This repo provides demos and packages to perform fast inference solutions for BLOOM. Some of the solutions have their own repos in which case a link to the corresponding repos is provided instead.
We support HuggingFace accelerate and DeepSpeed Inference for generation.
Install required packages:
pip install flask flask_api gunicorn pydantic accelerate huggingface_hub>=0.9.0 deepspeed>=0.7.3 deepspeed-mii==0.0.2alternatively you can also install deepspeed from source:
git clone https://github.com/microsoft/DeepSpeed
cd DeepSpeed
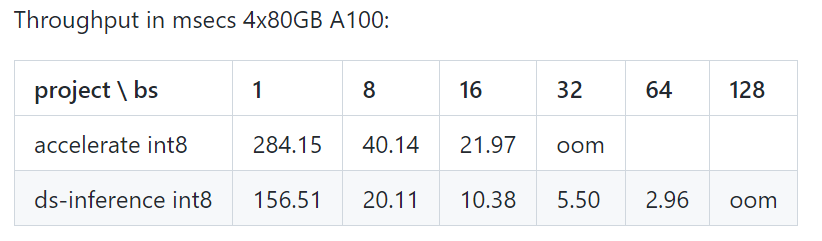
CFLAGS="-I$CONDA_PREFIX/include/" LDFLAGS="-L$CONDA_PREFIX/lib/" TORCH_CUDA_ARCH_LIST="7.0" DS_BUILD_CPU_ADAM=1 DS_BUILD_AIO=1 DS_BUILD_UTILS=1 pip install -e . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-checkAll the provided scripts are tested on 8 A100 80GB GPUs for BLOOM 176B (fp16/bf16) and 4 A100 80GB GPUs for BLOOM 176B (int8). These scripts might not work for other models or a different number of GPUs.
DS inference is deployed using logic borrowed from DeepSpeed MII library.
Note: Sometimes GPU memory is not freed when DS inference deployment crashes. You can free this memory by running killall python in terminal.
For using BLOOM quantized, use dtype = int8. Also, change the model_name to microsoft/bloom-deepspeed-inference-int8 for DeepSpeed-Inference. For HF accelerate, no change is needed for model_name.
HF accelerate uses LLM.int8() and DS-inference uses ZeroQuant for post-training quantization.
This asks for generate_kwargs everytime. Example: generate_kwargs =
{"min_length": 100, "max_new_tokens": 100, "do_sample": false}- using HF accelerate
python -m inference_server.cli --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --generate_kwargs '{"min_length": 100, "max_new_tokens": 100, "do_sample": false}'- using DS inference
python -m inference_server.cli --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --generate_kwargs '{"min_length": 100, "max_new_tokens": 100, "do_sample": false}'make <model_name> can be used to launch a generation server. Please note that the serving method is synchronous and users have to wait in queue until the preceding requests have been processed. An example to fire server requests is given here. Alternativey, a Dockerfile is also provided which launches a generation server on port 5000.
An interactive UI can be launched via the following command to connect to the generation server. The default URL of the UI is http://127.0.0.1:5001/. The model_name is just used by the UI to check if the model is decoder or encoder-decoder model.
python -m ui --model_name bigscience/bloomThis command launches the following UI to play with generation. Sorry for the crappy design. Unfotunately, my UI skills only go so far. 😅😅😅

- using HF accelerate
python -m inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework hf_accelerate --benchmark_cycles 5- using DS inference
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5alternatively, to load model faster:
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name microsoft/bloom-deepspeed-inference-fp16 --model_class AutoModelForCausalLM --dtype fp16 --deployment_framework ds_inference --benchmark_cycles 5- using DS ZeRO
deepspeed --num_gpus 8 --module inference_server.benchmark --model_name bigscience/bloom --model_class AutoModelForCausalLM --dtype bf16 --deployment_framework ds_zero --benchmark_cycles 5If you run into things not working or have other questions please open an Issue in the corresponding backend:
If there a specific issue with one of the scripts and not the backend only then please open an Issue here and tag @mayank31398.
Solutions developed to perform large batch inference locally:
JAX:
A solution developed to be used in a server mode (i.e. varied batch size, varied request rate) can be found here. This is implemented in Rust.