A simple and easy to use search server written in node.js and MongoDb.
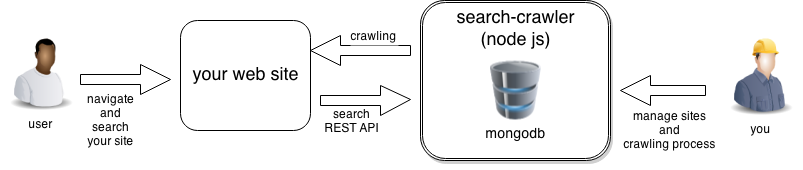
Search-Crawler is composed by a Node.Js web application to manage one or more websites and a set of json based REST API that can be used to query crawled pages and integrate the result inside any existing website.
Website crawling is implemented using Christopher Giffard's SimpleCrawler. Pages are stored in a MongoDb and search is powered by a full text mongodb query, see full text index.
- Embedded crawler and parser
- MongoDB powered full text search
- Available as REST API
- Can manage multiple websites
- Customizable content selector (you can select which part of the page to parse)
- Can crawl an entire domain or just a website section
- Scheduled crawling with cron syntax (using https://github.com/ncb000gt/node-cron)
To install search-crawler you need the following components:
- Node.Js (>= 0.10.28)
- MongoDb (>= 2.6)
Get the latest version of search-crawler at github. Install it by running the following command inside the folder where you have downloaded the package:
npm install
These will install in the current folder all the required libraries.
After installation you can execute the node.js application by executing:
npm run server
or
node index.js
The web server is created at port 8181, so you can browse it at http://localhost:8181. Search-Crawler try to connect to a mongo database using the following url:
mongodb://localhost:27017/search-crawler
See Configuration section for more information.
./src/config.js file contains all the parameters used by search-crawler.
Here some of the parameters:
// Allowed extension for crawling
config.crawler.allowedUrlPatterns = [
"/[^./]*$" // extension less
,"\\.(html|htm|aspx|php)$" // .html + .htm
];
// List of content types to process
config.crawler.contentTypes = ["text/html"];
// crawler interval
config.crawler.interval = 300;
// crawler maxConcurrency
config.crawler.maxConcurrency = 2;
// mongo host and database (mongodb version => 2.6 required)
config.db.mongo = {};
config.db.mongo.ip = process.env.IP || "localhost";
config.db.mongo.url = "mongodb://" + config.db.mongo.ip + ":27017/search-crawler";
// html "jquery style" selector for the body content (es. "body", "article", "div#text")
// can be override on each site
config.parser.defaultContentSelector = "body";
// nodejs server listening port
config.web.port = process.env.PORT || process.env.WEB_PORT || 8181;
config.web.ip = process.env.IP;
See ./src/config.js for all available parameters.
To create a custom configuration you can edit config.js file or you can create
a custom startup file like contoso.index.js with a content like:
// Here I can modify configuration...
var config = require('./src/config.js');
config.web.port = 8282;
// then run real index.js
require('./index.js');
And then instead of executing index.js you can execute your custom
contoso.index.js. This method has the advantage that you don't modify any
original file.
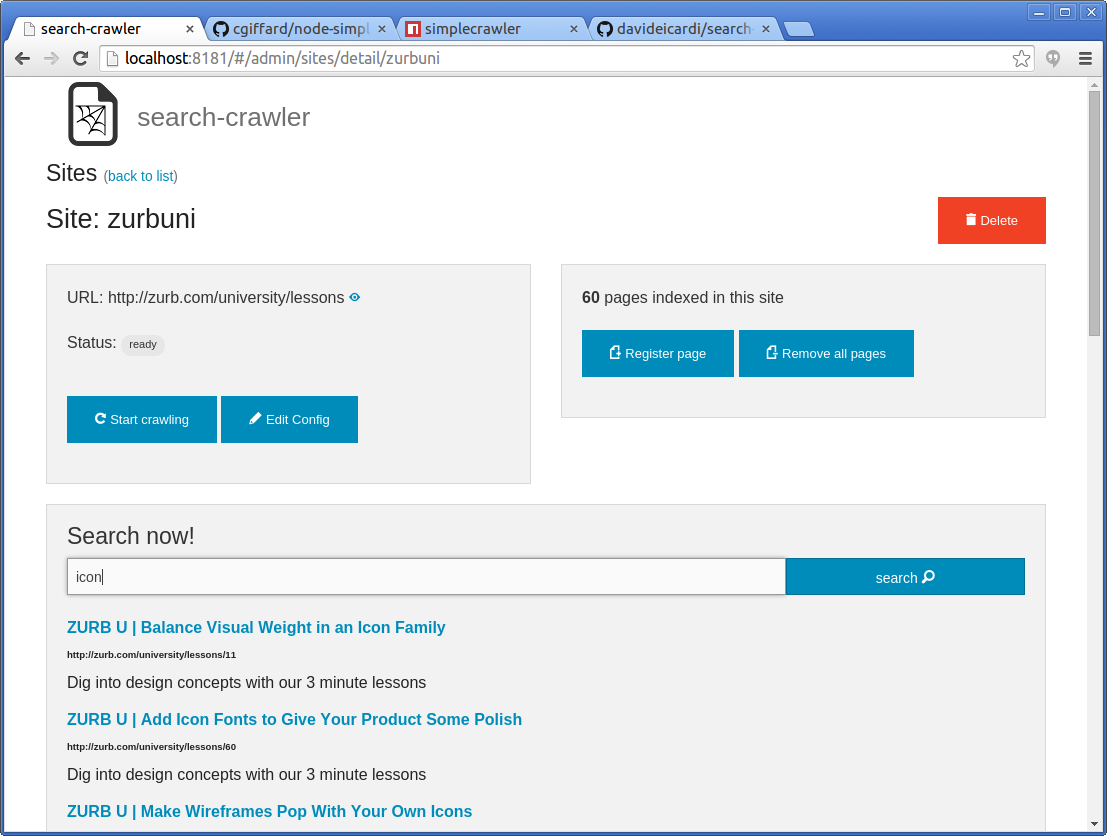
Each website has also it's own configuration (stored in mongodb inside each site document):
- site.config.contentSelector - the HTML selector that must be used for text search
- site.config.urlPattern - regex pattern that urls must match
- site.config.crawlingCron - (optional) cron expression to controll the scheduled crawling
These configuration can be edited using the web application or through the API.
To configure automatic crawling of website you should set the crawlingCron
configuration with your required frequency specified as a cron expression.
Below a quick CRON guide.
Remember that to apply any changed in the cron scheduled expression you have to reload jobs using the appropriate command or restart the node application.
* * * * * *= every seconds0 * * * * *= every minutes at second 00 5 * * * *= every hours at minute 50 0 1 * * *= every days at 1 AM
Other then the user interface the following REST API are available:
Search for a given expression inside a site. The result is a json with the list of pages that match the query with the following format:
[
{
"_id": "54550c07b242a89d4c862e6e",
"title": "Page Title",
"description": "Page description",
"url": "http://pageurl",
"score": 1.5690104166666665,
"keywords": [
"key1",
"key2"
]
},
{
...
}
]
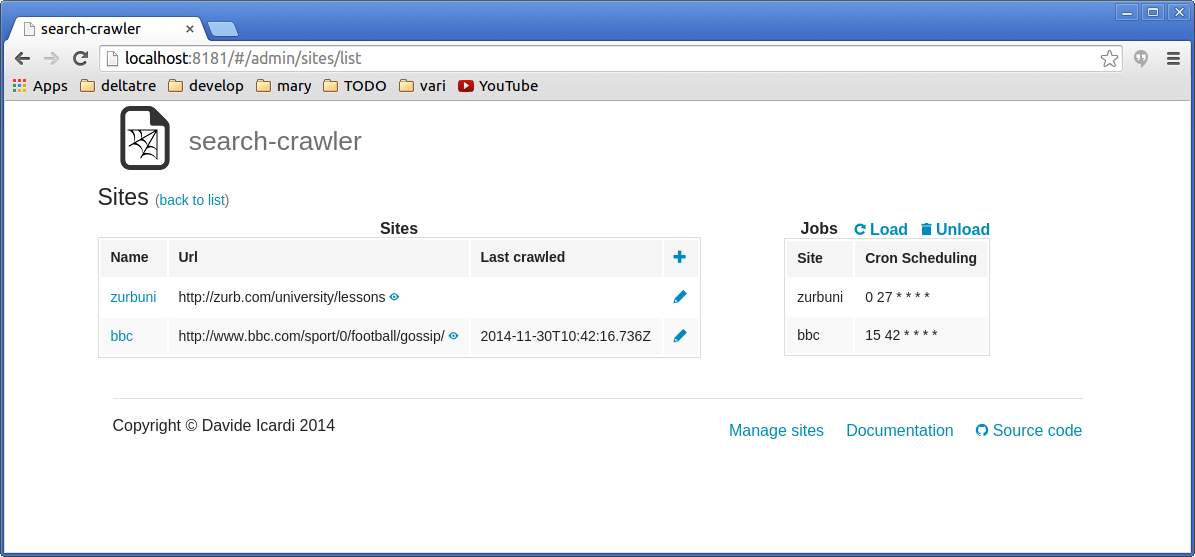
Get the list of registered sites
Get a specific site by its name
Get the list of pages of a specific site
Create a new site
Update a site configuration
Delete a specific site
Start crawling process of a specific site
Add a specific page to a site
Remove all the pages from a site
Get the registered page count of a site
Get all the configured jobs
Load all the available jobs
Unload and stop all the jobs
You can debug Search-Crawler using node inspector with the following command:
npm run server-debug
Run karma unit tests with the following command:
npm run test-unit
Run mocha end to end tests with the following command:
npm run test-e2e
- Node.js tests: http://www.clock.co.uk/join-us#op-42180-placement-software-engineer
- mongoose-q: https://github.com/iolo/mongoose-q/blob/master/index.js
- Add authentication (for administration and API)
- Better text() on parser (add space between tags)
- Crawling job
- Better crawling experience inside administration web site (start/stop, percentage, pages crawled, ...)
- Support for robots.txt
- Support for sitemaps
MIT License
Copyright (c) 2014 Davide Icardi
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
- The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
- THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.


