Data Science Experience is now Watson Studio. Although some images in this code pattern may show the service as Data Science Experience, the steps and processes will still work.
In any business, word documents are a common occurence. They contain information in the form of raw text, tables and images. All of them contain important facts. The data used in this code pattern comes from two Wikipedia articles. The first is taken from the Wikipedia page of oncologist Suresh H. Advani the second is from the Wikipedia page about Oncology. These files are zipped up as Archive.zip.
In the figure below, there is a textual information about an oncologist Suresh H. Advani present in a word document. The table consists of the awards that he has been awarded by various organisations.

In this Code pattern, we address the problem of extracting knowledge out of text and tables in word documents. A knowledge graph is built from the knowledge extracted making the knowledge queryable.
Some of the challenges in extracting knowledge from word documents are:
- The Natural Language Processing (NLP) tools cannot access the text inside word documents. The word documents need to be converted to plain text files.
- There are business and domain experts who understand the keywords and entities that are present in the documents. But training the NLP tool to extract domain specific keywords and entities is a big effort. Also, it is impractical in many scenarios to find sufficient number of documents to train the NLP tool to process the text.
This pattern uses the below methodology to overcome the challenges:
- The
python package mammothis used to convert.docxfiles to html (semi-structured format). - Watson Natural Language Understanding (Watson NLU) is used to extract the common entities
- A rules based approach that is explained in the code pattern Extend Watson text Classification is used to augment the output from Watson NLU. The rules based approach does not require training documents or training effort. A configuration file is taken as input by the algorithm. This file needs to be configured by the domain expert.
- Watson NLU is used to extract the relations between entities
- A rules based approach that is explained in the code pattern Watson Document Correlation is used to augment the output from Watson NLU. A configuration file is taken as input by the algorithm. This file needs to be configured by the domain expert.
The best of both worlds - training and rules based approach is used to extract knowledge out of documents.
In this Pattern we will demonstrate:
- Extracting the information from the documents- free-floating text and Table text.
- Cleaning the data pattern to extract entities from documents
- Use Watson Document Correlation pattern to extract relationships between entities
- Build a knowledge base(graph) from it.
What makes this Code Pattern valuable:
- The ability to process the tables in docx files along with free-floating text.
- And also the strategy on combining the results of the real-time analysis by Watson NLU and the results from the rules defined by a Subject matter expert or Domain expert.
This Code Pattern is intended to help Developers, Data Scientists to give structure to the unstructured data. This can be used to shape their analysis significantly and use the data for further processing to get better Insights.

- The unstructured text data from the docx files (html tables and free floating text) that need to be analyzed and correlated is extracted from the documents using python code.
- Use Extend Watson text Classification text is classified using Watson NLU and also tagged using the code pattern - Extend Watson text classification
- The text is correlated with other text using the code pattern - Correlate documents
- The results are filtered using python code.
- The knowledge graph is constructed.
-
IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
-
IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost effective apps and services with high reliability and fast speed to market.
-
Watson Natural Language Understanding: A IBM Cloud service that can analyze text to extract meta-data from content such as concepts, entities, keywords, categories, sentiment, emotion, relations, semantic roles, using natural language understanding.
- Jupyter Notebooks: An open-source web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text.
Follow these steps to setup and run this code pattern. The steps are described in detail below.
Create the following IBM Cloud service and name it wdc-NLU-service:

-
Log in or sign up for IBM's Watson Studio.
-
Select the
New Projectoption from the Watson Studio landing page and choose theJupyter Notebooksoption.

- To create a project in Watson Studio, give the project a name and either create a new
Cloud Object Storageservice or select an existing one from your IBM Cloud account.

- Upon a successful project creation, you are taken to a dashboard view of your project. Take note of the
AssetsandSettingstabs, we'll be using them to associate our project with any external assets (datasets and notebooks) and any IBM cloud services.

Once the service is open, click the Service Credentials menu on the left.
- From the project dashboard view, click the
Assetstab, click the+ New notebookbutton.

- Give your notebook a name and select your desired runtime, in this case we'll be using the associated Spark runtime.

- Now select the
From URLtab to specify the URL to the notebook in this repository.

- Click the
Createbutton.
When a notebook is executed, what is actually happening is that each code cell in the notebook is executed, in order, from top to bottom.
Each code cell is selectable and is preceded by a tag in the left margin. The tag
format is In [x]:. Depending on the state of the notebook, the x can be:
- A blank, this indicates that the cell has never been executed.
- A number, this number represents the relative order this code step was executed.
- A
*, this indicates that the cell is currently executing.
There are several ways to execute the code cells in your notebook:
- One cell at a time.
- Select the cell, and then press the
Playbutton in the toolbar.
- Select the cell, and then press the
- Batch mode, in sequential order.
- From the
Cellmenu bar, there are several options available. For example, you canRun Allcells in your notebook, or you canRun All Below, that will start executing from the first cell under the currently selected cell, and then continue executing all cells that follow.
- From the
- At a scheduled time.
- Press the
Schedulebutton located in the top right section of your notebook panel. Here you can schedule your notebook to be executed once at some future time, or repeatedly at your specified interval.
- Press the
- From the
My Projects > Defaultpage, UseFind and Add Data(look for the10/01icon) and itsFilestab. - Click
browseand navigate to Archive.zip - Click
browseand navigate to config_relations.txt - Click
browseand navigate to config_classification.txt

Note: It is possible to use your own data and configuration files. If you use a configuration file from your computer, make sure to conform to the JSON structure given in
data/config_classification.txt.
Under the File menu, there are several ways to save your notebook:
Savewill simply save the current state of your notebook, without any version information.Save Versionwill save your current state of your notebook with a version tag that contains a date and time stamp. Up to 10 versions of your notebook can be saved, each one retrievable by selecting theRevert To Versionmenu item.
You can share your notebook by selecting the “Share” button located in the top right section of your notebook panel. The end result of this action will be a URL link that will display a “read-only” version of your notebook. You have several options to specify exactly what you want shared from your notebook:
Only text and output: will remove all code cells from the notebook view.All content excluding sensitive code cells: will remove any code cells that contain a sensitive tag. For example,# @hidden_cellis used to protect your dashDB credentials from being shared.All content, including code: displays the notebook as is.- A variety of
download asoptions are also available in the menu.
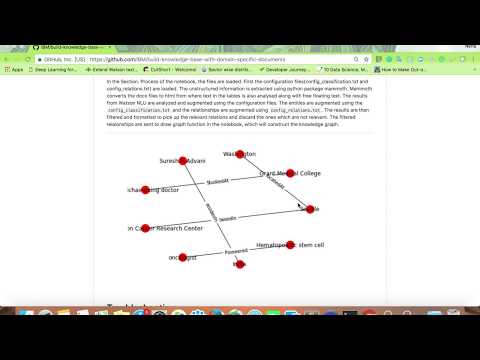
In the Section. Process of the notebook, the files are loaded. First the configuration files(config_classification.txt and config_relations.txt) are loaded. The unstructured information is extracted using python package mammoth. Mammoth converts the docx files to html from where text in the tables is also analysed along with free floating text. The results from Watson NLU are analyzed and augmented using the configuration files. The entities are augmented using the config_classification.txt and the relationships are augmented using config_relations.txt. The results are then filtered and formatted to pick up the relevant relations and discard the ones which are not relevant. The filtered relaionships are sent to draw graph function in the notebook, which will construct the knowledge graph.

- Data Analytics Code Patterns: Enjoyed this Code Pattern? Check out our other Data Analytics Code Patterns
- AI and Data Code Pattern Playlist: Bookmark our playlist with all of our Code Pattern videos
- Watson Studio: Master the art of data science with IBM's Watson Studio
- Spark on IBM Cloud: Need a Spark cluster? Create up to 30 Spark executors on IBM Cloud with our Spark service




