![]()



This is the PyTorch implementation of the paper: Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems. Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher and Pascale Fung. ACL 2019. [PDF]
This code has been written using PyTorch >= 1.0. If you use any source codes or datasets included in this toolkit in your work, please cite the following paper. The bibtex is listed below:
@InProceedings{WuTradeDST2019,
author = "Wu, Chien-Sheng and Madotto, Andrea and Hosseini-Asl, Ehsan and Xiong, Caiming and Socher, Richard and Fung, Pascale",
title = "Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
year = "2019",
publisher = "Association for Computational Linguistics"
}
Over-dependence on domain ontology and lack of knowledge sharing across domains are two practical and yet less studied problems of dialogue state tracking. Existing approaches generally fall short in tracking unknown slot values during inference and often have difficulties in adapting to new domains. In this paper, we propose a Transferable Dialogue State Generator (TRADE) that generates dialogue states from utterances using a copy mechanism, facilitating knowledge transfer when predicting (domain, slot, value) triplets not encountered during training. Our model is composed of an utterance encoder, a slot gate, and a state generator, which are shared across domains. Empirical results demonstrate that TRADE achieves state-of-the-art joint goal accuracy of 48.62% for the five domains of MultiWOZ, a human-human dialogue dataset. In addition, we show its transferring ability by simulating zero-shot and few-shot dialogue state tracking for unseen domains. TRADE achieves 60.58% joint goal accuracy in one of the zero-shot domains, and is able to adapt to few-shot cases without forgetting already trained domains.


Download the MultiWOZ dataset and the processed dst version.
❱❱❱ python3 create_data.py

An example of multi-domain dialogue state tracking in a conversation. The solid arrows on the left are the single-turn mapping, and the dot arrows on the right are multi-turn mapping. The state tracker needs to track slot values mentioned by the user for all the slots in all the domains.
Check the packages needed or simply run the command
❱❱❱ pip install -r requirements.txtIf you run into an error related to Cython, try to upgrade it first.
❱❱❱ pip install --upgrade cythonTraining
❱❱❱ python3 myTrain.py -dec=TRADE -bsz=32 -dr=0.2 -lr=0.001 -le=1Testing
❱❱❱ python3 myTest.py -path=${save_path}- -bsz: batch size
- -dr: drop out ratio
- -lr: learning rate
- -le: loading pretrained embeddings
- -path: model saved path
[2019.08 Update] Now the decoder can generate all the (domain, slot) pairs in one batch at the same time to speedup decoding process. You can set flag "--parallel_decode=1" to decode all (domain, slot) pairs in one batch.
Training
❱❱❱ python3 myTrain.py -dec=TRADE -bsz=32 -dr=0.2 -lr=0.001 -le=1 -exceptd=${domain}Testing
❱❱❱ python3 myTest.py -path=${save_path} -exceptd=${domain}- -exceptd: except domain selection, choose one from {hotel, train, attraction, restaurant, taxi}.
Training Naive
❱❱❱ python3 fine_tune.py -bsz=8 -dr=0.2 -lr=0.001 -path=${save_path_except_domain} -exceptd=${except_domain}EWC
❱❱❱ python3 EWC_train.py -bsz=8 -dr=0.2 -lr=0.001 -path=${save_path_except_domain} -exceptd=${except_domain} -fisher_sample=10000 -l_ewc=${lambda}GEM
❱❱❱ python3 GEM_train.py -bsz=8 -dr=0.2 -lr=0.001 -path={save_path_except_domain} -exceptd=${except_domain}- -l_ewc: lambda value in EWC training
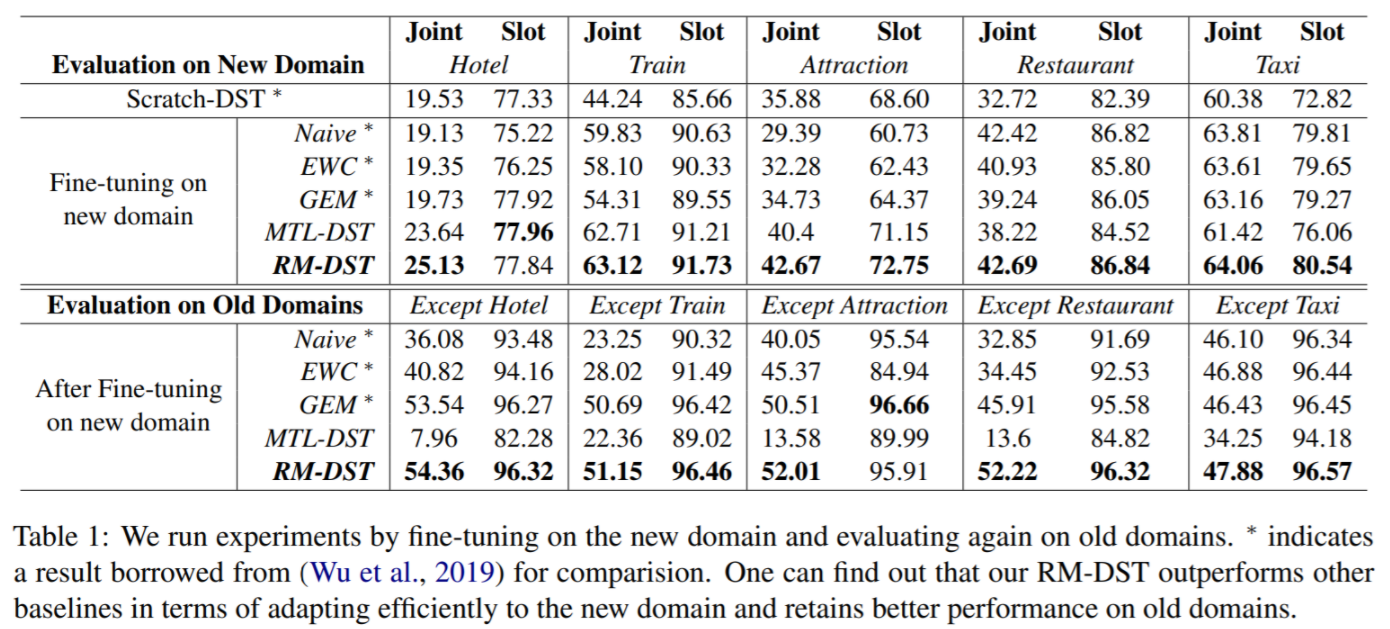
- We found that there might be some variances in different runs, especially for the few-shot setting. For our own experiments, we only use one random seed (seed=10) to do the experiments reported in the paper. Please check the results for average three runs in our ACL presentation.
Feel free to create an issue or send email to [email protected]
copyright 2019-present https://jasonwu0731.github.io/
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.