You can use this file as a template for your writeup if you want to submit it as a markdown file, but feel free to use some other method and submit a pdf if you prefer.
Behavioral Cloning Project
The goals / steps of this project are the following:
- Use the simulator to collect data of good driving behavior
- Build, a convolution neural network in Keras that predicts steering angles from images
- Train and validate the model with a training and validation set
- Test that the model successfully drives around track one without leaving the road
- Summarize the results with a written report
Here I will consider the rubric points individually and describe how I addressed each point in my implementation.
My project includes the following files:
- model.py containing the script to create and train the model
- drive.py for driving the car in autonomous mode
- model.h5 containing a trained convolution neural network
- writeup_report.md or writeup_report.pdf summarizing the results
- visual.py is used to take some example images
Using the Udacity provided simulator and my drive.py file, the car can be driven autonomously around the track by executing
python drive.py model.h5The model.py file contains the code for training and saving the convolution neural network. The file shows the pipeline I used for training and validating the model, and it contains comments to explain how the code works.
The network that I used is inspired by the NVIDIA model
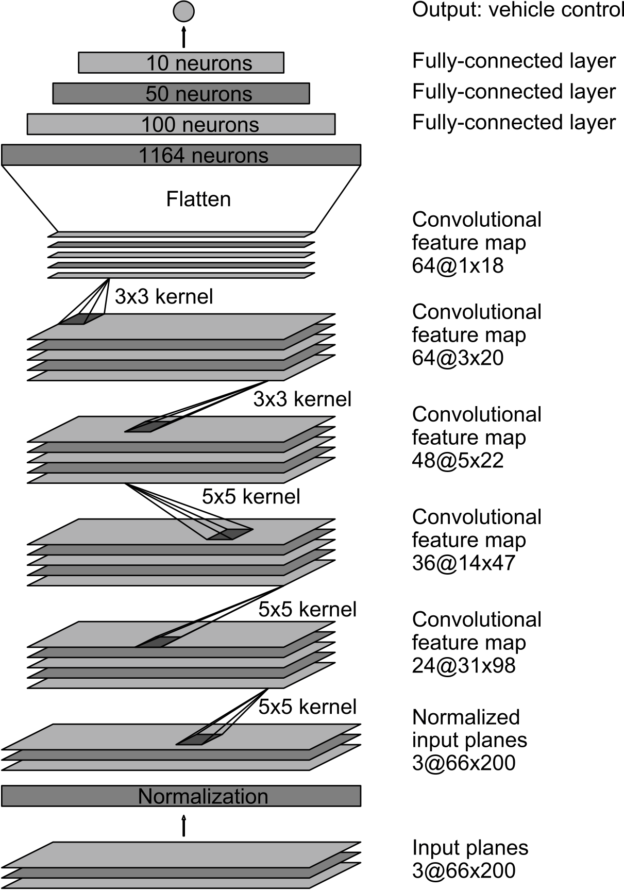
the lambda_1 layer accept image size of 66x200 and the image is normalized ((image data divided by 127.5 and subtracted 1.0))
but I add a Drop layer to with drop prob 0.5 after the last Convolutional layer to reduce the overfit.
The model contains dropout layers in order to reduce overfitting
model.add(Dropout(0.5))I tried to gather the data by driving 4 circles. 2 for clockwise and 2 for anti-clockwise.
The model used an adam optimizer, so the learning rate was not tuned manually
Training data was chosen to keep the vehicle driving on the road. I used a combination of center lane driving, recovering from the left and right sides of the road ...
For details about how I created the training data, see the next section.
Because the simulator is very lag , so I can not gather more data by driving the car. But I apply some random jitter to the image that the course provide to overcome the overfit.
The overall strategy for deriving a model architecture was to ...
My first step was to use a convolution neural network model similar to the NVIDIA I thought this model might be appropriate because it as adopted by NVIDIA team for their end-to-end training a self-driving car.
I tried to modify the model in there ways :
- without dropout layer and do not resize the image(model.h5)
- add droupout layer(model-improved.h5)
- argument the data(model-improved-withjitter.h5)
the result are shown in video run-test1.mp4, run-test2.mp4 and run-test3.mp4
The final model architecture is as follows (printed by using print(model.summary()))
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lambda_1 (Lambda) (None, 66, 200, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 31, 98, 24) 1824
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 47, 36) 21636
_________________________________________________________________
conv2d_3 (Conv2D) (None, 5, 22, 48) 43248
_________________________________________________________________
conv2d_4 (Conv2D) (None, 3, 20, 64) 27712
_________________________________________________________________
conv2d_5 (Conv2D) (None, 1, 18, 64) 36928
_________________________________________________________________
dropout_1 (Dropout) (None, 1, 18, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1152) 0
_________________________________________________________________
dense_1 (Dense) (None, 100) 115300
_________________________________________________________________
dense_2 (Dense) (None, 50) 5050
_________________________________________________________________
dense_3 (Dense) (None, 10) 510
_________________________________________________________________
dense_4 (Dense) (None, 1) 11
=================================================================
Total params: 252,219
Trainable params: 252,219
Non-trainable params: 0
_________________________________________________________________To capture good driving behavior, I first recorded two laps on track one using center lane driving. Here is an example image of center lane driving:
I then recorded the vehicle recovering from the left side and right sides of the road back to center so that the vehicle would learn to .... These images show what a recovery looks like starting from ... :
I use images taken from the 3 cameras fixed on center,right and left.



Then I do a pre-process for all these 3 images by crop and resize them to 60x200



To save memory and get more data,I crafted a generator as below:
def generate_batch_image(samples, batch_size=BATCH_SIZE):
while True:
shuffle(samples)
for offset in range(0, len(samples), batch_size):
batch_samples = samples[offset:offset + batch_size]
_images = []
_measurements = []
for line in batch_samples:
for i in range(3):
path = PATH + (line[i].strip())
image = imread(path)
image = preprocess_image(image)
if i == 1:
measurement = float(line[3]) + SHEAR_CORRECTION
elif i == 2:
measurement = float(line[3]) - SHEAR_CORRECTION
else:
measurement = float(line[3])
trans_image,trans_measurement = argument(image,measurement)
_images.append(image)
_measurements.append(measurement)
_images.append(np.fliplr(image))
_measurements.append(-measurement)
_images.append(trans_image)
_measurements.append(trans_measurement)
X_train = np.array(_images)
y_train = np.array(_measurements)
yield shuffle(X_train, y_train)In the generator , I argumented the image data by:
1.flip the image 2.adding translation and random brightness






I finally randomly shuffled the data set and put 20% of the data into a validation set.
I used this training data for training the model. The validation set helped determine if the model was over or under fitting. The ideal number of epochs was 5 I used an adam optimizer and set the learning rate to 10e-4.










