My heart's in the Highlands a-chasing the deer -
A-chasing the wild deer, and following the roe;
My heart's in the Highlands, wherever I go.
— Robert Burns
Highlands is a set of scripts used to manage Facebook Buck project workspace in a certain manner.
-
Generates library definition from Maven Central artifacts and maintains supplementary lock file. The generated lock file (JSON) and library definitions (comprised of
BUCKfiles withprebuilt_jarandremote_filerules) then stored in Git, so that reliable and reproducible builds are possible. Such libraries are defined using simple DSL-ish calls in "up" file and can easily be updated and regenerated. -
Generates decent Java projects and modules for Intellij IDEA and Eclipse IDEs. Annotation processing is supported by linking generated source folders.
-
Gets basic info on Maven Central artifacts in JSON format.
Up to date version of Node JS is required to be installed. For example, brew install node on Mac with Homebrew will be just fine.
Highlands scripts are self-sufficient and dependency-less, i.e. do not have any remote npm modules to be downloaded, only standard Node modules are used. To install this set of scripts — just copy them. You can use tagged released archives to download the same file
Given that current directory is Buck project root dir and there's "up" file (see below), usage is just call node on the up script.
$ node up --help
Usage: <this-cmd> [<options>]
--help Prints usage and option hints
--trace Enable tracing of command line calls and created files
--uplock Use up.js library definitions to update lib lock
--lib Generate library rules and jar symlinks
--intellij Generates project for Intellij IDEA
--eclipse Generates project for Eclipse
--mvn Prints JSON info about Maven coordinates
All output goes to stderr, except for JSON output of --mvn command which goes to stdout so it can be redirected to a file etc. Successful execution returns 0 status as expected.
Edit up.js so library definitions will be updated, then run lock-file update and refresh library BUCK files
$ node up --uplock --lib
Use the flag for --intellij. Make sure libs are already generated/exists in the repo.
$ node up --intellij
$ node up --mvn org.immutables:value:2.7.3
{
"coords": "org.immutables:value:2.7.3",
"groupId": "org.immutables",
"artifactId": "value",
"version": "2.7.3",
"jar": {
"uri": "https://repo1.maven.org/maven2/org/immutables/value/2.7.3/value-2.7.3.jar",
"sha1": "91d271437be1e14438a2da6c5c3e9f8db061a7b9"
},
"sources": {
"uri": "https://repo1.maven.org/maven2/org/immutables/value/2.7.3/value-2.7.3-sources.jar",
"sha1": "da58a1979724a3d20ab976762faf640d3e463493"
}
}
The entry point for script execution is "up" file. The actual name can be different, but for simplicity let's assume it's will be just up.js. It contain require instruction to import Highlands script, DSL-ish function calls to define libraries and finalizing run() to perform actions. Actions are specified by command line options (see usage).
// up.js file, put it to the root folder
// require by relative name to downloaded dir with scripts,
// ending slash in the path is a must for index.js to be picked
require('./highlands/')
.lib('//lib/some/library', 'group:artifact:version')
.lib('//lib/other/library:classifier', 'group:artifact:classifier:version')
.lib('//lib/junit', ['junit:junit:4.12', 'org.hamcrest:hamcrest-core:1.3'])
.run() // <- finishing move, required to launch the script execution .lib('//lib/some/library', 'group:artifact:version', options)Library definition contains library's canonical Buck path. By convention, if :target part is omitted it is considered the same as last segment of a path, so //lib/one is equivalent to //lib/one:one and is so called default target. Non-default targets are also supported and can be used for classifier jars or logically "sibling" jars/flavors. The example uses //lib/ shared suffix for such libraries and it is not mandatory — use the path you want, but it's usually a good idea to have such common prefix (//lib, //extern, //third-party/ etc are commonly used).
Then, as second argument, Maven coordinates string in the form of <groupId>:<artifactId>:<version> or <groupId>:<artifactId>:<classifier>:<version> is used to specify artifact in Maven Central. More than one artifact can be used if wrapped in an array. All such artifacts will comprise a single Buck library with a given path. No transitive dependencies are resolved, so, please, collect all needed dependencies in an array and/or add additional libraries as dependencies via options.deps see below.
The third, optional, argument is used to pass options:
-
options.depsadditional dependencies for the lib rules can be passed in form of an array of Buck targets. These are added as exported dependencies to the library rule -
options.processorcan specify Java annotation processor class. The processor option will turn a lib into an annotation processor "plugin". Plugins are added aspluginsattribute array to ajava_libraryrule. Additionaloptions.processorLibraryused to add local rule name to define intermediate annotation processor library which can be used by external rules as a library as opposed to a plugin, the plugin will also be defined in this case but it will also add this processor library as dependency.
// Immutables annotation processor example
.lib('//lib/immutables/value', 'org.immutables:value:2.7.3', {
processor: 'org.immutables.processor.ProxyProcessor'
})-
options.srcscan be used to specify alternative artifacts used to attach as source jars. The option accepts an array of Maven coordinates or a single Maven coordinates string. The number of src elements should be exactly the same as for library jars (second argument to.libcall) and have corresponding order, so they can be matched by position. This, probably, is a very rare case to hit, but can be useful if you need to use specific repackaged artifact for which there are no sources, but there are sources for a regular artifact. Also, an empty array can be supplied to suppress using source jars (in this case rule to have the same number of src jars as library jars does not apply). -
options.repoallows to specify remote repository for an artifact. Accepts uri prefix (no auto-slashes auto-added, leave trailing one) or a special values such as'central'for Maven Central andjcenterfor Bintray's JCenter. When not specified, the default is to use Maven Central. The repo will be used for all artifacts in this library. -
options.internal = trueinternal flag turn treats this library as internal to the repo, rather than downloaded external one. It is expected that there are rules which output jars under the library path. Example: for internal library//some/target:goalwe will expect output files availablegoal.jarandgoal.src.jarfor rules in this folder (/some/target).options.jarandoptions.srccan be used to override these names, this is not tied to any existing rule names and theiroutfilename, however those should eventually match to build output of targets in the folder. When generating IDE files, library will reference class and src jars as (generated) symlinks under//some/target/.outfolder.options.generatedSourcePathoption with a value of target(s) (relative or absolute) can be used to attach additional sources (IntelliJ only) generated by annotation processors of the specified target. Most of the time, sources generated by annotation processors are compiled into class files in jar, but the sources themselves are not being packaged in any jar (transient java files), sogeneratedSourcePathattaches source folders to internal library definition to complete a library: original sources + generated sources + jar with all classes.
.up.lock.json file is generated in the repository/project directory. By default all option-commands use preexisting .up.lock.json and if it's missing there will be an error. If --uplock option is specified, definitions from up.js will be used to query for checksums from Maven Central and regenerate lock file. Make sure to call this command when connection is secure etc. In theory lock file can be redundant if we can fully encode the information in generated BUCK libraries (see --lib option), however, consolidated lock file is easier to deal with in practice. Both lock file and generated libraries should be checked in repository, so whenever repository is checked out, clean reproducible build can be performed. This assumes that buck fetch command can download and cache remote artifacts. --lib option will call buck fetch //... automatically.
In addition to library BUCK files, there will be .out/ directory generated along each BUCK file containing output that can be generated by following rules: remote_file, genrule, java_binary, http_file, http_archive, zip_file. If you want to force some other rule that have output (for example java_library) to be symlinked too, use label labels = ['symlink_out] as part of the rule definition. Created .out/ directory will contains symlinks to jars stored deep inside buck-out/. The names of the jars are derived either from out attribute or a target name. Having these jar symlinks is useful for ad hoc build tools and scripts, for making references from IDE project files etc. We trying to avoid relying on the particular internal structure of buck-out/ storage. These destination paths inside buck-out/ are not hardcoded by Highlands scripts, but queried from Buck itself. It's recommended to keep .out/ out of the source code repo (git ignore) so they can be easily regenerated by --lib. Please note that generated symlinks may be broken until build is performed for the corresponding rules, so that build will actully generate output files and symlink will not point to created files.
Calling node up --intellij or node up --eclipse will generate project and module files for respective IDEs.
Common for both IDEs is the way in which modules are discovered. The module is defined by a directory with a BUCK file defining default rule/target (the one having the name which is the same as directory name) such that it's:
- Either
java_libraryrule withresource_rootspecifying a source/resource folder - Or it can use
label = ['ide_mod'], if it's notjava_libraryand have no source folders
There can be many rules with resource_root defined once module dir is discovered. Mind how rules under same module would or wouldn't have clashes in sources / dependencies.
The most easy and recommended approach to source folders, which stems from how modules are defined and discovered is following:
srcdirectory for compile classes and classpath resources.testdirectory for test classes and test resourcessrc-gen,test-genetc symlinks will be auto-created for annotation processing sources
Note: it is strongly recommended to stay away from useless and unwieldy Maven directory structure which introduces useless segments (duplicating filename extension roles) and overall brings structure which is not beneficial in any way, yet makes all paths longer, harder to type by hand if ever needed and makes it harder synchronizing parallel package structures.
Example of such module's BUCK files
# //modules/module1/BUCK
java_library(
name = 'module1', # <- Default target in this directory
srcs = glob(['src/**/*.java']),
resources = glob(['src/**'], excludes = ['src/**/*.java']),
resources_root = 'src', # <- Bingo! we have a module
deps = [
'//lib/google/common:common',
],
tests = [':test'],
visibility = ['PUBLIC'],
)
java_test(
name = 'test',
srcs = glob(['test/**/*.java']),
resources = glob(['test/**']),
resources_root = 'test', # <- Defines test source folder
deps = [
':module1',
'//lib/junit:junit',
],
)The modules will have references to other modules in case they depend on rules from other modules. Likewise, referenced library jars will be added to a module classpath. Definitely, there's no 1:1 correspondence between Buck rules and IDE modules with regard to granularity and scope of dependencies so expect that more complicated rule arrangements will just not translate correctly to IDE.
- IDE module names will be by default derived from the directory (simple) name where possible. In case of clashes additional (disambiguating) segments will be added to module name.
- In Eclipse, as there are both flat and hierarchical views are available for modules, all modules will be prefixed with the name of the root module.
- Classpath/library files for IDEs will reference jars as symlinks generated in
.out/directories. - Provided/exported/test dependency scopes are honored to the degree possible in specific IDE. Eclipse only supports "exported" dependencies.
- Annotation processing will work from Buck build, and IDE will have generated sources attached. Support for in-IDE annotation processing can be added in future.
- In Intellij, in the a module all folders are marked as excluded except the ones which contain modules.
- Can create resource-only
java_libraryrule and addlabel = ['ide_res']orlabel = ['ide_test_res']to markresources_rootfolder as java resources or test resources in Intellij IDEA. These rules still need to be added as dependency to anyjava_libraryrule which wants to access these resources on the classpath.
Note: clearly, you can skip using this script and just use buck project --ide ij if it suits your needs. We believe Highlands project generation adds some fine touches and may result in better IDE experience.
-
Only Java 8, 9, 10, 11, 12, 13 seems to be supported as of now. In
.buckconfig, usetools.javac,tools.java,java.source_level,java.target_levelto configure. Buck itself only runs under Java 8, so for 9+ only external compiler/vm should be used. -
This repo is released by tagging, you can use released zip from Github or clone the repo and use/copy from there. Make sure to calculate and verify checksum if in any automatic download script.
-
Add
--traceCLI option every time you're investigating/troubleshooting script execution, this will give nice colored output providing tracing information about shell commands called and files/symlinks created.
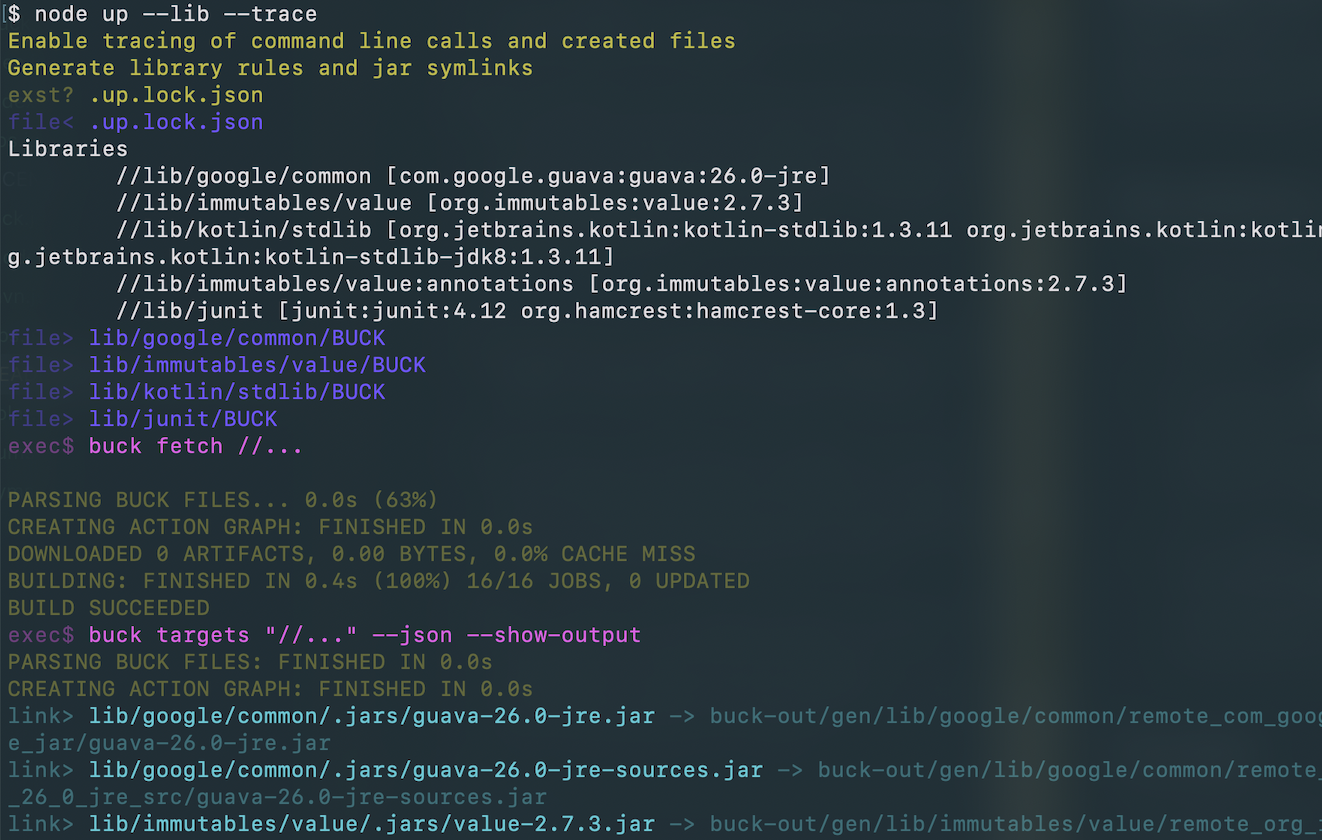
--publishcan publish artifacts (libraries havingmaven_coordsset), also java binaries via.fatJar(target)and zip archives.zip(folder, options)declared inup.js. It publishes to maven-like repository (configured viaPUBLISH_REPOSITORY,PUBLISH_USERNAME,PUBLISH_PASSWORDenv variables) or local.outfolder if no remote repo provided
This repository also contains branch example which contains full sample Buck project ready to be managed by Highland scripts. It has Java, annotation processor and Kotlin rules used to add some variety.










