janlaywss / blog Goto Github PK
View Code? Open in Web Editor NEW个人技术博客 / 总结 / 经验分享
个人技术博客 / 总结 / 经验分享






近些年,随着工业互联网的发展,越来越多的应用选择了在浏览器端实现。浏览器开放的功能也越来越多。
可是,在浏览器功能越来越强大的日子,前端也变的繁重起来。状态仓库需要存放的东西也越来越多。如一个简单的前端监控系统,就涉及到错误展示,数据报表,错误筛选查询等等功能。这其中有许多数据都是存在交集的
一旦我们的数据获取存在交集,则就意味着有以下问题存在:
当然,以上是交集存在的问题。这也会导致单条数据不纯,无法做到很高的抽象和通用性。久而久之,此类管理方式存放的数据模型会越来越混杂,越来越多,造成管理上的麻烦。
于是,我们非常希望可以将数据的管理模型使其更加抽象,使其可以在任意业务场景都可以灵活组装和使用。
这一点也和函数式编程中的“纯函数”概念类似:
纯函数 + 纯函数 = 纯函数
我们将视角转向后端来看。假设错误监控的后端接口,要给我们返回一条 错误捕获信息,后端的数据查询逻辑又该如何编写呢?
下图是2张表的联查实现。其中一张issue表,一张error表。在后端的数据库设计中,issue和error关联,常常以引用对方的id来实现。这样我们就可以将2张表解耦设计,在需要联合查询时再进行组装。
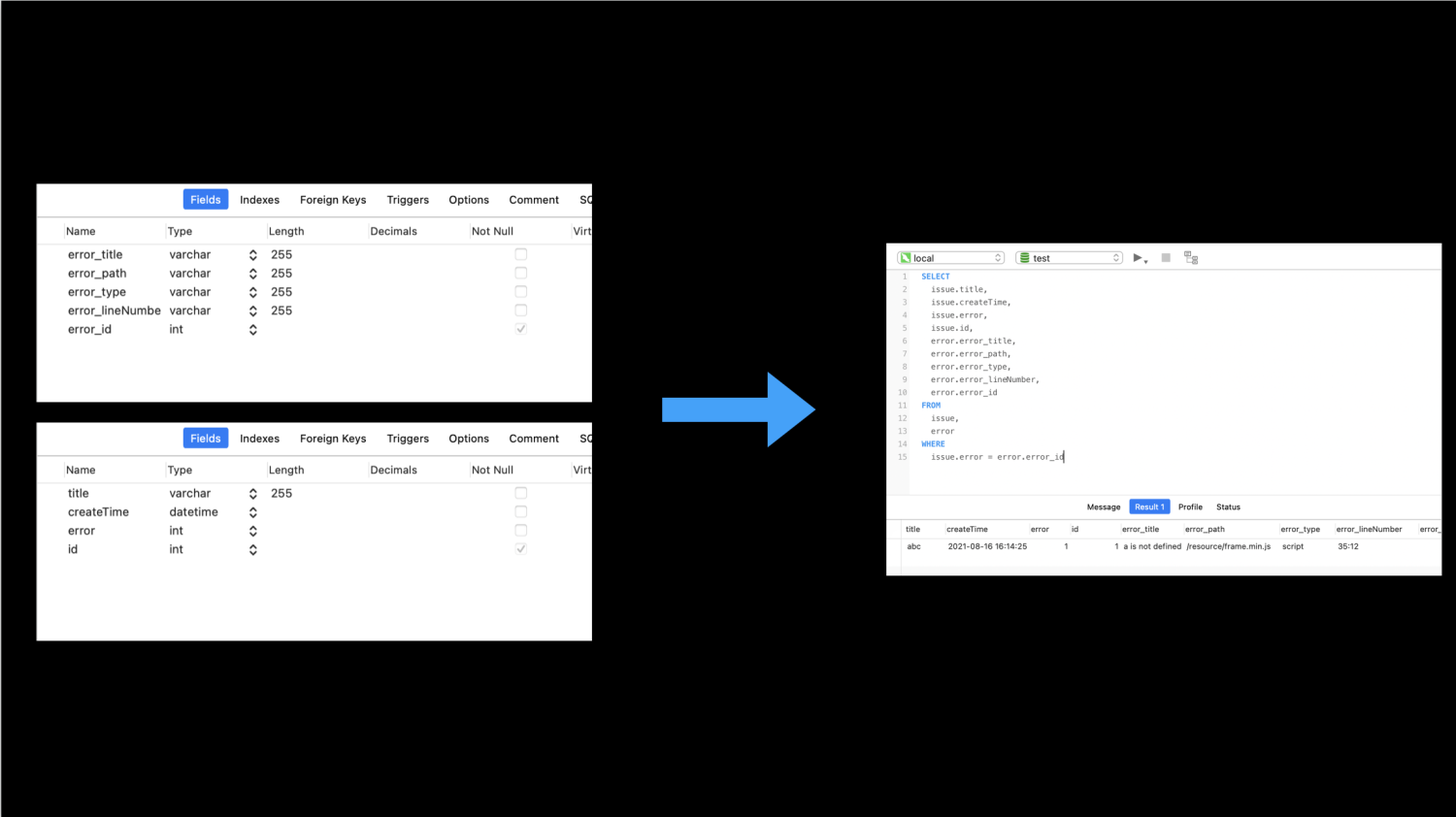
可以看到,得益于许多数据库的多表联查,后端可以轻松地从多张表中拿到想要的数据,最后组装起来,通过接口进行返回。
基于以上考虑,我们可以采用状态范式化方案。在使用范式化方案之前,我们先来了解一下它到底是什么。
根据redux官方文档的介绍(https://redux.js.org/usage/structuring-reducers/normalizing-state-shape#designing-a-normalized-state):
Each type of data gets its own "table" in the state. (每种类型的数据在状态树中应该有属于自己的表)
Each "data table" should store the individual items in an object, with the IDs of the items as keys and the items themselves as the values.(每一条数据都应当把数据存在一个对象里面。项目的ID作为key,本身作为value)
Any references to individual items should be done by storing the item's ID.(对于单个数据模型的引用应当通过存储ID来实现)
Arrays of IDs should be used to indicate ordering.(应该用包含ID的数组来声明所有数据的排列顺序)
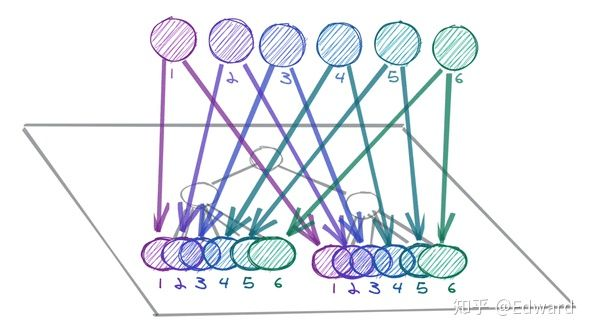
简单来讲,就是将我们的数据从立体化变为扁平化,将可以抽象的数据模型进一步独立管理,数据之间连接模型用ID进行引用连接查找,可以加快查找数据的速度。如:
这种存取查找方式,类似数据库的多表联查一样。所以在很多时候,我们期待前端的范式化模型和数据库的模型一一对应。我们根据范式化的概念,可以将我们目前的状态根据模型进行抽象。根据模型将数据抽离,随后根据查询关系,做关联引用
抽象完毕后,我们在业务中查找数据的方案也需要进行联合查询。这样以来,我们查询的复杂度就由O(N)降为了O(1)。查询性能大幅度提升
当然,这样的数据组装方式虽然让读取速度加快,但也让源数据的分离实现变得复杂起来。
这里我们可以使用 Redux 官方推荐的 normalizr.js,他可以根据预先设置好的数据模型,把我们的数据快速根据模型进行剥离,我们的数据转换可以变的更加简单。
我们可以经过简单的数据模型定义,就可以将数据按照模型进行分离。像上面的演示转换结果一样
import { normalize, schema } from 'normalizr';
// Define a users schema
const user = new schema.Entity('users');
// Define your comments schema
const comment = new schema.Entity('comments', {
commenter: user
});
// Define your article
const article = new schema.Entity('articles', {
author: user,
comments: [comment]
});
const normalizedData = normalize(originalData, article);
当然,redux 天生的状态管理方案是存在巨大的性能问题的 —— 需要将状态提升到公共组件去管理。
这种实现方式常常会导致不必要的组件重新生成组件树。
举个例子,我们有一个错误监控系统,当我们获取最新的错误信息列表时:虽然我们的错误信息条目有所增加,错误类型却始终没有变化。但只使用错误类型的组件依然触发了重新渲染。
我们当然不希望这种状况存在,毕竟如果碰到比较复杂的计算时,不必要的重复渲染往往对性能影响都比较大。
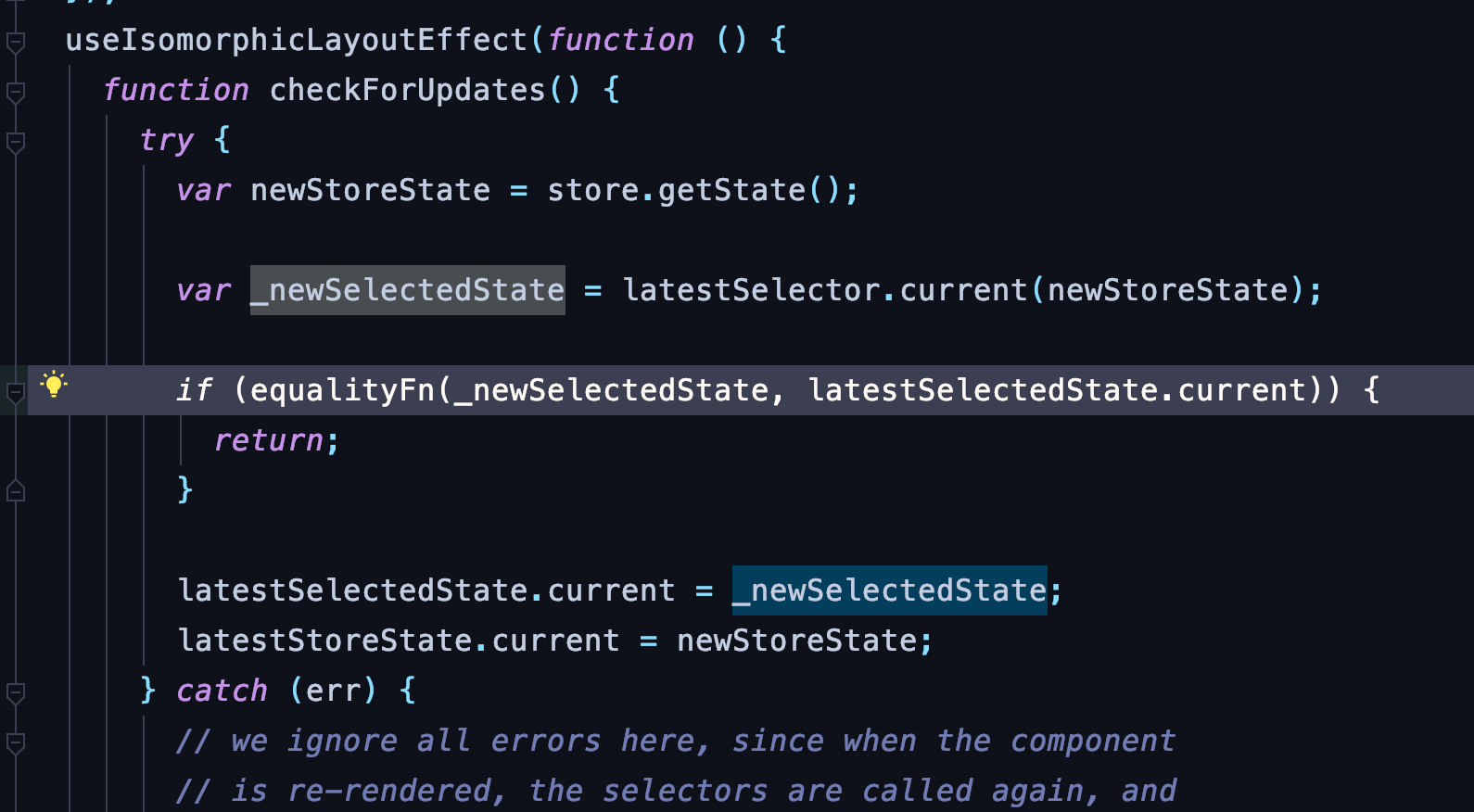
当然,我们可以借助 react-redux 的 useSelector 钩子来筛选需要的 state。useSelector 自身拥有了多级缓存,可以确保只有在用到的数据更新时,才会触发组件,不会造成不必要的组件更新。
从源码中可以看到,每次提交 action 后,都会去执行 equalityFn 函数,将本次 selector 的执行结果于上次的结果进行对比。如果一致,则直接 return。不会触发后面重复渲染的逻辑
但这种方案依然存在缺陷。在每次 action 提交后,虽然组件不会重新生成,useSelctor的selector的选择函数依然会重新生成(虽然有 reselect,但缓存也是个成本)。
且倡导一个useSelctor每次只返回单个非引用类型字段值,不然触发浅比较会导致组件再次重新渲染。
Recoil 是 Facebook 推出的基于 React 的状态管理框架(目前还是试验阶段)。它的最大优势就是可以基于正交有向图,精准的只触发渲染状态更新的组件,而这一切都是基于订阅来实现。
基于订阅,也就避免了 useSelector 的选择器,每次状态更新都需要重新生成的问题。
下图可以看到,比起之前redux一颗全局大的状态树的玩法,recoil 更推荐将状态拆为一个个碎片状态,只与用到的组件进行共享。
在recoil中,有2个最核心的概念:atom和 selector。atom是状态的最小单位。当atom被更新时,订阅的组件也会被触发更新。如果多个组件都订阅了同一个atom,则它们共享这份状态。你可以简单地认为,atom 是recoil中最小的数据源
const fontSizeState = atom({
key: 'fontSizeState',
default: 14,
});
而 selector 的意义则是搭配 atom 使用。selector 可以为 atom 加入自定义的 getter 和setter。而 atom 发生更改时,订阅它的 selector 也会发生变化,从而被订阅 selector 的组件重新 render
const fontSizeLabelState = selector({
key: 'fontSizeLabelState',
get: ({get}) => {
const fontSize = get(fontSizeState);
const unit = 'px';
return `${fontSize}${unit}`;
},
});当然,recoil 也支持状态的读写粒度不一致问题。例如我的状态中包含了 a 和 b 两个属性,我在读的时候,只读其中的 a 属性,则只用到 b 属性的组件不会更改。
这一点对性能的提升巨大,也一定程度上间接避免了recoil的状态拆分过细问题
当然,Recoil 最赞的地方是 状态读取支持异步函数。且同步异步可以混用,同步函数也可以接受异步读取的值。 当然,这一个点要配合 Suspense 优势才最大。
例如下面代码。我在 selector 中定义的状态 get 为异步函数,而在我组件中使用时却是同步的。这对于使用者来说是无感使用的。
当然,配合 Suspense 的效果更好,我们就不需要另外的状态,来判断这个异步计算是否已经拿到数据。
const currentUserIDState = atom({
key: 'CurrentUserID',
default: 1,
});
const currentUserNameQuery = selector({
key: 'CurrentUserName',
get: async ({get}) => {
const response = await myDBQuery({
userID: get(currentUserIDState),
});
return response.name;
},
});
function CurrentUserInfo() {
const userName = useRecoilValue(currentUserNameQuery);
return <div>{userName}</div>;
}
function MyApp() {
return (
<RecoilRoot>
<React.Suspense fallback={<div>加载中。。。</div>}>
<CurrentUserInfo />
</React.Suspense>
</RecoilRoot>
);
}如果你还不懂什么是 Server Component,请一定要看:
应用中心是一个许多场景都常见的需求。近段时间,React Server Component 逐渐火了起来。虽然暂时没法上生产,但也给应用的实现方式带来了一种可能。本文面向加密应用的场景,对 Server Component 的实现做个简单的改造和适配。
React Server Component 可能更重在优化渲染的性能。带来的好处如:
于是 React 在从一开始设计编写的方向,就是打算开发一套全新的开发模式。但此模式也暴露出一些弊端。如:无法很优雅地存储 Server Component 的状态,起码这在当前的开发模式中是无法忍受的(在未来也无法忍受)
下文这套方案的初衷方向,是为了组件加密执行。Server Component 的 bundle 并不落前端浏览器,于是也不会存在源码泄露问题,从源头上解决了泄密问题。对于一些开放平台的收费应用,此方向有很棒的效果。
所以在设计此方案时,考虑在 Node 侧使用沙箱选择了屏蔽一些 Node 的 API(具体看下文),像fs、http等。同时又开放了一些自定义的 API 在里面。这些都是为特殊场景做的努力
对于状态管理,React Server Component 的初衷是希望组件不要拥有自己的状态,于是 hook 功能失效。但考虑到开发便捷性,下文方案还是选择了对组件树中的 hook 状态做了单独剥离出来,同时有安全存取的方案。
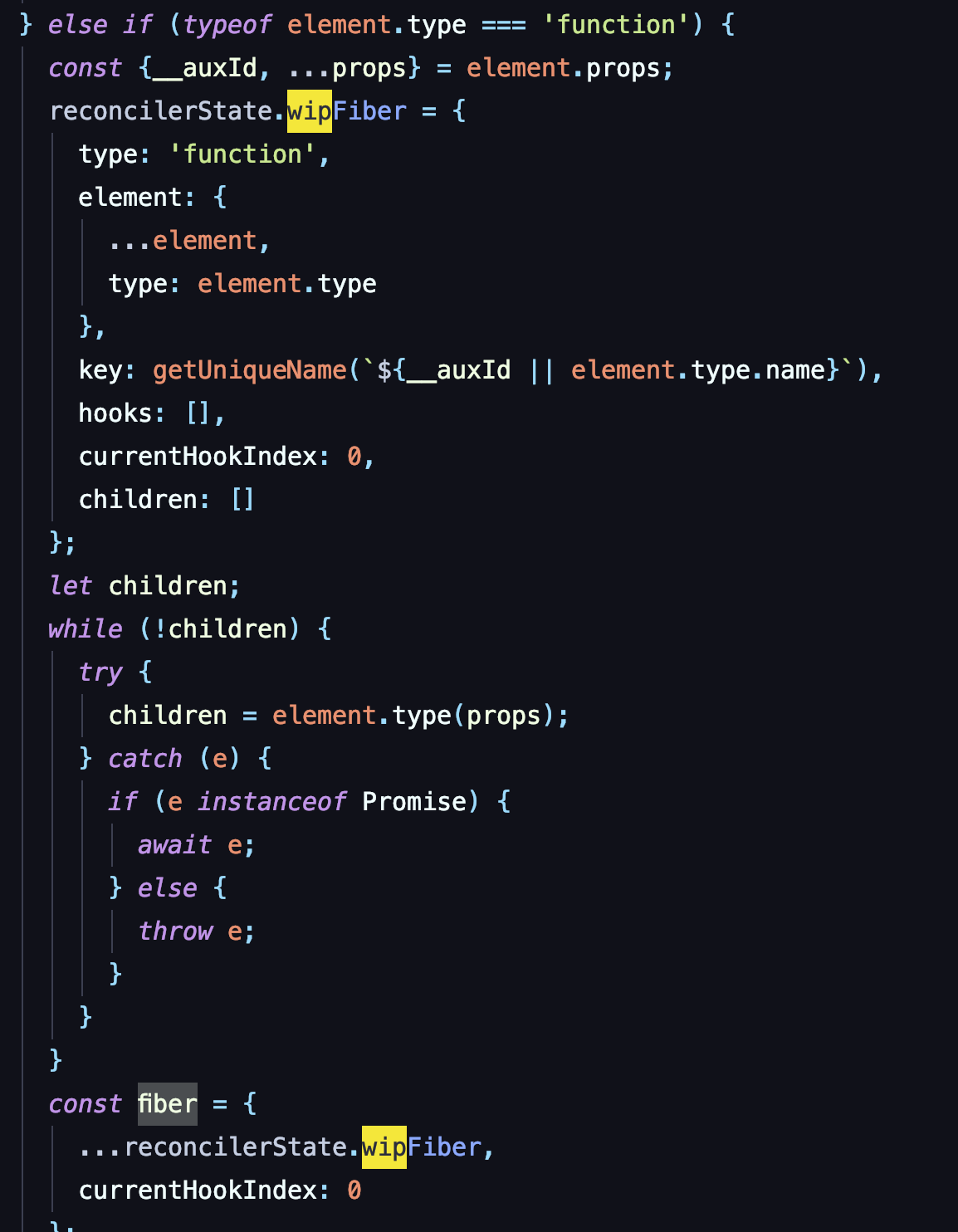
主渲染器的主要作用,是将对应的组件通过 Reconciler (协调渲染器) 生成 DSL(这里也可以简单地理解为vdom一类的东西,但不映射任何dom元素),接着返回给前端进行递归渲染。
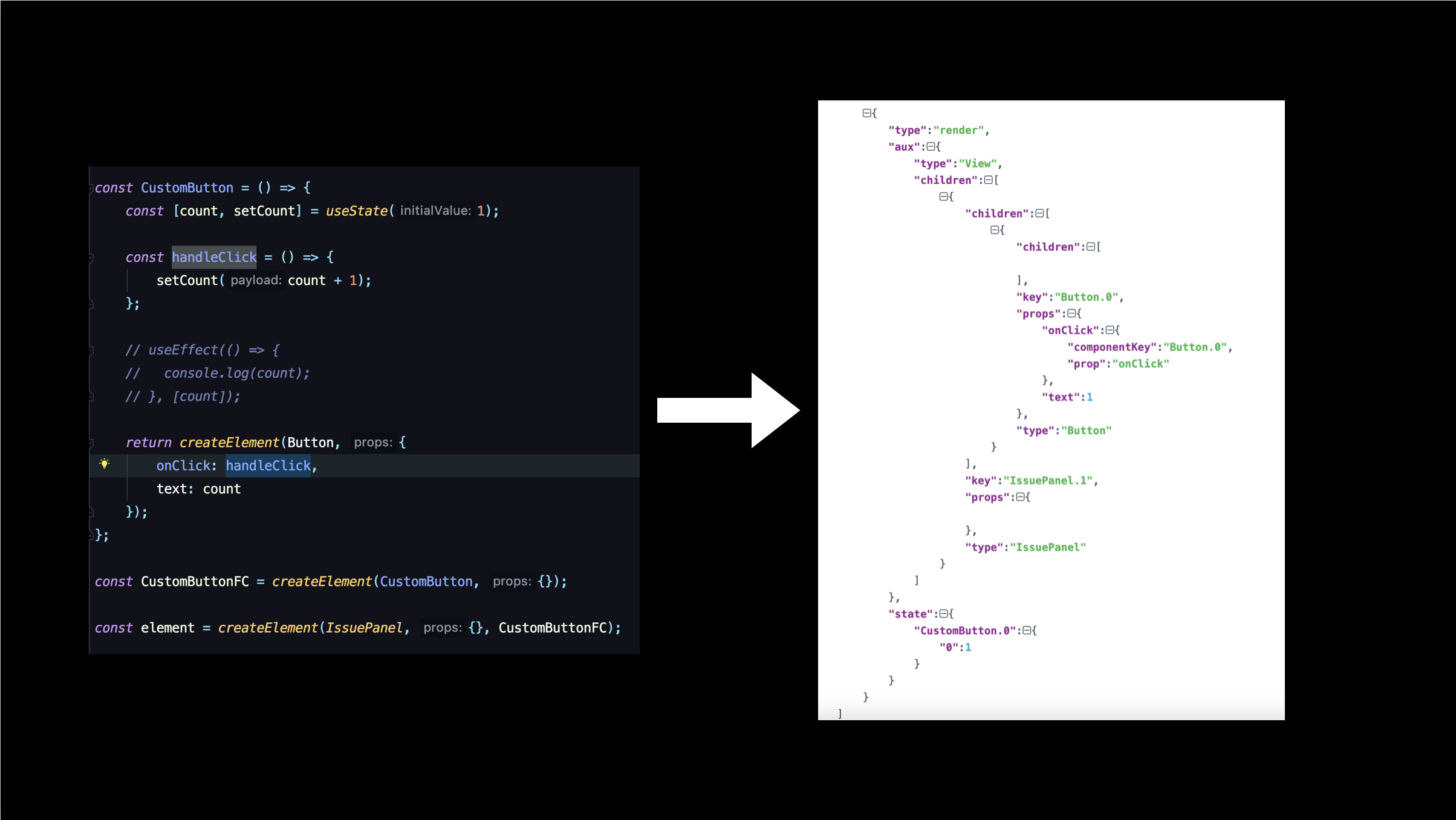
举个例子,我的组件代码是下图这样编写。那么在经过 Reconciler 之后,会变成对应的DSL。返回给前端,拿到 DSL 之后,才可以进行自定义的递归渲染。
上图为一套简单的完整实现流程。可以看到不同于Server Component的是,将hook状态树完全独立地剥离了出来,解决了 Server Component 组件状态的麻烦问题。下面就让我们一步步来解析其实现原理
在我们定义好一个组件之后,我们就可以将其与状态树进行组合,交给渲染器。在这一步,我们的 effects 只有一个:initialize 初始化。
effects 的含义是事件记录。例如初始化事件,或者按钮的onclick事件。
在准备好后,就可以开始渲染了。
我们将拿到的 effect,进行遍历组合执行,如果是 initialize 状态,第一步则将当前的组件转化为fiber节点。
这里的fiber节点不仅存放了组件的类型、子组件fiber、key,还存放了当前组件hook的值。
在拿到fiber之后,简单地递归生成DSL。这一步没什么好说的,代码很简单
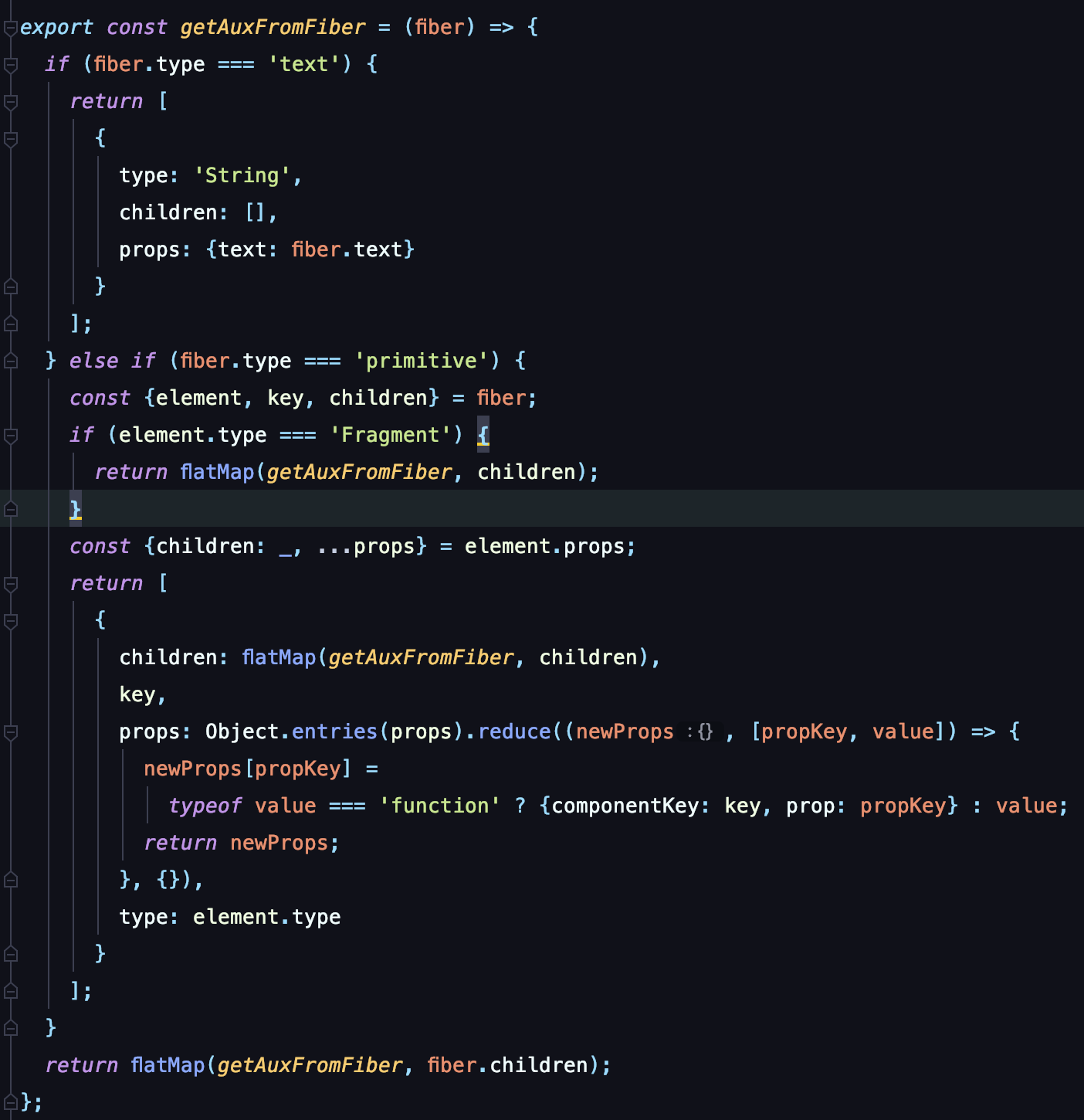
当然,生成DSL之后,还要生成一颗独立的状态树存放组件的状态。这里的实现也很简单:从fiber当中递归拿到对应的hook值,根据组件的key存放在JS对象当中
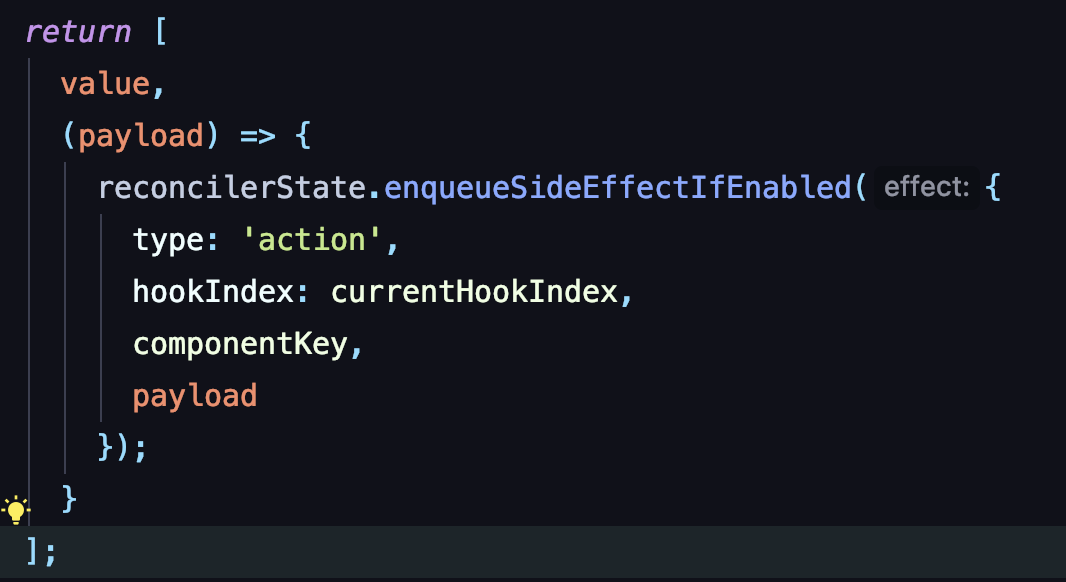
到这一步,最后DSL的完整生成就结束了。这里贯穿全程的是一个 reconcilerState 实例。其作用是:
这套技术方案与 Server Component 相比,最香的地方可能莫过于使用 hook 了。由于设计时独立出来一颗状态树,使得在组件中使用 hook 也存在可能。
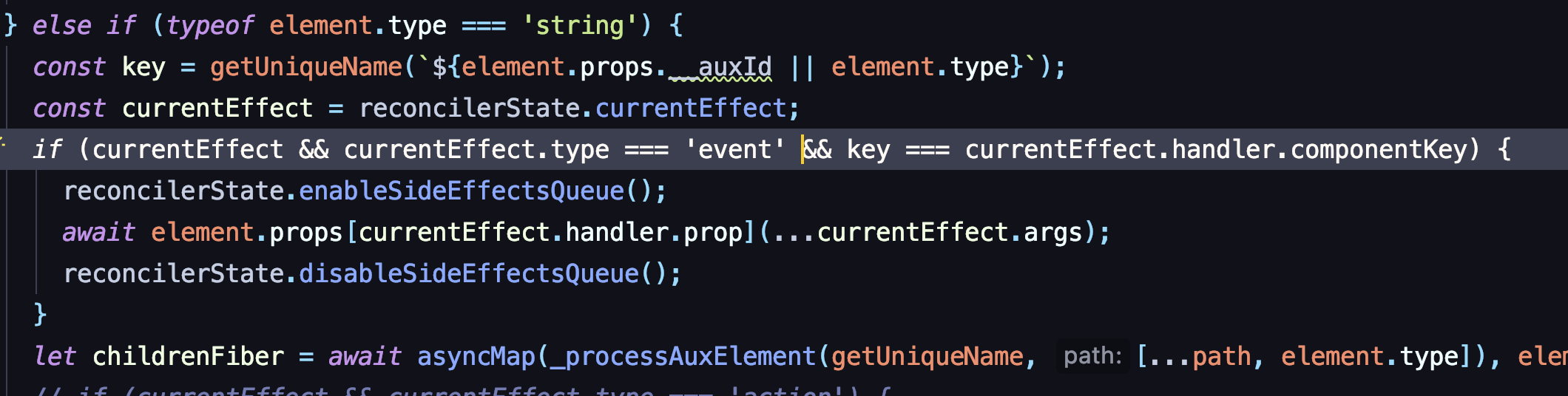
这一步依然重复上面的 fiber 生成。但生成的同时,也会去检查当前的 effect 队列有没有匹配的事件。如果有,则触发事件:
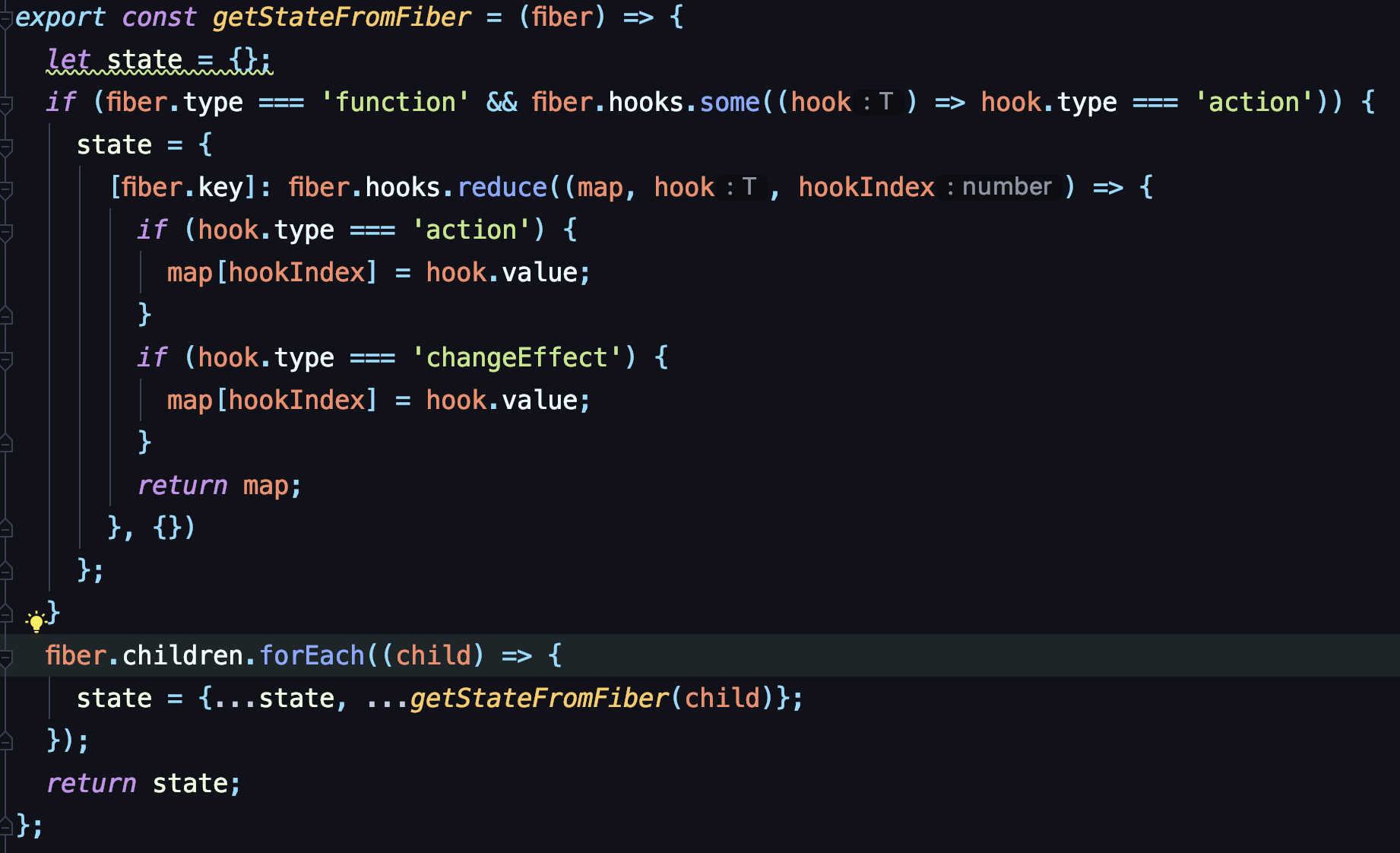
如果事件当中,碰到了有状态更新,则会调用之前定义的 useState 的更新事件。hook更新函数则会扔到effect队列中一条 action 执行事件。
在原本的 event 事件(按钮点击事件)流程走完后,会获得一条 action 事件(状态更新事件),这就是 hook 的更新事件
这一步的状态,和初始化渲染要执行的函数逻辑是一样的。同样是构建fiber节点,创建 DSL,创建状态树。最后结束返回 DSL 到前端。
这里使用的是深度 + 层级数字自增的key。同时为了避免生成有问题,搭配对应的babel插件进行编译时添加。
考虑到数据需要进行传递,链表的数据打印后层级会很深,不便于数据进行序列化和反序列化,于是还是选择了对象拍平的方式存储值。
在 React Server Component 中,提倡组件可以直接访问后端,甚至通过Node Api操作db。但在开放场景的情况下,此操作是非常高危的,需要屏蔽一些模块访问
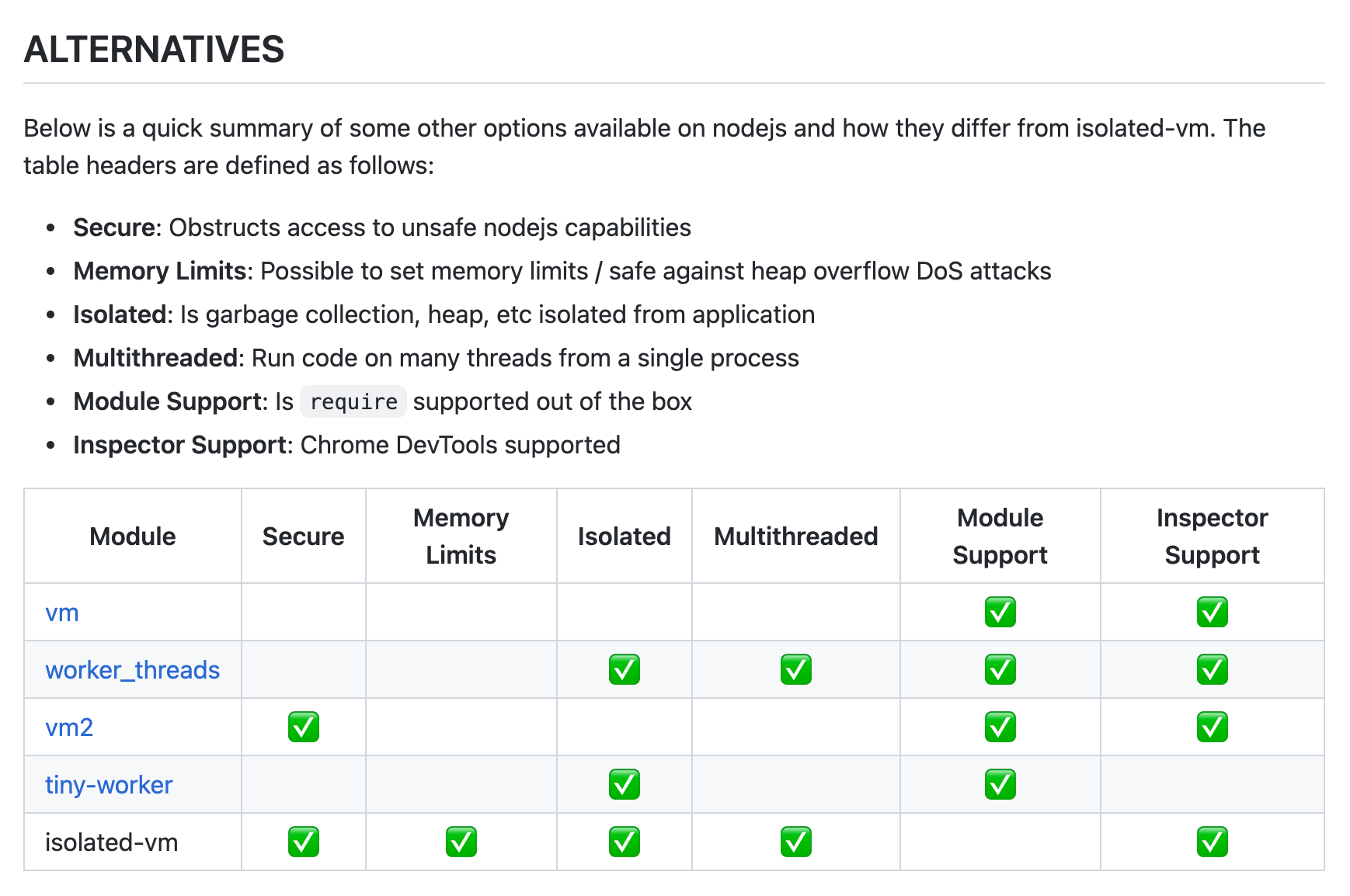
于是选择基于开源的 isolated-vm 做沙箱方案。isolated-vm 是基于c++ 编写的 Node 原生模块。安全,多线程,还可以控制内存大小和超时时间,甚至可以接入 Chrome Devtools 做调试。
但有一个缺点:不支持模块化。不过也有方案解决。我们可以将上面的方案通过构建工具打包为一个整体的 bundle,然后再交给 Sandbox 执行。
对于hook的状态,这部分可以利用一些第三方加密服务进行存取。大体逻辑如下:
目前来看,因为 Server Component 始终执行在 Node 端,所以概念上是无法操作 DOM 的。这也进一步受限了它的场景。不过可以通过在 Client Component 侧封装一些需要操作 DOM 的组件,例如拖动 Panel 等,在Server Component 定义,在前端渲染。
前几天,React 18的正式版发布了,一瞬间我的朋友圈动态都被刷屏了。
其中,有一个新特性很有意思:Suspense SSR。看起来这是在SSR场景下,针对以往 Suspense 实现的适配。今天我们来聊一聊这个 feature
在开始了解Suspense SSR之前,我们需要了解Suspense是个啥。
在React 16.6 中新增了Suspense组件,其用处是更加优雅地加载一个异步需求的组件。如异步拆包的路由,需要异步请求结果的组件等。
下图是异步组件在Suspense中的应用。当异步组件还未加载过来时,Suspense会首先加载fallback中的loading组件,等异步组件加载后渲染其加载结果。
const ProfilePage = React.lazy(() => import('./ProfilePage')); // Lazy-loaded
// Show a spinner while the profile is loading
<Suspense fallback={<Spinner />}>
<ProfilePage />
</Suspense>这样的方式优雅且易用。但是,在SSR场景下,现有的renderToString都是同步的。服务端场景下也不支持类似浏览器端 requestIdleCallback 的调度。服务端应用也无法主动让出调度任务,以换取更高的效率。
同步的最大问题,就是渲染时间长会拖慢性能。由于服务端渲染是CPU密集型计算,所以服务端渲染服务的tps,往往不尽人意。如果还要等待 Suspense 的异步渲染,则处理时间更无法保证。
于是,React 为了在服务端适配 Suspense,做了个一举两得的事情。既适配了功能,还做了优化。
在新的服务端实现中,我们依然选择了递归的方式renderString。但遇到Suspense时,其逻辑发生了变化。
在 Suspense 到来时,首屏会先将 fallback 中的 loading 渲染。此时子组件的 promise 会被推进异步队列,等待 promise 完毕时,再通过HTTP分块技术推送到浏览器进行替换。
其逻辑大致的代码如下。在promise结束后,服务端推送一个 replace("1", "2") 函数,将异步结果的dom替换之前的loading``dom
<div>
<!--$?-->
<div id="1">Loading...</div>
<!--/$-->
</div>
<div hidden id="2">
<div>Actual Content</div>
</div>
<script>
replace("1", "2");
</script>其中,异步结果的推送并没有新开一个http请求,而是基于之前的http请求基础上,通过分块传输的特性推送过去的。造成了一种长连接的假象。 接下来,我们分析一下分块传输的玩法。
要先讲分块传输,首先先要从HTTP协议的结束符开始讲起。在一个HTTP报文中,如何判断一个请求/响应体结束呢?通常有2个方案:
content-length:这种方案是在请求/响应体报文上增加一个content-length请求头,值是响应体的字节数。如果浏览器在接收到 content-Length 单位个字节后,就会视为本次请求完毕。Transfer-Encoding: chunked:这个方案代表开启了不定长度的分块传输。我们需要通过发送终结符来告诉浏览器请求体结束。而Suspense SSR正是利用这个实现,将Suspense渲染后的结果一点点推送过去。其中Transfer-Encoding: chunked的优先级要大于content-length。ps:不过判断数据块结束最严谨的方式,是提前计算好长度,而不是使用终结符。不过在绝大多数场景,长度还是能够被确定计算的。
接下来我们做个实验,来看一下分块传输在抓包工具下的现象。
我们用express启动一个服务,来模拟一下分块传输的逻辑。代码逻辑大致为:
html整体骨架,包括html标签,编码格式,body标签。在这个情况下,我们可以模拟Suspense SSR在异步情况下推送结果的原理实现。
const express = require('express')
const app = express()
const port = 3677;
const renderToStream = (res) => {
return new Promise((resolve, reject) => {
let count = 0;
let timeId = setInterval(() => {
if (count === 10) {
res.write("<p>已经推送了" + count + "次</p>");
clearInterval(timeId);
resolve();
return;
}
res.write("<p>每1秒钟推送1次</p>");
count++;
}, 1000)
})
}
app.get('/stream', (req, res) => {
res.write("<!DOCTYPE html>");
res.write("<head><meta charset='UTF-8'/><title>test stream</title></head>");
res.write("<body></body>");
renderToStream(res).then(() => {
res.end();
})
})
app.listen(port, () => {
console.log(`Example app listening on port ${port}`)
})我们打开Wireshark,启动对服务的监控,然后刷新页面开始请求
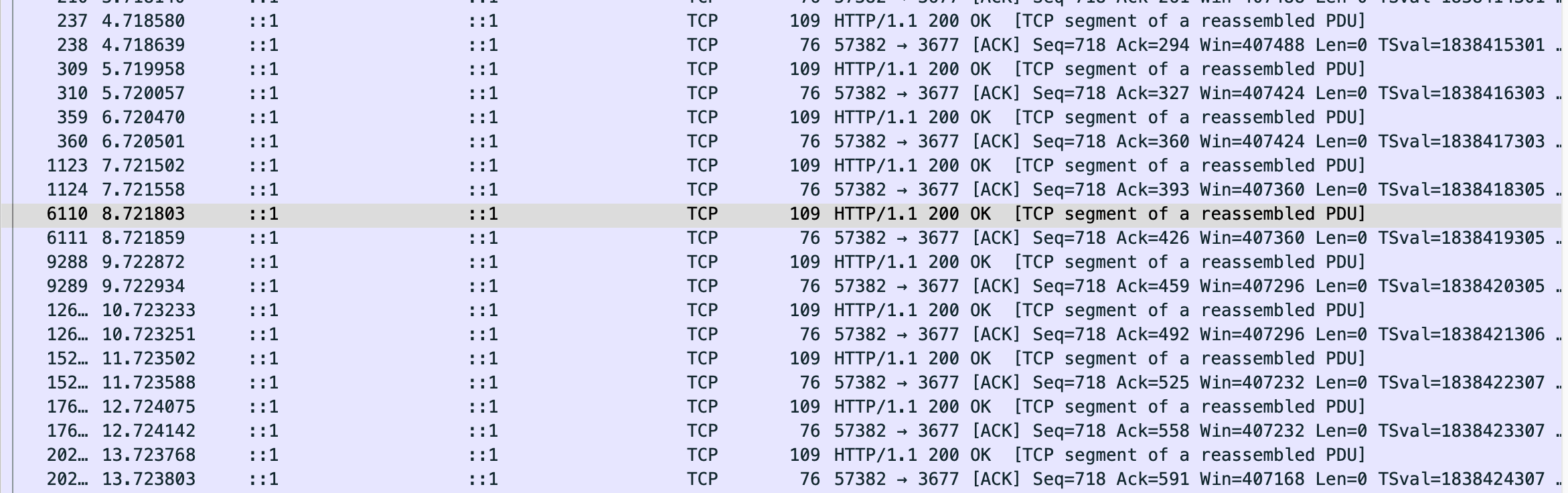
可以看到,当我们开始请求时,首先服务端先给我们推送了请求头、body、html标签等信息。其中,Transfer-Encoding: chunked 在此刻就已经被确定。

随后的每一秒,都会捕获到一条TCP数据包和其ack确认消息。TCP数据包是响应内容,ack是浏览器发回去的确认报文,刚好10对。
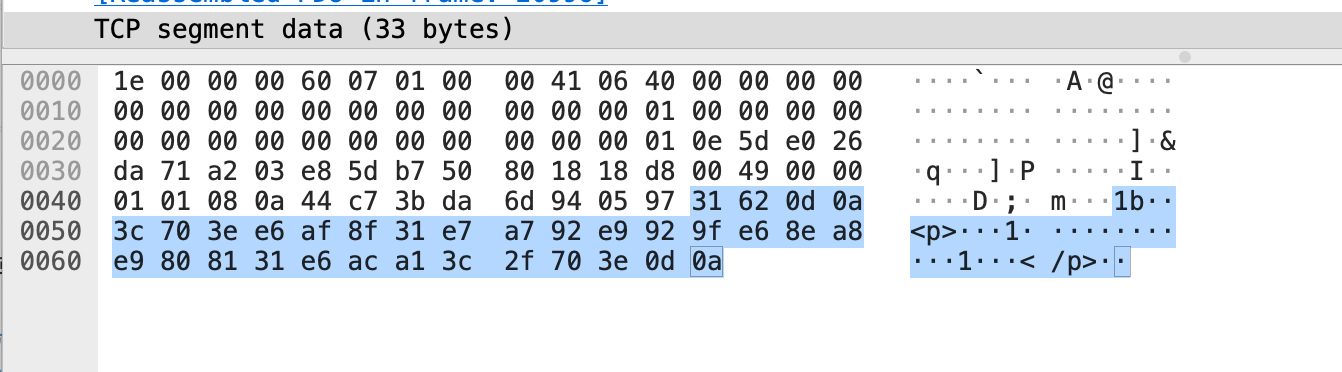
TCP数据包中,包含着我们每次推送的信息:
我们也可以在维基百科中验证到这个逻辑,毕竟这就是规范定义的 🤗
每一个非空的块都以该块包含数据的字节数(字节数以十六进制表示)开始,跟随一个CRLF (回车及换行),然后是数据本身,最后块CRLF结束。在一些实现中,块大小和CRLF之间填充有白空格(0x20)。
https://zh.wikipedia.org/wiki/%E5%88%86%E5%9D%97%E4%BC%A0%E8%BE%93%E7%BC%96%E7%A0%81
在经历10次的推送后,最终会产生一个HTTP响应报文。这个报文里面综合了前面的TCP数据包块。在所有数据包的末尾,会填充一个0、空白单行与0x0d,0x0a,代表响应体的结束:
这里为啥是0?很简单,空白单行的字节数就是0
这里说明一点:我们第一次推送的html骨架,第二次推送的p标签都会被拼接到请求尾部。浏览器自动帮我们做了矫正,拼到了body里面。
Suspense SSR就通过这样的方式,将每次的渲染结果和替换函数推送到前端。
React 费这么大力气,就为了适配 Suspense 吗?显然不是。如果我们再一次站在当年fiber架构出现的时刻看这个问题,就再也不奇怪了。
原有的fiber架构,花大力气把组件树从树改为链表,其目的就是为了链表能够在遍历时可以打断。而树的递归遍历,只能一次性从根节点遍历到叶子结点,中间无法暂停。
如果遍历可以中断,中断后我们就可以借助浏览器的调度能力,看看我们的遍历时间会不会影响浏览器的渲染。如果影响,那就等下一次调度的时候再继续渲染。
但服务端是没有浏览器的调度API的。而服务端渲染又是CPU密集计算型应用,每次渲染一次非常耗时且占资源。
Suspense SSR 则借助适配 Suspense 这个理由,将Suspense的异步渲染推进异步队列,在等待异步渲染结果之前,此时我们的主线程还可以让出时间来处理其他的渲染请求,提升可处理的渲染任务数量。 这个做法让体验和性能一举两得。
快去升级尝试吧!
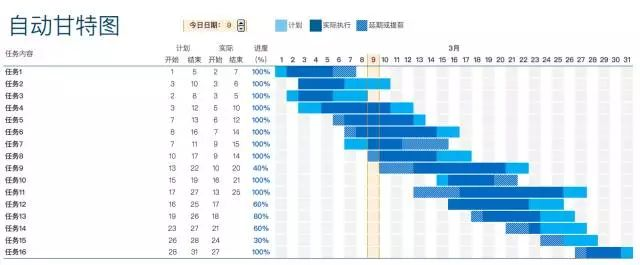
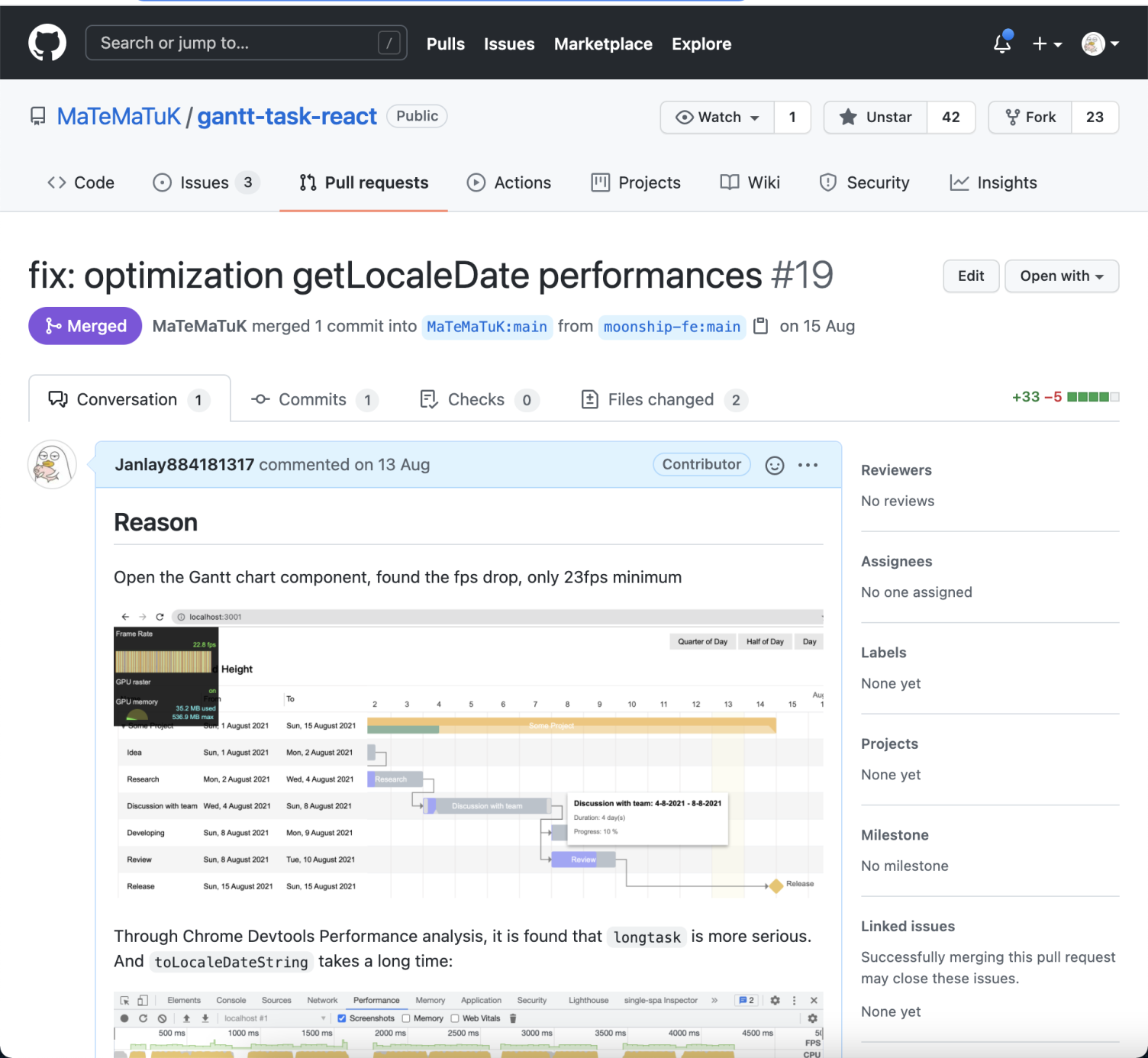
公司项目最近用到甘特图功能,于是集成了一款开源的甘特图插件。
甘特图的主要作用是项目管理,可以用图示的方式通过活动列表和时间刻度形象地表示出任何特定项目的活动顺序与持续时间,如下图
玩过甘特图的同学都知道,甘特图的前端实现基本靠绘画。而绘画是对前端的开发和性能要求非常高的一项技术。而频繁的交互操作,也会导致开发的性能要求进一步严格。
其基础现象很简单。当我拖动甘特图的视图区域时,明显感受到卡顿和拖影。各位同学都明白,涉及到绘画相关的动画操作,要60fps才能够到顺滑的阶段。30fps勉强卡顿,20fps就卡顿拖影严重了。
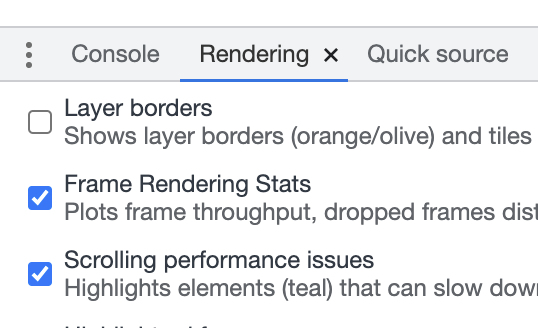
于是我采用了 Frame Rendering Stats 工具先进行肉眼观察帧率数值。他的主要作用除了观察当前页面操作的fps数值外,还可以监控gpu的内存用量。当然这个工具的位置也很容易找。就在 Chrome Devtools 的 Rendering 选项中,勾选开启即可
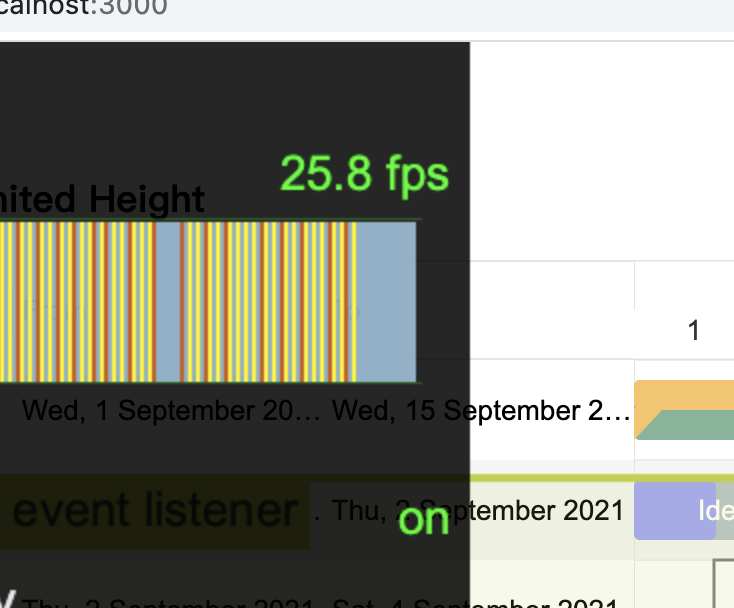
当我使用工具进行 fps 的观察,同时视图区域进行稳定匀速的滑动时,能够感受到明显的卡顿和拖影。其检测数值最高仅有31fps,最低有26fps。卡顿的级别基本上属于严重卡顿了,如果换一台低端一点的设备,那么其展示效果肯定无法想象。
既然我们发现了问题,那么就分析下问题到底出在哪里。接着打开 Performance 工具并开始录制,录制的同时对视图区域进行稳定匀速的滑动,滑动几秒后停止录制,拿到一份这样的分析报告:
甘特图插件和主要技术栈都是react。在react16中,当我们去做一些频繁触发render的操作时,都要对有状态更改的组件重新生成vdom,然后再决定是否更新真实dom,这些都是消耗的时间。而根据一般的显示器刷新率(60hz)和目前的浏览器所支持的最高刷新率来算,平均下来每一帧的任务时长一般只有16.6ms。当单帧任务时长超过16.6ms时,就会产生卡顿和掉帧。
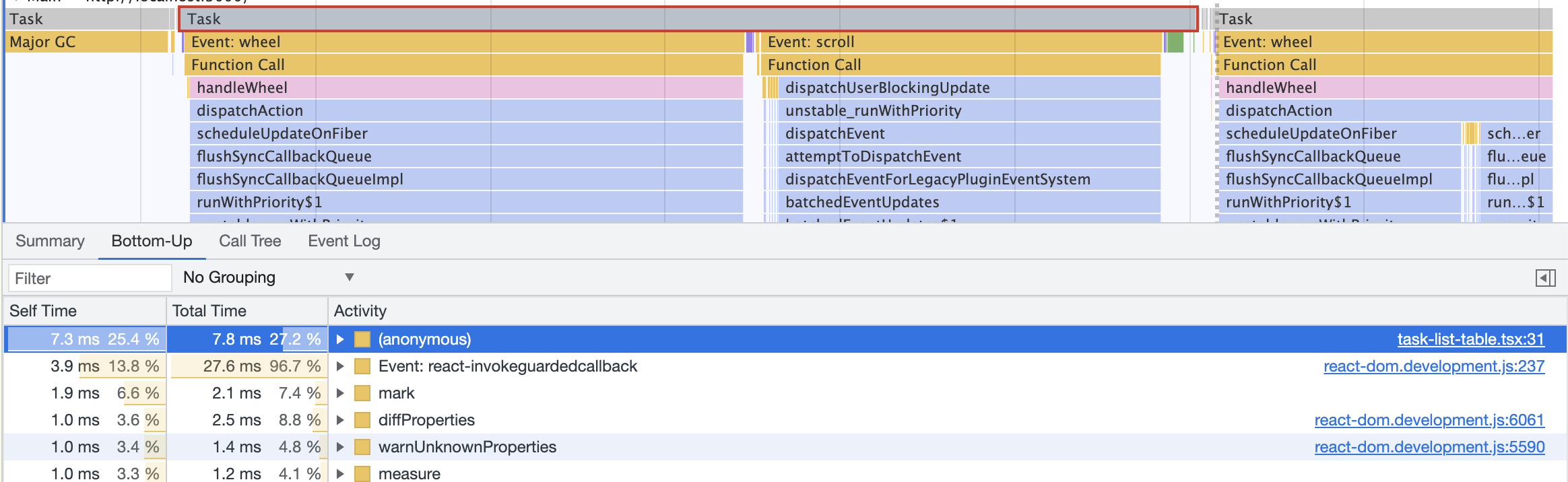
但是根据分析情况来看,上图滚动时产生的任务绝大多数都大于40ms,甚至还会产生longtask(Chrome官方对longtask的定义是大于50ms,即20fps)。所以接着展开来看,看看单任务中到底是哪些事件导致的执行时间长。
接着点开其中一个任务,放大详情。可以看到selftime(自身执行时间)排名第一的是一个匿名函数。继续点开右侧的代码堆栈,去看看哪行代码执行时间比较长。
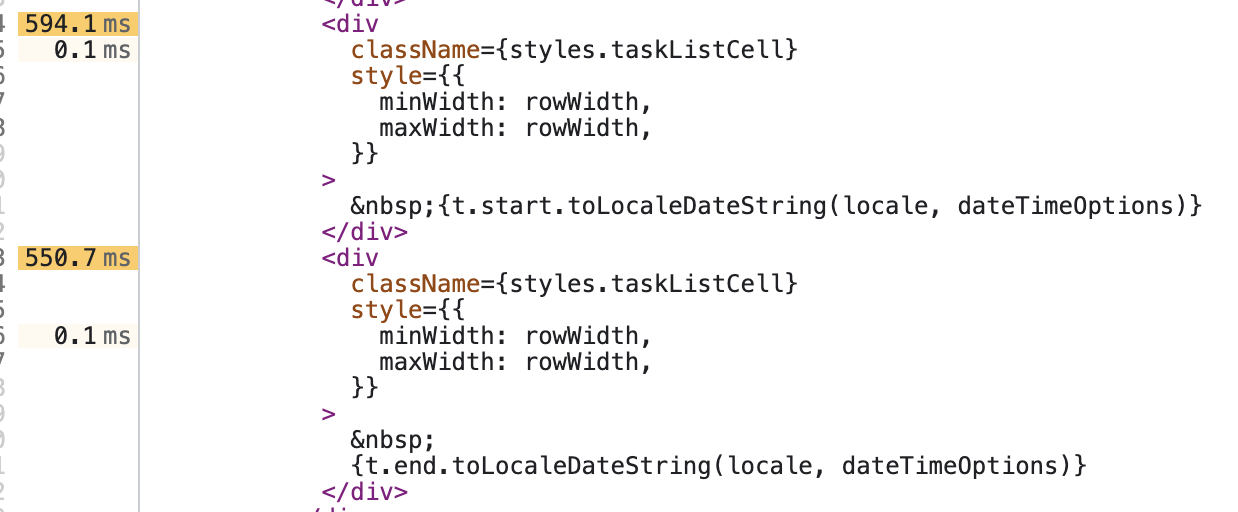
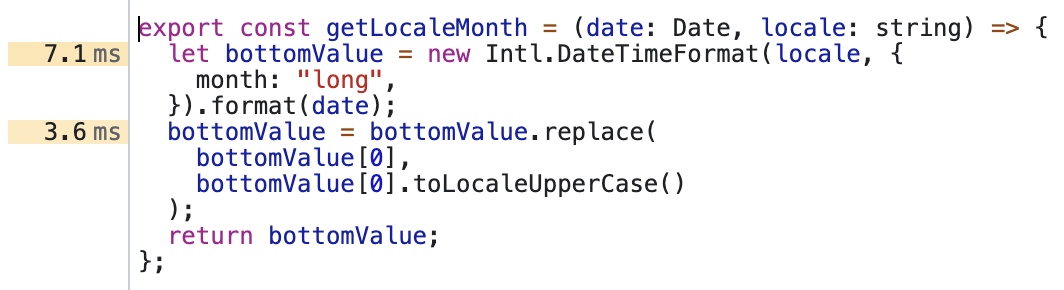
点开后,会自动帮我们跳转到 Devtools 中的 source 模块,还会将代码的执行时间标在函数的左侧。从下文可以分析,第74行的 toLocaleDateString 的耗时非常严重。因为函数组件/类组件的渲染生成是同步的,所以耗时长会拖慢 render 的效率,进而拖慢整体的帧率。
Date.prototype.toLocaleDateString() 的作用是对不同语言的时间文本进行转换。例如
const event = new Date(Date.UTC(2012, 11, 20, 3, 0, 0));
const options = { weekday: 'long', year: 'numeric', month: 'long', day: 'numeric' };
console.log(event.toLocaleDateString('de-DE', options));
// expected output: Donnerstag, 20. Dezember 2012
console.log(event.toLocaleDateString('ar-EG', options));
// expected output: الخميس، ٢٠ ديسمبر، ٢٠١٢
console.log(event.toLocaleDateString(undefined, options));
// expected output: Thursday, December 20, 2012 (varies according to default locale)但是这样一个看起来人畜无害的方法,怎么会耗时这么长呢?
鉴于直接翻看v8的这部分源码比较硬核,我们选择去查看 toLocaleDateString 的 polyfill —— formatjs。这个库一直作为 Date 方面的国际化polyfill存在着,包括时区国际化和时间文本国际化。
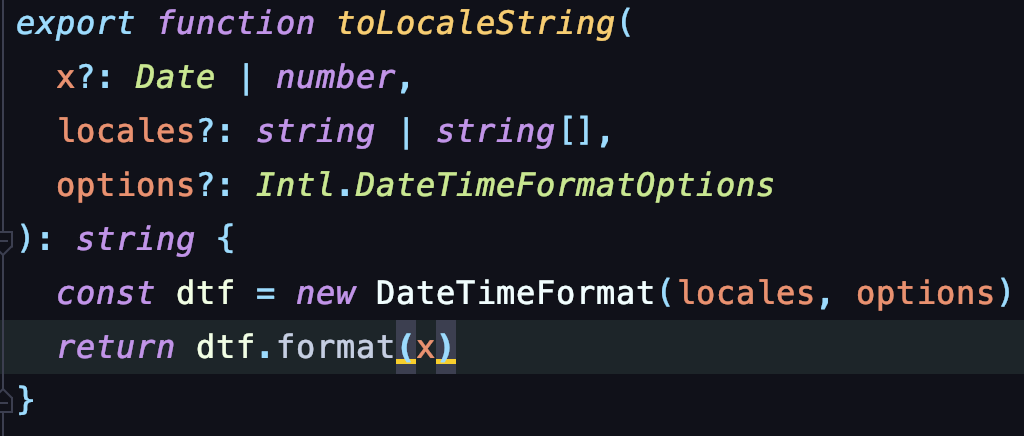
我们找到 formatjs 中的 packages/intl-datetimeformat/src/to_locale_string.ts 中的 toLocaleString 方法。这个方法创造了一个时间格式化对象:
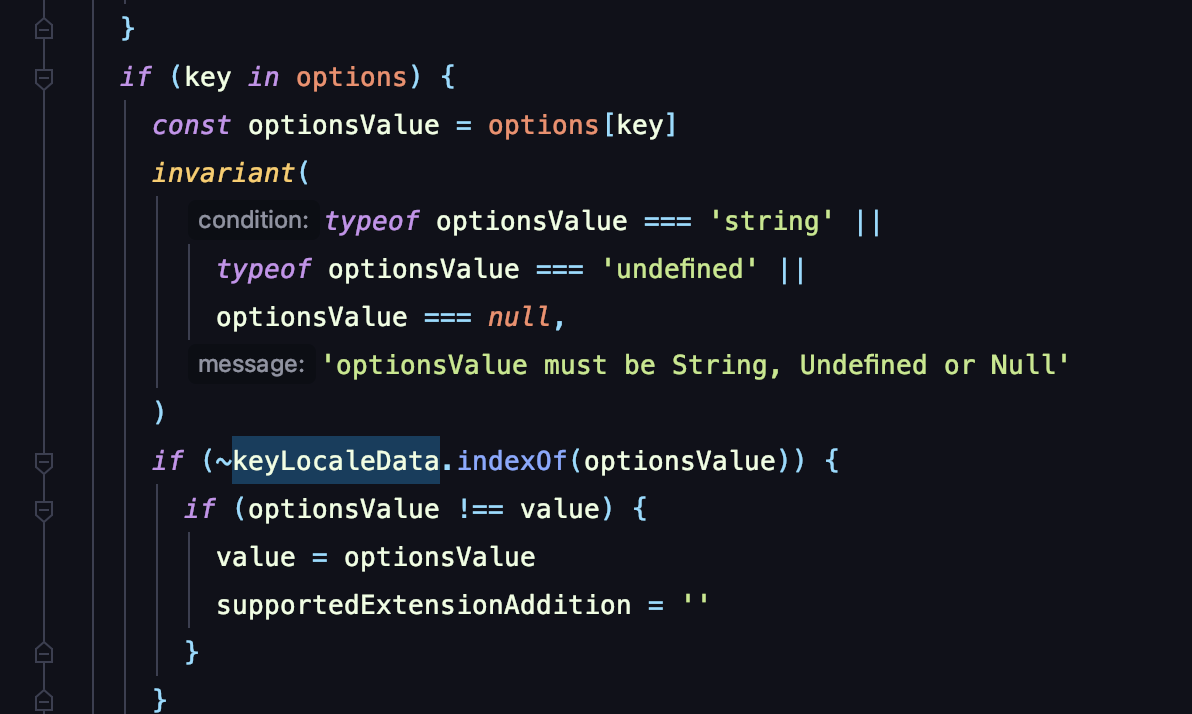
继续跟踪 DateTimeFormat 类的实现,可以看到有一个叫做 localeData 的变量。这个变量就是我们做国际化时的各国语言文本内容。同样上面有一个叫 tzData 变量,是时区数据库的内容:
接着一路跟踪,会发现 ResolveLocale 方法是处理当前选中时区的核心方法。在那里面,所有的国际化文本都会经过运算筛选,再与当前选中的语言文本进行匹配(尤其是下图当中这种 indexOf 高耗时方法)
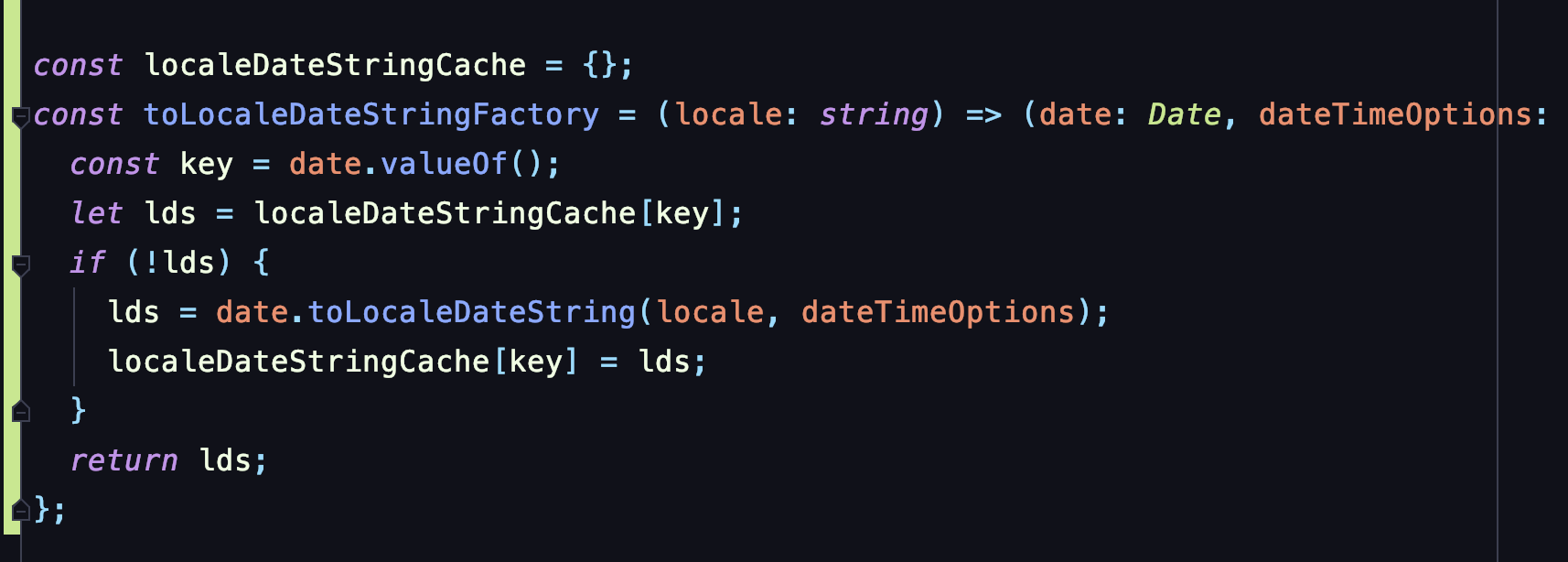
对于此类调用耗时问题,唯一的解决就是对现有的执行结果加缓存memo。方案很简单:将时间转化为时间戳作为缓存的key,存入缓存,后续直接从缓存读取即可:
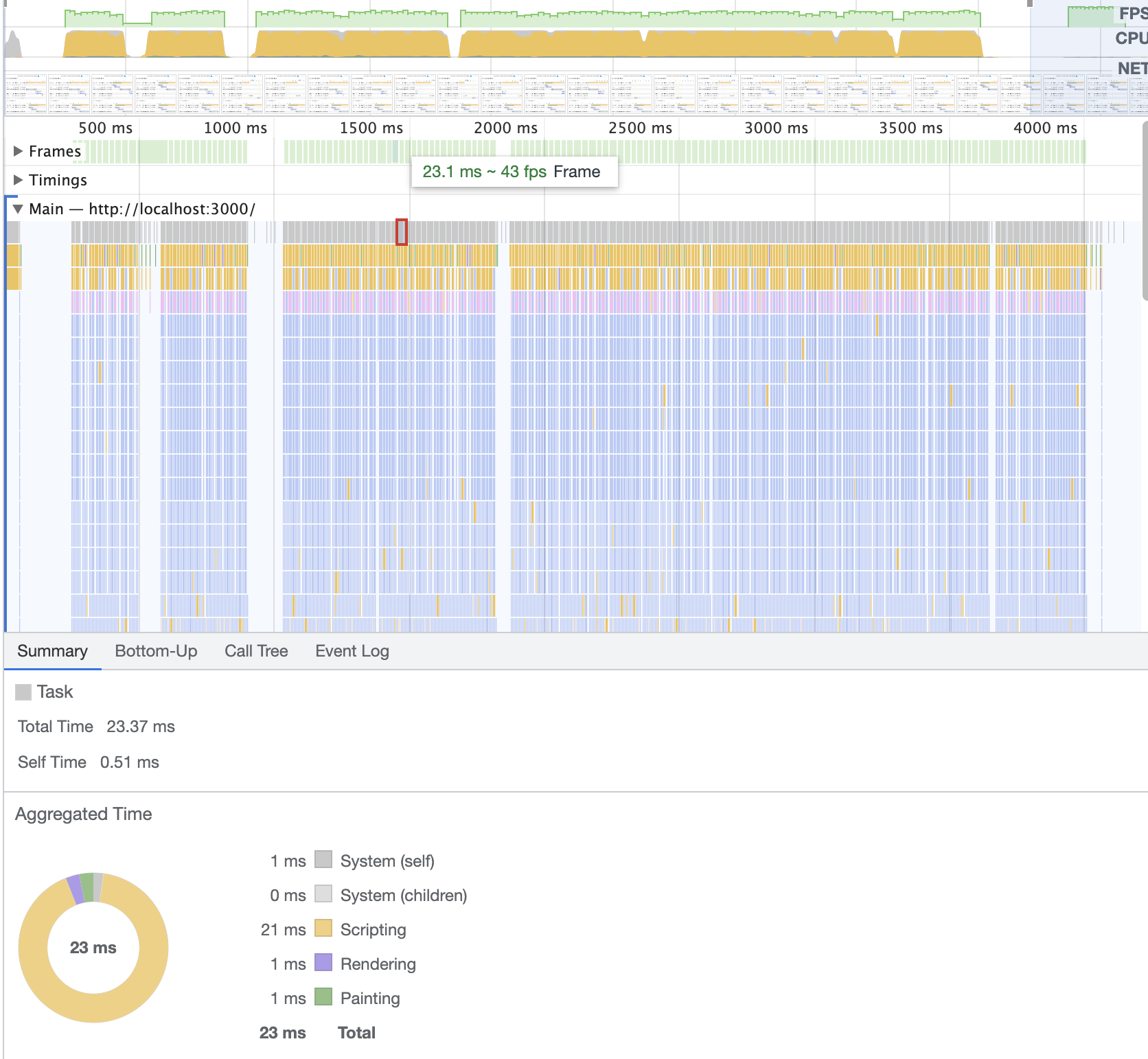
优化后,我们再次用performance进行分析。发现不仅fps有肉眼和数值的显著提升,且longtask也不再存在,平均任务耗时被压缩到了23ms。基本上实现了流畅,解决了卡顿问题。
但,我们还要继续解决 toLocaleDateString 的兄弟api:Intl.DateTimeFormat。
Intl.DateTimeFormat 是一个比较新的时间格式化api。他与 toLocaleDateString 在使用上最大的不同时,支持对任意的date对象进行format,api设计上偏向构造器,更加利于缓存设计。例如用法:
console.log(new Intl.DateTimeFormat('en-US').format(date));
// expected output: "12/20/2020"
console.log(new Intl.DateTimeFormat('en-GB', { dateStyle: 'full', timeStyle: 'long' }).format(date));
// Expected output "Sunday, 20 December 2020 at 14:23:16 GMT+11"同样,在对上面的 toLocaleDateString 进行性能优化完毕后,排在react耗时后面的
Intl.DateTimeFormat 也值得处理。继续查看代码耗时:
发现此方法的耗时也不低:7.1ms,有提升空间。
而此方法的polyfill实现,也和上面的 toLocaleDateString 一致,都是实例化 DateTimeFormat 对象才可以用。只不过区别是一个手动实例化,一个帮你实例化:
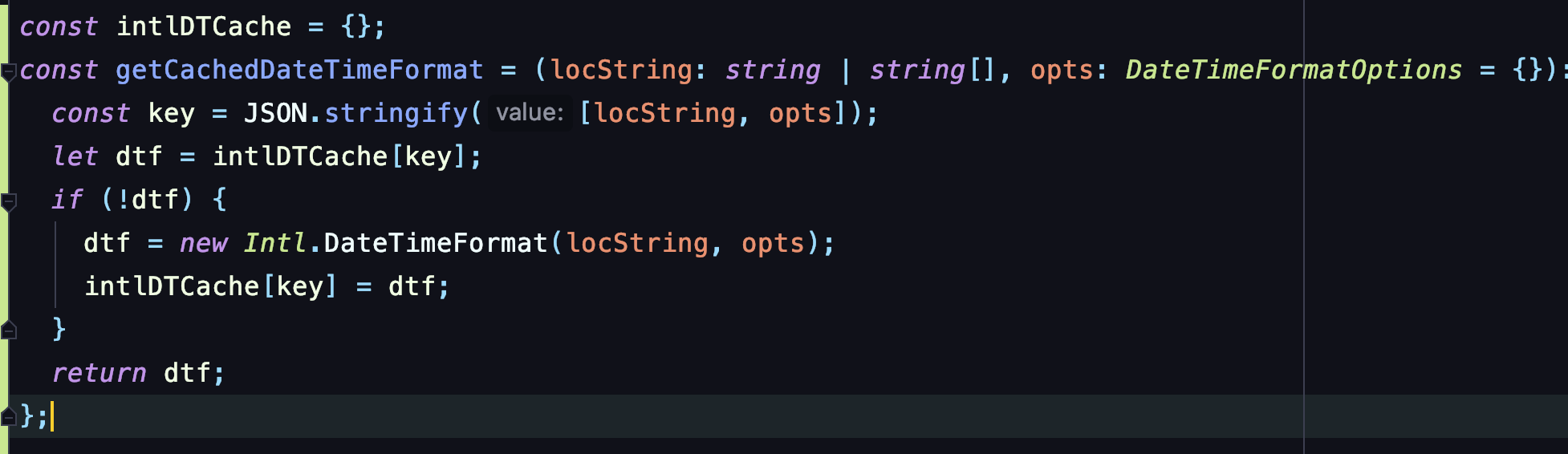
那我们就继续对 Intl.DateTimeFormat 增加缓存。
按照对 toLocaleDateString 的优化思路,我们只需要对 Intl.DateTimeFormat 实例进行优化即可。依然是做缓存,只不过 key 换成了地区 + 转化选项这唯一的参数:
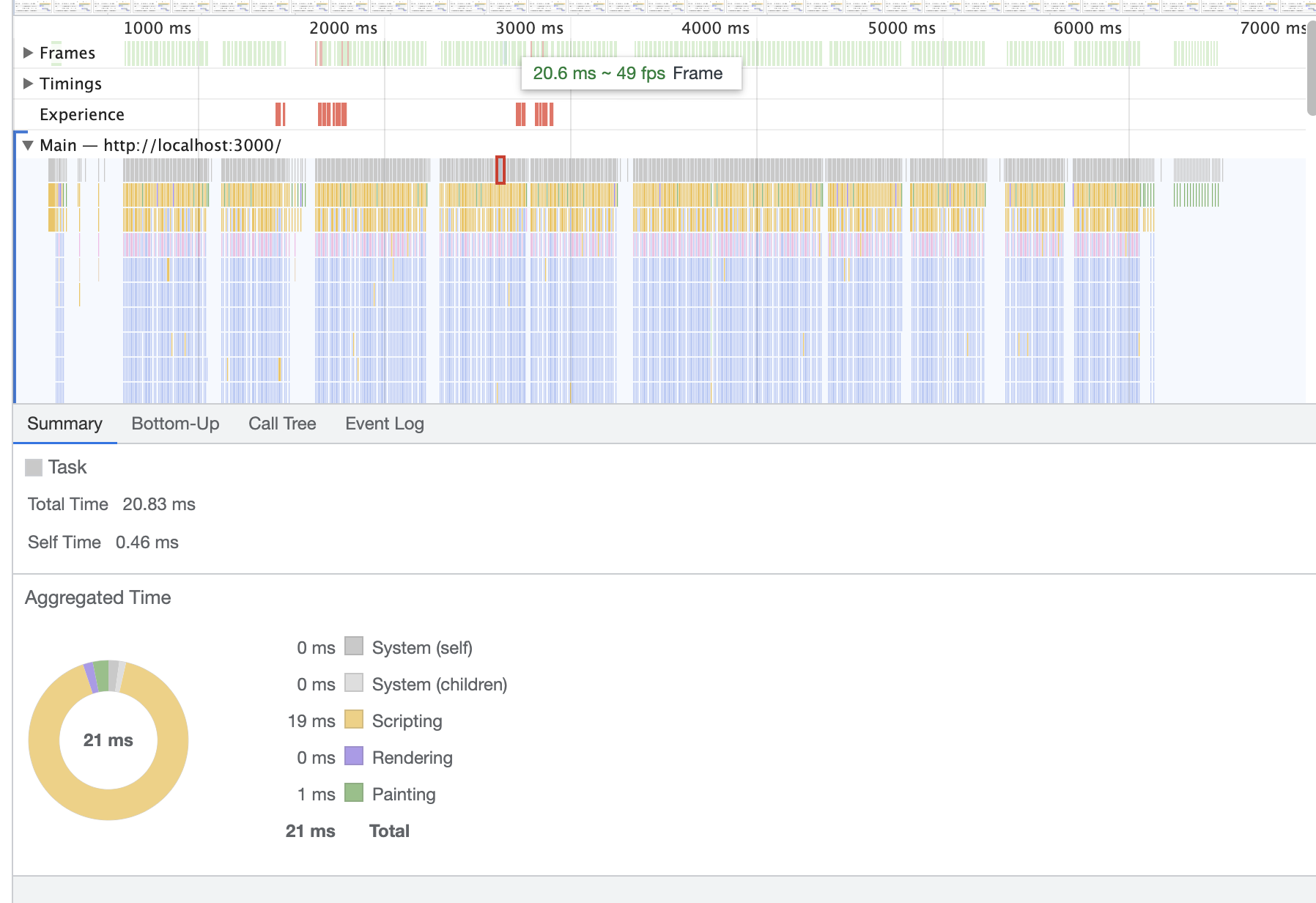
优化完毕后,我们再次采集一份performance样本。
通过检测,fps已经达到了最低45,最高50的数据。基本上实现流畅(因Devtools开启状态下也耗性能,实际使用帧率比这个高)。相比与优化前,提升了61%。long task消失不存在
当然,这份优化历程只是个初步优化。可以看到,虽然单个任务的耗时有所大幅度下降,但是还有提升空间存在。要尽量低于16.6ms才能够实现完全流畅。
总结一下:尽量采用 Intl.DateTimeFormat 来替代 toLocaleDateString,并对构造器进行缓存提升性能。在其他国际化的场景(例如数字等)也要注意这一点
此外,这份性能优化的方案已经提交给了上游开源项目,并在8.15日已经合并进仓库:MaTeMaTuK/gantt-task-react#19
首先先祝大家1024程序员节节日快乐!
注意:本文不涉及微应用与主应用的状态共享,只考虑进行双向通信。
在我们之前对现有的项目进行微前端改造时,总会有一些无法改造为微前端项目,或者涉及成本不容易改造的项目。如: ssr,jsp/php 项目等。但不管成本有多大,而我们总要用各种方式接入进来。所以在有些场景下,我们一般会将微前端的改造降级为iframe,以适应我们的需求。
但微前端的通信,与iframe的通信有着很大的区别。
由于微前端的实现容器,依然是与父项目在同一JavaScript执行环境中,所以通信也会变得非常简单。但iframe的执行环境与父项目隔离,也就提升了通信的困难。在非跨域情况下,我们也可以通过使用与微前端相似的通信方式进行通信(直接调用window.parent对象)。mdn的介绍
但在跨域情况下,浏览器的安全策略是不允许iframe采用这样直接的通信方式,而是采用postMessage的方式异步通信,且传递的数据只能被结构化克隆算法序列化。关于结构化克隆算法,可以看下面的介绍:
https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Structured_clone_algorithm
微前端与iframe通信方式的差异区别,导致了其通信的思路也有很大差距。但无论如何,微应用下的通信方式我们要尽可能做到抹平差异。所以要设计一套通用的通信sdk,让任何支持的应用类型都可以自由接入,通信的API使用也完全一致。
SDK要抹平在使用层面上的差异,架构的设计也要有一定要求。
一般聚合设计思路可能只是ifelse,例如阿里某小程序SDK聚合框架的设计。这个方式是最简单直接粗暴的,也是最有效的。但实现上却不是很优雅,维护成本也会变高。这种情况可以利用设计模式中的 “适配器模式” 进行改造实现。
由于许多前端同学对 发布订阅模式 和生产者消费者模式 了解更多,这里我就科普一下适配器模式。举个例子:有时候,其他国家/地区的电器插头与**大陆的电器插头是不一致的。例如在香港,电器插头一般比大陆的插头要大一些(如下图)。所以我们买回来香港的电器,是不能直接用的。需要购买一个适配器来进行转换(如下图),这就是适配器模式在现实生活中的应用。
适配器模式的作用就是解决两个软件实体间的接口不兼容问题。使用适配器模式后,两个因为接口不兼容而无法共同工作的实体可以一起工作。 适配器模式的概念其实不难理解,但在代码中如何实现呢?
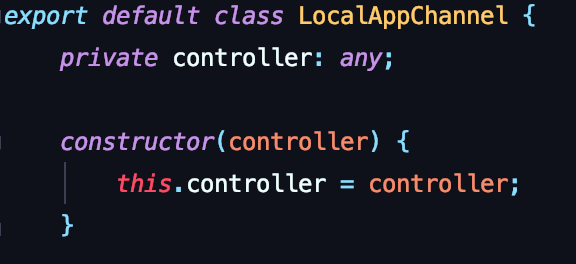
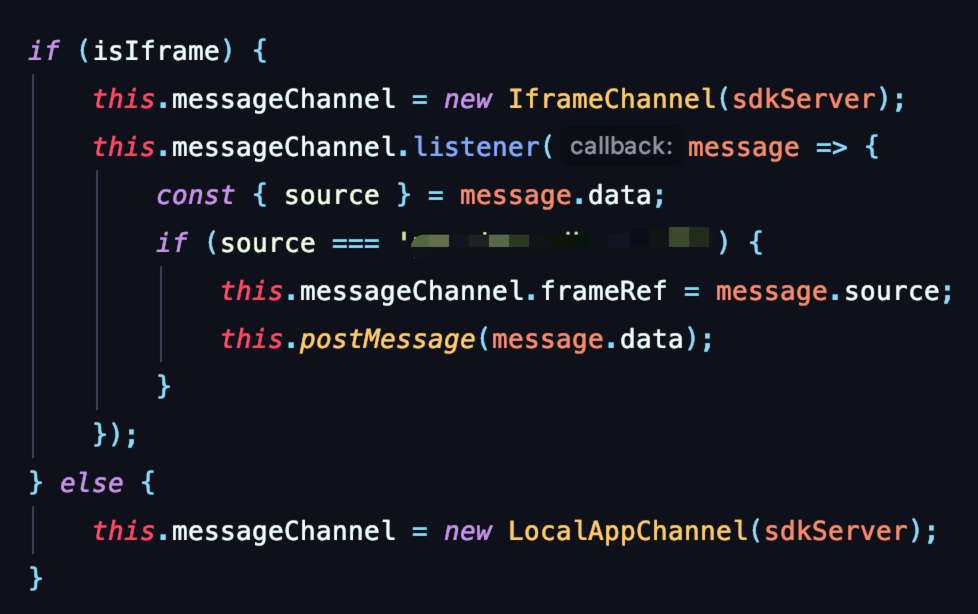
我们将iframe和微前端,分为两个类分别实现。分别为 IframeChannel 和 LocalAppChannel。两个类中分别实现各自的逻辑。IframeChannel 中有着对异步回调的逻辑,还有对message监听的处理逻辑。
但无论实现如何,IframeChannel 和 LocalAppChannel 这两个类所暴露的api都是完全一致的。最后在sdk的入口里面,根据判断当前页面是不是iframe,选择实例化不同的适配器
这样我们利用适配器模式,我们可以为微前端和iframe单独封装不同的cannel,并通过一个统一的类将其聚合起来。这样一来,无论是微前端还是iframe的通信代码,都尽可能地不污染主体通信逻辑的实现。
不过,最佳实践和设计模式都不是一劳永逸的。依然可能会有少量的侵入性代码。我们只能尽量做到维护成本最小。
日常开发中,难免会遇到一些异步通信的场景。
例如:让主项目给你某个数据,让主项目打开个弹窗等等。但异步有一个最大的问题,就是会导致竞态。举个例子:你发送了2条异步消息出去,异步消息的返回先后顺序,是不确定的。 而如果不理顺这两条消息的先后顺序,对业务逻辑的影响是很严重的。
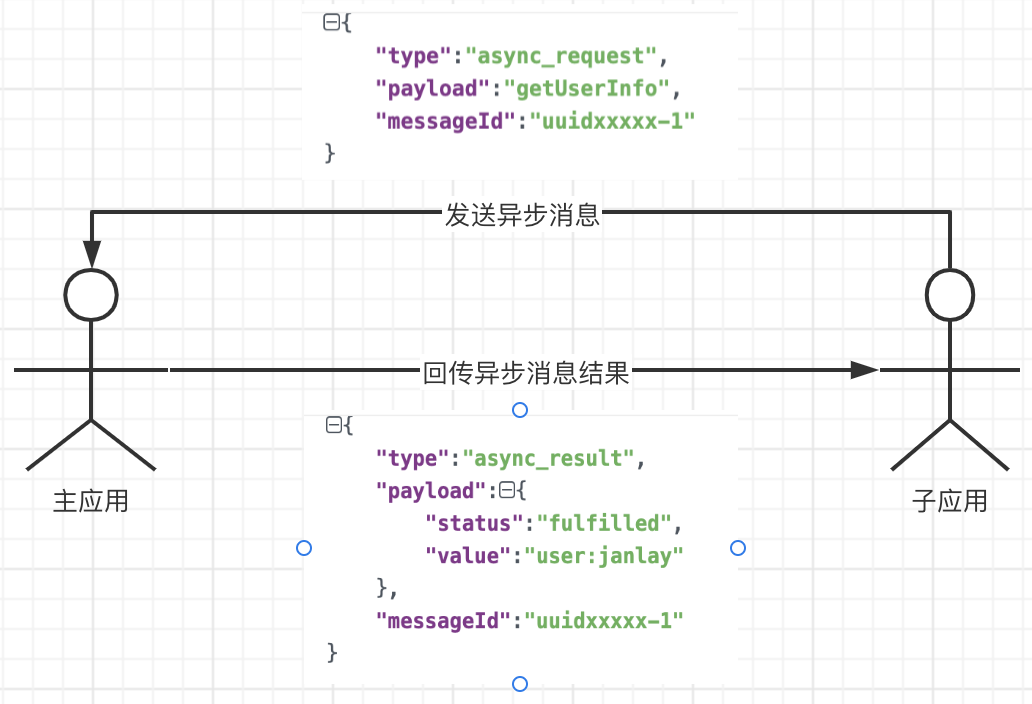
这种情况,在 iframe 场景更为突出。postmessage 本身就是异步的消息通信。 可能会面临着,并发2条消息出去,但分不清这两条消息的返回到底归属哪一条。针对这个问题,可以选择为每一条消息都携带一个唯一id。
在发送消息时,携带一个唯一id发出去,并利用消息id作为key,将resolve和reject存入我们的全局map中。
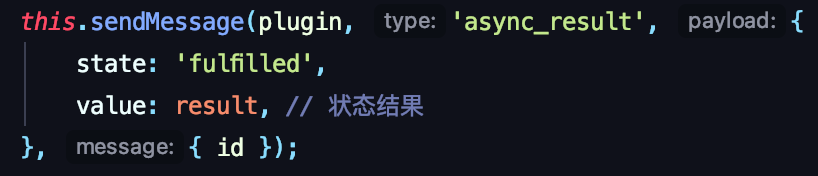
在给子应用发送异步结果消息时,也携带之前的唯一id回传回去。
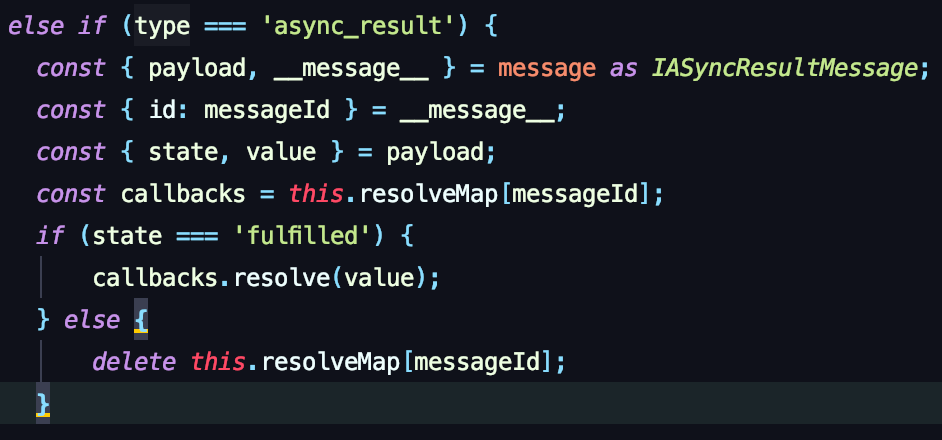
子应用拿到id后,找到对应的异步回调函数并触发。
同时,为了所有消息都能互相掌握状态,无论是父应用给子应用发消息,还是子应用给父应用发消息,都要求对方回传一条 ACK 信息确保对方收到且完成消息处理,这个思路源于网络协议。同时利用ACK确认消息的设计,也可以做超时的处理逻辑。
前面我们提到了,发送消息时要携带一个唯一的消息ID,以便于后面进行身份识别。消息ID的选型也有以下几种:
计数器的实现,一般是根据发送的消息ID自增的序号。由于JavaScript是单线程运行,也就不会出现类似java那样多线程语言的变量冲突问题。于是我们的消息ID生成规则,可以采用UUID + 计数器来组合处理,这样最大程度的避免ID冲突问题
未来还会根据需求,可能去做跨子应用之间的通信,跨页面应用的通信。
在我们内部的项目中,已经实现了这部分的功能代码,本文只是提供了一个思路。如果有想参观代码的,欢迎加入我们团队。我的邮箱:[email protected]
我叫王圣松,英文名叫Janlay
因为是学Java出身,启蒙于Android,接触到的第一个前端框架叫layui,于是叫Janlay。
目前在Gitee Devops团队,担任前端开发工程师。
写博客的目的为了记录成长,也给和我一样曾经迷茫过的前端朋友们指一条明路。
你也可以在这里找到我:
这篇是react作者dan昨天在twitter发的感悟小作文,我翻译了一下。原文也被yyx pick了
原文:https://twitter.com/youyuxi/status/1463735120922230791?s=21
开源维护者如何选择“投资”哪些贡献者(例如投入时间、精力、指导等)?
How do open source maintainers pick which contributors to “invest” in (time, effort, mentorship, etc)?
我不知道其他人对于这件事的看法。但对我来说,我最看重的不是编码技能。 我在开源贡献者中寻找的主要判断依据是良好的判断力。 这个概念可能听起来很模糊……🧵
How do open source maintainers pick which contributors to “invest” in (time, effort, mentorship, etc)? I don’t know about others but for me the main thing isn’t coding skill. The main thing I’m looking for in a contributor is good judgement. This concept may sound fuzzy… 🧵
首先,什么标准不是好的判断呢?例如来自哪里、你如何展现自己、你的年龄、甚至你拥有多少年的专业经验,这些条件都和好判断无关。
First, what good judgement is NOT. It has nothing to do with where you’re from, how you present yourself, how old you are, or even how many years of professional experience you have.
好的判断条件和 影响力 或 知名度 没有关系。 有些人虽然有 5 个粉丝,但他们比拥有大量粉丝的知名人物更值得让我相信。
Good judgement also has nothing to do with the “clout” or being known. There are people with 5 followers whose judgment I would trust more than well-known characters with latge audiences.
那么我认为的,所谓的 良好的判断力 到底是什么意思? 我无法给出准确的定义,但我会描述与这样的人一起工作的感觉。
So what do I mean by “good judgment”? I can’t give a precise definition but I’ll describe what working with a person like this feels like.
在我看来,阅读他们的Pull Request描述是一种享受。他们在Pull Request上写清楚了足够详细的提交细节。但细节并不是在解释代码的逻辑,而是在解释他们在做什么、如何做、最重要的是为什么这样做。
他们还会提到自己的思考过程,例如为什么用这种方法去实现、替代方案被拒绝、他们如何进行的代码测试。
Reading their PR descriptions is a treat. They use the right amount of detail — not paraphrasing the code but enough to explain what they’re doing, how, and most importantly, why. They mention their thought process — why this approach, alternatives rejected, how they tested.
他们会注重一个开源项目更长远的未来。 例如如果代码发生了崩溃,他们不只是在崩溃的代码上添加 != null 检查。 他们纠结于为什么这个地方是空的、它是否应该是空的?假设逻辑不正确的地方、以及修复的好方法。
They look at a bigger picture. For example, if there is a crash, they don’t just add != null check on the line that crashes. They look at why that thing is null, whether it’s supposed to ever be null or not, where the assumptions were violated, and what’s a good place to fix.
他们不会将代码看做是静态的,不会想“这只是给计算机运行的内容”。他们会把代码当成活生生的给人阅读的逻辑,并去试图弄清楚(编写它的人的)过去的意图,跟踪这段代码变化的历史(例如哪次修改引入了错误)。并为下一个代码贡献者留下标记提醒
They don’t look at code as a static “here’s what the computer runs” level. They see a living body of work. They try to figure out the past intentions (of the people who wrote it), track the history of changes (where was a mistake introduced?), leave breadcrumbs for next readers.
他们端到端地查看结果。如果他们修复了一个bug,他们不会将“测试用例通过”作为唯一的通过指标。 他们会将其放入重现该bug的项目中,并验证该bug是否已消失。 (这是一个秘密:如果你不这样做,仓库的维护者会说谢谢并会为你做。)
They look at the result end-to-end. If they fix a bug, they don’t rely on “tests pass” as the only signal. They put it in a project that reproduces the bug, and verify that the bug is gone. (Here’s a secret: if you don’t do this, the maintainer says thanks but does it for you.)
他们会保持提交的质量。 他们会投入等量的工作来验证他们的修改是否正确,并且在更改本身中按预期工作。 很明显他们很关心提交的质量。 他们为自己的工作充当无情的 QA,不去回避额外花费几个小时进行有意义的测试。
They maintain quality. They put in equal amount of work in verifying their change is right and works as intended as into the change itself. It’s noticeable they CARE. They act as a merciless QA for their own work — not shying away from spending hours on meaningful testing.
当我看到贡献者说:"我在三个浏览器中测试了三个分辨率,并经历了场景 X、Y 和 Z"(或同样做了对项目有意义的事情)时,我的心充满了喜悦。 这个人自己自觉无论如何他都必须这样做,而且他们已经表现出了先做这件事的礼貌。这里我要对他们说一句谢谢。
When I see “I tested on three resolutions in three browsers and went through scenarios X, Y and Z” (or equivalent that makes sense for the project) my heart fills with joy. This person knows I’ll have to do this anyway and they’ve shown the courtesy of doing it first. Thanks.
但是,这并不意味着他们不会搞砸事情(我们作为作者,也是一样会出错误)。但是他们足够勤奋,以至于有些错误都是自己得来的。把 "一些东西漏掉了" 和 "字面上不用心检查变化是否会起作用" 这两个是有区别的。要做你自己的 QA,我会信任你。
This doesn’t mean they can’t screw up. All of us can! But they take enough diligence that the mistakes feel earned. There’s a difference between something slipping through and literally not bothering to chrck whether the change does the thing. Be your own QA and I’ll trust you.
这听起来可能有些忘恩负义,但在许多情况下,开源项目的维护者会去帮助你在一个受欢迎的项目中提交一个commit,以得良好的贡献经验。
一般情况下,开源项目的维护者自己本身可以快速地完成一样的提交。但维护者希望这个事情是你来做,并协助你去花几天的时间来回修改。
This might sound ungrateful, but in many cases the maintainer helping you — to land a commit in a popular project, to have a good contributing experience, etc. Often, they can do an equivalent change fast but they want it to be yours and spend days on back-and-forth.
他们对上下文非常敏感。除了遵循“贡献指南”之外,他们还尽力推断出可能无法直接看到的事物。例如:假设、项目愿望、质量标准、技术债务、令人不愉快的提交流程、故意的偷工减料、风格、共鸣等(这里指项目的目标愿望,协作方式,构建流程,技术债务等等)
They are very perceptibe to the context. Beyond following the guidelines, they try their best to infer the things that may not be directly visible — assumptions, project aspirations, quality bar, tech debt areas, frustrating workflows, intentionally cut corners, style, vibes.
他们将最终结果视为一个整体产品。他们会在在项目的目标、其他人的问题、和其他解决方案的背景下看待自己的提交变化,他们会表现得好像要对整个项目负责(be owner)。即使他们只是修改改变了一小部分。
They see the end result as a holistic product. They look at their change in the context of the goals of the project, other people’s issues, other solutions. They act as if they are responsible for the whole thing—even if at the moment they only change a small part.
责任是核心。大多数贡献虽然很棒,但需要仓库维护者为他们的提交内容付出更多的责任。例如测试他的更改,弄清楚此代码以前如何工作,研究浏览器的差异等等。但有些贡献者会主动承担这部分责任。
Responsibility is central to this. Most contributions—while great—need maintainers to add more responsibility to their plates. Test this change, figure out how this code worked before, research browser differences, etc. But there are some contributors who take responsibility.
他们会寻找机会并提出有意义的改变。例如范围内的、务实的、通常是增量的变化。他们的变化感觉更像是“雕刻出”应该已经存在的东西,而不是附加一些额外的内容。它们会让 $PROJECT 感觉更像 $PROJECT-y。
They look for opportunities and propose meaningful changes. Changes that are scoped, pragmatic, usually incremental. Their changes “feel” more like “carving out” what should be “already there” rather than attaching something extra. They make the $PROJECT feel more $PROJECT-y.
他们的工作中没有自我。很明显,他们不只是提交它来建立自己的简历(指水提交)。他们的首要任务是为项目找到正确的变更(并弄清楚它到底是什么!),而不是坚持自己的确切想法。他们可能会发送一些简单的提交,但不会提交无意义的修改。
There is no ego in their work. It’s clear they’re not just sending it to build up a resume. Their priority is to land the right change for the project (and figure out what it is!) rather than to land their exact idea. They might send simple changes but not spammy ones.
到目前为止,我一直专注于仓库的核心代码(尽管这同样适用于文档)。但是在项目的主要结构内容之外(例如测试用例,文档等等),它们通常也很活跃。事实上,我经常看到这些人从一些外部的贡献开始,例如帮助人们解决问题,测试其他人提交的 PR,为错误报告的 Issue 制作重现的testcase
So far I’ve focused on the code (although the same applies to documentation too). However, they are usually active beyond that. In fact, I usually see these people start outside code: helping people in issues, testing other PRs, making reproducing cases for bug reports.
这是有道理的,因为对于已完善的开源项目,许多有价值的活动是来自于非核心贡献的。想要获得 PR 并没有错,但是当一个人有更多社区/产品驱动的心态,并且从仓库维护者的盘子里拿走一些日常工作(帮助大家回答Issue问题,处理杂事等等)时,这一点就很明显了。
This makes sense because for established projects, many valuable activities are external to code. There’s nothing wrong with wanting to score a PR, but it’s noticeable when a person has a more community/product-driven mindset, and takes some routine work off maintainers’ plate.
他们会表现出一种有趣的平衡:即为他们感兴趣的部分培养目标,同时保持真正的好奇心并保护项目的整体现有愿景。
They show an interesting balance of cultivating a vision for the parts they’re interested in while staying genuinely curious and protective of the project’s oberall existing vision.
这些意识怎么学?我不清楚。我见过刚从训练营毕业的人在这方面表现出色,我也见过有 10 年以上经验的人不擅长。你如果对项目有同理心,在这方面是有帮助的。如果您能想象自己成为维护者,那么你很快就会做好成为维护者的准备。
How does one learn this? I don’t know. I’ve seen people fresh out of bootcamp who excel at this and I’ve also seen people with 10+ years of experience who don’t. Empathy helps. If you can imagine what it’s like to be in maintainer’s shoes, you’ll soon be ready to be a maintainer.
我最近看到一些人在做这类的工作:
A few people I’ve seen do this type of work recently: @sebsilbermann has been spectacularly helpful on the React repo and everywhere around (we don’t deserve him), @sylwiavargas with new React Docs example content, @harishkumar_s_s helping with the new React Docs website.
我必须澄清一下,简单的驱动式 PR 没有做这些事情的任何必要(包括我自己也提交了许多)。我的内容是关于如何脱颖而出,这些是我在被邀请参与不同项目的人身上观察到的品质。
I should clarify that there’s nothing wrong about simple drive-by PRs that do none of those things. (I send quite a few of those myself!) My thread is about how to stand out — these are the qualities I’ve observed in people who get invited to co-maintain in different projects.
但归根结底,它也是开源的。读到这里你可能会想:wtf,所有这些工作都是免费的?不过这还算公平。我并不希望任何开发人员想要去做这一切,有些人可能想要但也没有时间做这么多额外的工作。
At the end of the day, it’s open source. Reading this might make you think: “wtf, all this work and for free?” That’s fair. I wouldn’t expect any developer to want to do all of this. Some might want to but not have the time to do so much extra work either.
尽管如此,对于平均的评判标准已经足够低,通过稍微多加努力就可以在其中脱颖而出。此外,也许不要从大型项目的 PR 开始贡献 —— 通常它们的维护人员根本没有时间。较小的项目通常有更多可操作的问题需要解决,审查时间也更快。
Still, the average bar is low enough that by putting in slightly more effort you can already stand out. Also, maybe don’t start with PRs to huge projects — often maintainers don’t have time at all. Smaller projects often have more actionable things to fix and faster review times.
此外,这并不是说作为维护者,你应该只帮助那些已经在这方面做得很好的人。我也很开心在时间允许的情况下帮助那些正在努力提高技能的人。我所描述的更多是关于提交者如何长期获得对项目的信任。
Also, this isn’t to say that as a maintainer you should only help people who are already great at this. It’s a pleasure to help someone who is struggling to grow their skillset — when time allows. What I described is more about how people earn trust on projects in longterm.
我确实一直想强调,这一切都与工作的数量无关(如果有的话,较大的 PR 很少达到那个质量标准),这是关于在提交中值得注意的事项。即使他可能是个小事情(提交)
I do want to emphasize though that none of this is about the volume of the work. (If anything, larger PRs are very rarely hitting that quality bar!) It’s about thoughtfulness and care noticeable in the approach. Even for small things.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.