iilab / contentascode Goto Github PK
View Code? Open in Web Editor NEWContent as Code
Home Page: http://iilab.github.io/contentascode
License: GNU General Public License v3.0
Content as Code
Home Page: http://iilab.github.io/contentascode
License: GNU General Public License v3.0
Despite trying to create a smaller language for version control than git, some abstractions will need to be exposed especially when dealing with conflicts and merges.
If the UI would expose choices based on graphical representation like here https://developer.atlassian.com/blog/2014/12/pull-request-merge-strategies-the-great-debate/
It might make these concepts easier to grasp.
There's a need to look at the range of main and corner cases such as:
See http://iilab.github.io/contentascode/technology/workflow/#notifications
Related to #43
Some of the use cases for this would be:
Areas of interest could be mapped to a folder or subrepo if they are clearly mapped to the site content structure, or could be mapped to grouping of issues if they have their own logic (like project management, or a categorisation that's somewhat orthogonal from content):
UPDATE: Moving notes to the issue tracker integration issue #40
Iterate on the ecosystem design approach described at http://iilab.github.io/contentascode/approach/ and develop some non-technical introduction document to the benefits and features of such an approach. (An example of this is to enable workflows where open contribution to a website is easy and works with translation workflows).
When a project contains several subrepos (like the contentascode spike developed for the open integrity project) it would be good to allow linking across parent repo and subrepo in a way that is simple for instance
[Link in the parent repo to a sub folder in the parent repo](/subfolder/file.md)[Link in the parent repo to a subrepo](/subrepo_a/folder/file.md) -> We need to manage subfolder/subrepo name collisions (via the pre-commit validation run? #11)[Link from a subrepo to the parent repo](/subfolder/file.md)[Link from a subrepo to another subrepo](/subrepo_b/file.md)With the baseurl problem (when sites are served from scheme://host/folder/) this needs some kind of pre-processing.
It will make things nicer and more up to date with current practices. Relates to #7
| Markdown | Git | Inplace | Active | |
|---|---|---|---|---|
| Prose | Yes | github | No | No |
| Gitbook | Yes | git | No | Yes |
| Dillinger | Yes | github | No | |
| Aloha | Yes | |||
| Pen Editor | Yes | No | Yes | Yes |
| ContentEditable | No | No | Yes | Yes |
| Realms.io | Yes | Yes | Preview | Yes |
| Substance | No | No | Preview | Yes |
| PubPub | Yes | ? | Preview | Yes |
| VisualEditor | No | ? | Yes | Yes |
See the current analysis at http://iilab.github.io/contentascode/technology/authoring/
Here's some thoughts about the approach to exporting existing content in a "content as code"
One of the driving principles is to focus on AX (the Author's Experience). Therefore the content should be in a simple file structure that strongly reflect the organisation of the content in "its natural habitat" i.e. where it's meant to be displayed in the end. This will make it easy to find content. Here's an example of this with Open Mentoring
The content on the app here :

The file structure on prose/github is very similar:

The UX could be improved more by dealing with titles better. (Here Dealing with Emergencies is practice-1-emergencies and Getting Started is 0-getting-started).
Here's an example of how the file structure is on the Open Mentoring app:
/ # root folder
en/ # top level folder for each language
resources/ # Static or dynamic content that are not part of exchanged
# content (they hold information but are not meant to be
# structured like learning content)
topics/ # Contains Topics.
a-topic/
another-topic/ # Contains Units
a-unit/
another-unit/ # Contains Stacks
1-intro.md # Example Stack.
1-intro-hrd.md # Example Stack for the hrd profile.
...
Another important consideration is how the content is broken down. Currently in Open Mentoring the approach is to have "stacks" be Markdown files. Read more about in the openmentoring MODEL.md doc.
Multiple stacks are then aggregated into single pages on the web:

And an individual stack (here under the Scenario heading) is actually split (using <br> as the token right now) into cards on the mobile app like this:

And this is what it looks like on Prose

The source Markdown for this is here:
What I'd like is to maintain a AX focused approach here, but this probably means allowing authors to switch context depending on what they want to look at (web view, mobile view,...). Right now there's a trade off in Open Mentoring in order to make it easy
Currently the openmentoring-curation layer also allows to specify metadata that will be inherited by the children files, which helps DRY for instance the source metadata key in the index.md file here will be applied to all the stacks in the same folder.
Also to avoid having to add frontmatter metadata (or companion metadata files - like having a content.md with only markdown and content.json or content.yaml with only metadata) openmentoring uses keywords in file names to create metadata keys (which is also described in the MODEL.md file).
There will be cases where particular pieces of content are reused in different places in the app. My current thinking is to have these reusable components included via symlinks for content that's in a file, or some kind of block level include syntax (see middlematter discussion in #12) which could also work for including remote content.
The usability of this completely depends on building on top of a content authoring tool like prose, developing plugins to deal with middlematter, symlinks or remote includes in a way that is natural for authors.
This was brought up in #25 (comment)
YAML is the default legacy choice because of Jekyll and its Ruby heritage. It makes sense to start with it to have more compatibility out of the gate but there are a lot of interesting and maybe better (to at least some people) formats out there that could be used as well as they are terse, human readable (so thanks no XML), have a resilient syntax (which makes JSON too easy to break)
| Format | Link | Readability | Resilience | Adoption | Other |
|---|---|---|---|---|---|
| YAML | ++ | - | +++ | ||
| ArchieML | archieml.org | = | ++ | + | |
| TOML | https://github.com/toml-lang/toml | + | - | Unstable | |
| CSON | https://github.com/bevry/cson | + | - | - | |
| MSON | https://github.com/apiaryio/mson | ++ | ? | ? |
Software libraries and projects both have:
It seems to make sense to also think about packaging content units when they are part of the same release cycle, and would benefit from being tagged with a version number, for instance to update clients that use the content package. This seems that it would be a building block of a technical approach to content reuse, where content packages would be collaboratively maintained and reusable.
I think there's a lot to learn from OFK's Data Packages which recently hit 1.0.
I've done some basic implementation piggy backing on the npm registry for safetag with:
docsmith feature which automates npm to download the latest package.content.yml description which contains content package dependencies for a particular project.Some open questions and directions of work are:
The idea is that a statistics microservice would be able to be queried by the static website pipeline and that the results could be used to for instance order post by most viewed. #7
Feeding into #7 implementing a server side link checker would be a good PoC. What would be even better is an isomorphic link checker.
A nice markdown editor:
https://prosemirror.net/demo/collab.html#edit-Example
It also allow collaborative editing.
Then we would need to figure out, how/when to save the document collaboratively edited to git.
Related to #15
This repo is currently an implementation of the
stack-github-pagesapproach. Not sure it can be made completely fork and play as it might always require to activate Pages on the github repo.Moving to the
stack-github-jekyll-travisapproach will add the following features:
- Build/CI process! Server side integration tests link link checking #11
- Notifications of Build success and failure on Pull Requests
- Build badges
From a DX standpoint, moving to this stack should be as simple as changing branches and merging (and configuring travis). Will open a new issue to track this.
If we have a document.md file with this content:
# Title 1
Content 1.A
# Title 2
## Title 2.1
Content 2.B
## Title 2.2
Content 2.C
# Title 3
Content 3.D
I would like to be able to transclude a block inside this document for instance Content 2.C by using the syntax:
:[](document.md#title-2.2)
Needed features for a minimum viable implementation which would allow partners to adopt the workflow and technology in production.
There's a use case where specific pages on a site are discussed in specific github issues and could play the role of a type of forum as mentioned in #7.
The roadmap is currently based on milestones in Github and also published on the website
But there is work needed to:
Part of #8
The typical use case is:
The problem
Possible solutions (from how the code people do it)
Test
The upshot?
Other interesting approaches might include using the markdown structure as the underlying data and use other diffing tools for this.
Interestingly, I couldn't find research literature about applying these tools to natural language text...
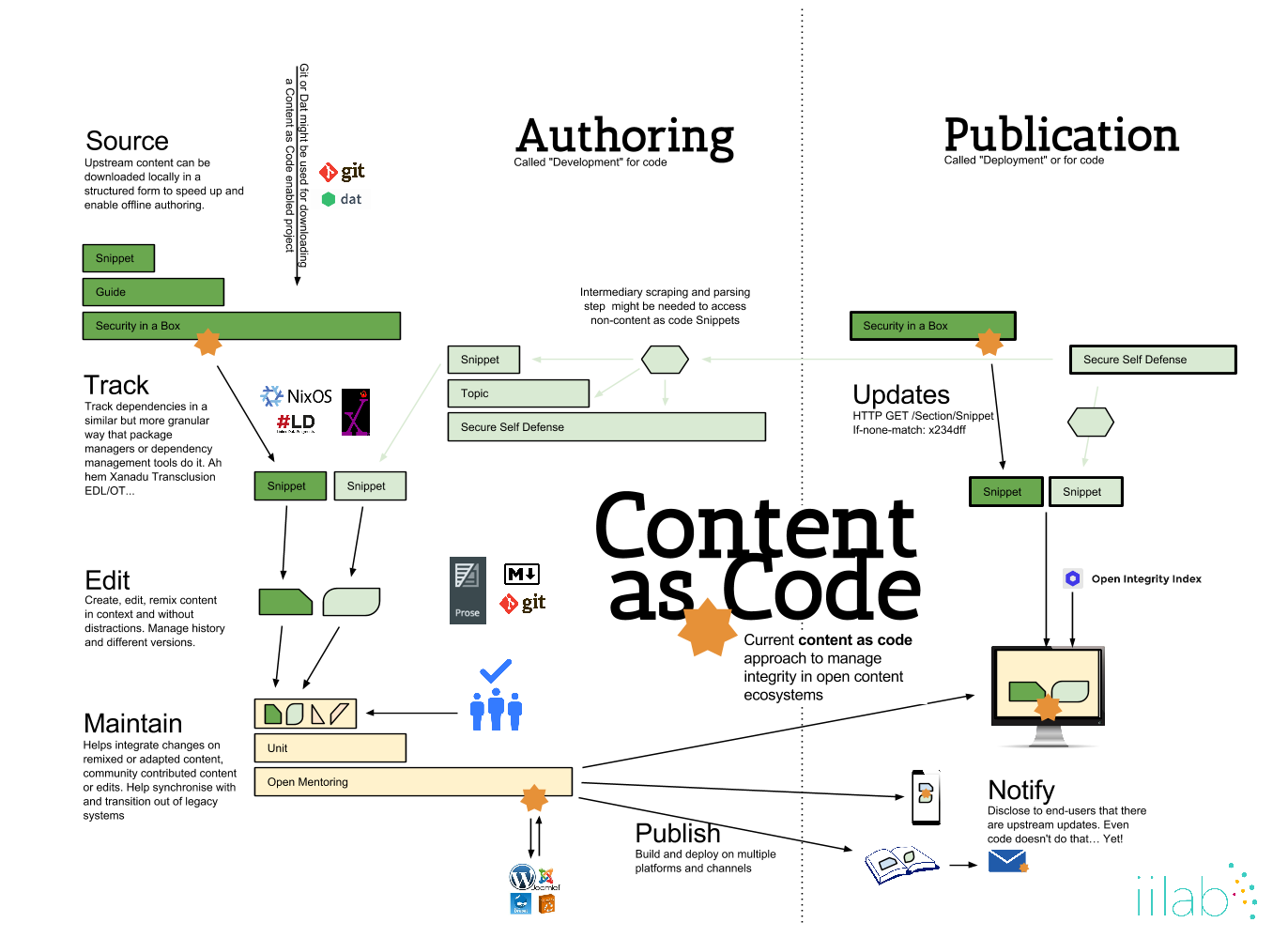
In order to manage the live display for clients of dependency status, notifications and so on (as show in the publication section on the right in the diagram below) we need a client side widget.
Such as with Carnival app carnivalapp.io
Check out http://www.mkdocs.org/
Would be nice to:
content use mkdocs -> installs mkdocs (plugging in other components of the pipeline), converts what can be converted of the current generator to the mkdoc config.
content build-> uses mkdocs build in the background.
Would allow a Gollum wiki to be a data source/sink. It would offer support for Github/Gitlab and Realms.io wikis.
Allow linked tasks to display an updated status on the page where they are in/trans-cluded
Here are some proposals for how to inline task info.
This is a linked task with only the task number [#45](https://github.com/iilab/contentascode/issues/45)
[This is a linked task with a whole sentence and the task number #45](https://github.com/iilab/contentascode/issues/45)
This is a linked task where the task title is transcluded :[#45 title](https://github.com/iilab/contentascode/issues/45)
Here's what it would look like when displayed on a web page if the task is completed:
This is a linked task with only the task number
#45
This is a linked task with a whole sentence and the task number #45This is a linked task where the task title is transcluded
Update linked task status #45
The advice from @alnermcgunn on this is that there are many dimension to content that are as many obstacles to reuse:
Other obstacles would be making the packaging, "client" use and upstream contribution workflows seamless.
Finding an practical example of a content package that could be a good candidate for reuse would be a good first step to explore this idea. Maybe a module on "Using PGP"...
Part of #7
My thoughts on this would be to focus on allowing user to start from a project scaffold:
We could create repos (contentascode-blog, contentascode-wiki, contentascode-website, contentascode-doc) that are ready to clone with some sensible defaults.
The default pipelines would have a travis.yml that push to a gh-pages branch.
We could also look into Grunt-init or Yeoman Project Scaffolding tools to allow configuration of various options such as:
We also need to think about migration and various options to use integrations to facilitate a progressive transition process.
| Name | Description | Repo | Editor | Generator | Build | Hosting | Services |
|---|---|---|---|---|---|---|---|
| scaffold-github-pages | Fork and play. | Github | Prose | Jekyll | Github Pages | Github | |
| scaffold-github-jekyll-travis | With Jekyll and Travis CI | Github | Prose | Jekyll | Travis | Github | |
| scaffold-github-metalsmith-travis | With Metalsmith and Travis CI | Github | Prose | Metalsmith | Travis | Github | |
| scaffold-jekyll-jenkins | Open souce stack | Gitlab | Hosted Prose | Jekyll | Jenkins | Self-Hosted | |
| scaffold-metalsmith-gitlabci | Open souce stack with metalsmith | Gitlab | Hosted Prose | Jekyll | Gitlab CI | Self-Hosted | |
| infra-heroku | Push to deploy micro-service infra | Gitlab | Hosted Prose | Jekyll | Jenkins | Heroku | Single container |
| infra-docker | Docker single server micro-service infra | Multi-container | |||||
| infra-ansible | Distributed micro-service infra | Multi-server |
As mentioned in this issue iilab/openmentoring-web#2 by @elationfoundation
When I added a similar issue for SAFETAG I decided to do my civic duty and searched all markdown files on github for cryptocat and added issues to any guides I found. One of the many benefits/problems to having low barriers to collaboration
And here it is in pictures from https://github.com/elationfoundation :

And here's how it looks like on our side when responding to the issue on iilab/openmentoring-web#2 (reference):

This is an awesome example of how collaboration looks like with a content as code approach.
Especially in content reuse scenarios, keeping metadata (in particular Provenance metadata) is key to keep track of upstream changes in complex aggregated content pipelines.
In addition to (awesome) approaches such as @elationfoundation which generates JSON-LD from Jekyll Frontmatter documents we will surely need to manage metadata for more granular blocks of content for instance in scenarios where larger documents are made of smaller parts.
There is a scenario where the content editor aggregates smaller files with their metadata each, but it seems to break the model of having Markdown fit the view/perspective of the Author rather than bending to technical requirements.
From a usability standpoint, the ability to add "chapters" or "sections" in this way without creating folders, subfolders and small files is important to consider.
When I think about this it seems to lead to the possibility to add block level metadata in markdown. Given that adding metadata at the top is a well adopted practice across static website generators and called a frontmatter, the idea to add metadata in the middle, instead of the front called therefore be called middlematter.
I'm thinking for instance of this type of syntax (with YAML single line maps) :
# An H1 without metadata
## An H2 level block with metadata --- {creator: 'seamus', source: 'elationfoundation/using-tor-browser-bundle'}
or
# An H1 without metadata
## An H2 level block with metadata
--- {creator: 'seamus', source: 'elationfoundation/using-tor-browser-bundle'}
or
# An H1 without metadata
## An H2 level block with metadata
---
creator: 'seamus'
source: 'elationfoundation/using-tor-browser-bundle'
---
I prefer 2. because it looks like a byline.
A content editor (#5) should probably hide inline block level metadata (the way prose hides document level metadata), and allow to surface them when needed.
This is an issue meant to keep track of various sub issues that relate to integration with code review tools as a user interaction mechanism (#28)
From #2
Just met @edbice and @caiosba from meedan and they mentioned bridge https://meedan.com/en/bridge/ and the aim to provide translation collaboration features. Do you know when it will be open sourced?
This ticket is to keep track of potential open source alternatives to transifex and specifically Bridge from meedan!
You can see it in action here:
https://yunohost.org/#/help
This is an issue meant to keep track of various sub issues that relate to integration with issue trackers as a user interaction and feedback mechanism (#28)
Semantics
The first step is to depend on an external service for notifications (despite the need to register/login). Good candidates are the Github/Gitlab issue trackers (Gitlab self-hosted allowing to avoid third party authentication dependencies).
In that case there should be mappings of content items to issues (#24) and notifications can be managed through the issue subscription mechanism. Here are possible approaches:
Example for one master repo
Repo: https://github.com/iilab/contentascode
Issues: https://github.com/iilab/contentascode/issues
One issue could be mapped to one page.
Implementation:
issue metadata key could be added with the issue number.One master repo, issues are orthogonal to the content (a more classical setup between code and issue tracking or documentation and issues)
Repo: https://github.com/iilab/openmentoring-mobile
Issues: https://github.com/iilab/openmentoring-mobile/issues
Multiple subrepos, corresponding to "areas of interest"
Repo: https://code.iilab.org/openintegrity/openintegrity.org
Subrepos:
A really nice tool:
https://github.com/hackmdio/hackmd
Here is the issue about git support: hackmdio/codimd#114
Dealing with migration in and out of Django would probably start with a simple case, looking at a model with a single table being identified as content, published through a REST API with a JSON format and rendered/parsed to markdown.
On the Django side the framework could be http://www.django-rest-framework.org/ allowing to GET/PUT/POST JSON objects first and maybe implement later renderers and parsers for our Markdown Data enabled flavor.
Export from Django would be done by making JSON objects (or arrays of JSON objects) available through an REST interface.
The creation of Markdown files would probably be using a similar approach of templated Markdown as here.
Block level metadata would be automatically constructed (using for instance JS dot notation by introspecting the template).
A JSON schema file would be produced to be used for both client/server side validation
The Markdown would be parsed as JSON and validated with the JSON Schema on the client and/or through a integration/build script (Travis for instance) before being submitted to the REST API.
Related to #4
Prototype should allow to do demos and showcase how key functionalities will work and improve existing content workflows.
Possible aspects of Prose integration which are relevant to contentascode are:
UPDATE: Shuffled things around and added some links.
There are a number of issues #21 #28 #40 #41 #35 #36 #37 #38 which point to various aspects of collaborative workflows.
This issue will keep track of aspects which relate to organising the Content as Code collaboration using Content as Code approaches, in the same way that the Content as Code website is an implementation of the Content as Code approach (currently with the Docsmith implementation - itself lagging a bit behind the experiments going on in the Open Integrity framework site)
Some of this is being described and developed on this page http://iilab.github.io/contentascode/technology/workflow/
This could be an underlying facility for #40 or #41 where the source of a page could describe an API endpoint (ideally serving a JSON object) and some form of templating to display data.
For instance:
/issues/index.md page with:---
source: https://github.com/api/blahblah
layout: issues
---/layouts/issues.jade file such aseach issue in issues
li= issue.name
a(href=issue.link) issue.descriptionThis should be fairly easy with Metalsmith and the metadata plugin after an API fetch to file step, or by creating a plugin that directly consumes the API at each generation run (which could be based on the contentful or primsic metalsmith plugins which do this).
:[](/issues):[](/issues#2) (related to #32 for transclusion of fragment blocks)The idea is to allow a fast deployment workflow of content as code site in the Deploy to Heroku button way. I can't remember where I saw a very impressive list of options to deploy a tool but it also had GCE, Digital Ocean and maybe Sandstorm. #7
I just came across the Web Annotation Architecture Document produced by the W3C Web Annotation group. I think that it lays out a very clear technological implementation for user-comments/annotations. I think that it would be a good idea to see if they have existing or upcoming implementations to extend/use.
Part of #8
This tool which maintains a Markdown representation of word docs could be a good starting point.
@elationfoundation
Following on our discussion and your great research work in this draft, I thought I'd take down some notes to continue the conversation in the open. By the way DocOps is a really cool moniker for this approach too :)
If we abstract away from particular implementation then one of the most important needs to allow some form of interoperability is to agree on metadata (or at least map metadata format to one another). There are possibly some data format considerations (for instance with #12) for interop at the implementation level but let's set them aside for now.
If we look at it from a use case perspective (looking through the metadata available here https://raw.githubusercontent.com/elationfoundation/using-tor-browser-bundle/master/metadata.md) then
I can think of other needs that could be included as metadata such as:
With other domain specific concerns (for instance with digital security education) other aspects will come up such as risk profiles or threats.
Needed features for a proof of concept implementation. Existing reference implementation is on this repo https://github.com/iilab/contentascode
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

{kind=link}