强了使用情景和体验。关于钉钉自定义机器人,官方文档也很详细,这里不多介绍实现过程。详细见:自定义机器人
以下主要是消息通知到群的 shell script.
# 前一个命令执行状态判断是成功信息还是失败信息
if [ "$?" -eq "0" ];then
log "[OK]"
DEPLOY_SYSTEM="${!YZT_ENV_SERVER_IP2}:${!YZT_ENV_SERVER_PORT2}"
sendDingTalkSuccessNotifications
else
logStep ">> $?"
DEPLOY_SYSTEM="${!YZT_ENV_SERVER_IP2}:${!YZT_ENV_SERVER_PORT2}"
sendDingTalkErrorNotifications
fi
# 相关脚本
function sendDingTalkErrorNotifications() {
DEPLOY_STATUS='部署失败!'
sendDingTalkNotifications
}
function sendDingTalkSuccessNotifications() {
DEPLOY_STATUS='部署成功!'
sendDingTalkNotifications
}
# 推送模板发送(模板拼接)
function sendDingTalkNotifications() {
logStep " STEP 5 - Send Notifications to DingTalk"
local title="「前端CI/CD」 ${PROJECT_NAME}"
local text="### ${title} \n #### 构建分支:${CI_COMMIT_REF_NAME} \n #### 构建状态:${DEPLOY_STATUS}\n #### 部署主机:${DEPLOY_SYSTEM} \n #### 提交者:${GITLAB_USER_EMAIL} \n\n\n ##### [流水线 Pipeline #${CI_PIPELINE_ID}](${CI_PROJECT_URL}/pipelines/${CI_PIPELINE_ID}) \n"
curl POST "$CI_DINGTALK_WEBHOOK_URL" -H 'Content-Type: application/json' -d "{\"msgtype\": \"markdown\",\"markdown\": {\"title\":\"$title\",\"text\": \"$text\"}}"
# curl POST "$CI_DINGTALK_WEBHOOK_URL" -H 'Content-Type: application/json' -d '{ "msgtype": "markdown", "markdown": {"title":"CI/CD cmp-web","text": "##### 构建分支:test \n Pipelines状态:成功\n ######## [流水线Pipeline #3181](http://git.1ziton.com/front-end/cmp-web/pipelines/3181) \n"}}'
}
function log() {
echo "$(date):$@"
}
function logStep() {
echo "$(date):====================================================================================="
echo "$(date):$@"
echo "$(date):====================================================================================="
echo ""
}

搭建服务之前,需要了解CoolQ是如何工作的,以及如何通过 CoolQ HTTP API 来推送信息,官方文档:https://cqhttp.cc/docs/
本人在windows 非 Docker 的方式搭建过了一次,然后再在 Linux 系统上搭建过一次,总体觉得,还是Docker 比较方便。安装官方提供的 Docker 服务,部署测试通过后,写对应的脚本来实现消息推送到QQ群。
官方文档:Docker,以下是个人操作步骤记录。
(1)拉取 cqhttp 镜像
docker pull richardchien/cqhttp:latest(2)新建一个文件夹,用于存储 酷Q 的程序文件
mkdir coolq (3)后台运行 docker 服务
docker run -d --rm --name cqhttp-devops -v $(pwd)/coolq:/home/user/coolq -p 9000:9000 -p 18936:5700 -e COOLQ_ACCOUNT=你要登录的QQ号码 -e CQHTTP_POST_URL=http://你的服务器ip:8080 -e CQHTTP_SERVE_DATA_FILES=yes richardchien/cqhttp:latest介绍一下简单的docker操作命令给新人,查看 cqhttp-devops 的 docker日记可以用 docker logs -f cqhttp-devops , 删除命令:docker rm -f cqhttp-devops
(4)访问 http://服务器ip:9090
访问正常后,表示服务正常,点击连接,输入默认密码 MAX8char ,即可进入虚拟机,登录机器人用的QQ账号即可,安全问题,酷Q限制必须是开启了 登录保护 的QQ,才可以登录。
登录成功后,运行CoolQ Air , 会如下图所示,可以查看HTTP API的应用目录

(5)修改 AccessToken
这两个东西是要在接口请求的时候做认证的,保证安全性,避免被别人直接走接口发送信息。
进入第四步骤中 http api 对应的目录下,找到自己登录的 qq 号对应的json文件修改即可。比如 123456.json,如果没有,就是 .ini 后缀,详细见官方文档说明 Configuration
我的配置是如下,操作时改为自己的即可。
[general]
host = 0.0.0.0
post_url = http://192.168.100.100:8080
[3616909583]
access_token = Mgep4rV49rM8Jf
port = 5700
创建一个群,或者拉你所用的QQ机器人到一个群里,使用curl 方式或者 postman 测试都可以,也可以使用 node.js 脚本测试
测试方式1:postman get请求测试

测试方式2:nodejs代码测试:
const request = require('request');
const COOLQ_HTTP_URL = '192.168.100.100:18936'; // 你的ip:端口(docker部署运行时设置好的)
const ACCESS_TOKEN = 'Bearer 你的accessToken';
const configOptions = {
url: `http://${COOLQ_HTTP_URL}/send_group_msg`,
method: 'get',
headers: {
// 'Content-Type': 'application/json',
authorization: ACCESS_TOKEN
},
qs: {
message: 'test23232322',
group_id: '807533895'
}
};
function getOption(params) {
const message =
`「${params.title}」\n` +
`内容:${params.content}\n` +
'----------------------------------\n' +
`原链接:${params.url}\n`;
configOptions.qs = {
message,
group_id: params.group_id
};
return configOptions;
}
function sendGroupMsg(body) {
let opt = getOption(body);
request(opt, function(error, response, body) {
if (!error && response.statusCode == 200) {
console.log('success');
console.log(body);
}
});
}
sendGroupMsg({
text: 'text',
title: 'CoolQ/DingTalk 实现CI/CD消息推送到群',
content: '内容',
url: 'https://github.com/giscafer/front-end-manual/issues/31',
group_id: '807533895'
});
效果:

结合 Gitlab CI 流水线最终效果:

到此,就完成了测试了,整个过程已经联调通,最后至于使用shell来直接请求推送消息,还是通过node.js、python等脚本来推送消息,都可以,看个人喜好了。
搭建过程,试了远程执行shell script和node.js 脚本,不亦乐乎(注意脚本安全性)。

成员加群,自动发送欢迎消息,自动回复信息等,可以通过CQHttp提供的 事件上报 来实现。
demo代码:https://github.com/1ziton/cqrobot

Author: @giscafer,原文地址:front-end-manual/CoolQ/DingTalk 实现CI/CD消息推送到群 ,
欢迎讨论
问题收集于网络,答案是个人整理,@giscafer(仅供学习参考,有不对之处请指出)
声明必须是 HTML 文档的第一行,位于 标签之前。 声明不是 HTML 标签;它是指示 web 浏览器关于页面使用哪个 HTML 版本进行编写的指令。在 HTML 4.01 中,<!DOCTYPE> 声明引用 DTD,因为 HTML 4.01 基于 SGML。DTD 规定了标记语言的规则,这样浏览器才能正确地呈现内容。
HTML5 不基于 SGML,所以不需要引用 DTD。
提示:请始终向 HTML 文档添加 <!DOCTYPE> 声明,这样浏览器才能获知文档类型。
严格模式
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
混杂模式
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
上边问题已经说,HTML5 不基于 SGML,所以不需要引用 DTD。
CSS规范规定,每个元素都有display属性,确定该元素的类型,每个元素都有默认的display值,
比如div默认display属性值为“block”,成为“块级”元素;
span默认display属性值为“inline”,是“行内”元素。
行内元素有:a b span img input select strong(强调的语气)
块级元素有:div ul ol li dl dt dd h1 h2 h3 h4…p
知名的空元素:
<br> <hr> <img> <input> <link> <meta>
鲜为人知的空元素:
<area> <base> <col> <command> <embed> <keygen> <param> <source> <track> <wbr>
隶属上的差别
link属于HTML标签,而@import完全是CSS提供的一种方式。
@import次数限制
@import只能引入31次css文件。
加载顺序的不同
当页面被加载的时候,link引用的CSS会同时被加载,而@import引用的CSS 会等到页面全部被下载完再被加载。所以有时候浏览@import加载CSS的页面时开始会没有样式,然后突然样式会出现,网速慢的时候还挺明显。
兼容性上的差别
由于@import是CSS2.1提出的,@import只有在IE5以上的才能识别,而link标签无此问题
使用DOM控制样式时的差别
当使用javascript控制DOM(document.styleSheets)去改变样式的时候,只能使用link标签,因为@import不是dom可以控制的。
那内核是什么呢?内核只是一个通俗的说法,其英文名称为“Layout engine”,翻译过来就是“排版引擎”,也被称为“页面渲染引擎”(下文中各种说法通用)。它负责取得网页的内容(HTML、XML、图像等等)、整理信息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要排版引擎。
不同的浏览器内核对网页编写语法的解释也有不同,因此同一网页在不同的内核的浏览器里的渲染(显示)效果也可能不同,这也是网页编写者需要在不同内核的浏览器中测试网页显示效果的原因。
这就是编写网页的麻烦所在啊。。。要让所有浏览器显示大概一致,有时候很麻烦。
现在市面上常见的 内核基本是一下4种:
Trident:
这是微软开发的一种排版引擎。该内核程序在1997年的IE4中首次被采用,是微软在Mosaic代码的基础之上修改而来的,并沿用到目前的 IE7。Trident实际上是一款开放的内核,其接口内核设计的相当成熟,因此才有许多采用IE内核而非IE的浏览器涌现(如 Maxthon、The World 、TT、GreenBrowser、AvantBrowser等)。此外,为了方便也有很多人直接简称其为IE内核(当然也不排除有部分人是因为不知道内 核名称而只好如此说,至少老N就是如此。。。)。自从发布后,Trident不断地被更新和完善:
Trident II(IE5)——增进对CSS1.0的支持及对CSS2重大的变更;
Trident III(IE5.5)——修正部分CSS的排版控制;
Trident IV(IE6)——修正了一部分box-model的错误以及增加了“兼容模式(Quirks Mode)”切换功能,以增加对文件类型描述(Document Type Definition,DTD)的支持;
Trident V(IE7)——修正许多CSS排版处理上的错误以及增加对PNG格式alpha通道(半透明)的支持。(这就是IE6经常被诟病的对png图片支持不良的之处!)
Geckos:
Gecko是套开放源代码的、以C++编写的网页排版引擎。这软件原本是由网景通讯公司开发的,Netcape6开始采用该内核。后来的 Mozilla FireFox也采用了该内核,Geckos的特点是代码完全公开,因此,其可开发程度很高,全世界的程序员都可以为其编写代码,增加功能。Geckos 现在由Mozilla基金会维护。
Presto:
Presto是一个由Opera Software开发的浏览器排版引擎,该内核在2003年的Opera7中首次被使用,该款引擎的特点就是渲染速度的优化达到了极致,也是目前公认网页浏览速度最快的浏览器内核。
Webkit:
苹果公司自己的内核,也是苹果的Safari浏览器使用的内核。 Webkit引擎包含WebCore排版引擎及JavaScriptCore解析引擎,均是从KDE的KHTML及KJS引擎衍生而来,它们都是自由软 件,在GPL条约下授权,同时支持BSD系统的开发。所以Webkit也是自由软件,同时开发源代码。在安全方面不受IE、Firefox的制约,所以 Safari浏览器在国内还是很安全的。
简单的总结一下:
本问题答案来自出处
下边是获取浏览器信息的片段代码
var browser = {
versions: function () {
var u = navigator.userAgent, app = navigator.appVersion;
return {//移动终端浏览器版本信息
trident: u.indexOf('Trident') > -1, //IE内核
presto: u.indexOf('Presto') > -1, //opera内核
webKit: u.indexOf('AppleWebKit') > -1, //苹果、谷歌内核
gecko: u.indexOf('Gecko') > -1 && u.indexOf('KHTML') == -1, //火狐内核
mobile: !!u.match(/AppleWebKit.*Mobile.*/), //是否为移动终端
ios: !!u.match(/\(i[^;]+;( U;)? CPU.+Mac OS X/), //ios终端
android: u.indexOf('Android') > -1 || u.indexOf('Linux') > -1, //android终端或者uc浏览器
iPhone: u.indexOf('iPhone') > -1 || u.indexOf('Mac') > -1, //是否为iPhone或者QQHD浏览器
iPad: u.indexOf('iPad') > -1, //是否iPad
webApp: u.indexOf('Safari') == -1 //是否web应该程序,没有头部与底部
};
} (),
language: (navigator.browserLanguage || navigator.language).toLowerCase()
}
console.log("语言版本: " + browser.language);
console.log(" 是否为移动终端: " + browser.versions.mobile);
console.log(" ios终端: " + browser.versions.ios);
console.log(" android终端: " + browser.versions.android);
console.log(" 是否为iPhone: " + browser.versions.iPhone);
console.log(" 是否iPad: " + browser.versions.iPad);
console.log(navigator.userAgent);
console.log(browser.versions);或者使用ua-parser-js
HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加。
拖拽释放(Drag and drop) API
语义化更好的内容标签(header,nav,footer,aside,article,section)
音频、视频API(audio,video)
画布(Canvas) API
地理(Geolocation) API
本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失;
sessionStorage 的数据在浏览器关闭后自动删除
表单控件,calendar、date、time、email、url、search
新的技术webworker, websocket, Geolocation
移除的元素
纯表现的元素:basefont,big,center,font, s,strike,tt,u;
对可用性产生负面影响的元素:frame,frameset,noframes;
支持HTML5新标签:
IE8/IE7/IE6支持通过document.createElement方法产生的标签,
可以利用这一特性让这些浏览器支持HTML5新标签,
浏览器支持新标签后,还需要添加标签默认的样式:
当然最好的方式是直接使用成熟的框架、使用最多的是html5shim框架
如何区分: DOCTYPE声明\新增的结构元素\功能元素
什么是HTML语义化?
HTML标签可以分为有语义的标签,和无语义的标签。比如table表示表格,form表示表单,a标签表示超链接,strong标签表强调。无语义标签典型的有
2、为什么要语义化?
为了在没有CSS的情况下,页面也能呈现出很好地内容结构、代码结构:为了裸奔时好看;
3、写HTML代码时应注意什么?
文章一:http://www.codeceo.com/article/html5-cache.html
文章二:http://www.hello-code.com/question/html5/201408/1684.html
文章三:https://segmentfault.com/a/1190000002422341
https://segmentfault.com/a/1190000002723469
iframe的优点:
iframe的缺点:
分析了这么多,现在基本上都是用Ajax来代替iframe,所以iframe已经渐渐的退出了前端开发。
W3C里面关于label的定义和用法如下:
标签为 input 元素定义标注(标记)。
label 元素不会向用户呈现任何特殊效果。不过,它为鼠标用户改进了可用性。如果您在 label 元素内点击文本,就会触发此控件。就是说,当用户选择该标签时,浏览器就会自动将焦点转到和标签相关的表单控件上。
autocomplete属性(自动完成功能)新属性
所谓的自动完成功能就是浏览器帮助记忆之前输入的数据,当再次输入相同数据时,将自动显示之前曾输入的数据作为候补。用户可以选择其中之一。 该内容属性为列举属性。可以指定的值为on、off。
on : autocomplete属性有效
off: autocomplete属性无效
autocomplete属性的默认值为on,即封装了该自动完成功能的浏览器即使没有指定该属性, 也会默认自动完成功能有效。但是出于安全需要,输入的内容不需要浏览器记忆,这时,最好设置自动完成功能无效。
当input元素的type属性的值为text、 search、url、tel、 email、password、 datetime、date、 month、week、time、 datetime-local、number、 range、color时,可以使用autocomplete属性
调用LocalStorage 、Cookies等本地存储方式
对不兼容的浏览器加载WebSocket.swf和WebSocket.js文件
Adobe Flash Socket 、 ActiveX HTMLFile (IE) 、 基于 multipart 编码发送 XHR 、 基于长轮询的 XHR
http://www.tuicool.com/articles/EF7Nni
http://www.zhangxinxu.com/wordpress/2012/11/page-visibility-api-introduction-extend/
http://www.tuicool.com/articles/BfIjYf
椭圆点击参考:http://www.cnblogs.com/hongru/p/3187934.html
……
网站SEO优化中tilte与h1的区别、b与strong的区别、i与em的区别
The End
Create by @giscafer
To be continued
JavaScript 共有8中数据类型,其中有7中原始类型(Number\String\Boolean\undefined\null\BigInt\Symbol)和1种引用类型(Object)。原始类型的赋值会完整的赋值变量值,引用类型的赋值是复制引用地址。
JavaScript 的内存模型分为三种:代码空间、栈空间、堆空间。
原始类型的数据存放在栈中,引用类型存在堆中。堆中的数据是通过引用和变量关联起来的,JavaScript 的变量没有数据类型,值才有数据类型,变量可以持有任何数据类型的数据。

为什么引用数据类型放在堆空间?因为该类型数据占用的空间往往比较大,如果放在栈中,会影响到调用栈的执行上下文的切换效率,也可能导致栈空间不足;而堆空间比较大,能存放很多大的数据。
程序中,有些数据在使用之后,我们不再需要了,这种数据就称为垃圾数据。只有回收了垃圾数据,才能释放内存空间,无法回收或回收不及时的情况,我们就称为内存泄漏。
JavaScript 的垃圾是由垃圾回收器自动回收的。数据存放在“栈空间”和“堆空间”,那垃圾回收器是如何回收的呢?
调用栈在入栈时存储上下文数据,当某上下文执行完成出栈(pop stack) 后,就销毁掉了执行上下文,相应的内存空间就会被回收。
调用栈中通过记录当前执行状态的指针(称为 ESP)下移操作,来销毁执行完毕的函数存在栈中的执行上下文的过程。
回收堆中的垃圾数据,如要利用 JavaScript 的垃圾回收器。
代际假说(The Generational Hypothesis)
V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象。新生代区通常只支持 1~8M 的容量,老生代区则容量大很多。这两块区域,V8分别使用了不同的垃圾回收器,以便更高效的实施垃圾回收。
副垃圾回收器使用 Scavenge 算法 结合 对象晋升策略。
主垃圾回收器使用 **标记-清除(Mark-Sweep)算法进行垃圾回收,然后使用标记-整理(Mark-Compact)**进行内存整理。
由于垃圾回收器是运行在 JavaScript 主线程上的,单线程的原因,执行垃圾回收算法的时候使得 JavaScript 脚本执行暂停,导致性能下降。为了解决这个问题,V8 将垃圾回收中的标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,知道标记阶段完成(增量标记 Incremental Marking 算法)。
编译型语言 在执行程序之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。比如 C/C++、GO、Java等。
解释型语言 在每次运行时都需要通过解释器对程序进行动态的解释和执行。比如 Python、JavaScript。

V8 依据 JavaScript 代码生成 AST 和执行上下文,再基于 AST 生成字节码(编译),然后通过解释器执行字节码,通过编译器来优化编译字节码。
JavaScript 中编译面向的是全局代码或函数,比如下载完一个js文件,先编译这个js文件,但是js文件内定义的函数是不会编译的,等调用到该函数的时候,JavaScript 引擎才会去编译该函数。
可以吧 JavaScript 的编译看成部分:
参考资源:《浏览器的工作原理与实践》极客时间-李兵
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.





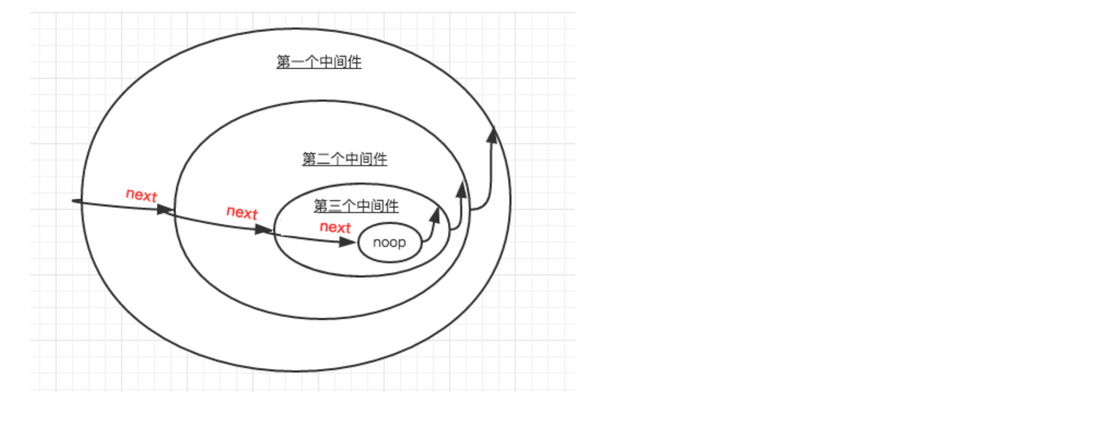
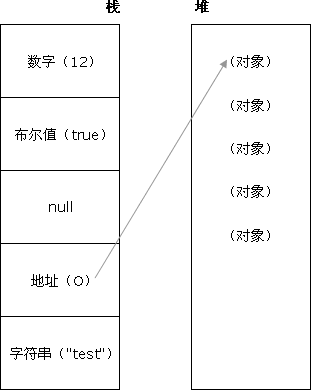

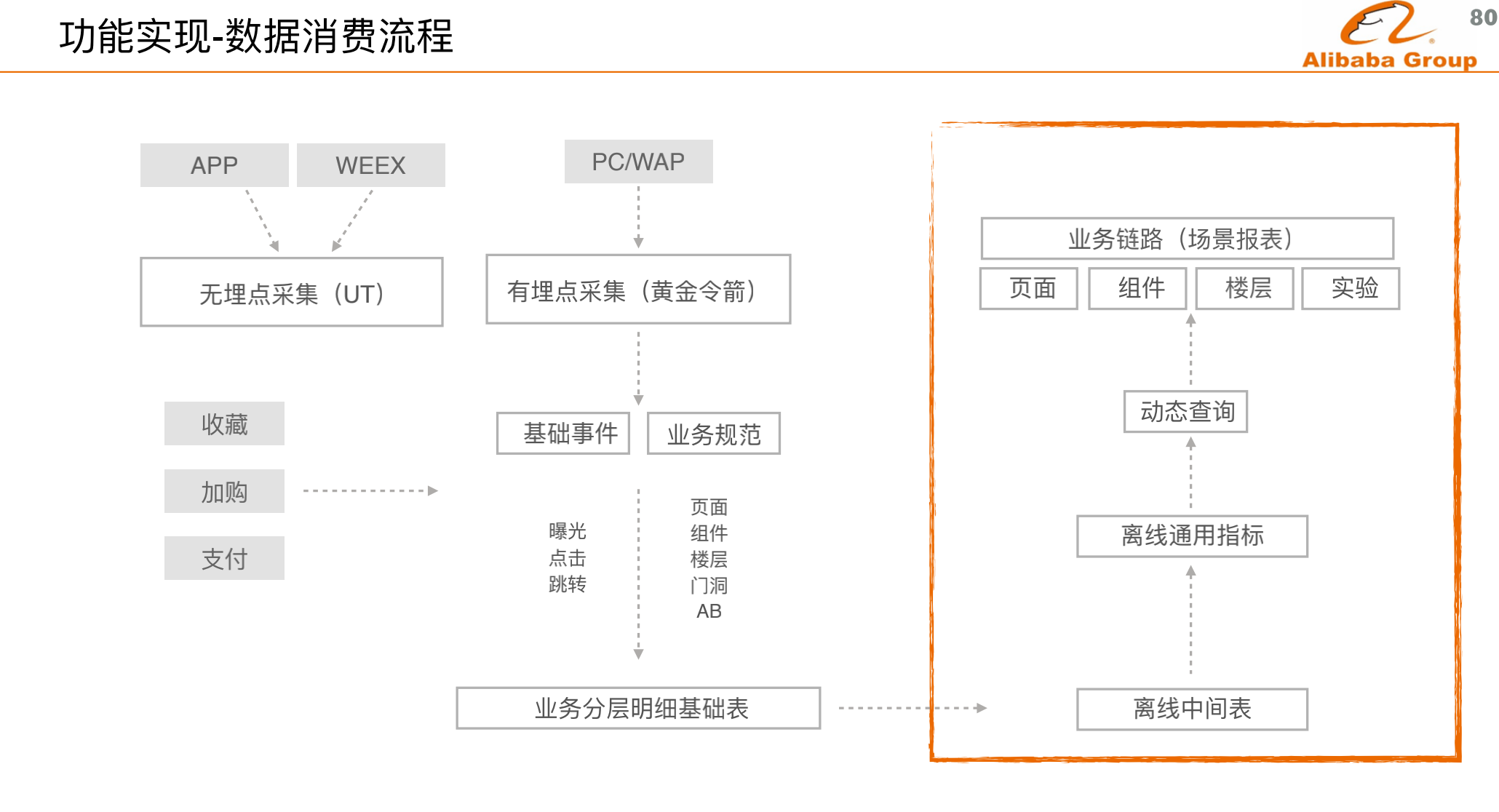

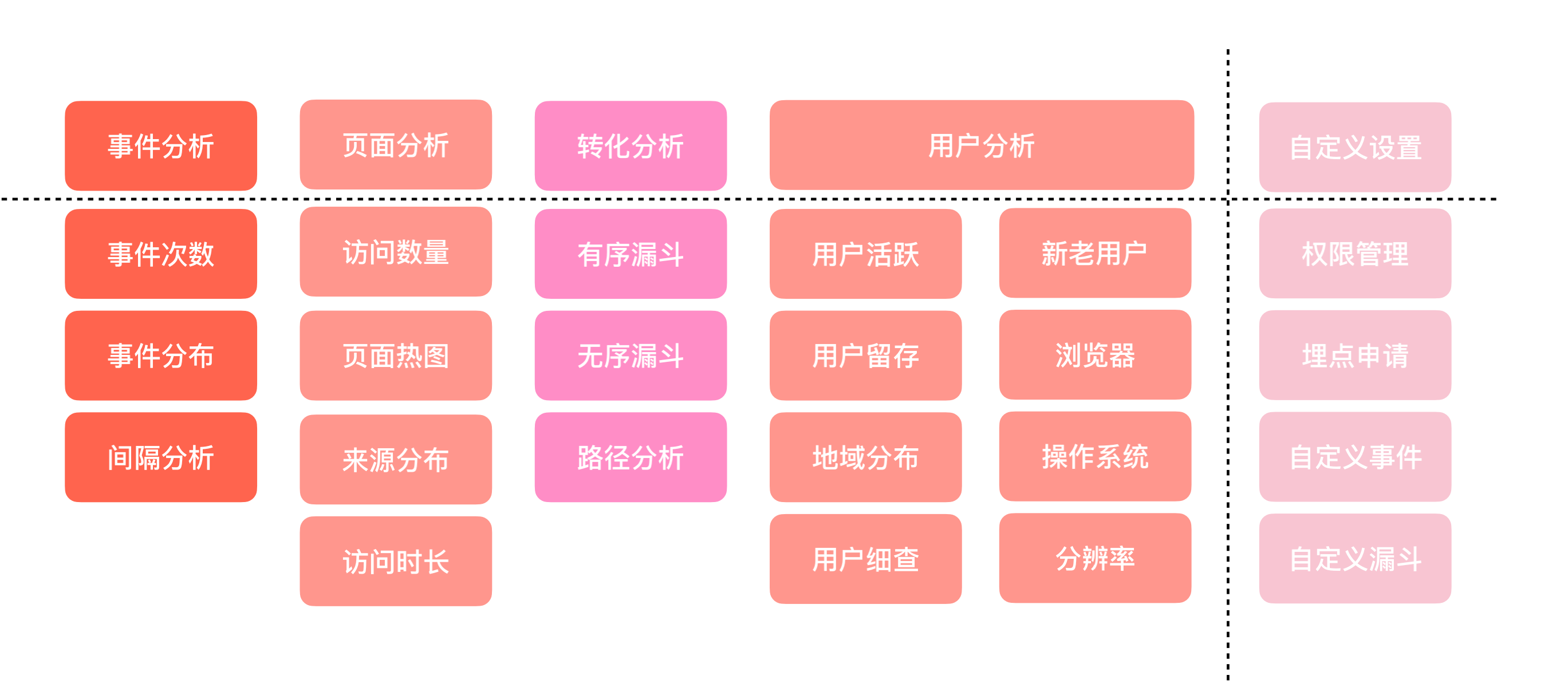
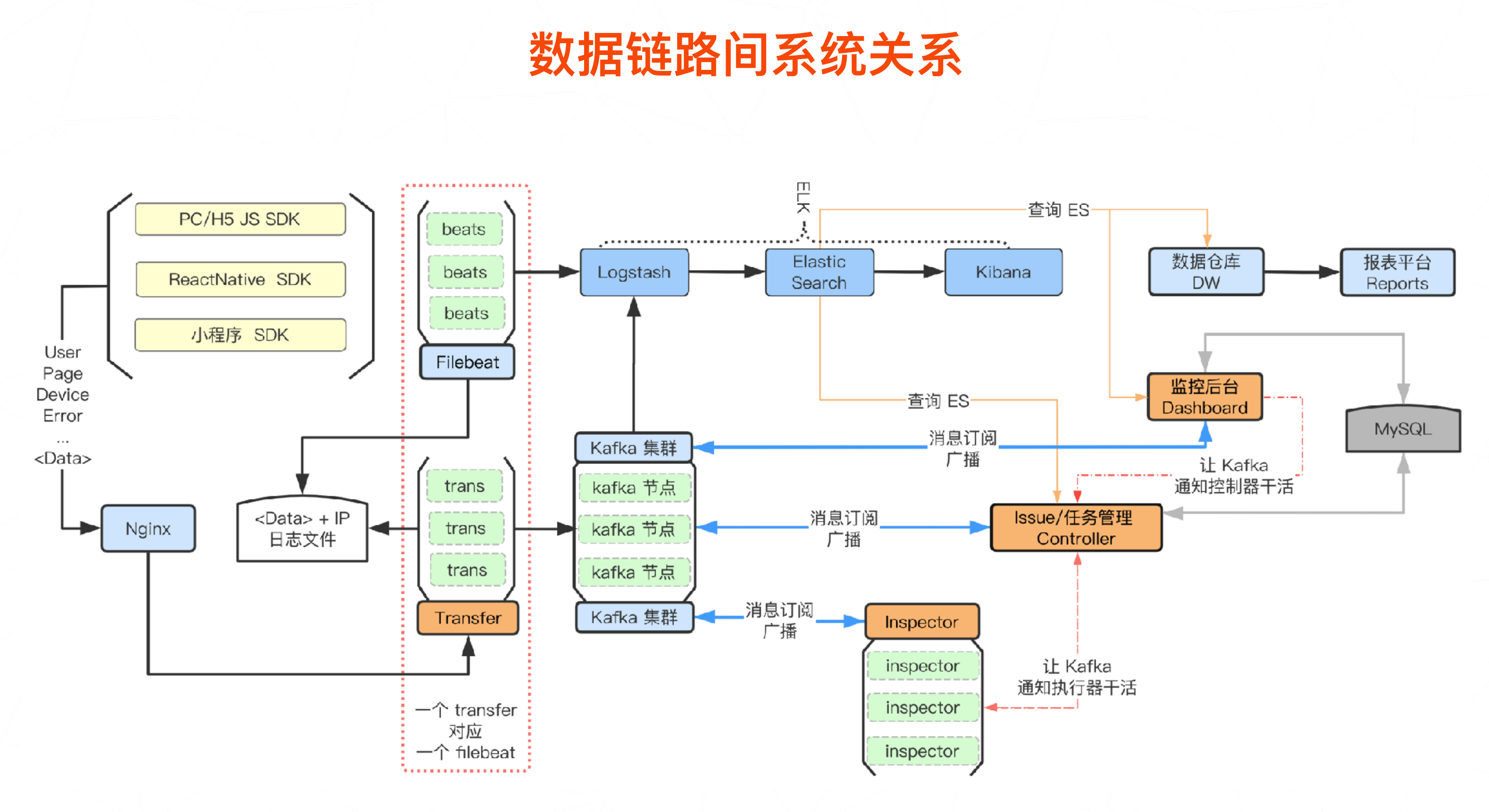
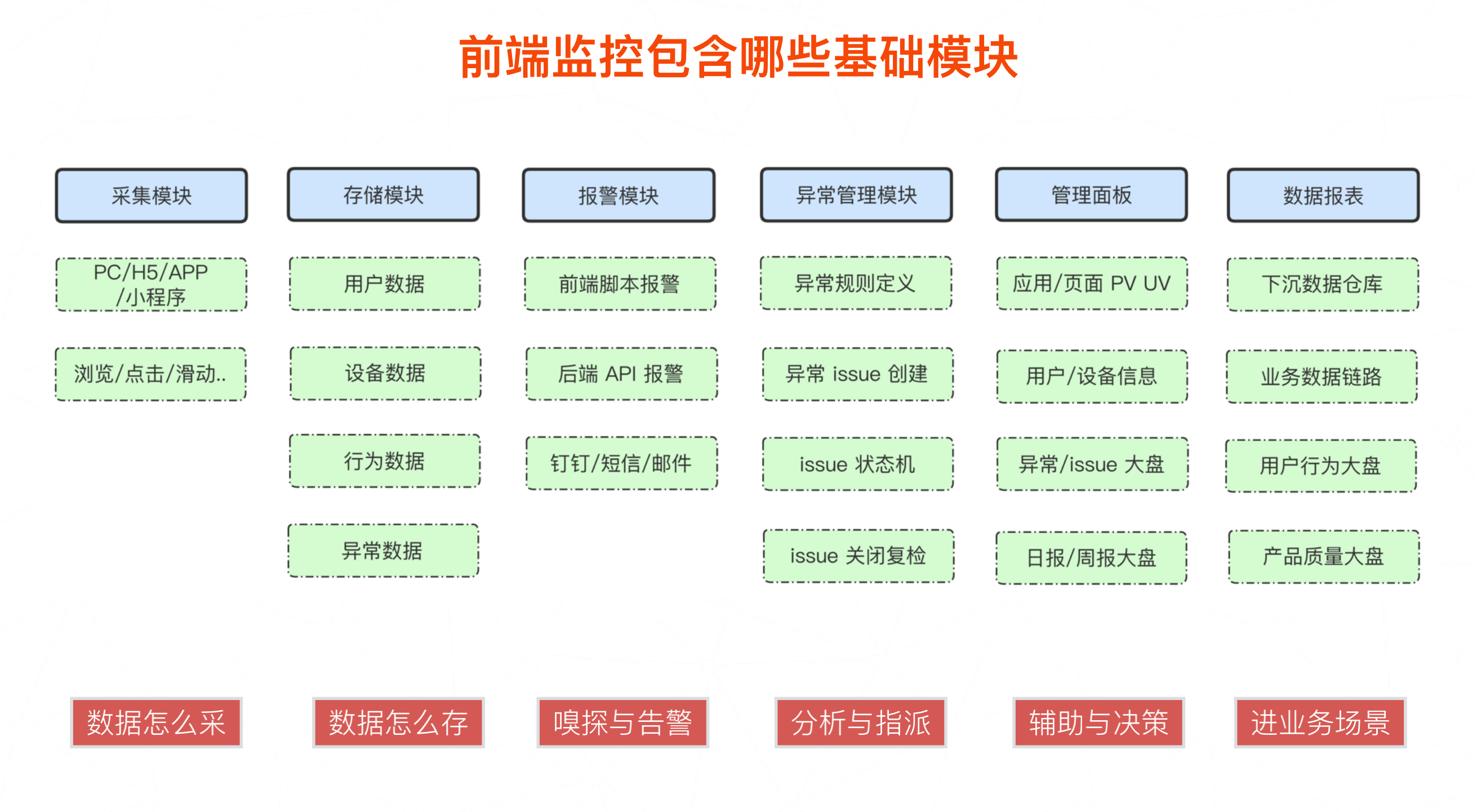
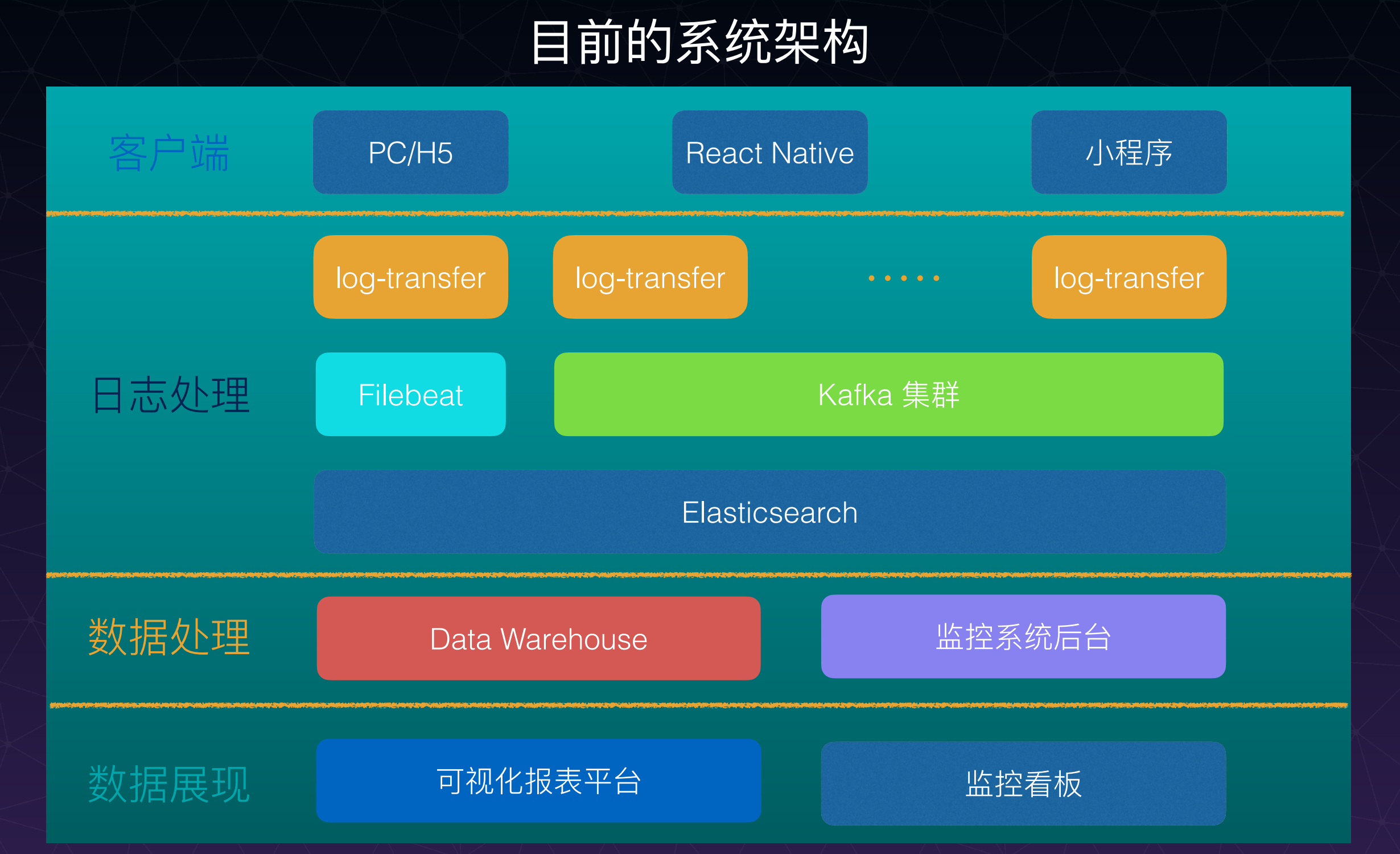
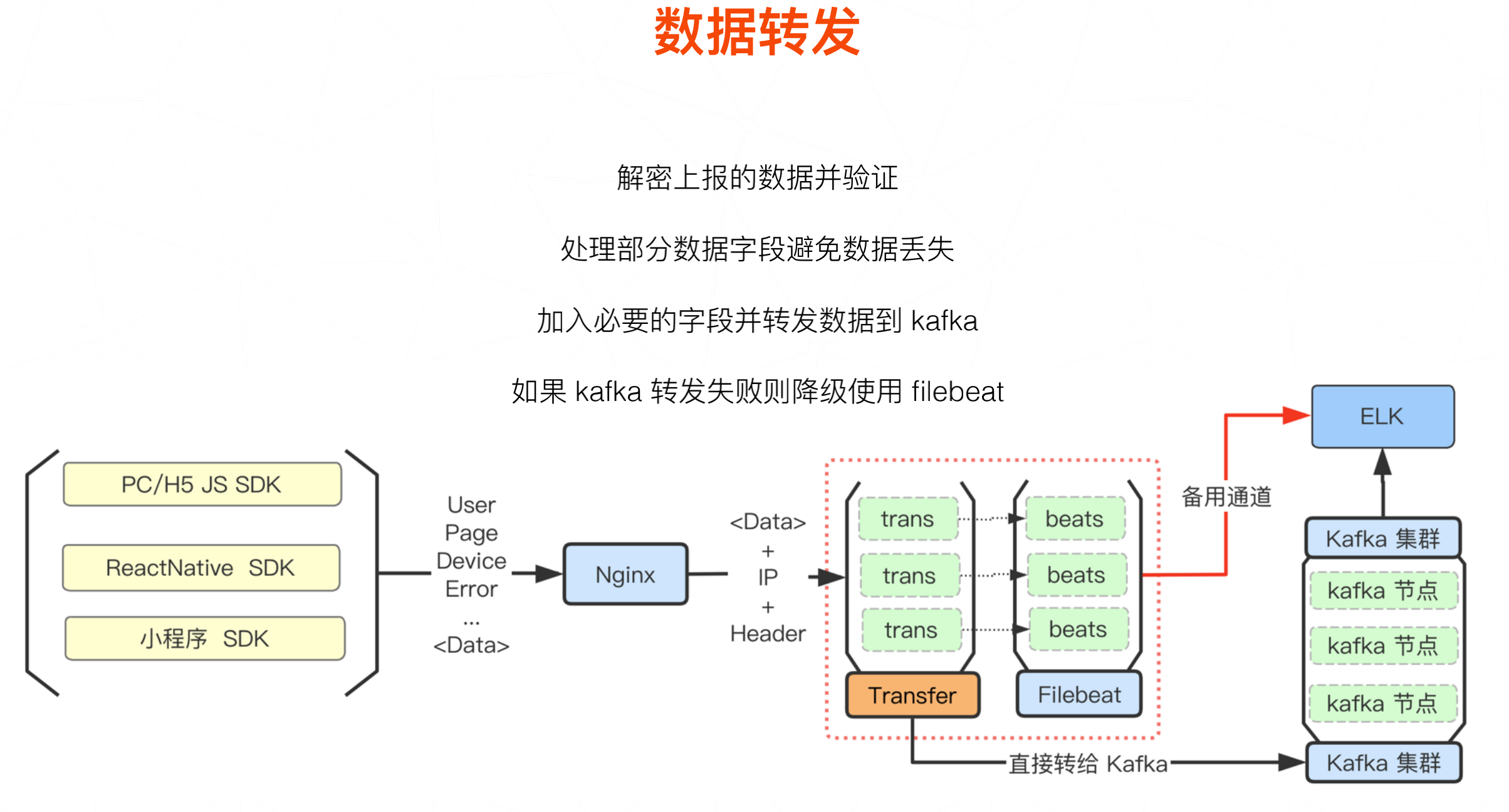
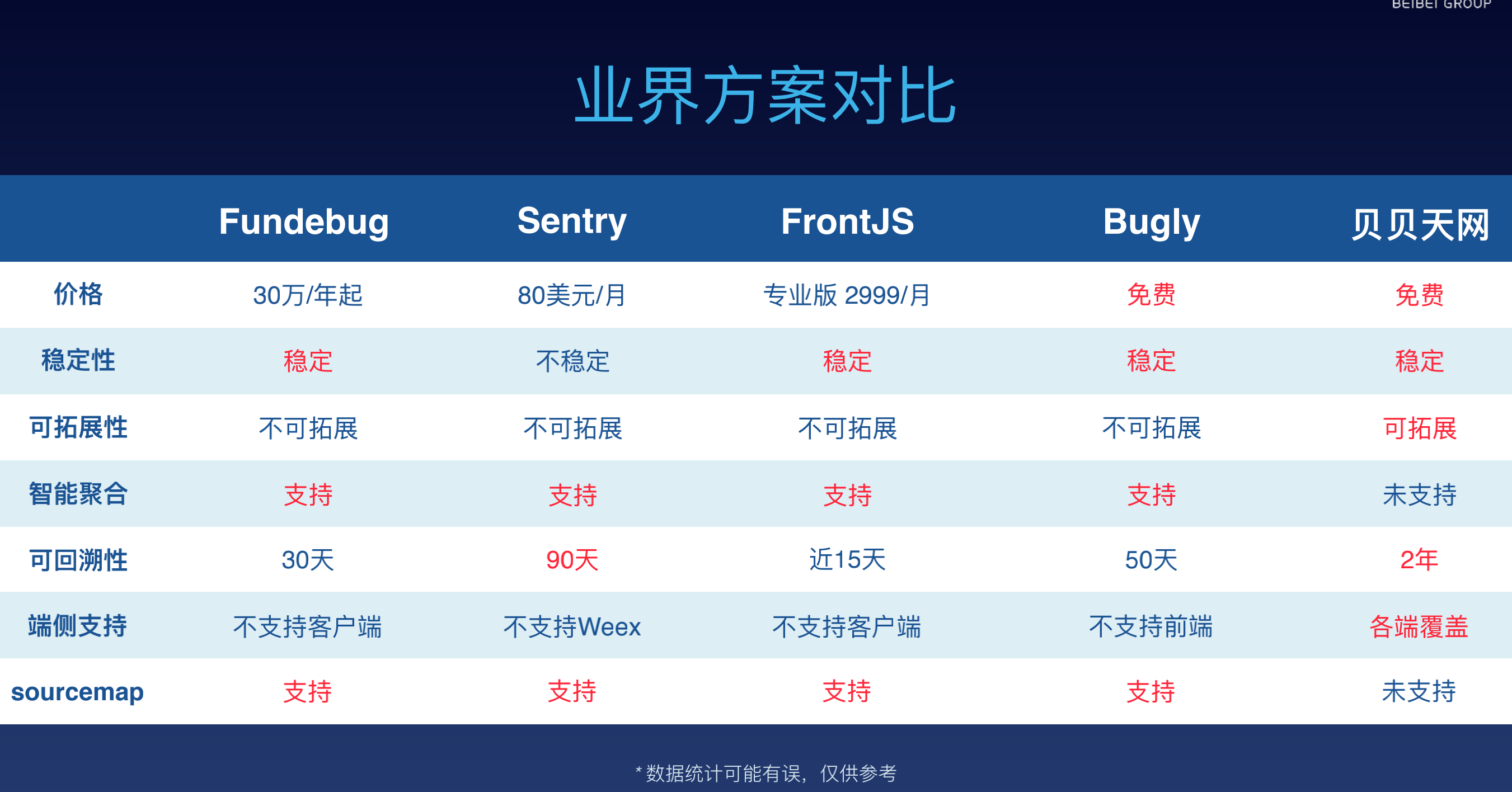
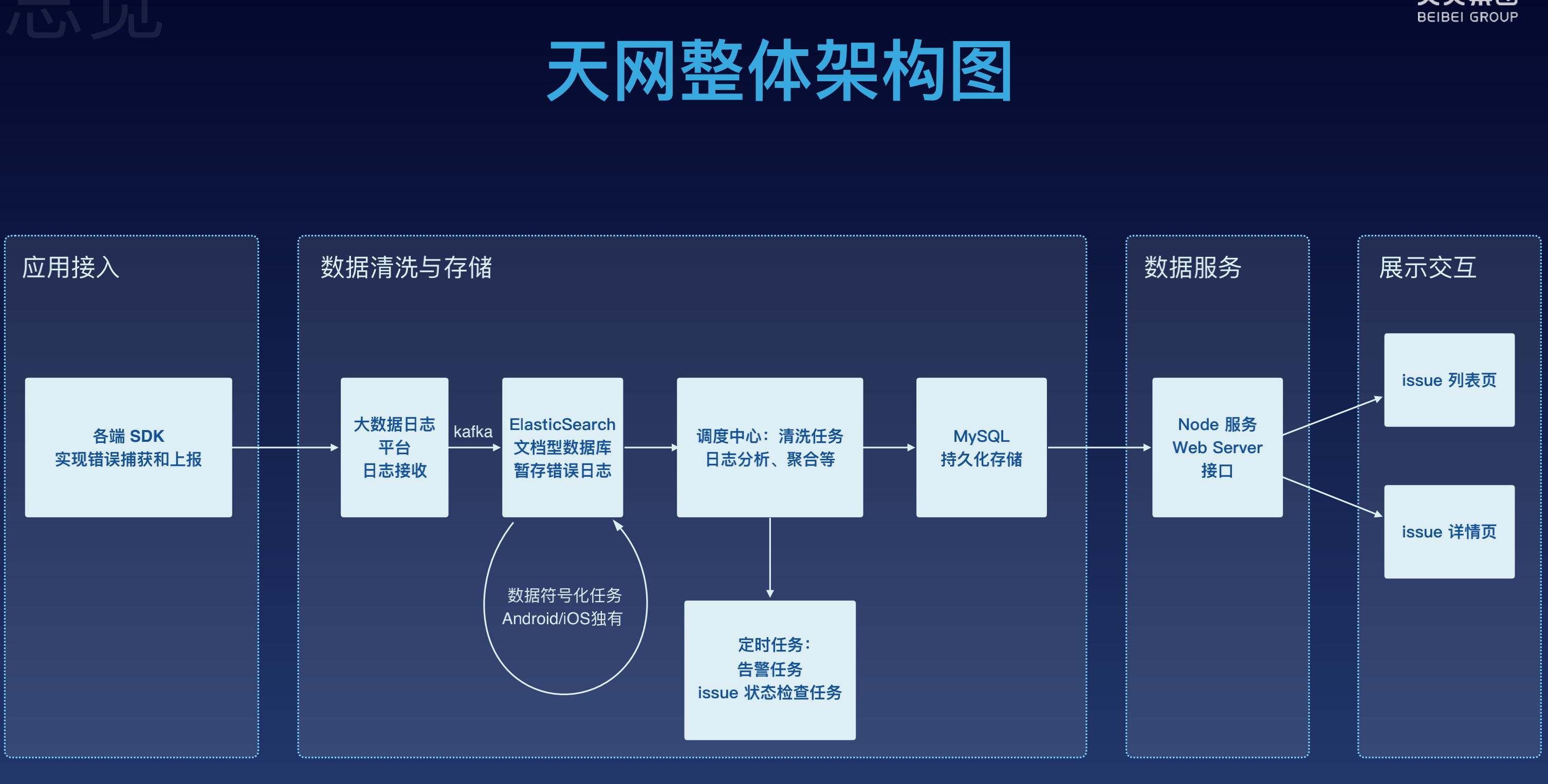
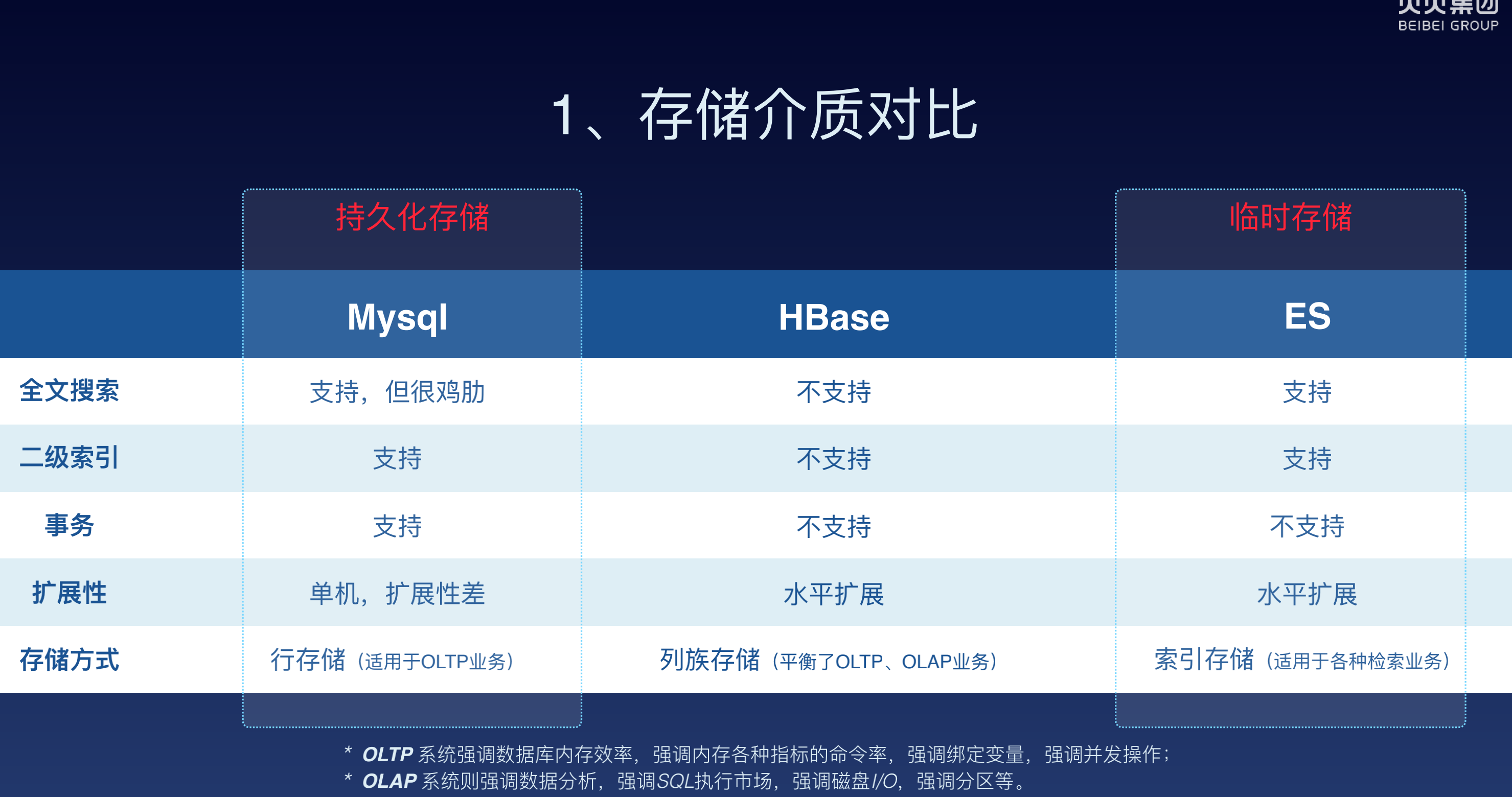




{kind=link}