heyushuo / blob Goto Github PK
View Code? Open in Web Editor NEW日常博客总结
日常博客总结




















最近一个需求,app 内嵌的 h5 需要做任务,但是任务是在一个原生的页面中,产品的需求是如果用户做了任务,返回 h5 后,任务自动标识为完成,一般情况下我们这安卓都会有一些操作后的返回监听,但是这次比较特殊,需要前端来做处理。
Document.hidden(只读属性)返回布尔值,表示页面是(true)否(false)隐藏。(当为 true 的时候说明页面隐藏了,当为 false 的时候说明展示了)
var hiddenProperty = 'hidden' in document ? 'hidden' : 'webkitHidden' in document ? 'webkitHidden' : 'mozHidden' in document ? 'mozHidden' : null;
console.log(hiddenProperty);
document.addEventListener('visibilitychange', () => {
if (document[hiddenProperty]) {
//当离开H5 跳转到app原生的页面时,这里会被触发
console.log('页面隐藏了');
} else {
//当从原生页面用户一系列操作后,返回H5的时候,这里会被触发
console.log('页面展示了');
}
});在 PC 端可以通过通过切换 tab 来触发此事件
如果现在的 H5 有倒计时,用户离开当前 App,等会又回来,此时你会发现倒计时已经混乱了,这里可以用到这个属性,页面隐藏了先把定时器关掉,页面展示了在开始倒计时
或者有的时候需要控制 h5 中视频或者音频的暂停和播放(当离开 H5 后有的视频和音频还在播放)
在官网给了一个最基础的 npm 包的 package.json 配置文件如下
{
"name": "my_package", //发布npm包的名字
"description": "", //对组件的描述
"version": "1.0.0", //版本号
"main": "index.js", //定义了包的入口文件
"scripts": {
"test": ""
},
"repository": {
"type": "git",
"url": "" //输入git的地址
},
"keywords": [], //关键字,方便别人搜索
"author": "", //作者自己的名字
"license": "ISC",
"bugs": {
"url": "" //方便别人给你提issue的地址
},
"homepage": "" //可以指向自己的github地址
}官网地址 creating-a-package-json-file
2.1 在上边 package.json 的基础上我们需要添加devDependencies 字段和 dependencies字段,用来添加项目开发依赖和项目依赖
{
"name": "heyushuo-toast",
"version": "1.0.0",
"description": "弹窗组件",
"main": "dist/toast.min.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack-dev-server --hot --inline",
"build": "webpack --display-error-details --config webpack.config.js"
},
"author": "heyushuo",
"license": "ISC",
"repository": {
"type": "git",
"url": "https://github.com/heyushuo/npm-package"
},
"devDependencies": {
"babel-core": "^6.26.0",
"babel-loader": "^7.1.2",
"babel-plugin-transform-object-rest-spread": "^6.26.0",
"babel-plugin-transform-runtime": "^6.23.0",
"babel-polyfill": "^6.26.0",
"babel-preset-env": "^1.7.0",
"babel-preset-es2015": "^6.24.1",
"babel-preset-stage-2": "^6.24.1",
"css-loader": "^0.28.7",
"es6-promise": "^4.1.1",
"less": "^2.7.3",
"less-loader": "^4.0.5",
"node-sass": "^4.9.4",
"sass": "^1.14.3",
"sass-loader": "^7.1.0",
"style-loader": "^0.19.0",
"url-loader": "^0.6.2",
"vue": "^2.5.9",
"vue-hot-reload-api": "^2.2.4",
"vue-html-loader": "^1.2.4",
"vue-loader": "^13.5.0",
"vue-router": "^3.0.1",
"vue-style-loader": "^3.0.3",
"vue-template-compiler": "^2.5.9",
"vuex": "^3.0.1",
"webpack": "^3.9.1",
"webpack-dev-server": "^2.9.5"
},
"dependencies": {
"axios": "^0.18.0"
}
}当用户在下载你的包的时候,devDependencies 字段下依赖包并不会下载,dependencies 字段是必须安装的依赖
2.2 此时我们需要安装依赖包
npm install2.3 根目录下新增 webpack.config.js 文件,并添加配置
const path = require("path");
const webpack = require("webpack");
const uglify = require("uglifyjs-webpack-plugin");
module.exports = {
entry: "./src/index.js", //入口文件,就是在src目录下的index.js文件,
output: {
path: path.resolve(__dirname, "./dist"), //输出路径dist目录
publicPath: "/dist/",
filename: "toast.min.js", //打包后输出的文件名字,这里需要和package.json文件下main应该写为:'dist/toast.min.js'
libraryTarget: "umd",
// libraryTarget:为了支持多种使用场景,我们需要选择合适的打包格式。libraryTarget 属性。这是可以控制 library 如何以不同方式暴露的选项。
umdNamedDefine: true
},
//这里我们可以剔除掉一些通用包,自己的包不打包这些类库,需要用户环境来提供
externals: {
vue: "vue",
axios: "axios"
},
module: {
rules: [
{
test: /\.vue$/,
loader: "vue-loader"
},
{
test: /\.scss$/,
use: [
{
loader: "style-loader"
},
{
loader: "css-loader"
},
{
loader: "scss-loader"
}
]
},
{
test: /\.js$/,
exclude: /node_modules/,
loader: "babel-loader" //babel的相关配置在.babelrc文件里
},
{
test: /\.(png|jpg|gif|ttf|svg|woff|eot)$/,
loader: "url-loader",
query: {
limit: 30000 //把一些小图片打包为base64
}
}
]
},
plugins: [
//压缩js代码
new webpack.optimize.UglifyJsPlugin({
//输出不显示警告
compress: {
warnings: false //默认值
},
//输出去掉注释
output: {
comments: false //默认值
}
})
]
};umdNamedDefine

2.4 开始开发自己的组件了
在 src 目录下创建一个 index.js 最为 webpack 的入口文件,创建一个 component 文件写自己的组件,common 放一些公用样式或者文件

在 index.js 文件引入写好的组件,并导出组件
import toast from "./component/index.vue";
export default toast;接下来可以执行如下命令,生成需要发布包的文件
npm run build
//这里打包后的文件与package.json文件内的main字段相对应
"main": "dist/toast.min.js",到这里第二部就算完成了,大家也可以把自己平时写的组件全部复制过来就可以.
接下来就是最重要的一步注册 npm 包,发布自己的包
这里需要注意:一定要确保本地镜像为 npm,不然无法提交成功
// 1.查询当前配置的镜像
npm get registry
//https://registry.npmjs.org/
// 设置成淘宝镜像
npm config set registry http://registry.npm.taobao.org/
// 换成原来的
npm config set registry https://registry.npmjs.org/npm 发布包的一些相关命令
npm login //登录npm
npm publish //发布包
npm unpublish //删除包再发布前需要配置.npmignore 文件,忽略一些无用的文件
.*
/node_modules
/src
package-lock.json
webpack.config.js
如下图看一下具体执行的过程

以上就完成了发布自己的包
队列只能在队尾插入元素,在队首删除元素。队列用于存储按顺序排列的数据,先进先出(FIFO,First-In-First-Out)可以将队列想象成在银行前排队的人群,排在最前面的人第一个办理业务,新来的人只能在后面排队,直到轮到他们为止。队列是一种先进先出(First-In-First-Out,FIFO)的数据结构。
在 JavaScript 中数组专门提供了push()和 shift()方法,以便
实现类似队列的行为,接下来咱们使用ES6的class实现一个队列
首先我们需要知道队列常用的几个方法如下
class Queue {
constructor(items) {
this.items = items || []
}
enqueue(element){
this.items.push(element) //从队尾添加一个元素
}
dequeue(){
return this.items.shift() //从队首删除一个元素
}
head(){
return this.items[0] //返回队首的元素
}
tail(){
return this.items[this.item.length-1] //返回队尾的元素
}
clear(){
this.items = []
}
size(){
return this.items.length
}
isEmpty(){
return !this.items.length
}
}接下来使用一下定义的队列
var queue = new Queue();
//从队尾添加一个元素
queue.enqueue(1)
queue.enqueue(2)
queue.enqueue(3)
// 返回队尾的元素
console.log(queue.head()); //队首1
console.log(queue.tail()); // 队尾3
//从队列首删除元素
queue.dequeue()
console.log(queue.head()); //队首2
console.log(queue.tail()); // 队尾31.有一个数组存放了 100 个数据 0-99,要求每隔两个数删除一个数,到末尾时再循环至开头继续进行,求最后一个被删除的数字。(约瑟夫环问题).
解题思路
- 先将这 100 个数据放入队列,用 while 循环,终止的条件是队列里只有一个元素。
- 定义 index 变量从 0 开始计数,从队列头部删除一个元素,index + 1
- 如果 index%3 === 0 ,说明这个元素需要被移除队列,否则的话就把它添加到队列的尾部
说白了就是 index%3如果为 0 直接删除如果不为 0 放到队列尾部,为了下次从头开始循环
//创建一个0-99的数组
var arr = Array.from({length:100}, (v,index) => index);
function find(arr) {
var queue = new Queue(); //创建爱你一个队列
var index = 0;
for (let i = 0; i < arr.length; i++) {
queue.enqueue(i) //将数据入队
}
while (queue.size()!==1) {
var item = queue.dequeue();//出队一个元素,根据index%3==0,来决定是否要放到队列的尾部
index= index + 1;
if(index%3!=0){
//需要放到队列尾部,下次循环可以达到从头开始的效果
queue.enqueue(item);
}
}
return queue.head()
}
console.log("最后一个被删除的数字是" + find(arr)); // 902.根据顺序输出二叉树的每个节点的值
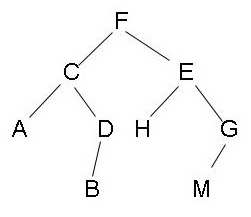
解题思路
使用队列的思路,队列中先放入第一个值,然后判断是否有子节点如果有子节点,就往队列中尾部添加
代码实现如下:
var node9 = {
num: M,
children: []
}; //节点7
var node8 = {
num: B,
children: []
};
var node7 = {
num: G,
children: [node9]
}; //节点7
var node6 = {
num: H,
children: []
};
var node5 = {
num: D,
children: [node8]
};
var node4 = {
num: A,
children: []
};
var node3 = {
num: E,
children: [node6, node7]
};
var node2 = {
num: C,
children: [node4, node5]
};
var node1 = {
num: F,
children: [node2, node3]
};
var queue = []; //队列
queue.push(node1);//现将第一个节点push进去
var i =0;
while (i<queue.length) {
var node = queue[i];
console.log(node.num);
if(node.children.length!==0){
for (let j = 0; j < node.children.length; j++) {
queue.push(node.children[j]);
}
}
i++
}
// 最后打印的结果
// F
// C
// E
// A
// D
// H
// G
// B
// M3.打印杨辉三角,对应的数学计算公式是,fn[i][j] = fn[i-1][j-1]+fn[i-1],i 代表行数,j 代表列数,如果 j=0 或者 j=i那么fn[i][j]=1
解题思路
- 只需要将当前行队列里的数据依次出队列,并进行计算得到下一行的数值存储到队列中.
function add(n) {
var queue = []; //创建一个队列
queue.push(1); //先把第一个放进去
//这层循环控制有多少行
for (let i = 1; i <= n; i++) {
var row = "";
var start = 0; //加的基数从0开始
//控制当前行的数据
for (let j = 0; j < i; j++) {
var item = queue.shift(); //把队列中的元素移除
var value = start + item; //计算当前数据的值
start = item; //
row = row + item + " "; //当前行的数据需要打印出来
queue.push(value); //再把计算好的值存入队列,供下一次循环使用
}
queue.push(1); // 将每层的最后一个数值 1 存入队列中
console.log(row);
}
}var arr = [1, 6, 4, 6, 6, 4, 2, "a", "a"];
var array = [];
var obj = {};
for (var i = 0; i < arr.length; i++) {
if (!obj[arr[i]]) {
obj[arr[i]] = true;
array.push(arr[i]);
}
}
console.log(array); //[1, 6, 4, 2, "a"]var arr = [1, 6, 4, 6, 6, 4, 2, "a", "a"];
var array = [];
for (var i = 0; i < arr.length; i++) {
for (var j = 0; j < array.length; j++) {
if (arr[i] == array[j]) {
break;
}
}
//如果这两个数相等说明循环完了,没有相等的元素
if (j == array.length) {
array.push(arr[i]);
}
}
console.log(array); //[1, 6, 4, 2, "a"]var arr = [1, 6, 4, 6, 6, 4, 2, "a", "a"];
var array = [];
for (var i = 0; i < arr.length; i++) {
if (array.indexOf(arr[i]) == -1) {
array.push(arr[i]);
}
}
console.log(array); //[1, 6, 4, 2, "a"]var arr = [1, 6, 4, 6, 6, 4, 2, "a", "a"];
var array = [];
arr.forEach(function(item, index) {
if (array.indexOf(item) == -1) {
array.push(item);
}
});
console.log(array); //[1, 6, 4, 2, "a"]var arr = [1, 6, 4, 6, 6, 4, 2, "a", "a"];
var array = arr.filter(function(item, index) {
return arr.indexOf(item) == index;
});
console.log(array); //[1, 6, 4, 2, "a"]var arr = [1, 6, 4, 6, 6, 4, 2, "a", "a"];
//第一种
var newarr = Array.from(new Set(arr));
console.log(newarr); //[1, 6, 4, 2, "a"]
//第二种
var newarr1 = [...new Set(arr)];
console.log(newarr1); //[1, 6, 4, 2, "a"]var arr = [1, 6, 4, 6, 6, 4, 2, "a", "a"];
var array = [];
arr.forEach(function(item, index) {
if (!array.includes(item)) {
array.push(item);
}
});
console.log(array); //[1, 6, 4, 2, "a"]字典是一种以键 - 值对形式存储数据的数据结构,JavaScript 的 Object 类就是以字典的形式设计的,Object 的这种映射关系称之为字典,有的编程语言也称之为 Map,ES6 的原生 Map 类已经实现了字典的全部功能。
相当于把 ES6 的 Map 类型的方法实现一遍,代码如下:
class Dictionary {
constructor() {
this.items = {};
}
set(key, value) {
// 向字典中添加或修改元素
this.items[key] = value;
}
get(key) {
// 通过键值查找字典中的值
return this.items[key];
}
delete(key) {
// 通过使用键值来从字典中删除对应的元素
if (this.has(key)) {
delete this.items[key];
return true;
}
return false;
}
has(key) {
// 判断给定的键值是否存在于字典中
return this.items.hasOwnProperty(key);
}
clear() {
// 清空字典内容
this.items = {};
}
size() {
// 返回字典中所有元素的数量
return Object.keys(this.items).length;
}
keys() {
// 返回字典中所有的键值
return Object.keys(this.items);
}
values() {
// 返回字典中所有的值
return Object.values(this.items);
}
getItems() {
// 返回字典中的所有元素
return this.items;
}
}使用一下实现的字典
let dictionary = new Dictionary();
dictionary.set("name", "heyushuo");
dictionary.set("age", "18");
dictionary.set("height", "180");
console.log(dictionary.has("name")); // true
console.log(dictionary.size()); // 3
console.log(dictionary.keys()); // [ 'name', 'age', 'height' ]
console.log(dictionary.values()); // [ 'heyushuo', '18', '180' ]
console.log(dictionary.get("name")); // heyushuo
dictionary.delete("age");
console.log(dictionary.keys()); // [ 'name', 'height' ]以上代码现实的和ES6的Map还是有区别的,其中values()方法和keys()方法返回的不是一个数组,而是Iterator迭代器。另一个就是这里的size是一个属性而不是方法,然后就是Map类没有getItems()方法,取而代之的是entries()方法,它返回的也是一个Iterator。
function Parent() {
this.name = ["heyushuo", "kebi"];
}
function Child() {
Parent.call(this);
// 或者 Parent.apply(this);
}
var Person1 = new Child();
Person1.name.push("kuli");
console.log(Person1.name); //["heyushuo", "kebi","kuli"];
var Person2 = new Child();
console.log(Person2.name); //["heyushuo", "kebi"];
// 通过上边的两个打印,Child的两个实例继承的name属性不会互相影响
// 因为,创建Child实例的环境下调用Parent构造函数,这样可以使得每个实例都会具有自己的name属性,所以两个不会互相影响2. 优点(可以传递参数)
function Parent(name) {
this.name = name;
}
function Child() {
Parent.call(this, "heyushuo");
//或者Parent.apply(this, ["heyushuo"]);
}
var Person = new Child();
console.log(Person.name); //heyushuo
// 需要注意的:为了确保Parent构造函数不会重写子类型的属性,需要在Parent.call(this)之后在定义子类型中的属性3.构造函数的缺点
因为方法和属性只能写在构造函数中,因此不能实现函数复用 只能继承父类的实例属性和方法,不能继承原型属性/方法 (原型中定义的方法和属性对于子类是不可见的)
通俗来讲就是用原型链实现对原型属性和方法的继承,用借用构造函数继承来实现对实例属性的继承。
function Parent(name) {
this.name = name;
this.newArr = ["red", "blue", "green"];
}
Parent.prototype.sayName = function() {
console.log(this.name);
};
function Child(name) {
Parent.call(this, name);
this.age = 26;
}
Child.prototype = new Parent();
//重写Child.prototype的constructor属性,使其执行自己的构造函数Child
Child.prototype.constructor = Child;
Child.prototype.sayAge = function() {
console.log(this.age);
};
var Person1 = new Child("heyushuo");
console.log(Person1);
Person1.newArr.push("yellow");
console.log(Person.newArr); //["red", "blue", "green","yellow"]
Person.sayName(); //heyushuo
var Person2 = new Child("kebi");
console.log(Person2.newArr); //["red", "blue", "green"]
Person.sayName(); //kebi通过一张图来看一下:
reduce() 方法从数组的第一项开始,逐个遍历到最后。返回的任何值都会作为第一个参数自动传给下一项。
array.reduce(function(total, currentValue, currentIndex, arr) {
//需要的操作
}, initialValue);var values = [1, 2, 3, 4, 5];
var sum = values.reduce(function(prev, cur, index, array) {
return prev + cur;
});
var sum1 = values.reduce(function(prev, cur, index, array) {
return prev * cur;
});
console.log(sum); //15 1+2+3+4+5 = 15
console.log(sum1); // 120 1*2*3*4*5 = 1201.合并二维数组
var newArr = [[1, 2, 3], ['a', 'b', 'c'], [9, 10]];
newArr.reduce(function(init, item, index) {
return init.concat(item);
}, []);
console.log(result); //[1, 2, 3, "a", "b", "c", 9, 10]
//可以使用ES5的方法实现
var arr2 = [].concat.apply([], newArr);
console.log(arr2); //[1, 2, 3, "a", "b", "c", 9, 10]
//可以使用ES6的方法实现
var arr3 = newArr.flat();
console.log(arr3); //[1, 2, 3, "a", "b", "c", 9, 10]2.找到字符串中每个字母出现的次数
var arr = 'bcdaabcddddddweeeee';
var info = arr.split('').reduce(function(init, item, index) {
init[item] ? init[item]++ : (init[item] = 1);
return init;
}, {});
console.log(info); //{a: 2,b: 2,c: 2,d: 7,e: 5,w: 1}
//那如何找到最大的那一项呢?
var max = Object.entries(info); //[["b", 2], ["c", 2], ["d", 7],["a", 2],["w", 1],["e", 5]]
var maxArr = max.reduce(function(pre, next) {
return pre[1] > next[1] ? pre : next;
});
console.log(maxArr); //["d", 7]
//使用for循环找到最大值
var maxNum = 0;
var maxKey = '';
for (const key in info) {
if (info[key] > maxNum) {
maxNum = info[key];
maxKey = key;
}
}
console.log(maxNum); // 7
console.log(maxKey); // dvar filterArr = [
{
name: 'liming',
age: 31,
score: 100
},
{
name: 'kebi',
age: 36,
score: 60
},
{
name: 'heyushuo',
age: 26,
score: 40
}
];
var result = filterArr.reduce(function(init, item) {
return init + item.score;
}, 0);
console.log(result); // 200var a1 = [1, 2, 3, 4, 6, 7, 8, 9, 10];
var a2 = ['a', 'b', 'c', 'd', 'e'];
var result = a1.reduce(function(init, item, index) {
if (index % 2 == 0 && index != 0) {
init.push(a2.shift());
}
init.push(item);
return init;
}, []);
console.log(result); //[1, 2, "a", 3, 4, "b", 6, 7, "c", 8, 9, "d", 10]var doubleArray = [1, 2, [3, [4, 5]]];
//ES6的写法
console.log(doubleArray.flat(2));
//用reduce实现
function flat(arr) {
return arr.reduce(function(init, item) {
return init.concat(Array.isArray(item) ? flat(item) : item);
}, []);
}
//使用for循环实现
// function flat(array) {
// var result = [];
// for (let i = 0; i < array.length; i++) {
// var item = array[i]
// if (Array.isArray(item)) {
// result = result.concat(flat(item));
// } else {
// result.push(item)
// }
// }
// return result
// }最近做活动需要做跑马灯效果,其他同事也有实现,本来打算复制他们代码,发现都是使用setInterval实现了,也没有封装为组件,所以自己用CSS3实现了一下跑马灯效果,并封装为组件,这样以后在需要写的时候,只需要引入组件就可以了。

HTML 结构父盒子固定,子盒子移动,并包含需要效果的内容CSS3 实现肯定需要 infinite (循环执行动画)wrapWidth),还有子盒子的总宽度(offsetWidth)CSS3动画需要的时间duration向外暴露三个参数
源码中大部分都添加了注释,如有问题请指出谢谢
<template>
<div ref="wrap" class="wrap">
<div ref="content" class="content" :class="animationClass" :style="contentStyle" @animationend="onAnimationEnd" @webkitAnimationEnd="onAnimationEnd">
<slot></slot>
</div>
</div>
</template>
<script>
export default {
props: {
content: {
default: ''
},
delay: {
type: Number,
default: 0.5
},
speed: {
type: Number,
default: 100
}
},
mounted() {},
data() {
return {
wrapWidth: 0, //父盒子宽度
firstRound: true, //判断是否
duration: 0, //css3一次动画需要的时间
offsetWidth: 0, //子盒子的宽度
animationClass: '' //添加animate动画
};
},
computed: {
contentStyle() {
return {
//第一次从头开始,第二次动画的时候需要从最右边出来所以宽度需要多出父盒子的宽度
paddingLeft: (this.firstRound ? 0 : this.wrapWidth) + 'px',
//只有第一次的时候需要延迟
animationDelay: (this.firstRound ? this.delay : 0) + 's',
animationDuration: this.duration + 's'
};
}
},
watch: {
content: {
//监听到有内容,从后台获取到数据了,开始计算宽度,并计算时间,添加动画
handler() {
this.$nextTick(() => {
const { wrap, content } = this.$refs;
const wrapWidth = wrap.getBoundingClientRect().width;
const offsetWidth = content.getBoundingClientRect().width;
this.wrapWidth = wrapWidth;
this.offsetWidth = offsetWidth;
this.duration = offsetWidth / this.speed;
this.animationClass = 'animate';
});
}
}
},
methods: {
//这个函数是第一次动画结束的时候,第一次没有使用infinite,第一次动画执行完成后开始使用添加animate-infinite动画
onAnimationEnd() {
this.firstRound = false;
//这是时候样式多出了padding-left:this.wrapWidth;所以要想速度一样需要重新计算时间
this.duration = (this.offsetWidth + this.wrapWidth) / this.speed;
this.animationClass = 'animate-infinite';
}
}
};
</script>
<style scoped>
.wrap {
width: 100%;
height: 24px;
overflow: hidden;
position: relative;
background: rgba(211, 125, 066, 1);
position: relative;
padding: 0;
}
.wrap .content {
position: absolute;
white-space: nowrap;
}
.animate {
animation: paomadeng linear;
}
.animate-infinite {
animation: paomadeng-infinite linear infinite;
}
@keyframes paomadeng {
to {
transform: translate3d(-100%, 0, 0);
}
}
@keyframes paomadeng-infinite {
to {
transform: translate3d(-100%, 0, 0);
}
}
</style>请参考我的另外一篇文章,如何将自己的 vue 组件发布为 npm 包
npm install heyushuo-marquee --save
import PaoMaDeng from 'heyushuo-marquee';
<PaoMaDeng :delay="0.5" :speed="100" :content="arr">
<span v-for="(item, index) in arr" :key="index">{{item}}</span>
</PaoMaDeng>参加工作来第一次做年度总结,也希望通过这次总结认真回顾一下 2018 年工作上做了些什么?自己私下做了些什么?技术上得到了那些提升?同时也给自己立下 2019 年的 flag,希望自己成为一个更有深度的高级前端开发工程师。
2018 上半年我主要负责在 2017 年做完一个 app 和一个 pc 端的系统的维护,这段维护的日子里真的是太清闲了,大部分时间都是在自己学习新技能,所以在五月份的时候,换了新工作开始自己 2018 年的下半年的工作,同时也在自己 github 开源了一个 mpvue 开发的小程序还在 github 建立自己的博客库。
2018 年前半年我一直还停留在 jq 时代,Pc 端没有前后端分离,但是 App 是前后端分离的,当时这两个差不多都开发完了,大部分时间在维护和迭代,负责维护的 App 当时技术选型比较陋,我直接使用 Hbuild 开发的 App 没有使用 ReactNative 高大尚的框架(当时团队就我一个前端还有四个后端一个技术老大),当时每天的工作就是和全国各省不同地区对接 App 的接入,还有 Pc 端的一些更新,自己多余时间很多,不干堕落开始自己学习之路。
每天自己的时间还是很多的,为了提升自己开始接触 Vue,先把 Vue 的官网从头到尾看了个边,学完基础后,开始看慕课网的实战视频,大概看了两三个实战视频,从而了解 Vue 开发大致步骤和流程,当时为了让自己对 Vue 理解更加深刻,联合网友一块在业余时间模仿 boss 直聘用用 Vue 写了一遍,虽然很陋但也是对自己这一段时间学习的一个产出吧,在这个期间我还看了 React 的官方文档,接着也看了几个慕课网关于 React 的实战视频,也尝试自己弄了一套 React 项目的 webpack 配置。
通过这半年的学习,最后在五月份的时候成功跳槽到现在的公司。
进入新公司,才感受到做一个需求的整体流程,先需求评审,预估工期,开发完后,测试开始测试,在发到线上,然后在回测,然后才算整个过程完成,在上个公司的时候真的是一点都不规范啊,新公司技术栈 Vue 为主,在新公司主要工作是 App 内嵌 H5 还有后台管理系统,一直相接触小程序开发,但是公司驾考宝典小程序已经成型了,没机会从新开始了,这时候我接触到了mpvue这个框架,这个框架可以用 Vue 的写法去写小程序,瞬间让我有了自己写一个小程序的想法
使用 mpvue 开发小程序,接下来几个月我就开始研究 mpvue,想着怎么写接口自己弄一个完整的上线的小程序,无意中发现一个网友爬取的网易严选商城的一些数据大概一共有 20 张表,后来决定用这些数据来写接口,学了半个月PHP,发现需要学习的成本太高了,最终还是选择用 Node 来写接口,大概用了一个多月的时间终于把自己仿网易严选的小程序写出来了,小程序服务端源码地址这些代码仅供学习参考,感觉有很多地方写的不是很规范
前端:小程序、mpvue、async、await
后端:Node、koa2、mysql、knex.js 操作数据库,可视化工具使用的 Navicat
最后买服务器买域名,域名备案(备案了大半个月),最后把项目部署到服务器上了,但是最后发现小程序无法过审,个人不能提交商城类的小程序
我们前端组每个星期都有团队内分享,当时也把mpvue这个框架在组内进行了分享,后期在公司也做了一个小的倒流的小程序,当时我直接用的mpvue进行开发的,做完这个后,公司又开了一个教练宝典小程序因为和同事合作开发,所以直接用的原生小程序进行开发的,也算是把小程序练了一把(使用原生和 mpvue)。
下半年的思考,发现自己一直停留在用的阶段,不管是 Vue、mpvue 还是 Node
很少关心原理还有 Javascript 基础方面,所以就开始想着着手去弄明白原理不能只停留在用的层面上,要想原理弄明白,肯定 JavaScript 基础必须要过关,然后我就开始阅读《高级程序设计三》,只是读了很快就会忘记,在 10 月份末的时候我就在自己的 github 上开了一个博客库,并强迫自己每周输出两篇文章,也算是对自己读书的一个总结,前期可能都是一些 JavaScript 基础的博客,看完基础后后期会加入一些深入的博客以及源码的解析
2018 年自己还算过得比较充实,但是路不能走的太快,需要沉淀,原本觉得自己 2018 年没怎么可总结的,但是通过写加回想这一年还是经历了很多,回想中也看到自己进步的同时也发现了自己的不足。
新的一年新的征程,也要为新的征程制定相应的计划
1、再过一遍《高级程序设计三》加强基础
2、看完《你不知道的 JavaScript》上中下卷
3、坚持 github 上的博客库,跟新基础知识、技术总结和项目开发中遇到的问题
4、更加深入的去理解 Vue 和 Node,同时尝试一下服务端渲染
5、至少写一个 React 相关的项目
6、持续输出,完成 Linmi 主编组织的《开发者写作计划》33 篇文章
7、打算结个婚
8、每周尽量腾出半天时间去打篮球
新的一年希望自己成为有深度的高级前端开发工程师。
最后附一张科比大佬的呐喊!!!
链表的数据结构如下:

单链表,由于标识出链表的起始节点却有点麻烦,随意大部分链表最前面有一个特殊的节点,叫做头节点,链表结构改造如下

链表插入或删除一个元素效率非常高,只需要修改相应元素上的指针就可以了.
下图展示了向链表插入一个 cookies 元素和删除一个 Bacon 元素
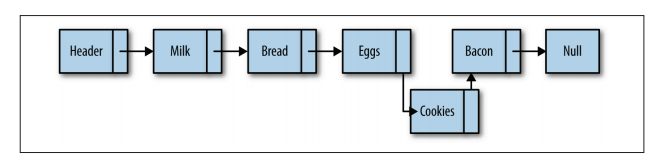

链表还有其他一些操作,但插入和删除元素最能说明链表为什么如此有用
设计一个链表包含两个类
Node 类包含两个属性:data 用来保存节点上的数据,next 用来保存指向下一个节点的链接。
var Node = function(data) {
this.data = data;
this.next = null;
};LinkList 类提供了插入节点/删除节点/显示列表元素的方法,以及一些辅助方法
function LList() {
//链表只有一个属性,那就是使用一个 Node 对象来保存该链表的头节点
this.head = new Node("head");
this.find = find; //查找方法
this.insert = insert; //插入方法
this.remove = remove; //删除方法
this.display = display; //展示节点
}链表只有一个属性head,那就是使用一个 Node 对象来保存该链表的头节点,head 节点的 next 属性被初始化为 null,当有新元素插入时,next 会指向新的元素
接下来实现一下链表的其他方法
find方法(这里需要注意一点当查询到最后一个的时候next指向null)function find(item) {
var currNode = this.head;
//从起点开始迭代列表直到找到元素
while (!(currNode.next == null) && currNode.data != item) {
currNode = currNode.next;
}
return currNode;
}2.insert方法,链表中插入一个节点。向链表中插入新节点时,需要明确指出要在哪个节点前面或后面插入。
function insert(newElement, item) {
var newNode = new Node(newElement);
//找到需要插入节点的位置
var current = this.find(item);
//把新节点的next指向(`current.next`这个是下一个节点)
newNode.next = current.next;
//然后再把current.next指向新的节点
current.next = newNode;
}3.remove方法,从链表中删除节点时,需要先找到待删除节点前面的节点.找到节点后,修改它的 next 属性,使其不再指向待删除节点,而是指向待删除节点的下一个节点.
//找到待删除节点前面的节点
function findPrevious(item) {
var currNode = this.head;
while (!(currNode.next == null) && currNode.next.data != item) {
currNode = currNode.next;
}
return currNode;
}
function remove(item) {
//找到待删除节点前面的节点
var prevNode = findPrevious(item);
if (!(prevNode.next == null)) {
//把前一个的节点,指向要删除节点的下一个节点
prevNode.next = prevNode.next.next;
}
}4.display方法,显示链表中的所有元素
function display() {
var currNode = this.head;
while (!(currNode.next == null)) {
console.log(currNode.data);
currNode = currNode.next;
}
}用 ES6 的 class 整体上实现以下
class Node {
constructor() {
this.data = data;
this.next = null;
}
}
class LList {
constructor() {
this.head = new Node("head");
}
find(item) {
var currNode = this.head;
//从起点开始迭代列表直到找到元素
while (!(currNode.next == null) && currNode.data != item) {
currNode = currNode.next;
}
return currNode;
}
insert(newElement, item) {
var newNode = new Node(newElement);
//找到需要插入节点的位置
var current = this.find(item);
//把新节点的next指向(`current.next`这个是下一个节点)
newNode.next = current.next;
//然后再把current.next指向新的节点
current.next = newNode;
}
findPrevious(item) {
var currNode = this.head;
while (!(currNode.next == null) && currNode.next.data != item) {
currNode = currNode.next;
}
return currNode;
}
remove(item) {
//找到待删除节点前面的节点
var prevNode = findPrevious(item);
if (!(prevNode.next == null)) {
//把前一个的节点,指向要删除节点的下一个节点
prevNode.next = prevNode.next.next;
}
}
display() {
var currNode = this.head;
while (!(currNode.next == null)) {
console.log(currNode.data);
currNode = currNode.next;
}
}
}测试一下实现的方法
var cities = new LList();
cities.insert("kebi", "head");
cities.insert("yaoming", "kebi");
cities.insert("heyushuo", "yaoming");
cities.display(); //kebi yaoming heyushuo
console.log("-----------");
cities.insert("aaa", "yaoming");
cities.display(); //kebi yaoming aaa heyushuo
cities.remove("aaa");
console.log("-----------");
cities.display(); //kebi yaoming heyushuo双向链表是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
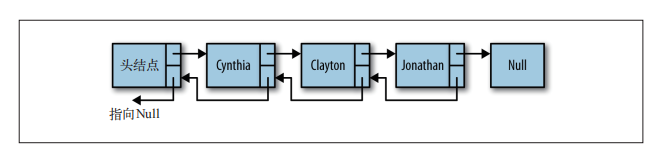
此时向链表插入一个节点需要更多的工作,我们需要指出该节点正确的前驱和后继。但是在从链表中删除节点时,效率提高了,不需要再查找待删除节点的前驱节点了。
循环链表和单向链表相似,节点类型都是一样的。将单链表中尾结点的指针由空指针指向头节点,就使整个单链表形成一个环,这种头尾相接的单链表就简称为循环链表。

双向链表和循环链表就不一一实现了,可以看《JavaScript 数据结构与算法》了解更多
参考
《JavaScript 数据结构与算法》参考
1.ES6 引入 Class(类)这个概念,作为对象的模板。通过 class 关键字,可以定义类。
class Point {
constructor(name, age) {
this.name = name;
this.age = age;
}
toString() {
console.log(this.name + this.age);
}
}
// ES5实现ES6同样的效果
function Point(name, age) {
this.name = name;
this.age = age;
}
Point.prototype.toString = function() {
console.log(this.name + this.age);
};// ES6
class Point {
constructor(x, y) {
// ...
}
toString() {
// ...
}
}
Object.keys(Point.prototype);
//[] 不可枚举的
ES6;
var Point = function(x, y) {
// ...
};
Point.prototype.toString = function() {
// ...
};
Object.keys(Point.prototype);
// ["toString"] 可以枚举的2.constructor 方法
3.类的实例对象
生成类的实例对象的写法,与 ES5 完全一样,也是使用 new 命令
class Point {
// ...
}
// 报错
var point = Point(2, 3);
// 正确
var point = new Point(2, 3);4.Class 表达式
const MyChild = class Child {
toString() {
console.log(Child.name); //name属性总是返回紧跟在class关键字后面的类名。
}
};
//类的名字是MyChild而不是Child,Child只在Class内部代码可用
let mychild = new MyChild();
mychild.toString(); // Child
//如果函数内部用不到Child,也可以省略
const MyChild = class {
// ...
};5.Class 的静态方法
类相当于实例的原型,所有在类中定义的方法,都会被实例继承。如果在一个方法前, 加上 static 关键字,就表示该方法不会被实例继承,而是直接通过类来调用,这就称为“静态方法”。
class Foo {
static className() {
console.log("heyushuo");
}
}
Foo.className(); //heyushuo 不能通过实例调用会报错
// 注意,如果静态方法包含this关键字,这个this指的是类,而不是实例。
class Foo {
static bar() {
this.baz();
}
static baz() {
console.log("hello");
}
baz() {
console.log("world");
}
}
Foo.bar(); // hello
// 1.静态方法bar调用了this.baz,这里的this指的是Foo类,而不是Foo的实例,等同于调用Foo.baz。
// 2.静态方法可以与非静态方法重名。
// 父类的静态方法,可以被子类继承。
class Foo {
static classMethod() {
return "hello";
}
}
class Bar extends Foo {}
Bar.classMethod(); // 'hello'1.Class 可以通过 extends 关键字实现继承,这比 ES5 的通过修改原型链实现继承,要清晰和方便很多。
class Parent {
constructor(name, age) {
this.name = name;
this.age = age;
}
toString() {
console.log("年龄:" + this.age + "姓名:" + this.name);
}
}
class Child extends Parent {
constructor(name, age, height) {
super(name, age); //调用父类的constructor(构造方法)
this.height = height;
}
sayInfo() {
super.toString(); // 调用父类的toString()
console.log(`身高:${this.height}`);
}
}
var person = new Child("heyushuo", 24, 180);
person.sayInfo(); //年龄:24姓名:heyushuo 身高:180父类的静态方法,也会被子类继承。
// 父类的静态方法,也会被子类继承。
class A {
static hello() {
console.log("hello world");
}
}
class B extends A {}
B.hello(); // hello world
// hello()是A类的静态方法,B继承A,也继承了A的静态方法。2.super 关键字
super 关键字,既可以当做函数使用,也可以当做对象使用.
super 作为函数
class A {}
class B extends A {
constructor() {
super();
}
}
// 注意, super虽然代表了父类A的构造函数, 但是返回的是子类B的实例,
//即super内部的this指的是B,因此super() 在这里相当于A.prototype.constructor.call(this)。super 作为对象时
参考:
将值从一种类型转换为另一种类型通常称为类型转换, 在 JavaScript 中通常称为强制类型转换,本书为了跟好理解把强制类型转换分为两种隐式强制类型转换和显式强制类型转换
// 例如:
var a = 42;
var b = a + ''; // "42" 隐式强制类型转换
var c = String(a); //"42" 显式强制类型转换ES5 规范中定义了一些“抽象操作”(即“仅供内部使用的操作”)和转换规则。(ToString``、ToNumber 和 ToBoolean)
2.1 ToString
抽象操作 ToString,它负责处理非字符串到字符串的强制类型转换。
var num = 666;
//极大数字
var infinityNum = 1.07 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000 * 1000;
var obj = {
name: 'kebi',
age: 36
};
var arr = [1, 2, 3];
//null和undefined没有toString() 方法
String(null); //"null"
String(undefined); //"undefined"
String(true); //"true"
num.toString(); //"666"
obj.toString(); //"[object Object]"
infinityNum.toString(); // "1.07e21"
arr.toString(); //1,2,3 数组的默认 toString() 方法经过了重新定义,将所有单元字符串化以后再用 "," 连接起来2.2 ToNumber
有时我们需要将非数字值当作数字来使用,比如数学运算。为此 ES5 规范定义了抽象操作 ToNumber。
// 以下是Number处理基础类型的返回值
Number(false); //0
Number(null); //0
Number(true); //1
Number(undefined); //NAN
//
//
//
//但是对于对象(包括数组) 会首先被转换为相应的基本类型值,如果返回的是非数字的基本类型
值,则再遵循以上规则将其强制转换为数字。
valueOf() 方法。如果有并且返回基本类型值, 就使用该值进行强制类型转换。toString()的返回值( 如果存在) 来进行强制类型转换。valueOf() 和 toString()均不返回基本类型值, 会产生TypeError错误。注从 ES5 开始,使用 Object.create(null) 创建的对象 [[Prototype]] 属性为 null,并且没有 valueOf() 和 toString() 方法,因此无法进行强制类型转换。
var a = {
valueOf: function() {
return '42';
}
};
var b = {
toString: function() {
return '42';
}
};
var c = [4, 2];
c.toString = function() {
return this.join(''); // "42"
};
Number(a); // 42
Number(b); // 42
Number(c); // 42
Number(''); // 0
Number([]); // 0
Number(['abc']); // NaN2.3ToBoolean
JavaScript 中的值可以分为以下两类:
// 以下这些是假值:
Boolean(undefined);
Boolean(null);
Boolean(false);
Boolean(+0);
Boolean(-0);
Boolean(NaN);
Boolean('');
// 除了上边的以外都是真值
// 综上也可以看出以下所有值都是true
Boolean([]);
Boolean({});3.1 字符串和数字之间的显式转换
//第一种方式
var a = 42;
var b = String(a);
var c = '3.14';
var d = Number(c);
b; // "42"
d; // 3.14
// 第二种方式
var a = 42;
var b = a.toString();
var c = '3.14';
var d = +c;
b; // "42"
d; // 3.14toString() 对 42 这样的基本类型值不适用,所以 JavaScript 引擎会自动为 42 创建一个封装对象,然后对该对象调用 toString()。+c 是+ 运算符的一元( unary) 形式( 即只有一个操作数)。+ 运算符显式地将 c 转换为数字, 而非数字加法运算日期显式转换为数字
var d = new Date('Mon, 18 Aug 2014 08:53:06 CDT');
+d; // 1408369986000
// 获取时间戳
var timestamp = +new Date();
// 一些常用的转换为时间戳
new Date().getTime();
Date.now();我们不建议对日期类型使用强制类型转换,应该使用 Date.now() 来获得当前的时间戳,使用 new Date(..).getTime() 来获得指定时间的时间戳。
3.2 显式解析数字字符串
解析字符串中的数字和将字符串强制类型转换为数字的返回结果都是数字。但是解析和强制类型转换两者有明显的区别
var a = '42';
var b = '42px';
Number(a); // 42
parseInt(a); // 42
Number(b); // NaN
parseInt(b); // 42解析允许字符串中含有非数字字符,解析按从左到右的顺序,如果遇到非数字字符就停止。而转换不允许出现非数字字符,否则会失败并返回 NaN
parseInt(..) 针对的是字符串值,非字符串参数会首先被强制类型转换为字符串,应该避免向 parseInt(..) 传递非字符串参数。
3.3 显式转换为布尔值
从非布尔值强制类型转换为布尔值的情况
// 从非布尔值强制类型转换为布尔值的情况
var a = '0';
var b = [];
var c = {};
var d = '';
var e = 0;
var f = null;
var g;
Boolean(a); // true
Boolean(b); // true
Boolean(c); // true
Boolean(d); // false
Boolean(e); // false
Boolean(f); // false
Boolean(g); // false
// 虽然 Boolean(..) 是显式的,但并不常用,常用如下写法
var a = '0';
var b = [];
var c = {};
var d = '';
var e = 0;
var f = null;
var g;
!!a; // true
!!b; // true
!!c; // true
!!d; // false
!!e; // false
!!f; // false
!!g; // false在 if(..).. 这样的布尔值上下文中,如果没有使用 Boolean(..) 和 !!,就会自动隐式地进行 ToBoolean 转换。建议使用 Boolean(..) 和 !! 来进行显式转换以便让代码更清晰易读。
隐式强制类型转换的作用是减少冗余,让代码更简洁,同时会让代码变得晦涩难懂
4.1 字符串和数字之间的隐式强制类型转换
+ 运算符即能用于数字加法,也能用于字符串拼接。如果某个操作数是字符串或者能够通过抽象操作转换为字符串的话,+将进行拼接操作。如果其中一个操作数是对象(包括数组),则首先对其调用抽象操作(toValue、toString)
var a = [1, 2]; //调用toString()得到 "1,2"
var b = [3, 4]; //调用toString()得到 "3,4"
var obj = {
name: 'kebi'
}; //调用toString()得到 "[object Object]"
var num = 12;
var str = '12';
a + b; // "1,23,4"
a + obj; // "1,2[object Object]"
num + str; //"1212"
num + ''; //"12"-减运算符
// 减运算符
var a = '3.14';
var b = a - 0;
b; // 3.14
// - 是数字减法运算符,因此 a - 0 会将 a 强制类型转换为数字。
var a = [3];
var b = [1];
a - b; // 2
//为了执行减法运算,a 和 b 都需要被转换为数字,它们首先被转换为字符串,然后再转换为数字。4.2 布尔值到数字的隐式强制类型转换
true 为 1,false 为 0
4.3 隐式强制类型转换为布尔值
相对布尔值,数字和字符串操作中的隐式强制类型转换还算比较明显。下面的情况会发生布尔值隐式强制类型转换
非布尔值会被隐式强制类型转换为布尔值,例子如下
var a = 42;
var b = 'abc';
var c;
var d = null;
if (a) {
console.log('yep'); // yep
}
while (c) {
console.log('nope, never runs');
}
c = d ? a : b;
c; // "abc"
if ((a && d) || c) {
console.log('yep'); // yep
}&& 和|| 运算符的返回值并不一定是布尔类型,而是两个操作数其中一个的值
var a = 42;
var b = 'abc';
var c = null;
a || b; // 42
a && b; // "abc"
c || b; // "abc"
c && b; // null||来说,如果条件判断结果为 true 就返回第一个操作数(a 和 c)的值,如果为 false 就返回第二个操作数(b)的值。&& 则相反,如果条件判断结果为 true 就返回第二个操作数(b)的值,如果为 false 就返 回第一个操作数(a 和 c)的值。ES6 允许从符号到字符串的显式强制类型转换,然而隐式强制类型转换会产生错误。
var s1 = Symbol('cool');
String(s1); // "Symbol(cool)"
var s2 = Symbol('not cool');
s2 + ''; // TypeError符号不能够被强制类型转换为数字(显式和隐式都会产生错误),但可以被强制类型转换 为布尔值(显式和隐式结果都是 true)。
宽松相等(loose equals)== 和严格相等(strict equals)=== 都用来判断两个值是否“相
等”,常见的误区是“== 检查值是否相等,=== 检查值和类型是否相等”,正确的解释是:“== 允许在相等比较中进行强制类型转换,而 === 不允许。
5.1 字符串和数字之间的相等比较
var a = 42;
var b = '42';
a === b; // false
a == b; // true如果两个值的类型不同,则对其中之一或两者都进行强制类型转换,根据规范,"42" 应该被强制类型转换为数字以便进行相等比较。
5.2 其他类型和布尔类型之间的相等比较
布尔类型会转换为 Number 类型 true 为 1,false 为 0
var a = '42';
var b = true;
a == b; // false (1==42)5.3 null 和 undefined 之间的相等比
null 和 undefined 之间的 == 也涉及隐式强制类型转换。
这也就是说在 == 中 null 和 undefined 是一回事,可以相互进行隐式强制类型转换。
a === undefined || a === null 效果和 a == null
5.4 对象和非对象之间的相等比较
关于对象(对象 / 函数 / 数组)和标量基本类型(字符串 / 数字 / 布尔值)之间的相等比教对象会调用抽象操作(valueOf 或者 toSring),布尔值会先转换为数字
var a = 42;
var b = [42];
a == b; // true1.这种方法并没有使用严格意义上的构造函数,借助原型可以基于已有的对象创建新的对象
function object(o) {
function F() {}
F.prototype = o;
return new F();
}
// 在object()函数内部,先创建一个临时性的构造函数,然后将传入的对象作为这个构造函数原型,最后返回了这个临时类型的一个新实例.
// object()本质上对其中传入的对象进行了一次浅复制
// 看如下的例子:
var person = {
name: "kebi",
friends: ["kuli", "hadeng"]
};
var onePerson = object(person);
onePerson.name = "heyushuo";
onePerson.friends.push("heyushuo");
var twoPerson = object(person);
twoPerson.name = "yaoming";
twoPerson.friends.push("yaoming");
//这里打印
console.log(twoPerson); //['kuli','hadeng','heyushuo','yaoming']缺点: 包含引用类型的属性值始终都会共享相应的值,和原型链继承一样。
2.ES5 通过新增 Object.create()方法规范化了原型式继承,此方法可以接受两个参数,第一个参数最为新对象原型的对象 和一个为新对象定义额外属性的对象.
var person = {
name: "kebi",
friends: ["kuli", "hadeng"]
};
var onePerson = Object.create(person, {
name: "heyushuo"
});
onePerson.friends.push("heyushuo");
var twoPerson = Object.create(person, {
name: "yaoming"
});
twoPerson.friends.push("yaoming");
//这里打印
console.log(twoPerson); //['kuli','hadeng','heyushuo','yaoming']
// 主:在没有必要创建构造函数,而是指向让一个对象与另外一个对象保持类似的情况下,原型式继承完全可以胜任创建一个仅用于封装继承过程的函数,该函数在内部以某种形式来做增强对象,最后返回对象。
function createAnother(original) {
var clone = object(original); // 通过调用 object() 函数创建一个新对象
clone.sayHi = function() {
// 以某种方式来增强对象
console.log("hi");
};
return clone; // 返回这个对象
}
// 函数的主要作用是为构造函数新增属性和方法,以增强函数
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = createAnother(person);
anotherPerson.sayHi(); //"hi"```缺点:
寄生组合式继承, 即通过借用构造函数来继承属性, 在原型上添加共用的方法, 通过寄生式实现继承.
//寄生式继承的基本模式
function inheritPrototype(subType, superType) {
var prototype = Object.create(superType.prototype); // 创建对象,创建父类原型的一个副本
prototype.constructor = subType; // 增强对象,弥补因重写原型而失去的默认的constructor 属性
subType.prototype = prototype; // 指定对象,将新创建的对象赋值给子类的原型
}
// 父类初始化实例属性和原型的属性和方法
function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function() {
console.log(this.name);
};
// 借用构造函数继承构造函数的实例的属性(解决引用类型共享的问题)
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
// 将子类型的原型重写替换成父类的原型
inheritPrototype(SubType, SuperType);
// 对子类添加自己的方法
SubType.prototype.sayAge = function() {
console.log(this.age);
};
var instance1 = new SubType("heyushuo");
var instance2 = new SubType("kebi");
instance1.sayName(); //heyushuo
instance2.sayName(); //kebi
instance1.colors.push("yellow"); // ["red", "blue", "green", "yellow"]
instance1.colors.push("black"); // ["red", "blue", "green", "black"]上边的例子高效的体现了只调用了一次 SuperType 构造函数,并且因此也避免了在 SubType.prototype 上面创建不必要的 多余的属性.与此同时,原型链还能保持不变
在事件被触发 n 秒后再执行回调,如果在这 n 秒内又被触发,则重新计时。
function debounce(func, time) {
var timeout;
return function() {
var _this = this;
var args = arguments;
//清除定时器
clearTimeout(timeout);
timeout = setTimeout(function() {
func.apply(_this, args);
}, time);
};
}
function scrollEvent() {
var scrollTop = document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop; //滚动高度
var viewPortHeight = window.innerHeight || document.documentElement.clientHeight; //可视区的高度
var docHeight = document.documentElement.scrollHeight; //document.documentElement.offsetHeight 整个网页文档的高度
if (scrollTop + viewPortHeight > docHeight - 20) {
console.log('滚动到底部了');
}
}
var optimize = debounce(scrollEvent, 200);
document.addEventListener('scroll', function() {
//停止滚动之后开始计算
optimize();
});规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。
1.时间戳
第一种使用时间戳(第一次会立即执行,在 wait 时间内在执行是无效的)
function throttle(func, wait){
var resulTime = 0;
return function (){
var new = + new Date(); //时间戳
var _this = this;
vat args = arguments;
// now - resulTime只有大于wait才会执行,在wait时间内只执行一次
if(now - resulTime>wait){
func.apply(_this,args);
resulTime = now;
}
}
}2.设置定时器
第二种设置定时器(时间不会立即执行,在 wait 时间后开始执行)
function throttle(func, wait) {
var timeout;
return function() {
var _this = this;
var args = arguments;
if (!timeout) {
timeout = setTimeout(function() {
func.apply(_this, args);
timeout = null;
}, wait);
}
};
}//使用方法
function scrollThrottle() {
console.log('heyushuo');
}
var optimizeThrottle = throttle(scrollThrottle, 3000);
document.addEventListener('scroll', function() {
optimizeThrottle();
});第一种事件会立刻执行, 第二种事件会在 n 秒后第一次执行
手写实现 call、apply 和 bind,首先我们需要了解三个方法的区别,我以前写过一篇文章详细介绍了三者的区别,读完再读本文会更容易理解
实现思路就是这段话所描述的,引用你不知道的 JavaScript 中的一段话当函数引用有上下文对象时,隐式绑定规则会把函数调用中的 this 绑定到这个上下文对象。
Function.prototype.myCall = function(context) {
context = context || window; // 如果context传的是null或者undefined则默认context是window
context.fn = this; //这里this指的是调用myCall的函数;
var args = [...arguments].slice(1); //把arguments伪数组变成数组,在截取除了第一个之后的参数
var result = context.fn(...args); //立即执行函数,执行函数的时候把参数传入
delete context.fn; //把函数删除掉,为了还原外部obj对象,把添加到他上边的属性在删除掉
return result;
};
function ceshi() {
console.log(this.name); //kebi
console.log([...arguments]); //['25']
}
var obj = {
name: 'kebi'
};
ceshi.myCall(obj, '25');apply 第二个参数是数组
Function.prototype.myApply = function(context) {
context = context || window; // 如果context传的是null或者undefined则默认context是window
context.fn = this;
var args = arguments[1]; // 取传参数的第二个参数
var result;
if (args) {
result = context.fn(...args);
} else {
result = context.fn();
}
delete context.fn; //把函数删除掉,为了还原外部obj对象,把添加到他上边的属性在删除掉
return result;
};
function ceshi() {
console.log(this.name); //kebi
console.log([...arguments]); //[1, 2, 3]
}
var obj = {
name: 'kebi'
};
ceshi.myApply(obj, [1, 2, 3]);bind 方法不会立即执行函数,需要我们返回一个函数
Function.prototype.myBind = function(context) {
var _this = this;
var args = [...arguments].slice(1); //把arguments伪数组变成数组,在截取除了第一个之后的参数或者 Array.prototype.slice.call(arguments, 1);
return function() {
//获取执行bind绑定函数返回的函数的参数
var bingArgs = [...arguments];
return _this.apply(context, args.concat(bingArgs));
};
};
function bindFn() {
console.log('姓名:' + this.name + '年龄:' + this.age); //姓名:kebi 年龄:3
console.log([...arguments]); // [[1,2,3],测试]
}
var bindObj = {
name: 'kebi',
age: 35
};
var fun = bindFn.myBind(bindObj, [1, 2, 3], '测试');
fun(); //执行函数bind 实现到这里还是有点问题的,当把 bind 返回的函数当做构造函数,new 的时候 this 的指向就变了,需要了解详细的可以查看下边连接
作用域即定义变量的区域,javascript 是不存在块级作用域的(例如 if 和 for 体现了没有块级作用域),javascript 除了全局作用域之外,只有函数可以创建的作用域。
// 例如:
if (true) {
var name = "kebi";
}
console.log(name); //kebi 此时name是全局作用域,说明没有块级作用域
// ES6的出现 提供了两个定义变量的方式 let/const ,存在块级作用域
// 例如:
if (true) {
const globalName = "kebi";
}
console.log(globalName); //直接报错 is not defined注意:函数创建的作用域在函数定义时就已经确定了。而不是在函数调用时确定。(这是因为 js 采用的是词法作用域或者静态作用域)(这一点非常重要重要举一个例子)
// 例子一:
var name = "kebi";
function foo() {
console.log(name);
}
function bar() {
var name = "heyushuo";
foo();
}
bar(); //这里打印的是 kebi
//在执行bar函数内部的foo()的时候,应为foo是在全局创建的,所以是在全局作用域,此时全局作用域中name=kebi,所以打印出来的是kebi
// 例子二:
var name = "kebi";
function bar() {
var name = "heyushuo";
function foo() {
console.log(name);
}
foo();
}
bar(); //这里打印的是 heyushuo
//在执行bar函数内部的foo()的时候,应为foo是在bar作用域下创建的,所以是在bar作用域下,此时bar作用域中name=heyushuo,所以打印出来的是heyushuo通过一张图片更清晰的看一下作用域
如上图,全局代码和 fn、bar 两个函数都会形成一个作用域。而且,作用域有上下级的关系,上下级关系的确定就看函数是在哪个作用域下创建的。例如,fn 作用域下创建了 bar 函数,那么“fn 作用域”就是“bar 作用域”的上级。 作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突
通过一个例子来看作用域链;
var name = "kebi";
var age = "36";
function foo() {
var sex = "男";
function bar() {
console.log(name);
}
bar();
}
foo(); //执行这个方法
// bar()函数中打印的是什么呢?
// 1.先在bar作用域里查找变量name,不存在
// 2.接着要到创建这个函数的那个作用域中取值——是“创建”,即foo作用域内,发现还是没有
// 3.最后就是向全局作用域去寻找,发现name是kebi,结束,打印 出 kebi
// 这样一步一步的找,直到找到全局作用域为止,这个路线我们称之为作用域链参考:
我们创建每一个函数都有一个 prototype(原型)属性,这个属性是一个指针,指向一个对象.(即 prototype 即为函数的原型该原型指向的是一个原型对象)
1.proto是什么呢?
2. constructor 是什么呢?
通过一张图片和代码展示他们之间的关系
//创建一个构造函数,并在构造函数的原型上添加一个name属性
function Person() {}
Person.prototype.name = "kebi";
var person1 = new Person();
console.log(person1.name); //kebi
var perso2 = new Person();
console.log(person2.name); //kebi
console.log(person.__proto__ === Person.prototype); // true 他两个的关系也是完全相等的
console.log(Person.prototype.constructor == Person); // true
// 顺便学习一个ES5的方法,可以获得对象的原型
console.log(Object.getPrototypeOf(person) === Person.prototype); // true
//b.isPrototypeOf(a) 这个方法的意思是,a对象是否指向b对象
Person.prototype.isPrototypeOf(person1); //true 因为person1中有一个__proto__属相指向原型对象(Person.prototype)
Person.prototype.isPrototypeOf(person2); //true 同理3.总结一下 prototype 和__proto__到底是什么关系呢?
__proto__属性, 可以称之为隐式原型属性(简称: 隐式原型)__proto__属性指向的对象1.原型的搜索机制
function Person() {}
Person.prototype.name = "heyushuo";
var person = new Person();
person.name = "kebi";
console.log(person.name); // kebi
delete person.name;
console.log(person.name); //heyushuo在这个例子中,我们给实例对象 person 添加了 name 属性,当我们打印 person.name 的时候,结果自然为 kebi。
但是当我们删除了 person 的 name 属性时,读取 person.name,从 person 对象中找不到 name 属性就会从 person 的原型也就是 person.__proto__,也就是 Person.prototype 中查找 (原型对象中),幸运的是我们找到了 name 属性,结果为 heyushuo。
但是万一还没有找到呢?原型的原型又是什么呢? ( 肯定需要一环一环地前行到原型链的末端才会停下来)
2.最顶层为默认的原型
所有的函数的默认原型都是 Object 的实例,所以默认原型都会包含一个内部指针,指向 Object.prototype(默认原型的原型对象),这也真是所有自定义类型都会继承 toString()/valueOf 等默认的方法的根本原因.一直查到最顶层才算一个完整的原型链
如图所示: 蓝色线为完整的原型链
二叉树是一种树形结构,树最上面的节点称为根节点,如果一个节点下面连接多个节点,那么该节点称为父节点,它下面的节点称为子节点。二叉树是一种特殊的树,它的子节点个数不超过两个。没有任何子节点的节点称为叶子节点。

二叉搜索树(BST——Binary Search Tree)是二叉树的一种,它规定在左子节点上存储小(比父节点)的值,在右子节点上(比父节点)存储大(或等于)的值。二叉搜索树的数据结构示意图如下:

下面是将要在树类中实现的方法
首先先创建一个二叉搜索树类,二叉树是由节点组成,在创建一个节点类
//节点类
class Node {
constructor(key) {
this.key = key; //节点的值
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor() {
this.root = null;
}
// 向树中插入一个节点
insert(key) {}
// 通过中序遍历方式遍历树中的所有节点
inOrderTraverse() {}
// 通过先序遍历方式遍历树中的所有节点
preOrderTraverse() {}
// 通过后序遍历方式遍历树中的所有节点
postOrderTraverse() {}
// 在树中查找一个节点
search(key) {}
// 返回树中的最小节点
min() {}
// 返回树中的最大节点
max() {}
// 从树中移除一个节点
remove(key) {}
}向树中插入一个节点
insert(key){
let newNode = new Node(key);
if(this.root==null){
this.root = newNode;
}else{
this.insertNode(this.root,newNode);
}
}insertNodeinsertNode(node,newNode){
if(newNode.key<node.key){
//值小于要插入的,那这个插入的在node的左节点
if(node.left===null){
node.left= newNode;
}else{
this.insertNode(node.left,newNode);
}
}else{
if(node.right === null){
node.right = newNode;
}else{
this.insertNode(node.right,newNode)
}
}
}insertNode方法的时候需要传入树的根节点和要插入的节点.insertNode方法,继续找到树的下一层.insertNode方法,继续找到树的下一层.让我们通过一个例子跟好的理解这个过程,目前有一个树结构如下图:

现在我们向这个树结构中插入 6,我们分析一下整个执行过程调用insert(6)方法
insertNode(root,newNode)6<11,说明是在左节点,发现左节点有值,执行insertNode(root.left,newNode)6<7,说明还是在左节点,左节点有值,执行insertNode(root.left.left)6>5,说明在右节点,右节点没有值,所有直接把值插入到此处即可如下是通过图来展示插入的过程

接下来我们来看一下树的三种遍历方式(中序、先序、后序):
中序遍历是一种以上行顺序访问 BST 所有节点的遍历方式,也就是以最小到最大的顺序访问所有节点。中序遍历的一种应用就是对树进行排序操作。
inOrderTraverse(callback){
inOrderTraverseNode(this.root, callback);
}
inOrderTraverseNode(node, callback) {
if (node !== null) {
this.inOrderTraverseNode(node.left, callback);
callback(node.key);
this.inOrderTraverseNode(node.right, callback);
}
};还按上方的树形结构此时执行
inOrderTraverse(function(value) {
console.log(value);
});
//3 5 6 7 8 9 10 11 12 13 14 15 18 20 25访问路径如下图所示:

先序遍历是以优先于后代节点的顺序访问每个节点的(先访问父在访问子)。先序遍历的一种应用是打印一个结构
化的文档。
preOrderTraverse(callback) {
this.preOrderTraverseNode(this.root, callback);
};
preOrderTraverseNode(node, callback) {
if (node !== null) {
callback(node.key); //{1}
this.preOrderTraverseNode(node.left, callback); //{2}
this.preOrderTraverseNode(node.right, callback); //{3}
}
};还按上方的树形结构此时执行
preOrderTraverse(function(value) {
console.log(value);
});
//11 7 5 3 6 9 8 10 15 13 12 14 20 18 25访问路径如下图所示:

后序遍历则是先访问节点的后代节点,再访问节点本身。后序遍历的一种应用是计算一个目
录和它的子目录中所有文件所占空间的大小
postOrderTraverse (callback) {
this. postOrderTraverseNode(this.root, callback);
};
postOrderTraverseNode(node, callback) {
if (node !== null) {
this. postOrderTraverseNode(node.left, callback);
this. postOrderTraverseNode(node.right, callback);
callback(node.key);
}
};还按上方的树形结构此时执行
postOrderTraverse(function(value) {
console.log(value);
});
//3 6 5 8 10 9 7 12 14 13 18 25 20 15 11访问路径如下图所示:

搜索树中的值经常执行的搜索类型有最小值、最大值、搜索特定的值
我们使用下面的树作为例子:
用肉眼直接就能看出最大值和最小值了,接下来用代码实现以下
最小值
min() {
return this.minNode(this.root)
}
minNode(node){
if(node){
while (node&&node.left!=null) {
node = node.left;
}
return node.key;
}
return null
}最大值
// 返回树中的最大节点
max() {
return this.maxNode(this.root)
}
maxNode(node){
if(node){
while (node&&node.right!=null) {
node = node.right
}
return node.key
}
return null
}搜索特定的值
search(key) {
return this.searchNode(root, key);
};
searchNode(node, key) {
if (node === null) {
return false;
}
if (key < node.key) {
return searchNode(node.left, key);
} else if (key > node.key) {
return searchNode(node.right, key);
} else {
return true;
}
};接下来实现最后一个方法移除一个节点
remove(key) {
this.root = this.removeNode(this.root, key);
};
removeNode(node, key) {
if (node === null) {
return null;
}
if (key < node.key) {
node.left = removeNode(node.left, key);
return node;
} else if (key > node.key) {
node.right = removeNode(node.right, key);
return node; //{8}
} else {
//值等于node.key
//第一种情况如果此时没有子节点,直接让node执行null就可以
if (node.left === null && node.right === null) {
node = null;
return node;
}
//第二种情况只有一个子节点的节点,把node指向子节点(相当于node变成子节点)
if (node.left === null) {
node = node.right;
return node;
} else if (node.right === null) {
node = node.left;
return node;
}
//第三种情况——一个有两个子节点的节点
var aux = this.findMinNode(node.right);
node.key = aux.key;
node.right = this.removeNode(node.right, aux.key);
return node;
}
};
findMinNode(node){
if(node){
while (node&&node.left!=null) {
node = node.left;
}
return node;
}
return null
}第一种情况移除没有子节点的节点,直接把这个节点指向 null,就表示移除了.下图展现了移除一个叶节点的过程:

第二种情况移除有一个左侧或右侧子节点的节点,直接把这个节点指向左节点或者右节点.下图展现了移除一个叶节点的过程:

第三种情况移除有两个子节点的节点,这种情况,先找到这个节点右节点以下的最小节点,当前节点和最小节点的值替换,然后再把最小节点删除.下图展现了移除一个叶节点的过程:

完整代码如下:
//节点类
class Node {
constructor(key) {
this.key = key; //节点的值
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor() {
this.root = null;
}
// 向树中插入一个节点
insert(key) {
let newNode = new Node(key);
if (this.root == null) {
this.root = newNode;
} else {
this.insertNode(this.root, newNode);
}
}
//辅助方法
insertNode(node, newNode) {
if (newNode.key < node.key) {
//值小于要插入的,那这个插入的在node的左节点
if (node.left === null) {
node.left = newNode;
} else {
this.insertNode(node.left, newNode);
}
} else {
if (node.right === null) {
node.right = newNode;
} else {
this.insertNode(node.right, newNode);
}
}
}
// 通过中序遍历方式遍历树中的所有节点
inOrderTraverse(callback) {
this.inOrderTraverseNode(this.root, callback);
}
inOrderTraverseNode(node, callback) {
if (node !== null) {
this.inOrderTraverseNode(node.left, callback);
callback(node.key);
this.inOrderTraverseNode(node.right, callback);
}
}
// 通过先序遍历方式遍历树中的所有节点
preOrderTraverse(callback) {
this.preOrderTraverseNode(this.root, callback);
}
preOrderTraverseNode(node, callback) {
if (node !== null) {
callback(node.key); //{1}
this.preOrderTraverseNode(node.left, callback); //{2}
this.preOrderTraverseNode(node.right, callback); //{3}
}
}
// 通过后序遍历方式遍历树中的所有节点
postOrderTraverse(callback) {
this.postOrderTraverseNode(this.root, callback);
}
postOrderTraverseNode(node, callback) {
if (node !== null) {
this.postOrderTraverseNode(node.left, callback);
this.postOrderTraverseNode(node.right, callback);
callback(node.key);
}
}
// 在树中查找一个节点
search(key) {}
// 返回树中的最小节点
min() {
return this.minNode(this.root);
}
minNode(node) {
if (node) {
while (node && node.left != null) {
node = node.left;
}
return node.key;
}
return null;
}
// 返回树中的最大节点
max() {
return this.maxNode(this.root);
}
maxNode(node) {
if (node) {
while (node && node.right != null) {
node = node.right;
}
return node.key;
}
return null;
}
// 从树中移除一个节点
remove(key) {
this.root = this.removeNode(this.root, key);
}
removeNode(node, key) {
if (node === null) {
return null;
}
if (key < node.key) {
node.left = this.removeNode(node.left, key);
return node;
} else if (key > node.key) {
node.right = this.removeNode(node.right, key);
return node; //{8}
} else {
//值等于node.key
//第一种情况如果此时没有子节点,直接让node执行null就可以
if (node.left === null && node.right === null) {
node = null;
return node;
}
//第二种情况只有一个子节点的节点,把node指向子节点(相当于node变成子节点)
if (node.left === null) {
node = node.right;
return node;
} else if (node.right === null) {
node = node.left;
return node;
}
//第三种情况——一个有两个子节点的节点
var aux = this.findMinNode(node.right);
node.key = aux.key;
node.right = this.removeNode(node.right, aux.key);
return node;
}
}
findMinNode(node) {
if (node) {
while (node && node.left != null) {
node = node.left;
}
return node;
}
return null;
}
}栈 是一种遵从先进后出或者说后进先出(LIFO,last-in-first-out)原则的有序集合;由于栈具有先进后出(后进先出)的特点,所以任何不在栈顶的元素都无法访问。为了得到栈底的元
素,必须先拿掉上面的元素。
咖啡厅内的一摞盘子是现实世界中常见的栈的例子。只能从最上面取盘子,盘子洗净后,也只能摞在这一摞盘子的最上面。
在 JavaScript 中数组专门提供了push()和 pop()方法,以便
实现类似栈的行为,接下来咱们使用ES6的class实现一个栈
首先我们需要知道栈常用的几个方法如下
代码实现如下:
class stack {
constructor(){
this.stackArr=[]
}
push(elm){
this.stackArr.push(elm); //向栈中添加一个数据
}
pop(elm){
return this.stackArr.pop(); //把栈顶的元素移除,并返回栈顶元素
}
peek(){
return this.stackArr[this.stackArr.length]; //返回栈顶元素但是不会移除栈顶元素
}
size() {
return this.stackArr.length; // 返回栈的大小
}
clear() {
this.stackArr = []; // 清空栈
}
}接下来使用一下咱们定义的栈
var stack = new Stack();
stack.push(1)
stack.push(3)
console.log(stack.peek()); //3
console.log(stack.size()); //2
console.log(stack.pop()); //3
//使用栈的pop后,返回栈顶元素并移除栈顶元素
console.log(stack.size()); //1通过上边栈的实现我们也发现了,栈不会像数组那样通过索引可以获取到元素,栈提供的方法只允许你操作栈顶的元素,也就是数组的最后一个元素.
1.假设想将数字 n 转换为以 b 为基数的数字,实现转换的算法如下(可以将数字转化为二至九进制的数字)
function mulBase(num, base) {
var s = new Stack();
do {
s.push(num % base) //把第一个余数放入栈中
num = Math.floor(num / base); //拿到接下来需要计算的值
} while (num > 0);
var result = "";
while (s.size() > 0) {
result += s.pop()
}
return result;
}
console.log(mulBase(5, 2)); //1012.回文的判断
平时大家判断回文都会用如下的方法
function isPalindrome(word){
return word.split('').reverse().join('')==word
}接下来咱们使用栈来实现
function isPalindrome(word) {
var s = new Stack();
for (let i = 0; i < word.length; i++) {
s.push(word[i])
}
var result = "";
while (s.size() > 0) {
result += s.pop();
}
// console.log(result);
// console.log(word);
return result == word
}
console.log(isPalindrome('101'));
console.log(isPalindrome('abc'));3.给定一个字符串(([]()[])[]),逐个提取出()/[],并输出出来
解题思路
- 循环字符串把
( 或 [压入栈中- 当不是
( 或 [的时候,和栈中最后一个进行比较
var str = "(([]()[])[])";
var stack = [];
for (let i = 0; i < str.length; i++) {
var item = str[i]
if (item == '(' || item == '[') {
stack.push(item)
} else {
var lastItem = stack[stack.length - 1]
if (countNum(item) + countNum(lastItem) == 0) {
console.log(lastItem + item);
stack.pop(); //抵消之后需要把队列中的删除
} else {
stack.push(item)
}
}
}
//为了方便匹配每个字符,将字符用数字表示
function countNum(chr) {
switch (chr) {
case '(':
return 1;
break;
case ')':
return -1;
break;
case '[':
return 2;
break;
case ']':
return -2;
break;
default:
return 0;
}
}4.判断这段字符串()ss()ss(sss(ss)(ss)ss)里边的括号是否是成对出现的
()ss()ss(sss(ss)(ss)ss) 合法 ()ss()ss(sss(ss)(ss)ss)) 不合法
此题的思路可以用对象的思路,分别在对象中存左括号和右括号的个数,如果相等则正确,或者使用数组两个数组分别保存左括号和右括号,如果两个数组长度相等则正确
下边咱们使用栈来解决这个问题
function isDouuble(str) {
const stack = new Stack();
const len = str.length;
for (let i = 0; i < len; i++) {
const item = str[i];
if (item === "(") {
stack.push(item); // 入栈
} else if (item === ")") {
if (stack.size() === 0) {
return false;
} else {
stack.pop(); // 出栈
}
}
}
return stack.size() === 0;
}参考
《JavaScript 数据结构与算法》
__proto__ 指向 构造函数的原型对象prototype)。//第一个参数传构造函数
function creat() {
//1.创建一个全新对象
var obj = {};
//获取到第一个参数(即为构造函数)
var Con = [].shift().call(arguments);
//2.这个新对象会被执行 [[ 原型 ]] 连接
obj.__proto__ = Con.prototype;
//3.this 绑定
Con.apply(obj, arguments);
//返回这个新对象
return obj;
}集合(set)是一种包含不同元素的数据结构。与数学中的集合概念类似,集合也具有空集(即集合的内容为空)、交集、并集、差集、子集的特性。集合的两个最重要特性是:
其实集合可以看成是一种特殊的数组但是有两点不一样
在 ES6 中,原生的 Set 类已经实现了集合的的大部分方法,直接来用 JS 实现一个集合
使用 JavaSctipt 的对象来实现一个集合
class Set {
constructor() {
this.items = {};
}
add(value) {
// 向集合中添加元素
if (!this.has(value)) {
this.items[value] = value;
return true;
}
return false;
}
delete(value) {
// 从集合中删除对应的元素
if (this.has(value)) {
delete this.items[value];
return true;
}
return false;
}
has(value) {
// 判断给定的元素在集合中是否存在
return this.items.hasOwnProperty(value);
}
clear() {
// 清空集合内容
this.items = {};
}
size() {
// 获取集合的长度
return Object.keys(this.items).length;
}
values() {
// 返回集合中所有元素的内容
return Object.values(this.items);
}
}使用一下实现的集合
var set = new Set();
set.add("a");
set.add("b");
set.add("b");
set.add("b");
set.add("a");
console.log(set.values()); // ['a', 'b']
console.log(set.has("b")); // true
console.log(set.size()); // 2
set.delete("a");
console.log(set.values()); // [ b ]接下来实现以下集合的交集、并集、差集、子集
交集,就是两个集合**有元素的新集合
intersection (item){
let intersectionSet = new Set();
this.values.forEach((value)=>{
if(item.has(value)){
intersectionSet.add(value);
}
})
return intersectionSet;
}并集,就是两个集合的所有元素并去重,集合本省就有去重的功能,所有就是创建一个新集合,把两个集合都添加到新集合中就行
union (item) { // 并集
let unionSet = new Set();
this.values().forEach(value => unionSet.add(value));
item.values().forEach(value => unionSet.add(value));
return unionSet;
}对于给定的两个集合,差集返回一个包含所有存在于第一个集合且不存在于第二个集合的元素的新集合。
difference (item) { // 差集
let differenceSet = new Set();
this.values().forEach(value => {
if (!item.has(value)) differenceSet.add(value);
});
return differenceSet;
}验证一个给定集合是否是另一个集合的子集,需判断给定集合中所有元素是否都存在于另一个集合中,如果是,则这个集合就是另一个集合的子集,反之则不是。
subset (item) { // 子集
//如果当前集合比传的集合size都大,肯定不是传入集合的子集
if (this.size() > item.size()) return false;
//every函数必须都满足才会返回true,否则返回false
return this.values().every(value => {
return item.has(value);
});
}到此集合的全部方法已经实现了
1.概念
在 javascript 中,call 和 apply 都是为了改变某个函数运行时的上下文(context)而存在的,换句话说,就是为了改变函数体内部 this 的指向。
2.区别
call()和 apply()唯一区别在于传参数,apply()接收两个参数,一个是在其运行函数中的作用域,另外一个是参数数组其中,第二参数可以是 Array 的实例,也可以是 arguments 对象,call()第一个参数和 apply()一样,第二个参数必须逐个列举出来,通过代码展示
function sum(num1, num2) {
return num1 + num2;
}
function applySum(num1, num2) {
console.log(arguments);
//此时this对象是全局window对象
return sum.apply(this, arguments);
// 或者
return sum.apply(this, [num1, num2]);
}
console.log(applySum(1, 2));
/**
call()和apply()发放唯一区别在于传参数.call()传参数必须逐个列举出来
*/
function callSum(num1, num2) {
console.log(...arguments);
//此时this对象是全局window对象
return sum.call(this, num1, num2);
// 或者使用ES6的语法
return sum.call(this, ...arguments);
}
console.log(callSum(1, 2));3.传递参数并非 apply 和 call 的真正的用武之地,他们真正强大的地方是能够扩充函数赖以运行的作用域
var o = {
name: "kebi"
};
window.name = "heyushuo";
function sayName() {
console.log(this.name);
}
sayName.call(this); //heyushuo
sayName.call(window); //heyushuo
sayName.call(o); //kebi 此时函数的执行环境不一样了,因为此时函数体内的this对象指向了o,于是结果显示的是'kebi'
//call和apply来扩充作用域的最大好处就是对象不需要与方法有任何耦合关系,4.apply 和 call 的一些*操作
//1.数组合并
var arr1 = [1, 2, 3];
var arr2 = ["heyushuo", "kebi"];
//arr1改变数组的作用域,arr2传的参数
Array.prototype.push.apply(arr1, arr2); //[1,2,3,'heyushuo','kebi']
//或者
arr1.concat(arr2)
// 或者ES6的语法
[...arr1, ...arr2];
//2.数组中的最大值
Math.max.apply(Math,arr1);
//或者es6的语法
Math.max(...arr1);
//3.判断对象的数据类型
//在最原始的对象中进行,不能直接arr1.toString() 或者 o.tosString() 因为对象和数组已经把原始对象的toString()方法进行了修改
Object.prototype.toString.call(arr1); // [object Array]
Object.prototype.toString.call(o)); //[object Object]
//4.可以把伪数组变成真正的数组,例如 arguments / document.getElementsByTagName("span")
Array.prototype.slice.call(document.getElementsByTagName("span"), 0))
//或者使用es6的语法
[...document.getElementsByTagName("span")]解释: bind()和 call,apply 的作用是一样的,bind()这个方法会创建一个函数的实例,该方法可传入两个参数,第一个参数作为 this,第二个及以后的参数则作为函数的参数调用,这个方法和 call,apply 最重要的区别是,绑定 bind()后会创建一个新的函数,并且不会自动执行,需要调用执行
//通过这个例子看一下三者的区别
var o = {
name: "kebi"
};
window.name = "heyushuo";
function sayName() {
console.log(this.name);
}
sayName.call(window); //heyushuo
sayName.call(o); //kebi
sayName.apply(window); //heyushuo
sayName.apply(o); //kebi
//这是bind的用法
var objName = sayName.bind(o); //ie9+
objName(); //kebi高级程序设计三中:闭包是指有权访问另外一个函数作用域中的变量的函数.可以理解为(能够读取其他函数内部变量的函数)
闭包的作用: 正常函数执行完毕后,里面声明的变量被垃圾回收处理掉,但是闭包可以让作用域里的 变量,在函数执行完之后依旧保持没有被垃圾回收处理掉
// 创建闭包最常见的方式函数作为返回值
function foo() {
var name = "kebi";
return function() {
console.log(name);
};
}
var bar = foo();
bar(); //打印kebi --外部函数访问内部变量接下来通过一个实例来感受一下闭包的作用:
接下来实现一个计数器大家肯定会觉得这不是很简单吗
var count = 0;
function add() {
count = count + 1;
console.log(count);
}
add(); //确实实现了需求
//但是如果需要第二个计数器呢?
//难道要如下这样写吗?
var count1 = 0;
function add1() {
count1 = count1 + 1;
console.log(count1);
}
add1(); //确实实现了需求当我们需要更多地时候,这样明显是不现实的,这里我们就需要用到闭包.
function addCount() {
var conut = 0;
return function() {
count = count + 1;
console.log(count);
};
}这里解释一下上边的过程: addCount() 执行的时候, 返回一个函数, 函数是可以创建自己的作用域的, 但是此时返回的这个函数内部需要引用 addCount() 作用域下的变量 count, 因此这个 count 是不能被销毁的.接下来需要几个计数器我们就定义几个变量就可以,并且他们都不会互相影响,每个函数作用域中还会保存 count 变量不被销毁,进行不断的累加
var fun1 = addCount();
fun1(); //1
fun1(); //2
var fun2 = addCount();
fun2(); //1
fun2(); //21. for 循环中打印
for (var i = 0; i < 4; i++) {
setTimeout(function() {
console.log(i);
}, 300);
}上边打印出来的都是 4, 可能部分人会认为打印的是 0,1,2,3
原因:js 执行的时候首先会先执行主线程,异步相关的会存到异步队列里,当主线程执行完毕开始执行异步队列, 主线程执行完毕后,此时 i 的值为 4,说以在执行异步队列的时候,打印出来的都是 4(这里需要大家对 event loop 有所了解(js 的事件循环机制))
如何修改使其正常打印:(使用闭包使其正常打印)
//方法一:
for (var i = 0; i < 4; i++) {
setTimeout(
(function(i) {
return function() {
console.log(i);
};
})(i),
300
);
}
// 或者
for (var i = 0; i < 4; i++) {
setTimeout(
(function() {
var temp = i;
return function() {
console.log(temp);
};
})(),
300
);
}
//这个是通过自执行函数返回一个函数,然后在调用返回的函数去获取自执行函数内部的变量,此为闭包
//方法发二:
for (var i = 0; i < 4; i++) {
(function(i) {
setTimeout(function() {
console.log(i);
}, 300);
})(i);
}
// 大部分都认为方法一和方法二都是闭包,我认为方法一是闭包,而方法二是通过创建一个自执行函数,使变量存在这个自执行函数的作用域里2.真实的获取多个元素并添加点击事件
var op = document.querySelectorAll("p");
for (var j = 0; j < op.length; j++) {
op[j].onclick = function() {
alert(j);
};
}
//alert出来的值是一样的
// 解决办法一:
for (var j = 0; j < op.length; j++) {
(function(j) {
op[j].onclick = function() {
alert(j);
};
})(j);
}
// 解决办法二:
for (var j = 0; j < op.length; j++) {
op[j].onclick = (function(j) {
return function() {
alert(j);
};
})(j);
}
//解决方法三其实和二类似
for (var j = 0; j < op.length; j++) {
op[j].onclick = (function() {
var temp = j;
return function() {
alert(j);
};
})();
}
//这个例子和例子一几乎是一样的大家可以参考例子一3.闭包的缺陷:
通过上边的例子也发现, 闭包会导致内存占用过高,因为变量都没有释放内存
this 关键字在 Javascript 中非常常见,但是很多开发者很难说清它到底指向什么。大部分人会从字面意思上去理解 this,认为 this 指向函数自身,实际上this 是在运行时进行绑定的,并不是在编写时绑定,它的上下文取决于函数调
用时的各种条件。this 的绑定和函数声明的位置没有任何关系,只取决于函数的调用方式。
总结: 函数被调用时发生 this 绑定,this 指向什么完全取决于函数在哪里被调用。
this 一共有 4 中绑定规则,接下来一一介绍每种规则的解释和规则直接的优先级
独立函数调用
function foo() {
console.log(this.a);
}
var a = 2;
foo(); // 2严格模式下:
function foo() {
"use strict";
console.log(this); //undefined
console.log(this.a); //Uncaught TypeError: Cannot read property 'a' of undefined
}
var a = 2;
foo();注意下边两种情况
var age = "18";
var obj = {
name: "heyushuo",
age: 25,
fn: function() {
function sayName() {
console.log(this); //window
console.log(this.age); //undefined
}
sayName();
}
};
obj.fn();函数 sayName 虽然是在 obj.fn 内部定义的,但是它仍然是一个独立函数调用,this 仍然指向 window。
var a = "global";
var obj = {
a: 2,
foo: function() {
console.log(this.a); //global
}
};
var bar = obj.foo; // 函数别名!
bar();虽然 bar 是 obj.foo 的一个引用,但是实际上,它引用的是函数本身,因此此时的
bar() 其实是一个不带任何修饰的独立函数调用,因此应用了默认绑定。
当函数引用有上下文对象时(例如:obj.foo 这个时候使用 obj 上下文来引用函数 foo),隐式绑定规则会把函数中的 this 绑定到这个上下文对象。
var obj = {
name: "heyushuo,
foo: function() {
console.log(this.name); //heyushuo
}
};
obj.foo();对象属性引用链中只有上一层或者说最后一层在调用中起作用。
var obj = {
name: "heyushuo",
obj1: {
name: "kebi",
foo: function() {
console.log(this.name); // kebi
}
}
};
obj.obj1.foo();隐式丢失
被隐式绑定的函数会丢失绑定对象,而应用默认绑定,把 this 绑定到全局对象或者 undefined(严格模式) 上。
第一种
var a = "global";
var obj = {
a: 2,
foo: function() {
console.log(this.a); //global
}
};
var bar = obj.foo; // 函数别名!
bar();虽然 bar 是 obj.foo 的一个引用,但是实际上,它引用的是函数本身,因此此时的
bar() 其实是一个不带任何修饰的独立函数调用,因此应用了默认绑定。
第二种传入回调函数时:
var a = "global";
var obj = {
a: 2,
foo: function() {
console.log(this.a); //global
}
};
var bar = obj.foo; // 函数别名!
function doFoo(fn) {
fn(); // <-- 调用位置!
}
doFoo(bar); //global
//和下边这种一样
setTimeout(obj.foo, 300);通过 call() 或者 apply()方法。第一个参数是一个对象,在调用函数时将这个对象绑定到 this 上,称之为显示绑定。
function foo() {
console.log(this.a);
}
var obj = {
a: 2
};
foo.call(obj); // 2显示绑定引申出来一个硬绑定,代码如下
function foo(something) {
console.log(this.a, something);
return this.a + something;
}
// 简单的辅助绑定函数
function bind(fn, obj) {
return function() {
return fn.apply(obj, arguments); //内部已经强制绑定了传入函数this的指向
};
}
var obj = {
a: 2
};
var bar = bind(foo, obj);
var b = bar(3); // 2 3
console.log(b); // 5bar 函数无论如何调用,它总会手动在 obj 上调用 fn,强制把 fn 的 this 绑定到了 obj。这样也解决前面提到的丢失绑定问题
由于硬绑定是一种非常常用的模式,所以在 ES5 中提供了内置的方法 Function.prototype.bind
function foo(something) {
console.log(this.a, something);
return this.a + something;
}
var obj = {
a: 2
};
var bar = foo.bind(obj);
var b = bar(3); // 2 3
console.log(b); // 5使用 new 来调用函数,或者说发生构造函数调用时,会自动执行下面的操作。
例如:
function foo() {
this.name = "heyushuo";
this.age = 25;
}
foo.prototype.sayName = function() {
console.log(this.name + this.age);
};
var bar = new foo();
console.log(bar); //{name: "heyushuo", age: 25}
//这个新对象会绑定到函数调用的 this。所以此时的this就是bar对象
console.log(bar.age); // 25如下图是 new foo() 这个对象
判断 this,可以按照下面的顺序来进行判断:
var bar = new foo();var bar = foo.call(obj2);var bar = obj1.foo();var bar = foo();把 null 或者 undefined 作为 this 的绑定对象传入 call、apply 或者 bind,这些值在调用时会被忽略,实际应用的是默认规则。(this 指向 window)
例如:
function foo() {
console.log(this.a);
}
var a = 2;
foo.call(null); // 2下面两种情况下会传入 null
使用 apply(..)来“展开”一个数组,并当作参数传入一个函数
bind(..)可以对参数进行柯里化(预先设置一些参数)
function foo(a, b) {
console.log("a:" + a + ", b:" + b);
}
// 把数组“展开”成参数
foo.apply(null, [2, 3]); // a:2, b:3
// 使用 bind(..) 进行柯里化
var bar = foo.bind(null, 2);
bar(3); // a:2, b:3这两种方法都需要传入一个参数当作 this 的绑定对象。如果函数并不关心 this 的话,你仍然需要传入一个占位值,这时 null 可能是一个不错的选择(更安全的做法就是传入一个特殊的对象(空对象),把 this 绑定到这个对象不会对你的程序产生任何副作用。JS 中创建一个空对象最简单的方法是**Object.create(null)**,这个和{}很像,但是并不会创建 Object.prototype 这个委托,所以比{}更空。)
以上四条规则已经可以包含所有正常的函数。但是 ES6 中介绍了一种无法使用这些规则的特殊函数类型:箭头函数。
箭头函数不使用this 的四种标准规则,而是根据外层(函数或者全局)作用域来决定 this。
看一下下边这个例子:
function foo() {
// 返回一个箭头函数
return a => {
//this 继承自 foo()
console.log(this.a);
};
}
var obj1 = {
a: 2
};
var obj2 = {
a: 3
};
var bar = foo.call(obj1);
bar.call(obj2); // 2, 不是 3 !foo() 内部创建的箭头函数会捕获调用时 foo() 的 this。由于 foo() 的 this 绑定到 obj1,bar(引用箭头函数)的 this 也会绑定到 obj1,箭头函数的绑定无法被修改。
箭头函数最常用于回调函数中,例如事件处理器或者定时器:
function foo() {
setTimeout(() => {
// 这里的 this 在此法上继承自 foo()
console.log(this.a);
}, 100);
}
var obj = {
a: 2
};
foo.call(obj); // 2在 ES6 之前我们就已经在使用一种几乎和箭头函数完全一样的模式。
function foo() {
var self = this; // lexical capture of this
setTimeout(function() {
console.log(self.a);
}, 100);
}
var obj = {
a: 2
};
foo.call(obj); // 2var name = "heyushuo";
function foo() {
var name = "kebi";
this.name = "yaoming";
console.log(name);
}
foo();var name = "heyushuo";
function foo() {
this.name = "kebi";
console.log(name);
}
foo();var name = "heyushuo";
function foo() {
this.name = "kebi";
}
foo.prototype.sayName = function() {
console.log(name);
};
var bar = new foo();
bar.sayName();var name = "heyushuo";
setInterval(function() {
var name = "kebi";
console.log(this.name);
}, 100);答案:
var name = "heyushuo";
var obj = {
name: "kebi",
sayName: () => {
console.log(this.name);
}
};
obj.sayName();var name = "heyushuo";
var obj = {
name: "kebi",
sayName: function {
setTimeout(function(){
console.log(this.name);
}, 100);
}
};
obj.sayName();var name = "heyushuo";
var obj = {
name: "kebi",
sayName: function {
setTimeout(()=>{
console.log(this.name);
}, 100);
}
};
obj.sayName();var name = "heyushuo";
var obj = {
name: "kebi",
sayName: function {
return function(){
console.log(this.name);
}
}
};
obj.sayName()();var name = "heyushuo";
var obj = {
name: "kebi",
sayName: function {
return ()=>{
console.log(this.name);
}
}
};
obj.sayName()();答案:
var name = "kebi";
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.sayName = function() {
this.sayAge();
console.log(this.name);
};
Person.prototype.sayAge = function() {
console.log(this.age);
};
var person = new Person("heyushuo", 25);
person.sayName();var name = "kebi";
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.sayName = function() {
setTimeout(function() {
console.log(this.name);
}, 100);
};
var person = new Person("heyushuo", 25);
person.sayName();var name = "kebi";
function Person(name, age) {
this.name = name;
this.age = age;
}
Person.prototype.sayName = function() {
setTimeout(() => {
console.log(this.name);
}, 100);
};
var person = new Person("heyushuo", 25);
person.sayName();答案:
1.执行上下文
当执行一段代码的时候, JavaScript 引擎会首先进入一个准备阶段, 准备阶段结束后才会进入代码执行阶段, 我们称这个准备阶段为
执行上下文, 执行上下文包含了三种全局执行环境,函数体执行环境,eval 代码(不清楚)
举个例子:
var name = "科比"; //全局执行上下文
function sayName() { //当调用sayName()的时候会产生 函数执行上下文
console.log(naem);
}谈到执行上下文需提到另外一个概念就是变量对象
2.变量对象
高级程序设计三中对变量对象的描述:
每个执行环境(执行上下文)都有一个与之关联的变量对象,执行环境(执行上下文)中定义的
所有变量和函数都保存在这个对象中.
这个变量对象都包含写什么呢?
当进入执行上下文时, 这时候还没有执行代码, 变量对象会包括:
下边例子来解释一下上边所说的
function foo(a) {
var b = 2;
function c() {}
var d = function () {};
b = 3;
}
foo(1);
// 在进入执行上下文的时候
// 此时变量对象都包含如下内容
{
arguments: { //函数的参数对象
0: 1,
length: 1
},
a: 1, //传的参数
b: undefined, //定义的变量
c: function c() {}, //函数声明
d: undefined // 函数表达式
}如果函数声明和变量声明名字重复了会怎么操作呢?
// 例如:
console.log(foo);
function foo() {
console.log("foo");
}
var foo = 1;
// 会打印函数,而不是 undefined 。这是因为在进入执行上下文时,首先会处理函数声明,其次会处理变量声明,
如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性。
给执行上下文环境下一个通俗的定义——在执行代码之前,把将要用到的所有的变量都事先拿出来,有的直接赋值了,有的先用 undefined 占个空。
这里需要提到另外一个概念: 执行上下文栈
执行上下文栈用来管理执行上下下文
例子:
var name = "科比"; //全局执行上下文
function sayName() {
console.log(this.name);
}
sayName();首先栈里会存入 全局上下文, 函数调用会存入函数执行上下文, 执行完代码后, 函数的执行上下文会被销毁
需要了解执行栈详细信息的可以参考:https://www.cnblogs.com/wangfupeng1988/p/3989357.html
参考:
大家平时开发项目,请求后台接口,肯定分为了测试域名下的接口和正式域名下的接口,当项目提测的时候我们打包需要把请求接口修改为测试的域名,当项目要上线的时候又需要改为线上的域名,如果有的时候出现线上需要修改东西,本地修改好了还得先改为测试,测试通过,再给为线上进行发布,相当繁琐,所以我们需要进行一些配置摆脱繁琐.(本文主要以 vue 脚手架的环境进行讲解如何配置)
官网解释: process 对象是一个全局变量,提供 Node.js 进程的有关信息以及控制进程。 因为是全局变量,所以无需使用 require()。
官网解释:process.env 返回用户的环境信息
具体返回那些信息呢?,我在本地创建了一个 index.js,在内部直接打印 process.env,直接用 node 运行这个 index.js 打印如下所示,我只是截取了部分信息
{
COMMONPROGRAMFILES: 'C:\\Program Files\\Common Files',
CommonProgramW6432: 'C:\\Program Files\\Common Files',
COMPUTERNAME: 'HEYUSHUO',
COMSPEC: 'C:\\Windows\\system32\\cmd.exe',
CONFIG_SITE: '/mingw64/etc/config.site',
DISPLAY: 'needs-to-be-defined',
EXEPATH: 'D:\\Git',
FP_NO_HOST_CHECK: 'NO',
HOMEDRIVE: 'C:',
HOSTNAME: 'heyushuo',
INFOPATH: '/usr/local/info:/usr/share/info:/usr/info:/share/info',
JAVA_HOME: 'D:\\JDK\\jdk',
LANG: 'zh_CN.UTF-8@cjknarrow',
LOGONSERVER: '\\\\MicrosoftAccount',
MINGW_CHOST: 'x86_64-w64-mingw32',
MINGW_PACKAGE_PREFIX: 'mingw-w64-x86_64',
MINGW_PREFIX: '/mingw64',
MSYSTEM: 'MINGW64',
MSYSTEM_CARCH: 'x86_64',
MSYSTEM_CHOST: 'x86_64-w64-mingw32',
MSYSTEM_PREFIX: '/mingw64',
NUMBER_OF_PROCESSORS: '4',
ORIGINAL_TEMP: '/tmp',
ORIGINAL_TMP: '/tmp',
OS: 'Windows_NT',
PLINK_PROTOCOL: 'ssh',
}我们在 vue 脚手架的 webpack 配置里或者在一些 node 开发的项目中经常看到如下代码
process.env.NODE_ENV;
从字面上看(node environment)意思为环境变量,这个变量可以判断当前处于开发环境还是生产环境,这对与是否打印日志或一些警告很有用,在 webpack 配置中通过这个字段来进行不同的打包操作
如下是设置方式:

这样就把 NODE_ENV 属性注入到了 process.env 对象上,并且值为 production,以上我们所说的都是必须在 node 环境下才可以访问到,同样的 vue 脚手架中的任何配置文件中都可以去访问,但是在 web 端的 js 中,以及时 vue 的项目中是访问不到的,这里咱们需要在项目中方问到这个变量来区分开发生成使用不同的接口域名,那如何在项目中能访问到呢?

这个的作用是什么呢?在 node 环境中我们可以使用 process.env.NODE_ENV 来区分不同的环境,但是现在我们同样需要在 web 端也能区分出不同的环境这个时候就需要用 wbepack 这个插件
//我们这样设置之后
new webpack.DefinePlugin({
"process.env": {
NODE_ENV: "production"
}
});
//在我们web项目正常的js文件中可以直接进行判断
if (process.env.NODE_ENV == "production") {
//开发环境
}接下来,在 vue 脚手架的基础上我们来进行修改
在 vue 脚手架的 build 文件夹下 webpack.dev.conf.js 和 webpack.prod.conf.js 两个文件中,我们可以看到脚手架配置中已经默认帮我们配置了 DefinePlugin 插件
//webpack.dev.conf.js 开发环境
new webpack.DefinePlugin({
"process.env": require("../config/dev.env") //引用的是config下的文件
});
//webpack.prod.conf.js 生成环境
new webpack.DefinePlugin({
"process.env": require("../config/prod.env") //引用的是config下的文件
});
这两个文件里的内容大致表达的就是如下的意思
//dev.env.js 开发环境
module.exports = {
NODE_ENV: '"development"'
};
//prod.env.js 生产环境
module.exports = {
NODE_ENV: '"production"'
};现在开发环境咱们可以不用动,现在需要区分生产环境中的(即打包时候需要区分是测试打包还是正式打包)
正常打包咱们都是执行
//package.json
"build": "node build/build.js",
//执行命令
npm run build现在为了区分这两种方式咱们在 package.json 里在增加一个打包方式
//package.json
"test": "node build/build.js",
//执行命令
npm run test修改如下图:

现在最关键的一步到了,我们要在 prod.env.js 文件中去区分这两种打包方式
npm 提供一个 npm_lifecycle_event 变量,返回当前正在运行的脚本名称,比如 pretest、test、posttest 等等。所以可以利用这个变量,来区分是 build 打包的还是 test 打包的;
在上边已经说过了在 node 环境下 process.env 可以提供用的环境信息,此时就可以在 process.env.npm_lifecycle_event 拿到当前执行的那个脚本名称
所以 prod.env.js 文件中的代码我们可以这样按如下的方式写
const target = process.env.npm_lifecycle_event;
if (target == "test") {
var obj = {
NODE_ENV: '"test"'
};
} else {
var obj = {
NODE_ENV: '"production"'
};
}
module.exports = obj;在自己的 web 项目中我们就可以按如下去判断不同的请求地址了
if (process.env.NODE_ENV == "test" || process.env.NODE_ENV == "development") {
var host = "测试域名";
} else if (process.env.NODE_ENV == "production") {
var host = "正式域名";
} else {
//开发环境
// 一般情况下开发环境和测试情况下的域名是相同的;
}以上就是对 process.env.NODE_ENV 以及 webpack 的 DefinePlugin 的两个的含义和区别,和对 vue 脚手架的设置
webpack.DefinePlugin 是为了让 web 端同样可以达到 node 环境中的 process.env.NODE_ENV 的效果
如有问题请指出
cnpm i -D webpack@latest webpack-cli@latest然后运行 npm run dev 运行之后报错
Error: Cannot find module 'webpack/bin/config-yargs'
at Function.Module._resolveFilename (internal/modules/cjs/loader.js:636:15)
at Function.Module._load (internal/modules/cjs/loader.js:562:25)
at Module.require (internal/modules/cjs/loader.js:692:17)
at require (internal/modules/cjs/helpers.js:25:18)
at Object.<anonymous> (E:\project\heyushuo-cli\node_modules\_webpack-dev-server@2.11.5@webpack-dev-server\bin\webpack-dev-server.js:54:1)通过报错大概知道是webpack-dev-server版本不匹配所以升级版本
cnpm i -D webpack-dev-server@latest:\project\heyushuo-cli\node_modules\_html-webpack-plugin@2.30.1@html-webpack-plugin\lib\compiler.js:81
var outputName = compilation.mainTemplate.applyPluginsWaterfall('asset-path', outputOptions.filename, {
^
TypeError: compilation.mainTemplate.applyPluginsWaterfall is not a function
at E:\project\heyushuo-cli\node_modules\_html-webpack-plugin@2.30.1@html-webpack-plugin\lib\compiler.js:81:51
at compile (E:\project\heyushuo-cli\node_modules\_webpack@4.43.0@webpack\lib\Compiler.js:343:11)
at hooks.afterCompile.callAsync.err (E:\project\heyushuo-cli\node_modules\_webpack@4.43.0@webpack\lib\Compiler.js:681:15)从报错中可以看出是html-webpack-plugin插件中的某些函数报错了,接着升级到最新版本
cnpm i -D html-webpack-plugin@latestModule build failed (from ./node_modules/_eslint-loader@1.9.0@eslint-loader/index.js):
TypeError: Cannot read property 'eslint' of undefined
at Object.module.exports (E:\project\heyushuo-cli\node_modules\_eslint-loader@1.9.0@eslint-loader\index.js:148:18)可以看出是eslint报错的原因,接着升级,把package.json中所有和eslint相关的都升级一下
cnpm i D eslint@latest eslint-config-standard@latest eslint-friendly-formatter@latest eslint-loader@latest eslint-plugin-import@latest eslint-plugin-node@latest eslint-plugin-promise@latest eslint-plugin-standard@latest eslint-plugin-vue@latest eslint-plugin-html@latestModule build failed (from ./node_modules/_vue-loader@13.7.3@vue-loader/index.js):
TypeError: Cannot read property 'vue' of undefined
at Object.module.exports (E:\project\heyushuo-cli\node_modules\_vue-loader@13.7.3@vue-loader\lib\loader.js:61:18)可以看出是vue-loader报错的原因(顺便把和vue相关的都进行升级),接着升级到最新版本
cnpm i D vue-loader@latest vue-style-loader@latest vue-template-compiler@latestModule Error (from ./node_modules/_vue-loader@15.9.2@vue-loader/lib/index.js):
vue-loader was used without the corresponding plugin. Make sure to include VueLoaderPlugin in your webpack config.报错可以看出Make sure to include VueLoaderPlugin in your webpack config需要修改webpack配置如下
//分别在webpack.base.conf.js中添加VueLoaderPlugin
const { VueLoaderPlugin } = require('vue-loader')
plugins:[
new VueLoaderPlugin()
]Error: webpack.optimize.CommonsChunkPlugin has been removed, please use config.optimization.splitChunks instead.
at Object.get [as CommonsChunkPlugin] (E:\project\heyushuo-cli\node_modules\_webpack@4.43.0@webpack\lib\webpack.js:189:10)由于webpack4 移除了 CommonsChunkPlugin,所以需要在配置上做一些修改。去除webpack.prod.conf.js中与 CommonsChunkPlugin,webpack4中使用optimization替换掉了CommonsChunkPlugin
// split vendor js into its own file
// new webpack.optimize.CommonsChunkPlugin({
// name: 'vendor',
// minChunks(module) {
// // any required modules inside node_modules are extracted to vendor
// return (
// module.resource &&
// /\.js$/.test(module.resource) &&
// module.resource.indexOf(
// path.join(__dirname, '../node_modules')
// ) === 0
// )
// }
// }),
// // extract webpack runtime and module manifest to its own file in order to
// // prevent vendor hash from being updated whenever app bundle is updated
// new webpack.optimize.CommonsChunkPlugin({
// name: 'manifest',
// minChunks: Infinity
// }),
// // This instance extracts shared chunks from code splitted chunks and bundles them
// // in a separate chunk, similar to the vendor chunk
// // see: https://webpack.js.org/plugins/commons-chunk-plugin/#extra-async-commons-chunk
// new webpack.optimize.CommonsChunkPlugin({
// name: 'app',
// async: 'vendor-async',
// children: true,
// minChunks: 3
// }),optimization默认使用''压缩代码性能要比UglifyJsPlugin好,所以直接把vue-cli中使用`UglifyJsPlugin'地方去掉就可以了
Error: Chunk.entrypoints: Use Chunks.groupsIterable and filter by instanceof Entrypoint instead
at Chunk.get (E:\project\heyushuo-cli\node_modules\_webpack@4.43.0@webpack\lib\Chunk.js:866:9)
at E:\project\heyushuo-cli\node_modules\_extract-text-webpack-plugin@3.0.2@extract-text-webpack-plugin\dist\index.js:176:48
at Array.forEach (<anonymous>)
at E:\project\heyushuo-cli\node_modules\[email protected]@extract-text-webpack-plugin\dist\index.js:171:18由报错可以看出是ExtractTextWebpackPlugin 插件的问题,通过查看官网有这样一句话
⚠️ Since webpack v4 the extract-text-webpack-plugin should not be used for css. Use mini-css-extract-plugin instead.
webpack4中不能使用extract-text-webpack-plugin来提取css,需要使用mini-css-extract-plugin插件
cnpm i D mini-css-extract-plugin修改webpack.prod.conf中的内容如下
// webpack4不支持extrack-text-webpack-plugin 用在css上
// const ExtractTextPlugin = require('extract-text-webpack-plugin')
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
new MiniCssExtractPlugin({
filename: utils.assetsPath('css/[name].[contenthash:8].css'),
chunkFilename: utils.assetsPath('css/[name].[contenthash:8].css')
})修改build/utils.js中的内用如下
// const ExtractTextPlugin = require('extract-text-webpack-plugin')
const MiniCssExtractPlugin = require('mini-css-extract-plugin')
if (options.extract) {
//webpack4已经不支持了
// return ExtractTextPlugin.extract({
// use: loaders,
// fallback: 'vue-style-loader'
// })
return [MiniCssExtractPlugin.loader].concat(loaders)
} else {
return ['vue-style-loader'].concat(loaders)
}building for production...Unhandled rejection Error: "dependency" is not a valid chunk sort mode
at HtmlWebpackPlugin.sortEntryChunks (E:\project\heyushuo-cli\node_modules\_html-webpack-plugin@4.3.0@html-webpack-plugin\index.js:472:11)通过全局搜索"dependency" 在``
new HtmlWebpackPlugin({
filename: process.env.NODE_ENV === 'testing' ?
'index.html' : config.build.index,
template: 'index.html',
inject: true,
minify: {
removeComments: true,
collapseWhitespace: true,
removeAttributeQuotes: true
// more options:
// https://github.com/kangax/html-minifier#options-quick-reference
},
// necessary to consistently work with multiple chunks via CommonsChunkPlugin
chunksSortMode: 'dependency'
}),通过官网查看 chunksSortMode可使用的值如下,控制插入html的js的顺序的,manual手动排序,将chunks按引入的顺序排序['vender','main']
chunksSortMode:
Allows to control how chunks should be sorted before they are included to the HTML. Allowed values are 'none' | 'auto' | 'manual' | {Function}
webpack4新增了mode字段,在开发环境加上mode:'development' 生产环境添加mode: 'production',默认会添加很多默认配置和优化(包括代码分割),具体默认配置可以查看链接,分别在webpack.dev.conf.js和webpack.prod.conf.js文件做修改
const devWebpackConfig = merge(baseWebpackConfig, {
mode: 'development'
}在开发环境加上mode:'development'
会将 DefinePlugin 中 process.env.NODE_ENV 的值设置为 development。启用 NamedChunksPlugin 和 NamedModulesPlugin。可以把vue-cli中的这两个插件注释掉
// new webpack.DefinePlugin({
// 'process.env': require('../config/dev.env')
// }),
// new webpack.NamedModulesPlugin(),开启mode: 'development'相当于开启如下默认配置和优化
module.exports = {
+ mode: 'development'
- devtool: 'eval',
- cache: true,
- performance: {
- hints: false
- },
- output: {
- pathinfo: true
- },
- optimization: {
- namedModules: true,
- namedChunks: true,
- nodeEnv: 'development',
- flagIncludedChunks: false,
- occurrenceOrder: false,
- sideEffects: false,
- usedExports: false,
- concatenateModules: false,
- splitChunks: {
- hidePathInfo: false,
- minSize: 10000,
- maxAsyncRequests: Infinity,
- maxInitialRequests: Infinity,
- },
- noEmitOnErrors: false,
- checkWasmTypes: false,
- minimize: false,
- },
- plugins: [
- new webpack.NamedModulesPlugin(),
- new webpack.NamedChunksPlugin(),
- new webpack.DefinePlugin({ "process.env.NODE_ENV": JSON.stringify("development") }),
- ]
}开启mode: 'production '相当于开启如下默认配置和优化,可以把vue-cli中相应的地方注释掉
// webpack.production.config.js
module.exports = {
+ mode: 'production',
- performance: {
- hints: 'warning'
- },
- output: {
- pathinfo: false
- },
- optimization: {
- namedModules: false,
- namedChunks: false,
- nodeEnv: 'production',
- flagIncludedChunks: true,
- occurrenceOrder: true,
- sideEffects: true,
- usedExports: true,
- concatenateModules: true,
- splitChunks: {
- hidePathInfo: true,
- minSize: 30000,
- maxAsyncRequests: 5,
- maxInitialRequests: 3,
- },
- noEmitOnErrors: true,
- checkWasmTypes: true,
- minimize: true,
- },
- plugins: [
- new TerserPlugin(/* ... */),
- new webpack.DefinePlugin({ "process.env.NODE_ENV": JSON.stringify("production") }),
- new webpack.optimize.ModuleConcatenationPlugin(),
- new webpack.NoEmitOnErrorsPlugin()
- ]
}- building for production...(node:7012) DeprecationWarning: Tapable.plugin is deprecated. Use new API on `.hooks` instead
Hash: a38a1834a1cb2ff61367
Version: webpack 4.43.0犹豫新版本的webpack的hook做了修改,替换了新的api,所以尽量把所有得loader或者plugin都做一个升级
如下是我的项目中的一些loader
cnpm i D css-loader@latest url-loader@latest postcss-loader@latest file-loader@latest vue-style-loader@latest vue-template-compiler@latest如下是一些项目中用的plugin
cnpm i D optimize-css-assets-webpack-plugin@latest copy-webpack-plugin@latest friendly-errors-webpack-plugin@latest 都升级一遍后继续 npm run dev ,擦直接报错了如下
plugins: [new VueLoaderPlugin()],
TypeError: VueLoaderPlugin is not a constructor在Vueloader的官网查到了,点击查看具体
// webpack.config.js
const VueLoaderPlugin = require('vue-loader/lib/plugin')
plugins: [
// 请确保引入这个插件!
new VueLoaderPlugin()
]到此终于完成升级了
其实在跟新的时候还会遇到各种问题,需要自己来判断解决
"babel-core": "^6.22.1",
"babel-eslint": "^8.2.1",
"babel-helper-vue-jsx-merge-props": "^2.0.3",
"babel-loader": "^7.1.5",
"babel-plugin-syntax-jsx": "^6.18.0",
"babel-plugin-transform-runtime": "^6.22.0",
"babel-plugin-transform-vue-jsx": "^3.5.0",
"babel-preset-env": "^1.3.2",
"babel-preset-stage-2": "^6.22.0",
"babel-register": "^6.26.0","@babel/core"
"@babel/preset-env"
"@babel/polyfill"
cnpm install --save core-js@3babel6使用如下几个插件支持 jsx
"babel-plugin-syntax-jsx": "^6.18.0",
"babel-plugin-transform-vue-jsx": "^3.5.0",
"babel-helper-vue-jsx-merge-props": "^2.0.3",
babel7替换成了如下插件
@vue/babel-plugin-transform-vue-jsx
因为使用了@babel/preset-env设置polyfill按需引用了,就不用如下方式了,下边的方式有自己优势,也有自己的缺点
cnpm install --save-dev @babel/plugin-transform-runtime
cnpm install --save @babel/runtime
babel7去掉了stage-x这个功能,如果需要使用在提案中的功能需要自己单独引入.例如如下插件(使用import(),跟好的使用Es6的class)
@babel/plugin-syntax-dynamic-import
@babel/plugin-proposal-class-properties
栈是后进先出(LIFO),队列是先进先出(FIFO),接下用两个队列去实现一个栈,主要实现 push 和 pop 操作,再用用两个栈实现一个队列,主要实现栈的 enqueue 和 dequeue.
解题思路
- 给两个栈分别命名 stack1,和 stack2,一个用来储存数据(stack1),一个用来操作(stack2).
- stack1 实现队列的 enqueue 方法,直接调用 push 方法把数据添加到栈中
- dequeue 方法是从队列的头部删除元素,然而此时 stack1 的的头部在栈的底部,是无法直接删除栈底的元素的
- 这个时候可以使用 stack2 了,把 stack1 的数据依次移除并压入 stack2 栈中,这样的话,stack2 的栈顶就变成队列的头部元素了,可以直接调用 stack2 的 pop 方法移除元素了
当 stack1 和 stack2 都空的时候,队列中就没有元素了
当 stack1 有元素,stack2 没有元素的时候,把 stack1 的数据移除压入 stack2 中
这里咱们直接用数组当成栈,不做封装
class Queue {
constructor() {
this.stack1 = [];
this.stack2 = [];
}
initStack() {
var length1 = this.stack1.length;
var length2 = this.stack2.length;
if (length1 == 0 && length2 == 0) {
//此时两个栈都是空的了
return "";
}
//如果stack2是空的
if (length2 == 0) {
// 需要把stack1压栈到stack2中
while (this.stack1.length != 0) {
this.stack2.push(this.stack1.pop());
}
}
}
// 向队尾添加一个元素
enqueue(item) {
this.stack1.push(item); // 把数据存入到stack1中
}
// 删除队首的一个元素
dequeue() {
//删除的先把stack1中的数据添加到stack2中
this.initStack();
return this.stack2.pop();
}
}
var que = new Queue();
que.enqueue("a");
que.enqueue("b");
que.enqueue("c");
console.log(que); //Queue { stack1: [ 'a', 'b', 'c' ], stack2: [] }
que.dequeue();
console.log(que); //Queue { stack1: [], stack2: [ 'c', 'b' ] }解题思路
- 给两个队列分别命名 queue1,和 queue2.
- queue1 实现栈的 push 方法,直接调用 push 方法把数据添加到栈中即可
- pop 方法是从栈的顶部删除元素,然而此时 queue1 的的顶部是无法直接删除的需要从队列头部开始删除
- 可以通过把 queue1 通过 dequeue 方法,把元素放入到 queue2,直到 queue1 队列中只剩一下一个元素,这个时候再把 queue2 中的元素全部放回 queue1 中,然后在执行 queue1 的 dequeue 方法即可把元素输出
class Stack {
constructor() {
//创建两个队列
this.queue1 = [];
this.queue2 = [];
}
initQueue() {
//如果为空
if (!this.queue2.length) {
//把queue1中的放到queue2中最后只保留一个
while (this.queue1.length != 1) {
this.queue2.push(this.queue1.shift());
}
//然后再把队列2中的元素全部放回到1中
while (this.queue2.length > 0) {
this.queue1.push(this.queue2.shift());
}
}
}
push(item) {
this.queue1.push(item);
}
pop() {
this.initQueue();
this.queue1.shift();
}
}
var stac = new Stack();
stac.push("a");
stac.push("b");
stac.push("c");
console.log(stac); //Stack { queue1: [ 'a', 'b', 'c' ], queue2: [] }
stac.pop();
console.log(stac); //Stack { queue1: [ 'a', 'b' ], queue2: [] }var arr = ["a", "b", 1, 3, 6];
console.log(arr.toString()); // a,b,1,3,6
console.log(arr.valueOf()); // ["a", "b", 1, 3, 6]
console.log(arr.join(",")); // a,b,1,3,6
console.log(arr.join("/")); //打印 a/b/1/3/6var colors = ["red", "green", "blue"];
var count = colors.push("black");
console.log(count); // 4
var item = colors.pop();
console.log(item); // blackvar colors = ["red", "green", "blue"];
var count = colors.push("black");
console.log(count); // 4
var item = colors.shift();
console.log(item); // red
console.log(colors); //["green", "blue", "black"]
var count1 = colors.unshift("yellow");
console.log(count1); //4
console.log(colors); // ["yellow", "green", "blue", "black"]var values = [0, 1, 5, 10, 15];
values.sort();
console.log(values);
//升序
values.sort((a, b) => a - b);
console.log(values); //[0, 1, 5, 10, 15]
//降序
values.sort((a, b) => b - a);
console.log(values); // [15, 10, 5, 1, 0]//concat()
var colors = ["red", "green", "blue"];
var colors2 = colors.concat(["black", "brown"]);
console.log(colors); // 原数组不变 ["red", "green", "blue"]
console.log(colors2); // ["red", "green", "blue", "black", "brown"]
//slice()
var colors = ["red", "green", "blue", "yellow", "purple"];
var colors3 = colors.slice(1);
var colors4 = colors.slice(1, 4);
console.log(colors3); //["green", "blue", "yellow", "purple"]
console.log(colors4); //["green", "blue", "yellow"]
// 注意:如果 slice()方法的参数中有一个负数,则用数组长度加上该数来确定相应的位
// 置。例如,在一个包含 5 项的数组上调用 slice(-2,-1)与调用 slice(3,4)得到的
// 结果相同。如果结束位置小于起始位置,则返回空数组splice()
var colors = ["red", "green", "blue"];
var removed = colors.splice(0, 1); // 删除第一项
console.log(colors); //["green", "blue"]
console.log(removed); //["red"] 返回删除的项
removed = colors.splice(1, 0, "yellow", "orange"); // 从位置 1 开始插入两项
console.log(colors); //["green", "yellow", "orange", "blue"]
console.log(removed); //[] 返回删除的项没删除所以为空var numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
console.log(numbers.indexOf(4)); //3
console.log(numbers.lastIndexOf(4)); //5var numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
var everyNum = numbers.every(function(item, index) {
return item > 0;
});
console.log(everyNum); //true
var someNum = numbers.some(function(item, index) {
return item > 3;
});
console.log(someNum); //true
var filterNum = numbers.filter(function(item, index) {
return item > 1;
});
console.log(filterNum); // [2, 3, 4, 5, 4, 3, 2]
var mapNum = numbers.map(function(item, index) {
return item * 2;
});
console.log(mapNum); // [2, 4, 6, 8, 10, 8, 6, 4, 2]
//forEach和for一样就是单纯的循环数组
numbers.forEach(function(item, index, array) {
//执行某些操作
});var values = [1, 2, 3, 4, 5];
var sum = values.reduce(function(prev, cur, index, array) {
return prev + cur;
});
var sum1 = values.reduce(function(prev, cur, index, array) {
return prev * cur;
});
console.log(sum); //15 1+2+3+4+5 = 15
console.log(sum1); // 120 1*2*3*4*5 = 120参考:高级程序设计三
函数柯里化是一种将使用多个参数的函数转换成一系列使一个参数的函数
使用如下例子介绍一下函数柯里化
function add(a, b, c) {
return a + b + c;
}
// 正常函数
add(1, 2, 3); //6
//函数柯里化后
function curry(a) {
return function(b) {
return function(c) {
return a + b + c;
};
};
}
curry(1)(2)(3); // 6但是如果参数多了呢?不可能一直在内部 return,接下来咱们来实现一个可以使其他函数柯里化的函数
需要实现的点
add(1,2,3) add(1,2)(3) add(1)(2)(3) add(1)(1,2)...)function currying(fn, length) {
//第一次调用获取函数 fn 参数的长度
var length = length || fn.length;
return function() {
var args = Arrary.prototype.slice.call(arguments); //把类数组转换为数组,方便后边调用函数的时候传参数
if (args.length >= length) {
//说明参数调用完了,该执行函数了,
return fn.apply(this, args);
} else {
//这个时候fn不能执行,所以使用bind返回一个新的函数并把这次的参数传进去,剩余参数的长度现在变为length-args.length
return currying(fn.bind(this, ...args), length - args.length);
}
};
}这里难理解的地方是 return currying(fn.bind(this, ...args), length - args.length);
这里如果大家了解bind是如何实现的这边就好理解了,如下是 bind 如何实现的代码
Function.prototype.mybind = function(context) {
var fn = this; //获取绑定的函数
var args = Arrary.prototype.slice.call(arguments, 1); //把第一个参数后的参数取出来,并变成数组
return function() {
var bingargs = Arrary.prtotype.slice.call(arguments); //获取执行函数时传的参数
// 执行函数
return fn.apply(context, args.concat(bingargs));
};
};这里在理解一下return currying(fn.bind(this, ...args), length - args.length);这段代码其实这个时候我们是不需要执行 fn 函数的,但是又需要把此时的参数传递进去,所以这里使用 bind 函数正常又返回一个函数同时也把参数传递进去了至此,咱们就把柯里化函数 currying 实现了
add(1, 2, 3); //6
var curry = currying(add);
curry(1, 2, 3); // 6
curry(1, 2)(3); // 6
curry(1)(2)(3); // 6
curry(1)(2, 3); // 6// 这里在Vue源码中就有体现,Vue在渲染的时候有两个平台一个是weex一个是web
// 其中有这样一段代码,这里就使用了柯里化的技巧,createPatchFunction是一个方法,他返回了一个纯净的函数,传的参数其实是对不同平台DOM的操作
//这个createPatchFunction函数可以在web平台和weex两个平台去调用但是需要传不同平台需要的操作
export const patch: Function = createPatchFunction({ nodeOps, modules });add(1, 2, 3); //6
var curry = currying(add);
var next = curry(1); //未真正求值
var next1 = next(2); //未真正求值
next1(3); //求值了用一个具体代码展示一下参数复用
// 没有柯里化之前会这样调用
function eat(name, goods) {
console.log(name + "想吃" + goods);
}
eat("heyushuo", "鸭子");
eat("heyushuo", "橘子");
eat("heyushuo", "香蕉");
//函数柯里化后
var curryEat = currying(eat);
var eatGoods = curryEat("heyushuo");
eatGoods("鸭子");
eatGoods("橘子");
eatGoods("香蕉");Array.from 方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括 ES6 新增的数据结构 Set 和 Map)。
let arrayLike = {
"0": "a",
"1": "b",
"2": "c",
length: 3
};
// ES5的写法
var arr1 = [].slice.call(arrayLike); // ['a', 'b', 'c']
// ES6的写法
let arr2 = Array.from(arrayLike); // ['a', 'b', 'c']
//任何有length属性的对象,都可以通过Array.from方法转为数组,而此时扩展运算符就无法转换。
//扩展运算符只能对部署 Iterator 接口的类数组转换为真正的数组
//console.log([...arrayLike]); // 报错 TypeError: Cannot spread non-iterable object
//Array.from还可以接受第二个参数,作用类似于数组的map方法
var map = Array.from(arrayLike, x => x + x);
console.log(map); // ["aa", "bb", "cc"]Array.of 方法用于将一组值,转换为数组。弥补数组构造函数 Array()的不足。因为参数个数的不同,会导致 Array()的行为有差异。
//如下代码看出差异
Array.of(3); // [3]
Array.of(3, 11, 8); // [3,11,8]
new Array(3); // [, , ,]
new Array(3, 11, 8); // [3, 11, 8]
// Array.of方法可以用下面的代码模拟实现。
function ArrayOf() {
return [].slice.call(arguments);
}//find()
var item = [1, 4, -5, 10].find(n => n < 0);
console.log(item); // -5
//find 也支持这种复杂的查找
var points = [
{
x: 10,
y: 20
},
{
x: 20,
y: 30
},
{
x: 30,
y: 40
},
{
x: 40,
y: 50
},
{
x: 50,
y: 60
}
];
points.find(function matcher(point) {
return point.x % 3 == 0 && point.y % 4 == 0;
}); // { x: 30, y: 40 }
``;var points = [
{
x: 10,
y: 20
},
{
x: 20,
y: 30
},
{
x: 30,
y: 40
},
{
x: 40,
y: 50
},
{
x: 50,
y: 60
}
];
points.findIndex(function matcher(point) {
return point.x % 3 == 0 && point.y % 4 == 0;
}); // 2
points.findIndex(function matcher(point) {
return point.x % 6 == 0 && point.y % 7 == 0;
}); //1fill()方法使用给定值, 填充一个数组。
fill 方法还可以接受第二个和第三个参数,用于指定填充的起始位置和结束位置。
// fill方法使用给定值, 填充一个数组。
var fillArray = new Array(6).fill(1);
console.log(fillArray); //[1, 1, 1, 1, 1, 1]
//fill方法还可以接受第二个和第三个参数,用于指定填充的起始位置和结束位置。
["a", "b", "c"].fill(7, 1, 2);
// ['a', 7, 'c']
// 注意,如果填充的类型为对象,那么被赋值的是同一个内存地址的对象,而不是深拷贝对象。
let arr = new Array(3).fill({
name: "Mike"
});
arr[0].name = "Ben";
console.log(arr);
// [{name: "Ben"}, {name: "Ben"}, {name: "Ben"}]entries(),keys()和 values()——用于遍历数组,可以用 for...of 循环进行遍历,唯一的区别是 keys()是对键名的遍历、values()是对键值的遍历,entries()是对键值对的遍历。
for (let index of ["a", "b"].keys()) {
console.log(index);
}
// 0 1
for (let elem of ["a", "b"].values()) {
console.log(elem);
}
// a b
for (let [index, elem] of ["a", "b"].entries()) {
console.log(index, elem);
}
// 0 "a"
// 1 "b"
var a = [1, 2, 3];
[...a.values()]; // [1,2,3]
[...a.keys()]; // [0,1,2]
[...a.entries()]; // [ [0,1], [1,2], [2,3] ][1, 2, 3]
.includes(2) // true
[(1, 2, 3)].includes(4) // false
[(1, 2, NaN)].includes(NaN); // true
//includes方法弥补了indexOf方法不够语义化和误判NaN的缺点includes 方法弥补了 indexOf 方法不够语义化和误判 NaN 的缺点
//flat()
[1, 2, [3, [4, 5]]].flat()
// [1, 2, 3, [4, 5]]
[1, 2, [3, [4, 5]]].flat(2)
// [1, 2, 3, 4, 5]
//flatMap()
[2, 3, 4].flatMap((x) => [x, x * 2])
//map执行完后是[[2, 4], [3, 6], [4, 8]]
//然后在执行flat()方法得到下边的结果
// [2, 4, 3, 6, 4, 8]
// flatMap()只能展开一层数组。
// 相当于 .flat()
[1, 2, 3, 4].flatMap(x => [
[x * 2]
])
//map执行完后是[[[2]], [[4]], [[6]], [[8]]]
//然后在执行flat()方法得到如下结果
// [[2], [4], [6], [8]]
参考:
阮一峰 es6
你不知道的 Javascript(下卷)
原型链作为实现继承的主要方法,其基本思路是利用原型让一个引用类型继承另一个引用类型的属性和方法, 构造函数,原型和实例之间的关系通过一张图来解释一下,需要详细了解的可以看一下我的另外一篇文章
原型链继承的基本模式如下:
function Parent() {
this.name = "heyushuo";
}
Parent.prototype.sayParentName = function() {
console.log(this.name);
};
function Child() {
this.name = "kebi";
}
//1.此时把Child的原型重写了,换成了Parent的实例
//2.换句话说,原来存在Parent的实例中的属性和方法,现在也存在Child.prototype中了
Child.prototype = new Parent();
//3.在继承了Parent实例中的属性和方法后基础上,又添加了属于自己的一个新方法(这里两个名字一样会覆盖)
Child.prototype.sayChildName = function() {
console.log(this.name);
};
var Person = new Child();
console.log(Person);
//所以现在Person指向Child的原型,Child的原型指向Parent的原型(因为Child的原型对象等于了Parent的实例,这个实例指向Parent的原型)通过如下图打印的 Person 看一下他们的关系:
这里特别需要注意的是 Person.constructor 现在指向的是 Parent,因为 Child.prototype 中的 constructor 被重写了 可以通过如下代码改变 constructor 的指向
//改变 constructor 的指向
Child.prototype.constructor = Child;1. instanceof (实例对象是否是构造函数函数的实例)
console.log(Person instanceof Child); //true
console.log(Person instanceof Parent); //true
console.log(Person instanceof Object); //true
//由于原型链的关系,可以说Person是他们三个中任何一个类型的实例2.isPrototypeOf(Person) 只要原型链中出现过的原型,都可以说是该原型链派生的实例的原型(可以理解为是否是实例的原型) Object.prototype.isPrototypeOf(Person) //true Parent.prototype.isPrototypeOf(Person) //true Child.prototype.isPrototypeOf(Person) //true
再给 Child 添加新的方法的时候,一定要在原型继承父元素后添加,这样可以防止自己定义的方法,会和继承来的方法名字相同,导致 Child 自己定的方法被覆盖
1.实例共享引用类型
虽然原型链继承很强大, 但是存在一个问题, 最主要的问题是包含引用类型值的原型, 因为包含引用类型值的原型属性会被所有的实例共享, 而在通过原型来实现继承的时候, 原型实际变成了另外一个函数的实例(这里边就有可能存在引用类型)
通过一个例子看一下
function Parent() {
this.newArr = ["heyushuo", "kebi"];
}
function Child() {
this.name = "kebi";
}
Child.prototype = new Parent();
var Person1 = new Child();
Person1.newArr.push("kuli");
console.log(Person1.newArr); // ["heyushuo","kebi","kuli"]
var Person2 = new Child();
console.log(Person2.newArr); // ["heyushuo","kebi","kuli"]2.在创建 Child 的子类的时候,无法像继承元素传递参数
浅复制是指只复制一层对象的属性,不会复制对象中的对象的属性,对象的深复制会复制对象中层层嵌套的对象的属性。(单来说浅复制只复制一层对象的属性,而深复制则递归复制了所有层级。)
全局例子都使用如下对象
var info = {
name: "heyushuo",
age: 25,
arr: [1, 2, 3],
obj: {
name: "kebi",
age: 36
},
say: function () {
console.log("heyushuo");
},
reg: new RegExp(/[0-9]/),
date: new Date()
};2.1 ES6 的 Object.assign
将所有可枚举的属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。如果目标对象中的属性具有相同的键,则属性将被源中的属性覆盖。后来的源的属性将类似地覆盖早先的属性
//实现浅复制
var target = {};
Object.assign(target, info);
target.arr[0] = 100;
console.log(info.arr[0]); //100
// info中的arr也发生了变化,实现的是浅复制2.2 ES5 的 Object.create
复制对象到当前对象的原型上
var obj = Object.create(info);
console.log(obj); //100如下如所示:
2.3 数组的 concat()和 slice()方法可以实现对数组的浅复制
var newArray = ['a',1,2,{name:'heyushuo'}];
var clone1 = newArray.concat();
var clone2 = newArray.slice(0);
clone1[3].name = "kebi";
console.log(clone2.name) //kebi
console.log(newArray.name) //kebi
//通过上边例子可以看到如上两个方法实现的是浅复制ES6 提供的扩展运算符实现数组的复制也是浅复制
const a1 = [1, 2];
const a2 = [...a1];2.4 自己封装一个浅复制方法
function clone(obj){
if(typeof obj != 'object'){
return 'need a object';
}
var object = obj.constructor === Array?[]:{};
for(var i in obj){
object[i] = obj[i];
}
return object;
}
clone(info);3.1 实现深复制最简单的方式
JSON 对象是 ES5 中引入的新的类型(支持的浏览器为 IE8+),JSON 对象 parse 方法可以将 JSON 字符串反序列化成 JS 对象,stringify 方法可以将 JS 对象序列化成 JSON 字符串,借助这两个方法,也可以实现对象的深拷贝。
/**
* 大多数情况下,上面的就可以满足要求了,但一些时候,我们需要把函数,
* 正则等特殊数据类型也考虑在内,或者当前环境不支持JSON时,上面的方法也就不适用了。这时,我们可以通过递归来实现对象的深层复制
**/
var str = JSON.stringify(info);
console.log(str);
console.log(JSON.parse(str));这个方法的缺点如下图所示
3.2 手写实现深复制的函数
function deepCopy(obj) {
if (typeof obj != "object") {
return "need a object";
}
var object = obj.constructor == Array ? [] : {};
for (var i in obj) {
//判断是对象还是普通类型
if (typeof obj[i] == "object") {
//这里需要判断一下是否是正则RegExp 还是 Date 时间
if (obj[i].constructor === RegExp || obj[i].constructor === Date) {
object[i] = obj[i];
} else {
object[i] = deepCopy(obj[i]);
}
} else {
object[i] = obj[i];
}
}
return object;
}
console.log(deepCopy(info));
//完全拷贝下来了通过如上函数实现一个对象的合并
function mergeObj(target,obj) {
if (typeof obj != "object") {
return "need a object";
}
var object = target;
for (var i in obj) {
//判断是对象还是普通类型
if (typeof obj[i] == "object") {
//这里需要判断一下是否是正则RegExp 还是 Date 时间
if (obj[i].constructor === RegExp || obj[i].constructor === Date) {
object[i] = obj[i];
} else {
object[i] = deepCopy(obj[i]);
}
} else {
object[i] = obj[i];
}
}
return object;
}
var heyushuo = mergeObj({
a: "sdfsadfsdf",
name: "2123123"
}, {
c: "2323",
d: "8989",
name: ["sdf", 23, 123]
});
console.log(heyushuo);
// {
// a: "sdfsadfsdf",
// c: "2323",
// d: "8989",
// name: ["sdf", 23, 123]
// }
- 原文地址:A practical guide to writing more functional JavaScript
- 原文作者:Nadeesha Cabral
- 本文永久链接:github-heyushuo-blob
- 译者:heyushuo
一切皆为函数
函数式编程很棒。随着 React 的引入,越来越多的 JavaScript 前端代码正在考虑 FP 原则。但是我们如何在我们编写的日常代码中开始使用 FP 思维模式?我将尝试使用日常代码块并逐步重构它。
我们的问题:用户来到我们的登录页面链接后会带一个redirect_to 参数。就像/login?redirect_to =%2Fmy-page。请注意,当%2Fmy-page 被编码为 URL 的一部分时,它实际上是/ my-page。我们需要提取此参数,并将其存储在本地存储中,以便在完成登录后,可以将用户重定向到 my-page页面。
如果我们以最简单方式来呈现这个解决方案,我们将如何编写它?我们需要如下几个步骤
我们还必须将不安全的函数放到try catch块中。有了这些,我们的代码将如下所示:
function persistRedirectToParam() {
let parsedQueryParam;
try {
//获取连接后的参数{redirect_to:'/my-page'}
parsedQueryParam = qs.parse(window.location.search); // https://www.npmjs.com/package/qs
} catch (e) {
console.log(e);
return null;
}
//获取到参数
const redirectToParam = parsedQueryParam.redirect_to;
if (redirectToParam) {
const decodedPath = decodeURIComponent(redirectToParam);
try {
localStorage.setItem("REDIRECT_TO", decodedPath);
} catch (e) {
console.log(e);
return null;
}
//返回 my-page
return decodedPath;
}
return null;
}暂时,让我们忘记 try catch 块并尝试将所有内容表达为函数。
// 让我们声明所有我们需要的函数
const parseQueryParams = query => qs.parse(query);
const getRedirectToParam = parsedQuery => parsedQuery.redirect_to;
const decodeString = string => decodeURIComponent(string);
const storeRedirectToQuery = redirectTo =>
localStorage.setItem("REDIRECT_TO", redirectTo);
function persistRedirectToParam() {
//使用它们
const parsed = parseQueryParams(window.location.search);
const redirectTo = getRedirectToParam(parsed);
const decoded = decodeString(redirectTo);
storeRedirectToQuery(decoded);
return decoded;
}当我们开始将所有“结果”用函数的方式表示时,我们会看到我们可以从主函数体中重构的内容。这样处理后,我们的函数变得更容易理解,并且更容易测试。
早些时候,我们将测试主要函数作为一个整体。但是现在,我们有 4 个较小的函数,其中一些只是代理其他函数,因此需要测试的足迹要小得多。
让我们识别这些代理函数,并删除代理,这样我们就可以减少一些代码。
const getRedirectToParam = parsedQuery => parsedQuery.redirect_to;
const storeRedirectToQuery = redirectTo =>
localStorage.setItem("REDIRECT_TO", redirectTo);
function persistRedirectToParam() {
const parsed = qs.parse(window.location.search);
const redirectTo = getRedirectToParam(parsed);
const decoded = decodeURIComponent(redirectTo);
storeRedirectToQuery(decoded);
return decoded;
}好的。现在,似乎 persistRedirectToParam 函数是 4 个其他函数的“组合”让我们看看我们是否可以将此函数编写为合成,从而消除我们存储为 const 的中间结果。
const getRedirectToParam = (parsedQuery) => parsedQuery.redirect_to;
// we have to re-write this a bit to return a result.
const storeRedirectToQuery = (redirectTo) => {
localStorage.setItem("REDIRECT_TO", redirectTo)
return redirectTo;
};
function persistRedirectToParam() {
const decoded = storeRedirectToQuery(
decodeURIComponent(
getRedirectToParam(
qs.parse(window.location.search)
)
)
)
return decoded;
}
这很好。但是我同情读取这个嵌套函数调用的人。如果有办法解开这个混乱,那就太棒了。
如果你已经完成了以上的一些重构,那么你就会遇到compose 。Compose 是一个实用函数,它接受多个函数,并返回一个逐个调用底层函数的函数。还有其他很好的资源来学习 composition,所以我不会在这里详细介绍。
使用 compose,我们的代码将如下所示:
const compose = require("lodash/fp/compose");
const qs = require("qs");
const getRedirectToParam = parsedQuery => parsedQuery.redirect_to;
const storeRedirectToQuery = redirectTo => {
localStorage.setItem("REDIRECT_TO", redirectTo);
return redirectTo;
};
function persistRedirectToParam() {
const op = compose(
storeRedirectToQuery,
decodeURIComponent,
getRedirectToParam,
qs.parse
);
return op(window.location.search);
}compose 内的函数执行顺序为从右向左,即最右边的函数(最后一个参数)最先执行,执行完的结果作为参数传递给前一个函数。因此,在 compose 链中调用的第一个函数是最后一个函数。
如果你是一名数学家并且熟悉这个概念,这对你来说不是一个问题,所以你自然会从右到左阅读。但对于熟悉命令式代码的其他人来说,我们想从左到右阅读。
幸运的是这里有pipe(管道)和 compose 做了同样的事情,但是执行顺序和 compose 是相反的,因此链中的第一个函数最先执行,执行完的结果作为参数传递给下一个函数。
而且,似乎我们的 persistRedirectToParams 函数已经成为另一个我们称之为 op 的函数的包装器。换句话说,它所做的只是执行op。我们可以摆脱包装并“扁平化”我们的函数。
const pipe = require("lodash/fp/pipe");
const qs = require("qs");
const getRedirectToParam = parsedQuery => parsedQuery.redirect_to;
const storeRedirectToQuery = redirectTo => {
localStorage.setItem("REDIRECT_TO", redirectTo);
return redirectTo;
};
const persistRedirectToParam = fp.pipe(
qs.parse,
getRedirectToParam,
decodeURIComponent,
storeRedirectToQuery
);差不多了。请记住,我们适当地将 try-catch 块留在后面,以使其达到正确的状态?好的接下来,我们需要一些方式来介绍它。qs.parse 和 storeRedirectToQuery 都是不安全。一种选择是使它们成为包装函数并将它们放在 try-catch 块中。另一种函数式方式是将 try-catch 表示为一种函数。
有一些实用程序做到了这一点,但让我们自己尝试写一些东西。
function tryCatch(opts) {
return args => {
try {
return opts.tryer(args);
} catch (e) {
return opts.catcher(args, e);
}
};
}我们的函数在这里需要一个包含 tryer 和 catcher 函数的 opts 对象。它将返回一个函数,当使用参数调用时,使用所述参数调用 tryer 并在失败时调用 catcher。现在,当我们有不安全的操作时,我们可以将它们放入 tryer 部分,如果它们失败,则从捕获器部分进行救援并提供安全结果(甚至记录错误)。
因此,考虑到这一点,我们的最终代码如下:
const pipe = require("lodash/fp/pipe");
const qs = require("qs");
const getRedirectToParam = parsedQuery => parsedQuery.redirect_to;
const storeRedirectToQuery = redirectTo => {
localStorage.setItem("REDIRECT_TO", redirectTo);
return redirectTo;
};
const persistRedirectToParam = fp.pipe(
tryCatch({
tryer: qs.parse,
catcher: () => {
return {
redirect_to: null // we should always give back a consistent result to the subsequent function
};
}
}),
getRedirectToParam,
decodeURIComponent,
tryCatch({
tryer: storeRedirectToQuery,
catcher: () => null // if localstorage fails, we get null back
})
);
// to invoke, persistRedirectToParam(window.location.search);这或多或少是我们想要的。但是为了确保代码的可读性和可测试性得到改善,我们也可以将“安全”函数(tryCatch 函数)分解出来。
const pipe = require("lodash/fp/pipe");
const qs = require("qs");
const getRedirectToParam = parsedQuery => parsedQuery.redirect_to;
const storeRedirectToQuery = redirectTo => {
localStorage.setItem("REDIRECT_TO", redirectTo);
return redirectTo;
};
const safeParse = tryCatch({
tryer: qs.parse,
catcher: () => {
return {
redirect_to: null // we should always give back a consistent result to the subsequent function
};
}
});
const safeStore = tryCatch({
tryer: storeRedirectToQuery,
catcher: () => null // if localstorage fails, we get null back
});
const persistRedirectToParam = fp.pipe(
safeParse,
getRedirectToParam,
decodeURIComponent,
safeStore
);现在,我们得到的是一个更强大功能的函数,由 4 个独立的函数组成,这些函数具有高度内聚性,松散耦合,可以独立测试,可以独立重用,考虑异常场景,并且具有高度声明性。
有一些 FP 语法糖使这变得更好,但是这是以后的某一天。
如果发现译文存在错误或其他需要改进的地方请指出。
在 ECMAScript 中有 5 种简单的数据类型(也称为基本数据类型):Undefined、Null、Boolean、Number 和 String
还有一种复杂数据类型(也成为引用类型)- Object,ES6 中又新增了 symbol(符号)类型,属于基本数据类型
综上 JavaScript 中包含七种内置类型
数据类型判断
在平时做项目中,对类型的判断是必不可少的,类型判断大致分为如下四种 typeof、instanceof 、constructor 和 Object.prototype.toString
分别看一下这几种方式的优缺点,还有哪一种判断是最靠谱的
最常用的数据类型判断,接下来看一下它适合判断什么呢?
//基本数据类型
typeof 'kebi'; // string
typeof 1; // number
typeof true; //boolean
typeof undefined; //undefined
typeof Symbol(); // symbol
typeof null; //object
// ---------------分割线------------------
//复杂数据类型
typeof []; //object
typeof {}; //object
typeof new Date(); //object
typeof new RegExp(); //object
typeof new Function(); // function综上得出结论
null 返回的是 Object,其他都返回相应的类型function 返回的是 function,其他都是返回 objecttypeof 只适用于 Undefined、Boolean、Number、String、symbol 和对象中的 function 这几种类型的判断typeof 无法对引用类型进行准确的判断, 所以 ECMAScript 引入了另外一个 instanceof 运算符,
用于识别处理对象的类型,与 typeof 方法不同的是,instanceof 方法要求开发者明确地确认对象为某特定类型。
instanceof 判断一个变量是否是某个对象的实例(判断一个实例是否属于某种类型)。
//对于基础类型我们需要,明确对象为某特种类型
var num = new Number('123');
var str = new String('kebi');
var obj = {};
var arr = [1, 2, 3, 4];
var fun = function() {};
var reg = /kebi/;
var date = new Date();
console.log(num instanceof Number); //true
console.log(str instanceof String); //true
console.log(obj instanceof Object); //true
console.log(arr instanceof Array); //true
console.log(fun instanceof Function); //true
console.log(reg instanceof RegExp); //true
console.log(date instanceof Date); //true
// 通过上边貌似感觉instanceof完美解决了复杂类型的判断,接下来看一下边打印的是什么
console.log(num instanceof Object); //true
console.log(str instanceof Object); //true
console.log(arr instanceof Object); //true
console.log(fun instanceof Object); //true
console.log(reg instanceof Object); //true
console.log(date instanceof Object); //true你会发现上边所有都是打印的 true,这里涉及到 instanceof 内部实现机制和 JavaScript 原型继承机制,内部实现方法代码大致如下
function instance_of(L, R) {
//L 表示左表达式,R 表示右表达式
var O = R.prototype; // 取 R 的显示原型
L = L.__proto__; // 取 L 的隐式原型
while (true) {
if (L === null) return false;
if (O === L)
// 这里重点:当 O 严格等于 L 时,返回 true
return true;
L = L.__proto__;
}
}那其中的一个作为例子讲解一下 arr instanceof Object
arr.__proto__( Array.prototype) === Object.prototype 不等于接着循环Array.prototype.__proto__ === Object.prototype 恒等返回 true[点击深入理解 instanceof 内部实现](https: //www.ibm.com/developerworks/cn/web/1306_jiangjj_jsinstanceof/index.html)
综上得出结论
每一个实例都可以通过 constructor 对象访问到它的构造函数
var num = 123;
var str = 'kebi';
var flag = true;
var obj = {};
var arr = [1, 2, 3, 4];
var fun = function() {};
var reg = /kebi/;
var date = new Date();
console.log(num.constructor); //ƒ Number() { [native code] }
console.log(str.constructor); //ƒ String() { [native code] }
console.log(flag.constructor); //ƒ Boolean() { [native code] }
console.log(obj.constructor); //ƒ Object() { [native code] }
console.log(arr.constructor); //ƒ Array() { [native code] }
console.log(fun.constructor); //ƒ Function() { [native code] }
console.log(reg.constructor); //ƒ RegExp() { [native code] }
console.log(date.constructor); //ƒ Date() { [native code] }
//例子如下
console.log(arr.constructor == Array); //true综上得出结论
toString() 是 Object 的原型方法,调用该方法,默认返回当前对象的 [[Class]] 。这是一个内部属性,其格式为 [object xxx] ,其中 xxx 就是对象的类型。对于 Object 对象,直接调用 toString() 就能返回 [object Object] 。而对于其他对象,则需要通过 call / apply 来调用才能返回正确的类型信息。
Object.prototype.toString()是 javascript 中判断类型最准确的方式了,代码如下
Object.prototype.judgeTypes = function() {
var toString = Object.prototype.toString;
var map = {
'[object Boolean]': 'boolean',
'[object Number]': 'number',
'[object String]': 'string',
'[object Symbol]': 'symbol',
'[object Function]': 'function',
'[object Array]': 'array',
'[object Date]': 'date',
'[object RegExp]': 'regexp',
'[object Undefined]': 'undefined',
'[object Null]': 'null',
'[object Object]': 'object',
'[object Arguments]': 'arguments',
'[object Error]': 'error',
'[object Window]': 'window',
'[object HTMLDocument]': 'document',
'[object Map]': 'map',
'[object Set]': 'set',
'[object WeakMap]': 'weakmap'
};
var el = this instanceof Element ? 'element' : map[toString.call(this)];
return el;
};
// 以后判断类型可以直接如下方式使用了
console.log([1, 2, 3].judgeTypes()); //arrayA declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.









