blog's People
Contributors

Stargazers

Watchers

blog's Issues
Alfred 自动代理
打开或关闭代理
- 创建workflows
- 填写名称描述,选择类型
- 填写唯一ID,Bundle Id,这里必须唯一,一般为仓库名称
- 空白地方右键 inputs->keyword,然后输入相关信息,然后保存,这里是主要用于填写触发的关键字
- 空白地方右键 actions->Run NSAppleScript,输入以下内容,以下内容为通过iterm执行命令
on alfred_script(q)
tell application "iTerm"
tell the current session of current window
write text "networksetup -setproxyautodiscovery 'Wi-Fi' on"
end tell
end tell
end alfred_script
- 关联两个模块,完成
vue 源码笔记 (草稿)
vue 实例化过程
1、Vue实例化调用构造,调用init
2、合并参数
3、初始化声明周期相关参数
4、初始化监听
5、初始化render需要的参数声明
6、beforeCreate 回调
7、initInjections 声明注入数据
8、initState 初始化数据,并observe
9、initProvide 注入数据
10、created 回调
11、挂载
VUE源码学习(3)-vue核心内容简单实现3
知识点
- Node 的nodeType的使用 文档
通过模版绑定数据进行更新渲染
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Simple Vue</title>
</head>
<style>
#app {
text-align: center;
}
</style>
<body>
<div id="app">
<p>{{success}}</p>
<p>{{success}}</p>
<p>{{error}}</p>
<p>{{error}}</p>
<p>{{error}}</p>
</div>
</body>
<script>
// 被监听的数据
let data = { success: "1111", error: "2222" };
// 监听和分发集合
let dep = {
success: {
subs: [],
notify() {
this.subs.forEach(item => {
item.update();
})
}
},
error: {
subs: [],
notify() {
this.subs.forEach(item => {
item.update();
})
}
}
}
Object.keys(data).forEach(key => {
let val = data[key];
// 设置监听数据的getter和setter
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get() {
return val;
},
set(newVal) {
// 如果值一样,不更新dom
if (newVal === val) {
return;
}
val = newVal;
// 触发所有监听
dep[key].notify();
}
});
})
// 虚拟dom集合
let nodes = [];
// 设置虚拟dom
let el = document.querySelector("#app");
const fragment = document.createDocumentFragment();
let firster = el.firstChild;
while (firster) {
fragment.appendChild(firster)
firster = el.firstChild;
}
fragment.childNodes.forEach(item => {
// NodeType请参考 https://developer.mozilla.org/zh-CN/docs/Web/API/Node/nodeType
if (item.nodeType == 1) {
let text = item.textContent;
const reg = /\{\{(.*)\}\}/;
let key = reg.exec(text)[1];
if (data[key]) {
// 设置监听
let watcher = {
update() {
// 更新dom
item.textContent = data[key]
}
};
// 添加监听到集合中
dep[key].subs.push(watcher)
}
}
})
console.log(dep, data);
el.appendChild(fragment)
// 定时更新数据,更新dom
setInterval(() => {
data.success = "当前时间戳为:" + Date.now()
data.error = "当前时间戳为:" + Date.now()
}, 1000);
</script>
</html>
nextjs 渲染组件报错window is not defined 解决方法
今天使用Braft Editor做富文本框时,报错window is not defined,原因是使用了nextjs做ssr(服务端渲染),nodejs中是没有window的,所以无法渲染。
import BraftEditor from 'braft-editor'
// 报错window is not defined
查阅了一些资料,可以使用懒加载方式进行加载,然后禁止使用ssr,在nextjs中可以使用dynamic进行异步导入,dynamic中设置ssr:false,可禁止模块在服务端渲染。
import dynamic from 'next/dynamic'
const BraftEditor = dynamic(import('braft-editor'), {
ssr: false // 禁用服务端渲染
})
一键生成免费https证书
一键生成免费https证书
- 中文文档 https://github.com/Neilpang/acme.sh/wiki/%E8%AF%B4%E6%98%8E
- 下载项目 https://github.com/Neilpang/acme.sh.git
详细步骤
# 配置nginx
cd /etc/nginx/sites-enabled
# 设置配置文件(文件名要和域名相同,否则acme无法识别)
vim iliuyt.com
# 文件内容
server {
listen 80;
server_name iliuyt.com;
root /data/www/iliuyt/;
index index.html;
}
# 进入根目录
cd ~
# 下载acme
git clone https://github.com/Neilpang/acme.sh.git
# 执行命令(开启debug模式)
sh acme.sh --issue -d iliuyt.com --nginx --debug
# 配置https nginx配置
server {
listen 443;
server_name iliuyt.com;
root /site/weixin/;
index index.html;
ssl_certificate /root/.acme.sh/iliuyt.com/fullchain.cer;
ssl_certificate_key /root/.acme.sh/iliuyt.com/iliuyt.com.key;
}
-
执行成功后会输出以下内容
[Wed Oct 24 10:50:26 CST 2018] Cert success.
-----BEGIN CERTIFICATE-----
MIIGDzCCBPegAwIBAgISA5HxJT3JIjrcJMthK4f7L6sNMA0GCSqGSIb3DQEBCwUA
MEoxCzAJBgNVBAYTAlVTMRYwFAYDVQQKEw1MZXQncyBFbmNyeXB0MSMwIQYDVQQD
ExpMZXQncyBFbmNyeXB0IEF1dGhvcml0eSBYMzAeFw0xODEwMjQwMTUwMjVaFw0x
OTAxMjIwMTUwMjVaMBUxEzARBgNVBAMTCmlsaXV5dC5jb20wggEiMA0GCSqGSIb3
DQEBAQUAA4IBDwAwggEKAoIBAQC9tRxp24PdjN7L7QqkcqsuzMnyOvoHsCLO0sz7
WKqVlz9u4r4Vome/0OZK+RfgNY8wWAPONoa5+tn++Y5kMPoRdBaTqjyZS47vrAUI
3sJSWeaMQGGHPhiSrCaKZXktNqugU8ewa0FRgoukCuvPENx8fEtQid4fZIW8UBm5
ajny/OzzCpw6kqVH14gn8bjg8YePdDxrdLHKifXmUzNQ2+EjFyrOzEpEHn7QGkkS
hHrwb31HKiZZyV/ymf6xOeNgBn0bdkzK0qMQWwelAsTODFddF+Q66b/++G/ZJ2Gx
GOuJyRIfbmqh3nzk6jLBMSOjYsquEJykdRSqXQ08E/LWIToXAgMBAAGjggMiMIID
HjAOBgNVHQ8BAf8EBAMCBaAwHQYDVR0lBBYwFAYIKwYBBQUHAwEGCCsGAQUFBwMC
MAwGA1UdEwEB/wQCMAAwHQYDVR0OBBYEFKoeBwz8lPHWLlfjKjnyAQG1LJ5GMB8G
A1UdIwQYMBaAFKhKamMEfd265tE5t6ZFZe/zqOyhMG8GCCsGAQUFBwEBBGMwYTAu
BggrBgEFBQcwAYYiaHR0cDovL29jc3AuaW50LXgzLmxldHNlbmNyeXB0Lm9yZzAv
BggrBgEFBQcwAoYjaHR0cDovL2NlcnQuaW50LXgzLmxldHNlbmNyeXB0Lm9yZy8w
JQYDVR0RBB4wHIIOYXBwLmlsaXV5dC5jb22CCmlsaXV5dC5jb20wgf4GA1UdIASB
9jCB8zAIBgZngQwBAgEwgeYGCysGAQQBgt8TAQEBMIHWMCYGCCsGAQUFBwIBFhpo
dHRwOi8vY3BzLmxldHNlbmNyeXB0Lm9yZzCBqwYIKwYBBQUHAgIwgZ4MgZtUaGlz
IENlcnRpZmljYXRlIG1heSBvbmx5IGJlIHJlbGllZCB1cG9uIGJ5IFJlbHlpbmcg
UGFydGllcyBhbmQgb25seSBpbiBhY2NvcmRhbmNlIHdpdGggdGhlIENlcnRpZmlj
YXRlIFBvbGljeSBmb3VuZCBhdCBodHRwczovL2xldHNlbmNyeXB0Lm9yZy9yZXBv
c2l0b3J5LzCCAQQGCisGAQQB1nkCBAIEgfUEgfIA8AB2AFWB1MIWkDYBSuoLm1c8
U/DA5Dh4cCUIFy+jqh0HE9MMAAABZqP6960AAAQDAEcwRQIgY0crPrUM5ZXcjY6Z
YpB41qrIlYYC8TXA5eTFp6x+jCYCIQCDrBFMUfPTNnxwFFsw+oSKVG9YR5/l6dNn
qZg5vTFxdgB2AGPy283oO8wszwtyhCdXazOkjWF3j711pjixx2hUS9iNAAABZqP6
9uYAAAQDAEcwRQIhAJvLNc7BpI5216K/wK+h03loTLim9jxbwIT28aUEvU11AiBy
XNYxFKSeaivwrT/5qJKJMeuUTo3ZRfg6I8wxSUlwnTANBgkqhkiG9w0BAQsFAAOC
AQEAcJR4Yq8KP83VPO8UamleNgVNnF4IYsnStN8vtU+v2Ki0CkevZ7K2QnN6o5Qv
G8T9WzuhRmL8WK1qspfhNtdPmEumrjWg/XB49fes+4HJaWwnbhA4xm5RenevsL22
1JqM23IQzhHstM4xApxhv+3jcNlO+sRv33HIdAyjsbMsyAvvqxTSuQ1o8ULX6+/M
+hFP1GV8K17ZF06yLUzsPElYL69Gnl1PNn9pOWBsS6iL6AtrQrhQUoXIxqv2JYFb
GJYvSkz2Ue4c06eRudrmcaRq/tX4TI+P9hrecc1BLV1aKcrpK9WNHddwOGnJN1vd
PZC7Ug2mbRldPxKUqsioVoKsDQ==
-----END CERTIFICATE-----
[Wed Oct 24 10:50:26 CST 2018] Your cert is in /root/.acme.sh/iliuyt.com/iliuyt.com.cer
[Wed Oct 24 10:50:26 CST 2018] Your cert key is in /root/.acme.sh/iliuyt.com/iliuyt.com.key
[Wed Oct 24 10:50:26 CST 2018] The intermediate CA cert is in /root/.acme.sh/iliuyt.com/ca.cer
[Wed Oct 24 10:50:26 CST 2018] And the full chain certs is there: /root/.acme.sh/iliuyt.com/fullchain.cer -
nginx设置
ssl_certificate /root/.acme.sh/iliuyt.com/fullchain.cer;
ssl_certificate_key /root/.acme.sh/iliuyt.com/iliuyt.com.key;
资料地址
注意
1、证书申请是有限制的,详情查看https://letsencrypt.org/docs/rate-limits/
2、nginx 配置文件名称应该与域名一样,例如iliuyt.com域名的配置文件应该也叫iliuty.com,这样acme才能识别
etcd 安装详细
创建目录
mkdir -p /etc/etcd.d/
mkdir -p /var/lib/etcd/
下载
wget https://github.com/coreos/etcd/releases/download/v3.2.9/etcd-v3.2.9-linux-amd64.tar.gz
解压
tar xzvf etcd-v3.2.9-linux-amd64.tar.gz
mv ./etcd-v3.2.9-linux-amd64/etcd /usr/bin
mv ./etcd-v3.2.9-linux-amd64/etcdctl /usr/bin
配置
cat <<EOF | tee /etc/etcd.d/etcd.conf
#节点名称
ETCD_NAME=$(hostname -s)
#数据存放位置
ETCD_DATA_DIR=/var/lib/etcd
EOF
服务配置
cat <<EOF | tee /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
Documentation=https://github.com/coreos/etcd
After=network.target
[Service]
User=root
Type=notify
EnvironmentFile=-/etc/etcd.d/etcd.conf
ExecStart=/usr/bin/etcd
Restart=on-failure
RestartSec=10s
LimitNOFILE=40000
[Install]
WantedBy=multi-user.target
EOF
启动
systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
shell
#!/bin/bash
ETCD_VER=v3.2.9
GITHUB_URL=https://github.com/coreos/etcd/releases/download
DOWNLOAD_URL=${GITHUB_URL}
mkdir -p /etc/etcd.d/
mkdir -p /var/lib/etcd/
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test
cd /tmp/etcd-download-test
wget ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf etcd-v3.2.9-linux-amd64.tar.gz
mv ./etcd-v3.2.9-linux-amd64/etcd /usr/bin
mv ./etcd-v3.2.9-linux-amd64/etcdctl /usr/bin
rm -rf /tmp/etcd-download-test
cat <<EOF | tee /etc/etcd.d/etcd.conf
#节点名称
ETCD_NAME=$(hostname -s)
#数据存放位置
ETCD_DATA_DIR=/var/lib/etcd
EOF
cat <<EOF | tee /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
Documentation=https://github.com/coreos/etcd
After=network.target
[Service]
User=root
Type=notify
EnvironmentFile=-/etc/etcd.d/etcd.conf
ExecStart=/usr/bin/etcd
Restart=on-failure
RestartSec=10s
LimitNOFILE=40000
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload && systemctl enable etcd -f && systemctl restart etcd
参数理解
--name:方便理解的节点名称,默认为default,在集群中应该保持唯一,可以使用 hostname
--data-dir:服务运行数据保存的路径,默认为 ${name}.etcd
--snapshot-count:指定有多少事务(transaction)被提交时,触发截取快照保存到磁盘
--heartbeat-interval:leader 多久发送一次心跳到 followers。默认值是 100ms
--eletion-timeout:重新投票的超时时间,如果 follow 在该时间间隔没有收到心跳包,会触发重新投票,默认为 1000 ms
--listen-peer-urls:和同伴通信的地址,比如 http://ip:2380,如果有多个,使用逗号分隔。需要所有节点都能够访问,所以不要使用 localhost!
--listen-client-urls:对外提供服务的地址:比如 http://ip:2379,http://127.0.0.1:2379,客户端会连接到这里和 etcd 交互
--advertise-client-urls:对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点
--initial-advertise-peer-urls:该节点同伴监听地址,这个值会告诉集群中其他节点
--initial-cluster:集群中所有节点的信息,格式为 node1=http://ip1:2380,node2=http://ip2:2380,…。注意:这里的 node1 是节点的 --name 指定的名字;后面的 ip1:2380 是 --initial-advertise-peer-urls 指定的值
--initial-cluster-state:新建集群的时候,这个值为new;假如已经存在的集群,这个值为 existing
--initial-cluster-token:创建集群的token,这个值每个集群保持唯一。这样的话,如果你要重新创建集群,即使配置和之前一样,也会再次生成新的集群和节点 uuid;否则会导致多个集群之间的冲突,造成未知的错误
所有以--init开头的配置都是在bootstrap集群的时候才会用到,后续节点的重启会被忽略
集群配置脚本
这里有坑
坑1
注意端口开放
坑2
注意参数端口配置,一定要参照官方配置
坑3
官方没有给出data-dir的配置,但是我们一定要配置,否则systemctl启动不起来
坑4
设置data-dir之前一定要清理目录,否则配置可能无法起效,删除目录要根据情况而定,如果不需要数据就删除data-dir
大坑5
最少要3台服务器,否则无法执行算法选举
#!/bin/bash
rm -rf /var/lib/etcd/
# 参数1获取IP的网卡
# 参数2为discovery的地址
LOCAL_IP=`ifconfig $1|sed -n 2p|awk '{ print $2 }'|awk -F : '{ print $2 }'`
NAME=`hostname -s`
rm -rf /var/lib/etcd/$NAME
mkdir -p /var/lib/etcd/$NAME
cat <<EOF | tee /etc/etcd.d/etcd.conf
ETCD_NAME=$NAME
ETCD_DATA_DIR=/var/lib/etcd/$NAME
ETCD_INITIAL_ADVERTISE_PEER_URLS=http://$LOCAL_IP:2380
ETCD_LISTEN_PEER_URLS=http://$LOCAL_IP:2380
ETCD_LISTEN_CLIENT_URLS=http://$LOCAL_IP:2379,http://127.0.0.1:2379
ETCD_ADVERTISE_CLIENT_URLS=http://$LOCAL_IP:2379
ETCD_DISCOVERY=$2
EOF
# 端口开放
iptables -I INPUT -p tcp -m multiport --dport 2379,2380 -j ACCEPT
iptables-save
systemctl daemon-reload && systemctl enable etcd -f && systemctl restart etcd
公共discovery
获取token地址
curl -w "\n" 'https://discovery.etcd.io/new?size=3'
https://discovery.etcd.io/fc3aae2dc792783b2a1e723622eb2951
查看节点
curl -w '\n' https://discovery.etcd.io/fc3aae2dc792783b2a1e723622eb2951
问题记录
执行
systemctl enable etcd
报错1
Failed to execute operation: Unit file is masked
解决
查看etcd.service文件内容是否为空。可能写入内容的时候写入失败
报错2
Failed to execute operation: File exists
解决
systemctl enable etcd -f
报错3
discovery: error #0: x509: failed to load system roots and no roots provided
discovery: cluster status check: error connecting to https://discovery.etcd.io, retrying in 16s
解决
查看容器是否支持HTTPS,discovery地址是否为https地址
graphql 基础学习
graphqlHTTP 参数理解
schema
graphql的定义模型,个人把他理解为api的定义,定义了有哪些api,api的参数,返回的参数等等
rootValue
graphql模型的具体实现,也就是说graphql schema中定义的字段、方法,如何实现,例如定义了getUser,具体如何实现需要rootValue来编写
context
可以自定义改参数,如果没有定义默认为请求的request
构建类型
graphql.GraphQLSchema
使用graphql.GraphQLSchema构建schema,参数分别是query和mutation两个字段,分别表示查询和变更
class GraphQLSchema {
constructor(config: GraphQLSchemaConfig)
}
type GraphQLSchemaConfig = {
query: GraphQLObjectType;
mutation?: ?GraphQLObjectType;
}
graphql.GraphQLObjectType
graphql.GraphQLObjectType用于构建对象类型,
-
name 对象的名称
-
interfaces
-
fields 对象包含的字段
-
isTypeOf
-
description 对象的描述
class GraphQLObjectType {
constructor(config: GraphQLObjectTypeConfig)
}type GraphQLObjectTypeConfig = {
name: string;
interfaces?: GraphQLInterfacesThunk | Array;
fields: GraphQLFieldConfigMapThunk | GraphQLFieldConfigMap;
isTypeOf?: (value: any, info?: GraphQLResolveInfo) => boolean;
description?: ?string
}
分享 javascript 重头再来
javascript 重头再来
隐式声明全局变量
先来看以下代码,输出为什么
const run = (a, b) => {
obj={
a:a,
b:b
}
result = a + b
let c = d = result
let f = g = obj;
return c
}
run(1, 2)
console.log(result)
console.log(d)
console.log(obj)
console.log(g)
result = 12
delete obj.a;
console.log(result)
console.log(d)
console.log(obj)
console.log(g)
// 输出
3
3
{ a: 1, b: 2 }
{ a: 1, b: 2 }
12
3
{ b: 2 }
{ b: 2 }
这里变量obj、result、d 、g做了隐式的全局变量声明。所以一定要注意在javascript中在使用变量时,先做声明。另外在javascript中尽量少用全局变量,因为你不知道你声明的变量是否会覆盖其他插件或他人代码的全局变量,这样会可能会导致严重的BUG。在commonJs中,提出了模块规范,使用module变量代表当前模块,通过exports表现对外接口,通过require加载模块内容,module可以很好的避免全局变量混乱的问题,每一个在module中声明的变量都是局部变量,每一个在modul中声明的方法未exports的都是私有方法。模块化开发更加方便协作开发。
扩展知识点
delete对全局变量的操作,判断以下速出内容
// 声明
var global_var=1;
// 未声明
global_novar=2;
// 隐身全局变量
(()=>{
global_funvar=3;
})
// 试图删除
console.log(delete global_var);
console.log(delete global_novar);
console.log(delete global_funvar);
// 测试该删除
console.log(typeof global_var);
console.log(typeof global_novar);
console.log(typeof global_funvar);
// 输出
false
true
true
"number"
"undefined"
"undefined"
for的理解
看以下代码,进行理解for循环的运行机制。
for (let arr = ['a', 'b', 'c'], i = arr.length; console.log(i), i--; console.log(arr[i]))
{
console.log(i)
}
标准库对for语法的解释
initialization:一个表达式或变量声明。可省略条件
condition:是否执行下一次循环的条件。可省略条件
final-expression:每次循环最后执行的表达式,可省略条件
for ([initialization]; [condition]; [final-expression])
statement
不常见的for循环使用
let arr = ['a', 'b', 'c'];
let index = arr.length;
let newArr=[];
for (;index--;newArr.push(arr[index]));
console.log(newArr); // ['c','b','a']
// 变形
for (;index--;){
newArr.push(arr[index])
}
// 变形
for (;;newArr.push(arr[index])){
if(!index){
break;
}
index--;
}
// 变形
for(;;){
if(!index){
break;
}
index--;
newArr.push(arr[index]
}
// 相当于while
while(index){
index--;
newArr.push(arr[index]
}
花括号
看以下代码判断会输出什么。
function func() {
return
{
name : "Batman"
}
}
console.log(func())
出现这种情况是因为javascript的分号补全机制,javascript运行时会默认在一行的结束位置输出一个分号。所以在规范括号的格式时候,应保持左花括号在当前行,而非换行,保持一致统一。
理解括号、函数声明、函数表达式、立即执行函数
// 函数声明
function foo(){
}
// 函数表达式
const bar = function foo(){
}
// 括号运算符
const a=(1+2)*3
// 立即执行函数
(function foo(){
console.log(1);
}())
函数声明就是声明一个函数,很简单,函数表达式指的是一个函数在表达式中,那么这个函数是不会被声明的,表达式无法声明函数。大部分含有运算符号的都是表达式。
理解立即执行函数
立即执行函数最外层的括号是运算符,这样导致括号里的函数声明隐式转换为表达式,里面的括号也是运算符,当括号前有函数的话,运行函数,如果没有函数的话运行括号里的内容,如果括号里没有内容,会直接报错。
通过后台输出json,前端动态生成页面
form-create:http://www.form-create.com/v2/guide/global-api.html#setparser
思路:页面加载前访问api获取所有页面json,然后vue进行渲染组件,然后渲染路由,最后挂载页面
mac 通过命令行更改代理配置
# 设置自动发现代理
networksetup -setproxyautodiscovery <networkservice> <on off>
# 设置自动代理配置
networksetup -setautoproxyurl <networkservice> <url>
# http代理
networksetup -setwebproxy <networkservice> <on off>
networksetup -setwebproxy <networkservice> <url><port>
# https代理
networksetup -setsecurewebproxy <networkservice> <on off>
networksetup -setsecurewebproxy <networkservice> <url><port>
#其他类似可以去网上直接查networksetup即可
NSSH 通过Node对SSH密钥管理
NSSH
通过NSSH可以管理SSH密钥,一条命令,生成密钥,拷贝到服务器,添加配置,通过别名进行无密码登陆。
测试了Windows和ubuntu,没有mac电脑,没有测试mac,如果有BUG大家给我留言,谢谢。
功能
* 一键创建密钥,并拷贝的远程主机,通过别名直接登录
* 对SSH密钥可以创建,删除,查看列表
* 通过别名管理密钥
* 选择和设置默认密钥
* 拷贝密钥到远程主机
* 对SSH 密钥别名进行重命名
安装
npm install nssh -g
使用
$ nssh
Usage: nssh <command> [options]
Options:
-V, --version output the version number
-h, --help output usage information
Commands:
init 初始化SSH key库
ls 查看SSH key列表
use <name> 切换SSH key
rm <name> 删除SSH key
rn <name> <new> 修改SSH key名称
create <name> 创建SSH key
copy <name> <host> 创建SSH key
help [cmd] display help for [cmd]
首次使用
$ nssh init
✔ 密钥库初始化完成
密钥库地址为:C:\Users\liuyt\.nssh\
注意:如果您在$home/.ssh已经有id_rsa、id_rsa.pub密钥对,那么初始化将会将其移动到$HOME/.nssh/default
创建SSH KEY,通过别名登录
$ nssh create work1 -t 3 -h [email protected]
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in C:\Users\liuyt\.nssh\.tmp\id_rsa.
Your public key has been saved in C:\Users\liuyt\.nssh\.tmp\id_rsa.pub.
The key fingerprint is:
SHA256:IoWtg5M1+7VUANVB/JdU2EYVGjzMh5he/iSkwNfjRp4 liuyt@DESKTOP-48BGCR8
The key's randomart image is:
+---[RSA 2048]----+
| .o++o.B..**|
| o +o+ %=.o|
| + o =.Oo=o |
| + = . o.Eo. |
| + = . S ..+ |
| . + + . . |
| . . |
| |
| |
+----[SHA256]-----+
密钥已生成
ssh-copy-id: INFO: Source of key(s) to be installed: "C:\Users\liuyt\.nssh\.tmp\id_rsa.pub"
ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
[email protected]'s password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '[email protected]'"
and check to make sure that only the key(s) you wanted were added.
密钥拷贝完成,主机:[email protected]
配置添加完成,配置地址:C:\Users\liuyt\.ssh\config
✔ 密钥创建成功
$ ssh work1
Welcome to Ubuntu 16.04.2 LTS (GNU/Linux 4.4.0-63-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Welcome to Alibaba Cloud Elastic Compute Service !
Last login: Thu Dec 7 16:56:53 2017 from 2.3.1.1
root@iZ1193ih9wgZ:~#
创建密钥
$ nssh create
Usage: nssh-create <name>
Options:
-t --type <n> 0:仅创建SSH key 1:创建SSH key并生成配置 2:创建SSH key 并拷贝到远程主机 3、创建SSH key,生成配置并拷贝到远程主机
-h --host [value] 主机地址
-h, --help output usage information
Examples:
# 通过nssh创建密钥
$ nssh create node0
# 通过nssh创建密钥并生成配置
$ nssh create node1 -t 1 -h [email protected]
# 通过nssh创建密钥并生成github配置
$ nssh create github.com -t 1 -h [email protected]
# 通过nssh创建密钥并拷贝到192.168.0.2
$ nssh create node1 -t 2 -h [email protected]
# 通过nssh创建密钥,生成配置并拷贝到192.168.0.2
$ nssh create node1 -t 3 -h [email protected]
查看密钥列表
$ nssh ls
✔ 找到2个密钥
-> test (current)
test2
切换密钥
$ nssh use test2
✔ 当前使用的密钥:test2
$ nssh ls
✔ 找到2个密钥
test
-> test2 (current)
重命名密钥
$ nssh rn test2 nsew
✔ test2重命名为:new
$ nssh ls
✔ 找到2个密钥
-> new (current)
test2
删除密钥
$ nssh rm new
? 确定要删除 new 吗? (Y/n)
? 确定要删除 new 吗? Yes
✔ 删除密钥new完成
$ nssh ls
✔ 找到1个密钥
test2
拷贝已存在的密钥到主机
$ nssh copy
Usage: nssh-copy <name> <host>
Options:
-h, --help output usage information
Examples:
# 通过nssh拷贝密钥到远程主机
$ nssh copy node1 [email protected]
感谢
NSSH的大部分思路来源与SKM,参考了大部分代码,只是通过Node实现了而已,在此特别声明,非常感谢。
Licence
VUE源码学习(1)-vue核心内容简单实现1
知识点
- 虚拟dom的使用createDocumentFragment,关机在于可以通过更改node的textContent来更新数据
- 属性设置的使用defineProperty,如何通过defineProperty来设置getter 和 setter,这里非常重要
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Simple Vue</title>
</head>
<style>
#app {
text-align: center;
}
</style>
<body>
<div id="app">
<p id="vdom">初始化中</p>
</div>
</body>
<script>
// 被监听的数据
let data = { message: "" };
// 虚拟dom集合
let nodes = [];
// 设置虚拟dom
let el = document.querySelector("#app");
const fragment = document.createDocumentFragment();
let child = document.querySelector("#vdom");;
fragment.appendChild(child)
nodes.push(fragment.childNodes[0])
el.appendChild(fragment)
// 设置监听
let watcher = {
update() {
// 更新dom
nodes[0].textContent = data.message
}
};
// 监听和分发集合
let dep = {
subs: [],
notify() {
this.subs.forEach(item => {
item.update();
})
}
}
// 设置监听数据的getter和setter
Object.defineProperty(data, 'message', {
enumerable: true,
configurable: true,
get() {
return this.value;
},
set(newVal) {
// 如果值一样,不更新dom
if (newVal === this.value) {
return;
}
this.value = newVal;
// 触发所有监听
dep.notify();
}
});
// 添加监听到集合中
dep.subs.push(watcher)
// 定时更新数据,更新dom
setInterval(() => {
data.message = "当前时间戳为:" + Date.now()
}, 1000);
</script>
</html>
mysql 数据导出与导入
DataGrip 导出
- 选中数据库右键Dump with 'mysqldump'
- 设置mysqldump的路径,如果不知道mysql装在什么地方,可以在系统偏好设置->mysql->configuration 看一下mysql安装目录,mysqldump在mysql安装目录的bin下面
- 设置out-path
- 可以在最下面的输入框输入一些自己想要设置的参数
- 点击run即可
DataGrip导出出现的问题
点击run时报错
Unknown table 'COLUMN_STATISTICS' in information_schema
这个是因为版本的问题,新版本的mysqldump不兼容旧版本的mysql
相关资料
我们可以在out-path 下面生成命令的那个输入框里输入--column-statistics=0 即可
mysqldump
mysqldump是一个单独的插件,可以单独拿出来使用,我们可通过mysqldump直接进行命令行导出数据,具体使用方法请看文档
导入数据库
因为我们导出的数据库文件一般都比较大,通过工具打开再进行导入非常卡,所以我们使用命令行导入非常快,以下是两种命令行导入的方式 参考资料
-
在未连接数据库的情况下输入mysql -h 服务器名称或地址 -u用户名称 -p 数据库名 <脚本全路径
如:mysql -h localhost -uroot -p mydatabase <~/product.sql -
在已经连接数据库的情况下,此时命令提示符为mysql>,输入source 脚本全路径 或者 . 脚本全路径 如:source ~/product.sql
构建ETCD镜像
本地版本
FROM alpine:3.2
ENV ETCD_VERSION 3.2.10
COPY etcd-v${ETCD_VERSION}-linux-amd64.tar.gz etcd.tar.gz
RUN tar xzf etcd.tar.gz && \
mv etcd-*/etcd /bin/ && \
/bin/etcd --version && \
rm -rf etcd.tar.gz etcd-
VOLUME /data
EXPOSE 2379 2380
ENTRYPOINT ["etcd"]
网络下载版本
FROM alpine:3.2
ENV ETCD_VERSION 3.2.10
COPY wget -o etcd.tar.gz https://github.com/coreos/etcd/releases/download/v${ETCD_VERSION}/etcd-v${ETCD_VERSION}-linux-amd64.tar.gz
RUN tar xzf etcd.tar.gz && \
mv etcd-*/etcd /bin/ && \
/bin/etcd --version && \
rm -rf etcd.tar.gz etcd-
VOLUME /data
EXPOSE 2379 2380
ENTRYPOINT ["etcd"]
docker 基础
docker run
- --rm 当容易运行结束后自动删除,适合测试和使用--volume进行挂载的时候使用
- --user 设置当前docker运行时的用户
- --volume 挂载目录,例如redis,mongodb的数据不能因docker删除而删除,所以需要保持在实体机上
null
面试题-带标签的模版字符串
题目
下列代码最终返回什么
let print = function(strs, ...arg) {
let rtn = "";
strs.map((str, index) => {
rtn += str;
if (index < arg.length) {
rtn += arg[index];
}
});
console.log(rtn);
};
let person = "liuyt";
let age = 25;
print`that ${person} is a ${age}`;答案
返回 that liuyt is a 25
why
在模版字符串前加一个函数,函数会执行,参数依次是根据${}分割的字符串数组和${}计算后的值
vue 源码分析草稿
VUE初始化
1、package.json查看构建
2、构建执行了script/build.js
3、build调用了config.js,可以看到config中配置了各种环境的构建参数
4、我们看一下浏览器开发环境的构建 web-full-dev,这里引用了web/entry-runtime-with-compiler.js
5、看一下web/entry-runtime-with-compiler.js中重写了$mount,代码可以看到在解析完模板后重新调用vue原型的$mount
6、Vue引用来自./runtime/index文件
7、Vue引用来自/core/index文件
8、Vue 来源于 '/core/instance/index'
9、/core/instance/index 定义了真正的vue。调用Vue时,会执行一系列mixin,
10、以下为初始化mixin,这里主要用于拆分模块进行定义
initMixin:vue初始化方法
stateMixin:数据方法定义
eventsMixin;事件方法初定义
lifecycleMixin:声明周期方法定义
renderMixin:渲染方法定义
11、除了这些之外,在core/index中还进行定义了全局api方法
initGlobalAPI:全局api定义,方法定义在global-api/index下
全局定义主要方法有use,mixin,extend,ASSET_TYPES,set,delete,nextTick等等
调试方法
vue cli通过在配置文件中设置vue别名实现(这里设置vue为别名会出现问题,我会改成别的名字进行引用,例如Avue,Bvue这样)
const path = require("path");
function resolve(dir) {
return path.join(__dirname, dir);
}
module.exports = {
chainWebpack: config => {
config.resolve.alias.set("vue", resolve("node_modules/vue/dist/vue.esm.js"));
}
};
webpack的话同样的道理,更改别名引用即可
数据驱动
起步
1、Vue构造函数中调用了_init方法,init方法在initMixin时初始化好了,
2、可以看到initMixin中_init方法进行了一系列对vue对象实例的初始化,
3、其中initState对数据进行了初始化。
4、initState分别对props,methods,data,computed,watch进行了初始化
5、initData对data进行了初始化,然后进行了校验判断(props,method判断),属性代理(proxy),最好做了一个observe监听
6、watcher observe dep之间的关系 watcher定义后调用get方法,get方法设置Dep.target,同时设置触发update,update获取observe数据,调用observe的get,
get收集Dep.target,即watcher,放入dep的subs里,observe被调用set时候,set调用dep的notify,通知watcher的update进行更新
7、watcher和dep是多对多的关系,watcher存了dep的id数组,dep中存了watcher实例数组,在收集watcher的时候会进行去重判断,否则就无限循环了
挂载
1、如果有render函数,会直接执行render函数,否则会将templete转换成render函数,最终执行mountComponent方法
2、mountComponent 方法来自 core/instance/lifecycle,下面看下 mountComponent 都做了什么
- 判断render 函数是否存在,否认默认 render空节点
- 触发 beforeMount 生命周期事件
- 执行 _update 方法
- 创建一个渲染watcher,定义watcher触发事件处理和 触发 beforeUpdate 声明周期事件
- 判断是否为 vnode 元素,如果是,触发 mounted 生命周期事件
- 返回组件
render 函数
1、_render就是吧VUE的createElement函数穿进去,具体createElement怎么去实现可以参照文档即可,最终返回vnode。
2、这里需要看一下render函数是可以返回vnode数组的,会默认取第一个元素,如果是非vnode元素,会创建一个空vnode。vnode中会挂载当前组件的vm
什么是虚拟dom
1、个人理解就是把dom的结构描述存在内存里,在内存里进行操作,只渲染最终的结果。
createElement
1、createElement 其实就是将相关的参数赋值给vnode,生成vnode节点
2、normalizationType 这个参数是用来区分是系统编译的render还是用户手写的
3、vnode生成时候,会对tag走一些判断,判断是注册的组件还是普通的vnode
update
1、只有在首次渲染和数据响应时进行渲染执行。
2、update最终将vnode渲染成真正的dom元素,核心方法__patch__,具体实现在src/platforms/web/runtime/patch.js中,根据平台不同,目录也不同
3、这里注意下vm._vnode,每次upadte都会将子vnode设置到当前vm的_vnode下
渲染
render具体做了什么?
render生成一个vnode,vnode中挂载了子组件的vm
所以在循环中判断vnode是组件的话,直接在vnode中获取vm,然后进行init,
然后再调用mount进行循环,这样就可以递归渲染下去。
我这边简单的理解vnode是vm的子类,vnode同时又包含了自己的vm,这样就形成了递归。
递归中非常重要的一个函数componentVNodeHooks
// 实例化vm
var child = (vnode.componentInstance = createComponentInstanceForVnode(vnode, activeInstance));
// 挂载vm 进行循环
child.$mount(hydrating ? vnode.elm : undefined, hydrating);
$mount->mount->mountComponent->watcher->getter
->vnode=vm.render->vm._update(vnode)->vm.patch
->patch->createElm->createComponent
->componentVNodeHooks->vnode转vm->继续递归
->判断vnode
->是组件
-> 如果有parentElm就插入vnode.elm(dom元素)
->非组件
->document.createElement创建dom
->将当前元素插入父类元素(vnode.elm)
patchVnode
1、相同节点直接返回vnode
2、key相同的静态节点或克隆节点或只渲染一次的节点替换dom(elm)和vm(componentInstance)
updateChildren
开始
必须有oldStart和oldEnd
对比逻辑
oldStart->newStart
oldEnd->newEnd
oldStart->newEnd
oldEnd->newStart
都不符合
1、获取old->key组成对象OldKey
2、判断oldKeys[new.key]是否存在
3、如果不存在遍历old查找new的key
4、如果都没有就创建dom
5、如果有就对比vnode,相同就继续patchVnode
6、否则就创建dom
循环开始的步骤直到结束
如果old循环完了,那就把剩下的new创建dom添加到当前循环完的位置
如果new循环完了,那就把剩下的old删除
// 未编译
<template>
<div id="app">
<h1>{{ computed }}</h1>
<button @click="change">更改</button>
</div>
</template>
<script>
export default {
name: "app",
data: function() {
return {
message: "asdfasfasdf",
none: "none",
};
},
computed: {
computed: function() {
return this.none+"333"
},
},
methods: {
change() {
this.none = "set";
},
},
};
</script>
// 编译后
var render = function() {
var _vm = this
var _h = _vm.$createElement
var _c = _vm._self._c || _h
return _c("div", { attrs: { id: "app" } }, [
_c("h1", [_vm._v(_vm._s(_vm.computed))]),
_c("button", { on: { click: _vm.change } }, [_vm._v("更改")])
])
}
var staticRenderFns = []
render._withStripped = true
export { render, staticRenderFns }
解决国内 Mac 安装 brew 速度很慢问题
一、获取 install 文件
把官网给的脚本拿下来
curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install >> brew_install
二、更改脚本中的资源链接
这里我替换成清华大学的镜像,修改如下两句:
BREW_REPO = “https://github.com/Homebrew/brew“.freeze
CORE_TAP_REPO = “https://github.com/Homebrew/homebrew-core“.freeze
更改为这两句
BREW_REPO = "https://mirrors.ustc.edu.cn/brew.git".freeze
CORE_TAP_REPO = "https://mirrors.ustc.edu.cn/homebrew-core.git".freeze
也可以换成别家的。
三、运行脚本
/usr/bin/ruby brew_install
安装成功后,输入如下命令检查是否安装成功:
注,添加清华大学镜像源:
echo 'export HOMEBREW_BOTTLE_DOMAIN=https://mirrors.tuna.tsinghua.edu.cn/homebrew-bottles'>> ~/.bash_profile
source ~/.bash_profile
注,
最新版的已经没有CORE_TAP_REPO参数了,可以直接去GitHub或者去镜像源下载,然后放在/usr/local/Homebrew/Library/Taps/homebrew/homebrew-core目录下(没有目录需要创建目录),再运行一次脚步安装。
最简单的方法是科学上网,因为公司网络访问github很奇怪,ss也无法下载GitHub,所以使用的手机网络,一键完成
面试题整理
// 第一题
// 思路
// 截断2部分需要一个节点,截断三部分需要两个节点,依次类推,N个部分需要N-1个节点
// 成本等于节点的值相加,那么只要找到所有节点的值进行排序,取最小的N-1数量个便是最小成本
// 题目指出两个节点相减大于1 我们把这个值设为M,也就是说两个节点不是紧连着的,那么要排除N-1个节点中有相连的节点
// 那么我们最多找出 (N-1)(1+M)的最小节点,然后排除两个连续值之间的间距大于M,也就是数组的下标相减绝对值大于M
// 从(N-1)(1+M)个最小节点中找出N-1个值即完成
function demo1(numbers, count) {
let newNums = numbers.slice(1, numbers.length - 1);
let minNumCount = (count - 1) * 2
let minNums = new Array(minNumCount).fill({
index: -1,
value: 1000000
})
newNums.map((value, index) => {
for (let minIndex in minNums) {
let minVal = minNums[minIndex];
if (minVal.value >= value) {
minNums.splice(minIndex, 0, {
value,
index
})
break;
}
}
if (minNums.length > minNumCount) {
minNums = minNums.slice(0, minNumCount)
}
})
let indexs = []
let values = []
for (let index in minNums) {
let item = minNums[index]
if (index == 0 || Math.abs(item.index - indexs[indexs.length - 1]) > 1) {
// 因为之前去掉了第一个元素,所以下标要加一才能对应上原来的数组下标
indexs.push(item.index + 1)
values.push(item.value)
}
if (values.length >= (count - 1)) {
break;
}
}
console.log(`成本最低断开方案 (${indexs.join(',')}):成本是 ${values.join('+')}=${eval(values.join("+"))}`)
}
// 第二题
function demo2(numbers, count) {
// 参数判断
if (count <= 0) return;
if (Array.isArray(numbers) && numbers.length < 2) return;
numbers.sort(function (a, b) {
if (!Number.isInteger(a) || !Number.isInteger(b)) throw '数组元素必须为数字'
return a - b;
});
let maxNums = numbers.slice(-count).reverse();
console.log(`最大的${count}个元素为 ${maxNums.join(',')}`);
}
// 第三题
// 思路
// 找到最大的正方形,找不到正方形,返回0
// 移动,否则回滚
// 判断是否到底部,到底部返回
function demo3() {
function formatData(list) {
let newList = [];
list.map((item, y) => {
let xList = []
item.map((subitem, x) => {
let xx = (subitem ? '1' : '0');
let yy = xx;
if (newList.length > 0) {
if (newList[y - 1]) {
yy = newList[y - 1][x].yy + yy;
}
if (xList[x - 1]) {
xx = xList[x - 1].xx + xx;
}
}
xList.push({
xx,
yy
})
})
newList.push(xList)
})
return newList;
}
function getMaxLen() {
let width = list[0].length;
let height = list.length;
return width >= height ? height : width;
}
let list = [
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
];
let newList = formatData(list);
let maxLen = getMaxLen(list);
function exec() {
// 获取最大的正方形
let isSuccess = getMaxSquare();
if (!isSuccess) {
console.log('没有可以移动到右下角的正方形', maxLen)
return maxLen;
}
let isMv = mvTo(0, 0);
if (!isMv) {
// 缩减正方形大小
maxLen--;
return exec()
}
console.log('success', maxLen)
return maxLen;
}
// 移动正方形
function mvTo(x, y) {
if (maxLen === 1) {
console.log('记录', x, y)
}
if (x == 2 && y == 3) {
console.log('记录', x, y)
}
// 判断是否移动到右下角
if (y + maxLen >= newList.length && x + maxLen >= newList[0].length) {
return true
}
let downMv = function () {
if (isSquare(x, y + 1)) {
return mvTo(x, y + 1);
}
return false;
}
let rightMv = function () {
if (isSquare(x + 1, y)) {
return mvTo(x + 1, y);
}
return false;
}
if (downMv()) {
console.log('向下移动')
return true;
} else if (rightMv()) {
console.log('向右移动')
return true;
} else {
return false;
}
}
// 获取最大正方形
function getMaxSquare() {
// 长度小于0,返回false
if (maxLen <= 0) {
return false
}
// 正方形返回true
if (isSquare(0, 0)) {
return true;
}
// 减小宽度
maxLen--;
return getMaxSquare()
}
// x,y为正方形右上角位置
function isSquare(x, y) {
// 标识符
let tag = ''.padEnd(maxLen, '1')
// 获取右下角元素
x = maxLen + x - 1;
y = maxLen + y - 1;
// 判断右下角是否存在,不存在返回false
if (!newList[y] || !newList[y][x]) {
return false;
}
// 获取x,y字符串进行对比
let { xx, yy } = newList[y][x];
// 获取元素
xx = xx.slice(-maxLen)
yy = yy.slice(-maxLen)
// 判断是否为长度为width的正方形
return xx === yy && xx === tag;
}
exec();
}
// 第四题
function demo4() {
let list = [
[1, 2, 3, 4],
[14, 15, 16, 5],
[13, 20, 17, 6],
[12, 19, 18, 7],
[11, 10, 9, 8],
];
let width = list[0].length;
let height = list.length;
let DIR = {
RIGHT: 0,
DOWN: 1,
LEFT: 2,
UP: 3
};
// 设置起始坐标为-1,0
let x = -1;
let y = 0;
let currentDir = DIR.RIGHT;
// 转向获取数字
function turn() {
if ([DIR.RIGHT, DIR.LEFT].includes(currentDir)) {
height--;
} else {
width--;
}
if (currentDir === DIR.UP) {
currentDir = DIR.RIGHT
}
currentDir++;
}
// 获取数字
function getNum() {
let len = 0;
// 根据方向获取长度
if ([DIR.RIGHT, DIR.LEFT].includes(currentDir)) {
len = width;
} else {
len = height;
}
// 根据长度判断是否结束
if (len == 0) {
return;
}
// 循环长度
for (let i = 0; i < len; i++) {
switch (currentDir) {
case DIR.RIGHT:
x++;
break;
case DIR.LEFT:
x--;
break;
case DIR.DOWN:
y++;
break;
case DIR.UP:
y--;
break;
default:
break;
}
console.log(list[y][x])
}
// 转向,缩减长度
turn();
// 回调获取数字
getNum();
}
getNum();
}
// 第五题
function demo5() {
console.log(第一个手机确定范围,第二个手机确定精度, 假如总次数N不变,那么第一个手机第一次扔N层,如果碎了,第二个手机从1开始扔到N-1层找出破碎的楼层 如果第一个手机第一次没碎,那么第一个手机第二次扔N+(N-1)层, 如果还没碎,那么第三次扔N+(N-1)+(N-2)层, 因为总次数不变,为了保证第二个手机的精确度,所以第一个手机每扔一次,下一次的要增加的楼层就减少一层。 那么如果第一个手机扔了N次都没有碎,那么也就是N+(N-1)+(N-2)+...+(N-N)>=100 等差数列求和N(N+1)/2>=100,通过计算最优解N=14)
}
koa2 + webpack 热更新
网上有很多express+webpack的热更新,但是koa2的很少,这两天研究了一下子,写一个简单的教程。
1、需要的包
- webpack:用于构建项目
- webpack-dev-middleware:用于处理静态文件
- webpack-hot-middleware:用于实现无刷新更新
2、webpack.config配置
- entry配置webpack-hot-middleware脚本
entry: {
app:["webpack-hot-middleware/client?noInfo=true&reload=true","./src/module1.js","./src/module2.js"],
app2:["webpack-hot-middleware/client?noInfo=true&reload=true","./src/module2.js","./src/module3.js"]
}
- plugins配置HotModuleReplacementPlugin插件用于热更新
plugins: [
new webpack.HotModuleReplacementPlugin()
]
3. koa2支持的中间件webpack-dev-middleware的实现
// devMiddleware.js
const webpackDev = require('webpack-dev-middleware')
const devMiddleware = (compiler, opts) => {
const middleware = webpackDev(compiler, opts)
return async (ctx, next) => {
await middleware(ctx.req, {
end: (content) => {
ctx.body = content
},
setHeader: (name, value) => {
ctx.set(name, value)
}
}, next)
}
}
module.exports=devMiddleware;
4. koa2支持的中间件webpack-hot-middleware的实现
// hotMiddleware.js
const webpackHot = require('webpack-hot-middleware')
const PassThrough = require('stream').PassThrough;
const hotMiddleware = (compiler, opts) => {
const middleware = webpackHot(compiler, opts);
return async (ctx, next) => {
let stream = new PassThrough()
ctx.body = stream
await middleware(ctx.req, {
write: stream.write.bind(stream),
writeHead: (status, headers) => {
ctx.status = status
ctx.set(headers)
}
}, next)
}
}
module.exports = hotMiddleware;
5. koa2实现添加中间件
const Koa = require('koa');
const app = new Koa();
const serve = require('koa-static');
const webpack = require("webpack");
const webpackConfig = require("./webpack.config");
const devMiddleware = require("./devMiddleware");
const hotMiddleware = require('./hotMiddleware');
const compiler = webpack(webpackConfig);
app.use(devMiddleware(compiler));
app.use(hotMiddleware(compiler));
app.use(serve(__dirname + "/dist/", {extensions: ['html']}));
app.listen(3000, () => {
console.log('app listen at 3000')
});
ok,现在可以运行了
我的机器相关配置整理
终端
zsh
apt 更新
apt update
安装zsh
apt install zsh
默认shell改为zsh
chsh -s /bin/zsh
安装zsh-autosuggestions语法历史记录插件
1、下载项目
git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
2、修改~/.zshrc插件配置
plugins=(zsh-autosuggestions)
安装autojump
1、下载并安装
cd ~/.oh-my-zsh/plugins
git clone git://github.com/joelthelion/autojump.git
cd autojump
./install.py
# 卸载
./uninstall.py
2、在shell下添加一下命令
vim .zshrc
[[ -s ~/.autojump/etc/profile.d/autojump.sh ]] && . ~/.autojump/etc/profile.d/autojump.sh
VIM
色彩下载
vivify是一个可以选择或自己配色vim的站点,完成后下载放在vim下的colors中即可,如果没有colors文件夹,创建一个即可
vim 配置
syntax on
set number
set ruler
set background=dark
colorscheme solarized
set fileencodings=utf-8,ucs-bom,gb18030,gbk,gb2312,cp936
set termencoding=utf-8
set encoding=utf-8
Docker Compose
下载
sudo curl -L "https://github.com/docker/compose/releases/download/1.23.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
设置执行权限
chmod +x /usr/local/bin/docker-compose
docker-compose --version
docker compose 启用mysql
创建docker compose 目录
mkdir -p ~/docker_compose/mysql
创建 docker-compose.yml 文件
vim docker-compose.yml
version: '3'
services:
db:
image: mysql:5.7
command: --default-authentication-plugin=mysql_native_password
restart: always
container_name: mysql
environment:
MYSQL_ROOT_PASSWORD: lyt5217199
volumes:
- /var/lib/mysql:/var/lib/mysql
ports:
- '3306:3306'
redis:
restart: always
image: redis:3.2
volumes:
- /var/lib/redis:/data
ports:
- "6379:6379"
command: redis-server --appendonly yes --requirepass 123456
运行docker
docker-compose up -d
开放3306端口,并保存
apt install iptables
iptables -I INPUT -p tcp --dport 3306 -j ACCEPT
iptables-save
SSH 配置
解决隔一段时间ssh断开问题
sudo vim /etc/ssh/ssh_config
添加两行配置,即每隔10秒,向服务器发出一次心跳。若超过10次请求,都没有发送成功,则会主动断开与服务器端的连接
ServerAliveInterval 10
ServerAliveCountMax 10
报错解决方案
登录后报错,manpath: can't set the locale; make sure $LC_* and $LANG are correct
apt install -y language-pack-zh-hans
vscode配置
终端快捷键
// 将按键绑定放在此文件中以覆盖默认值auto[]
[
// 终端配置
{
// 终端向上切换
"key": "ctrl+oem_3 ctrl+up",
"command": "workbench.action.terminal.focusPrevious"
},
{
// 终端向下切换
"key": "ctrl+oem_3 ctrl+down",
"command": "workbench.action.terminal.focusNext"
},
{
// 终端获取焦点
"key": "ctrl+oem_3 ctrl+oem_3",
"command": "workbench.action.terminal.focus"
},
{
// 关闭终端
"key": "ctrl+oem_3 ctrl+w",
"command": "workbench.action.terminal.kill"
},
{
// 运行文本在终端
"key": "ctrl+oem_3 ctrl+r",
"command": "workbench.action.terminal.runSelectedText"
},
{
// 切割终端
"key": "ctrl+oem_5",
"command": "-workbench.action.terminal.split",
"when": "terminalFocus"
}
]
vscode eslint 和 prettier整理
1、vscode eslint读取配置顺序,.eslintrc.js>package.json
2、vscode prettier读取配置顺序 user setting< .prettierrc < package.json,不会覆盖权重小的文件,是直接不读取。例如在package.json中设置了prettier:{},无论prettierrc 设置什么都不会读取,因为不会再读取这些文件
浅拷贝和深拷贝
1、为什么会有浅拷贝和深拷贝
首先要知道JS中数据结构分为值类型和引用类型。
值类型直接指向一块内存,内存中村放的是变量的值。
引用类型也会指向一块内存,内存中存放的是变量值的地址,而不是真的值本身。
那么引用类型中,值的变化会导致所有指向这块内存地址的变量获得的返回值都发生改变。在实际开发中,有时候我们并不希望如此,所以就出现了拷贝。
那么拷贝的含义就是把引用类型的值,重新开一个新的内存,放进去,这样在更改原来的值时,现有的值不会更改,引用类地址的变量也就不会更改了。
2、浅拷贝
浅拷贝只会获取对象的第一层属性或方法,如果属性依旧是一个对象,那么浅拷贝不会对属性里的对象的值再次开一个内存做存储,而是依旧沿用原来的地址。在简单的对象中使用浅拷贝即可。
3、浅拷贝的实现
大部分原声的函数返回一个新的对象都是浅拷贝。
例如:
1、Object.assign();
2、Array.concat();
4、深拷贝
深拷贝是对对象中每一层的对象进行拷贝。浅拷贝中,不是完整的拷贝。如果属性的对象的值发生变化依然能够影响拷贝后的对象,所以就需要深拷贝。
5、深拷贝的实现
如果是简单的对象,没有方法,那么最简单的方式是通过JSON进行转换,能满足大部分需求。需要注意的是,浏览器是否支持JSON
代码:
var newObject = JSON.parse(JSON.stringify(oldObject));
自定义函数:
function deepCopy(o) {
var out, v, key;
out = Array.isArray(o) ? [] : {};
for (key in o) {
v = o[key];
out[key] = (typeof v === "object") ? deepCopy(v) : v;
}
return out;
}
参考
stackoverflow地址:
http://stackoverflow.com/questions/122102/what-is-the-most-efficient-way-to-deep-clone-an-object-in-javascript/122704#
我的书签
SSH无密别名登录
检查服务器SSH登录
# 打开配置文件
vi /etc/ssh/sshd_config
# 修改此项为允许root登录
PermitRootLogin yes
# 重启SSH
service ssh restart
# 按提示设置root用户密码
passwd
客户端生成密钥
# 密钥生成
ssh-keygen
# 拷贝到服务器
ssh-copy-id [email protected]
# 拷贝指定密钥到服务器
ssh-copy-id -i ~/.ssh/id_rsa_tmp.pub [email protected]
创建或修改config
# 打开ssh目录
cd ~/.ssh
# 创建或打开文件config(没有后缀名)
# 添加以下内容
# node0节点服务器
Host node0
HostName 192.168.0.2
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa_tmp
User root
测试
ssh node0
正则表达式基础
正则表达式特殊字符
开头 ^
匹配字符串的开头
结尾 $
匹配字符串的结尾
匹配空白符 \s
匹配非空白符 \S
匹配0次或多次 * 等价于{0,}
匹配1次或多次 + 等价于{1,}
匹配任何单个字符 .
匹配前面表达式0次或1次 ?
匹配前面表达式0次或1次,等价于{0,1}
const input = 'aaa';
const regexp1 = /a+/
// 非贪婪模式
const regexp2 = /a+?/
const regexp3 = /a{0,1}/
let ret1 = regexp1.exec(input);
let ret2 = regexp2.exec(input);
let ret3 = regexp3.exec(input);
console.log(ret1, ret2, ret3)
多次重复 {n} {n,m}
{n}表示重复次数
{n,m} n表示最少重复次数,m表示做的重复次数,m或n为0代表忽略匹配
捕获模式 ()
匹配括号里的内容,并记住匹配项
const input = `key=ad&df=fd`
const regg = /(.[^&]+)=(.[^&]+)&{0,1}/g
console.log(input.replace(regg, '$1:$2,'));
非捕获模式 (?:)
通过?:进行非捕获模式
const input = 'abc=bcd';
const regexp1 = /(?:[a-z]+)=(?:[a-z]+)/
console.log(regexp1.exec(input))
反向引用 \1 \2
在捕获模式中,对捕获内容进行引用即反向引用
const input = 'abc=abc&bcd=bcd';
const regexp = /(abc)=\1&(bcd)=\2/g
let ret = regexp.exec(input);
console.log(ret)
字符集 []
[]是一个字符集,可以理解为一个数组,匹配人数组里的任意字符即true
[^]排除字符集,可以理解为一个数组,匹配人数组里的任意字符即false
正向查找 x(?=y)
匹配x并且x后面为y
const input = `xaxbxyxcxd`
const regg = /x(?=y)/g
console.log(regg.exec(input));
反向查找 x(?!y)
匹配x并且x后面不能为y
const input = `xyxyxdxy`
const regg = /x(?!y)/g
console.log(regg.exec(input));
正则表达式方法 exec 和 test
exec
exec返回一个数组,返回内容的格式为 [[0]:匹配的到元素,[n]:捕获的字符串,index:匹配元素开始的位置,input:被匹配的字符串],如果未匹配到,则返回null
const input = 'haha haha haha'
const regg = /haha/g
console.log('输出:',regg.exec(input));
// 输出:[ 'haha', index: 0, input: 'haha haha haha' ]
console.log('输出:',regg.exec(input));
// 输出:[ 'haha', index: 5, input: 'haha haha haha' ]
console.log('输出:',regg.exec(input));
// 输出:[ 'haha', index: 10, input: 'haha haha haha' ]
console.log('输出:',regg.exec(input));
// 输出:null
test
test返回true或false,表示字符串是否符合正则匹配
const input = 'haha haha haha'
const regg = /haha/g
console.log('输出:',regg.test(input)); // 输出: true
console.log('输出:',regg.test(input)); // 输出: true
console.log('输出:',regg.test(input)); // 输出: true
console.log('输出:',regg.test(input)); // 输出: false
正则匹配 flags
g 全局搜索
i 不区分大小写
m 多行搜索
y粘贴搜索
/g全局搜索与/y粘贴搜索的不同,在于全局搜索如果匹配失败会跳过失败继续后续匹配后面的字符串,而粘贴搜索在匹配失败后会重头开始搜索
const input = 'haha haha haha'
const regg = /haha/g
console.log('全局模式', regg.test(input), regg.lastIndex)
console.log('全局模式', regg.test(input), regg.lastIndex, '空格不匹配后,跳过空格继续搜索后面的字符串,设置lastIndex为9')
console.log('全局模式', regg.test(input), regg.lastIndex)
const regy = /haha/y
console.log('粘贴模式', regy.test(input), regy.lastIndex)
console.log('粘贴模式', regy.test(input), regy.lastIndex, '空格不匹配后,直接返回false,重置lastIndex')
console.log('粘贴模式', regy.test(input), regy.lastIndex, '重头开始搜索')
/y有一个隐式的功能,就是每一次匹配都将lastIndex作为开头进行匹配
const input = 'haha';
const regy = /a/y;
console.log('输出:', regy.test(input), regy.lastIndex)
// lastIndex=0,返回false,然后重置lastIndex=0
regy.lastIndex = 1
console.log('输出:', regy.test(input), regy.lastIndex)
// lastIndex=1,返回ture,然后设置lastIndex=2
regy.lastIndex = 2
console.log('输出:', regy.test(input), regy.lastIndex)
// lastIndex=2,返回ture,然后重置lastIndex=0
regy.lastIndex = 3
console.log('输出:', regy.test(input), regy.lastIndex)
// lastIndex=3,返回ture,然后设置lastIndex=4
参考文章
面试题-const的理解
题目
下列代码依次输出什么
// 1、
const data = {};
data.name = "liuyt";
console.log(data);
// 2、
const prop = { type: "node" };
data[prop] = "prop";
console.log(data);
// 3、
const pnewPop = { level: 2 };
data[pnewPop] = "pnewPop";
console.log(data);
// 4、
data = {};
console.log(data);答案
{name: "liuyt"}
{name: "liuyt", [object Object]: "prop"}
{name: "liuyt", [object Object]: "pnewPop"}
Uncaught TypeError: Assignment to constant variable.
at <anonymous>:16:6
why
const 的值不能通过重新赋值来改变,并且不能重新声明。
步骤1、2、3都没有更改const的引用,只是更改了值
步骤4对值做了更改所以报错
另外我们看到2、3都是用对象当key来设置值的,最终打印出来的key是[object Object],所以可以知道,当使用非字符串的值当key时,会隐式的进行toString()操作,所以步骤3的值覆盖了步骤2的值
koa 源码分析
koa源码之ctx.body
-
ctx.body在lib/context.js的第200行进行设置,可以看到ctx.body通过delegates代理了response.body。
-
response.body在lib/response.js中对body进行了重写getter和setter
-
response.body在set时,判断了返回状态status和返回内容的类型。根据返回内容的类型是否为string、buffer、stream、json来进行不同的处理.
-
string 类型处理时,判断是否有html标签来判断是否为html,否则返回text类型,返回时计算Content-Length
-
buffer 类型处理时,设置返回的Content-Length,设置返回类型为bin
-
stream 类型处理时,绑定在请求完成后流销毁事件,监听流的错误事件,设置返回类型为bin
-
json 类型处理,如果以上模型都没有匹配到,那么默认按json类型处理
-
在设置完ctx.body并且所有中间件执行完成后,会根据ctx.body的类型进行返回内容,代码在lib/application 的respond方法中,这里主要说一下流的处理,如果body设置的是一个流,那么会使用body.pipe(res),将ctx.body的流写入到res流中
koa源码之 ctx.status ctx.respond ctx.writable
- koa框架默认设置statusCode为404(lib/application.js中的handleRequest方法),所以在返回时需要明确设置返回的code,否则返回的code就会为404
- koa框架中,默认在执行完所有中间件后,会执行respond方法(lib/application.js中的handleRequest方法和respond方法),来设置返回内容, 设置ctx.respond=false后,在执行完中间件后不再执行任何内容,当有特殊需求需要自定义返回时,可以更改respond方法或设置为false.
- ctx.writable 指的是当当前请求或res.socket流是否执行完成,只读选项,不可设置,可以在response.js中的get writable方法中查看详细
在koa框架中使用exceljs执行流输出遇到的坑
execljs只执行流输出时候,需要调用workbook.xlsx.write方法,参数需要为一个stream,我们可以res返回流传入进去,但是使用koa框架时,传入ctx.res会出现很多坑,网上也有些使用ctx.body=stream的方法来输出流,这就需要额外声明一个转换流来让exceljs写入,让ctx.res读取,总觉得很别扭,所以索性翻开koa的源码和exceljs的源码来看一下如何实现exceljs直接写入res流中
坑1
koa默认在中间件执行完成后,根据body的类型不同做处理,在stream中采用了ctx.body.pipe(res),所以要使用koa返回只能多设置一个流。但是respond方法中有一个ctx.respond===false return的代码,那么koa是允许不执行respond,所以我们设置respond=false,进行自定义返回
坑2
在请求进来时候,默认设置了ctx.status=404,并且在设置ctx.body时,如果没有设置status,会默认设置status为200,所以如果我们没有设置ctx.status=200的话,那么默认的status为404,一样拿不到数据,所以一定要设置status为200
代码实现
const Koa = require('koa');
const execl = require('exceljs');
let app = new Koa();
app.use(async ctx => {
let workbook = getWorkbook();
ctx.set('Content-Type', 'application/vnd.openxmlformats');
ctx.attachment('hello.xlsx');
ctx.respond = false;
ctx.status = 200;
workbook.xlsx.write(ctx.res);
});
app.listen(9001);
function getWorkbook() {
let workbook = new execl.Workbook();
let ws = workbook.addWorksheet('二货列表');
let data = {
name: '二货',
sex: '男',
age: 22,
address: '上海市长宁区'
};
let vals = [];
for (let key in data) {
vals.push(data[ key ]);
}
ws.addRow(Object.keys(data));
let i = 0;
do {
i++;
ws.addRow(vals);
}
while (i < 1000);
return workbook;
}
ee-first
同时监听多个事件,如果触发了其中一个事件,释放其他所有事件
on-finished
on-finished通过onFinished方法进行绑定回调,可以多次绑定,
onFinished方法会在res上挂载一个单例__onFinished,单例__onFinished是一个回调函数,__onFinished有一个属性queue用于存储通过onFinished设置的回调函数
onFinished通过监听res的end或finish方法,或者是socket的close或error方法来获取请求是否结束,请求结束后,调用单例res上的单例__onFinished,清理单例__onFinished,并循环调用__onFinished上queue的回调方法
koa-compose
将多个中间件function合并,每个中间件的第二个参数为下一个要执行的中间件,中间件为一个promise
koa执行流程
application.js->http.createServer->this.callback->this.createContext->this.handleRequest->fnMiddleware->respond
application文件中的listen中通过http.createServer创建服务,在回调方法中首先创建了ctx,然后执行中间件,最后执行respond方法结束。
创建ctx是通过Object.assign来创建新的context,request,response实例,然后绑定、代理、重写res,req的属性和方法,具体可以看context.js request.js response.js
VUE源码学习(2)-vue核心内容简单实现2
对上一个例子进行以下升级,我们一次更新多个dom
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Simple Vue</title>
</head>
<style>
#app {
text-align: center;
}
</style>
<body>
<div id="app">
<p id="vdom1">初始化中</p>
<p id="vdom2">初始化中</p>
</div>
</body>
<script>
// 被监听的数据
let data = { message: "" };
// 监听和分发集合
let dep = {
subs: [],
notify() {
this.subs.forEach(item => {
item.update();
})
}
}
// 设置监听数据的getter和setter
Object.defineProperty(data, 'message', {
enumerable: true,
configurable: true,
get() {
return this.value;
},
set(newVal) {
// 如果值一样,不更新dom
if (newVal === this.value) {
return;
}
this.value = newVal;
// 触发所有监听
dep.notify();
}
});
// 虚拟dom集合
let nodes = [];
// 设置虚拟dom
let el = document.querySelector("#app");
const fragment = document.createDocumentFragment();
let firster = el.firstChild;
while (firster) {
fragment.appendChild(firster)
firster = el.firstChild;
}
fragment.childNodes.forEach(item => {
// 设置监听
let watcher = {
update() {
// 更新dom
item.textContent = data.message
}
};
// 添加监听到集合中
dep.subs.push(watcher)
})
el.appendChild(fragment)
// 定时更新数据,更新dom
setInterval(() => {
data.message = "当前时间戳为:" + Date.now()
}, 1000);
</script>
</html>
node-gyp configure 代码执行流程
原由
最近在windows安装node包时,总是出现编译通过的问题,后来发现是我安装的VS是2017的问题,总是报莫名其妙的错误,决定研究一下为什么设置了msvs_version=2017还是出现问题。
下面是执行node-gyp configure的代码运行流程
第一步,实例化
node-gyp\lib\node-gyp.js 文件
// 默认实例化
function gyp () {
return new Gyp()
}
function Gyp () {
var self = this
this.devDir = ''
this.commands = {}
// 设置command,返回引用的文件
commands.forEach(function (command) {
self.commands[command] = function (argv, callback) {
log.verbose('command', command, argv)
return require('./' + command)(self, argv, callback)
}
})
}
第二步,执行configure命令
node-gyp\lib\configure.js 文件
1、执行configure函数,第30行
2、执行findPython函数,第39行
3、找到python位置后,获取node目录,执行getNodeDir函数,第48行
4、获取node位置后,创建build文件夹,执行第58或81行,执行createBuildDir函数,第86行
5、判断是否是windows,判断版本是不是2017,在第91行
if (win && (!gyp.opts.msvs_version || gyp.opts.msvs_version === '2017'))
如果是windows并且是2017,查找VS2017位置,执行第92行代码
6、查找VS2017直接看下一步,这里继续步骤,目录创建好后,创建配置文件,执行createConfigFile函数,第106行
7、注意查看150行,这里强制设置GYP为2015,也给出了说明,GYP不支持VS2017
if (vsSetup) {
// GYP doesn't (yet) have support for VS2017, so we force it to VS2015
// to avoid pulling a floating patch that has not landed upstream.
// Ref: https://chromium-review.googlesource.com/#/c/433540/
gyp.opts.msvs_version = '2015'
process.env['GYP_MSVS_VERSION'] = 2015
process.env['GYP_MSVS_OVERRIDE_PATH'] = vsSetup.path
defaults['msbuild_toolset'] = 'v141'
defaults['msvs_windows_target_platform_version'] = vsSetup.sdk
variables['msbuild_path'] = path.join(vsSetup.path, 'MSBuild', '15.0','Bin', 'MSBuild.exe')
}
8、最后写入配置,然后执行findConfigs函数,查找配置文件,第190行
9、递归获取config名称,结束后执行Gyp命令,看第193行,运行函数runGyp,第211行
10、打印参数并且通过gyp执行命令,第325行,命令执行完成后退出,执行onCpExit,调用callback
findVS2017如何运行
node-gyp\lib\find-vs2017.js 文件
1、执行findVS2017函数,第5行
2、获取powershell.exe位置
3、获取c#编写的Find-VS2017.cs文件位置
4、通过child_process.execFile,调用powershell执行Find-VS2017.cs文件的Main.Query()
node-gyp\lib\Find-VS2017.cs 文件
5、Query中的代码我大概猜测是查询VS的信息,可以看下面链接
https://msdn.microsoft.com/en-us/library/microsoft.visualstudio.setup.configuration.isetupinstance(v=vs.150).aspx
6、重点看CheckInstance函数,检查查询内容,第209行
7、CheckInstance函数分别检测了以下内容
Windows10SDK or Windows81SDK
Visual Studio C++ core features
VC++ 2017 v141 toolset (x86,x64)
也就是说必须安装以上内容才能执行2017,所以设置msvs_version=2017,要查看是否安装以上内容
结论
设置msvs_version=2017请确保安装了以下内容,另外如果使用node-gyp不建议使用2017,
毕竟gyp不支持2017,还是使用2015靠谱,不知道会出什么乱七八糟的错误
Windows10SDK or Windows81SDK
Visual Studio C++ core features
VC++ 2017 v141 toolset (x86,x64)
图解vue数据渲染流程

关于this一段代码的思考
一段代码引发的思考
coffee.js
class Other
test: =>
"this is another class"
module.exports = Other
javascript.js
(function() {
var Other,
__bind = function(fn, me){ return function(){ return fn.apply(me, arguments); }; };
Other = (function() {
function Other() {
this.test = __bind(this.test, this);
}
Other.prototype.test = function() {
return "this is another class";
};
return Other;
})();
module.exports = Other;
}).call(this);
这应该是一段coffee转成js的代码,我不懂coffe,但是非常闹不明白转换的js为什么要把test方法再次bind一次,这完全没有影响啊。
var __bind = function (fn, me) {
return function () {
return fn.apply(me, arguments);
};
};
function Person() {
this.name = 'liuyt'
// this.sayName = __bind(this.sayName, this);
}
Person.prototype.sayName = function () {
console.log(this);
};
var p = new Person
p.sayName()
在注释和取消注释的情况下,分别打印一下内容,this指向没有问题
// 注释的情况打印
Person {name: "liuyt"}
// 取消注释的情况打印
Person {name: "liuyt", sayName: ƒ}
settimeout的时候this会指向window,然后尝试更改代码,查看到底this是否会有影响。
// 修改sayName
Person.prototype.sayName = function () {
setTimeout(function() {
console.log(this);
}, 10);
};
结果无论注释和非注释bind代码,this都指向window,那么就非常的苦恼,为什么非要bind呢?
终于在stackoverflow找到了答案
在注释bind代码,并添加执行以下代码会发生什么呢?打印的this为window,取消bind注释后,打印为person。为什么会发生这样?
var f=p.sayName();
f();
因为this的指向是在函数运行时,调用函数的对象,那么在注释bind的情况下f的调用对象肯定是window,打印也就是window
那么在取消bind的情况下f函数是什么呢?
f = function () {
return p.sayName.apply(p, arguments);
};
//f()等于p.sayName.apply(p, arguments);
这下就明白为什么要bind了,因为coffee希望无论函数如何引用,最终都执行this对象都是实例本身。
至此疑惑解开。
高性能缓存架构笔记
缓存穿透
缓存穿透是指,缓存没有命中,需要去存储系统查询数据。分为以下两种情况
-
存储数据不存在
存储系统数据确实不存在,导致每次查询缓存不存在,都要去存储系统查询一次
解决方案是,在查询存储系统数据确实不存在时,设置一个默认值到缓存系统,第二次再查询时,获取一个�默认值,不在查询存储系统
-
存储数据失效,生成新缓存期间导致穿透
缓存失效,生成缓存需要大量时间,在生成缓存期间,大量穿透访问存储系统
缓存雪崩
大量缓存穿透,导致大量访问存储系统,�造成数据库���宕机,引起系统崩溃。
解决方案:
-
更新锁
使用更新锁,只能有个线程进行更新,分布式系统要使用分布式锁,其他线程需要等待更新锁释放后,重新读取缓存,或超时返回空值或默认数据
-
后台更新
缓存设置永久有效,由专门的后台线程进行定时更新,业务线程不进行更新操作。这里需要考虑缓存系统内存不足,需要踢掉一些缓存数据,踢到缓存后,业务系统发现缓存失效后,应发生队列消息通知后台更新线程更新缓存
-
双key方案
设置一个k1为有有效期的缓存,设置k2为永久缓存,当读取k1无效时,返回k2的值,发生消息队列给后台更新线程,更新k1和k2的值,k1作为更新锁进行更新,因为大量的请求后台更新线程也会有可能导致雪崩,为了防止缓存后台更新线程雪崩,需要先查询k1是否存在,如果存在就不进行更新。
缓存热点
对于部分热点数据进行多副本备份,缓解缓存压力,不同副本的缓存有效期,通过在key后面加上随机编号进行缓存,每次读取缓存都是随机读取某一份缓存,需要注意的时,缓存有效期不要设置为相同的时间,这样避免缓存在同一时间失效,需要设置一个失效时间范围,随机进行失效。
多组合条件查询结果缓存
常用组合条件使用后台更新进行统一缓存,统一更新,不常用缓存使用md5(sql)缓存结果60秒。注意这里的业务查询需要容忍不一致性。
设计缓存需要考虑的问题
1.什么数据应该缓存
2.什么时机触发缓存和以及触发方式是什么
3.缓存的层次和粒度( 网关缓存如 nginx,本地缓存如单机文件,分布式缓存如redis cluster,进程内缓存如全局变量)
4.缓存的命名规则和失效规则
5.缓存的监控指标和故障应对方案
6.可视化缓存数据如 redis 具体 key 内容和大小
热点数据突发性导致来不及扩容应该怎么办
1. 限流
2. 容器化+动态化
3. 业务降级,例如限制评论
关于mysql缓存和redis缓存的差别
1. mysql第一种缓存叫sql语句结果缓存,但条件比较苛刻,程序员不可控,我们的dba线上都关闭这个功能,具体实现可以查一下
2. mysql第二种缓存是innodb buffer pool,缓存的是磁盘上的分页数据,不是sql的查询结果,sql的执行过程省不了。而mc,redis这些实际上都是缓存sql的结果,两种缓存方式,性能差很远。
因此,可控性,性能是数据库缓存和独立缓存的主要区别
其他
1、使用缓存就需要业务容忍一定时间内的不一致性,所以关键信息不要进行缓存例如库存,价格等
2、我是实现了个框架:https://github.com/qiujiayu/AutoLoadCache,用于解决一下问题:
1. 缓存操作与业务代码耦合问题;
2. 缓存穿透问题;
3. 异步在缓存快要过期时,异步刷新缓存;
4. 使用“拿来主义机制”,降低回源并发量
3、缓存框架,由框架统一管理缓存,看看Ehcache
阿里云新机器装nodejs
1、阿里云镜像安装nodejs
wget https://npm.taobao.org/mirrors/node/v8.7.0/node-v8.7.0-linux-x64.tar.gz
2、 解压
tar zxf node-v6.3.1-linux-x64.tar.gz
3、移动
mv node-v6.3.1-linux-x64 /usr/local/node
4、软连接,要在usr/bin下面才是全局的软连接
cd /usr/bin
ln -s /usr/local/node/bin/node node
ln -s /usr/local/node/bin/npm npm
5、安装https
apt-get install apt-transport-https ca-certificates
6、设置yarn镜像源
curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list
7、安装yarn
yarn apt-get install yarn
8、安装cnpm
npm install -g cnpm --registry=https://registry.npm.taobao.org
nodejs require加载顺序
require 加载顺序
1、内部文件
2、带路径文件
2.1、转换成绝对路径
2.2、查找缓存,如果缓存有获取缓存内容
2.3、查找当前目录文件 没有后缀名,依次按照 .js .json .node顺序查找
2.4、如果没有,路径作为文件夹,遍历目录下文件,依次为 pagepack.json index.js index.json index.node
3、如果不是路径,那查找node_modules,然后一层一层父类目录查找,如果没有报错
作用域常见问题
// run方法内的a与全局变量a指向同一内存,所以可以更改全局变量的值,
// 当函数内的a重新指向新的内存时,就无法更改全局变量了,这里理解函数内的a为局部变量非全局变量
var a = [1, 2, 3];
function run(a) {
// var 局部a=全局a
a[3] = 4;
a = [10];
}
run(a);
console.log(a);
// 函数内直接使用全局变量
var a = [1, 2, 3];
function run() {
a[3] = 4;
a = [10];
}
run();
console.log(a);
// 函数内局部变量undefine导致设置a[3]异常
var a = [1, 2, 3];
function run() {
a[3] = 4;
var a = [10];
}
run();
console.log(a);
// 函数内for局部变量声明
var a = 20;
function test() {
// 有声明局部,没声明全局
console.log(a);
a = 10;
console.log(a);
for (var a = 20; a < 10; a++) {}
console.log(a);
}
test();
function fun(a, b) {
console.log(a, b);
return {
fun: function (c) {
return fun(c, a);
},
};
}
// #1
var d = fun(0);
d.fun(1);
d.fun(2);
d.fun(3);
// #2
var d1 = fun(0).fun(1).fun(2).fun(3);
// #3
var d2 = fun(0).fun(1);
d2.fun(2);
d2.fun(3);
// 解析
// 先把迷惑人的命名改了,结构给明确一下
function main(a, b) {
// 注意a和b为闭包的参数,result.fun调用时,调用的时候这里的a
console.log(a, b);
let result = {
fun: function (c) {
// 这里的a为闭包的a
return main(c, a);
},
};
return result;
}
// #1
// main方法会console,并且返回一个result1对象,result1对象里会有a,b两个闭包参数
var result1 = main(0);
// 这里会执行main 函数,main的a参数为闭包a的值为0,
// main函数执行时候会console.log(1,0),并且返回result2的对象,
// 这个result2的对象的与d不同,他的闭包参数a,b变成了1,0
var result2 = result1.fun(1);
// 与result1.fun(1)同理
var result3 = result1.fun(2);
// #2
// 这里fun是故意迷惑的,我们转换下 var d1 = fun(0).fun(1).fun(2).fun(3);
// main返回result
var result1 = main(0);
// result1.fun会执行main(),会继续返回result2,注意这时候闭包内的参数改变了
var result2 = result1.fun(1);
// 下面一样
var result3 = result2.fun(2);
var result4 = result3.fun(3);
// #3 理解了上面,下面就很清晰了,无非有事result里的闭包ab参数更改了
var result1 = main(0);
var result2 = result1.fun(1);
result2.fun(1);
result2.fun(2);
// 闭包理解
function makeFunc() {
var name = "Mozilla";
function displayName() {
alert(name);
}
return displayName;
}
var myFunc = makeFunc();
myFunc();
// 分解闭包
function makeFunc() {
var name = "Mozilla";
var result = {
// args为闭包的参数
args: {
name: name,
},
// 返回的方法
displayName: function () {
alert(this.args.name);
},
};
return result;
}
var myFuncResult = makeFunc();
myFuncResult.displayName();
HTTP2请求流程解析
通过wireshark抓取HTTP2请求截图
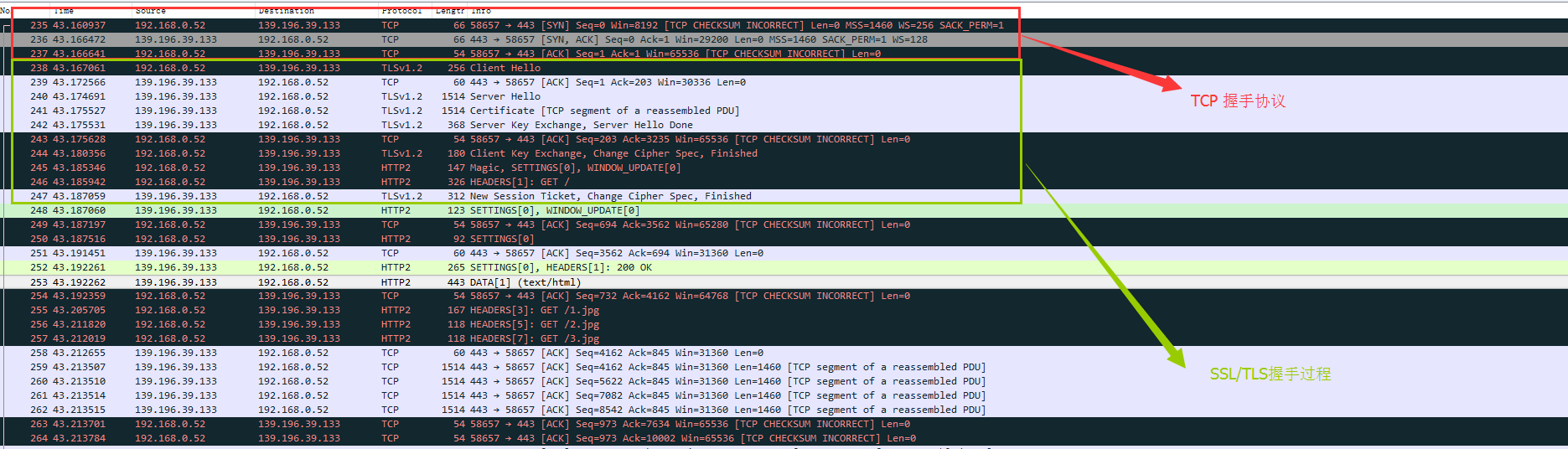
TCP握手
这里还是简单说一下TCP握手,加深下自己的印象。
字段介绍
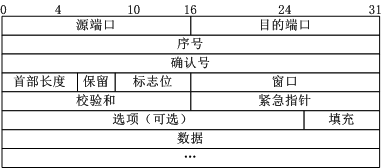
1、序号:Seq序号,占32位,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记
2、确认序号:Ack序号,占32位,只有ACK标志位为1时,确认序号字段才有效,Ack=Seq+1。
3、标志位:
* F : FIN - 结束; 结束会话
* S : SYN - 同步; 表示开始会话请求
* R : RST - 复位;中断一个连接
* P : PUSH - 推送; 数据包立即发送
* A : ACK - 应答
* U : URG - 紧急
* E : ECE - 显式拥塞提醒回应
* W : CWR - 拥塞窗口减少
注意
ACK和ack是大小写不一样是两个不同的东西
ACK是确认报文是否有效,在标志位中,只有ACK=1请求才是有效的。
ack是确认序号,ack=seq+1
握手过程
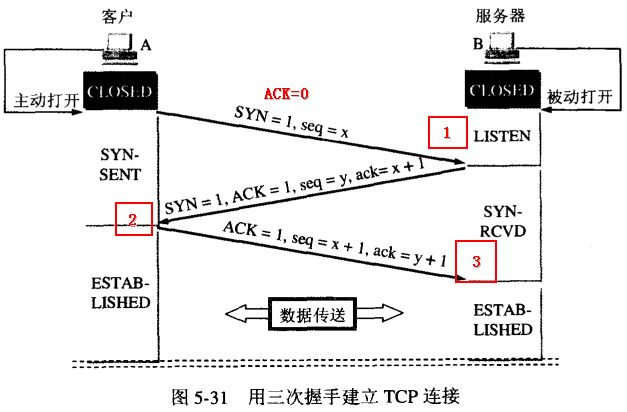
1、客户端发出请求,SYN=1,ACK=0,ACK为默认值为0 seq=x,x为随机数(通俗语言:你能听见吗?)
2、服务端发出回复,SYN=1,ACK=1,seq=y,y为随机数,ack=客户端发送的seq+1=x+1(通俗语言:能,你能听到我说话吗?)
3、客户端发出请求,ACK=1,seq=客户端继续生成一个线性增长随机数,ack=服务端发送的seq+1=y+1(通俗语言:我听得到你,你也听到我了,那么我开始说正事)
关于seq序号生成
seq生成是一个不完全随机的,而是随着时间而线性增长的到了2^32尽头再回滚,为了让攻击者难以猜测seq
TCP四次挥手 (题外话)
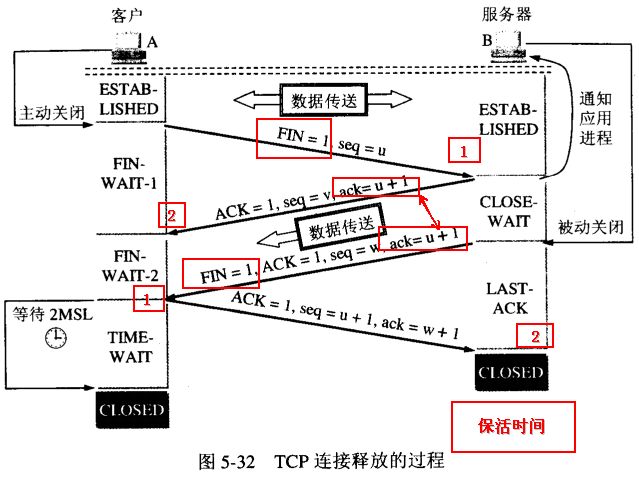

挥手过程
1、客户端发出FIN请求,客户端进入等待接收数据状态FIN-WAIT(通俗语言:我发完数据了,你还有数据吗?我等你发。)
2、服务端进入CLOSE_WAIT状态,应答客户端FIN请求(通俗语言:我知道了,我关闭接收通道,你等我消息。)
2.x、服务端可以继续发送数据,可以客户端可以继续接收数据。
3、服务端数据发送完成。(通俗语言:我也发完了,你关闭链接吧,我准备关闭了)
4、客户端回复客户端关闭请求(通俗语言:我关闭连接了)
为什么四次关闭
因为建立请求后,请求SYN和应答ACK可以同时发送,但是关闭连接时,FIN和ACK需要分开发送。
简单的说,在建立连接的第二步,服务端同时做了两件事
1、我收到你的请求
2、你在吗?
而关闭连接的第二步却不能同时回复
1、我收到了你的请求。
2、我发送完了数据,可以关闭连接
因为,第二步也可能是
1、我收到了你的请求
2、我还有123数发送
所以这一步是分了两步,一个是应答客户端请求,一个是回复客户端数据。所以关闭请求需要四步
为什么要等待2MSL
主动关闭的一方为:A 被动关闭的一方为:B
A发送FIN给B,A状态为A进入FIN_WAIT_1,B回复ACK,A接受后状态为FIN_WAIT_2,B发送FIN,A接受后状态为TIME_WAIT,立即发送ACK给B,如果网络不稳定,导致ACK丢失,那么B会再超时后,再次发送FIN,如果A的状态是TIME_WAIT,那么A会再次回复ACK,如果非TIME_WAIT,会回复RST,导致B异常。
简述SSL/TLS协议
直接引用网络上的一段话描述
第一步,爱丽丝给出协议版本号、一个客户端生成的随机数(Client random),以及客户端支持的加密方法。
第二步,鲍勃确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数(Server random)。
第三步,爱丽丝确认数字证书有效,然后生成一个新的随机数(Premaster secret),并使用数字证书中的公钥,加密这个随机数,发给鲍勃。
第四步,鲍勃使用自己的私钥,获取爱丽丝发来的随机数(即Premaster secret)。
第五步,爱丽丝和鲍勃根据约定的加密方法,使用前面的三个随机数,生成"对话密钥"(session key),用来加密接下来的整个对话过程。
简单的说
(1)生成对话密钥一共需要三个随机数。
(2)握手之后的对话使用"对话密钥"加密(对称加密),服务器的公钥和私钥只用于加密和解密"对话密钥"(非对称加密),无其他作用。
(3)服务器公钥放在服务器的数字证书之中。
session简述
握手阶段用来建立SSL连接。如果出于某种原因,对话中断,就需要重新握手。
这时有两种方法可以恢复原来的session:一种叫做session ID,另一种叫做session ticket。
session ID的**很简单,就是每一次对话都有一个编号(session ID)。如果对话中断,下次重连的时候,只要客户端给出这个编号,且服务器有这个编号的记录,双方就可以重新使用已有的"对话密钥",而不必重新生成一把。
session ticket是加密的,只有服务器才能解密,其中包括本次对话的主要信息,比如对话密钥和加密方法。当服务器收到session ticket以后,解密后就不必重新生成对话密钥了。
SSL/TLS握手过程
1、客户端 Client Hello 图中序号:238
a、客户端支持的版本协议
b、客户端支持的加密算法
c、客户端生成的随机数
2、服务端 Server Hello 图中序号:240
a、确认协议版本
b、服务器生成随机数
c、确认加密算法
3、服务端发送服务器证书 Certificate 图中序号:241
4、服务端发送DH参数 Server Key Exchange 图中序号:242
5、客户端端发送DH参数 Client Key Exchange,握手完成 图中序号:244
6、服务端生成Session Ticket 图中序号:247
ALPN扩展
什么是NPN和ALPN
NPN(Next Protocol Negotiation,下一代协议协商),是一个TLS 扩展,由Google 在开发SPDY 协议时提出,也就是服务端和浏览器之间用来决定使用HTTP/1.1 还是最新的HTTP/2 的协议。随着SPDY 被HTTP/2 取代,NPN 也被修订为ALPN(Application Layer Protocol Negotiation,应用层协议协商)。二者的目标一致,都是用来在服务端和浏览器之间协商使用哪个HTTP 版本,但实现细节不一样,相互无法兼容。
HTTP2中的ALPN如何应用的
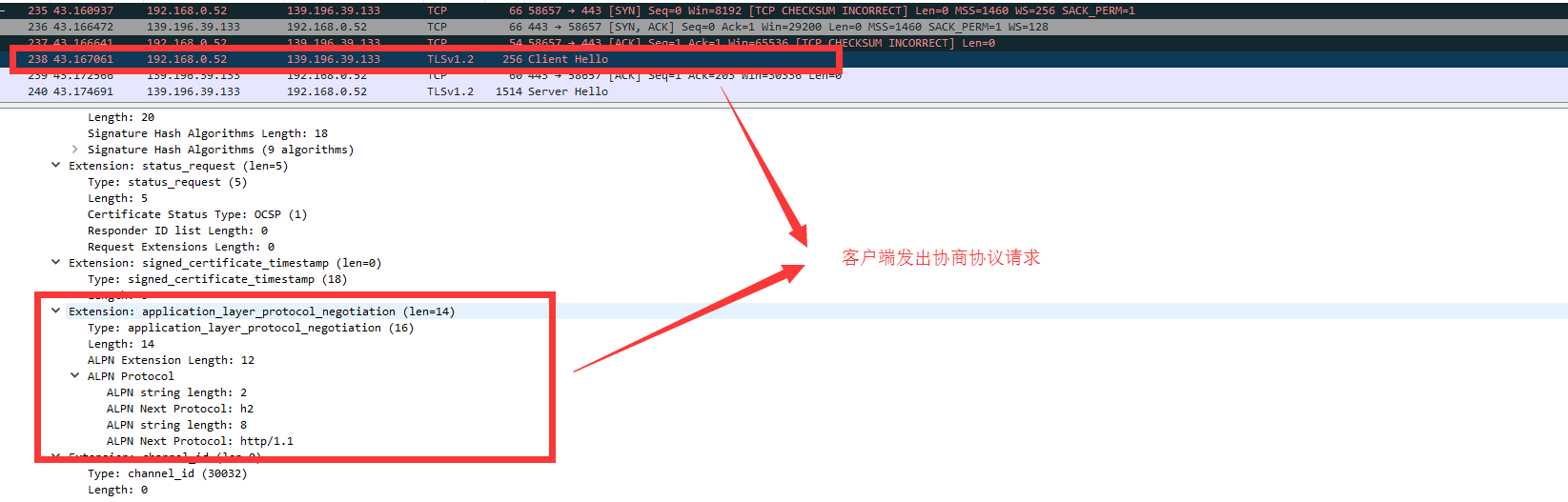
在SSL/TLS握手过程中,客户端发送Client Hello中,扩展了ALPN(Application Layer Protocol Negotiatio),上图是HTTP2扩展的ALPN,可以看到Client Hello中与服务器协商使用什么协议,客户端提供了httP/1.1和h2,服务器回复的Server Hello中确认了使用的协议为h2。
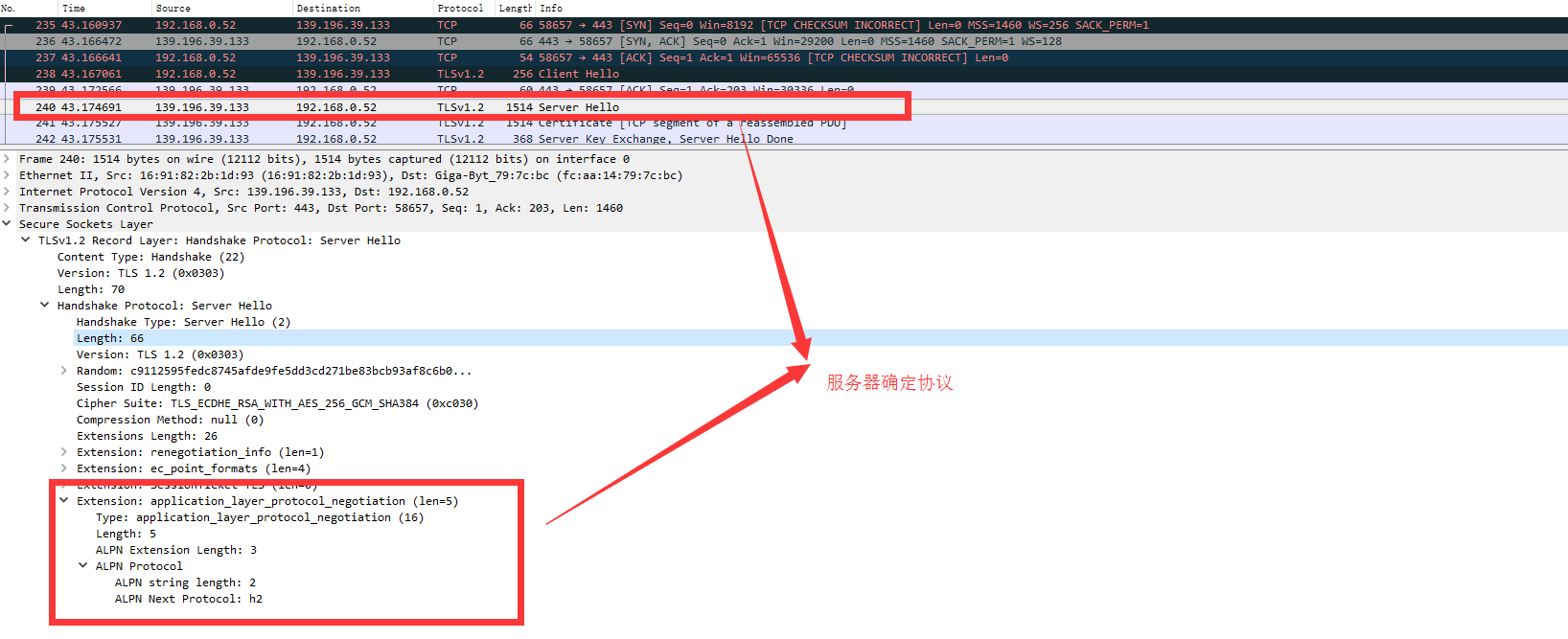
HTTPS版本HTTP2请求
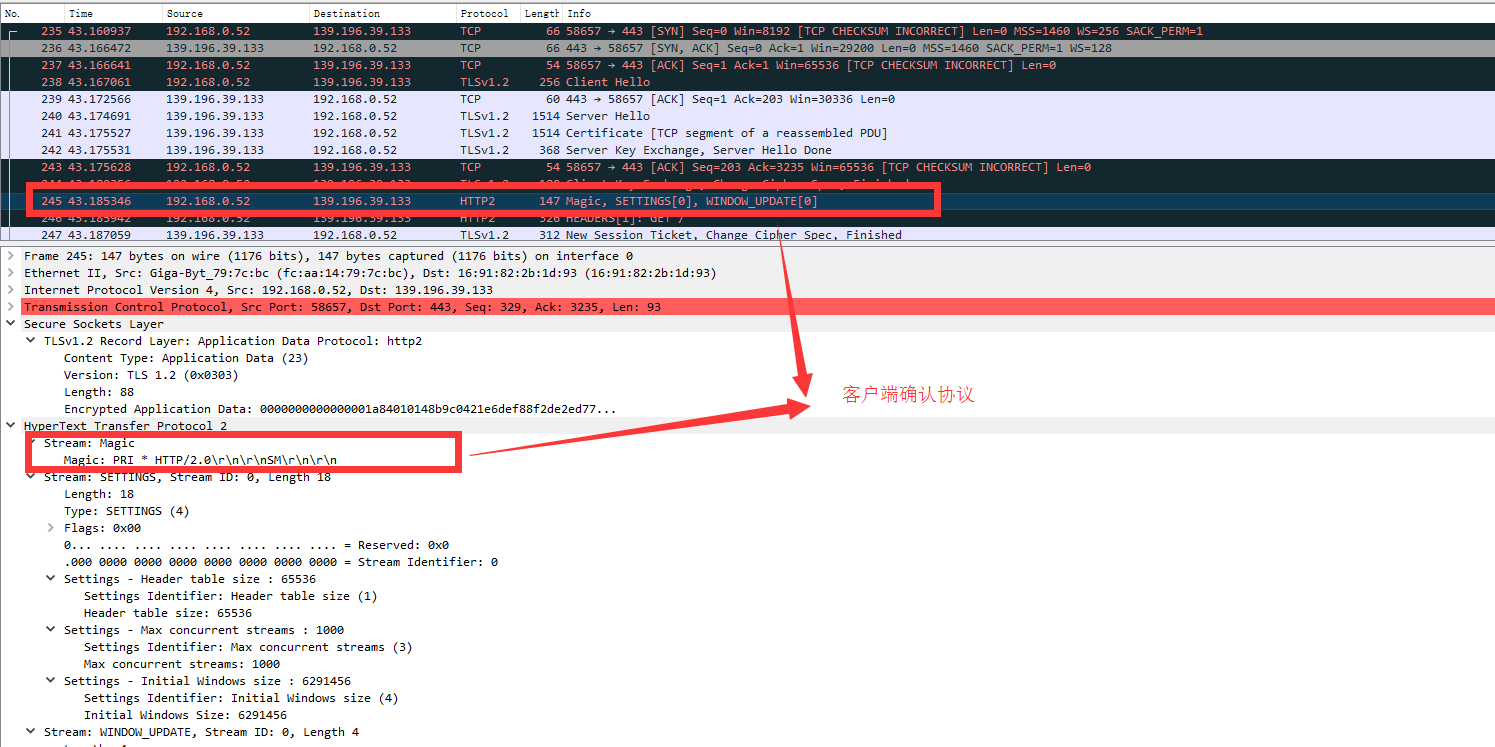
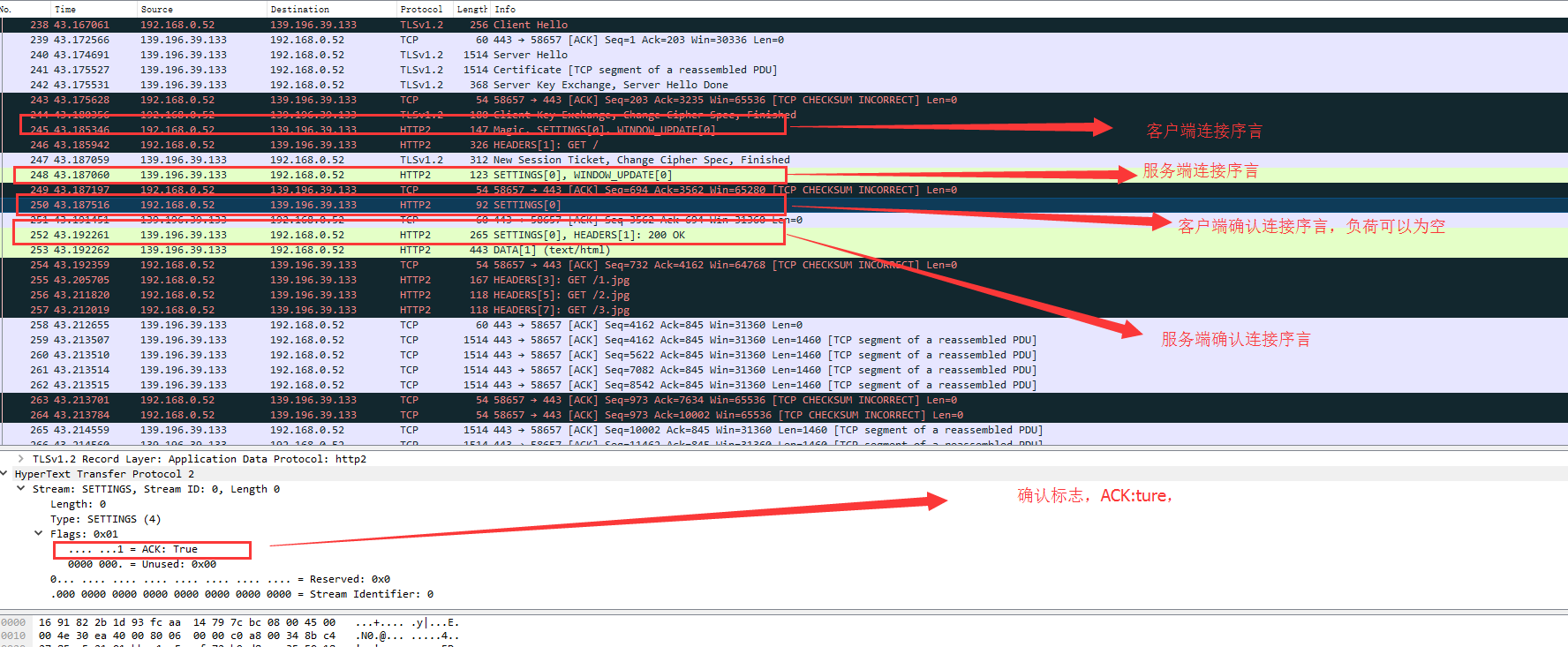
1、客户端和服务端TLS层协商(HTTP2中的ALPN如何应用的已经说明了如何协商)
2、一旦确认HTTP2格式,客户端立即发送链接序言,图中序号:245
连接序言格式
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n // 纯字符串表示,翻译成字节数为24个字节
SETTINGS帧 // 其负载可能为空
3、服务器端发送连接序言 图中序号:248
4. 接收到客户端连接序言之后,双方各自确认SETTINGS帧,图中序号:250,252
头部压缩
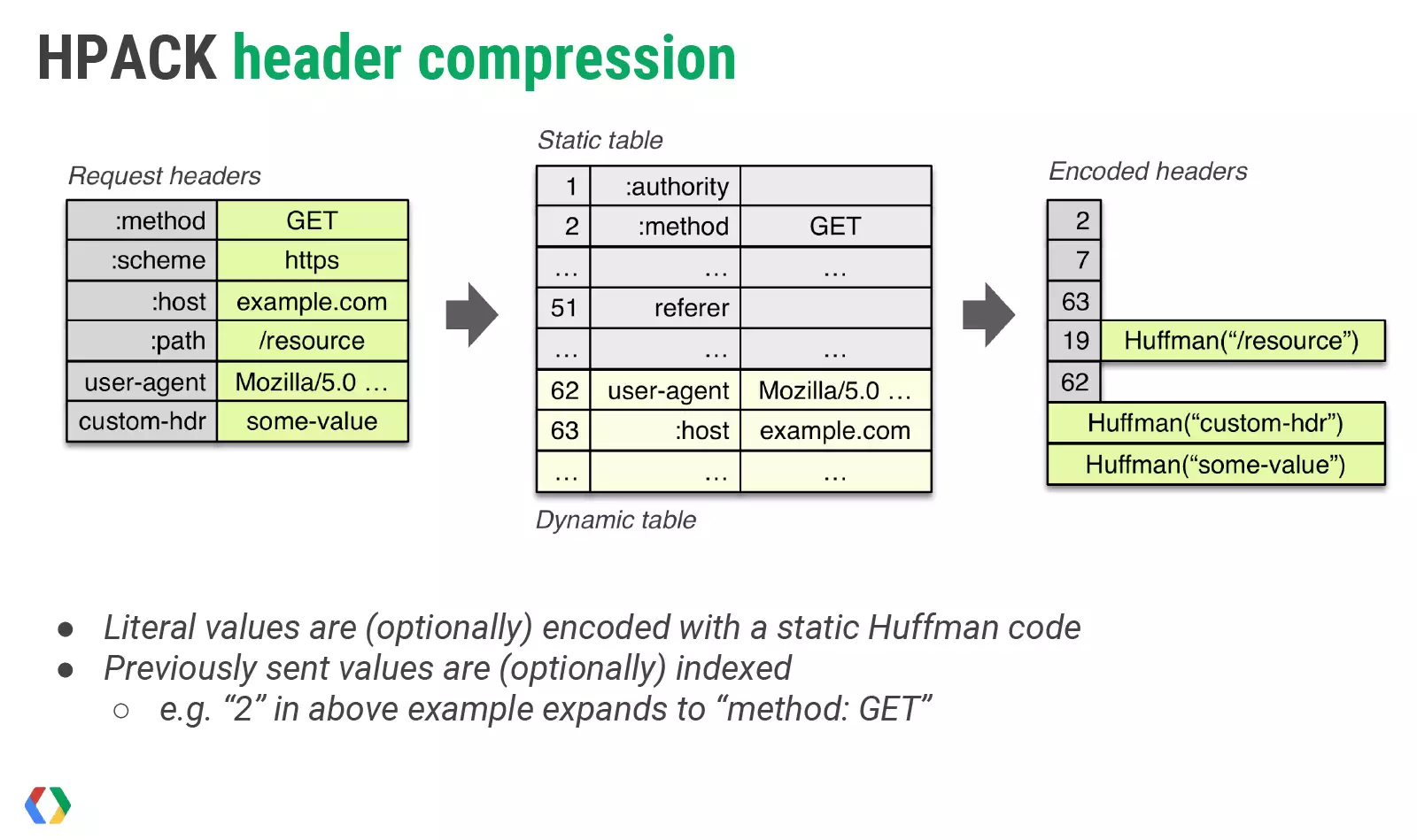
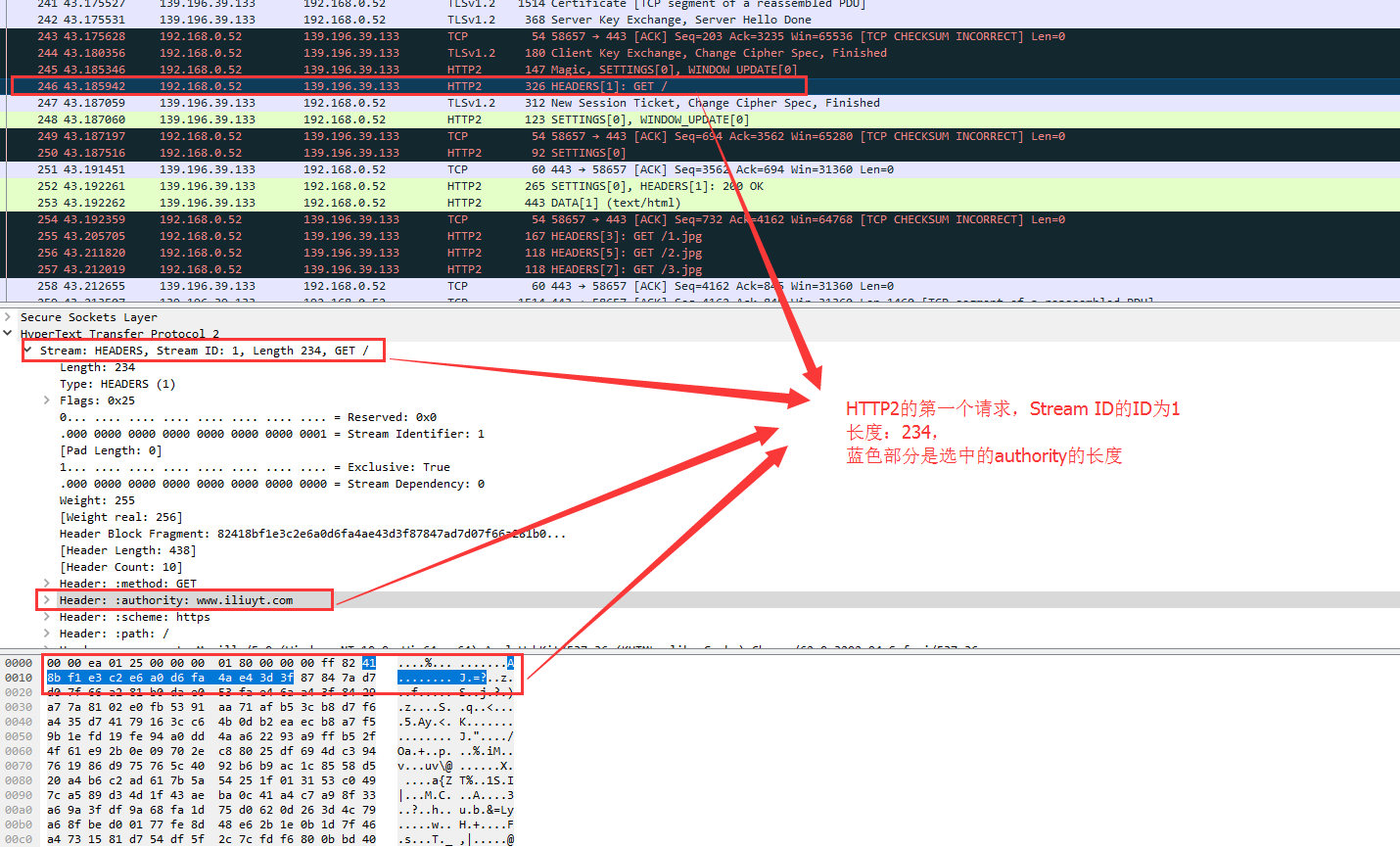
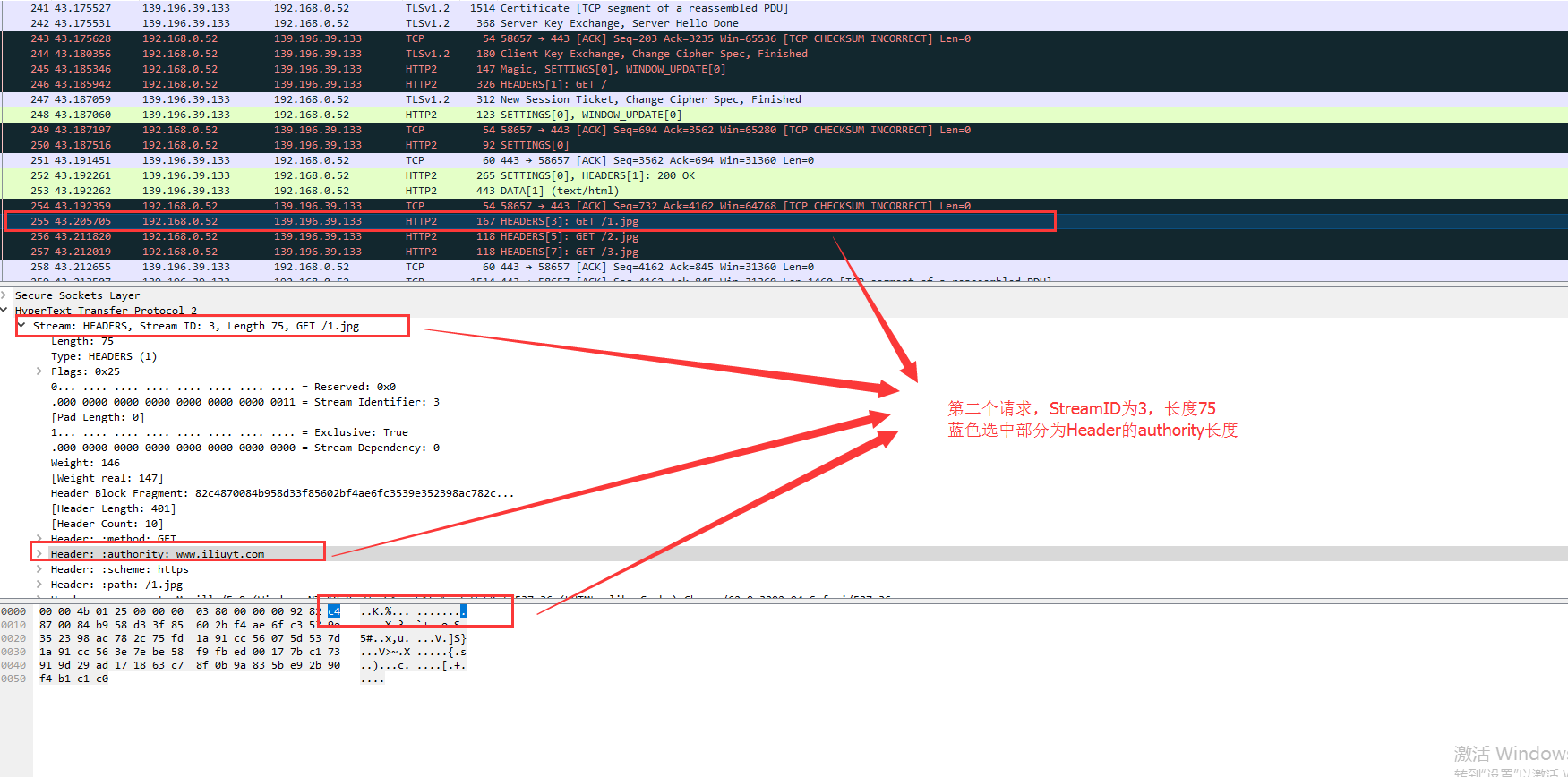
HTTP2通过首部表压缩头部信息,首部表由服务端和客户端共同维护。通过上图可以很清晰的看到HTTP2是如何进行压缩的,和压缩有的效果。
首部表维护的猜想
首部表是在创建连接时候创建一个属于该域名的首部表(猜想),然后服务端和客户端共同维护该表。
HTTP2相关资料查阅
docker玩一玩
1、安装
apt-get install -y docker.io
2、相关资料
// 步骤
http://www.cnblogs.com/liusc/p/docker_node.html
// pull 问题解决
https://segmentfault.com/q/1010000006032930
3、 阿里安装
https://cr.console.aliyun.com/?spm=5176.1971733.0.2.e0XKej#/accelerator
拉取镜像
sudo docker pull node:latest
创建Node.js程序
{
"name": "website",
"version": "0.0.1",
"description": "Node.js on Docker",
"author": "weiqinl",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.13.3"
}
}
'use strict';
var express = require('express');
var PORT = 8888;
var app = express();
app.get('/', function (req, res) {
res.send('Hello world\n');
});
app.listen(PORT);
console.log('Running on http://localhost:' + PORT);
创建Dockerfile
#设置基础镜像,如果本地没有该镜像,会从Docker.io服务器pull镜像
FROM node
#创建app目录,保存我们的代码
RUN mkdir -p /usr/src/node
#设置工作目录
WORKDIR /usr/src/node
#复制所有文件到 工作目录。
COPY . /usr/src/node
#编译运行node项目,使用npm安装程序的所有依赖,利用taobao的npm安装
WORKDIR /usr/src/node/website
RUN npm install --registry=https://registry.npm.taobao.org
#暴露container的端口
EXPOSE 8888
#运行命令
CMD ["npm", "start"]
构建Image
sudo docker build -t weiqinl/node .
查看镜像
sudo docker images
运行镜像
sudo docker run -d --name nodewebsite -p 8888:8888 weiqinl/node:latest
-d 表示容器在后台运行
--name 表示给容器别名 nodewebsite
-p 表示端口映射。把本机的8888端口映射到容器的8888端口,这样外网就能通过本机的8888端口,访问我们的web了。
后面的 weiqinl/node 是image的REPOSITORY, latest的镜像的TAG
测试镜像
curl -i localhost:8888
删除none镜像
docker rmi $(docker images -f "dangling=true" -q)
删除容器
docker rm $(docker ps -a -q)
nodejs 事件循环理解草稿
node 事件循环
timers
1、根据超时时间排序,获取最近的定时器
2、判断时间是否到期,如果不到期,跳出timers阶段
3、查看定时器中是否还有定时,如果有就创建一个定时器
4、执行回掉函数
5、nextTick->promise->退出
pending
1、检测是否有io 回调,如果有,执行回调。
2、nextTick->promise->退出
poll
1、是否有未完成的回调,没有退出
2、回调是否可用
2.1.1、有可用的,执行执行所有可用回调
2.1.2、nextTick->promise->退出
2.2、没有可用的,判断是否有immediate回调,有退出,没有就阻塞进行监听,直到超时或有事件进来。
check
1、执行immediate回调
2、nextTick->promise->退出
close
1、socket断开时,会执行这个阶段
2、nextTick->promise->退出
关于restful api
restful 是什么
通过URI对资源进行定位,通过http的method来描述对资源的操作
api是什么
api是什么?api就是接口,提供一个可以操作的窗口,方便别人操作。
restful api
restful api是什么?restful api就是基于restful的**开发的api,重点在于restful是一种**,服务于api,我们真正要做的是api, api的根本就是对于方便调用者,所以脱离了场景restful就是扯淡。
然后再说资源,不同的场景下对于资源的需求的表达是不同的,所以API的重点在于如何在当前场景下合适的表达资源,我们可以使用restful的**使用uri + http.method 的方式来描述资源和操作资源,但是资源真正的描述不是restful应关系的
例如,GET http://127.0.0.1/user 用于获取用户信息,但是具体获取用户信息加班级信息还是只获取用户昵称,由api来决定,所以资源具体是指什么?restful的资源并不是指的具体实体,如数据库定义的user表,而是根据场景不同实体合适的表达方式
最终api是要服务于调用者,所以更多的还是要方便调用者。
api需要考虑哪些东西 内容来源知乎
功能处理
错误处理、并发修改、部分修改、重试机制
描述处理
1.1 极简
用尽量少的API表达出你的场景。
1.2 完备
完备的API是指期望有的功能都包含了。这点会和保持API极简有些冲突。
1.3 语义清晰简单
就像其他的设计一样,我们应该遵守最少意外原则(the principle of least
surprise)。好的API应该可以让常见的事完成的更简单,并有可以完成不常见的事的可能性,但是却不会关注于那些不常见的事。解决的是具体问题;当没有需求时不要过度通用化解决方案。
1.4 符合直觉
就像计算机里的其他事物一样,API应该符合直觉。对于什么是符合直觉的什么不符合,不同经验和背景的人会有不同的看法。API符合直觉的测试方法:经验不很丰富的用户不用阅读API文档就能搞懂API,而且程序员不用了解API就能看明白使用API的代码。
1.5 易于记忆
为使API易于记忆,API的命名约定应该具有一致性和精确性。使用易于识别的模式和概念,并且避免用缩写。
1.6 引导API使用者写出可读代码
代码只写一次,却要多次的阅读(还有调试和修改)。写出可读性好的代码有时候要花费更多的时间,但对于产品的整个生命周期来说是节省了时间的。
部分内容来源知乎
理解 promise 核心内容
- Promise 本身是一个同步方法,在构造函数中已经执行了传入的函数,所以Promise 构造函数并不是异步,异步的是我们传入的函数。
- then catch 等方法的核心**也是把回调暂存起来,等到resolve和reject的时候进行回调。
- Promise为了统一所有返回都是异步,所以会对resolve,reject进行异步处理,这样即使传入的函数是同步代码,返回也是异步返回的。
class MyPromise {
constructor(handle) {
try {
// 立即执行函数
handle(this._resolve.bind(this), this._reject.bind(this));
} catch (err) {
this._reject(err);
}
}
// 存储成功回调
_fulfilledQueues = [];
// 存储失败回调
_rejectedQueues = [];
// 添加resovle时执行的函数
_resolve(val) {
let run = () => {
let cb;
// 执行失败回调
while ((cb = this._fulfilledQueues.shift())) {
cb(err);
}
};
// 统一异步返回
setTimeout(run, 0);
}
// 添加reject时执行的函数
_reject(err) {
let run = () => {
let cb;
// 执行失败回调
while ((cb = this._rejectedQueues.shift())) {
cb(err);
}
};
// 统一异步返回
setTimeout(run, 0);
}
// 添加then方法
then(onFulfilled, onRejected) {
this._fulfilledQueues.push(onFulfilled);
this._rejectedQueues.push(onRejected);
}
// 添加catch方法
catch(onRejected) {
return this.then(undefined, onRejected);
}
}
let myp = new MyPromise(function(resolve, reject) {
setTimeout(() => {
resolve(1);
});
});
myp.then(function(num) {
console.log("result", num);
});Dockerfile命令
FROM
FROM指定一个基础镜像, 一般情况下一个可用的 Dockerfile一定是 FROM 为第一个指令。至于image则可以是任何合理存在的image镜像。
FROM 一定是首个非注释指令 Dockerfile.
FROM 可以在一个 Dockerfile 中出现多次,以便于创建混合的images。
如果没有指定 tag ,latest 将会被指定为要使用的基础镜像版本。
MAINTAINER
这里是用于指定镜像制作者的信息
RUN
RUN命令将在当前image中执行任意合法命令并提交执行结果。命令执行提交后,就会自动执行Dockerfile中的下一个指令。
层级 RUN 指令和生成提交是符合Docker核心理念的做法。它允许像版本控制那样,在任意一个点,对image 镜像进行定制化构建。
RUN 指令缓存不会在下个命令执行时自动失效。比如 RUN apt-get dist-upgrade -y 的缓存就可能被用于下一个指令. --no-cache 标志可以被用于强制取消缓存使用。
ENV
ENV指令可以用于为docker容器设置环境变量
ENV设置的环境变量,可以使用 docker inspect命令来查看。同时还可以使用docker run --env <key>=<value>来修改环境变量。
USER
USER 用来切换运行属主身份的。Docker 默认是使用 root,但若不需要,建议切换使用者身分,毕竟 root 权限太大了,使用上有安全的风险。
WORKDIR
WORKDIR 用来切换工作目录的。Docker 默认的工作目录是/,只有 RUN 能执行 cd 命令切换目录,而且还只作用在当下下的 RUN,也就是说每一个 RUN 都是独立进行的。如果想让其他指令在指定的目录下执行,就得靠 WORKDIR。WORKDIR 动作的目录改变是持久的,不用每个指令前都使用一次 WORKDIR。
COPY
COPY 将文件从路径 <src> 复制添加到容器内部路径 <dest>。
<src> 必须是想对于源文件夹的一个文件或目录,也可以是一个远程的url,<dest> 是目标容器中的绝对路径。
所有的新文件和文件夹都会创建UID 和 GID 。事实上如果 <src> 是一个远程文件URL,那么目标文件的权限将会是600。
ADD
ADD 将文件从路径 <src> 复制添加到容器内部路径 <dest>。
<src> 必须是想对于源文件夹的一个文件或目录,也可以是一个远程的url。<dest> 是目标容器中的绝对路径。
所有的新文件和文件夹都会创建UID 和 GID。事实上如果 <src> 是一个远程文件URL,那么目标文件的权限将会是600。
VOLUME
创建一个可以从本地主机或其他容器挂载的挂载点,一般用来存放数据库和需要保持的数据等。
EXPOSE
EXPOSE 指令指定在docker允许时指定的端口进行转发。
CMD
Dockerfile.中只能有一个CMD指令。 如果你指定了多个,那么最后个CMD指令是生效的。
CMD指令的主要作用是提供默认的执行容器。这些默认值可以包括可执行文件,也可以省略可执行文件。
当你使用shell或exec格式时, CMD 会自动执行这个命令。
ONBUILD
ONBUILD 的作用就是让指令延迟執行,延迟到下一个使用 FROM 的 Dockerfile 在建立 image 时执行,只限延迟一次。
ONBUILD 的使用情景是在建立镜像时取得最新的源码 (搭配 RUN) 与限定系统框架。
ARG
ARG是Docker1.9 版本才新加入的指令。
ARG 定义的变量只在建立 image 时有效,建立完成后变量就失效消失
LABEL
定义一个 image 标签 Owner,并赋值,其值为变量 Name 的值。(LABEL Owner=$Name )
ENTRYPOINT
是指定 Docker image 运行成 instance (也就是 Docker container) 时,要执行的命令或者文件。
Confd教程
GitHub项目地址
下载
wget https://github.com/kelseyhightower/confd/releases/download/v0.14.0/confd-0.14.0-linux-amd64
创建目录
mkdir -p /opt/confd/bin
mv confd-0.14.0-linux-amd64 /opt/confd/bin/confd
chmod +x /opt/confd/bin/confd
export PATH="$PATH:/opt/confd/bin"
配置目录
mkdir -p /etc/confd/conf.d
mkdir -p /etc/confd/templates
添加模板配置
[template]
src = "config.json.tmpl"
dest = "/code/config/config.json"
keys = [
"/mysql/host",
"/mysql/port",
]
添加模板
{
mysql:{
host:{{getv "/mysql/host"}},
port:{{getv "/mysql/port"}},
}
}
通过etcd启动
confd -onetime -backend etcd -node http://127.0.0.1:2379
脚本
#!/bin/bash
wget https://github.com/kelseyhightower/confd/releases/download/v0.14.0/confd-0.14.0-linux-amd64
mv confd-0.14.0-linux-amd64 /usr/bin/confd
chmod +x /usr/bin/confd
mkdir -p /etc/confd/conf.d
mkdir -p /etc/confd/templates
cat <<EOF | tee /etc/confd/conf.d/config.toml
[template]
src = "config.json.tmpl"
dest = "/tmp/config.json"
keys = [
"/mysql/host",
"/mysql/port",
]
reload_cmd = "echo 'reload' > /tmp/confd.log"
EOF
cat <<EOF | tee //etc/confd/templates/config.json.tmpl
{
mysql:{
host:{{getv "/mysql/host"}},
port:{{getv "/mysql/port"}},
}
}
EOF
cat <<EOF | tee /etc/systemd/system/confd.service
[Unit]
Description=Confd Server
After=network.target
[Service]
User=root
Type=notify
ExecStart=/usr/bin/etcd --watch -backend etcd -node http://127.0.0.1:2379
Restart=on-failure
RestartSec=10s
LimitNOFILE=40000
[Install]
WantedBy=multi-user.target
EOF
etcdctl set /mysql/host 192.168.0.1
etcdctl set /mysql/port 8888
confd -onetime -backend etcd -node http://127.0.0.1:2379
swarm 部署集群的想法
swarm
swarm 创建集群
注意集群最好是3 5 7个主机,并且要有多个管理员,否则一旦管理员挂了就挂了(未测试)
## 集群初始化
docker swarm init --listen-addr 192.168.99.100:2377 --advertise-addr 192.168.99.100
## 工作机假如
docker swarm join-token worker
## 管理加入
docker swarm join-token manager
## 加入集群
docker swarm join --token
swarm 创建网络
## 查看网络
docker network ls
## 创建网络
docker network create --driver overlay swarm_test
etcd
构建镜像
注意这里要用ENTRYPOINT,否则容易覆盖
FROM alpine:3.2
ENV ETCD_VERSION 3.2.10
COPY etcd-v${ETCD_VERSION}-linux-amd64.tar.gz etcd.tar.gz
RUN tar xzf etcd.tar.gz && \
mv etcd-*/etcd /bin/ && \
/bin/etcd --version && \
rm -rf etcd.tar.gz etcd-
COPY ./start.sh /bin
EXPOSE 2379 2380
ENTRYPOINT ["/bin/sh","/bin/start.sh"]
镜像脚本
注意:报奇怪的错误时,第一时间想到是因为文件格式问题,通过VIM创建文件编写文件
通过docker service create,容器内无法获取宿主机IP,可以继续研究
#!/bin/bash
LOCAL_IP=`ifconfig eth0|sed -n 2p|awk '{ print $2 }'|awk -F : '{ print $2 }'`
NAME=`hostname -s`
etcd --name $NAME \
--initial-advertise-peer-urls http://$LOCAL_IP:2380 \
--listen-peer-urls http://0.0.0.0:2380 \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://$LOCAL_IP:2379
swarm部署
### 注意discovery地址是http,https需要服务器支持
docker service create --name test \
--network etcd_network \
--publish 2379:2379 \
--publish 2380:2380 \
--replicas 3 \
--detach=true \
--env ETCD_DISCOVERY=http://discovery.etcd.io/b2e95d029b61e65ddd90421979efd7f6 \
registry.cn-hangzhou.aliyuncs.com/liuyt/etcd:sh
confd
安装confd
根据etcd更新nginx配置
部署应用
swarm 创建应用
遗留问题
etcd
为什么--listen-peer-urls和--listen-client-urls在docker集群中必须写0.0.0.0,通信到底是什么样样子的
0.0.0.0代表缺省地址,代表的时候,请求无法处理时按0.0.0.0处理
docker service
在docker service create中,添加了replicas参数后无法使用名称做ip,原因是什么,为什么可以使用名称做路由
通过名称做路由参考文章http://blog.51cto.com/nosmoking/1962483
在docker service create中如何获取每一个容器的ip
需要做的
脚本或node快速添加ssh登录
动态设置hostname,根据下面地址API教程
https://docs.docker.com/engine/reference/commandline/service_create/#create-services-using-templates
注册Docker论坛 http://dockone.io/
未完待编辑
分享 了解集群Docker、Swarm、Etcd、Docker-machine
Docker
含义
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
特点
轻量级
docker启动快,资源占用小,一个最小的Dokcer系统只需要5M。
构建标准化的运行环境
统一环境,版本控制,Docker不关心宿主机是什么运行环境,通过images统一运行环境,可以在任何环境的宿主机进行运行,方便自动化测试、持续集成和部署。
Docker-machine
用于统一管理运行Dokcer的宿主机,不同环境的系统安装Docker命令不一样,通过Docker Machine可以一条命令创建Docker运行环境。Docker Machine可以管理宿主机,通过Docker Machine直接运行其他主机上的程序。
特点
1、在任何环境下安装docker环境
2、远程连接管理主机
3、显示主机列表
4、重启主机
5、删除主机
6、支持各种驱动
amazonec2
azure
digitalocean
exoscale
generic
google
none
openstack
rackspace
softlayer
virtualbox
vmwarevcloudair
vmwarevsphere
Swram 容器集群管理
Swram是Docker官方出品,100%支持Docker API。最新版本的docker不需要在下载swarm镜像,Docker默认集成Swram。
阿里云Swram在创建集群时默认做了Docker-Machine
Swram节点调度
spread:如果节点配置相同,选择一个正在运行的容器数量最少的那个节点,即尽量平摊容器到各个节点;
binpack:跟 spread 相反,尽可能的把所有的容器放在一台节点上面运行,即尽量少用节点,避免容器碎片化。
random:直接随机分配,不考虑集群中节点的状态,方便进行测试使用。
Swram过滤器
Swarm 的调度器可以按照指定调度策略自动分配容器到节点。但有些时候希望能对这些分配加以干预。比如说,让 IO 敏感的容器分配到安装了 SSD 的节点上;让计算敏感的容器分配到 CPU 核数多的机器上;让网络敏感的容器分配到高带宽的机房;让某些容器尽量放同一个节点……。
节点过滤
以Docker Deamon的配置或Docker主机的特性为条件进行过滤的
Constraint:对节点添加标签,启动容器时,对应标签部署
health: 健康检查(重点会将)
容器过滤
以Docker容器的配置作为条件过滤
Affinity:通过查找已部署容器的名称或ID,或镜像的名称来对应部署
Port: 在运行容器时,通过-p指定主机与容器的端口映射,在swarm环境中,会自动选择指定端口可用(未被占用)的主机,避免端口冲突。
dependency:容器依赖性过滤器在相同节点上共同调度相关容器。目前,依赖声明如下:
--volumes-from=dependency (共享卷)
--link=dependency:alias (链接)
--net=container:dependency (共享网络堆栈)
Swram 健康检查
健康检查用于检查容器的健康状态,通过状态判断来制定容器的策略,例如:当容器健康状态为不健康的时候,可以对容器进行重启或停止,并重新创建一台容器,这样就可以做到无停止更新服务。
etcd
含义
etcd 是一个应用在分布式环境下的 key/value 存储服务。利用 etcd 的特性,应用程序可以在集群**享信息、配置或作服务发现,etcd 会在集群的各个节点中复制这些数据并保证这些数据始终正确。
GitHub项目地址
安装
confd
含义
是客户端的配置管理,通过监听ETCD或其他服务,通过定制模板生成配置文件。
特点
通过监听配置文件变化,更新配置文件,并可以在配置文件更新后执行相关命令
安装
速记
2018年11月28日
1、【坑】webview更改url不会本地刷新只会会创建新的页面,倒退时无法倒退到小程序,参考借鉴方案http://www.php.cn/xiaochengxu-407648.html
2、【坑】 wxml中不支持new String,在模拟器中可以运行,在ios无法运行,安卓未测试
3、【资料】无限层级路由解决方案https://juejin.im/post/5ba206a15188255ca00c8aa9
4、【坑】 上传图片会触发一系列流程,page hide -> app hide -> 上传图片->上传完成 -> app load -> app show -> page show
5、【资料】 富文本解析成小程序http://www.wxapp-union.com/article-1205-1.html https://github.com/ifanrx/wxParser
6、【坑】一个域名解析到多台服务器,导致访问错乱
7、【资料】linux权限设置 https://blog.csdn.net/u013197629/article/details/73608613
8、【资料】 brew 国内镜像更换 https://www.jianshu.com/p/5f1efab5a40a
9、【资料】 mac 安装nginx https://blog.csdn.net/yqh19880321/article/details/70478827
10、【资料】 前端错误监控 https://www.fundebug.com/
2018年12月04日
1、【资料】监控小程序是否关闭重新打开,在app.js的 onHide进行监控 https://developers.weixin.qq.com/community/develop/doc/000262d75a0eb84ab8178bafd51c00
2、【坑】nginx 301重定向或404可能是因为文件夹权限问题,导致无法访问
3、【资料】使用css将图片转为灰色 https://www.zhangxinxu.com/wordpress/2012/08/css-svg-filter-image-grayscale/
4、【资料】rpx rem em px是什么,什么关系?https://www.jianshu.com/p/5523ff70de31
5、【资料】通过FileReader进行图片预览 https://segmentfault.com/a/1190000008774643
6、【资料】EGG 表单上传多个文件 https://github.com/eggjs/egg-multipart
7、【坑】wireshark抓包如果想看传输html只能通过追踪http请求看到,可以通过抓包抓取微信浏览器内容。
8、【资料】阿里云控制台中的spm编码 https://www.oschina.net/question/168245_58280
9、【资料】微信浏览器禁止页面下拉 https://segmentfault.com/a/1190000014134234
10、【资料】事件监听中的 passive 参数详解https://zhuanlan.zhihu.com/p/24555031
2019-01-18
1、vimium 复制粘贴不是特别好用,有时候会出现问题,出现按钮失灵
2、有些单页应用,因为焦点的问题无法进行滚动
2019-07-1
实现表单引擎的一些想法
后端
通用引擎
-> 插件
-> 查询(包视图和表)
-> 执行 (增删改查 包括可以针对视图进行增删改查)
引擎确定入参和出参,json格式返回
前端
通用引擎
-> 插件
-> 列表查询
-> 新增修改
-> 删除
前端通过json进行渲染
一些想法:
1、socket通信
2、定时任务
3、前端表单逻辑
4、手动生成表单页面
2019-07-4
看到的页面25个左右
翻一倍算50个页面
每个页面按3天算
150人天
后台未知的情况下
按前台一样的工作了估计150人天
共300人天
一个商场项目大概就是150天到200天,50个页面左右,估价大概在20W到40万
VUE源码学习(4)-vue核心内容简单实现4
知识点
这里重点在于
- dep的作用域发生了变化
- 设置一个当前监听全局变量,通过getter来添加监听
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Simple Vue</title>
</head>
<style>
#app {
text-align: center;
}
</style>
<body>
<div id="app">
<p id="vdom1">{{success}}</p>
<p id="vdom2">{{success}}</p>
<p id="vdom2">{{error}}</p>
<p id="vdom2">{{error}}</p>
<p id="vdom2">{{error}}</p>
</div>
</body>
<script>
// 被监听的数据
let data = { success: "1111", error: "2222" };
// 虚拟dom集合
let nodes = [];
// 当前监听
let currentWatcher = null;
Object.keys(data).forEach(key => {
let val = data[key];
// 监听和分发集合
var dep = {
subs: [],
notify() {
this.subs.forEach(item => {
item.update();
})
}
}
// 设置监听数据的getter和setter
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
// 通过getter获取当前监听
get() {
if (currentWatcher) {
dep.subs.push(currentWatcher)
}
return val;
},
set(newVal) {
// 如果值一样,不更新dom
if (newVal === val) {
return;
}
val = newVal;
// 触发所有监听
dep.notify();
}
});
})
// 设置虚拟dom
let el = document.querySelector("#app");
const fragment = document.createDocumentFragment();
let firster = el.firstChild;
while (firster) {
fragment.appendChild(firster)
firster = el.firstChild;
}
fragment.childNodes.forEach(item => {
// NodeType请参考 https://developer.mozilla.org/zh-CN/docs/Web/API/Node/nodeType
if (item.nodeType == 1) {
let text = item.textContent;
const reg = /\{\{(.*)\}\}/;
let key = reg.exec(text)[1];
if (key in data) {
// 注意!!!
// 之前这里我一直在想如果并发怎么办,其实想多了,js单线程处理,这里又是同步执行所以不可能并发
// 设置监听
currentWatcher = {
update() {
// 更新dom
item.textContent = data[key]
}
};
// 通过getter添加当前监听到dep中
let getValue = data[key];
// 设置完监听后重置为空
currentWatcher = null
}
}
})
el.appendChild(fragment)
// 定时更新数据,更新dom
setInterval(() => {
data.success = "当前时间戳为:" + Date.now()
data.error = "当前时间戳为:" + Date.now()
}, 1000);
</script>
</html>
禁用mac版chrome自带双指手势前进后退功能
mac版chrome自带双指手势前进后退功能,经常误操作,一直想把它关闭了,但chrome的设置里没有,后来发现可以这样操作
鼠标
defaults write com.google.Chrome AppleEnableMouseSwipeNavigateWithScrolls -bool false
触控板
defaults write com.google.Chrome AppleEnableSwipeNavigateWithScrolls -bool false
null
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.