Ver Instrucciones de instalación
Una vez instalado, hay que lanzarlo usando el comandopyspark en lugar de `jupyter notebook``
- Si tenemos muchos esclavos y le llega todo de golpe al master, peude tener problemas de procesameinto. Normalemten además el master no suele ser un ordenador mejor que los esclavos.
- La distribución de trabajo es una tarea completada.
- Si un nodo peta, en un cluster tradicional, la tarea peta en general.
- Si la red es mala, también tenemos problemas.
Por tanto, en los kernels tradicionales se gastan un pastón en redes y buenos nodos.
Si dos personas están trabajando en el mismo clúster, podría haber dos programas ejectuándose a la vez. Para eso hace falta un scheduler, que permite orquestar eso, dando por ejemplo unos cuantos nodos para la tarea del primero programa y otros cuantos.
Lo inventó Google para sus búsquedas.
En un clúster hadoop, las cosas son un poco distintas. Cada nodo es responsable de su storage (físicamente no tiene por qué estar en ese nodo, nosotros podemos abstraernos de eso). El paradigma es que todo se ha haga lo más localmente posibie, por lo que podemos ahorrarnos en red.

Además, en un Hadoop Clúster, tenemos un diagrama, un grafo, de lo que tenemos que hacer. En los tradicionales, donde no lo teníamos, si había un error, no éramos capaces de recuperarnos. Aquí sí. Así, tenemos un grafo representando cada mini tarea. Si falla una, soomos capaces de saber por dónde nos quedamos, rpetirla en otro nodo y seguir con las siguientes.
MapReduce era como se llamaba antes Hadoop.
Hadoop funciona con storage, spark hace lo mismo que Hadoop, pero lo hace en RAM. Por tanto, Spark vuela comparado con Hadoop (hasta 100 veces).
Hadopp está diseñado sabiendo que va a fallar.
En Storage tradicional, se usaban sistemas RAID más complejos.
Lo que hace hadoop es decir: ok, si el nodo tiene 1 tb de storage, en lugar de eso, le decimos que tiene 500 gb y los otros 500 los usamos para duplicar información (de otro nodo, claro, no vas a hacerte copia de los datos en el mismo nodo).
Esto sería para factor de duplicidad = 2. Para 3, tendríamos sólo un tercio de nuestro disco duro para meter nuestros datos. El resto, para duplicar datos de otros nodos.
Todo esto orquedtado por el máster. Veremos cuando hagamos cosas con hadoop que el fichero tiene dos tamaños: 100 y 300, por ejemplo. Ocupa 100 en un nodo pero 300 en total porque el factor de duplicidad es 3.
Partición: una división adicional (lógica) dentro de un nodo. Es una tarea, con su propia memoria reservada, etc.
Map: es una transformación de una cosa a otra.
Shuffle: la operación más costosa en distribución. Que cada nodo se comunique con el otro. Por ejemplo, para una ordenación es necesario. Se intenta evitar lo más posible, porque es costosa y no resiliente.
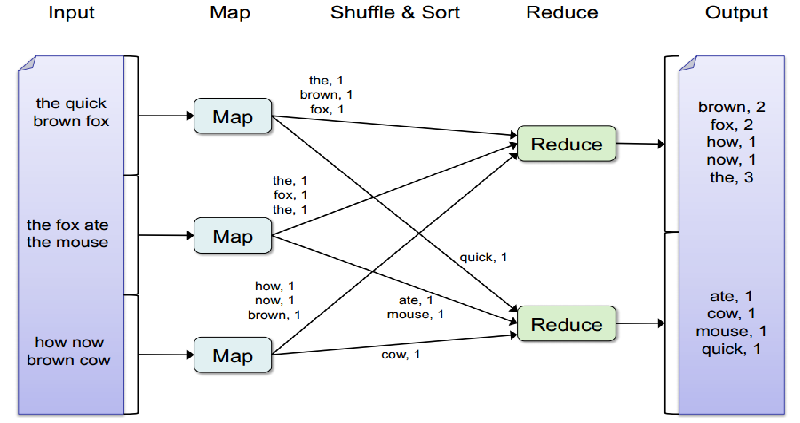
Reduce: a partir de los elementos transformados, tenemos que sacar un resultado que suele ser una agregación. Eso es el reduce.
Como todo esá distribuido, tenemos que evitar el uso de datos mutables. Tenemos que tendre a un enfoque funcional. Es decir
El programa global enviado no debe depender de un estado, sino que debe tener un enfoque funcional.
Recomendación: este curso sobre functional programming.
Herramienta de ETL para grandes cantidades de datos. Framework the computación mediante clúster. 100 veces más rápido que MapReduce (en aplicaciones donde el hecho de que se use memoria en lugar de disco, se nota). El original es en Scala, pero está pyspark, que es un port.
Cuando se trabaja con spark es fundamental saber que estamos cambiando el paradigma a la hora de resover el problema. Debemos dejar de pensar en secuencia, para pensar en distribuido.
Un ejemplo de aplcicación: tenemos una tabla con todos los datos de facturación, y hacemos que cada nodo se encargue de un periodo de tiempo.
Hay componentes por encima de Spark para ayudar:
- Spark SQL: para trabajar sobre él usando SQL.
- Spark Streaming: para trabajar con datos en streaming. & MLig: para machine learning. Basado en las librerías de python.
La abstracción bíasca de Spark es el Resilient Distributed Dataset (RDD). Son como dataframes pero distintosl Son immnuitables, almacenan sólo las transformaciones, no los datos en sí. Permiten al usuario elegir la partición. Normalmente se usan dataframes normales, porque Spark tiene herramientas que te o
Hasta hace poco, Scala le daba mil vueltas a Python para Spark. Hoy ha mejorado brutalmente aunque aún se nota un poco.
